
Stance Classification of Social Media Texts for Under-Resourced Scenarios in Social Sciences †


Abstract
:1. Introduction
2. Related Work
2.1. Data-Related Concerns for Text Mining Tasks
2.2. Sentiment and Stance Analysis
2.3. Sentiment Analysis Approaches for Swedish Text Data
3. Methods
3.1. Datasets and Tasks
3.2. Processing Pipeline
4. Results
4.1. Training Classic Machine Learning Models
4.2. Training Neural Network Models
4.3. Making Use of Modern Language Models
4.4. Qualitative Assessment of the Classification Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
| 1 | ©2021 IEEE. Reprinted, with permission, from 2021 Swedish Workshop on Data Science (SweDS). V. Yantseva and K. Kucher. Machine Learning for Social Sciences: Stance Classification of User Messages on a Migrant-Critical Discussion Forum. doi:10.1109/SweDS53855.2021.9637718 |
References
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Ceron, A.; Curini, L.; Iacus, S.M.; Porro, G. Every Tweet Counts? How Sentiment Analysis of Social Media can Improve our Knowledge of Citizens’ Political Preferences With an Application to Italy and France. New Media Soc. 2014, 16, 340–358. [Google Scholar] [CrossRef]
- Åkerlund, M. The Importance of Influential Users in (Re)Producing Swedish Far-right Discourse on Twitter. Eur. J. Commun. 2020, 35, 613–628. [Google Scholar] [CrossRef]
- Loureiro, M.L.; Alló, M. Sensing Climate Change and Energy Issues: Sentiment and Emotion Analysis with Social Media in the U.K. and Spain. Energy Policy 2020, 143, 111490. [Google Scholar] [CrossRef]
- Pope, D.; Griffith, J. An Analysis of Online Twitter Sentiment Surrounding the European Refugee Crisis. In Proceedings of the International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 16, Porto, Portugal, 9–11 November 2016; SciTePress: Setúbal, Portugal, 2016; pp. 299–306. [Google Scholar] [CrossRef]
- Yantseva, V. Migration Discourse in Sweden: Frames and Sentiments in Mainstream and Social Media. Soc. Media + Soc. 2020, 6. [Google Scholar] [CrossRef]
- Macnair, L.; Frank, R. The Mediums and the Messages: Exploring the Language of Islamic State Media Through Sentiment Analysis. Crit. Stud. Terror. 2018, 11, 438–457. [Google Scholar] [CrossRef]
- Colleoni, E.; Rozza, A.; Arvidsson, A. Echo Chamber or Public Sphere? Predicting Political Orientation and Measuring Political Homophily in Twitter Using Big Data. J. Commun. 2014, 64, 317–332. [Google Scholar] [CrossRef]
- Anastasopoulos, L.J.; Williams, J.R. A Scalable Machine Learning Approach for Measuring Violent and Peaceful Forms of Political Protest Participation with Social Media Data. PLoS ONE 2019, 14, e0212834. [Google Scholar] [CrossRef]
- Sheetal, A.; Savani, K. A Machine Learning Model of Cultural Change: Role of Prosociality, Political Attitudes, and Protestant Work Ethic. Am. Psychol. 2021, 76, 997–1012. [Google Scholar] [CrossRef]
- Blomberg, H.; Stier, J. Flashback as a Rhetorical Online Battleground: Debating the (Dis)guise of the Nordic Resistance Movement. Soc. Media + Soc. 2019, 5. [Google Scholar] [CrossRef]
- Törnberg, A.; Törnberg, P. Muslims in Social Media Discourse: Combining Topic Modeling and Critical Discourse Analysis. Discourse Context Media 2016, 13 Pt B, 132–142. [Google Scholar] [CrossRef] [Green Version]
- Malmqvist, K. Satire, Racist Humour and the Power of (Un)Laughter: On the Restrained Nature Of Swedish Online Racist Discourse Targeting EU-Migrants Begging for Money. Discourse Soc. 2015, 26, 733–753. [Google Scholar] [CrossRef] [Green Version]
- Rouces, J.; Borin, L.; Tahmasebi, N. Creating an Annotated Corpus for Aspect-Based Sentiment Analysis in Swedish. In Proceedings of the Conference of the Association of Digital Humanities in the Nordic Countries. CEUR Workshop Proceedings, DHN’20, Riga, Latvia, 21–23 October 2020; pp. 318–324. [Google Scholar]
- Del Vigna, F.; Cimino, A.; Dell’Orletta, F.; Petrocchi, M.; Tesconi, M. Hate Me, Hate Me Not: Hate Speech Detection on Facebook. In Proceedings of the First Italian Conference on Cybersecurity. CEUR Workshop Proceedings, ITASEC’17, Venice, Italy, 17–20 January 2017; Volume 1816, pp. 86–95. [Google Scholar]
- Schmidt, A.; Wiegand, M. A Survey on Hate Speech Detection using Natural Language Processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media, SocialNLP’17, Valencia, Spain, 3 April 2017; ACL: Stroudsburg, PA, USA, 2017; pp. 1–10. [Google Scholar] [CrossRef] [Green Version]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. Proc. Int. AAAI Conf. Web Soc. Media 2017, 11, 512–515. [Google Scholar] [CrossRef]
- Waseem, Z.; Davidson, T.; Warmsley, D.; Weber, I. Understanding Abuse: A Typology of Abusive Language Detection Subtasks. In Proceedings of the First Workshop on Abusive Language Online, ALW’17, Vancouver, BC, Canada, 4 August 2017; ACL: Stroudsburg, PA, USA, 2017; pp. 78–84. [Google Scholar] [CrossRef] [Green Version]
- Yantseva, V.; Kucher, K. Machine Learning for Social Sciences: Stance Classification of User Messages on a Migrant-Critical Discussion Forum. In Proceedings of the Swedish Workshop on Data Science, SweDS’21, Växjö, Sweden, 2–3 December 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Manning, C.D.; Schütze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Aggarwal, C.C. Machine Learning for Text; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Almeida, F.; Xexéo, G. Word Embeddings: A Survey. arXiv 2019, arXiv:1901.09069. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, PMLR, ICML’14, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Liu, J.; Chang, W.C.; Wu, Y.; Yang, Y. Deep Learning for Extreme Multi-Label Text Classification. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’17, Tokyo, Japan, 7–11 August 2017; ACM: Singapore, 2017; pp. 115–124. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained Models for Natural Language Processing: A Survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 604–624. [Google Scholar] [CrossRef] [Green Version]
- Snow, R.; O’Connor, B.; Jurafsky, D.; Ng, A. Cheap and Fast—But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP’08, Honolulu, HI, USA, 25–27 October 2008; ACL: Stroudsburg, PA, USA, 2008; pp. 254–263. [Google Scholar]
- Settles, B. Active Learning. Synth. Lect. Artif. Intell. Mach. Learn. 2012, 6, 1–114. [Google Scholar] [CrossRef]
- Mohammad, S.; Turney, P. Emotions Evoked by Common Words and Phrases: Using Mechanical Turk to Create an Emotion Lexicon. In Proceedings of the NAACL HLT Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, CAAGET’10, Los Angeles, CA, USA, 5 June 2010; ACL: Stroudsburg, PA, USA, 2010; pp. 26–34. [Google Scholar]
- Hamilton, W.L.; Clark, K.; Leskovec, J.; Jurafsky, D. Inducing Domain-Specific Sentiment Lexicons from Unlabeled Corpora. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP’16, Austin, TX, USA, 1–5 November 2016; ACL: Stroudsburg, PA, USA, 2016; pp. 595–605. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), NAACL-HLT’19, Minneapolis, MN, USA, 2–7 June 2019; ACL: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Hemmatian, F.; Sohrabi, M.K. A Survey on Classification Techniques for Opinion Mining and Sentiment Analysis. Artif. Intell. Rev. 2019, 52, 1495–1545. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. In Proceedings of the International AAAI Conference on Weblogs and Social Media, ICWSM’14, Ann Arbor, MI, USA, 27–29 May 2014; AAAI: Menlo Park, CA, USA, 2014. [Google Scholar]
- Loria, S. TextBlob: Simplified Text Processing. 2013. Available online: https://github.com/sloria/TextBlob (accessed on 15 July 2022).
- Jindal, K.; Aron, R. A Systematic Study of Sentiment Analysis for Social Media Data. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Ay Karakuš, B.; Talo, M.; Hallaç, İ.R.; Aydin, G. Evaluating Deep Learning Models for Sentiment Classification. Concurr. Comput. 2018, 30, e4783. [Google Scholar] [CrossRef]
- Mohammad, S.M. Sentiment Analysis: Detecting Valence, Emotions, and Other Affectual States from Text. In Emotion Measurement; Woodhead Publishing: Thorston, UK, 2016; pp. 201–237. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Sobhani, P.; Kiritchenko, S. Stance and Sentiment in Tweets. ACM Trans. Internet Technol. 2017, 17, 1–23. [Google Scholar] [CrossRef]
- Skeppstedt, M.; Simaki, V.; Paradis, C.; Kerren, A. Detection of Stance and Sentiment Modifiers in Political Blogs. In Speech and Computer; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10458, pp. 302–311. [Google Scholar] [CrossRef] [Green Version]
- Simaki, V.; Paradis, C.; Skeppstedt, M.; Sahlgren, M.; Kucher, K.; Kerren, A. Annotating Speaker Stance in Discourse: The Brexit Blog Corpus. Corpus Linguist. Linguist. Theory 2020, 16, 215–248. [Google Scholar] [CrossRef] [Green Version]
- Eisenstein, J. Unsupervised Learning for Lexicon-Based Classification. Proc. AAAI Conf. Artif. Intell. 2017, 31, 3188–3194. [Google Scholar] [CrossRef]
- Raza, H.; Faizan, M.; Hamza, A.; Mushtaq, A.; Akhtar, N. Scientific Text Sentiment Analysis Using Machine Learning Techniques. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 157–165. [Google Scholar] [CrossRef] [Green Version]
- Abd El-Jawad, M.H.; Hodhod, R.; Omar, Y.M. Sentiment Analysis of Social Media Networks Using Machine Learning. In Proceedings of the International Computer Engineering Conference, ICENCO’18, Cairo, Egypt, 29–30 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 174–176. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8. [Google Scholar] [CrossRef] [Green Version]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. Proc. AAAI Conf. Artif. Intell. 2015, 29, 2267–2273. [Google Scholar] [CrossRef]
- Chen, W.F.; Ku, L.W. UTCNN: A Deep Learning Model of Stance Classification on Social Media Text. In Proceedings of the International Conference on Computational Linguistics—Technical Papers, COLING’16, Osaka, Japan, 11–16 December 2016; ACL: Stroudsburg, PA, USA, 2016; pp. 1635–1645. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, EACL’17, Valencia, Spain, 3–7 April 2017; ACL: Stroudsburg, PA, USA, 2017; pp. 427–431. [Google Scholar]
- Bender, E.M.; Koller, A. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, ACL’20, Online, 5–10 July 2020; ACL: Stroudsburg, PA, USA, 2020; pp. 5185–5198. [Google Scholar] [CrossRef]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the ACM Conference on Fairness, Accountability, and Transparency, FAccT’21, Online, 3–10 March 2021; ACM: New York, NY, USA, 2021; pp. 610–623. [Google Scholar] [CrossRef]
- Desai, S.; Durrett, G. Calibration of Pre-trained Transformers. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP’20, Online, 16–20 November 2020; ACL: Stroudsburg, PA, USA, 2020; pp. 295–302. [Google Scholar] [CrossRef]
- Heitmann, M.; Siebert, C.; Hartmann, J.; Schamp, C. More Than a Feeling: Benchmarks for Sentiment Analysis Accuracy. Soc. Sci. Res. Netw. 2020. [Google Scholar] [CrossRef]
- Gröndahl, T.; Pajola, L.; Juuti, M.; Conti, M.; Asokan, N. All You Need is “Love”: Evading Hate Speech Detection. In Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security, AISec’18, Toronto, ON, Canada, 19 October 2018; ACL: Stroudsburg, PA, USA, 2018; pp. 2–12. [Google Scholar] [CrossRef] [Green Version]
- Giachanou, A.; Crestani, F. Like It or Not: A Survey of Twitter Sentiment Analysis Methods. ACM Comput. Surv. 2016, 49, 1–41. [Google Scholar] [CrossRef]
- Santos, J.; Bernardini, F.; Paes, A. Measuring the Degree of Divergence when Labeling Tweets in the Electoral Scenario. In Proceedings of the Brazilian Workshop on Social Network Analysis and Mining, BraSNAM’21, Florianópolis, SC, Brazil, 18–22 July 2021; SBC: Porto Alegre, RS, Brazil, 2021; pp. 127–138. [Google Scholar] [CrossRef]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 Task 4: Sentiment Analysis in Twitter. In Proceedings of the International Workshop on Semantic Evaluation, SemEval-2017, Vancouver, BC, Canada, 3–4 August 2017; ACL: Stroudsburg, PA, USA, 2017; pp. 502–518. [Google Scholar] [CrossRef] [Green Version]
- Cieliebak, M.; Deriu, J.M.; Egger, D.; Uzdilli, F. A Twitter Corpus and Benchmark Resources for German Sentiment Analysis. In Proceedings of the International Workshop on Natural Language Processing for Social Media, SocialNLP’17, Valencia, Spain, 3 April 2017; ACL: Stroudsburg, PA, USA, 2017; pp. 45–51. [Google Scholar] [CrossRef]
- Alexandridis, G.; Varlamis, I.; Korovesis, K.; Caridakis, G.; Tsantilas, P. A Survey on Sentiment Analysis and Opinion Mining in Greek Social Media. Information 2021, 12, 331. [Google Scholar] [CrossRef]
- Rogers, A.; Romanov, A.; Rumshisky, A.; Volkova, S.; Gronas, M.; Gribov, A. RuSentiment: An Enriched Sentiment Analysis Dataset for Social Media in Russian. In Proceedings of the International Conference on Computational Linguistics, COLING’18, Santa Fe, NM, USA, 20–26 August 2018; ACL: Stroudsburg, PA, USA, 2018; pp. 755–763. [Google Scholar]
- Habernal, I.; Ptáček, T.; Steinberger, J. Sentiment Analysis in Czech Social Media Using Supervised Machine Learning. In Proceedings of the Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, WASSA’13, Atlanta, GA, USA, 14 June 2013; ACL: Stroudsburg, PA, USA, 2013; pp. 65–74. [Google Scholar]
- Elenius, K.; Forsbom, E.; Megyesi, B. Language Resources and Tools for Swedish: A Survey. In Proceedings of the International Conference on Language Resources and Evaluation, LREC’08, Marrakech, Morocco, 28–30 May 2008; ELRA: Paris, France, 2008. [Google Scholar]
- Nivre, J.; Nilsson, J.; Hall, J. Talbanken05: A Swedish Treebank with Phrase Structure and Dependency Annotation. In Proceedings of the International Conference on Language Resources and Evaluation, LREC’06, Genoa, Italy, 22–28 May 2006; ELRA: Paris, France, 2006. [Google Scholar]
- Vrelid, L.; Nivre, J. When Word Order and Part-of-speech Tags are not Enough—Swedish Dependency Parsing with Rich Linguistic Features. In Proceedings of the International Conference on Recent Advances in Natural Language Processing, RANLP’07, Borovets, Bulgaria, 27–29 September 2007. [Google Scholar]
- Östling, R. Stagger: An Open-Source Part of Speech Tagger for Swedish. North Eur. J. Lang. Technol. 2013, 3, 1–18. [Google Scholar] [CrossRef]
- Ek, T.; Kirkegaard, C.; Jonsson, H.; Nugues, P. Named Entity Recognition for Short Text Messages. Procedia-Soc. Behav. Sci. 2011, 27, 178–187. [Google Scholar] [CrossRef] [Green Version]
- Skeppstedt, M.; Kvist, M.; Dalianis, H. Rule-based Entity Recognition and Coverage of SNOMED CT in Swedish Clinical Text. In Proceedings of the International Conference on Language Resources and Evaluation, LREC’12, Istanbul, Turkey, 23–25 May 2012; ELRA: Paris, France, 2012; pp. 1250–1257. [Google Scholar]
- Lundberg, J.; Nordqvist, J.; Laitinen, M. Towards a Language Independent Twitter Bot Detector. In Proceedings of the Conference of the Association of Digital Humanities in the Nordic Countries. CEUR Workshop Proceedings, DHN’19, Copenhagen, Denmark, 6–8 March 2019; Volume 2364, pp. 308–319. [Google Scholar]
- Rouces, J.; Borin, L.; Tahmasebi, N.; Rødven Eide, S. SenSALDO: A Swedish Sentiment Lexicon for the SWE-CLARIN Toolbox. In Proceedings of the Selected Papers from the CLARIN Annual Conference 2018; Linköping University Electronic Press: Linköping, Sweden, 2019; pp. 177–187. [Google Scholar]
- Malmsten, M.; Börjeson, L.; Haffenden, C. Playing with Words at the National Library of Sweden—Making a Swedish BERT. arXiv 2020, arXiv:2007.01658. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), EMNLP-IJCNLP’19, Hong Kong, China, 3–7 November 2019; ACL: Stroudsburg, PA, USA, 2019; pp. 3982–3992. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP’20, Online, 16–20 November 2020; ACL: Stroudsburg, PA, USA, 2020; pp. 4512–4525. [Google Scholar] [CrossRef]
- Rekathati, F. The KBLab Blog: Introducing a Swedish Sentence Transformer. 2022. Available online: https://kb-labb.github.io/posts/2021-08-23-a-swedish-sentence-transformer/ (accessed on 15 July 2022).
- Heidenreich, T.; Eberl, J.M.; Lind, F.; Boomgaarden, H. Political Migration Discourses on Social Media: A Comparative Perspective on Visibility and Sentiment Across Political Facebook Accounts in Europe. J. Ethn. Migr. Stud. 2020, 46, 1261–1280. [Google Scholar] [CrossRef]
- Berdicevskis, A. Svensk ABSAbank-Imm 1.0: An Annotated Swedish Corpus for Aspect-Based Sentiment Analysis (A Version of Absabank). 2021. Available online: https://spraakbanken.gu.se/resurser/absabank-imm (accessed on 15 July 2022).
- Rouces, J.; Borin, L.; Tahmasebi, N. Tracking Attitudes Towards Immigration in Swedish Media. In Proceedings of the Conference of the Association of Digital Humanities in the Nordic Countries. CEUR Workshop Proceedings, DHN’19, Copenhagen, Denmark, 6–8 March 2019; Volume 2364, pp. 387–393. [Google Scholar]
- Fernquist, J.; Lindholm, O.; Kaati, L.; Akrami, N. A Study on the Feasibility to Detect Hate Speech in Swedish. In Proceedings of the IEEE International Conference on Big Data, Big Data’19, Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4724–4729. [Google Scholar] [CrossRef]
- Borg, A.; Boldt, M. Using VADER Sentiment and SVM for Predicting Customer Response Sentiment. Expert Syst. Appl. 2020, 162, 113746. [Google Scholar] [CrossRef]
- Fernquist, J.; Kaati, L.; Schroeder, R. Political Bots and the Swedish General Election. In Proceedings of the IEEE International Conference on Intelligence and Security Informatics, ISI’18, Miami, FL, USA, 9–11 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 124–129. [Google Scholar] [CrossRef]
- Wickham, H. rvest: Easily Harvest (Scrape) Web Pages. 2016. Available online: https://cran.r-project.org/web/packages/rvest (accessed on 15 July 2022).
- Artstein, R.; Poesio, M. Inter-Coder Agreement for Computational Linguistics. Comput. Linguist. 2008, 34, 555–596. [Google Scholar] [CrossRef] [Green Version]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly: Sebastopol, CA, USA, 2009. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’16, San Francisco, CA, USA, 13–17 August 2016; ACL: Stroudsburg, PA, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Schwenk, H.; Douze, M. Learning Joint Multilingual Sentence Representations with Neural Machine Translation. In Proceedings of the Workshop on Representation Learning for NLP, RepL4NLP’17, Vancouver, BC, Canada, 3 August 2017; ACL: Stroudsburg, PA, USA, 2017; pp. 157–167. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the USENIX Symposium on Operating Systems Design and Implementation, OSDI’16, Savannah, GA, USA, 2–4 November 2016; USENIX Association: Berkeley, CA, USA, 2016; pp. 265–283. [Google Scholar]
- Yang, Y.; Cer, D.; Ahmad, A.; Guo, M.; Law, J.; Constant, N.; Hernandez Abrego, G.; Yuan, S.; Tar, C.; Sung, Y.H.; et al. Multilingual Universal Sentence Encoder for Semantic Retrieval. In Proceedings of the Annual Meeting of the Association for Computational Linguistics: System Demonstrations, ACL’20, Online, 5–10 July 2020; ACL: Stroudsburg, PA, USA, 2020; pp. 87–94. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Sydney, Australia, 2019; Volume 32. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations, EMNLP’20, Online, 16–20 November 2020; ACL: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Zheng, Z.; Wu, X.; Srihari, R. Feature Selection for Text Categorization on Imbalanced Data. ACM SIGKDD Explor. Newsl. 2004, 6, 80–89. [Google Scholar] [CrossRef]
- MacAvaney, S.; Yao, H.R.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate Speech Detection: Challenges and Solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef] [PubMed]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Plank, B.; Hovy, D.; Søgaard, A. Linguistically Debatable or Just Plain Wrong? In Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL’14, Baltimore, MD, USA, 22–27 June 2014; ACL: Stroudsburg, PA, USA, 2014; pp. 507–511. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Wu, T.; Guestrin, C.; Singh, S. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, ACL’20, Online, 5–10 July 2020; ACL: Stroudsburg, PA, USA, 2020; pp. 4902–4912. [Google Scholar] [CrossRef]
- Chen, S.; Lin, L.; Yuan, X. Social Media Visual Analytics. Comput. Graph. Forum 2017, 36, 563–587. [Google Scholar] [CrossRef]
- Kucher, K.; Paradis, C.; Kerren, A. The State of the Art in Sentiment Visualization. Comput. Graph. Forum 2018, 37, 71–96. [Google Scholar] [CrossRef] [Green Version]
- Alharbi, M.; Laramee, R.S. SoS TextVis: An Extended Survey of Surveys on Text Visualization. Computers 2019, 8, 17. [Google Scholar] [CrossRef] [Green Version]
- Baumer, E.P.S.; Jasim, M.; Sarvghad, A.; Mahyar, N. Of Course It’s Political! A Critical Inquiry into Underemphasized Dimensions in Civic Text Visualization. Comput. Graph. Forum 2022, 41, 1–14. [Google Scholar] [CrossRef]
- Chatzimparmpas, A.; Martins, R.M.; Jusufi, I.; Kucher, K.; Rossi, F.; Kerren, A. The State of the Art in Enhancing Trust in Machine Learning Models with the Use of Visualizations. Comput. Graph. Forum 2020, 39, 713–756. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics, DSAA’18, Turin, Italy, 1–3 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 80–89. [Google Scholar] [CrossRef] [Green Version]
- Clinciu, M.A.; Hastie, H. A Survey of Explainable AI Terminology. In Proceedings of the Workshop on Interactive Natural Language Technology for Explainable Artificial Intelligence, NL4XAI’19, Tokyo, Japan, 29 October–1 November 2019; ACL: Stroudsburg, PA, USA; pp. 8–13. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-Agnostic Interpretability of Machine Learning. In Proceedings of the ICML Workshop on Human Interpretability in Machine Learning, WHI’16, New York, NY, USA, 23 June 2016. [Google Scholar] [CrossRef]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [Green Version]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning Word Vectors for 157 Languages. In Proceedings of the International Conference on Language Resources and Evaluation, LREC’18, Miyazaki, Japan, 7–12 May 2018; ELRA: Paris, France, 2018. [Google Scholar]
- Adewumi, T.P.; Liwicki, F.; Liwicki, M. Exploring Swedish & English fastText Embeddings for NER with the Transformer. arXiv 2021, arXiv:2007.16007. [Google Scholar]
- Aroyo, L.; Welty, C. Truth is a Lie: Crowd Truth and the Seven Myths of Human Annotation. AI Mag. 2015, 36, 15–24. [Google Scholar] [CrossRef]
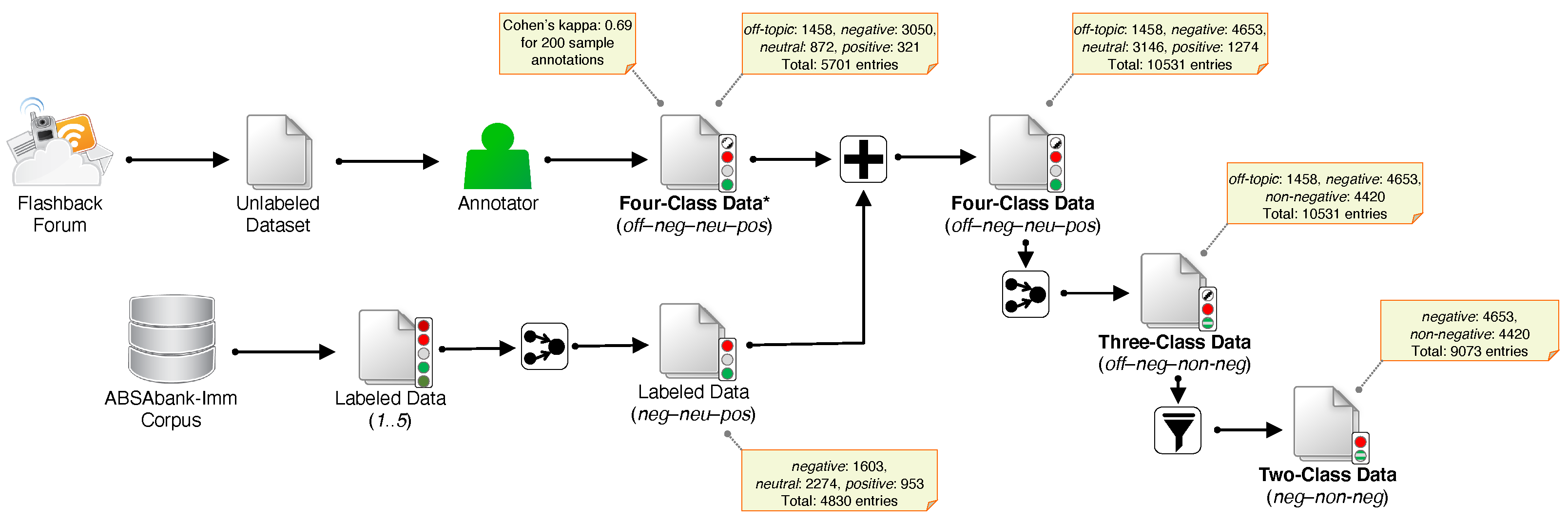


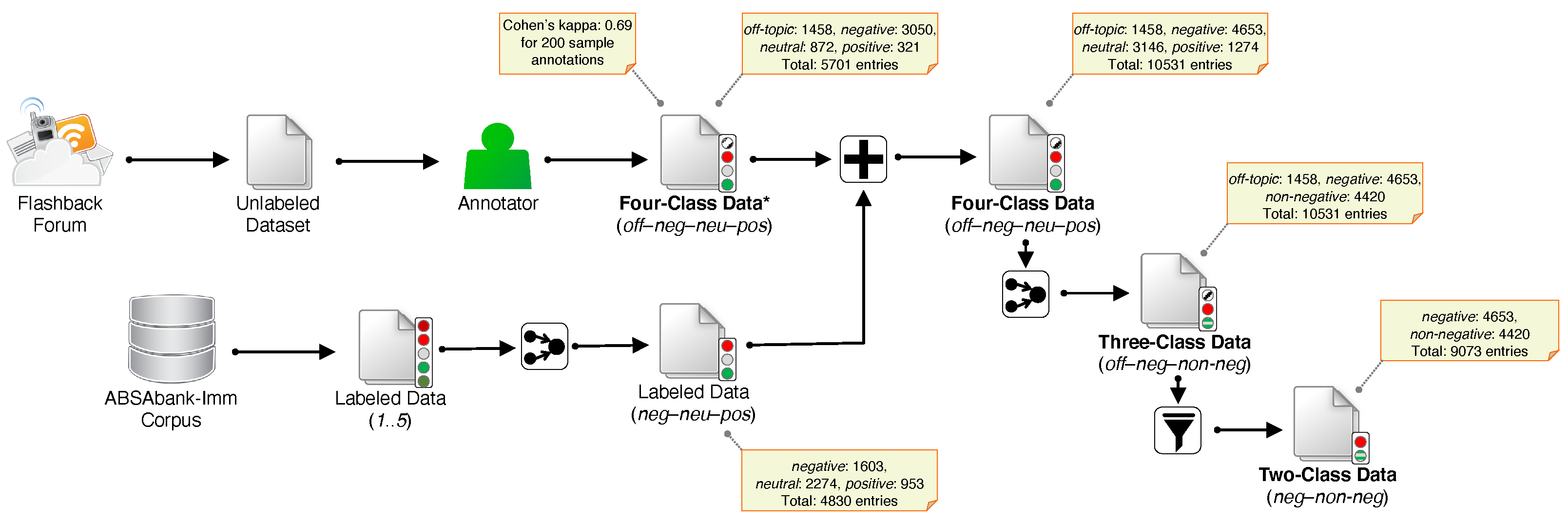{kind=link}
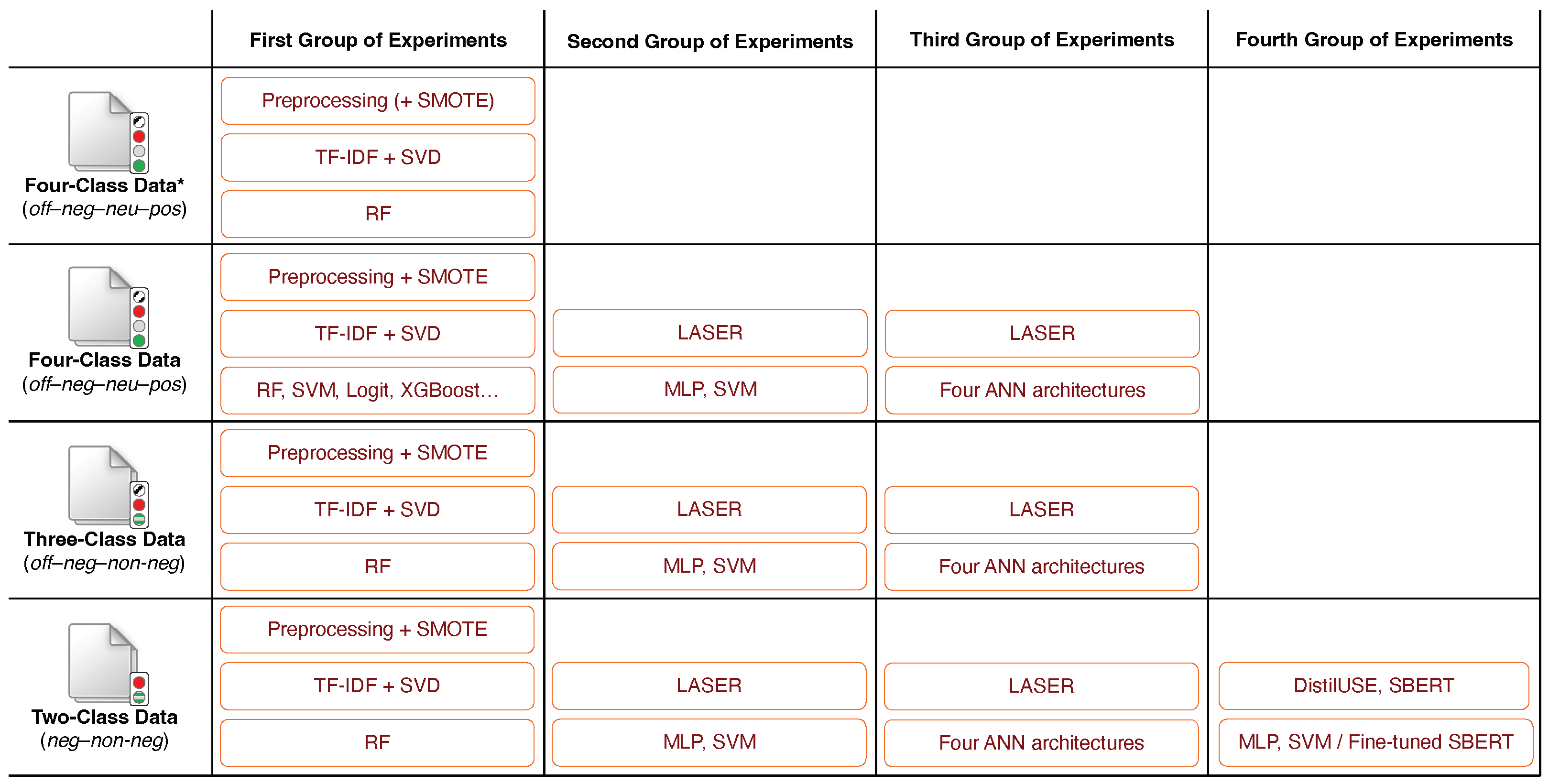{kind=link}
| Classification Model | Accuracy, Training (CV) | F1, Training (CV) | Accuracy, Test Data | Precision, Test Data | Recall, Test Data | F1, Test Data | F1, Test Data, Negative |
|---|---|---|---|---|---|---|---|
| Four classes*, SVD, no resampling, RF | 0.60 | 0.31 | 0.61 | 0.75 | 0.33 | 0.31 | 0.74 |
| Four classes*, SVD, SMOTE resampling, RF | 0.86 | 0.86 | 0.59 | 0.42 | 0.37 | 0.38 | 0.73 |
| Four classes, SVD, SMOTE resampling, ADABoost | 0.55 | 0.55 | 0.42 | 0.41 | 0.43 | 0.40 | 0.51 |
| Four classes, SVD, SMOTE resampling, XGBoost | 0.85 | 0.85 | 0.51 | 0.46 | 0.44 | 0.44 | 0.63 |
| Four classes, SVD, SMOTE resampling, Logit | 0.50 | 0.51 | 0.50 | 0.46 | 0.49 | 0.46 | 0.61 |
| Four classes, SVD, SMOTE resampling, SVM | 0.74 | 0.74 | 0.51 | 0.47 | 0.49 | 0.47 | 0.62 |
| Four classes, SVD, SMOTE resampling, RF | 0.86 | 0.86 | 0.54 | 0.49 | 0.46 | 0.47 | 0.64 |
| Four classes, LASER, MLP | 0.59 | 0.52 | 0.61 | 0.59 | 0.53 | 0.54 | 0.70 |
| Four classes, LASER, SVM | 0.57 | 0.55 | 0.58 | 0.55 | 0.59 | 0.56 | 0.65 |
| Three classes, SVD, SMOTE resampling, RF | 0.70 | 0.69 | 0.61 | 0.59 | 0.57 | 0.57 | 0.63 |
| Three classes, LASER, MLP | 0.66 | 0.64 | 0.67 | 0.68 | 0.64 | 0.66 | 0.68 |
| Three classes, LASER, SVM | 0.66 | 0.65 | 0.67 | 0.65 | 0.70 | 0.66 | 0.67 |
| Two classes, SVD, SMOTE resampling, RF | 0.70 | 0.70 | 0.67 | 0.68 | 0.66 | 0.66 | 0.72 |
| Two classes, LASER, MLP | 0.72 | 0.72 | 0.71 | 0.71 | 0.71 | 0.71 | 0.73 |
| Two classes, LASER, SVM | 0.73 | 0.73 | 0.72 | 0.72 | 0.72 | 0.72 | 0.73 |
| Model/Class | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| LASER, SVM, off-topic | 0.52 | 0.80 | 0.63 | 438 |
| LASER, SVM, negative | 0.73 | 0.58 | 0.65 | 1396 |
| LASER, SVM, neutral | 0.55 | 0.55 | 0.55 | 944 |
| LASER, SVM, positive | 0.39 | 0.45 | 0.42 | 382 |
| LASER, MLP, off-topic | 0.70 | 0.56 | 0.62 | 438 |
| LASER, MLP, negative | 0.64 | 0.73 | 0.68 | 1396 |
| LASER, MLP, non-negative | 0.69 | 0.64 | 0.66 | 1326 |
| LASER, SVM, off-topic | 0.53 | 0.79 | 0.63 | 438 |
| LASER, SVM, negative | 0.71 | 0.63 | 0.67 | 1396 |
| LASER, SVM, non-negative | 0.70 | 0.67 | 0.68 | 1326 |
| LASER, SVM, negative | 0.73 | 0.72 | 0.73 | 1396 |
| LASER, SVM, non-negative | 0.71 | 0.72 | 0.71 | 1326 |
| Classification Model | Accuracy, Training | Loss, Training | Accuracy, Test Data | Loss, Test Data |
|---|---|---|---|---|
| Four classes, LASER, three dense layers | 0.85 | 0.40 | 0.58 | 1.60 |
| Four classes, LASER, LSTM and dense layers | 0.74 | 0.67 | 0.58 | 1.14 |
| Four classes, LASER, Conv1D and dense layers | 0.67 | 0.81 | 0.58 | 0.99 |
| Four classes, LASER, Covd1D, LSTM, and dense layers | 0.70 | 0.75 | 0.58 | 1.12 |
| Three classes, LASER, three dense layers | 0.90 | 0.24 | 0.64 | 1.48 |
| Three classes, LASER, LSTM and dense layers | 0.80 | 0.48 | 0.65 | 0.98 |
| Three classes, LASER, Conv1D and dense layers | 0.76 | 0.55 | 0.66 | 0.76 |
| Three classes, LASER, Conv1D, LSTM, and dense layers | 0.69 | 0.67 | 0.66 | 0.72 |
| Two classes, LASER, three dense layers | 0.90 | 0.23 | 0.70 | 1.02 |
| Two classes, LASER, LSTM and dense layers | 0.82 | 0.37 | 0.70 | 0.69 |
| Two classes, LASER, Conv1D and dense layers | 0.80 | 0.43 | 0.72 | 0.57 |
| Two classes, LASER, Conv1D, LSTM, and dense layers | 0.82 | 0.40 | 0.71 | 0.63 |
| Classification Model | Accuracy, Training (CV) | F1, Training (CV) | Accuracy, Test Data | Precision, Test Data | Recall, Test Data | F1, Test Data | F1, Test Data, Negative |
|---|---|---|---|---|---|---|---|
| Two classes, DistilUSE, MLP | 0.71 | 0.71 | 0.70 | 0.70 | 0.70 | 0.70 | 0.71 |
| Two classes, DistilUSE, SVM | 0.73 | 0.73 | 0.71 | 0.71 | 0.71 | 0.71 | 0.73 |
| Two classes, Sentence-BERT, MLP | 0.73 | 0.73 | 0.72 | 0.72 | 0.72 | 0.72 | 0.72 |
| Two classes, Sentence-BERT, SVM | 0.75 | 0.75 | 0.76 | 0.76 | 0.76 | 0.76 | 0.77 |
| Two classes, Sentence-BERT, fine-tuning | - | - | 0.76 | 0.76 | 0.76 | 0.76 | 0.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yantseva, V.; Kucher, K. Stance Classification of Social Media Texts for Under-Resourced Scenarios in Social Sciences. Data 2022, 7, 159. https://doi.org/10.3390/data7110159
Yantseva V, Kucher K. Stance Classification of Social Media Texts for Under-Resourced Scenarios in Social Sciences. Data. 2022; 7(11):159. https://doi.org/10.3390/data7110159
Chicago/Turabian StyleYantseva, Victoria, and Kostiantyn Kucher. 2022. "Stance Classification of Social Media Texts for Under-Resourced Scenarios in Social Sciences" Data 7, no. 11: 159. https://doi.org/10.3390/data7110159
APA StyleYantseva, V., & Kucher, K. (2022). Stance Classification of Social Media Texts for Under-Resourced Scenarios in Social Sciences. Data, 7(11), 159. https://doi.org/10.3390/data7110159