
Lessons Learnt from Engineering Science Projects Participating in the Horizon 2020 Open Research Data Pilot




Abstract
1. Introduction
2. Framework and Practice
2.1. FAIR Data in Practice
- Findable—data and supplementary materials have sufficiently rich metadata and a unique and persistent identifier;
- Accessible—metadata and data are understandable to humans and machines. Data are deposited in a trusted repository;
- Interoperable—metadata use a formal, accessible, shared and broadly applicable language for knowledge representation;
- Reusable—data and collections have a clear usage license and provide accurate information on provenance.
2.2. DMP in Practice—The Case of EC-Funded Projects
- Data Summary
- Purpose of the data collection/generation and its relation to the objectives of the project;
- Types and formats of data generated/collected;
- Information on use of any existing data;
- Origin of the data;
- Expected size-volume of the data;
- Data utility—beneficiaries;
- FAIR Data;
- Allocation of Resources:
- Costs for making data FAIR;
- Responsible partner/individual for data management of the data of subject;
- Data Security:
- Provisions in place for data security (including data recovery as well as secure storage and transfer of sensitive data);
- Information about safe storage, long-term preservation and curation;
- Ethical Aspects:
- Ethical or legal issues that can have an impact on data sharing;
- Other Issues.
2.3. EC-Funded Engineering Materials Projects
2.4. Author-Led ORD Activities
3. Discussion
3.1. Challenges
3.2. Solutions
4. Conclusions
- Give due consideration at the proposal preparation stage to roles, responsibilities and resourcing and to establishing a Data Committee to take responsibility for leading data management activities;
- Assign data management responsibilities to early-career researchers, thereby enhancing career development and promoting the longer-term prospects of research data management;
- Employ data citation to promote data discovery, accessibility and sharing;
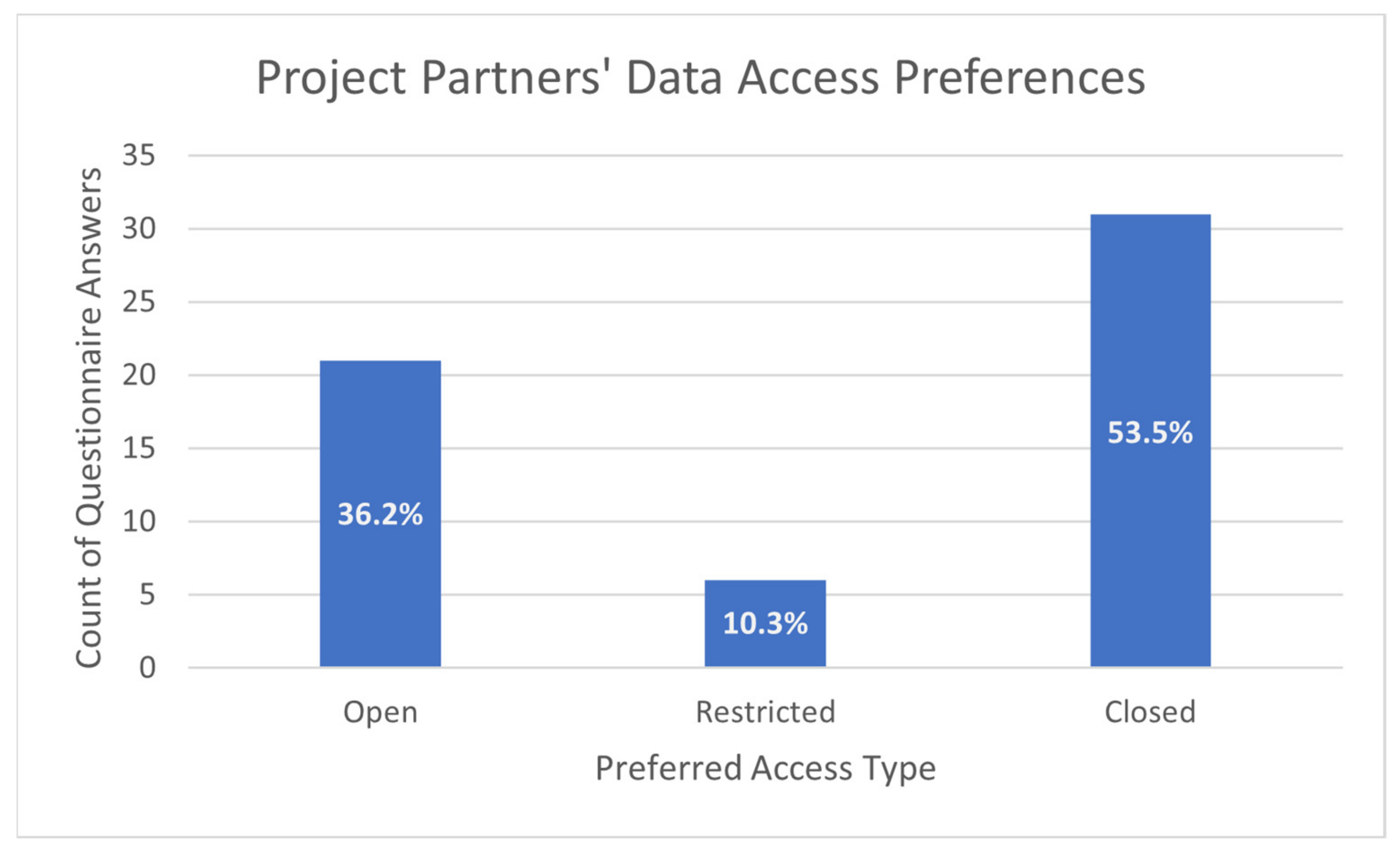
- While giving due attention to the H2020 principle that data should be “as open as possible, as closed as necessary”, tailor the data access model to the needs of the project, its research objectives and the competitive interests (intellectual and commercial) of project partners;
- Engage in the development and/or utilisation of interoperability standards that are tailored to the immediate interests of the project but also complementary to community initiatives.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Digital Agenda and Open Data—From Crisis of Trust to Open Governing. 2012. Available online: https://europa.eu/rapid/press-release_SPEECH-12-149_en.htm (accessed on 30 October 2020).
- Communication on Data-Driven Economy|Shaping Europe’s Digital Future. 2014. Available online: https://ec.europa.eu/digital-single-market/en/towards-thriving-data-driven-economy (accessed on 30 October 2020).
- A European Strategy for Data|Shaping Europe’s Digital Future. 2020. Available online: https://ec.europa.eu/digital-single-market/en/policies/building-european-data-economy (accessed on 30 October 2020).
- Digitising European Industry|Shaping Europe’s Digital Future. 2020. Available online: https://ec.europa.eu/digital-single-market/en/policies/digitising-european-industry (accessed on 30 October 2020).
- COM 102 Final. A New Industrial Strategy for Europe. 2020. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52020DC0102&from=EN (accessed on 25 May 2021).
- COM 66 Final. A European Strategy for Data. 2020. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52020DC0066&from=EN (accessed on 25 May 2021).
- State of the Union Address by President von der Leyen at the European Parliament Plenary. 2020. Available online: https://ec.europa.eu/commission/presscorner/detail/en/SPEECH_20_1655 (accessed on 30 October 2020).
- Overview of Funders’ Data Policies|Digital Curation Centre. Available online: http://www.dcc.ac.uk/resources/policy-and-legal/overview-funders-data-policies (accessed on 30 October 2020).
- Reporting Standards and Availability of Data, and Protocols|Nature Research. Available online: https://www.nature.com/nature-research/editorial-policies/reporting-standards (accessed on 30 October 2020).
- Research Data—Elsevier. Available online: https://www.elsevier.com/about/policies/research-data (accessed on 30 October 2020).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Collins, S.; Genova, F.; Harrower, N.; Hodson, S.; Jones, S.; Laaksonen, L.; Mietchen, D.; Petrauskaitė, R.; Wittenburg, P. Turning FAIR into Reality. Final Report and Action Plan from the European Commission Expert Group on FAIR Data; Publications Office of the European Union: Luxembourg, 2018. [Google Scholar] [CrossRef]
- Data Management—H2020 Online Manual. Available online: https://ec.europa.eu/research/participants/docs/h2020-funding-guide/cross-cutting-issues/open-access-data-management/data-management_en.htm (accessed on 1 October 2020).
- Jacobsen, A.; Azevedo, R.D.M.; Juty, N.; Batista, D.; Coles, S.; Cornet, R.; Courtot, M.; Crosas, M.; Dumontier, M.; Evelo, C.T.; et al. FAIR Principles: Interpretations and Implementation Considerations. Data Intell. 2020, 2, 10–29. [Google Scholar] [CrossRef]
- Groth, P.; Cousijn, H.; Clark, T.; Goble, C. FAIR data reuse–the path through data citation. Data Intell. 2020, 2, 78–86. [Google Scholar] [CrossRef]
- Weigel, T.; Schwardmann, U.; Klump, J.; Bendoukha, S.; Quick, R. Making Data and Workflows Findable for Machines. Data Intell. 2020, 2, 40–46. [Google Scholar] [CrossRef]
- Implementing FAIR Data Principles The Role of Libraries. 2017. Available online: https://libereurope.eu/wp-content/uploads/2017/12/LIBER-FAIR-Data.pdf (accessed on 30 October 2020).
- Mons, B.; Neylon, C.; Velterop, J.; Dumontier, M.; da Silva Santos, L.O.B.; Wilkinson, M.D. Cloudy, Increasingly FAIR; Revisiting the FAIR Data Guiding Principles for the European Open Science Cloud. Inform. Serv. Use 2017, 37, 49–56. [Google Scholar] [CrossRef]
- The FAIR Maturity Evaluation Service. Available online: https://fairsharing.github.io/FAIR-Evaluator-FrontEnd (accessed on 13 August 2021).
- Wilkinson, M.D.; Sansone, S.-A.; Schultes, E.; Doorn, P.; Santos, L.O.B.D.S.; Dumontier, M. A design framework and exemplar metrics for FAIRness. Sci. Data 2018, 5, 180118. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, M.D.; Dumontier, M.; Sansone, S.A.; da Silva Santos, L.O.B.; Prieto, M.; Batista, D.; McQuilton, P.; Kuhn, T.; Rocca-Serra, P.; Crosas, M.; et al. Evaluating FAIR maturity through a scalable, automated, community-governed framework. Sci. Data 2019, 6, 174. [Google Scholar] [CrossRef] [PubMed]
- DataCite. Available online: https://datacite.org (accessed on 1 October 2020).
- Spichtinger, D.; Blumesberger, S. FAIR data and data management requirements in a comparative perspective: Horizon 2020 and FWF policies. Mitt. Ver. Osterr. Bibl. Bibl. 2020, 73, 207–216. [Google Scholar] [CrossRef]
- Masó Pau, J.; Serral Montoro, I. Results of the Data Management Plan (DMP) and Report on the Participation in the Pilot on Open Research Data in Horizon 2020. 2017. Available online: https://cordis.europa.eu/project/id/641538/results (accessed on 28 October 2020).
- Kuberek, M. Guidance for Creating a Data Management Plan in Horizon 2020 Projects; DepositOnce; Technische Universität Berlin: Berlin, Germany, 2018. [Google Scholar] [CrossRef]
- Procopio, I.; Cicero, S.; Mottershead, K.; Bruchhausen, M.; Cuvilliez, S. INCEFA-PLUS (Increasing safety in NPPs by covering gaps in environmental fatigue assessment). Procedia Struct. Integr. 2018, 13, 97–103. [Google Scholar] [CrossRef]
- Multiscale Modelling for Fusion and Fission Materials|M4F Project|H2020|CORDIS|European Commission. Available online: https://cordis.europa.eu/project/id/755039 (accessed on 14 November 2020).
- Open Characterisation and Modelling Environment to Drive Innovation in Advanced Nano-Architectured and Bio-Inspired Hard/Soft Interfaces, OYSTER Grant Agreement ID: 760827. Available online: http://www.oyster-project.eu (accessed on 1 October 2020).
- Smart by Design and Intelligent by Architecture for Turbine Blade Fan and Structural Components Systems, SMARTFAN Grant Agreement ID: 760779. Available online: https://www.smartfan-project.eu (accessed on 6 November 2020).
- Recycling of Coated and Painted Textile and Plastic Materials, DECOAT Grant Agreement ID: 814505. Available online: http://decoat.eu (accessed on 6 November 2020).
- Recycling and Repurposing of Plastic Waste for Advanced 3D Printing Applications, REPAIR3D Grant Agreement ID: 814588. Available online: http://www.repair3d.net (accessed on 6 November 2020).
- Ecosystem for Upscaling Production of Lightweight Metal Alloy Composites, LIGHTME Grant Agreement ID: 814552. Available online: http://lightme-ecosystem.eu (accessed on 6 November 2020).
- Zenodo. Available online: https://zenodo.org (accessed on 1 October 2020).
- Efthymiadis, Τ.; Paraskevoudis, Κ.; Koumoulos, E.P. Data Management Ontology (Version: v01.001); Zenodo: Geneva, Switzerland, 2019. [Google Scholar] [CrossRef]
- M4F Data Management Plan. Available online: https://cordis.europa.eu/project/id/755039/results (accessed on 30 October 2020).
- Bloemers, M.; Montesanti, A. The FAIR Funding Model: Providing a Framework for Research Funders to Drive the Transition toward FAIR Data Management and Stewardship Practices. Data Intell. 2020, 2, 171–180. [Google Scholar] [CrossRef]
- INcreasing Safety in NPPs by Covering Gaps in Environmental Fatigue Assessment—Focusing on Gaps between Laboratory Data and Component SCALE | INCEFA-SCALE Project|H2020|CORDIS|European Commission. Available online: https://cordis.europa.eu/project/id/945300 (accessed on 28 February 2021).
- INCEFA-PLUS Findings on Environmental Fatigue, 2020. Available online: https://incefaplus.unican.es/dissemination-and-training/public-documents (accessed on 30 October 2020).
- Vankeerberghen, M.; Doremus, L.; Spätig, P.; Bruchhausen, M.; Le Roux, J.-C.; Twite, M.; Cicero, R.; Platts, N.; Mottershead, K. Ensuring data quality for environmental fatigue—INCEFA-PLUS testing procedure and data evaluation. In Proceedings of the Pressure Vessels and Piping Conference, 15–20 July 2018, Prague, Czech Republic; American Society of Mechanical Engineers: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Wellington, B. How We Found the Worst Place to Park in New York City—Using Big Data, TED Talk. Available online: https://www.ted.com/talks/ben_wellington_how_we_found_the_worst_place_to_park_in_new_york_city_using_big_data/transcript (accessed on 9 December 2020).
- Guedj, D.; Ramjoué, C. European Commission Policy on Open-Access to Scientific Publications and Research Data in Horizon 2020. Biomed. Data J. 2015, 1, 11–14. [Google Scholar] [CrossRef][Green Version]
- DataCite Fabrica. Available online: https://doi.datacite.org (accessed on 30 October 2020).
- DataCite Statistics. Available online: https://stats.datacite.org (accessed on 30 October 2020).
- Cousijn, H.; Kenall, A.; Ganley, E.; Harrison, M.; Kernohan, D.; Lemberger, T.; Murphy, F.; Polischuk, P.; Taylor, S.; Martone, M.; et al. A data citation roadmap for scientific publishers. Sci. Data 2018, 5, 180259. [Google Scholar] [CrossRef]
- Jeliazkova, N.; Chomenidis, C.; Doganis, P.; Fadeel, B.; Grafström, R.; Hardy, B.; Hastings, J.; Hegi, M.; Jeliazkov, V.; Kochev, N.; et al. The eNanoMapper database for nanomaterial safety information. Beilstein J. Nanotechnol. 2015, 6, 1609–1634. [Google Scholar] [CrossRef]
- Virtual Materials Market Place (VIMMP). Available online: https://cordis.europa.eu/project/id/760907 (accessed on 1 October 2020).
- H2020 MarketPlace. Available online: https://www.the-marketplace-project.eu (accessed on 1 October 2020).
- CWA 17157:2017. Engineering Materials—Electronic Data Interchange—Formats for Fatigue Test Data. 2017. Available online: https://www.nen.nl/cwa-17157-2017-en-239775 (accessed on 25 August 2021).
- CWA 17552:2020. Engineering Materials—Electronic Data Interchange—Instrumented Indentation Test Data. 2020. Available online: https://www.nen.nl/cwa-17552-2020-en-277220 (accessed on 25 August 2021).
- CWA 17284:2018. Materials Modelling—Terminology, Classification and Metadata. 2018. Available online: https://www.cencenelec.eu/research/CWA/Pages/default.aspx (accessed on 14 November 2020).
- CEN/WS OYSTER on Materials Characterisation—Terminology, Classification and Metadata. 2020. Available online: https://www.cencenelec.eu/news/workshops/pages/ws-2020-007.aspx (accessed on 14 November 2020).
- The European Materials Modelling Council, EMMC. Available online: https://emmc.eu (accessed on 28 October 2020).
- The European Materials Characterisation Council, EMCC. Available online: http://www.characterisation.eu (accessed on 28 October 2020).
- Koumoulos, E.P.; Sebastiani, M.; Romanos, N.; Kalogerini, M.; Charitidis, C. Data Management Plan Template for H2020 Projects (Version v01.100419); Zenodo: Geneva, Switzerland, 2019. [Google Scholar] [CrossRef]
- Chada DMP. Available online: http://dmp.innovation-res.com/home (accessed on 28 October 2020).
- Williams, M.; Bagwell, J.; Zozus, M.N. Data management plans: The missing perspective. J. Biomed. Inform. 2017, 71, 130–142. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Findable | Accessible | Interoperable | Re-usable |
|---|---|---|---|
| - Data and metadata are assigned a globally unique and eternally persistent identifier. | - Data and metadata are retrievable by their identifier using a standardised communications protocol. | - Data and metadata are retrievable by their identifier using a standardised communications protocol. | - (Meta)data use a formal, accessible, shared and broadly applicable language for knowledge representation |
| - Data are described with rich metadata. | - The protocol is open, free and universally implementable. | - The protocol is open, free and universally implementable. | - (Meta)data use vocabularies that follow FAIR principles |
| - Data and metadata are registered or indexed in a searchable resource. | - The protocol allows for an authentication and authorisation procedure, where necessary. | - The protocol allows for an authentication and authorisation procedure, where necessary. | - (Meta)data include qualified references to other (meta)data |
| - Metadata specify the data identifier. | - Metadata are accessible, even when the data are no longer available. | - Metadata are accessible, even when the data are no longer available. | - (Meta)data use a formal, accessible, shared and broadly applicable language for knowledge representation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Austin, T.; Bei, K.; Efthymiadis, T.; Koumoulos, E.P. Lessons Learnt from Engineering Science Projects Participating in the Horizon 2020 Open Research Data Pilot. Data 2021, 6, 96. https://doi.org/10.3390/data6090096
Austin T, Bei K, Efthymiadis T, Koumoulos EP. Lessons Learnt from Engineering Science Projects Participating in the Horizon 2020 Open Research Data Pilot. Data. 2021; 6(9):96. https://doi.org/10.3390/data6090096
Chicago/Turabian StyleAustin, Timothy, Kyriaki Bei, Theodoros Efthymiadis, and Elias P. Koumoulos. 2021. "Lessons Learnt from Engineering Science Projects Participating in the Horizon 2020 Open Research Data Pilot" Data 6, no. 9: 96. https://doi.org/10.3390/data6090096
APA StyleAustin, T., Bei, K., Efthymiadis, T., & Koumoulos, E. P. (2021). Lessons Learnt from Engineering Science Projects Participating in the Horizon 2020 Open Research Data Pilot. Data, 6(9), 96. https://doi.org/10.3390/data6090096