
An AI-Enabled Approach in Analyzing Media Data: An Example from Data on COVID-19 News Coverage in Vietnam

 ,
,  ,
, 
 and
and 
Abstract
:Abstract
Data Set:
Data Set License:
1. Summary
2. Data Description
- Date: The date of publication of the crawled news articles.
- Title: The title of the crawled news articles.
- Url: The Uniform Resource Locators (URLs), or the web addresses, of the crawled news articles.
- Detail: The content of the crawled news articles, which will be used for analysis.
3. Methods
3.1. System Overview
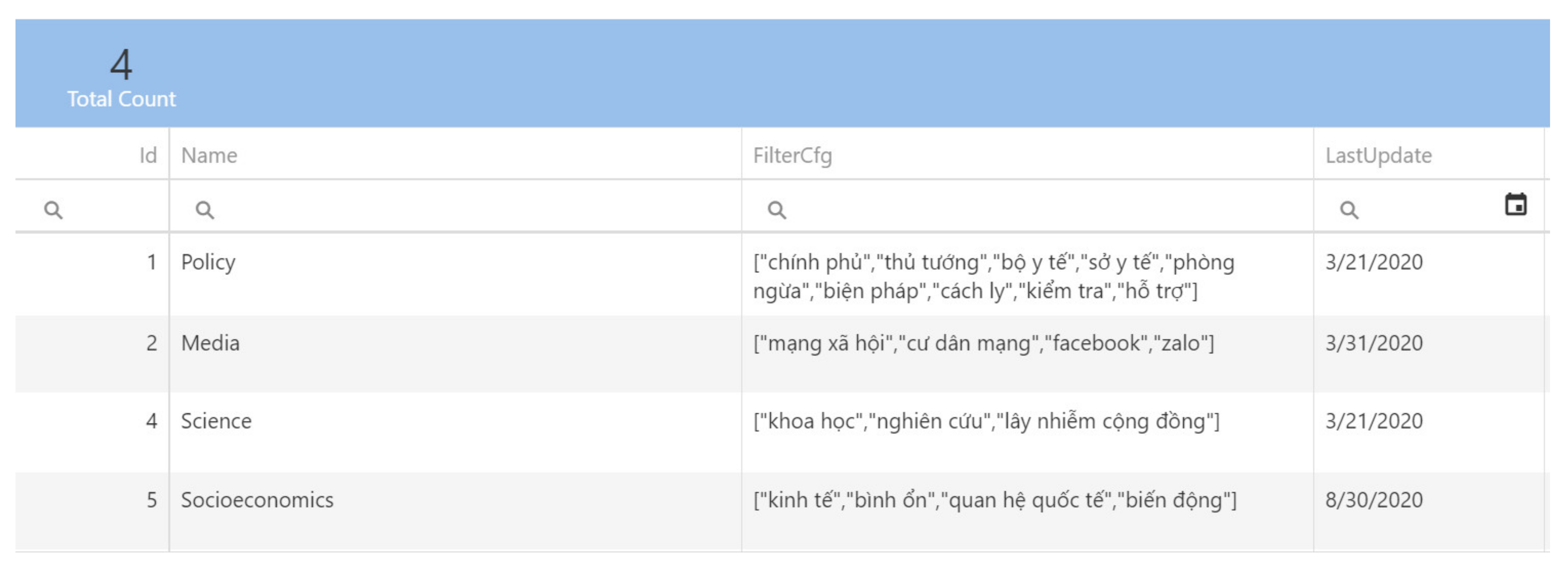
- Projects and Data Sources: The component includes online websites allocated into different categories, the HTML parse of the websites, projects, and sources of data for each project, as well as the projects’ data filter.
- Data Logging: The component stores the queue of crawling URLs and notes on the collected or appropriate news.
- News and Keyword Filter: The component includes structured news articles that were collected and filtered according to keywords for each project.
- Research Subjects and Characteristics: Tables contain information about the research subjects, their characteristics, connection among research objects, and news articles.
- Text Data Analyzer: Tables consist of a Vietnamese dictionary, a data table of place names and proper names, and a data table to train the artificial intelligence (AI) model in separating Vietnamese words.
3.2. Crawling Workflow
3.3. Crawler
3.4. Word Tokenizer
Bộ Y tế chiều 28/8 ghi nhận hai ca nhiễm nCoV, trong đó một ca Đà Nẵng, một ca rời khu cách ly tại Hải Dương về đến Hà Nội thì xét nghiệm dương tính.
[BW] [BW IW] [BW] [BW] [BW IW] [BW] [BW] [BW] [BW] [O] [BW IW] [BW] [BW] [BW IW] [O] [BW] [BW] [BW] [BW] [BW IW] [BW] [BW IW] [BW] [BW] [BW IW] [BW] [BW IW] [BW IW]
[Bộ] [Y tế] [chiều] [28/8] [ghi nhận] [hai] [ca] [nhiễm] [nCoV], [trong đó] [một] [ca] [Đà Nẵng], [một] [ca] [rời] [khu] [cách ly] [tại] [Hải Dương] [về] [đến] [Hà Nội] [thì] [xét nghiệm] [dương tính]
- A syllable joined with 2 syllables after it to create 3 syllables (tri-gram) in the dictionary.
- A syllable joined with 2 syllables in front of it to create 3 syllables (tri-gram) in the dictionary.
- A syllable joined with 2 syllables in front of and after it to create 3 syllables (tri-gram) in the dictionary.
- A syllable joined with a syllable after it to create 2 syllables (bi-gram) in the dictionary.
- A syllable joined with a syllable in front of it to create 2 syllables (bi-gram) in the dictionary.
- A syllable that is at the beginning of a sentence.
- A syllable that is at the end of a sentence.
- A syllable that is a number.
- A syllable that contains a number.
- A syllable that is a special character.
3.5. Analysis
- Research object: Environment-related events, organizations participated in the events.
- Characteristics of the research object: Type of event, time of the event, the degree of impact, type of organization.
3.6. Keywords Logical Tree
3.7. Object Classification
- vectorizer = CountVectorizer(lowercase=True,ngram_range = (1,1),tokenizer = WordTokenizer.tokenize)
- X = vectorizer.fit_transform(x)
- X_train, X_test, y_train, y_test = train_test_split(
- X, y, test_size=0.3, random_state=1)
- # Model Generation Using Multinomial Naive Bayes
- clf = MultinomialNB().fit(X_train, y_train)
- predicted= clf.predict(X_test)
3.8. User Interface
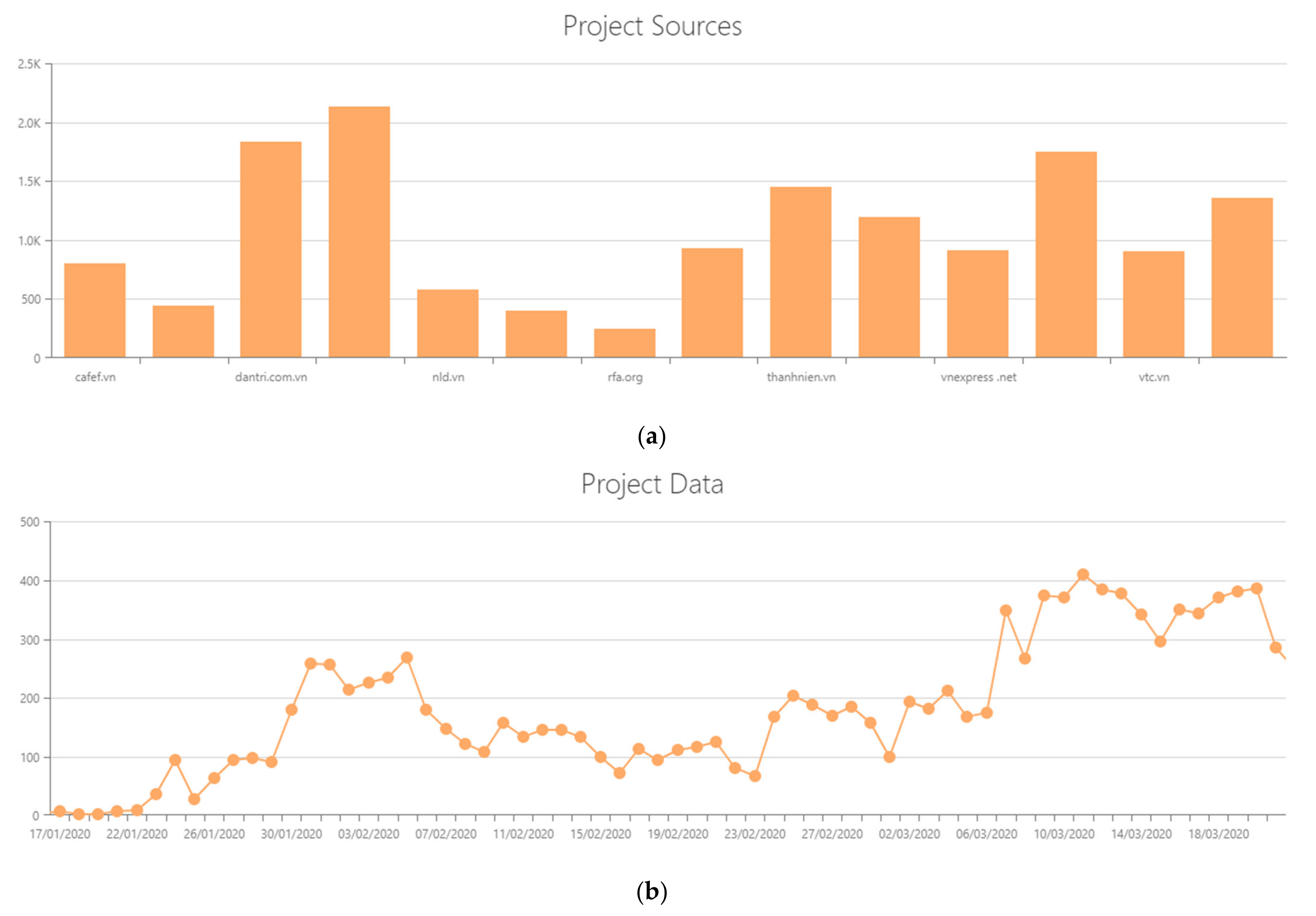
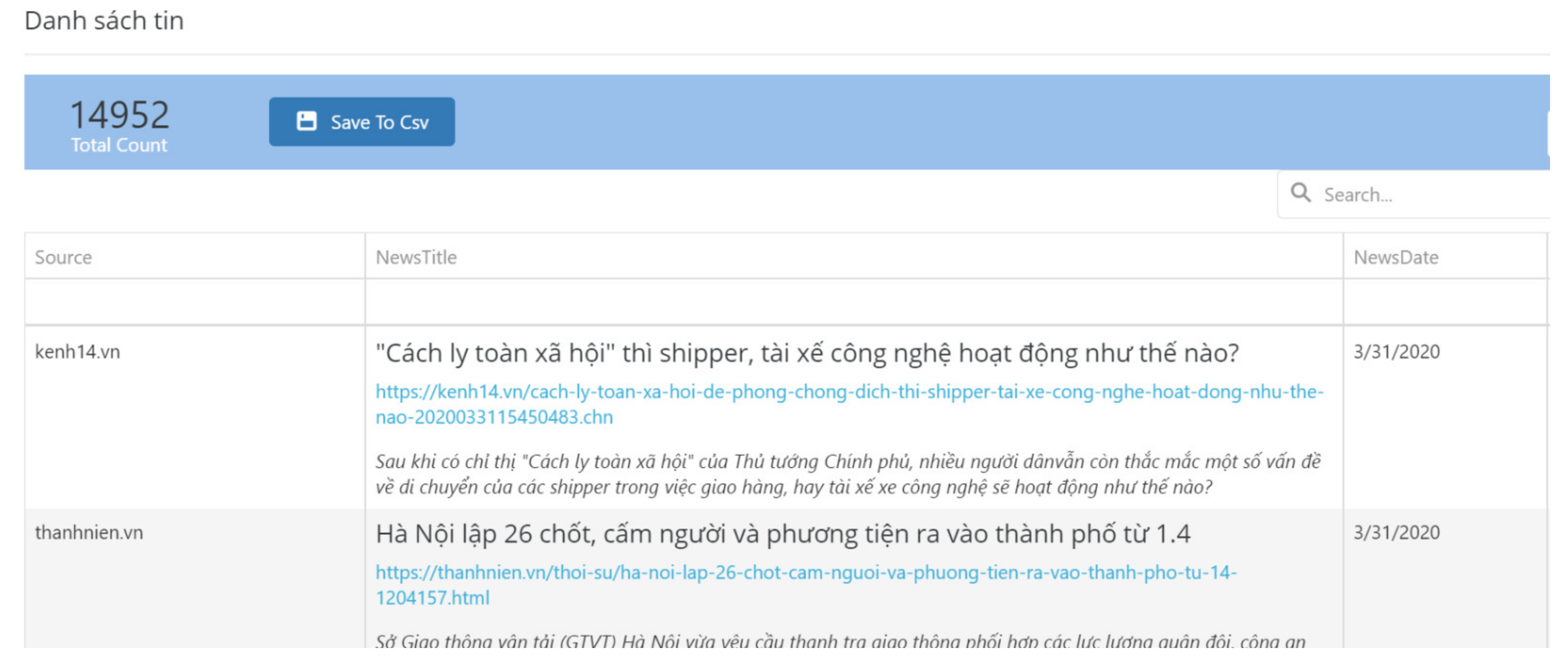
Project Management and Configuration
4. Examples of Analysis
5. Limitations
6. Usage Notes
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vu, H.T.; Liu, Y.; Tran, D.V. Nationalizing a global phenomenon: A study of how the press in 45 countries and territories portrays climate change. Glob. Environ. Chang. 2019, 58, 101942. [Google Scholar] [CrossRef] [PubMed]
- La, V.-P.; Pham, T.-H.; Ho, T.; Nguyen, M.-H.; Nguyen, K.-L.P.; Vuong, T.-T.; Nguyen, H.-K.T.; Tran, T.; Khuc, Q.; Vuong, Q.-H. Policy Response, Social Media and Science Journalism for the Sustainability of the Public Health System Amid the COVID-19 Outbreak: The Vietnam Lessons. Sustainability 2020, 12, 2931. [Google Scholar] [CrossRef] [Green Version]
- Vuong, Q.H.; La, V.-P.; Nguyen, H.T.; Ho, M.; Vuong, T. Identifying the moral–practical gaps in corporate social responsibility missions of Vietnamese firms: An event-based analysis of sustainability feasibility. Corp. Soc. Responsib. Environ. Manag. 2021, 28, 30–41. [Google Scholar] [CrossRef]
- Van Khuc, Q.; Tran, B.Q.; Meyfroidt, P.; Paschke, M.W. Drivers of deforestation and forest degradation in Vietnam: An exploratory analysis at the national level. For. Policy Econ. 2018, 90, 128–141. [Google Scholar] [CrossRef]
- Vuong, Q.H.; Ho, T.; Nguyen, H.-K.T.; Nguyen, M.-H. The trilemma of sustainable industrial growth: Evidence from a piloting OECD’s Green city. Palgrave Commun. 2019, 5, 1–14. [Google Scholar] [CrossRef]
- Neuendorf, K.-A.; Kumar, A. Content Analysis. In The International Encyclopedia of Political Communication; Mazzoleni, G., Ed.; Wiley Blackwell: Hoboken, NJ, USA, 2016; pp. 1–10. [Google Scholar]
- Trinh, M.; Tran, P.; Tran, N. Collecting Chinese-Vietnamese Texts from Bilingual Websites. In Proceedings of the 2018 5th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 23–24 November 2018. [Google Scholar]
- Bandy, J.; Diakopoulos, N. Auditing News Curation Systems: A Case Study Examining Algorithmic and Editorial Logic in Apple News. In Proceedings of the International AAAI Conference on Web and Social Media, Online, Atlanta, GA, USA, 8–11 June 2019; Volume 14, pp. 36–47. [Google Scholar]
- Chen, H.; Huang, X.; Li, Z. A content analysis of Chinese news coverage on COVID-19 and tourism. Curr. Issues Tour. 2020, 1–8. [Google Scholar] [CrossRef]
- Tonkovic, P.; Kalajdziski, S.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Pires, I.M.; Garcia, N.M.; Loncar-Turukalo, T.; Trajkovik, V. Literature on Applied Machine Learning in Metagenomic Classification: A Scoping Review. Biology 2020, 9, 453. [Google Scholar] [CrossRef] [PubMed]
- Van., T.-P.; Thanh, T.M. Vietnamese News Classification Based on BoW with Keywords Extraction and Neural Network. In Proceedings of the 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), Hanoi, Vietnam, 15–17 November 2017; pp. 43–48. [Google Scholar]
- Hoang, V.-C.-D.; Dinh, D.; Nguyen, N.-L.; Ngo, H.-Q. A Comparative Study on Vietnamese Text Classification Methods. In Proceedings of the 2007 IEEE International Conference on Research, Innovation and Vision for the Future, Hanoi, Vietnam, 5–9 March 2007; pp. 267–273. [Google Scholar]
- Le, V.-B.; Besacier, L. Automatic Speech Recognition for Under-Resourced Languages: Application to Vietnamese Language. In IEEE Transactions on Audio, Speech, and Language Processing; IEEE: New York, NY, USA, 2009; Volume 17, pp. 1471–1482. [Google Scholar]
- Vu, D.-L.; Truong, N.-V. Bayesian Spam Filtering for Vietnamese Emails. In Proceedings of the 2012 International Conference on Computer & Information Science (ICCIS), Kuala Lumpur, Malaysia, 12–14 June 2012; pp. 190–193. [Google Scholar]
- Nguyen, T.; Nguyen, H.; Tran, P. Mixed-Level Neural Machine Translation. Comput. Intell. Neurosci. 2020, 2020, 1–7. [Google Scholar] [CrossRef]
- Corizzo, R.; Ceci, M.; Zdravevski, E.; Japkowicz, N. Scalable auto-encoders for gravitational waves detection from time series data. Expert Syst. Appl. 2020, 151, 113378. [Google Scholar] [CrossRef]
- Corizzo, R.; Zdravevski, E.; Russell, M.; Vagliano, A.; Japkowicz, N. Feature extraction based on word embedding models for intrusion detection in network traffic. J. Surveill. Secur. Saf. 2020, 1, 140–150. [Google Scholar] [CrossRef]
- Ferrari, A.; Donati, B.; Gnesi, S. Detecting Domain-Specific Ambiguities: An NLP Approach Based on Wikipedia Crawling and Word Embeddings. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017; pp. 393–399. [Google Scholar]
- Prokhorov, S.; Safronov, V. AI for AI: What NLP Techniques Help Researchers Find the Right Articles on NLP. In Proceedings of the 2019 International Conference on Artificial Intelligence: Applications and Innovations (IC-AIAI), Belgrade, Serbia, 30 September–4 October 2019; pp. 76–765. [Google Scholar]
- Vuong, Q.-H. Reform retractions to make them more transparent. Nat. Cell Biol. 2020, 582, 149. [Google Scholar] [CrossRef]
- Vuong, Q.-H. The (ir)rational consideration of the cost of science in transition economies. Nat. Hum. Behav. 2018, 2, 5. [Google Scholar] [CrossRef] [PubMed]
- Vuong, Q.-H. Breaking barriers in publishing demands a proactive attitude. Nat. Hum. Behav. 2019, 3, 1034. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vuong, Q.H.; Ho, M.T.; Nguyen, H.K.; Vuong, T.T. Healthcare consumers’ sensitivity to costs: A reflection on behavioural economics from an emerging market. Palgrave Commun. 2018, 4, 70. [Google Scholar] [CrossRef]
- Vuong, Q.H. Be rich or don’t be sick: Estimating Vietnamese patients’ risk of falling into destitution. SpringerPlus 2015, 4, 529. [Google Scholar] [CrossRef] [PubMed]
- Vuong, Q.H. Survey data on Vietnamese propensity to attend periodic general health examinations. Sci. Data 2017, 4, 170142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vuong, Q.-H.; La, V.-P.; Nguyen, M.-H.; Ho, M.-T.; Tran, T. Bayesian analysis for social data: A step-by-step protocol and interpretation. MethodsX 2020, 7, 100924. [Google Scholar] [CrossRef] [PubMed]
- Vuong, Q.-H.; La, V.-P.; Nguyen, M.-H.; Ho, T.; Mantello, P. Improving Bayesian statistics understanding in the age of Big Data with the bayesvl R package. Softw. Impacts 2020, 4, 100016. [Google Scholar] [CrossRef]
- La, V.-P.; Vuong, Q.-H. Bayesvl: Visually Learning the Graphical Structure of Bayesian Networks and Performing MCMC with ‘Stan’. Available online: https://cran.r-project.org/web/packages/bayesvl/index.html (accessed on 31 August 2020).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Purposes | Code |
|---|---|
| Building the features | features ={ ‘w.islower’: word.islower(), ‘w.isupper’: word.isupper(), ‘w.istitle’: word.istitle(), ‘w.ispunct’: word.isPuncts(), ‘w.isBOS’: isBOS(), ‘w.isEOS’: isEOS(), ‘-1:w.bi_gram’: ‘ ‘.join([word1, word]).lower() in bi_grams, ‘+1:w.bi_gram’: ‘ ‘.join([word, word1]).lower() in bi_grams ‘-2:w.tri_gram’: ‘ ‘.join([word2, word1, word]).lower() in tri_grams, ‘+2:w.tri_gram’: ‘ ‘.join([word, word1, word2]).lower() in tri_grams, } |
| Training the model | model = sklearn_crfsuite.CRF( algorithm=‘lbfgs’, c1=0.1, c2=0.1, max_iterations=2000, all_possible_transitions=True, model_filename=‘models/model.bin’ ) model.fit(X_train, y_train) y_pred = model.predict(X) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vuong, Q.-H.; La, V.-P.; Nguyen, T.-H.T.; Nguyen, M.-H.; Le, T.-T.; Ho, M.-T. An AI-Enabled Approach in Analyzing Media Data: An Example from Data on COVID-19 News Coverage in Vietnam. Data 2021, 6, 70. https://doi.org/10.3390/data6070070
Vuong Q-H, La V-P, Nguyen T-HT, Nguyen M-H, Le T-T, Ho M-T. An AI-Enabled Approach in Analyzing Media Data: An Example from Data on COVID-19 News Coverage in Vietnam. Data. 2021; 6(7):70. https://doi.org/10.3390/data6070070
Chicago/Turabian StyleVuong, Quan-Hoang, Viet-Phuong La, Thanh-Huyen T. Nguyen, Minh-Hoang Nguyen, Tam-Tri Le, and Manh-Toan Ho. 2021. "An AI-Enabled Approach in Analyzing Media Data: An Example from Data on COVID-19 News Coverage in Vietnam" Data 6, no. 7: 70. https://doi.org/10.3390/data6070070
APA StyleVuong, Q.-H., La, V.-P., Nguyen, T.-H. T., Nguyen, M.-H., Le, T.-T., & Ho, M.-T. (2021). An AI-Enabled Approach in Analyzing Media Data: An Example from Data on COVID-19 News Coverage in Vietnam. Data, 6(7), 70. https://doi.org/10.3390/data6070070