A Geo-Tagged COVID-19 Twitter Dataset for 10 North American Metropolitan Areas over a 255-Day Period



Abstract
:1. Summary
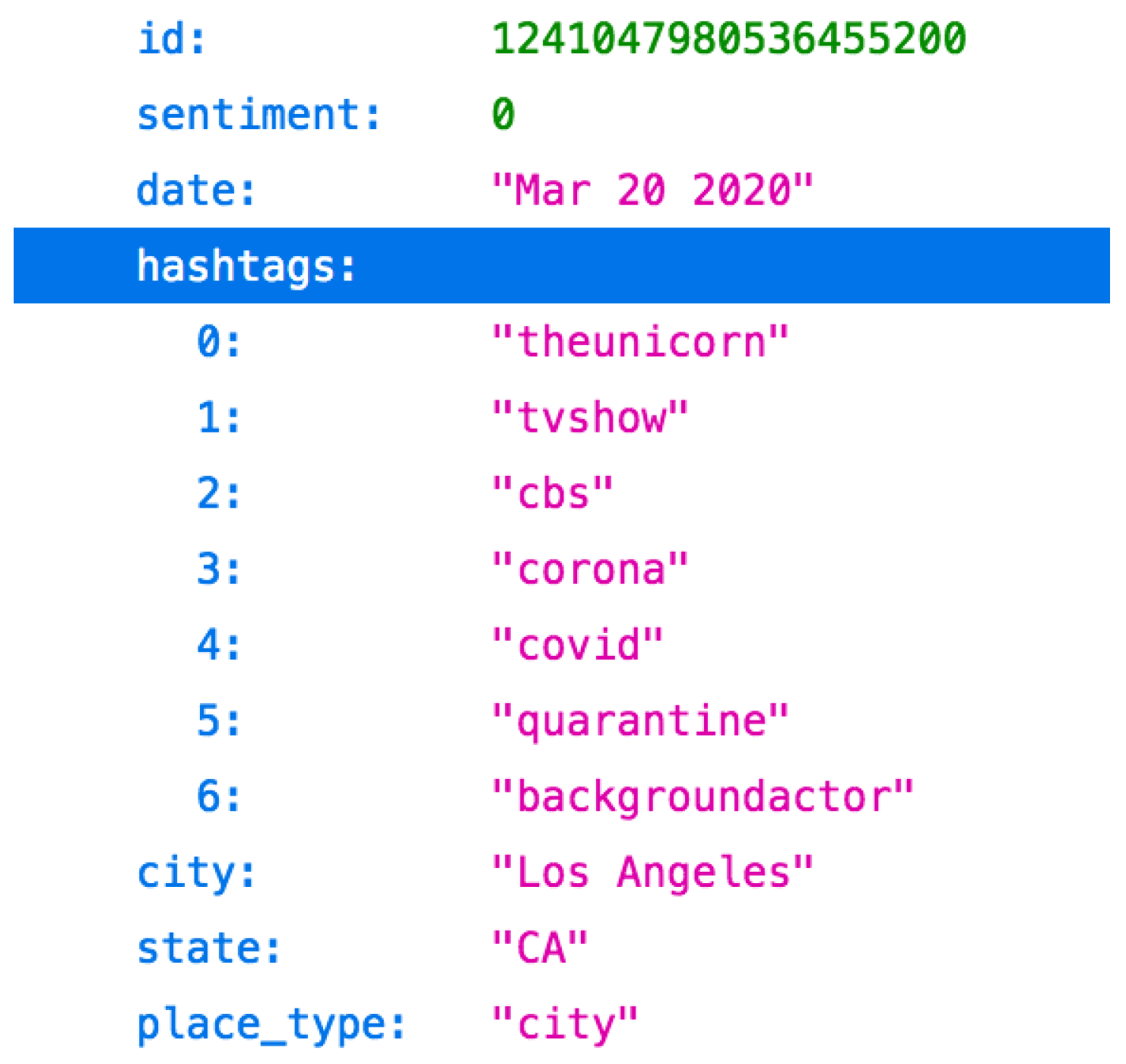
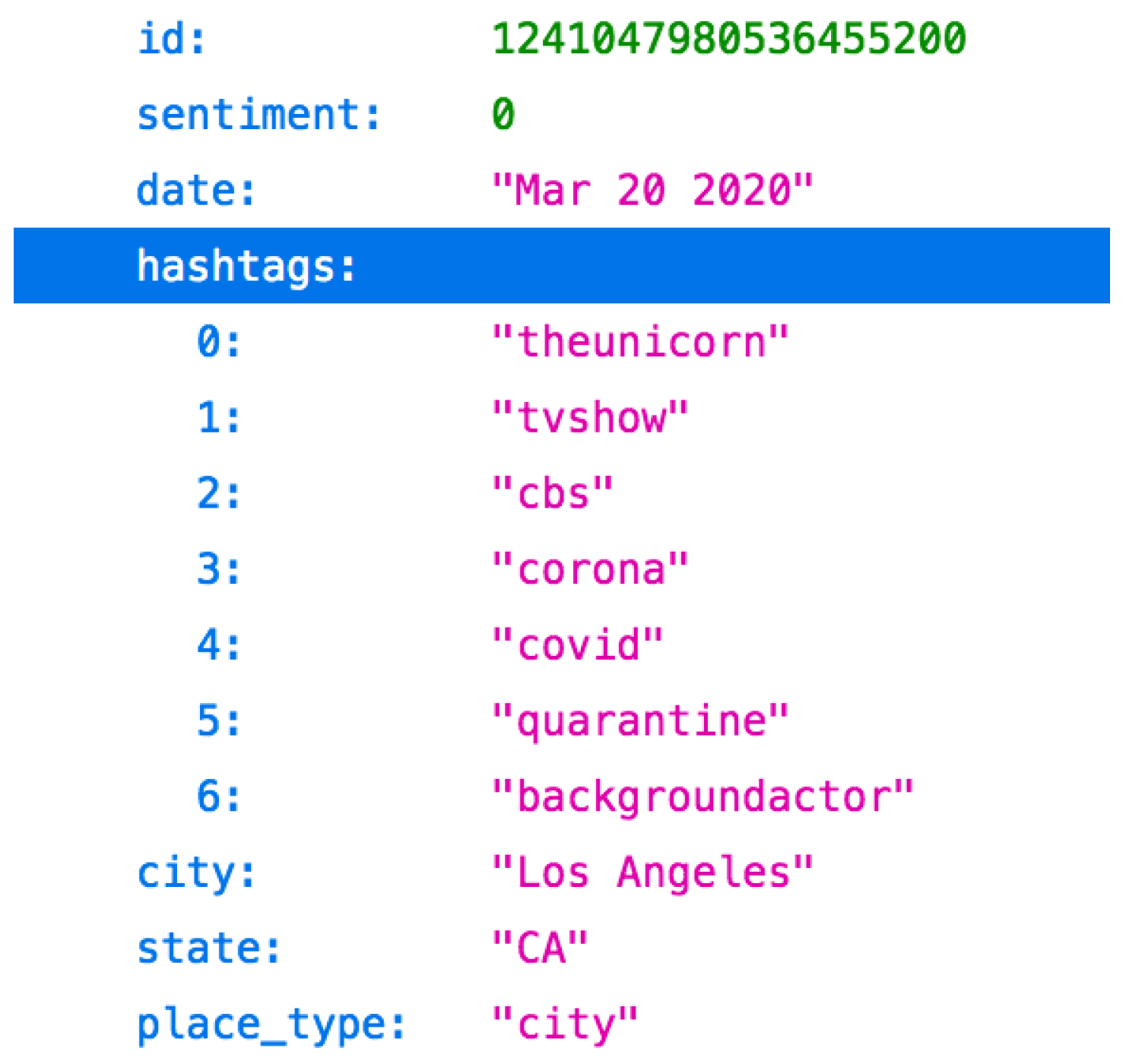
2. Data Description
3. Methods
3.1. Preliminaries: GeoCOV19Tweets Dataset
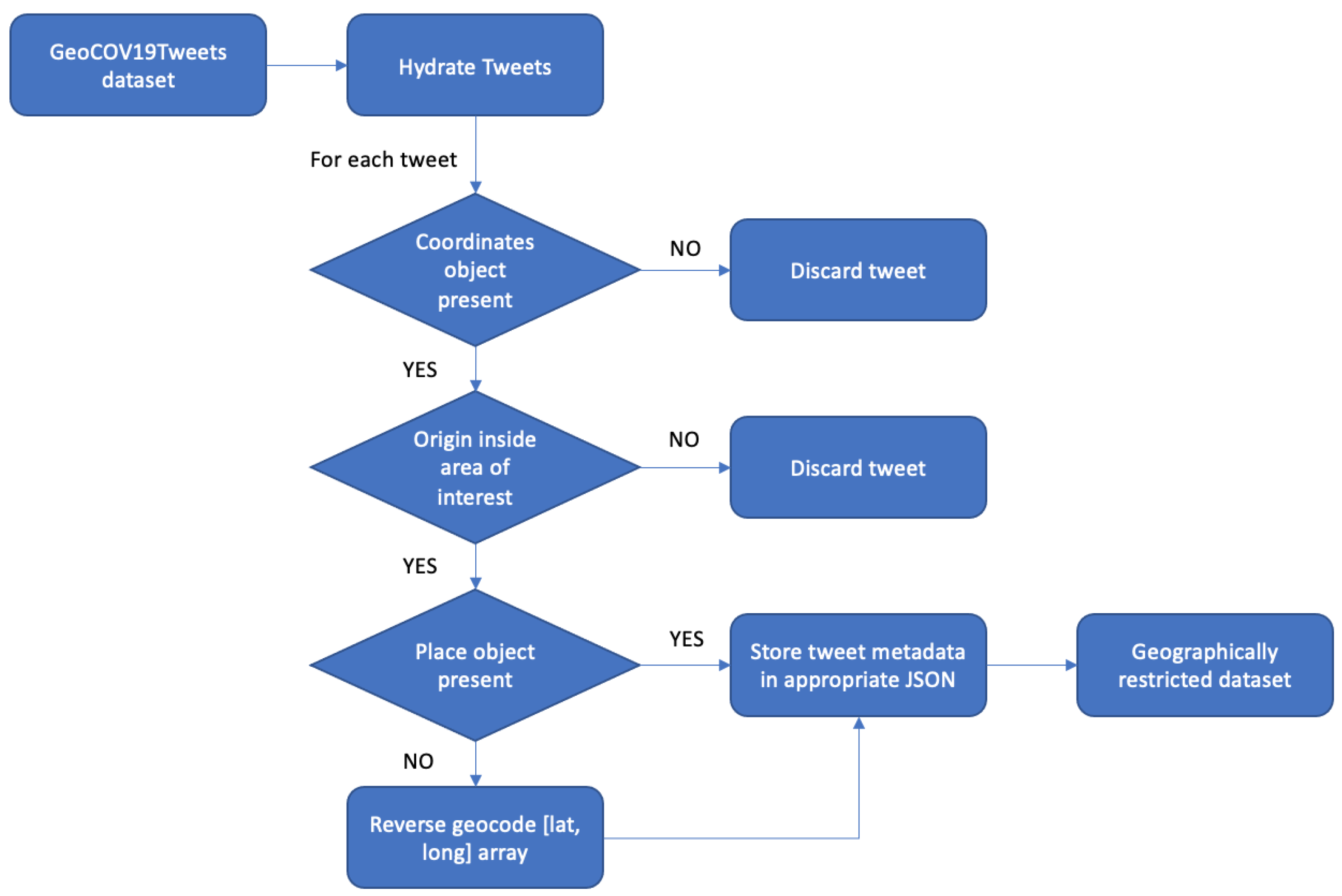
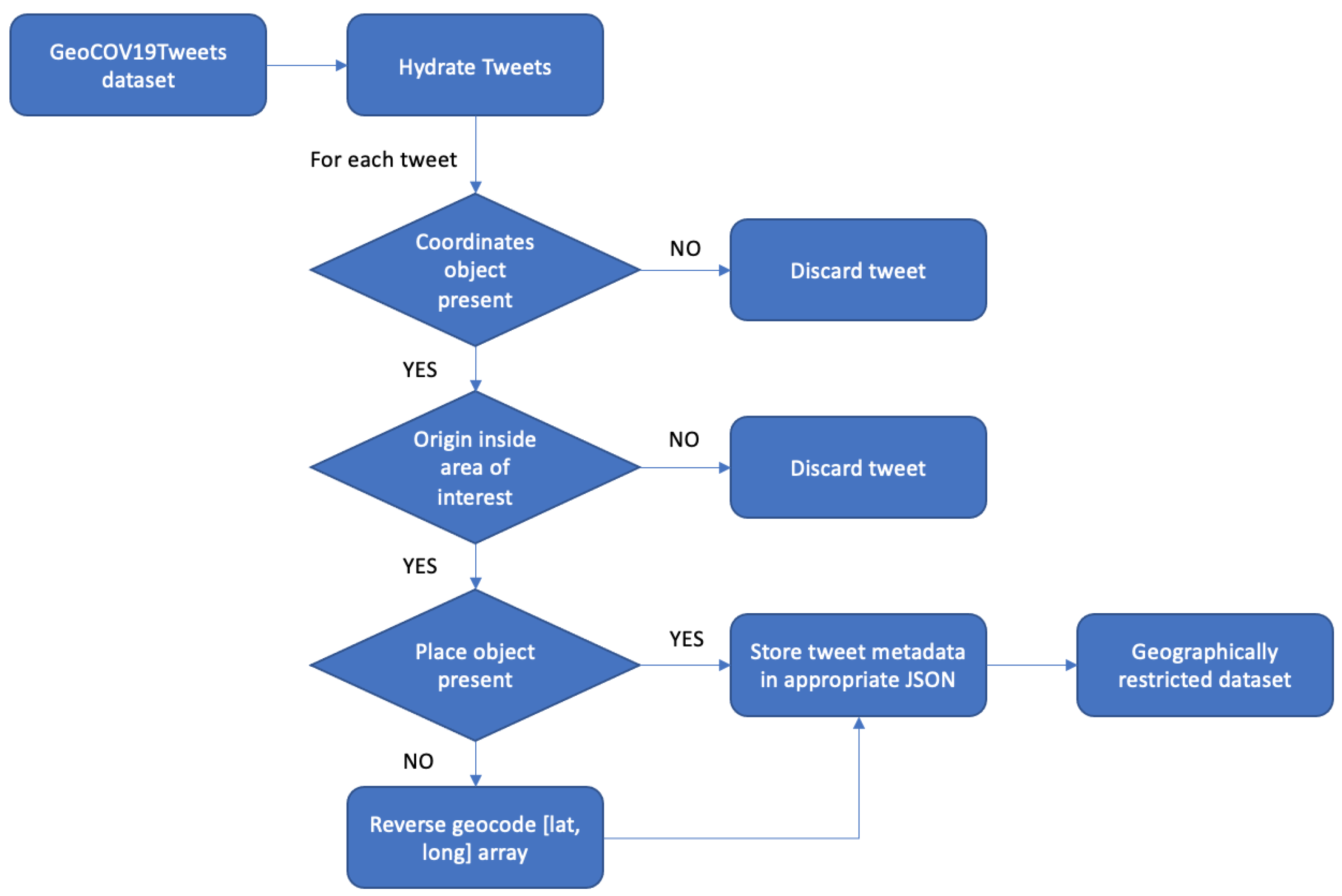
3.2. Collection Methodology
3.2.1. Hydrating Tweets
3.2.2. Determining Tweet Origin
3.2.3. Reverse-Geocoding
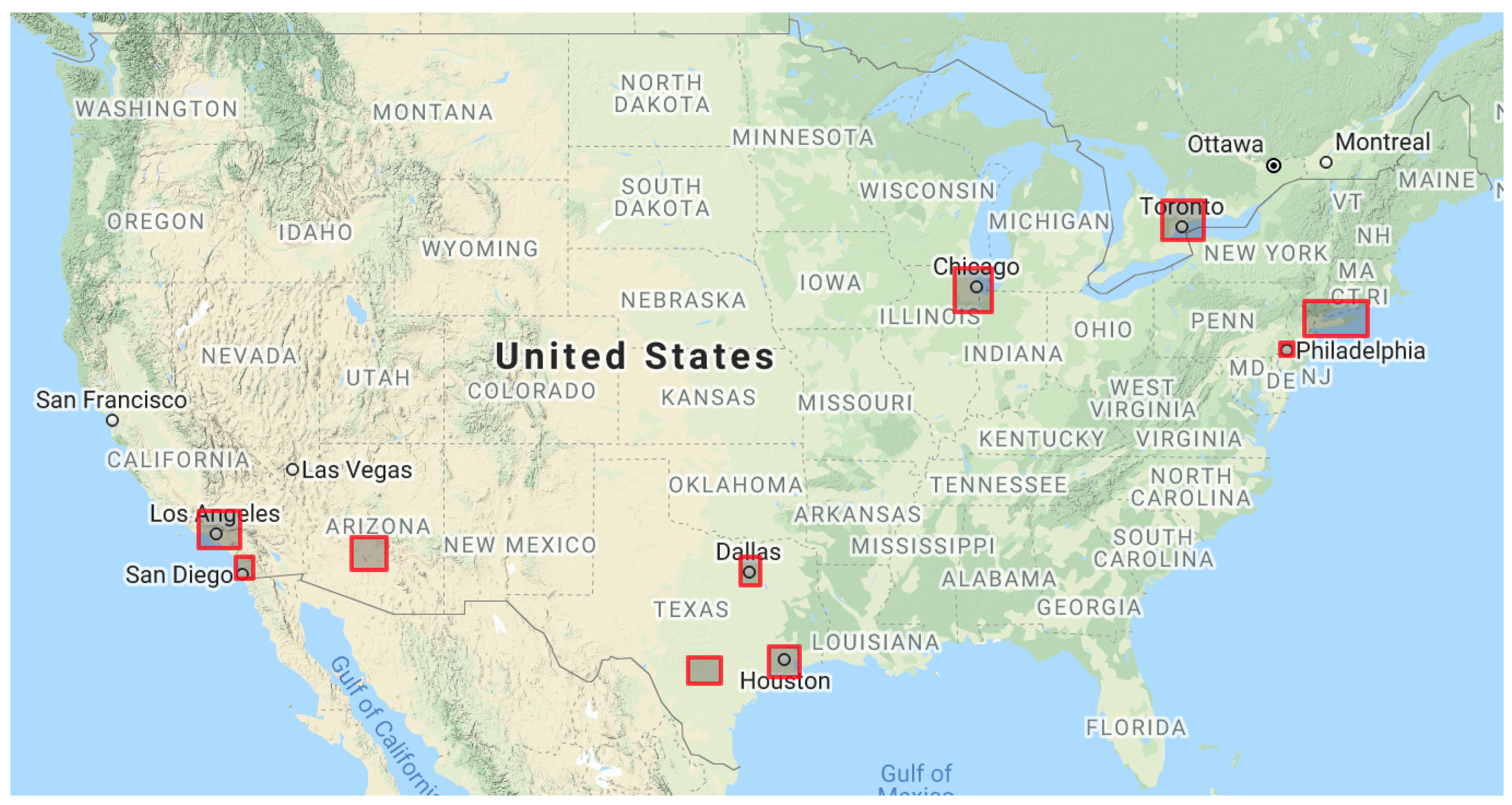
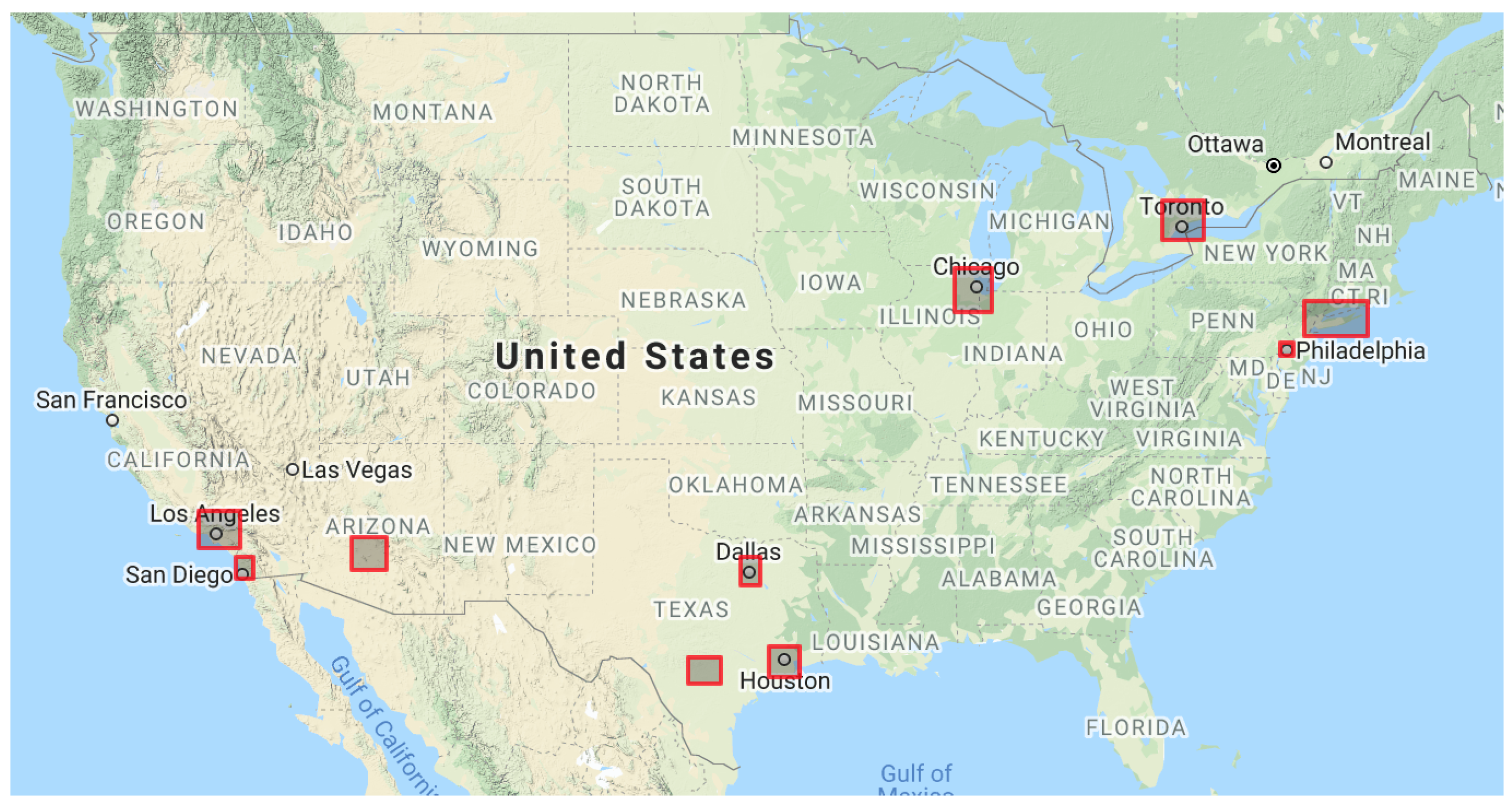
3.2.4. Selecting Metropolitan Areas
3.2.5. Location-Based Filtering
3.3. Related Datasets
3.4. Ethical Considerations
3.5. Possible Compliance with FAIR
3.6. Statistical Summary
4. Detailed Statistics and Usage Notes
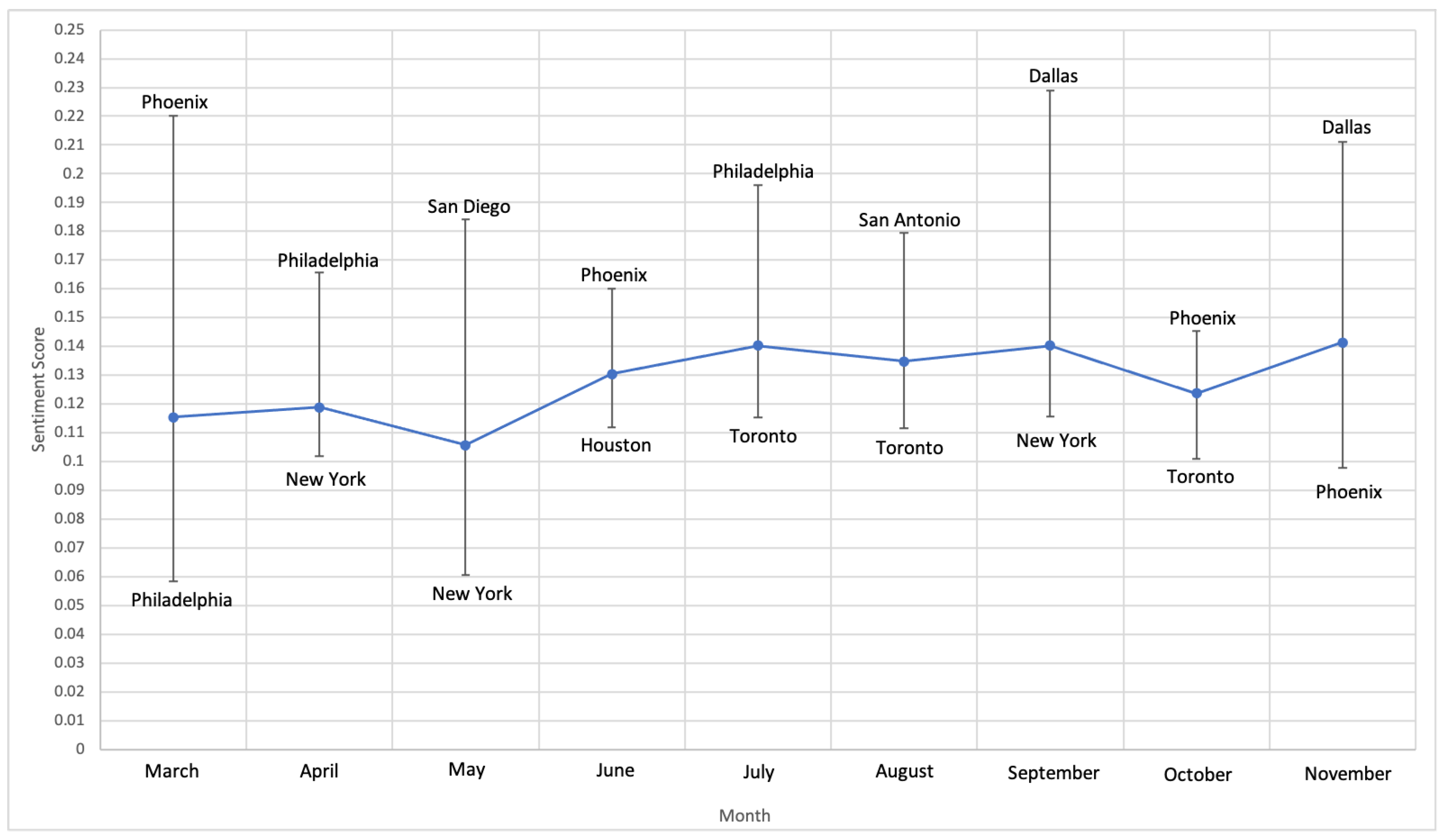
4.1. Statistics on Sentiment Scores
4.2. Statistics on Hashtags
4.3. Possible Use-Cases
- Given that different metropolitan areas were impacted differently by COVID-19 (in particular, New York was hit hard in the early days), how is this impact reflected in social media?
- Can tweets from areas (with different socioeconomic profiles) within metropolitan cities shed light on how socioeconomic status is correlated with COVID-19 impacts, and how such correlations manifest on social media? While limited surveys and studies have confirmed that COVID-19 disproportionately affected lower socioeconomic-status groups, to our knowledge, a full study through a social media lens has not yet emerged.
- Given policy measures that were enacted in different cities over time, what can we say about longitudinal differences (especially in terms of sentiment) between these cities?
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bowleg, L. We’re not all in this together: on COVID-19, intersectionality, and structural inequality. Am. J. Public Health 2020, 110, 917. [Google Scholar] [CrossRef] [PubMed]
- Patel, J.; Nielsen, F.; Badiani, A.; Assi, S.; Unadkat, V.; Patel, B.; Ravindrane, R.; Wardle, H. Poverty, inequality and COVID-19: The forgotten vulnerable. Public Health 2020, 183, 110. [Google Scholar] [CrossRef] [PubMed]
- Blundell, R.; Costa Dias, M.; Joyce, R.; Xu, X. COVID-19 and Inequalities. Fisc. Stud. 2020, 41, 291–319. [Google Scholar] [CrossRef]
- Abedi, V.; Olulana, O.; Avula, V.; Chaudhary, D.; Khan, A.; Shahjouei, S.; Li, J.; Zand, R. Racial, economic, and health inequality and COVID-19 infection in the United States. J. Racial Ethn. Health Disparities 2020, 8, 732–742. [Google Scholar] [CrossRef] [PubMed]
- Gruzd, A.; Mai, P. COVID-19 Twitter Dataset; Scholars Portal Dataverse: Vancouver, Canada, 2020. [Google Scholar] [CrossRef]
- Chen, E.; Lerman, K.; Ferrara, E. Tracking Social Media Discourse About the COVID-19 Pandemic: Development of a Public Coronavirus Twitter Data Set. JMIR Public Health Surveill 2020, 6, e19273. [Google Scholar] [CrossRef] [PubMed]
- Qazi, U.; Imran, M.; Ofli, F. GeoCoV19: A Dataset of Hundreds of Millions of Multilingual COVID-19 Tweets with Location Information. Sigspatial Spec. 2020, 12, 6–15. [Google Scholar] [CrossRef]
- Baran, E.; Dimitrov, D. TweetsCOV19-A Knowledge Base of Semantically Annotated Tweets about the COVID-19 Pandemic. 2020. Available online: https://dl.acm.org/doi/abs/10.1145/3340531.3412765 (accessed on 15 June 2021).
- Lamsal, R. Design and analysis of a large-scale COVID-19 tweets dataset. Appl. Intell. 2020, 51, 2790–2804. [Google Scholar] [CrossRef]
- Starbird, K. Disinformation’s spread: Bots, trolls and all of us. Nature 2019, 571, 449–450. [Google Scholar] [CrossRef] [PubMed]
- Loria, S. Textblob Documentation. Release 0.15. 2018. Available online: https://buildmedia.readthedocs.org/media/pdf/textblob/latest/textblob.pdf (accessed on 15 June 2021).
- Gupta, R.K.; Vishwanath, A.; Yang, Y. Covid-19 twitter dataset with latent topics, sentiments and emotions attributes. arXiv 2020, arXiv:2007.06954. [Google Scholar]
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Chowell, G. A large-scale COVID-19 Twitter chatter dataset for open scientific research—An international collaboration. arXiv 2020, arXiv:2004.03688. [Google Scholar]
- Alqurashi, S.; Alhindi, A.; Alanazi, E. Large arabic twitter dataset on covid-19. arXiv 2020, arXiv:2004.04315. [Google Scholar]
- Feng, Y.; Zhou, W. Is working from home the new norm? An observational study based on a large geo-tagged covid-19 twitter dataset. arXiv 2020, arXiv:2006.08581. [Google Scholar]
| 1. | Montreal is excluded due to its significant French-speaking population, as discussed in Collection Methodology. |
| 2. | According to its documentation, GeoCOV19Tweets itself used the Python-based TextBlob package (on the text of the tweet) to automatically obtain a sentiment score. |
| 3. | While the place_type usually contains a string indicating the type of the place (e.g., ‘city’), in some cases, it may store the zipcode due to the need for a reverse geocoding service, as discussed in Collection Methodology. |
| 4. | https://textblob.readthedocs.io/en/dev/ (accessed on 15 June 2021). |
| 5. | https://scholarslab.github.io/learn-twarc/ (accessed on 15 June 2021). |
| 6. | The GeoCOV19Tweets dataset begins on 20 March 2020. |
| 7. | https://www.geocod.io/ (accessed on 15 June 2021). |
| 8. | |
| 9. | According to https://www.census.gov/newsroom/press-releases/2020/south-west-fastest-growing.html (accessed on 15 June 2021); and https://www12.statcan.gc.ca/census-recensement/2016/as-sa/98-200-x/2016001/98-200-x2016001-eng.cfm (accessed on 15 June 2021). |
| 10. | As mentioned, the original dataset began sampling tweets on 20 March 2020. The average sentiment score for March is therefore taken over an 11-day period. |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Top Left | Bottom Right | Tweet Count | Percentage (%) | |
|---|---|---|---|---|
| New York | (41.415634, −74.485085) | (40.411124, −71.853181) | 20,979 | 40.3163 |
| Los Angeles | (34.820691, −118.946542) | (33.602688, −117.275379) | 13,893 | 26.6988 |
| Toronto | (44.383080, −80.114152) | (43.284905, −78.473654) | 5505 | 10.5792 |
| Chicago | (42.391280, −88.501901) | (41.122449, −87.009653) | 3171 | 6.0939 |
| Houston | (30.218201, −95.934175) | (29.136616, −94.729970) | 2220 | 4.2663 |
| Phoenix | (33.942208, −112.752517) | (32.812873, −111.362060) | 1123 | 2.1581 |
| Philadelphia | (40.158714, −75.403683) | (39.777982, −74.913390) | 1413 | 2.7154 |
| San Antonio | (29.850468, −99.185990) | (28.902995, −97.884110) | 697 | 1.3395 |
| San Diego | (33.249462, −117.432605) | (32.533032, −116.733257) | 1411 | 2.7116 |
| Dallas | (33.249352, −97.130478) | (32.326729, −96.342209) | 1624 | 3.1209 |
| Total | 52,036 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melotte, S.; Kejriwal, M. A Geo-Tagged COVID-19 Twitter Dataset for 10 North American Metropolitan Areas over a 255-Day Period. Data 2021, 6, 64. https://doi.org/10.3390/data6060064
Melotte S, Kejriwal M. A Geo-Tagged COVID-19 Twitter Dataset for 10 North American Metropolitan Areas over a 255-Day Period. Data. 2021; 6(6):64. https://doi.org/10.3390/data6060064
Chicago/Turabian StyleMelotte, Sara, and Mayank Kejriwal. 2021. "A Geo-Tagged COVID-19 Twitter Dataset for 10 North American Metropolitan Areas over a 255-Day Period" Data 6, no. 6: 64. https://doi.org/10.3390/data6060064
APA StyleMelotte, S., & Kejriwal, M. (2021). A Geo-Tagged COVID-19 Twitter Dataset for 10 North American Metropolitan Areas over a 255-Day Period. Data, 6(6), 64. https://doi.org/10.3390/data6060064