
Mexican Emotional Speech Database Based on Semantic, Frequency, Familiarity, Concreteness, and Cultural Shaping of Affective Prosody



Abstract
:1. Introduction
2. Results
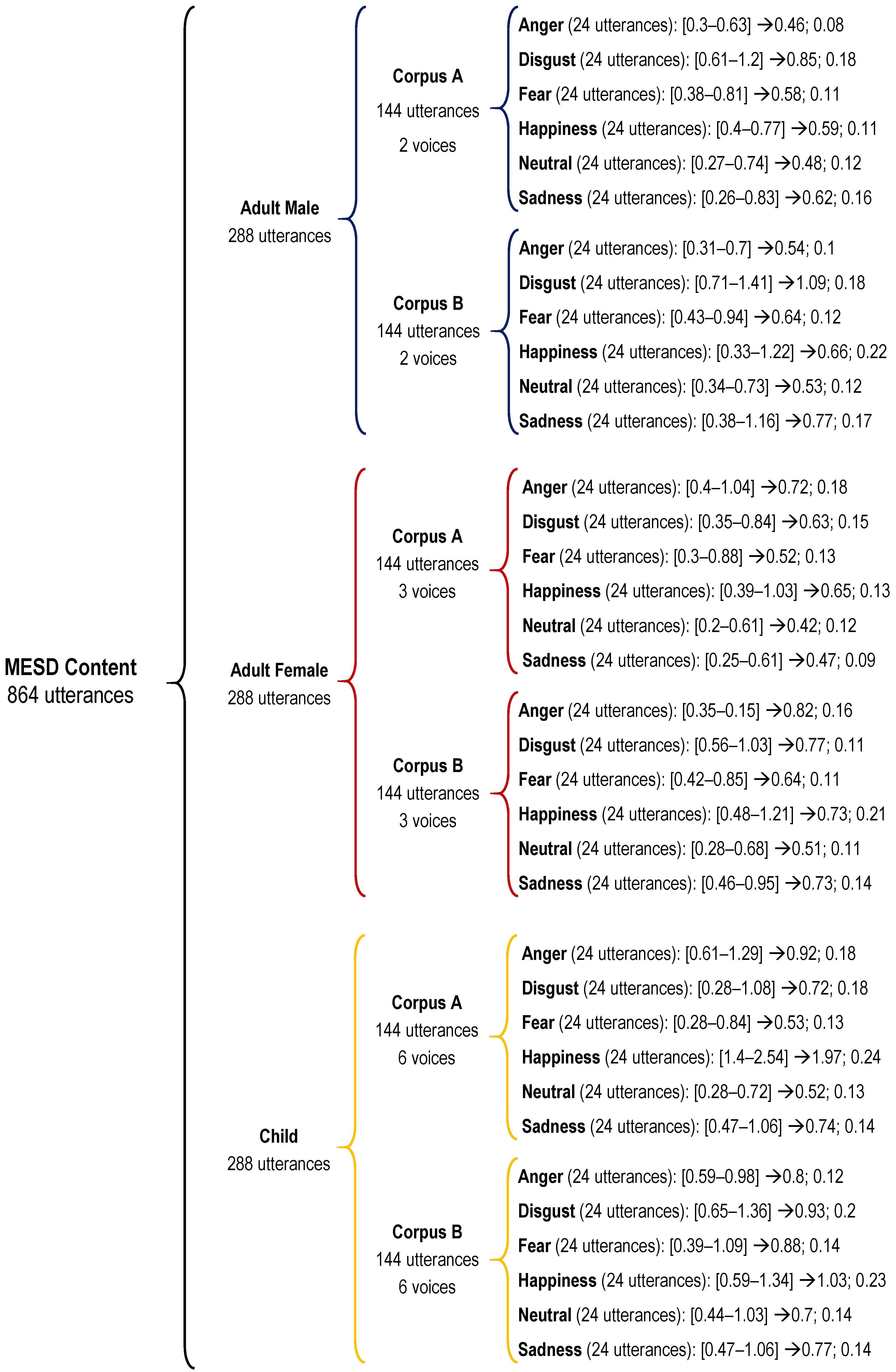
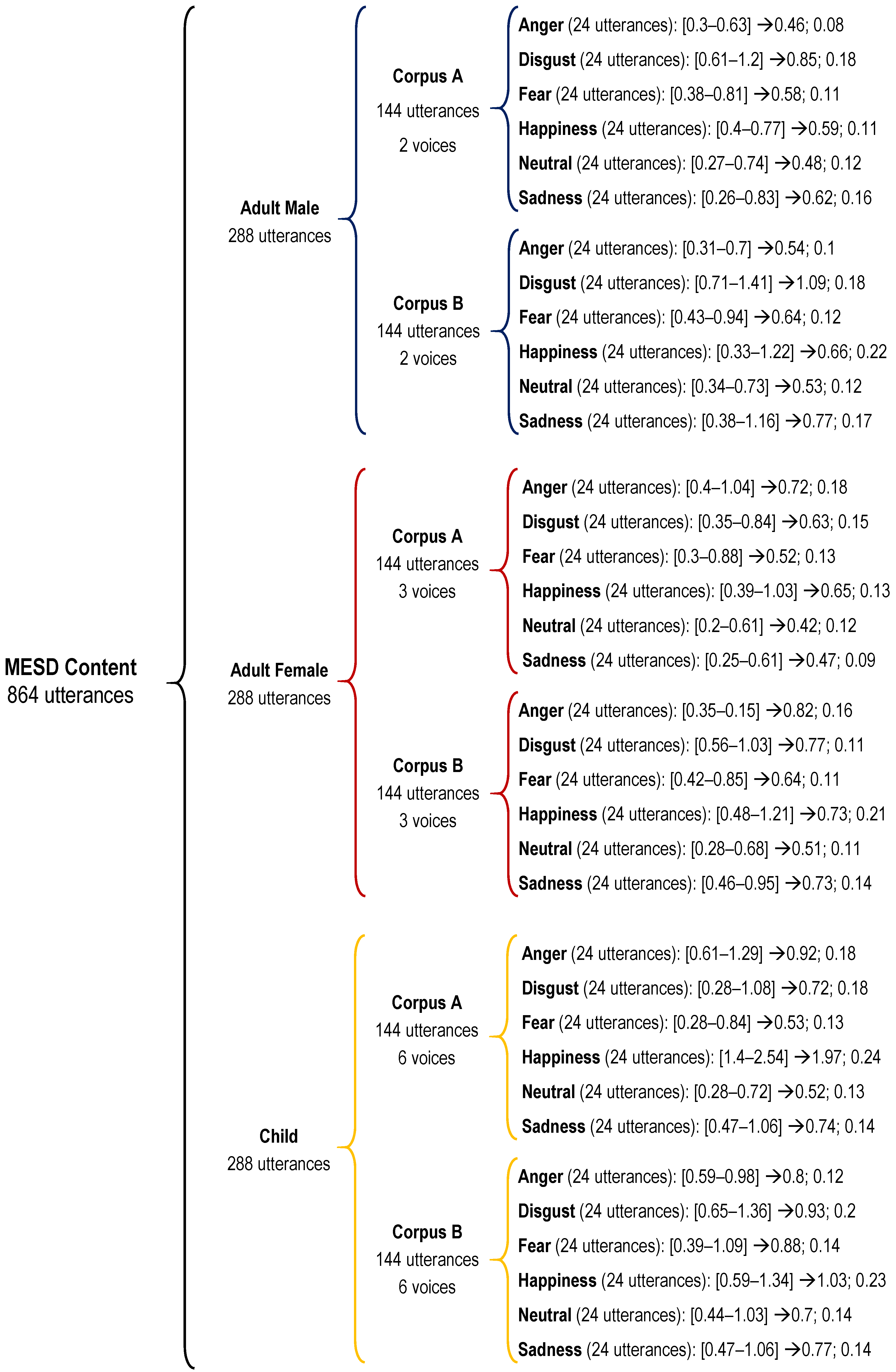
2.1. MESD Speech Corpus: Corpus B
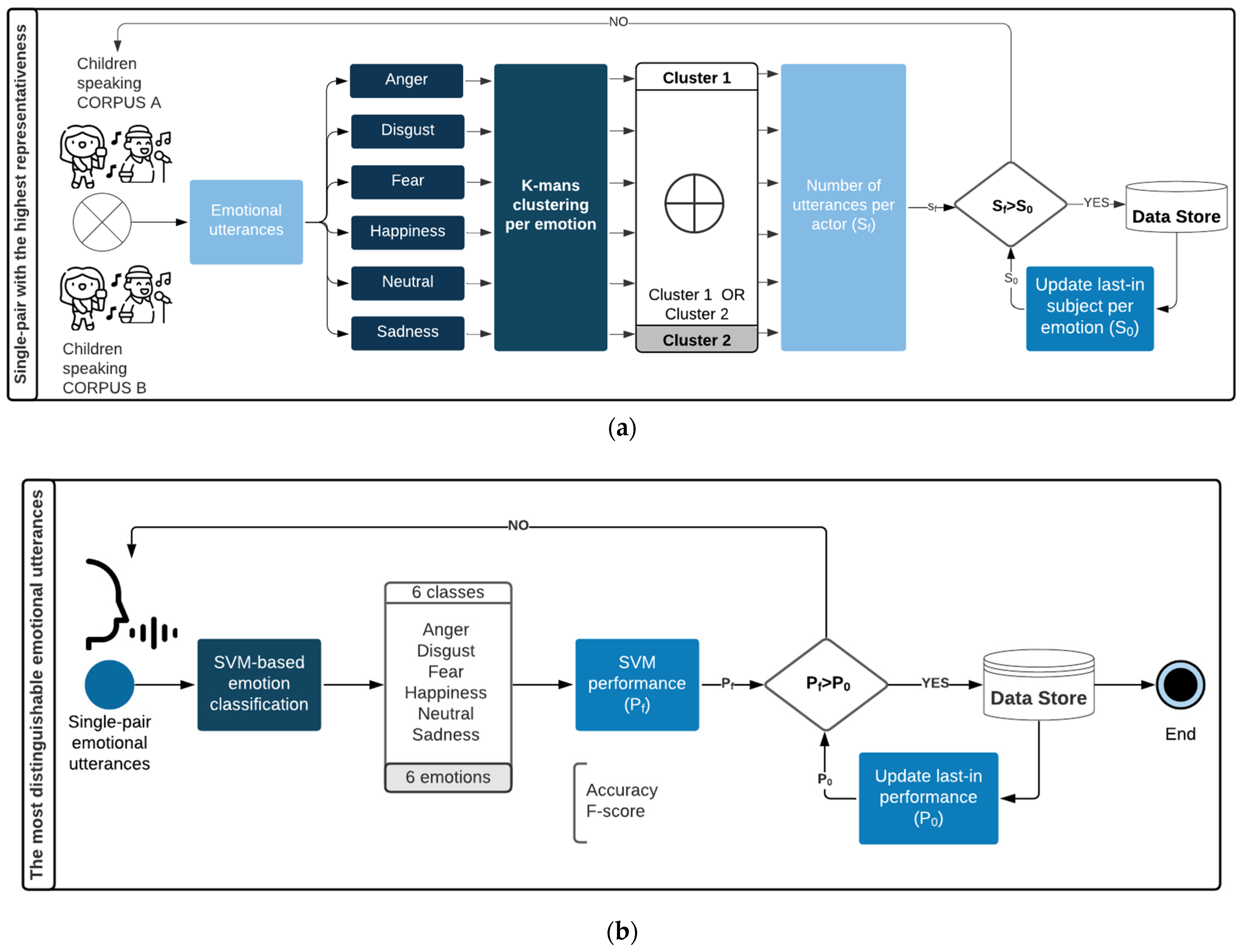
2.2. SVM-Based Validation Method
2.2.1. Female Adult Voice
2.2.2. Male Adult Voice
2.2.3. Child Voice
2.3. Statistical Analysis
2.3.1. Effects of Emotions and Cultures
2.3.2. Effects of Words Familiarity, Frequency and Concreteness
3. Discussion
3.1. SVM-Based Validation Process
3.2. Emotion Induction
3.3. Effect of Controlling Familiarity, Frequency, and Concreteness
3.4. Cultural Variations in Emotional Prosodies
3.5. Value of the Data and Contributions
- The presented dataset provides a Mexican cultural shaping of emotional linguistic utterances with adult male, adult female and child voices for six emotional states: (1) anger, (2) disgust, (3) fear, (4) happiness, (5) neutral and (6) sadness. The MESD seems to be the first set of single-word emotional utterances that includes both adult and child voices for the Mexican population.
- Engineers and researchers can use this database to train predictive model algorithms for emotion recognition. For instance, it could help smart healthcare systems for classification of emotional speech-related diseases such as depression or autism [65], or to help identify specific personality traits from speech [66].
- The MESD may be used as auditive and linguistic emotional stimuli for the exploration of emotional processing in healthy and/or pathological populations.
- The MESD provides emotional utterances from two corpora: (corpus A) nouns and adjectives that are repeated across emotional prosodies and types of voice (female, male and child), and (corpus B) words controlled for age-of-acquisition, frequency of use, familiarity, concreteness, valence, arousal and discrete emotion dimensionality ratings.
- Results from statistical analysis confirmed the existence of trade-off effects between words’ emotional semantics, frequency, familiarity, concreteness, and emotional prosodies expression, as well as prosodic cultural variations between Mexican and Castilian Spanish.
4. Materials and Methods
4.1. Acquisition of the Castilian Spanish INTERFACE Database
4.2. MESD Speech Corpus
4.3. Participants for MESD Setting-Up
4.4. Material and Procedure for Recording MESD
4.5. MESD Validation Based on Supervised Identification of Emotional Patterns
4.5.1. Acoustic Feature Extraction
4.5.2. Data Normalization
4.5.3. SVM-Based Validation Method
4.5.4. Machine Learning Procedure for Adult Voices
4.5.5. Machine-Learning Procedure for Child Voices
4.6. Statistical Analysis
4.6.1. Inter-Emotion and Inter-Culture Comparisons
4.6.2. Effects of Word Familiarity, Frequency, and Concreteness
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HNR | Harmonics-to-noise ratio |
| MESD | Mexican Emotional Speech Database |
| MFCC | Mel-Frequency Cepstral Coefficients |
| PCA | Principal Component Analysis |
| SVM | Support Vector Machines |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus A | |||||
|---|---|---|---|---|---|
| Emotion | Type of Voice for Emotional Utterance | Spanish | English Translation | ||
| Anger | Adult female Adult male Child | Abajo | Basta ya | Below | Enough |
| Ayer | Arriba | Yesterday | Above | ||
| Disgust | Fuera | Gracias | Outside | Thank you | |
| Hola | Por favor | Hello | Please | ||
| Fear | Hoy | De nada | Today | Your welcome | |
| No | Izquierda | No | Left | ||
| Happiness | Sí | Derecha | Yes | Right | |
| Adiós | Dentro | Goodbye | Within | ||
| Neutral | Nunca | Pronto | Never | Soon | |
| Lento | Rápido | Slowly | Quick | ||
| Sadness | Tarde | Detrás | Afternoon/Late | Behind | |
| Antes | Delante | Before | Ahead | ||
| Corpus B | |||||
|---|---|---|---|---|---|
| Anger | Disgust | Fear | Happiness | Neutral | Sadness |
| Adult Female | |||||
| Relajación | Relajación | Tristeza | Calmado | Agencia | Tristeza |
| Amenazado | Abuso | Abuso | Cómico | Barba | Relajación |
| Insultado | Oruga | Delincuencia | Delfín | Caducado | Abandono |
| Atasco | Creído | Amenazado | Estudioso | Religioso | Ceguera |
| Ceguera | Monstruoso | Explosivo | Fresco | Consciente | Injusticia |
| Odioso | Cucaracha | Araña | Bebé | Pelirrojo | Delincuencia |
| Torturado | Delincuencia | Furia | Clavel | Contrario | Abuso |
| Conflicto | Amenazador | Ceguera | Masaje | Desierto | Monstruoso |
| Abuso | Horroroso | Relajación | Oasis | Extenso | Desmayo |
| Delincuencia | Injusticia | Desmayo | Refrescante | Acuático | Enfriamiento |
| Explosión | Atasco | Horroroso | Delicadeza | Bola | Explosivo |
| Amenazador | Insultado | Dificultad | Calma | Fecha | Fracasado |
| Monstruoso | Jeringuilla | Engañado | Rosa | Acuarela | Hambre |
| Explosivo | Monstruo | Amenazador | Siesta | Garganta | Cansancio |
| Furia | Araña | Estricto | Ternura | Temporal | Odioso |
| Huracán | Conflicto | Aguijón | Chimenea | Giro | Huracán |
| Ataque | Náusea | Explosión | Velas | Hondo | Insultado |
| Estricto | Oloroso | Cucaracha | Afición | Mentiroso | Llanto |
| Injusticia | Puñalada | Fantasma | Aglomeración | Elevado | Metralleta |
| Ira | Engañado | Alarma | Fantástico | Metro | Explosión |
| Irrespetuoso | Robo | Huracán | Atractivo | Mojado | Mortal |
| Engañado | Abandono | Cirugía | Aventurero | Paella | Náusea |
| Ofensa | Chistoso | Conflicto | Baile | Mecánico | Conflicto |
| Pesadilla | Torturado | Infarto | Bello | Presumido | Ofensa |
| English translation | |||||
| Relaxation | Relaxation | Sadness | Calmed | Agency | Sadness |
| Threated | Abuse | Abuse | Comedian | Beard | Relaxation |
| Insulted | Caterpillar | Crime | Dolphin | Expired | Abandonment |
| Traffic jam | Vain | Threated | Studious | Religious | Blindness |
| Blindness | Monstrous | Explosive | Fresh | Aware | Injustice |
| Hateful | Cockroach | Spider | Baby | Redhead | Crime |
| Tortured | Crime | Fury | Carnation | Opposite | Abuse |
| Conflict | Threatening | Blindness | Massage | Desert | Monstrous |
| Abuse | Dreadful | Relaxation | Oasis | Wide | Faint |
| Crime | Injustice | Faint | Refreshing | Aquatic | Cooling |
| Explosion | Traffic jam | Dreadful | Fineness | Ball | Explosive |
| Threatening | Insulted | Difficulty | Calm | Date | Loser |
| Monstrous | Syringe | Deceived | Rose | Watercolor | Hunger |
| Explosive | Monster | Threatening | Nap | Throat | Tiredness |
| Fury | Spider | Strict | Tenderness | Temporary | Hateful |
| Hurricane | Conflict | Sting | Fireplace | Turn | Hurricane |
| Attack | Nausea | Explosion | Candles | Deep | Insulted |
| Strict | Odorous | Cockroach | Hobby | Liar | Cry |
| Injustice | Stab | Ghost | Conglomerate | High | Machine gun |
| Rage | Deceived | Alarm | Fantastic | Subway | Explosion |
| Disrespectful | Theft | Hurricane | Attractive | Wet | Mortal |
| Deceived | Abandonment | Surgery | Adventurous | Paella | Nausea |
| Offense | Humorous | Conflict | Dance | Mechanic | Conflict |
| Nightmare | Tortured | Heart attack | Beautiful | Boastful | Offense |
| Adult Male | |||||
| Aguijón | Aguijón | Inconsciente | Antiguo | Alto | Funeraria |
| Farsa | Amenazado | Amenazador | Ducha | Artículo | Tristeza |
| Ansiedad | Celda | Delincuencia | Baile | Ferrocarril | Abandono |
| Conflicto | Monstruo | Ataque | Aventurero | Átomo | Celda |
| Delincuencia | Operación | Celda | Pelirrojo | Extenso | Danza |
| Ataque | Desorden | Araña | Respiración | Babosa | Dificultad |
| Dificultad | Caprichoso | Danza | Siesta | Chulo | Antiguo |
| Encadenado | Estafa | Aguijón | Tranquilidad | Consciente | Ira |
| Estafa | Araña | Enojo | Confidente | Delgado | Encadenado |
| Abandono | Metralleta | Cirugía | Agua | Desierto | Amenazado |
| Furia | Abandono | Estafa | Satisfacción | Abierto | Furia |
| Hambre | Cucaracha | Furia | Broma | Estación | Delincuencia |
| Desorden | Mutilado | Dificultad | Afición | Despistado | Estafa |
| Huracán | Náusea | Conflicto | Calmado | Arroz | Ansiedad |
| Danza | Delincuencia | Ansiedad | Ensueño | Escalera | Hambre |
| Amenazador | Odioso | Huracán | Calma | Azulejo | Huracán |
| Impaciencia | Eructo | Imprudente | Alegría | Colorado | Infarto |
| Enojo | Puñalada | Abandono | Fresco | Estrecho | Conflicto |
| Disputa | Sangre | Cucaracha | Amistad | Agencia | Enojo |
| Amenazado | Terrorismo | Encadenado | Espléndido | Botón | Injusticia |
| Injusticia | Encadenado | Infarto | Atractivo | Congelado | Llanto |
| Atasco | Furia | Amenazado | Relajación | Escurridizo | Locura |
| Ira | Monstruoso | Explosión | Astuto | Fecha | Ataque |
| Malévolo | Torturado | Ira | Bebé | Bola | Metralleta |
| English translation | |||||
| Sting | Sting | Unconscious | Antique | Tall | Funeral parlor |
| Sham | Threated | Threatening | Shower | Article | Sadness |
| Anxiety | Cell | Crime | Dance | Railway | Abandonment |
| Conflict | Monster | Attack | Adventurous | Atom | Cell |
| Crime | Operation | Cell | Redhead | Wide | Dance |
| Attack | Mess | Spider | Breathing | Slug | Difficulty |
| Difficulty | Capricious | Dance | Nap | Pimp | Antique |
| Chained | Scam | Sting | Tranquility | Aware | Rage |
| Scam | Spider | Annoyance | Informer | Thin | Chained |
| Abandonment | Machine gun | Surgery | Water | Desert | Threatened |
| Fury | Abandonment | Scam | Satisfaction | Open | Fury |
| Hunger | Cockroach | Fury | Joke | Station | Crime |
| Mess | Amputee | Difficulty | Hobby | Absentminded | Scam |
| Hurricane | Nausea | Conflict | Calmed | Rice | Anxiety |
| Dance | Crime | Anxiety | Daydream | Stairs | Hunger |
| Threatening | Hateful | Hurricane | Calm | Tile | Hurricane |
| Impatience | Burp | Imprudent | Happiness | Red-colored | Heart attack |
| Annoyance | Stab | Abandonment | Fresh | Narrow | Conflict |
| Argument | Blood | Cockroach | Friendship | Agency | Annoyance |
| Threated | Terrorism | Chained | Magnificent | Button | Injustice |
| Injustice | Chained | Heart attack | Attractive | Frozen | Cry |
| Traffic jam | Fury | Threatened | Relaxation | Slippery | Madness |
| Rage | Monstrous | Explosion | Clever | Date | Attack |
| Wicked | Tortured | Rage | Baby | Ball | Machine gun |
| Child | |||||
| Amenazado | Abuso | Desmayo | Acogedora | Botón | Cansancio |
| Catástrofe | Repulsivo | Abuso | Clavel | Congelado | Desmayo |
| Explosivo | Monstruoso | Amenazador | Afición | Delgado | Tristeza |
| Estricto | Atasco | Catástrofe | Fresco | Espacial | Traición |
| Ceguera | Crisis | Ceguera | Masaje | Extenso | Ataque |
| Injusticia | Delincuencia | Delincuencia | Oasis | Bola | Catástrofe |
| Abandono | Estafa | Araña | Baile | Ferrocarril | Humillación |
| Robo | Aguijón | Cirugía | Relax | Hondo | Ceguera |
| Dañino | Furia | Alarma | Fantástico | Labrador | Injusticia |
| Ataque | Humillación | Conflicto | Celebración | Mecánico | Dañino |
| Delincuencia | Injusticia | Humillación | Chistoso | Elevado | Abandono |
| Abuso | Abandono | Abandono | Atractivo | Pelirrojo | Disputa |
| Amenazador | Suspenso | Disputa | Bebé | Colorado | Enojo |
| Disputa | Insultado | Estricto | Coordinación | Rizado | Amenazado |
| Enojo | Monstruo | Injusticia | Bello | Rueda | Explosión |
| Condena | Mutilado | Robo | Calmado | Seco | Abuso |
| Estafa | Cucaracha | Aguijón | Aventurero | Escurridizo | Estafa |
| Alterado | Araña | Alterado | Rosa | Temporal | Condena |
| Explosión | Náusea | Cucaracha | Cita | Vapor | Explosivo |
| Dificultad | Amenazador | Dañino | Aplausos | Mojado | Furia |
| Furia | Odioso | Estafa | Creativo | Estrecho | Robo |
| Impaciencia | Irrespetuoso | Condena | Danza | Húmedo | Conflicto |
| Atasco | Puñalada | Explosión | Delicioso | Robusto | Delincuencia |
| Humillación | Robo | Amenazado | Carcajada | Mimado | Infarto |
| English translation | |||||
| Threatened | Abuse | Faint | Cozy | Button | Tiredness |
| Catastrophe | Repulsive | Abuse | Carnation | Frozen | Faint |
| Explosive | Monstrous | Threatening | Hobby | Thin | Sadness |
| Strict | Traffic jam | Catastrophe | Fresh | Spatial | Treason |
| Blindness | Crisis | Blindness | Massage | Wide | Attack |
| Injustice | Crime | Crime | Oasis | Ball | Catastrophe |
| Abandonment | Scam | Spider | Dance | Railway | Humiliation |
| Theft | Sting | Surgery | Relax | Deep | Blindness |
| Harmful | Fury | Alarm | Fantastic | Farmer | Injustice |
| Attack | Humiliation | Conflict | Celebration | Mechanic | Harmful |
| Crime | Injustice | Humiliation | Humorous | High | Abandonment |
| Abuse | Abandonment | Abandonment | Attractive | Redhead | Argument |
| Threatening | Fail | Argument | Baby | Red-colored | Annoyance |
| Argument | Insulted | Strict | Coordination | Curly | Threatened |
| Annoyance | Monster | Injustice | Beautiful | Wheel | Explosion |
| Condemnation | Amputee | Theft | Calmed | Dry | Abuse |
| Scam | Cockroach | Sting | Adventurous | Slippery | Scam |
| Annoyed | Spider | Annoyed | Rose | Temporary | Condemnation |
| Explosion | Nausea | Cockroach | Date | Steam | Explosive |
| Difficulty | Threatening | Harmful | Applause | Wet | Fury |
| Fury | Hateful | Scam | Creative | Narrow | Theft |
| Impatience | Disrespectful | Condemnation | Dance | Moist | Conflict |
| Traffic jam | Stab | Explosion | Delicious | Robust | Crime |
| Humiliation | Theft | Threatened | Guffaw | Spoiled | Heart attack |
References
- Kamińska, D. Emotional Speech Recognition Based on the Committee of Classifiers. Entropy 2019, 21, 920. [Google Scholar] [CrossRef] [Green Version]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on Speech Emotion Recognition: Features, Classification Schemes, and Databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Cowen, A.S.; Laukka, P.; Elfenbein, H.A.; Liu, R.; Keltner, D. The Primacy of Categories in the Recognition of 12 Emotions in Speech Prosody across Two Cultures. Nat. Hum. Behav. 2019, 3, 369–382. [Google Scholar] [CrossRef]
- Gendron, M.; Roberson, D.; van der Vyver, J.M.; Barrett, L.F. Cultural Relativity in Perceiving Emotion From Vocalizations. Psychol. Sci. 2014, 25, 911–920. [Google Scholar] [CrossRef] [Green Version]
- Laukka, P.; Elfenbein, H.A.; Thingujam, N.S.; Rockstuhl, T.; Iraki, F.K.; Chui, W.; Althoff, J. The Expression and Recognition of Emotions in the Voice across Five Nations: A Lens Model Analysis Based on Acoustic Features. J. Personal. Soc. Psychol. 2016, 111, 686–705. [Google Scholar] [CrossRef]
- Elfenbein, H.A. Nonverbal Dialects and Accents in Facial Expressions of Emotion. Emot. Rev. 2013, 5, 90–96. [Google Scholar] [CrossRef]
- Laukka, P.; Elfenbein, H.A. Cross-Cultural Emotion Recognition and In-Group Advantage in Vocal Expression: A Meta-Analysis. Emot. Rev. 2021, 13, 3–11. [Google Scholar] [CrossRef]
- Song, P.; Zheng, W.; Ou, S.; Zhang, X.; Jin, Y.; Liu, J.; Yu, Y. Cross-Corpus Speech Emotion Recognition Based on Transfer Non-Negative Matrix Factorization. Speech Commun. 2016, 83, 34–41. [Google Scholar] [CrossRef]
- Caballero-Morales, S.-O. Recognition of Emotions in Mexican Spanish Speech: An Approach Based on Acoustic Modelling of Emotion-Specific Vowels. Sci. World J. 2013, 2013, 162093. [Google Scholar] [CrossRef]
- Steber, S.; König, N.; Stephan, F.; Rossi, S. Uncovering Electrophysiological and Vascular Signatures of Implicit Emotional Prosody. Sci. Rep. 2020, 10, 5807. [Google Scholar] [CrossRef] [PubMed]
- Bestelmeyer, P.E.G.; Kotz, S.A.; Belin, P. Effects of Emotional Valence and Arousal on the Voice Perception Network. Soc. Cogn. Affect. Neurosci. 2017, 12, 1351–1358. [Google Scholar] [CrossRef] [Green Version]
- Ghiasi, S.; Greco, A.; Barbieri, R.; Scilingo, E.P.; Valenza, G. Assessing Autonomic Function from Electrodermal Activity and Heart Rate Variability During Cold-Pressor Test and Emotional Challenge. Sci. Rep. 2020, 10, 5406. [Google Scholar] [CrossRef]
- Scherer, K.R.; Clark-Polner, E.; Mortillaro, M. In the Eye of the Beholder? Universality and Cultural Specificity in the Expression and Perception of Emotion. Int. J. Psychol. 2011, 46, 401–435. [Google Scholar] [CrossRef] [Green Version]
- Scherer, K.R.; Sundberg, J.; Tamarit, L.; Salomão, G.L. Comparing the Acoustic Expression of Emotion in the Speaking and the Singing Voice. Comput. Speech Lang. 2015, 29, 218–235. [Google Scholar] [CrossRef] [Green Version]
- Arruti, A.; Cearreta, I.; Álvarez, A.; Lazkano, E.; Sierra, B. Feature Selection for Speech Emotion Recognition in Spanish and Basque: On the Use of Machine Learning to Improve Human-Computer Interaction. PLoS ONE 2014, 9, e108975. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.-T.; Wu, M.; Cao, W.-H.; Mao, J.-W.; Xu, J.-P.; Tan, G.-Z. Speech Emotion Recognition Based on Feature Selection and Extreme Learning Machine Decision Tree. Neurocomputing 2018, 273, 271–280. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oğuz, K. Speech Emotion Recognition: Emotional Models, Databases, Features, Preprocessing Methods, Supporting Modalities, and Classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- Bhavan, A.; Chauhan, P.; Hitkul; Shah, R.R. Bagged Support Vector Machines for Emotion Recognition from Speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; Andre, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva Minimalistic Acoustic Parameter Set (GeMAPS) for Voice Research and Affective Computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.-T.; Xie, Q.; Wu, M.; Cao, W.-H.; Mei, Y.; Mao, J.-W. Speech Emotion Recognition Based on an Improved Brain Emotion Learning Model. Neurocomputing 2018, 309, 145–156. [Google Scholar] [CrossRef]
- Nasr, M.A.; Abd-Elnaby, M.; El-Fishawy, A.S.; El-Rabaie, S.; Abd El-Samie, F.E. Speaker Identification Based on Normalized Pitch Frequency and Mel Frequency Cepstral Coefficients. Int. J. Speech Technol. 2018, 21, 941–951. [Google Scholar] [CrossRef]
- Swain, M.; Routray, A.; Kabisatpathy, P. Databases, Features and Classifiers for Speech Emotion Recognition: A Review. Int. J. Speech Technol. 2018, 21, 93–120. [Google Scholar] [CrossRef]
- Gangamohan, P.; Kadiri, S.R.; Yegnanarayana, B. Analysis of Emotional Speech—A Review. In Toward Robotic Socially Believable Behaving Systems; Esposito, A., Jain, L.C., Eds.; Intelligent Systems Reference Library; Springer International Publishing: Cham, The Netherlands, 2016; Volume 105, pp. 205–238. ISBN 978-3-319-31055-8. [Google Scholar]
- Kadiri, S.R.; Gangamohan, P.; Gangashetty, S.V.; Alku, P.; Yegnanarayana, B. Excitation Features of Speech for Emotion Recognition Using Neutral Speech as Reference. Circuits Syst. Signal Process. 2020, 39, 4459–4481. [Google Scholar] [CrossRef] [Green Version]
- Arias, P.; Rachman, L.; Liuni, M.; Aucouturier, J.-J. Beyond Correlation: Acoustic Transformation Methods for the Experimental Study of Emotional Voice and Speech. Emot. Rev. 2021, 13, 12–24. [Google Scholar] [CrossRef]
- Lammert, A.C.; Narayanan, S.S. On Short-Time Estimation of Vocal Tract Length from Formant Frequencies. PLoS ONE 2015, 10, e0132193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Toutios, A.; Lee, S.; Narayanan, S.S. Vocal Tract Shaping of Emotional Speech. Comput. Speech Lang. 2020, 64, 101100. [Google Scholar] [CrossRef] [PubMed]
- Ancilin, J.; Milton, A. Improved Speech Emotion Recognition with Mel Frequency Magnitude Coefficient. Appl. Acoust. 2021, 179, 108046. [Google Scholar] [CrossRef]
- Li, D.; Zhou, Y.; Wang, Z.; Gao, D. Exploiting the Potentialities of Features for Speech Emotion Recognition. Inf. Sci. 2021, 548, 328–343. [Google Scholar] [CrossRef]
- Hozjan, V.; Kacic, Z.; Moreno, A.; Bonafonte, A.; Nogueiras, A. Interface Databases: Design and Collection of a Multilingual Emotional Speech Database. In Proceedings of the 3rd International Conference on Language Resources and Evaluation, LREC 2002 2024–2028 5, Las Palmas, Spain, 29–31 May 2002. [Google Scholar]
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic Speech Recognition: A Survey. Multimed. Tools Appl. 2020, 80, 9411–9457. [Google Scholar] [CrossRef]
- Yang, N.; Dey, N.; Sherratt, R.S.; Shi, F. Recognize Basic Emotional Statesin Speech by Machine Learning Techniques Using Mel-Frequency Cepstral Coefficient Features. J. Intell. Fuzzy Syst. 2020, 39, 1925–1936. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Akagi, M. Two-Stage Dimensional Emotion Recognition by Fusing Predictions of Acoustic and Text Networks Using SVM. Speech Commun. 2021, 126, 9–21. [Google Scholar] [CrossRef]
- Wang, K.; An, N.; Li, B.N.; Zhang, Y.; Li, L. Speech Emotion Recognition Using Fourier Parameters. IEEE Trans. Affect. Comput. 2015, 6, 69–75. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Raoof, K.; Mbarki, M.; Mahjoub, M.A.; Cleder, C. Automatic Speech Emotion Recognition Using an Optimal Combination of Features Based on EMD-TKEO. Speech Commun. 2019, 114, 22–35. [Google Scholar] [CrossRef]
- Segrin, C.; Flora, J. Fostering Social and Emotional Intelligence: What Are the Best Current Strategies in Parenting? Soc. Pers. Psychol. Compass 2019, 13, e12439. [Google Scholar] [CrossRef]
- Coutinho, E.; Schuller, B. Shared Acoustic Codes Underlie Emotional Communication in Music and Speech—Evidence from Deep Transfer Learning. PLoS ONE 2017, 12, e0179289. [Google Scholar] [CrossRef] [Green Version]
- Campayo–Muñoz, E.; Cabedo–Mas, A. The Role of Emotional Skills in Music Education. Brit. J. Music Ed. 2017, 34, 243–258. [Google Scholar] [CrossRef]
- Amado-Alonso, D.; León-del-Barco, B.; Mendo-Lázaro, S.; Sánchez-Miguel, P.; Iglesias Gallego, D. Emotional Intelligence and the Practice of Organized Physical-Sport Activity in Children. Sustainability 2019, 11, 1615. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Wang, Q. Culture in Emotional Development. In Handbook of Emotional Development; LoBue, V., Pérez-Edgar, K., Buss, K.A., Eds.; Springer International Publishing: Cham, The Netherlands, 2019; pp. 569–593. ISBN 978-3-030-17331-9. [Google Scholar]
- Pérez-Espinosa, H.; Reyes-García, C.A.; Villaseñor-Pineda, L. EmoWisconsin: An Emotional Children Speech Database in Mexican Spanish. In Affective Computing and Intelligent Interaction; D’Mello, S., Graesser, A., Schuller, B., Martin, J.-C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6975, pp. 62–71. ISBN 978-3-642-24570-1. [Google Scholar]
- Pérez-Espinosa, H.; Martínez-Miranda, J.; Espinosa-Curiel, I.; Rodríguez-Jacobo, J.; Villaseñor-Pineda, L.; Avila-George, H. IESC-Child: An Interactive Emotional Children’s Speech Corpus. Comput. Speech Lang. 2020, 59, 55–74. [Google Scholar] [CrossRef]
- Hammerschmidt, K.; Jürgens, U. Acoustical Correlates of Affective Prosody. J. Voice 2007, 21, 531–540. [Google Scholar] [CrossRef] [PubMed]
- Lausen, A.; Hammerschmidt, K. Emotion Recognition and Confidence Ratings Predicted by Vocal Stimulus Type and Prosodic Parameters. Humanit. Soc. Sci. Commun. 2020, 7, 2. [Google Scholar] [CrossRef]
- Ding, J.; Wang, L.; Yang, Y. The Dynamic Influence of Emotional Words on Sentence Processing. Cogn. Affect. Behav. Neurosci. 2015, 15, 55–68. [Google Scholar] [CrossRef] [PubMed]
- Hinojosa, J.A.; Moreno, E.M.; Ferré, P. Affective Neurolinguistics: Towards a Framework for Reconciling Language and Emotion. Lang. Cogn. Neurosci. 2020, 35, 813–839. [Google Scholar] [CrossRef]
- Kotz, S.A.; Paulmann, S. When Emotional Prosody and Semantics Dance Cheek to Cheek: ERP Evidence. Brain Res. 2007, 1151, 107–118. [Google Scholar] [CrossRef]
- Paulmann, S.; Kotz, S.A. An ERP Investigation on the Temporal Dynamics of Emotional Prosody and Emotional Semantics in Pseudo- and Lexical-Sentence Context. Brain Lang. 2008, 105, 59–69. [Google Scholar] [CrossRef]
- Hinojosa, J.A.; Albert, J.; López-Martín, S.; Carretié, L. Temporospatial Analysis of Explicit and Implicit Processing of Negative Content during Word Comprehension. Brain Cogn. 2014, 87, 109–121. [Google Scholar] [CrossRef] [PubMed]
- Yao, Z.; Yu, D.; Wang, L.; Zhu, X.; Guo, J.; Wang, Z. Effects of Valence and Arousal on Emotional Word Processing Are Modulated by Concreteness: Behavioral and ERP Evidence from a Lexical Decision Task. Int. J. Psychophysiol. 2016, 110, 231–242. [Google Scholar] [CrossRef]
- Pauligk, S.; Kotz, S.A.; Kanske, P. Differential Impact of Emotion on Semantic Processing of Abstract and Concrete Words: ERP and FMRI Evidence. Sci. Rep. 2019, 9, 14439. [Google Scholar] [CrossRef]
- Scott, G.G.; O’Donnell, P.J.; Leuthold, H.; Sereno, S.C. Early Emotion Word Processing: Evidence from Event-Related Potentials. Biol. Psychol. 2009, 80, 95–104. [Google Scholar] [CrossRef]
- Méndez-Bértolo, C.; Pozo, M.A.; Hinojosa, J.A. Word Frequency Modulates the Processing of Emotional Words: Convergent Behavioral and Electrophysiological Data. Neurosci. Lett. 2011, 494, 250–254. [Google Scholar] [CrossRef]
- Hinojosa, J.A.; Rincón-Pérez, I.; Romero-Ferreiro, M.V.; Martínez-García, N.; Villalba-García, C.; Montoro, P.R.; Pozo, M.A. The Madrid Affective Database for Spanish (MADS): Ratings of Dominance, Familiarity, Subjective Age of Acquisition and Sensory Experience. PLoS ONE 2016, 11, e0155866. [Google Scholar] [CrossRef]
- Ferré, P.; Guasch, M.; Moldovan, C.; Sánchez-Casas, R. Affective Norms for 380 Spanish Words Belonging to Three Different Semantic Categories. Behav. Res. 2012, 44, 395–403. [Google Scholar] [CrossRef]
- Cordaro, D.T.; Sun, R.; Keltner, D.; Kamble, S.; Huddar, N.; McNeil, G. Universals and Cultural Variations in 22 Emotional Expressions across Five Cultures. Emotion 2018, 18, 75–93. [Google Scholar] [CrossRef]
- Gendron, M. Revisiting Diversity: Cultural Variation Reveals the Constructed Nature of Emotion Perception. Curr. Opin. Psychol. 2017, 17, 145–150. [Google Scholar] [CrossRef]
- Laukka, P.; Neiberg, D.; Elfenbein, H.A. Evidence for Cultural Dialects in Vocal Emotion Expression: Acoustic Classification within and across Five Nations. Emotion 2014, 14, 445–449. [Google Scholar] [CrossRef]
- Cordaro, D.T.; Keltner, D.; Tshering, S.; Wangchuk, D.; Flynn, L.M. The Voice Conveys Emotion in Ten Globalized Cultures and One Remote Village in Bhutan. Emotion 2016, 16, 117–128. [Google Scholar] [CrossRef] [Green Version]
- Paulmann, S.; Uskul, A.K. Cross-Cultural Emotional Prosody Recognition: Evidence from Chinese and British Listeners. Cogn. Emot. 2014, 28, 230–244. [Google Scholar] [CrossRef] [Green Version]
- Kirchhoff, C.; Desmarais, E.E.; Putnam, S.P.; Gartstein, M.A. Similarities and Differences between Western Cultures: Toddler Temperament and Parent-Child Interactions in the United States (US) and Germany. Infant Behav. Dev. 2019, 57, 101366. [Google Scholar] [CrossRef] [PubMed]
- Mastropieri, D.; Turkewitz, G. Prenatal Experience and Neonatal Responsiveness to Vocal Expressions of Emotion. Dev. Psychobiol. 1999, 35, 204–2014. [Google Scholar] [CrossRef]
- Chronaki, G.; Wigelsworth, M.; Pell, M.D.; Kotz, S.A. The Development of Cross-Cultural Recognition of Vocal Emotion during Childhood and Adolescence. Sci. Rep. 2018, 8, 8659. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kilford, E.J.; Garrett, E.; Blakemore, S.-J. The Development of Social Cognition in Adolescence: An Integrated Perspective. Neurosci. Biobehav. Rev. 2016, 70, 106–120. [Google Scholar] [CrossRef]
- Alhussein, M.; Muhammad, G. Automatic Voice Pathology Monitoring Using Parallel Deep Models for Smart Healthcare. IEEE Access 2019, 7, 46474–46479. [Google Scholar] [CrossRef]
- Pérez-Espinosa, H.; Gutiérrez-Serafín, B.; Martínez-Miranda, J.; Espinosa-Curiel, I.E. Automatic Children’s Personality Assessment from Emotional Speech. Expert Syst. Appl. 2022, 187, 115885. [Google Scholar] [CrossRef]
- Duville, M.M.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Improving Emotional Speech Processing in Autism Spectrum Disorders: Toward the Elaboration of a Drug-Free Intervention Based on Social StoriesTM and NAO Social Robot Interactions. ISRCTN 2020. [Google Scholar] [CrossRef]
- Duville, M.M.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Electroencephalographic Correlate of Mexican Spanish Emotional Speech Processing in Autism Spectrum Disorder: To a Social Story and Robot-Based Intervention. Front. Hum. Neurosci. 2021, 15, 626146. [Google Scholar] [CrossRef]
- Hinojosa, J.A.; Martínez-García, N.; Villalba-García, C.; Fernández-Folgueiras, U.; Sánchez-Carmona, A.; Pozo, M.A.; Montoro, P.R. Affective Norms of 875 Spanish Words for Five Discrete Emotional Categories and Two Emotional Dimensions. Behav. Res. 2016, 48, 272–284. [Google Scholar] [CrossRef] [PubMed]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A Comprehensive Survey on Support Vector Machine Classification: Applications, Challenges and Trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, L. Review on Landslide Susceptibility Mapping Using Support Vector Machines. CATENA 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Duville, M.M.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Mexican Emotional Speech Database (MESD). Mendeley Data V2 2021. [Google Scholar] [CrossRef]











| Type | Feature | Description | Interpretation |
|---|---|---|---|
| Prosodic | Fundamental frequency or pitch (Hertz) | Minimal frequency of a period. | High or low frequency perception. |
| Speech rate | Number of syllables per unit of time. | Index of speaker arousal. | |
| Intensity (dB) and Energy (Volts) | Mean intensity Root mean square energy. | Loudness | |
| Voice quality | Jitter (%) | Index of frequency variations from period to period. | Pitch fluctuations. |
| Shimmer (%) | Index of amplitude variations from period to period. | Loudness fluctuations. | |
| Harmonics-to-noise ratio (dB) | Relation of the energy of harmonics against the energy of noise-like frequencies. | Voice breathiness and roughness. | |
| Spectral | Formants (Hertz) | Frequencies of highest energy. | Amplification of frequencies caused by resonances in the vocal tract. |
| Mel Frequency Cepstral Coefficients (MFCC) | Discrete cosine transform of the log power spectrum filtered by a Mel-filter bank. | Representation of spectral information according to the human auditory frequency response. |
| Participant | Anger | Disgust | Fear | Happiness | Neutral | Sadness | Total |
|---|---|---|---|---|---|---|---|
| Female | |||||||
| P1 | 41.7 | 33.3 | 58.3 | 50 | 33.3 | 66.7 | 47.2 |
| P2 | 85.7 | 72 | 41.7 | 66.7 | 87 | 47.6 | 66.8 |
| P6 | 66.7 | 48 | 58.3 | 66.7 | 66.7 | 30 | 56 |
| P13 | 50 | 56 | 40 | 55.6 | 45.5 | 45.5 | 48.7 |
| Male | |||||||
| P3 | 95.2 | 90.9 | 70 | 84.6 | 100 | 76.2 | 86.1 |
| P8 | 53.3 | 46.1 | 40 | 44.4 | 55.6 | 28.6 | 44.7 |
| P12 | 84.2 | 91.7 | 69.6 | 80 | 84.2 | 90.9 | 83.4 |
| P14 | 63.1 | 37.5 | 53.8 | 38.5 | 36.4 | 52.2 | 46.9 |
| Database | Anger | Disgust | Fear | Happiness | Neutral | Sadness | Total |
|---|---|---|---|---|---|---|---|
| MESD | 90 | 87 | 83.3 | 95.7 | 100 | 80 | 89.3 |
| INTERFACE | 90.9 | 85.7 | 90 | 95.7 | 95.7 | 87 | 90.9 |
| Database | Anger | Disgust | Fear | Happiness | Neutral | Sadness | Total |
|---|---|---|---|---|---|---|---|
| MESD | 95.2 | 100 | 90.9 | 91.7 | 90.9 | 95.2 | 94 |
| INTERFACE | 76.2 | 78.3 | 100 | 100 | 95.7 | 85.9 | 89.3 |
| Actor Pairs Resulting from Clustering | Single-Pair F-Score (%) from Emotion Classification | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Index | Pair | ||||||||
| Participant Who Uttered Words from Corpus A | Participant Who Uttered Words from Corpus B | Anger | Disgust | Fear | Happiness | Neutral | Sadness | Total | |
| 1 | P15 | P9 | 50 | 66.7 | 40 | 60 | 63.6 | 28.6 | 51.5 |
| 2 | P15 | P17 | 36.4 | 46.2 | 27.3 | 90 | 38.1 | 28.6 | 44.4 |
| 3 | P5 | P16 | 80 | 52.2 | 78.3 | 63.7 | 36.4 | 81.2 | 59.2 |
| 4 | P7 | P16 | 60 | 52.2 | 48 | 47.7 | 66.7 | 54.6 | 54.9 |
| 5 | P15 | P4 | 32 | 25 | 37 | 66.6 | 37.5 | 36.4 | 39.1 |
| 6 | P10 | P9 | 30.8 | 34.8 | 56 | 22.2 | 63.2 | 47.7 | 42.5 |
| 7 | P5 | P17 | 43.5 | 42.1 | 33.3 | 40 | 46.2 | 64 | 44.9 |
| 8 | P10 | P4 | 32.3 | 10.5 | 09.5 | 52.2 | 44.4 | 30 | 29.9 |
| 9 | P5 | P9 | 66.7 | 55.2 | 57.1 | 70 | 33.3 | 69.6 | 58.7 |
| 10 | P10 | P16 | 63.7 | 52.2 | 74.1 | 11.8 | 27.3 | 38.1 | 41.9 |
| Database | Anger | Disgust | Fear | Happiness | Neutral | Sadness | Total |
|---|---|---|---|---|---|---|---|
| MESD | 80 | 76.9 | 84.2 | 100 | 76.2 | 83.3 | 83.4 |
| Acoustic Feature | Significant Trends | ||||
|---|---|---|---|---|---|
| Female | Male | Child | |||
| INTERFACE | MESD | INTERFACE | MESD | MESD | |
| Rate | J 1 > D 2, J > S 3, N 4 > S, A > F/N, A > D/S, J > F/N, F/N > D | N > A 5, F 6 > D, N > D, F > H 7, N > F, N > H, S > H, N > S, F/S > A, F/S > H | A > D, N > A, S > D, F/J > A, J/N/F > D, J/N/F > S | A > F/H, S > D, N > F, F > S, N > H, A/N > D, F/H > D, A/N > S | N > H, N > A/D/S, A/D/F/S > H |
| Mean pitch | A > D, J > A, A > N, F > D, J > D, D > N, J > F, F > N, F > S, J > N, J > S, S > N | H > A, D > N, H > N, S > N, D/F/S > A, H > F/S/D, F > N | F > A, A > S, F > D, F > J, F > N, F > S, J > S, A/J > D/N, D/N > S | N > D, A/H > D, F/S > D, A/H > N, F/S > N, F/S > H, F/S > A | H > D/N, H > A/S, A/F/S > D/N |
| SD pitch | A > N, J > N, J > S, A > D/F/S, D/F/S > N | D/H > A, A > N/S, D/H > F/N/S | D > A, D > F, D > J, A/F/J > N/S | A > N, D/F/H/S > N, A > D/F/H/S | A/D/H > F/N/S |
| Jitter local | A > J, D > F, N > J, N > D/S, N > F/A, D/S > J | F/N > A/D/H/S | S > D, J > F, S > F, S > J, S > N, D/N > A/F | A > F, H > S, D > A/N, D > H, D > S/F, A/N > S | A > H, F > H, D > A/F/N/S, N/S > H |
| Jitter ppq5 | A > J, N > A, S > F, N/S > J, D/F > J, D/S > A, N > F/D | D/S > A, F/N > A, F/N > D/S, D/S > H, F/N > H | D > A, S > A, D > F, D > J, S > D, N > F, S > F, S > J, S > N | N > S, A > F/H/S, D > F/H/S | A > H, D > H, D > S, F/N/S > H, D > A/F |
| Shimmer local | A/N > F | S > A, F > H, F > S, F/N > A/D, S/N > H | A > F, A > N, D > F, J > F, S > F, D/S > A/J, D/S > N | A > D, A > F, A > H, A > N, A > S, D > H, D/F > S, N > H, H > S, N > S | N > A, N > H, N > S, A/D/F/S > H |
| Shimmer rapq5 | A > F | F > S, F/N > D, F/N > A/H, D/S > A/H | S > F, A/D > F, D/S > J/N | A > S, A > D/F/H/N, D/F/H/N > S | N > S, A/D/F/N > H |
| Mean HNR | F/S > A, J/N/D > A, F/S > D, F/S > J, F/S > N | N/S/D/A > F/H | F > A, F > D, S > D, F > J, F > N, F > S, J/N > A/D | D > A, F > A, H > A, N > A, S > A, F > D, H > D, N > D, S > D, F > H, F > N, S > F, N > H, S > H, S > N | S > D, A/F/H/N > D, S > A/F/H/N |
| Mean intensity | F > N, A/D/J/S > N, F > D/S/J | A > F, A > S, D > S, F > S, A > D/H/N, H/N/D > F, H/N > S | F > A, J > A, F > D, J > D, S > D, F > J, F > N, F > S, J > N, J > S, N > S, A/N > D | A > D, A > H, A > N, H > D, N > D, H > F, H > N, H > S, A > S/F, S/F > D, S/F > N | A > D, H > A, H > D, D > N/S, H > N/F/S, A > N/F/S |
| SD intensity | None | None | S > D, S > N, A/S > J/F | S > A/D | None |
| F1 * | D > S | F/H/S > A/D/N | A/D > F | A > S, A > D/F/H/N, D/H/N > S | H/D/F > N/S |
| F2 * | None | F/H/S > A/D, H/S > N | None | D/H > F, D > N, S > A, | A/D/F/N > H |
| F3 * | D > A/F/J | H > F | D > S, D/F > A/J/N | A > N, D > N, S > F, S > H, S > N, D > A/F/H | D > A/F/N/S, A/F/N/S > H |
| B1 † | None | None | A/S > N/J/F | A > D/S, H > S | D > N/S |
| B2 † | J > N, F/S > J, F/S > A | None | S > J | None | None |
| B3 † | F/N > A, F/N > J | None | F/N > A/J | None | A > H, D > F/H/N/S |
| RMS ⁺ Energy | F > D, F > N, A > D/J, A > N/S, D/J > N, J/F > S | A > D/H/N, A > F/S, S > F/S, H/N > F/S | A > D, F > A, J > A, F > D, J > D, F > J, F > N, F > S, J > N, J > S, N/S > D | A > H, H > D, H > F, H > N, H > S, F/S >D, A > D/N, A > F/S, F/S > N | A > D, H > A, A > N, H > D, D > N, F > N, H > N, S > N |
| Acoustic Feature | Inter-Culture (Mexican versus Spanish) Significant Trends | |
|---|---|---|
| Female | Male | |
| Rate | I 1 (A 2) > M 3 (A), M (S 4) > I (S) | I (F) > M(F) |
| Mean pitch | I (A) > M (A), M (D 5) > I (D), I (F 6) > M (F), M (N 7) > I (N) | M (S) > I (S) |
| SD pitch | M (D) > I(D), M (H 8) > I (J 9), M (N) > I (N) | M (A) > I (A), M (H) > I (J), I (N) > M (N), M (S) > I (S) |
| Jitter local | None | I (S) > M (S) |
| Jitter ppq5 | None | I (F) > M (F), I (S) > M (S) |
| Shimmer local | I (A) > M (A), M (F) > I (F), I (J) > M (H) | I (S) > M (S) |
| Shimmer rapq5 | I (A) > M (A) | M (A) > I (A), M (N) > I (N) |
| Mean HNR | M (A) > I (A), I (F) > M (F) | I (A) > M (A), M (N) > I (N), M (S) > I (S) |
| Mean intensity | M (A) > I (A), M (D) > I (D), I (F) > M (F), M (H) > I (J), M (N) > I (N) | M (A) > I (A), I (D) > M (D), I (F) > M (F), I (J) > M (H), I (N) > M (N) |
| SD intensity | None | None |
| F1 * | M (S) > I (S) | None |
| F2 * | None | None |
| F3 * | M (D) > I (D), M (H) > I (J) | M (S) > I (S) |
| B1 † | None | M (A) > I (A), M (D) > I (D), M (F) > I (F), M (H) > I (J), M (N) > I (N), M (S) > I (S) |
| B2 † | None | None |
| B3 † | I (A) > M (A), I (D) > M (D), I (F) > M (F), I (N) > M (N), I (S) > M (S) | None |
| RMS ⁺ Energy | I (F) > M (F), I (S) > M (S) | I (D) > M (D), I (F) > M (F), I (J) > M (H), I (N) > M (N), I (S) > M (S) |
| Acoustic Feature | Inter-Corpus (Corpus A versus Corpus B) Significant Trends | ||
|---|---|---|---|
| Female | Male | Child | |
| Rate | None | None | M 1 (A 2) > I 3 (A), M (H 4) > I (H) |
| Mean pitch | I (A) > M (A), I (D 5) > M (D), I (N) > M (N), | None | M (A) > I (A), M (F 6) > I(F), M(H) > I(H), M (N 7) > I (N), M (S 8) > I (S) |
| SD pitch | I (D) > M (D) | None | M (A) > I (A), M (D) > I (D), M (F) > I (F), M (N) > I (N), M (S) > I (S) |
| Jitter local | None | M (F) > I (F) | I (F) > I (M), M (H) > I (H) |
| Jitter ppq5 | None | M (F) > I (F) | M (D) > I (D), M (H) > I (H) |
| Shimmer local | M (A) > I (A) | None | M (A) > I (A), M (H) > I (H), I (S) > M (S) |
| Shimmer rapq5 | M (A) > I (A) | None | M (A) > I (A), M (H) > I (H), M (N) > I (N) |
| Mean HNR | None | I (F) > M (F), I (H) > M (H), I (N) > M (N) | M (F) > I (F), I (H) > M (H) |
| Mean intensity | I (S) > M (S) | M (F) > I (F), M (H) > I (H), M (N) > I (N) | None |
| SD intensity | None | None | None |
| F1 * | None | None | M (H) > I (H) |
| F2 * | None | M (A) > I (A), M (F) > I (F), M (H) > I (H) | M (S) > I (S) |
| F3 * | M (A) > I (A), M (H) > I (H) | M (A) > I (A), M (D) > I (D) | M (D) > I (D), M (H) > I (H), M (S) > I (S) |
| B1 † | None | None | I (N) > I (N) |
| B2 † | None | None | I (F) > I (F), I (H) > I (H) |
| B3 † | M (A) > I (A), M (F) > I (F), M (N) > I (N) | None | None |
| RMS ⁺ Energy | None | M (F) > I (F), M (H) > I (H), M (N) > I (N), I (S) > M (S) | I (D) > M (D), I (F) > M (F) |
| Reference | Database | Supervised Machine-Learning Approach | Average Emotion Recognition Accuracy |
|---|---|---|---|
| [34] | Berlin Database of Emotional Speech | SVM based on a Gaussian radial basis function kernel with harmonic frequency indices (Fourier Parameters) as inputs | 88.9% |
| CASIA Chinese emotional corpus | 79% | ||
| Chinese elderly emotional speech database | 76% | ||
| [35] | Berlin Database of Emotional Speech | SVM on modulation spectral and frequency features, energy cepstral coefficients, frequency weighted energy cepstral coefficients, and MFCC based on reconstructed signal | 86.2% |
| INTERFACE for Castilian Spanish | 90.4% | ||
| Present work | MESD | Cubic SVM with spectral, prosodic and voice quality features as inputs | 88.9% |
| INTERFACE for Castilian Spanish | 90.2% |
| Type | Feature | Description | Mathematical Expression |
|---|---|---|---|
| Prosodic | Fundamental frequency or pitch (Hertz) | Mean and standard deviation over the entire waveform. | is the standard deviation, N is the total number of samples and n is a sample of signal x. |
| Speech rate | Number of syllables per second. | ||
| Root mean square energy (Volt) | Index of the energy of the signal over the entire waveform. | where N is the total number of samples and n is a sample of signal x. | |
| Intensity (dB) | Mean and standard deviation over the entire waveform. | is the standard deviation, N is the total number of samples and X(n) is the intensity in dB at sample n. | |
| Voice quality | Jitter (%) | Jitter local: average absolute difference between two consecutive periods, divided by the average period. | is the duration of ith period, and P is the number of periods. |
| Jitter ppq5: 5-point period perturbation quotient. It is the average absolute difference between a period and the average of it and its four closest neighbors, divided by the average period. | is the duration of ith period, and P is the number of periods. | ||
| Shimmer (%) | Shimmer local: the average absolute difference between the amplitude of two consecutive periods, divided by the average amplitude. | is the duration of ith period, and P is the number of periods. | |
| Shimmer rapq5: 5-point amplitude perturbation quotient. It is the average absolute difference between the amplitude of a period and the average of the amplitude of it and its four closest neighbors, divided by the average amplitude. | is the duration of ith period, and P is the number of periods. | ||
| Mean harmonics-to-noise ratio (HNR; dB) | Relation of the energy of harmonics against the energy of noise-like frequencies. | If 99% of the signal is composed of harmonics and 1% is noise, then HNR is defined by: Mean harmonics-to-noise ratio between time point is defined by: where x(t) is the HNR (in dB) as a function of time. | |
| Spectral | Formants (Hertz) | F1, F2, F3: Mean and bandwidth in center. | |
| MFCC | 1–13 coefficients. | Conversion to Mel scale following:
where fMel is the frequency in Mel scales, and flinear is the frequency in the linear scale (Hertz). |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duville, M.M.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Mexican Emotional Speech Database Based on Semantic, Frequency, Familiarity, Concreteness, and Cultural Shaping of Affective Prosody. Data 2021, 6, 130. https://doi.org/10.3390/data6120130
Duville MM, Alonso-Valerdi LM, Ibarra-Zarate DI. Mexican Emotional Speech Database Based on Semantic, Frequency, Familiarity, Concreteness, and Cultural Shaping of Affective Prosody. Data. 2021; 6(12):130. https://doi.org/10.3390/data6120130
Chicago/Turabian StyleDuville, Mathilde Marie, Luz María Alonso-Valerdi, and David I. Ibarra-Zarate. 2021. "Mexican Emotional Speech Database Based on Semantic, Frequency, Familiarity, Concreteness, and Cultural Shaping of Affective Prosody" Data 6, no. 12: 130. https://doi.org/10.3390/data6120130
APA StyleDuville, M. M., Alonso-Valerdi, L. M., & Ibarra-Zarate, D. I. (2021). Mexican Emotional Speech Database Based on Semantic, Frequency, Familiarity, Concreteness, and Cultural Shaping of Affective Prosody. Data, 6(12), 130. https://doi.org/10.3390/data6120130