Seized Ecstasy Pills: Infrared Spectra and Image Datasets



Abstract
:1. Summary
2. Data Description
3. Methods
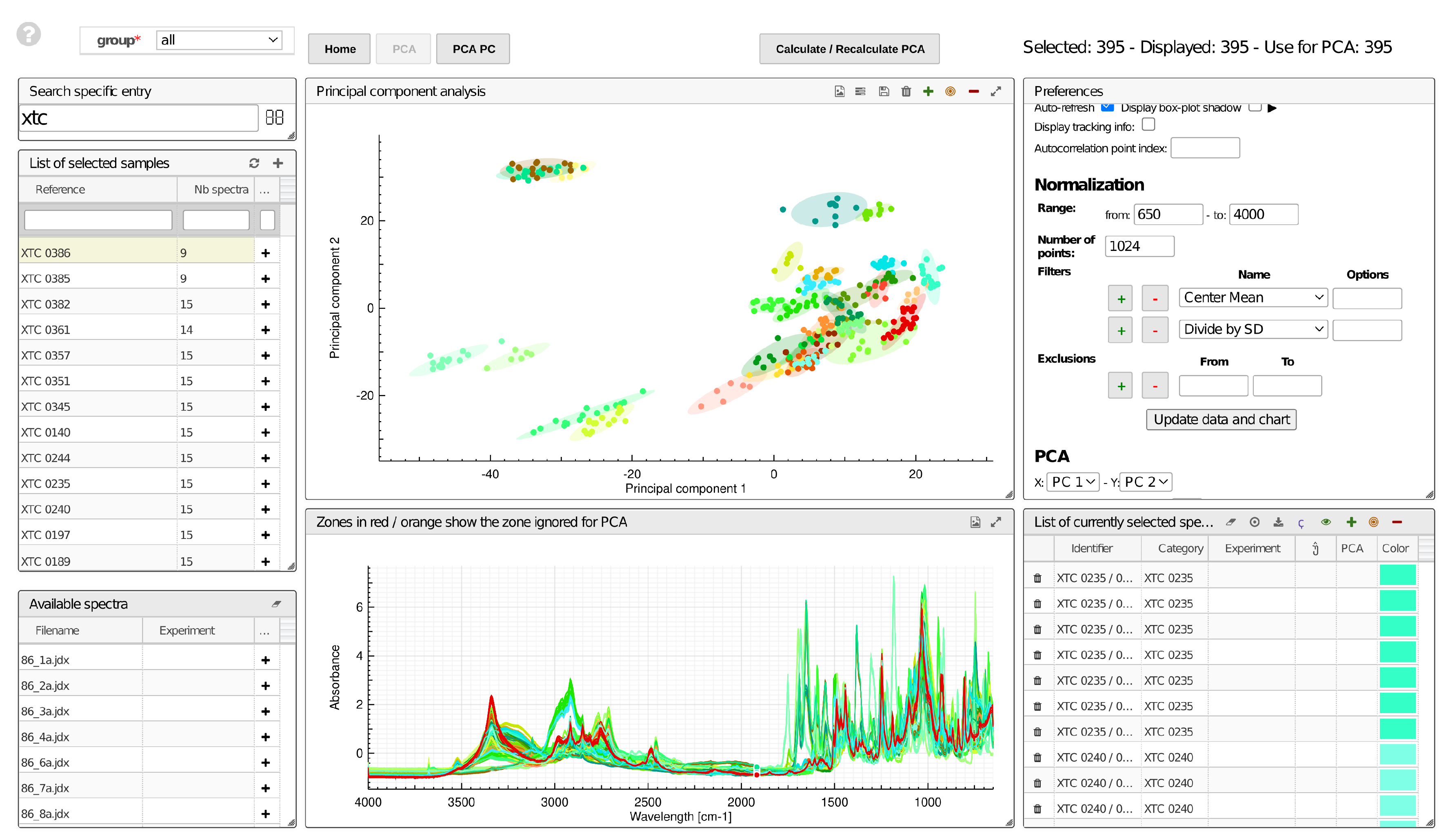
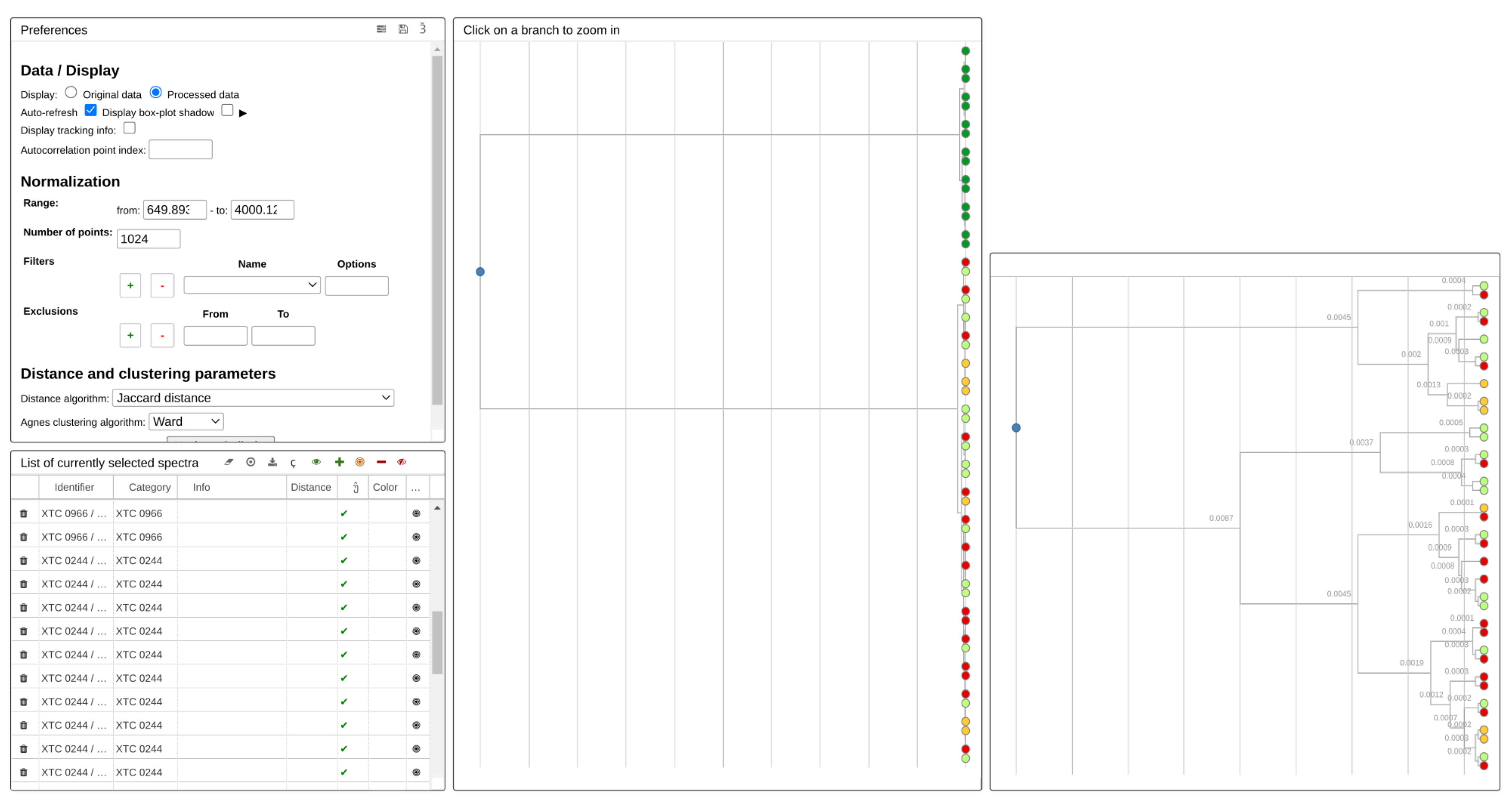
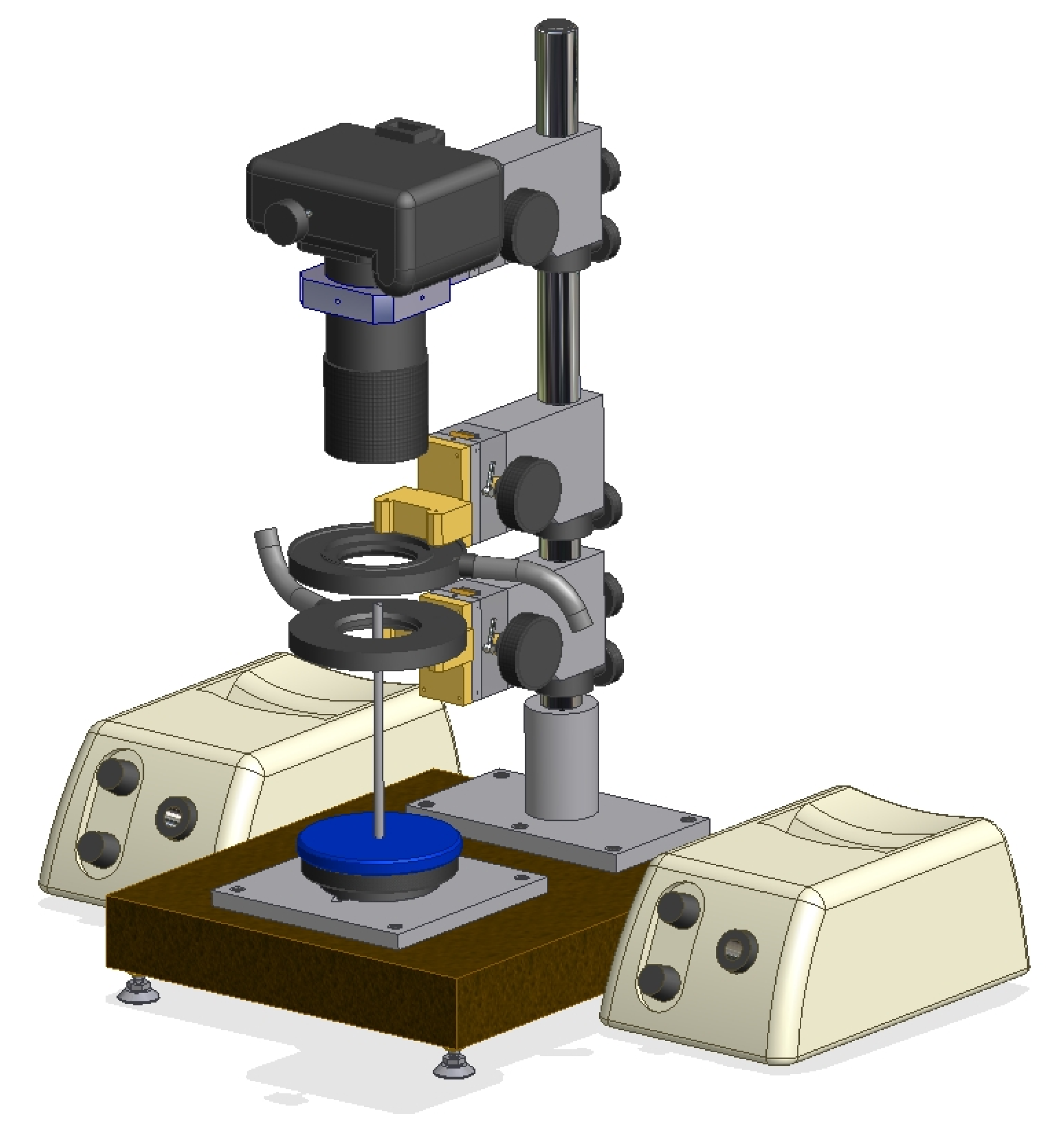
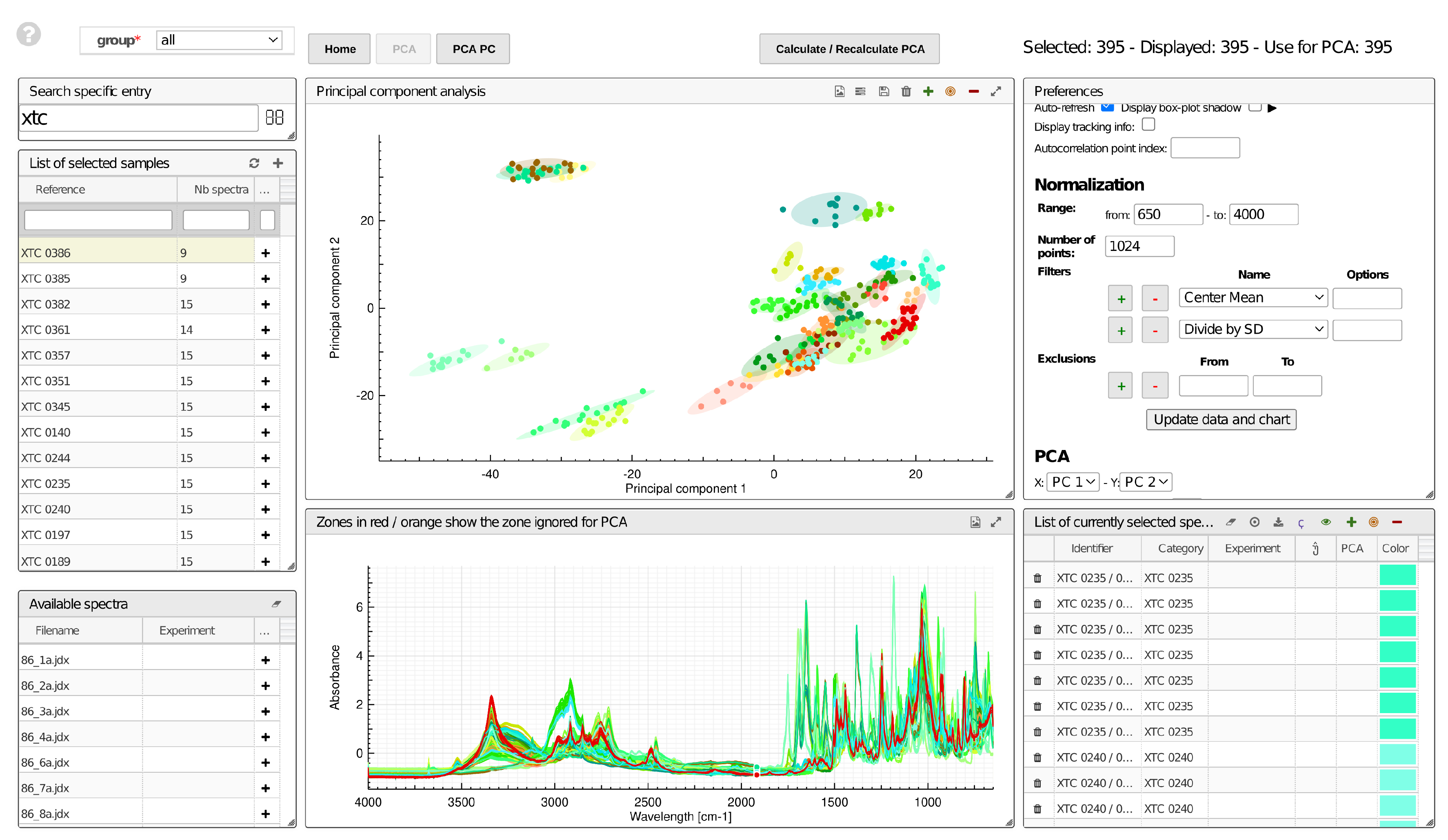
3.1. Imaging
3.2. mIR Spectra
4. Usage Note
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of Open Access Journals |
| TLA | Three Letter Acronym |
| LD | Linear Dichroism |
References
- Zingg, C. The Analysis of Ecstasy Tablets in a Forensic Drug Intelligence Perspective. Ph.D. Thesis, Ecole Polytechnique Fédérale de Zürich, Zürich, Switzerland, 2005. [Google Scholar]
- World Drug Report 2020. Available online: https://wdr.unodc.org/wdr2020/index.html (accessed on 8 October 2020).
- Couchman, L.; Frinculescu, A.; Sobreira, C.; Shine, T.; Ramsey, J.; Hecht, M.; Kipper, K.; Holt, D.; Johnston, A. Variability in content and dissolution profiles of MDMA tablets collected in the UK between 2001 and 2018—A potential risk to users? Drug Test. Anal. 2019, 11, 1172–1182. [Google Scholar] [CrossRef] [PubMed]
- Hussain, J.H.; Gilbert, N.; Costello, A.; Schofield, C.J.; Kemsley, E.K.; Sutcliffe, O.B.; Mewis, R.E. Quantification of MDMA in seized tablets using benchtop 1H NMR spectroscopy in the absence of internal standards. Forensic Chem. 2020, 20, 100263. [Google Scholar] [CrossRef]
- Almeida, N.S.; Benedito, L.E.C.; Maldaner, A.O.; Oliveira, A.L.D. A Validated NMR Approach for MDMA Quantification in Ecstasy Tablets. J. Braz. Chem. Soc. 2018, 29, 1944–1950. [Google Scholar] [CrossRef]
- Teófilo, K.R.; Arantes, L.C.; Marinho, P.A.; Macedo, A.A.; Pimentel, D.M.; Rocha, D.P.; de Oliveira, A.C.; Richter, E.M.; Munoz, R.A.A.; dos Santos, W.T.P. Electrochemical detection of 3,4-methylenedioxymethamphetamine (ecstasy) using a boron-doped diamond electrode with differential pulse voltammetry: Simple and fast screening method for application in forensic analysis. Microchem. J. 2020, 157, 105088. [Google Scholar] [CrossRef]
- Rashed, A.M.; Anderson, R.A.; King, L.A. Solid-phase extraction for profiling of ecstasy tablets. J. Forensic Sci. 2000, 45, 413–417. [Google Scholar] [CrossRef]
- Cheng, J.Y.K.; Chan, M.F.; Chan, T.W.; Hung, M.Y. Impurity profiling of ecstasy tablets seized in Hong Kong by gas chromatography-mass spectrometry. Forensic Sci. Int. 2006, 162, 87–94. [Google Scholar] [CrossRef]
- Camargo, J.; Esseiva, P.; González, F.; Wist, J.; Patiny, L. Monitoring of illicit pill distribution networks using an image collection exploration framework. Forensic Sci. Int. 2012, 223, 298–305. [Google Scholar] [CrossRef]
- Coppey, F.; Bécue, A.; Sacré, P.Y.; Ziemons, E.M.; Hubert, P.; Esseiva, P. Providing illicit drugs results in five seconds using ultra-portable NIR technology: An opportunity for forensic laboratories to cope with the trend toward the decentralization of forensic capabilities. Forensic Sci. Int. 2020, 317, 110498. [Google Scholar] [CrossRef] [PubMed]
- Baer, I.; Gurny, R.; Margot, P. NIR analysis of cellulose and lactose–application to ecstasy tablet analysis. Forensic Sci. Int. 2007, 167, 234–241. [Google Scholar] [CrossRef] [PubMed]
- Qing, Y.; Cheng, Y.F.; Zhang, X.M. Field and fast determination of ketamine and caffeine in ecstasy. Chem. Res. Appl. 2011. Available online: http://en.cnki.com.cn/Article_en/CJFDTotal-HXYJ201107023.htm (accessed on 24 October 2020).
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- McDonald, R.S.; Wilks, P.A. JCAMP-DX: A Standard Form for Exchange of Infrared Spectra in Computer Readable Form. Appl. Spectrosc. 1988, 42, 151–162. [Google Scholar] [CrossRef]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard Normal Variate Transformation and De-trending of Near-Infrared Diffuse Reflectance Spectra. Appl. Spectrosc. 1989, 43, 772–777. [Google Scholar] [CrossRef]
- Dhanoa, M.S.; Lister, S.J.; Sanderson, R.; Barnes, R.J. The Link between Multiplicative Scatter Correction (MSC) and Standard Normal Variate (SNV) Transformations of NIR Spectra. J. Near Infrared Spectrosc. 1994, 2, 43–47. [Google Scholar] [CrossRef]
- Patiny, L.; Zasso, M.; Kostro, D.; Bernal, A.; Castillo, A.M.; Bolaños, A.; Asencio, M.A.; Pellet, N.; Todd, M.; Schloerer, N.; et al. The C6H6 NMR repository: An integral solution to control the flow of your data from the magnet to the public. Magn. Reson. Chem. 2017, 56, 520–528. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Seizures | 19 | 1 | 99 | 2 | 2 | 1 | 2 | 1 | 5 | 13 |
| Number of Pills Analyzed | 10 | 19 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Number of Seizures | 8 | 2 | 19 | 1 | 9 | 2 |
| Number of Pills Analyzed | 10 | 14 | 15 | 21 | 6 | 6 |
| Crystal | Diamond, single reflexion (45) n = 2.419 |
| Range | 4000–650 cm |
| Number of Scans | 32 |
| Resolution | 4 cm |
| Collection Length | 52 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patiny, L.; Zasso, M.; Esseiva, P.; Wist, J. Seized Ecstasy Pills: Infrared Spectra and Image Datasets. Data 2020, 5, 116. https://doi.org/10.3390/data5040116
Patiny L, Zasso M, Esseiva P, Wist J. Seized Ecstasy Pills: Infrared Spectra and Image Datasets. Data. 2020; 5(4):116. https://doi.org/10.3390/data5040116
Chicago/Turabian StylePatiny, Luc, Michaël Zasso, Pierre Esseiva, and Julien Wist. 2020. "Seized Ecstasy Pills: Infrared Spectra and Image Datasets" Data 5, no. 4: 116. https://doi.org/10.3390/data5040116
APA StylePatiny, L., Zasso, M., Esseiva, P., & Wist, J. (2020). Seized Ecstasy Pills: Infrared Spectra and Image Datasets. Data, 5(4), 116. https://doi.org/10.3390/data5040116