Abstract
Facial recognition, as well as other types of human recognition, have found uses in identification, security, and learning about behavior, among other uses. Because of the high cost of data collection for training purposes, logistical challenges and other impediments, mirroring images has frequently been used to increase the size of data sets. However, while these larger data sets have shown to be beneficial, their comparative level of benefit to the data collection of similar data has not been assessed. This paper presented a data set collected and prepared for this and related research purposes. The data set included both non-occluded and occluded data for mirroring assessment.
Dataset: Due to size, the dataset was split into six files: 10.17632/7w73p32pcn.1; 10.17632/2hxckw6y32.1; 10.17632/fxc4b539hx.1; 10.17632/zhnv3ns8hh.1; 10.17632/c2ggy8fvz8.1; 10.17632/63j23pw3rd.1.
1. Summary
Human and facial recognition [1] have a wide variety of prospective uses. The applications of facial recognition include retail store customer identification [2,3], applicant screening [4], and access control [5]. Facial and human recognition are also used by law enforcement entities [6].
In addition to simply recognizing an individual, facial imagery can be further analyzed to learn or infer about the subject. Age [7] and gender [7,8] can, in many cases, be easily determined from imagery. It can suggest individuals’ interest levels [9] and emotional state [9].
A variety of techniques have been proposed for identification and classification. Neural networks [10] are commonly used for this purpose. Facial and human data also suffers from numerous problems relating to subject state and collection. Thus, a variety of techniques for dealing with a wide number of issues, including lighting conditions, distortion [11,12], and occlusion [11,12,13,14], as well as having only limited training data [15] and subjects’ facial expressions [16], have been developed.
One particular use of facial recognition is to identify an individual for security [17,18,19,20] purposes. Recognition can be used to grant access [21,22] or validate identity [18,23]. When used for security applications, the system must be robust to attacks that may try to confuse or deny recognition capabilities.
Mirroring has been used extensively as part of recognition and, in particular, facial and human recognition studies. Several studies [24,25,26] have used mirroring to expand a training dataset, including removal of the need to photograph subjects from certain perspectives that correspond to the mirror of other ones [27]. Mirroring has also been used to aid recognition by replacing data that is either missing or occluded [28] and to expand a shape model [29] used as part of the recognition process. Studies have also used mirroring in conjunction with other image manipulation techniques, including cropping [30], pixel movement [31,32], rotation [32,33], scaling [32,33,34], blurring [35], and noise addition [35].
Despite the recurrent use of mirroring for facial and other recognition applications, only limited studies of its effectiveness have been performed. Hu et al. [36] evaluate the use of both flip-augmented and non-augmented data sets, showing a limited benefit to augmentation. Miclut et al. [37] compare non-augmented data sets’ effectiveness with mirrored and combined mirrored and rotated augmented data sets. No study was located where the use of augmented data was compared to the use of collected data from the corresponding positions.
This data set provided data that can be used to validate the efficacy of the use of mirroring for training or presenting images for recognition to facial recognition systems. It was designed to facilitate this assessment under a variety of conditions that these systems may face.
To this end, it includes imagery of subjects from multiple perspectives, with multiple lighting conditions and multiple lighting brightness and temperature levels. Most importantly, it includes data for five positions that have been manually collected and two positions that have been generated based on mirroring data from two other manually collected positions. A total of 245 images were included per subject, including 175 collected images and 70 which were generated through mirroring. In addition to these non-occluded images, the dataset includes images where the subject’s face is partially occluded by a hat or a pair of glasses. Thus, the data set includes 735 images for each subject, of which 525 are manually collected and 210 are generated through mirroring.
This dataset:
- Facilitates the testing of the impact of the use of mirrored imagery for testing facial recognition algorithms and for comparing this impact between algorithms.
- Includes mirrored and non-mirrored data for different subject positions, lighting angles, lighting brightness, and lighting temperature conditions.
- Includes mirrored and non-mirrored non-occluded data and data with hat and glasses occlusions.
- The data was collected in a controlled environment with a consistent background.
2. Data Description
The data set was comprised of 735 images in JPEG format, including 525 manually collected images and 210 images that were mirrored images of the images from the third and fourth subject orientation positions, as shown in Figure 1.
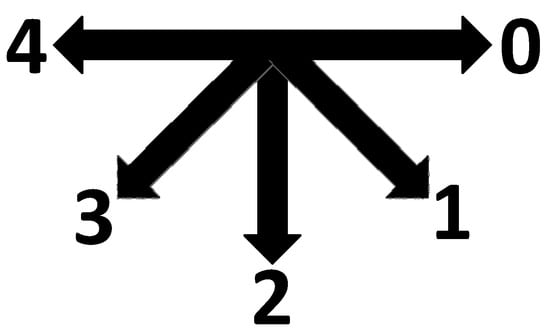
Figure 1.
Orientation of subjects as described in Reference [38].
The images were of males between 18 and 26 years old. Many had similar skin tones and facial and upper chest characteristics, to facilitate testing of the systems’ ability to correctly identify similar subjects. The JPEG images could be opened and processed by numerous application programs and they contained the original metadata from the camera that was used to collect them. The resolution of the images was 5184 × 3456 pixels.
2.1. Data Organization
The organization convention for the data set is as follows. The top-level directories are named with a number that represents the subject, for example, “3”. In each of these directories are three subfolders called, “vanilla”, “glasses”, and “hat”. “Vanilla” contains all of the subject’s images without them wearing any occlusion, “glasses” contains all of their images with them wearing glasses, and “hat” contains all of their images with them wearing a hat. In each of these directories, are a set of five “position” subdirectories, each of which includes the subject’s orientation positions. These are labeled as pos_0 to pos_4. In addition, the two mirrored positions are labeled as m_pos_3 and m_pos_4. In each position directory, there are lighting angle subdirectories which correspond to each of the light’s positions. These are labeled as angle_1 to angle_7. Finally, in each lighting subdirectory, there are five images of the subject labeled in the format of IMG_####.JPG in the following order: warm, cold, low, medium, and high. In the mirrored directories, the naming format is ###_IMG_####.JPG; however, the ordering still corresponds to warm, cold, low, medium, and high. The labels of the individual images (warm, cold, low, medium, and high) correspond to the lighting settings, which are discussed in detail in the following section.
2.2. Comparison to Other Data Sets
A variety of other facial recognition datasets exist. Learned-Miller et al. [39] created a “Labeled Faces in the Wild” data set that was harvested from websites. This data set included data for 5749 people; however, it only included approximately two images per individual (13,000 images in total). Guo et al. [40] also harvested images from the web for their dataset, “MS-Celeb-1M.” This data set is comprised of 10,000,000 images of 100,000 people. Both of these data sets were collected automatically and could potentially have duplicates that were not detected by the creators’ algorithms, incorrect association of images to a single individual, or other characteristics associated with the curating algorithms. Another data set, entitled “IARPA Janus Benchmark A” [41] has images of 500 people, but only an average of 11.4 images per individual. The “Pgu-Face” dataset [42], similarly, had 896 images covering 224 subjects. The “Extended Cohn-Kanade Dataset (CK+)” dataset [43] had slightly more images per individual, covering 210 individuals with only 23 images per subject. The “FRGC 1.0.4” dataset [44] includes 152 subjects, but only an average of five images per individual. The “Face Recognition Technology (FERET)” data set [45] includes 14,126 images covering 1199 subjects (for about 12 images per subject). Finally, the “ORL Database of Faces” [46] contains only 400 images covering 40 individuals with only 10 images per subject.
The dataset presented herein covers only 11 subjects (which is less than other datasets); however, it includes 735 images per subject, which is far more than any of the other data sets. In terms of the total number of images, the dataset described herein has 8085 images, making it the fourth largest of the datasets. Two of these datasets were automatically generated (“Labeled Faces in the Wild” and “MS-Celeb-1M”), and it is thus the second largest manually collected dataset, from those surveyed (the NIST FERET data set is larger, being comprised of 14,126 images).
3. Methods
The image data set was collected using a Cannon EOS Rebel T2i camera with a 60 mm Ultrasonic EFS lens and set in aperture priority mode with an ISO of 800 and an FSTOP of eight. AI focus, peripheral illumination correction, red eye reduction, auto white balance, and spot metering were enabled, and auto exposure bracketing was set at 01. The flash was disabled. The camera was oriented in landscape mode.
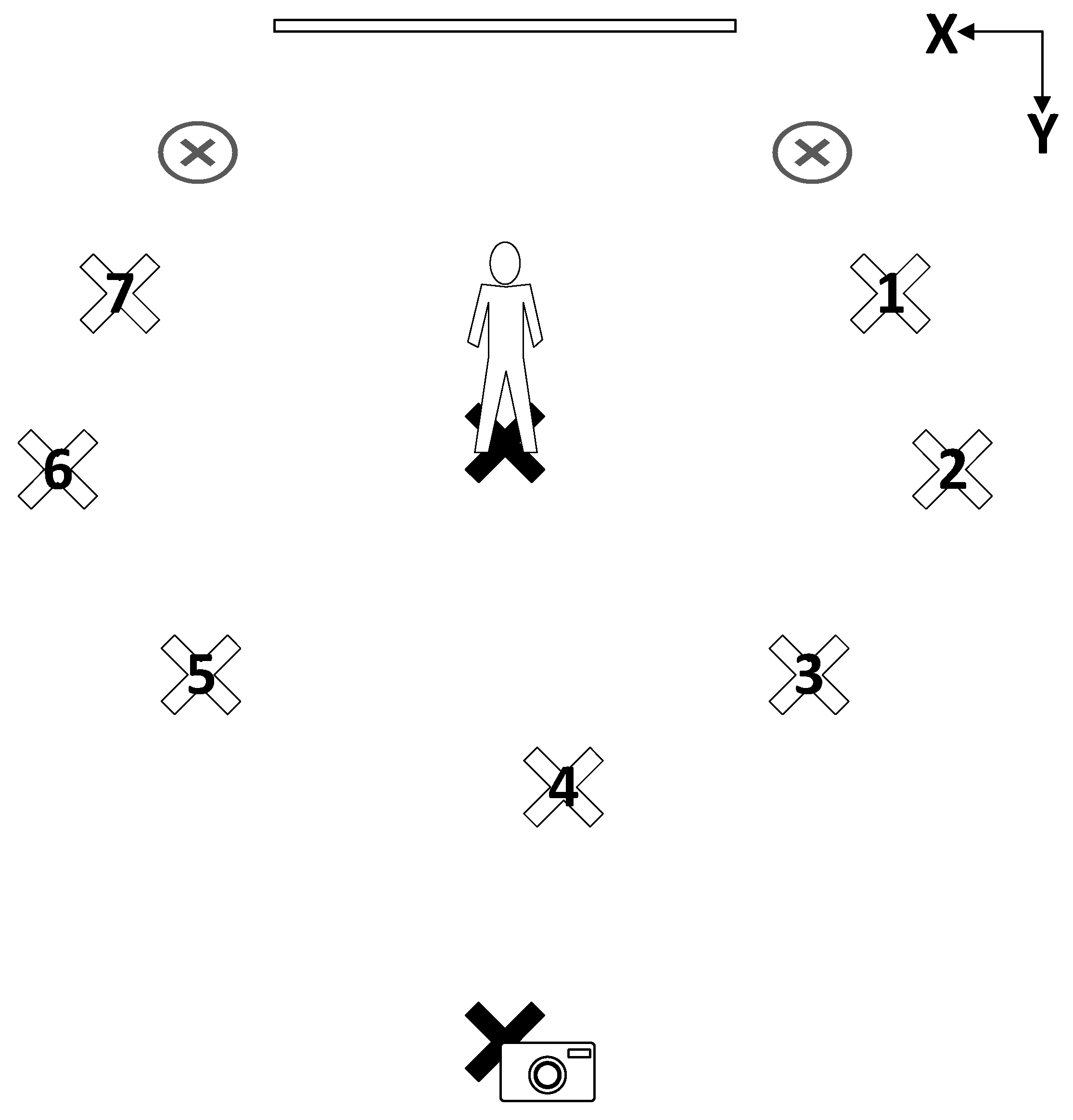
Two Neewer LED500LRC lights were used to illuminate the background and one Yongnuo YN600L light was used to illuminate the subject. A projector screen was used as the backdrop. The camera, subject, and lighting locations are shown in Figure 2. The non-numbered ‘X’ locations are the positions of the background lights. The camera and subject positions are identified by an image of a camera and human, respectively. The numbered ‘X’ locations correspond to the seven subject illumination lighting positions (which create the seven lighting angles). The exact coordinates of the subject, camera, and lights are provided in Table 1.
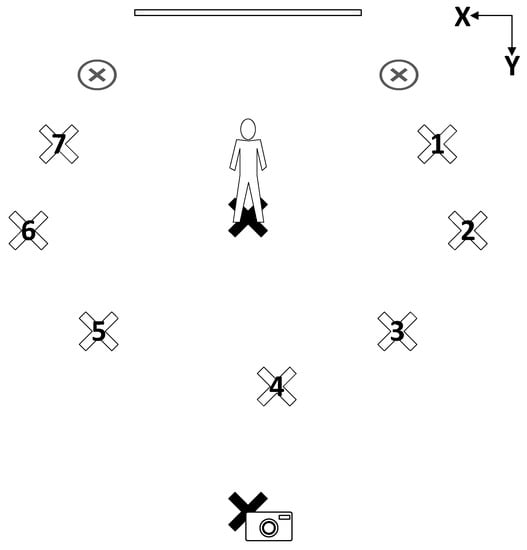
Figure 2.
Subject, lighting, and camera positions [38].

Table 1.
Camera, lighting, and subject positions (in inches) [38].
The subjects were photographed in five different positions (as shown in Figure 3). Additionally, the data was processed to mirror the position 0 and 1 images (the two leftmost images in Figure 3), to replace the data collected at positions 3 and 4. Figure 4 depicts the mirrored images shown in positions 3 and 4 (the two rightmost images), along with the collected data in positions 0, 1, and 2.

Figure 3.
Subjects were photographed in five different positions.

Figure 4.
Photos of three different positions (left three images) with two mirrored images (right two images).
For each of the five positions (including both the mirrored and non-mirrored ones), photos were taken with seven different lighting angles. The seven angles of light are depicted in Figure 2, and images demonstrating the effect of these lighting angles are presented in Figure 5. For each position and lighting angle, images were collected at five different lighting settings. These lighting settings are listed in Table 2 and are visually depicted in Figure 6.

Figure 5.
Photos were taken with seven different lighting angles at each position.
Table 2.
Lighting configurations and their titles [38].

Figure 6.
Five different lighting settings were used for each subject position and lighting angle. From left to right, shown are: warm, cold, low, medium, and high.
The images that are used in mirrored positions 3 and 4 were created through a pixel-by-pixel replacement from the left of the image to the right and vice versa. Figure 7 depicts this mirroring for the forward-facing position. Note that both images look similar, but are distinguishable by comparing small features, such as looking at the patterns of hair on the left and right of the head.

Figure 7.
Cropped mirrored and captured images from subject position 2 (center).
However, the mirrored images could not just be directly swapped. The lighting angles had to be reversed to most closely replicate or approximate the collected images, both in terms of subject position and in terms of the incident angle of the lighting. For example, to generate the mirrored image for subject position 4, lighting angle 7, the image from subject position 0, lighting angle 1 was used and flipped horizontally.
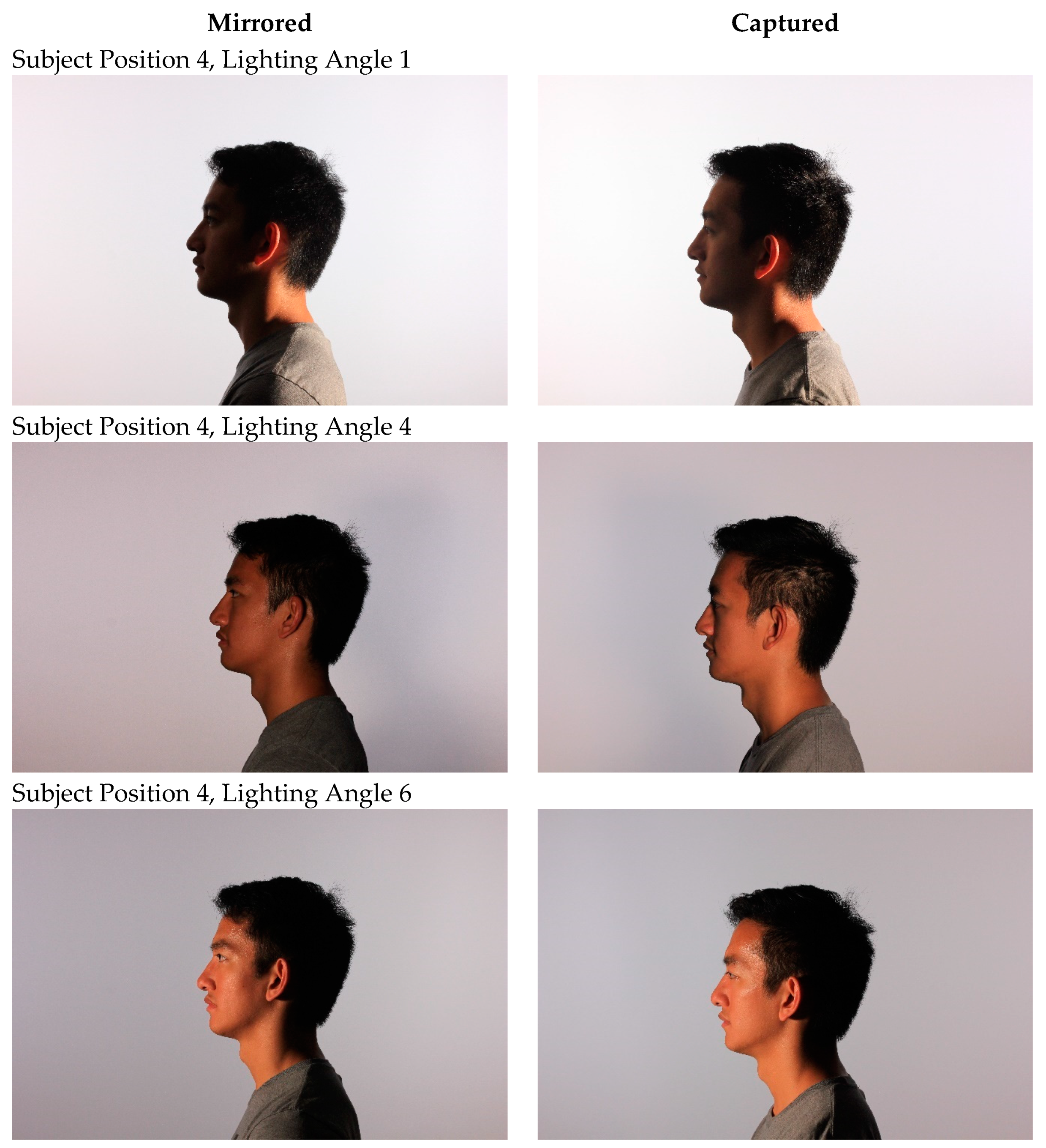
Even with this, the mirrored images for the subject positions 3 and 4, in this dataset, do not have exactly the same lighting angles of incidence, as the lighting configuration of the experimental setup was not perfectly symmetrical. Table 3 lists the angle of incidence for all the lighting and position combinations (including both mirrored and non-mirrored configurations). Figure 8 and Figure 9 depict this visually for positions 3 and 4, respectively.
Table 3.
Lighting angle (in degrees) for subject positions and lighting angles, where 3′ and 4′ refer to the mirrored images.

Figure 8.
Comparison of the mirrored and collected images for subject position 3 at lighting angles 2, 4, and 7.
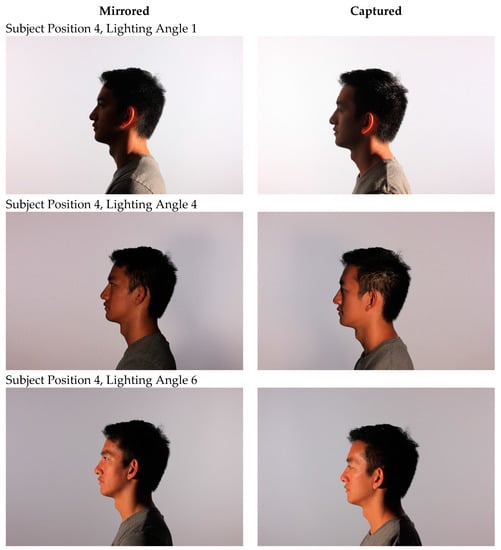
Figure 9.
Comparison of mirrored and collected images for subject position 4 at lighting angles 1, 4, and 6.
Mirroring images collected from subject positions 0 and 1, to substitute in place of images collected from the remaining subject positions could be used to offset the image asymmetry created by the lighting placement asymmetry. However, the combination of the mirrored and non-mirrored data produces a greater set of lighting incidence angles than either full collection or half-collection and mirroring alone. Note also that some lighting angles are the same or very similar, while other lighting angles are further removed. Because of this, the data set can be used to assess the impact of mirroring and lighting angle changes, both together and independently, by looking at the impact relative to positions with more and less similar angles of incidence between the collected and mirrored data.
Subjects were asked to keep a neutral face while being photographed, and to face forward relative to their body orientation. The individual rotated to each position and the Yongnuo YN600L light was moved between positions and had its settings altered, while the subject remained stationary. Images were reviewed after each set to ensure that the subject did not move, blink, or show expression and to verify that all required images were present and of suitable quality. Subjects’ attire (shirt) was not controlled and there were minor fluctuations in the subjects’ position and facial state. All other aspects of data collection were controlled.
Author Contributions
conceptualization, C.G. and J.S.; methodology, C.G. and J.S.; validation, C.G.; resources, J.S.; data curation, C.G.; writing—original draft preparation, C.G. and J.S.; writing—review and editing, C.G. and J.S.; supervision, J.S.; project administration, J.S.; funding acquisition, J.S.
Funding
The collection of this data was supported by the United States National Science Foundation (NSF award # 1757659).
Acknowledgments
Thanks is given to William Clemons and Marco Colasito who aided in the collection of this data. Facilities and some equipment used for the collection of this data were provided by the North Dakota State University Institute for Cyber Security Education and Research and the North Dakota State University Department of Computer Science.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face recognition. ACM Comput. Surv. 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Denimarck, P.; Bellis, D.; McAllister, C. Biometric System and Method for Identifying a Customer upon Entering a Retail Establishment. U.S. Patent 09/909,576, 23 January 2003. [Google Scholar]
- Lu, D.; Kiewit, D.A.; Zhang, J. Market research method and system for collecting retail store and shopper market research data. U.S. Patent 5,331,544, 19 July 1994. [Google Scholar]
- Payne, J.H. Biometric face recognition for applicant screening. U.S. Patent No. 6,072,894, 6 June 2000. [Google Scholar]
- Kail, K.; Williams, C.; Kail, R. Access control system with RFID and biometric facial recognition. U.S. Patent Application 11/790,385, 1 November 2007. [Google Scholar]
- Introna, L.; Wood, D. Picturing algorithmic surveillance: the politics of facial recognition systems. Surveill. Soc. 2004, 2, 177–198. [Google Scholar] [CrossRef]
- Ramesha, K.B.R.K.; Raja, K.B.; Venugopal, K.R.; Patnaik, L.M. Feature Extraction based Face Recognition, Gender and Age Classification. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.163.4518 (accessed on 5 February 2019).
- Wiskott, L.; Fellous, J.-M.; Krüger, N.; von der Malsburg, C. Face Recognition and Gender Determination. 1995, pp. 92–97. Available online: http://cogprints.org/1485/2/95_WisFelKrue+.pdf (accessed on 5 February 2019).
- Yeasin, M.; Sharma, R.; Yeasin, M.; Member, S.; Bullot, B. Recognition of facial expressions and measurement of levels of interest from video. IEEE Trans. Multimed. 2006, 8, 500–508. [Google Scholar] [CrossRef]
- Lin, S.-H.; Kung, S.-Y.; Lin, L.-J. Face Recognition/Detection by Probabilistic Decision-Based Neural Network. IEEE Trans. Neural Netw. 1997, 8, 114–132. [Google Scholar] [PubMed]
- Martinez, A.M. Recognizing imprecisely localized, partially occluded, and expression variant faces from a single sample per class. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 748–763. [Google Scholar] [CrossRef]
- Kim, J.; Choi, J.; Yi, J.; Turk, M. Effective representation using ICA for face recognition robust to local distortion and partial occlusion. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1977–1981. [Google Scholar] [CrossRef] [PubMed]
- Venkat, I.; Khader, A.T.; Subramanian, K.G.; De Wilde, P. Psychophysically Inspired Bayesian Occlusion Model to Recognize Occluded Faces. In Computer Analysis of Images and Patterns; Springer: Berlin/Heidelberg, Germany, 2011; pp. 420–426. [Google Scholar]
- Norouzi, E.; Ahmadabadi, M.N.; Araabi, B.N. Attention control with reinforcement learning for face recognition under partial occlusion. Mach. Vis. Appl. 2011, 22, 337–348. [Google Scholar] [CrossRef]
- Tan, X.; Chen, S.; Zhou, Z.-H.; Zhang, F. Face recognition from a single image per person: A survey. Pattern Recognit. 2006, 39, 1725–1745. [Google Scholar] [CrossRef]
- Drira, H.; Ben Amor, B.; Srivastava, A.; Daoudi, M.; Slama, R. 3D Face Recognition under Expressions, Occlusions, and Pose Variations. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2270–2283. [Google Scholar] [CrossRef] [PubMed]
- Coffin, J.S.; Ingram, D. Facial recognition system for security access and identification. U.S. Patent 5,991,429, 23 November 1999. [Google Scholar]
- Schroeder, C.C. Biometric security process for authenticating identity and credit cards, visas, passports and facial recognition. U.S. Patent 5,787,186, 28 July 1998. [Google Scholar]
- Bowyer, K.W. Face recognition technology: Security versus privacy. IEEE Technol. Soc. Mag. 2004, 23, 9–19. [Google Scholar] [CrossRef]
- Jain, A.K.; Ross, A.; Pankanti, S. Biometrics: A Tool for Information Security. IEEE Trans. Inf. Forensics Secur. 2006, 1, 125–143. [Google Scholar] [CrossRef]
- Ijiri, Y.; Sakuragi, M.; Lao, S. Security Management for Mobile Devices by Face Recognition. In Proceedings of the 7th International Conference on Mobile Data Management (MDM’06), Nara, Japan, 10–12 May 2006; p. 49. [Google Scholar]
- Lemelson, J.H.; Hoffman, L.J. Facial-recognition vehicle security system and automatically starting vehicle. U.S. Patent 7,116,803, 3 October 2006. [Google Scholar]
- Karovaliya, M.; Karedia, S.; Oza, S.; Kalbande, D.R. Enhanced Security for ATM Machine with OTP and Facial Recognition Features. Procedia Comput. Sci. 2015, 45, 390–396. [Google Scholar] [CrossRef]
- Milborrow, S.; Nicolls, F. Locating Facial Features with an Extended Active Shape Model. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 504–513. [Google Scholar]
- Tarrés, F.; Rama, A. A Novel Method for Face Recognition under partial occlusion or facial expression Variations 1. In Proceedings of the 47th International Symposium ELMAR, Zadar, Croatia, 8–10 June 2005; pp. 163–166. [Google Scholar]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time human pose recognition in parts from single depth images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Milborrow, S.; Morkel, J.; Nicolls, F. The MUCT Landmarked Face Database. Pattern Recogni. Assoc. South Afr. 2010. Available online: http://www.dip.ee.uct.ac.za/~nicolls/publish/sm10-prasa.pdf (accessed on 5 February 2019).
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Martin, C.; Werner, U.; Gross, H.-M. A Real-time Facial Expression Recognition System based on Active Appearance Models using Gray Images and Edge Images. In Proceedings of the 8th IEEE International Conference on Face and Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. arXiv, 2014; arXiv:1405.3531. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 Computer Vision and Pattern Recognition Conference, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xiao, R.; Li, M.-J.; Zhang, H.-J. Robust Multipose Face Detection in Images. IEEE Trans. CIRCUITS Syst. VIDEO Technol. 2004, 14. [Google Scholar] [CrossRef]
- Lienhart, R.; Liang, L.; Kuranov, A. A detector tree of boosted classifiers for real-time object detection and tracking. In In Proceedings of the 2003 International Conference on Multimedia and Expo. ICME ’03. Proceedings (Cat. No.03TH8698), Baltimore, MD, USA, 6–9 July 2003. [Google Scholar]
- Rowley, H.A.; Baluja, S.; Kanade, T. Neural network-based face detection. In Proceedings of the CVPR IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 1996; pp. 203–208. [Google Scholar]
- Rozantsev, A.; Lepetit, V.; Fua, P. On Rendering Synthetic Images for Training an Object Detector. Comput. Vision Image Underst. 2014, 137, 24–37. [Google Scholar] [CrossRef]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Christmas, W.; Li, S.Z.; Hospedales, T. When Face Recognition Meets with Deep Learning: an Evaluation of Convolutional Neural Networks for Face Recognition. In Proceedings of the 2015 International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Miclut, B.; Käster, T.; Martinetz, T.; Barth, E. Committees of deep feedforward networks trained with few data; In Proceedings of the German Conference on Pattern Recognition (GCPR 2014), Münster, Germany, 2–5 September 2014.
- Gros, C.; Straub, J. Human face images from multiple perspectives with lighting from multiple directions with no occlusion, glasses and hat. Data Br. 2019, 22, 522–529. [Google Scholar] [CrossRef] [PubMed]
- Learned-Miller, E.; Huang, G.B.; RoyChowdhury, A.; Li, H.; Hua, G. Labeled Faces in the Wild: A Survey. In Advances in Face Detection and Facial Image Analysis; Springer International Publishing: Cham, Switzerland, 2016; pp. 189–248. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 87–102. [Google Scholar]
- Klare, B.F.; Klein, B.; Taborsky, E.; Blanton, A.; Cheney, J.; Allen, K.; Grother, P.; Mah, A.; Jain, A.K.; Klare, B.; et al. Pushing the Frontiers of Unconstrained Face Detection and Recognition: IARPA Janus Benchmark A. In Proceedings of the Computer Vision and Pattern Recognition 2015 Conference, Boston, MA, USA, 7–12 June 2015; pp. 1931–1939. [Google Scholar]
- Salari, S.R.; Rostami, H. Pgu-Face: A dataset of partially covered facial images. Data Br. 2016, 9, 288–291. [Google Scholar] [CrossRef] [PubMed]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Ahonen, T.; Rahtu, E.; Ojansivu, V.; Heikkila, J. Recognition of blurred faces using Local Phase Quantization. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- NIST Face Recognition Technology (FERET). Available online: https://www.nist.gov/programs-projects/face-recognition-technology-feret (accessed on 29 January 2019).
- AT&T The Database of Faces. Available online: https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html (accessed on 29 January 2019).






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).