In this section, we introduce the concept of a cluster graph approach and describe how to formulate our land cover classification boosting problem as an undirected graph. We then describe the details of how a cluster graph can be used to formulate an inference procedure on this graph to perform classification boosting for our land cover problem.
3.1. Cluster Graph
Cluster graph is a structured probabilistic model, where the structure comprises disjoint union of complete graphs and represents conditional dependencies among random variables. Cluster graphs are known for their ability to perform inference over problem spaces with many inter-dependencies, and it is a useful tool for approaching problems which are difficult to define and solve algorithmically. In a general sense, cluster graph can be seen as a method whereby a large system is broken down and clustered into smaller sections, such that these sections can be connected in a graph structure. This graph structure allows these smaller systems to communicate about their combined outcome, and thus perform inference. Therefore, cluster graph can be described as a tool to reason about large-scale probabilistic systems in a computationally efficient manner.
A cluster graph is a compact representation of a probabilistic space as the product of smaller, conditionally independent distributions, referred to as factors. Each factor defines a probabilistic relationship over its associated cluster of variables. For discrete classification problems, such as our land cover classification problem, these factors will have a discrete probability table of either a prior, marginal, or conditional distribution. In practice, these factors are built-up from any available knowledge and assumptions (i.e., educated guesses, or expert knowledge) about the variables and the relationships within the model.
As a means to inference, explicitly calculating the product of these factors is useful, but typically not computationally feasible. A cluster graph rather connects factors into a graph structure with the factors as nodes and connections holding a set of variables, called a sepset. Information may be passed between factors through connecting sepsets in one of the many probabilistic graphical model (PGM) inference techniques. Typically, the factors of a cluster graph are initialized using the prior beliefs of the system. These beliefs are then updated by passing information about neighboring sepset variables, and factors around, until all the beliefs reach convergence. This produces an approximation of the posterior distribution over the factors, and thus a solution to the problem at hand. The details of message passing in graphical models and determining convergence of sepsets of beliefs are beyond the scope of this paper and for this we refer the reader to Koller and Friedman [
29].
3.2. Proposed Approach
Given the situation where multiple, independent, non-agreeing, classifications exist, we can combine these classifications to obtain a new, more accurate classification in an approach referred to as classification boosting.
Many approaches of classification boosting exist and have varying degrees of success dependent on the problem at hand. The most notable are naive boosting, where the mode of the different classifications is selected as the output class, and ensemble methods, where an optimal combination of existing classifiers is learned to produce a new classification [
30]. To this end, we propose the use of cluster graph to solve the classification boosting problem.
Cluster graphs has numerous benefits over existing approaches since they make defining variables and relationships easy and exhibit powerful inference abilities. Furthermore, unlike the naive and ensemble methods of classification boosting, cluster graphs can extrapolate expert knowledge to reclassify regions which were probabilistically unlikely in the original classification. Therefore, it can be argued that cluster graphs are positioned somewhere between learning a new classifier and pure classification boosting.
To model the land cover classification problem, we made the following assumptions about the nature of the land cover classification data we are using.
The classifications are noisy observations which correlate with the true underlying class.
The underlying land cover map can be sufficiently divided up into small squares, similar to pixels, with the observations sub-sampled to correspond to these locations.
Adapting Tobler’s first law of geography [
31], locations in close proximity have a higher likelihood to be of the same class than locations further away.
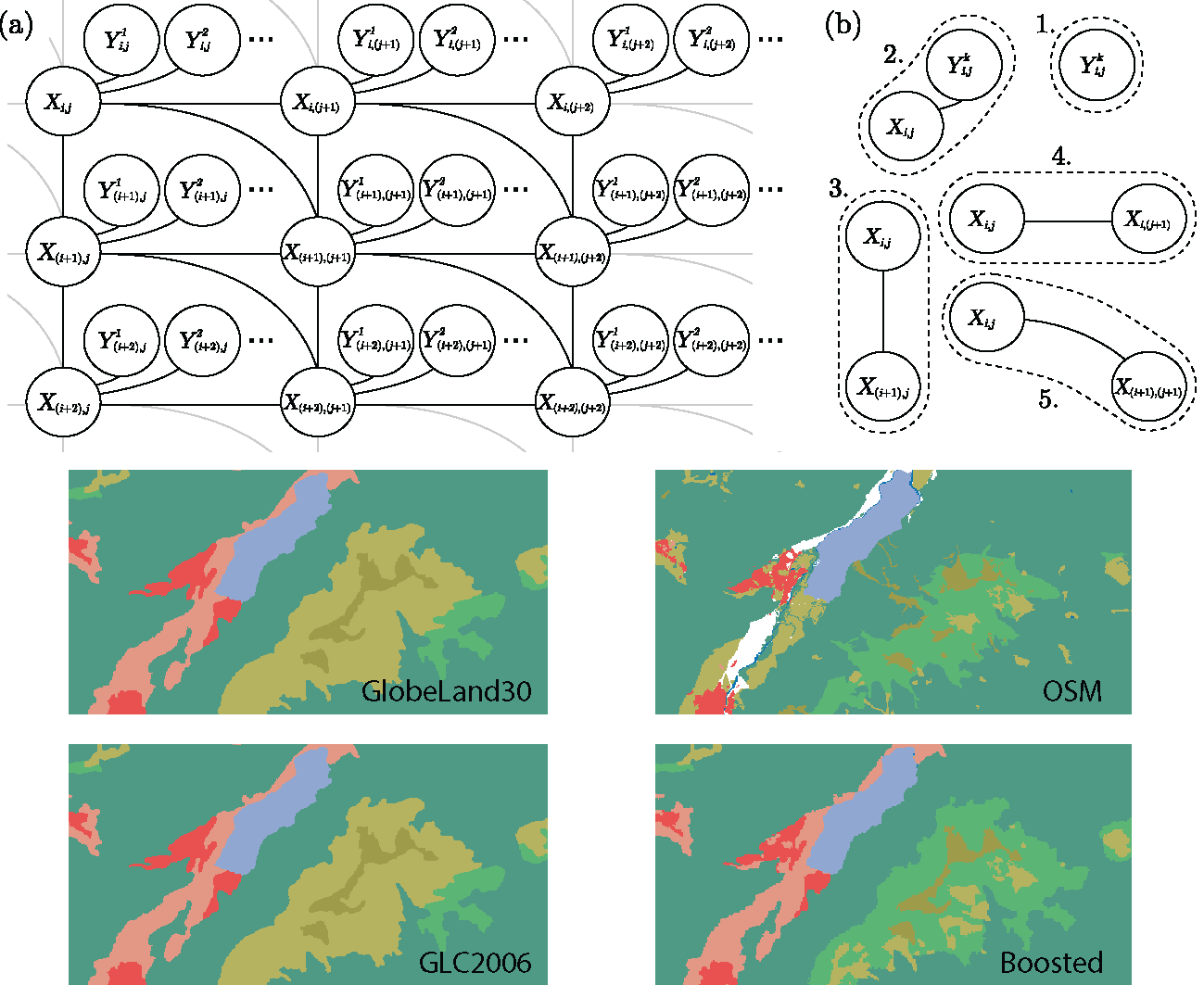
We simplified these assumptions into the following relationship model. We split our underlying map into
pixels and assign a random variable
to each pixel as a representation of the underlying class. For data taken from
K different approaches (in our case
K different land cover classification maps), we assign the variable
as an observation correlating with
by sampling from the classification
k at pixel
. We also assign a relationship between each
and its associated state
. Finally, we assign a relationship between all neighboring pixels of
to enforce Tobler’s first law of geography. These variables and relationships are illustrated in
Figure 1a.
For a PGM formulation of this model, we choose the factors in a manner that would capture the relationships of the model and can easily be initialized from the land cover data. This choice is outlined in
Figure 1b and
Table 1, along with a brief description of the purpose of each set of factors in the relationship model.
Our factors are then initialized according to the land cover classifications and assumptions in the form of expert knowledge. The idea is simple: we assign a discrete probability table to each factor according to an underlying relationship. More specifically, we set the observation variables
according to the land cover classification
k: for hard classifications we have
and
, and for soft classifications we make use of joint probability tables initialized by expert knowledge about the likelihood of class co-occurrence in the defined region, and the class-specific classification quality, see
Table 2. Furthermore, for the relational factors (such as
Table 1 factors 2 to 5) the variables are more likely to have the same outcome.
Using our defined and initialized factors we (a) construct a cluster graph, (b) obtain a posterior distribution over this graph by means of PGM inference techniques and (c) extract the random variables from the posterior as the most likely land cover classifications. Thus, completing the boosting process by creating the boosted land cover classification using the variables.
A full discussion on the construction of a cluster graph, and PGM inference over the graph are beyond the scope of this paper. For this we refer the reader to in-depth literature on the topic such as Koller and Friedman [
29]. However, a summarized overview of the construction, inference and settings used are presented below.
Configuring a cluster graph correctly is not a trivial task and requires some heuristics. For the construction of our cluster graph we make use of the LTRIP procedure described by Streicher and du Preez [
32].
We used belief update, also known as the Lauritzen-Spiegelhalter algorithm [
33] to perform inference over the graph.
The convergence of the system, as well as the scheduling of messages, is determined according to the Kullbach-Leibler divergence between the newest and immediately preceding sepset beliefs.
The distribution over a single variable is found by locating a factor containing the variable and then marginalizing out to that variable. For example,
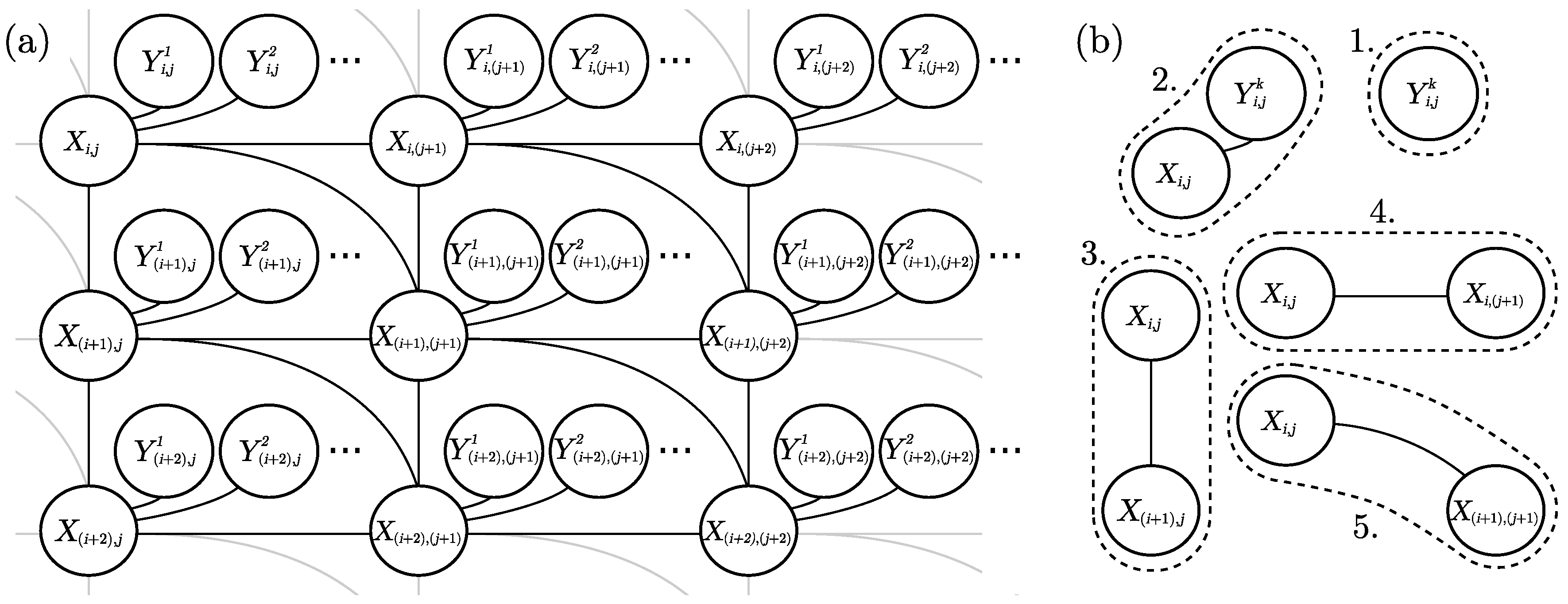
To better understand the proposed cluster graph architecture and inference process, see the reduced example presented in
Figure 2. For illustrative purposes, we only consider the spatial factors (lines 3–5 of
Table 1), we reduce the location grid to
and use a constant probability to define all inter-class relationships. In practice the prior probabilities are to be specified by expert knowledge, and all factors need to be included to boost the original land cover datasets.
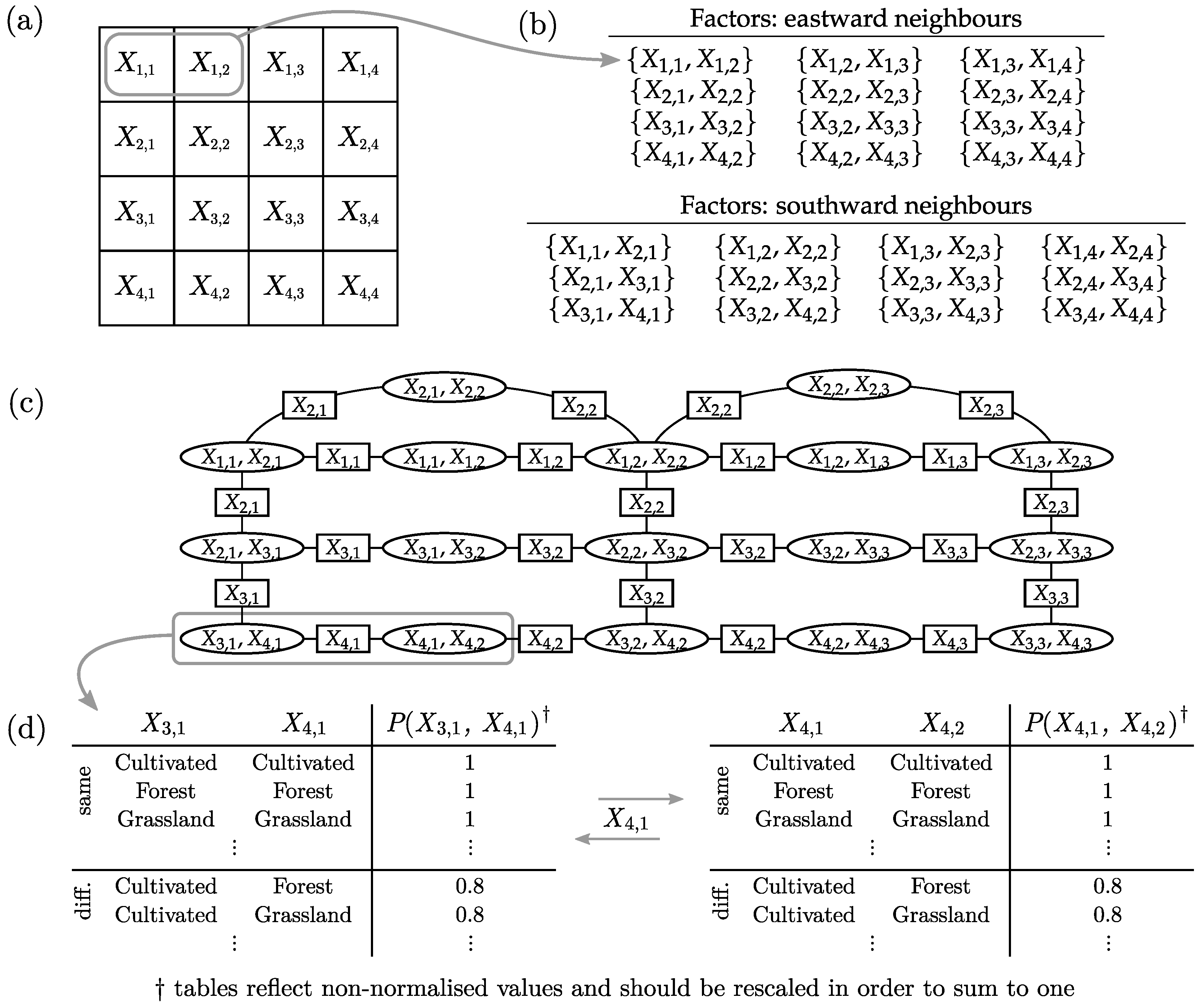
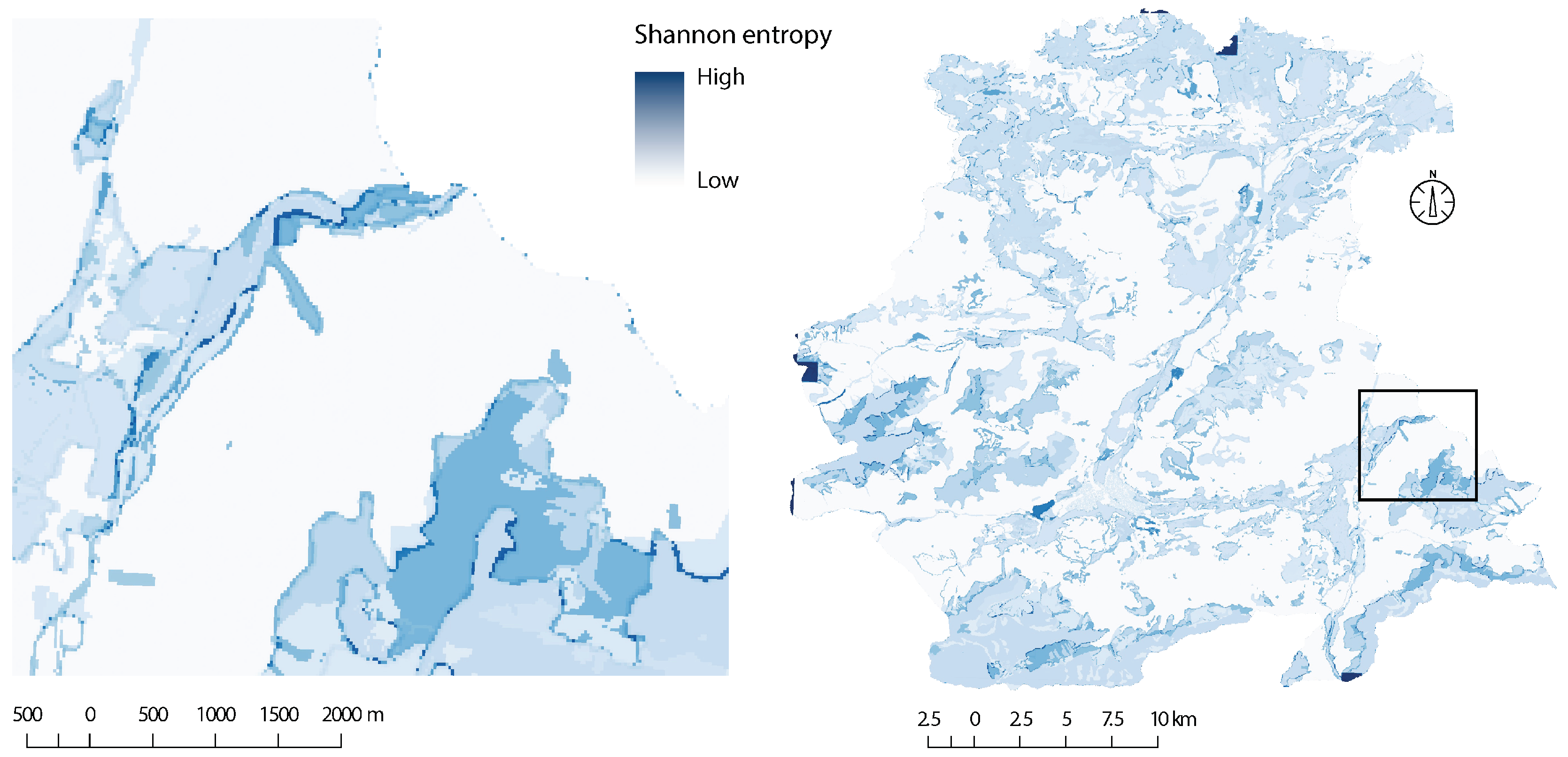
As a final note, since the number of factors grow by order
, it is useful to split the problem up into smaller sections which can be processed in parallel. We found it safe to assume that regions sufficiently far apart have near-zero influence on each other from a factor point of view. Thus, we segmented the region into non-overlapping sub-regions, with an overlapping boundary to enforce smoothness along the edges. We then ran the cluster graph process on each of these sub-regions in parallel and finally stitched the posteriors together along the sub-region boundaries, while discarding the overlapping regions which may contain conflicting results. For a more intuitive understanding of this process, please refer to
Figure 3.
3.3. Dataset
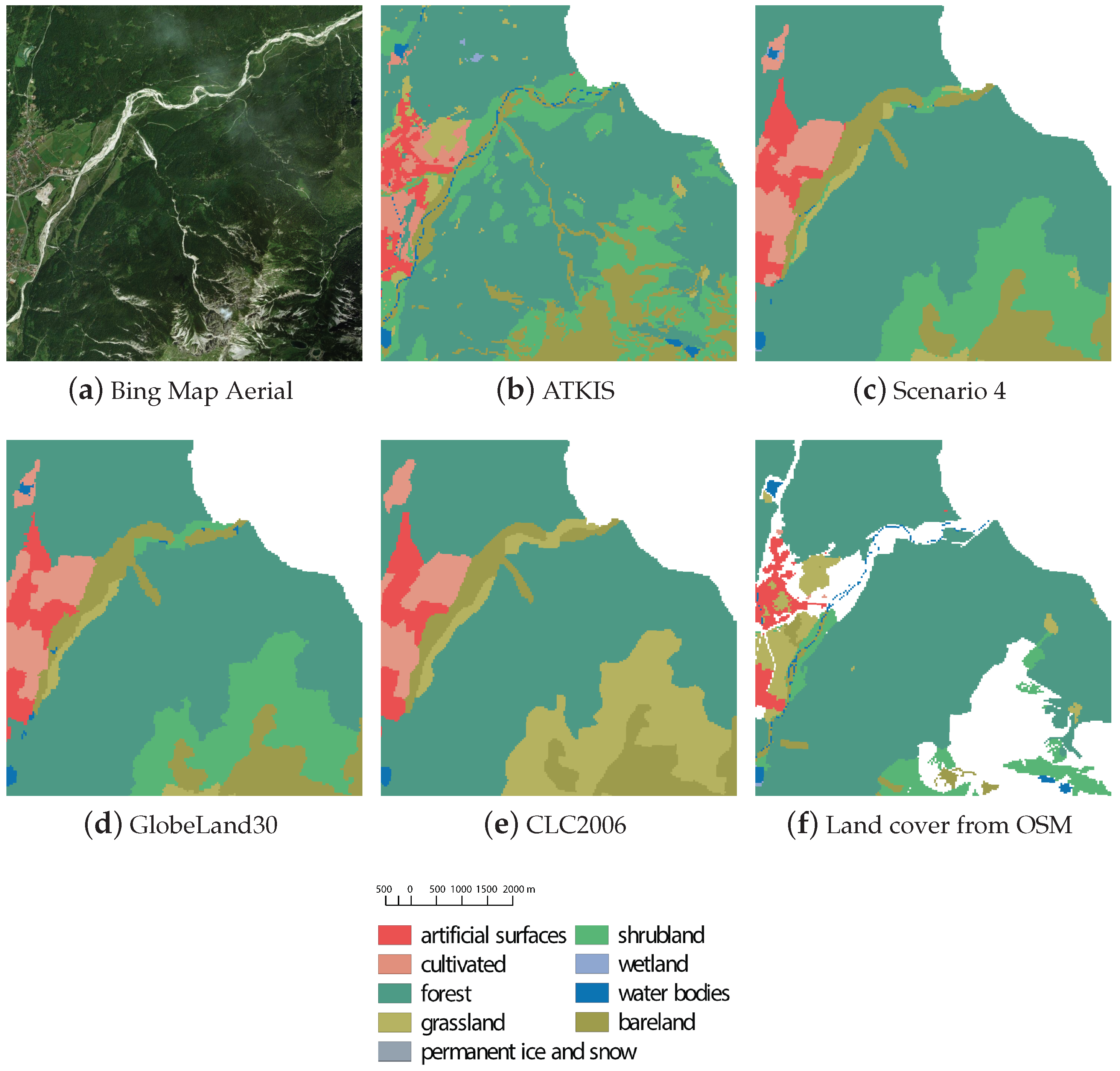
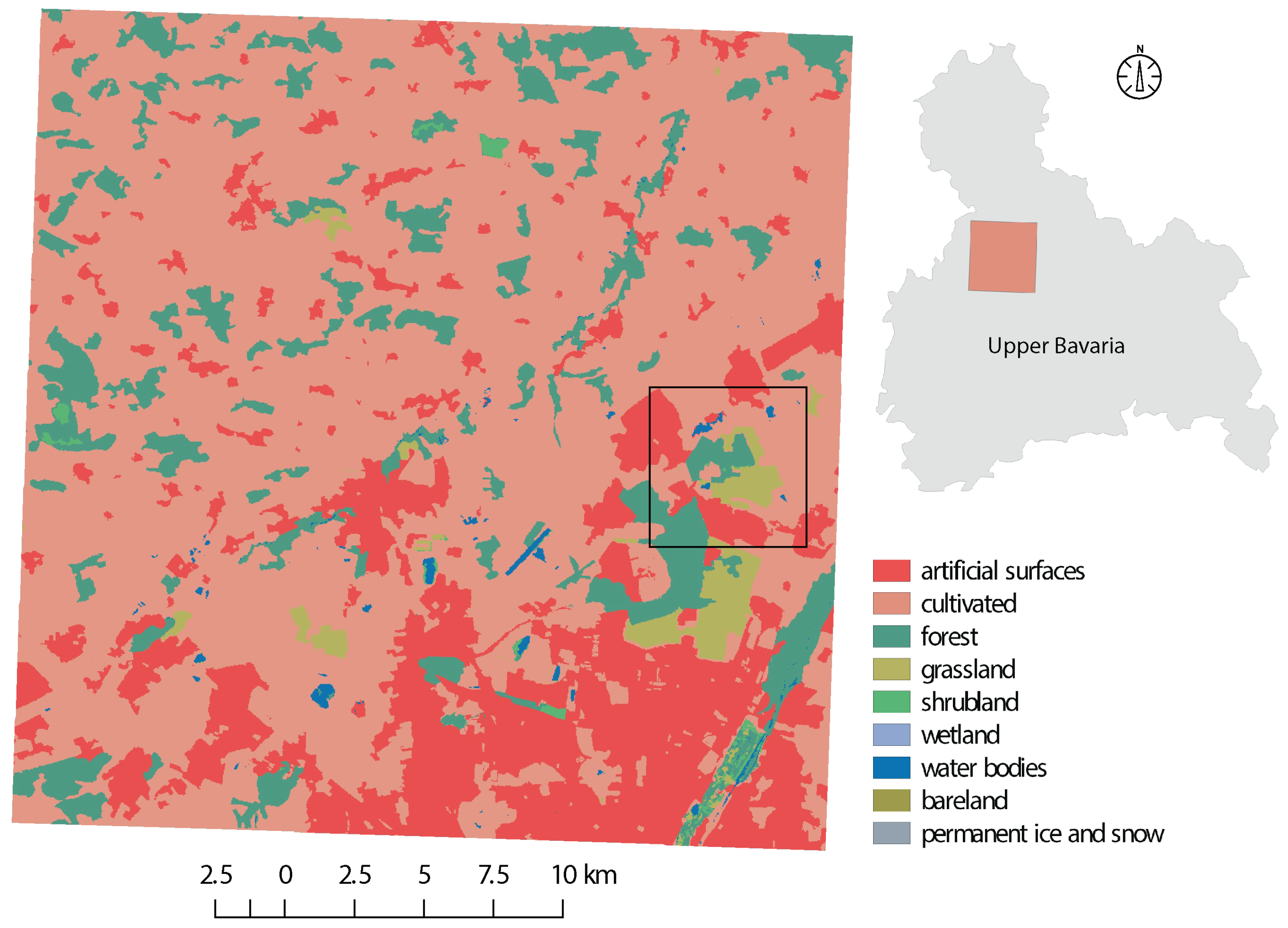
To assess our proposed approach, we selected two commonly used land cover datasets, namely GlobeLand30, CORINE Land Cover (CLC2006, Garmisch-Partenkirchen, Germany), and additionally land cover data derived from Volunteered Geographic Information (VGI) such as OpenStreetMap. The test region of Garmisch-Partenkirchen, Germany (101,224 km) was selected due to the availability of high-quality data sets and sufficient diversity in the distribution of land classes. The land cover classifications are temporally independent of one another, each having been derived from imagery captured over different periods of time. While the temporal disparity between the datasets could cause problems in boosting applications, due to conflicting information caused by large temporal change events. The assumption was made that little temporal change has occurred over the dataset acquisition period, due to the nature of the test location. Thus, despite the temporal data heterogeneity, the benefit of the current work is seen in applying cluster graph approach for boosting land cover classifications.
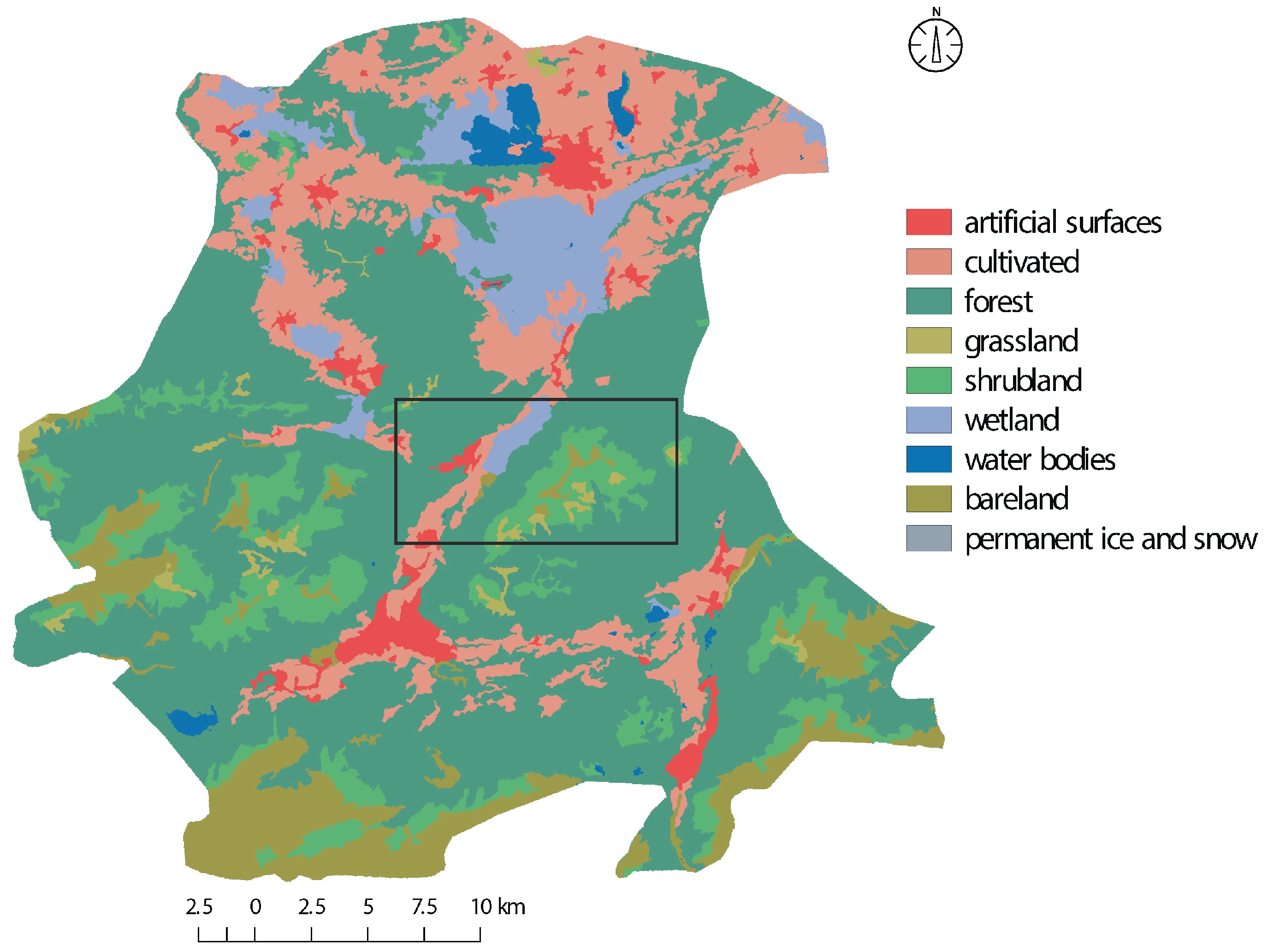
GlobeLand30 is a global scale land cover product of 30m resolution for two base-line years (2000 and 2010). For this study we make use of the 2010 version of the dataset. This dataset is comprised of 10 major land cover classes, namely cultivated areas, forests, grassland, shrubland, wetland, water bodies, tundra, artificial surfaces, bare land and permanent snow and ice. Although the GlobeLand30 dataset is comprised of 10 major classes, only 9 of these classes are present in our study region. The classes which are defined for our study area are depicted in
Figure 4 with examples of the visual appearance of each class.
To reduce the effects of cloud cover on the creation of the GlobeLand30 dataset, the raw remote sensing imagery was selected to coincide with the local vegetation growth season [
2]. Thus, the land cover classification was created based on mosaic of suitable images with minimal cloud occlusions. According to data provider, the land cover classifications of our study area were generated from a mosaic of images acquired on 31 August 2009. Previous studies indicate that the overall classification accuracy of GlobeLand30 can range from 46% [
34] and up to 80% [
2,
35,
36], and thus the true accuracy of the dataset is heterogeneous.
Land cover mapping that specifically focuses on the EU countries is realized within the CORINE (“Coordination of Information on the Environment”) program. The CLC2006 (CORINE Land Cover 2006) dataset for the area of Germany follows common European-wide CORINE Land Cover nomenclature that consists of 44 classes, where 37 classes are relevant for Germany and 29 classes are relevant for the study area. We scaled down the class complexity to provide consistent classification for all the data sources. This was achieved by reassigning the 44 CORINE land cover classes into the 10 classes provided by the GlobeLand30 classification. The details of the reclassification processes can be seen in
Table 3.
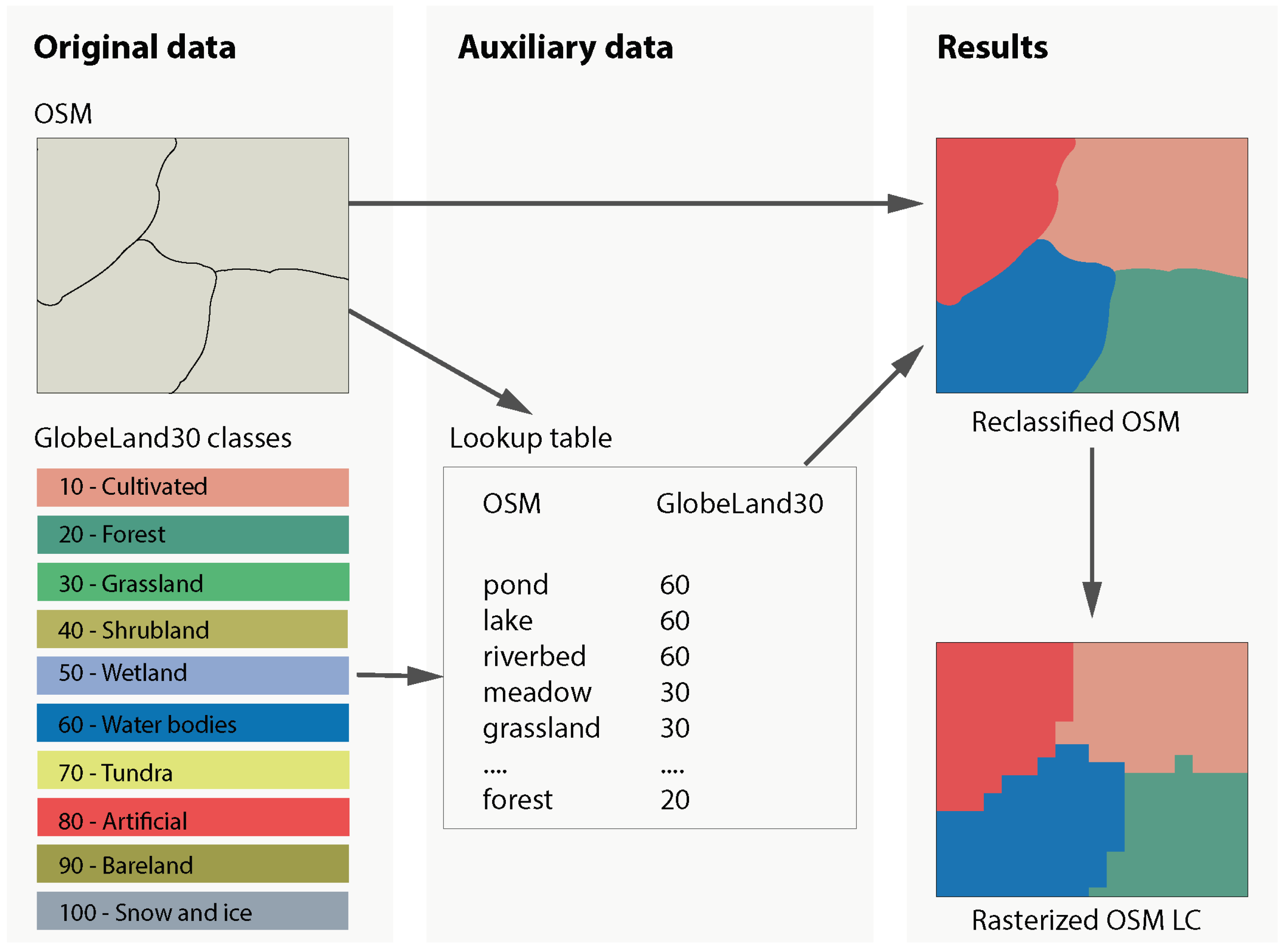
Along with GlobeLand30 and CORINE (CLC2006), data from OpenStreetMap (OSM) plays an important role in this study as an auxiliary source. The OSM (openstreetmap.org) is one of the most widespread and well-recognized VGI projects. Although the OSM data is not specifically tailored to the needs of land cover mapping and the OSM data and user community is very heterogeneous, the data has valuable input for the land cover classification. In our research, we implemented a method suggested by [
37] for deriving a land cover map from the OSM database as shown in
Figure 5. To preserve the entire content of the database, we use a complete XML-encoded extract of the OSM database, representing our study area, instead of pre-processed Shapefiles distributed by OSM data providers. The data pre-processing has been done in a combination of automatic and manual OSM tag annotations to GlobeLand30 classification scheme. For the derivation of the land cover map, a subset of the OSM tags, namely “amenity”, “building”, “historic”, “land use”, “leisure”, “natural”, “shop”, “tourism”, and “waterway” are considered. This mapping is only conducted for polygon features, since point and line features do not provide immediate information about the coverage of an area. We define a mapping from the OSM attributes to the classes used in the GlobeLand30 classification scheme.
The data is then rasterized and resampled using a nearest neighbor approach to generate a land cover classification with the same resolution and spatial alignment as the GlobeLand30 dataset. The workflow for converting the OSM data into a land cover raster product is depicted in
Figure 5.
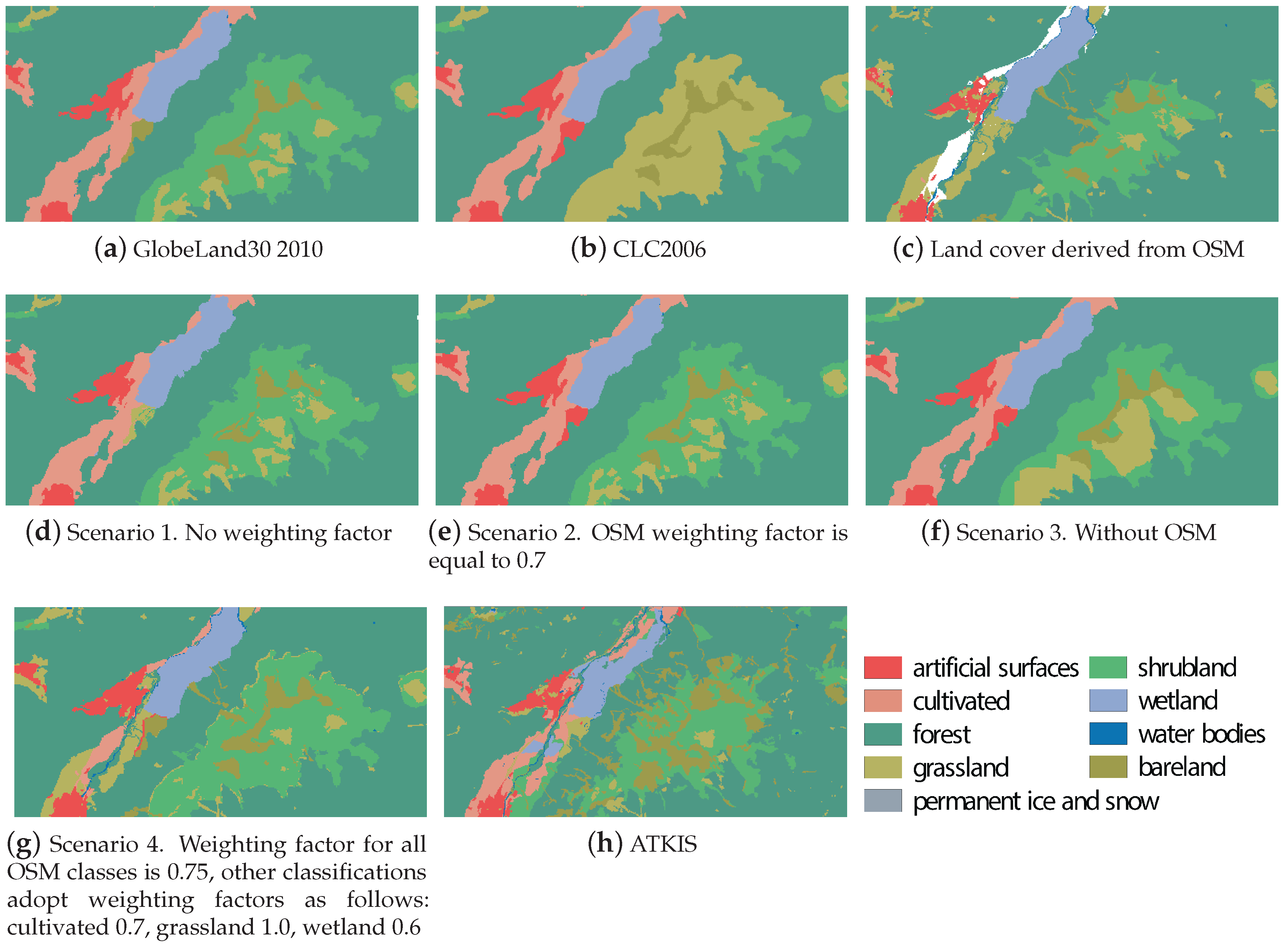
To accurately access our classification boosting approach a ground-truth dataset was required. As it is intractable to obtain a truly accurate land cover classification for the whole study area, and thus an accurate reference dataset, we chose to make use of a well maintained, and frequently updated, official land cover classification for this purpose. The national dataset called Amtliches Topographisch-Kartographisches Information System (ATKIS) was selected as the reference dataset for our investigation. This dataset represents a Digital Landscape Model of scale 1:10,000 and 1:25,000 (Basis-DLM), and was provided by an official national cartographic authority (Bundesamt für Kartographie und Geodäsie). Our selection was further motivated by the reported use of this dataset as a reference map by numerous other authors [
36,
38].
Dataset Pre-Processing
Pre-processing and harmonization of the classes among these three heterogeneous datasets was performed to simplify the construction of the cluster graph. However, it should be noted, that this step is not required and merely reduces the complexity in defining the inter-class relationships between the various datasets by ensuring a common set of class labels exist for all the datasets.
The details of our pre-processing steps are outlined below:
3.4. Definition of Priors and Parameters
In addition to the cluster graph implementation and dataset, our approach requires an inter-class joint probability table, a per map confidence factor as well as the definition of sub-region and boundary size.
The joint probability table is defined based on expert knowledge and fundamental laws of geography. Classes which are likely to occur next to each other are assigned to a high probability, while classes unlikely to neighbor each other—based on region, geography, and expert assumptions, are assigned a low value. The self-occurrence probability of each class
is assigned the highest value to add dependence on Tobler’s first law of geography. Due to the nature of inference in cluster graphs, and PGMs in general, the values defined in the prior joint probability table do not need to be exact probabilities, but rather need to reflect the relative relationships between various classes. For instance if
and
this reflects that it is equally likely that class
b or
c could neighbor class
a and that it is significantly less likely that class
d would neighbor class
a. The full joint probability table used in our experiments can be seen in
Table 4.
In addition to introducing expert knowledge into the inference process through the inter-class joint probability table, we also include further expert knowledge in the form of a classification map confidence factor. This factor can be used to weight the confidence in each of the input datasets as a whole, or in a class-wise manner, and the weighting factor can either be set by expert opinion or through more complex statistics.
To assess the effects of including VGI, in the form of OSM data, we performed multiple experiments where the confidence in the OSM data was adjusted according to expert opinion. The confidence factors for the CLC2006 and GlobeLand30 datasets were kept constant to only assess the effect of VGI data which is often an incomplete, and noisy source of land cover information.
The selected confidence factors are described in
Table 5 and each of our experimental setups are detailed below:
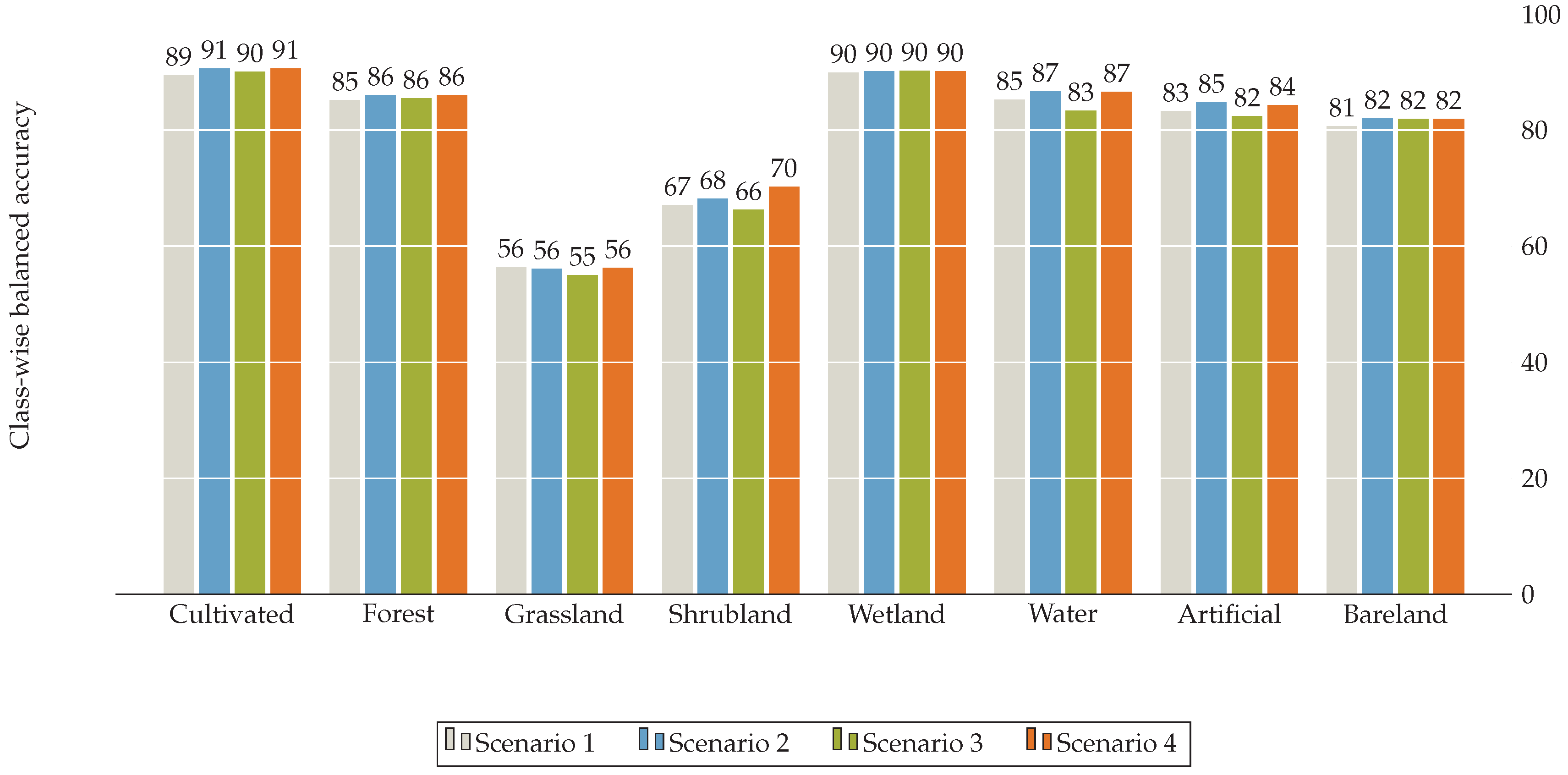
Scenario 1: All land cover maps were assumed to be of equal quality ().
Scenario 2: OSM data was assumed to be less accurate overall ().
Scenario 3: OSM data was excluded completely from the boosting process ().
Scenario 4: OSM data is assumed to be less accurate overall, except for grassland. The classes are weighted as follows: overall OSM weighting: 0.75, cultivated: 0.7, wetland: 0.6 and grassland: 1.0.
Lastly, the size of the sub-regions and boundaries was defined such that each sub-region was square with a side length of (1050 m) and a boundary of (180 m). It was found that a total boundary width (left + right, or top + bottom) which is between 25% and 50% of the sub-region width or length is appropriately large that the edge factors have a negligible influence. In our case our boundary was defined as .


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
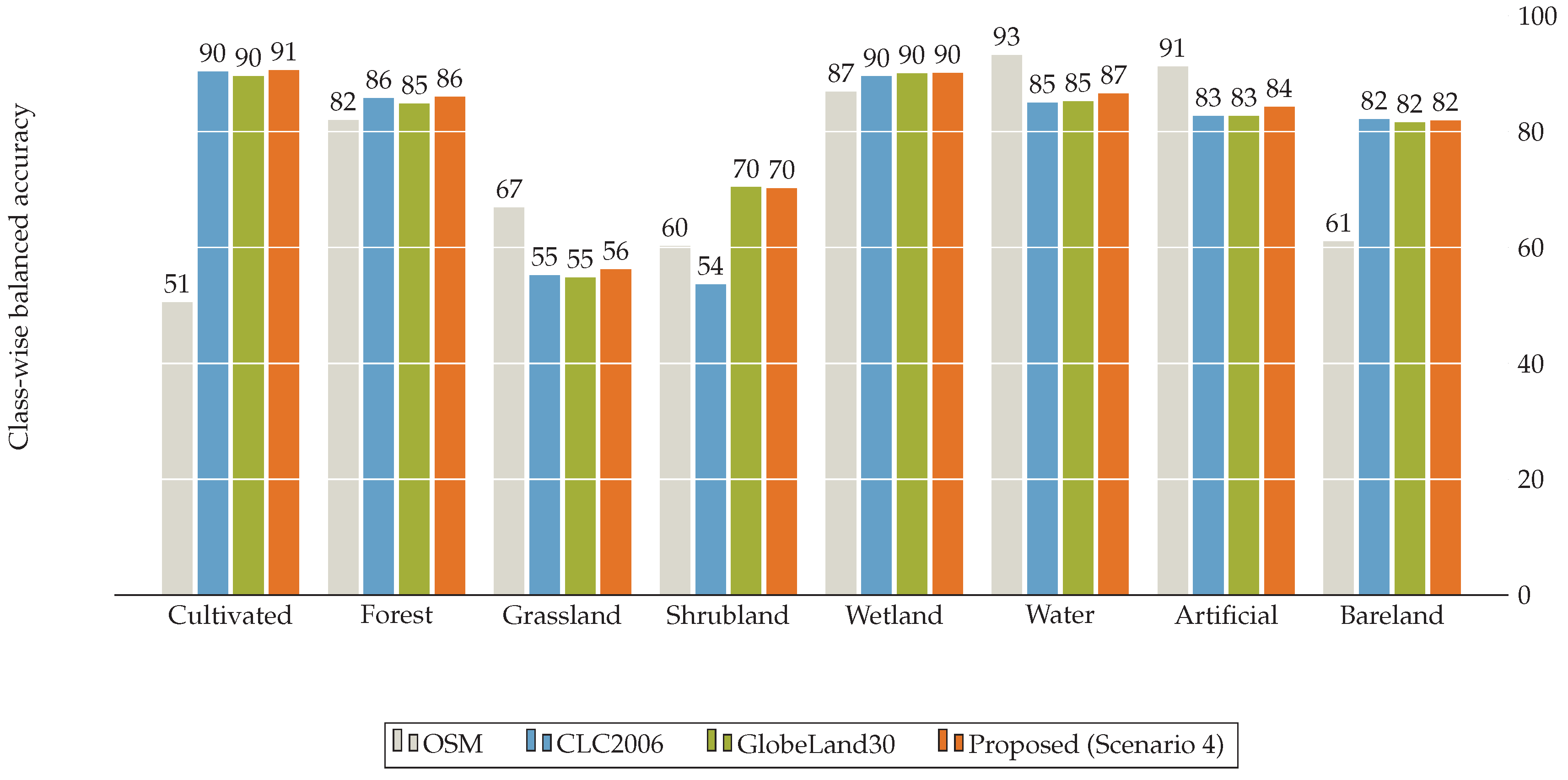{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
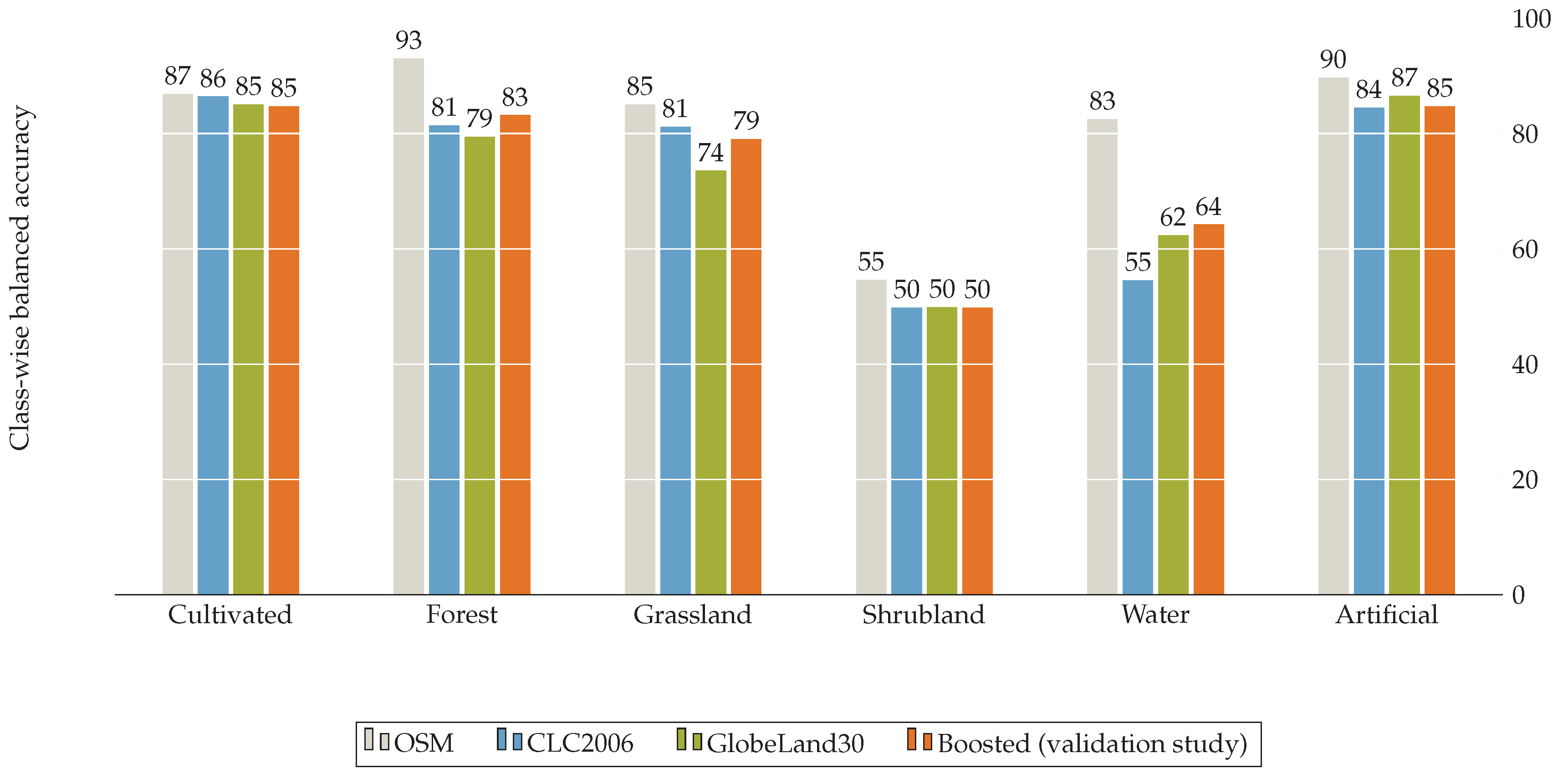{kind=link}