Similar Text Fragments Extraction for Identifying Common Wikipedia Communities

 , ,
, , 
 and
and
Abstract
:1. Introduction
2. Related Work
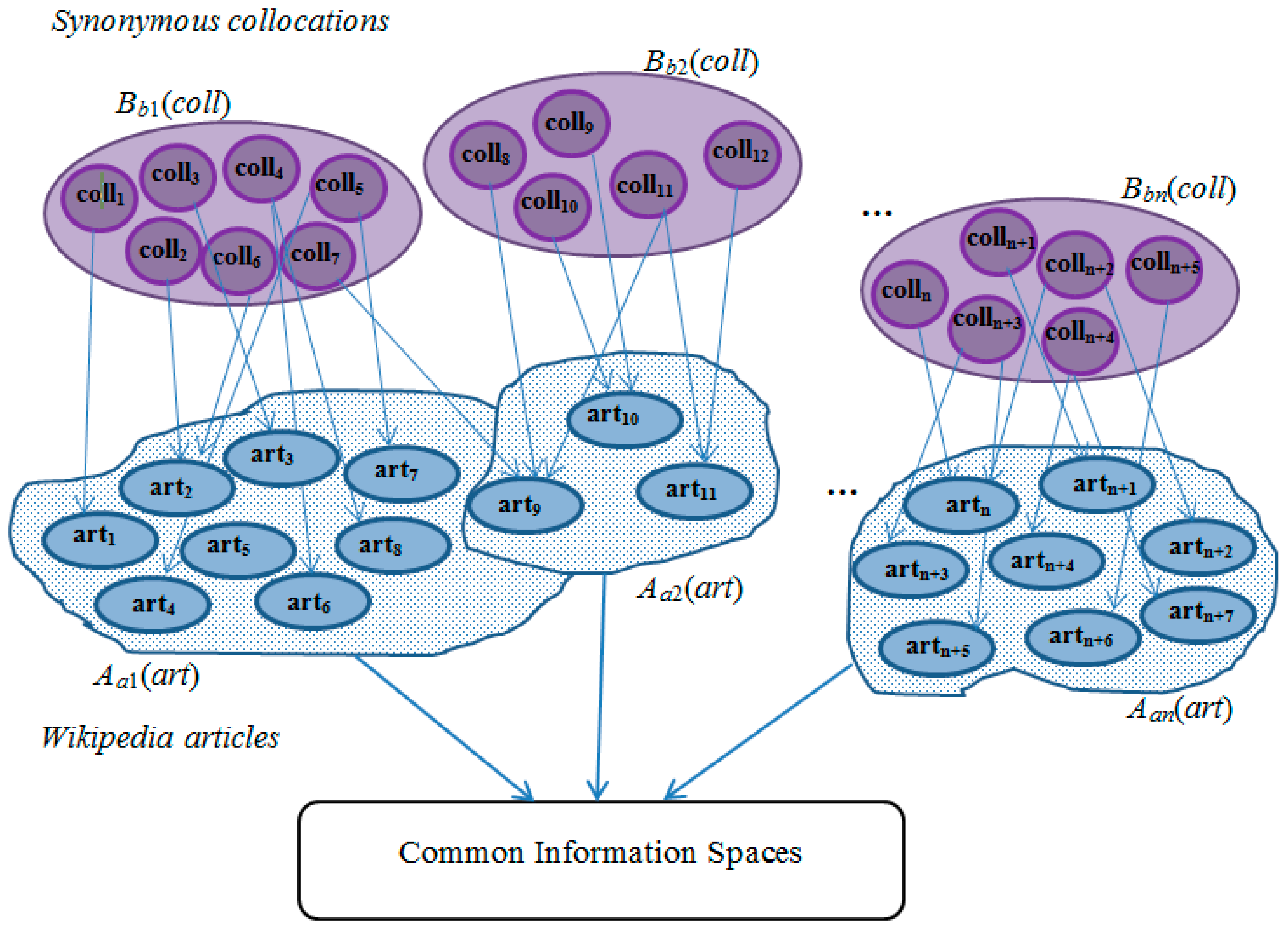
3. Mathematical Model
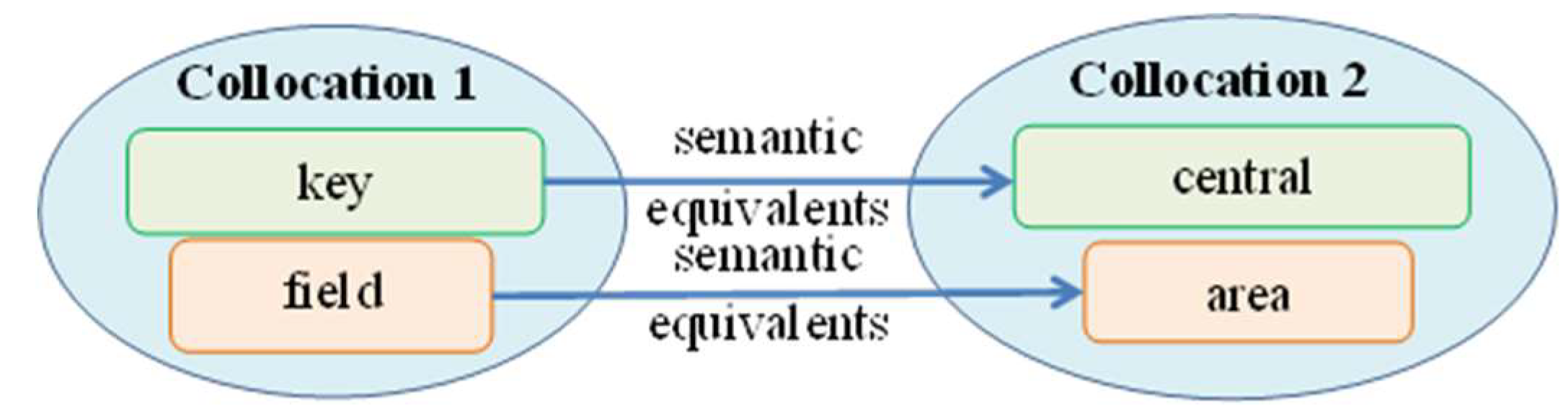
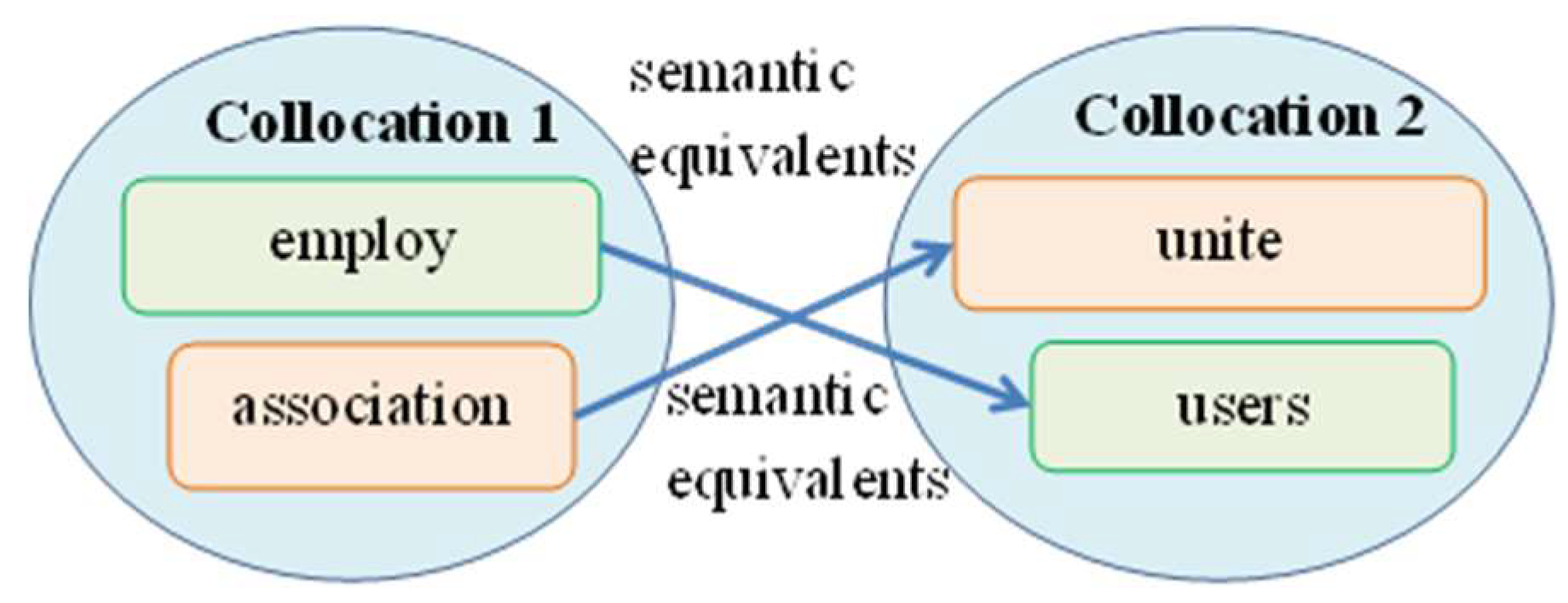
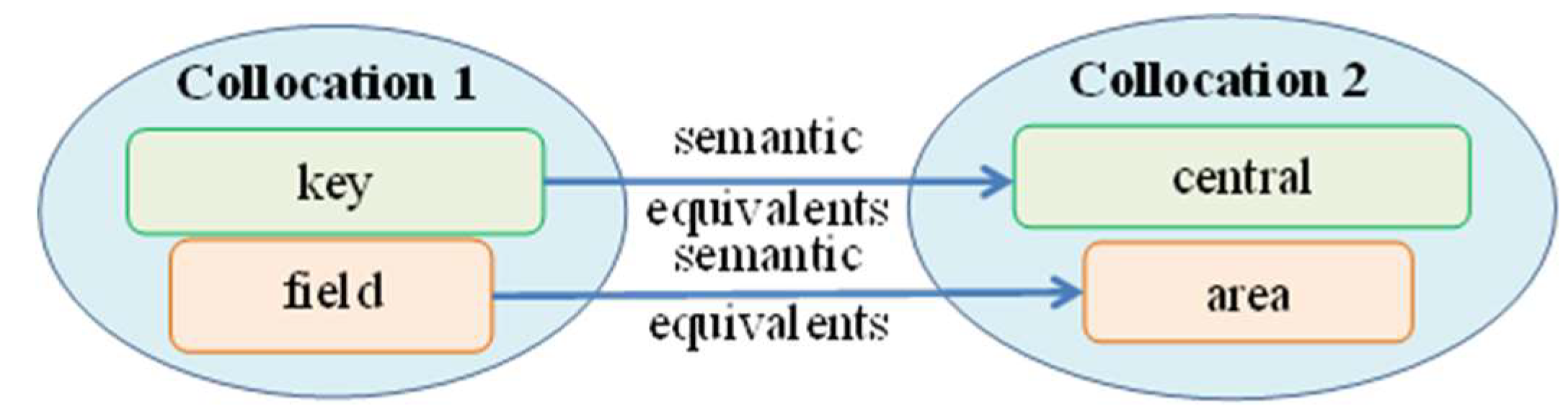
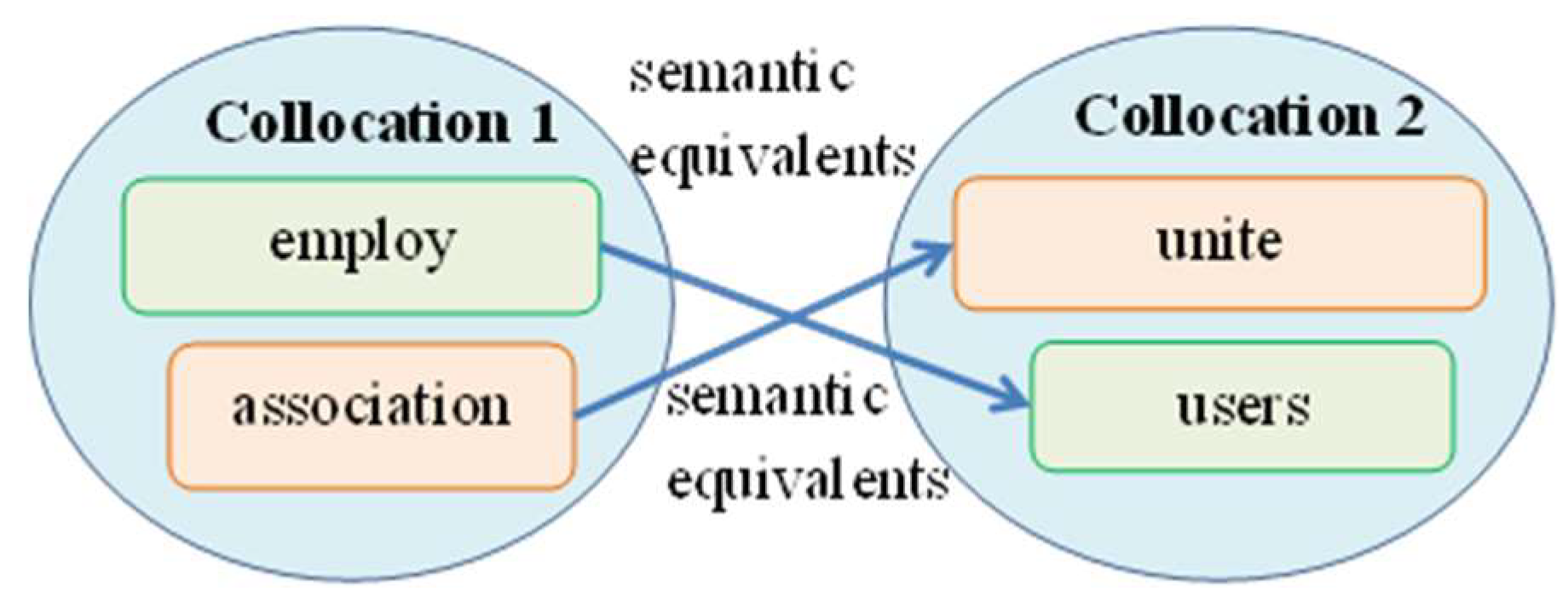
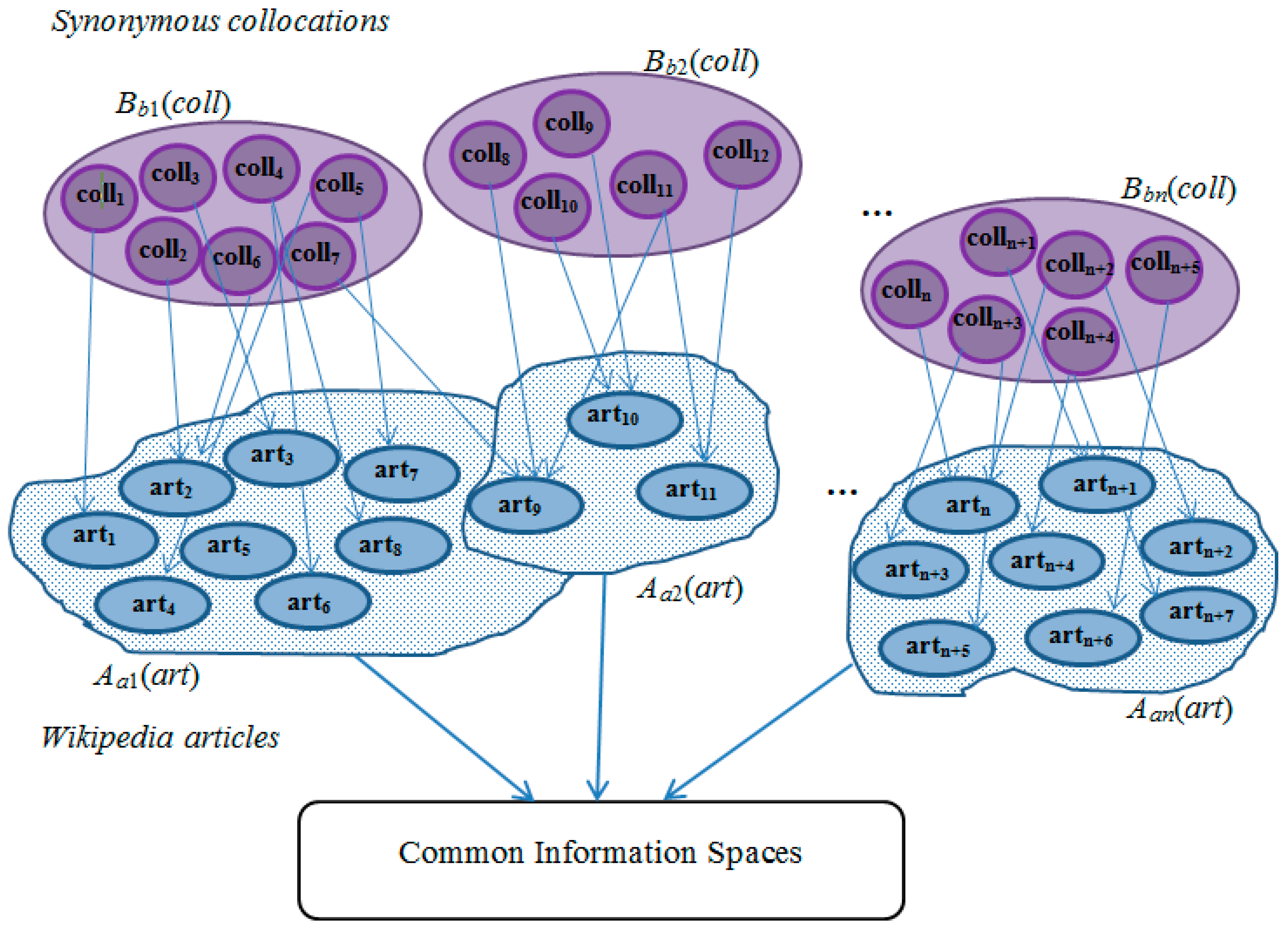
Example Description
4. Technology Design
- the extraction of semantic-grammatical characteristics of words that can potentially be elements of substantive, attributive and verbal collocations;
- the identification of collocations, i.e., phrases formed by two adjacent word forms;In order to identify the grammatical characteristics, we exploit Stanford Part-Of-Speech (POS) tagger and Stanford Universal Dependencies (UD) parser. The tagger identifies morphological features of words and UD parser determines syntactic links between the words in a sentence;
- the discovery of synonymous collocation words using WordNet synsets;
- the identification of semantic equivalence of two-word collocations, i.e., word combinations that have common elements of meaning.
5. Data Description
6. Experimental Evaluation
- substantive collocations that are presented by two connected nouns;
- attributive collocations where a noun is the main word and an adjective is the dependent word;
- verbal collocations that are represented by a verb (the main word) and a noun (the dependent word).
Results Analysis
7. Conclusions and Further Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Wikipedia Community. Available online: https://en.wikipedia.org/wiki/Wikipedia_community (accessed on 30 November 2018).
- Research Fronts. 2017. Available online: https://clarivate.com.cn/research_fronts_2017/2017_research_front_en.pdf (accessed on 15 September 2018).
- Chaikovsky, Y.B.; Silkina, Y.V.; Pototska, O.Y. Scientometric databases and their quantitative indices (Part I. Comparative characteristic of scientometric databases). Bull. Natl. Acad. Sci. Ukraine 2013, 8, 89–98. [Google Scholar]
- Hsu, J.W.; Huang, D.W. Correlation between impact and collaboration. Scientometrics 2011, 86, 317–324. [Google Scholar] [CrossRef]
- Marshakova-Shaikevich, I. Bibliomertrics—What and how we can evaluate in science. Large Syst. Manag. 2013, 44, 210–247. [Google Scholar]
- Parvez, A.K.; Manasi, P.; Pushkar, J. Towards a new perspective on context based citation index of research articles. Scientometrics 2016, 107, 103–121. [Google Scholar] [CrossRef]
- Brizan, D.G.; Gallagher, K.; Jahangir, A.; Brown, T. Predicting citation patterns: Defining and determining influence. Scientometrics 2016, 108, 183–200. [Google Scholar] [CrossRef]
- Shvets, A.V.; Devyatkin, D.A.; Smirnov, I.V.; Tikhomirov, I.A.; Popov, K.V.; Yarygin, K.N. The study of systems and methods for scientometric analysis of scientific publications. Sci. Tech. Inf. Process. 2015, 42, 359–366. [Google Scholar] [CrossRef]
- Boyack, K.W.; Small, H.; Klavans, R. Improving the accuracy of co-citation clustering using full text. J. Am. Soc. Inf. Sci. Technol. 2013, 64, 1759–1767. [Google Scholar] [CrossRef]
- Thijs, B.; Glänzel, W.; Meyer, M. Using noun phrases extraction for the improvement of hybrid clustering with text- and citation-based components. The example of “information System Research”. In Proceedings of the 1st Workshop on Mining Scientific Papers: Computational Linguistics and Bibliometrics, Istanbul, Turkey, 29 June 2015; Volume 1384, pp. 28–33. [Google Scholar]
- Zhang, M.; Li, W.; Zhang, H. Paraphrase Collocations Extraction Based on Concept Expansion. In Knowledge Engineering and Management; Wen, Z., Li, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 278, pp. 191–199. [Google Scholar]
- Wang, R.; Callison-Burch, C. Paraphrase Fragment Extraction from Monolingual Comparable Corpora. In Proceedings of the 4th Workshop on Building and Using Comparable Corpora, Portland, OR, USA, 24 June 2011; pp. 52–60. [Google Scholar]
- Lytras, M.D.; Aljohani, N.; Damiani, E.; Chui, K.T. Innovations, Developments, and Applications of Semantic Web and Information Systems; IGI Global: Hershey, PA, USA, 2018; 473p. [Google Scholar]
- Santanu, P.; Pintu, L.; Sudip, K.N. Role of paraphrases in PB-SMT. In Proceedings of the 15th International Conference on Computational Linguistics and Intelligent Text Processing, Kathmandu, Nepal, 6–12 April 2014; Volume 8404, pp. 242–253. [Google Scholar] [CrossRef]
- Barzilay, R.; Elhadad, N. Sentence alignment for monolingual comparable corpora. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Sapporo, Japan, 11–12 July 2003; pp. 25–32. [Google Scholar] [CrossRef]
- Nelken, R.; Shieber, S.M. Towards robust context-sensitive sentence alignment for monolingual corpora. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 161–168. [Google Scholar]
- Coster, W.; Kauchak, D. Simple English Wikipedia: A new text simplification task. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 665–669. [Google Scholar]
- Bott, S.; Saggion, H. An unsupervised alignment algorithm for text simplification corpus construction. In Proceedings of the Workshop on Monolingual Text-To-Text Generation, Portland, OR, USA, 24 June 2011; pp. 20–26. [Google Scholar]
- Petrasova, S.; Khairova, N.; Lewoniewski, W. Building the semantic similarity model for social network data streams. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing, Lviv, Ukraine, 21–25 August 2018; pp. 21–24. [Google Scholar] [CrossRef]
- Khairova, N.; Petrasova, S.; Lewoniewski, W.; Mamyrbayev, O.; Mukhsina, K. Automatic Extraction of Synonymous Collocation Pairs from a Text Corpus. In Proceedings of the 2018 Federated Conference on Computer Science and Information Systems, Poznan, Poland, 9–12 September 2018; Volume 15, pp. 485–488. [Google Scholar] [CrossRef]
- Wikipedia:WikiProject_Albums. Available online: https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Albums (accessed on 25 April 2018).
- Wikipedia:WikiProject_Film. Available online: https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Film (accessed on 15 April 2018).
- Wikipedia:WikiProject_Biography/Politics_and_government. Available online: https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Biography/Politics_and_government (accessed on 25 April 2018).
- Wikipedia:WikiProject_Biography/Science_and_academia. Available online: https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Biography/Science_and_academia (accessed on 25 April 2018).

{kind=link}
{kind=link}
{kind=link}
| Type of Collocations | Dependencies of Collocates | Grammatical Characteristics | Semantic Characteristics of Nouns | |||||
|---|---|---|---|---|---|---|---|---|
| Ag | Att | Pac | Adr | Ins | M | |||
| Substantive | x | NSub/NSubOf | q1 | q2 | q3 | q4 | q5 | q6 |
| NObjOf | - | q7 | q8 | q9 | q10 | q11 | ||
| y | NObj | - | q12 | q13 | q14 | q15 | q16 | |
| Attributive | y | AAtt | q17 | |||||
| APr | q18 | |||||||
| x | NSub/NSubOf | q19 | q20 | q21 | q22 | q23 | q24 | |
| NObjOf/NObj | - | q25 | q26 | q27 | q28 | q29 | ||
| Verbal | x | VTr | q30 | |||||
| VIntr | q31 | |||||||
| y | NObjOf/NObj | - | q32 | q33 | q34 | q35 | q36 | |
| Wikiportals | Wikiprojects | Number of Articles | Word Count | Unique Word Count |
|---|---|---|---|---|
| Art | Album | 151,906 | 30,251,335 | 336,307 |
| Film | 154,739 | 62,375,950 | 609,645 | |
| Biography | Politics and government | 129,360 | 58,756,954 | 584,779 |
| Science and academia | 66,749 | 30,619,991 | 511,985 |
| Wikiprojects (Wikiportals) | The Relative Frequency of Synonymous Collocations | ||
|---|---|---|---|
| Substantive | Attributive | Verbal | |
| Film (Art)—Science and academia (Biography) | 2,194,584 | 1,929,280 | 47,378 |
| Film (Art)—Politics and government (Biography) | 1,902,138 | 1,846,881 | 41,455 |
| Album (Art)—Science and academia (Biography) | 1,742,395 | 1,450,203 | 37,581 |
| Album (Art)—Politics and government (Biography) | 1,286,855 | 1,171,775 | 28,193 |
| Wikiportals | Wikiprojects | The Relative Frequency of Synonymous Collocations | ||
|---|---|---|---|---|
| Substantive | Attributive | Verbal | ||
| Art | Album—Film | 2,022,808 | 1,674,018 | 59,603 |
| Biography | Politics and government—Science and academia | 2,016,960 | 1,634,659 | 39,469 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrasova, S.; Khairova, N.; Lewoniewski, W.; Mamyrbayev, O.; Mukhsina, K. Similar Text Fragments Extraction for Identifying Common Wikipedia Communities. Data 2018, 3, 66. https://doi.org/10.3390/data3040066
Petrasova S, Khairova N, Lewoniewski W, Mamyrbayev O, Mukhsina K. Similar Text Fragments Extraction for Identifying Common Wikipedia Communities. Data. 2018; 3(4):66. https://doi.org/10.3390/data3040066
Chicago/Turabian StylePetrasova, Svitlana, Nina Khairova, Włodzimierz Lewoniewski, Orken Mamyrbayev, and Kuralay Mukhsina. 2018. "Similar Text Fragments Extraction for Identifying Common Wikipedia Communities" Data 3, no. 4: 66. https://doi.org/10.3390/data3040066
APA StylePetrasova, S., Khairova, N., Lewoniewski, W., Mamyrbayev, O., & Mukhsina, K. (2018). Similar Text Fragments Extraction for Identifying Common Wikipedia Communities. Data, 3(4), 66. https://doi.org/10.3390/data3040066