1. Introduction
In the field of biomedical sciences, vast quantities of data are generated every year and are available as free texts for natural language processing (NLP) tasks. Substantial efforts were made over the past decades to develop methods and tools to extract useful information from textual records such as full-text journal articles, medical narratives, clinical reports and to organize them in structured data.
In order to automatically process the biomedical literature data, some manually annotated biomedical corpora were developed and used for supervised training of and for evaluating the systems. For example, gold standard corpora have been created for different types of tasks such as part-of-speech tagging [
1], named entity recognition [
2], relation extraction [
3], event extraction [
4].
Lately, a slightly increasing number of resources specific to this field have been created for languages other than English. For example, Boytcheva et al. [
5] created a biomedical corpus which contains 6400 words, 2000 of them belonging to the Bulgarian medical terminology. For French, Aurélie Névéol et al. created the Quaero French medical corpus [
6] that comprises a total of 103,056 words annotated at entity and concept level. Isabel Moreno et al. developed DrugSemantics corpus [
7], a collection of Summaries of Product Characteristics in Spanish that contains 226,729 tokens annotated with pharmacotherapeutic named entities. It is necessary to have resources for a variety of languages in order to develop methods and tools useful for various NLP tasks and also for the biomedical community (decision support systems, cohort identification).
NLP subtasks are chained together to form processing pipelines; therefore, errors produced in these basic subtasks, tokenization, part-of-speech (POS) tagging and named entity recognition (NER), affect the main objectives of the biomedical text mining techniques. The availability of annotated biomedical textual data still remains a barrier in developing state-of-the-art NLP systems, especially for underresourced languages, Romanian among others.
State-of-the-art POS taggers based on statistical approaches achieve an accuracy of between 93–98%. The main problem encountered when using statistical POS taggers is the fact that most of them need corpora annotated with POS labels as training and testing data. In the case of a specialized domain, the main issue is that the accuracy of POS taggers drops on unknown words. For example, the TnT tagger [
8] performs at 97% accuracy on known words, but the accuracy decreases to 89% for unknown words. Because of the differences between general language and domain specific vocabulary the accuracy of a tagger decreases when the percentage of unknown words increases. For example, the Romanian TTL POS tagger [
9] has an accuracy of 98.23% on newswire domain and 97.83% on biomedical terminology [
10]. In order to achieve a good POS tagging accuracy, domain specific annotated gold standard corpora are needed.
Named entity recognition (NER) is another NLP basic task which deals with boundaries identification of domain specific terms such as diseases, procedures, and chemicals for the biomedical domain. Even though multiple efforts have been made to develop domain specific resources useful for biomedical NER (NCBI corpus [
11], CHEMDNER corpus [
12], BioInfer [
13]), the availability of annotated corpora is limited mostly to English. Therefore, in order to evaluate the robustness of NER systems for other languages than English, high quality annotated corpora for the respective languages are needed.
Moreover, it was shown that joint part-of-speech tags and named entities can be used as features to improve the performance of NLP systems. György Móra [
14] showed that joint labeling can be used to exploit labels of one task as features in the other task, improving the accuracy for both tasks.
In this paper, we describe the first version of the gold standard morphologically and named entity annotated Romanian medical corpus (MoNERo). In the next section, we describe the corpus: selection of the texts to include in it, annotation levels and guidelines for both morphology and named entities (NEs), and the annotation process. The results are presented in
Section 3: descriptive statistics of the corpus, inter-annotator agreement for NER, manual corrections of the POS tagging. The conclusions section closes the paper, with some references to prospective work, too.
The creation of MoNERo is part of a larger effort of developing language resources for Romanian, namely a priority project of the Romanian Academy for creating a large corpus of contemporary Romanian [
15].
3. Results
3.1. Descriptive Statistics of the Corpus
After the annotation process, a corpus of 14,021 tokens (out of which 2018 are punctuation) resulted, distributed into 506 sentences annotated with POS tags and NEs (
Table 4). The average sentence length is quite big, namely 27.69 tokens/sentence. The number of unique lemmas is relevant for calculating the average frequency of each lemma, which is 4.19, irrespective of the type of word (functional or content), although it is widely known that functional words are more frequent than content ones.
The frequency of content words is presented in
Table 5 for each part of speech: nouns are the most numerous, but adjectives come second; as also noted by [
22], medical terms tend to be descriptive and the morphological reflexion of this fact is the high occurrence of adjectives in medical terms structure. Moreover, some medical terms include even several adjectives:
insuficiență renală cronică (“chronic renal insufficiency”),
mușchi drepți abdominali (“rectus abdominis muscles”),
necroze subutanată tisulară (“subcutaneous tissue necrosis”), etc.
Table 6 shows the types and the number of NE annotations in the corpus. The most frequent NE categories are CHEM and DISO, while PROC is rare. This distribution is a consequence of the fact that disorder and medicine names are more frequent in journal articles and medical blog posts. The information provided by this table is very useful in terms of balance if one trains an automatic NER system on this corpus.
As far as the distribution of NEs over the three medical domains is concerned, we notice in
Table 7 the predominance of DISO in cardiology and endocrinology, in both of which the number of PROC is quite low. On the other side, diabetes is dominated by CHEM, while the number of PROC is low as well here. The cardiology field includes many heart diseases (DISO-arrhythmias, cardiac failure, hypertension or myocardial infarction), having different options of pharmacological (CHEM) or interventional treatment (PROC), while most of the anatomical terms are used to explain mainly physiopathological mechanisms. The diabetes category deals particularly with molecular processes (CHEM), such as insulin’s mechanisms of action and the effects of different types of treatments, whereas terms tagged as ANAT or DISO are used almost with the same frequency because in diabetes, one deals with the disorder of one anatomical structure (pancreas). Endocrinology follows the same pattern as cardiology, due to the existence of multiple endocrine glands pathologies, with chemical structures (CHEM) that include pharmacological treatment or active molecules, i.e., hormones.
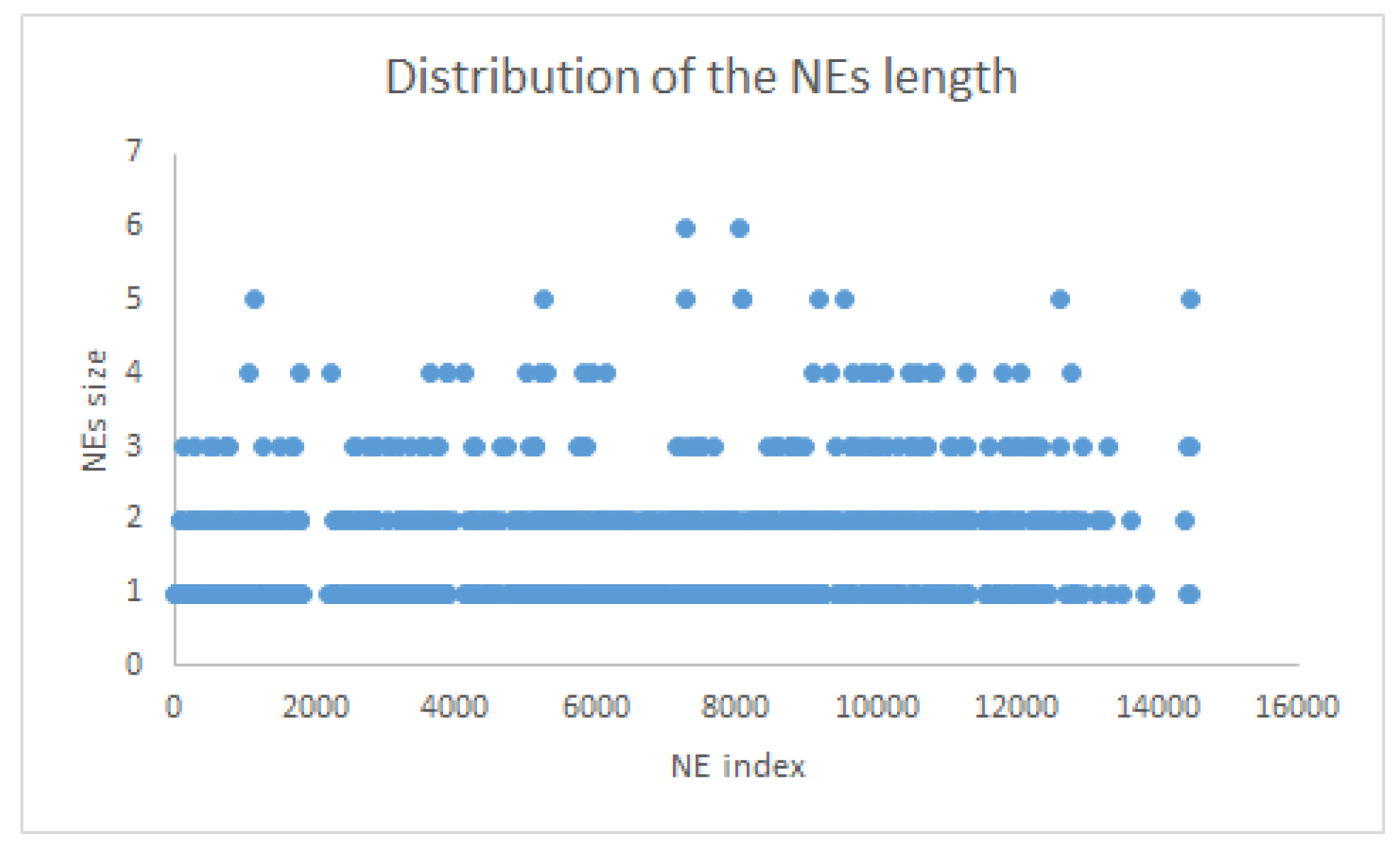
The majority of medical NEs are formed of more than one token, and a few of them even have more than three tokens (see
Figure 1).
As can be seen in
Table 8, the CHEM category has the shortest NEs and the PROC category has the longest ones. The average span of a NE is very relevant in the process of selecting the features for the NER systems due to the fact that the context window size is different in the case of compact NEs compared with the case of long-range NEs.
The statistics reported in the paper were calculated on a previous version of the corpus. Since the corpus is still under development, we uploaded on our website a newer version of the corpus. The reproducibility of some of the statistics will be possible at the end of this process, when we will will release the final version of the corpus.
3.2. Measurement of Inter-Annotator Agreement
In order to establish the consistency of the annotation, the inter-annotator agreement was computed between the two annotators of NEs on a sample of 1628 tokens (more than 10%) of the corpus. The sample of the corpus used to calculate the inter-annotator agreement was randomly chosen. The measurement of the reliability of the data was done by computing the Cohen Kappa [
26,
27] coefficient, which is defined as computing the observed agreement
A0 and the agreement expected by chance
Ae:
The observed agreement
A0 is the proportion of times the annotators actually agree. The agreement expected by chance
Ae is the proportion of times the annotators are expected to agree due to chance. For the sample selected, the Cohen Kappa coefficient was 92.8%, which shows a very high agreement, considering the fact that for most NLP classification tasks a relevant agreement lies between 70% and 80% [
27]. For example, for Quaero corpus [
6], the authors reported an agreement on entities at the mention and category level for two sets which had 92% agreement.
3.3. Annotation Challenges for Part of Speech Tagging
POS tagging errors were the most numerous (see
Table 3). A linguist, with high experience in working with the MULTEXT-East specifications for Romanian, went through the whole corpus and made all the necessary corrections manually. Two major types of errors were found: errors of part of speech and errors of morphological categories. The former implies the wrong identification of the part of speech: for example, a word is analyzed as an adjective instead of an adverb. In
Table 9 we show the frequent confusions between parts of speech. Cells are left empty when no confusions of that kind were found in the corpus or the number of cases was very low.
n.a. stands for
not applicable; the first column contains the parts of speech that were wrongly identified by TTL, while the first row contains the correct parts of speech, as introduced by the annotator. Most frequently such type of error affects the nouns, then the adjectives and verbs. This type of errors rarely affects adverbs and pronouns, thus they were not added to the table rows. Nouns are usually confused with adjectives (in 10 cases), adjectives with adverbs (13 cases), verbs with adjectives (12 cases) and adverbs with adjectives (52 cases). Here are some examples of these types:
nouns wrongly annotated as adjectives: Alterarea podocitelor este implicată în patogeneza... (En. The alteration of podocytes is involved in the pathogenesis...)
adjectives wrongly annotated as adverbs: Un studiu recent a arătat că... (En. A recent study showed that...)
verbs wrongly annotated as adjectives: ... vor trebui upgradate ulterior sau chiar înlocuite (En. ... will have to be eventually updated or even replaced)
adverbs wrongly annotated as adjectives: S-a demonstrat recent experimental... (En. It has recently been proved experimentally...)
The confusion between adjectives and adverbs can be explained through the homonymy between the two parts of speech: their lemma is identical. However, the homonymy is partial: while the adverb does not inflect, the adjective inflects for gender, number, case and may take the definite article and only its masculine singular form is identical with the adverb. The confusion between adjectives and nouns can be explained through the fact that there are frequent cases of zero derivation from adjectives to nouns and the fact that an adjective, especially one unknown to the TTL tool, occurs in prenominal position and takes the definite article, the definiteness being specific to nouns.
The second type of POS tagging errors concerns the morphological categories; the part of speech is correctly identified but some of its characteristics are wrong. This is due to the homonymous forms in the inflection paradigm of the respective words. In the case of nouns there are confusions concerning their gender, number and cases (which are correlated with each other), but also definiteness, although extremely rarely. With verbs the most frequent such type of error concerns the tense: the present of some verbs is mistaken for their past simple, which is a homograph of the present form for some persons. Whenever a verb displays this homonymy of forms, the tagger annotates its forms as being past tense ones, thus offering a consistent annotation. However, we cannot find an explanation for this preference of the tagger.
Most of these types of errors are specific to the language in general, they are independent of the domain to which a text belongs. The only ones that have a higher frequency than in general language corpora are those involving the categories X and Y. The former is attributed to residual words in the corpus, i.e., strings made up of alphanumeric characters or foreign words. Such tokens are quite frequent in the medical corpus:
T1DM,
Ca2,
anti-CD38,
T0, etc. Sometimes, foreign words (mainly English ones) are used, probably because of the absence of an equivalent Romanian one or because the foreign one is shorter than the existing Romanian one:
tehnicilor tension-free (“tension-free techniques”),
testarea cognitivă Mini Mental State (“Mini Mental State examination”), etc. Class Y is the class of abbreviations. In
Table 9, one can see that many abbreviations were misanalysed as nouns (more exactly as proper nouns, given the use of capitals in their written form) by TTL and corrected by the human annotator.
4. Discussion
MoNERo is a small-sized corpus; the number of tokens is low, as well as the number of medical subdomains represented in it and, consequently, their specific terminology. We are aware that this reduced dimension has an impact on the corpus utility in different bio-NLP tasks, such as named entity recognition, relation extraction, term extraction. We plan to release the final version of the MoNERo corpus in the near future. The dimension of that version will be enough to train and test different systems designed for named entity recognition and different information extraction tasks.
However, as proved by Névéol et al. [
28], there is still the need for annotated medical corpora in languages other than English in order to foster development in the biomedical domain. We report here only our first step towards the creation of such a resource for Romanian.



{kind=link}