Associative Root–Pattern Data and Distribution in Arabic Morphology


Abstract
:1. Introduction and Motivation
- Statistical language modeling requires a large-scale corpus to statistically consider the implicit, inherent differences in a language.
- The cognitive and statistical dimension of the non-linearity of the Arabic morphology has been considered in the form of handling a phonetic pattern as a statistical variable and not relying only on the co-occurrence of its instantiated word forms. For example, a root might be incorporated with a large number of patterns delivering multiple word syntactical forms with different meanings. This analysis is rather intended to provide researchers with basic and initial predictive values based on the association between a root and a pattern.
- A term is considered as an applicative function instantiating a pattern for some root [11] unless it is not derivable; i.e., if it cannot be reduced to a known root.
- Operating on root–pattern, root–root, root–stem, root–particle, and pattern–pattern associative probabilistic relationships represent a higher level of abstraction than computing co-occurrences of their instances. For example, root–root co-occurrence as an abstract associative relationship implies multiple term–term co-occurrences5.
1.1. A Preliminary Note on Non-Linear and Cognitive Aspects of the Arabic Morphology
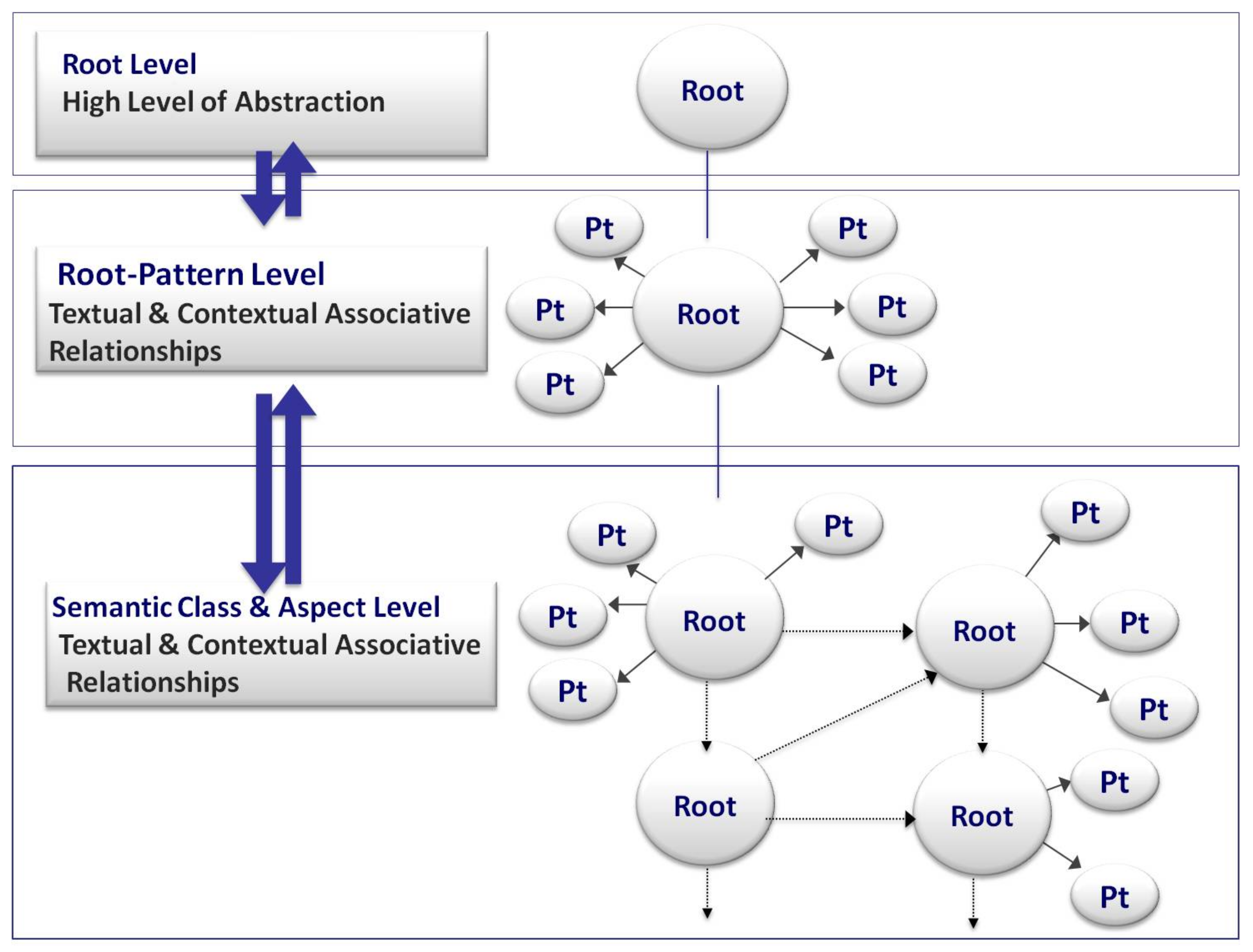
- A root level, which mostly consists of three consonants symbolizing the highest preeminent semantic abstraction and is unmodifiable. An associative set of roots conveys an abstract semantic description without clear phonetic information.
- A templatic pattern in the form of consonant–vowel arrangement picturing the morpho-phonetic structure of a word form completing possible phonetic, syntactic, and semantic information6.
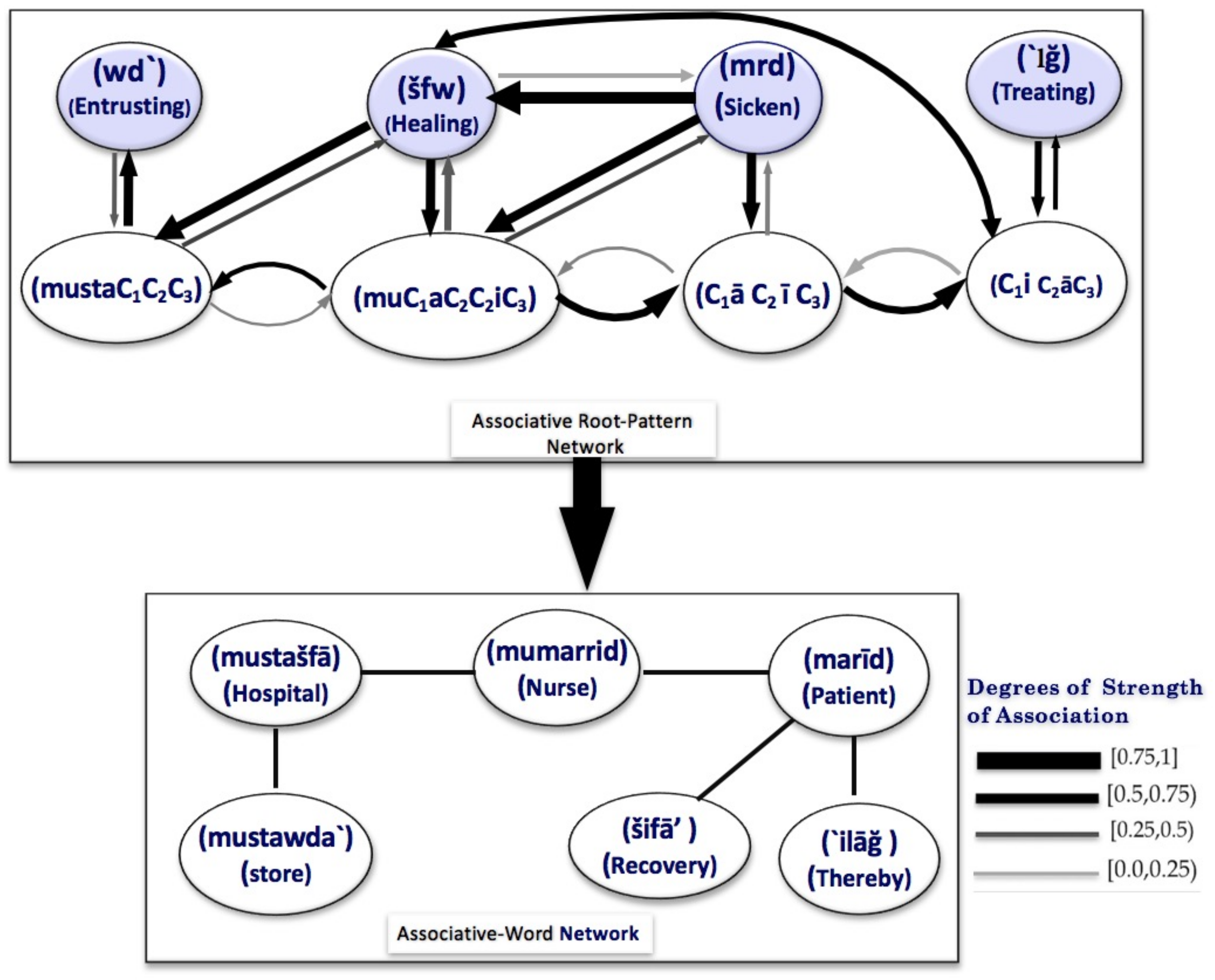
- An associative root–pattern relationship. A templatic pattern can be perceived by establishing the most plausible associative relationship between a pattern and a root relying on a bi-directional cognitive process. (see Figure 2)
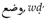 , and the pattern (see Appendix A, Adopted Transliteration) as a canonical template describing the morpho-phenetic structure of a word integrating phonetic, syntactic, and semantic information is estimated in the form of different values. Examples include as follows:
, and the pattern (see Appendix A, Adopted Transliteration) as a canonical template describing the morpho-phenetic structure of a word integrating phonetic, syntactic, and semantic information is estimated in the form of different values. Examples include as follows:- The degree of association for the pattern considering the root is estimated by
![Data 03 00010 i002]()
- The degree of association for the root /
![Data 03 00010 i001]() /, considering the pattern is estimated by
/, considering the pattern is estimated by
![Data 03 00010 i003]()

 , 〉 such as 〈
, 〉 such as 〈  , 〉 might have different co-occurrence values when operating in their abstract form. The concept of interpreting bi-directional grades of association between root and pattern as predictive and root-predictive values has been successfully employed in the detection and correction of non-words and spelling errors—in particular, to detect cognitive spelling errors [16]. For example, the estimated values in Table 1 support the view that humans would not construct a word based on the root 〈
, 〉 might have different co-occurrence values when operating in their abstract form. The concept of interpreting bi-directional grades of association between root and pattern as predictive and root-predictive values has been successfully employed in the detection and correction of non-words and spelling errors—in particular, to detect cognitive spelling errors [16]. For example, the estimated values in Table 1 support the view that humans would not construct a word based on the root 〈 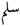 , slm, being safe〉 and the pattern 〈
, slm, being safe〉 and the pattern 〈 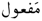 , 〉. However, it is conceivable to construct a word using another root such as 〈
, 〉. However, it is conceivable to construct a word using another root such as 〈 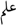 , ‘lm, knowing〉. Analogously, we can construct word vectors based on this morpho-phonetic characteristic of Arabic and Semitic languages.
, ‘lm, knowing〉. Analogously, we can construct word vectors based on this morpho-phonetic characteristic of Arabic and Semitic languages.1.2. Scope of the Presentation
2. Related Work
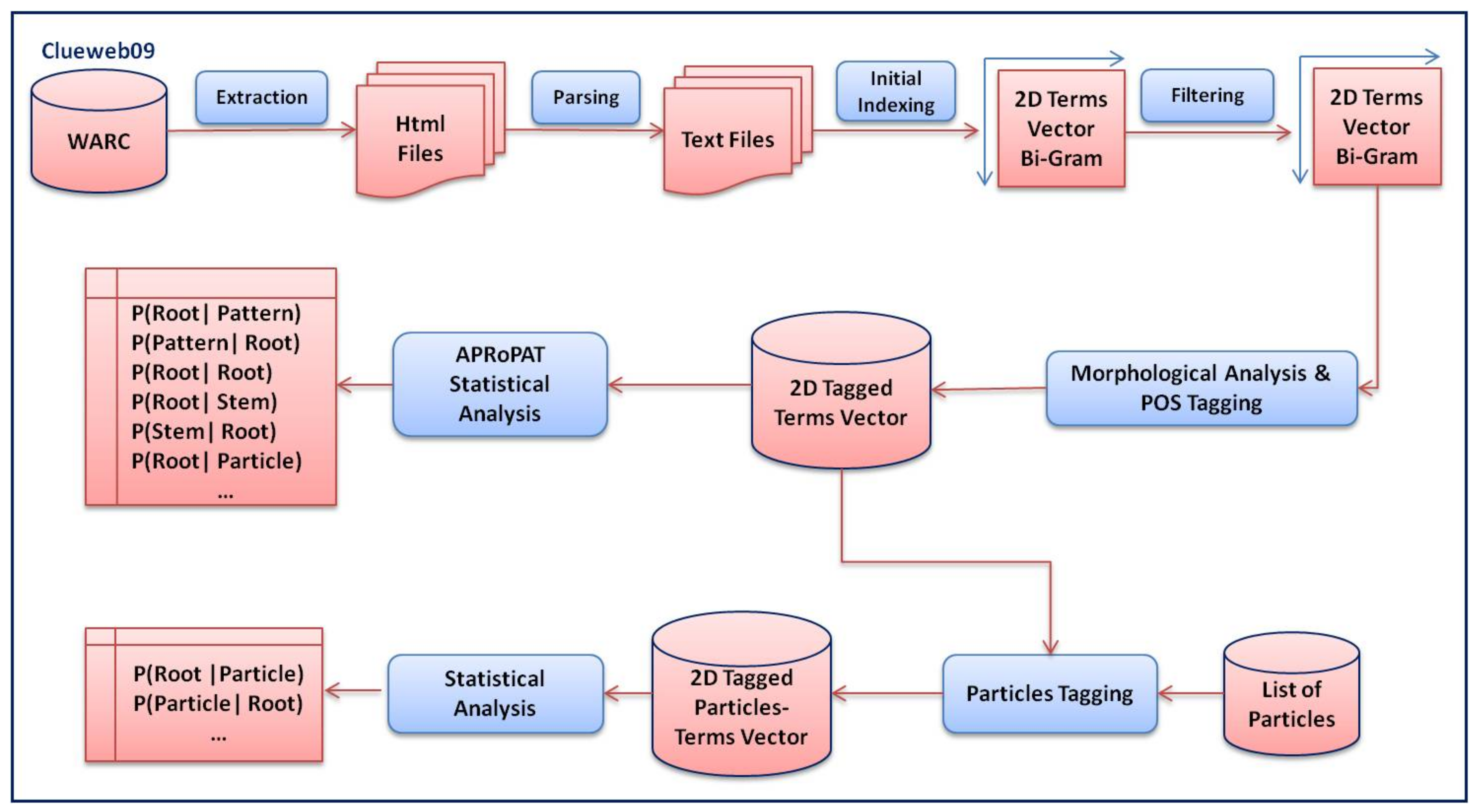
3. Building APRoPAT Corpus
- Extraction. HTML file extraction from compressed WARC archives, provided by ClubWeb.
- HTML File-Parsing. Converting HTML files into plain text files.
- Bi-Gram Analysis and Initial Indexing: Establishing a vector space of all distinct terms of the parsed text with frequencies of each term. In addition, this step includes generating a two-dimensional matrix from the vector space with frequencies of every two consecutive terms as a basic feature.
- Filtering. Removing all non-Arabic terms that might still be remaining (e.g., Persian words). The Arabic subset of ClueWeb is actually not clean.
- Morphological Analysis and POS Tagging. Analyzing all corpus terms considering all possible roots, stems, patterns, and parts of speech tagging. At this step, Petra-Morph was predominantly utilized.
- Core APRoPAT Statistical Analysis, which includes the following:
- ▪
- Computing Basic Quantitative Features.
- ▪
- Bi-Directional Root–Pattern Analysis.
- ▪
- Bi-Directional Root–Root Analysis.
- ▪
- Bi-Directional Root–Stem Analysis.
- ▪
- Pattern–Pattern Analysis.
- ▪
- Particle Tagging. Specifying the involved particles dataset.
- ▪
- Bi-Directional Root–Particle Analysis. Computing root–particle probabilities.
- ▪
- Computing Bi-Directional Specific Entropies.
3.1. Web Dataset Pre-Processing
3.2. Initial N-Gram Indexing and Non-Arabic Text Filtering
4. The APRoPAT Morpho-Phonetic Dataset
- Simple orthographic errors, e.g.,
![Data 03 00010 i008]() cognitive errors, e.g.,
cognitive errors, e.g., ![Data 03 00010 i009]() and run-on errors; e.g.,
and run-on errors; e.g., ![Data 03 00010 i010]() More details of such error types and how to deal with them can be found in [16].
More details of such error types and how to deal with them can be found in [16]. - Arabized proper names, e.g.,
![Data 03 00010 i011]()
- Arabized technical terms, e.g.,
![Data 03 00010 i012]()
- Fictive words (non-words), e.g.,
![Data 03 00010 i013]()
- Technical and political abbreviations, e.g.,
![Data 03 00010 i014]()
- Dialects, e.g.,
![Data 03 00010 i015]()
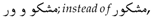
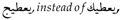
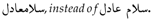
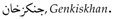

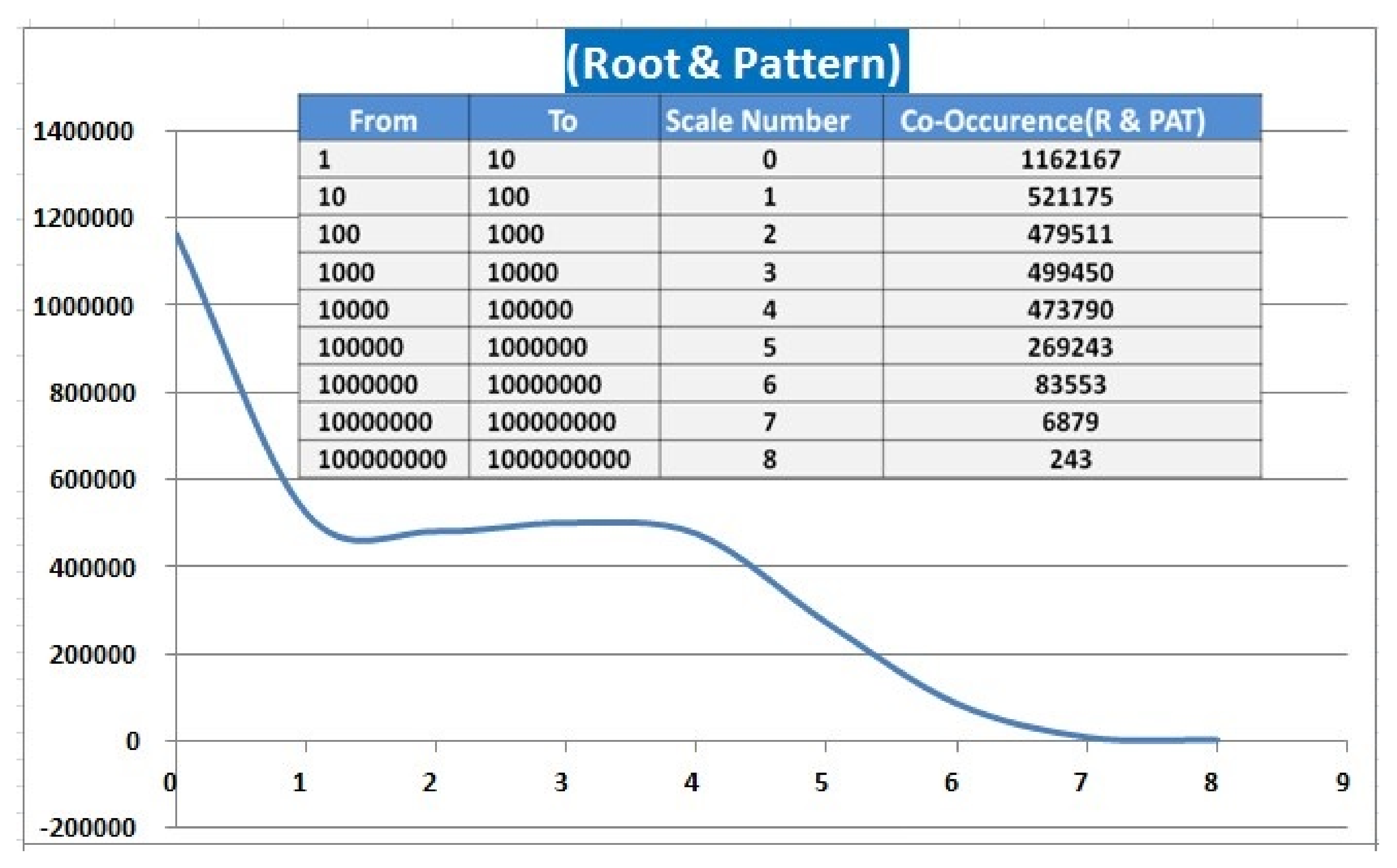
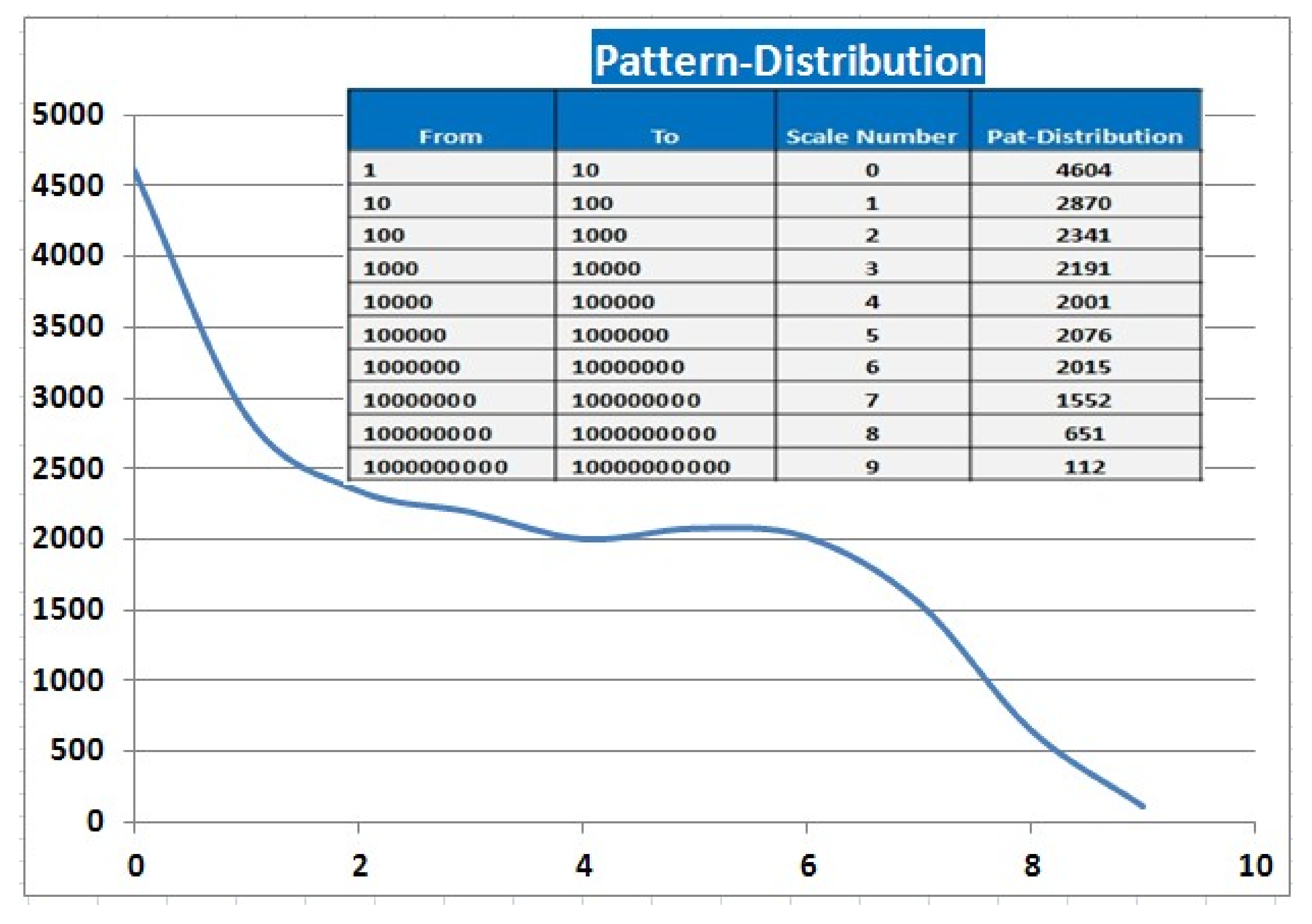
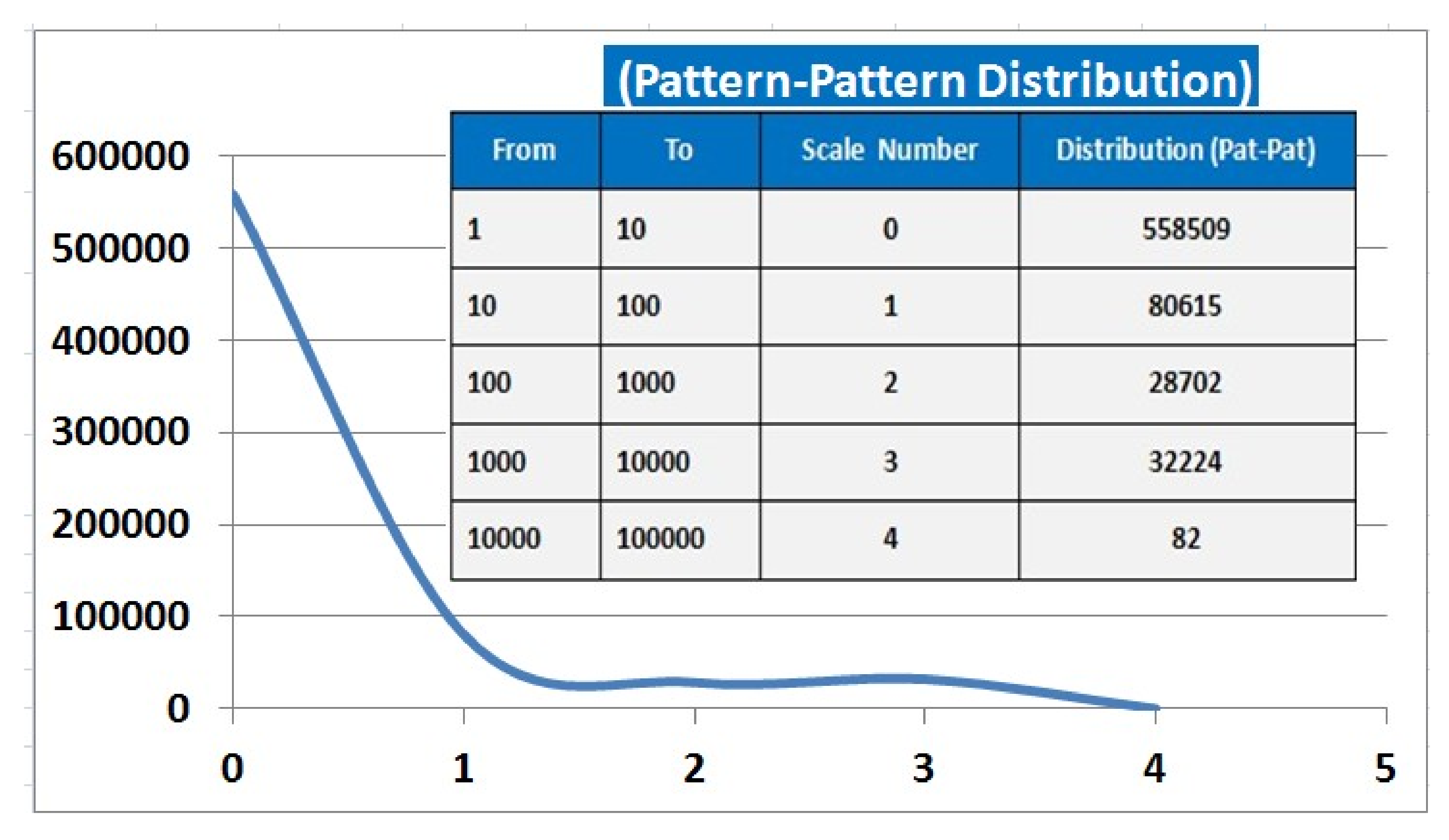
Root–Pattern Statistics
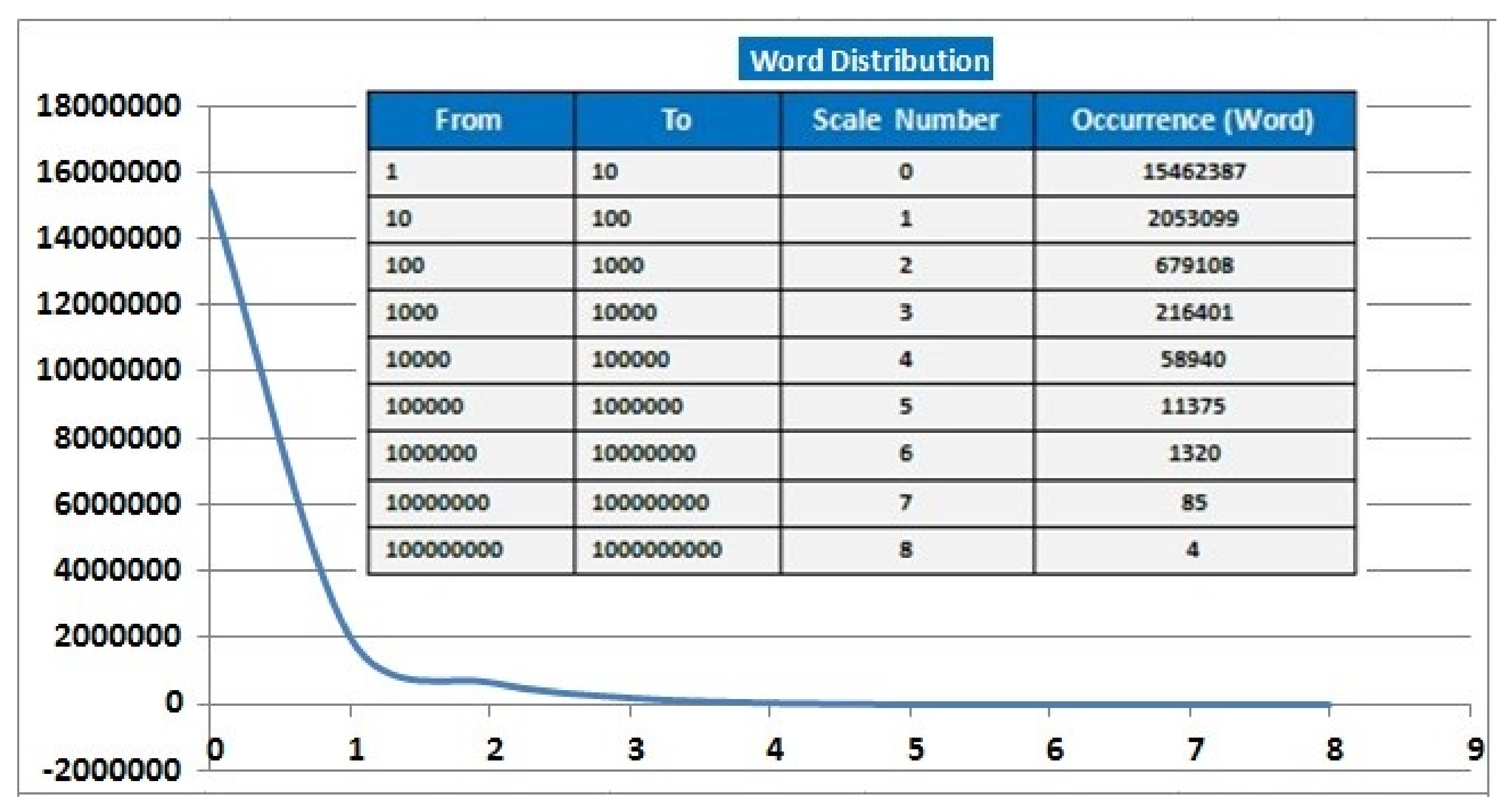
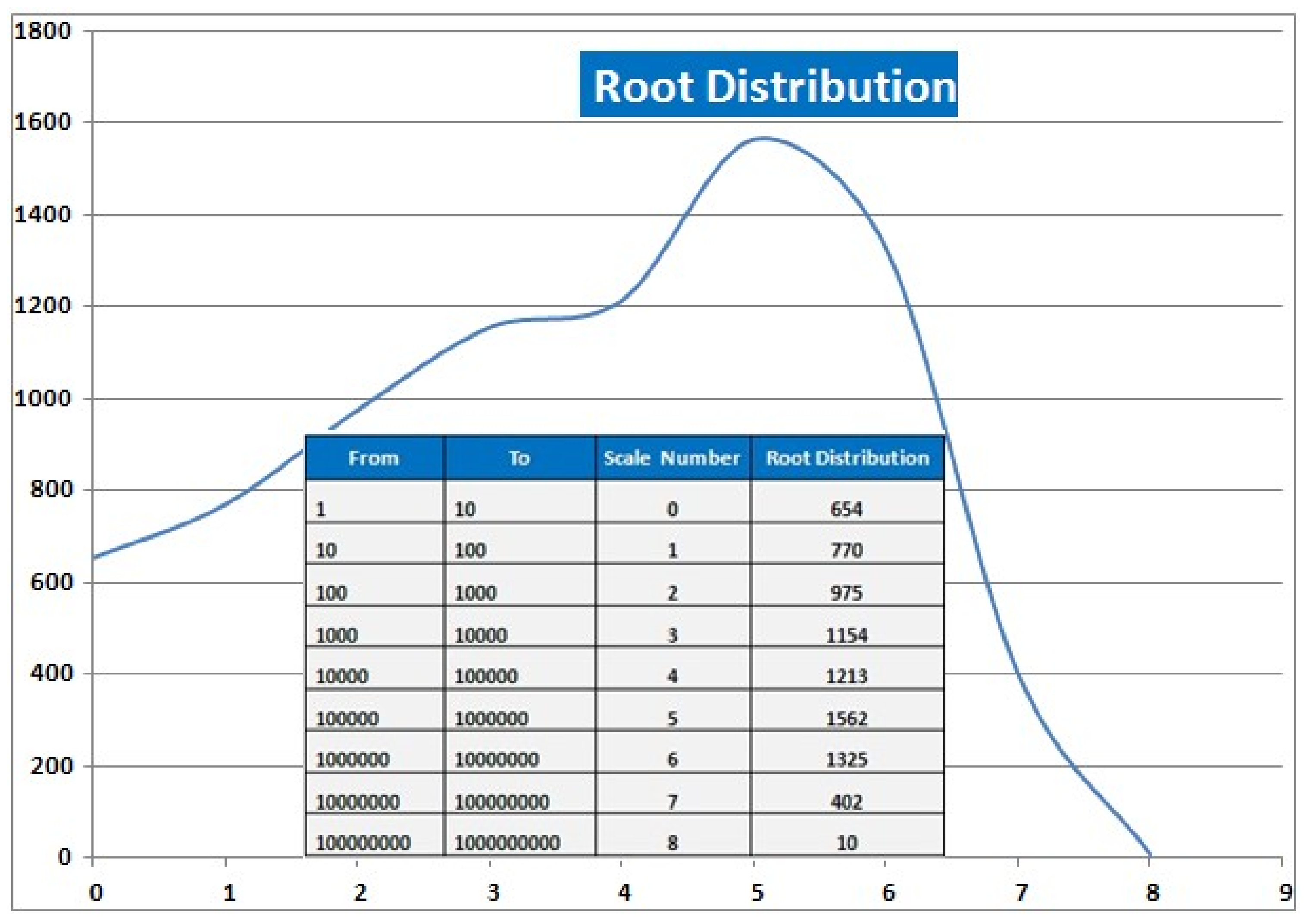
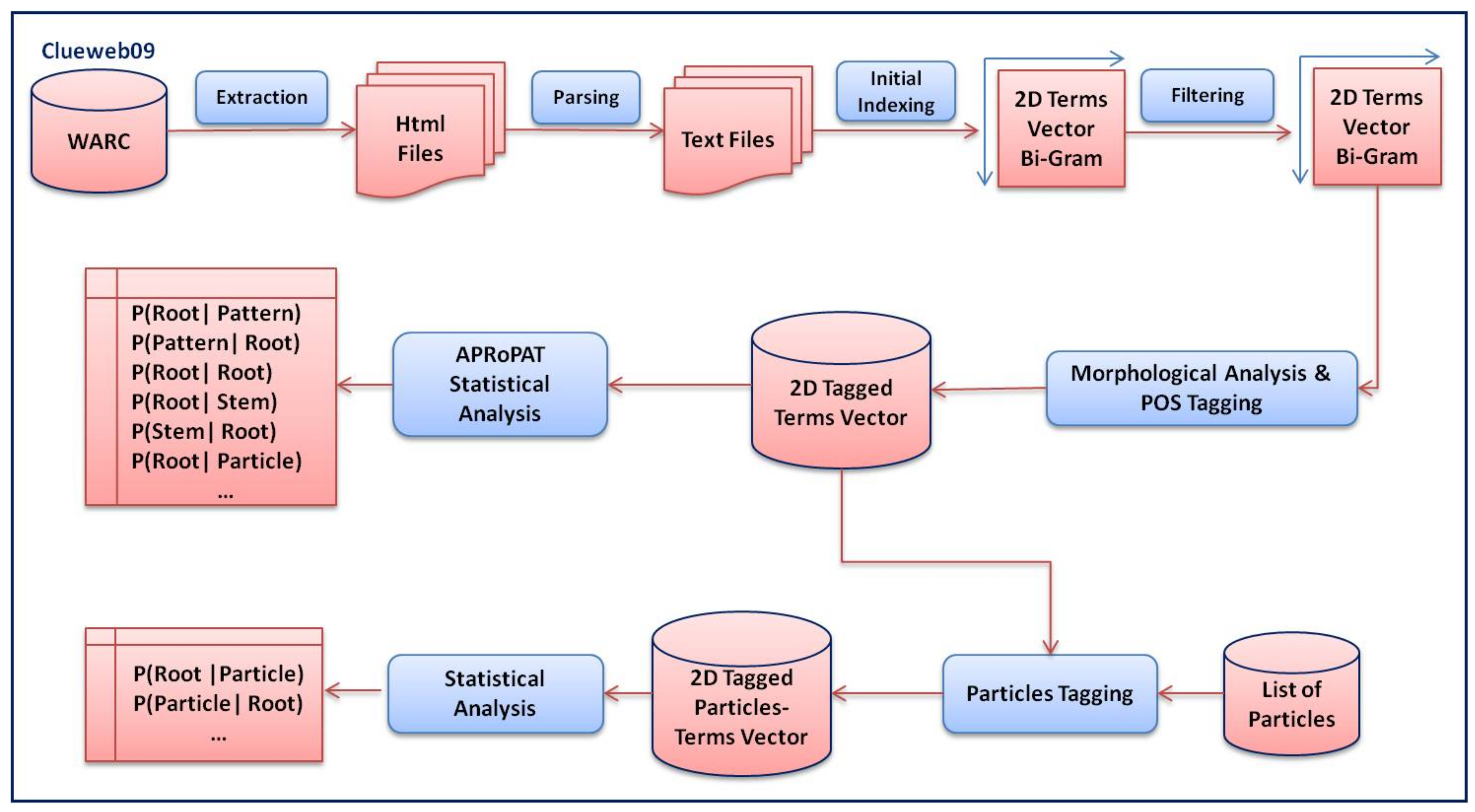
5. Corpus Size and Distribution
6. Outlook and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Adopted Transliteration
- A root , the set of all roots is depicted as three arguments (Arabic, Latin Transliteration, and Abstract Meaning), e.g., the root instance
![Data 03 00010 i016]()
- A pattern , the set of all patterns, is also depicted as two arguments: 〈Latin transliteration and root radical non-linear template positions〉, whereas , , and represent root radical variables such as in ; i.e., , , and .

Appendix B. Performance and Running Time
- Reducing reading and/writing from the hard disk and relying on memory as much as possible.
- Avoiding excessive processing on the word level as much as possible, and postponing it until the unique 2D vector space for each associative relation was created during bi-gram analysis as these 2D vectors contain much less data to process.
- Taking advantage of the ability of the CPU to execute instructions in parallel as much as possible.
- Implementing efficient data structures such as hash tables to hold the words and their frequencies.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Process | Running Time | Input Data | Output Data |
|---|---|---|---|
| HTML files Extraction and Parsing | ∼ 4 days | 975 WARC files (240 GB compressed, 1 TB uncompressed) | 975 text files (180 GB) |
| Initial Indexing | ∼ 2 days | 975 text files (180 GB) | 39 index files (26.5 GB) |
| Morphological Analysis | ∼ 6 h | 1 unigram list file (408 MB), and 15 Petra-Morph Database Files (7.98 GB) | 1 Morph Database File (2.16 GB) |
| Uni-gram Frequencies | ∼ 3 h | 1 unigram list file (408 MB), and 1 Morph Database File (2.16 GB), and 1 Particles List File | 5 Frequencies Files (364 MB) |
| Statistical Probabilities | ∼ 45 min | 11 Frequencies Files 401.8 MB | 8 probabilities files 420 MB |
| APRoPAT Text Dataset Indexing | 5 days | 975 WARC files (240 GB compressed, 1 TB uncompressed) | 44 index files (89.5 GB), and 1 main index file (438 MB) |
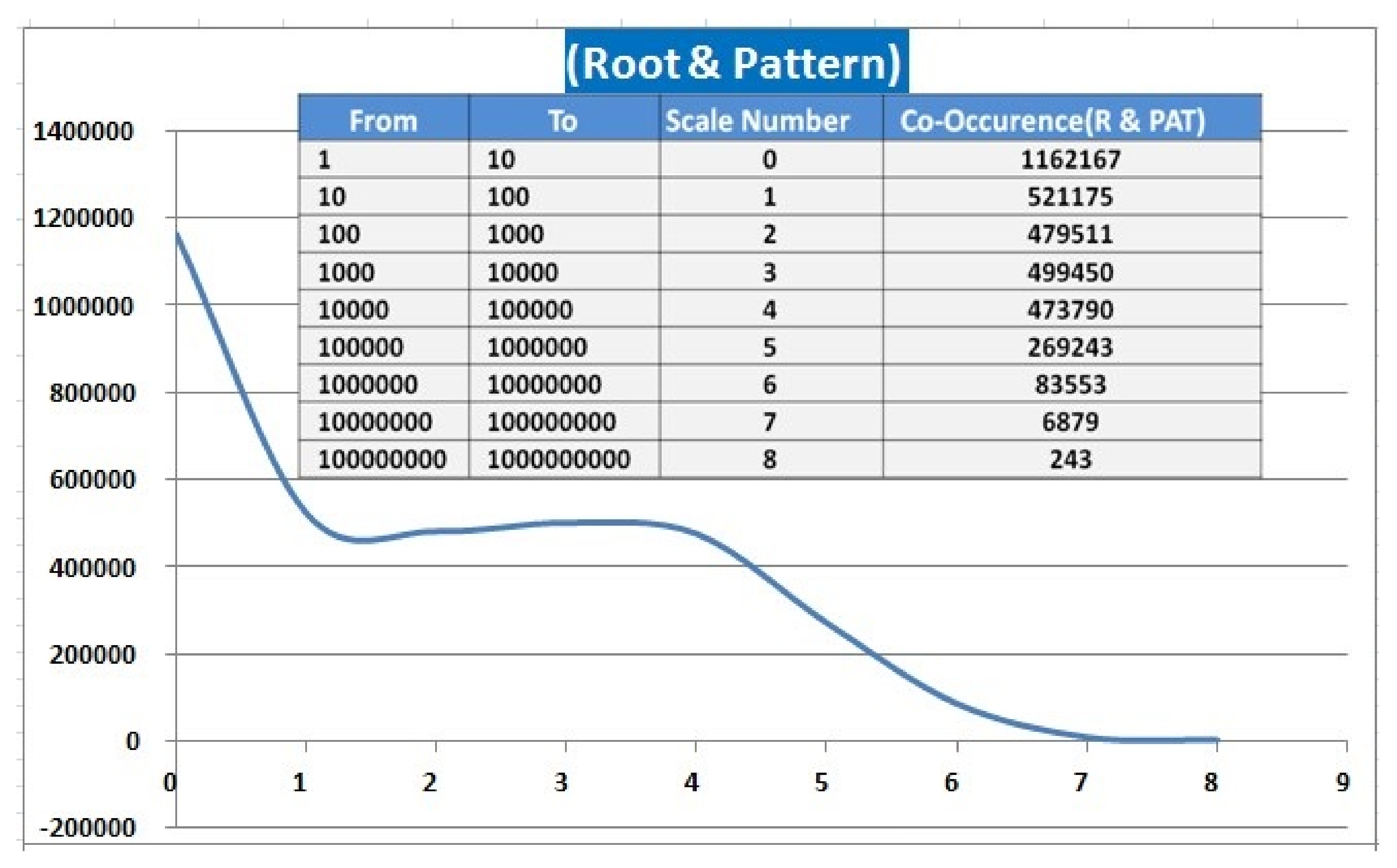
Appendix C. Dataset Distribution
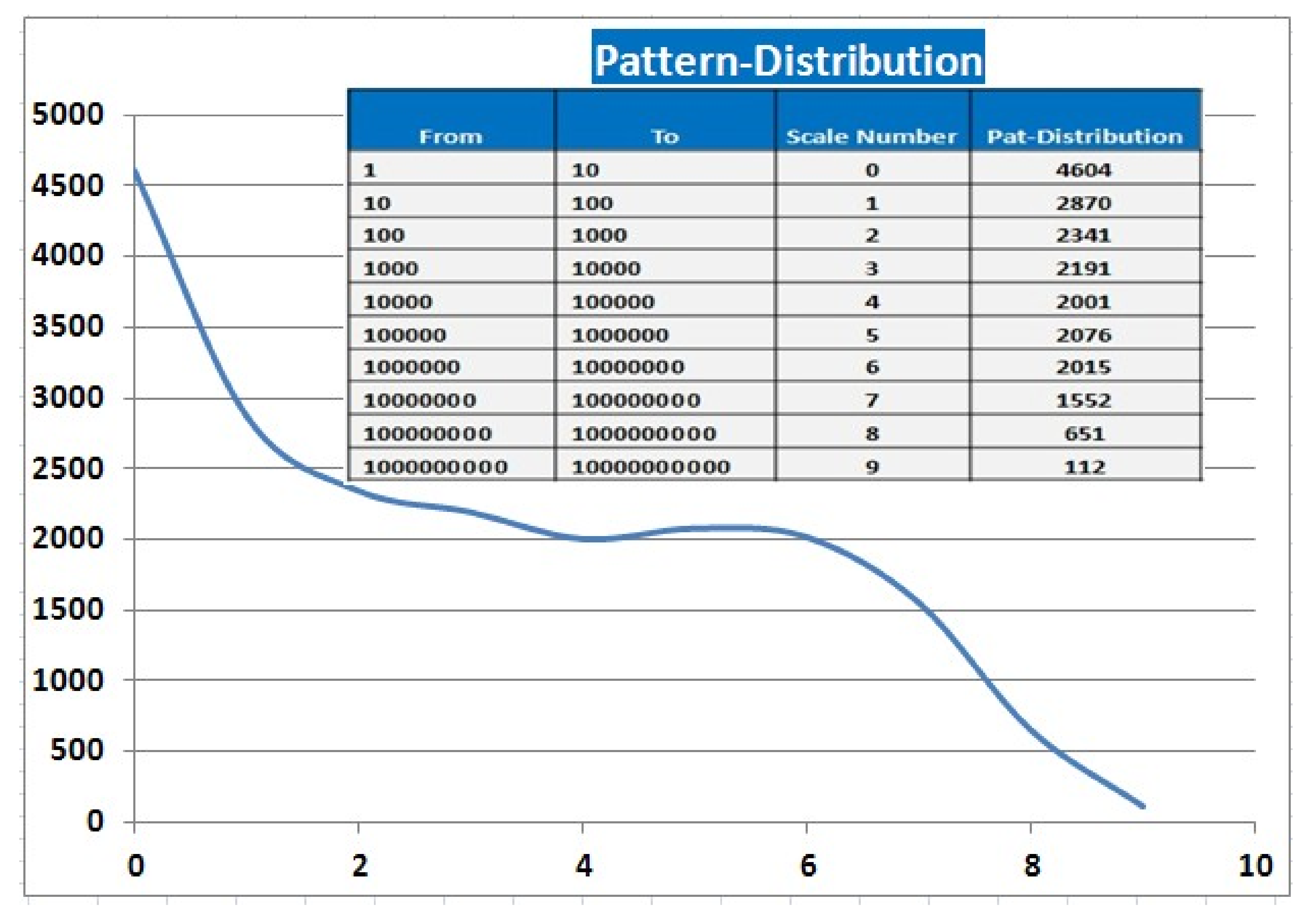
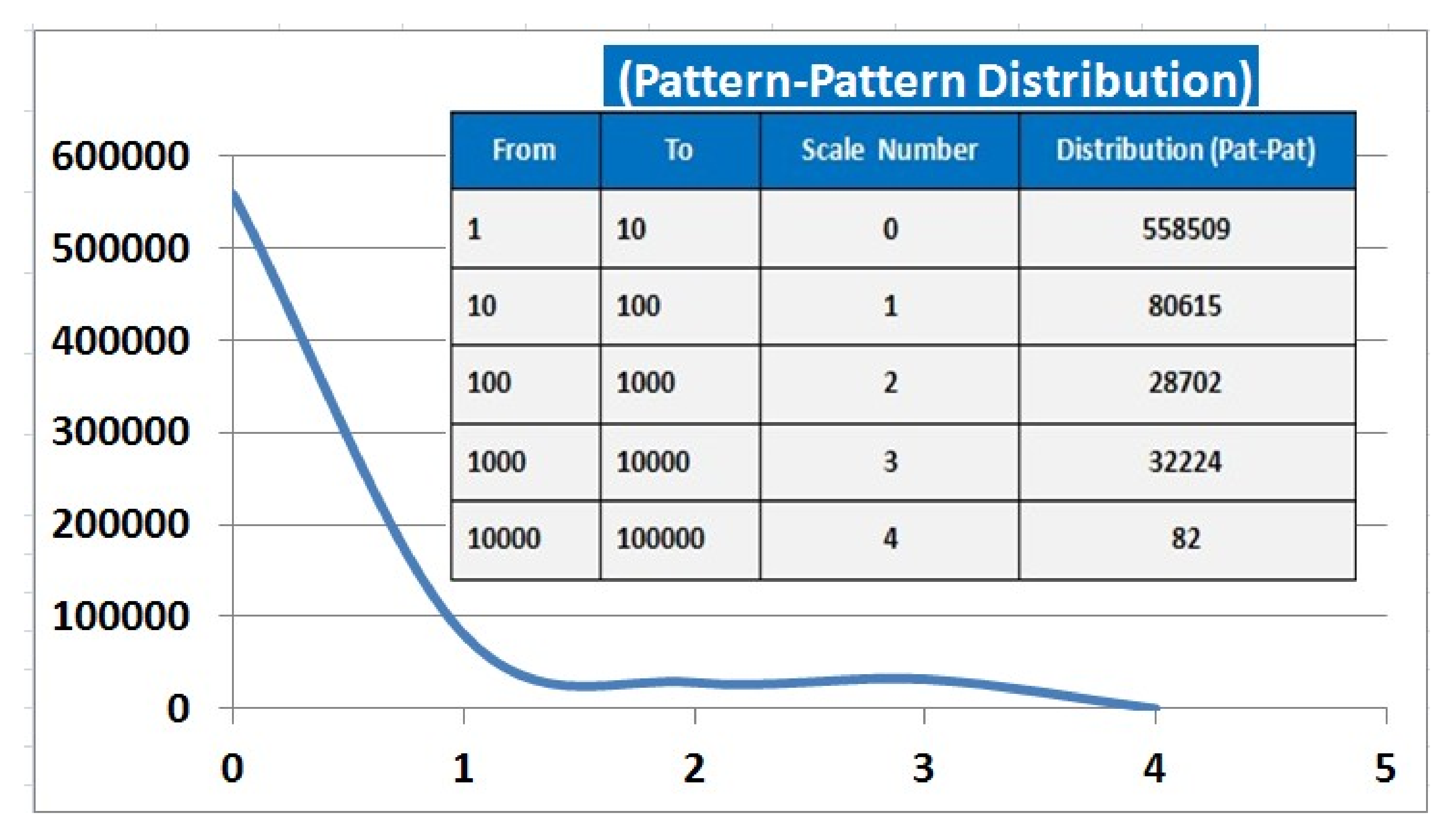
References
- Baranyi, P.; Csapo, A.; Sallai, G. Cognitive Infocommunications (CogInfoCom); Springer International Publishing: Basel, Switzerland, 2015. [Google Scholar]
- Arabic. Available online: http://en.wikipedia.org/wiki/Arabic_language (accessed on 28 March 2018).
- Al-Thubaity, A.; Khan, M.; Al-Mazura, M.; Al-Mousa, M. New Language Resources for Arabic: Corpus Containing More Than Two Million Words and A Corpus Processing Tool. In Proceedings of the International Conference on Asian Language Processing (IALP), Urumqi, China, 17–19 August 2013. [Google Scholar]
- Zaghouan, W. Critical Survey of the Freely Available Arabic Corpora. In Proceedings of the Workshop on Free/Open-Source Arabic Corpora and Corpora Processing Tools, Reykjavik, Iceland, 27 May 2014. [Google Scholar]
- Al-Sulaiti, L.; Atwell, E.S. The design of a corpus of contemporary Arabic. Int. J. Corpus Linguist. 2006, 11, 135–171. [Google Scholar] [CrossRef]
- El-Haj, M.; Kruschwitz, U.; Fox, C. Creating language resources for under-resourced languages: Methodologies, and experiments with Arabic. In Language Resources and Evaluation; Springer: Dordrecht, The Netherlands, 2014. [Google Scholar]
- Haddad, B. Semantic Representation of Arabic: A logical Approach towards Compositionality and Generalized Arabic Quantifiers. Int. J. Comput. Process. Orient. Lang. 2007, 20. [Google Scholar] [CrossRef]
- Bentin, S.; Forst, R. Morphological Factors in word Identification in Hebrew. In Morphological Aspects of Language Processing; Feldman, L., Ed.; Erlbaum: Hillsdale, NJ, USA, 1994; pp. 271–292. [Google Scholar]
- Boudelaa, S. Is the Arabic Mental Lexicon Morpheme-Based or Stem-Based? Implications for Spoken and Written Word Recognition. In Handbook of Arabic Literacy, Literacy Studies 9; Springer: Dordrecht, The Netherlands, 2014. [Google Scholar]
- Haddad, B. Cognitive Aspects of a Statistical Language Model for Arabic based on Associative Probabilistic Root-PATtern Relations: A-APRoPAT. Available online: http://www.infocommunications.hu/documents/169298/393366/2013_4_2Haddad.pdf (accessed on 28 March 2018).
- Haddad, B. Probabilistic Bi-Directional Root-Pattern Relationships as Cognitive Model for Semantic Processing of Arabic. In Proceedings of the 3rd IEEE International Conference on Cognitive Infocommunication 2012, Kosice, Slovakia, 2–5 December 2012. [Google Scholar]
- Croft, W.; Cruse, D.A. Cognitive Linguistics; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Langacker, R.W. An Introduction to Cognitive Grammar. Cogn. Sci. 1986, 10, 1–40. [Google Scholar] [CrossRef]
- Haddad, B. Cognitively-Motivated Query Abstraction Model based on Associative Root-Pattern Networks. To be published, draft is available upon request. 2018. [Google Scholar]
- Haddad, B. Representation of Arabic Words: An Approach towards Probabilistic Root-Pattern Relationship. In Proceedings of the International Conference on Knowledge Engineering and Ontology Development, Madeira, Portugal, 6–8 October 2009. [Google Scholar]
- Haddad, B.; Yaseen, M. Detection and Correction of Non-Words in Arabic: A Hybrid Approach. Int. J. Comput. Process. Orient. Lang. IJCPOL 2007, 20, 237. [Google Scholar] [CrossRef]
- Haddad, B.; El-Khalili, N.; Hattab, M. A Cognitive Query Model for Arabic based on Probabilistic Associative Morpho-Phonetic Sub-Networks. In Proceedings of the 5th IEEE Conference on Cognitive Infocommunications-CogInfoCom, Vietri sul Mare, Italy, 5–7 November 2014. [Google Scholar]
- El-Khalili, N.; Haddad, B.; El-Ghalayini, H. Language Engineering for Creating Relevance Corpus. Int. J. Softw. Eng. Appl. 2015, 9, 107–116. [Google Scholar]
- Meyer, C.F. English Corpus Linguistics An Introduction; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Wang, S.-p. Corpus-based approaches and discourse analysis in relation to reduplication and repetition. J. Pragmat. 2005, 37, 505–540. [Google Scholar] [CrossRef]
- Alansary, S.; Nagi, M.; Adly, N. Towards Analyzing the International Corpus of Arabic (ICA): Progress of Morphological Stage. Available online: https://www.researchgate.net/profile/Sameh_Alansary/publication/263541571_Towards_Analyzing_the_International_Corpus_of_Arabic_ICA_Progress_of_Morphological_Stage/links/0a85e53b2e2622211d000000/Towards-Analyzing-the-International-Corpus-of-Arabic-ICA-Progress-of-Morphological-Stage.pdf (accessed on 28 March 2018).
- Yu, C.-H.; Chen, H.-H. Chinese Web Scale Linguistic Datasets and Toolki. Available online: http://www.aclweb.org/anthology/C12-3063 (accessed on 28 March 2018).
- Pomikalek, J.; Jakubicek, M.; Rychly, P. Building a 70 Billion Word Corpus of English from ClueWeb. Available online: http://www.lrec-conf.org/proceedings/lrec2012/pdf/1047_Paper.pdf (accessed on 28 March 2018).
- Belinkov, Y.; Habash, N.; Kilgarriff, A.; Ordan, N.; Roth, R.; Suchomel, V. arTenTen: A new, vast corpus for Arabic. Available online: https://www.sketchengine.co.uk/wp-content/uploads/arTenTen_corpus_for_Arabic_2013.pdf (accessed on 28 March 2018).
- Eckart, T.; Alshargi, F.; Quasthoff, U.; Goldhahn, D. Large Arabic Web Corpora of High Quality: The Dimensions Time and Origin. Available online: http://www.lrec-conf.org/proceedings/lrec2014/workshops/LREC2014Workshop-OSACT%20Proceedings.pdf#page=35 (accessed on 28 March 2018).
- Maamouri, M.; Bies, A.; Buckwalter, T.; Mekki, W. The Penn Arabic Treebank: Building a Large-Scale Annotated Arabic Corpus. Available online: https://www.researchgate.net/profile/Mohamed_Maamouri/publication/228693973_The_penn_arabic_treebank_Building_a_large-scale_annotated_arabic_corpus/links/0046351802c78190c5000000.pdf (accessed on 28 March 2018).
- Yaseen, M.; Attia, M.; Maegaard, B.; Choukri, K.; Paulsson, N.; Haamid, S.; Krauwer, S.; Bendahman, C.; Fersoe, H.; Rashwan, M.; et al. Building Annotated Written and Spoken Arabic LR’s in NEMLAR Project. Available online: https://pdfs.semanticscholar.org/95d7/1fc0a2de2228d62372026ff0913cf2a83959.pdf (accessed on 28 March 2018).
- Alrabiah, M.; Al-Salman, A.; Atwell, E. The design and construction of the 50 million words KSUCCA. In Proceedings of the Second Workshop on Arabic Corpus Linguistics (WACL-2), Lancashire, UK, 22 July 2013. [Google Scholar]
- Hattab, M.; Haddad, B.; Yaseen, M.; Duraidi, A.; Shmias, A.A. Addaall Arabic Search Engine: Improving Search based on Combination of Morphological Analysis and Generation Considering Semantic Patterns. Available online: http://fafs.uop.edu.jo/download/research/members/202_778_Mamo.pdf (accessed on 28 March 2018).
- Fischer, W. Grammatik des Klassischen Arabisch; Harrassowitz Vrlag: Wiesbaden, Germany, 1972. [Google Scholar]
| 1 | Arabic is an official language of 27 states, the third most prevalent after English and French, spoken by 420 million speakers, and it is one of six official languages of the United Nations [2]. |
| 2 | Stands for “Arabic Associative Probabilistic RooT PATtern Model.” |
| 3 | |
| 4 | In cognitive science, the human language can be divided into different linguistic levels or strata, such as phonology, morphology, syntax, and semantics. For example, the Cognitive Grammar Theory relies merely on two levels, namely phonology and semantics. A grammar is, in this context, meaningful and does not represent an autonomous level, and lexicon and grammar form a continuum consisting in assemblies of such structures [12,13]. Construction-grammar-based theories recognize constructions mediating the two levels (phonetic and semantic), such as morphology and syntax [12]. Arabic and Semitic word cognition seems to handle the constructions in a unique way. Phonology and morphology of Arabic words are non-concatenative or, more precisely, are predominantly non-linear [8,9] |
| 5 | In the APRoPAT Model, such relations are defined as binary associative relationships on the morpho-phonetic level of cognition. The degree of association is associated with some COgnitive Degree of Association Strength Function; i.e., , where and can be a ROOT, PATTERN, STEM, or a PARTICLE [14]. |
| 6 | In the statistical analysis of each pattern, syntactical suffixes are also considered to form multiple phonetic patterns conveying additional syntactical information at the end of a pattern. |
| 7 | Clueweb 12 was released during the production of this manuscript. Unfortunately it contains a very small collection of Arabic webpages: http://www.lemurproject.org/clueweb12.php/. |
| 8 | |
| 9 | |
| 10 | |
| 11 | As reading and writing to a hard disk is a slow process, the code was changed so that only the HTML file in memory was extracted and then parsed, and the extracted text result was then saved to disk |
| 12 | Jsoup HTML Parser, written in Java, was used, as it allowed us to process the HTML file while in memory without the need to call another program or to save it to hard disk |
| 13 | Petra-Morph is a morphological analyzer and POS tagger that is based on the work of Arabic Textware ’morphological analyzer. Arabic Textware (ATW) developed its morphological analyzer for the purpose of indexing Arabic text in 2001. It was used in the Addaall search engine [29], the company’s enterprise search product. ATW’s morphology analyzer uses a finite state approach, utilizing a database of more than 6000 Arabic roots and more than 600 Arabic patterns. It includes lists of prefixes, affixes, and suffixes and a list of special words. The speed of the morphological analyzer suited the purpose of fast indexing, analyzing thousands of words per second. When applied to Arabic ClueWeb, its coverage reached 82%. This percentage of coverage required a University of Petra research team to make modifications to the system by adding two layers to enhance its coverage and quality of results. The first layer was to normalize the input words, and the second to modify its stemmer, and to redirect the analyzer to process the new stem. The new product we named Petra-Morph reached a better percentage of coverage reaching 87%. The last modification under the umbrella of Petra-Morph was to reduce the number of roots to a list related to Modern Standard Arabic, excluding the abandoned traditional roots. This process enhanced the quality of the results by reducing the number of possibilities the analyzer generated for each word. |
| 14 | |
| 15 | a modified version of http://zeus.cs.pacificu.edu/shereen/ArabicStemmerCode.zip. |
| 16 | While testing the Al-khalil morphological analyzer, we found that it was relatively slow, especially for big data, so we accelerated the Al-Khalil morphological analyzer in .Net in several steps (using parallel processing and pre-loading). For Khoja stemmer, we also had to rewrite it in C# to enhance its performance (done by preloading and caching all of the required files instead of reading them from the disk each time). To compare the coverage of a file of 2.16 GB that contains stems, and possibly some roots and patterns with an indicator to the source of the analysis for each word (Petra-Morph, Al-Khalil, or Khoja), the Petra-Morph covered about 25% of the total number of words, while Al-Khalil covered 0.05% more words, and the Khoja stemmer covered the remaining 70% of the words. We should notice that these percentages do not reflect necessarily the actual representation of these words in the Clueweb09 database, so these words might only have stems and non-words and might have much lower frequencies in the Clueweb database compared to the words that have roots and patterns. |
| 17 | In terms of the APRoPAT model, these represent cognitive variables on morpho-phonetic level of cognition. |
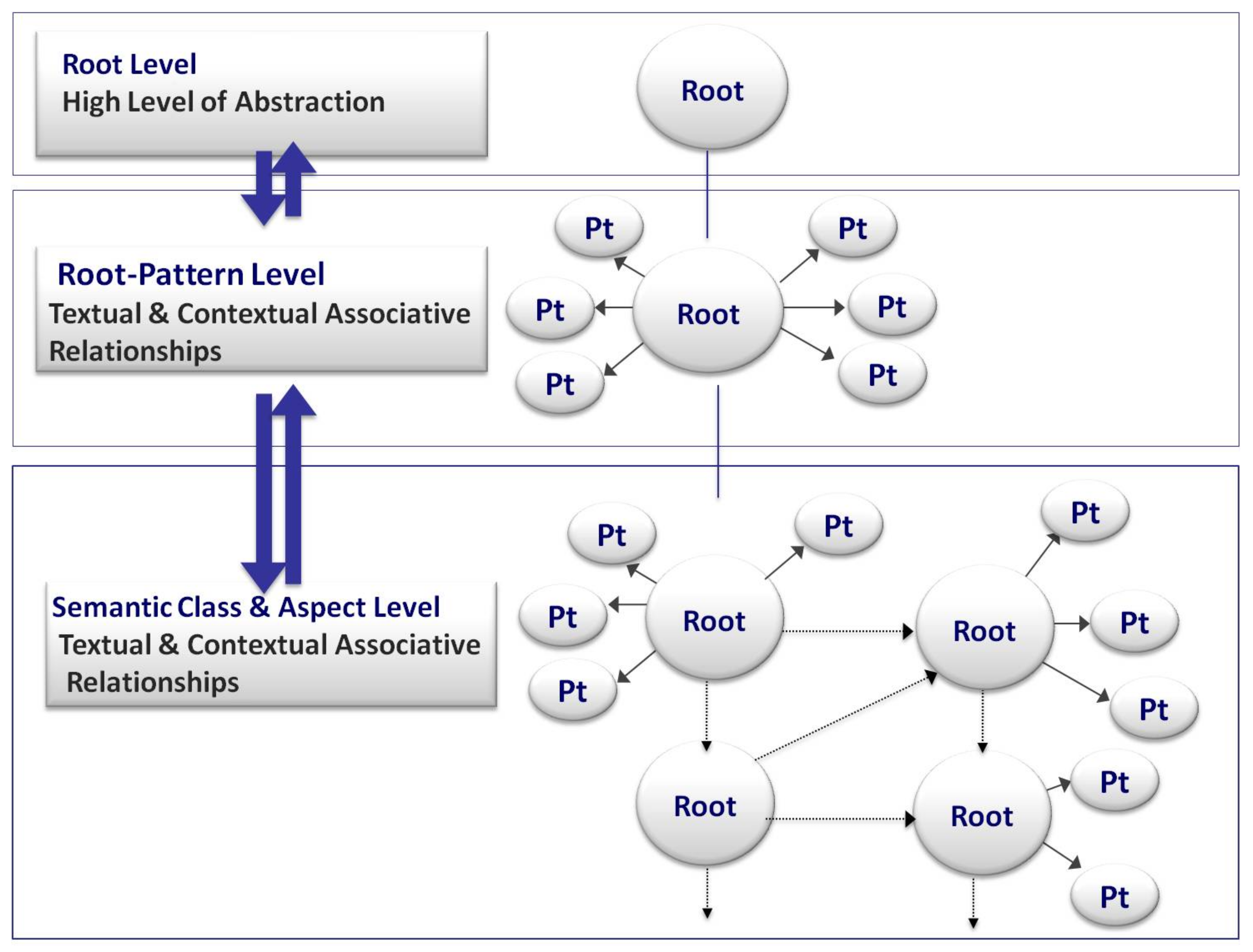
 mustašfā, Hospital), but it is cognitively imperceptible without an instantiation with a root such as
mustašfā, Hospital), but it is cognitively imperceptible without an instantiation with a root such as 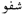 , šfw, . The strength of association is depicted according to a value within the unit interval, which can be estimated and locally computed. This presentation is concerned with the estimation of such prior values.
mustašfā, Hospital), but it is cognitively imperceptible without an instantiation with a root such as , šfw, . The strength of association is depicted according to a value within the unit interval, which can be estimated and locally computed. This presentation is concerned with the estimation of such prior values.
, šfw, . The strength of association is depicted according to a value within the unit interval, which can be estimated and locally computed. This presentation is concerned with the estimation of such prior values.
mustašfā, Hospital), but it is cognitively imperceptible without an instantiation with a root such as , šfw, . The strength of association is depicted according to a value within the unit interval, which can be estimated and locally computed. This presentation is concerned with the estimation of such prior values.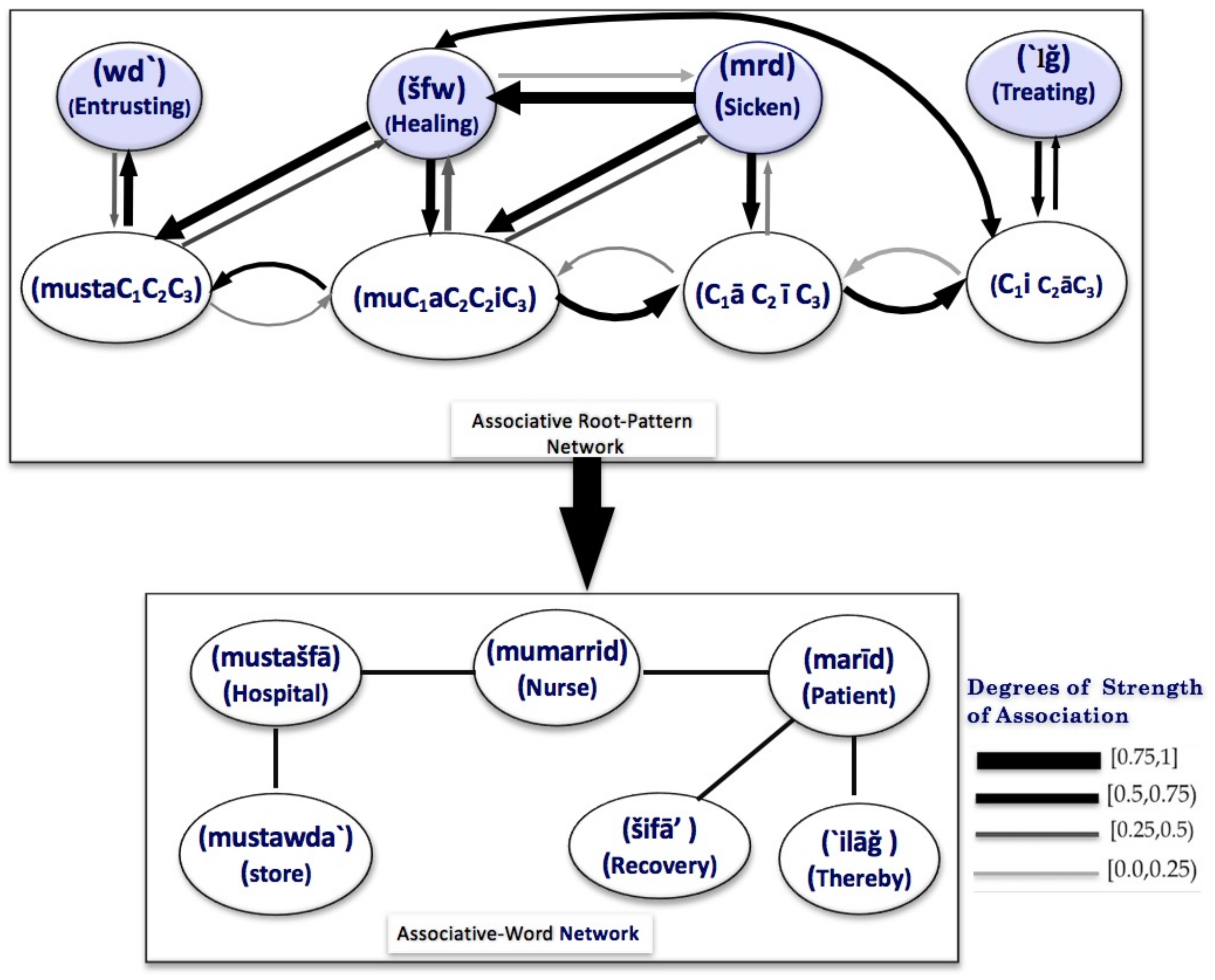
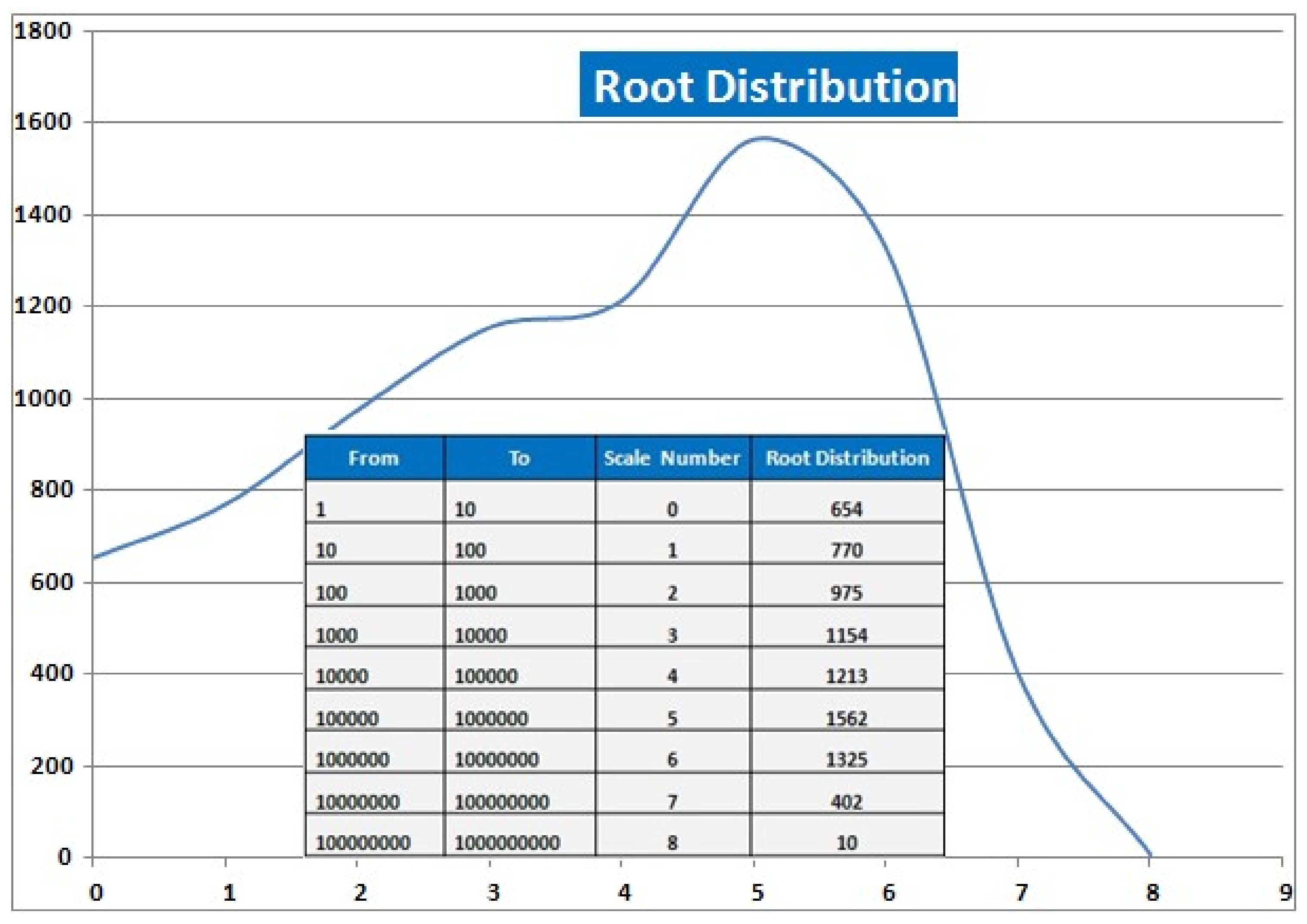
| ROOT | Root-Occ |  |  |  | |||
|---|---|---|---|---|---|---|---|
| R→P | R←P | R→P | R←P | R→P | R←P | ||
 | 39485264 | 0.00228212 | 0.2650689 | 0.0000116728 | 0.0038521 | 0.000578 | 0.00008432 |
 | 85620930 | 0.00000691 | 0.00067412 | 0.0192878 | 0.0694434 | 0.0012404 | 0.01846788 |
 | 18789183 | 0.000000001 | 0.000000001 | 0.00962323 | 0.0003241 | 0.00149652 | 0.00027534 |
 | 60361866 | 0.0000018767 | 0.02654881 | 0.00049551695 | 0.0050278676 | 0.00005864 | 0.000008413 |
 | 61034613 | 0.0000002227 | 0.000399877 | 0.00000097145 | 0.0004955169 | 0.0027966 | 0.00241713 |
 | 49405697 | 0.00000003237 | 0.000004704 | 0.0000024709 | 0.00102028 | 0.030609488 | 0.02141586 |
 | 67039191 | 0.0000078228 | 0.015421753 | 0.000000180 | 0.000101108 | 0.000000001 | 0.000000001 |
| Morpho-Constituent | Size | Comment |
|---|---|---|
| Roots | 8065 | Predominantly based on Petra-Morph and the Alkalil Database |
| Patterns | 5737 | Patterns and all of their syntactical variations based on Petra-Morph. |
| Particles | 281 | |
| Word forms without Root–Pattern Relation | 11,322,272 | These Data represent the non-derivative part of the corpus; i.e., words without a clear root–pattern relationships such as certain country’s names, proper names, and others. Frequency distribution shows that this type has a much lower frequency in the corpus compared to the words that have root–pattern relationships. |
| Quantitative Feature | Size | Comment |
|---|---|---|
| Document (webpages) | 29,192,662 | 975 text files (180 GB) for each, with 30,000 webpages. ClueWeb 975 WARC in 240 GB compressed files and in 1 TB uncompressed |
| Word-Forms | 11,437,025,140 | |
| Vocabulary | 18,482,719 | Distinct words types stored in one 398 MB file. |
| Persian Bigrams Word Forms | 122,516,474 | Total frequency of Persian bigrams. ClueWeb is not clean; it contains multiple Persian and Urdu word forms. |
| Persian Bigram Types | 10,739,392 | These data were excluded from the Arabic vocabulary. It has a relatively small ratio; approx. 2% of the unique Arabic bi-grams and around 8% of the total count of the bi-gram analysis. However, it constitutes a large portion of the vocabulary |
| Roots | 8065 | The large number of roots represents how many abstract concepts there are in the corpus. Furthermore, the concepts seems to be nearly balanced and normally distributed (see also Figure 5). Around 40% of the Arabic roots were very frequent. However, the occurrence of stems and non-derivative word forms have not been considered in this analysis, as the focus of the presentation was set on computing associative root–pattern relationships. |
| Morpho-Associative Feature | Size |
|---|---|
| Bi-Directional Pattern–Pattern | 1,152,310 |
| Bi-Directional Root–Pattern | 6,992,022 |
| Bi-Directional Root–Root | 149,870 |
| Bi-Directional Root–Particle | 513,538 |
| Bi-Directional Root–Stem | 503,506 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haddad, B.; Awwad, A.; Hattab, M.; Hattab, A. Associative Root–Pattern Data and Distribution in Arabic Morphology. Data 2018, 3, 10. https://doi.org/10.3390/data3020010
Haddad B, Awwad A, Hattab M, Hattab A. Associative Root–Pattern Data and Distribution in Arabic Morphology. Data. 2018; 3(2):10. https://doi.org/10.3390/data3020010
Chicago/Turabian StyleHaddad, Bassam, Ahmad Awwad, Mamoun Hattab, and Ammar Hattab. 2018. "Associative Root–Pattern Data and Distribution in Arabic Morphology" Data 3, no. 2: 10. https://doi.org/10.3390/data3020010
APA StyleHaddad, B., Awwad, A., Hattab, M., & Hattab, A. (2018). Associative Root–Pattern Data and Distribution in Arabic Morphology. Data, 3(2), 10. https://doi.org/10.3390/data3020010