Figure 1.
Architecture of VGG-19.
Figure 1.
Architecture of VGG-19.
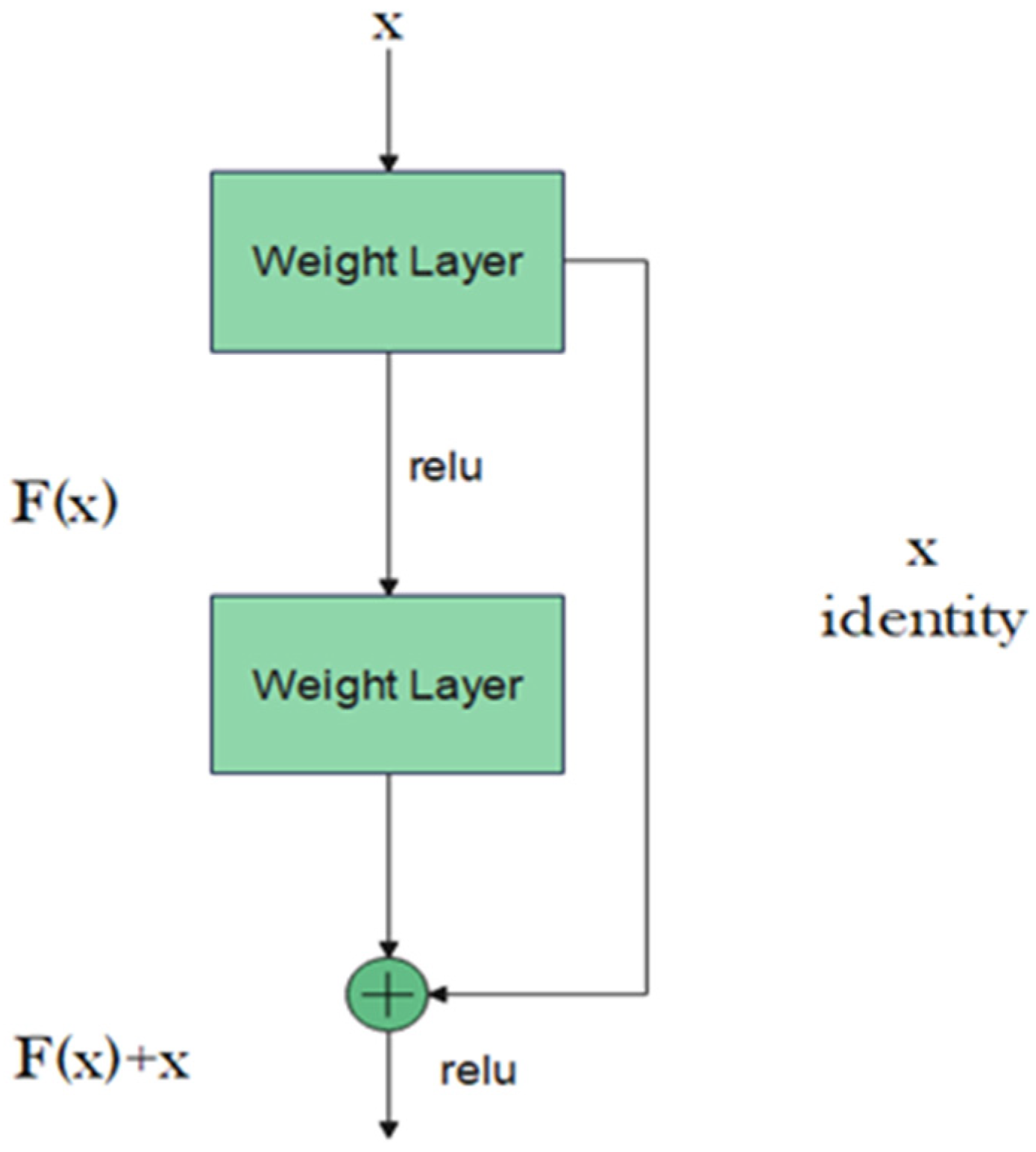
Figure 2.
Residual block.
Figure 2.
Residual block.
Figure 3.
Bottleneck design of the residual block.
Figure 3.
Bottleneck design of the residual block.
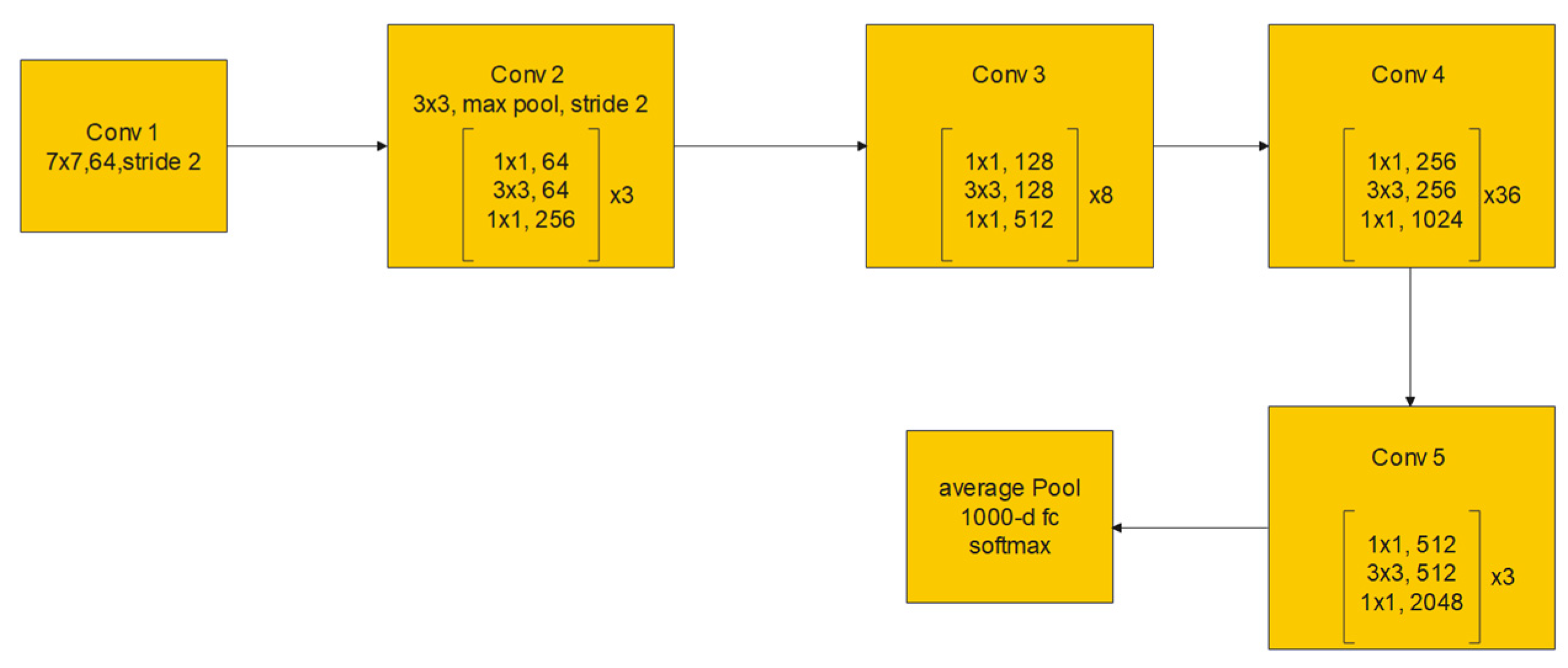
Figure 4.
ResNet-152 architecture.
Figure 4.
ResNet-152 architecture.
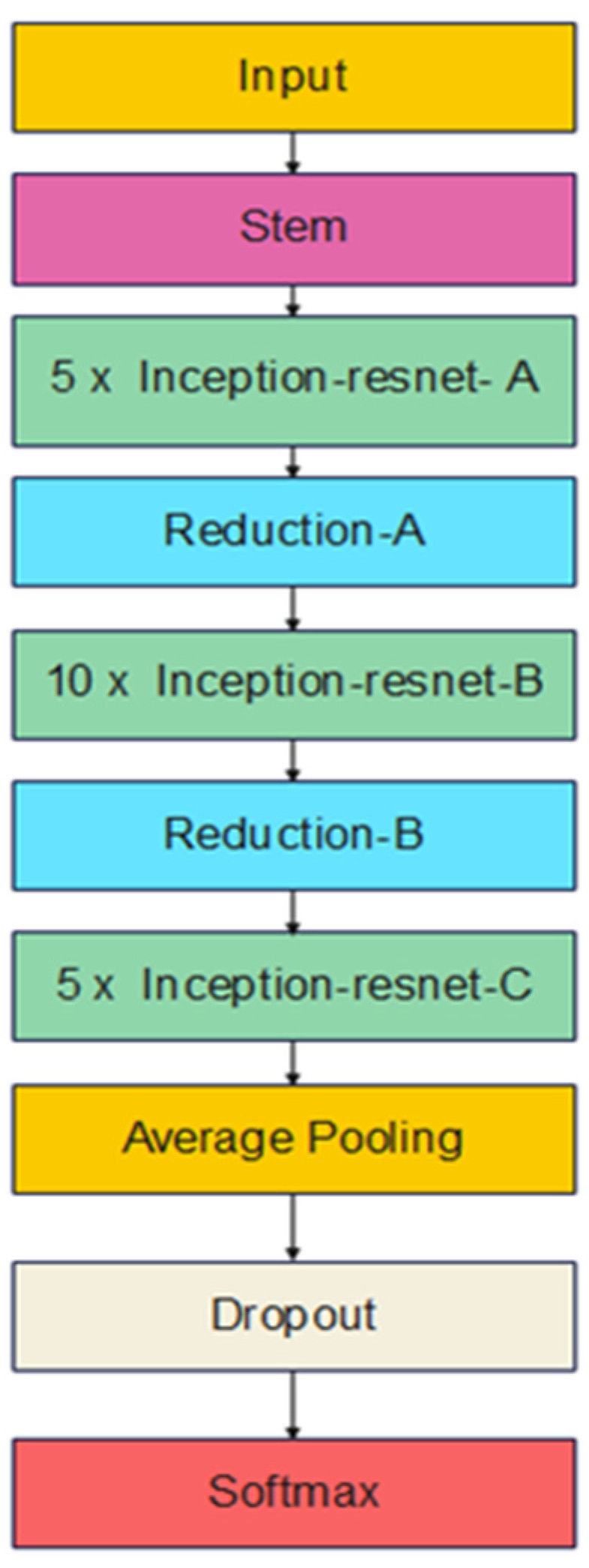
Figure 5.
InceptionResNetV2 architecture.
Figure 5.
InceptionResNetV2 architecture.
Figure 6.
Three-layers dense block.
Figure 6.
Three-layers dense block.
Figure 7.
DenseNet-201 architecture, every convolutional layer corresponds to the series BN-ReLU-Conv.
Figure 7.
DenseNet-201 architecture, every convolutional layer corresponds to the series BN-ReLU-Conv.
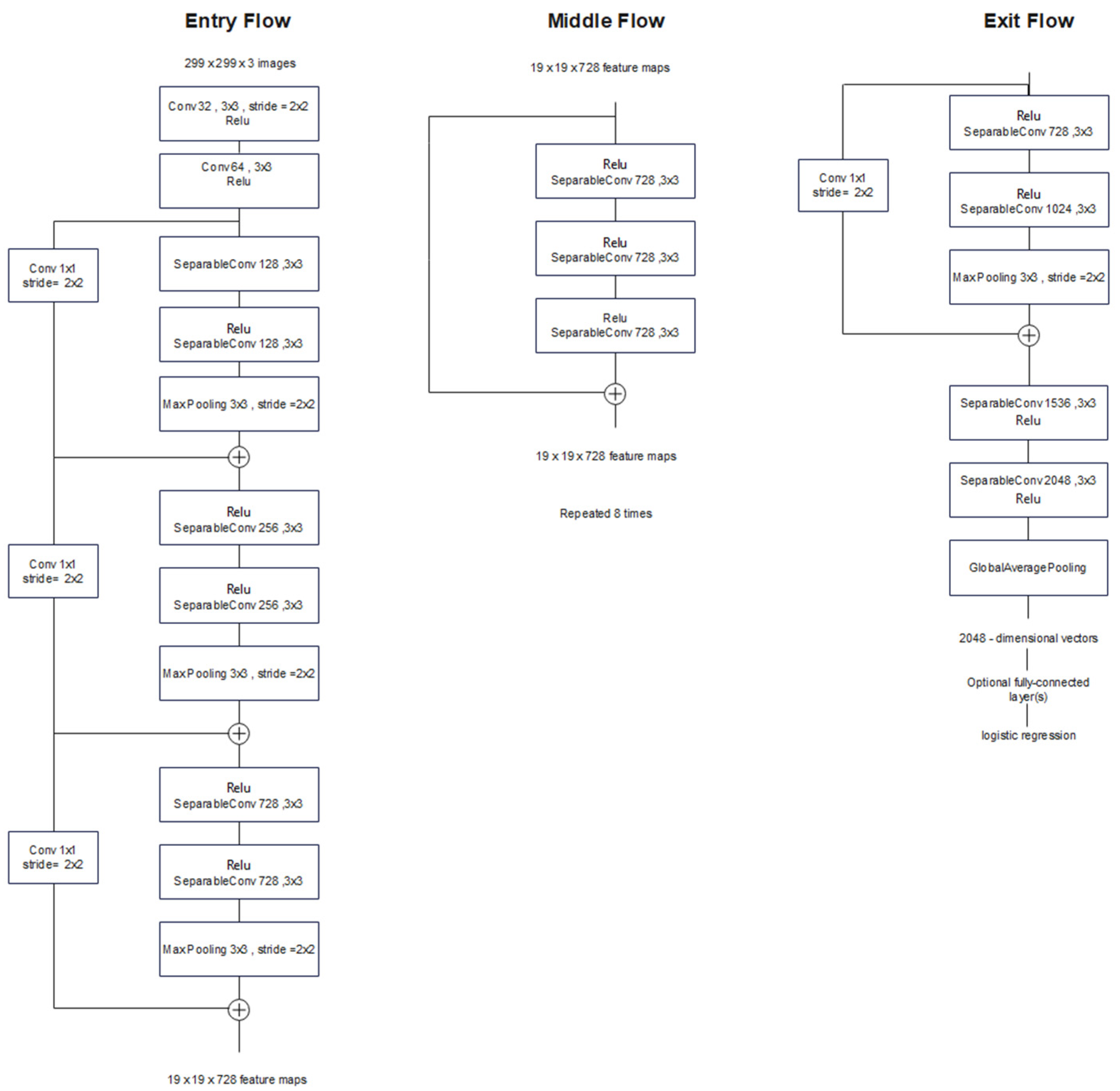
Figure 8.
Xception architecture; the input data flow is divided into three parts, starting with the entry flow then moving through the middle flow and ending with the exit flow.
Figure 8.
Xception architecture; the input data flow is divided into three parts, starting with the entry flow then moving through the middle flow and ending with the exit flow.
Figure 9.
Random samples selected from BreakHis dataset.
Figure 9.
Random samples selected from BreakHis dataset.
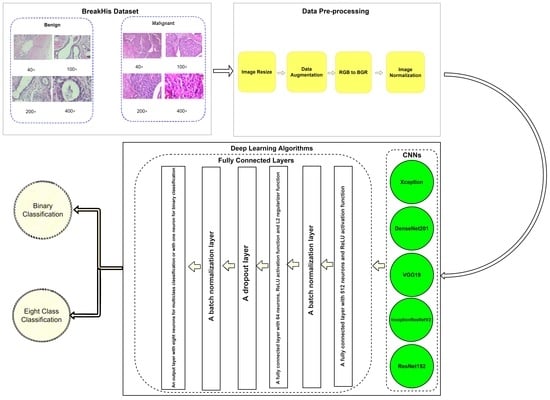
Figure 10.
Architecture of the proposed approach including the data pre-processing stage and the designed fully connected layers.
Figure 10.
Architecture of the proposed approach including the data pre-processing stage and the designed fully connected layers.
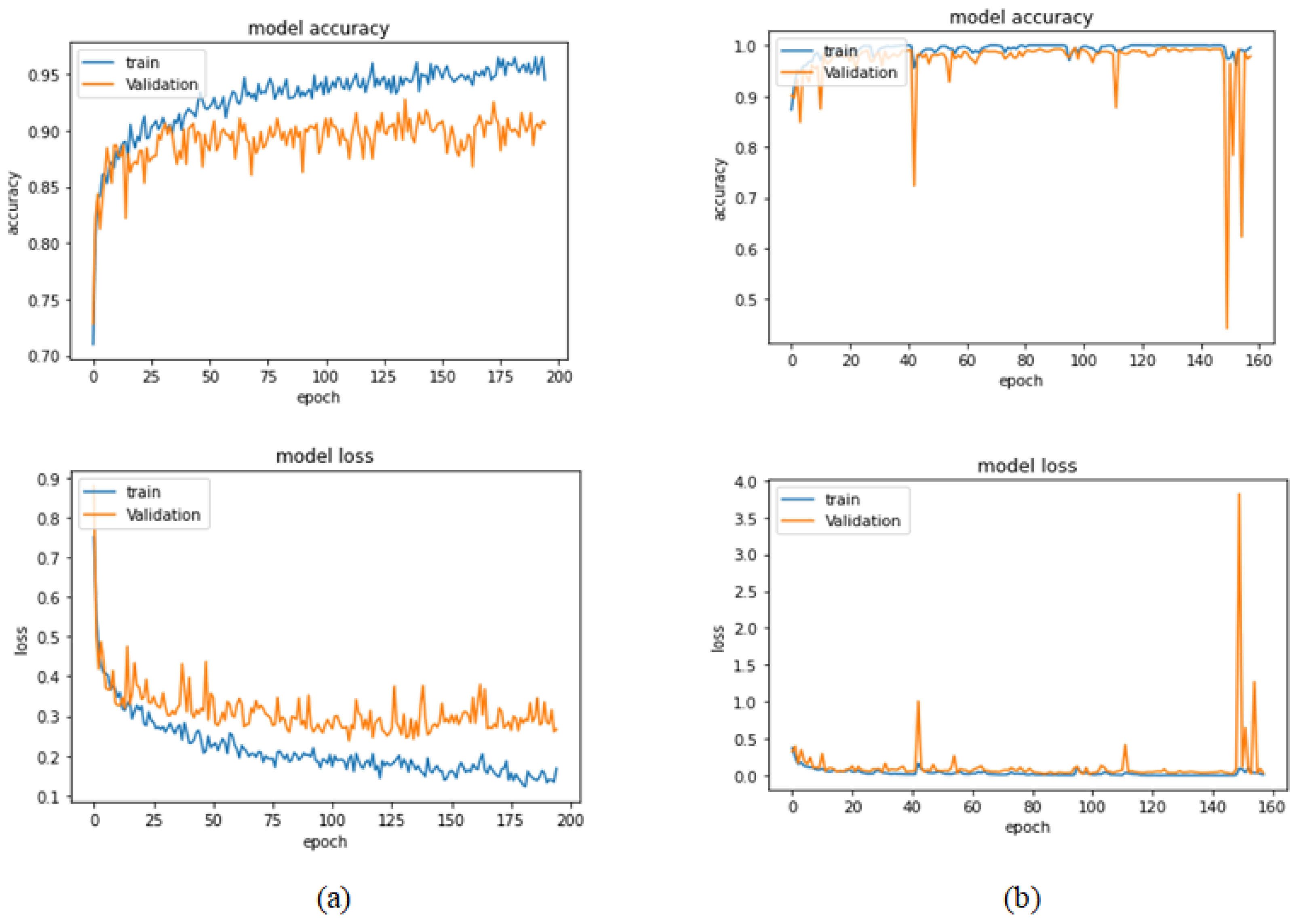
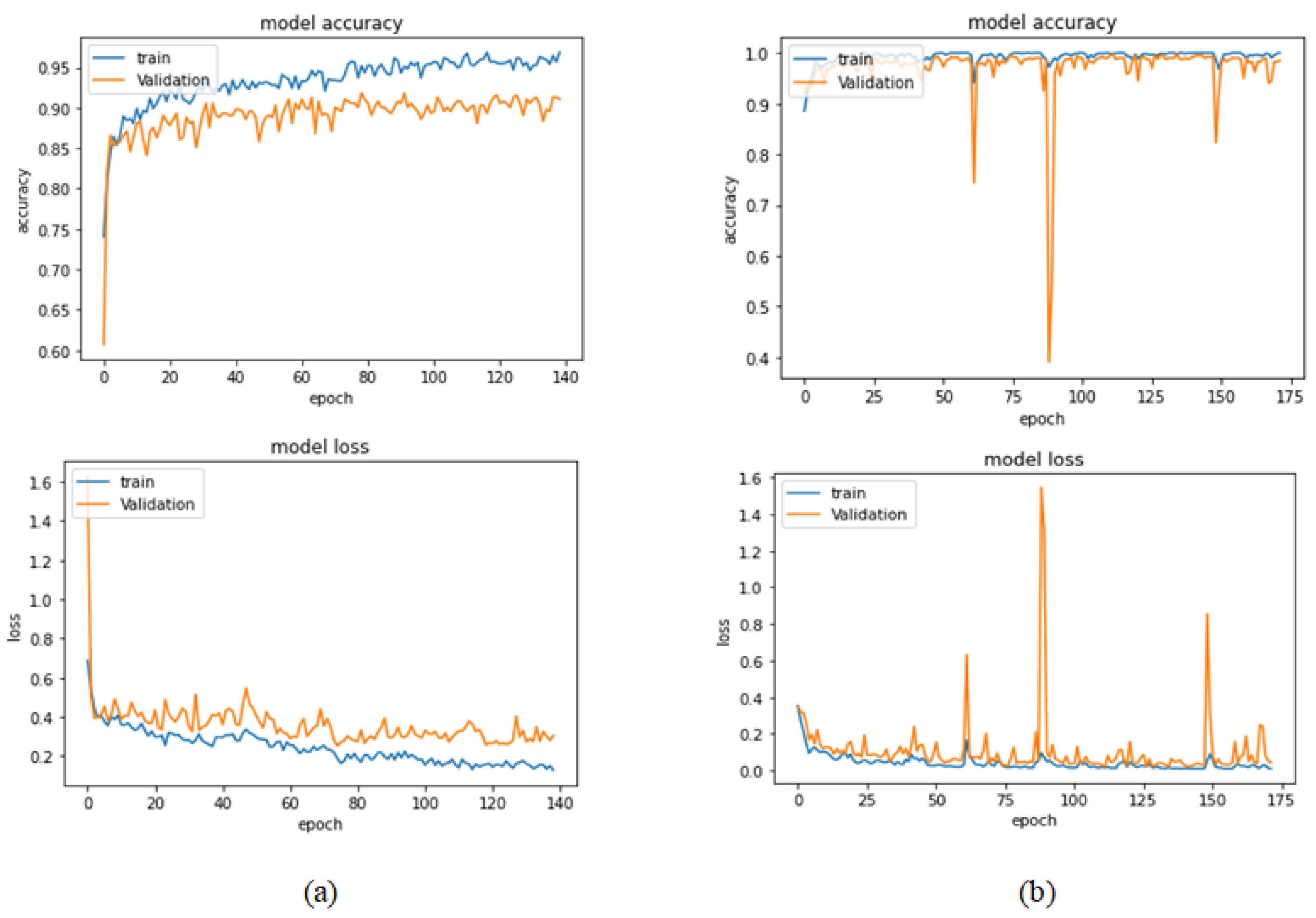
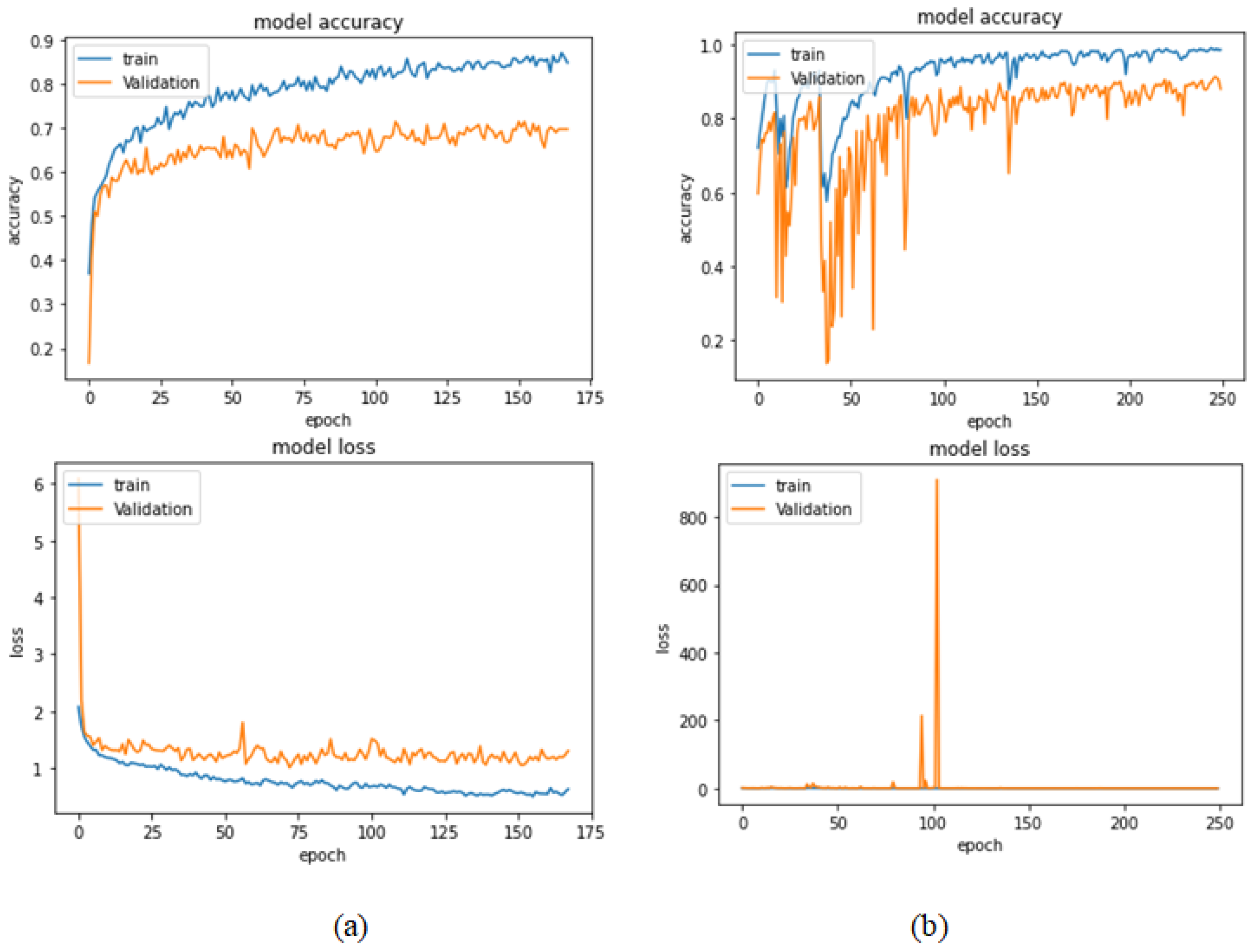
Figure 11.
Learning curves for the best obtained results in magnification-independent binary classification, which are achieved by Xception model at 0.0001 learning rate. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 11.
Learning curves for the best obtained results in magnification-independent binary classification, which are achieved by Xception model at 0.0001 learning rate. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
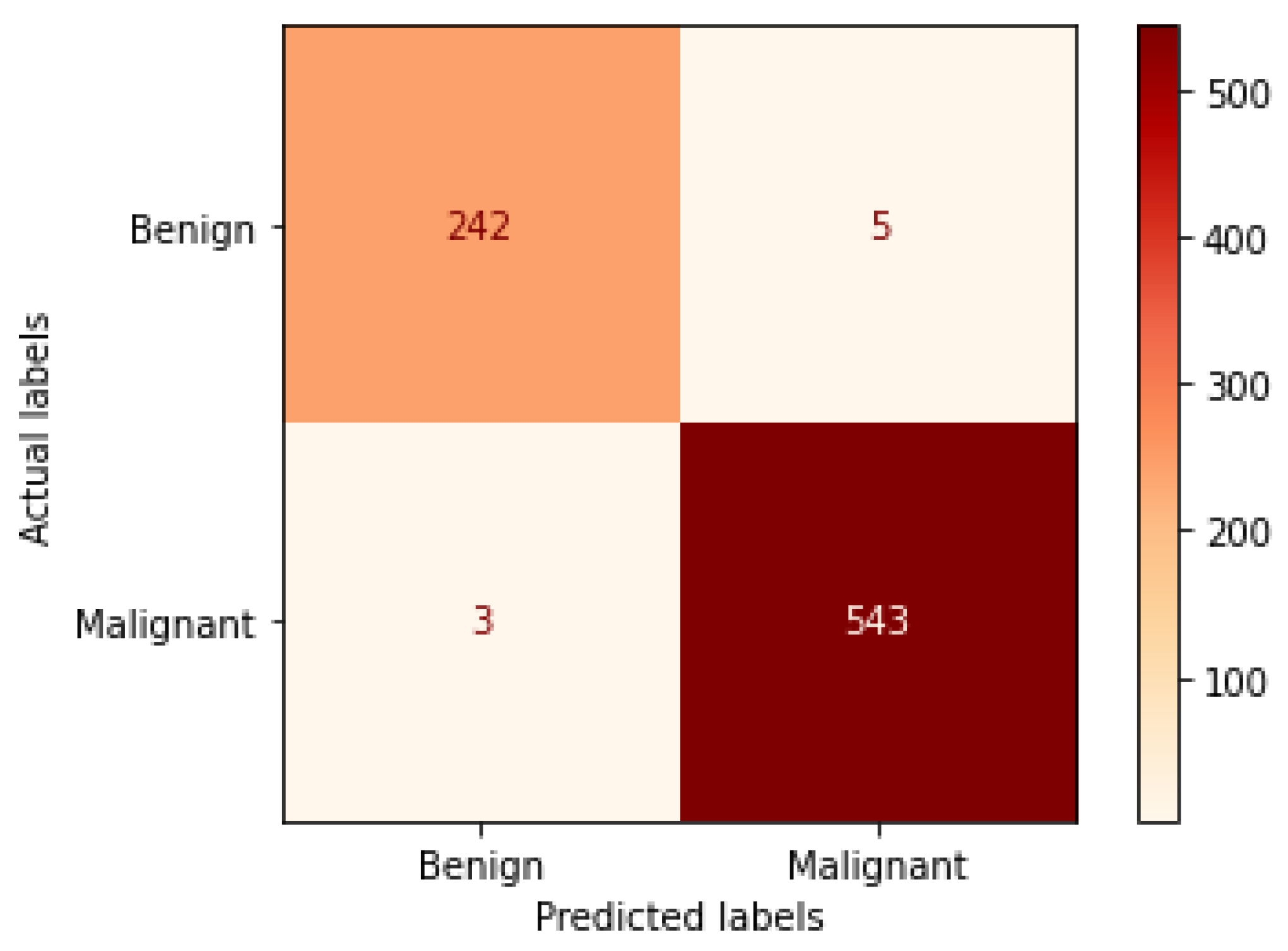
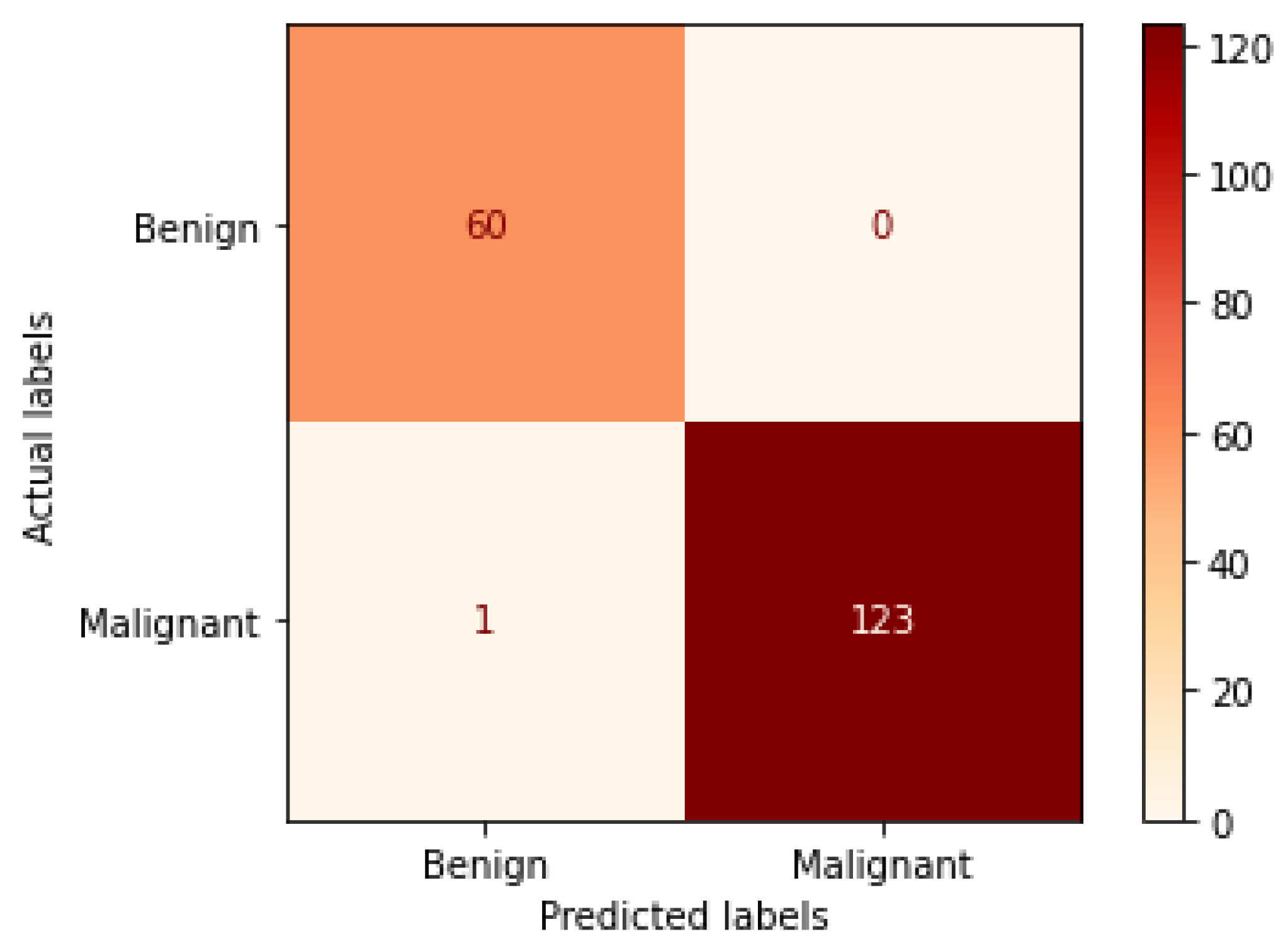
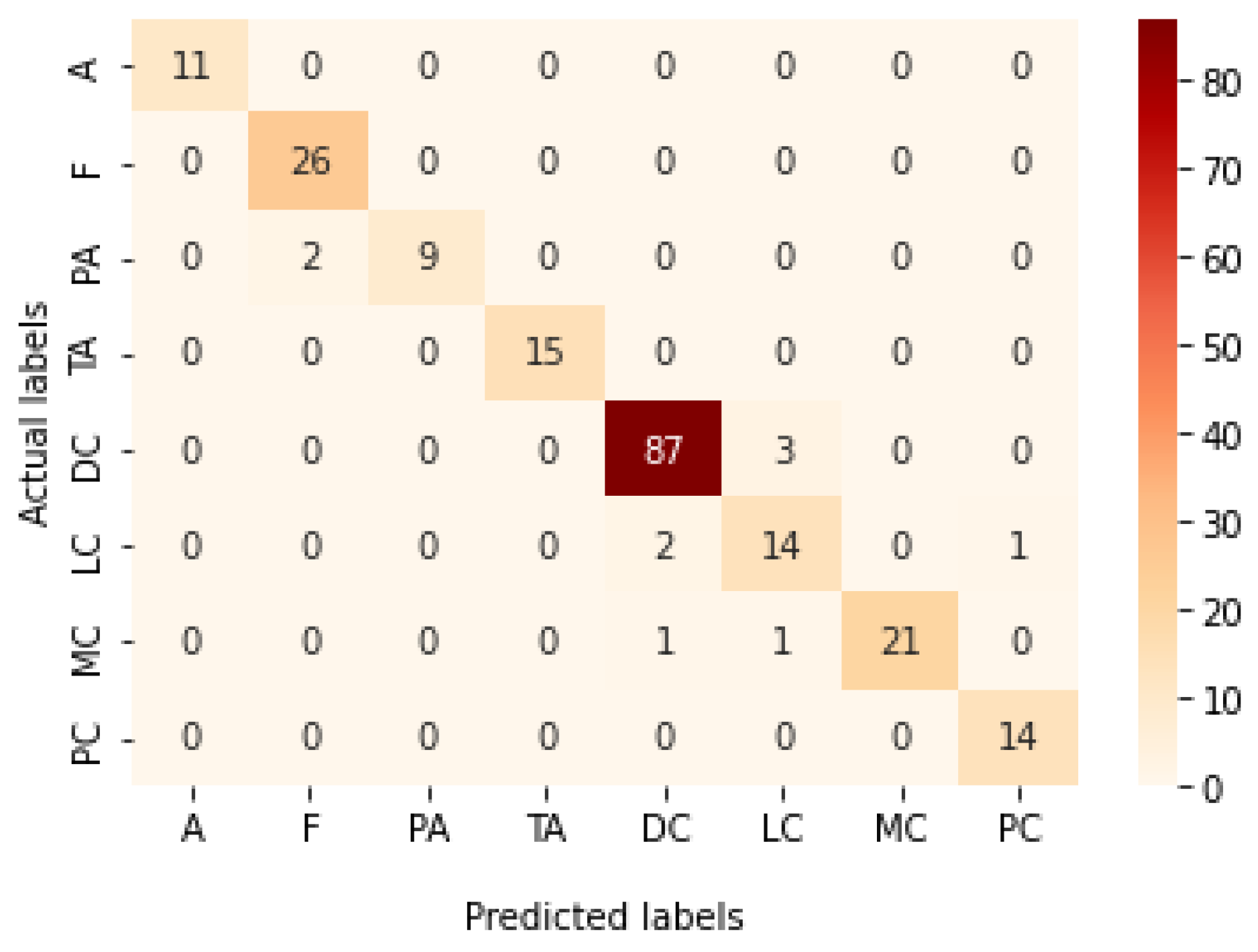
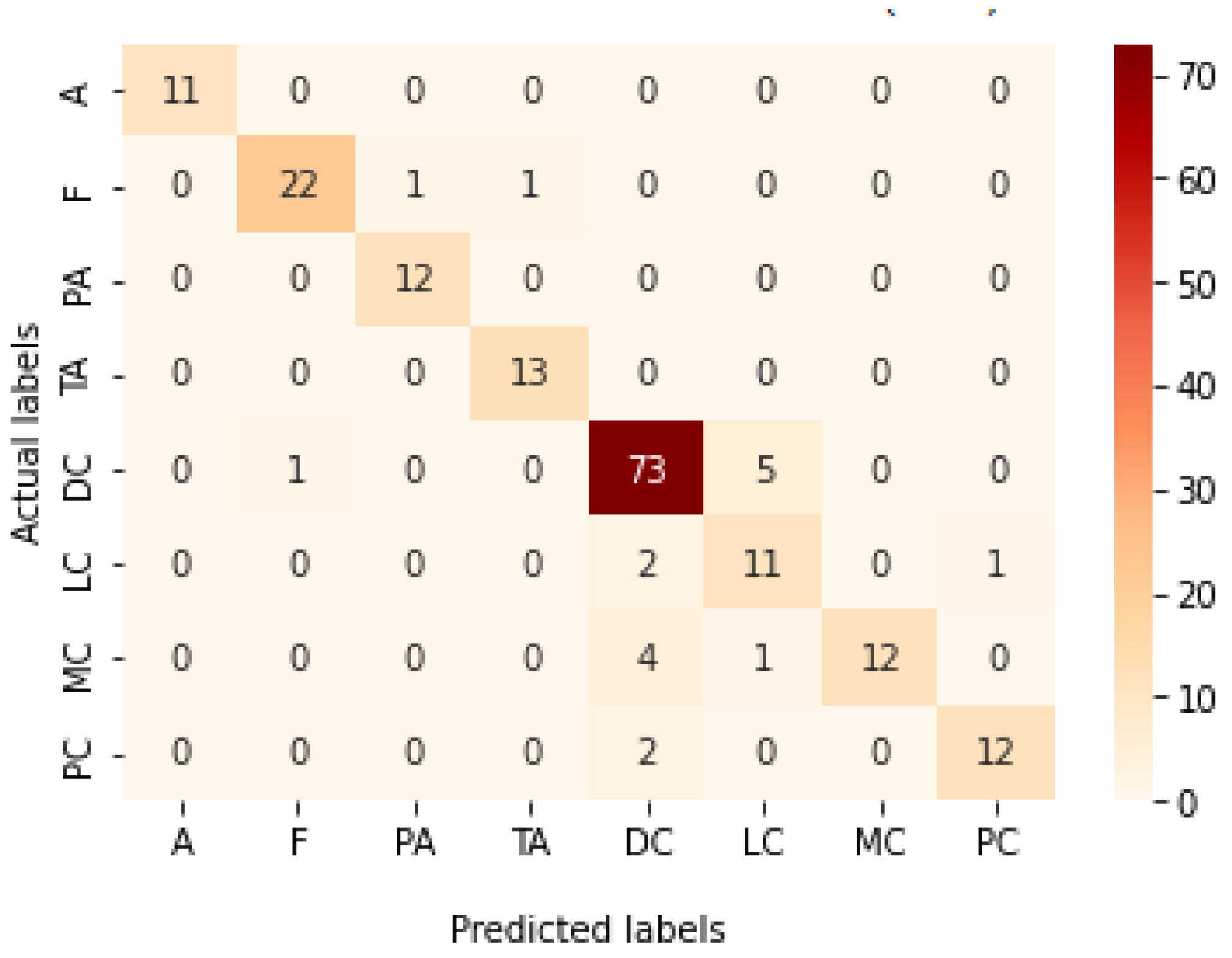
Figure 12.
Confusion matrix of Xception model in magnification-independent binary classification experiment.
Figure 12.
Confusion matrix of Xception model in magnification-independent binary classification experiment.
Figure 13.
Learning curves for VGG19 at 0.00001 learning rate in 40× magnification dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 13.
Learning curves for VGG19 at 0.00001 learning rate in 40× magnification dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
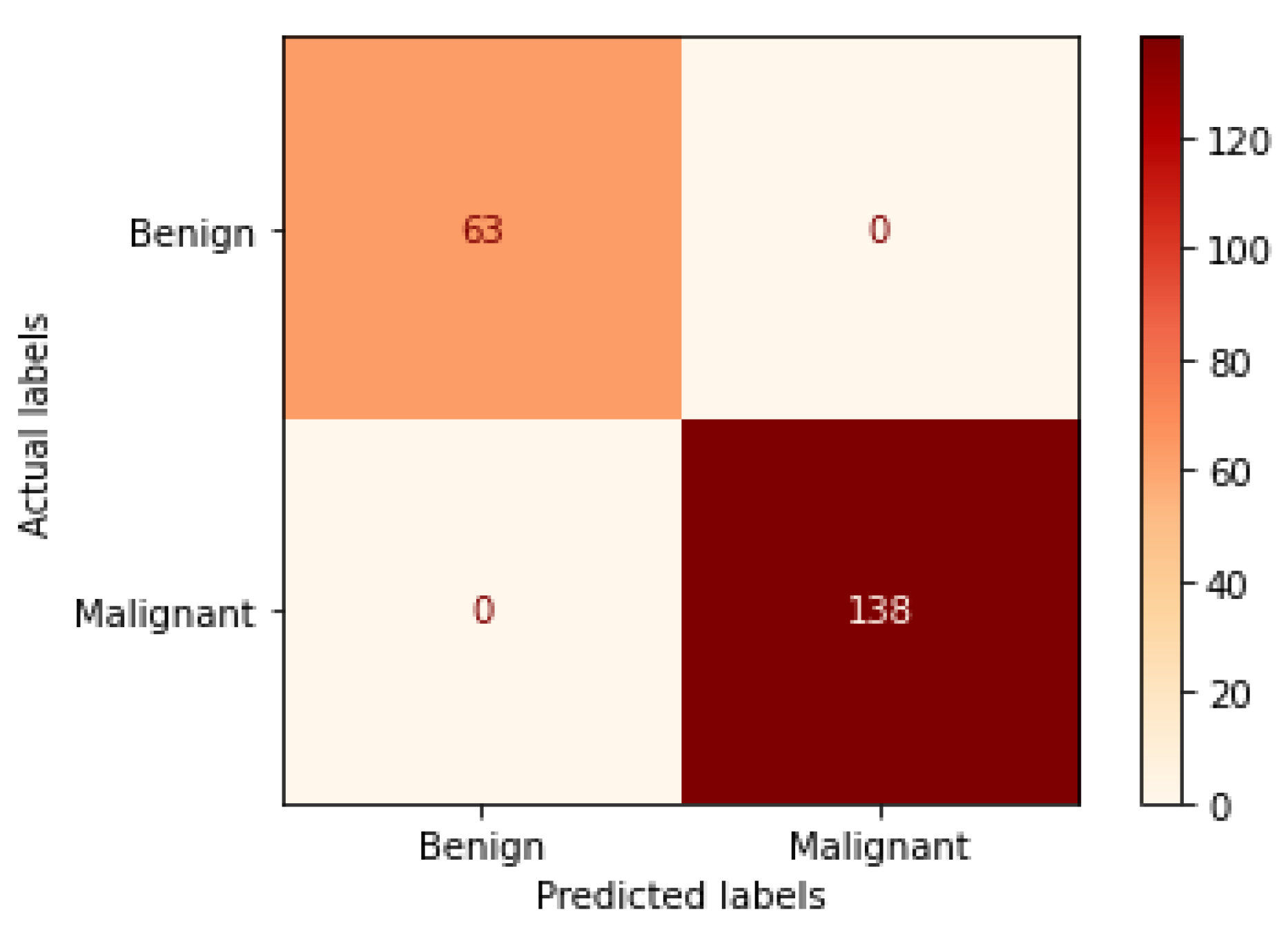
Figure 14.
Confusion matrix of VGG19 model in 40× magnification-dependent binary classification.
Figure 14.
Confusion matrix of VGG19 model in 40× magnification-dependent binary classification.
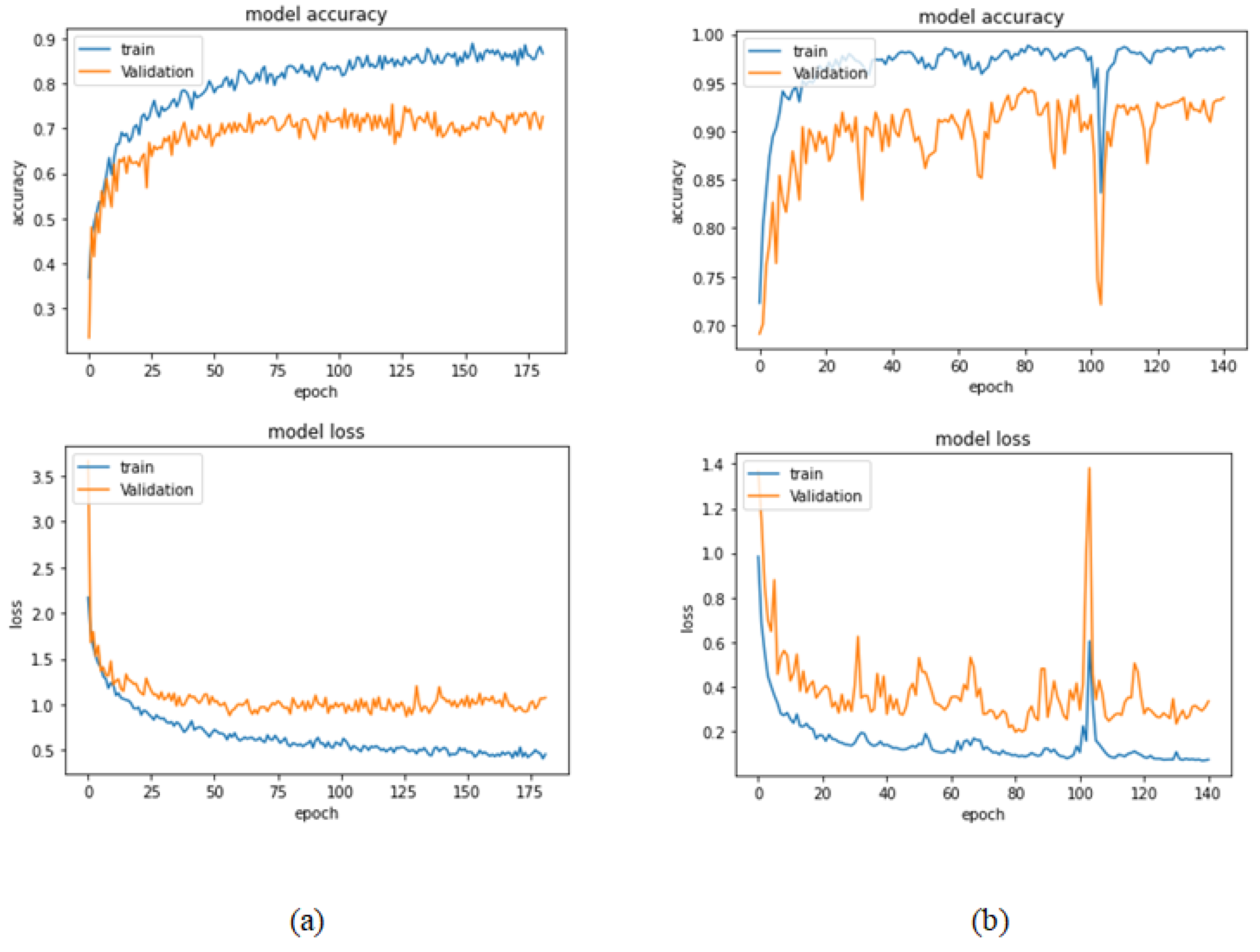
Figure 15.
Learning curves for Xception at 0.0001 learning rate in 100× magnification-dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 15.
Learning curves for Xception at 0.0001 learning rate in 100× magnification-dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
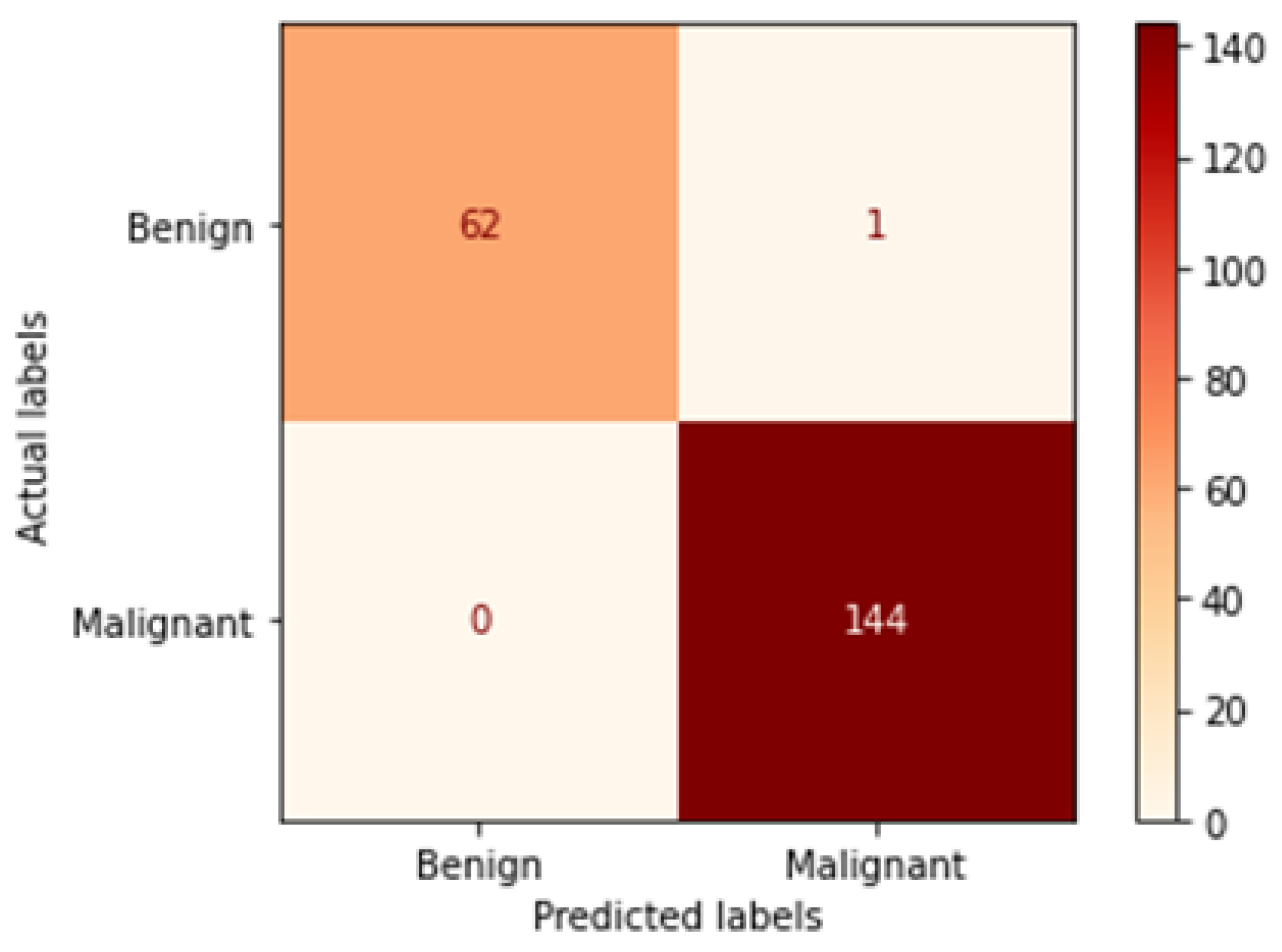
Figure 16.
Confusion matrix of Xception model in 100× magnification-dependent binary classification.
Figure 16.
Confusion matrix of Xception model in 100× magnification-dependent binary classification.
Figure 17.
Learning curves for Xception at 0.0001 learning rate in 200× magnification-dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 17.
Learning curves for Xception at 0.0001 learning rate in 200× magnification-dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 18.
Confusion matrix of Xception model in 200× magnification-dependent binary classification.
Figure 18.
Confusion matrix of Xception model in 200× magnification-dependent binary classification.
Figure 19.
Learning curves for Xception at 0.0001 learning rate in 400× magnification-dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 19.
Learning curves for Xception at 0.0001 learning rate in 400× magnification-dependent binary classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 20.
Confusion matrix of Xception model in 400× magnification-dependent binary classification.
Figure 20.
Confusion matrix of Xception model in 400× magnification-dependent binary classification.
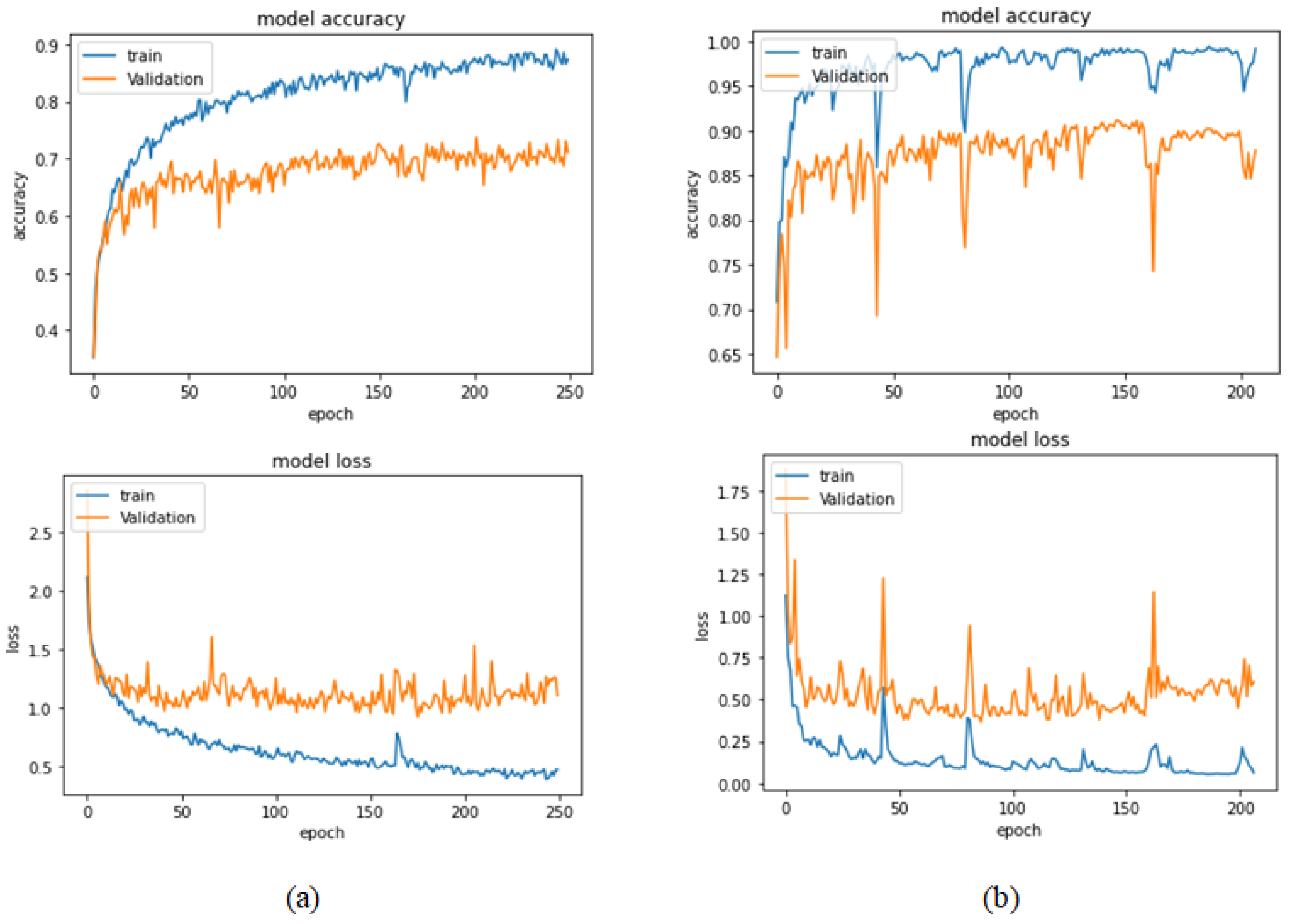
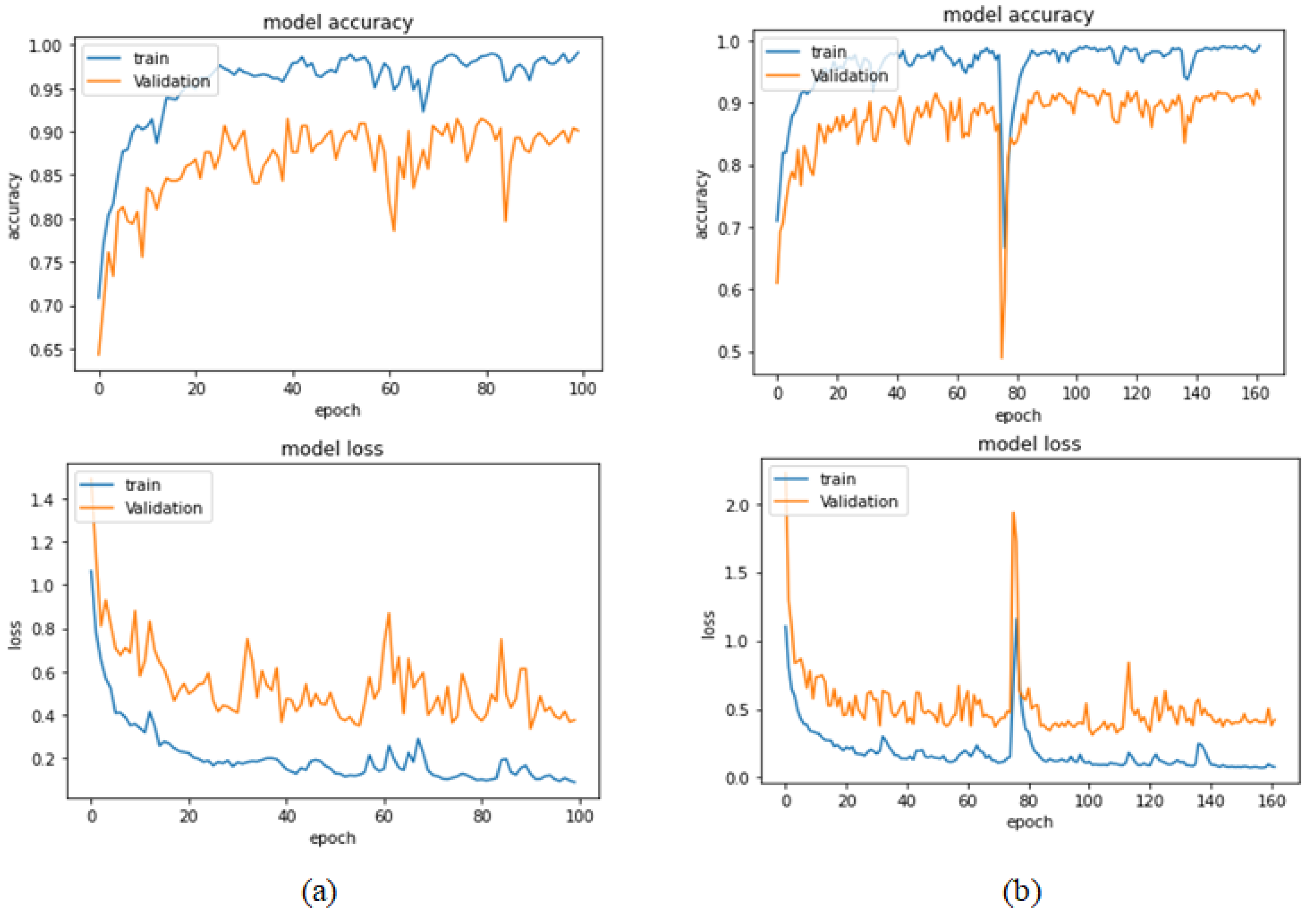
Figure 21.
Learning curves for Xception at 0.0001 learning rate in magnification-independent multi-classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 21.
Learning curves for Xception at 0.0001 learning rate in magnification-independent multi-classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
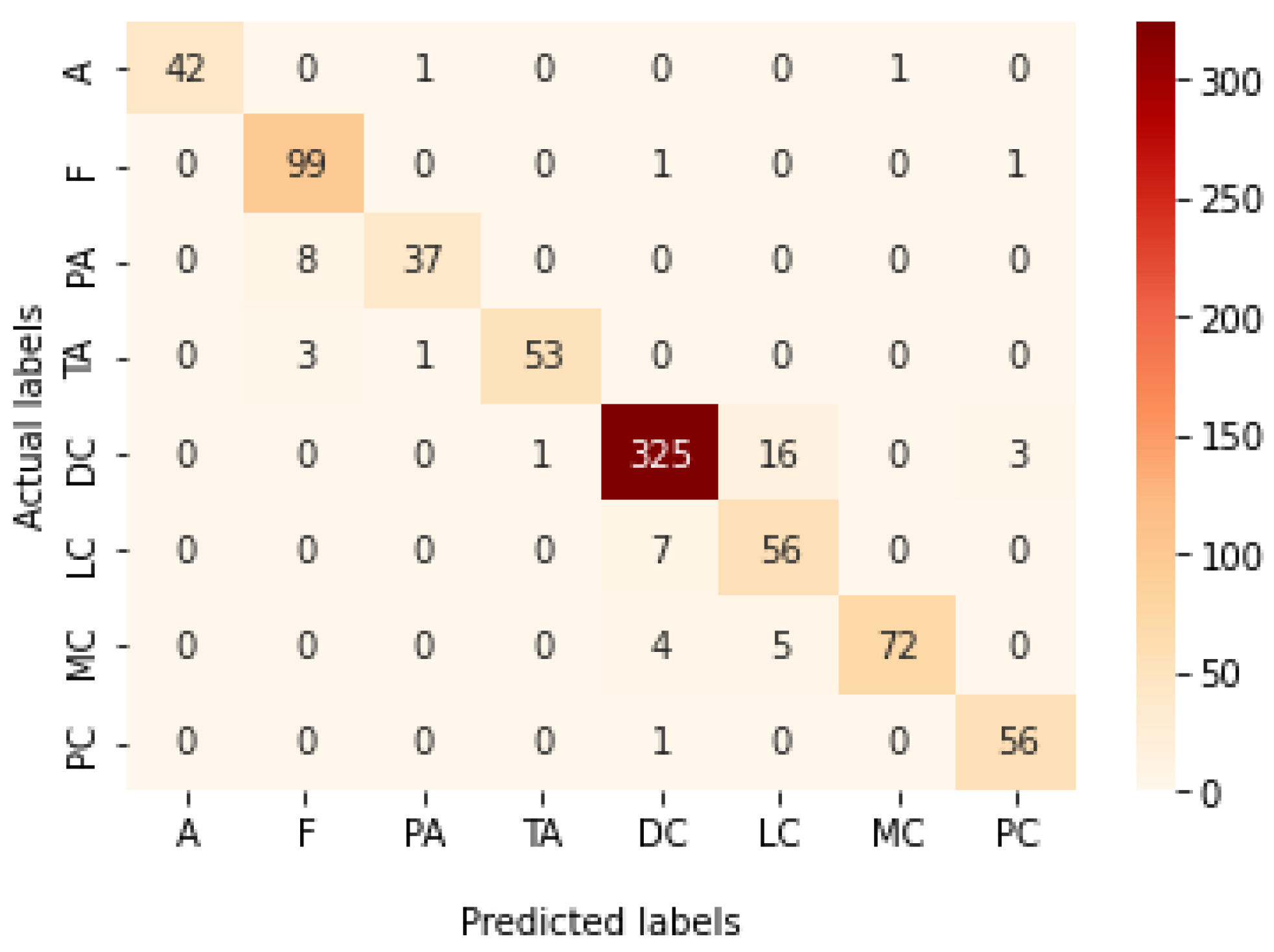
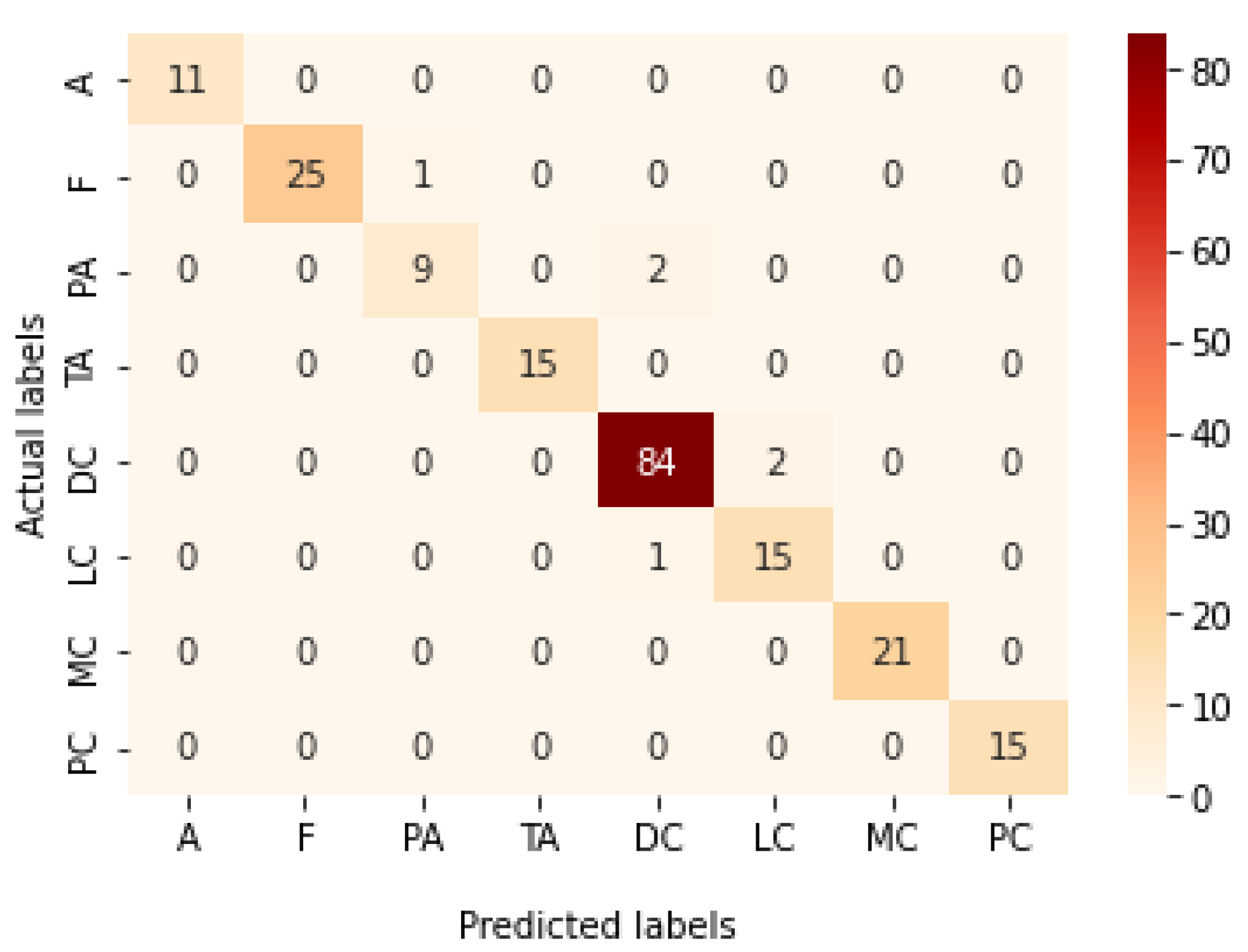
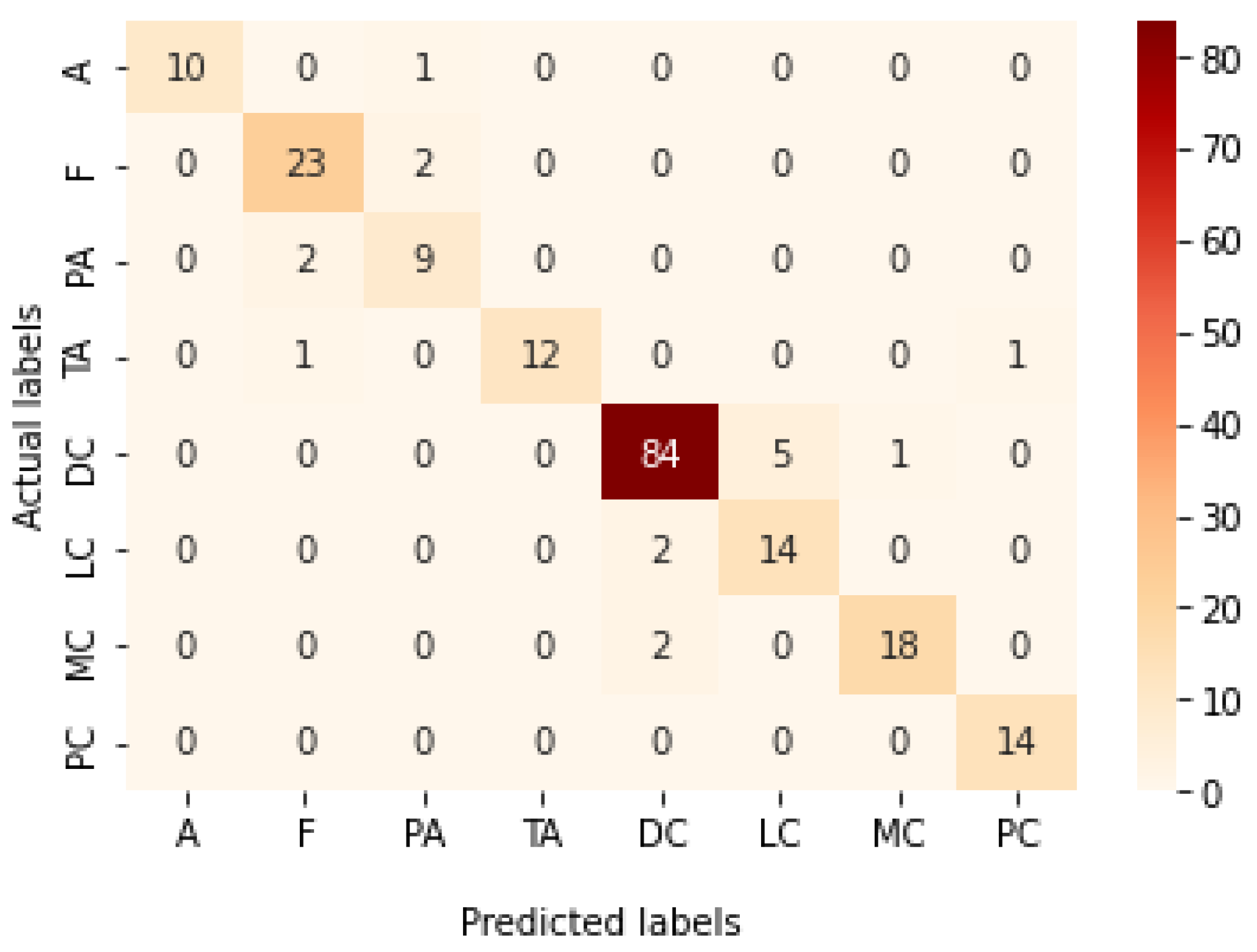
Figure 22.
Confusion matrix of Xception model in magnification-independent multi-classification experiment.
Figure 22.
Confusion matrix of Xception model in magnification-independent multi-classification experiment.
Figure 23.
Learning curves for Xception at 0.0001 learning rate in 40× magnification-dependent multi-classification (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 23.
Learning curves for Xception at 0.0001 learning rate in 40× magnification-dependent multi-classification (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 24.
Confusion matrix of Xception model in 40× magnification-dependent multi-classification.
Figure 24.
Confusion matrix of Xception model in 40× magnification-dependent multi-classification.
Figure 25.
Learning curves for Xception at 0.0001 learning rate in 100× magnification-dependent multi-classification (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 25.
Learning curves for Xception at 0.0001 learning rate in 100× magnification-dependent multi-classification (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 26.
Confusion matrix of Xception model in 100× magnification-dependent multi-classification.
Figure 26.
Confusion matrix of Xception model in 100× magnification-dependent multi-classification.
Figure 27.
Learning curves for Xception at 0.0001 learning rate in 200× magnification-dependent multi-classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 27.
Learning curves for Xception at 0.0001 learning rate in 200× magnification-dependent multi-classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 28.
Confusion matrix of Xception model in 200× magnification-dependent multi-classification.
Figure 28.
Confusion matrix of Xception model in 200× magnification-dependent multi-classification.
Figure 29.
Learning curves for Xception at 0.0001 learning rate in 400× magnification-dependent multi-classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 29.
Learning curves for Xception at 0.0001 learning rate in 400× magnification-dependent multi-classification. (a) Accuracy and loss curves of Phase 1 of training. (b) Accuracy and loss curves of Phase 2 of training.
Figure 30.
Confusion matrix of Xception model in 400× magnification-dependent multi-classification.
Figure 30.
Confusion matrix of Xception model in 400× magnification-dependent multi-classification.
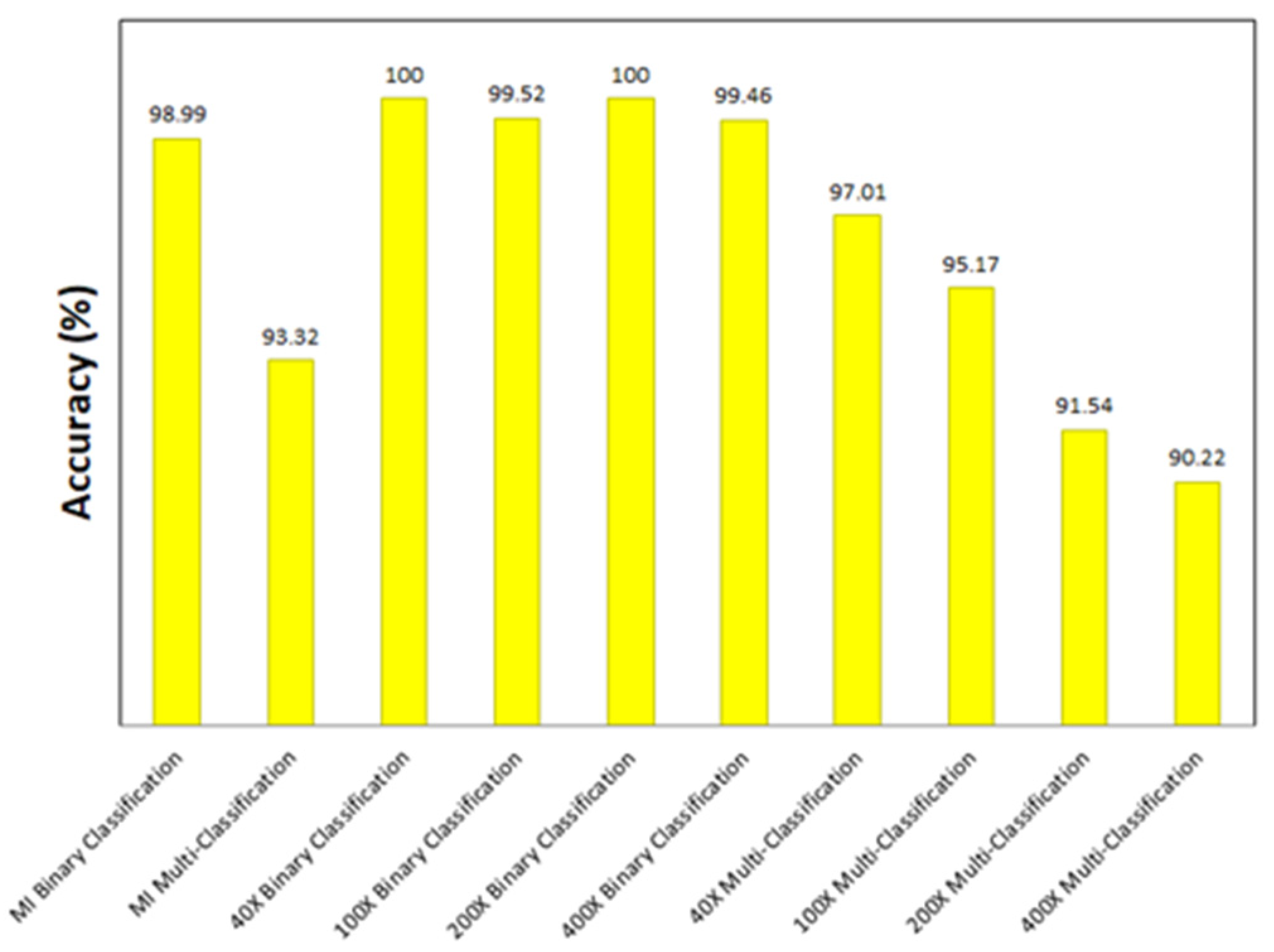
Figure 31.
Accuracy achieved by the best model for all the experiments.
Figure 31.
Accuracy achieved by the best model for all the experiments.
Table 2.
Distribution of data in BreakHis dataset.
Table 2.
Distribution of data in BreakHis dataset.
| | Benign | Malignant | |
|---|
| | A | F | PT | TA | DC | LC | MC | PC | Sum |
|---|
| 40× | 114 | 253 | 109 | 149 | 864 | 156 | 205 | 145 | 1995 |
| 100× | 113 | 260 | 121 | 150 | 903 | 170 | 222 | 142 | 2081 |
| 200× | 111 | 264 | 108 | 140 | 896 | 163 | 196 | 135 | 2013 |
| 400× | 106 | 237 | 115 | 130 | 788 | 137 | 169 | 138 | 1820 |
| Sum | 444 | 1014 | 453 | 569 | 3451 | 626 | 792 | 560 | 7909 |
Table 3.
Distribution of data in the training, validation, and test datasets.
Table 3.
Distribution of data in the training, validation, and test datasets.
| | Benign | Malignant | |
|---|
| | | A | F | PT | TA | DC | LC | MC | PC | Sum |
|---|
| Training | 40× | 80 | 176 | 76 | 104 | 606 | 109 | 143 | 102 | 1396 |
| 100× | 79 | 182 | 86 | 105 | 632 | 119 | 155 | 100 | 1458 |
| 200× | 78 | 186 | 76 | 98 | 627 | 114 | 137 | 94 | 1410 |
| 400× | 74 | 166 | 80 | 91 | 551 | 96 | 118 | 96 | 1272 |
| Sum | 311 | 710 | 318 | 398 | 2416 | 438 | 553 | 392 | 5536 |
| Validation | 40× | 23 | 51 | 22 | 30 | 172 | 31 | 41 | 28 | 398 |
| 100× | 23 | 52 | 24 | 30 | 181 | 34 | 44 | 28 | 416 |
| 200× | 22 | 53 | 21 | 28 | 179 | 33 | 39 | 27 | 402 |
| 400× | 21 | 47 | 23 | 26 | 158 | 27 | 34 | 28 | 364 |
| Sum | 89 | 203 | 90 | 114 | 690 | 125 | 158 | 111 | 1580 |
| Test | 40× | 11 | 26 | 11 | 15 | 86 | 16 | 21 | 15 | 201 |
| 100× | 11 | 26 | 11 | 15 | 90 | 17 | 23 | 14 | 207 |
| 200× | 11 | 25 | 11 | 14 | 90 | 16 | 20 | 14 | 201 |
| 400× | 11 | 24 | 12 | 13 | 79 | 14 | 17 | 14 | 184 |
| Sum | 44 | 101 | 45 | 57 | 345 | 63 | 81 | 57 | 793 |
Table 4.
Performance metrics collected for magnification-independent binary classification; the highest results are shown in bold.
Table 4.
Performance metrics collected for magnification-independent binary classification; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 98.99 | 98.93 | 98.71 | 98.82 | 0.9764 |
| DenseNet201 | 98.61 | 98.33 | 98.44 | 98.38 | 0.9677 |
| Inception ResNet V2 | 98.49 | 98.24 | 98.24 | 98.24 | 0.9647 |
| VGG19 | 97.86 | 97.01 | 98.11 | 97.53 | 0.9511 |
| ResNet152 | 68.85 | 34.43 | 50.00 | 40.78 | 0 |
| 0.00001 | Xception | 98.61 | 98.44 | 98.33 | 98.38 | 0.9676 |
| DenseNet201 | 98.49 | 98.24 | 98.24 | 98.24 | 0.9647 |
| Inception ResNet V2 | 97.23 | 96.97 | 96.54 | 96.75 | 0.9351 |
| VGG19 | 98.74 | 98.53 | 98.53 | 98.53 | 0.9705 |
| ResNet152 | 97.86 | 97.76 | 97.22 | 97.49 | 0.9498 |
Table 5.
Results of 40× magnification factor in binary classification mode; the highest results are shown in bold.
Table 5.
Results of 40× magnification factor in binary classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 100 | 100 | 100 | 100 | 1 |
| DenseNet201 | 99.50 | 99.22 | 99.64 | 99.42 | 0.9886 |
| Inception ResNet V2 | 97.51 | 96.32 | 98.19 | 97.17 | 0.9449 |
| VGG19 | 99.50 | 99.22 | 99.64 | 99.42 | 0.9886 |
| ResNet152 | 81.09 | 86.09 | 70.70 | 73.22 | 0.5467 |
| 0.00001 | Xception | 99 | 98.46 | 99.28 | 98.85 | 0.9773 |
| DenseNet201 | 100 | 100 | 100 | 100 | 1 |
| Inception ResNet V2 | 99.50 | 99.22 | 99.64 | 99.42 | 0.9887 |
| VGG19 | 100 | 100 | 100 | 100 | 1 |
| ResNet152 | 98.01 | 97.01 | 98.55 | 97.73 | 0.9555 |
Table 6.
Results of 100× magnification factor in binary classification mode; the highest results are shown in bold.
Table 6.
Results of 100× magnification factor in binary classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 99.52 | 99.66 | 99.21 | 99.43 | 0.9886 |
| DenseNet201 | 97.58 | 96.96 | 97.37 | 97.16 | 0.9433 |
| Inception ResNet V2 | 96.62 | 96.20 | 95.78 | 95.99 | 0.9198 |
| VGG19 | 98.55 | 98.98 | 97.62 | 98.27 | 0.9659 |
| ResNet152 | 87.44 | 91.28 | 79.81 | 83.09 | 0.7016 |
| 0.00001 | Xception | 97.58 | 96.96 | 97.37 | 97.16 | 0.9433 |
| DenseNet201 | 99.52 | 99.66 | 99.21 | 99.43 | 0.9886 |
| Inception ResNet V2 | 96.62 | 95.83 | 96.23 | 96.02 | 0.9206 |
| VGG19 | 99.03 | 99.32 | 98.41 | 98.85 | 0.9772 |
| ResNet152 | 95.17 | 95.09 | 93.40 | 94.19 | 0.8848 |
Table 7.
Results of 200× magnification factor in binary classification mode; the highest results are shown in bold.
Table 7.
Results of 200× magnification factor in binary classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 100 | 100 | 100 | 100 | 1 |
| DenseNet201 | 98.01 | 98.10 | 97.18 | 97.62 | 0.9528 |
| Inception ResNet V2 | 98.01 | 98.61 | 96.72 | 97.60 | 0.9531 |
| VGG19 | 95.52 | 94.89 | 94.47 | 94.68 | 0.8937 |
| ResNet152 | 69.65 | 34.83 | 50.00 | 41.06 | 0 |
| 0.00001 | Xception | 97.01 | 96.10 | 96.93 | 96.50 | 0.9303 |
| DenseNet201 | 98.51 | 98.03 | 98.47 | 98.24 | 0.9649 |
| Inception ResNet V2 | 98.01 | 98.10 | 97.18 | 97.62 | 0.9528 |
| VGG19 | 96.02 | 96.69 | 93.91 | 95.15 | 0.9056 |
| ResNet152 | 91.04 | 89.16 | 89.87 | 89.50 | 0.7903 |
Table 8.
Results of 400× magnification factor in binary classification mode; the highest results are shown in bold.
Table 8.
Results of 400× magnification factor in binary classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 99.46 | 99.18 | 99.60 | 99.38 | 0.9878 |
| DenseNet201 | 96.74 | 97.15 | 95.43 | 96.22 | 0.9257 |
| Inception ResNet V2 | 97.83 | 97.95 | 97.10 | 97.51 | 0.9504 |
| VGG19 | 96.20 | 94.78 | 97.18 | 95.79 | 0.9192 |
| ResNet152 | 89.67 | 90.97 | 85.46 | 87.48 | 0.7623 |
| 0.00001 | Xception | 95.65 | 94.74 | 95.48 | 95.10 | 0.9022 |
| DenseNet201 | 97.28 | 96.41 | 97.55 | 96.95 | 0.9396 |
| Inception ResNet V2 | 95.65 | 94.27 | 96.34 | 95.17 | 0.9059 |
| VGG19 | 96.20 | 95.50 | 95.89 | 95.69 | 0.9139 |
| ResNet152 | 91.04 | 89.16 | 89.87 | 89.50 | 0.7903 |
Table 9.
Results of magnification-independent multi-classification; the highest results are shown in bold.
Table 9.
Results of magnification-independent multi-classification; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 93.32 | 92.98 | 92.36 | 92.44 | 0.9129 |
| DenseNet201 | 91.80 | 91.04 | 90.10 | 90.33 | 0.8923 |
| Inception ResNet V2 | 89.79 | 90.71 | 85.87 | 87.75 | 0.8650 |
| VGG19 | 91.05 | 91.17 | 0.8880 | 89.94 | 0.8816 |
| ResNet152 | 43.51 | 5.440 | 12.50 | 7.580 | 0 |
| 0.00001 | Xception | 90.79 | 91.69 | 88.03 | 89.59 | 0.8786 |
| DenseNet201 | 93.19 | 92.80 | 91.61 | 92.00 | 0.9107 |
| Inception ResNet V2 | 65.70 | 60.27 | 52.83 | 55.68 | 0.5342 |
| VGG19 | 92.18 | 91.01 | 90.61 | 90.71 | 0.8972 |
| ResNet152 | 86.63 | 86.04 | 82.93 | 84.17 | 0.8229 |
Table 10.
Results of 40× magnification factor in multi-classification mode; the highest results are shown in bold.
Table 10.
Results of 40× magnification factor in multi-classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 97.01 | 96.85 | 96.17 | 96.47 | 0.9610 |
| DenseNet201 | 94.53 | 95.18 | 94.87 | 94.76 | 0.9289 |
| Inception ResNet V2 | 94.53 | 93.09 | 94.71 | 93.81 | 0.9290 |
| VGG19 | 66.17 | 38.88 | 41.87 | 39.45 | 0.5471 |
| ResNet152 | 42.79 | 5.35 | 12.50 | 7.490 | 0 |
| 0.00001 | Xception | 92.04 | 92.75 | 90.75 | 91.42 | 0.8962 |
| DenseNet201 | 91.54 | 92.33 | 88.91 | 90.23 | 0.8891 |
| Inception ResNet V2 | 93.03 | 92.77 | 92.29 | 92.44 | 0.9089 |
| VGG19 | 96.52 | 96.74 | 95.01 | 95.77 | 0.9546 |
| ResNet152 | 83.58 | 83.28 | 80.15 | 80.48 | 0.7847 |
Table 11.
Results of 100× magnification factor in multi-classification mode; the highest results are shown in bold.
Table 11.
Results of 100× magnification factor in multi-classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 95.17 | 95.08 | 94.02 | 94.37 | 0.9367 |
| DenseNet201 | 92.27 | 91.95 | 90.83 | 90.99 | 0.8991 |
| Inception ResNet V2 | 86.96 | 87.98 | 83.19 | 84.29 | 0.8284 |
| VGG19 | 89.37 | 92.99 | 85.29 | 88.04 | 0.8600 |
| ResNet152 | 43.48 | 5.430 | 12.50 | 7.580 | 0 |
| 0.00001 | Xception | 84.06 | 86.09 | 79.29 | 81.69 | 0.7879 |
| DenseNet201 | 89.86 | 91.16 | 84.74 | 87.23 | 0.8658 |
| Inception ResNet V2 | 87.92 | 88.78 | 84.54 | 86.25 | 0.8399 |
| VGG19 | 90.34 | 88.42 | 90.14 | 88.69 | 0.8752 |
| ResNet152 | 80.68 | 81.18 | 72.78 | 75.39 | 0.7425 |
Table 12.
Results of 200× magnification factor in multi-classification mode; the highest results are shown in bold.
Table 12.
Results of 200× magnification factor in multi-classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 91.54 | 90.08 | 90.16 | 89.91 | 0.8884 |
| DenseNet201 | 85.07 | 84.38 | 79.29 | 79.20 | 0.8070 |
| Inception ResNet V2 | 89.55 | 88.07 | 87.90 | 87.31 | 0.8638 |
| VGG19 | 54.23 | 26.65 | 26.93 | 24.78 | 0.3374 |
| ResNet152 | 44.78 | 5.60 | 12.50 | 7.73 | 0 |
| 0.00001 | Xception | 82.59 | 82.59 | 76.40 | 78.68 | 0.7658 |
| DenseNet201 | 86.07 | 87.79 | 79.69 | 82.50 | 0.8127 |
| Inception ResNet V2 | 85.07 | 85.55 | 80.61 | 82.26 | 0.8006 |
| VGG19 | 82.59 | 81.25 | 77.42 | 77.86 | 0.7699 |
| ResNet152 | 62.19 | 47.33 | 48.65 | 46.85 | 0.4954 |
Table 13.
Results of 400× magnification factor in multi-classification mode; the highest results are shown in bold.
Table 13.
Results of 400× magnification factor in multi-classification mode; the highest results are shown in bold.
| Learning Rate | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| 0.0001 | Xception | 90.22 | 90.99 | 89.87 | 89.97 | 0.8725 |
| DenseNet201 | 90.22 | 91.18 | 87.22 | 88.95 | 0.8714 |
| Inception ResNet V2 | 85.87 | 86.86 | 81.34 | 83.60 | 0.8133 |
| VGG19 | 76.63 | 73.82 | 65.42 | 66.81 | 0.6894 |
| ResNet152 | 48.37 | 11.94 | 19.52 | 14.71 | 0.2267 |
| 0.00001 | Xception | 84.78 | 85.62 | 80.14 | 81.99 | 0.7995 |
| DenseNet201 | 85.87 | 85.42 | 80.94 | 82.87 | 0.8137 |
| Inception ResNet V2 | 78.80 | 83.68 | 71.06 | 75.84 | 0.7171 |
| VGG19 | 84.24 | 84.44 | 80.36 | 81.79 | 0.7925 |
| ResNet152 | 78.26 | 79.20 | 68.45 | 71.68 | 0.7109 |
Table 14.
Results of the best-performing model (Xception model at a learning rate of 0.0001) in all conducted experiments.
Table 14.
Results of the best-performing model (Xception model at a learning rate of 0.0001) in all conducted experiments.
| Experiment | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | MCC |
|---|
| Magnification-independent binary classification | 98.99 | 98.93 | 98.71 | 98.82 | 0.9764 |
| Magnification-independent multi-classification | 93.32 | 92.98 | 92.36 | 92.44 | 0.9129 |
| 40× binary classification | 100 | 100 | 100 | 100 | 1 |
| 100× binary classification | 99.52 | 99.66 | 99.21 | 99.43 | 0.9886 |
| 200× binary classification | 100 | 100 | 100 | 100 | 1 |
| 400× binary classification | 99.46 | 99.18 | 99.60 | 99.38 | 0.9878 |
| 40× multi-classification | 97.01 | 96.85 | 96.17 | 96.47 | 0.9610 |
| 100× multi-classification | 95.17 | 95.08 | 94.02 | 94.37 | 0.9367 |
| 200× multi- classification | 91.54 | 90.08 | 90.16 | 89.91 | 0.8884 |
| 400× multi- classification | 90.22 | 90.99 | 89.87 | 89.97 | 0.8725 |


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}