CNN outputs presented in Equation (
5) are linearly projected into query, key, and value matrices. These form the basis for the Transformer attention mechanism. Each matrix allows learning of temporal relationships across EEG segments. It sets the stage for contextual attention.
Equation (
6) computes the attention score between two EEG time points
i and
j. A dot product similarity is scaled and normalized. This score allows focusing on key moments in the EEG. The softmax ensures weights sum to one.
Weighted summation of value vectors is performed in Equation (
7) using attention scores. This generates a context vector summarizing important time steps. It allows the network to incorporate temporal dependencies. The output is rich in sequential information.
Equation (
8) combines CNN and Transformer outputs through residual connections. Layer normalization is applied for stable learning. It prevents internal covariant shifts. This fusion strengthens model capacity.
A two-layer fully connected classifier presented in Equation (
9) maps learned features to relapse probability. ReLU adds non-linearity, and softmax generates class probabilities. The output is interpretable as likelihoods. This is the decision layer of the model.
Equation (
10) aggregates sentiment features across time using dynamic weights
. It captures behavioral instability preceding relapse. By weighting emotional signals, it enhances context-awareness. Sentiment time-series are derived from patient speech/text.
Medication adherence presented in Equation (
11) is transformed into a probabilistic score using logistic regression. Non-adherence increases relapse risk, captured by
. This models clinical compliance effects. The output integrates into overall relapse fusion.
Equation (
12) aggregates clinical variables such as age, diagnosis type, and comorbidities. Weights
are learnable and represent feature importance. The model prioritizes stronger relapse indicators. It builds a global clinical health score.
A weighted sum presented in Equation (
13) combines relapse predictions from EEG, sentiment, and medication adherence.
are fusion coefficients trained during backpropagation. This hybrid index increases predictive accuracy. It yields the model’s final relapse risk.
Data augmentation from Equation (
14) is applied by injecting Gaussian noise
into EEG signals. This simulates real-world artifacts and improves generalization. The model learns to be robust to noisy measurements. Helps overcome data scarcity.
Temporal shifting of EEG in Equation (
15) mimics delayed or misaligned brain responses. The shift
varies randomly across samples. It supports learning of time-invariant features. Aids generalization across asynchronous event patterns.
EEG signals presented in Equation (
16) are segmented into overlapping windows of length
L. Each
captures localized signal activity. This improves spatial-temporal encoding. It supports CNN-based feature extraction.
Cross-entropy loss from Equation (
17) is used for supervised classification between true labels
and predictions
. It penalizes incorrect assignments. A lower
indicates better prediction alignment. Optimized during training.
Equation (
18) adds a regularization term
to the main classification loss. The coefficient
balances performance and overfitting. Regularization helps generalize across test samples. It is critical in small-sample medical tasks.
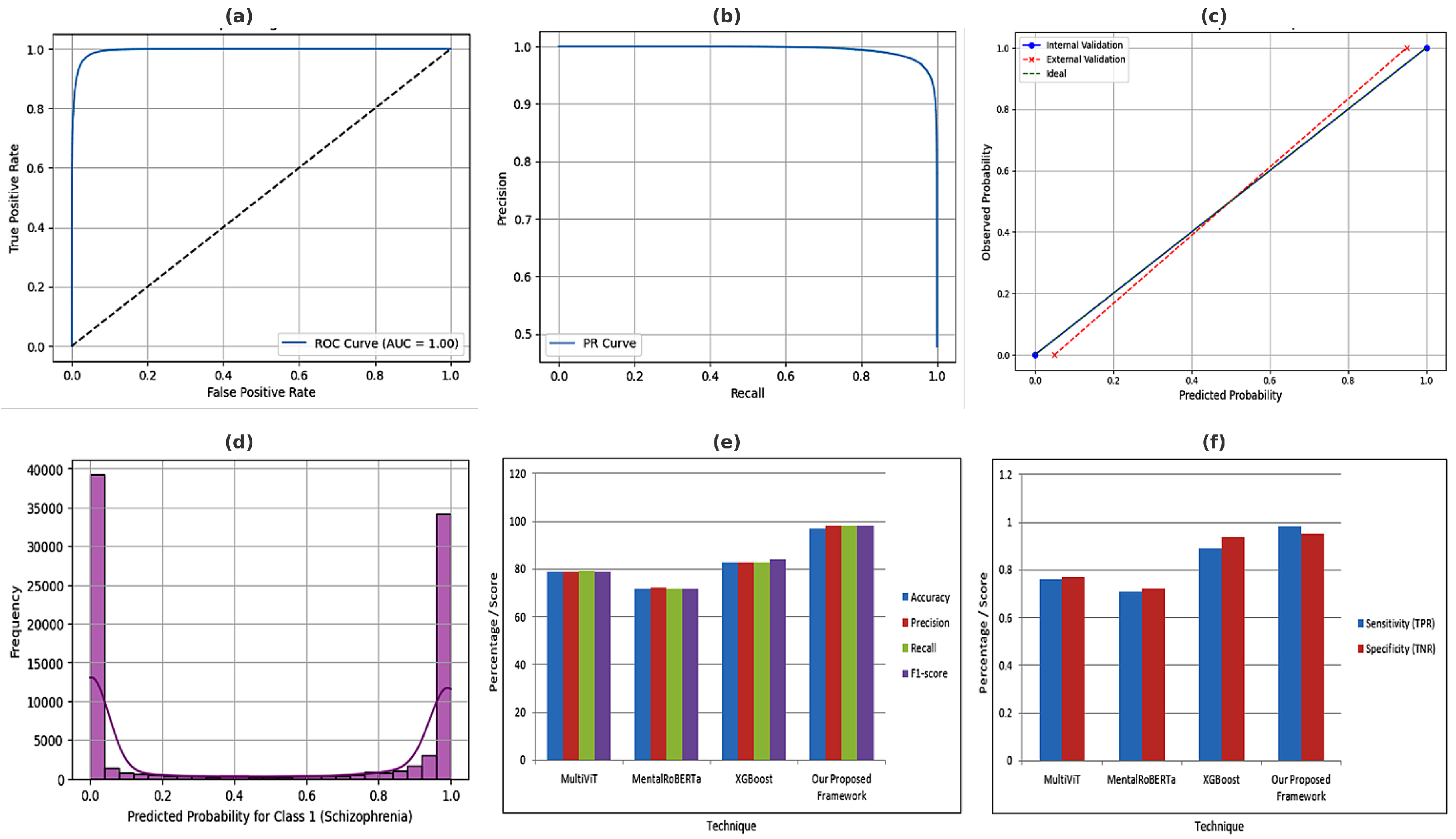
The F1-score from Equation (
19) combines precision
P and recall
R into a harmonic mean. This metric is valuable in imbalanced data. A high F1-score means fewer false negatives. Critical for clinical reliability.
Q-learning update from Equation (
20) used in reinforcement learning. It models sequential decision-making for adaptive interventions. The model updates expected reward
based on observed reward
r and future value. Useful in dynamic patient monitoring.
Federated averaging from Equation (
21) computes a global weight vector across
N local models. Each weight
is scaled by local data size
. Enables decentralized learning without sharing raw data. Critical for privacy-aware hospital collaboration.
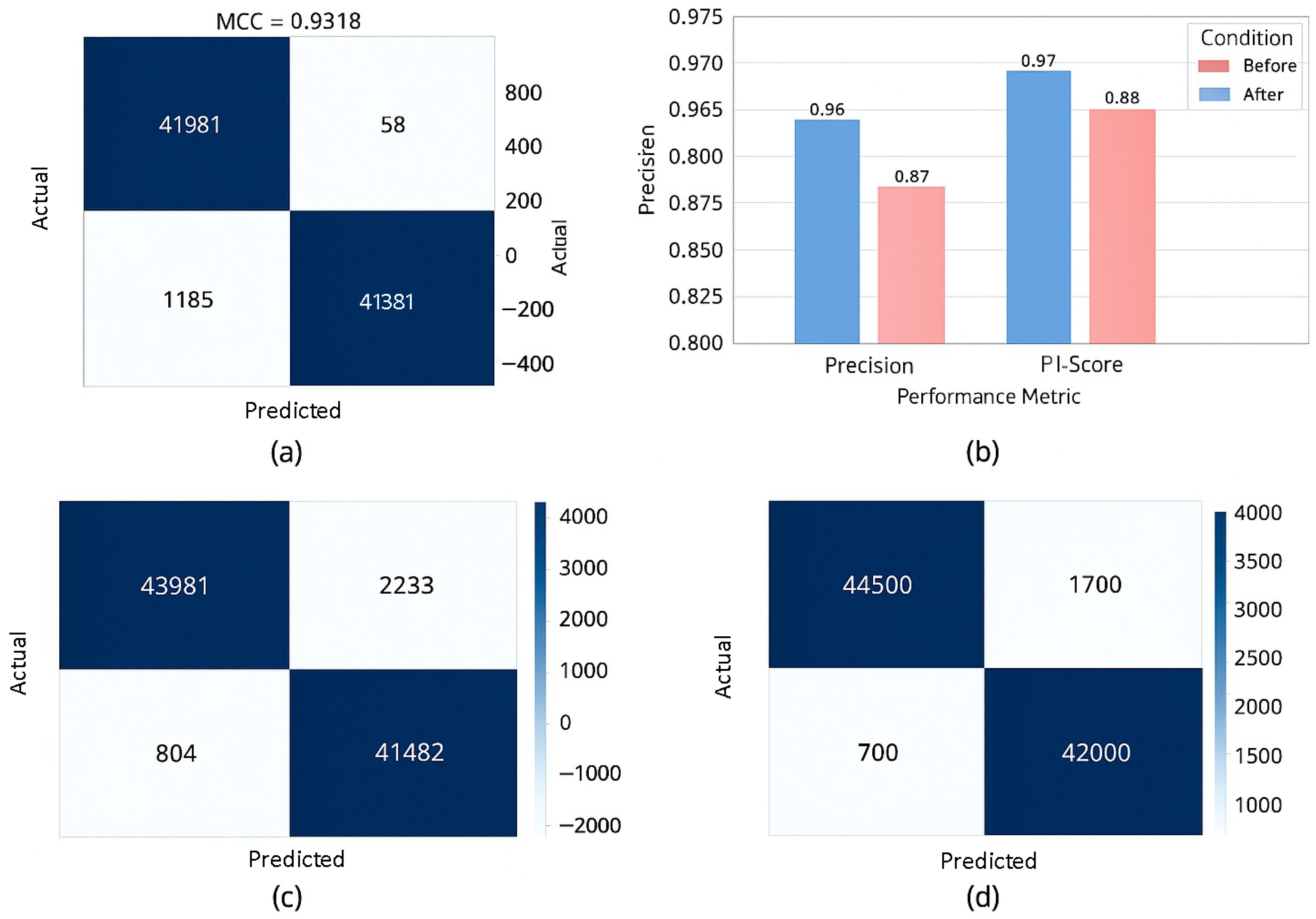
The Matthews Correlation Coefficient presented in Equation (
22) balances all outcomes from the confusion matrix. It is especially robust in imbalanced scenarios. MCC ranges from −1 to 1; higher is better. Preferred for medical diagnostics with unequal class distributions.
Equation (
23) normalizes clinical variables such as lab values and demographics. It ensures all features contribute equally to learning. Reduces biases due to different scales. Enhances fusion compatibility with EEG features.
An autoregressive (AR) model from Equation (
24) describes relapse dynamics over time. It reflects temporal dependency on past relapse scores. Coefficients
determine memory depth. Noise term
captures unmodeled variability.
A thresholding rule presented in Equation (
25) converts the continuous relapse risk
into a binary decision. Patients above
are predicted to relapse. This supports clinical actionability. Enables classification-based evaluation metrics.
Fusion loss from Equation (
26) minimizes the distance between EEG and clinical embeddings. It encourages the learning of shared latent patterns. The alignment enforces multimodal coherence. Important for synchronized interpretation of biological and clinical data.
Multi-head attention from Equation (
27) combines outputs from
H different attention heads. Each
captures distinct relational patterns in time. Weighted sum aggregates global context. Improves interpretability and robustness.
Equation (
28) computes global mean squared error across all clients in federated learning. It helps in monitoring convergence during training. Minimizing
promotes global model consistency. Vital for decentralized relapse prediction.
Equation (
29) presents penalty term flags, sharp spikes in EEG signal gradients. It activates when change exceeds a threshold
. Reduces model sensitivity to noise artifacts. Encourages smoother signal interpretation.
Classification entropy from Equation (
30) quantifies uncertainty in model predictions. Higher entropy indicates indecisiveness. Useful for trust calibration and uncertainty-based pruning. Helps filter unreliable outputs.
Equation (
31) computes the squared norm of gradient differences between consecutive epochs. Large changes may indicate instability. Monitoring
helps in diagnosing learning issues. It supports early stopping and adaptive learning rate strategies.
A fusion function from Equation (
32)
combines EEG and clinical embeddings into a joint representation. Concatenation (
) aggregates multimodal features. The fused vector enables holistic understanding. Supports downstream decision-making.
Contrastive loss from Equation (
33) pulls together embeddings of samples from the same class. It improves class-specific cluster formation. This strengthens feature discrimination. Especially useful for medical cases with subtle inter-class differences.
Equation (
34) initializes EEG-related weights via pretraining on historical relapse labels. Pretraining accelerates convergence and improves early performance. Enables reuse of prior knowledge. Reduces dependency on labeled data.
KL divergence from Equation (
35) measures how prediction distribution
P deviates from reference
Q. It is used to monitor dataset shift or training instability. Helps maintain consistency between client models in federated settings. Useful for regularization.
Final model parameters presented in Equation (
36)
are obtained by minimizing total loss. This marks the end of the optimization process. Optimal
improves generalization. Supports deployment readiness.
Equation (
37) adds positional encoding
to the fused embeddings. It introduces temporal awareness in Transformer models. Helps distinguish events across time. Critical for sequence modeling.
Area under the ROC curve from Equation (
38) quantifies the trade-off between sensitivity and specificity. AUC is threshold-independent. High AUC indicates strong discrimination power. Essential for clinical model evaluation.
Equation (
39) applies L1 regularization across model layers. It encourages sparsity in weight matrices. Helps prune irrelevant neurons. Reduces model complexity.
The sigmoid classifier from Equation (
40) maps fused features into relapse probability. Weighted sum of latent vector
captures predictive signal. Output is interpretable and bounded. Forms the core relapse prediction output.
This trust metric from Equation (
41) quantifies the reliability of model decisions. A higher
indicates more consistent correct predictions. Useful for clinicians to gauge confidence in predictions. Supports safe AI deployment in sensitive contexts.
Entropy presented in Equation (
42) masking suppresses ambiguous EEG segments during training.
acts as a binary mask highlighting valid time steps. Reduces noisy attention behavior. Enhances model robustness.
Saliency map technique from Equation (
43) measures how much the EEG input at time
t affects the output. It enables interpretability by identifying critical time points. A key method in explainable AI (XAI). Helps gain clinician trust.
Training stability presented in Equation (
44) is measured by how much model parameters change between epochs. Low fluctuation implies convergence. Useful for early stopping and training diagnostics. Indicates when learning has saturated.
The final relapse prediction function presented in Equation (
45)
fuses EEG embeddings, clinical variables, and behavioral data. This comprehensive model accounts for neurological, medical, and social dimensions. Supports robust, context-aware prediction. Enables multimodal decision-making. Further,
Table 3 lists the acronyms used in this paper.






 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}