1. Introduction
Multivariate failure time data frequently arise in biomedical research, particularly when patients may experience multiple types of events or failures over the course of their diseases and treatments. For instance, in cancer studies, researchers may track various events such as time to recurrence, time to metastases, time to progression, and time to death for each patient. Identifying predictors associated with each failure time is crucial, especially in high-dimensional space when the number of potential covariates (
p) far exceeds the sample size (
n) in the presence of genetic and omics data [
1,
2,
3,
4]. Thus, effective variable selection methods play a pivotal role in distinguishing truly influential predictors from noisy variables and building parsimonious predictive models for multivariate failure times.
The predictor space in these biomedical studies is often heterogeneous, consisting of diverse data types. These include demographic characteristics (e.g., age, ethnicity), established clinical variables (e.g., disease stage, performance status, laboratory measures such as PSA or LDH), treatment-related variables, and increasingly, high-throughput omics data. The latter may comprise genetic variants such as single-nucleotide polymorphisms (SNPs), gene expression profiles, or proteomic markers, which can be continuous, binary, or categorical in nature. The complexity is further amplified when modeling multiple event types simultaneously, as associations between covariates and different failure outcomes may vary. In this setting, the extreme dimensionality of the data () poses significant challenges for conventional modeling approaches, underscoring the need for robust and scalable variable selection techniques.
Our motivating example stems from the problem of identifying variables pertinent to two time-to-event endpoints, overall survival (OS) and progression-free survival (PFS), in men with advanced prostate cancer within a phase III clinical trial, where OS is typically defined as the time from randomization to death from any cause and PFS is defined as the time from randomization to disease progression or death from any cause, whichever occurs first. Alongside this trial, clinical factors and massive genetic data, including SNPs and plasma angiokines, were collected to gain a comprehensive understanding of the prognosis for both endpoints. In a metastatic disease state model where patients progress before death, the biological rationale suggests that factors predicting one outcome, such as PFS, are highly likely to predict the other outcome (OS). Given the strong correlation between OS and PFS, it naturally prompts the question: what are the most prognostic features associated with both endpoints? Instead of modeling each outcome individually, we seek to effectively determine the common predictors by integrating information from both endpoints. By identifying predictors for both outcomes, we enhance our understanding of prognoses, and these can be used in future trial design, thereby facilitating patient care and ultimately leading to improved clinical outcomes.
Various methodologies have been developed to identify relevant variables of outcomes, and these generally fall into three categories: filter [
5,
6,
7], wrapper [
8,
9,
10], and embedded methods [
11,
12,
13,
14]. Among them, penalized regression methods have gained a lot of traction since the introduction of the least absolute shrinkage and selection operator (LASSO) [
11] in linear regression analysis. Examples of other commonly used penalized regression methods include the smoothly clipped absolute deviation (SCAD) [
13], adaptive LASSO [
12], and the minimax concave penalty (MCP) [
14].
For survival data, adaptations and extensions of these penalized regression methods have been extensively explored for variable selection within the proportional hazards (PH) model [
15,
16,
17,
18]. For the analysis of multivariate failure data, researchers have proposed various methods including the penalized pseudo-partial likelihood method and the partially linear hazard regression model [
19,
20,
21]. It is worth noting that these methods either assume a common parameter for each covariate across all types of outcomes or perform individual-level selection, thereby yielding varying sets of selected variables for each type of failure time. Recently, Cai et al. (2022) introduced a method grouping unknown parameters corresponding to the same predictor and conducting both group-level and individual-level selection [
22]. However, their approach may still yield different selected variables for distinct types of outcomes. Furthermore, all the aforementioned penalized methods for multivariate failure time data impose a specific linear or partially linear form on the risk component within the hazard model. This entails a predefined structure for how covariates influence the hazard rate; however, the true relationship may be nonlinear and unknown in many real-world applications. For example, in biomedical studies, assuming a linear relationship might be overly restrictive, potentially failing to capture complex interactions between genetic markers and clinical variables, or non-monotonic effects common in biological systems, which could limit predictive accuracy.
To capture the complex relationship between predictors and time-to-event outcomes, Faraggi and Simon (1995) [
23] proposed extending the PH model with a neural network. Katzman et al. (2018) [
24] further investigated these models in the framework of deep learning, demonstrating that these novel networks could outperform the classical PH model in terms of the C-index. The application of advanced deep learning strategies continues to expand for tackling complex biomedical data challenges [
25,
26,
27]. Recent advancements have introduced regularized neural networks for feature selection [
28,
29,
30,
31,
32,
33,
34,
35]. For instance, the group LASSO penalty has been applied to the weight vector associated with each node to induce sparsity among input nodes [
29,
30,
31]. However, regularized neural networks incorporating LASSO tend to over-shrink the non-zero weight of relevant variables, leading to a high number of false positives in the selected model. To avoid the over-shrinkage of LASSO, Yamada et al. (2020) introduced stochastic gates to the input layer of neural networks and considered
-like regularization based on a continuous relaxation of the Bernoulli distribution [
33]. More recently, Luo and Halabi (2023) [
35] proposed a novel framework for sparse-input neural networks utilizing group concave regularization to address the limitations encountered with LASSO methods. However, these regularized neural net methods have not been developed yet for multivariate failure time data. Thus, there remains a critical need to develop methods that are capable of simultaneous variable selection and nonlinear function estimation for such data.
In this paper, we propose a novel framework designed for simultaneously selecting common variables and estimating models in the context of multivariate failure time data. Our approach starts by employing the penalized pseudo-partial likelihood method within the linear marginal hazard model. Specifically, we introduce a LASSO-type penalty to the norm of parameters associated with the same variables across all marginal hazard models. This group-level penalization facilitates the inclusion or exclusion of the entire group of parameters, enabling the identification of common variables relevant to multivariate failure time data. To overcome the potential limitations of linearity, we then significantly extend this framework to handle potentially complex, nonlinear relationships using sparse-input feed-forward neural networks, where each marginal hazard function is approximated by such a network with an identical input layer. Within the framework of the penalized pseudo-partial likelihood, we treat all outgoing connections from a single input neuron across feed-forward neural networks as a collective group and apply a proper penalty to the norm of weights within each group. By shrinking the weights of specific groups to exact zeros, our method yields a collection of neural networks utilizing only a concise subset of common variables. We validate our proposed approach through simulation studies and real data examples, demonstrating its satisfactory finite sample performance for bivariate failure time data. Furthermore, we show that the proposed framework effectively handles scenarios where the influential predictor sets only partially overlap between outcomes, enhancing its practical applicability.
The subsequent sections of this article are organized as follows: In
Section 2, we define the problem of feature selection within the framework of the marginal proportional hazards model and introduce our innovative approach for both linear and nonlinear hazards models. In
Section 3, we provide the details of implementation, including the optimization algorithm and the procedure for selecting tuning parameters. In
Section 4, we present extensive simulation studies to demonstrate the performance of the proposed methodology. We apply the proposed method to a real-world dataset in
Section 5. In
Section 6, we discuss the results and their implications. Finally,
Section 7 concludes the paper by summarizing our main findings and their broader significance.
3. Implementation
In this section, we detail the implementation of the proposed method. As previously described, the estimator in Equation (
2) for the linear hazards model is a special case of Equation (
3). Therefore, our attention is drawn to the optimization problem in Equation (
3). We use the composite gradient descent algorithm to solve for critical points for the objective function in Equation (
3) [
42]. Although the objective function is non-convex, the approach described by Gong (2013) [
43] enables us to apply composite gradient descent to non-convex optimization. The core algorithm aligns with the computational framework established in Luo and Halabi (2023) [
35], with the adaptation extending the loss function
to accommodate the multivariate failure time data.
We follow a two-step process in training the sparse-input neural networks in Equation (
3). Initially, a standard gradient descent step with learning rate
is applied to the smooth component of the objective function
, considering all weight parameters. The learning rate
can be set as a fixed value or determined by employing the backtracking line search method, as described in Nesterov (2013) [
42]. Subsequently, a proximal operator is employed on the weight parameters of the input layer. This sequential approach makes the procedure exceptionally straightforward to implement within prevalent machine learning frameworks. The outlined procedure is summarized in Algorithm 1. Here
represents the index set of
within
. Notably, the symbol
denotes the proximal operator determined by the form of the penalty function
. Choosing
as the LASSO and MCP penalty, it can be verified that the proximal operator takes the following form:
where
is the group soft-thresholding operator, defined as
| Algorithm 1: Training the multivariate regularized sparse-input neural network |
Input: Training dataset , feed-forward neural network for , increasing sequence of tuning parameters , regularization parameter , learning rate , number of epochs B Output: Solution path of weight parameters in trained neural networks Initialize model parameter , and set while
do for to B do Compute gradient of the smooth loss using back-propagation Update for top do Update end for end for Update Increment k end while
|
Algorithm 1 employs a backward path-wise optimization strategy, starting with a dense model at the minimum value of
(
) and progressing towards sparse models up to
(
), excluding all variables from the network. This warm start strategy, transitioning from dense to sparse, is also implemented in Luo and Halabi (2023) utilizing group concave regularization and has demonstrated the capability to yield a seamless transition from dense to sparse models [
35].
In addition to ensuring stable and smooth solution paths, the backward path-wise optimization approach offers computational advantages. The successive weight estimates along the path tend to exhibit similarity, thereby reducing the number of gradient descent iterations required per step. This concentration of computations primarily at enhances computational efficiency. Moreover, variables excluded from previous solutions are rarely reintroduced in subsequent solutions, leading to pruning along the path and reducing complexity as the model becomes sparse. This results in a substantial acceleration of computation, particularly beneficial for high-dimensional data.
Regarding implementation details, for the nonlinear marginal hazard models, where each risk function
is approximated by a neural network, we adopted a standardized architecture across all numerical studies to ensure fair comparisons. Specifically, we employed a multi-layer perceptron (MLP) with two hidden layers, each comprising 10 units and using rectified linear unit (ReLU) activation functions. Network weights were initialized from a Gaussian distribution with a mean of zero and standard deviation of 0.1, while bias terms were set to zero, to ensure a consistent starting point for optimization and to help break symmetry in the network. Additional details regarding scenario-specific settings, such as the number of training epochs and the ranges of hyperparameters considered, are provided in the
Supplemental Material, Section SA.
The proposed framework requires the tuning of two key hyperparameters: the group penalty coefficient
, which governs model sparsity, and the ridge penalty coefficient
, which mitigates the risk of overfitting. In our numerical study, we reserved a 20% validation set from the training data. The model was then trained on the remaining 80%, exploring a fine grid of
and
values. The optimal combination was selected as the one minimizing the negative log pseudo-partial likelihood evaluated on the validation set. This hyperparameter tuning procedure was applied independently for each training dataset in both the simulation replications and the real-data analysis. The final model performance was then assessed on a separate, unseen test set. Full details of this procedure are provided in
Section 4 and
Section 5.
The computational complexity of our proposed method is primarily determined by the number of samples (n), the total number of initial predictors (p), the number of failure types (J), the fixed neural network architecture specified for each outcome branch, and the parameters associated with path-wise optimization—namely, the number of regularization parameters (m) and the number of training epochs per value (T). The approximate overall complexity of computing the full solution path across all J outcomes can be characterized as , where denotes the average number of active (i.e., nonzero) input features along the solution path. Note that the use of warm starts and an aggressive feature pruning strategy—often resulting in under high-dimensional sparsity—yields substantial computational savings in practice.
Python code and examples for the proposed multivariate regularized neural networks are available at
https://github.com/r08in/GCRNN, accessed on 1 May 2025.
4. Simulation Studies
We evaluate the finite sample performance of the proposed regularized neural networks for feature selection and prediction through simulation studies. We simulate
failure types with bivariate survival time
generated from the multivariate Clayton and Cuzick distribution [
44], where the joint survival function is
where
is the marginal survival function for the
jth type of failure, which can be obtained from the marginal proportional hazards model in Equation (
1). The parameter
controls the dependence among survival time
and is related to Kendall’s
via
. Thus,
yields an increasing positive correlation, and
corresponds to independence. We set
to 0.01, 2, and 8 and the corresponding Kentall’s
, and
, respectively.
Specifically, the covariate vectors
are generated from the independent standard normal distribution. Thus,
for
, where
is the baseline cumulative hazard function for the
jth failure type, which is defined as
, and
are bivariate random variables with marginal uniform distribution in
and joint distribution function given by a Clayton copula
. In our simulation, we considered a Weibull hazard function for
, with the scale parameter
(
) and the shape parameter
(
and
). For the
jth failure type, we simulate data for
n individuals. A proportion
of the individuals are randomly selected to be censored, with censoring indicators defined as
for event occurrences and
for censored observations. The observed time is given by
where
denotes the event time and
is the censoring time. For censored individuals,
is independently drawn from a uniform distribution on
, ensuring that the censoring occurs prior to the event. We generate
n i.i.d. random samples with various forms of the risk function
in the following examples:
Example 1. (Linear Hazards Model). We consider a linear form of the risk function as follows: where ,
and . Here, the non-zero components of are independently generated from a standard Gaussian distribution. We consider a low-dimensional setting in this example with , , and the censoring rate and .
Example 2. (Nonlinear Hazards Model). We consider the nonlinear form of the risk function in the following two models:
We consider low-dimensional () and high-dimensional ( scenarios in this example with and .
We generated 200 replicates for each simulation configuration. For each replicate, the proposed models were first trained on a generated dataset of
n individuals. During this training process, optimal hyperparameters (such as
and
) were selected using the validation set methodology detailed in
Section 3, where 20% of the generated training data were reserved for this tuning purpose. The final tuned model’s performance in prediction and feature selection was then rigorously evaluated on a separate, independently generated test set, also comprising
n new random samples. This test set was drawn from the same underlying data-generating distribution as the training data but was not used during any phase of model training or hyperparameter selection. The following measures, calculated on this independent test set, were used to assess performance:
- (1)
The concordance index (C-index) is a standard metric that evaluates the predictive ability of the learned model in survival analysis by measuring the agreement between the ranking of the predicted and observed survival times. The C-index is reported for each type of failure.
- (2)
False positive rate (FPR) is the percentage of selected but unimportant covariates:
- (3)
False negative rate (FNR) is the percentage of non-selected but important covariates:
- (4)
Identical rate (IR) is the percentage of replicates where the exact same set of indices is selected across J failure types. For methods from the proposed frameworks, IR .
- (5)
Model size (MS) is the average number of selected covariates.
For this simulation, the true set of indices corresponding to important variables is . The set of indices for variables selected by the model is denoted by , as previously defined.
In our numerical studies, we utilize the MCP penalty in our proposed framework, as both the SCAD penalty and the MCP penalty perform similarly in general. For the analysis of bivariate failure time data, we refer to the method employing the group LASSO and group MCP for the linear marginal hazards model as Bi-LASSO and Bi-MCP, respectively. Additionally, we term the methods based on neural networks as Bi-GLASSONet and Bi-GMCPNet, respectively.
In Example 1 of linear hazards models, we compare the proposed estimator Bi-MCP with Bi-LASSO due to the lack of existing methods for simultaneous parameter estimation and selection of the same set of variables across different types of failures. To illustrate the advantages of using multivariate failure time data, we also include the standard MCP and LASSO methods applied to each type of failure for comparison. Moreover, we consider the oracle Cox’s estimator as a benchmark, where the true relevant variables are known in advance. For Example 2, which involves the nonlinear hazards models, we compared the proposed method Bi-GMCPNet with Bi-GLASSONet. In addition, we compare GMCPNet [
35] for single failure time data and the oracle neural networks (Oracle-NN) method using only the relevant variables as the benchmark. We also include random survival forests (RSF) for modeling each outcome separately. See the
supplementary file for the implementation details.
4.1. Results
Table 1 provides a comprehensive overview of the feature selection performance in Example 1. Across all scenarios for the linear hazards model, Bi-MCP consistently outperforms other methods in terms of feature selection, demonstrating lower FPR and FNR. It is important to highlight that Bi-LASSO tends to select more variables, resulting in larger model sizes across all settings. Additionally, both the standard MCP and LASSO exhibit relatively higher FPR and FNR for either one or both of the outcomes. In contrast, Bi-MCP enhances selection performance by incorporating information from bivariate failure times. Notably, the IR values for MCP and LASSO are nearly zero across all settings, indicating that the separately fitted models rarely select identical sets of variables. While they may capture overlapping predictors—including the true shared ones—their selections diverge considerably, likely due to stochastic variation in the inclusion of noise variables.
Figure 2 presents the predictive performance of each method under the linear hazards model (Example 1), based on 200 simulation replicates with a censoring rate of 30% and a sample size of
. Across varying levels of dependence between event times (Kendall’s
), the figure illustrates how well each approach distinguishes event orderings, as measured by the C-index. Similar results for other settings are observed as indicated in the
supplementary file. Bi-LASSO shows the lowest C-index for both survival outcomes, primarily due to issues related to over-selection. Conversely, Bi-MCP slightly outperforms MCP and LASSO due to more accurate variable selection and proves comparable to oracle Cox’s estimator in most scenarios. These results remain consistent across different censoring proportions and Kendall’s
for the strength of correlation of bivariate failure times.
Focusing on the nonlinear hazards models in Example 2,
Table 2 provides insights into the feature selection results. In low-dimensional settings (
), both Bi-GMCPNet and GMCPNet yield model sizes closely aligned with the true model, displaying low FPR and FNR across most scenarios. Bi-GMCPNet slightly outperforms GMCPNet by simultaneously analyzing bivariate failure times. Conversely, Bi-GLASSONet encounters challenges with over-selection, mirroring the results in Example 1. In high-dimensional settings (
), while GMCPNet tends to miss some important variables, resulting in higher FNR for both outcomes, our proposed Bi-GMCPNet maintains high accuracy in variable selection.
Figure 3 summarizes the performance of each method under nonlinear bivariate failure time models (Example 2) with Kendall’s
, across both low- and high-dimensional settings. In low-dimensional settings (
), Bi-GMCPNet exhibits performance similar to that of GMCPNet, and both are comparable to Oracle-NN. However, in high-dimensional settings with
, GMCPNet experiences a decline in prediction accuracy, yielding lower C-index values overall. In contrast, Bi-GMCPNet maintains performance comparable to oracle-NN, aligning with their variable selection capabilities. Notably, the issue of overselection in Bi-LASSO results in the poorest predictive performance. In addition, RSF consistently performs poorly compared to most other methods due to its inability to handle multivariate data and variable selection.
In summary, the results of our simulation underscore the superior performance of the proposed framework for multivariate failure time data in feature selection and prediction. Bi-MCP and Bi-GMCPNet enhance variable selection by incorporating multiple types of failure and provide consistent variable selection across different outcomes. The proposed framework shows promise in addressing the challenges of feature selection and prediction in high-dimensional data. Notably, as the tuning parameters are selected based on predictive performance on a validation set, the high FPR observed for Bi-LASSO and Bi-GLASSONet suggests that the LASSO penalty tends to include many false positives to offset its inherent bias, thereby enhancing predictive accuracy at the expense of model sparsity.
4.2. Relaxing the Common Predictor Assumption
To assess the robustness of the proposed methods when the assumption of a shared set of important predictors across all failure types is violated, we consider Example 3, a variant of the nonlinear model 2 (NLM2) used in Example 2.
Example 3. (Nonlinear Hazards Model with Different Predictor Sets). We retain the functional form of but modify to depend on a different subset of covariates. Specifically, we replace and in with and , yielding the following risk functions:In this setup, the true predictor set for the first failure type is , and for the second failure type, . The set of predictors common to both outcomes is , while the union of all relevant predictors is . We fix Kendall’s to reflect moderate dependence between failure times and examine both low-dimensional () and high-dimensional () settings with sample size and censoring rate . We compare our proposed Bi-GMCPNet with Bi-GLASSONet and the single-outcome GMCPNet applied separately to each failure type.
Table 3 presents the results. In the low-dimensional case (
), Bi-GMCPNet identifies a model with average size 7.1, aligning closely with
. This indicates that the method successfully captures all predictors relevant to at least one failure type. From the union perspective, this yields zero false negatives (FNR = 0%), although the inclusion of outcome-specific predictors leads to a slightly elevated false positive rate (FPR = 14%) relative to the minimal set for a single outcome (size 5). Importantly, the method maintains strong predictive performance, as reflected in high C-index values. By contrast, Bi-GLASSONet selects all variables indiscriminately (FPR = 100%), demonstrating poor variable selection—consistent with its behavior observed in Example 2. Meanwhile, GMCPNet applied individually selects models closer to the size of the separate true sets (
and
).
In the high-dimensional setting (), the advantages of Bi-GMCPNet are even more pronounced. It selects a parsimonious model (average size 6.5), again approximating the true union set, with minimal FPR (0.1–0.2%). It successfully recovers the shared predictors and most of the outcome-specific ones, yielding false negative rates (FNR) of 11.2% for outcome 1 and, notably, 0% for outcome 2. In contrast, Bi-GLASSONet performs poorly, selecting an excessive number of variables (average model size = 265.4), with high FNRs and low predictive accuracy (as measured by the C-index). Compared to running GMCPNet separately for each outcome, Bi-GMCPNet achieves comparable or slightly better predictive performance (C-index: 0.820 and 0.923 vs. 0.820 and 0.910), while significantly improving variable selection. The separate applications of GMCPNet result in higher FNRs (13.5% and 14.7%), whereas Bi-GMCPNet, by leveraging its joint modeling framework, effectively borrows strength across outcomes—substantially reducing the FNR for outcome 2 and modestly improving it for outcome 1. This demonstrates its superior ability to recover relevant predictors, even when the sets are not completely shared.
These results illustrate the robustness of Bi-GMCPNet to violations of the common predictor assumption. Its group-penalization strategy implicitly encourages selection of the union of important predictors (), rather than restricting to the intersection (). This behavior is practically beneficial, as it yields a unified model that retains all relevant prognostic variables across failure types while remaining sparse and interpretable. In contrast to Bi-GLASSONet and the outcome-specific GMCPNet, Bi-GMCPNet offers superior selection and prediction performance, even in challenging high-dimensional settings with only partially overlapping predictor sets. These findings highlight its utility as a robust and unified approach for analyzing multivariate failure time data.
5. Real Data Example
We leverage data from the CALGB-90401 study [
45], a double-blinded phase III clinical trial comparing docetaxel and prednisone with or without bevacizumab in men with metastatic castration-resistant prostate cancer (mCRPC), to demonstrate the efficacy of our proposed method. The CALGB-90401 dataset comprises 498,801 single-nucleotide polymorphisms (SNPs) derived from blood samples of patients. Our primary aim is to develop a single model for both OS and PFS utilizing the SNPs and clinical data, with a focus on 625 DNA damage repair genes [
46,
47,
48,
49,
50,
51,
52]. Adopting a dominant model, each SNP is treated as a binary variable. Additionally, we incorporate eight clinical variables recognized as established prognostic markers for overall survival in mCRPC patients [
53]: opioid analgesic use (PAIN), ECOG performance status, albumin (ALB), disease site (classified as lymph node only, bone metastases with no visceral involvement, or any visceral metastases), LDH greater than the upper limit of normal (LDH.High), hemoglobin (HGB), PSA, and alkaline phosphatase (ALKPHOS). The final dataset consists of
variables, with
patients and censoring rates of
for OS and
for PFS.
We adopt the marginal proportional hazards model represented by Equation (
1) for our proposed methods, aiming to identify clinical variables or SNPs predictive of both OS and PFS in patients with mCRPC. To assess the performance and stability of our proposed methods on real-world data, we employed a rigorous internal validation strategy based on repeated random subsampling (i.e., Monte Carlo cross-validation). Specifically, the complete CALGB-90401 dataset (
) was randomly partitioned 100 times into training (83%,
) and testing (17%,
) subsets. For each of the 100 iterations, the following procedure was applied:
Model Training and Hyperparameter Tuning: Models were trained exclusively on the training data. Within each training set, hyperparameters (
and
) were selected using the validation approach described in
Section 3. This involved further splitting the training data into an 80% fitting set and a 20% internal validation set, with the optimal parameters chosen based on the validation-set performance.
Performance Evaluation: The predictive performance of the tuned model was then evaluated on the held-out testing set using the time-dependent area under the receiver operating characteristic curve (tAUC), calculated via Uno’s estimator [
54]. The tAUC is a summary measure that captures how well each model discriminates between patients who experience an event versus those who do not, across all time points.
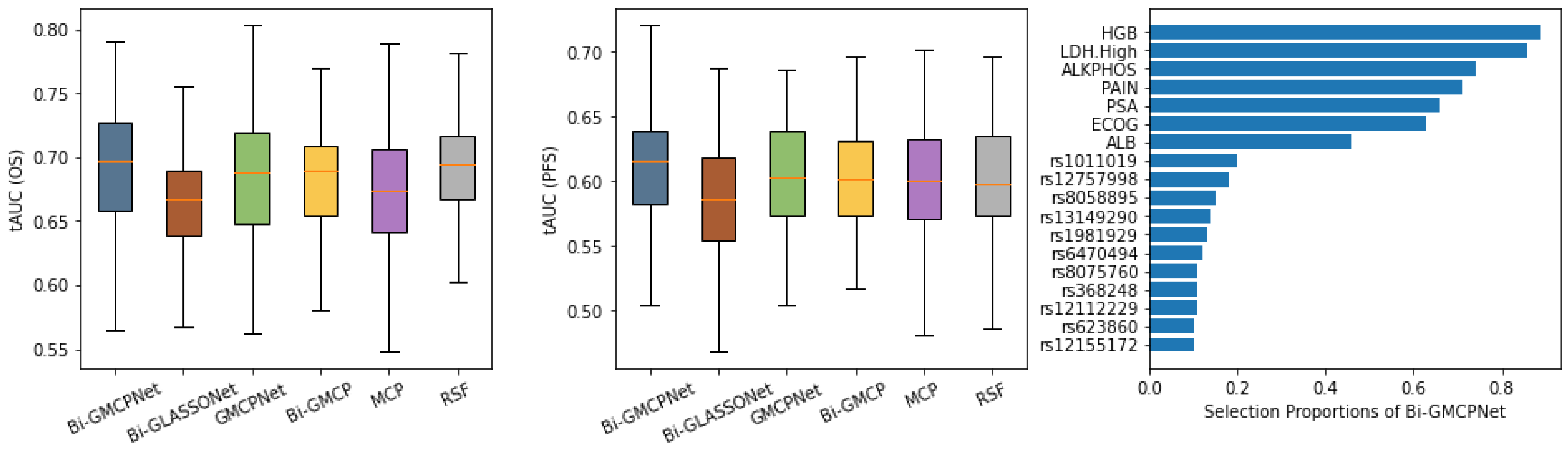
Figure 4 presents the evaluation of model performance on the CALGB-90401 advanced prostate cancer dataset using 100 random train/test splits. The left and middle panels summarize predictive accuracy for overall survival (OS) and progression-free survival (PFS), respectively, based on the tAUC. In predicting OS (left panel), our proposed bivariate methodology, Bi-MCP (linear model) and Bi-GMCPNet (nonlinear model) outperform their respective single-variate counterparts, MCP and GMCPNet. Notably, Bi-GMCPNet demonstrates superior performance across all methods, as indicated by higher tAUC in overall survival prediction. The efficacy of Bi-GMCPNet is particularly pronounced for PFS (middle panel), indicating the importance of integrating information from multivariate outcomes in the processes of both feature selection and modeling. It is worth noting that the Bi-GLASSONet method exhibits the lowest predictive performance, displaying a tendency to over-select variables, which is consistent with our simulation results.
The right panel of
Figure 4 displays the consistency of variable selection by Bi-GMCPNet, showing clinical features and SNPs selected in at least 10% of the data splits. These results highlight the model’s ability to identify most of the clinically significant variables and select crucial SNPs in the prediction of both OS and PFS. Notably, seven out of eight clinical variables previously established as prognostic markers for overall survival in mCRPC were selected with high proportions by our model [
53]. This alignment highlights the model’s capability to robustly identify clinically meaningful predictors. Among the selected SNPs, several have been linked to prostate cancer progression and mortality, particularly those involved in DNA repair and immune regulation. For instance, rs12757998 in RNASEL, a gene critical for antiviral defense and apoptosis, has been associated with high-grade prostate cancer and may influence response to radiation therapy (Meyer et al., 2010 [
55]). SNPs in DNA repair genes—such as rs8058895 in FANCA, rs623860 in ATM, and rs1981929 in MSH2—have been implicated in increased risk of aggressive prostate cancer and worse clinical outcomes, likely due to impaired DNA damage response (Pritchard et al., 2016 [
56]; Na et al., 2017 [
57]; Mateo et al., 2020 [
58]). Similarly, rs12112229 in PMS2, another mismatch repair gene, has been linked to prostate cancer recurrence and progression (Norris et al., 2009 [
59]; Fukuhara et al., 2015 [
60]). rs8075760 in RAD51D, which plays a role in homologous recombination, has also been associated with elevated cancer risk, including ovarian cancer (Loveday et al., 2011 [
61]). While these variants show compelling associations with disease severity and mortality, other SNPs—such as rs1011019 (ERCC3), rs13149290 (ZNF827), rs6470494 (PCAT2), rs368248 (SLC8A1), and rs12155172 (LINC01162)—have limited or emerging evidence regarding their role in prostate cancer death and require further investigation. These genetic markers offer valuable insight into the biological underpinnings of prostate cancer and may serve as potential prognostic tools for identifying patients at higher risk of lethal disease.
6. Discussion
This paper has introduced a novel regularized framework designed for simultaneous variable selection and flexible model estimation in the complex setting of multivariate failure time data. We have presented approaches for both linear and nonlinear marginal hazard models, leveraging group-level penalization to identify common predictors. The preceding sections detailed the methodology and demonstrated its performance through extensive simulations and a real-world application. In this section, we will further elaborate on the significance and interpretation of these findings, discuss the advantages and robustness of our proposed methods in comparison to alternatives, address their potential limitations, and outline promising avenues for future research.
The results of our simulation studies clearly demonstrate several key advantages of our proposed framework, particularly when compared against common alternative approaches or methods that do not jointly model multiple outcomes. For linear hazard models, the proposed Bi-MCP outperformed methods applied to individual outcomes by showing lower FPR and FNR. This approach successfully identified common prognostic factors for both time-to-event outcomes, demonstrating its robustness. Furthermore, for nonlinear hazard models, Bi-GMCPNet exhibited superior performance in capturing complex relationships between covariates and outcomes. It outperformed classical linear models, which are inherently unable to capture such nonlinearities, as well as standard neural network approaches when applied to individual outcomes without joint modeling. This capability of Bi-GMCPNet to utilize neural networks for nonlinear function approximation, while simultaneously enforcing sparsity among input features through group-level penalties, proved highly effective and addresses a notable gap where many existing penalized methods for multivariate failure time data are restricted to linear assumptions. Such group-level penalties not only simplified the models but also ensured that the selected variables were consistently relevant across multiple outcomes.
Regarding the performance of Bi-GLASSONet in high-dimensional settings (e.g.,
in
Table 2 and
Figure 3), its relatively higher false positive rates and less competitive predictive accuracy—compared to Bi-GMCPNet—can be attributed to well-known limitations of the LASSO penalty, which underlies the GLASSO framework. LASSO is known to introduce shrinkage bias, particularly for large true coefficients, and often includes noise variables as a compensatory effect [
12,
13]. This over-selection occurs in both low- and high-dimensional settings, but its impact is more severe when
, where the risk of overfitting increases and predictive performance deteriorates [
62,
63]. As demonstrated in our simulations, this issue becomes especially relevant when tuning parameters are selected to optimize validation performance, as such criteria can favor overly complex models—a phenomenon also documented in theoretical studies of LASSO with cross-validation [
64]. In contrast, the MCP penalty employed in our Bi-MCP and Bi-GMCPNet methods is specifically designed to reduce shrinkage bias and limit overselection [
14,
65]. Our simulation results consistently show that MCP-based approaches yield substantially lower false positive rates by more effectively distinguishing signal from noise in high-dimensional contexts. This leads to more parsimonious models and, consequently, improved predictive performance, as observed with Bi-GMCPNet.
Our investigations also extended to scenarios where the key assumption of identical predictor sets across outcomes was deliberately violated (Example 3). The results demonstrate the robustness of the proposed Bi-GMCPNet approach. Rather than limiting selection to the intersection of the true predictor sets (), Bi-GMCPNet consistently identified the union (), capturing variables associated with either failure type. This behavior is practically advantageous, as it produces a single parsimonious model that comprehensively reflects the relevant prognostic factors. Importantly, even under this assumption violation, the joint modeling framework allowed Bi-GMCPNet to borrow strength across outcomes, leading to improved variable detection—specifically, lower false negative rates for at least one outcome—compared to fitting separate models. This flexibility underscores the practical value of the method in multivariate survival analysis settings where predictor sets are partially overlapping rather than fully shared.
Historically, the disease state model has been widely applied to various types of cancer to provide a structured framework for understanding patient prognoses. This model outlines the patient journey from diagnosis through recurrence, progression to metastasis, and ultimately, death. Within this framework, the selection of appropriate outcomes is crucial, as different biological behaviors influence prognoses and clinical outcomes. Typically, clinical trials are designed with a primary endpoint tailored to each disease state. Commonly used endpoints in oncology include overall survival (OS) and composite endpoints such as progression-free survival (PFS) and disease-free survival (DFS), both of which incorporate death as a component.
In recent years, many randomized phase III trials have adopted co-primary endpoints. However, stratification in randomization is often based on one outcome (e.g., OS), which can lead to imbalances in baseline patient characteristics if stratification is based on prognostic factors for only one outcome, without accounting for others. Our focus is on understanding how multiple predictors simultaneously and consistently influence the timing of several clinically meaningful events. For example, understanding how predictors impact both OS and PFS is crucial for prognosis, treatment decision making, and drug development, especially in heterogeneous patient populations.
A key challenge lies in identifying prognostic factors by integrating information from multiple endpoints both within and across disease states. This requires modeling the potentially varying effects of prognostic variables across different outcomes. Our study addresses this challenge by proposing a novel method for analyzing multivariate failure time data. By identifying common prognostic factors across multiple outcomes, our approach can inform clinical trial design—particularly in selecting prognostic variables for stratification and identifying high-risk patients who may benefit from personalized treatment strategies. Although our motivation stems from composite outcomes that include death, our method is equally applicable to non-fatal endpoints and other time-to-event outcomes. Importantly, our approach differs from competing risk frameworks such as the cause-specific hazard model [
66,
67] or the Fine–Gray subdistribution hazard model [
68]. Rather than treating death as a competing risk, our model treats it as an outcome of interest, thereby maximizing the relationship between multiple time-to-event outcomes.
One notable design choice of the proposed method is its exclusive use of group-level sparsity, which assumes that multiple time-to-event outcomes share a common set of relevant predictors. This assumption is motivated by the biological and clinical plausibility that distinct endpoints in complex diseases often arise from shared underlying mechanisms. For example, in prostate cancer, clinical variables such as ECOG performance status, disease stage, and time of diagnosis are known to influence both OS and PFS [
69]. By encouraging joint variable selection, our approach enhances interpretability, improves statistical power, and simplifies computation. While this shared structure necessarily excludes within-group sparsity—i.e., selecting a variable for only a subset of the outcomes—it was a deliberate modeling strategy aimed at identifying predictors with consistent effects across endpoints. Our method enforces this structure by grouping model parameters associated with each variable across outcomes and applying a sparsity-inducing penalty that promotes between-group sparsity, thereby selecting or excluding entire variable groups simultaneously. Despite this limitation, our simulation studies under model misspecification (Example 3,
Section 4.2) demonstrated that the method remains robust in identifying the union of relevant predictors—a property that is often sufficient and practically useful in multivariate survival analysis. For applications requiring outcome-specific variable selection, incorporating bi-level sparsity—achieving both group- and outcome-level selection—would provide additional flexibility. Developing such an extension within a nonlinear neural network framework poses notable methodological and computational challenges, making it a promising direction for future research. Potential approaches may involve adapting bi-level regularization techniques, such as the sparse group lasso [
70] or composite penalties [
41], to nonlinear modeling frameworks implemented via neural networks. Furthermore, establishing theoretical guarantees for our method, including selection consistency and convergence rates, remains an important future goal to strengthen its foundation.
Further limitations of the proposed methods also warrant consideration. While our approach achieves variable selection by inducing sparsity at the input layer, the nonlinear transformations within hidden layers can obscure interpretability compared to traditional linear models. Future work may explore strategies to enhance the transparency of these learned functions. Additionally, model performance is sensitive to architectural choices and hyperparameter tuning, particularly the group penalty (
) and ridge penalty (
). Although we adopted a validation-based tuning strategy (
Section 3), selecting optimal values and defining appropriate search ranges—such as
spanning from a dense to an empty model—can be a non-trivial aspect of the modeling pipeline and may require iterative refinement. A potential direction for future work is to incorporate advanced hyperparameter selection techniques, such as the method proposed for high-dimensional Cox models in Sancar et al. (2023) [
71], to further enhance our approach. Finally, in ultra-high-dimensional settings (e.g., hundreds of thousands of variables), as noted in Luo and Halabi (2023) [
35], the proposed method may encounter scalability issues due to a complex optimization landscape. In such cases, preliminary feature screening may offer a practical way to reduce dimensionality prior to model fitting [
65,
72].
7. Conclusions
In this paper, we introduced and validated a novel regularized framework for simultaneous variable selection and model estimation in the context of multivariate failure time data, a common challenge in modern biomedical research. Our approach extends beyond traditional linear hazard models by first employing a penalized pseudo-partial likelihood method with group LASSO-type penalties (Bi-LASSO and Bi-MCP) for linear settings. We then significantly advanced this concept to capture complex, nonlinear predictor relationships using sparse-input feed-forward neural networks that share a common input layer and incorporate group-level penalization on input neuron weights (Bi-GLASSONet and Bi-GMCPNet).
Key findings from our extensive simulation studies demonstrated the superior performance of our proposed methods, particularly Bi-MCP for linear models and Bi-GMCPNet for nonlinear scenarios. These methods consistently achieved greater accuracy in variable selection, exhibiting lower false positive and false negative rates and enhanced predictive power compared to approaches applied to individual outcomes or standard LASSO-based group selection techniques. Notably, Bi-GMCPNet proved highly effective in high-dimensional settings and when handling intricate nonlinear associations, and it also showed remarkable robustness in identifying relevant predictors (capturing the union of influential variables) even when the assumption of perfectly identical predictor sets across outcomes was not met. The application of our framework to a real-world dataset from the CALGB-90401 advanced prostate cancer trial further underscored its practical utility. Bi-GMCPNet successfully identified established clinical prognostic factors and potentially important SNPs associated with both overall survival and progression-free survival, outperforming counterpart methods.
In summary, our novel method addresses key challenges in modeling individual survival outcomes. Its innovation lies in its ability to jointly model multiple endpoints, accounting for their interdependence while treating death as an outcome rather than a competing risk. The successful application of our method to both simulated and real-world data demonstrates its potential to advance prognostic research and improve clinical outcomes—not only in oncology but also in other complex disease areas. This comprehensive approach provides a powerful tool for identifying common prognostic factors, ultimately enhancing our understanding and management of disease through personalized treatment strategies.







{kind=link}
{kind=link}
{kind=link}
{kind=link}