

Dual-Branch Network with Hybrid Attention for Multimodal Ophthalmic Diagnosis


Abstract
1. Introduction
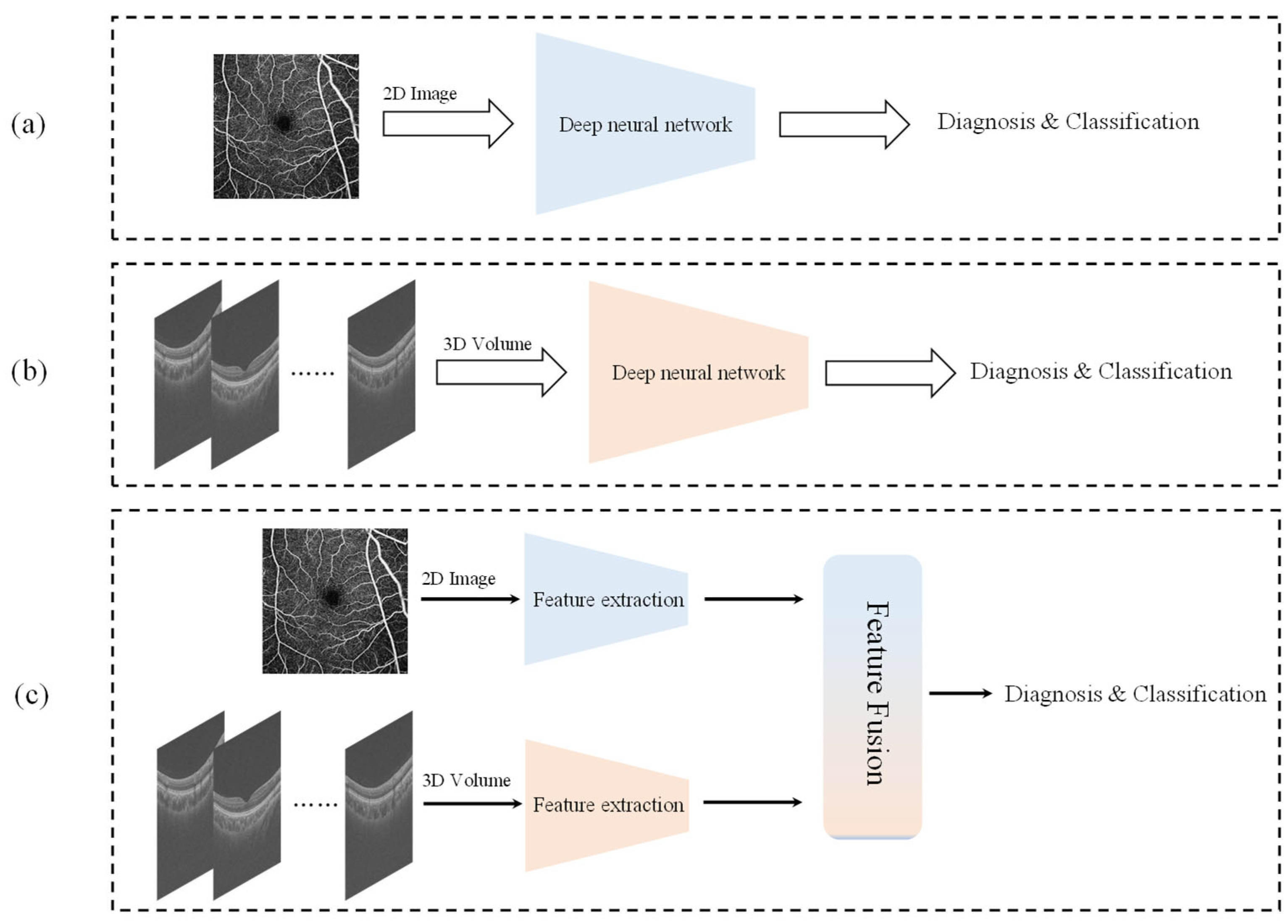
- The MOD-Net is proposed, and experiments on two ophthalmic multimodal datasets, GAMMA and OCTA-500, show that the multimodal nature of the MOD-Net achieves better classification performance for ophthalmic disease diagnosis on small-sample datasets with multiclass imbalance, compared with traditional single-branch networks.
- A feature extraction optimization process, based on a hybrid attention module FTCA with non-local receptive fields and cross-scale fusion within the convolutional units, is proposed to optimize the feature extraction over the channel and the spatial information of the branching network so that it can better capture the key features of the image.
- Dual-feature fusion (DFF), a multi-attention mechanism module for 2D and 3D modal feature fusion, is proposed that effectively improves the model’s ability to characterize data features, achieves better feature fusion performance between different modalities, and further improves the image classification and diagnosis performance.
- Using migration learning and data augmentation, pre-trained weight parameters are migrated into the feature extraction branch network, thereby accelerating the training process and improving the overall generalization ability of the model.
2. Related Work
3. Materials and Methods
3.1. Overall Architecture
3.2. FTCA Module
3.3. DFF Module
4. Experiment
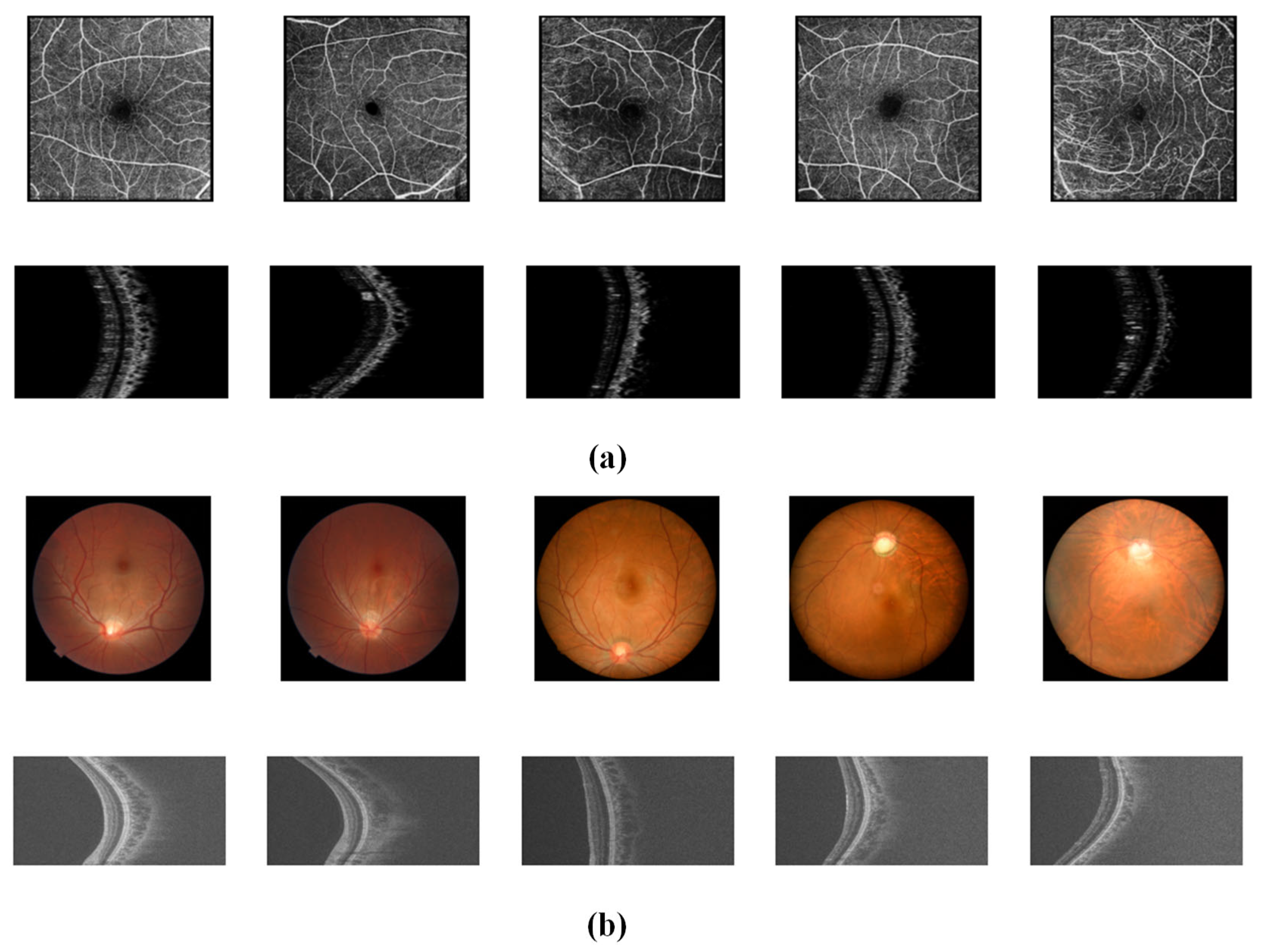
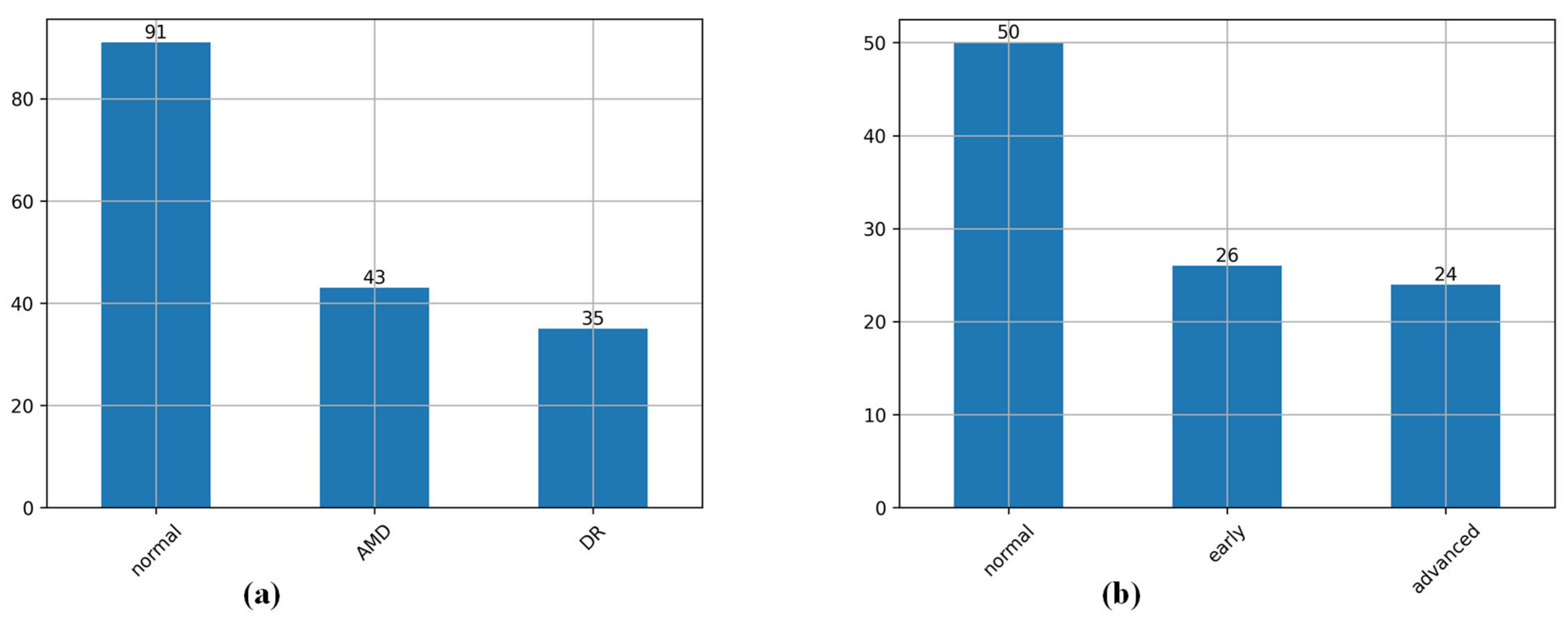
4.1. Datasets
4.2. Pre-Processing
4.3. Performance Metrics and Experimental Settings
4.4. Results and Visualization
4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- Abràmoff, M.D.; Lavin, P.T. Artificial intelligence in ophthalmology: A review. Ophthalmology 2018, 125, 1351–1361. [Google Scholar]
- Weinreb, R.N.; Aung, T.; Medeiros, F.A. The Pathophysiology and Treatment of Glaucoma: A Review. JAMA 2014, 311, 1901–1911. [Google Scholar] [CrossRef] [PubMed]
- Guymer, R.H.; Campbell, T.G. Age-related macular degeneration. Lancet 2023, 401, 1459–1472. [Google Scholar] [CrossRef]
- Antonetti, D.A.; Klein, R.; Gardner, T.W. Diabetic Retinopathy. N. Engl. J. Med. 2012, 366, 1227–1239. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.X.; Zeng, D.; Zhu, Z.; Li, D.; Liu, Y.; Sheng, B.; Grzybowski, A.; Wong, T.Y. Artificial intelligence-enhanced retinal imaging as a biomarker for systemic diseases. Theranostics 2025, 15, 3223–3233. [Google Scholar] [CrossRef]
- Li, T.; Bo, W.; Hu, C.; Kang, H.; Liu, H.; Wang, K.; Fu, H. Applications of deep learning in fundus images: A review. Med. Image Anal. 2021, 69, 101971. [Google Scholar] [CrossRef] [PubMed]
- Mantel, I.; Lasagni Vitar, R.M.; De Zanet, S. Modeling pegcetacoplan treatment effect for atrophic age-related macular degeneration with AI-based progression prediction. Int. J. Retin. Vitr. 2025, 11, 14. [Google Scholar] [CrossRef]
- Tukur, H.N.; Uwishema, O.; Akbay, H.; Sheikhah, D.; Correia, I.F. AI-assisted ophthalmic imaging for early detection of neurodegenerative diseases. Int. J. Emerg. Med. 2025, 18, 90. [Google Scholar] [CrossRef]
- Racioppo, P.; Alhasany, A.; Pham, N.V.; Wang, Z.; Corradetti, G.; Mikaelian, G.; Paulus, Y.M.; Sadda, S.R.; Hu, Z. Automated Foveal Avascular Zone Segmentation in Optical Coherence Tomography Angiography Across Multiple Eye Diseases Using Knowledge Distillation. Bioengineering 2025, 12, 334. [Google Scholar] [CrossRef]
- Korot, E.; Wood, E.; Weiner, A.; Sim, D.A.; Trese, M. A renaissance of teleophthalmology through artificial intelligence. Eye 2019, 33, 861–863. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; Yeo, I.Y.S.; Lee, S.Y.; et al. Development and Validation of a Deep Learning System for Diabetic Retinopathy and Related Eye Diseases Using Retinal Images From Multiethnic Populations with Diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Cheng, J.; Xu, Y.; Zhang, C.; Wong, D.W.K.; Liu, J.; Cao, X. Disc-Aware Ensemble Network for Glaucoma Screening From Fundus Image. IEEE Trans. Med. Imaging 2018, 37, 2493–2501. [Google Scholar] [CrossRef] [PubMed]
- Ghamsarian, N.; Taschwer, M.; Sznitman, R.; Schoeffmann, K. DeepPyramid: Enabling Pyramid View and Deformable Pyramid Reception for Semantic Segmentation in Cataract Surgery Videos. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2022; Wang, L., Dou, Q., Fletcher, P.T., Speidel, S., Li, S., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13435. [Google Scholar]
- Saraei, M.; Kozak, I.; Lee, E. ViT-2SPN: Vision Transformer-based Dual-Stream Self-Supervised Pretraining Networks for Retinal OCT Classification. arXiv 2025, arXiv:2501.17260. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, L.; Huang, X.; Huang, C.; Wang, Z.; Bian, Y.; Wan, Y.; Zhou, Y.; Han, T.; Yi, M. A self-supervised spatio-temporal attention network for video-based 3D infant pose estimation. Med. Image Anal. 2024, 96, 103208. [Google Scholar]
- Ran, A.R.; Tham, C.C.; Chan, P.P.; Cheng, C.-Y.; Tham, Y.-C.; Rim, T.H.; Cheung, C.Y. Deep learning in glaucoma with optical coherence tomography: A review. Eye 2021, 35, 188–201. [Google Scholar] [CrossRef]
- Warner, E.; Lee, J.; Hsu, W.; Syeda-Mahmood, T.; Kahn, C.E.; Gevaert, O.; Rao, A. Multimodal Machine Learning in Image-Based and Clinical Biomedicine: Survey and Prospects. Int. J. Comput. Vis. 2024, 132, 3753–3769. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef]
- Wang, Y.; Zhen, L.; Tan, T.-E.; Fu, H.; Feng, Y.; Wang, Z.; Xu, X.; Goh, R.S.M.; Ng, Y.; Calhoun, C.; et al. Geometric Correspondence-Based Multimodal Learning for Ophthalmic Image Analysis. IEEE Trans. Med. Imaging 2024, 43, 1945–1957. [Google Scholar] [CrossRef]
- Yang, H.; Hu, M.; Xu, Y. Regression prediction of multimodal ophthalmology images based on deep learning. J. Beijing Univ. Chem. Technol. 2021, 48, 81–87. [Google Scholar]
- Bayoudh, K. A survey of multimodal hybrid deep learning for computer vision: Architectures, applications, trends, and challenges. Inf. Fusion 2024, 105, 102217. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Qi, X.; Zhi, M. Review of Attention Mechanisms in Image Processing. J. Front. Comput. Sci. Technol. 2024, 18, 345–362. [Google Scholar]
- Wang, H.; Fan, Y.; Wang, Z.; Jiao, L.; Schiele, B. Parameter-Free Spatial Attention Network for Person Re-Identification. arXiv 2018, arXiv:1811.12150. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates, Inc.: Brooklyn, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Chen, C.F.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhang, Q.; Zhang, J.; Xu, Y.; Tao, D. Vision Transformer with Quadrangle Attention. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 3608–3624. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 3816–3830. [Google Scholar]
- Tsai, Y.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal Transformer for Unaligned Multimodal Language Sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 6558–6569. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P.H. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Tsiknakis, N.; Theodoropoulos, D.; Manikis, G.; Ktistakis, E.; Boutsora, O.; Berto, A.; Scarpa, F.; Scarpa, A.; Fotiadis, D.I.; Marias, K. Deep learning for diabetic retinopathy detection and classification based on fundus images: A review. Comput. Biol. Med. 2021, 135, 104599. [Google Scholar] [CrossRef] [PubMed]
- Puchaicela-Lozano, M.S.; Zhinin-Vera, L.; Andrade-Reyes, A.J.; Baque-Arteaga, D.M.; Cadena-Morejón, C.; Tirado-Espín, A.; Ramírez-Cando, L.; Almeida-Galárraga, D.; Cruz-Varela, J.; Meneses, F.V. Deep Learning for Glaucoma Detection: R-CNN ResNet-50 and Image Segmentation. J. Adv. Inf. Technol. 2023, 14, 1186–1197. [Google Scholar] [CrossRef]
- Jain, A.; Bhardwaj, A.; Murali, K.; Surani, I. A Comparative Study of CNN, ResNet, and Vision Transformers for Multi-Classification of Chest Diseases. arXiv 2024, arXiv:2406.00237. [Google Scholar]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A Comprehensive Survey of Loss Functions in Machine Learning. Ann. Data. Sci. 2022, 9, 187–212. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Bergland, G.D. A guided tour of the fast fourier transform. IEEE Spectr. 1969, 6, 41–52. [Google Scholar] [CrossRef]
- Chi, L.; Tian, G.; Mu, Y.; Xie, L.; Tian, Q. Fast non-local neural networks with spectral residual learning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Li, M.; Huang, K.; Xu, Q.; Yang, J.; Zhang, Y.; Ji, Z.; Xie, K.; Yuan, S.; Liu, Q.; Chen, Q. OCTA-500: A Retinal Dataset for Optical Coherence Tomography Angiography Study. Med. Image Anal. 2024, 93, 103092. [Google Scholar] [CrossRef]
- Wu, J.; Fang, H.; Li, F.; Fu, H.; Lin, F.; Li, J.; Huang, Y.; Yu, Q.; Song, S.; Xu, X.; et al. GAMMA challenge: Glaucoma grading from multi-modality images. arXiv 2022, arXiv:2202.06511. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Ding, M.; Xiao, B.; Codella, N.; Luo, P.; Wang, J.; Yuan, L. DaViT: Dual Attention Vision Transformers. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13684. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling Up Your Kernels to 31 × 31: Revisiting Large Kernel Design in CNNs. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11953–11965. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. Visual attention network. Comp. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Zhang, X.; Tian, Y.; Xie, L.; Huang, W.; Dai, Q.; Ye, Q.; Tian, Q. HiViT: A Simpler and More Efficient Design of Hierarchical Vision Transformer. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Kashani, A.H.; Chen, C.-L.; Gahm, J.K.; Zheng, F.; Richter, G.M.; Rosenfeld, P.J.; Shi, Y.; Wang, R.K. Optical coherence tomography angiography: A comprehensive review of current methods and clinical applications. Prog. Retin. Eye Res. 2017, 60, 66–100. [Google Scholar] [CrossRef]
- Kalloniatis, M.; Wang, H.; Phu, J.; Tong, J.; Armitage, J. Optical coherence tomography angiography in the diagnosis of ocular disease. Clin. Exp. Optom. 2024, 107, 482–498. [Google Scholar] [CrossRef] [PubMed]
- Zhao, R.; Chen, X.; Liu, X.; Chen, Z.; Guo, F.; Li, S. Direct Cup-to-Disc Ratio Estimation for Glaucoma Screening via Semi-Supervised Learning. IEEE J. Biomed. Health Inform. 2020, 24, 1104–1113. [Google Scholar] [CrossRef]
- Chang, L.; Pan, C.-W.; Ohno-Matsui, K.; Lin, X.; Cheung, G.C.; Gazzard, G.; Koh, V.; Hamzah, H.; Tai, E.S.; Lim, S.C.; et al. Myopia-Related Fundus Changes in Singapore Adults With High Myopia. Am. J. Ophthalmol. 2013, 155, 991–999.e1. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Author | Accuracy (↑) | Precision (↑) | F1weighted (↑) | Recall (↑) |
|---|---|---|---|---|---|
| VGG | Simonyan, K et al. | 0.5185 | 0.3426 | 0.4011 | 0.5185 |
| ResNet | He, K et al. | 0.7037 | 0.7530 | 0.6728 | 0.7037 |
| EfficientNet | Tan, Mingxing et al. | 0.7037 | 0.6285 | 0.6583 | 0.7037 |
| Swin Transformer | Z. Liu et al. | 0.5185 | 0.2689 | 0.3541 | 0.5185 |
| DaViT | Ding, Mingyu et al. | 0.5185 | 0.2689 | 0.3541 | 0.5185 |
| RepLKNet | Ding, Xiaohan et al. | 0.6296 | 0.7202 | 0.6634 | 0.6296 |
| VAN | Guo, Meng-Hao et al. | 0.4444 | 0.2705 | 0.3363 | 0.4444 |
| ConvNeXt V2 | Woo, S et al. | 0.5185 | 0.2689 | 0.3541 | 0.5185 |
| HiViT | Zhang, Xiaosong et al. | 0.4815 | 0.2593 | 0.3370 | 0.4815 |
| GeCoM-Net | Wang, Y et al. | 0.7241 | 0.7786 | 0.6936 | 0.7241 |
| ViT-2SPN | Saraei, Mohammadreza et al. | 0.7293 | 0.7913 | 0.7225 | 0.7293 |
| MOD-Net | Our study | 0.7407 | 0.8049 | 0.7445 | 0.7407 |
| Method | Author | Accuracy (↑) | Precision (↑) | F1weighted (↑) | Recall (↑) |
|---|---|---|---|---|---|
| VGG | Simonyan, K et al. | 0.4500 | 0.3281 | 0.3403 | 0.3500 |
| ResNet | He, K et al. | 0.4000 | 0.2800 | 0.2927 | 0.4000 |
| EfficientNet | Tan, Mingxing et al. | 0.5000 | 0.6633 | 0.4302 | 0.5000 |
| Swin Transformer | Liu, Z et al. | 0.3500 | 0.1225 | 0.1815 | 0.3500 |
| DaViT | Ding, Mingyu et al. | 0.3500 | 0.1225 | 0.1815 | 0.3500 |
| RepLKNet | Ding, Xiaohan et al. | 0.4500 | 0.3801 | 0.3750 | 0.4500 |
| VAN | Guo, Meng-Hao et al. | 0.4000 | 0.4861 | 0.2835 | 0.4000 |
| ConvNeXt V2 | Woo, S et al. | 0.3500 | 0.1225 | 0.1815 | 0.3500 |
| HiViT | Zhang, Xiaosong et al. | 0.4500 | 0.3775 | 0.3442 | 0.3775 |
| GeCoM-Net | Wang, Y et al. | 0.7035 | 0.7245 | 0.6882 | 0.7035 |
| ViT-2SPN | Saraei, Mohammadreza et al. | 0.7200 | 0.7333 | 0.7015 | 0.7200 |
| MOD-Net | Our study | 0.7500 | 0.7500 | 0.7400 | 0.7500 |
| Method | FTCA | DFF | Accuracy (↑) | Precision (↑) | F1weighted (↑) | Recall (↑) |
|---|---|---|---|---|---|---|
| MOD-Net 0 | ✓ | 0.7037 | 0.7615 | 0.7076 | 0.7037 | |
| MOD-Net 1 | ✓ | 0.6667 | 0.7333 | 0.6673 | 0.6667 | |
| MOD-Net | ✓ | ✓ | 0.7407 | 0.8049 | 0.7445 | 0.7407 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Cao, A.; Fan, C.; Tan, Z.; Wang, Y. Dual-Branch Network with Hybrid Attention for Multimodal Ophthalmic Diagnosis. Bioengineering 2025, 12, 565. https://doi.org/10.3390/bioengineering12060565
Wang X, Cao A, Fan C, Tan Z, Wang Y. Dual-Branch Network with Hybrid Attention for Multimodal Ophthalmic Diagnosis. Bioengineering. 2025; 12(6):565. https://doi.org/10.3390/bioengineering12060565
Chicago/Turabian StyleWang, Xudong, Anyu Cao, Caiye Fan, Zuoping Tan, and Yuanyuan Wang. 2025. "Dual-Branch Network with Hybrid Attention for Multimodal Ophthalmic Diagnosis" Bioengineering 12, no. 6: 565. https://doi.org/10.3390/bioengineering12060565
APA StyleWang, X., Cao, A., Fan, C., Tan, Z., & Wang, Y. (2025). Dual-Branch Network with Hybrid Attention for Multimodal Ophthalmic Diagnosis. Bioengineering, 12(6), 565. https://doi.org/10.3390/bioengineering12060565