1. Introduction
During the COVID-19 pandemic, healthcare systems faced immense challenges, often operating at full capacity or beyond. One of the key issues was the absence of effective triage methods to quickly identify patients in critical need of care. As COVID-19 primarily affects the respiratory system, lung involvement was recognized as a reliable indicator for assessing disease severity. This measure became essential not only for determining which patients required immediate intervention, but also for monitoring their progress over time. Assessing lung involvement has since proven valuable as a biomarker for tracking recovery and identifying complications, making it a crucial tool for evaluating lung health in both acute and long-term care.
In the current clinical care pathway, access to diagnostic ultrasound is often limited to a few tertiary hospitals that have well-trained sonographers and radiologists to interpret LUS images. Currently, lung examinations depend on expensive imaging technologies like X-ray, CT, and MRI, which are often inaccessible to remote communities and underserved populations, and may not be suitable for ongoing or periodic monitoring. These models fail to reach rural and remote centers where there is a need for continuous assessment of pulmonary health using low-cost imaging equipment. Point-of-care ultrasound (POCUS) [
1] has emerged as a valuable diagnostic tool in these settings, due to its portability, safety, and affordability, offering a non-invasive, radiation-free, real-time, and cost-effective imaging solution. Unlike traditional imaging modalities, POCUS devices are compact and can be operated with minimal setup, making them ideal for bedside assessments. Additionally, their usability by lightly trained personnel, such as nurses, enhances their accessibility in various clinical settings. Despite these benefits, interpreting ultrasound images remains a significant challenge, as it requires specialized training. In POCUS images, identifying features such as A-lines and B-lines manually can be time-consuming. Hence, there is a need for automated tools to assist in image interpretation and ensure consistent diagnostic accuracy in LUS.
Lung POCUS shows different ultrasound patterns in COVID-19 compared to pulmonary edema, bacterial pneumonia, and other viral pneumonias, and is thus useful in differentiating between these conditions [
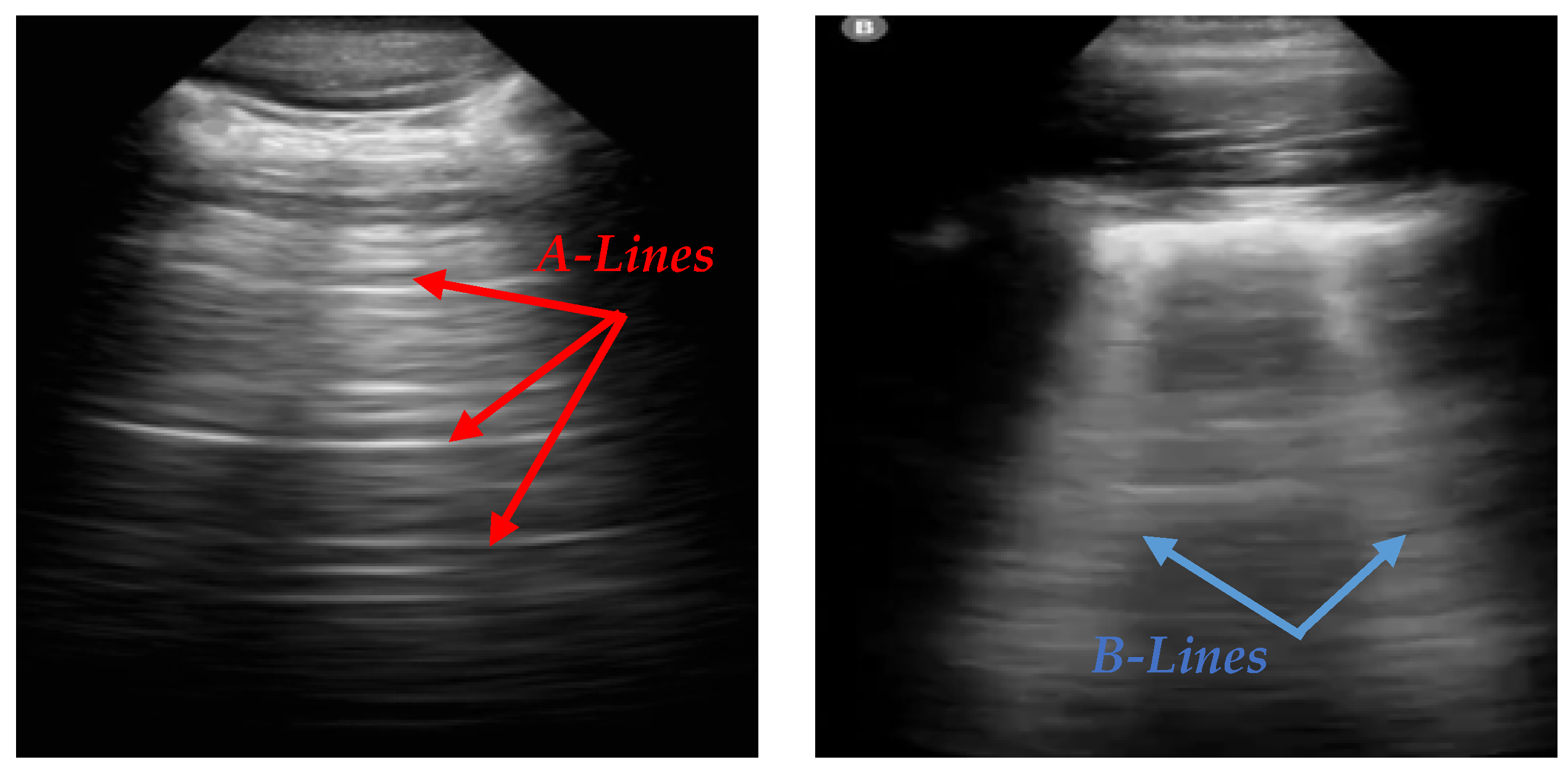
2]. In LUS, A-lines and B-lines serve as crucial markers in the evaluation of lung health. A-lines are horizontal, reverberation artifacts seen in healthy, aerated lung tissue. These lines are typically observed when there is no abnormal fluid accumulation in the lungs, indicating normal lung conditions. B-lines are vertical, hyperechoic artifacts that extend from the pleural line to the bottom of the ultrasound image, often seen in pathological conditions. The presence of B-lines can indicate interstitial lung disease, pulmonary edema, or lung infections such as COVID-19 [
3]. Various tools, like ExoLungAI, have been developed to detect these artifacts in ultrasound videos, categorizing them based on the quantity of A-lines and B-lines. Videos with more than five B-lines are classified as B-line cases, while those with dominant A-lines fall into a separate category [
4].
Figure 1 illustrates the appearance of A-lines and B-lines in the lung ultrasound images used in this study.
Increasing numbers of B-lines can signify lung pathologies such as interstitial lung disease or pulmonary edema, or infection, particularly COVID-19. Accurate detection and quantification of these lines is essential for diagnosing and monitoring diseases by LUS, particularly in settings such as the COVID-19 pandemic. However, identifying A-lines and B-lines in ultrasound images poses several challenges. The quality of the ultrasound image can vary significantly depending on operator skill, patient anatomy, and equipment settings. Additionally, distinguishing these features requires expertise and a trained eye, which are often not available outside of tertiary hospital settings. This challenge is further compounded by the need to quickly and consistently analyze large numbers of images in high-demand clinical environments.
To address the challenges in interpreting lung ultrasound images, particularly in identifying A-lines and B-lines, we propose TransBound-UNet, a segmentation pipeline inspired by TransUNet [
6], incorporating a transformer-based encoder and boundary-aware Dice loss. We use pre-processing steps like noise reduction and contrast enhancement to improve the visibility of key features. The model employs a hybrid architecture that integrates the strengths of transformers and convolutional neural networks (CNNs) for efficient segmentation. Additionally, we propose a composite loss function that combines Dice loss for overall segmentation optimization with a boundary-aware component, ensuring the separation of adjacent regions and reducing the likelihood of unintended connections. Post-processing is then applied to analyze the segmented regions and accurately detect and count A-lines and B-lines, offering a solution for LUS analysis.
The main contributions of this work are as follows:
Proposing a lightweight model, inspired by the architecture of TransUNet, that combines transformer components with a convolutional network. We hypothesize that this reduction in architectural complexity improves the generalizability of the model.
Designing a novel loss function that integrates classic Dice loss with a boundary-weighted penalty, improving segmentation performance, particularly around the boundaries of target regions.
Developing a post-processing pipeline for counting A-lines and B-lines, enabling efficient and accurate analysis of lung ultrasound images.
The rest of this paper is organized as follows:
Section 2 describes the related work, summarizing previous efforts in lung ultrasound analysis, including methods for A-line and B-line detection.
Section 3 presents our proposed pipeline.
Section 4 outlines the experimental setup, including data sources and implementation details.
Section 5 provides the discussion.
Section 6 concludes the paper and outlines future work.
2. Related Work
The analysis of LUS images, particularly the detection of A-lines and B-lines, has been a growing research area, due to the importance of these features in diagnosing and tracking respiratory disorders. This section reviews the existing literature relevant to our work, categorized into three main areas: A-line and B-line segmentation, automated analysis of LUS, and medical image segmentation techniques.
2.1. A-Line and B-Line Segmentation
Early approaches for automatic segmentation of A-lines and B-lines in lung ultrasound relied on classical image processing techniques. Algorithms such as edge detectors, along with the Hough Transform, were used for edge line detection [
7]. Traditional machine learning techniques complemented these methods: PCA and Independent Component Analysis (ICA) facilitated feature extraction, while classifiers like SVM, Random Forest, KNN, and logistic regression were applied for classification tasks. SVM, in particular, was preferred in COVID-19 LUS analyses for its robustness with high-dimensional data [
8]. Despite their effectiveness in certain datasets, these approaches often gave poor results when validated on images of variable quality, complex anatomical structures, and overlapping artifacts, hence limiting their broader clinical application.
Deep learning methods were widely utilized for LUS segmentation and classification. Convolutional neural networks, including U-Net and its variants, were successfully used for identifying and segmenting A-lines and B-lines by learning hierarchical features directly from data. For instance, Howell et al. [
9] developed a lightweight U-Net for multi-class segmentation of ribs, pleural lines, and artifacts, demonstrating promising results, even with limited clinical data. Advanced architectures further expanded the scope of DL in LUS. Shea et al. [
10] combined LSTM-CNN frameworks for video-level pleural effusion detection and frame-level B-line annotation. Ebadi et al. [
11] utilized the Kinetics-I3D network for rapid and reliable interpretation of ultrasound videos. For addressing challenges like feature blurring, Yuanlu Ni et al. [
12] proposed MEVAL (Multi-Enhanced Views Active Learning), a method that improved classification accuracy for patterns such as A-lines, B-lines, consolidation, and pleural effusion. Nekoui et al. [
4] evaluated the performance of ExoLungAI, a tool designed to visualize A-lines and B-lines in lung ultrasound videos. The tool counts B-lines based on the affected rib space, and classifies videos by comparing the number of affected frames to a threshold. Videos with more than five B-lines are categorized as B-line cases, while those with significant A-line presence are classified accordingly. An improved Faster R-CNN model was developed to accurately locate the pleural line, followed by segmentation of the LUS image below the pleural line to exclude interference from similar structures [
13]. Image processing techniques, including total variation, matched filter, and gray difference, were then applied for automatic A-line detection.
2.2. Automated Analysis of Lung Images
The integration of AI into lung imaging has revolutionized diagnostic approaches, particularly for lung ultrasound. AI-based techniques aim to enhance accuracy, reduce variability, and enable automated analysis, addressing challenges in traditional interpretation methods.
A review highlighted AI’s transformative role in LUS, especially for COVID-19 pneumonia [
8]. LUS combined with AI is a safe and cost-effective tool that improves diagnostic accuracy and reduces variability. It also supports remote diagnostics through innovations like automated scoring and telerobotic systems. However, challenges like poor image quality, operator dependency, and limited datasets hinder model generalizability. Despite this, AI-integrated LUS and telehealth technologies promise real-time monitoring and broader healthcare advancements.
Another review [
14] on deep learning applications in LUS for COVID-19 provided a comprehensive analysis of ultrasound systems, datasets, and various deep learning models, including CNNs, U-Net [
15], ResNet [
16], DenseNet [
17], Inception [
18], Mo-bileNet [
19], NASNet [
20], and COVID-CAPS [
21]. The authors concluded that these models show significant potential in aiding COVID-19 diagnosis through LUS. They review also highlighted several challenges in developing deep learning models for LUS analysis, including operator dependency, the need for diverse datasets, and limitations in model interpretability. Addressing these challenges is crucial for improving model reliability in clinical settings.
A 2024 paper [
22] explores key aspects of Computer-Aided Diagnosis Systems (CADSs) leveraging deep learning methods for diagnosing COVID-19. It covers segmentation, classification, explainable AI (XAI), and predictive research across various medical imaging modalities, including CT, ultrasound, and X-rays. The study highlights models such as CNNs, autoencoders [
23], GANs [
24], attention mechanisms [
25], transformers [
26], and RNNs [
27]. In the segmentation section, architectures like SegNet [
28] and U-Net are discussed. The authors also enumerate challenges, including distribution shifts, generalization issues, and resource limitations, emphasizing the need for robust and adaptable solutions in CADS development.
2.3. Medical Image Segmentation Techniques
Deep learning has significantly advanced medical image analysis, with improvements in both classification and segmentation. Hussain et al. [
29] enhanced explainability in classification tasks by integrating pretrained VGG-19 with Grad-CAM, improving diagnostic support through better visualization. Similarly, Alam et al. [
30] focused on fracture prediction using X-ray image analysis, incorporating YOLOv8 for ROI detection and evaluating multiple classification algorithms.
Parallel to these advancements in classification, medical image segmentation has rapidly evolved with the development of deep convolutional neural networks (CNNs), transformers, and hybrid architectures. Among these, TransAttUnet [
31] stands out as a notable Transformer-based Attention Guided Network designed to enhance semantic segmentation. By integrating multi-level guided attention and multi-scale skip connections, TransAttUnet strengthens feature representation across different resolutions.
Recent approaches in medical image segmentation have explored the integration of attention mechanisms, graph neural networks [
32], and domain adaptation techniques [
33] to further improve performance. Methods like nnU-Net [
34] have set benchmarks by automating hyperparameter selection and achieving exceptional generalizability across various medical imaging modalities. Hussain et al. [
35] proposed MAGRes-Unet, which enhances U-Net with multi-attention gate modules and residual blocks to improve feature learning and focus on small-scale tumors.
Transformer-based architectures, including TransUNet [
6], have demonstrated the potential to bridge local and global feature learning, making them highly effective for tasks requiring both fine-grained and holistic contextual understanding. The Swin Transformer [
36] is a hierarchical vision transformer that partitions the image into non-overlapping windows and shifts them between layers to capture both local and global dependencies efficiently.
TransUNet is a hybrid architecture combining the strengths of U-Net and Transformers, and has gained significant attention in medical image segmentation. By embedding Transformer layers into the encoder, TransUNet leverages self-attention mechanisms to capture long-range dependencies, while maintaining the localization capabilities of the U-Net’s convolutional structure. This hybrid design makes TransUNet particularly well suited for tasks where both local boundary precision and global context are critical. However, vanilla TransUNet has shown uneven performance in ultrasound segmentation, due to the highly variable nature of ultrasound images, which contain speckle noise, low contrast, and heterogeneous anatomical structures. These challenges necessitate a more robust and adaptive approach that integrates transformer components with a lightweight convolutional network to enhance both segmentation consistency and efficiency.
3. Methodology
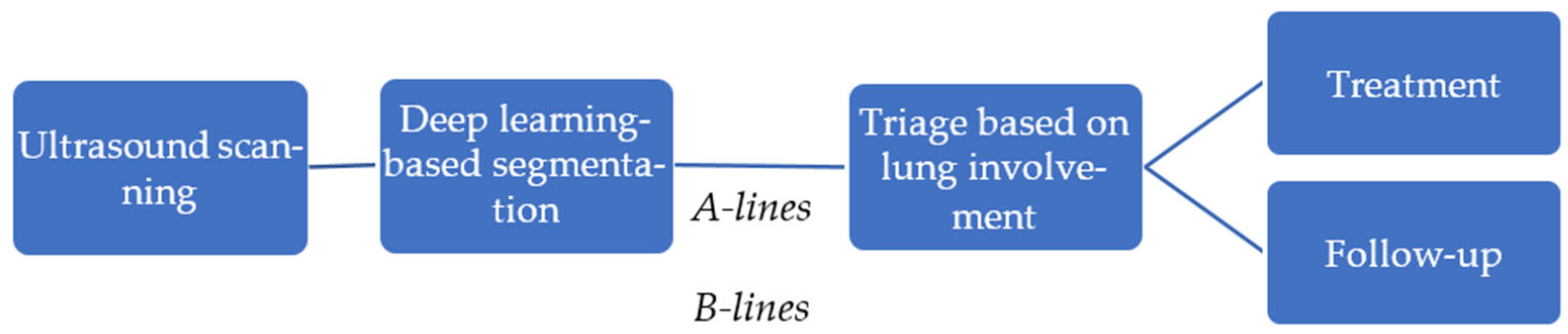
In this study, we propose an automated pipeline for lung ultrasound image segmentation to identify clinically relevant features, such as A-lines and B-lines, aimed at assisting in the management of COVID-19 patients. Ultrasound scanning plays a pivotal role in bedside evaluation, especially in emergency triage settings, offering a rapid, non-invasive assessment of lung involvement. Using deep learning-based segmentation techniques, clinically relevant features, such as A-lines and B-lines, are identified, providing critical insights into lung pathology. This automated analysis enables efficient triage by evaluating the extent of lung involvement, guiding immediate treatment decisions, and facilitating long-term monitoring of patients, especially in the case of Long COVID.
Figure 2 illustrates the steps involved in the pipeline. It shows how segmentation results can be integrated into clinical workflows to support personalized treatment plans and follow-up strategies, ultimately enhancing patient care and resource management in healthcare settings.
To achieve accurate and efficient lung ultrasound A-line and B-line counting and segmentation, the proposed methodology uses pre-processing, deep learning-based segmentation, and post-processing. These stages help to improve image quality and make it easier to extract important features. They also provide clear outputs that support better clinical decision-making. The proposed approach, TransBound-Unet, incorporates a transformer-based encoder to capture long-range dependencies, a Unet-style decoder, and a boundary-aware Dice loss to refine segmentation along object boundaries.
3.1. Pre-Processing for Ultrasound Image Segmentation
Pre-processing enhances ultrasound image quality, reduces noise, and standardizes input to improve training efficiency and model performance. In this study, non-local means filtering is applied to reduce noise and mitigate artifacts that are commonly found in ultrasound imaging. Contrast-Limited Adaptive Histogram Equalization (CLAHE) enhances the visibility of subtle features, such as A-lines and B-lines, that are crucial for clinical interpretation. Additionally, unsharp masking improves edge clarity, aiding in the identification of feature boundaries.
While these steps enhance data quality, the pre-processing pipeline is intentionally kept minimal to preserve critical features and leverage the deep learning model’s ability to learn directly from raw data. This balanced approach ensures that the model remains robust to diverse input conditions, while benefiting from improved image quality.
3.2. Deep Learning Architecture for A-Line and B-Line Segmentation
Inspired by TransUNet, we propose an improved segmentation framework tailored for lung ultrasound analysis. While transformer-based architectures have demonstrated strong performance in medical imaging, they typically require large amounts of data for optimal results. However, in tasks with limited or less diverse datasets, these models can be more sensitive to training variations and dataset characteristics. This variability is influenced by factors such as the dataset’s distribution, the composition of the training, validation, and test splits, and the stochastic nature of the training process. These effects are particularly noticeable in datasets with unique or non-uniform distributions, where model generalization can be more challenging.
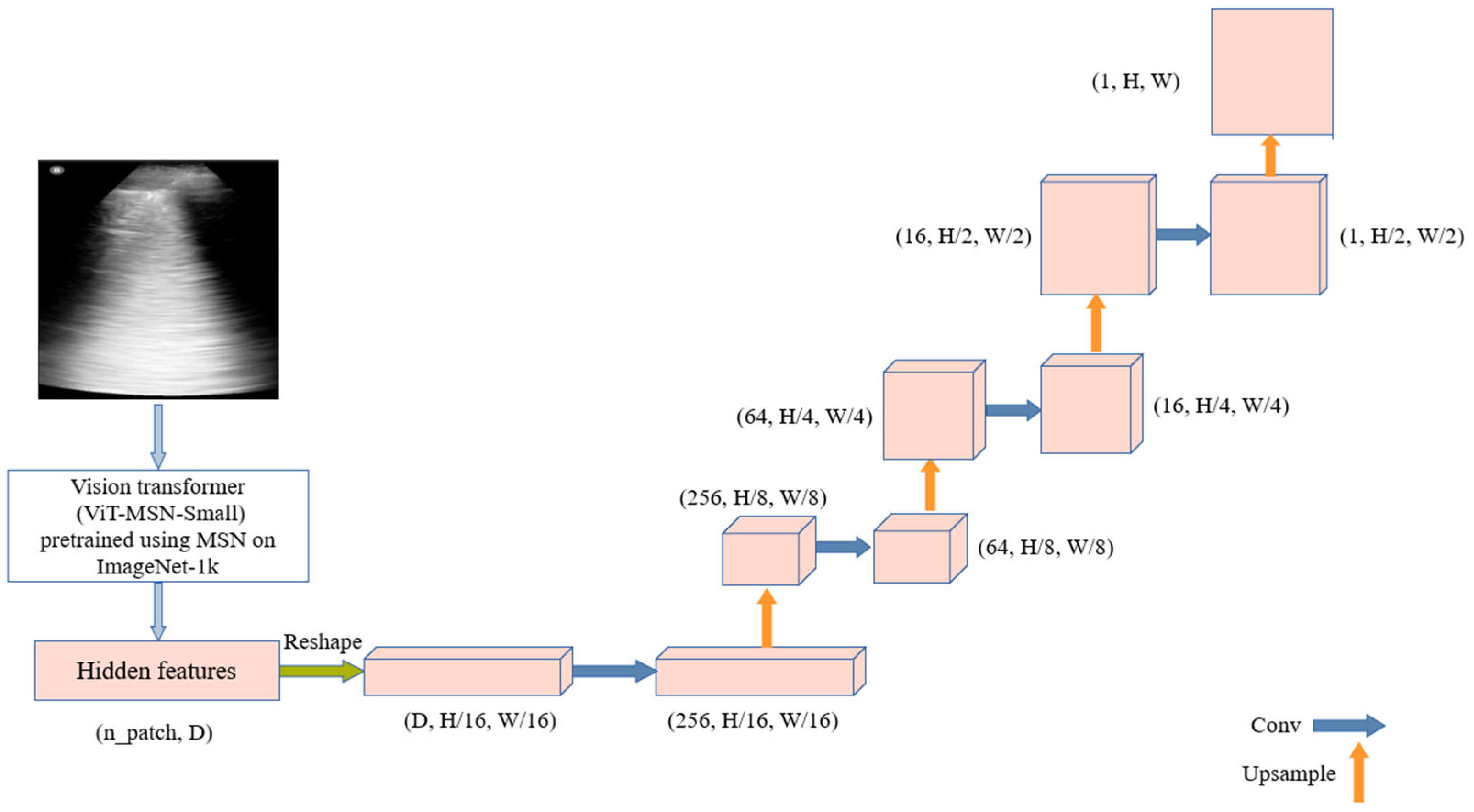
The process begins with ViT-MSN-Small, a vision transformer pretrained using Masked Siamese Networks (MSN) on ImageNet-1k, serving as a powerful backbone for feature extraction. The output of the ViT consists of hidden features, initially represented in a flat, patch-based form. These hidden features are reshaped into a spatial tensor, representing a coarse resolution of the original image. The decoder utilizes this low-dimensional tensor to reconstruct the segmentation mask. It is composed of multiple upsampling layers followed by convolutional layers, progressively refining the segmentation output. The architecture is illustrated in
Figure 3.
In the segmentation of A-lines and B-lines in lung ultrasound images, accurately preserving the boundaries between these lines and surrounding tissues is crucial for reliable diagnostic analysis. The close proximity of A-lines and B-lines, as well as their potential intersections with other structures such as lung tissue or artifacts, presents a significant challenge for segmentation. In LUS images, the tissue textures are complex, and the boundaries between A-lines, B-lines, and surrounding tissues are often blurred. We propose a boundary-aware loss function to improve segmentation performance.
To the best of our knowledge, while boundary-aware loss functions have been explored in general segmentation tasks, their application to A-line and B-line segmentation in lung ultrasound images remains relatively under-explored. In traditional segmentation tasks, boundary-aware losses have been successfully employed to enhance segmentation accuracy near object edges, allowing the model to preserve fine details, even in regions with closely spaced structures [
37]. In medical image segmentation, Li [
38] proposed a geometric boundary constraint loss that utilizes the boundary information of the target object. This information applies geometric constraints on the segmentation process, giving higher weights to the boundary areas for more accurate segmentation.
The proposed loss function combines the classic Dice loss with a boundary-weighted penalty to improve segmentation performance, especially around the boundaries of target regions. The Dice loss is used to measure the overlap between the predicted segmentation mask and the ground truth mask. It is defined as follows:
Here, is a small constant added to avoid zero division when both the target and the prediction are empty masks. This loss encourages maximizing the overlap between the prediction and target, while minimizing false positives and false negatives.
To enhance segmentation accuracy, particularly near region boundaries, the Boundary Loss applies a weighted penalty to areas close to the ground truth mask boundaries. The boundary of the ground truth mask is a binary mask that highlights pixels along the inner boundary of the target regions. This boundary mask is used to weight the Binary Cross Entropy (BCE) loss, emphasizing errors near the boundaries and ensuring that the model pays more attention to accurately segmenting these critical areas. The Boundary Loss is defined as follows:
The final Boundary-Aware Dice loss combines the Dice loss and the weighted Boundary Loss as follows:
3.3. Post-Processing for A-Line and B-Line Detection and Counting
After segmentation, various image processing operations were used to detect and classify lines in the segmented image as A-lines vs. B-lines. The segmented output was converted to a binary format and dilated. Contours were extracted and classified based on their geometric properties. Algorithm 1 shows a short pseudocode of the post-processing steps.
| Algorithm 1. Pseudocode for post-processing pipeline to detect and count A-lines and B-lines in lung ultrasound images |
Input: Segmented image
Convert the image to binary format and dilate using a small kernel.
Apply Gaussian blur and Canny edge detection.
Dilate the edges for better contour detection.
Extract contours from the processed image.
For contour in contours:
Calculate the bounding box dimensions (width, height).
Classify as A-line if width > 1.5 × height.
Classify as B-line if height > 1.5 × width.
If no contours are detected, retain the original segmented image.
Output: Count of A-lines and B-lines, visualization. |
4. Experiments and Results
The dataset used in this study consists of 2D LUS images obtained from subjects from Hospital Universitario Puerta de Hierro, Majadahonda, Spain [
39]. Ultrasound exams were performed with the patient in supine or sitting positions. The probe was placed obliquely along anatomical lines at the 2nd–4th ICS (parasternal, midclavicular, anterior axillary, midaxillary) and 2nd–10th ICS (paravertebral, sub-scapular, posterior axillary). The dataset includes a total of 4599 images, each accompanied by corresponding segmentation labels, without pre-determination or counting of the presence of A-lines and B-lines in each image.
For model development, 5-fold cross-validation was applied. Experiments were conducted on a Lambda laptop, manufactured by Clevo Co. (New Taipei City, Taiwan), with an NVIDIA RTX 3080 GPU, using PyTorch 2.5.1 for implementation. Before training, images were normalized using the pre-processing steps described in
Section 3.1. The model was trained using the Adam optimizer with a learning rate of 1 × 10
−4, a batch size of 16, and a weighted sum of Dice and boundary-aware loss to enhance segmentation. Training was conducted for 40 epochs.
To evaluate the performance of the proposed models, we utilized a diverse range of metrics.
The Dice Score measures the overlap between the predicted segmentation and the ground truth. The formula is given as follows:
Sensitivity, also referred to as Recall or the true positive rate, measures the ability to correctly detect true positives. Specificity, or the true negative rate, assesses the model’s ability to accurately identify true negative classes, such as the background class. These can be identified using the following formulas:
TP (true positive) denotes the pixels correctly predicted as belonging to the target class. FP (false positive) represents the pixels incorrectly classified as the target class.
FN (false negative) indicates the pixels that belong to the target class but are incorrectly classified as the background. TN (true negative) signifies the pixels correctly predicted as belonging to the background or non-target class.
Hausdorff Distance (HD) is a metric used to evaluate how well the predicted boundary matches the ground truth boundary. HD is mathematically expressed as follows:
Let A, B be two sets of points representing the boundaries of the predicted segmentation and ground truth. Let a and b represent individual points from sets A and B, respectively. The term is the Euclidean distance between the two points. For each point in the set, the closest point in set B is identified, and vice versa. The Hausdorff Distance is then calculated by taking the maximum of these minimum distances. This ensures that the HD captures the worst-case discrepancy, meaning the largest mismatch between the two sets.
Precision is another metric used to measure the accuracy of positive predictions made by a model. The formula is as follows:
The F1 Score is the harmonic mean of Precision and Recall. Maximizing the F1 Score ensures a balance between Precision and Recall, improving both simultaneously. It can be formulated as follows:
Finally, Intersection over Union (IoU) is a widely used metric for evaluating the accuracy of segmentation models. It measures the overlap between the predicted segmentation mask and the ground truth mask. The formula for IoU is as follows:
In our experiments with this dataset, TransUNet achieved high Dice Scores, reaching up to 88%. However, its performance varied across runs, with Dice Scores ranging from 0.64 to 0.88. Over 10 runs, the model achieved an average Dice Score of 75%. This variability highlights the challenges of segmentation consistency, particularly in datasets with diverse imaging conditions. To address this, we propose a method that integrates transformer components with a lightweight convolutional network, aiming to enhance both robustness and efficiency.
Table 1 presents a comparison of the TransBound-Unet, with and without the boundary-aware loss, against several state-of-the-art networks for medical image segmentation. These include U-Net [
15], a widely used encoder–decoder architecture for biomedical segmentation. Attention U-Net [
40] incorporates attention mechanisms to enhance focus on relevant regions. UNETR [
41] is a transformer-based model that leverages long-range dependencies in volumetric data. SwinUNETR [
42] combines the hierarchical features of Swin Transformers with UNETR to enhance both global and local feature extraction. TransUNet [
6] integrates transformers and CNNs to balance global context with local spatial details. Additionally, we include a recent lightweight U-Net variant [
9], specifically designed for LUS segmentation. This evaluation demonstrates the effectiveness of the proposed method in lung ultrasound segmentation. The results show that the proposed method with the boundary-aware loss consistently outperforms the other approaches across most metrics, demonstrating its superior performance in segmenting lung ultrasound images. Specifically, it achieves the highest Dice Score, indicating the best overlap between predicted and ground truth segmentation.
Following the segmentation performance analysis, the qualification results and post-processing steps for identifying and counting A-lines and B-lines were evaluated. After obtaining the segmentation masks, a post-processing pipeline was applied to detect lines indicative of A-lines and B-lines. The results demonstrate the proposed method’s high precision in distinguishing between these artifacts (
Figure 4). Additionally, SwinUNETR achieved the second-best segmentation performance, and its results are also presented in
Figure 4 for comparison. While the performance of other approaches was relatively close, SwinUNETR outperformed Attention U-Net by a small margin.
5. Discussion
This study introduces a novel deep learning-based framework, TransBound-UNet, for the detection and segmentation of A-lines and B-lines in LUS images. This task is crucial for the diagnosis of pulmonary conditions, where accurate segmentation of these lines can provide vital insights into the presence of diseases like pulmonary edema or interstitial lung disease. By simplifying the TransUNet architecture and incorporating a Boundary-Aware Dice loss into a hybrid Dice-BCE loss function, TransBound-UNet achieved significant improvements in segmentation accuracy, particularly along the boundaries of A-line and B-lines.
TransUNet has demonstrated significant potential in medical image segmentation by effectively combining convolutional layers with transformer blocks, capturing both local and global dependencies. Inspired by the success of TransUNet, we proposed a simplified architecture that leverages the strengths of transformers while reducing architectural complexity. TransBound-UNet maintains the core concept of using a Vision Transformer (ViT) for global feature extraction, specifically employing ViT-MSN-Small, a model pretrained using MSN on ImageNet-1k. To enhance efficiency and adaptability for binary classification tasks, such as lung ultrasound segmentation, we introduced a lightweight decoder.
TransBound-UNet and TransUNet both use a ViT backbone and a UNet-like decoder. However, TransBound-UNet differs by removing skip connections and simplifying the decoder to a lightweight convolutional structure. Instead of using both convolutional and transformer features, it relies entirely on transformer-derived features. These changes make the architecture more efficient by significantly reducing computational cost. Compared to the original TransUNet, TransBound-UNet lowers the FLOPs from 27.06 GFLOPs to 4.57 GFLOPs, an 83% reduction. The number of trainable parameters also decreases from 63 M to 23 M, reducing memory usage and making the model more lightweight and practical.
The proposed loss function enhances segmentation performance, particularly in capturing fine boundary details. By incorporating boundary-specific penalties, it improves edge delineation, which is crucial in medical imaging. The function balances global and local performance by combining Dice loss for overall overlap optimization with a boundary-aware component for precise edge segmentation. Its adaptability, through an adjustable weight parameter, allows for customization based on the specific characteristics of different datasets and tasks. Inspired by the need to address complex boundaries in medical imaging, this loss function ensures reliable and precise segmentation, supporting effective diagnosis and treatment planning.
Our developed model demonstrated excellent performance across multiple key metrics, often outperforming or matching other state-of-the-art methods. Its Dice Score was the highest among the compared models, highlighting the model’s strong capability in segmenting accurately. The model also excelled in Specificity, indicating its strong ability to exclude irrelevant regions from the segmentation mask, which is important for reducing false positives. Additionally, its Hausdorff Distance, a key measure of boundary accuracy, was lower than that of all the other models, by a considerable margin, demonstrating that TransBound-UNet produces more precise segmentation boundaries. The overall performance, reflected by the F1 Score and IoU, further highlights the model’s robustness.
Beyond segmentation, this approach could benefit downstream tasks such as disease detection and classification. For example, greater segmentation accuracy can enhance lesion detection and organ boundary delineation, ultimately improving diagnostic precision and clinical decision-making, particularly for lung diseases like COVID-19.
6. Conclusions and Future Works
In this work, we propose a lightweight deep learning architecture for lung ultrasound segmentation, leveraging the vision transformer ViT-MSN-Small. TransBound-UNet achieves high segmentation accuracy, while significantly reducing the number of trainable parameters compared to conventional deep learning models, making it a more computationally efficient solution for medical imaging applications. By incorporating a custom loss function designed to enhance boundary delineation, our model effectively captures fine anatomical structures, leading to a substantial reduction in the Hausdorff Distance. The results demonstrate that despite its reduced complexity, our method outperforms state-of-the-art architectures in key metrics such as Dice Score, Precision, and IoU, while maintaining high Specificity and Recall. This improvement highlights the potential of our approach for real-world deployment, particularly in resource-constrained clinical settings.
While TransBound-UNet shows promising results, several areas need further exploration. One major challenge in ultrasound imaging is its high operator dependence, which can lead to variability in multi-site datasets. Future research should focus on improving the model’s robustness to these inconsistencies, ensuring reliable performance across different users and imaging conditions.
Another important direction is incorporating self-supervised or semi-supervised learning to make better use of limited labeled data. Additionally, enhancing model interpretability would help clinicians to trust and understand the model’s decisions.
Finally, to assess its real-world impact, future studies should evaluate whether the model improves diagnostic accuracy—particularly, in clinical sensitivity and specificity for detecting lung diseases, including COVID-19—compared to state-of-the-art methods.
Author Contributions
Conceptualization, S.A., A.H., and J.L.J.; methodology, S.A.; software, S.A., M.E.; validation, A.S.W., S.G., and M.E.; formal analysis, S.A.; investigation, S.A.; resources, S.A., M.P., Y.T.C., A.H., and J.L.J.; data curation, M.P., and Y.T.C.; writing—original draft preparation, S.A.; writing—review and editing, S.A., A.S.W., S.G., M.E., M.P., Y.T.C., J.L.J., and A.H.; visualization, S.A; supervision, J.L.J., and A.H.; project administration, A.H.; funding acquisition, J.L.J., and A.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the IC-IMPACTS grant awarded to Dr. Hareendranathan, Alberta Innovates Accelerating Innovations into Care (AICE) Concepts grant and Dr. Jaremko’s Canada CIFAR AI Chair.
Institutional Review Board Statement
This study was approved by the University of Alberta Health Research Ethics Board-Health Panel Pro00100068.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available on request.
Acknowledgments
Protected academic time for Jaremko is provided by MIC Medical Imaging, Edmonton.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Moore, S.; Gardiner, E. Point of care and intensive care lung ultrasound: A reference guide for practitioners during COVID-19. Radiography 2020, 26, e297–e302. [Google Scholar] [CrossRef] [PubMed]
- Chua, M.T.; Boon, Y.; Yeoh, C.K.; Li, Z.; Goh, C.J.; Kuan, W.S. Point-of-care ultrasound use in COVID-19: A narrative review. Ann. Transl. Med. 2023, 12, 13. [Google Scholar] [CrossRef]
- Soldati, G.; Demi, M.; Smargiassi, A.; Inchingolo, R.; Demi, L. The role of ultrasound lung artifacts in the diagnosis of respiratory diseases. Expert Rev. Respir. Med. 2019, 13, 163–172. [Google Scholar] [CrossRef] [PubMed]
- Nekoui, M.; Seyed Bolouri, S.E.; Forouzandeh, A.; Dehghan, M.; Zonoobi, D.; Jaremko, J.L.; Buchanan, B.; Nagdev, A.; Kapur, J. Enhancing Lung Ultrasound Diagnostics: A Clinical Study on an Artificial Intelligence Tool for the Detection and Quantification of A-Lines and B-Lines. Diagnostics 2024, 14, 2526. [Google Scholar] [CrossRef]
- Ostras, O.; Soulioti, D.E.; Pinton, G. Diagnostic ultrasound imaging of the lung: A simulation approach based on propagation and reverberation in the human body. J. Acoust. Soc. Am. 2021, 150, 3904–3913. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Hliboký, M.; Magyar, J.; Bundzel, M.; Malík, M.; Števík, M.; Vetešková, Š.; Dzian, A.; Szabóová, M.; Babič, F. Artifact Detection in Lung Ultrasound: An Analytical Approach. Electronics 2023, 12, 1551. [Google Scholar] [CrossRef]
- Wang, J.; Yang, X.; Zhou, B.; Sohn, J.J.; Zhou, J.; Jacob, J.T.; Higgins, K.A.; Bradley, J.D.; Liu, T. Review of Machine Learning in Lung Ultrasound in COVID-19 Pandemic. J. Imaging 2022, 8, 65. [Google Scholar] [CrossRef]
- Howell, L.; Ingram, N.; Lapham, R.; Morrell, A.; McLaughlan, J.R. Deep Learning for Real-Time Multi-Class Segmentation of Artefacts in Lung Ultrasound. Ultrasonics 2024, 140, 107251. [Google Scholar] [CrossRef]
- Shea, D.E.; Kulhare, S.; Millin, R.; Laverriere, Z.; Mehanian, C.; Delahunt, C.B.; Banik, D.; Zheng, X.; Zhu, M.; Ji, Y.; et al. Deep learning video classification of lung ultrasound features associated with pneumonia. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 3103–3112. [Google Scholar] [CrossRef]
- Erfanian Ebadi, S.; Krishnaswamy, D.; Bolouri, S.E.S.; Zonoobi, D.; Greiner, R.; Meuser-Herr, N.; Jaremko, J.L.; Kapur, J.; Noga, M.; Punithakumar, K. Automated Detection of Pneumonia in Lung Ultrasound Using Deep Video Classification for COVID-19. Inform. Med. Unlocked 2021, 25, 100687. [Google Scholar] [CrossRef]
- Ni, Y.; Cong, Y.; Zhao, C.; Yu, J.; Wang, Y.; Zhou, G.; Shen, M. Active Learning Based on Multi-Enhanced Views for Classification of Multiple Patterns in Lung Ultrasound Images. Comput. Med. Imaging Graph. 2024, 118, 102454. [Google Scholar] [CrossRef] [PubMed]
- Xing, W.; Li, G.; He, C.; Huang, Q.; Cui, X.; Li, Q.; Li, W.; Chen, J.; Ta, D. Automatic Detection of A-Line in Lung Ultrasound Images Using Deep Learning and Image Processing. Med. Phys. 2023, 50, 330–343. [Google Scholar] [CrossRef]
- Zhao, L.; Bell, M.A.L. A Review of Deep Learning Applications in Lung Ultrasound Imaging of COVID-19 Patients. BME Front. 2022, 2022, 9780173. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Howard, A.G. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef]
- Afshar, P.; Heidarian, S.; Naderkhani, F.; Oikonomou, A.; Plataniotis, K.N.; Mohammadi, A. COVID-CAPS: A capsule network-based framework for identification of COVID-19 cases from X-ray images. Pattern Recognit. Lett. 2020, 138, 638–643. [Google Scholar] [CrossRef] [PubMed]
- Shoeibi, A.; Khodatars, M.; Jafari, M.; Ghassemi, N.; Sadeghi, D.; Moridian, P.; Khadem, A.; Alizadehsani, R.; Hussain, S.; Zare, A.; et al. Automated Detection and Forecasting of COVID-19 Using Deep Learning Techniques: A Review. Neurocomputing 2024, 577, 127317. [Google Scholar] [CrossRef]
- Scarpiniti, M.; Ahrabi, S.S.; Baccarelli, E.; Piazzo, L.; Momenzadeh, A. A novel unsupervised approach based on the hidden features of deep denoising autoencoders for COVID-19 disease detection. Expert Syst. Appl. 2022, 192, 116366. [Google Scholar] [CrossRef] [PubMed]
- Al-Shargabi, A.A.; Alshobaili, J.F.; Alabdulatif, A.; Alrobah, N. COVID-CGAN: Efficient deep learning approach for COVID-19 detection based on CXR images using conditional GANs. Appl. Sci. 2021, 11, 7174. [Google Scholar] [CrossRef]
- Zhou, T.; Canu, S.; Ruan, S. An automatic COVID-19 CT segmentation network using spatial and channel attention mechanism. Int. J. Imaging Syst. Technol. 2020, 31, 16–27. [Google Scholar] [CrossRef]
- Perera, S.; Adhikari, S.; Yilmaz, A. Pocformer: A lightweight transformer architecture for detection of COVID-19 using point-of-care ultrasound. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 195–199. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Yan, Q.; Wang, B.; Gong, D.; Luo, C.; Zhao, W.; Shen, J.; Shi, Q.; Jin, S.; Zhang, L.; You, Z. COVID-19 chest CT image segmentation—A deep convolutional neural network solution. arXiv 2020, arXiv:2004.10987. [Google Scholar]
- Hussain, T.; Shouno, H. Explainable deep learning approach for multi-class brain magnetic resonance imaging tumor classification and localization using gradient-weighted class activation mapping. Information 2023, 14, 642. [Google Scholar] [CrossRef]
- Alam, T.; Yeh, W.C.; Hsu, F.R.; Shia, W.C.; Singh, R.; Hassan, T.; Lin, W.; Yang, H.Y.; Hussain, T. An integrated approach using YOLOv8 and ResNet, SeResNet & Vision Transformer (ViT) algorithms based on ROI fracture prediction in X-ray images of the elbow. Curr. Med. Imaging 2024, 20, 1–13. [Google Scholar] [CrossRef]
- Chen, B.; Liu, Y.; Zhang, Z.; Lu, G.; Zhang, D. TransAttUnet: Multi-level Attention-guided U-net with Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2107.05274. [Google Scholar] [CrossRef]
- Gaggion, N.; Mansilla, L.; Mosquera, C.; Milone, D.H.; Ferrante, E. Improving Anatomical Plausibility in Medical Image Segmentation via Hybrid Graph Neural Networks: Applications to Chest X-ray Analysis. IEEE Trans. Med. Imaging 2022, 42, 546–556. [Google Scholar] [CrossRef]
- Munk, A.; Nielsen, M. MDD-UNet: Domain Adaptation for Medical Image Segmentation with Theoretical Guarantees, a Proof of Concept. In Proceedings of the Northern Lights Deep Learning Conference, Tromsø, Norway, 9 January 2024; PMLR: London, UK, 2024; pp. 174–180. [Google Scholar]
- Isensee, F.; Wald, T.; Ulrich, C.; Baumgartner, M.; Roy, S.; Maier-Hein, K.; Jaeger, P.F. nnU-Net Revisited: A Call for Rigorous Validation in 3D Medical Image Segmentation. arXiv 2024, arXiv:2404.09556. [Google Scholar]
- Hussain, T.; Shouno, H. MAGRes-UNet: Improved medical image segmentation through a deep learning paradigm of multi-attention gated residual U-Net. IEEE Access 2024, 12, 40290–40310. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Zhang, J.; Shao, M.; Wan, Y.; Meng, L.; Cao, X.; Wang, S. Boundary-Aware Spatial and Frequency Dual-Domain Transformer for Remote Sensing Urban Images Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–18. [Google Scholar] [CrossRef]
- Li, C.; Zhang, J.; Niu, D.; Zhao, X.; Yang, B.; Zhang, C. Boundary-Aware Uncertainty Suppression for Semi-Supervised Medical Image Segmentation. IEEE Trans. Artif. Intell. 2024, 5, 4074–4086. [Google Scholar] [CrossRef]
- Joseph, J.; Panicker, M.R.; Chen, Y.T.; Chandrasekharan, K.; Mondy, V.C.; Ayyappan, A.; Valakkada, J.; Narayan, K.V. Lungecho—Resource constrained lung ultrasound video analysis tool for faster triaging and active learning. Biomed. Eng. Adv. 2023, 6, 100094. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. UNETR: Transformers for 3D Medical Image Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1748–1758. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2022; Volume 12962, pp. 272–284. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}