

Encoder–Decoder Variant Analysis for Semantic Segmentation of Gastrointestinal Tract Using UW-Madison Dataset



Abstract
1. Introduction
- This manuscript conducts an exhaustive comparison of five encoders (ResNet50, EfficientNetB1, MobileNetV2, ResNeXt50, and Timm_Gernet_S) with five decoders (UNet, FPN, PSPNet, PAN, and DeepLab V3+) to determine the best encoder–decoder combination for GI tract segmentation on the UW-Madison dataset.
- A novel combination of DeepLab V3+ architecture with ResNet50 is proposed, and the effective use of multi-scale contextual information through atrous convolutions for a state-of-the-art performance on the dataset is carried out.
- Hyperparameter tuning and preprocessing tailored to the challenges of the UW-Madison dataset, including organ shape variability and class imbalance, significantly improve segmentation accuracy.
2. Related Work
3. Materials and Methods
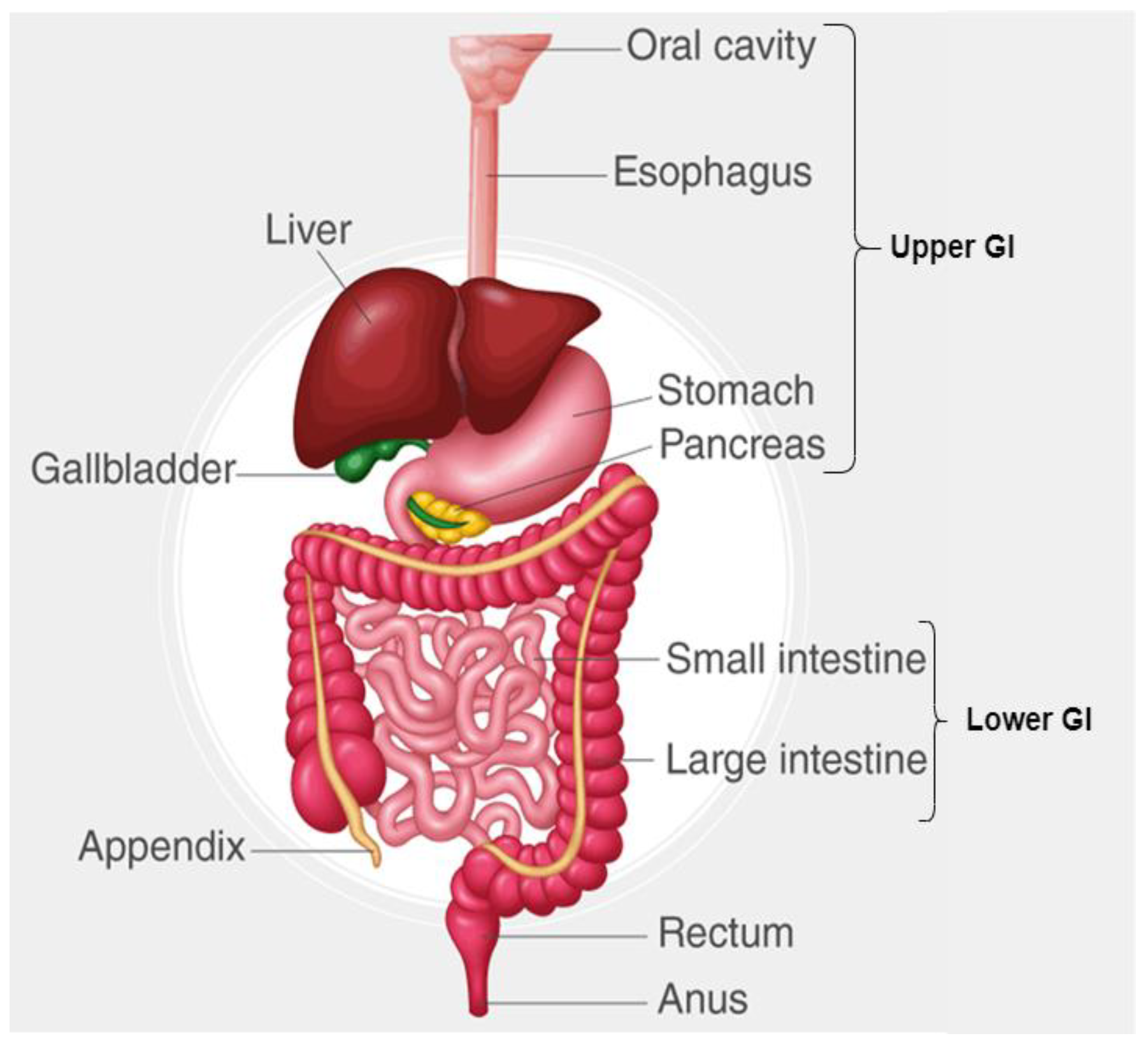
3.1. Dataset Description
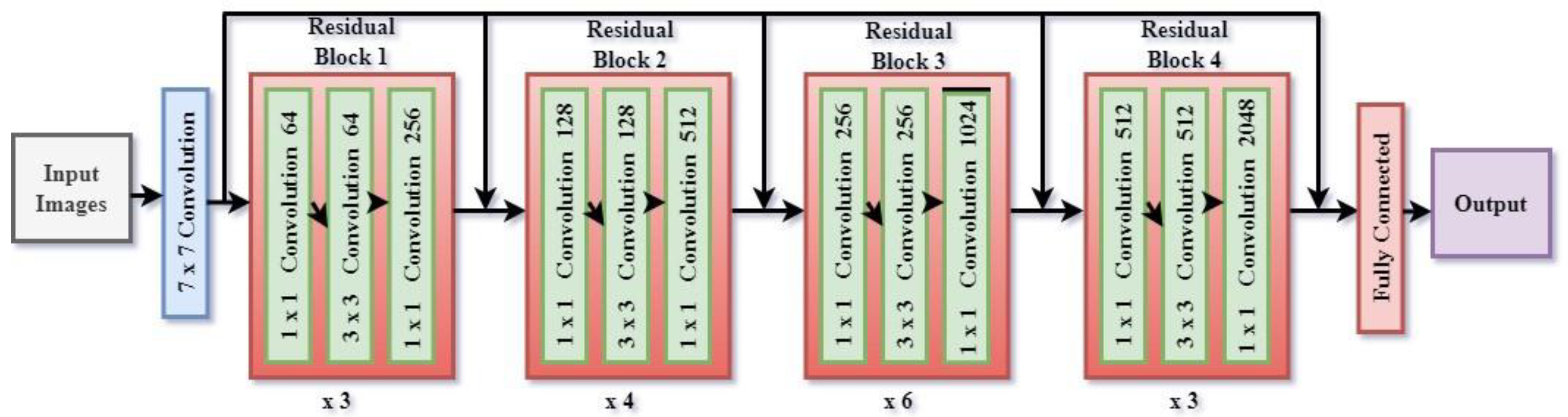
3.2. Encoder Variants
3.3. Decoder Variants
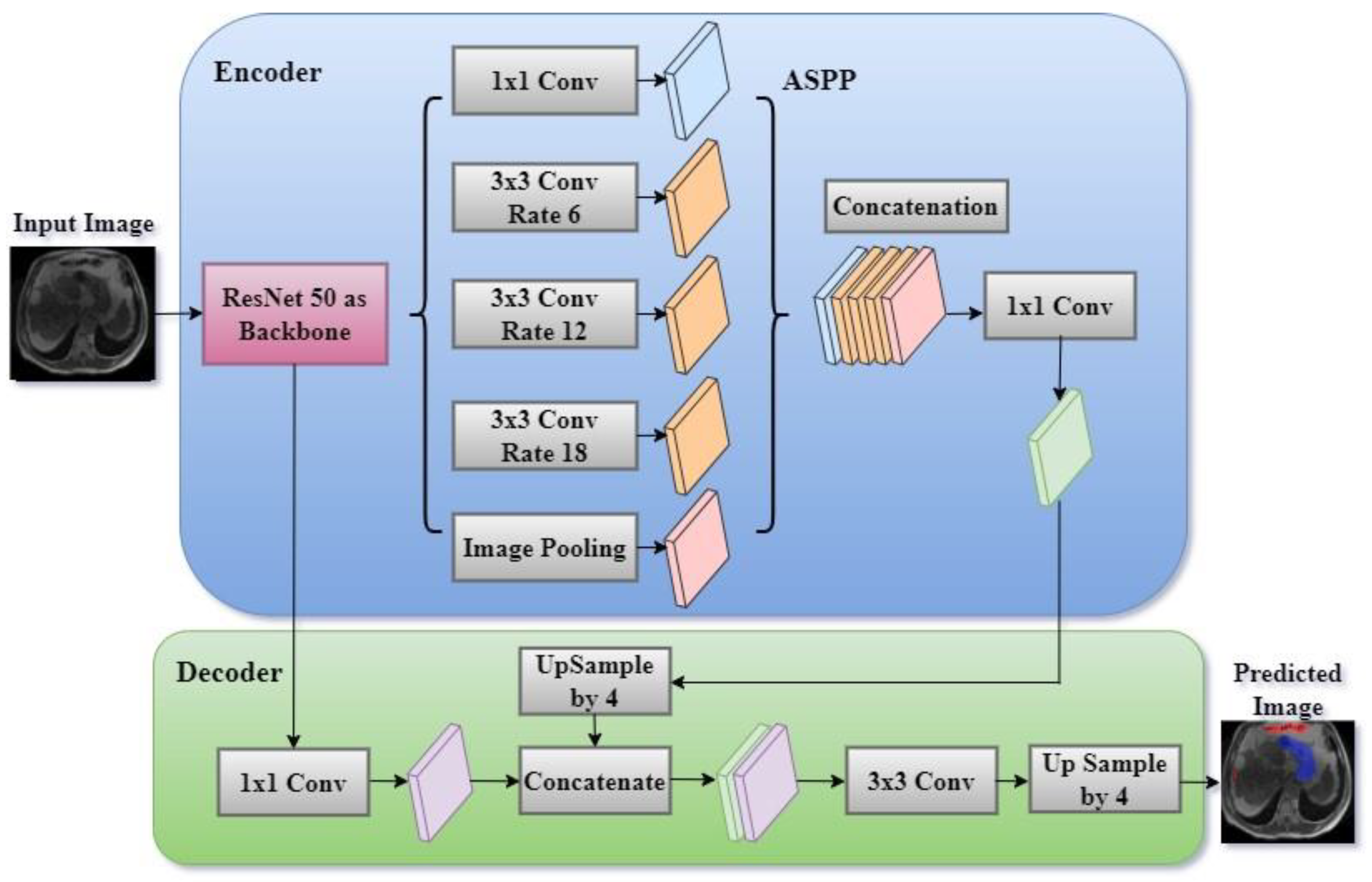
3.4. Proposed DeepLab V3+ Model with ResNet 50 Encoder
3.4.1. Atrous Spatial Pyramid Pooling (ASPP)
3.4.2. Decoder Module
3.4.3. Loss Function and Optimization
4. Results and Discussion
4.1. Analysis of Encoder–Decoder Variants Based on Model Loss
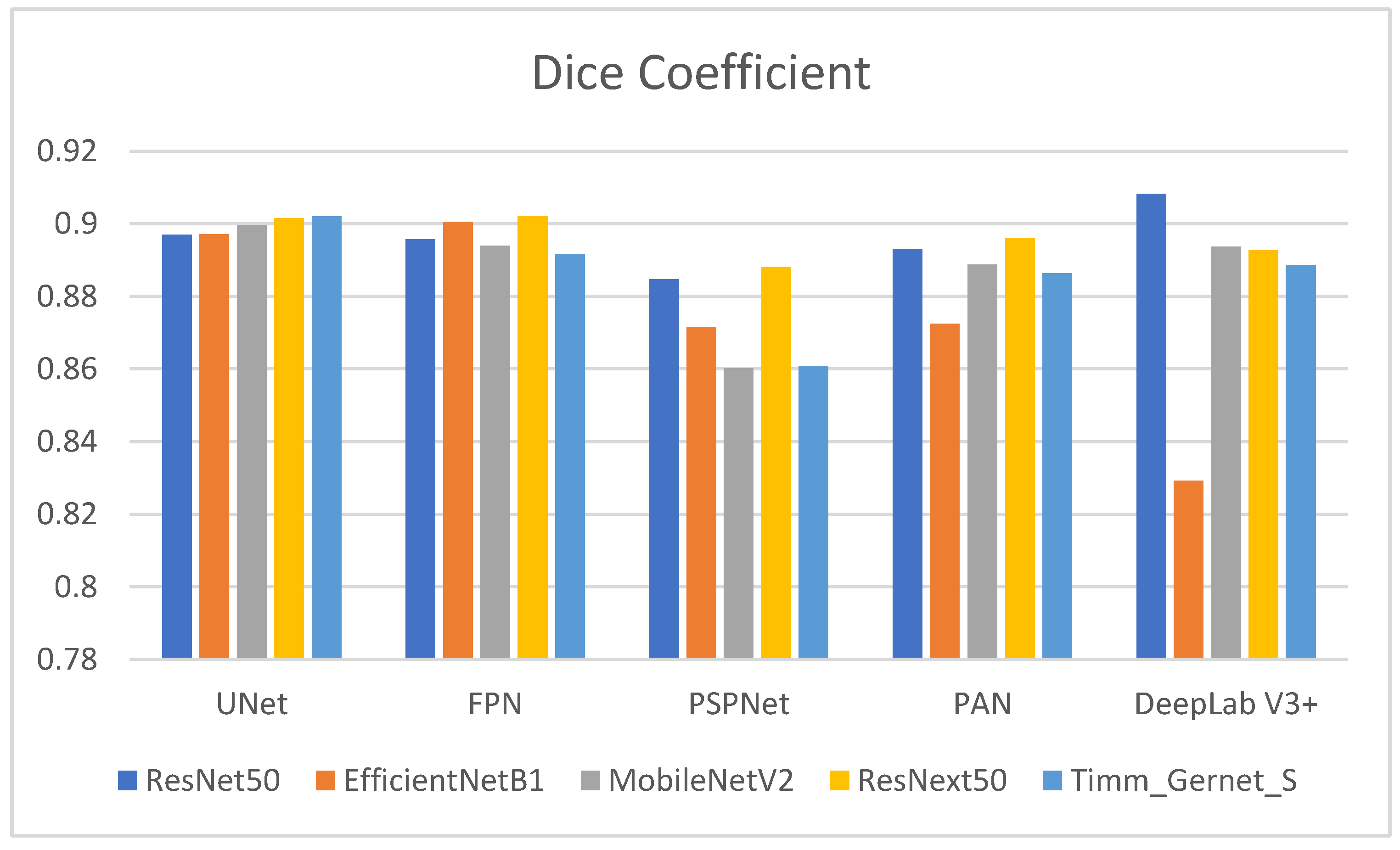
4.2. Analysis of Encoder–Decoder Variants Based on Dice Coefficient
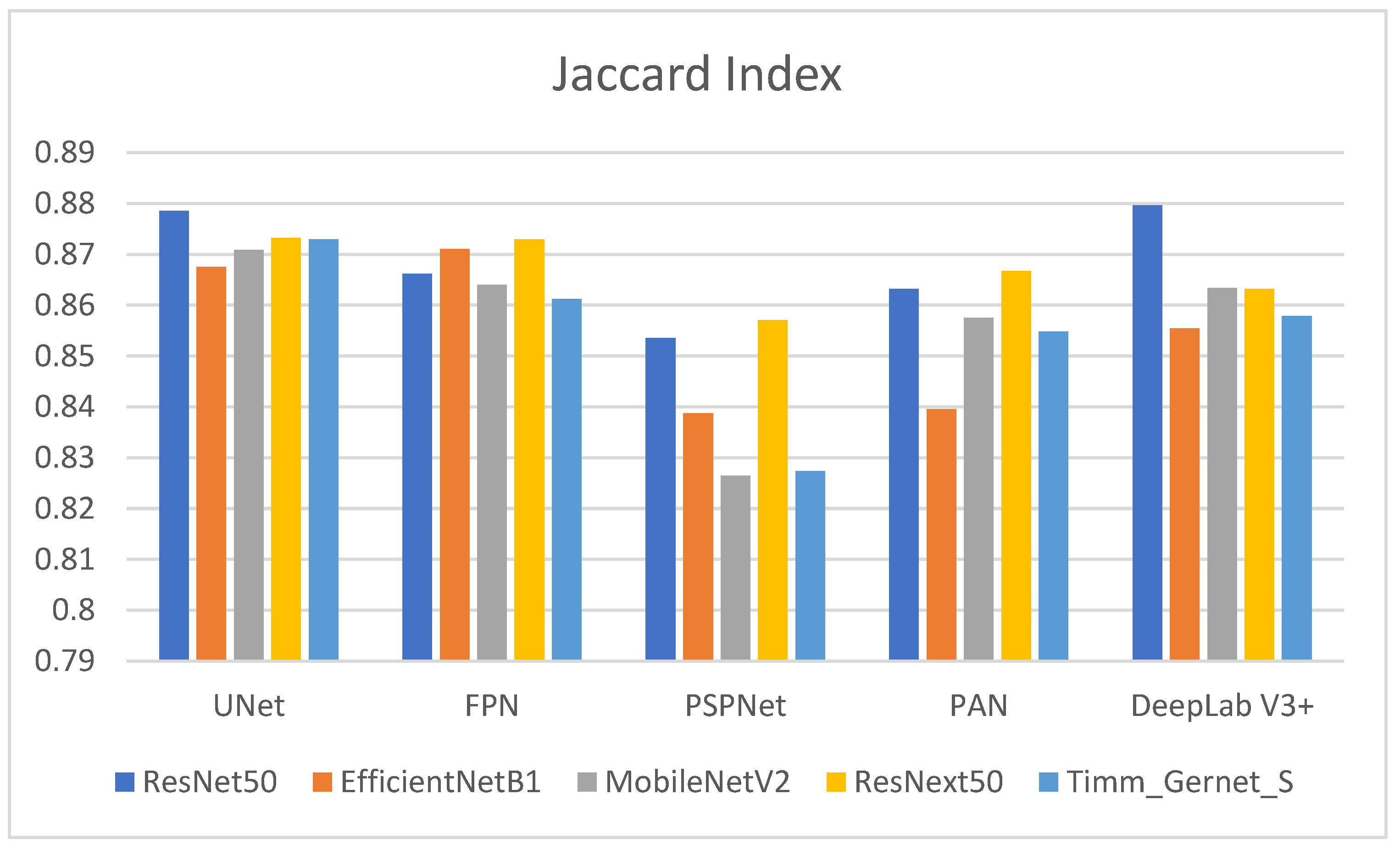
4.3. Analysis of Encoder–Decoder Variants Based on the Jaccard Index
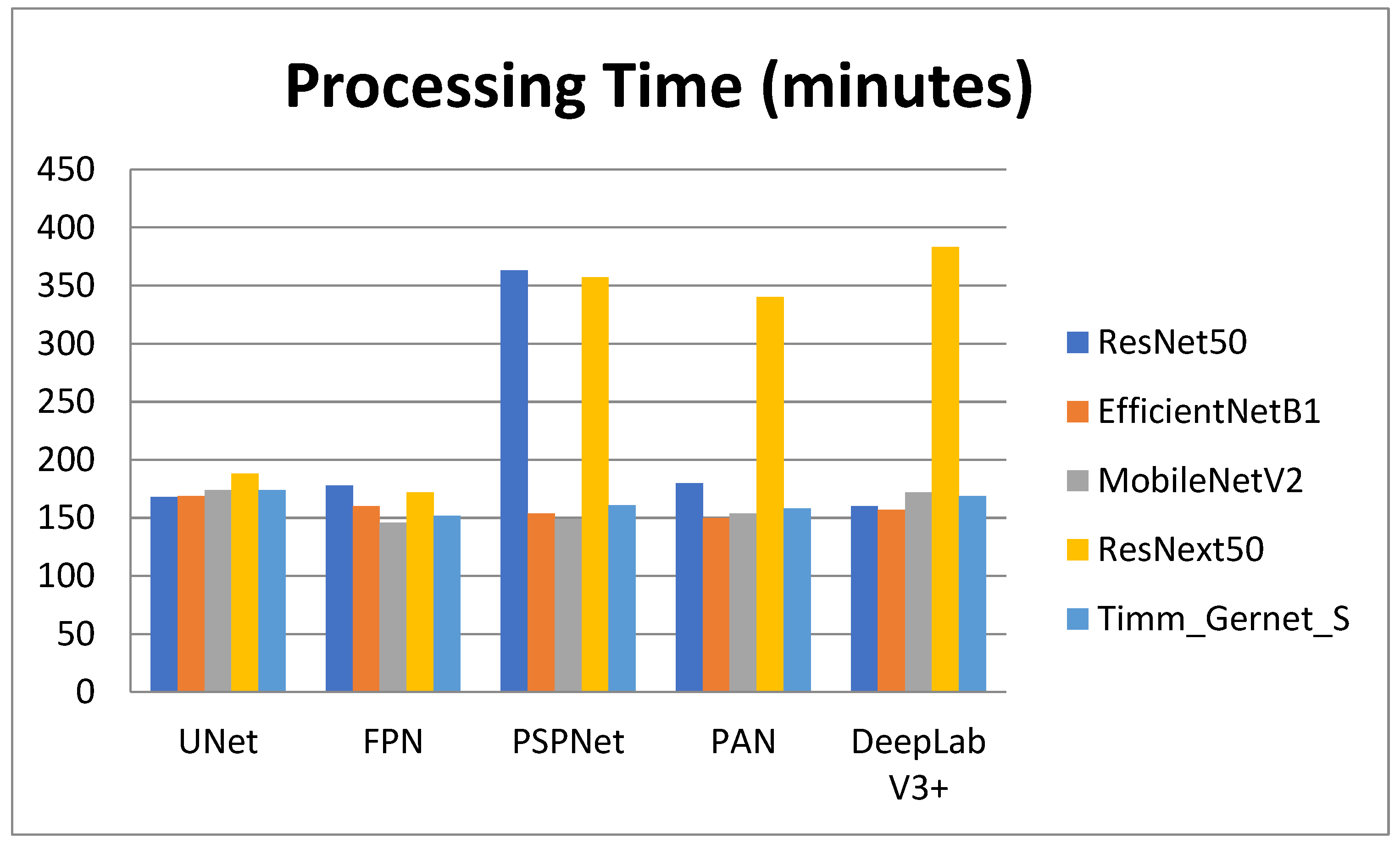
4.4. Analysis of Encoder–Decoder Variants Based on Processing Time
4.5. Fine-Tuning of the Proposed Model Using Optimizers
4.6. Ablation Study of the Proposed Model
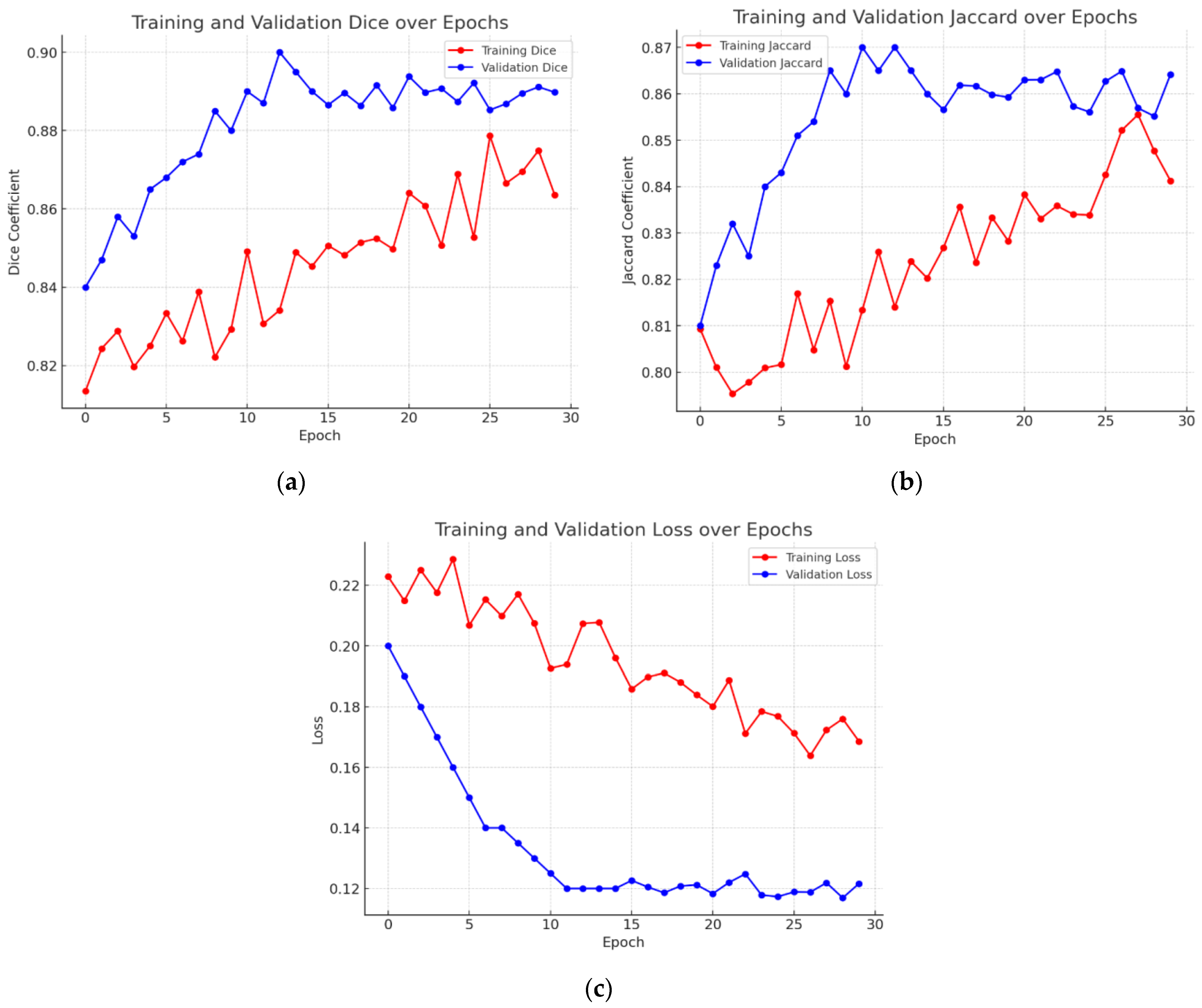
4.7. Graphical Analysis of Proposed Model
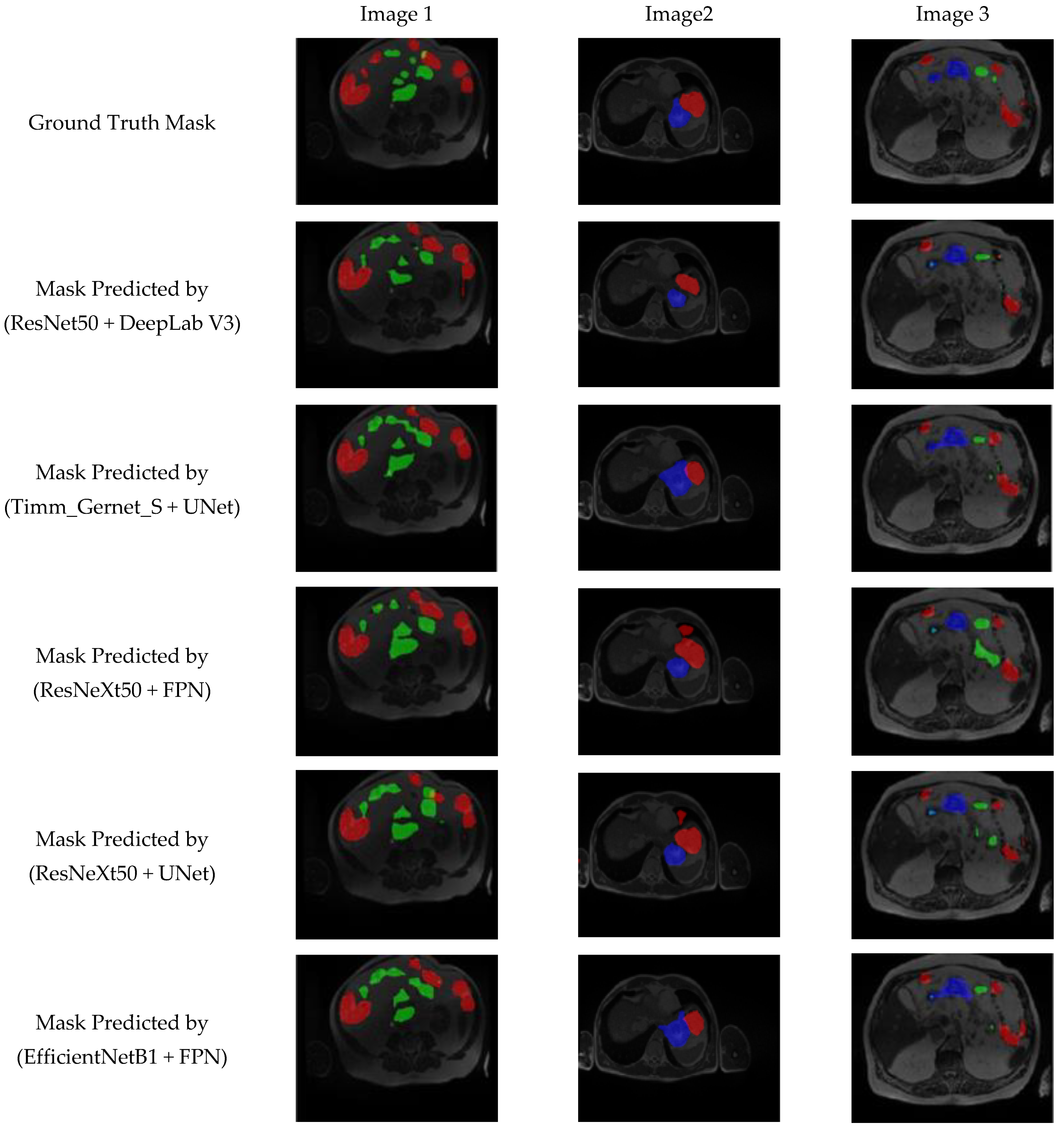
4.8. Visual Analysis of Proposed Model Segmentation Map
5. State-of-the-Art Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lafraxo, S.; El Ansari, M. GastroNet: Abnormalities Recognition in Gastrointestinal Tract through Endoscopic Imagery using Deep Learning Techniques. In Proceedings of the 2020 8th International Conference on Wireless Networks and Mobile Communications (WINCOM), Reims, France, 27–29 October 2020; pp. 1–5. [Google Scholar]
- Diamantis, D.E.; Zacharia, A.E.; Iakovidis, D.K.; Koulaouzidis, A. Towards the substitution of real with artificially generated endoscopic images for CNN training. In Proceedings of the 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE), Athens, Greece, 28–30 October 2019; pp. 519–524. [Google Scholar]
- Yogapriya, J.; Chandran, V.; Sumithra, M.G.; Anitha, P.; Jenopaul, P.; Suresh Gnana Dhas, C. Gastrointestinal tract disease classification from wireless endoscopy images using pretrained deep learning model. Comput. Math. Methods Med. 2021, 2021, 5940433. [Google Scholar] [CrossRef] [PubMed]
- Nemani, P.; Vollala, S. Medical Image Segmentation using LeViT-UNet++: A Case Study on GI Tract Data. arXiv 2022, arXiv:2209.07515. [Google Scholar]
- Ye, R.; Wang, R.; Guo, Y.; Chen, L. SIA-Unet: A Unet with Sequence Information for Gastrointestinal Tract Segmentation. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Shanghai, China, 10–13 November 2022; Springer: Cham, Switzerland, 2022; pp. 316–326. [Google Scholar]
- Chou, A.; Li, W.; Roman, E. GI Tract Image Segmentation with U-Net and Mask R-CNN. CS231n: Deep Learning for Computer Vision, Stanford University. 2022. Available online: https://cs231n.stanford.edu/reports/2022/pdfs/164.pdf (accessed on 1 February 2025).
- UW-Madison GI Tract Image Segmentation. Available online: https://www.kaggle.com/competitions/uw-madison-gi-tract-image-segmentation/data (accessed on 1 February 2025).
- Niu, H.; Lin, Y. SER-UNet: A Network for Gastrointestinal Image Segmentation. In Proceedings of the 2022 2nd International Conference on Control and Intelligent Robotics, Nanjing, China, 24–26 June 2022; pp. 227–230. [Google Scholar]
- Li, H.; Liu, J. Multi-view Unet for Automated GI Tract Segmentation. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 1067–1072. [Google Scholar]
- Tang, S.; Yu, X.; Cheang, C.F.; Liang, Y.; Zhao, P.; Yu, H.H.; Choi, I.C. Transformer-based multi-task learning for classification and segmentation of gastrointestinal tract endoscopic images. Comput. Biol. Med. 2023, 153, 106723. Available online: https://pubmed.ncbi.nlm.nih.gov/36907035/ (accessed on 1 February 2025). [CrossRef] [PubMed]
- Georgescu, M.I.; Ionescu, R.T.; Miron, A.I. Diversity-Promoting Ensemble for Medical Image Segmentation. arXiv 2022, arXiv:2210.12388. [Google Scholar]
- Sharma, M. Automated GI tract segmentation using deep learning. arXiv 2022, arXiv:2206.11048. [Google Scholar]
- Sai, M.J.; Punn, N.S. LWU-Net approach for efficient gastro-intestinal tract image segmentation in resource-constrained environments. medRxiv 2023. [Google Scholar] [CrossRef]
- Guggari, S.; Srivastava, B.C.; Kumar, V.; Harshita, H.; Farande, V.; Kulkarni, U.; Meena, S.M. RU-Net: A Novel Approach for Gastrointestinal Tract Image Segmentation Using Convolutional Neural Network. In Proceedings of the International Conference on Applied Machine Learning and Data Analytics, Tamaulipas, Mexico, 22–23 December 2022; Springer Nature: Cham, Switzerland, 2022; pp. 131–141. [Google Scholar]
- Qiu, Y. Upernet-Based Deep Learning Method for The Segmentation of Gastrointestinal Tract Images. In Proceedings of the 2023 8th International Conference on Multimedia and Image Processing, Tianjin, China, 21–23 April 2023; pp. 34–39. [Google Scholar]
- Jiang, X.; Ding, Y.; Liu, M.; Wang, Y.; Li, Y.; Wu, Z. BiFTransNet: A unified and simultaneous segmentation network for gastrointestinal images of CT & MRI. Comput. Biol. Med. 2023, 165, 107326. [Google Scholar]
- John, S.V.; Benifa, B. Automated Segmentation of Tracking Healthy Organs from Gastrointestinal Tumor Images. In Proceedings of the International Conference on Frontiers of Intelligent Computing: Theory and Applications, Cardiff, UK, 11–12 April 2023; Springer Nature: Singapore, 2023; pp. 363–373. [Google Scholar]
- Zhou, H.; Lou, Y.; Xiong, J.; Wang, Y.; Liu, Y. Improvement of deep learning model for gastrointestinal tract segmentation surgery. Front. Comput. Intell. Syst. 2023, 6, 103–106. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, Y.; Cui, D.; Li, X.; Shen, X. Deepgi: An automated approach for gastrointestinal tract segmentation in mri scans. arXiv 2024, arXiv:2401.15354. [Google Scholar]
- Devi, S.A.; Gunta, S.; Gutta, S.A.; Kataru, B.A.; Valeti, G. Attentional deep learning based efficient AGSDCLR unet model for gastrointestinal tract segmentation. Biomed. Signal Process. Control. 2025, 100, 106847. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Benkrama, S.; Hemdani, N.E.H. Deep Learning with EfficientNetB1 for detecting brain tumors in MRI images. In Proceedings of the 2023 International Conference on Advances in Electronics, Control and Communication Systems (ICAECCS), Blida, Algeria, 6–7 March 2023; pp. 1–6. [Google Scholar]
- Gulzar, Y. Fruit image classification model based on MobileNetV2 with deep transfer learning technique. Sustainability 2023, 15, 1906. [Google Scholar] [CrossRef]
- Hira, S.; Bai, A.; Hira, S. An automatic approach based on CNN architecture to detect COVID-19 disease from chest X-ray images. Appl. Intell. 2021, 51, 2864–2889. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.N.; Tran, T.D.; Cuong, P.V. Segmentation of Concrete Surface Cracks Using DeeplabV3+ Architecture. In Proceedings of the International Conference on Sustainable Civil Engineering and Architecture, Da Nang City, Vietnam, 19–21 July 2023; Springer Nature: Singapore, 2023; pp. 1531–1538. [Google Scholar]
- Sivagami, S.; Chitra, P.; Kailash GS, R.; Muralidharan, S.R. Unet architecture based dental panoramic image segmentation. In Proceedings of the 2020 International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 4–6 August 2020; pp. 187–191. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, H.; Li, X.; Feng, Y.; Han, S. Multiple attentional path aggregation network for marine object detection. Appl. Intell. 2023, 53, 2434–2451. [Google Scholar] [CrossRef]
- Wang, J.; Liu, X. Medical image recognition and segmentation of pathological slices of gastric cancer based on Deeplab v3+ neural network. Comput. Methods Programs Biomed. 2021, 207, 106210. [Google Scholar] [CrossRef] [PubMed]
- Su, Y.; Tian, X.; Gao, R.; Guo, W.; Chen, C.; Jia, D.; Li, H.; Lv, X. Colon cancer diagnosis and staging classification based on machine learning and bioinformatics analysis. Comput. Biol. Med. 2022, 145, 105409. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Chen, Y.; Ye, Z.; Yu, H.; Chan, K.F.; Xu, T.; Guo, Z.; Liu, W.; Zhang, L. Low-Friction Soft Robots for Targeted Bacterial Infection Treatment in Gastrointestinal Tract. Cyborg Bionic Syst. 2024, 5, 0138. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Wang, Z.; Guan, Z.; Miao, J.; Li, W.; Yu, P.; Jimenez, C.M. UCFN Net: Ulcerative colitis evaluation based on fine-grained lesion learner and noise suppression gating. Comput. Methods Programs Biomed. 2024, 247, 108080. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Wang, X.; Guo, Y.; Li, S.; Xia, B.; Hao, A. CenterFormer: A Novel Cluster Center Enhanced Transformer for Unconstrained Dental Plaque Segmentation. IEEE Trans. Multimedia 2024, 26, 10965–10978. [Google Scholar] [CrossRef]
- Nobel, S.M.N.; Sifat, O.F.; Islam, M.R.; Sayeed, M.S.; Amiruzzaman, M. Enhancing GI Cancer Radiation Therapy: Advanced Organ Segmentation with ResECA-U-Net Model. Emerg. Sci. J. 2024, 8, 999–1015. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UNet | FPN | PSPNet | PAN | DeepLab V3+ | |
|---|---|---|---|---|---|
| ResNet50 | 0.1239 | 0.1256 | 0.1323 | 0.1289 | 0.1177 |
| EfficientNetB1 | 0.1287 | 0.1270 | 0.1469 | 0.1461 | 0.1758 |
| MobileNetV2 | 0.1243 | 0.1321 | 0.1572 | 0.1413 | 0.1341 |
| ResNext50 | 0.1232 | 0.1239 | 0.1305 | 0.1265 | 0.1303 |
| Timm_Gernet_S | 0.1265 | 0.1364 | 0.1336 | 0.1468 | 0.1435 |
| UNet | FPN | PSPNet | PAN | DeepLab V3+ | |
|---|---|---|---|---|---|
| ResNet50 | 0.8970 | 0.8957 | 0.8847 | 0.8931 | 0.9082 |
| EfficientNetB1 | 0.8971 | 0.9005 | 0.8716 | 0.8724 | 0.8292 |
| MobileNetV2 | 0.8997 | 0.8940 | 0.8602 | 0.8887 | 0.8937 |
| ResNext50 | 0.9015 | 0.9020 | 0.8881 | 0.8961 | 0.8927 |
| Timm_Gernet_S | 0.9021 | 0.8915 | 0.8608 | 0.8864 | 0.8886 |
| UNet | FPN | PSPNet | PAN | DeepLab V3+ | |
|---|---|---|---|---|---|
| ResNet50 | 0.8786 | 0.8662 | 0.8535 | 0.8632 | 0.8796 |
| EfficientNetB1 | 0.8675 | 0.8711 | 0.8387 | 0.8395 | 0.8554 |
| MobileNetV2 | 0.8709 | 0.8640 | 0.8264 | 0.8575 | 0.8634 |
| ResNext50 | 0.8732 | 0.8730 | 0.8571 | 0.8667 | 0.8632 |
| Timm_Gernet_S | 0.8730 | 0.8612 | 0.8273 | 0.8548 | 0.8579 |
| UNet | FPN | PSPNet | PAN | DeepLab V3+ | |
|---|---|---|---|---|---|
| ResNet50 | 2 h 48 m 37 s | 2 h 58 m 26 s | 6 h 3 m 33 s | 3 h 0 m 28 s | 2 h 40 m 46 s |
| EfficientNetB1 | 2 h 49 m 20 s | 2 h 40 m 56 s | 2 h 34 m 0 s | 2 h 30 m 39 s | 2 h 37 m 40 s |
| MobileNetV2 | 2 h 54 m 55 s | 2 h 26 m 33 s | 2 h 29 m 2 s | 2 h 34 m 9 s | 2 h 52 m 8 s |
| ResNext50 | 3 h 8 m 32 s | 2 h 52 m 13 s | 5 h 57 m 37 s | 5 h 40 m 39 s | 6 h 23 m 17 s |
| Timm_Gernet_S | 2 h 54 m 3 s | 2 h 32 m 11 s | 2 h 41 m 47 s | 2 h 38 m 39 s | 2 h 49 m 29 s |
| Optimizer | Dice Coefficient (Mean ± Std) | Jaccard Index (Mean ± Std) | Loss (Mean ± Std) |
|---|---|---|---|
| SGD | 0.8889 ± 0.0042 | 0.8583 ± 0.0038 | 0.1352 ± 0.0027 |
| RMS Prop | 0.8878 ± 0.0039 | 0.8581 ± 0.0041 | 0.1362 ± 0.0029 |
| Adam | 0.9082 ± 0.0051 | 0.8796 ± 0.0047 | 0.1177 ± 0.0032 |
| Model | Dice Coefficent | Jaccard Index | Loss |
|---|---|---|---|
| DeepLab V3+ | 0.8372 | 0.8075 | 0.2013 |
| DeepLab V3+ with ResNet 50 Encoder | 0.8586 | 0.8369 | 0.1985 |
| DeepLab V3+ with ResNet 50 Encoder and Data Augmentation | 0.8856 | 0.8510 | 0.1425 |
| DeepLab V3+ with ResNet 50 Encoder, Data Augmentation and Adam Oprimizer | 0.9082 | 0.8796 | 0.1177 |
| Ref. No. | Year | Technique | Results |
|---|---|---|---|
| [4] | 2022 | CNN with Transformers | Dice-0.79 IoU-0.72 |
| [5] | 2022 | SIA-Unet | IoU-0.65 |
| [6] | 2022 | U-Net + Mask R-CNN | Dice-0.73 |
| [8] | 2022 | Unet for 2.5D | Dice-0.63 IoU-0.56 |
| [9] | 2022 | UNet with ResNet 50 | IoU-0.78 |
| [11] | 2022 | ResNet, EfficientNet, VGG16, and MobileNet encoders with UNet | IoU-0.84 |
| [15] | 2023 | Swin Transformer with EfficientNet B4 | Dice-0.8682 |
| [16] | 2023 | BiFTransNet transformer-based model | Dice-0.8951 |
| [17] | 2023 | UNet with EfficientNet B7 | Dice-0.8991 IoU-0.8693 |
| Proposed model | Proposed DeepLab V3+ Model with ResNet 50 Encoder | Dice-0.9082, IoU-0.8796 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, N.; Gupta, S.; Elkamchouchi, D.H.; Bharany, S. Encoder–Decoder Variant Analysis for Semantic Segmentation of Gastrointestinal Tract Using UW-Madison Dataset. Bioengineering 2025, 12, 309. https://doi.org/10.3390/bioengineering12030309
Sharma N, Gupta S, Elkamchouchi DH, Bharany S. Encoder–Decoder Variant Analysis for Semantic Segmentation of Gastrointestinal Tract Using UW-Madison Dataset. Bioengineering. 2025; 12(3):309. https://doi.org/10.3390/bioengineering12030309
Chicago/Turabian StyleSharma, Neha, Sheifali Gupta, Dalia H. Elkamchouchi, and Salil Bharany. 2025. "Encoder–Decoder Variant Analysis for Semantic Segmentation of Gastrointestinal Tract Using UW-Madison Dataset" Bioengineering 12, no. 3: 309. https://doi.org/10.3390/bioengineering12030309
APA StyleSharma, N., Gupta, S., Elkamchouchi, D. H., & Bharany, S. (2025). Encoder–Decoder Variant Analysis for Semantic Segmentation of Gastrointestinal Tract Using UW-Madison Dataset. Bioengineering, 12(3), 309. https://doi.org/10.3390/bioengineering12030309