
Geometric Self-Supervised Learning: A Novel AI Approach Towards Quantitative and Explainable Diabetic Retinopathy Detection

Abstract
1. Introduction
2. Methods and Materials
2.1. Study Cohorts
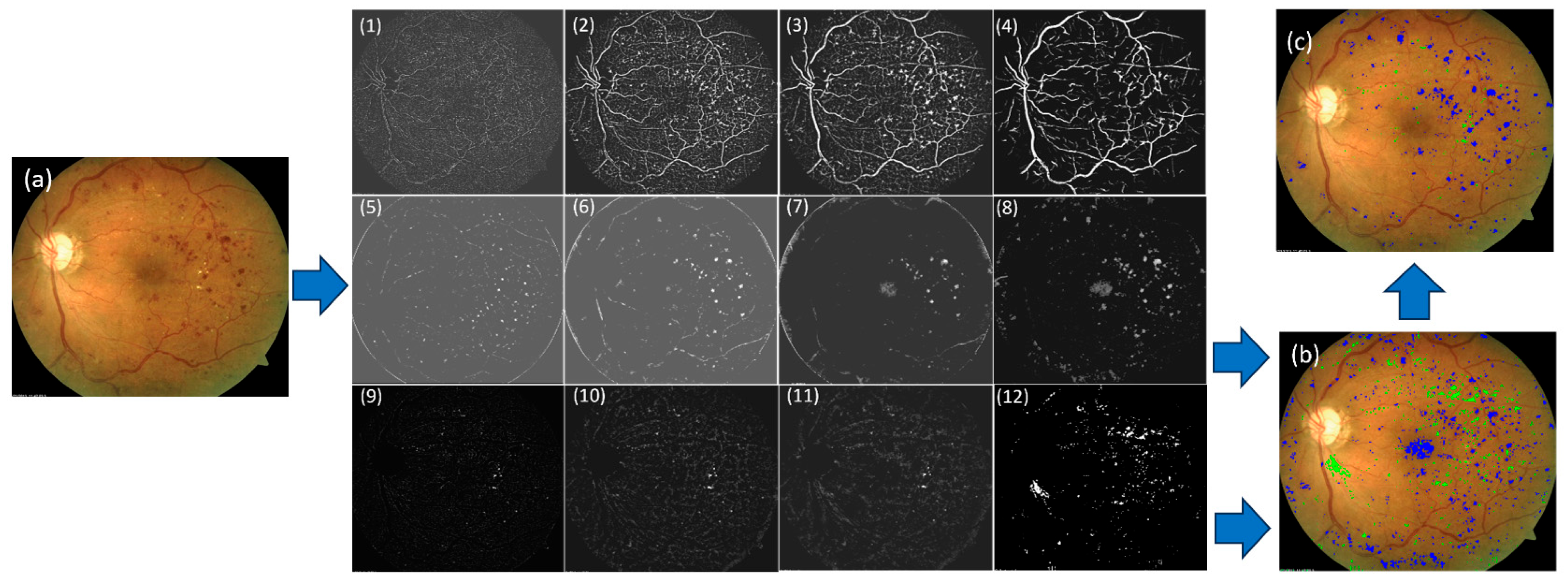
2.2. Algorithm Overview
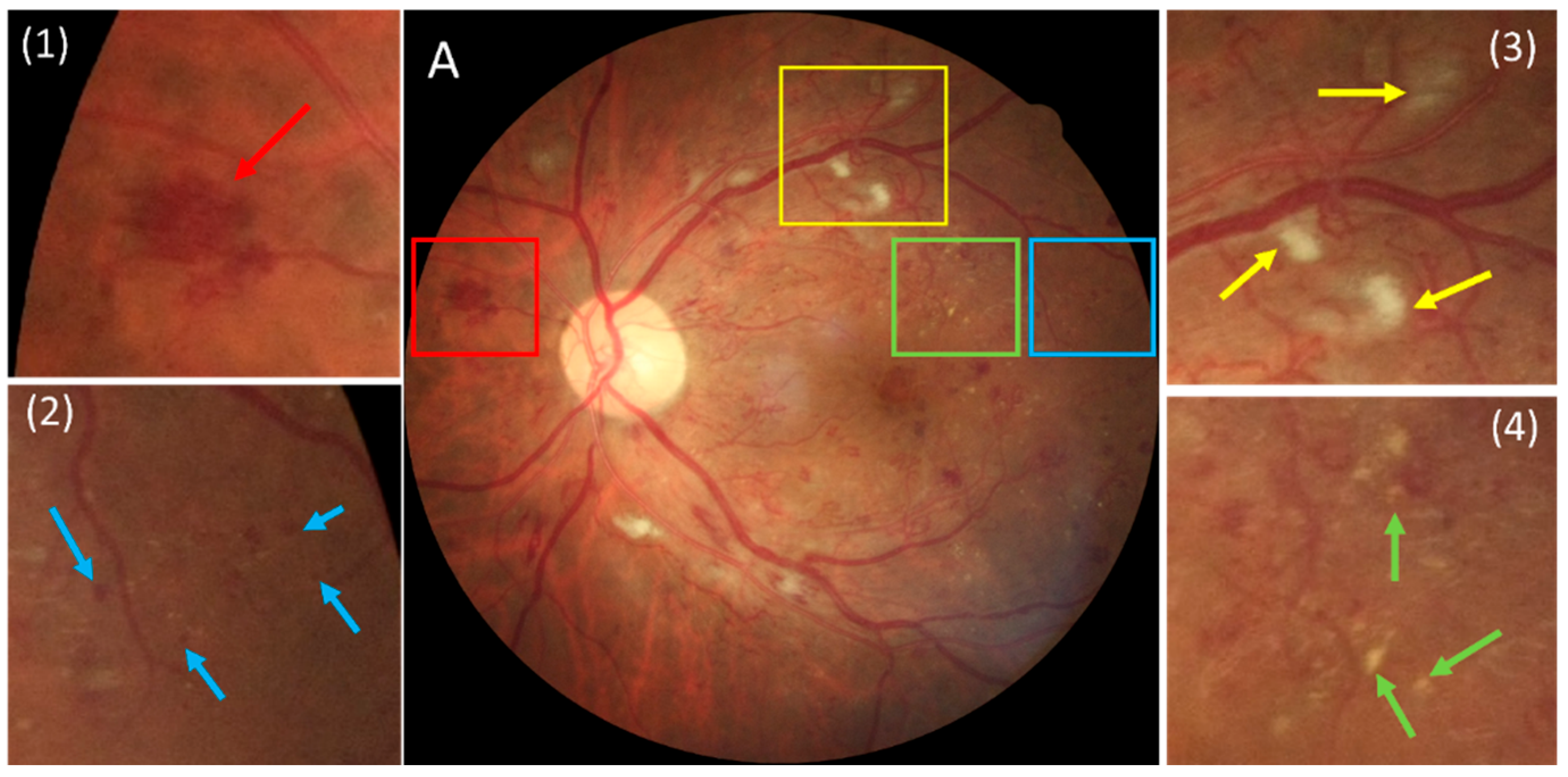
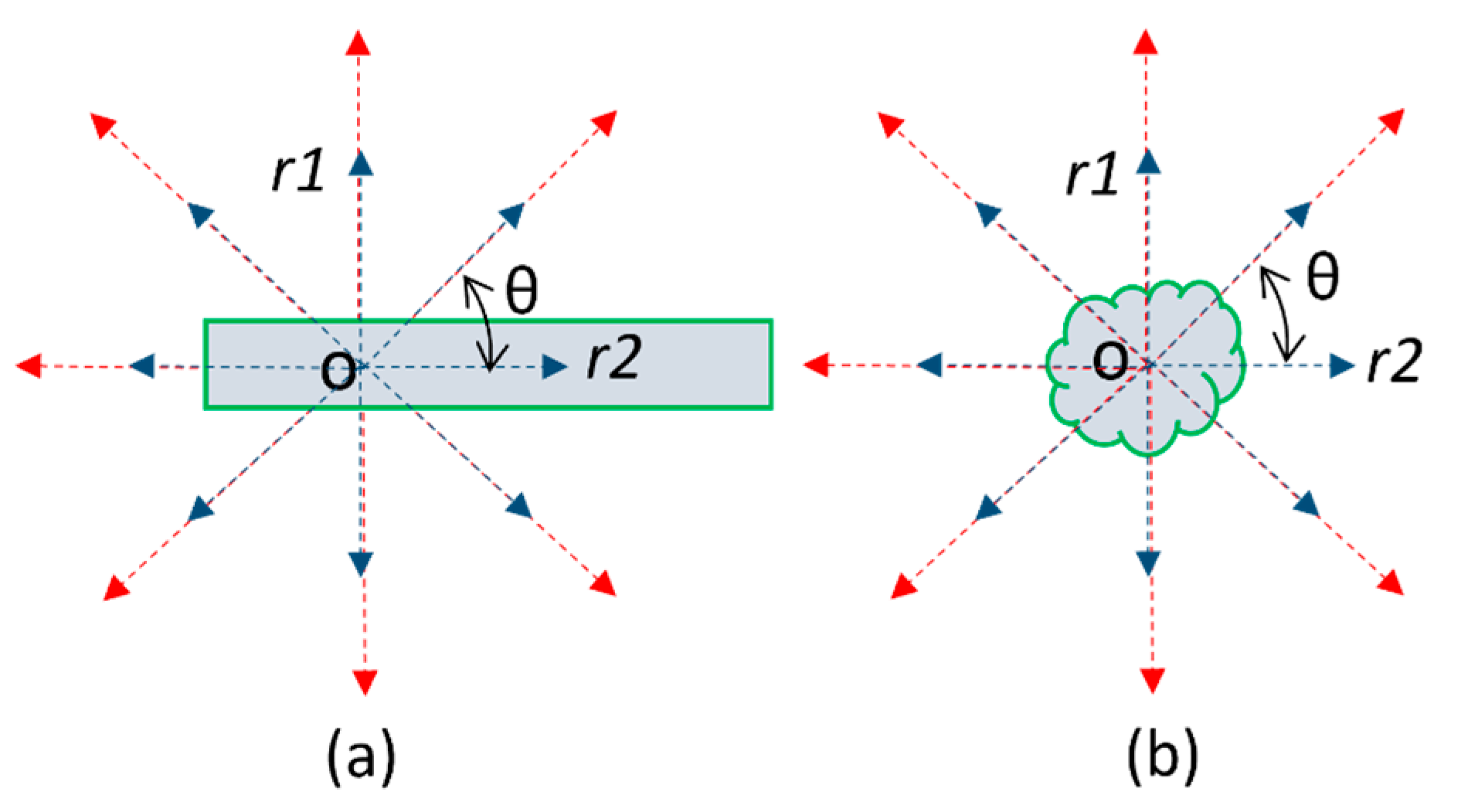
2.3. A Multiscale Contrast Shape Descriptor (MCSD)
2.4. Scoring of Identified Regions to Determine Their Confidence Levels
2.5. Rule-Based Differentiation of DR Lesion Types
2.6. Training a CNN-Based Segmentation for Detecting and Segmenting DR Lesions
2.7. Performance Evaluation
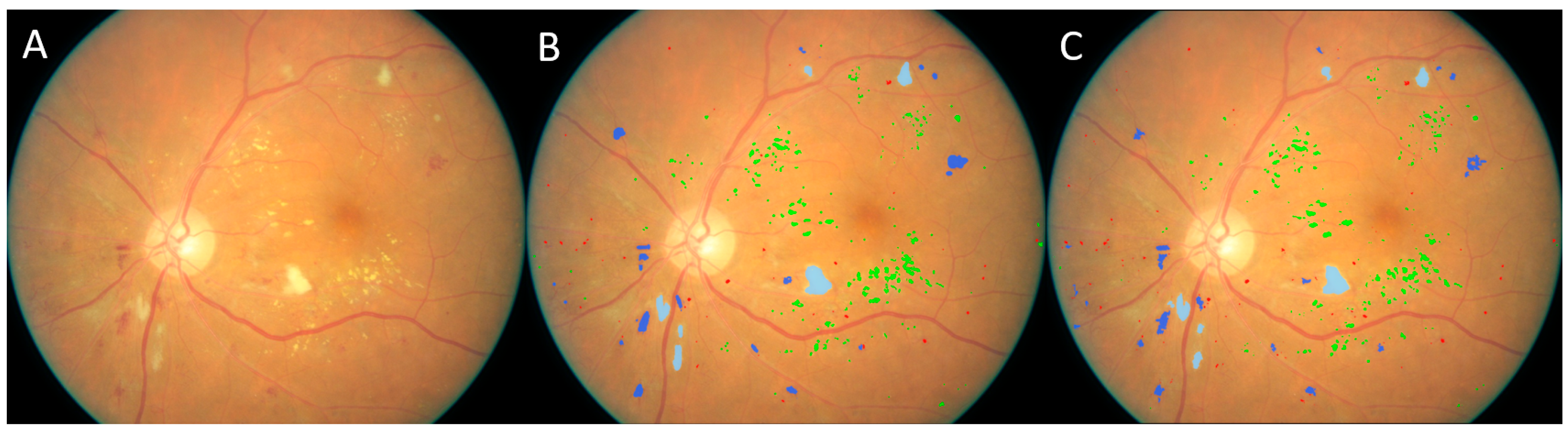
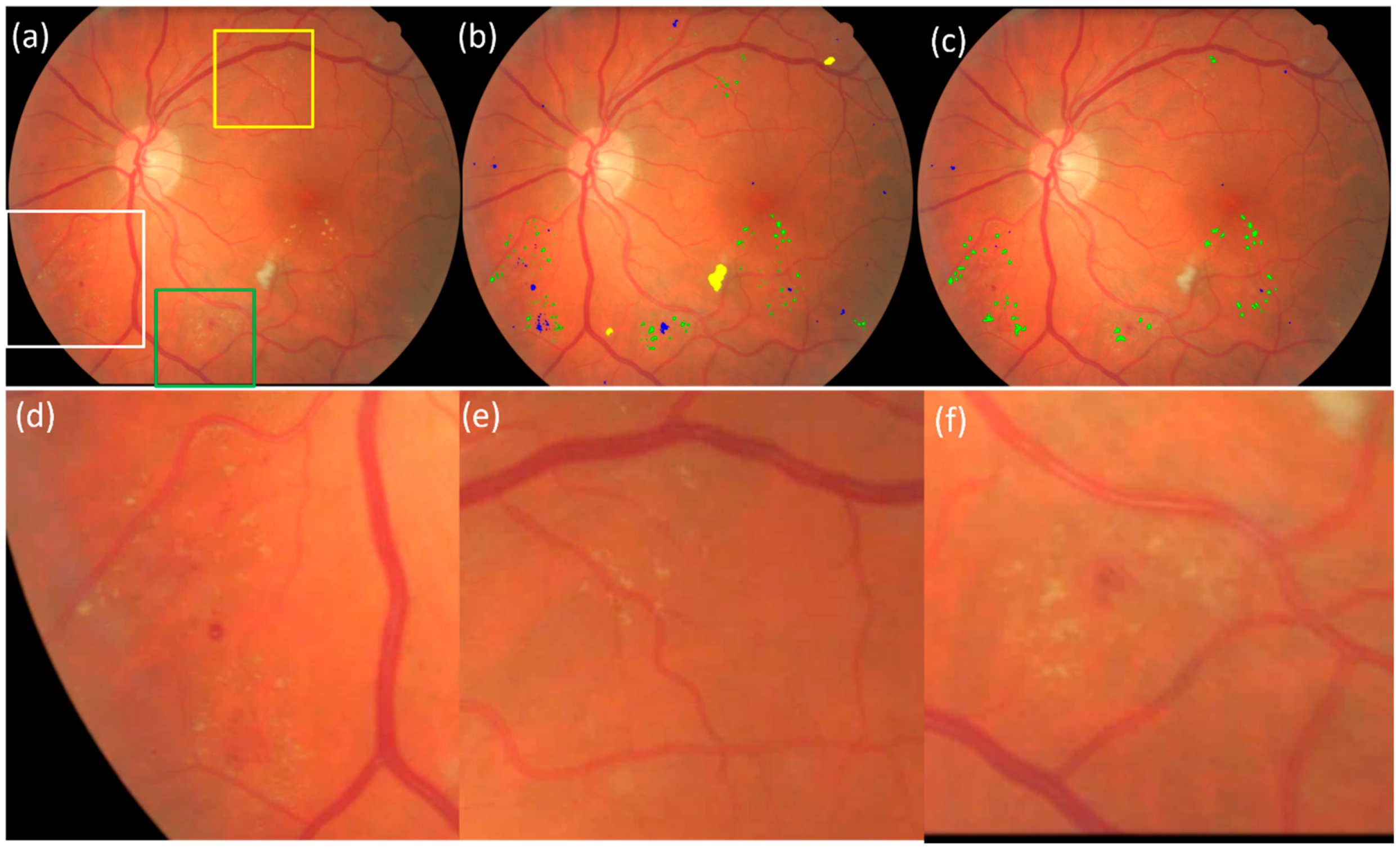
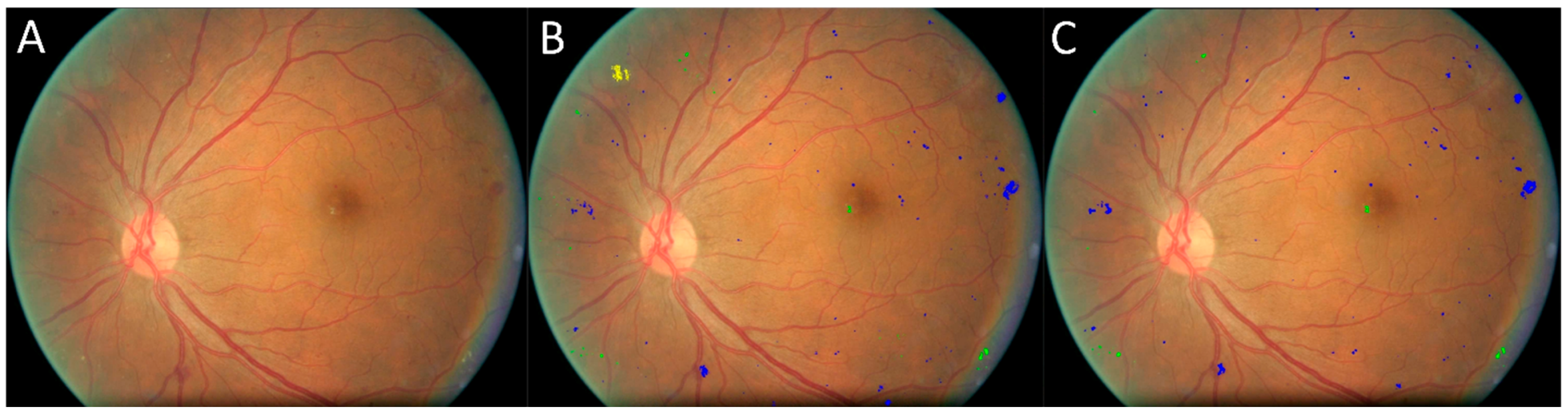
3. Results
3.1. Validation on the Kaggle-CFP Independent Test Set
3.2. Validation on the E-Ophtha Cohort
3.3. Validation on the UWF Independent Test Set
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Diabetes Around the World in 2021. Available online: https://idf.org/about-diabetes/diabetes-facts-figures/ (accessed on 24 February 2024).
- Fong, D.S.; Aiello, L.; Gardner, T.W.; King, G.L.; Blankenship, G.; Cavallerano, J.D.; Ferris, F.L., III; Klein, R.; American Diabetes, A. Diabetic Retinopathy. Diabetes Care 2003, 26, 226–229. [Google Scholar] [CrossRef] [PubMed]
- Flaxel, C.J.; Adelman, R.A.; Bailey, S.T.; Fawzi, A.; Lim, J.I.; Vemulakonda, G.A.; Ying, G.S. Diabetic Retinopathy Preferred Practice Pattern(R). Ophthalmology 2020, 127, P66–P145. [Google Scholar] [CrossRef] [PubMed]
- Klein, R.; Lee, K.E.; Gangnon, R.E.; Klein, B.E. The 25-year incidence of visual impairment in type 1 diabetes mellitus the wisconsin epidemiologic study of diabetic retinopathy. Ophthalmology 2010, 117, 63–70. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Resnikoff, S.; Lansingh, V.C.; Washburn, L.; Felch, W.; Gauthier, T.M.; Taylor, H.R.; Eckert, K.; Parke, D.; Wiedemann, P. Estimated number of ophthalmologists worldwide (International Council of Ophthalmology update): Will we meet the needs? Br. J. Ophthalmol. 2020, 104, 588–592. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Yim, D.; Chandra, S.; Sondh, R.; Thottarath, S.; Sivaprasad, S. Barriers in establishing systematic diabetic retinopathy screening through telemedicine in low- and middle-income countries. Indian. J. Ophthalmol. 2021, 69, 2987–2992. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Why Is AI Adoption in Health Care Lagging? Available online: https://www.brookings.edu/articles/why-is-ai-adoption-in-health-care-lagging/ (accessed on 9 March 2022).
- Yang, Z.; Tan, T.E.; Shao, Y.; Wong, T.Y.; Li, X. Classification of diabetic retinopathy: Past, present and future. Front. Endocrinol. 2022, 13, 1079217. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Chudzik, P.; Majumdar, S.; Caliva, F.; Al-Diri, B.; Hunter, A. Microaneurysm detection using fully convolutional neural networks. Comput. Methods Programs Biomed. 2018, 158, 185–192. [Google Scholar] [CrossRef] [PubMed]
- Tan, J.H.; Fujita, H.; Sivaprasad, S.; Bhandary, S.V.; Rao, A.K.; Chua, K.C.; Acharya, U.R. Automated segmentation of exudates, haemorrhages, microaneurysms using single convolutional neural network. Inf. Sci. 2017, 420, 66–76. [Google Scholar] [CrossRef]
- Orlando, J.I.; Prokofyeva, E.; Del Fresno, M.; Blaschko, M.B. An ensemble deep learning based approach for red lesion detection in fundus images. Comput. Methods Programs Biomed. 2018, 153, 115–127. [Google Scholar] [CrossRef] [PubMed]
- Benzamin, A.; Chakraborty, C. Detection of Hard Exudates in Retinal Fundus Images Using Deep Learning. In Proceedings of the 2018 IEEE International Conference on System, Computation, Automation and Networking (ICSCA), Pondicherry, India, 6–7 July 2018; pp. 1–5. [Google Scholar]
- Diabetic Retinopathy Detection. Available online: https://www.kaggle.com/competitions/diabetic-retinopathy-detection/data (accessed on 1 July 2022).
- Decencière, E.; Cazuguel, G.; Zhang, X.; Thibault, G.; Klein, J.C.; Meyer, F.; Marcotegui, B.; Quellec, G.; Lamard, M.; Danno, R.; et al. TeleOphta: Machine learning and image processing methods for teleophthalmology. IRBM 2013, 34, 196–203. [Google Scholar] [CrossRef]
- Liu, R.; Wang, X.; Wu, Q.; Dai, L.; Fang, X.; Yan, T.; Son, J.; Tang, S.; Li, J.; Gao, Z.; et al. DeepDRiD: Diabetic Retinopathy-Grading and Image Quality Estimation Challenge. Patterns 2022, 3, 100512. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Dashtbozorg, B.; Zhang, J.; Huang, F.; Ter Haar Romeny, B.M. Retinal Microaneurysms Detection Using Local Convergence Index Features. IEEE Trans. Image Process 2018, 27, 3300–3315. [Google Scholar] [CrossRef] [PubMed]
- Melo, T.; Mendonca, A.M.; Campilho, A. Microaneurysm detection in color eye fundus images for diabetic retinopathy screening. Comput. Biol. Med. 2020, 126, 103995. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Cao, Z.; Liao, D.; Lv, R. A Magnified Adaptive Feature Pyramid Network for automatic microaneurysms detection. Comput. Biol. Med. 2021, 139, 105000. [Google Scholar] [CrossRef] [PubMed]
- Eftekhari, N.; Pourreza, H.R.; Masoudi, M.; Ghiasi-Shirazi, K.; Saeedi, E. Microaneurysm detection in fundus images using a two-step convolutional neural network. Biomed. Eng. Online 2019, 18, 67. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Liu, Q.; Zou, B.; Chen, J.; Ke, W.; Yue, K.; Chen, Z.; Zhao, G. A location-to-segmentation strategy for automatic exudate segmentation in colour retinal fundus images. Comput. Med. Imaging Graph. 2017, 55, 78–86. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Thibault, G.; Decenciere, E.; Marcotegui, B.; Lay, B.; Danno, R.; Cazuguel, G.; Quellec, G.; Lamard, M.; Massin, P.; et al. Exudate detection in color retinal images for mass screening of diabetic retinopathy. Med. Image Anal. 2014, 18, 1026–1043. [Google Scholar] [CrossRef] [PubMed]
- Fraz, M.M.; Jahangir, W.; Zahid, S.; Hamayun, M.M.; Barman, S.A. Multiscale segmentation of exudates in retinal images using contextual cues and ensemble classification. Biomed. Signal Process. Control. 2017, 35, 50–62. [Google Scholar] [CrossRef]
- Das, V.; Puhan, N.B. Tsallis entropy and sparse reconstructive dictionary learning for exudate detection in diabetic retinopathy. J. Med. Imaging 2017, 4, 024002. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Piotr, C.; Somshubra, M.; Francesco, C.; Bashir, A.-D.; Andrew, H. (Eds.) Exudate Segmentation Using Fully Convolutional Neural Networks and Inception Modules; ProcSPIE: St Bellingham, WA, USA, 2018. [Google Scholar]
- Piotr, C.; Somshubra, M.; Francesco, C.; Bashir, A.-D.; Andrew, H. (Eds.) Microaneurysm Detection Using Deep Learning and Interleaved Freezing; ProcSPIE: St Bellingham, WA, USA, 2018. [Google Scholar]
- Wu, B.; Zhu, W.; Shi, F.; Zhu, S.; Chen, X. Automatic detection of microaneurysms in retinal fundus images. Comput. Med. Imaging Graph. 2017, 55, 106–112. [Google Scholar] [CrossRef] [PubMed]
- Canadian Ophthalmological Society Diabetic Retinopathy Clinical Practice Guideline Expert Committee; Hooper, P.; Boucher, M.C.; Cruess, A.; Dawson, K.G.; Delpero, W.; Greve, M.; Kozousek, V.; Lam, W.C.; Maberley, D.A. Canadian Ophthalmological Society Evidence-based Clinical Practice Guidelines for the Management of Diabetic Retinopathy—Executive summary. Can. J. Ophthalmol. 2012, 47, 91–96. [Google Scholar] [CrossRef] [PubMed]
- Harding, S.; Greenwood, R.; Aldington, S.; Gibson, J.; Owens, D.; Taylor, R.; Kohner, E.; Scanlon, P.; Leese, G.; Diabetic Retinopathy Grading and Disease Management Working Party. Grading and disease management in national screening for diabetic retinopathy in England and Wales. Diabet. Med. 2003, 20, 965–971. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DR Lesions | Count in Manual Results | Sensitivity | False Positives (Per Image) |
|---|---|---|---|
| Microaneurysm | 797 | 91.5% (729/797) | 9.04 (452/50) |
| Hemorrhage | 1623 | 92.6% (1503/1623) | 2.26 (113/50) |
| Hard exudates | 2319 | 92.3% (2140/2319) | 7.72 (386/50) |
| Soft exudates | 86 | 90.7% (78/86) | 0.18 (9/50) |
| Methods | Exudates | Microaneurysms | ||
|---|---|---|---|---|
| Sensitivity | False Positives | Sensitivity | False Positives | |
| (Liu et al., 2017) [21] | 0.760 | – | – | – |
| (Zhang et al., 2014) [22] | 0.740 | – | – | – |
| (Fraz et al., 2017) [23] | 0.812 | – | – | – |
| (Das et al., 2017) [24] | 0.858 | – | – | – |
| (Piotr et al., 2018) [25] | 0.846 | – | – | – |
| (Dashtbozorg et al., 2018) [17] | – | – | 0.638 | 8.0 |
| (Piotr et al., 2018) [26] | – | – | 0.621 | 8.0 |
| (Melo et al., 2020) [18] | – | – | 0.598 | 8.0 |
| (Eftekhari et al., 2019) [20] | – | – | 0.771 | 8.0 |
| (Sun et al., 2021) [19] | – | – | 0.835 | 8.0 |
| (Wu et al., 2017) [27] | – | – | 0.573 | 8.0 |
| (Orlando et al., 2018) [11] | – | – | 0.632 | 8.0 |
| Our method without correction * | 0.937 | 5.4 | 0.933 | 4.5 |
| Our method with correction * | 0.940 | 2.85 | 0.946 | 2.38 |
| Abnormal Findings | Spot Area (Pixels) | Count in Manual Results | Sensitivity | False Positives (Per Image) |
|---|---|---|---|---|
| Bleeding | (0,10) | 124 | 41.9% (52/124) | 6.48 |
| [10,50) | 457 | 68.5% (313/457) | 10.74 | |
| [50,100) | 179 | 84.9% (152/179) | 2.12 | |
| [100,∞) | 137 | 93.4% (128/137) | 5.80 | |
| Exudates | (0,10) | 252 | 86.9% (219/252) | 24.94 |
| [10,50) | 195 | 95.9% (187/195) | 37.10 | |
| [50,100) | 28 | 92.9% (26/28) | 33.96 | |
| [100,∞) | 26 | 96.2% (25/26) | 6.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, L.; Beale, O.; Meng, X. Geometric Self-Supervised Learning: A Novel AI Approach Towards Quantitative and Explainable Diabetic Retinopathy Detection. Bioengineering 2025, 12, 157. https://doi.org/10.3390/bioengineering12020157
Pu L, Beale O, Meng X. Geometric Self-Supervised Learning: A Novel AI Approach Towards Quantitative and Explainable Diabetic Retinopathy Detection. Bioengineering. 2025; 12(2):157. https://doi.org/10.3390/bioengineering12020157
Chicago/Turabian StylePu, Lucas, Oliver Beale, and Xin Meng. 2025. "Geometric Self-Supervised Learning: A Novel AI Approach Towards Quantitative and Explainable Diabetic Retinopathy Detection" Bioengineering 12, no. 2: 157. https://doi.org/10.3390/bioengineering12020157
APA StylePu, L., Beale, O., & Meng, X. (2025). Geometric Self-Supervised Learning: A Novel AI Approach Towards Quantitative and Explainable Diabetic Retinopathy Detection. Bioengineering, 12(2), 157. https://doi.org/10.3390/bioengineering12020157