1. Introduction
Glaucoma, a leading cause of permanent vision impairment worldwide [
1], demonstrates a particularly insidious nature in its initial phases due to the lack of observable symptoms. The number of glaucoma cases escalated to 64.3 million in 2013 and is projected to reach 113 million by 2040 [
2]. Regrettably, a significant number of individuals remain oblivious to their condition during the initial phases due to the lack of obvious symptoms. Glaucoma is characterized by intricate changes in the structure of the retina, resulting in considerable thinning of the retina, and the directional reflectivity of the RNFL also decreases with the functional progression of glaucoma [
3,
4]. This particular trait underscores the critical importance of early detection, as timely intervention plays a vital role in averting visual impairment and irreversible loss of vision [
1]. The utilization of fundus photographs serves to delineate the structural attributes of the eye, encompassing the retina, optic disc, macula, fovea, and posterior pole, all of which play a crucial role in visual acuity. The utilization of specialized equipment, such as fundus cameras or scanning laser ophthalmoscopes, is essential for capturing these images, thereby facilitating the identification and monitoring of various fundus disorders [
5].
However, the complex nature of initial pathological presentations and the rapid growth in the number of individuals impacted by glaucoma necessitate a significant amount of time and effort for the categorization of this condition, even among proficient ophthalmologists [
6]. Hence, the demand for automated methods in glaucoma classification is increasing in order to reduce the number of untreated individuals and alleviate the strain on healthcare professionals, particularly in regions with restricted medical facilities. Notable progress has been achieved in glaucoma classification in the last decade through the utilization of deep learning techniques [
5]. Various studies have used convolutional neural networks with fundus images to identify glaucoma [
7,
8,
9]. To address the redundancy issues that affect glaucoma identification, attention mechanisms were later introduced [
10,
11,
12,
13]. Additionally, incorporating extra information alongside fundus images has resulted in significant improvements in glaucoma classification [
14]. The annotation of the data into three groups was based on the diagnosis made in clinical practice by a glaucoma specialist. The dataset included color fundus photographs and 14 types of metadata (including visual field testing, retinal nerve fiber layer thickness, and cup–disc ratio). Deep learning (DL) was performed first using only the color fundus photographs and then using both the images and metadata, resulting in improved model performance. However, the mentioned methods are suspected to have locality bias and interpretability issues. On the other hand, vision transformers (ViTs) have recently improved the effectiveness of deep learning by incorporating a self-attention mechanism [
15,
16,
17], demonstrating superiority in various medical imaging modalities like computed tomography, X-ray, fundus images [
18], ophthalmoscope images [
14], and OCT [
17]. Several approaches have been employed to improve the classification of glaucoma, but challenges remain due to factors such as limited training data, differences in feature distribution, and sample quality issues. Fundus images display common patterns, recurring features, and slight variations in lesion sizes, which present obstacles in refining glaucoma classification using vision transformers [
7]. Prominent entities usually occupy a large percentage of natural photographs and have characteristic features [
19]. On the other hand, similar anatomical features and intensity profiles are frequently seen in medical images taken with the same modality, but this is insufficient to differentiate between disorders [
20]. Thus, in the context of illness discrimination in medical images, the incorporation of local precise information becomes crucial [
21,
22]. More focus on key areas and the preservation of fine details in learned representations are necessary to improve the performance of fundus image glaucoma classification [
16,
23]. Accordingly, numerous endeavors in the field of medical imaging have yielded remarkable successes. However, as far as we are aware, only a few research studies have used the vision transformer (ViT) architecture for the classification of glaucoma utilizing fundus images.
Among them, [
3] presented MIL-VT, a modified version of the ViT architecture that leverages features gathered from each patch by integrating a multiple-instance learning head into the vision transformer framework. The method showed slight improvements over CNN methods. Another study [
24] employed parameter tweaking in the ViT model and utilized the transfer learning principle. In their tests, the authors pooled five datasets to increase the quantity of training data and included augmentation techniques like flipping and rotation to increase the diversity of the data. They concluded that one crucial point to remember is that ViT models’ superiority over CNNs improves with the diversity and quantity of images [
24]. All the presented studies are limited to binary classification and are tested on small sample training datasets. Furthermore, the issues of repetitive characteristics and slight variations in lesion size are not addressed [
25]. The employment of transformers indicates a crucial transition toward sophisticated AI methodologies capable of effectively analyzing and deciphering extensive and complex datasets, presenting a promising trajectory for upcoming glaucoma investigations and clinical decision making [
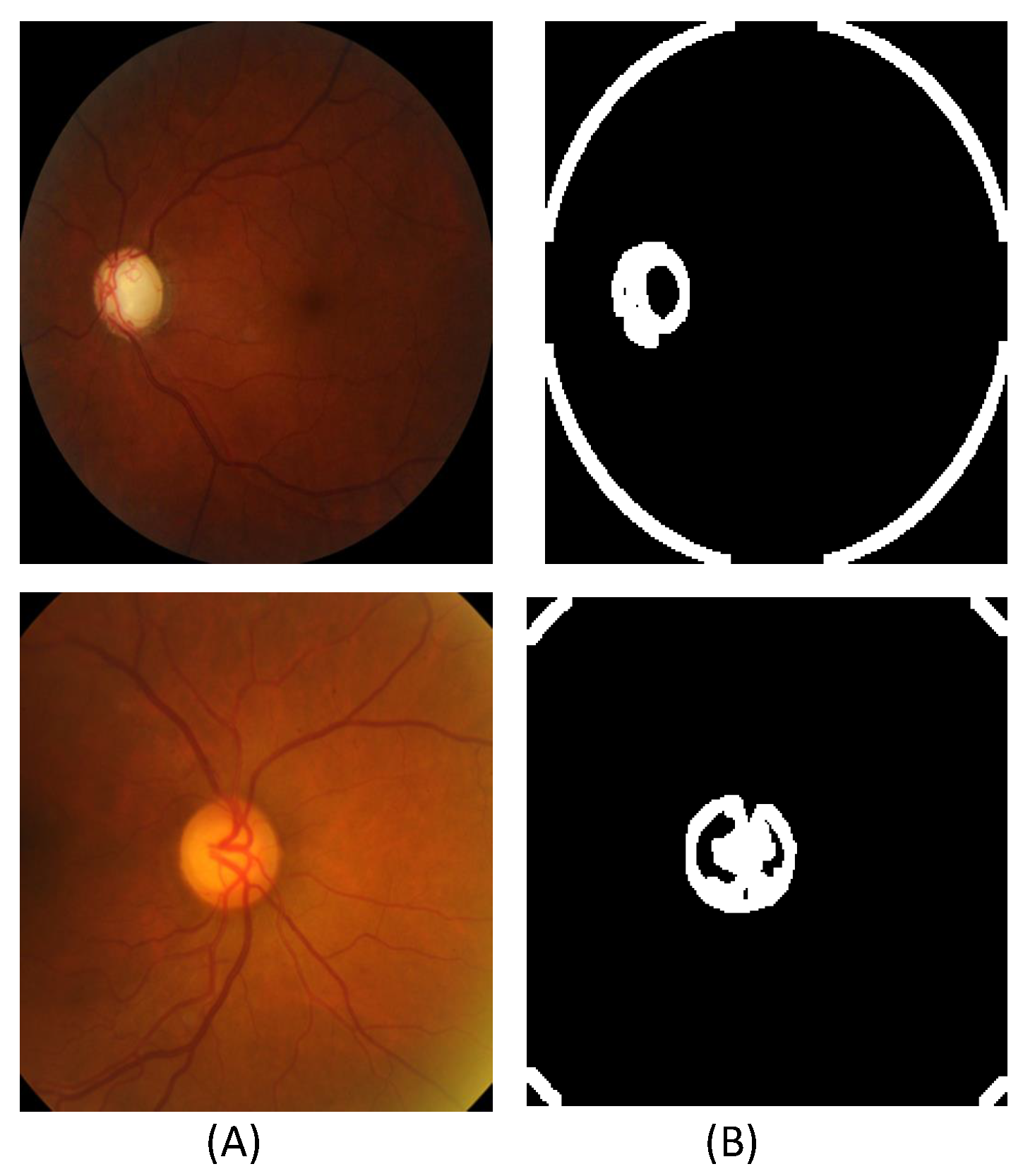
23]. Therefore applying vision transformers for glaucoma classification is an emerging and hot topic, and much work is needed in this area. To the best of our knowledge, the utilization of a contour-guided augmented vision transformer for the categorization of glaucoma in fundus images has not been previously investigated. The classification and generalization of multi-class diseases are indispensable not only for accurate diagnosis but also for mitigating training biases. This study introduces a contour-guided augmented vision transformer (CA-ViT) that incorporates contour information and enhances the training dataset through a CVGAN. Contours serve as distinctive features for the foreground of a fundus image, encompassing the optic disc/cup [
26]. The integration of contour details significantly boosts model performance by providing accurate boundary delineations that enhance object localization and delineation, resulting in more precise predictions [
26]. Geometric and structural details embedded in contours enrich feature representations, thereby reducing false positives and negatives, enabling models to effectively differentiate adjacent objects. This supplementary information enhances model resilience against variations in object shapes and sizes, making classifications more reliable [
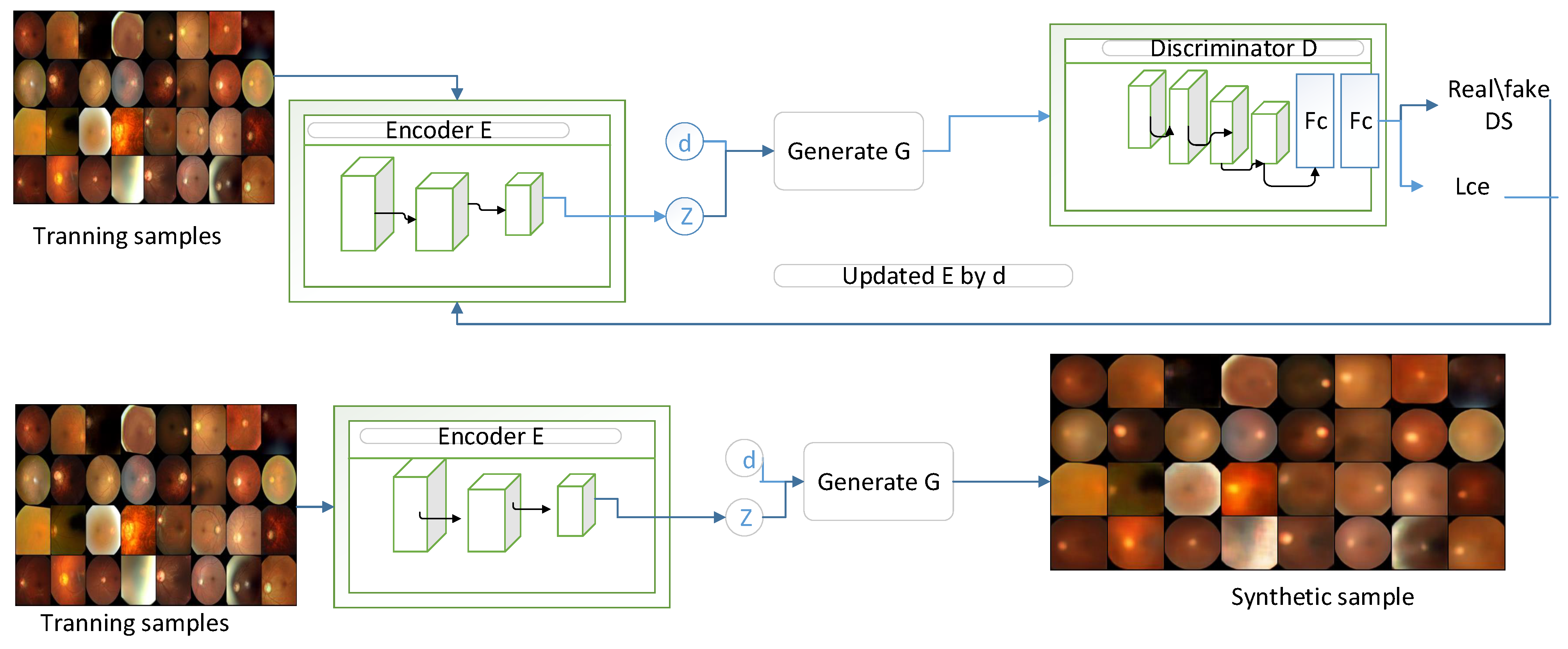
26]. The CVGAN is used to enhance the training set and dataset for image augmentation and reconstruction. By combining conditional sample generation with reconstruction, this network makes it easier to create features from previously unseen data. Next, we extracted contour information for the training, augmented, and generated images using a contour-guided module. The ViT backbone receives both the extracted contour information and the original images. Accordingly, feature alignment is performed. Finally, during the inference stage, the model categorizes glaucoma into multiple classes. The evaluation of the model’s performance is conducted using only the training, augmented, and generated data, excluding the contour information. The following are the study’s main contributions:
We introduce a CVGAN for augmentation to enlarge and diversify the training set of fundus images for glaucoma classification.
We propose a contour-guided module to enhance the classification task by extracting the optic disc and optic cup region, where the contour information provides supplementary details to the vision transformer model.
We propose a contour-guided and augmented vision transformer framework for multi-class glaucoma classification, enhancing disease diagnosis accuracy. This framework uses a guided contour module to extract detailed optic disc and optic cup features crucial for glaucoma assessment, a ViT backbone to process both the original and contour information, and applies feature alignment to prepare the data for categorization.
Rigorous testing and evaluation of the proposed model are conducted using the Standardized Multi-Channel Dataset for Glaucoma (SMDG), which consists of 19 publicly available datasets, such as EYEPACS, DRISHTI-GS, RIM-ONE, REFUGE, combined into a single dataset. This testing demonstrates the superior performance of the proposed model compared to state-of-the-art approaches. Further analysis using t-SNE provides a detailed visualization of the model’s effectiveness in distinguishing between different classes of glaucoma.
This research is structured as follows.
Section 2 discusses the related works.
Section 3 outlines the materials and methodologies employed. In
Section 4, an examination of the experimental configuration and outcomes is provided.
Section 5 delivers the results and a discussion.
Section 6 concludes this work by summarizing our findings and proposing avenues for future research.
5. Results and Discussion
In this section, the results from the experiments are presented along with a discussion. Two approaches are used to examine and describe the findings. The first approach is quantitative and makes use of a number of assessment metrics, including accuracy, precision, recall, and F1 score. Furthermore, training and validation accuracy graphs, as well as confusion matrices, are displayed. The second approach is qualitative and makes use of t-SNE analysis and attention heat maps. Furthermore, ablation studies are introduced and reviewed.
The model complexity comparisons between various CNN and ViT models, as shown in
Table 6, indicate that CNN models are relatively lightweight and require fewer parameters compared to ViT models. ResNet50 is efficient in terms of FLOPs and parameters but achieves lower accuracy. In contrast, ViT16, DeiT, and Swin have higher FLOPs and parameters due to their transformer architecture, leading to moderate accuracy. CaiT strikes a balance between parameters and FLOPs with reasonable accuracy. Finally, our model achieves the highest accuracy with relatively fewer parameters and FLOPs, demonstrating high computational efficiency. Therefore, the simplicity and interpretability of the proposed model enable its utilization without extensive computational resources, in contrast to other ViT models. In terms of performance, superior outcomes were achieved with the utilization of the suggested model, as depicted in
Table 6. Thus, its preference is justified by the combination of high performance results and its lightweight design.
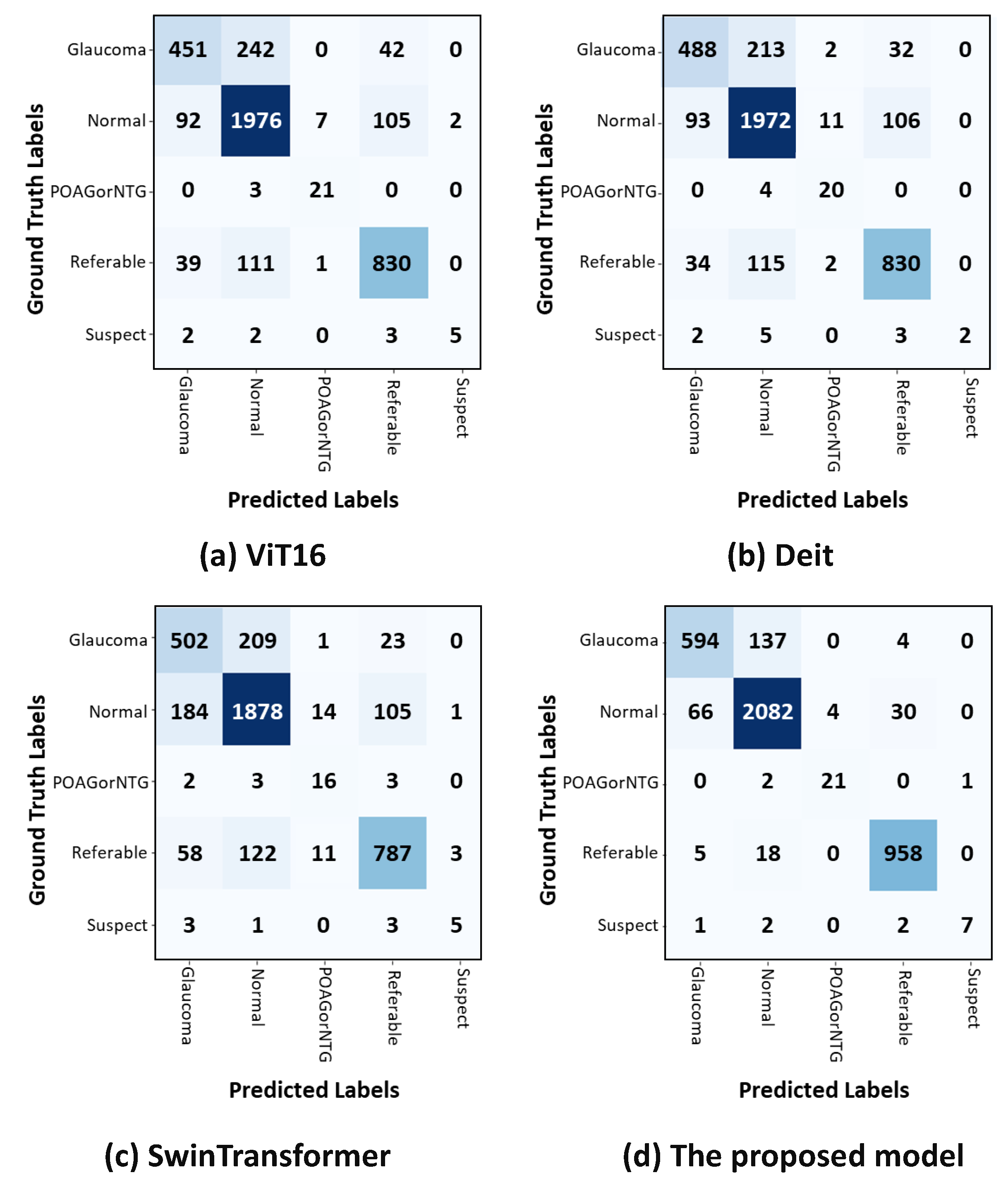
The confusion matrix in
Figure 4a shows that in the POAG/NTG classification, the ViT achieved the highest results with 87.5%, whereas in the glaucoma classification, it attained the lowest results with 61%.
Figure 4b shows that DeiT achieved the highest results in the POAG/NTG classification with 83%, whereas it faced challenges in classifying suspect classes, attaining the lowest results with 46%. The confusion matrix in
Figure 4c demonstrates the proposed method’s competitive classification performance. In the POAG/NTG class, the proposed approach achieved the lowest classification results (68%), but it more accurately identified referable cases (80%). In
Figure 4d, it can be seen that the proposed model (CA-ViT) surpassed all other approaches in classifying all classes of glaucoma. The attained results for classifications of normal (95%) and referable (97%) were high, and it demonstrated the lowest performance (80%) in the identification of the glaucoma class. The confusion matrix presented in
Figure 4 indicates that the number of fundus images within each class had a great impact on the accuracy achieved. The number of fundus images was very small for classes like suspect and POAG/NTG, resulting in lower confusion matrix values compared to the other three classes—specifically glaucoma, normal, and referable—which had higher numbers of fundus images. Although this outcome reflects the reality and robustness of the proposed model, balancing the class distribution is a good option to consider.
Table 7 shows a statistical comparison of the evaluation metrics, including precision, recall, F1 score, and accuracy. The proposed model achieved a precision of 93.0%, significantly higher than the 72.2% achieved by ResNet50 and the 73.4% achieved by ViT16. Similarly, the proposed model’s recall was 93.0%, compared to 72.1% for ResNet50 and 73.4% for ViT16. The F1 score for our model was 92.9%, much higher than the 72.2% achieved by ResNet50 and the 73.2% achieved by ViT16. Finally, in terms of accuracy, the proposed model achieved 93.0%, surpassing the 72.81% achieved by ResNet50 and the 73.31% achieved by ViT16. These values demonstrate that the proposed model outperformed traditional CNN and ViT methods across all evaluation metrics, indicating its superior performance in accurately classifying fundus images. This improvement is due to the innovative integration of contour and data generation methods.
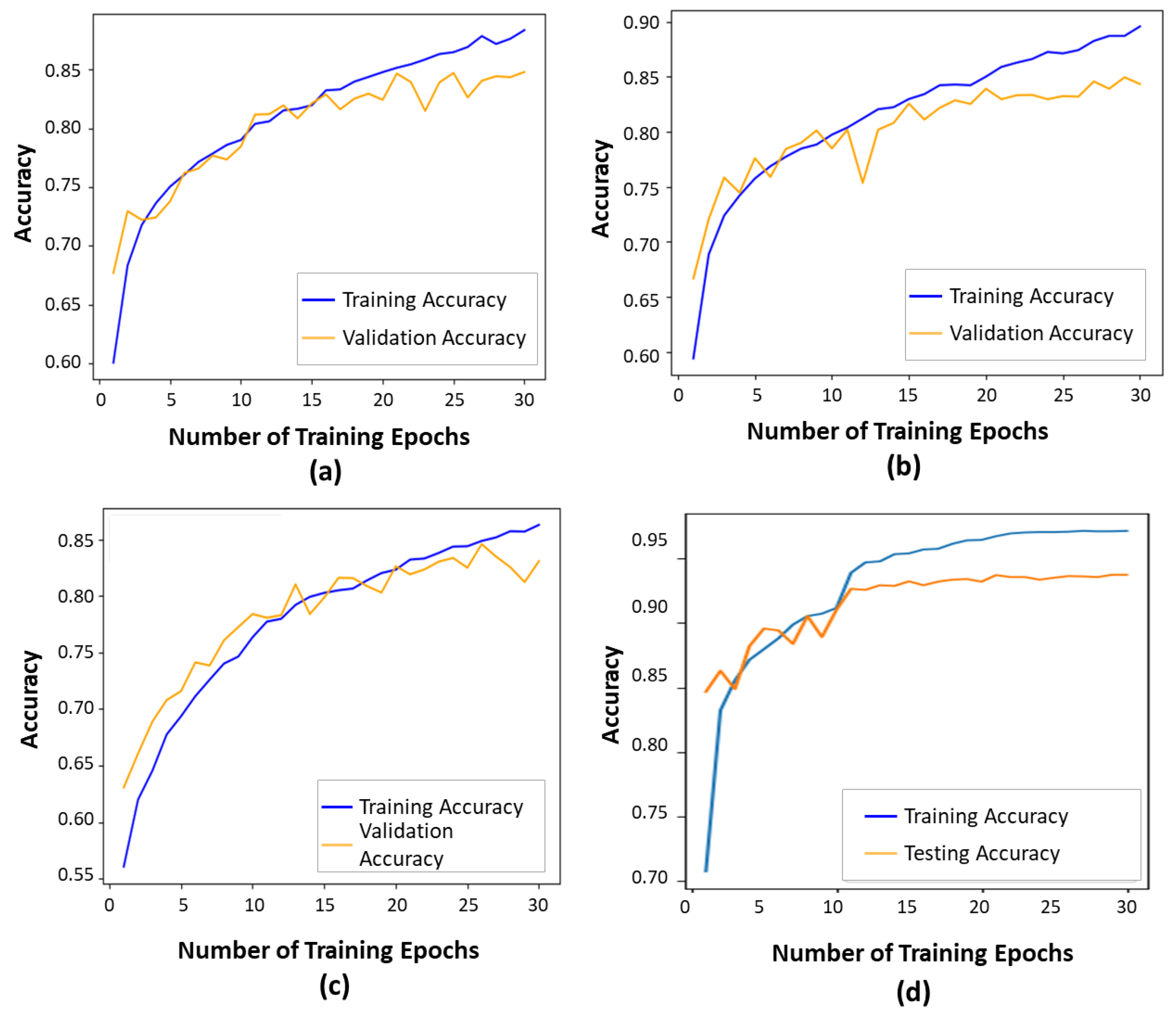
As presented in
Figure 5, the contour-guided and augmented vision transformer outperformed the state-of-the-art models in both training and validation accuracies. This indicates that the proposed model learned effective patterns as training progressed, achieving a training accuracy of 97% and a validation accuracy of 93.6%. Compared to the ViT16 model, the proposed model showed an improvement of 14% in validation accuracy and 4% in training accuracy. When compared to the DeiT transformer, we observed improvements of 12% in validation accuracy and 4% in training accuracy. Finally, compared to the Swin transformer, we observed improvements of 15% in validation accuracy and 7% in training accuracy. Overall, this shows that the proposed model learns better features than the SOTA models, making it a more effective strategy for improving glaucoma classification through optimal performance outcomes.
5.1. Ablation Studies
To comprehend the impact of each component of the proposed framework, we conducted extensive ablation experiments on the SMDG dataset [
42]. To the best of our knowledge, and since there was no baseline model, we used [
43] ViT+A as the baseline model and excluded the added components. Then, we assessed the impact of each of the following separately: the contour-guided module and the CVGAN-based augmentation technique.
5.1.1. Effect of CVGAN-Based Augmentation
Table 8 shows the effect of using CVGAN for augmentation purposes. To do this, we first assessed the baseline ViT model without incorporating the generated images from CVGAN. While isolated augmentation techniques provide essential data diversity for training robust deep learning models, incorporating a synthetic data generator offers significantly greater diversity. This is crucial for the vision transformer (ViT) model, as it results in superior performance [
28]. As presented in
Table 8, the proposed method enhanced performance by 3.7%, 4.1%, 4.0%, and 3.8% in terms of precision, recall, F1 score, and accuracy, respectively. Similarly, the
p-value of <0.05 indicates a statistically significant improvement when adding the data generator to the ViT + G model. This indicates that using CVGAN for augmentation purposes increases the sample size for training. The diverse dataset had a significant impact on enhancing glaucoma classification by improving the performance of the ViT + A model.
5.1.2. Effect of Contour Mechanism
To evaluate the efficacy of the contour mechanism in acquiring discriminative representations of the optic disc and the optic cup for the classification of glaucoma, we trained the proposed model both with and without the contour module. As shown in
Table 8, the contour-guided vision transformer (ViT) model reveals a statistically significant difference, with the results from the ViT model lacking the contour module (ViT + A) being substantially inferior to those from the ViT model that integrates the contour mechanism (ViT + C). Moreover, as shown in
Table 8, the proposed methodology resulted in improvements in performance metrics of 2.4%, 1.7%, 2.6%, and 2.0% with respect to precision, recall, F1 score, and accuracy, respectively. We computed a
p-value of less than 0.05, which indicates a statistically significant enhancement attributable to the incorporation of contour information into the ViT + A model. This observation suggests that the integration of contour information had a substantial influence on improving glaucoma classification, as evidenced by the superior performance outcomes of the ViT + C model compared to those of the ViT + A model.
5.1.3. Combined Effects of Augmentation, Generation, and Contour
The ViT [
43] model is based on a pre-trained ViT model using DETR [
48]. We assessed its impact by including and excluding the fine-tuning mechanism and found a significant difference in the performance of the model. Finally, we assessed the combined impact of all attributes—augmentation, generation, and contour—in the proposed CA-ViT model. When we evaluated the combined impact, the model’s performance was boosted by 8% across all performance metrics. It is highly likely that training on a large pre-trained image set improved glaucoma classification accordingly. The CA-ViT model, described as ViT + A + G + C in
Table 8, had a
p-value of <0.01, indicating a highly significant improvement when combining all attributes—augmentation, generation, and contour.
5.2. Qualitative Analysis
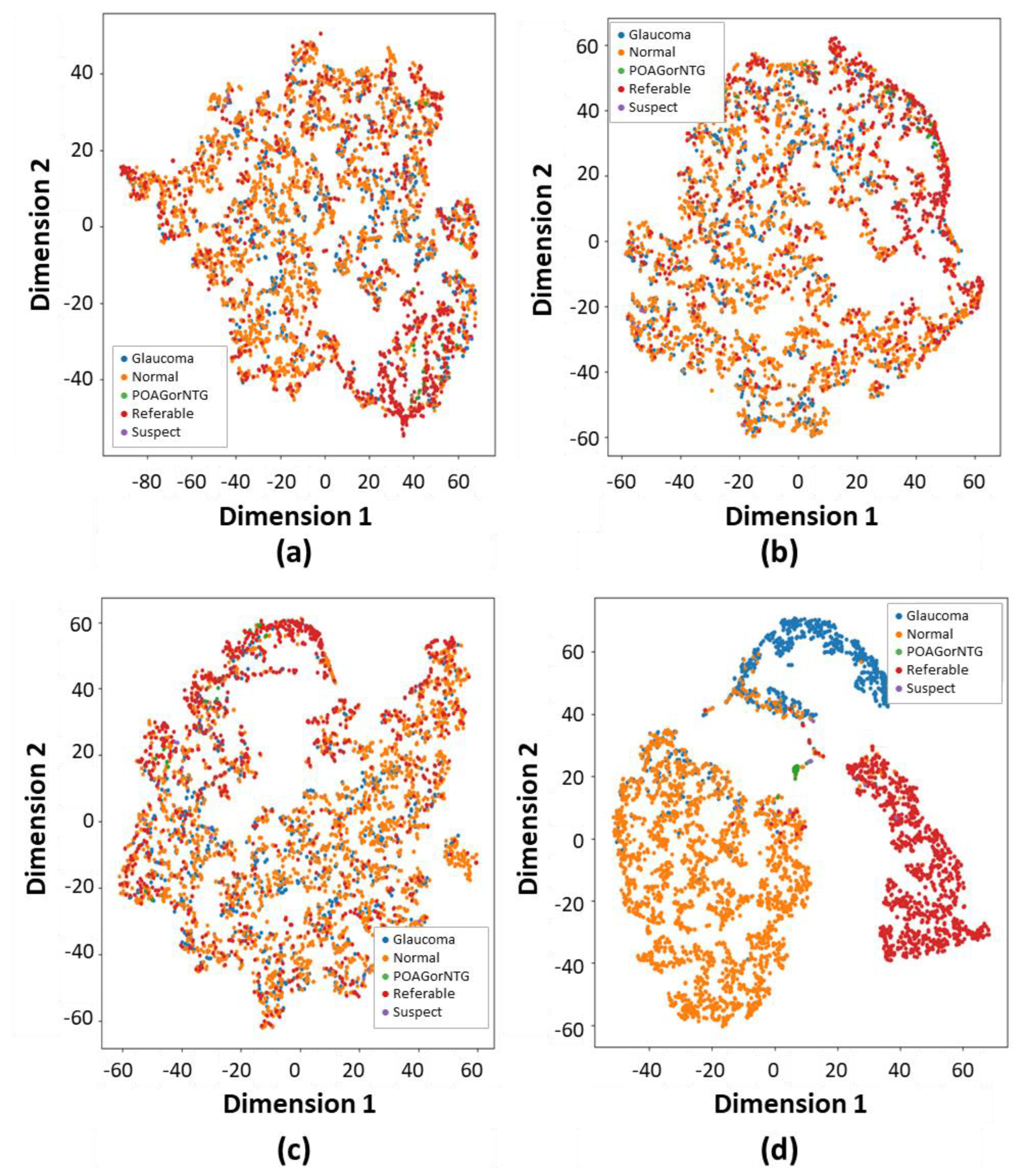
Evaluation of the effectiveness and interpretability of the proposed method to enhance glaucoma classification was measured by qualitative analysis using multi-head attention heat maps and the t-SNE. These are presented in
Figure 6 and
Figure 7, respectively. We generated the attention heat maps using CA-ViT and visualized them using multi-head attention [
21].
As demonstrated in
Figure 6, we applied t-distributed stochastic neighbor embedding (t-SNE) to delve deeper into the model outputs. Specifically, t-SNE was applied to visualize the output feature spaces of the SOTA ViT models and the proposed model’s feature extractors for slice 32, as depicted in
Figure 6, correspondingly. Upon comparing the spatial distributions of features between the normal, POAG/NTG, referable, suspect, and glaucoma classes, it was noted that the normal, glaucoma, and referable samples exhibited more condensed clustering within the feature space of contour-guided and augmented vision transformer compared to the SOTA models. This observation implies that the proposed contour-guided and augmented vision transformer demonstrates enhanced discriminative capabilities, proving to be more proficient in detecting and differentiating the intricate patterns specific to glaucoma in fundus images. The dataset we used exhibits a significant class imbalance, with only three dominant classes overshadowing others, such as suspect, mild, POAG/NTG, and various minor categories. This more accurately mirrors real-world clinical situations. These discrepancies highlight the enhanced generalizability and utility of the proposed model in precisely diagnosing glaucoma via multi-class fundus images.
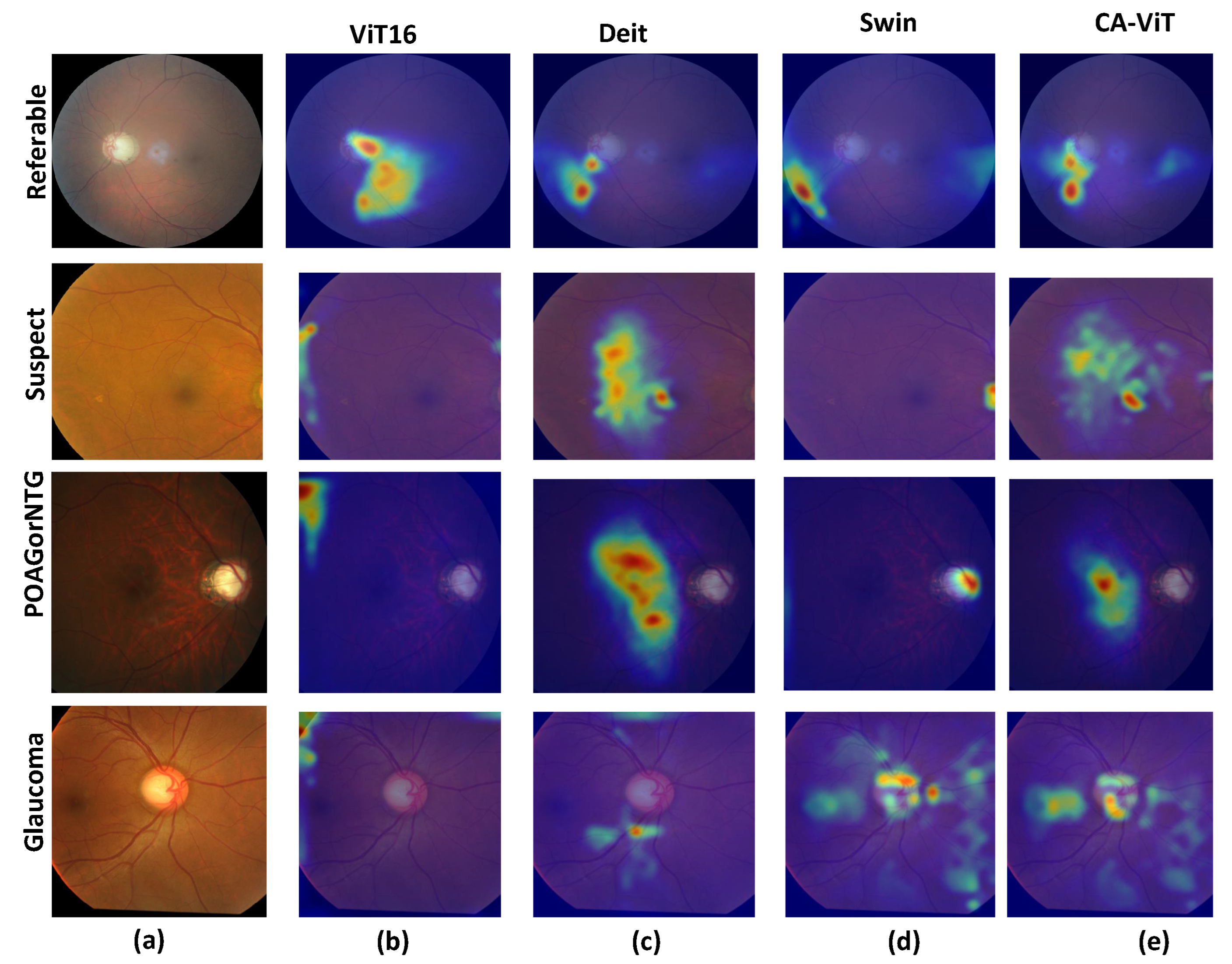
Figure 7 shows the heat maps for each of the SOTA models. The generated heat maps for four disease types reveal more suspected disease areas. As shown in
Figure 7b, the heat maps are located far from the optic disc and optic cup regions, indicating that the visualization results do not focus well on the required region. In
Figure 7c, we obtain slightly better visualization results since the generated heat maps are very close to the optic disc and optic cup regions.
Figure 7d shows slightly better results than the previous SOTA model, especially for the class POAG/NTG, which hits the focal points and achieves better results than CA-ViT. In
Figure 7e, the proposed model shows better visualization results by focusing on the required areas for glaucoma classification. It clearly identifies suspected areas of glaucoma much better than the previous SOTA models across all classes. This is due to the multi-head attention and contour information available in the proposed model. The proposed CA-ViT model has a heightened level of interpretability due to the utilization of the multi-head attention mechanism inherent in vision transformers. This mechanism enables the model to focus on different areas of the input image, effectively capturing diverse features and details crucial for precise diagnosis [
16]. It distinctly highlights areas requiring further scrutiny, as evidenced by the outcomes in the heat map.
Although the results achieved are encouraging because it is the first attempt to use contour and CVGAN for glaucoma classification, this study has some limitations. One of the main limitations is the absence of a multi-class glaucoma dataset, so all the results were evaluated only using SMDG, a combined dataset consisting of 19 publicly available datasets. Among these, the fundus images are not large enough, and some of the images are not labeled well. As a result, we achieved good classification results for three classes—normal, glaucoma, and referable—which were well represented in the dataset. However, the POAG/NTG and suspect classes need further representation and labeled data.
The CVGAN-based augmentation produces plausible fundus images when the given images are noise-free and of high quality. However, for low-contrast images and fuzzy borders, it fails to produce good-quality fundus images. To achieve good results with this approach, a large dataset is required. It would be better to use other mechanisms, such as diffusion models, which can produce good-quality images with fewer images under various conditions. In addition, the contour-guided information is also influenced by the quality of the input images. In the future, we will consider extracting high-quality contour information from noisy and low-quality images.
6. Conclusions
This paper presents a contour-guided and augmented vision transformer to enhance glaucoma classification in multi-class fundus images. Enhancing glaucoma classification is addressed by enlarging the data size using CVGAN-based augmentation techniques, as well as providing guidance information through a contour mechanism. The ViT backbone accepts both extracted contours and original images, and feature alignment is performed during training. The outcomes of the experimental analysis show good performance results with the efficacy of the framework, achieving a precision level of 93.0%, a recall rate of 93.08%, an F1 score of 92.9%, and an accuracy of 93%. These performance metrics exceed those attained by cutting-edge techniques, including the DeiT, Swin, and ViT16 models. Both the CVGAN-based augmentation and contour-guided modules significantly impact the model’s performance. In future investigations, we plan to extend our approach to OCT-based fundus or cross-sectional images for more efficient glaucoma detection, as well as apply it to other retinal diseases with similar pathology, such as Stargardt disease and Wet AMD. Additionally, we aim to incorporate diverse clinical data types, such as visual field tests and patient demographic information, to enhance diagnostic capabilities. Furthermore, investigating alternative data generation models, particularly for high-contrast fundus images, and integrating patch-to-patch attention mechanisms has the potential to enhance the efficacy of glaucoma diagnosis and classification, ultimately improving patient outcomes in glaucoma care.






 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}