
Segmentation of Heart Sound Signal Based on Multi-Scale Feature Fusion and Multi-Classification of Congenital Heart Disease


Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
2.2. Normalization and Denoising
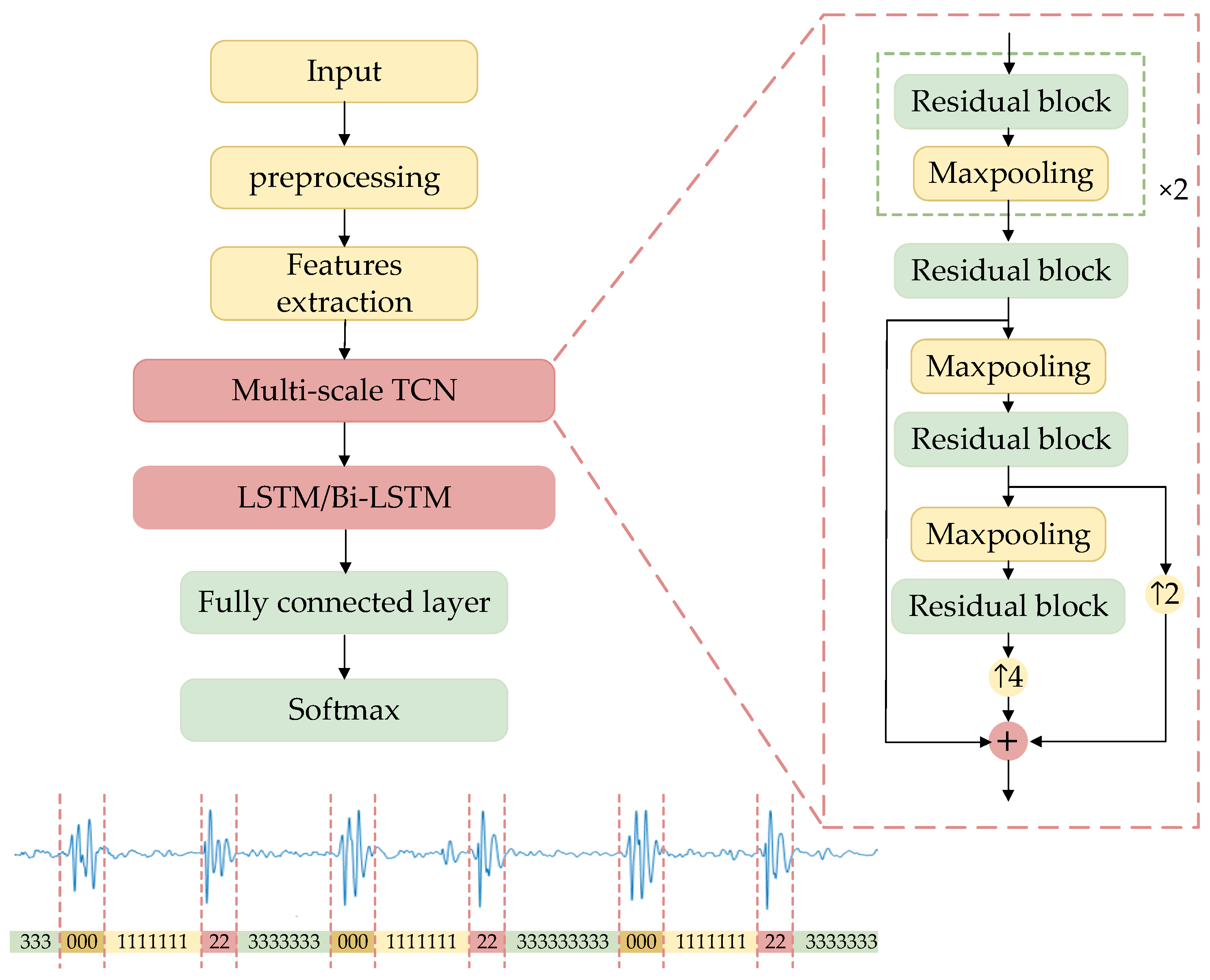
2.3. Segmentation Method
2.3.1. Envelope Extraction
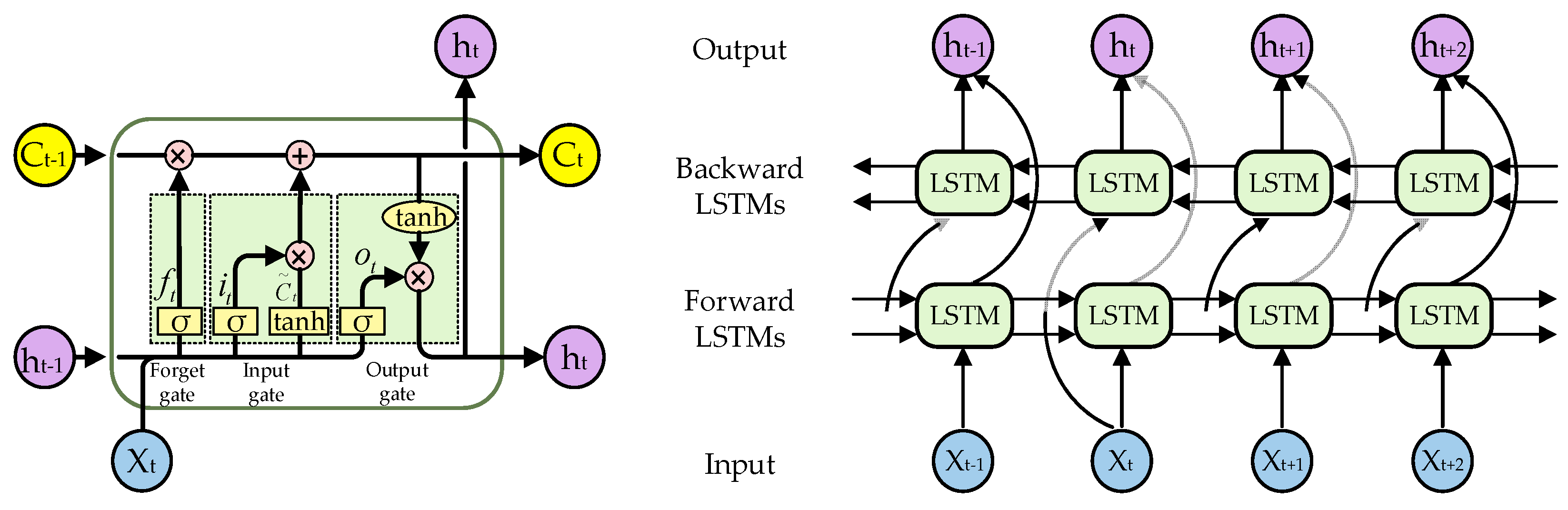
2.3.2. TBLSTM
2.4. Features Extraction and Classification
2.5. Evaluation Metric
3. Results
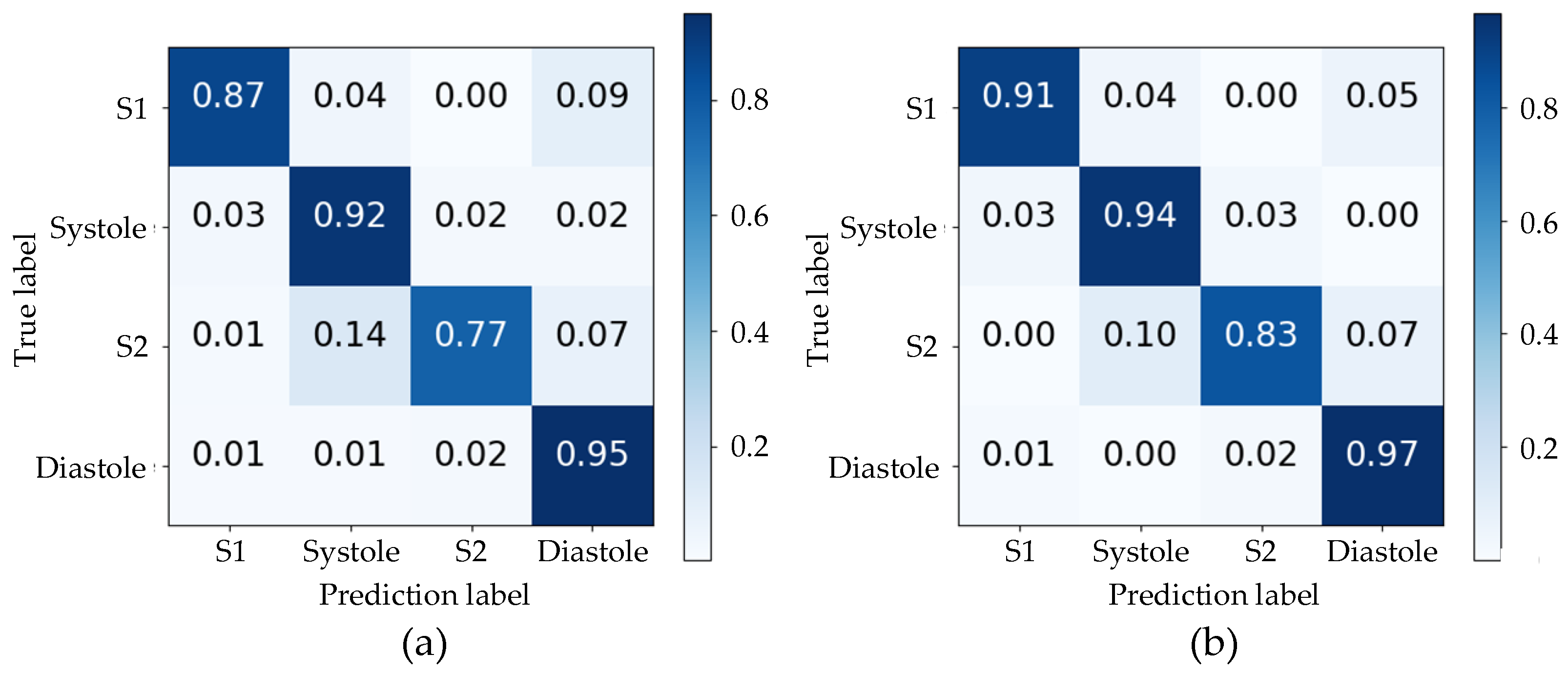
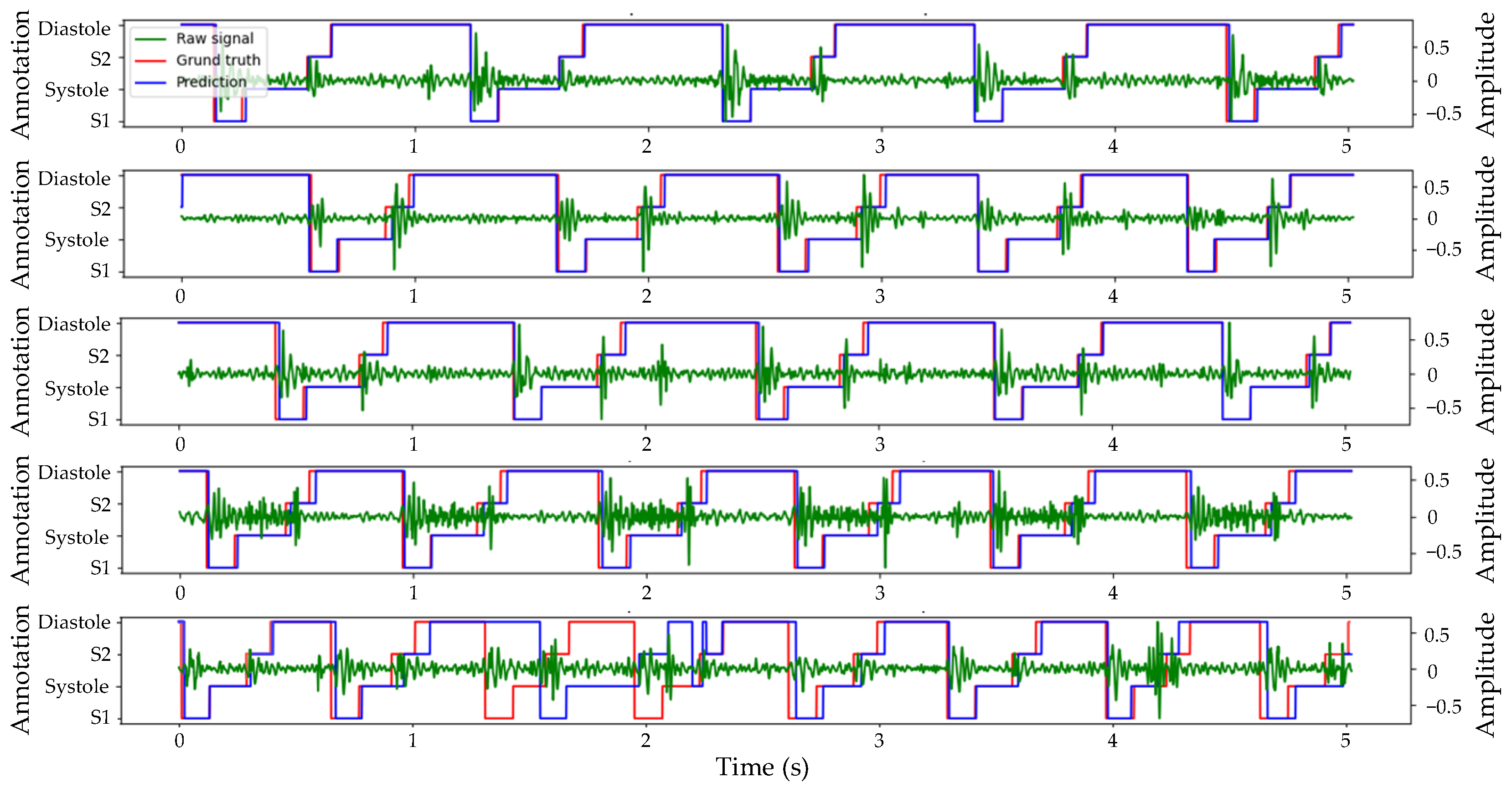
3.1. Segmentation Results
3.2. Classification Results
4. Discussion
4.1. Segmentation
4.2. Classification
4.3. Limitation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Q.; Niu, C.; Liu, F.; Wu, L.; Ma, X.; Huang, G. Accuracy of Cardiac Auscultation in Detection of Neonatal Congenital Heart Disease by General Paediatricians. Cardiol. Young 2019, 29, 679–683. [Google Scholar] [CrossRef]
- Huang, Y.; Zhong, S.; Zhang, X.; Kong, L.; Wu, W.; Yue, S.; Tian, N.; Zhu, G.; Hu, A.; Xu, J.; et al. Large Scale Application of Pulse Oximeter and Auscultation in Screening of Neonatal Congenital Heart Disease. BMC Pediatr. 2022, 22, 483. [Google Scholar] [CrossRef] [PubMed]
- Feltes, T.F.; Bacha, E.; Beekman, R.H.; Cheatham, J.P.; Feinstein, J.A.; Gomes, A.S.; Hijazi, Z.M.; Ing, F.F.; De Moor, M.; Morrow, W.R.; et al. Indications for Cardiac Catheterization and Intervention in Pediatric Cardiac Disease: A Scientific Statement from the American Heart Association. Circulation 2011, 123, 2607–2652. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Li, W.; Zhang, W.; Zhang, S.; Pi, X.; Liu, H. Research on segmentation and classification of heart sound signals based on deep learning. Appl. Sci. 2021, 11, 651. [Google Scholar] [CrossRef]
- Pelech, A.N. The Physiology of Cardiac Auscultation. Pediatr. Clin. N. Am. 2004, 51, 1515–1535. [Google Scholar] [CrossRef]
- Eisenberg, R.; Hultgren, H.N. Phonocardiographic Features of Atrial Septal Defect. Circulation 1959, 20, 490–497. [Google Scholar] [CrossRef]
- Van Der Hauwaert, L.; Nadas, A.S. Auscultatory Findings in Patients with a Small Ventricular Septal Defect. Circulation 1961, 23, 886–891. [Google Scholar] [CrossRef] [PubMed]
- Milani, M.G.M.; Abas, P.E.; De Silva, L.C. A critical review of heart sound signal segmentation algorithms. Smart Health 2022, 24, 100283. [Google Scholar] [CrossRef]
- Wang, J.; You, T.; Yi, K.; Gong, Y.; Xie, Q.; Qu, F.; Wang, B.; He, Z. Intelligent Diagnosis of Heart Murmurs in Children with Congenital Heart Disease. J. Healthc. Eng. 2020, 2020, 9640821. [Google Scholar] [CrossRef]
- Babu, K.A.; Ramkumar, B.; Manikandan, M.S. S1 and S2 Heart Sound Segmentation Using Variational Mode Decomposition. In Proceedings of the Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 1629–1634. [Google Scholar]
- Yin, Y.; Ma, K.; Liu, M. Temporal Convolutional Network Connected with an Anti-Arrhythmia Hidden Semi-Markov Model for Heart Sound Segmentation. Appl. Sci. 2020, 10, 7049. [Google Scholar] [CrossRef]
- Kamson, A.P.; Sharma, L.N.; Dandapat, S. Multi-Centroid Diastolic Duration Distribution Based HSMM for Heart Sound Segmentation. Biomed. Signal Process. Control 2019, 48, 265–272. [Google Scholar] [CrossRef]
- Wang, X.; Liu, C.; Li, Y.; Cheng, X.; Li, J.; Clifford, G.D. Temporal-Framing Adaptive Network for Heart Sound Segmentation Without Prior Knowledge of State Duration. IEEE Trans. Biomed. Eng. 2021, 68, 650–663. [Google Scholar] [CrossRef]
- Springer, D.; Tarassenko, L.; Clifford, G. Logistic Regression-HSMM-Based Heart Sound Segmentation. IEEE Trans. Biomed. Eng. 2015, 63, 822–832. [Google Scholar] [CrossRef]
- Gamero, L.G.; Watrous, R. Detection of the First and Second Heart Sound Using Probabilistic Models. In Proceedings of the 25th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Cancun, Mexico, 17–21 September 2003; pp. 2877–2880. [Google Scholar]
- Oliveira, J.; Mantadelis, T.; Coimbra, M. Why Should You Model Time When You Use Markov Models for Heart Sound Analysis. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Orlando, FL, USA, 16–20 August 2016; pp. 3449–3452. [Google Scholar]
- Renna, F.; Oliveira, J.; Coimbra, M.T. Convolutional Neural Networks for Heart Sound Segmentation. In Proceedings of the 2018 26th European Signal Processing Conference, Rome, Italy, 3–7 September 2018; pp. 757–761. [Google Scholar]
- Messner, E.; Zohrer, M.; Pernkopf, F. Heart Sound Segmentation—An Event Detection Approach Using Deep Recurrent Neural Networks. IEEE Trans. Biomed. Eng. 2018, 65, 1964–1974. [Google Scholar] [CrossRef]
- Fernando, T.; Ghaemmaghami, H.; Denman, S.; Sridharan, S.; Hussain, N.; Fookes, C. Heart Sound Segmentation Using Bidirectional LSTMs With Attention. IEEE J. Biomed. Health Inform. 2020, 24, 1601–1609. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Sun, Y.; Lv, J.; Jia, B.; Huang, X. End-to-End Heart Sound Segmentation Using Deep Convolutional Recurrent Network. Complex Intell. Syst. 2021, 7, 2103–2117. [Google Scholar] [CrossRef]
- Liu, C.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.W.; et al. An Open Access Database for the Evaluation of Heart Sound Algorithms. Physiol. Meas. 2016, 37, 2181–2213. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Sun, Q.; Chen, X.; Xie, G.; Wu, H.; Xu, C. Deep learning methods for heart sounds classification: A systematic review. Entropy 2021, 23, 667. [Google Scholar] [CrossRef]
- Yuenyong, S.; Nishihara, A.; Kongprawechnon, W.; Tungpimolrut, K. A Framework for Automatic Heart Sound Analysis without Segmentation. Biomed. Eng. OnLine 2011, 10, 13. [Google Scholar] [CrossRef]
- Ahmad, M.S.; Mir, J.; Ullah, M.O.; Shahid, M.L.U.R.; Syed, M.A. An Efficient Heart Murmur Recognition and Cardiovascular Disorders Classification System. Australas. Phys. Eng. Sci. Med. 2019, 42, 733–743. [Google Scholar] [CrossRef]
- Li, F.; Liu, M.; Zhao, Y.; Kong, L.; Dong, L.; Liu, X.; Hui, M. Feature Extraction and Classification of Heart Sound Using 1D Convolutional Neural Networks. EURASIP J. Adv. Signal Process. 2019, 2019, 59. [Google Scholar] [CrossRef]
- Zheng, Y.; Guo, X.; Wang, Y.; Qin, J.; Lv, F. A Multi-Scale and Multi-Domain Heart Sound Feature-Based Machine Learning Model for ACC/AHA Heart Failure Stage Classification. Physiol. Meas. 2022, 43, 065002. [Google Scholar] [CrossRef] [PubMed]
- Firuzbakht, F.; Fallah, A.; Rashidi, S.; Khoshnood, E.R. Abnormal Heart Sound Diagnosis Based on Phonocardiogram Signal Processing. In Proceedings of the Electrical Engineering, Mashhad, Iranian, 8–10 May 2018; pp. 1450–1455. [Google Scholar]
- El Badlaoui, O.; Benba, A.; Hammouch, A. Novel PCG Analysis Method for Discriminating Between Abnormal and Normal Heart Sounds. IRBM 2020, 41, 223–228. [Google Scholar] [CrossRef]
- Yadav, A.; Singh, A.; Dutta, M.K.; Travieso, C.M. Machine Learning-Based Classification of Cardiac Diseases from PCG Recorded Heart Sounds. Neural Comput. Appl. 2020, 32, 17843–17856. [Google Scholar] [CrossRef]
- Khan, K.N.; Khan, F.A.; Abid, A.; Olmez, T.; Dokur, Z.; Khandakar, A.; Chowdhury, M.E.H.; Khan, M.S. Deep Learning Based Classification of Unsegmented Phonocardiogram Spectrograms Leveraging Transfer Learning. Physiol. Meas. 2021, 42, 095003. [Google Scholar] [CrossRef]
- Deng, M.; Meng, T.; Cao, J.; Wang, S.; Zhang, J.; Fan, H. Heart Sound Classification Based on Improved MFCC Features and Convolutional Recurrent Neural Networks. Neural Netw. 2020, 130, 22–32. [Google Scholar] [CrossRef]
- Wang, T.; Chen, L.; Yang, T.; Huang, P.; Wang, L.; Zhao, L.; Zhang, S.; Ye, Z.; Chen, L.; Zheng, Z.; et al. Congenital Heart Disease and Risk of Cardiovascular Disease: A Meta-Analysis of Cohort Studies. J. Am. Heart Assoc. 2019, 8, e012030. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Yu, K.; Ye, J.; Li, H.; Chen, J.; Yin, F.; Xu, J.; Zhu, J.; Li, D.; Shu, Q. Automatic Pediatric Congenital Heart Disease Classification Based on Heart Sound Signal. Artif. Intell. Med. 2022, 126, 102257. [Google Scholar] [CrossRef]
- Liu, J.; Wang, H.; Yang, Z.; Quan, J.; Liu, L.; Tian, J. Deep Learning-Based Computer-Aided Heart Sound Analysis in Children with Left-to-Right Shunt Congenital Heart Disease. Int. J. Cardiol. 2022, 348, 58–64. [Google Scholar] [CrossRef]
- Aziz, S.; Khan, M.U.; Alhaisoni, M.; Akram, T.; Altaf, M. Phonocardiogram Signal Processing for Automatic Diagnosis of Congenital Heart Disorders through Fusion of Temporal and Cepstral Features. Sensors 2020, 20, 3790. [Google Scholar] [CrossRef]
- Ismail, S.; Ismail, B.; Siddiqi, I.; Akram, U. PCG Classification through Spectrogram Using Transfer Learning. Biomed. Signal Process. Control 2023, 79, 104075. [Google Scholar] [CrossRef]
- Abduh, Z.; Nehary, E.A.; Abdel Wahed, M.; Kadah, Y.M. Classification of Heart Sounds Using Fractional Fourier Transform Based Mel-Frequency Spectral Coefficients and Traditional Classifiers. Biomed. Signal Process. Control 2020, 57, 101788. [Google Scholar] [CrossRef]
- Phanphaisarn, W.; Roeksabutr, A.; Wardkein, P.; Koseeyaporn, J.; Yupapin, P.P. Heart Detection and Diagnosis Based on ECG and EPCG Relationships. Med. Devices Evid. Res. 2011, 133–144. [Google Scholar]
- Lehner, R.J.; Rangayyan, R.M. A three-channel microcomputer system for segmentation and characterization of the phonocardiogram. IEEE Trans Biomed Eng. 1987, 6, 485–489. [Google Scholar] [CrossRef]
- Wang, H.B.; Hu, Y.L.; Liu, L.H.; Wang, Y.; Zhang, J.B. Heart Sound Analysis Based on Autoregressive Power Spectral Density. In Proceedings of the 2010 2nd International Conference on Signal Processing Systems, Dalian, China, 5–7 July 2010; pp. V2-582–V2-586. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- El-Segaier, M.; Lilja, O.; Lukkarinen, S.; Sörnmo, L.; Sepponen, R.; Pesonen, E. Computer-Based Detection and Analysis of Heart Sound and Murmur. Ann. Biomed. Eng. 2005, 33, 937–942. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ||||||
|---|---|---|---|---|---|---|
| LR-HSMM | 92.12% | 92.36% | 92.18% | 88.66% | 81.14% | 92.27% |
| CLSTM | 92.74% | 96.45% | 85.65% | 87.57% | 82.61% | 91.07% |
| FPN | 87.07% | 87.47% | 86.73% | 84.97% | 78.14% | 87.11% |
| TLSTM (proposed) | 91.19% | 91.45% | 90.96% | 86.41% | 81.89% | 91.21% |
| TBLSTM (proposed) | 94.15% | 94.21% | 94.09% | 90.25% | 86.04% | 94.15% |
| Cycle | |||||
|---|---|---|---|---|---|
| 1 | 72.03% | 72.62% | 72.32% | 67.22% | 76.95% |
| 2 | 80.67% | 80.90% | 80.79% | 78.08% | 83.79% |
| 3 | 85.07% | 85.31% | 85.19% | 82.95% | 87.35% |
| 4 | 88.37% | 88.79% | 88.58% | 86.76% | 89.10% |
| 5 | 90.57% | 90.78% | 90.67% | 88.84% | 91.70% |
| 6 | 94.43% | 94.58% | 94.51% | 93.24% | 94.45% |
| 7 | 94.77% | 94.86% | 94.81% | 94.35% | 94.25% |
| 8 | 95.17% | 95.26% | 95.21% | 94.32% | 94.07% |
| 9 | 95.97% | 96.04% | 96.00% | 95.21% | 94.89% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Y.; Li, M.; He, Z.; Zhou, L. Segmentation of Heart Sound Signal Based on Multi-Scale Feature Fusion and Multi-Classification of Congenital Heart Disease. Bioengineering 2024, 11, 876. https://doi.org/10.3390/bioengineering11090876
Zeng Y, Li M, He Z, Zhou L. Segmentation of Heart Sound Signal Based on Multi-Scale Feature Fusion and Multi-Classification of Congenital Heart Disease. Bioengineering. 2024; 11(9):876. https://doi.org/10.3390/bioengineering11090876
Chicago/Turabian StyleZeng, Yuan, Mingzhe Li, Zhaoming He, and Ling Zhou. 2024. "Segmentation of Heart Sound Signal Based on Multi-Scale Feature Fusion and Multi-Classification of Congenital Heart Disease" Bioengineering 11, no. 9: 876. https://doi.org/10.3390/bioengineering11090876
APA StyleZeng, Y., Li, M., He, Z., & Zhou, L. (2024). Segmentation of Heart Sound Signal Based on Multi-Scale Feature Fusion and Multi-Classification of Congenital Heart Disease. Bioengineering, 11(9), 876. https://doi.org/10.3390/bioengineering11090876