
Difficult Airway Assessment Based on Multi-View Metric Learning


Abstract

1. Introduction
- A new network model is specifically designed for difficult airway assessment tasks.
- The proposed method combines multi-view learning and metric learning, fully utilizing the complementarity and consistency of information between multi-view data to improve the model’s accuracy and reliability.
- Clinical data of multi-view facial images are collected to validate the methods. Experimental evaluation demonstrates the efficiency of the proposed method.
2. Materials and Methods
2.1. Dataset
2.2. Data Preprocessing
2.2.1. Image Central Cropping
2.2.2. Data Augmentation
2.3. Model
| Algorithm 1: Algorithm of difficult airway classification with DMF-Net | |
| Input: multi-view data the label of data is . | |
| Initialize: randomly initialize model parameters . | |
| While not converged, perform the following: | |
| |
| end | |
| Output: trained parameters . | |
2.3.1. Feature Extractor Module
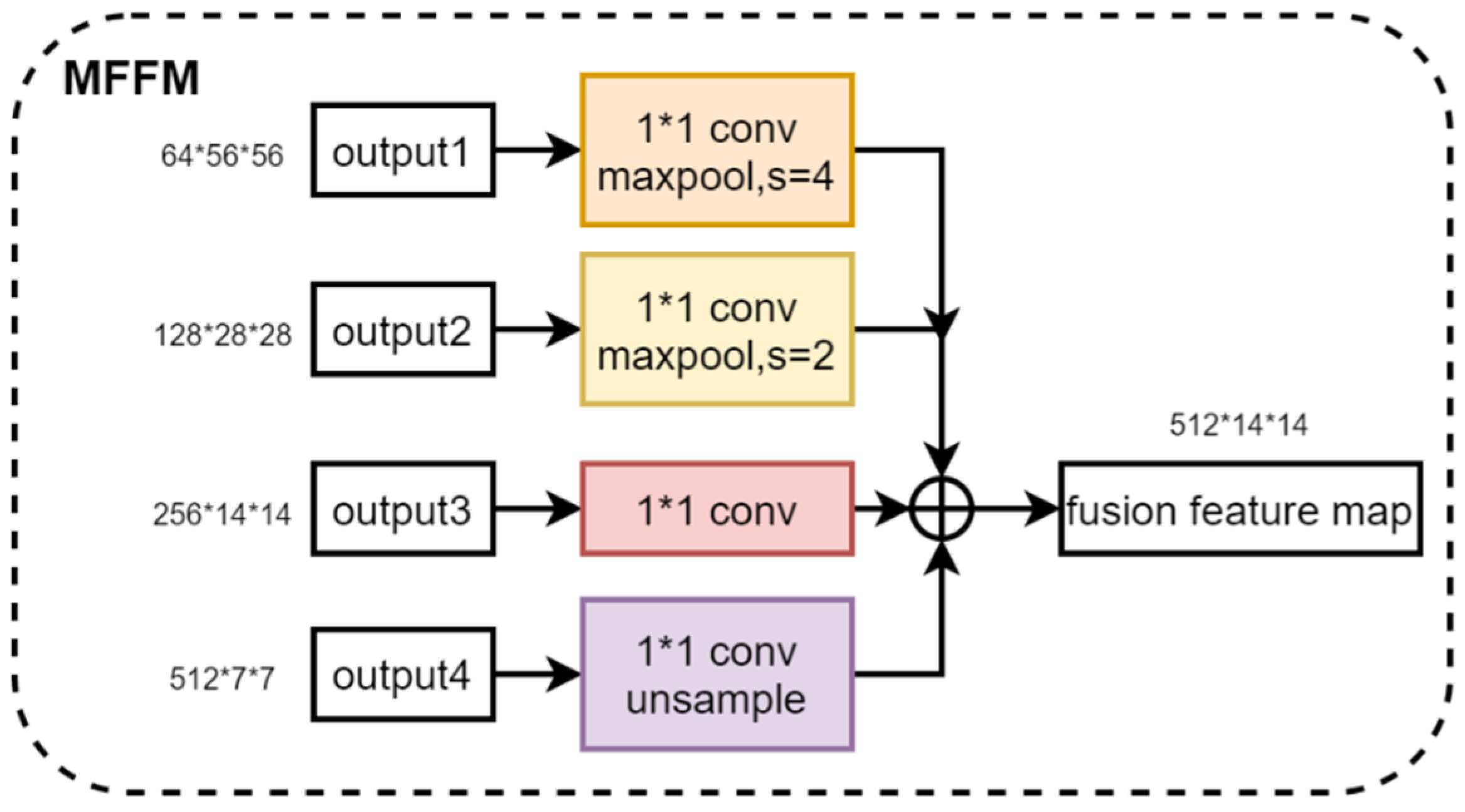
2.3.2. Multi-Scale Feature Fusion Module
2.3.3. Hybrid Co-Attention Module
2.3.4. Classifier Module
2.4. Objective Loss Function
2.4.1. Focal Loss
2.4.2. Complementarity Loss
2.4.3. Consistency Loss
3. Results
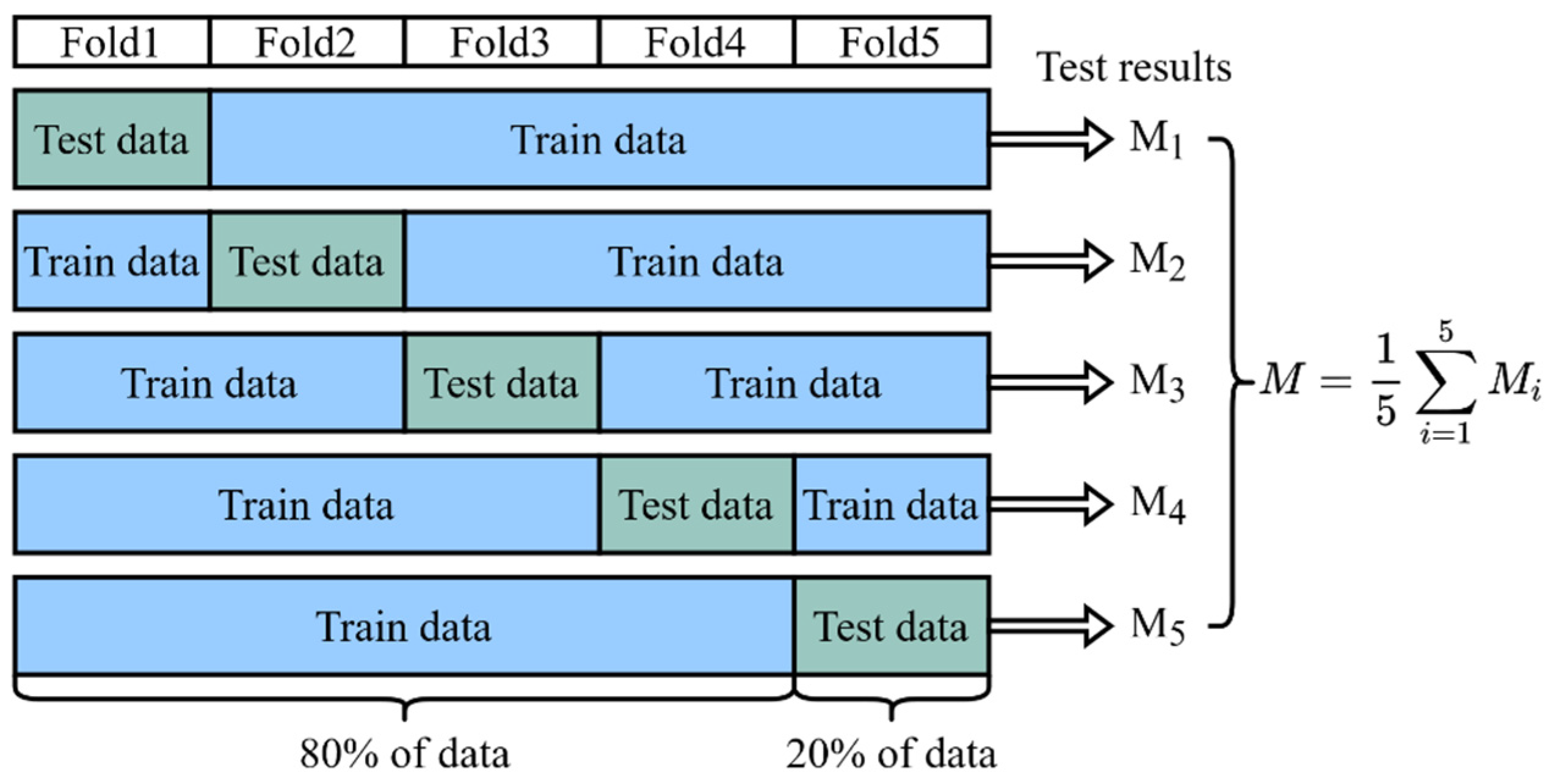
3.1. Experiment Settings
3.2. Evaluation Metrics
3.3. Experiment Analysis
3.4. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Apfelbaum, J.L.; Hagberg, C.A.; Connis, R.T.; Abdelmalak, B.B.; Agarkar, M.; Dutton, R.P.; Fiadjoe, J.E.; Greif, R.; Klock, P.A., Jr.; Mercier, D.; et al. 2022 American Society of Anesthesiologists practice guidelines for management of the difficult airway. Anesthesiology 2022, 136, 31–81. [Google Scholar] [CrossRef] [PubMed]
- Nørskov, A.K.; Rosenstock, C.; Wetterslev, J.; Astrup, G.; Afshari, A.; Lundstrøm, L. Diagnostic accuracy of anaesthesiologists’ prediction of difficult airway management in daily clinical practice: A cohort study of 188 064 patients registered in the Danish Anaesthesia Database. Anaesthesia 2015, 70, 272–281. [Google Scholar] [CrossRef] [PubMed]
- Langeron, O.; Masso, E.; Huraux, C.; Guggiari, M.; Bianchi, A.; Coriat, P.; Riou, B. Prediction of difficult mask ventilation. J. Am. Soc. Anesthesiol. 2000, 92, 1229–1236. [Google Scholar] [CrossRef] [PubMed]
- Kheterpal, S.; Han, R.; Tremper, K.K.; Shanks, A.; Tait, A.R.; O’Reilly, M.; Ludwig, T.A. Incidence and predictors of difficult and impossible mask ventilation. J. Am. Soc. Anesthesiol. 2006, 105, 885–891. [Google Scholar] [CrossRef] [PubMed]
- Detsky, M.E.; Jivraj, N.; Adhikari, N.K.; Friedrich, J.O.; Pinto, R.; Simel, D.L.; Wijeysundera, D.N.; Scales, D.C. Will this patient be difficult to intubate?: The rational clinical examination systematic review. JAMA 2019, 321, 493–503. [Google Scholar] [CrossRef] [PubMed]
- Kheterpal, S.; Healy, D.; Aziz, M.F.; Shanks, A.M.; Freundlich, R.E.; Linton, F.; Martin, L.D.; Linton, J.; Epps, J.L.; Fernandez-Bustamante, A.; et al. Incidence, predictors, and outcome of difficult mask ventilation combined with difficult laryngoscopy: A report from the multicenter perioperative outcomes group. Anesthesiology 2013, 119, 1360–1369. [Google Scholar] [CrossRef] [PubMed]
- Levitan, R.M.; Heitz, J.W.; Sweeney, M.; Cooper, R.M. The complexities of tracheal intubation with direct laryngoscopy and alternative intubation devices. Ann. Emerg. Med. 2011, 57, 240–247. [Google Scholar] [CrossRef] [PubMed]
- Cook, T.; Woodall, N.; Frerk, C.O. Major complications of airway management in the UK: Results of the Fourth National Audit Project of the Royal College of Anaesthetists and the Difficult Airway Society. Part 1: Anaesthesia. Br. J. Anaesth. 2011, 106, 617–631. [Google Scholar] [CrossRef] [PubMed]
- Cook, T.; MacDougall-Davis, S. Complications and failure of airway management. Br. J. Anaesth. 2012, 109, 68–85. [Google Scholar] [CrossRef] [PubMed]
- Heidegger, T. Management of the difficult airway. N. Engl. J. Med. 2021, 384, 1836–1847. [Google Scholar] [CrossRef] [PubMed]
- Chrimes, N.; Bradley, W.; Gatward, J.; Weatherall, A. Human factors and the ‘next generation’airway trolley. Anaesthesia 2019, 74, 427–433. [Google Scholar] [CrossRef] [PubMed]
- Mallampati, S.R.; Gatt, S.P.; Gugino, L.D.; Desai, S.P.; Waraksa, B.; Freiberger, D.; Liu, P.L. A clinical sign to predict difficult tracheal intubation; a prospective study. Can. Anaesth. Soc. J. 1985, 32, 429–434. [Google Scholar] [CrossRef] [PubMed]
- Lee, A.; Fan, L.T.; Gin, T.; Karmakar, M.K.; Kee, W.D.N. A systematic review (meta-analysis) of the accuracy of the Mallampati tests to predict the difficult airway. Anesth. Analg. 2006, 102, 1867–1878. [Google Scholar] [CrossRef] [PubMed]
- Nørskov, A.K.; Rosenstock, C.V.; Lundstrøm, L.H. Lack of national consensus in preoperative airway assessment. Changes 2016, 9, 13. [Google Scholar]
- Hayasaka, T.; Kawano, K.; Kurihara, K.; Suzuki, H.; Nakane, M.; Kawamae, K. Creation of an artificial intelligence model for intubation difficulty classification by deep learning (convolutional neural network) using face images: An observational study. J. Intensive Care 2021, 9, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Tavolara, T.E.; Gurcan, M.N.; Segal, S.; Niazi, M.K.K. Identification of difficult to intubate patients from frontal face images using an ensemble of deep learning models. Comput. Biol. Med. 2021, 136, 104737. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Li, C.; Tang, F.; Wang, Y.; Wu, S.; Zhi, H.; Zhang, F.; Wang, M.; Zhang, J. A fully- automatic semi-supervised deep learning model for difficult airway assessment. Heliyon 2023, 9, e15629. [Google Scholar] [CrossRef] [PubMed]
- García-García, F.; Lee, D.J.; Mendoza-Garcés, F.J.; García-Gutiérrez, S. Reliable prediction of difficult airway for tracheal intubation from patient preoperative photographs by machine learning methods. Comput. Methods Prog. Biomed. 2024, 248, 108118. [Google Scholar] [CrossRef] [PubMed]
- Cormack, R.; Lehane, J. Difficult tracheal intubation in obstetrics. Anaesthesia 1984, 39, 1105–1111. [Google Scholar] [CrossRef] [PubMed]
- Koh, L.; Kong, C.; Ip-Yam, P. The modified Cormack-Lehane score for the grading of direct laryngoscopy: Evaluation in the Asian population. Anaesth. Intensive Care 2002, 30, 48–51. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Wang, J.; Xia, M.; Zhou, R.; Cao, S.; Xu, T.Y.; Jiang, H. Analysis of facial features related to difficulty in exposing glottis through visual laryngoscopy. J. Second Milit. Med. Univ. 2021, 12, 1382–1387. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Acc/% | Spe/% | Sen/% | F1/% |
|---|---|---|---|---|
| Wang et al. [18] | 70.42 | 71.25 | 68.75 | 60.77 |
| Hayasaka et al. [16] | 65.83 | 69.37 | 58.75 | 53.40 |
| Tavolara et al. [17] | 65.42 | 65.62 | 65.00 | 55.61 |
| García-García et al. [19] | 72.08 | 71.88 | 72.50 | 63.39 |
| Ours | 77.92 | 75.62 | 82.50 | 71.35 |
| Backbone | Acc/% | Spe/% | Sen/% | F1/% | Params/M | FLOPs/G |
|---|---|---|---|---|---|---|
| AlexNet | 69.17 | 69.38 | 68.75 | 59.78 | 2.47 | 0.66 |
| GoogleNet | 72.50 | 71.88 | 73.75 | 64.13 | 5.60 | 1.51 |
| DenseNet121 | 78.33 | 75.62 | 83.75 | 72.04 | 6.95 | 2.90 |
| MobileNet_v2 | 71.67 | 71.25 | 72.50 | 63.04 | 2.22 | 0.33 |
| ShuffleNet_v2 | 72.92 | 71.89 | 75.00 | 64.86 | 1.25 | 0.15 |
| VGG16 | 75.42 | 73.75 | 78.75 | 68.10 | 14.17 | 15.34 |
| ResNet18 | 78.33 | 76.87 | 81.25 | 71.43 | 11.18 | 1.82 |
| Ours | 77.92 | 75.62 | 82.50 | 71.35 | 4.91 | 0.90 |
| Attention Mechanism | Acc/% | Spe/% | Sen/% | F1/% |
|---|---|---|---|---|
| — | 73.33 | 72.50 | 75.00 | 65.22 |
| SE | 74.17 | 73.12 | 76.25 | 66.30 |
| CBAM | 75.00 | 74.38 | 76.25 | 67.03 |
| CA | 74.17 | 72.50 | 77.50 | 66.67 |
| ECA | 76.67 | 73.12 | 83.75 | 69.52 |
| HCAM (Ours) | 77.92 | 75.62 | 82.50 | 71.35 |
| Acc/% | Spe/% | Sen/% | F1/% | |
|---|---|---|---|---|
| View 1 | 60.00 | 57.50 | 65.00 | 52.00 |
| View 2 | 65.83 | 68.75 | 60.00 | 53.93 |
| View 3 | 62.50 | 60.00 | 67.50 | 54.55 |
| View 4 | 57.50 | 45.00 | 82.50 | 56.41 |
| View 5 | 65.00 | 61.25 | 72.50 | 58.00 |
| View 1~5 | 77.92 | 75.62 | 82.50 | 71.35 |
| Component | Choice | ||||||
|---|---|---|---|---|---|---|---|
| Baseline | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| MFFM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| HCAM | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Focal Loss | ✓ | ✓ | ✓ | ✓ | |||
| Complement loss | ✓ | ✓ | |||||
| Consistence loss | ✓ | ✓ | |||||
| Acc/% | 69.17 | 71.66 | 73.33 | 74.58 | 75.42 | 75.42 | 77.92 |
| Spe/% | 68.75 | 71.25 | 73.12 | 72.50 | 73.12 | 73.75 | 75.62 |
| Sen/% | 70.00 | 72.25 | 73.75 | 78.75 | 80.00 | 78.75 | 82.50 |
| F1/% | 60.22 | 63.04 | 64.48 | 67.38 | 68.45 | 68.11 | 71.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Yao, Y.; Zhang, G.; Li, X.; Peng, B. Difficult Airway Assessment Based on Multi-View Metric Learning. Bioengineering 2024, 11, 703. https://doi.org/10.3390/bioengineering11070703
Wu J, Yao Y, Zhang G, Li X, Peng B. Difficult Airway Assessment Based on Multi-View Metric Learning. Bioengineering. 2024; 11(7):703. https://doi.org/10.3390/bioengineering11070703
Chicago/Turabian StyleWu, Jinze, Yuan Yao, Guangchao Zhang, Xiaofan Li, and Bo Peng. 2024. "Difficult Airway Assessment Based on Multi-View Metric Learning" Bioengineering 11, no. 7: 703. https://doi.org/10.3390/bioengineering11070703
APA StyleWu, J., Yao, Y., Zhang, G., Li, X., & Peng, B. (2024). Difficult Airway Assessment Based on Multi-View Metric Learning. Bioengineering, 11(7), 703. https://doi.org/10.3390/bioengineering11070703