
CL-SPO2Net: Contrastive Learning Spatiotemporal Attention Network for Non-Contact Video-Based SpO2 Estimation

Abstract
1. Introduction
2. Related Work
2.1. Extraction of Physiological Signals
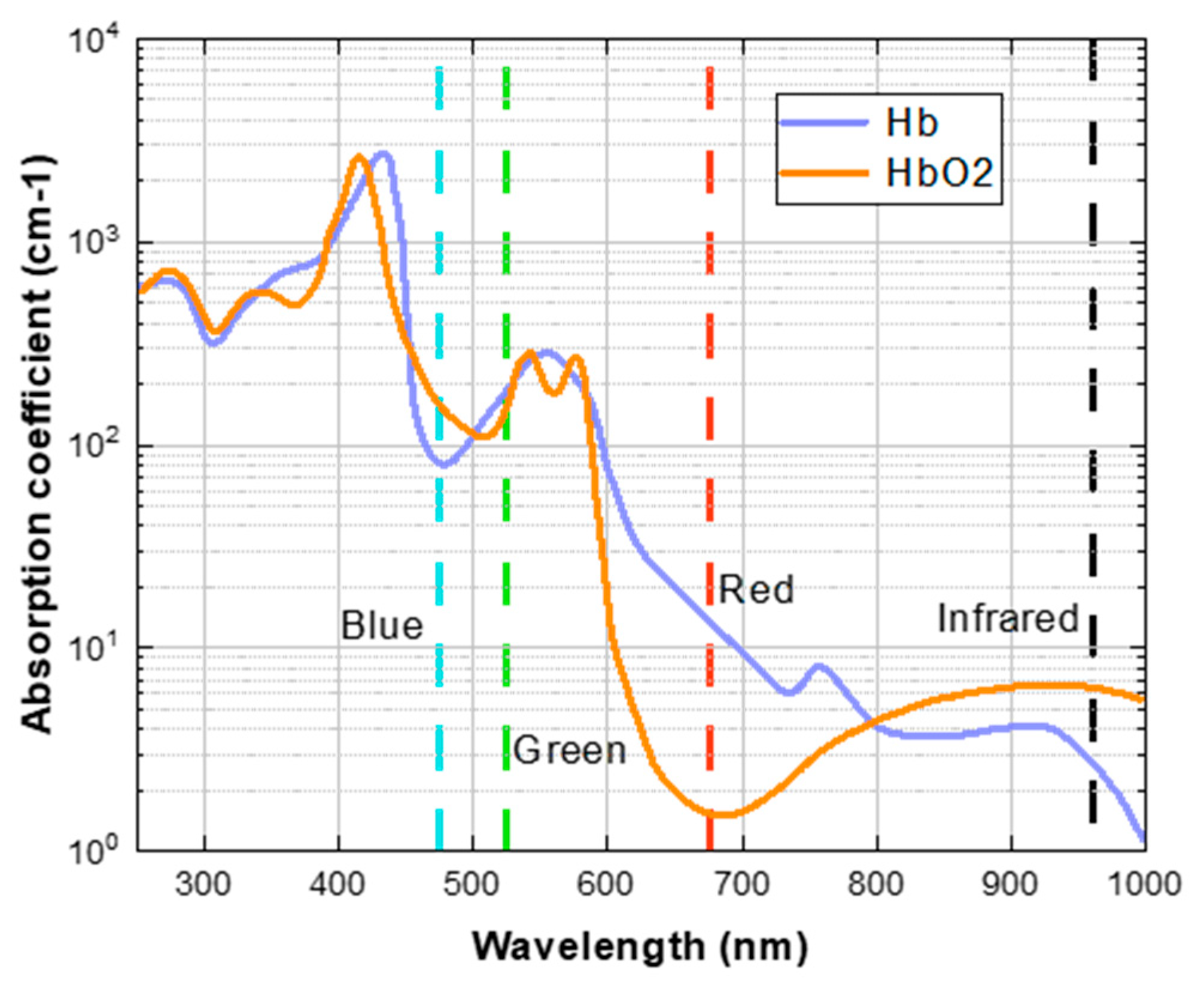
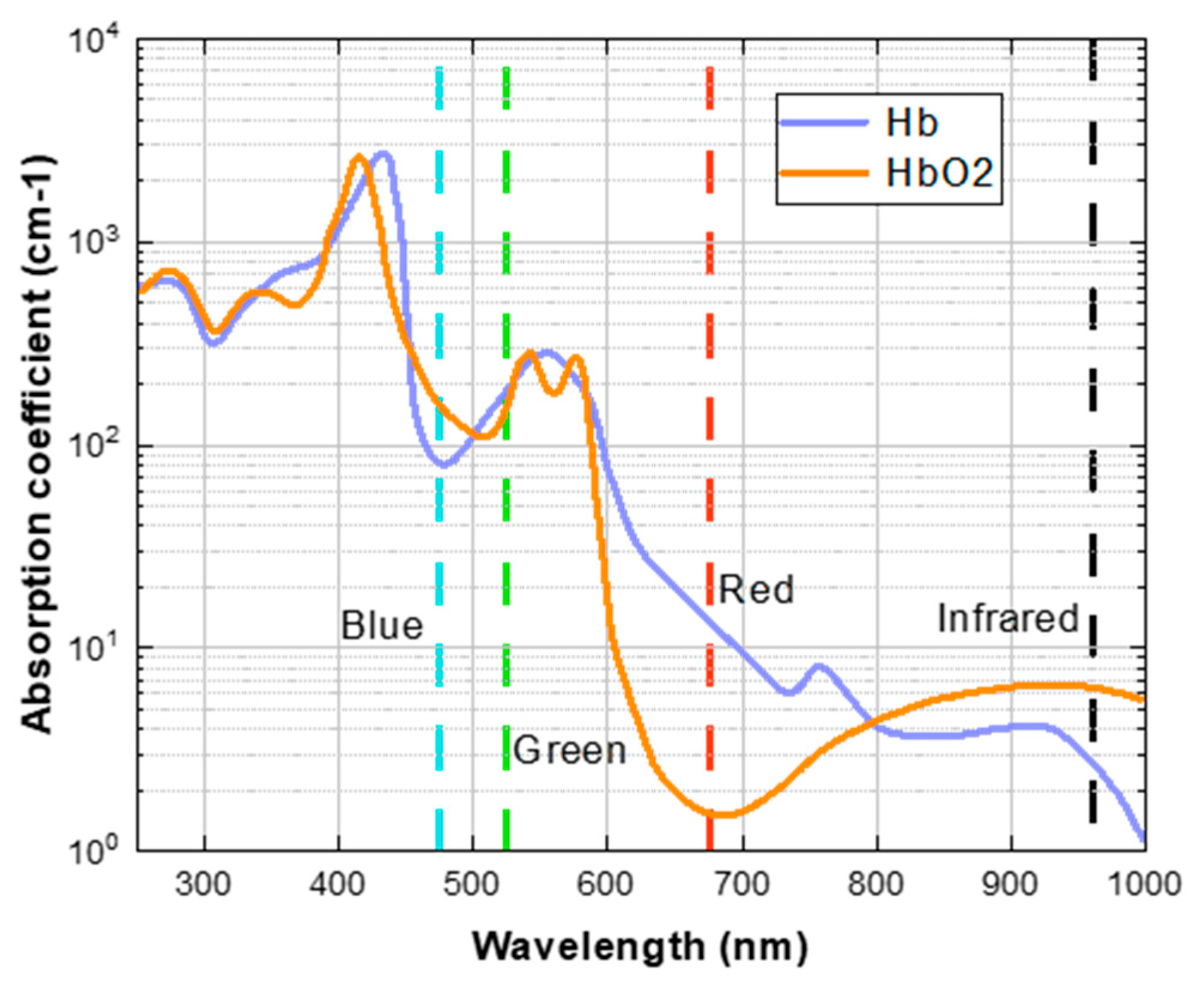
2.2. The Ratio-of-Ratios Principles for SpO2
2.3. Deep Learning Principles for SpO2
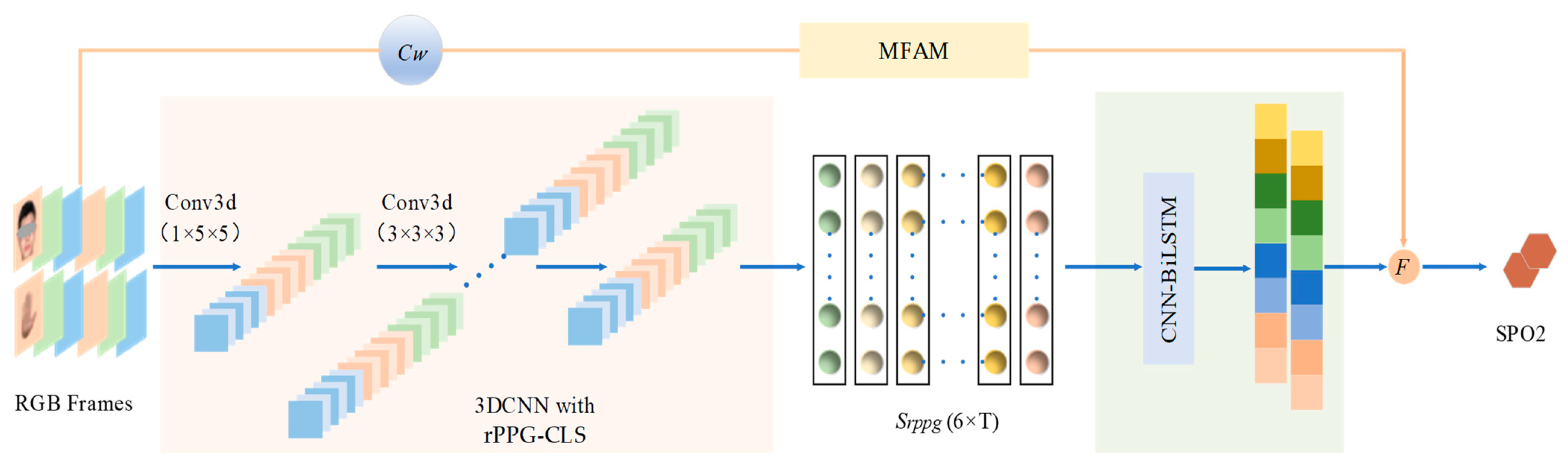
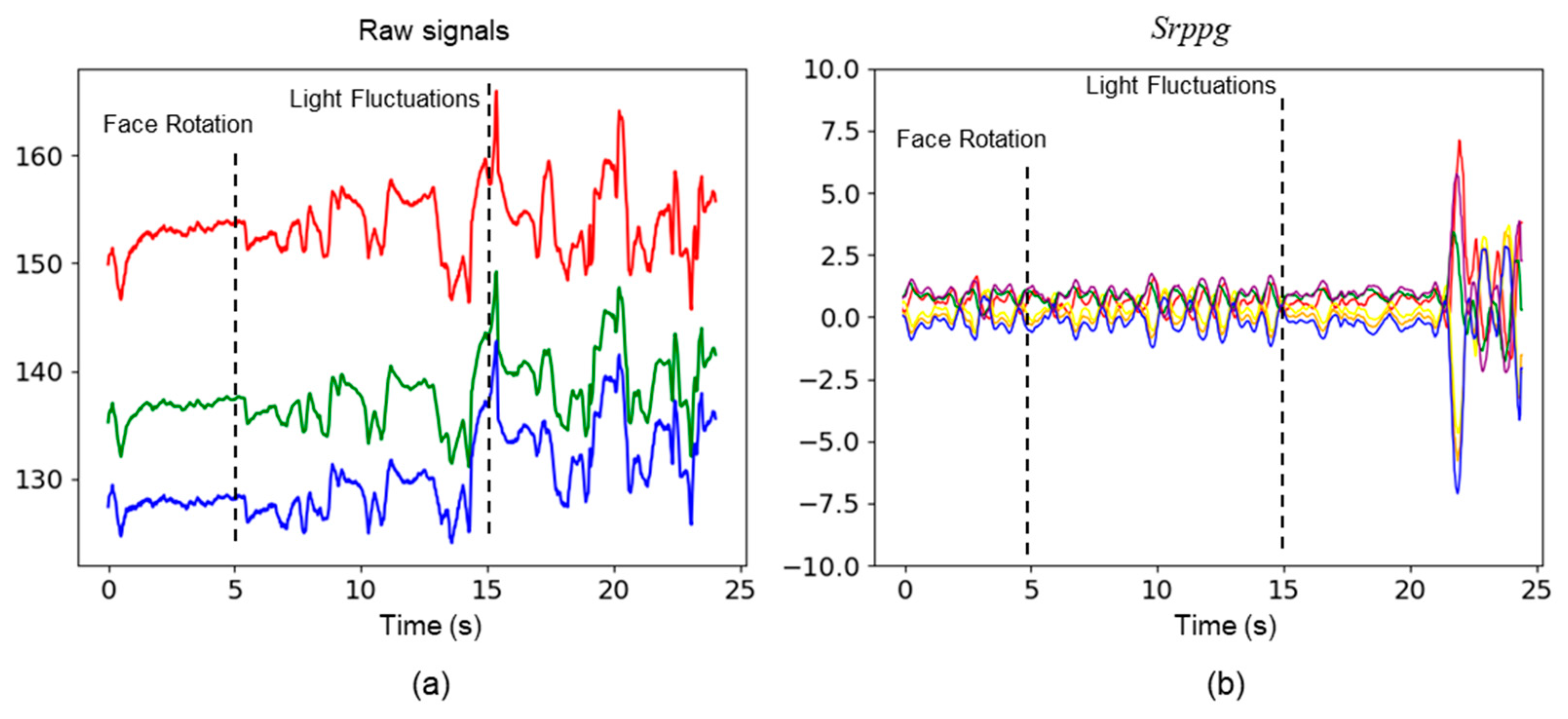
3. Materials and Methods
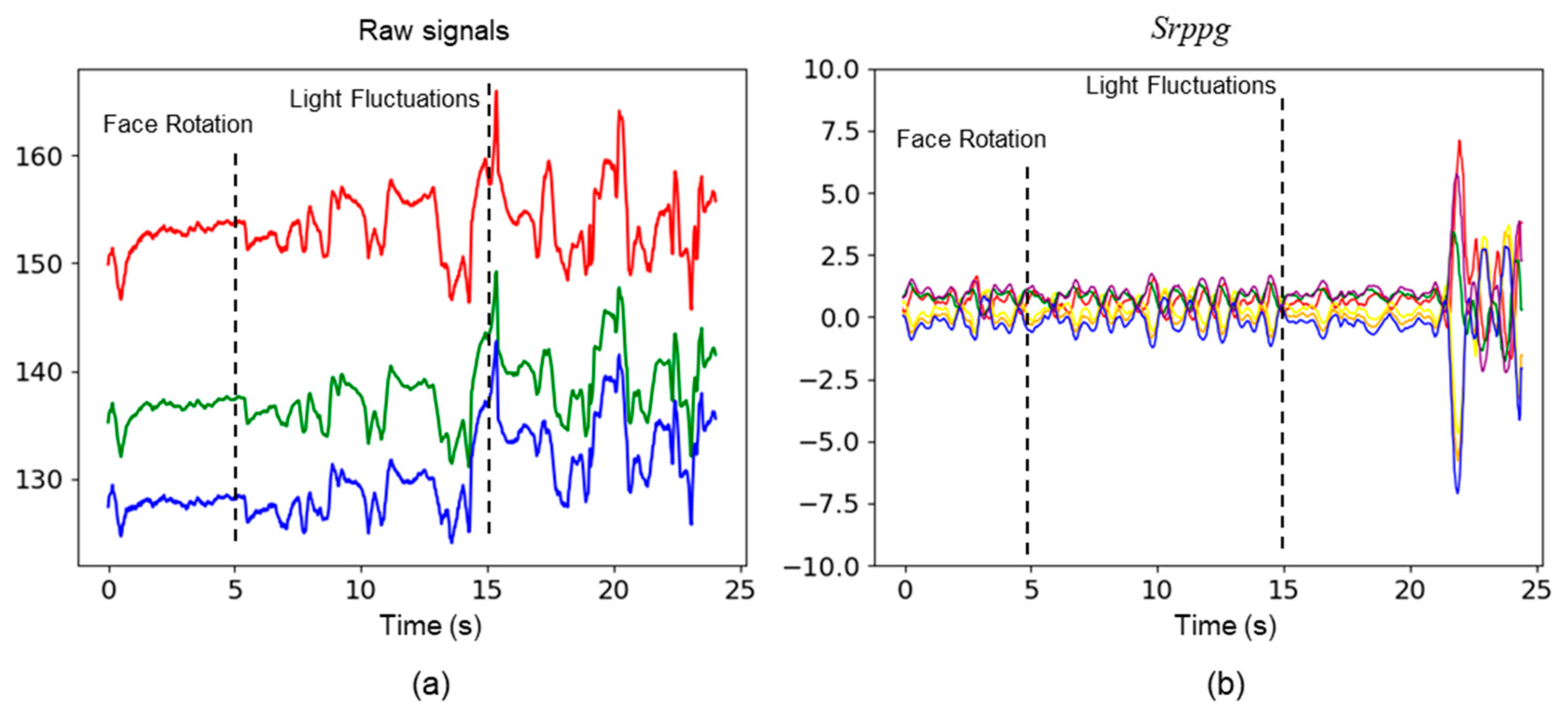
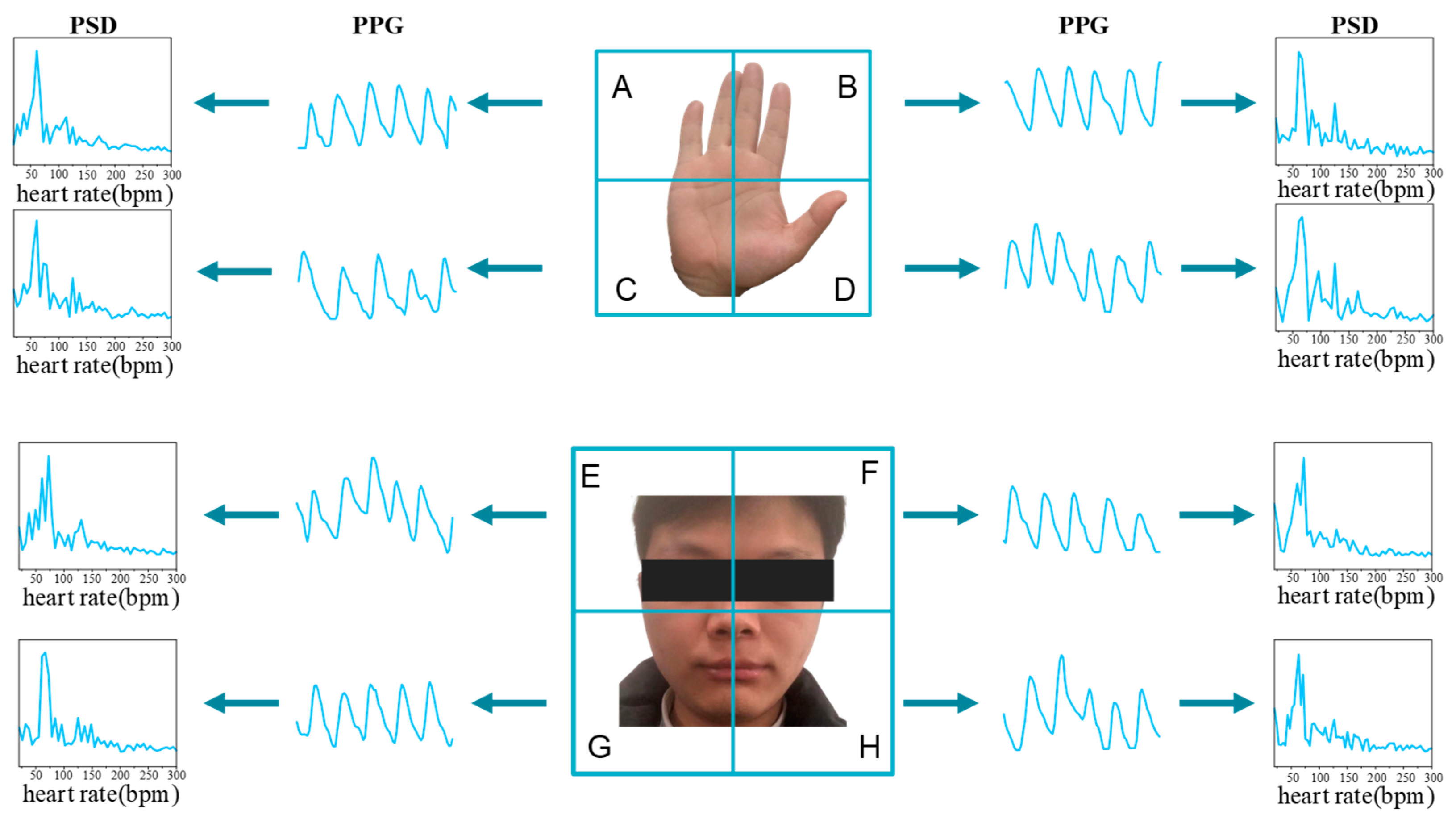
3.1. Data Pre-Processing
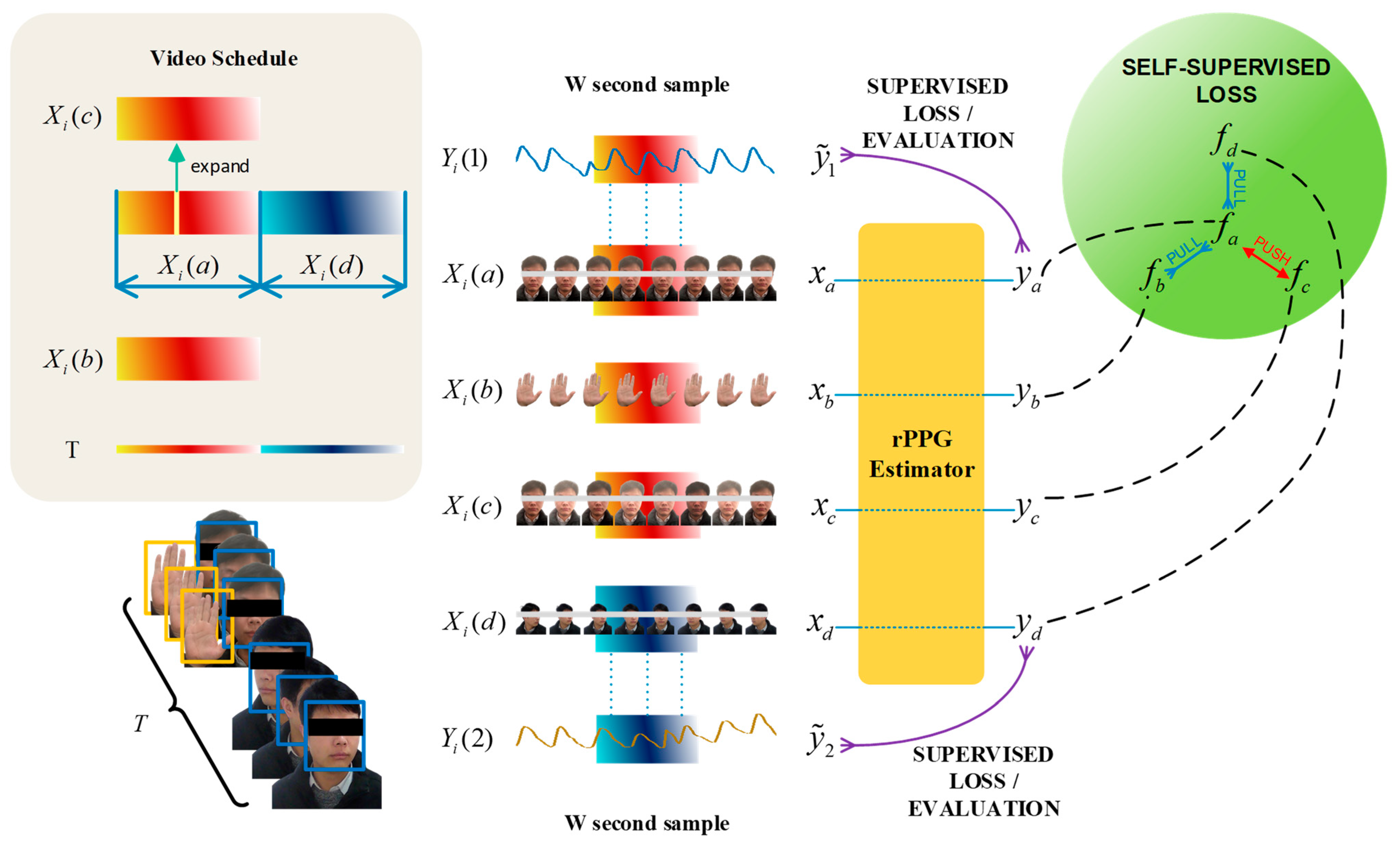
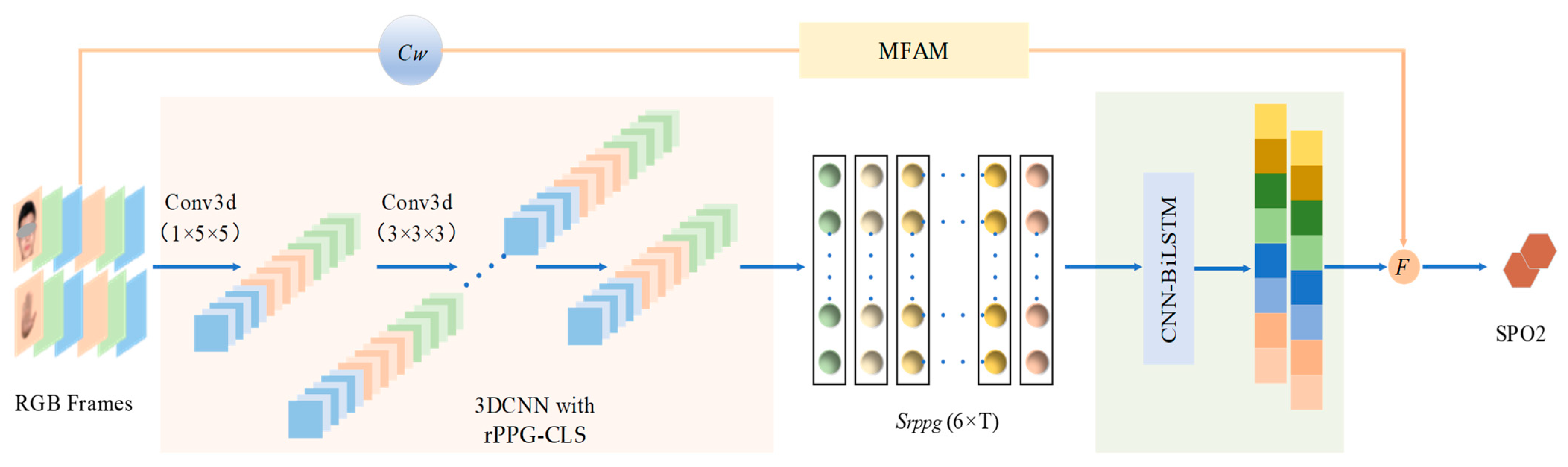
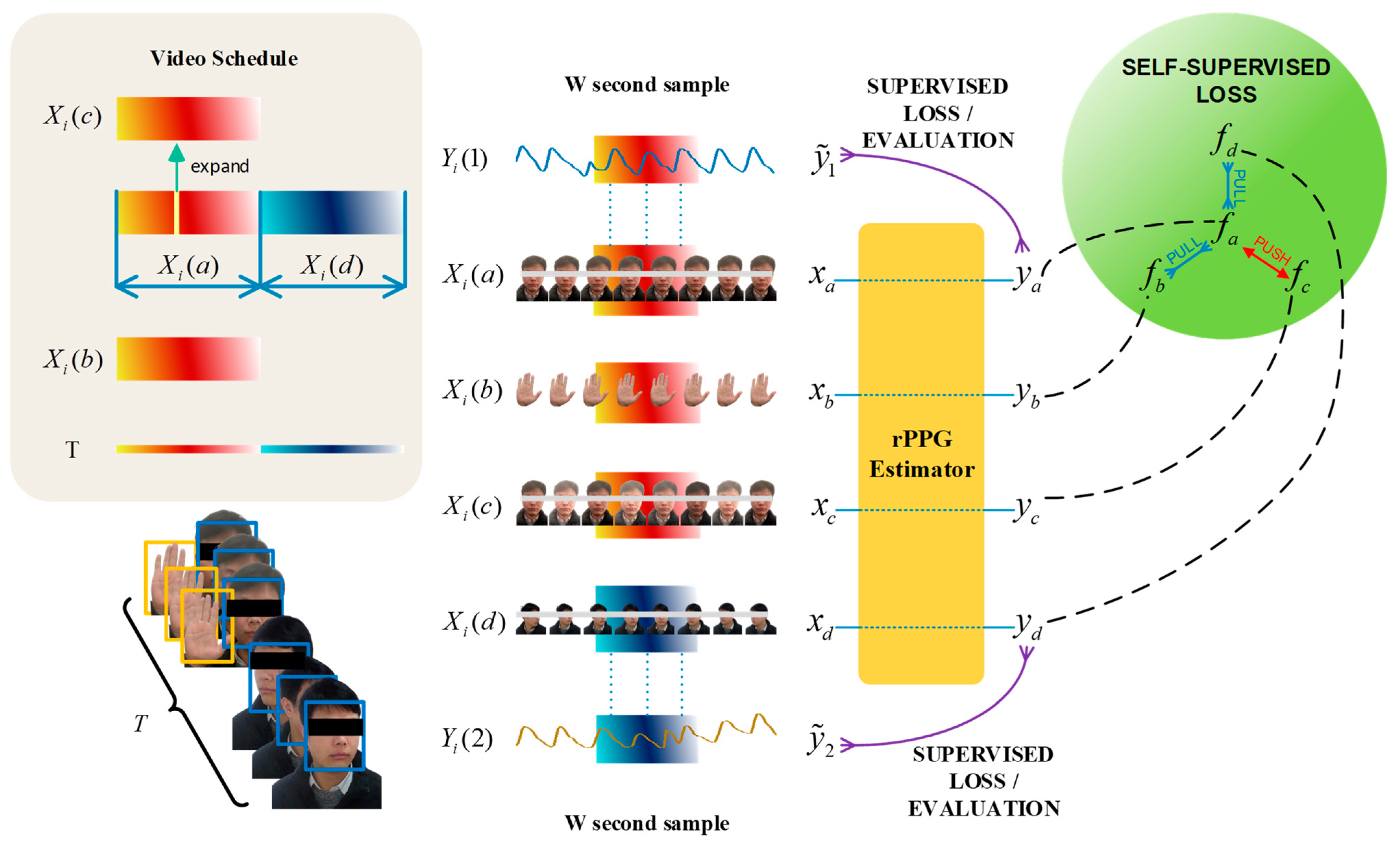
3.2. RPPG Contrastive Learning Strategy Based on 3DCNN
3.2.1. Proposed 3D Convolutional Neural Network
3.2.2. RPPG Contrastive Learning Strategy
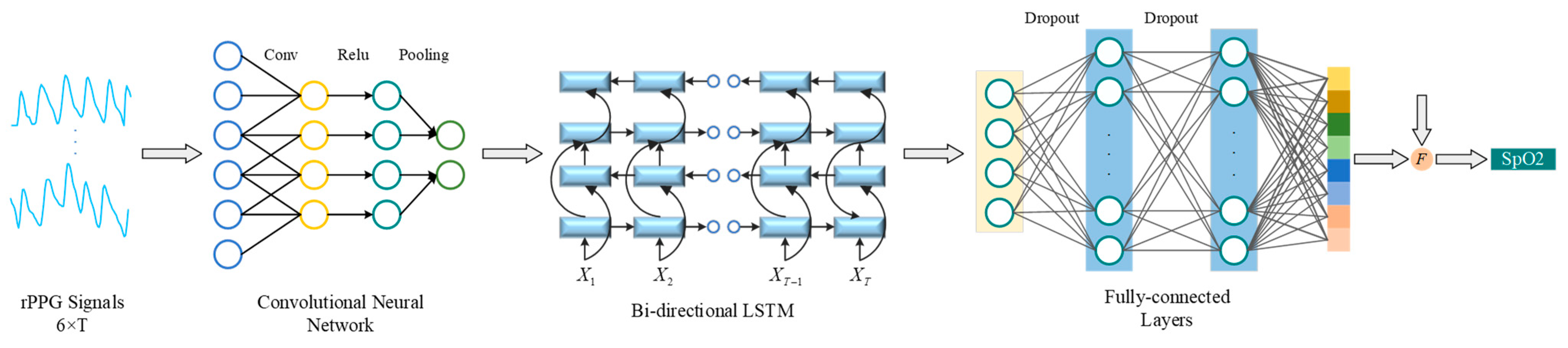
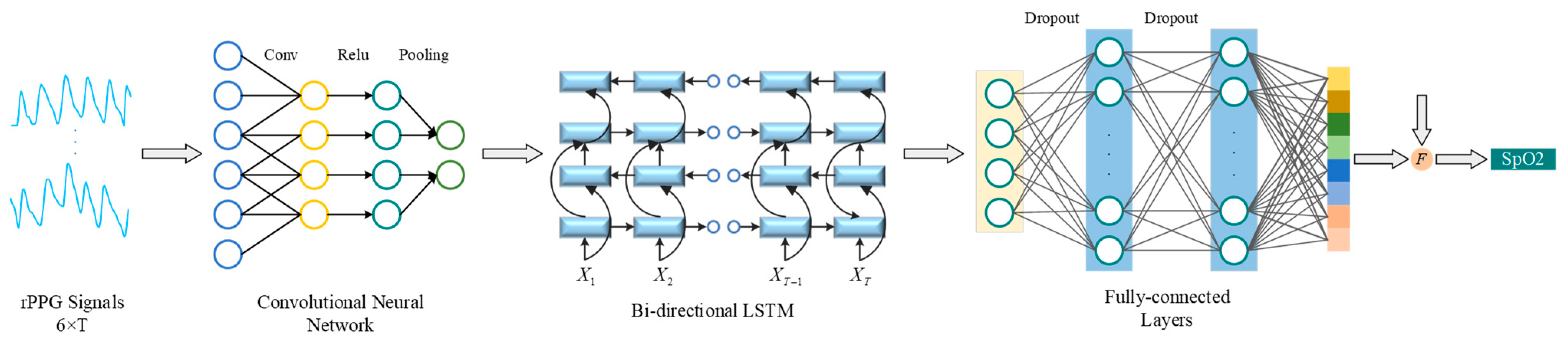
3.3. CNN-BiLSTM for SpO2 Estimation
3.4. Manual Feature Attention Module
3.5. Loss Function
3.5.1. Contrastive Learning Loss Function
3.5.2. Supervised Learning Loss Function for RPPG Signal
3.5.3. End-to-End Loss Function for SpO2
4. Results
4.1. Datasets
4.2. Experimental Setup
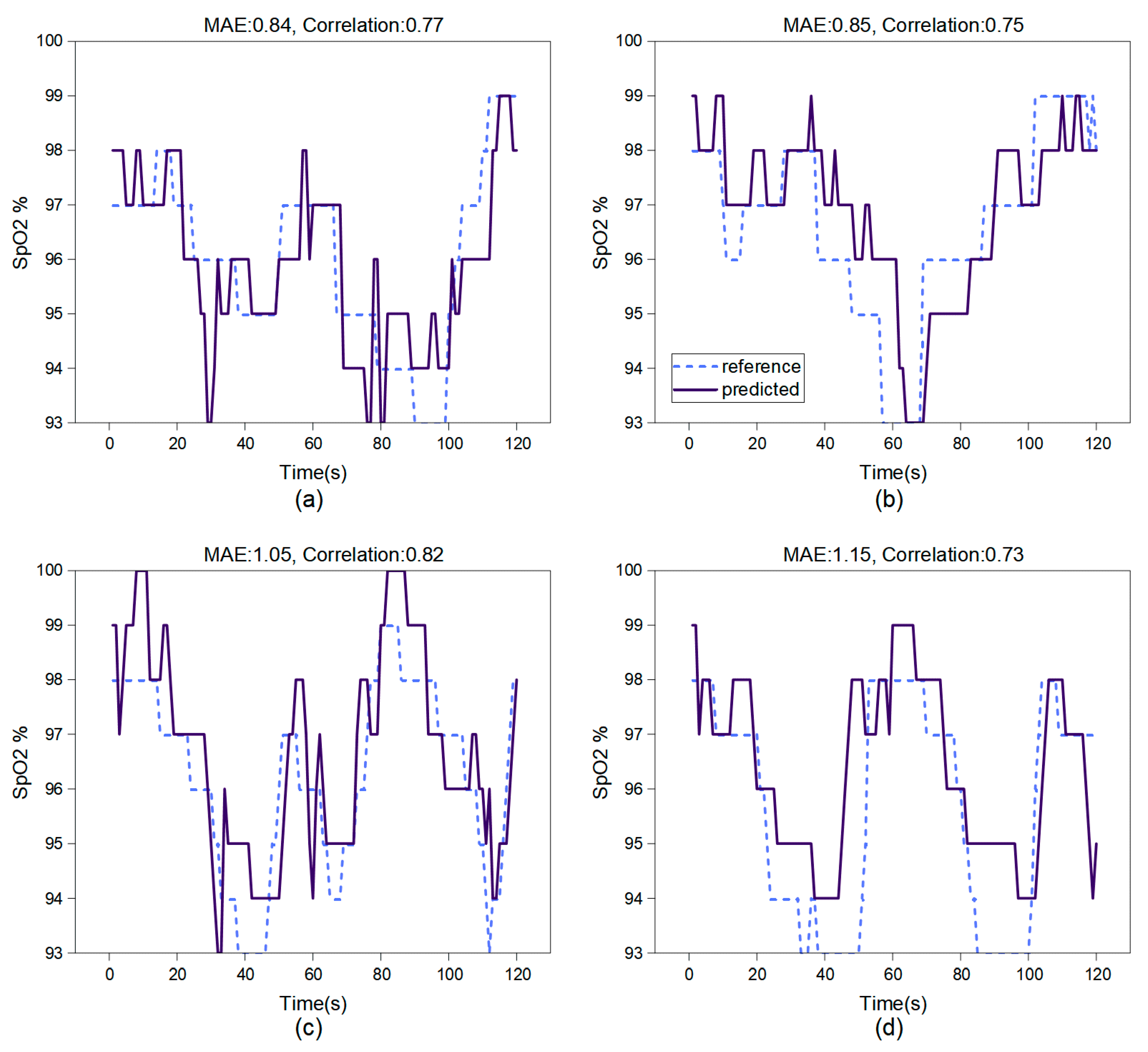
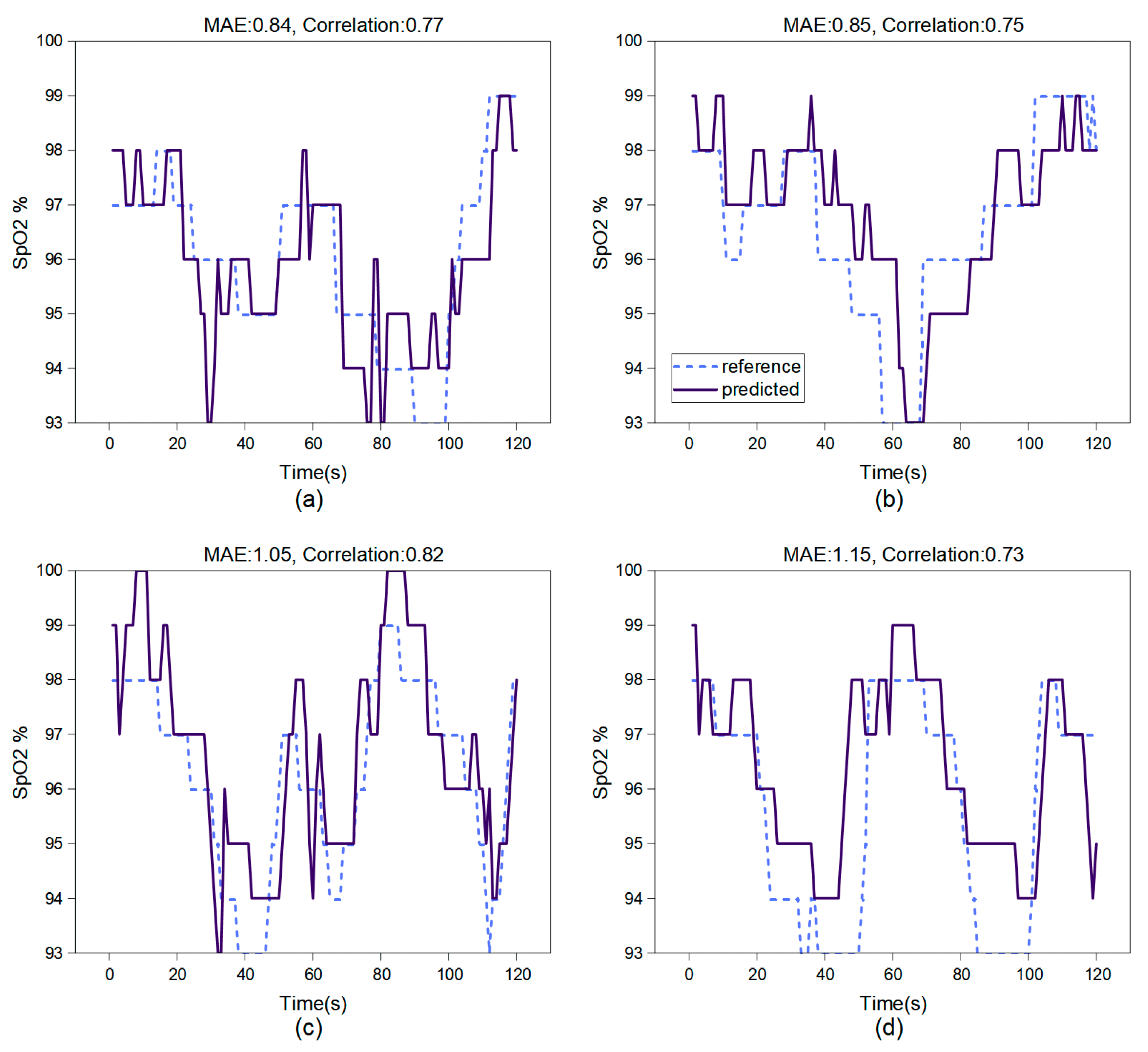
4.3. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- West, J.B. Pulmonary Pathophysiology: The Essentials; Lippincott Williams & Wilkins: Baltimore, MD, USA, 2008. [Google Scholar]
- Van Gastel, M.; Verkruysse, W.; de Haan, G. Data-driven calibration estimation for robust remote pulse-oximetry. Appl. Sci. 2019, 9, 3857. [Google Scholar] [CrossRef]
- Casalino, G.; Castellano, G.; Zaza, G. A mHealth solution for contact-less self-monitoring of blood oxygen saturation. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar]
- Kong, L.; Zhao, Y.; Dong, L.; Jian, Y.; Jin, X.; Li, B.; Feng, Y.; Liu, M.; Liu, X.; Wu, H. Non-contact detection of oxygen saturation based on visible light imaging device using ambient light. Opt. Express 2013, 21, 17464–17471. [Google Scholar] [CrossRef]
- Tamura, T. Current progress of photoplethysmography and SPO2 for health monitoring. Biomed. Eng. Lett. 2019, 9, 21–36. [Google Scholar] [CrossRef]
- Sun, Z.; Li, X. Contrast-Phys: Unsupervised video-based remote physiological measurement via spatiotemporal contrast. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 492–510. [Google Scholar]
- Singh, A.; Obaidat, M.S.; Singh, S.; Aggarwal, A.; Kaur, K.; Sadoun, B.; Kumar, M.; Hsiao, K.-F. A simulation model to reduce the fuel consumption through efficient road traffic modelling. Simul. Model. Pract. Theory 2022, 121, 102658. [Google Scholar] [CrossRef]
- Poh, M.-Z.; McDuff, D.J.; Picard, R.W. Advancements in noncontact, multiparameter physiological measurements using a webcam. IEEE Trans. Biomed. Eng. 2010, 58, 7–11. [Google Scholar] [CrossRef]
- Lee, T.-W.; Girolami, M.; Sejnowski, T.J. Independent component analysis using an extended infomax algorithm for mixed subgaussian and supergaussian sources. Neural Comput. 1999, 11, 417–441. [Google Scholar] [CrossRef]
- Lam, A.; Kuno, Y. Robust heart rate measurement from video using select random patches. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3640–3648. [Google Scholar]
- Tulyakov, S.; Alameda-Pineda, X.; Ricci, E.; Yin, L.; Cohn, J.F.; Sebe, N. Self-adaptive matrix completion for heart rate estimation from face videos under realistic conditions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2396–2404. [Google Scholar]
- Vogels, T.; Van Gastel, M.; Wang, W.; De Haan, G. Fully-automatic camera-based pulse-oximetry during sleep. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1349–1357. [Google Scholar]
- Feng, L.; Po, L.-M.; Xu, X.; Li, Y.; Ma, R. Motion-resistant remote imaging photoplethysmography based on the optical properties of skin. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 879–891. [Google Scholar] [CrossRef]
- An, B.; Lim, H.; Lee, E.C. Fake Biometric Detection Based on Photoplethysmography Extracted from Short Hand Videos. Electronics 2023, 12, 3605. [Google Scholar] [CrossRef]
- Sun, Z.; He, Q.; Li, Y.; Wang, W.; Wang, R.K. Robust non-contact peripheral oxygenation saturation measurement using smartphone-enabled imaging photoplethysmography. Biomed. Opt. Express 2021, 12, 1746–1760. [Google Scholar] [CrossRef]
- Lu, H.; Han, H.; Zhou, S.K. Dual-gan: Joint bvp and noise modeling for remote physiological measurement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12404–12413. [Google Scholar]
- Swinehart, D.F. The beer-lambert law. J. Chem. Educ. 1962, 39, 333. [Google Scholar] [CrossRef]
- Shao, D.; Liu, C.; Tsow, F.; Yang, Y.; Du, Z.; Iriya, R.; Yu, H.; Tao, N. Noncontact monitoring of blood oxygen saturation using camera and dual-wavelength imaging system. IEEE Trans. Biomed. Eng. 2015, 63, 1091–1098. [Google Scholar] [CrossRef]
- Scully, C.G.; Lee, J.; Meyer, J.; Gorbach, A.M.; Granquist-Fraser, D.; Mendelson, Y.; Chon, K.H. Physiological parameter monitoring from optical recordings with a mobile phone. IEEE Trans. Biomed. Eng. 2011, 59, 303–306. [Google Scholar] [CrossRef]
- Al-Naji, A.; Khalid, G.A.; Mahdi, J.F.; Chahl, J. Non-contact SpO2 prediction system based on a digital camera. Appl. Sci. 2021, 11, 4255. [Google Scholar] [CrossRef]
- Lamonaca, F.; Carnì, D.L.; Grimaldi, D.; Nastro, A.; Riccio, M.; Spagnolo, V. Blood oxygen saturation measurement by smartphone camera. In Proceedings of the 2015 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Torino, Italy, 7–9 May 2015; pp. 359–364. [Google Scholar]
- Tarassenko, L.; Villarroel, M.; Guazzi, A.; Jorge, J.; Clifton, D.; Pugh, C. Non-contact video-based vital sign monitoring using ambient light and auto-regressive models. Physiol. Meas. 2014, 35, 807. [Google Scholar] [CrossRef] [PubMed]
- Bal, U. Non-contact estimation of heart rate and oxygen saturation using ambient light. Biomed. Opt. Express 2015, 6, 86–97. [Google Scholar] [CrossRef]
- Guazzi, A.R.; Villarroel, M.; Jorge, J.; Daly, J.; Frise, M.C.; Robbins, P.A.; Tarassenko, L. Non-contact measurement of oxygen saturation with an RGB camera. Biomed. Opt. Express 2015, 6, 3320–3338. [Google Scholar] [CrossRef] [PubMed]
- Rosa, A.d.F.G.; Betini, R.C. Noncontact SpO2 measurement using Eulerian video magnification. IEEE Trans. Instrum. Meas. 2019, 69, 2120–2130. [Google Scholar] [CrossRef]
- Kim, N.H.; Yu, S.G.; Kim, S.E.; Lee, E.C. Non-Contact oxygen saturation measurement using YCgCr color space with an RGB camera. Sensors 2021, 21, 6120. [Google Scholar] [CrossRef]
- Kok, J. Neural Networks for Non-Contact Oxygen Saturation Estimation from the Face. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2022. [Google Scholar]
- Stricker, R.; Müller, S.; Gross, H.-M. Non-contact video-based pulse rate measurement on a mobile service robot. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; pp. 1056–1062. [Google Scholar]
- Ding, X.; Nassehi, D.; Larson, E.C. Measuring oxygen saturation with smartphone cameras using convolutional neural networks. IEEE J. Biomed. Health Inform. 2018, 23, 2603–2610. [Google Scholar] [CrossRef] [PubMed]
- Mathew, J.; Tian, X.; Wong, C.-W.; Ho, S.; Milton, D.K.; Wu, M. Remote blood oxygen estimation from videos using neural networks. IEEE J. Biomed. Health Inform. 2023, 27, 3710–3720. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Kumar, M.; Veeraraghavan, A.; Sabharwal, A. DistancePPG: Robust non-contact vital signs monitoring using a camera. Biomed. Opt. Express 2015, 6, 1565–1588. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Yuen, P.C.; Zhang, S.; Zhao, G. 3D mask face anti-spoofing with remote photoplethysmography. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 85–100. [Google Scholar]
- Liu, S.-Q.; Lan, X.; Yuen, P.C. Remote photoplethysmography correspondence feature for 3D mask face presentation attack detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 558–573. [Google Scholar]
- Wang, W.; den Brinker, A.C.; De Haan, G. Discriminative signatures for remote-PPG. IEEE Trans. Biomed. Eng. 2019, 67, 1462–1473. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; den Brinker, A.C.; Stuijk, S.; de Haan, G. Algorithmic principles of remote PPG. IEEE Trans. Biomed. Eng. 2017, 64, 1479–1491. [Google Scholar] [CrossRef] [PubMed]
- Kamshilin, A.A.; Miridonov, S.; Teplov, V.; Saarenheimo, R.; Nippolainen, E. Photoplethysmographic imaging of high spatial resolution. Biomed. Opt. Express 2011, 2, 996–1006. [Google Scholar] [CrossRef]
- Kamshilin, A.A.; Teplov, V.; Nippolainen, E.; Miridonov, S.; Giniatullin, R. Variability of microcirculation detected by blood pulsation imaging. PLoS ONE 2013, 8, e57117. [Google Scholar] [CrossRef]
- Gideon, J.; Stent, S. The way to my heart is through contrastive learning: Remote photoplethysmography from unlabelled video. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3995–4004. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Sabour, R.M.; Benezeth, Y.; De Oliveira, P.; Chappé, J.; Yang, F. UBFC-Phys: A multimodal database for psychophysiological studies of social stress. IEEE Trans. Affect. Comput. 2023, 14, 622–636. [Google Scholar] [CrossRef]
- Peng, J.; Su, W.; Tian, Z.; Zang, D.; Li, X.; Song, Z. MVPD: A multimodal video physiology database for rPPG. In Proceedings of the 2023 IEEE 3rd International Conference on Software Engineering and Artificial Intelligence (SEAI), Xiamen, China, 16–18 June 2023; pp. 173–177. [Google Scholar]
- Nemcova, A.; Jordanova, I.; Varecka, M.; Smisek, R.; Marsanova, L.; Smital, L.; Vitek, M. Monitoring of heart rate, blood oxygen saturation, and blood pressure using a smartphone. Biomed. Signal Process. Control. 2020, 59, 101928. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Blocks | Output Size |
|---|---|---|
| Input | standardization | |
| 3DConv1 | stride (1,1,1) | |
| Avgpooling1 | , stride (1,2,2) | |
| 3DConv2 | ||
| Avgpooling2 | , stride (2,2,2) | |
| 3DConv3 | ||
| Avgpooling3 | , stride (1,2,2) | |
| 3DConv4 | ||
| Interpolate1 | - | |
| 3DConv5 | ||
| Avgpooling4 | ||
| 3DConv6 |
| Method | Non- Contact? | ROI | Stable Environment | Light Fluctuations | Face Rotation | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE (%) | RMSE (%) | MAE (%) | RMSE (%) | MAE (%) | RMSE (%) | ||||||
| Ding et al. [29] | ✗ | Fingertip | 2.24 | 2.56 | 0.52 | - | - | - | - | - | - |
| Nemcova et al. [43] | ✗ | Fingertip | 1.10 | 1.23 | 0.43 | - | - | - | - | - | - |
| Kong et al. [4] | ✓ | Face | 1.39 | 1.75 | 0.71 | 2.13 | 2.27 | 0.45 | 1.83 | 1.71 | 0.69 |
| Scully et al. [19] | ✓ | Face | 1.28 | 1.84 | 0.85 | 1.86 | 2.11 | 0.74 | 2.30 | 2.51 | 0.57 |
| Shao et al. [18] | ✓ | Around the Lip | 1.05 | 1.32 | 0.93 | 2.35 | 2.62 | 0.61 | 2.55 | 2.89 | 0.58 |
| Kim et al. [26] | ✓ | Face | 0.54 | 0.69 | 0.92 | 1.99 | 1.93 | 0.71 | 1.58 | 1.98 | 0.79 |
| Sun et al. [15] | ✓ | Hand | 1.13 | 1.23 | 0.91 | 1.55 | 2.03 | 0.78 | - | - | - |
| Mathew et al. [30] | ✓ | Hand | 1.97 | 2.32 | 0.40 | - | - | - | - | - | - |
| CL-SPO2Net | ✓ | Face | 0.85 | 1.12 | 0.76 | 1.13 | 1.37 | 0.79 | 1.20 | 1.25 | 0.80 |
| Epoch | Validation MAE (%) | Validation RMSE (%) | ||
|---|---|---|---|---|
| 0 | 50 | 50 | 83.05 | 91.72 |
| 10 | 56 | 44 | 42.33 | 46.97 |
| 20 | 63 | 37 | 22.01 | 25.98 |
| 30 | 71 | 29 | 8.36 | 10.30 |
| 40 | 80 | 20 | 1.65 | 1.96 |
| 50 | 87 | 13 | 1.26 | 1.52 |
| Method | MAE (%) | RMSE (%) | ||
|---|---|---|---|---|
| Baseline (3DCNN-LSTM) | Median | 0.48 | 3.57 | 3.98 |
| IQR | 0.32 | 1.21 | 1.38 | |
| Proposed 3DCNN and CNN-BiLSTM | Median | 0.51 | 2.58 | 2.95 |
| IQR | 0.33 | 0.68 | 0.95 | |
| Model 1: Baseline + Contrastive Learning | Median | 0.62 | 0.89 | 1.30 |
| IQR | 0.31 | 0.52 | 0.63 | |
| Model 2: Baseline + MFAM | Median | 0.56 | 1.42 | 1.86 |
| IQR | 0.36 | 0.77 | 1.02 | |
| CL-SPO2Net | Median | 0.76 | 0.88 | 1.23 |
| IQR | 0.29 | 0.54 | 0.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, J.; Su, W.; Chen, H.; Sun, J.; Tian, Z. CL-SPO2Net: Contrastive Learning Spatiotemporal Attention Network for Non-Contact Video-Based SpO2 Estimation. Bioengineering 2024, 11, 113. https://doi.org/10.3390/bioengineering11020113
Peng J, Su W, Chen H, Sun J, Tian Z. CL-SPO2Net: Contrastive Learning Spatiotemporal Attention Network for Non-Contact Video-Based SpO2 Estimation. Bioengineering. 2024; 11(2):113. https://doi.org/10.3390/bioengineering11020113
Chicago/Turabian StylePeng, Jiahe, Weihua Su, Haiyong Chen, Jingsheng Sun, and Zandong Tian. 2024. "CL-SPO2Net: Contrastive Learning Spatiotemporal Attention Network for Non-Contact Video-Based SpO2 Estimation" Bioengineering 11, no. 2: 113. https://doi.org/10.3390/bioengineering11020113
APA StylePeng, J., Su, W., Chen, H., Sun, J., & Tian, Z. (2024). CL-SPO2Net: Contrastive Learning Spatiotemporal Attention Network for Non-Contact Video-Based SpO2 Estimation. Bioengineering, 11(2), 113. https://doi.org/10.3390/bioengineering11020113