
Mobile Application and Machine Learning-Driven Scheme for Intelligent Diabetes Progression Analysis and Management Using Multiple Risk Factors



Abstract
1. Introduction
- Designed and implemented an AI-enabled mobile system that integrates deep learning techniques to support multiple data collection methods, with a comprehensive system database to facilitate the collection of detailed and diverse patient data.
- Introduced the novel DiabMini dataset, which includes 127 features from 88 diabetic patients, covering personal, medical, and detailed dietary nutrition and lifestyle data. This dataset enables a more holistic and precise analysis of factors affecting diabetes progression.
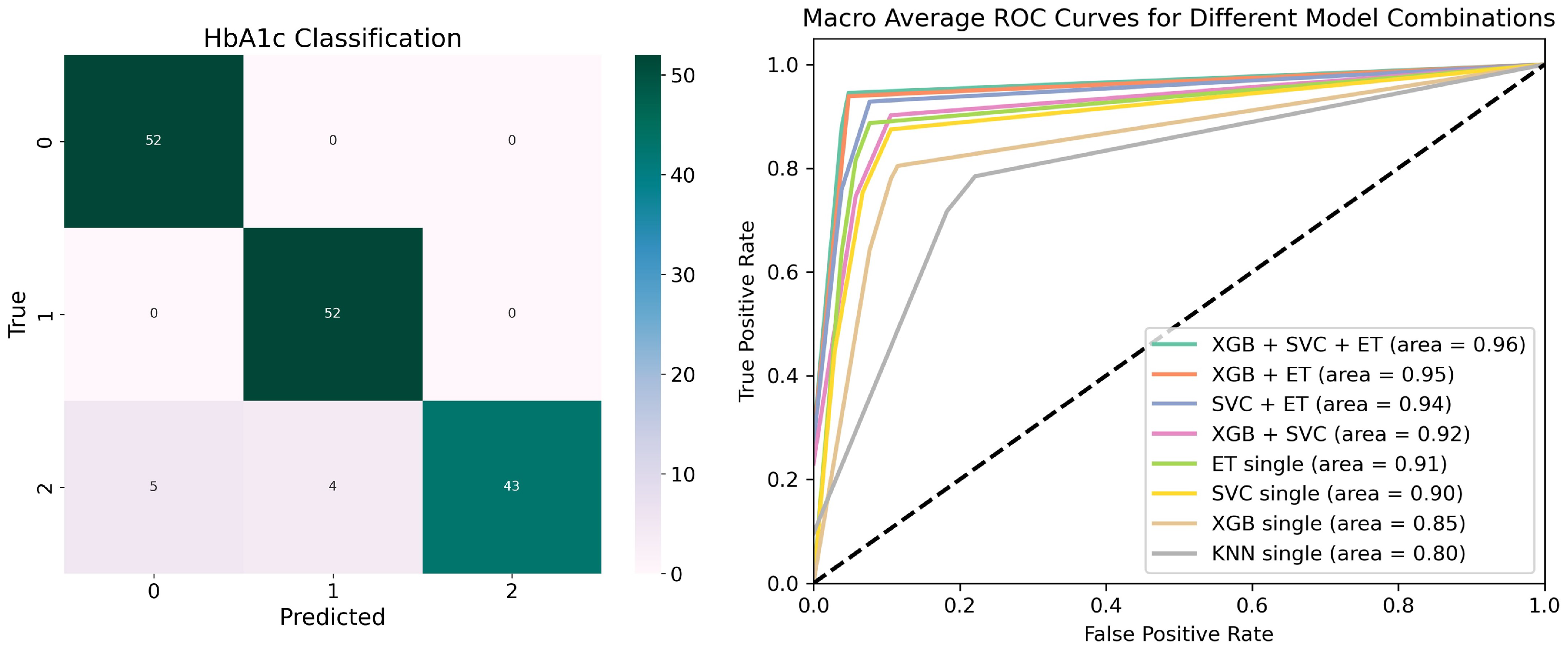
- Focused on HbA1c as a critical indicator of diabetes progression, we developed a stacking model integrating XGBoost, SVC, ET, and KNN to assess the relationship between various risk factors and HbA1c dynamics, achieving a classification accuracy of 94.23%.
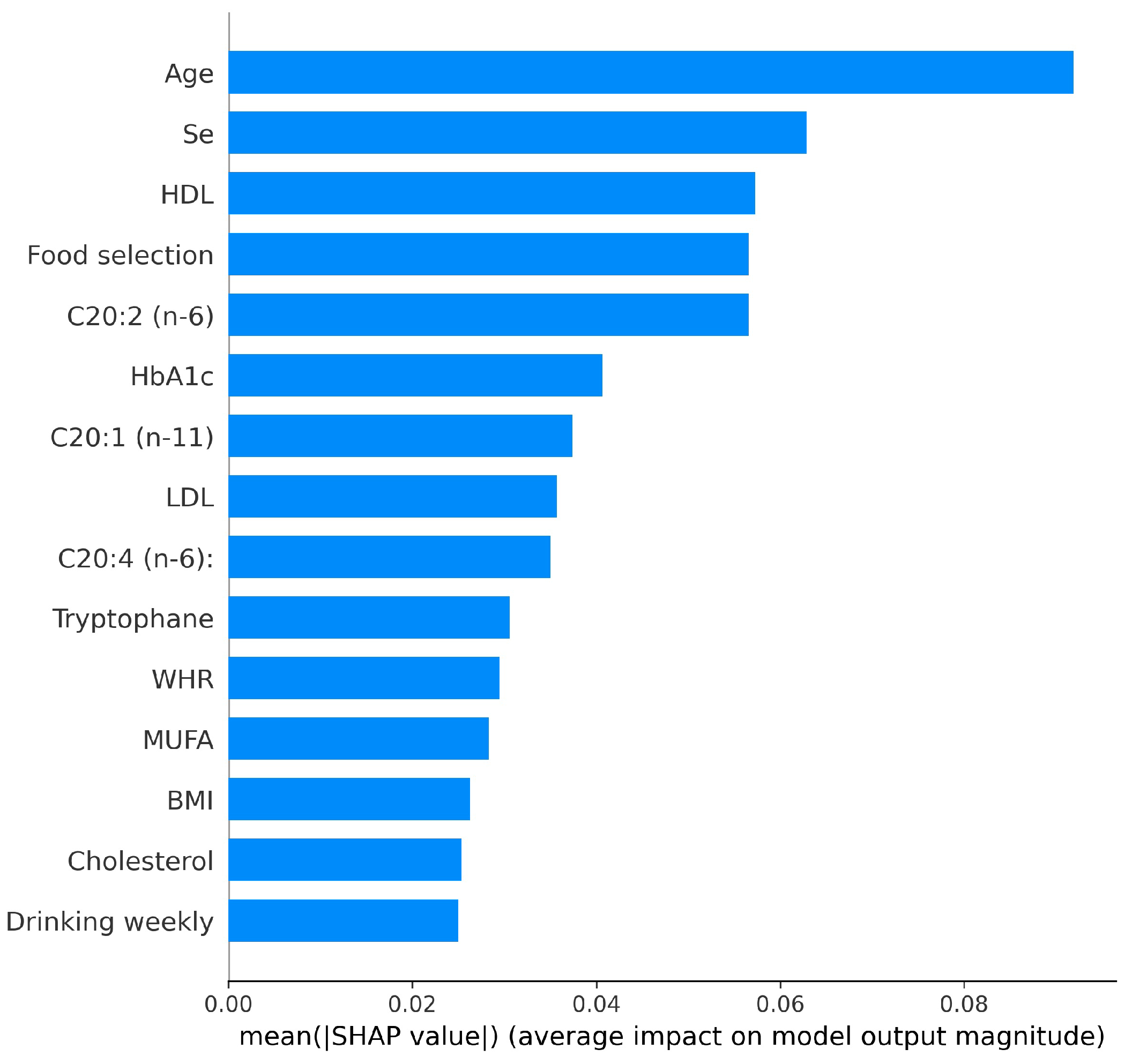
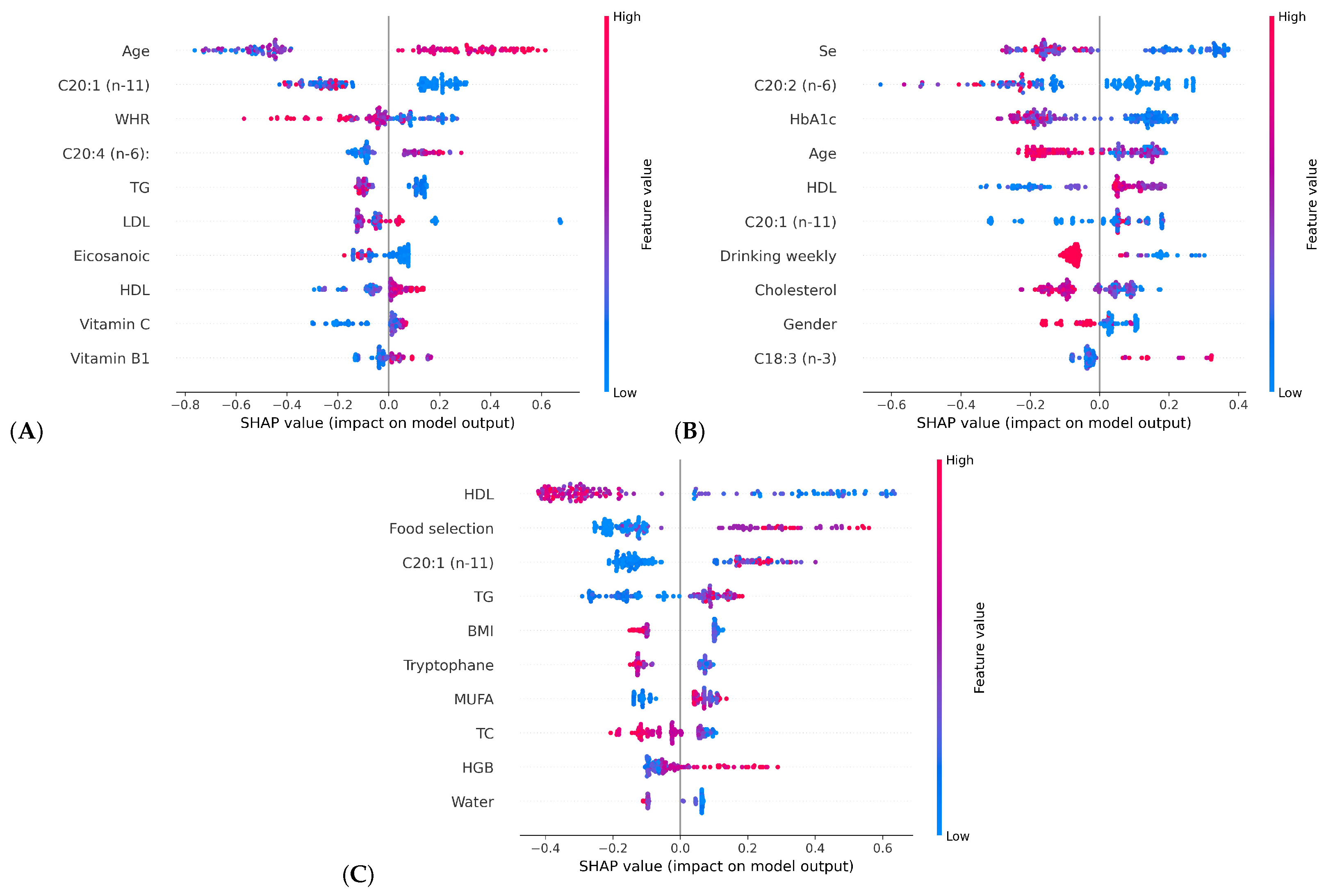
- Applied SHAP to illustrate the contributions of different influencing factors to HbA1c, improving the interpretability of the model’s predictions.
- Supported the advancement of diabetes research by combining continuous and detailed data collection with thorough data analysis, enabling a deeper understanding of diabetes management and progression.
2. Materials and Methods
2.1. Proposed AI-Enabled Mobile System
2.1.1. System Database
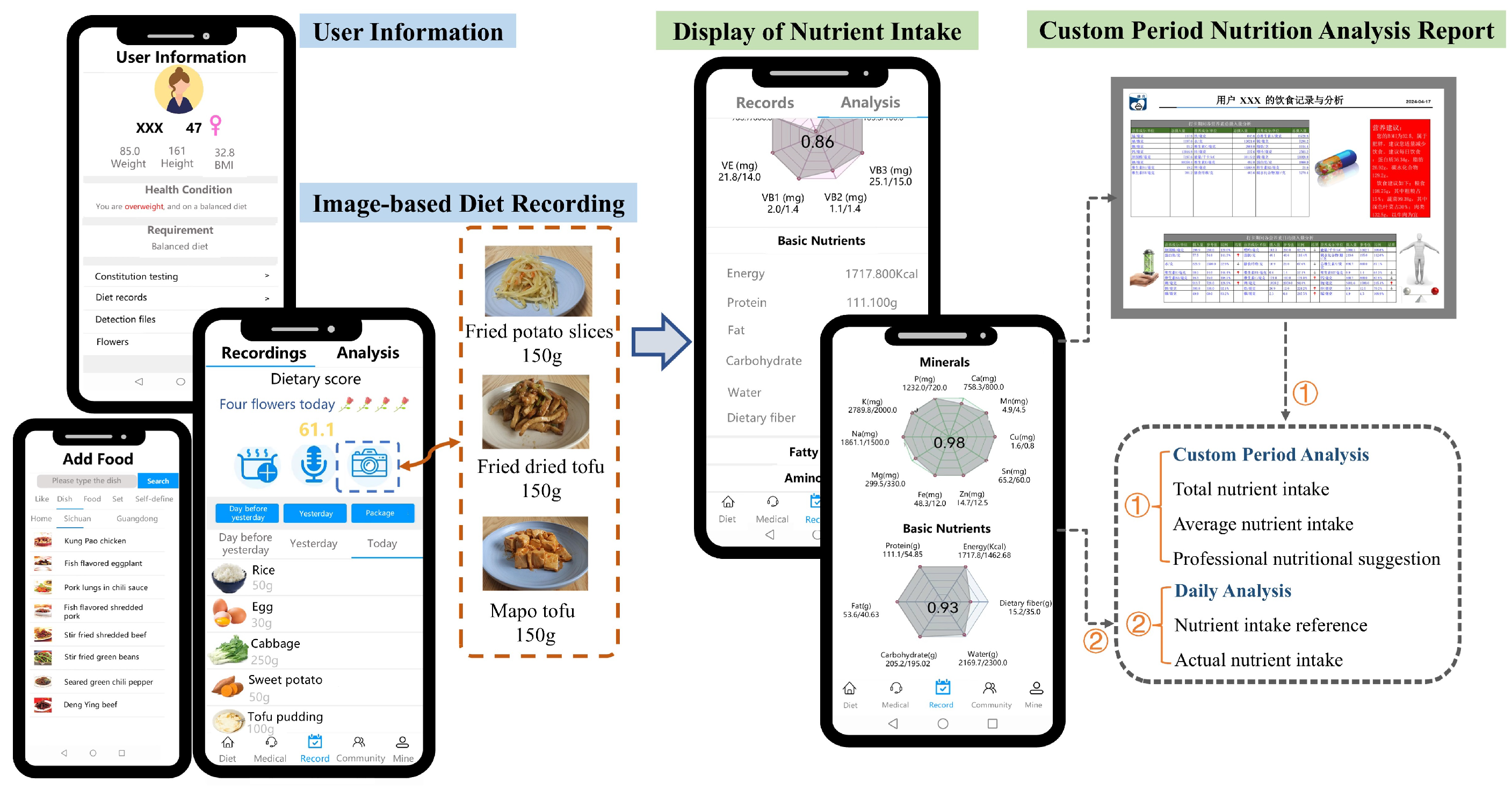
2.1.2. User Information Management
2.1.3. Diet Recording Methods
- A.
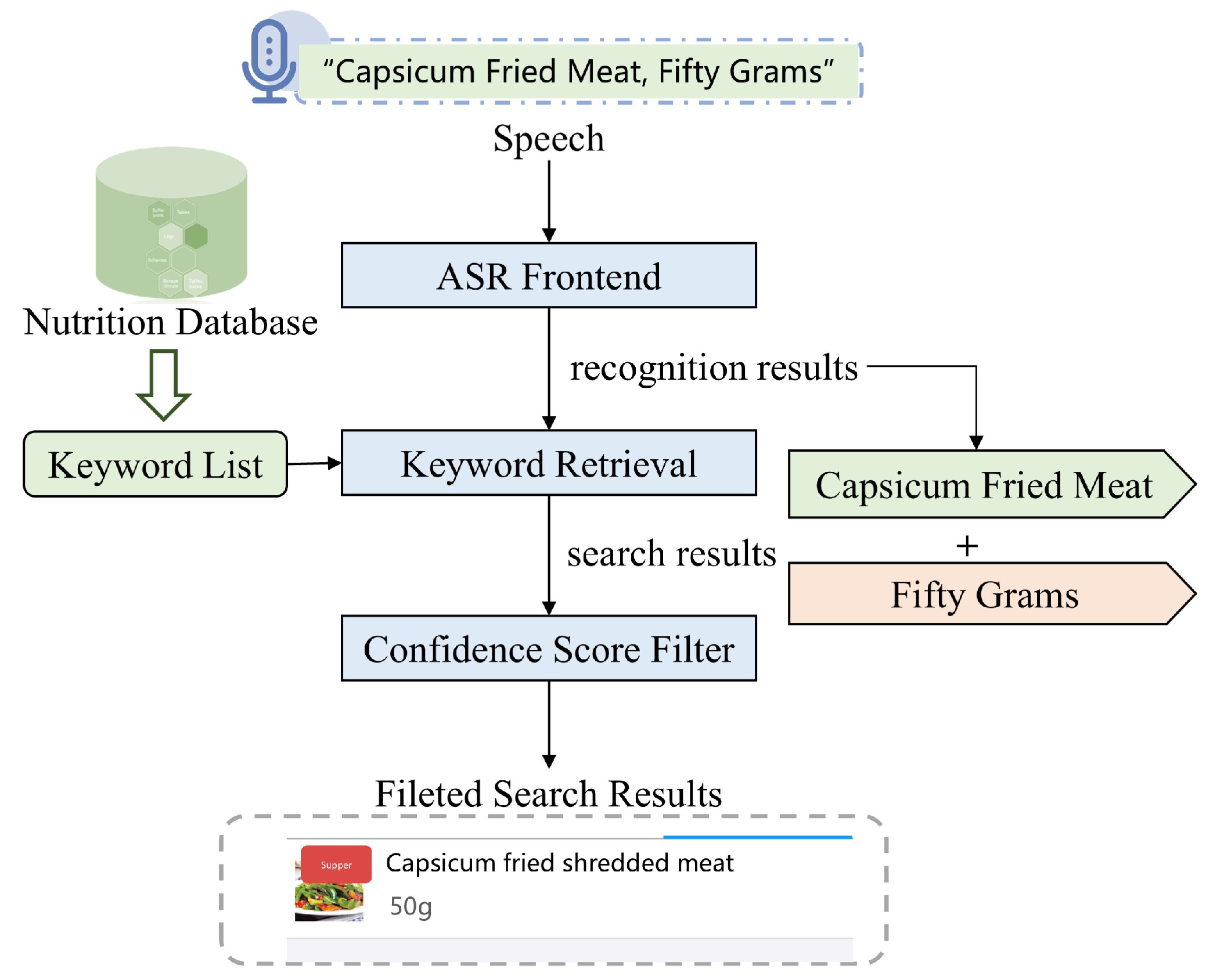
- Diet Recording by Voice Input
- B.
- Diet Recording by Single-Shot Cuisine Photography
2.2. The Smartphone Application for Data Recording and Analysis
2.3. Diabetes Progression Analysis
2.3.1. DiabMini Dataset
- Personal information (n = 6): Including basic information such as height and weight;
- Medical information (n = 32): Participants underwent two medical examinations, one before and one after the project, recording 16 test indicators through routine blood tests and body composition analysis. Both examinations were conducted by professional hospitals using consistent instruments and procedures;
- Lifestyle (n = 10): Lifestyle data were collected through an online questionnaire in the application. It contained ten questions about activities and habits, such as exercise frequency and sleep duration. These questions were designed based on physician expertise and diabetes risk factors;
- Nutrient intake (n = 79): Between two medical examinations, all participants were required to record their complete daily dietary intake for 14 days, including meals, beverages, snacks, and fruits. These records were automatically converted into the intake of 79 specific nutrients. The convenient recording methods and extensive food-nutrient database of the application ensured efficient dietary tracking.The detailed annotation of all data is presented in Appendix A.
2.3.2. Model Establishment and Evaluation
3. Results
3.1. HbA1c Classification Experimental Results
3.2. HbA1c Classification Model Interpretability
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- -
- Age— age, years
- -
- Gender—(1—Female, 2—male)
- -
- Chronic disease—(1—Heart disease, 2—Diabetes, 3—No, 4—Hypertension)
- -
- Height—height, centimeter
- -
- Weight—weight, kilogram
- -
- BMI—Body Mass Index
- -
- BFP: Body fat percentage, the proportion of total body fat to body weight
- -
- WHR: Waist to hip ratio, the ratio of waist circumference to hip circumference
- -
- VFA: Visceral fat area, refers to the tomographic area index of visceral fat in CT imaging
- -
- HbA1c: Glycosylated hemoglobin, the compounds that bind glucose and hemoglobin
- -
- FBG: Fasting blood glucose, the blood glucose measured before breakfast the next morning for more than eight to twelve hours of fasting overnight
- -
- TP: Total protein, the general name of albumin and globulin
- -
- Alb: Albumin, the most important protein in human plasma
- -
- TG: Serum triglycerides, the important component of blood lipids, mmol/L
- -
- TC: Serum total cholesterol, the sum of cholesterol contained in all lipoproteins in the blood, mmol/L
- -
- HDL: High-density lipoprotein, one of the serum proteins
- -
- LDL: Low-density lipoprotein, one of the lipoprotein components in blood lipids
- -
- AI: Arteriosclerosis index, the index to evaluate the degree of arteriosclerosis
- -
- WBC: White blood cell, the cells with motility and phagocytosis
- -
- RBC: Red blood cells, the most numerous types of blood cells in the blood
- -
- HGB: Hemoglobin, the protein contained in red blood cells
- -
- LY: Lymphocyte count, to count lymphocytes and calculate the percentage
- -
- Working hours—(1—8–12 h, 2—4–8 h, 3—Less than 4 h, 4— More than 12 h)
- -
- Work intensity—(1—Student, 2—Office work, 3—Retire, 4—High intensity)
- -
- Exercise weekly—(1—3–4 times, 2—1–2 times, 3—Occasionally or hardly, 4—More than 5 times)
- -
- Sleep time—(1—4–6 h, 2—6–8 h, 3—More than 8 h, 4—Less than 4 h)
- -
- Meal habits—(1—No breakfast, 2—Very irregular, 3—Three meals are regular)
- -
- Food selection—(1—Pay attention to nutritional value, 2—Personal preference, 3—Careful selection based on health condition)
- -
- Dietary preferences—(1—Vegetarian diet, 2—Balanced diet, 3—Meat diet)
- -
- Water intake daily—(1—1000–2000 mL, 2—2000–3000 mL, 3—More than 3000 mL, 4—0–1000 mL)
- -
- Drinking weekly—(1—3–4 times, 2—Less than 3 times, 3—Never or rarely, 4—More than 5 times)
- -
- Smoking daily—(1—5–10 cigarettes, 2—1–5 cigarettes, 3—No smoking, 4—More than 10 cigarettes)
- -
- Cholesterol: the component of lipids, mg
- -
- Purine: the organic compounds produced by the body’s metabolism, mg
- -
- Energy: kilocalorie, kcal
- -
- Protein: g
- -
- Fat: g
- -
- Carbohydrate: g
- -
- Water: g
- -
- Dietary fiber: g
- -
- Total vitamin A: g
- -
- Vitamin E: mg
- -
- Vitamin B1: mg
- -
- Vitamin B2: mg
- -
- Vitamin B3: mg
- -
- Vitamin C: mg
- -
- Ca: Calcium, mg
- -
- P: Phosphorus, mg
- -
- K: Potassium, mg
- -
- Na: Sodium, mg
- -
- Mg: Magnesium, mg
- -
- Fe: Iron, mg
- -
- Zn: Zinc, mg
- -
- Se: Selenium, g
- -
- Cu: Copper, mg
- -
- Mn: Manganese, mg
- -
- Total fatty acids: g
- -
- SFA: Saturated fatty acids, g
- -
- MUFA: Monounsaturated fatty acid, g
- -
- PUFA: Polyunsaturated fatty acid, g
- -
- Hexanoic (Caproic), mg
- -
- Octanoic (Caprylic), mg
- -
- Decanoic (Capric), mg
- -
- Henedecanoic (Undecylic), mg
- -
- Dodecanoic (Lauric), mg
- -
- Tridecanoic (Tridecylic), mg
- -
- Tetradecanoic (Myristic), mg
- -
- Pentadecanoic (Pentadecylic), mg
- -
- Hexadecanoic (Palmitic), mg
- -
- Heptadecanoic (Margaric), mg
- -
- Nonadecanoic (Nondecylic), mg
- -
- Eicosanoic (Arachidic), mg
- -
- Docosanoic (Behenic), mg
- -
- C14:1 (n-5): cis-9-Tetradecenoic, Myristoleic, mg
- -
- C15:1 (n-5): 10-Pentadecenoic, mg
- -
- C16:1 (n-7): cis-9-Hexadecenoic, Palmitoleic, mg
- -
- C17:1 (n-7): 10-Heptadecenoic, mg
- -
- C18:1 (n-9): cis-9-Octadecenoic, Oleic, mg
- -
- C20:1 (n-11): cis-9-Eicosenoic, Gadoleic, mg
- -
- C22:1 (n-13): cis-9-Docosenoic, mg
- -
- C16:2 (n-4): cis, cis-9,12-Hexadecadienoic, mg
- -
- C18:2 (n-6): cis, cis-9,12-Octadecadienoic, Linoleic, mg
- -
- C18:3 (n-3): all cis-9,12,15-Octadecatrienoic, -Linolenic, mg
- -
- C20:2 (n-6): cis, cis-11,14-Eicosadienoic, mg
- -
- C20:3 (n-9): all cis-5,8,11-Eicosatrienoic, Mead, mg
- -
- C20:4 (n-6): all cis-5,8,11,14-Eicosatetraenoic, Arachidonic, mg
- -
- C20:5 (n-3): all cis-5,8,11,14,17-Eicosapentaenoic, mg
- -
- C22:3 (n-3): all cis-13,16,19-Docosatrienoic, mg
- -
- C22:4 (n-6): all cis-7,10,13,16-Docosatetraenoic, mg
- -
- C22:5 (n-3): all cis-7,10,13,16,19-Docosapentaenoic, mg
- -
- C22:6 (n-3): all cis-4,7,10,13,16,19-Docosahexaenoic, mg
- -
- Isoleucine, mg
- -
- Leucine, mg
- -
- Lysine, mg
- -
- TSAA: Total sulfur containing amino acids, mg
- -
- Methionine, mg
- -
- Cystine, mg
- -
- TAAA: Total aromatic amino acids, mg
- -
- Phenylalanine, mg
- -
- Tyrosine, mg
- -
- Threonine, mg
- -
- Tryptophane, mg
- -
- Valine, mg
- -
- Arginine, mg
- -
- Histidine, mg
- -
- Alanine, mg
- -
- Aspartic acid, mg
- -
- Glutamic acid, mg
- -
- Glycine, mg
- -
- Proline, mg
- -
- Serine, mg
References
- Sun, H.; Saeedi, P.; Karuranga, S.; Pinkepank, M.; Ogurtsova, K.; Duncan, B.B.; Stein, C.; Basit, A.; Chan, J.C.; Mbanya, J.C.; et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res. Clin. Pract. 2022, 183, 109119. [Google Scholar] [CrossRef] [PubMed]
- American Diabetes Association. Standards of medical care in diabetes—2017. Diabetes Care 2017, 40, 1–142. [Google Scholar]
- Idf Diabetes Atlas, 10th ed. Available online: https://www.diabetesatlas.org (accessed on 23 July 2024).
- Teufel, F.; Seiglie, J.A.; Geldsetzer, P.; Theilmann, M.; Marcus, M.E.; Ebert, C.; Arboleda, W.A.L.; Agoudavi, K.; Andall-Brereton, G.; Aryal, K.K.; et al. Body-mass index and diabetes risk in 57 low-income and middle-income countries: A cross-sectional study of nationally representative, individual-level data in 685,616 adults. Lancet 2021, 398, 238–248. [Google Scholar] [PubMed]
- Ley, S.H.; Hamdy, O.; Mohan, V.; Hu, F.B. Prevention and management of type 2 diabetes: Dietary components and nutritional strategies. Lancet 2014, 383, 1999–2007. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Zhong, C.; Chen, R.; Zhou, X.; Wu, J.; Han, J.; Li, X.; Zhang, Y.; Gao, Q.; Xiao, M.; et al. Higher dietary vitamin C intake is associated with a lower risk of gestational diabetes mellitus: A longitudinal cohort study. Clin. Nutr. 2020, 39, 198–203. [Google Scholar] [CrossRef]
- Gao, H.; Yang, J.; Pan, W.; Yang, M. Iron Overload and Risk of Diabetes in General Population: Results from the Chinese Health and Nutrition Survey Cohort Study. Metabolism 2021, 116, 154474. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar] [CrossRef]
- Sankar Ganesh, P.; Sripriya, P. A comparative review of prediction methods for pima indians diabetes dataset. In Proceedings of the Computational Vision and Bio-Inspired Computing: ICCVBIC 2019, Coimbatore, India, 25–26 September 2019; pp. 735–750. [Google Scholar]
- Rashid, A. Diabetes Dataset. Available online: https://data.mendeley.com/datasets/wj9rwkp9c2/1 (accessed on 18 July 2020).
- Nouraei, H.; Nouraei, H.; Rabkin, S.W. Comparison of unsupervised machine learning approaches for cluster analysis to define subgroups of heart failure with preserved ejection fraction with different outcomes. Bioengineering 2022, 9, 175. [Google Scholar] [CrossRef]
- Bechelli, S.; Delhommelle, J. Machine learning and deep learning algorithms for skin cancer classification from dermoscopic images. Bioengineering 2022, 9, 97. [Google Scholar] [CrossRef]
- Al-Kharusi, G.; Dunne, N.J.; Little, S.; Levingstone, T.J. The role of machine learning and design of experiments in the advancement of biomaterial and tissue engineering research. Bioengineering 2022, 9, 561. [Google Scholar] [CrossRef]
- Sherwani, S.I.; Khan, H.A.; Ekhzaimy, A.; Masood, A.; Sakharkar, M.K. Significance of HbA1c test in diagnosis and prognosis of diabetic patients. Biomark. Insights 2016, 11, BMI-S38440. [Google Scholar] [CrossRef] [PubMed]
- Matabuena, M.; Félix, P.; García-Meixide, C.; Gude, F. Kernel machine learning methods to handle missing responses with complex predictors. Application in modelling five-year glucose changes using distributional representations. Comput. Methods Programs Biomed. 2022, 221, 106905. [Google Scholar]
- Zaitcev, A.; Eissa, M.R.; Hui, Z.; Good, T.; Elliott, J.; Benaissa, M. A deep neural network application for improved prediction of HbA1c in type 1 diabetes. IEEE J. Biomed. Health Inform. 2020, 24, 2932–2941. [Google Scholar] [CrossRef] [PubMed]
- Alhassan, Z.; Watson, M.; Budgen, D.; Alshammari, R.; Alessa, A.; Al Moubayed, N. Improving current glycated hemoglobin prediction in adults: Use of machine learning algorithms with electronic health records. JMIR Med. Inform. 2021, 9, e25237. [Google Scholar] [CrossRef] [PubMed]
- Alhassan, Z.; Budgen, D.; Alessa, A.; Alshammari, R.; Daghstani, T.; Al Moubayed, N. Collaborative denoising autoencoder for high glycated haemoglobin prediction. In Artificial Neural Networks and Machine Learning—ICANN 2019: Workshop and Special Sessions, Proceedings of the 28th International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Tetko, I., Kůrková, V., Karpov, P., Theis, F., Eds.; Springer: Cham, Switzerland, 2019; pp. 338–350. [Google Scholar]
- Nagaraj, S.B.; Sidorenkov, G.; van Boven, J.F.; Denig, P. Predicting short-and long-term glycated haemoglobin response after insulin initiation in patients with type 2 diabetes mellitus using machine-learning algorithms. Diabetes Obes. Metab. 2019, 21, 2704–2711. [Google Scholar] [CrossRef]
- Poplin, R.; Varadarajan, A.V.; Blumer, K.; Liu, Y.; McConnell, M.V.; Corrado, G.S.; Peng, L.; Webster, D.R. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat. Biomed. Eng. 2018, 2, 158–164. [Google Scholar] [CrossRef]
- Lin, C.S.; Lee, Y.T.; Fang, W.H.; Lou, Y.S.; Kuo, F.C.; Lee, C.C.; Lin, C. Deep learning algorithm for management of diabetes mellitus via electrocardiogram-based glycated hemoglobin (ECG-HbA1c): A retrospective cohort study. J. Pers. Med. 2021, 11, 725. [Google Scholar] [CrossRef]
- Over-Sampling Methods. Available online: https://imbalanced-learn.org/stable/references/over_sampling.html (accessed on 20 September 2024).
- Biswas, N.; Uddin, K.M.M.; Rikta, S.T.; Dey, S.K. A comparative analysis of machine learning classifiers for stroke prediction: A predictive analytics approach. Healthc. Anal. 2022, 2, 100116. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, G.; Pan, X. China Food Composition, 1st ed.; Peking University Medical Press: Beijing, China, 2002; pp. 24–325. [Google Scholar]
- National Institute of Nutrition and Food Safety of Chinese Center for Disease Control and Prevention. China Food Composition, 2nd ed.; Peking University Medical Press: Beijing, China, 2009; pp. 4–255. [Google Scholar]
- Yang, R.; Cheng, G.; Miao, H.; Li, T.; Zhang, P.; Yan, Y. Keyword search using attention-based end-to-end ASR and frame-synchronous phoneme alignments. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3202–3215. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ranstam, J.; Cook, J.A. LASSO regression. Br. J. Surg. 2018, 105, 1348. [Google Scholar] [CrossRef]
- Chinese Nutrition Society. Dietary Reference Intakes for China, 9th ed.; People’s Medical Publishing House: Beijing, China, 2022; pp. 53–459. [Google Scholar]
- Healthy Diet, Healthy Life. Available online: https://kangshilife.com/k/index_en.html (accessed on 20 September 2024).
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4768–4777. [Google Scholar]
- Zhang, T.; Jiang, W.; Xia, Y.; Mansell, T.; Saffery, R.; Cannon, R.D.; Seymour, J.D.; Zou, Z.; Xu, G.; Han, T.; et al. Complex patterns of circulating fatty acid levels in gestational diabetes mellitus subclasses across pregnancy. Clin. Nutr. 2021, 40, 4140–4148. [Google Scholar] [CrossRef] [PubMed]
- Karalis, D.T. The beneficiary role of selenium in type II diabetes: A longitudinal study. Cureus 2019, 11, e6443. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.C.; Combs, G.F., Jr.; Wu, T.L.; Zeng, H.; Cheng, W.H. Selenium status and type 2 diabetes risk. Arch. Biochem. Biophys. 2022, 730, 109400. [Google Scholar] [CrossRef] [PubMed]
- Lawal, T.A. Screening of Aqueous Extract of Persea americana Seeds for Alpha-Glucosidase Inhibitors. Biochem. Res. Int. 2022, 2022, 3492203. [Google Scholar] [CrossRef] [PubMed]
- Neuenschwander, M.; Hoffmann, G.; Schwingshackl, L.; Schlesinger, S. Impact of different dietary approaches on blood lipid control in patients with type 2 diabetes mellitus: A systematic review and network meta-analysis. Eur. J. Epidemiol. 2019, 34, 837–852. [Google Scholar] [CrossRef]
- Xepapadaki, E.; Nikdima, I.; Sagiadinou, E.C.; Zvintzou, E.; Kypreos, K.E. HDL and type 2 diabetes: The chicken or the egg? Diabetologia 2021, 64, 1917–1926. [Google Scholar] [CrossRef]
- Abdoli, S.; Hessler, D.; Doosti-Irani, M.; Chang, B.P.; Stuckey, H. The value of measuring diabetes burnout. Curr. Diabetes Rep. 2021, 21, 25. [Google Scholar]
- Zhao, J.; Zhang, Y.; Wei, F.; Song, J.; Cao, Z.; Chen, C.; Zhang, K.; Feng, S.; Wang, Y.; Li, W.-D. Triglyceride is an independent predictor of type 2 diabetes among middle-aged and older adults: A prospective study with 8-year follow-ups in two cohorts. J. Transl. Med. 2019, 17, 403. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, H.; Chen, M.; Luo, X.; Yao, W.; Liang, Q.; Yang, F.; Wang, X. Association of Triglyceride to high-density lipoprotein cholesterol ratio and incident of diabetes mellitus: A secondary retrospective analysis based on a Chinese cohort study. Lipids Health Dis. 2020, 19, 33. [Google Scholar] [CrossRef]
- Biancalana, E.; Parolini, F.; Mengozzi, A.; Solini, A. Short-term impact of COVID-19 lockdown on metabolic control of patients with well-controlled type 2 diabetes: A single-centre observational study. Acta Diabetol. 2021, 58, 431–436. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ingredient | Energy | Fat | Carbohydrate | Protein | Water | Dietary Fiber | Vitamin B1 | Ca | Fe | Na | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Rice | 116 kcal | g | g | g | g | g | mg | 7 mg | mg | mg | |
| Potato | 77 kcal | g | g | 2 g | g | g | mg | 8 mg | mg | mg | |
| Pork | 395 kcal | 37 g | g | g | g | - * | mg | 6 mg | mg | mg | |
| Chicken | 167 kcal | g | g | g | 69 g | - * | mg | 9 mg | mg | mg | |
| Mushroom | 24 kcal | g | g | g | g | g | mg | 6 mg | mg | mg | |
| Tomato | 20 kcal | g | 4 g | g | g | g | mg | 10 mg | mg | 5 mg | |
| ... | |||||||||||
| Packaged Foods | Energy | Fat | Carbohydrate | Protein | Na | ||||||
| Oatmeal | 377 kcal | g | g | 15 g | mg | ||||||
| Biscuit | 435 kcal | g | g | 9 g | mg | ||||||
| Fried Chips | 615 kcal | g | g | 4 g | mg | ||||||
| Spicy Kelp | kcal | g | g | g | 2590 mg | ||||||
| Cheese | 328 kcal | g | g | g | 584 mg | ||||||
| ... | |||||||||||
| Dishes | Ingredient | Amount | Ingredient | Amount | Ingredient | Amount | Ingredient | Amount | Ingredient | Amount | ... |
| Spaghetti with Sauce | Macaroni | 300 g | Pork | 100 g | Tomatoes | 100 g | Onion | 50 g | Pepper | 3 g | |
| Sandwich | Bread | 100 g | Luncheon Meat | 80 g | Cucumber | 50 g | Tomato | 50 g | Lettuce | 30 g | |
| Yam Sparerib Porridge | Yam | 150 g | Pork Chop | 150 g | Rice | 150 g | Water | 400 g | Coriander | 10 g | |
| Meat Floss Sushi | Rice | 200 g | Pork Floss | 50 g | Vinegar | 5 g | Laver | 3 g | Cucumber | 30 g | |
| Roast Chicken | Rice | 250 g | Chicken | 200 g | Cucumber | 80 g | Chinese Onion | 10 g | Ginger | 10 g | |
| ... |
| Base Model | Meta Model | Evaluation Metrics (%) | |||||
|---|---|---|---|---|---|---|---|
| XGBoost | SVC | ET | KNN | Accuracy | Macro-Precision | Macro-Recall | Macro-F1 |
| ✓ | - | - | - | 80.18 ± 6.66 | 82.70 ± 4.68 | 80.42 ± 6.33 | 79.91 ± 7.09 |
| - | ✓ | - | - | 86.51 ± 3.24 | 87.69 ± 3.67 | 86.55 ± 3.58 | 85.69 ± 3.82 |
| - | - | ✓ | - | 88.45 ± 3.33 | 89.40 ± 2.98 | 88.42 ± 3.42 | 88.46 ± 3.24 |
| - | - | - | ✓ | 73.04 ± 2.83 | 80.29 ± 2.10 | 73.15 ± 3.05 | 68.64 ± 3.95 |
| ✓ | ✓ | - | ✓ | 89.11 ± 2.52 | 91.16 ± 1.84 | 89.15 ± 2.73 | 88.59 ± 2.92 |
| ✓ | - | ✓ | ✓ | 93.59 ± 2.04 | 94.29 ± 1.76 | 93.64 ± 1.84 | 93.42 ± 2.08 |
| - | ✓ | ✓ | ✓ | 92.34 ± 3.16 | 93.36 ± 2.65 | 92.48 ± 2.94 | 92.12 ± 3.40 |
| ✓ | ✓ | ✓ | ✓ | 94.23 ± 1.27 | 94.97 ± 1.07 | 94.24 ± 1.24 | 94.16 ± 1.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, H.; Wang, H.; Pan, T.; Liu, Y.; Jing, P.; Liu, Y. Mobile Application and Machine Learning-Driven Scheme for Intelligent Diabetes Progression Analysis and Management Using Multiple Risk Factors. Bioengineering 2024, 11, 1053. https://doi.org/10.3390/bioengineering11111053
Jiang H, Wang H, Pan T, Liu Y, Jing P, Liu Y. Mobile Application and Machine Learning-Driven Scheme for Intelligent Diabetes Progression Analysis and Management Using Multiple Risk Factors. Bioengineering. 2024; 11(11):1053. https://doi.org/10.3390/bioengineering11111053
Chicago/Turabian StyleJiang, Huaiyan, Han Wang, Ting Pan, Yuhang Liu, Peiguang Jing, and Yu Liu. 2024. "Mobile Application and Machine Learning-Driven Scheme for Intelligent Diabetes Progression Analysis and Management Using Multiple Risk Factors" Bioengineering 11, no. 11: 1053. https://doi.org/10.3390/bioengineering11111053
APA StyleJiang, H., Wang, H., Pan, T., Liu, Y., Jing, P., & Liu, Y. (2024). Mobile Application and Machine Learning-Driven Scheme for Intelligent Diabetes Progression Analysis and Management Using Multiple Risk Factors. Bioengineering, 11(11), 1053. https://doi.org/10.3390/bioengineering11111053