
Verdiff-Net: A Conditional Diffusion Framework for Spinal Medical Image Segmentation

 , ,
, ,
Abstract

1. Introduction
- (1)
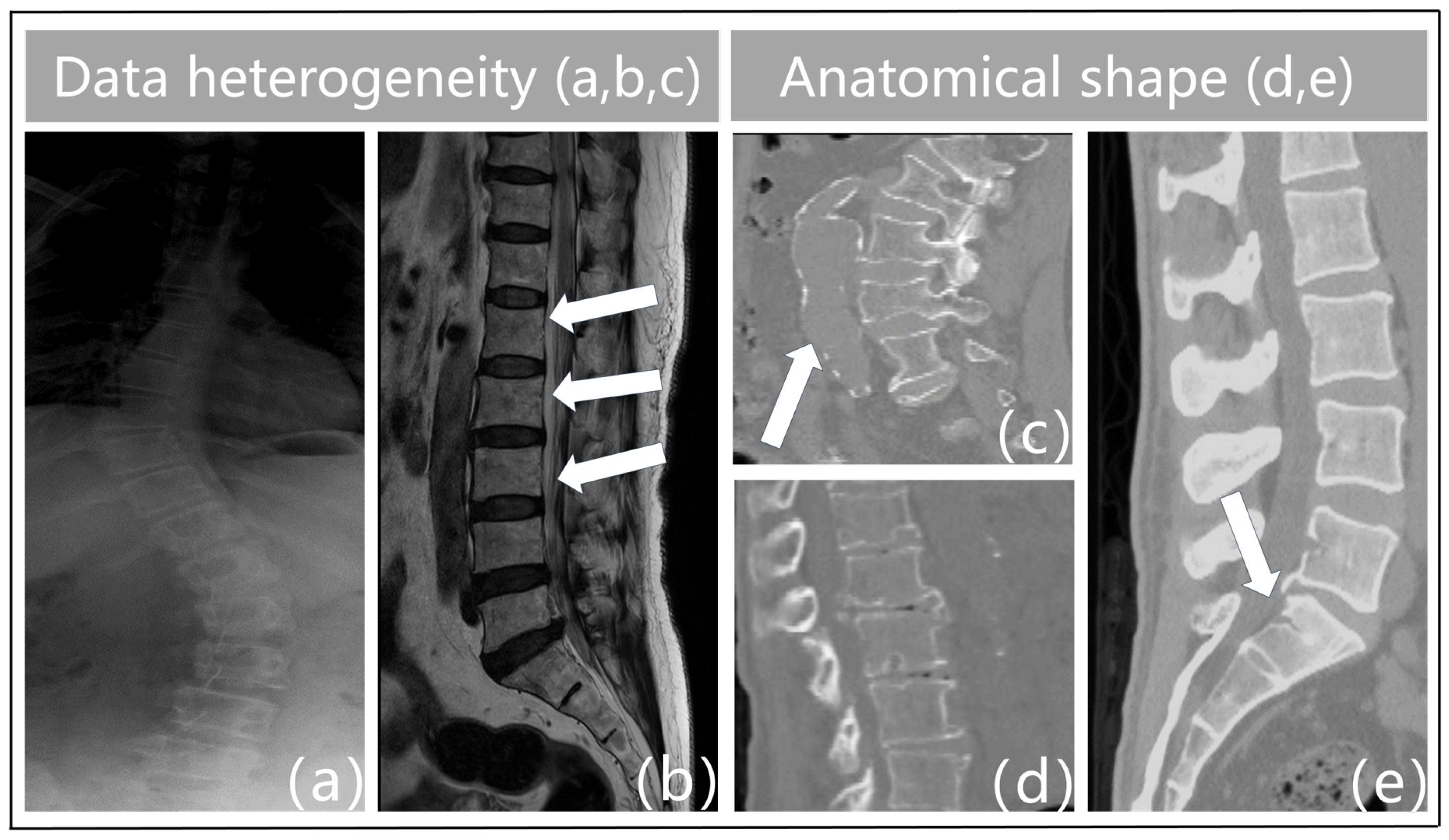
- Data heterogeneity. The term “heterogeneity of data” describes the variety and diversity of the data, or the variations in the data across various dimensions. These variations could be caused by a variety of things, including the characteristics of the chiropractic data itself, the acquisition technique, the equipment used, the duration of the acquisition, and more. For instance, feature extraction varies throughout different types of imaging data (e.g., MRI, X-ray, CT, etc.), and variations in acquisition equipment can result in issues with data quality such as noise and distortion in vertebrae imaging. Figure 1a illustrates the blurred outlines caused by the physical properties of X-ray imaging. Second, interclass similarity is seen in spinal MR images [5]. This means that neighboring vertebrae (intervertebral disks) in the same subject (Figure 1b) exhibit a high degree of morphological resemblance, making it more challenging to distinguish between individual vertebrae. The surrounding tissues in Figure 1c have similar physics and tissue densities to the vertebrae in CT imaging, which leads to identical CT values that confuse the background features and result in erroneous detections. Analogously, variations in the duration of acquisition may cause data drift and variability. As a result, data heterogeneity must be taken into account and managed throughout data processing and analysis since it is one of the key elements influencing the outcomes of data analysis and mining.
- (2)
- Anatomical shape. Vertebral pictures show features such as blurriness, uneven grayscale distribution, high noise levels, and low contrast because of the state of spinal medical imaging today. The vertebrae that make up the spinal structure also have a similar form but different types. Spinal illnesses like vertebral strain alter the anatomical form of the vertebral bodies, as shown in Figure 1d. Furthermore, the vertebrae are spatially displaced as a result of trauma, bad posture, muscular imbalance, and congenital deformities [7]. This causes aberrant modifications or misalignment of their locations in space, which severely distorts the morphology of the vertebral bodies. Particularly, in Figure 1e, the individual had fractures or breaks in the sacral vertebrae as a consequence of external pressures. This may lead to further deformation, which makes the connections between the lumbar and sacral vertebrae extremely tight. As such, defining the borders between these joint vertebrae based on pixel intensity is difficult. This frequently results in semantic segmentation of these linked vertebrae as a single object during vertebral segmentation, which causes misidentification as a single vertebra. Given the increased unpredictability in the contour forms and placements of the vertebral bodies, these features surely make vertebral segmentation tasks more challenging.
- (1)
- Synergistic combination of models: Verdiff-Net effectively blends the advantages of diffusion and conditional models, improving segmentation tasks’ accuracy and stability, especially when modeling discrete targets.
- (2)
- Multi-scale fusion module: Verdiff-Net integrates a multi-scale fusion module into the conditional U-Net to overcome the drawbacks of traditional diffusion models. By efficiently capturing and maintaining the underlying spinal feature information, this module lessens the loss that is commonly brought about by coarsely fusing image and mask features.
- (3)
- Noise semantic adapter (NSA): During the diffusion process, the NSA serves as a selective filter, drawing the model’s attention to important spinal aspects while rejecting unimportant data. This breakthrough increases inference efficiency as well as the model’s accuracy in spinal segmentation.
- (4)
- Comprehensive evaluation: The effectiveness and generalizability of the model are validated on four vertebrae medical datasets with three different modalities. To the best of our knowledge, this study is the first to thoroughly evaluate the model’s robustness and generalization on a multi-modality vertebrae dataset.
2. Methodology
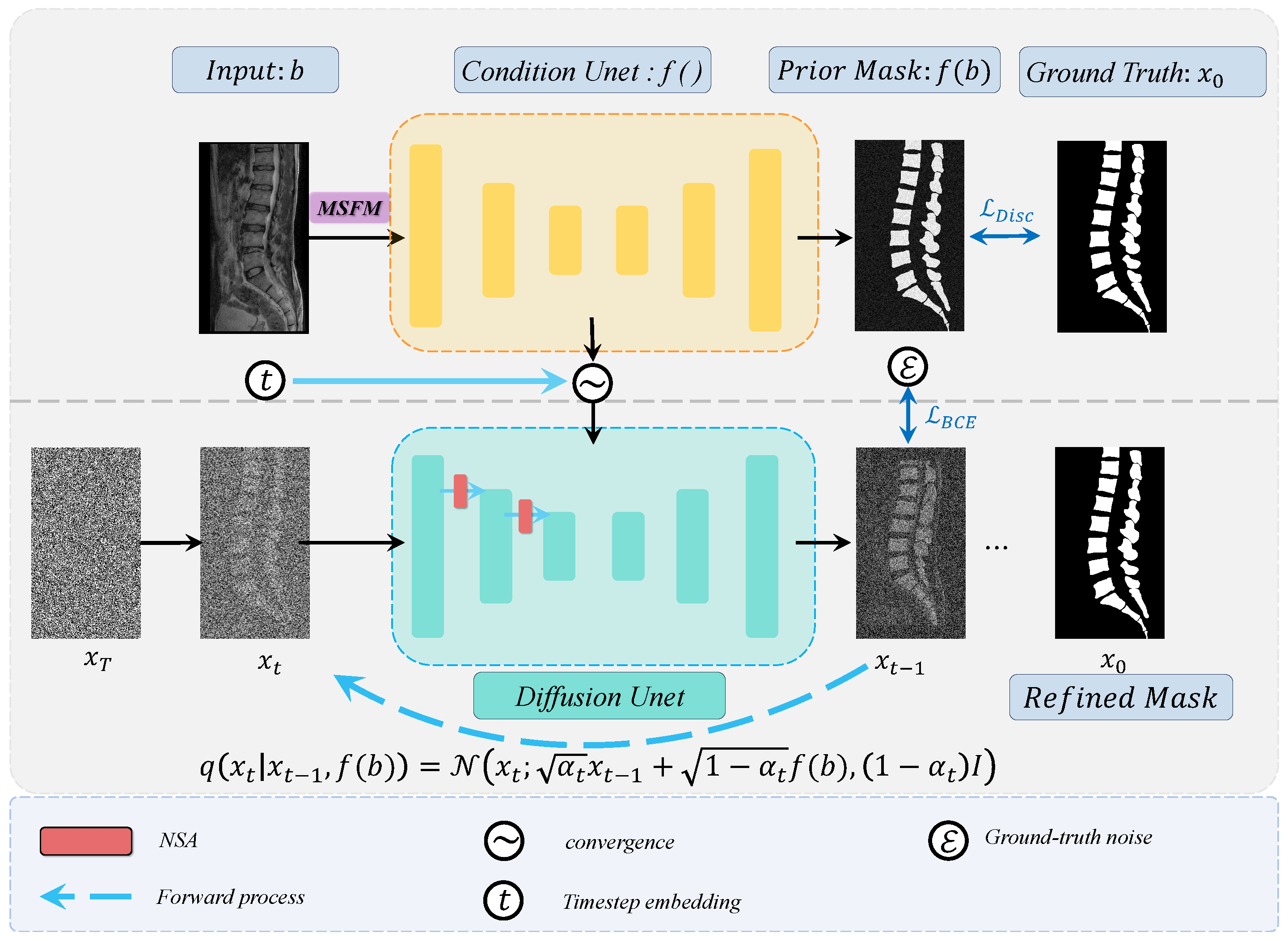
2.1. Framework Overview
2.2. Training Strategies for Diffusion Models
2.2.1. Diffusion Forward Process
2.2.2. Diffusion Reverse Process
| Algorithm 1: Training |
1. 2. 3. 4. Calculate Equation (5) 5. Take gradient descent on 6. until converged |
| Algorithm 2: Sampling |
1. 2. for do 3. if , else 4. 5. end for 6. return |
2.3. Multi-Scale Fusion Module (MSFM)
2.4. Noise Semantic Adapter (NSA)
3. Experiments and Results
3.1. Dataset Introduction
- Public CT dataset. We used the 42 sets of 3D spine1K data in the “verse” folder of the large-scale spine CT dataset called CTSpine1K. Based on this dataset, we conducted vertebrae segmentation experiments to select slices and contacted radiologists to manually select images one by one, and finally selected 2508 images with clear layers and anatomical information with masks for training and sampling. All the image sizes are standardized to 166 × 369.
- Private CT dataset. Sagittal CT images of the vertebrae were collected from 630 volunteers (396 females, 234 males; mean age 26 ± 3 years, range 19 to 36 years). Three radiologists and one vertebral surgeon labeled these vertebral image regions as the ground truth for the vertebrae segmentation task and checked the labeled regions against each other to ensure reliability. Thus, each subject had a T2-weighted MR image and a corresponding mask as the initial ground truth, where each vertebra was assigned a unique label. We chose images of clean lumbar vertebral regions containing the caudal vertebrae and standardized the dimensions to 534 × 768 as inputs.
- Private MR dataset. The dataset, collected from a local hospital, consists of T2-weighted MR volumetric images from 215 subjects. Among the 215 subjects, there were 6 normal subjects, 177 patients with vertebrae degeneration (VD), 204 patients with intervertebral disk degeneration (IDD), 21 patients with lumbar spondylolisthesis (LS), 91 patients with spinal canal stenosis (SCS), 22 patients with Schmorl’s node (SN), and 53 patients with vertebral endplate osteochondritis (VEO). The delineated mask was corrected by the senior expert using the ITK-SNAP1 to be the ground truth of vertebrae parsing [26]. The average pixel spacing within the plane of the MR image was 0.35 mm, while the average slice thickness was 4.42 mm. By focusing solely on segmenting the vertebrae and excluding the spinal fluid portion between them, we first removed the spinal fluid from the labels of these data. We then smoothly extracted the 3D raw data and their corresponding mask data from the sagittal plane, ultimately obtaining pure 880 × 880 paired images and mask.
- Public X-ray dataset. The dataset consists of 609 spinal anterior–posterior X-ray images [27]. The landmarks were provided by two professional doctors at the London Health Sciences Center. Each vertebra was located by four landmarks with respect to four corners. All the image sizes were 250 × 750. In addition, since the noise artifacts in this dataset were extremely severe, and some of the data were mixed with medical clinical instruments on the vertebrae, in order to further test the segmentation ability of the model in this particular condition, we ignored the detailed features of the vertebrae contour lines and performed a binary transform only for the vertebral trunk regions in order to obtain the original annotations.
3.2. Data Preprocessing
3.3. Training/Validation Setup and Evaluation Metrics
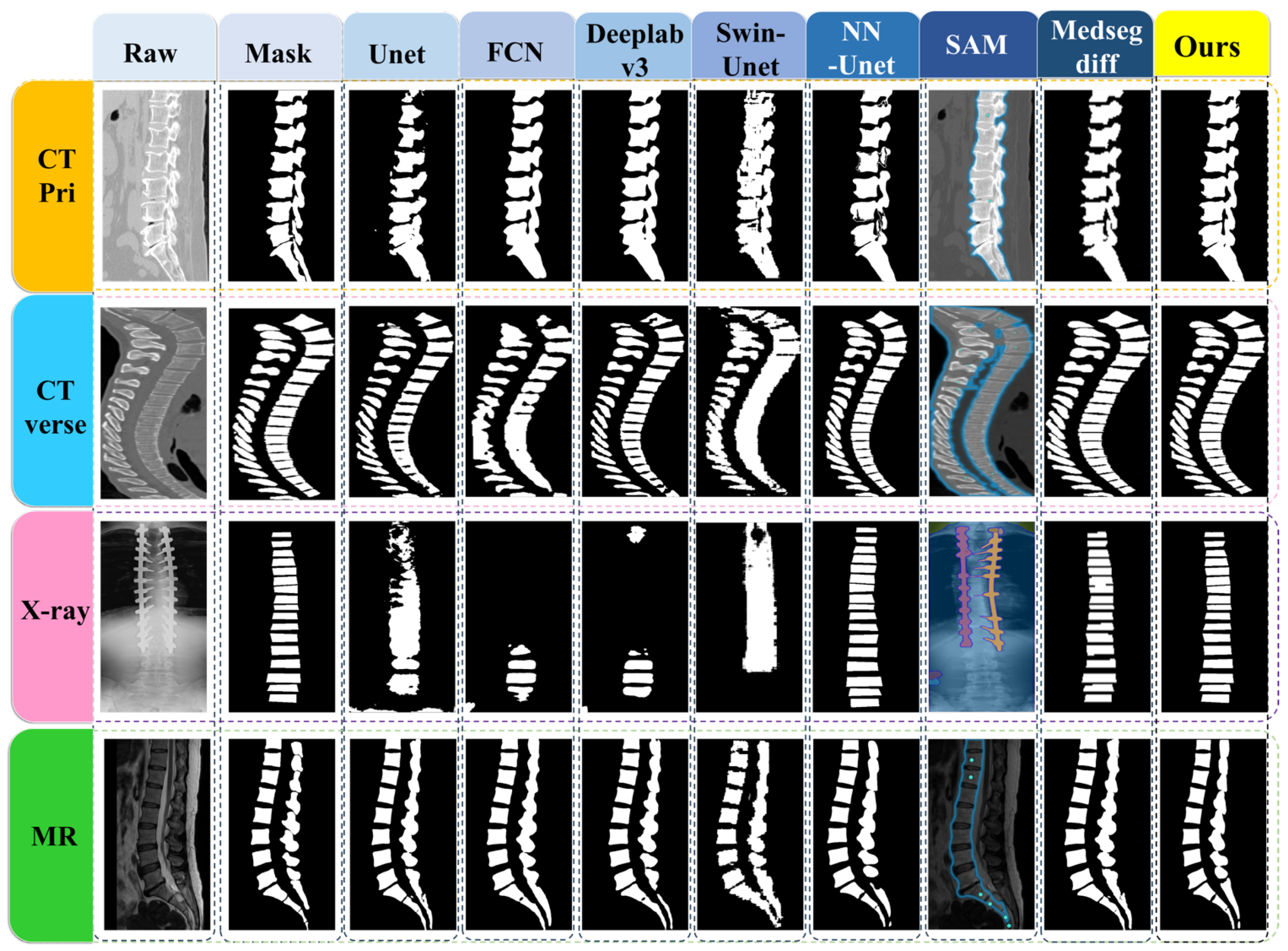
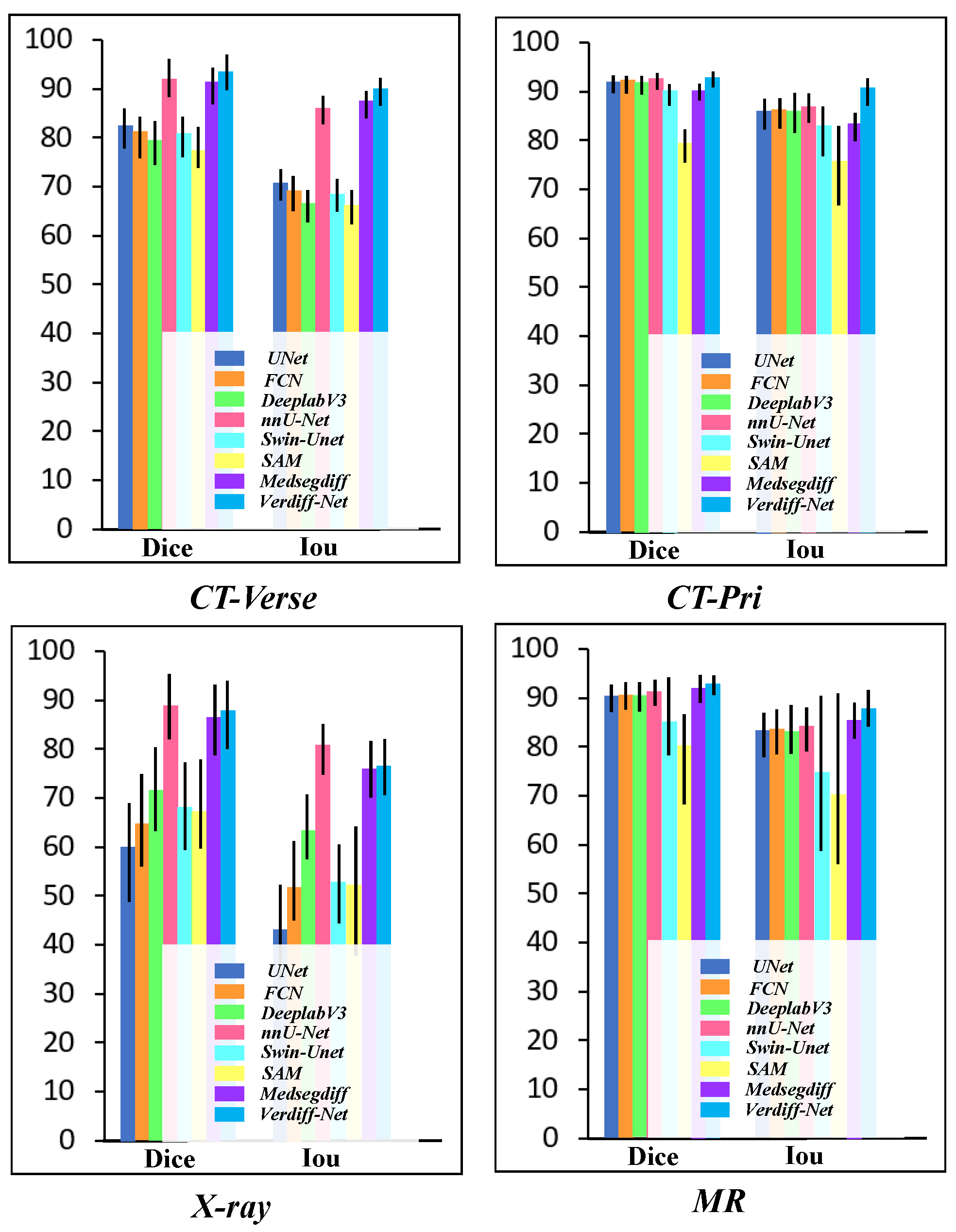
3.4. Vertebrae Segmentation Results
3.5. Comparison of the Results
3.6. Ablation Study
4. Discussion
4.1. Segmentation Effects
4.2. Limitation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Smith, M.W.; Reed, J.; Facco, R.; Hlaing, T.; McGee, A.; Hicks, B.M.; Aaland, M. The reliability of nonreconstructed computerized tomographic scans of the abdomen and pelvis in detecting thoracolumbar spine injuries in blunt trauma patients with altered mental status. JBJS 2009, 91, 2342–2349. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Burns, J.E.; Munoz, H.; Summers, R.M. Detection of vertebral body fractures based on cortical shell unwrapping. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2012: 15th International Conference, Nice, France, 1–5 October 2012; Proceedings, Part III 15. Springer: Berlin/Heidelberg, Germany, 2012; pp. 509–516. [Google Scholar]
- Huang, M.; Zhou, S.; Chen, X.; Lai, H.; Feng, Q. Semi-supervised hybrid spine network for segmentation of spine MR images. Comput. Med. Imaging Graph. 2023, 107, 102245. [Google Scholar] [CrossRef]
- Han, Z.; Wei, B.; Mercado, A.; Leung, S.; Li, S. Spine-GAN: Semantic segmentation of multiple spinal structures. Med. Image Anal. 2018, 50, 23–35. [Google Scholar] [CrossRef] [PubMed]
- Pang, S.; Pang, C.; Zhao, L.; Chen, Y.; Su, Z.; Zhou, Y.; Huang, M.; Yang, W.; Lu, H.; Feng, Q. SpineParseNet: Spine parsing for volumetric MR image by a two-stage segmentation framework with semantic image representation. IEEE Trans. Med. Imaging 2020, 40, 262–273. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, J.; Wang, X.; Wang, Y.; Zheng, H.; Chen, B.; Zeng, A.; Wei, F.; Al-Kindi, S.; Li, S. Attractive deep morphology-aware active contour network for vertebral body contour extraction with extensions to heterogeneous and semi-supervised scenarios. Med. Image Anal. 2023, 89, 102906. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Chen, B.; Li, S. Sequential conditional reinforcement learning for simultaneous vertebral body detection and segmentation with modeling the spine anatomy. Med. Image Anal. 2021, 67, 101861. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; pp. 272–284. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-margin softmax loss for convolutional neural networks. arXiv 2016, arXiv:1612.02295. [Google Scholar]
- Bernardo, J.; Bayarri, M.; Berger, J.; Dawid, A.; Heckerman, D.; Smith, A.; West, M. Generative or discriminative? Getting the best of both worlds. Bayesian Stat. 2007, 8, 3–24. [Google Scholar]
- Ardizzone, L.; Mackowiak, R.; Rother, C.; Köthe, U. Training normalizing flows with the information bottleneck for competitive generative classification. Adv. Neural Inf. Process. Syst. 2020, 33, 7828–7840. [Google Scholar]
- Liang, C.; Wang, W.; Miao, J.; Yang, Y. Gmmseg: Gaussian mixture based generative semantic segmentation models. Adv. Neural Inf. Process. Syst. 2022, 35, 31360–31375. [Google Scholar]
- Chen, T.; Wang, C.; Chen, Z.; Lei, Y.; Shan, H. HiDiff: Hybrid Diffusion Framework for Medical Image Segmentation. IEEE Trans. Med. Imaging 2024. [Google Scholar] [CrossRef] [PubMed]
- Rahman, A.; Valanarasu, J.M.J.; Hacihaliloglu, I.; Patel, V.M. Ambiguous medical image segmentation using diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 11536–11546. [Google Scholar]
- Xing, Z.; Wan, L.; Fu, H.; Yang, G.; Zhu, L. Diff-unet: A diffusion embedded network for volumetric segmentation. arXiv 2023, arXiv:2303.10326. [Google Scholar]
- Wu, J.; Fu, R.; Fang, H.; Zhang, Y.; Yang, Y.; Xiong, H.; Liu, H.; Xu, Y. Medsegdiff: Medical image segmentation with diffusion probabilistic model. In Proceedings of the Medical Imaging with Deep Learning, Paris, France, 3–5 July 2024; pp. 1623–1639. [Google Scholar]
- Ng, A.; Jordan, M. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. Adv. Neural Inf. Process. Syst. 2001, 14. [Google Scholar]
- Wolleb, J.; Sandkühler, R.; Bieder, F.; Valmaggia, P.; Cattin, P.C. Diffusion models for implicit image segmentation ensembles. In Proceedings of the International Conference on Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022; pp. 1336–1348. [Google Scholar]
- Amit, T.; Shaharbany, T.; Nachmani, E.; Wolf, L. Segdiff: Image segmentation with diffusion probabilistic models. arXiv 2021, arXiv:2112.00390. [Google Scholar]
- Guo, X.; Yang, Y.; Ye, C.; Lu, S.; Peng, B.; Huang, H.; Xiang, Y.; Ma, T. Accelerating diffusion models via pre-segmentation diffusion sampling for medical image segmentation. In Proceedings of the 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, 18–21 April 2023; pp. 1–5. [Google Scholar]
- Wu, J.; Ji, W.; Fu, H.; Xu, M.; Jin, Y.; Xu, Y. MedSegDiff-V2: Diffusion-Based Medical Image Segmentation with Transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 6030–6038. [Google Scholar]
- Yushkevich, P.A.; Pashchinskiy, A.; Oguz, I.; Mohan, S.; Schmitt, J.E.; Stein, J.M.; Zukić, D.; Vicory, J.; McCormick, M.; Yushkevich, N.; et al. User-guided segmentation of multi-modality medical imaging datasets with ITK-SNAP. Neuroinformatics 2019, 17, 83–102. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Bailey, C.; Rasoulinejad, P.; Li, S. Automatic landmark estimation for adolescent idiopathic scoliosis assessment using BoostNet. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; Proceedings, Part I 20. Springer: Berlin/Heidelberg, Germany, 2017; pp. 127–135. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CT-Verse | CT-Pri | X-ray | MR | |||||
|---|---|---|---|---|---|---|---|---|
| Dice (%) | IoU (%) | Dice (%) | IoU (%) | Dice (%) | IoU (%) | Dice (%) | IoU (%) | |
| U-Net [28] | 83.25 ± 4.08 | 71.35 ± 3.23 | 93.22 ± 1.83 | 87.34 ± 3.19 | 60.78 ± 10.23 | 43.75 ± 9.82 | 91.23 ± 2.76 | 84.00 ± 4.59 |
| FCN [29] | 82.22 ± 4.34 | 69.88 ± 3.61 | 93.24 ± 1.79 | 87.36 ± 3.07 | 65.30 ± 9.53 | 52.60 ± 8.17 | 91.50 ± 2.75 | 84.44 ± 4.57 |
| DeepLabv3 [30] | 80.41 ± 4.50 | 67.29 ± 3.27 | 93.06 ± 1.88 | 86.94 ± 4.05 | 72.44 ± 8.59 | 63.91 ± 6.72 | 91.06 ± 2.93 | 83.70 ± 5.15 |
| nnU-Net [31] | 92.98 ± 3.86 | 86.97 ± 2.93 | 93.33 ± 1.69 | 88.04 ± 2.97 | 89.77 ± 6.69 | 81.69 ± 5.26 | 92.16 ± 2.73 | 84.97 ± 4.53 |
| Swin-U-Net [12] | 81.65 ± 4.19 | 69.27 ± 3.44 | 91.27 ± 2.15 | 84.02 ± 5.64 | 68.93 ± 9.06 | 53.13 ± 8.08 | 85.86 ± 7.94 | 75.39 ± 16.48 |
| SAM [32] | 79.78 ± 4.23 | 66.89 ± 3.50 | 80.36 ± 3.44 | 76.35 ± 8.21 | 67.89 ± 9.22 | 52.56 ± 13.32 | 81.00 ± 9.27 | 70.92 ± 17.57 |
| MedSegDiff [20] | 92.44 ± 3.75 | 88.27 ± 2.91 | 91.07 ± 1.69 | 84.51 ± 2.86 | 87.59 ± 7.24 | 76.68 ± 5.78 | 92.96 ± 2.87 | 86.53 ± 3.71 |
| Verdiff-Net(ours) | 94.37 ± 3.73 | 90.89 ± 2.87 | 93.84 ± 1.56 | 91.87 ± 2.79 | 88.74 ± 7.04 | 77.04 ± 5.75 | 93.86 ± 1.98 | 88.58 ± 3.83 |
| MSFM | NSA | MR (Dice) | MR (Iou) |
|---|---|---|---|
| 0.8868 | 0.8396 | ||
| ✓ | 0.9196 | 0.8682 | |
| ✓ | 0.9027 | 0.8521 | |
| ✓ | ✓ | 0.9386 | 0.8858 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Liu, T.; Fan, G.; Pu, Y.; Li, B.; Chen, X.; Feng, Q.; Zhou, S. Verdiff-Net: A Conditional Diffusion Framework for Spinal Medical Image Segmentation. Bioengineering 2024, 11, 1031. https://doi.org/10.3390/bioengineering11101031
Zhang Z, Liu T, Fan G, Pu Y, Li B, Chen X, Feng Q, Zhou S. Verdiff-Net: A Conditional Diffusion Framework for Spinal Medical Image Segmentation. Bioengineering. 2024; 11(10):1031. https://doi.org/10.3390/bioengineering11101031
Chicago/Turabian StyleZhang, Zhiqing, Tianyong Liu, Guojia Fan, Yao Pu, Bin Li, Xingyu Chen, Qianjin Feng, and Shoujun Zhou. 2024. "Verdiff-Net: A Conditional Diffusion Framework for Spinal Medical Image Segmentation" Bioengineering 11, no. 10: 1031. https://doi.org/10.3390/bioengineering11101031
APA StyleZhang, Z., Liu, T., Fan, G., Pu, Y., Li, B., Chen, X., Feng, Q., & Zhou, S. (2024). Verdiff-Net: A Conditional Diffusion Framework for Spinal Medical Image Segmentation. Bioengineering, 11(10), 1031. https://doi.org/10.3390/bioengineering11101031