1. Introduction
Molecular dynamics (MD) simulations of chemical or material properties have been a very useful tool for understanding intricate experimental observations of bio-macromolecular systems, usually involving diverse spatial and temporal ranges. To obtain reliable MD simulation results, molecular modeling mainly relies on force field (FF) construction. The modeling of force fields usually starts with collecting observable data from distinct experiments. Together with statistical modeling methods, most traditional force field constructions employ a chemistry-based functional form, such as the famous Lennard-Jones potential, to model the empirical data available. This approach, usually called empirical force field (EFF) modeling, is favorable for obtaining a preliminary understanding of physical properties quickly. However, usually an EFF’s predictive power is weak. Not only the measured data input bears unknown empirical errors, but the chosen functional form may not be suitable for representing the intended force field. In practice, an EFF’s applicability is restricted to the boundaries of its original training set. Once far from the original training set, the predictive results become unreliable, and the conclusions are misleading. One way out of the first problem is to employ quantum chemistry-calculated ab initio energy data. These ab initio data can serve as a benchmark-level reference with minimum empirical information as the input.
In the past decade, we have witnessed an advancement in using quantum chemistry-calculated energy data to build potential energy surfaces (PESs) in the task of force field (FF) constructions [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. In particular, it is now a routine calculation task to employ highly correlated ab initio methods, such as the second-order Møller–Plesset perturbation theory (MP2), to obtain accurate energy data for small molecular dimers with the number of atoms being less than about 50. Recently, these ab initio data have been collected and organized as easy-to-use datasets. These ab initio data can be used to calibrate less accurate but more efficient quantum mechanical methods, such as semiempirical methods. However, it still requires balancing accuracy and efficiency for obtaining meaningful predictions of the structures and energies of biomolecular or macromolecular systems. For this purpose, it is better to use the alternative symmetry-adapted perturbation theory (SAPT) for obtaining intermolecular interaction energies with satisfying chemical accuracy in a reasonable computational time [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. Using the SAPT, one can directly calculate the interaction energies using the precalculated monomer properties. This method is favorable because it is free from basis set superposition errors (BSSEs) problems. Moreover, the theory divides the overall interaction energy into four theory-based terms: exchange, electrostatic, induction, and dispersion energy components. Thanks to these distinct features, the SAPT-calculated energy data are very useful in drug discovery and biomolecular recognition due to their acceptable accuracy and reasonable computational cost. Therefore, the SAPT method has been widely used in recent studies, with a great level of success in modeling biomolecular segments and motifs. In passing, we would like to mention that although these ab initio data are of very high accuracy, they are no substitute for reliable experimental data. The final judgment of the theory is still the experiment.
In our previous studies [
23,
24], we calculated the bonding structures and interaction energies for 31 homodimers of small organic functional groups dubbed the SOFG-31 dataset by using the MP2, CCSD(T), and the simplest SAPT0 level of theory. The SOFG-31 dataset consists of 31 monomers across 8 common classes, including 6 alkanes, 6 alkenes, 4 alkynes, 4 alcohols, 4 aldehydes, 3 ketones, 3 carboxylic acids, and 3 amides. Based on the SOFG-31 dataset, we also performed a parallel series of calculations to obtain the bonding structures and interaction energies for heterodimers selected from the combinations of monomers in the SOFG-31 dataset. This dataset is henceforth named the SOFG-31-heterodimer dataset. More specifically, the SOFG-31-heterodimer dataset contains 12 alkane-alkane (Aa-Aa), 16 alkane-alkene (Aa-Ae), 6 alkene-alkene (Ae-Ae), 16 alkane-alcohol (Aa-Ac), 16 alkane-aldehyde (Aa-Ad), 12 alkane-ketone (Aa-K), 16 alkene-alcohol (Ae-Ac), 16 alkene-aldehyde (Ae-Ad), 12 alkene-ketone (Ae-K), 12 alkane-carboxylic acid (Aa-Ca), 12 alkane-amide (Aa-Am), 12 alkene-carboxylic acid (Ae-Ca), 12 alkene-amide (Ae-Am), 6 alcohol-alcohol (Ac-Ac), 12 alcohol-carboxylic acid (Ac-Ca), 12 alcohol-amide (Ac-Am), 12 aldehyde-carboxylic acid (Ad-Ca), 12 aldehyde-amide (Ad-Am), and 15 binary complexes in the CAA-CAA set. These data are valuable thanks to their systematic organization according to the specific functional group types.
The second problem in force field modeling is how to model the ab initio data using a proper force function. This is the point where data analysis techniques can be very useful in this specific field of molecular modeling. The task of force field modeling over wide and diverse potential energy data, including both covalent and noncovalent interaction energies, usually involves a very complicated procedure and uses the special techniques of mathematical nonlinear regression. In practice, it is very difficult to uniquely determine a set of parameters with a given force function to represent the force field. Worse, when the dataset becomes larger, the corresponding parameter number also increases. Sometimes the parameter number is even greater than the data number, thus causing the overfitting problem. Recently, machine learning (ML) techniques have been used to solve this problem with a variable degree of success, and we would like to explore this interesting topic in traditional FF constructions.
Recent artificial intelligence (AI)-generated methods, such as machine learning (ML) techniques, have been widely used in nearly all scientific applications [
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39]. A great number of ML algorithms, such as artificial neural networks (ANNs), kernel-ridge regression (KRR), and graph convolutional networks (GCNs), have been developed and tested [
40,
41,
42,
43]. These ML algorithms are particularly useful together with modern computer hardware structures, such as graphics processing units (GPUs). The AI-generated methods have rendered both successful stories and controversial examples. The promising success of the ML model can be attributed to the predictive ability of its algorithm to perform estimation on the unknown domains of system features with fast and quantitative nonlinear regression of the training data. Although in principle there exists a sound theoretical foundation for the ML algorithms [
44,
45,
46,
47,
48,
49,
50], in practice most researchers reply to the more intuitive cycle of training, testing, and correcting. Therefore, it is very essential to prepare the input training data for ML modeling with the hope of finding a non-analytical function to represent the main features of a prepared dataset. To avoid immaterial outcomes, we should monitor the inherent black-box data propagation processes involved in the ML algorithm and judge the final results using human knowledge [
51]. In sum, these ML algorithms can help a lot in solving many intricate problems in data modeling [
52,
53,
54,
55,
56,
57,
58,
59,
60,
61].
Recently, successful cases of utilizing these ML algorithms in macromolecular modeling, such as drug discovery, have been reported [
62,
63]. The purpose of molecular modeling is to well represent the noncovalent interactions (NCIs) involved in highly heterogeneous chemical, material, and biological environments [
64,
65,
66]. These physical interactions are relatively weak as compared to usual chemical bonds but play a determining role in maintaining the equilibrium state of biomolecules such as lipids, proteins, and peptides in physiological conditions. The target object searched for in this kind of study is the unknown force functions for the NCIs, which are expected to be multidimensional. In this paper, we perform ML modeling on our previously constructed SOFG-31 and SOFG-31-heterodimer datasets. Our main purpose is to test a recently released ML algorithm called the CLIFF scheme [
67]. In a previous study [
68], we used a lower SAPT level of theory (SAPT0) to calculate the potential energy data and tested the ability of the CLIFF scheme to interpolate the datasets, with an emphasis on the possible overfitting problems. In this present paper, we would like to test the effect of changing the SAPT theory level on the predictive power and determine a minimum level of theory (SAPT2) for approaching the benchmark accuracy. The other parts of this paper are organized as follows: The main calculation results and due discussion are presented in
Section 2. The dataset descriptions and methodological details are summarized in
Section 3. The conclusions and perspectives are given in
Section 4.
2. Results and Discussion
2.1. Preparation of the SOFG-31 Training Dataset
For the preparation of initial training datasets, two issues are important. One is to select a suitable quantum chemistry theory level for calculating the interaction energies in order to achieve the desired accuracy. The other is to sample the molecular structures in order to cover a wide range of chemical configuration spaces. One can first obtain the structures and energies with lower-accuracy methods. For example, one can perform a series of MD simulations with a standard EFF for a small system of molecules. The simulation would yield a set of randomly distributed structures and the corresponding interaction energies. These data bear no specific structural fingerprints, so they are often used together with a supervised ML algorithm to train the force field. With these preliminary structures, one can next systematically optimize the molecular geometry and calculate the energies using higher-accuracy methods at the optimized structures. Because the data contain important information about the structural features, they are usually used in a semi-supervised ML algorithm.
In this paper, we use the SOFG-31 dataset as the training dataset. The SOFG-31 dataset was home-made in our lab. The interaction energy data were calculated using a series of quantum chemistry methods, including the SAPT0 method. The SOFG-31 dataset contains 31 small molecules chosen from eight organic functional groups: alkanes (methane, ethane, propane, butane, pentane, hexane), alkenes (ethylene, propylene, butylene, pentylene), alkynes (ethyne, propylene, butylene, pentylene), alcohols (methanol, ethanol, propanol, butanol), aldehydes (formaldehyde, acetaldehyde, propanaldehyde, butanal), ketones (acetone, butanone, pentanone), carboxylic acids (formic acid, acetic acid, propanoic acid), and amides (formamide, acetamide, propenamide). All the dimers are optimized and found stable using the MP2 level of theory. In particular, we deliberately organize these data with respect to their functional group types. This is because, as mentioned above, we would like to employ human knowledge in training the force fields. Here a specific group bears its typical chemical features, which are well-known and well-collected in organic chemistry. As we have demonstrated in a previous study, the contribution propensity of the hydrogen bond attraction increases across the alkane group to the amide group. It is expected to utilize these known features in machine learning processes. In fact, we built the training set by taking into account the energy patterns for each group. The SOFG-31 dataset has been extended to include heterodimers selected from the SOFG-31 set and is henceforth called the SOFG-31-heterodimer dataset. In this paper, the SOFG-31 and the SOFG-31-heterodimer datasets are used as the training and test sets, respectively.
We have calculated the bonding structures and interaction energies for 31 homodimers of small organic functional groups, dubbed the SOFG-31 dataset, by using the MP2, CCSD(T), and the simplest SAPT0 level of theory. All the single-point energy calculations are performed at the MP2-optimized structures. We have tested the correlation between the SAPT0-calculated data and the benchmark CCSD(T) data and found that the SAPT0 level of theory has not reached a satisfying accuracy of about 1 kcal/mol. Notice that in the SI unit system, the unit for energy is kJ (=kcal/4.18), which is more often used in engineering studies. Therefore, we re-calculate the dimeric energies for both the SOFG-31 and SOFG-31-heterodimer datasets by using the more advanced SAPT2 level of theory.
Table 1,
Table 2 and
Table 3 list the SAPT2-calculated interaction energies for the AaAeAy, AcAdK, and CAA subgroups, respectively. Notice that we have employed a wide series of basis sets, including the jun-cc-pVDZ (jDZ), jun-cc-pVTZ (jTZ), aug-cc-pVDZ (aDZ), and aug-cc-pVTZ (aTZ), in order to assess the basis set effects.
Next, we employ the SOFG-31 homodimer dataset calculated at the SAPT2/aTZ level of theory as our training set and utilize the CLIFF ML modeling scheme (see
Section 3 for methodological details). Our purpose in this task is to determine the global parameters that gauge the intermolecular pairwise interactions separated into the four SAPT components. This is achieved by a nonlinear regression of the calculated energies with adjustments to the running parameter values. For the optimization task, we use the BFGS (Broyden–Fletcher–Goldfarb–Shanno) method with a multi-object loss function
L. The mean square errors (MSEs) for the four SAPT component energies and the SAPT total energy are considered (Equation (1)), with the partition parameter γ = 0.4.
where
C represents the set of the four SAPT components.
Figure 1 shows the convergence trend of the loss function during the iteration process, where the value of
L is plotted versus the number of iterations. We observe a very quick convergence when the number of iterations exceeds about 700.
In
Table 4, we show the optimized global parameters using the CLIFF scheme. Notice that parameters used in the CLIFF scheme involve two types. One is monomer-specific atomic parameters, such as atomic widths and multipole moments. The other is the dimeric global parameters shown here. The former atomic parameters have been fixed during the fitting processes. This means that we do not consider the atomic environmental changes due to bonding. To include the environmental effects, the CLIFF employs atom types. For example, the hydrogen atom types are defined based on the element of their bonding partner. With this set of global parameters, we have a first-version ML potential (see
Section 3).
Using the SOFG-31 Training Set to Predict the SOFG-31-Heterodimer Test Set
To evaluate the performance of this ML potential, where the global parameters are derived from the SOFG-31 training set, we now predict the energies of the dimers in the SOFG-31-heterodimer dataset.
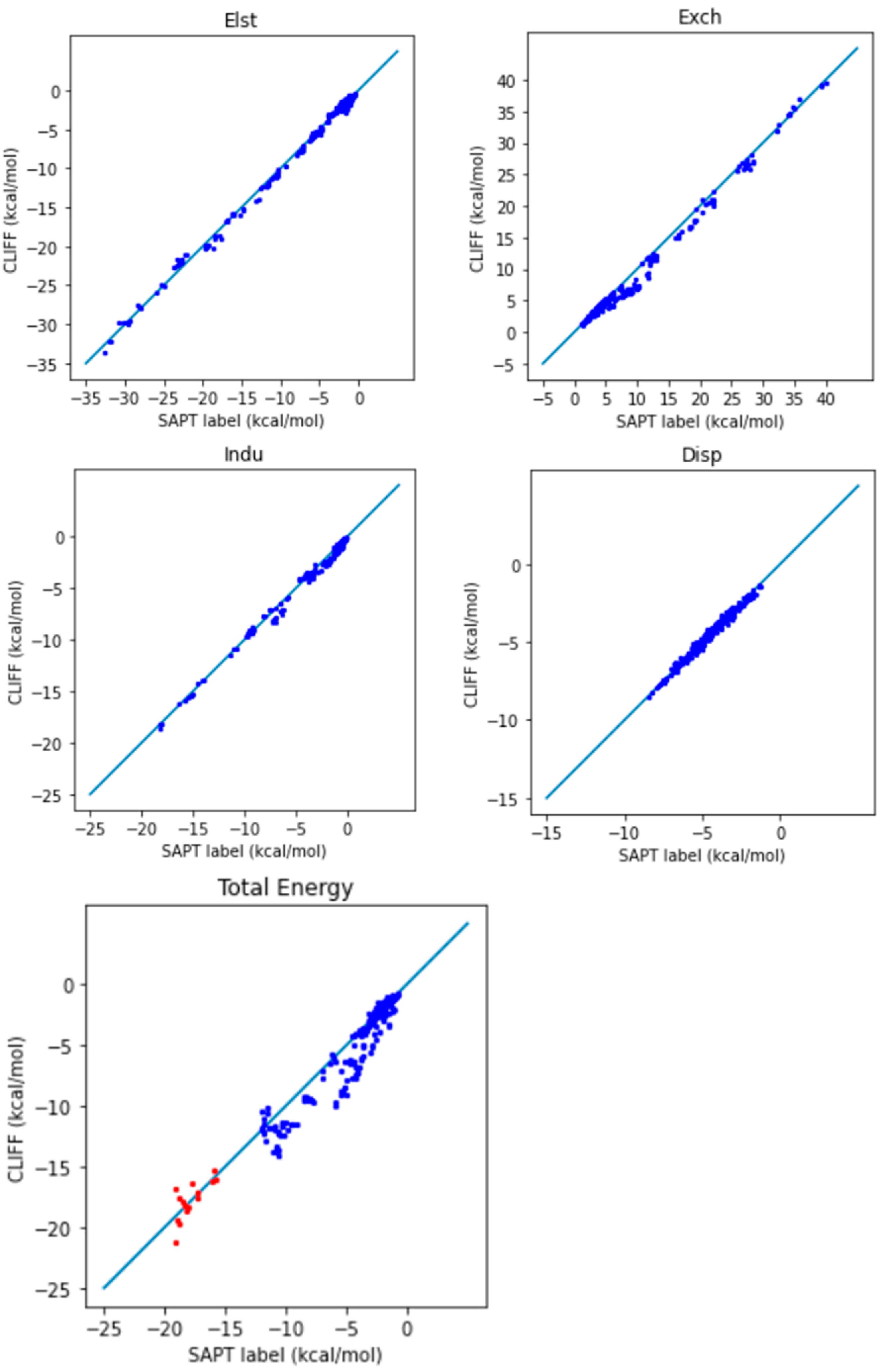
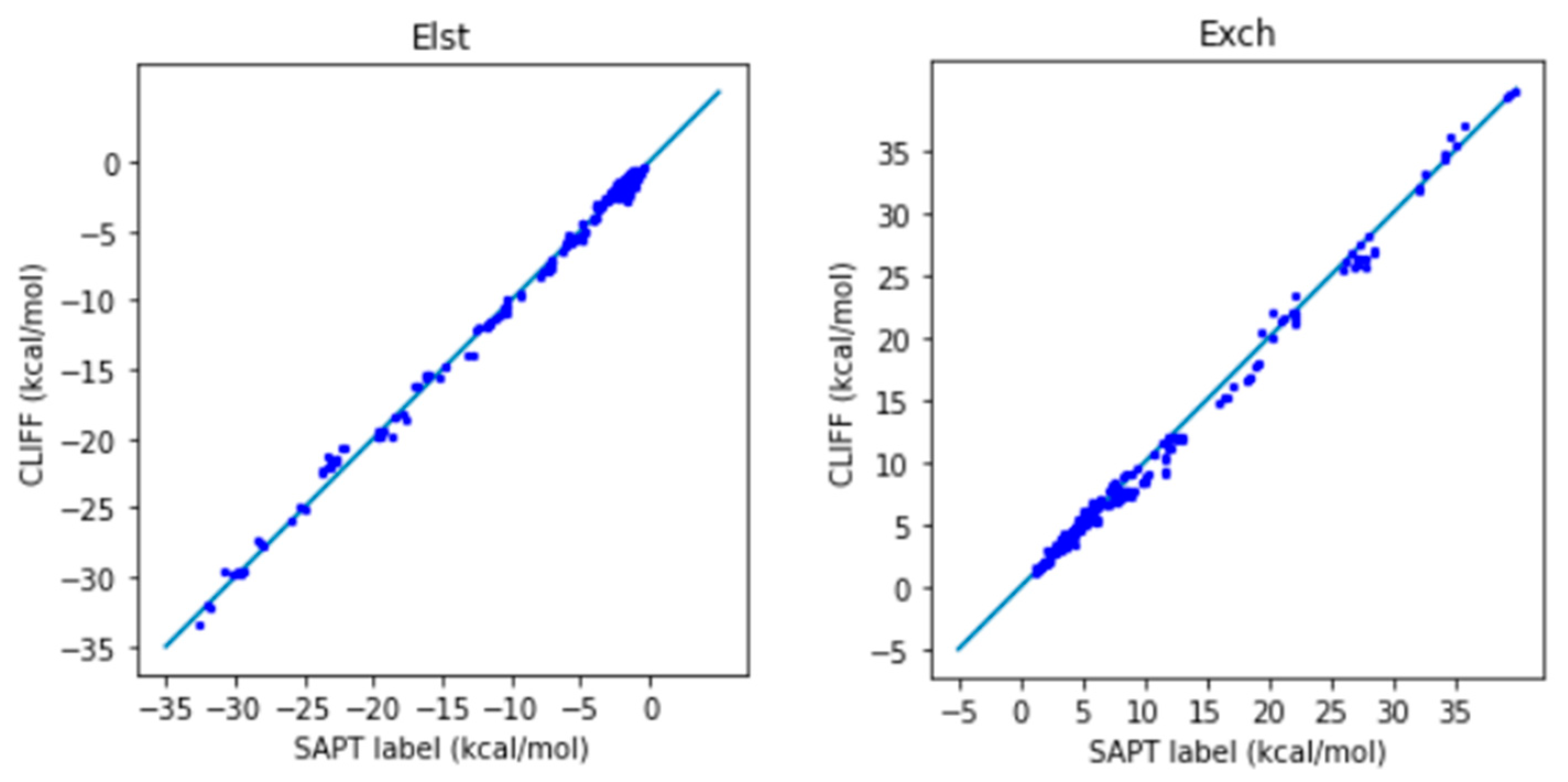
Table 5 lists the error measures between the predictive results and the reference SAPT2 energy data. Here, we use two length measures: the mean absolute error (MAE) and the root mean square error (RMSE). Both the SAPT component energies and the SAPT total energy have been tested. From
Table 5, we see that both the MAE and the RMSE error measures are around the chemical accuracy of about 1 kcal/mol. Larger errors are associated with the exchange energy component, whose absolute energy values are also numerically larger.
Figure 2 shows the correlation between the predicted energies and the reference SAPT2-calculated energies for the four SAPT energy components and the SAPT total energy. The deviation of the data distribution can be judged by the closeness of the points aligning along the diagonal reference line. We observe an overall well-aligned distribution of the predicted SAPT component energy data, albeit a biased underestimation of the exchange energy. Also notice that the van der Waals bounded dimers (i.e., those from the AaAeAy groups) exhibit a better symmetrical distribution. Again, the larger errors come from the exchange energy part.
For the total energy, the MAE using this ML potential is 0.932 kcal/mol, which is below the chemical accuracy of 1 kcal/mol. It is promising that the global parameters obtained by training the SOFG-31 dataset are suitable for predicting the energy data in the SOFG-31-heterodimer set. Though the training set contains only homodimers in equilibrium, the good predictive results for the heterodimers demand an explanation. The following facts may provide partial answers: The dimeric interaction energy is defined as a sum over paired atoms. Locally, the homodimer interactions include the pairwise information for the heterodimer interactions. That is, the homodimer interactions include interactions among different atom types, with a similar pattern to the heterodimers. It is thus understandable that we can use the ML potential derived from homodimer energies to predict or interpolate the heterodimer interactions.
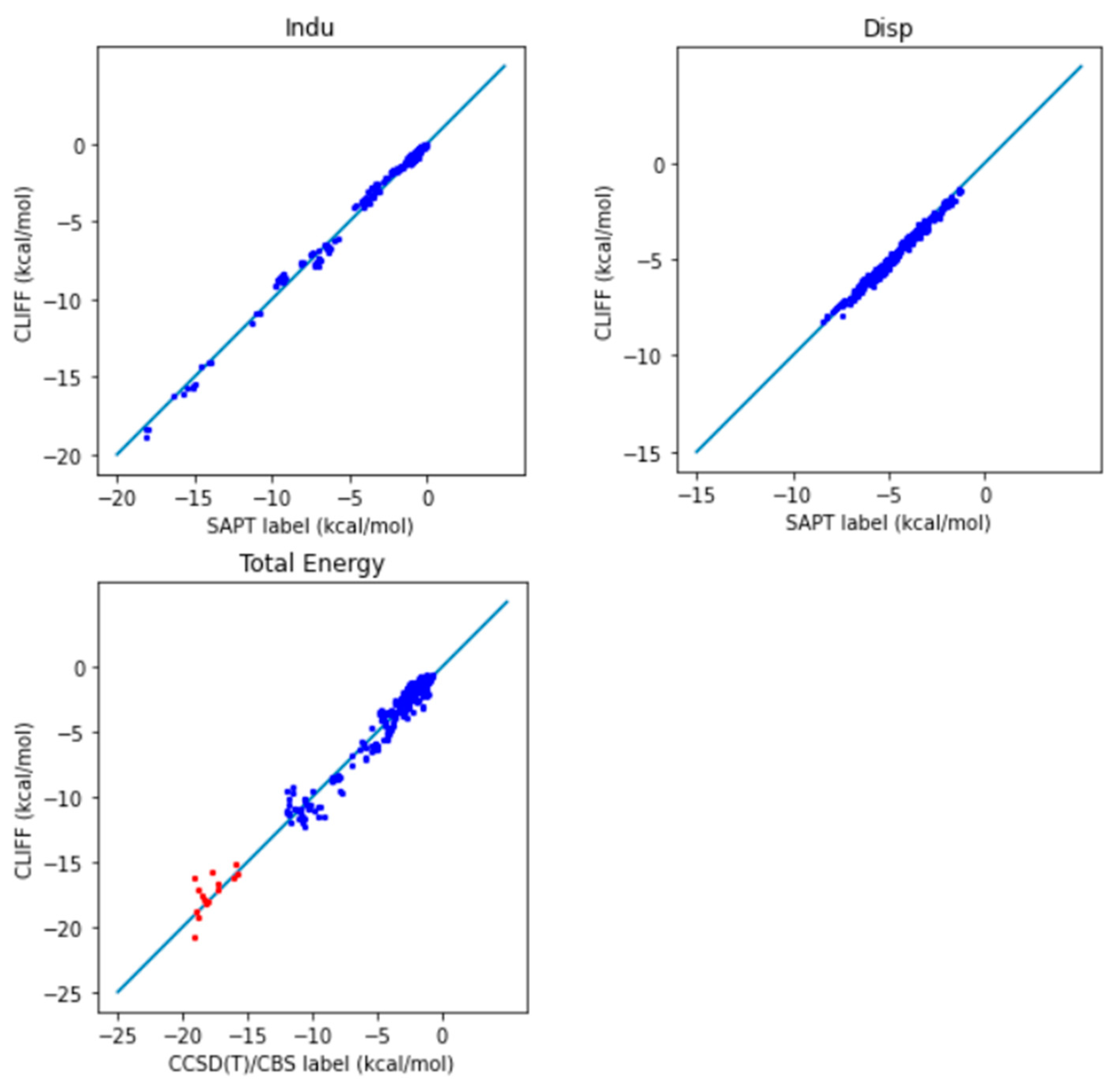
In addition, we further compare the predictive results with the well-recognized gold standard CCSD(T)/CBS reference data. The correlation plot between the predictive energies and the reference data is shown in
Figure 3. We see that the larger errors are associated with the hydrogen-bonded dimers (i.e., those from the CAA groups). For the total energy, the MAE is 0.991 (0.932) kcal/mol and the RMSE is 1.428 (1.380) kcal/mol, which should be compared with the previous results shown in the parentheses. These results show that using a higher level of theory is required for obtaining the benchmark energy data.
2.2. Employing the Dimer-31+9 as the Training Set
In order to make the predictive results closer to the benchmark energy data, we chose to include the heterodimers with large errors in the training set. For a specific subgroup, we gradually add the smaller heterodimers into the training set and perform the training. For each modification, we check whether the individual and the total errors are well controlled within 1 kcal/mol. In this way, we find it requires nine more heterodimers to obtain the best results. The nine dimers are Ethene-Methanol, Ethene-Ethanol, Ethene-Formic acid, Methanol-Formamide, Ethanol-Formamide, Formaldehyde-Formamide, Formaldehyde-Acetamide, Formaldehyde-Formic acid, and Formaldehyde-Acetic acid, and the new set is called the Dimer-31+9 training set. Next, the Dimer-31+9 dataset is used in the optimization process, as described in the last section.
Table 6 lists the set of global parameters.
We now employ the global parameters based on the Dimer31+9 training set to test the SAPT energy data in the SOFG-31-heterodimer test set.
Table 7 lists the error measures between the predictive results and the reference SAPT2 energy data. Again, two length measures, the MAE and the RMSE are used. We see clearly from
Table 7 that both error measures are now well below 1 kcal/mol, which shows the good predictive ability of the ML potential. The correlation plots for the predicted and the SAPT2-calculated energies are shown in
Figure 4 for the SAPT component and total energies, respectively. A closer distribution of points along the reference line indicates better prediction. We see that the predicted SAPT energy data are better aligned along the reference line. Also notice that the van der Waals-bounded dimers exhibit better alignment than the hydrogen-bonded dimers. The larger errors come from the exchange energy part. Our results clearly show that the MAE for the total SAPT energy is reduced from 0.932 kcal/mol to 0.605 kcal/mol, and the RMSE is reduced from 1.380 kcal/mol to 0.790 kcal/mol, which are significantly lower than the chemical standard. Here we demonstrate that adding a small set of heterodimers can greatly enhance the predictive power of the trained ML potential.
In addition, we further compare the predictive results with the well-recognized gold standard CCSD(T)/CBS reference data. The correlation plot between the predictive energies and the reference data is shown in
Figure 5. We see that the larger errors are associated with the hydrogen-bonded dimers (i.e., those from the CAA groups). For the total energy, the MAE is reduced from 0.991 to 0.643 kcal/mol and the RMSE from 1.428 to 0.858 kcal/mol. These results show that using a larger training set helps in obtaining the benchmark energy data. Because we have obtained a satisfying level of accuracy, we refer to the set of optimized global parameters as the CLIFF2 parameters, following the original CLIFF0 convention.
2.3. Using the CLIFF2 Parameters to Predict the Potential Energy Curves of the SOFG-31 and SOFG-31-Heterodimer Datasets
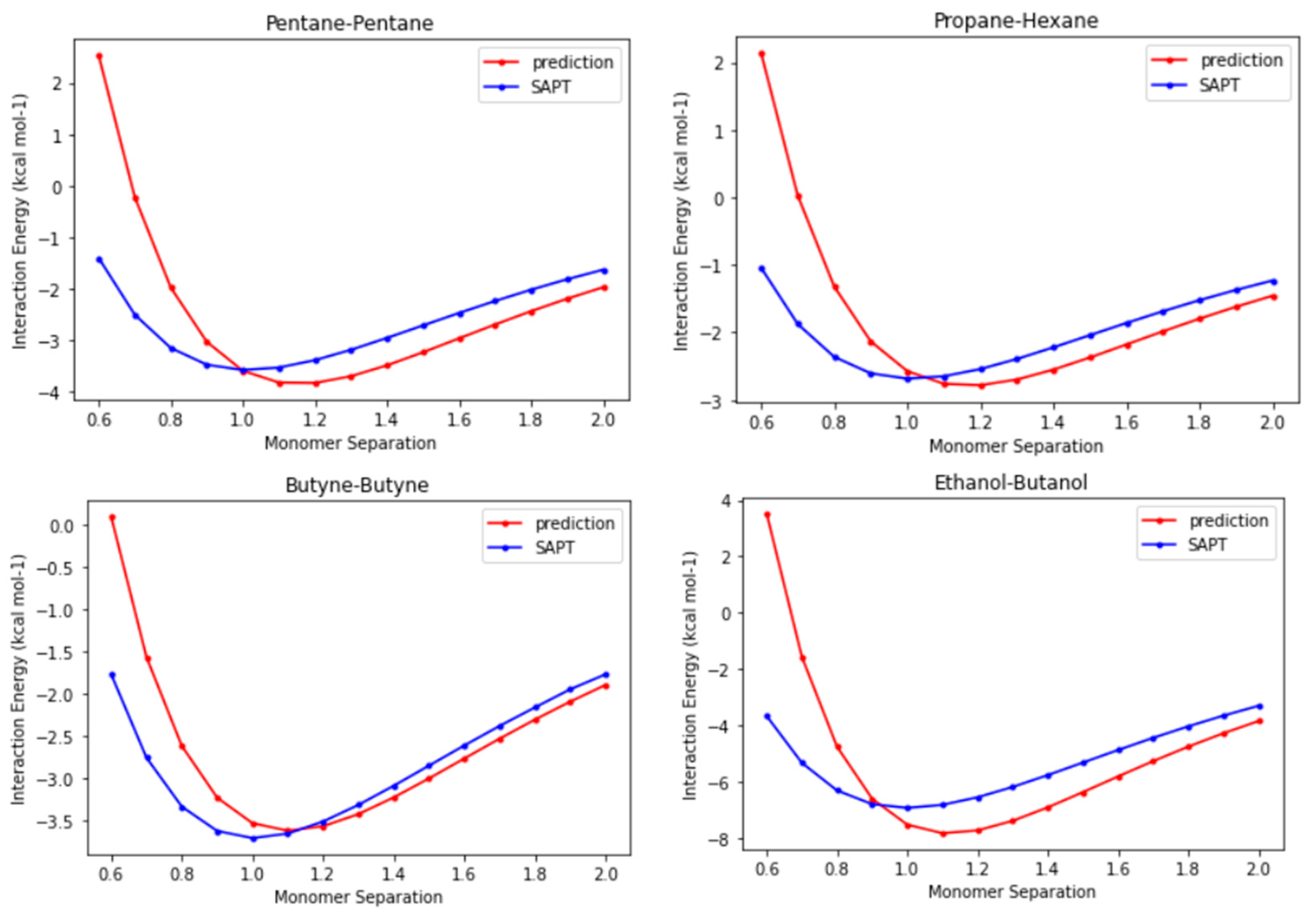
Until this point in time, we have verified that the CLIFF2 parameters perform well in reproducing the interaction energies of dimers at equilibrium points, with the results even approaching the benchmark energies. Because the functional forms for the SAPT energy components are explicitly implemented in the CLIFF ML scheme, it is interesting to show the preliminary outlook for the whole potential energy curves. In
Figure 6, we compare the prediction energy curves using the CLIFF2 parameters with the destined SAPT energy curves for four representative systems, namely, the pentane-pentane, the propane-hexane, the butyne-butyne, and the ethanol-butanol heterodimers. We plot the energy curves along the monomer separation, which is defined as the distance between the centers of mass of the involved monomers in the dimer. The distance unit is normalized to the equilibrium distance of the respective SAPT energy curve.
We first observe that the binding energies are well predicted with chemical accuracy. The equilibrium distances are not exactly reproduced, but they are all within 10% of the equilibrium distances. This is because in the CLIFF ML scheme, the geometry is unsupervised. For the far-distance side, the predicted energy curves are pretty precise if the equilibrium distances are shifted to the right places. However, the results for the short-distance side exhibit significant errors. The reason for this discrepancy can be partly attributed to the modeling formula for the exchange energy component (see
Section 3). Nonetheless, it is noteworthy that using only energy data at equilibrium points proves effective in predicting energy curves, with correct trends for the overall profiles. This indicates that the energy models employed properly approximate the energy variation with distance. It requires further study to improve the prediction results for the molecular geometry and the short-distance side of the energy curves.
3. Materials and Methods
The energy data of the SOFG-31 dataset are arranged into 8 organic functional groups: alkanes, alkenes, alkynes, alcohols, aldehydes, ketones, amines, and carboxylic acids, resulting in 31 homodimers. The basis set superposition error (BSSE)-corrected super-molecule approach was used to calculate the interaction energies. The second-order Møller–Plesset perturbation theory (MP2) with the aug-cc-pV(D, T, Q)Z basis sets was used in geometry optimization. The benchmark interaction energies were calculated by the coupled cluster with single, double, and perturbative triple excitations at the complete basis set limit [CCSD(T)/CBS]. The groups of alkanes, alkenes, and alkynes are collectively called the AaAeAy group, while those of alcohols, aldehydes, and ketones are called the AcAdK group. The groups of carboxylic acids and amides are called the CAA group. The SOFG-31-heterodimer dataset is derived from selecting combinations of monomers from the SOFG-31 dataset.
The total SAPT energy is decomposed into the following four components: exchange (Exch), electrostatic (Elst), dispersion (Disp), and induction (Indu) energies. The CLIFF scheme models these components using electronic density overlaps. Here we briefly summarize the mathematical equations for the four energy components, and the details should refer to the original CLIFF paper [
67].
In this scheme, the exchange energy is described as the sum of all the repulsive interactions due to the overlapping electron densities between pairs of atoms.
Here, the global parameters
, one for each atomic species, are determined through fitting to the SAPT-calculated exchange energies. The
S matrices are calculated through the atomic valence widths,
for atom-typed parameters
.
The electrostatic energy is modeled by the damped multipole electrostatic (DME) model, which considers interactions between the atomic nuclei for each atomic pair, between atomic nuclei and multipoles, and among multipoles [
69].
Each multipole matrix
Mi includes, in principle, all orders of multipoles, but in practice, the first non-vanishing multipoles are used. Here the
T matrices are the damping interaction tensors among atomic nuclei and multipoles, respectively. The damping functions
f are defined by the following equations:
where the global parameters
are determined by the ML modeling of the SAPT-calculated electrostatic energies. That is, the parameters are obtained by fitting the SAPT-calculated electrostatic energies.
The dispersion energy is modeled by the attractive interactions using the atomic polarization interacting with the involved electrons. Here, the popular Tang–Toennies model is used. Firstly, the coefficients for each atom pair are calculated using the following equations:
Here
hi designates the Hirshfeld ratio, defined as the ratio of the effective atoms-in-molecules (AIM) volume to the effective volume of the free atom,
.
stands for the monomer coefficients, and
represents the polarizability. The value
is determined by the free atomic density. To obtain
, we use
where
is the multipole expectation value from the atomic density. For
, we use
Here the Tang–Toennies damping function is used.
Finally, we obtain the dispersion energy using the equation.
The global parameters are determined by the ML modeling of the SAPT-calculated dispersion energies.
The induction energy is generated by the atomic polarization stimulated by the external electric field. Here, we use the Thole expression.
where
is the induced dipole, which can be derived from the iteration,
where
k sums over all other atoms (except the
i-th atom) in the dimer and ω = 0.7. The interaction tensor,
, is used to smear the atomic charge distributions.
where
is the smearing coefficient set to 0.39. The global parameters
are determined with the ML modeling of the SAPT-calculated induction energies.
Because these formulas are written in pairwise sums, we need to obtain the electron densities of a monomer and distribute them to the constitutive atoms. The partitioning is calculated using the atoms-in-molecules (AIM) method. The AIM densities represent the atom-centered electronic clouds where local chemical surroundings have been considered. Notice that there are two groups of parameters. The atomic parameters include the atomic widths, the atomic multipoles, and the Hirshfield ratios. The global parameters include . The CLIFF ML scheme utilizes the AIM method to obtain the atomic multipoles, the atomic widths, and the Hirshfeld ratios from the AIM electron densities. To calculate the atomic reference densities, the PBE0/aug-cc-pV(D+d)Z method was used for the quantum chemistry calculations. Next, the atomic properties were determined with the minimum basis iterative stockholder (MBIS) partition method and the Hirshfeld routines, both implemented in the Horton (version 2.1.1, 2017) software. For the calculations of atomic multipoles, atomic widths, and Hirshfeld ratios, the CLIFF employed a KRR machine learning model for eight chemical elements (C, O, N, H, S, F, Cl, and Br). The training dataset contained molecules retrieved from the ChEMBL database. Firstly, the CLIFF selected a set of about 872,000 drug-like molecules. Second, the CLIFF classified molecules with respect to 5 to 12 heavy atoms. Finally, the CLIFF distinguished 8,138 molecules as core monomers to form dimers. These molecules are representatives of a wide and diverse range of drug-like compounds of medical interest.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}