


RGGC-UNet: Accurate Deep Learning Framework for Signet Ring Cell Semantic Segmentation in Pathological Images



Abstract
:1. Introduction
- We propose an efficient and accurate deep learning framework for signet ring cell semantic segmentation in pathological images.
- We design a novel encoder that not only refines the network’s capability but also notably enhances its performance in segregating overlapping and clustered cells.
- We propose ghost coordinate attention, which can efficiently capture the long-range dependencies.
- We provide full mask labels of SRC on the DigestPath 2019 dataset, referred to as the SRC dataset.
- Our experimental findings validate that the network proposed in this study attains superior evaluation scores and generates more refined segmentation outcomes when compared to other state-of-the-art methods for SRC segmentation.
2. Methods
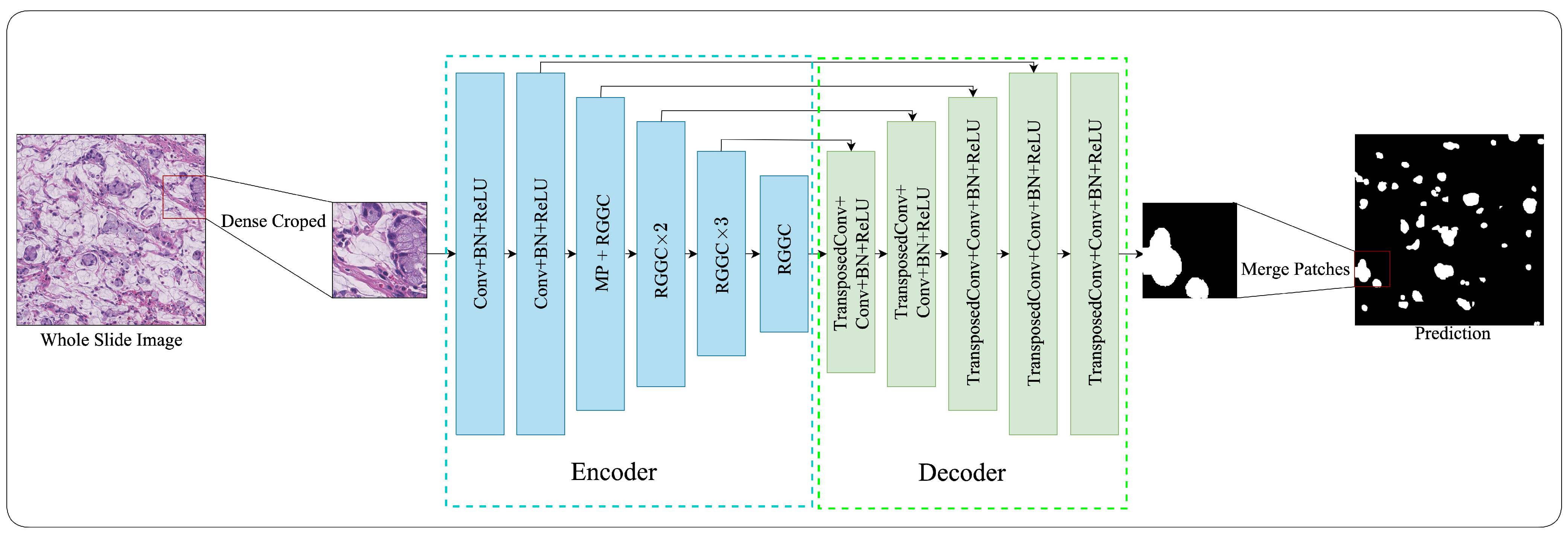
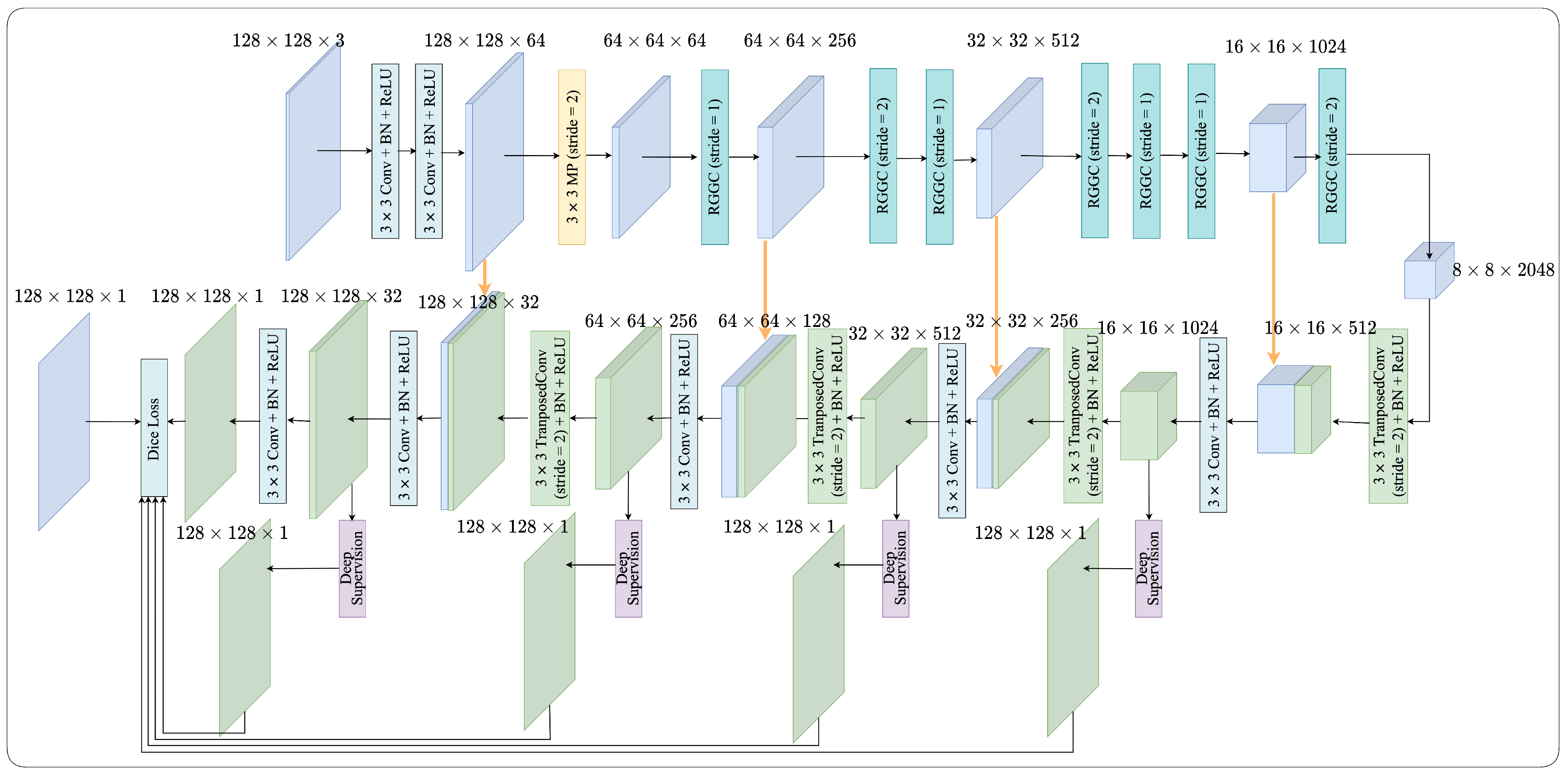
2.1. Network Architecture
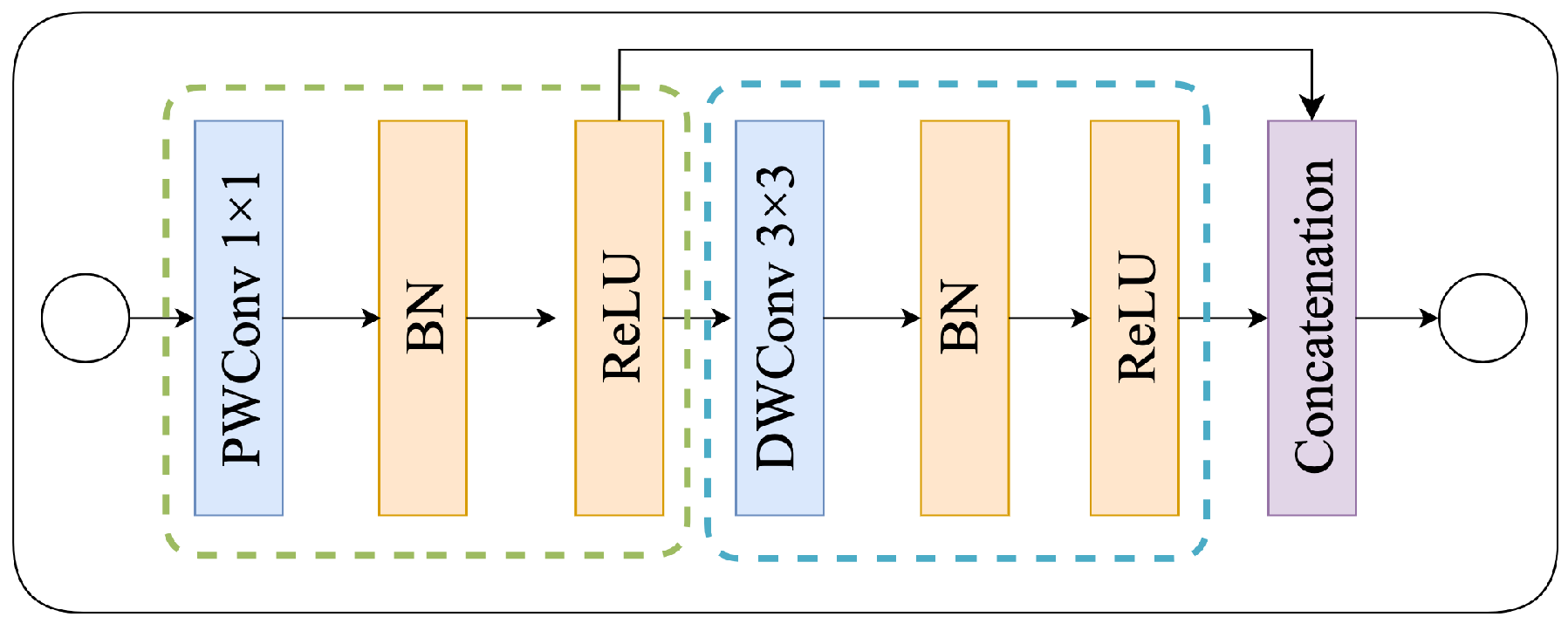
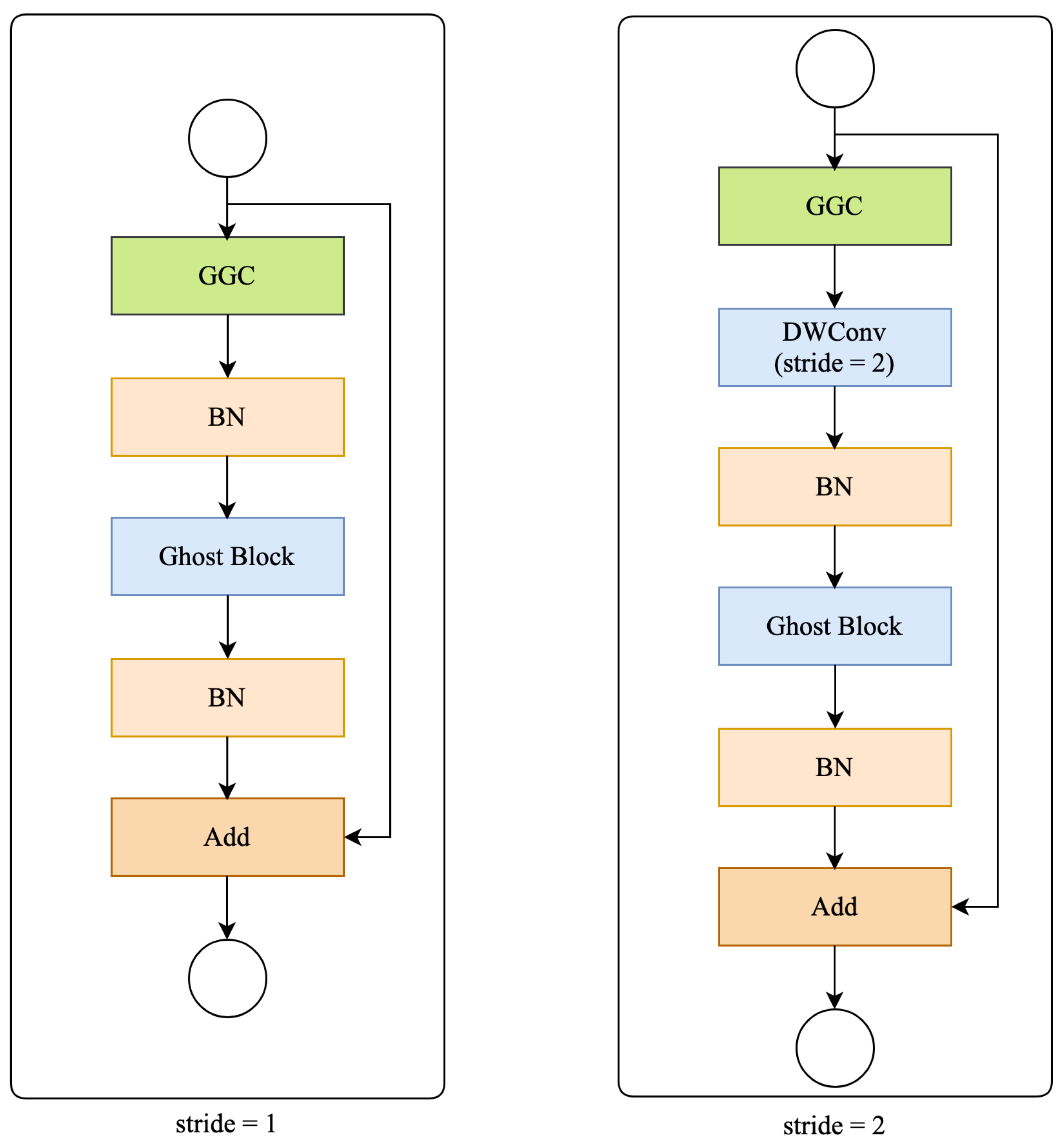
2.2. Encoder
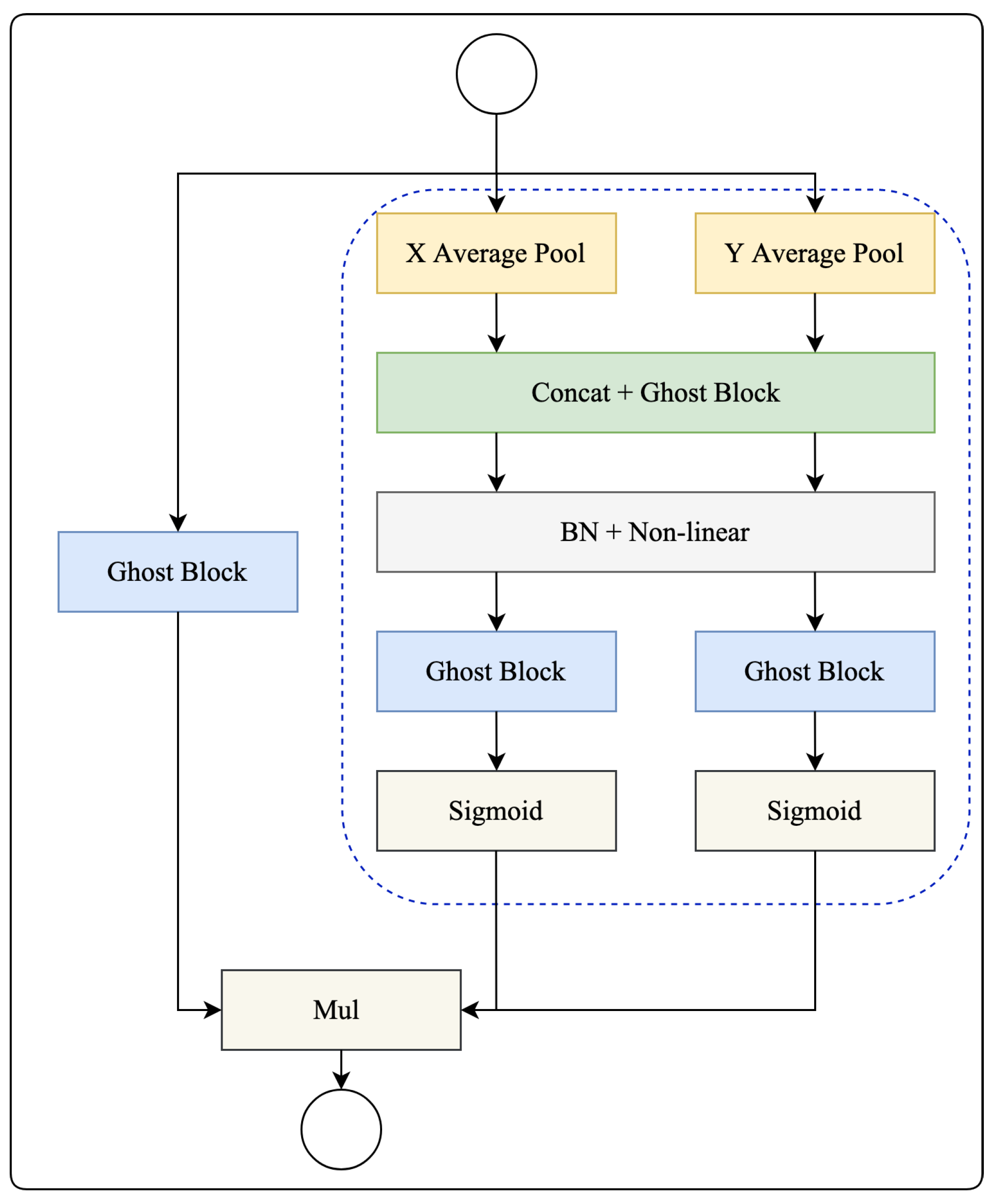
2.3. Ghost Coordinate Attention
2.4. Residual Ghost Block with Ghost Coordinate Attention
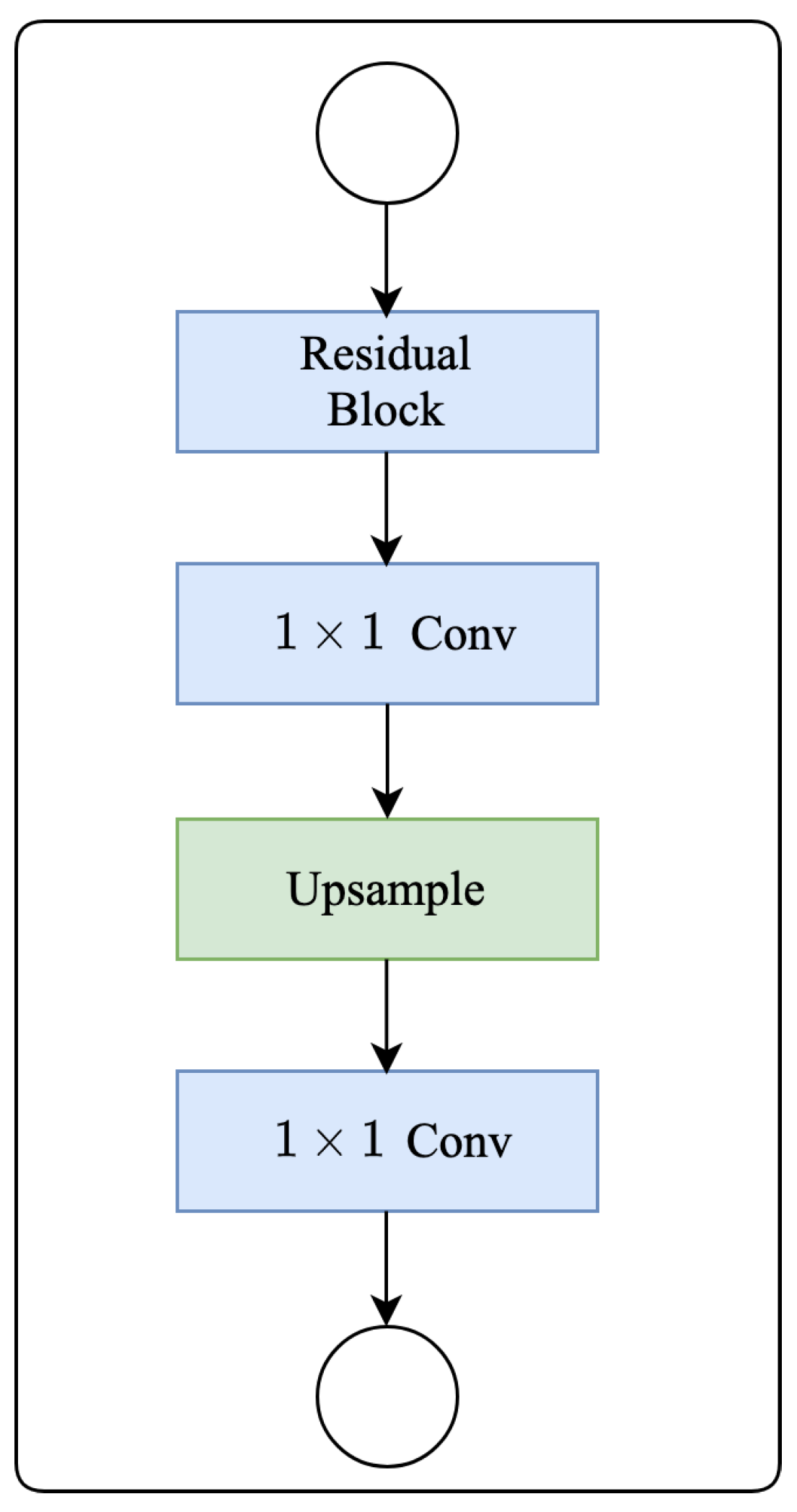
2.5. Decoder
2.6. Deep Supervision
2.7. Loss Function
3. Experiments
3.1. Dataset
3.2. Evaluation Metrics
3.3. Implementation Details
4. Discussion and Analysis
4.1. Discussion on Different Blocks
4.2. Comparison on SRC Dataset
4.3. Comparison on GlaS Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gnepp, D.R.; Henley, J.D.; Simpson, R.H.; Eveson, J. Chapter 6—Salivary and Lacrimal Glands. In Diagnostic Surgical Pathology of the Head and Neck, 2nd ed.; Gnepp, D.R., Ed.; W.B. Saunders: Philadelphia, PA, USA, 2009; pp. 413–562. [Google Scholar] [CrossRef]
- Benesch, M.G.; Mathieson, A. Epidemiology of Signet Ring Cell Adenocarcinomas. Cancers 2020, 12, 1544. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, S.R.; Aaltonen, L.A. Chapter 1—Tumours of the Oesophagus; IARC Press: Lyon, France, 2000; Volume 2, pp. 9–30. [Google Scholar]
- Ying, H.; Song, Q.; Chen, J.; Liang, T.; Gu, J.; Zhuang, F.; Chen, D.Z.; Wu, J. A semi-supervised deep convolutional framework for signet ring cell detection. Neurocomputing 2021, 453, 347–356. [Google Scholar] [CrossRef]
- Da, Q.; Huang, X.; Li, Z.; Zuo, Y.; Zhang, C.; Liu, J.; Chen, W.; Li, J.; Xu, D.; Hu, Z.; et al. DigestPath: A benchmark dataset with challenge review for the pathological detection and segmentation of digestive-system. Med. Image Anal. 2022, 80, 102485. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Yang, S.; Huang, X.; Da, Q.; Yang, X.; Hu, Z.; Duan, Q.; Wang, C.; Li, H. Signet Ring Cell Detection with a Semi-supervised Learning Framework. In Information Processing in Medical Imaging, Proceedings of the 26th International Conference IPMI 2019, Hong Kong, China, 2–7 June 2019; Chung, A.C.S., Gee, J.C., Yushkevich, P.A., Bao, S., Eds.; Springer: Cham, Switzerland, 2019; pp. 842–854. [Google Scholar] [CrossRef]
- Wang, S.; Jia, C.; Chen, Z.; Gao, X. Signet Ring Cell Detection with Classification Reinforcement Detection Network. In Bioinformatics Research and Applications, Proceedings of the 16th International Symposium, ISBRA 2020, Moscow, Russia, 1–4 December 2020; Cai, Z., Mandoiu, I., Narasimhan, G., Skums, P., Guo, X., Eds.; Springer: Cham, Switzerland, 2020; pp. 13–25. [Google Scholar] [CrossRef]
- Lin, T.; Guo, Y.; Yang, C.; Yang, J.; Xu, Y. Decoupled gradient harmonized detector for partial annotation: Application to signet ring cell detection. Neurocomputing 2021, 453, 337–346. [Google Scholar] [CrossRef]
- Zhang, S.; Yuan, Z.; Wang, Y.; Bai, Y.; Chen, B.; Wang, H. REUR: A unified deep framework for signet ring cell detection in low-resolution pathological images. Comput. Biol. Med. 2021, 136, 104711. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Wang, S.; Jia, C.; Hu, K.; Ye, X.; Li, X.; Gao, X. CRDet: Improving Signet Ring Cell Detection by Reinforcing the Classification Branch. J. Comput. Biol. 2021, 28, 732–743. [Google Scholar] [CrossRef] [PubMed]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Shan, P.; Wang, Y.; Fu, C.; Song, W.; Chen, J. Automatic skin lesion segmentation based on FC-DPN. Comput. Biol. Med. 2020, 123, 103762. [Google Scholar] [CrossRef]
- Sharma, A.; Mishra, P.K. DRI-UNet: Dense residual-inception UNet for nuclei identification in microscopy cell images. Neural Comput. Appl. 2023, 35, 19187–19220. [Google Scholar] [CrossRef]
- Zheng, Y.; Song, W.; Du, M.; Chow, S.S.M.; Lou, Q.; Zhao, Y.; Wang, X. Cryptography-Inspired Federated Learning for Generative Adversarial Networks and Meta Learning. In Advanced Data Mining and Applications, Proceedings of the International Conference on Advanced Data Mining and Applications, Shenyang, China, 27–29 August 2023; Springer: Cham, Switzerland, 2023; pp. 393–407. [Google Scholar] [CrossRef]
- Yuan, J.; Xiao, L.; Wattanachote, K.; Xu, Q.; Luo, X.; Gong, Y. FGNet: Fixation guidance network for salient object detection. Neural Comput. Appl. 2023, 1–16. [Google Scholar] [CrossRef]
- Heydarheydari, S.; Birgani, M.J.T.; Rezaeijo, S.M. Auto-segmentation of head and neck tumors in positron emission tomography images using non-local means and morphological frameworks. Pol. J. Radiol. 2023, 88, e365. [Google Scholar] [CrossRef] [PubMed]
- Hosseinzadeh, M.; Gorji, A.; Fathi Jouzdani, A.; Rezaeijo, S.M.; Rahmim, A.; Salmanpour, M.R. Prediction of Cognitive Decline in Parkinson’s Disease Using Clinical and DAT SPECT Imaging Features, and Hybrid Machine Learning Systems. Diagnostics 2023, 13, 1691. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Lu, Z.; Carneiro, G.; Bradley, A.P. An Improved Joint Optimization of Multiple Level Set Functions for the Segmentation of Overlapping Cervical Cells. IEEE Trans. Image Process. 2015, 24, 1261–1272. [Google Scholar] [CrossRef]
- Chen, H.; Qi, X.; Yu, L.; Heng, P.A. DCAN: Deep Contour-Aware Networks for Accurate Gland Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2487–2496. [Google Scholar] [CrossRef]
- Naylor, P.; Laé, M.; Reyal, F.; Walter, T. Segmentation of Nuclei in Histopathology Images by Deep Regression of the Distance Map. IEEE Trans. Med. Imaging 2019, 38, 448–459. [Google Scholar] [CrossRef]
- Graham, S.; Vu, Q.D.; Raza, S.E.A.; Azam, A.; Tsang, Y.W.; Kwak, J.T.; Rajpoot, N. Hover-Net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Med. Image Anal. 2019, 58, 101563. [Google Scholar] [CrossRef]
- Zhao, T.; Fu, C.; Tian, Y.; Song, W.; Sham, C.W. GSN-HVNET: A Lightweight, Multi-Task Deep Learning Framework for Nuclei Segmentation and Classification. Bioengineering 2023, 10, 393. [Google Scholar] [CrossRef]
- Zhou, Y.; Onder, O.F.; Dou, Q.; Tsougenis, E.; Chen, H.; Heng, P.A. CIA-Net: Robust Nuclei Instance Segmentation with Contour-Aware Information Aggregation. In Information Processing in Medical Imaging, Proceedings of the 26th International Conference IPMI 2019, Hong Kong, China, 2–7 June 2019; Chung, A.C.S., Gee, J.C., Yushkevich, P.A., Bao, S., Eds.; Springer: Cham, Switzerland, 2019; pp. 682–693. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Zhang, P.; Chen, H.; Xia, Y.; Shen, C. Light-weight hybrid convolutional network for liver tumor segmentation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019; Volume 2019, pp. 4271–4277. [Google Scholar]
- Zhao, Y.; Fu, C.; Xu, S.; Cao, L.; Ma, H.F. LFANet: Lightweight feature attention network for abnormal cell segmentation in cervical cytology images. Comput. Biol. Med. 2022, 145, 105500. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef]
- Feng, R.; Liu, X.; Chen, J.; Chen, D.Z.; Gao, H.; Wu, J. A Deep Learning Approach for Colonoscopy Pathology WSI Analysis: Accurate Segmentation and Classification. IEEE J. Biomed. Health Inform. 2021, 25, 3700–3708. [Google Scholar] [CrossRef]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Pravitasari, A.A.; Iriawan, N.; Almuhayar, M.; Azmi, T.; Irhamah, I.; Fithriasari, K.; Purnami, S.W.; Ferriastuti, W. UNet-VGG16 with transfer learning for MRI-based brain tumor segmentation. TELKOMNIKA (Telecommun. Comput. Electron. Control.) 2020, 18, 1310–1318. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Wang, X.; Yao, L.; Wang, X.; Paik, H.Y.; Wang, S. Global Convolutional Neural Processes. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 699–708. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UNet | ResGhost | GCA | DS | DSC |
|---|---|---|---|---|
| √ | 0.5298 | |||
| √ | √ | 0.5621 | ||
| √ | √ | 0.5635 | ||
| √ | √ | √ | 0.5827 | |
| √ | √ | √ | 0.7231 | |
| √ | √ | √ | √ | 0.7852 |
| Method | DSC | Jaccard | Precision | Recall |
|---|---|---|---|---|
| UNet(Baseline) [19] | 0.5621 | 0.4007 | 0.5160 | 0.6434 |
| UNet(Backbone: Vgg11) [32] | 0.5771 | 0.4160 | 0.5530 | 0.6271 |
| UNet(Backbone: Vgg16) [33] | 0.5817 | 0.4191 | 0.5599 | 0.6304 |
| UNet(Backbone: Vgg19) [31] | 0.5850 | 0.4232 | 0.5930 | 0.6036 |
| UNet(Backbone: ResNet50) [34] | 0.5531 | 0.3943 | 0.6512 | 0.5316 |
| DeepLabV3(Backbone:Mobilenet) [35] | 0.4620 | 0.3098 | 0.3320 | 0.7804 |
| DeepLabV3(Backbone: Drn) [35] | 0.4564 | 0.3035 | 0.3361 | 0.7340 |
| DeepLabV3(Backbone: ResNet50) [35] | 0.5200 | 0.3576 | 0.4210 | 0.6916 |
| DeepLabV3(Backbone: Xception) [35] | 0.5227 | 0.3599 | 0.4020 | 0.7572 |
| GCN [36] | 0.4574 | 0.3026 | 0.3691 | 0.6270 |
| SegNet [12] | 0.4728 | 0.3198 | 0.4084 | 0.5867 |
| Proposed | 0.7852 | 0.6482 | 0.7800 | 0.7964 |
| Model | GFLOPS | Params (M) |
|---|---|---|
| UNet (Baseline) [19] | 16.70 | 14.50 |
| UNet (Backbone: Vgg11) [32] | 17.66 | 17.47 |
| UNet (Backbone: Vgg16) [33] | 22.79 | 22.96 |
| UNet (Backbone: Vgg19) [31] | 25.51 | 28.27 |
| UNet (Backbone: ResNet50) [34] | 55.87 | 59.04 |
| DeepLabV3 (Backbone: Mobilenet) [35] | 4.45 | 7.55 |
| DeepLabV3 (Backbone: Drn) [35] | 23.31 | 40.73 |
| DeepLabV3 (Backbone: ResNet50) [35] | 11.06 | 59.22 |
| DeepLabV3 (Backbone: Xception) [35] | 10.33 | 54.5 |
| GCN [36] | 7.64 | 58.25 |
| SegNet [12] | 20.06 | 29.44 |
| Proposed | 51.86 | 48.03 |
| Method | DSC | Jaccard | Precision | Recall |
|---|---|---|---|---|
| UNet(Baseline) [19] | 0.5132 | 0.3745 | 0.9285 | 0.3549 |
| UNet(Backbone: Vgg11) [32] | 0.7486 | 0.6195 | 0.9313 | 0.6268 |
| UNet(Backbone: Vgg16) [33] | 0.7324 | 0.6038 | 0.8375 | 0.6507 |
| UNet(Backbone: Vgg19) [31] | 0.7289 | 0.600 | 0.7928 | 0.6747 |
| UNet(Backbone: ResNet50) [34] | 0.6511 | 0.5065 | 0.9375 | 0.4985 |
| DeepLabV3(Backbone:Mobilenet) [35] | 0.6839 | 0.5410 | 0.9367 | 0.5388 |
| DeepLabV3(Backbone: Drn) [35] | 0.7367 | 0.6039 | 0.9375 | 0.6065 |
| DeepLabV3(Backbone: ResNet50) [35] | 0.6887 | 0.5503 | 0.9358 | 0.5203 |
| DeepLabV3(Backbone: Xception) [35] | 0.6867 | 0.5564 | 0.9342 | 0.5430 |
| GCN [36] | 0.5696 | 0.4220 | 0.7863 | 0.4464 |
| SegNet [12] | 0.5206 | 0.3799 | 0.9445 | 0.3592 |
| Proposed | 0.9571 | 0.9190 | 0.9548 | 0.9611 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, T.; Fu, C.; Song, W.; Sham, C.-W. RGGC-UNet: Accurate Deep Learning Framework for Signet Ring Cell Semantic Segmentation in Pathological Images. Bioengineering 2024, 11, 16. https://doi.org/10.3390/bioengineering11010016
Zhao T, Fu C, Song W, Sham C-W. RGGC-UNet: Accurate Deep Learning Framework for Signet Ring Cell Semantic Segmentation in Pathological Images. Bioengineering. 2024; 11(1):16. https://doi.org/10.3390/bioengineering11010016
Chicago/Turabian StyleZhao, Tengfei, Chong Fu, Wei Song, and Chiu-Wing Sham. 2024. "RGGC-UNet: Accurate Deep Learning Framework for Signet Ring Cell Semantic Segmentation in Pathological Images" Bioengineering 11, no. 1: 16. https://doi.org/10.3390/bioengineering11010016
APA StyleZhao, T., Fu, C., Song, W., & Sham, C.-W. (2024). RGGC-UNet: Accurate Deep Learning Framework for Signet Ring Cell Semantic Segmentation in Pathological Images. Bioengineering, 11(1), 16. https://doi.org/10.3390/bioengineering11010016