
A Cross-Domain Weakly Supervised Diabetic Retinopathy Lesion Identification Method Based on Multiple Instance Learning and Domain Adaptation



Abstract
:1. Introduction
- We are the first to define DR lesion identification as a multi-label classification task, and propose a novel lesion-patch multiple instance learning method (LpMIL) to achieve it.
- We propose a semantic constraint adaptation method (LpSCA) to improve cross-domain DR lesion identification performance.
- We construct the largest fine-grained annotation dataset EyePACS-pixel, which can provide a data basis for DR lesion identification.
- Extensive experiments conducted on the public datasets FGADR and EyePACS-pixel show that, with only coarse-grained annotations, the proposed method can achieve competitive results compared with the existing dominant detection, segmentation, and weakly supervised object localization methods.
2. Related Work
2.1. Diabetic Retinopathy Lesion Identification
2.2. Multiple Instance Learning
2.3. Domain Adaptation
3. Materials and Methods
3.1. Datasets
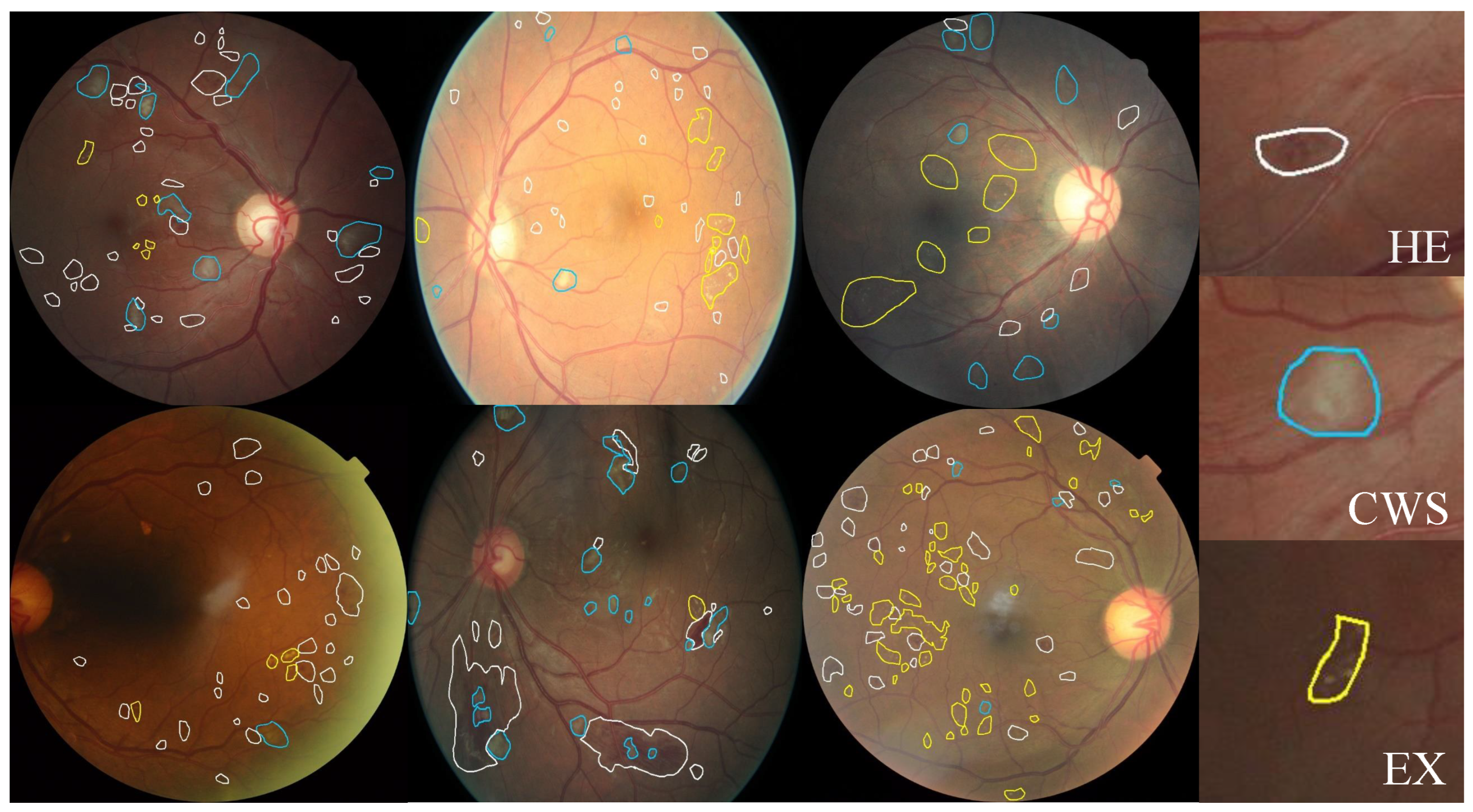
3.1.1. Our EyePACS-Pixel Dataset
3.1.2. FGADR Dataset
3.1.3. EyePACS Dataset
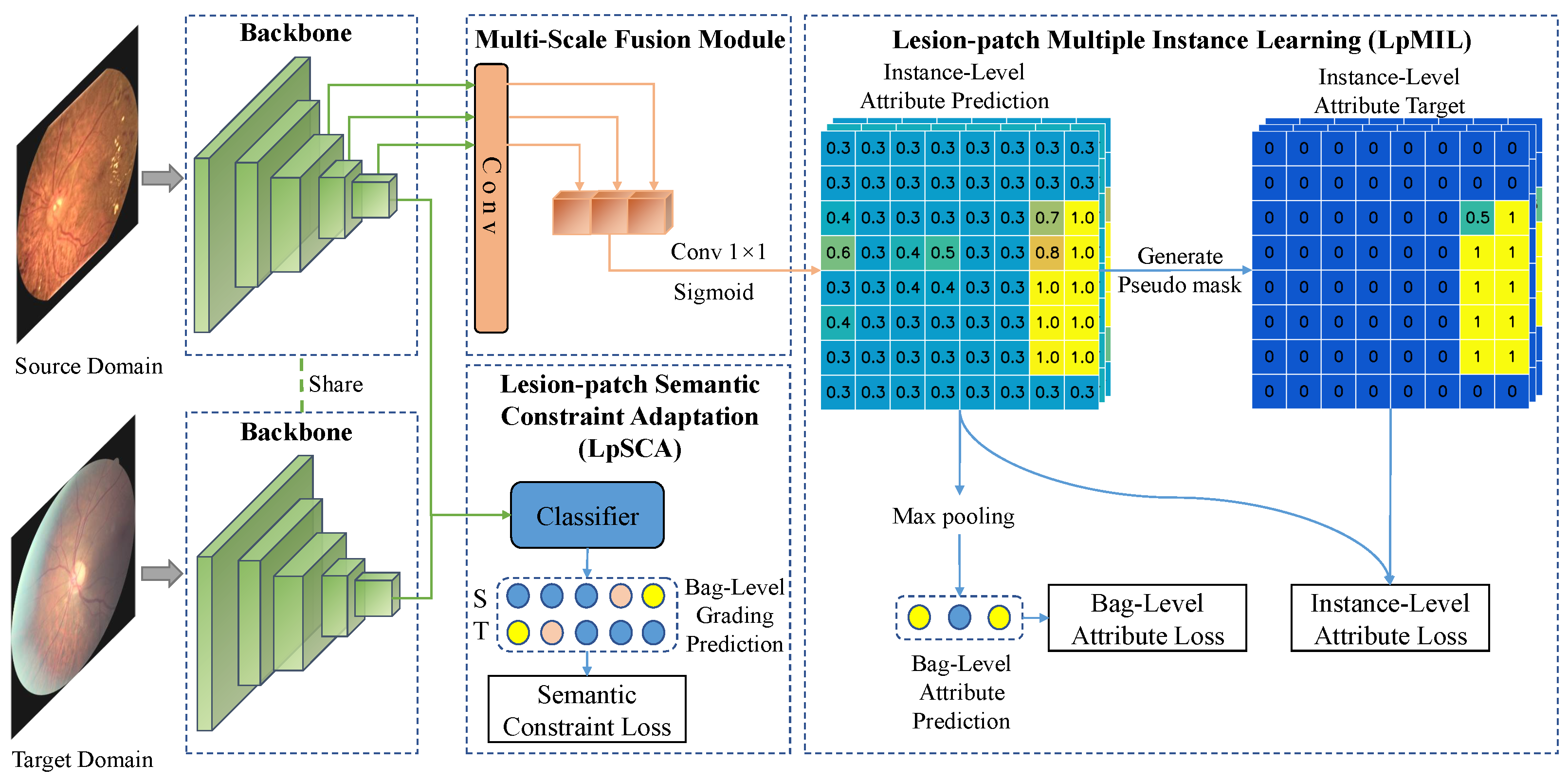
3.2. Methods Overview
3.3. Lesion-Patch Multiple Instance Learning for Lesion Identification
3.3.1. Multi-Scale Fusion Module
3.3.2. Lesion-Patch Multiple Instance Learning
3.4. Lesion-Patch Semantic Constraint Adaptation for Domain Adaptation
4. Results
4.1. Evaluation Metrics
4.2. Implementation Details
4.3. Ablation Studies
4.3.1. The Choice of L in the Multi-Scale Fusion Module
4.3.2. The Choice of the Threshold in LpMIL
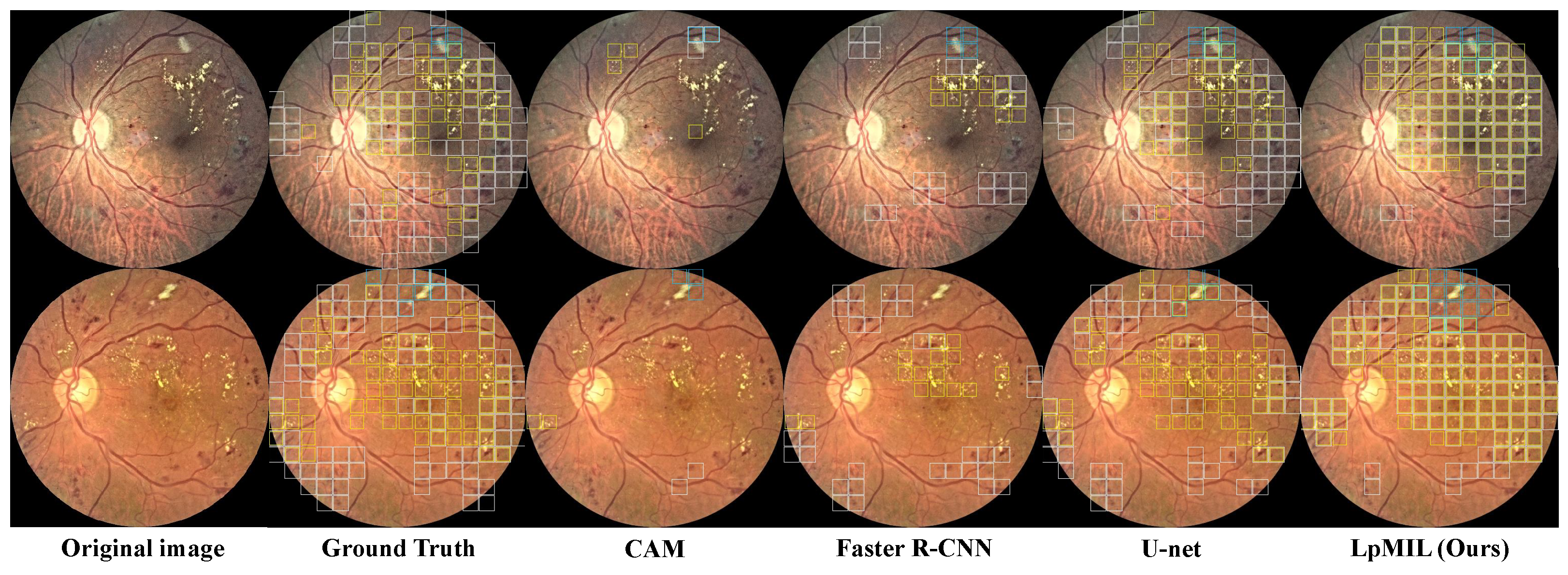
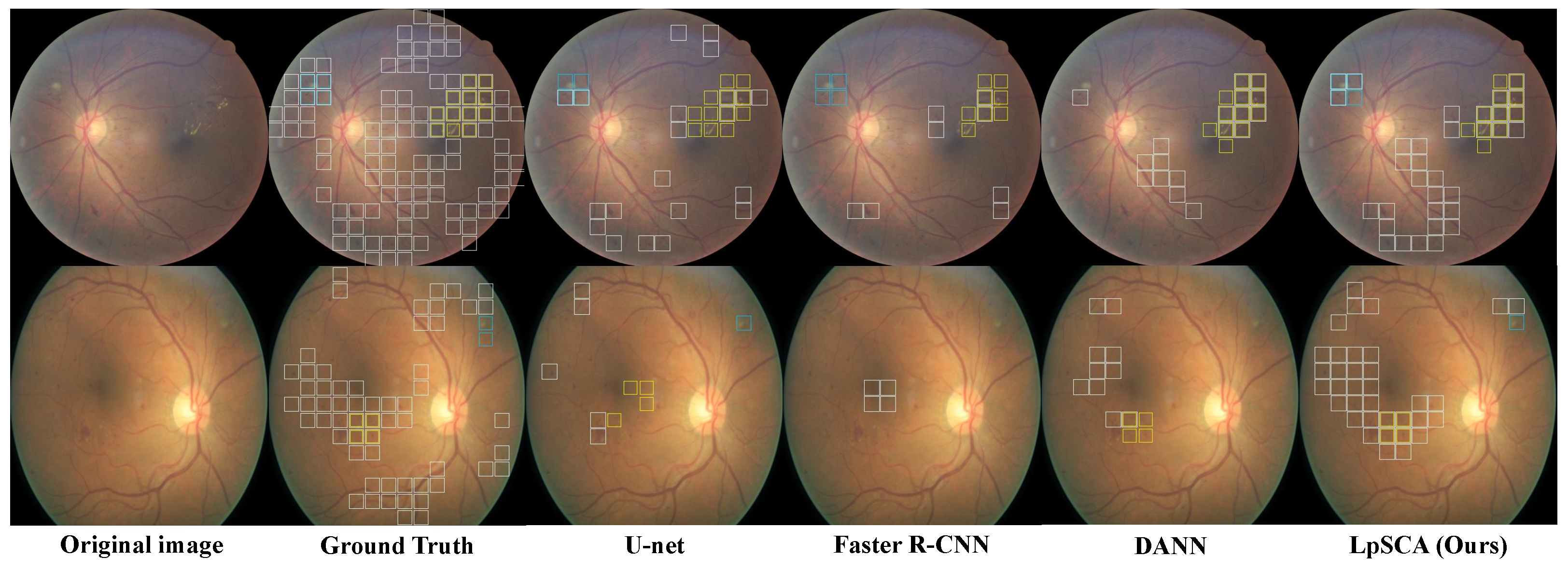
4.4. Comparisons with State-of-the-Art Methods
4.4.1. Lesion Identification Performance
4.4.2. Cross-Domain Lesion Identification Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS 2015), Montreal, QC, Canada, 7–10 December 2015; Volume 28. [Google Scholar]
- Zhou, Y.; Wang, B.; Huang, L.; Cui, S.; Shao, L. A benchmark for studying diabetic retinopathy: Segmentation, grading, and transferability. IEEE Trans. Med. Imaging 2020, 40, 818–828. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Y.; He, X.; Huang, L.; Liu, L.; Zhu, F.; Cui, S.; Shao, L. Collaborative learning of semi-supervised segmentation and classification for medical images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2079–2088. [Google Scholar]
- Wang, Z.; Yin, Y.; Shi, J.; Fang, W.; Li, H.; Wang, X. Zoom-in-net: Deep mining lesions for diabetic retinopathy detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; pp. 267–275. [Google Scholar]
- Sun, R.; Li, Y.; Zhang, T.; Mao, Z.; Wu, F.; Zhang, Y. Lesion-aware transformers for diabetic retinopathy grading. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10938–10947. [Google Scholar]
- Wang, X.; Gu, Y.; Pan, J.; Jia, L. Diabetic Retinopathy Detection Based on Weakly Supervised Object Localization and Knowledge Driven Attribute Mining. In Proceedings of the International Workshop on Ophthalmic Medical Image Analysis, Strasbourg, France, 27 September 2021; pp. 32–41. [Google Scholar]
- Yang, Y.; Li, T.; Li, W.; Wu, H.; Fan, W.; Zhang, W. Lesion detection and grading of diabetic retinopathy via two-stages deep convolutional neural networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; pp. 533–540. [Google Scholar]
- Lin, Z.; Guo, R.; Wang, Y.; Wu, B.; Chen, T.; Wang, W.; Chen, D.Z.; Wu, J. A framework for identifying diabetic retinopathy based on anti-noise detection and attention-based fusion. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 74–82. [Google Scholar]
- Foo, A.; Hsu, W.; Lee, M.L.; Lim, G.; Wong, T.Y. Multi-task learning for diabetic retinopathy grading and lesion segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13267–13272. [Google Scholar]
- Sudharshan, P.; Petitjean, C.; Spanhol, F.; Oliveira, L.E.; Heutte, L.; Honeine, P. Multiple instance learning for histopathological breast cancer image classification. Expert Syst. Appl. 2019, 117, 103–111. [Google Scholar] [CrossRef]
- Lerousseau, M.; Vakalopoulou, M.; Classe, M.; Adam, J.; Battistella, E.; Carré, A.; Estienne, T.; Henry, T.; Deutsch, E.; Paragios, N. Weakly supervised multiple instance learning histopathological tumor segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; pp. 470–479. [Google Scholar]
- Chikontwe, P.; Kim, M.; Nam, S.J.; Go, H.; Park, S.H. Multiple instance learning with center embeddings for histopathology classification. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; pp. 519–528. [Google Scholar]
- Li, H.; Yang, F.; Zhao, Y.; Xing, X.; Zhang, J.; Gao, M.; Huang, J.; Wang, L.; Yao, J. DT-MIL: Deformable transformer for multi-instance learning on histopathological image. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; pp. 206–216. [Google Scholar]
- Zhang, H.; Meng, Y.; Zhao, Y.; Qiao, Y.; Yang, X.; Coupland, S.E.; Zheng, Y. DTFD-MIL: Double-tier feature distillation multiple instance learning for histopathology whole slide image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18802–18812. [Google Scholar]
- Qian, Z.; Li, K.; Lai, M.; Chang, E.I.C.; Wei, B.; Fan, Y.; Xu, Y. Transformer based multiple instance learning for weakly supervised histopathology image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 160–170. [Google Scholar]
- Li, B.; Li, Y.; Eliceiri, K.W. Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14318–14328. [Google Scholar]
- Zhou, Y.; Sun, X.; Liu, D.; Zha, Z.; Zeng, W. Adaptive pooling in multi-instance learning for web video annotation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 318–327. [Google Scholar]
- Wang, Y.; Li, J.; Metze, F. A comparison of five multiple instance learning pooling functions for sound event detection with weak labeling. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 31–35. [Google Scholar]
- Ilse, M.; Tomczak, J.; Welling, M. Attention-based deep multiple instance learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2127–2136. [Google Scholar]
- Morfi, V.; Stowell, D. Data-efficient weakly supervised learning for low-resource audio event detection using deep learning. arXiv 2018, arXiv:1807.06972. [Google Scholar]
- Seibold, C.; Kleesiek, J.; Schlemmer, H.P.; Stiefelhagen, R. Self-Guided Multiple Instance Learning for Weakly Supervised Thoracic DiseaseClassification and Localizationin Chest Radiographs. In Proceedings of the ACCV, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Cui, S.; Wang, S.; Zhuo, J.; Su, C.; Huang, Q.; Tian, Q. Gradually vanishing bridge for adversarial domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12455–12464. [Google Scholar]
- Wei, G.; Lan, C.; Zeng, W.; Chen, Z. Metaalign: Coordinating domain alignment and classification for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16643–16653. [Google Scholar]
- Porwal, P.; Pachade, S.; Kamble, R.; Kokare, M.; Deshmukh, G.; Sahasrabuddhe, V.; Meriaudeau, F. Indian diabetic retinopathy image dataset (IDRiD): A database for diabetic retinopathy screening research. Data 2018, 3, 25. [Google Scholar] [CrossRef]
- Kaggle. Kaggle Diabetic Retinopathy Detection Competition. 2015. Available online: https://www.kaggle.com/c/diabetic-retinopathy-detection (accessed on 1 April 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Choe, J.; Lee, S.; Shim, H. Attention-based dropout layer for weakly supervised single object localization and semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4256–4271. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Annotation | Images | MA | HE | CWS | EX | IRMA | NV |
|---|---|---|---|---|---|---|---|---|
| IDRiD [27] | Pixel-level | 81 | 81 | 80 | 40 | 81 | - | - |
| FGADR [2] | Pixel-level | 1842 | 1424 | 1456 | 627 | 1279 | 159 | 49 |
| EyePACS-pixel | Pixel-level | 4401 | - | 4160 | 1550 | 2750 | - | - |
| L | HE | CWS | EX | Mean |
|---|---|---|---|---|
| 1 | 0.3363 | 0.2174 | 0.4529 | 0.3355 |
| 2 | 0.4086 | 0.2295 | 0.5011 | 0.3797 |
| 3 | 0.4113 | 0.2635 | 0.5140 | 0.3963 |
| 4 | 0.4261 | 0.1891 | 0.4939 | 0.3697 |
| HE | CWS | EX | Mean | |
|---|---|---|---|---|
| 0.1 | 0.4092 | 0.1956 | 0.4609 | 0.3553 |
| 0.2 | 0.4282 | 0.2373 | 0.4664 | 0.3773 |
| 0.3 | 0.4272 | 0.2400 | 0.4824 | 0.3832 |
| 0.4 | 0.4113 | 0.2635 | 0.5140 | 0.3963 |
| HE | CWS | EX | Mean | |
|---|---|---|---|---|
| Faster R-CNN * | 0.4029 | 0.4329 | 0.3002 | 0.3787 |
| U-net * | 0.5332 | 0.3101 | 0.5969 | 0.4801 |
| CAM | 0.2123 | 0.1813 | 0.3373 | 0.2437 |
| ADL | 0.2192 | 0.1432 | 0.3198 | 0.2274 |
| LpMIL (Ours) | 0.4113 | 0.2635 | 0.5140 | 0.3963 |
| HE | CWS | EX | Mean | |
|---|---|---|---|---|
| Faster R-CNN * | 0.0961 | 0.2064 | 0.0818 | 0.1281 |
| U-net * | 0.1659 | 0.2301 | 0.3502 | 0.2487 |
| CAM | 0.1851 | 0.2091 | 0.3836 | 0.2593 |
| ADL | 0.2126 | 0.1673 | 0.3484 | 0.2428 |
| LpMIL (Ours) | 0.2125 | 0.2632 | 0.5239 | 0.3332 |
| DANN | 0.2690 | 0.2783 | 0.5510 | 0.3661 |
| LpSCA (Ours) | 0.3985 | 0.3369 | 0.5769 | 0.4374 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, R.; Gu, Y.; Wang, X.; Pan, J. A Cross-Domain Weakly Supervised Diabetic Retinopathy Lesion Identification Method Based on Multiple Instance Learning and Domain Adaptation. Bioengineering 2023, 10, 1100. https://doi.org/10.3390/bioengineering10091100
Li R, Gu Y, Wang X, Pan J. A Cross-Domain Weakly Supervised Diabetic Retinopathy Lesion Identification Method Based on Multiple Instance Learning and Domain Adaptation. Bioengineering. 2023; 10(9):1100. https://doi.org/10.3390/bioengineering10091100
Chicago/Turabian StyleLi, Renyu, Yunchao Gu, Xinliang Wang, and Junjun Pan. 2023. "A Cross-Domain Weakly Supervised Diabetic Retinopathy Lesion Identification Method Based on Multiple Instance Learning and Domain Adaptation" Bioengineering 10, no. 9: 1100. https://doi.org/10.3390/bioengineering10091100
APA StyleLi, R., Gu, Y., Wang, X., & Pan, J. (2023). A Cross-Domain Weakly Supervised Diabetic Retinopathy Lesion Identification Method Based on Multiple Instance Learning and Domain Adaptation. Bioengineering, 10(9), 1100. https://doi.org/10.3390/bioengineering10091100