1. Introduction
Every year, over 36 million people die due to chronic diseases, which account for more than 60% of all deaths [
1]. These chronic diseases, including coronary artery disease, hypertension, and diabetes mellitus, frequently lead to vascular retinopathy. It is estimated that 233 million diabetic patients will suffer from retinopathy by the year 2040 [
2]. At present, the detection method necessitates the manual inspection of fundus images to identify the presence of the disease. However, this detection approach is considerably time-consuming and requires a significant number of healthcare professionals, resulting in delayed medical treatment for many patients. Despite doctors recommending regular retinal check-ups for diabetic patients, several cases remain undetected until the disease has advanced [
3]. Therefore, an automated system is essential for detecting retinopathy.
The continuous development of artificial intelligence technologies, such as machine learning [
4,
5,
6,
7,
8] and deep learning [
9,
10,
11], has made the high-performance detection of retinopathy possible. Traditional machine learning methods have been widely applied in this field. For example, Latha et al. [
4] introduced an efficient Splat feature classification method for detecting retinopathy features, including hemorrhages. This method improved data usability by performing operations like denoising, morphological processing, and dynamic thresholding on fundus image data. Subsequently, supervised learning methods were employed to implement retinopathy detection, and feature extraction was directly used to process retinal hemorrhages. The results demonstrated the improved recall (REC) and specificity (SPE) of the model, with an area under the curve (AUC) of 96.00%, surpassing the previous model’s implementation of 87.00%. Furthermore, Marin et al. [
5] screened for retinopathy, like diabetic macular edema and hard exudates, and obtained a set of candidate regions. They compared these regions with the results of support vector machine (SVM), multilayer perceptron, and K-nearest neighbor algorithms to validate them. Superior REC and SPE were achieved on a private dataset, and the classification results were very similar to those of ophthalmologists. Anton et al. [
6] combined SVM and differential evolution algorithms for retinopathy detection and extracted highly relevant characteristics of retinal features, such as microaneurysms, hemorrhages, and neovascularization using an optimization algorithm. The algorithm achieved superior diagnostic accuracy (ACC) on the dataset, reaching 95.23%, and demonstrating its effectiveness in retinopathy detection. In addition, Haloi et al. [
7] proposed a new algorithm for detecting microaneurysms in fundus images utilizing a local feature extraction algorithm. After preprocessing the fundus image data, the algorithm classified each pixel in the image as a microaneurysm or non-microaneurysm. The extracted features were then trained and tested using a model. The experiment demonstrated the superior classification performance of this method on a public dataset, with a REC of 96.54%. Finally, Kandhasamy et al. [
8] used an SVM with selectively extracted features combined with genetic algorithms to perform clustering using mathematical morphology operations. The results were then passed to a multilevel set segmentation algorithm to statistically analyze the texture features of fundus images. The extracted features were finally classified using an SVM. Experimental validation showed excellent classification results for this algorithm.
Deep learning has emerged as the primary approach for detecting retinopathy, complementing conventional machine learning techniques. For example, Krishnan et al. [
9] proposed a method that used convolutional neural networks (CNNs) and transfer learning to detect such lesions. They evaluated the performance of classic network models such as ResNet and InceptionResNetV2 by measuring the quadratic weighted Kappa values of different CNN architectures. Subsequently, they selectively fused the features of the best-performing models. The algorithm was validated on publicly available datasets, achieving a quadratic weighted Kappa value of 0.76, and thereby confirming the effectiveness of their proposed retinal detection algorithm. Similarly, Andronic et al. [
10] constructed a CNN for diagnosing retinopathy and compared it with various classic neural network architectures such as ConvNets, GoogleNet, InceptionV4, and ResNeXT. Their proposed algorithm was also validated on public datasets, achieving a quadratic weighted Kappa value of 0.786, thus demonstrating superior classification performance. Moreover, Jiang et al. [
11] preprocessed fundus images, then used transfer learning and a composite scaling model to detect retinopathy. They resolved the vanishing gradient problem caused by excessively deep models by introducing residual modules, allowing the model to focus more on regions with richer information features. Experimental results on public datasets verified that their proposed algorithm outperformed many advanced models currently in use.
Despite achieving superior classification performance, many retinopathy detection algorithms still fall short of meeting clinical practice requirements regarding diagnostic ACC and precision (PRE). Traditional image feature extraction algorithms can extract targeted lesion features but require professional medical knowledge [
4,
5,
6,
7,
8]. Conversely, traditional direct image feature extraction algorithms have a stronger generalization ability but cannot accurately detect the specific scope of lesions, resulting in insufficient diagnostic ACC [
4,
5,
6,
7,
8]. Artificial intelligence diagnostic algorithms based on neural networks require a large number of labeled sample data and massive computing resources [
9,
10,
11]. A scarcity of samples and inadequate device computing power greatly affect the classification performance of a model. Moreover, overly complex network models and large input images increase the parameter quantity and computational cost, prolonging the model training time, thereby negatively impacting the diagnostic efficiency of retinopathy detection models [
9,
10,
11].
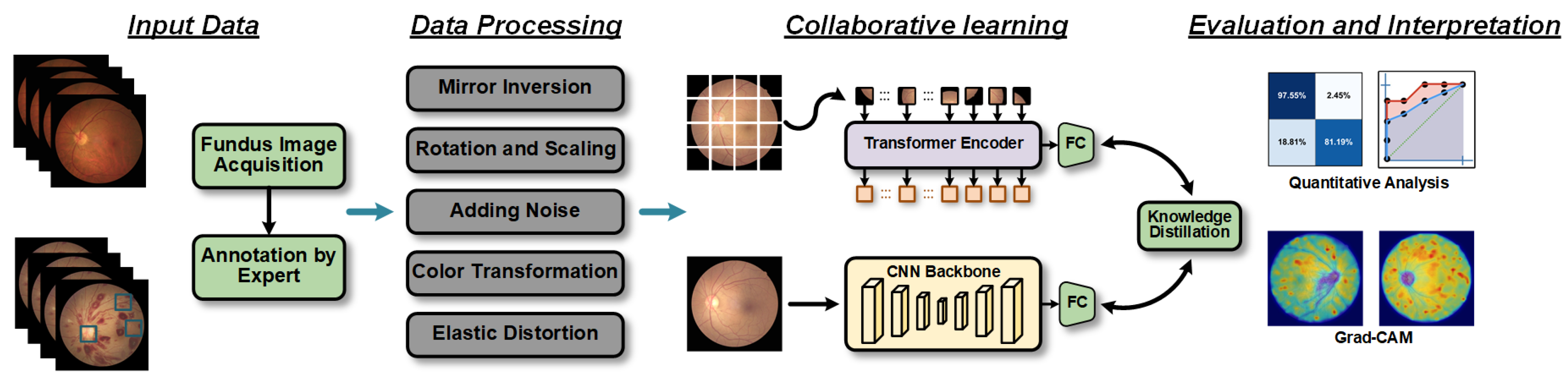
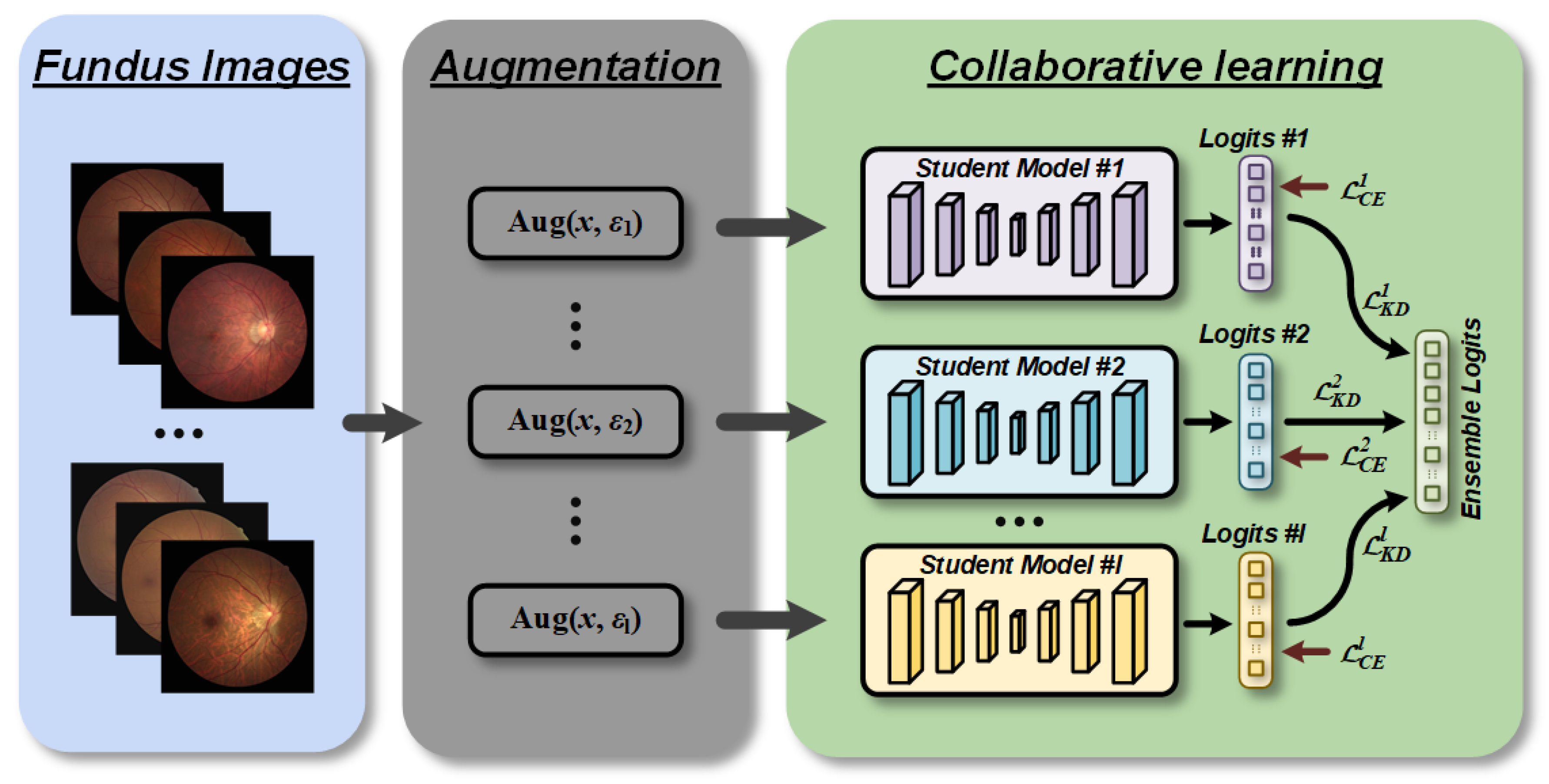
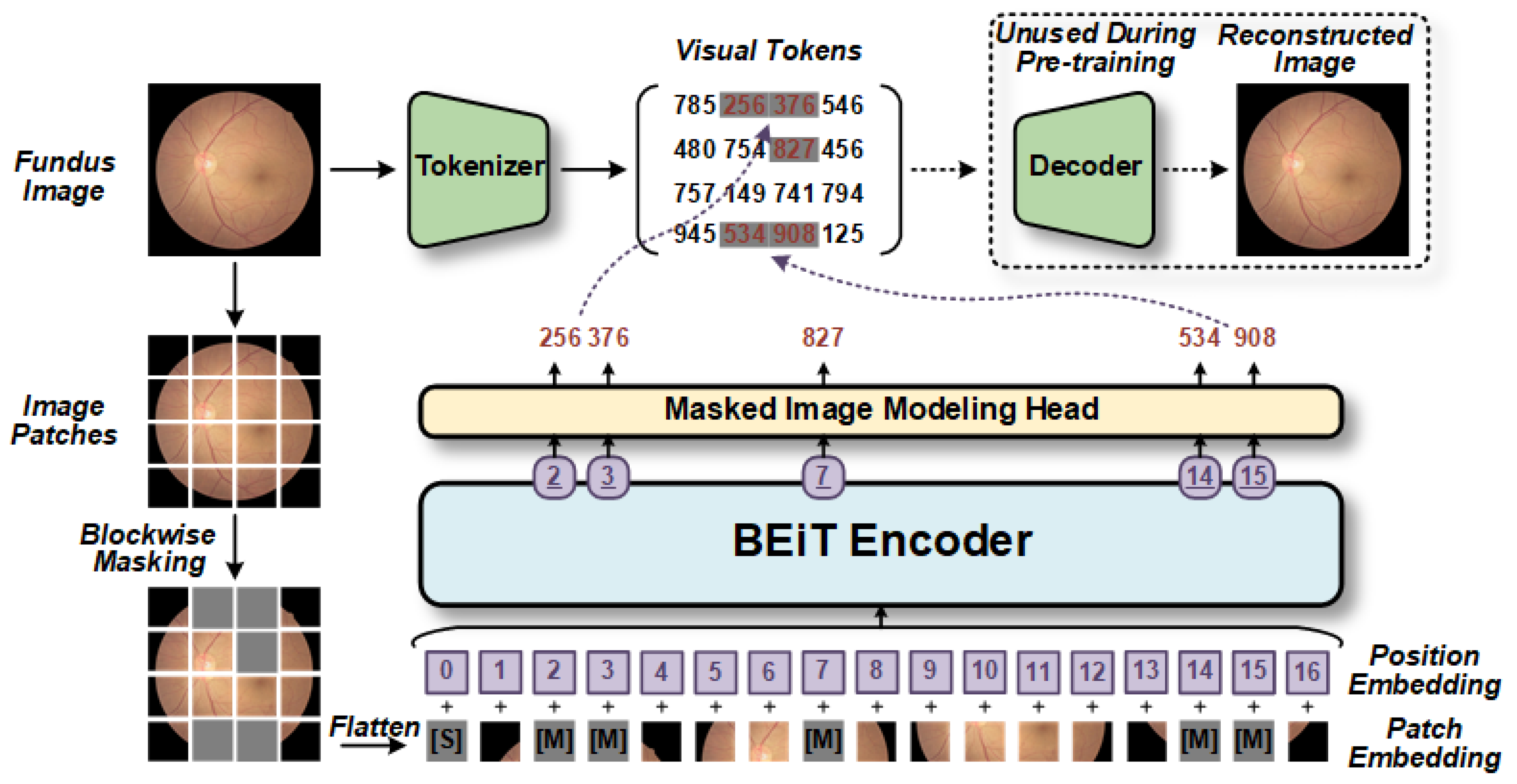
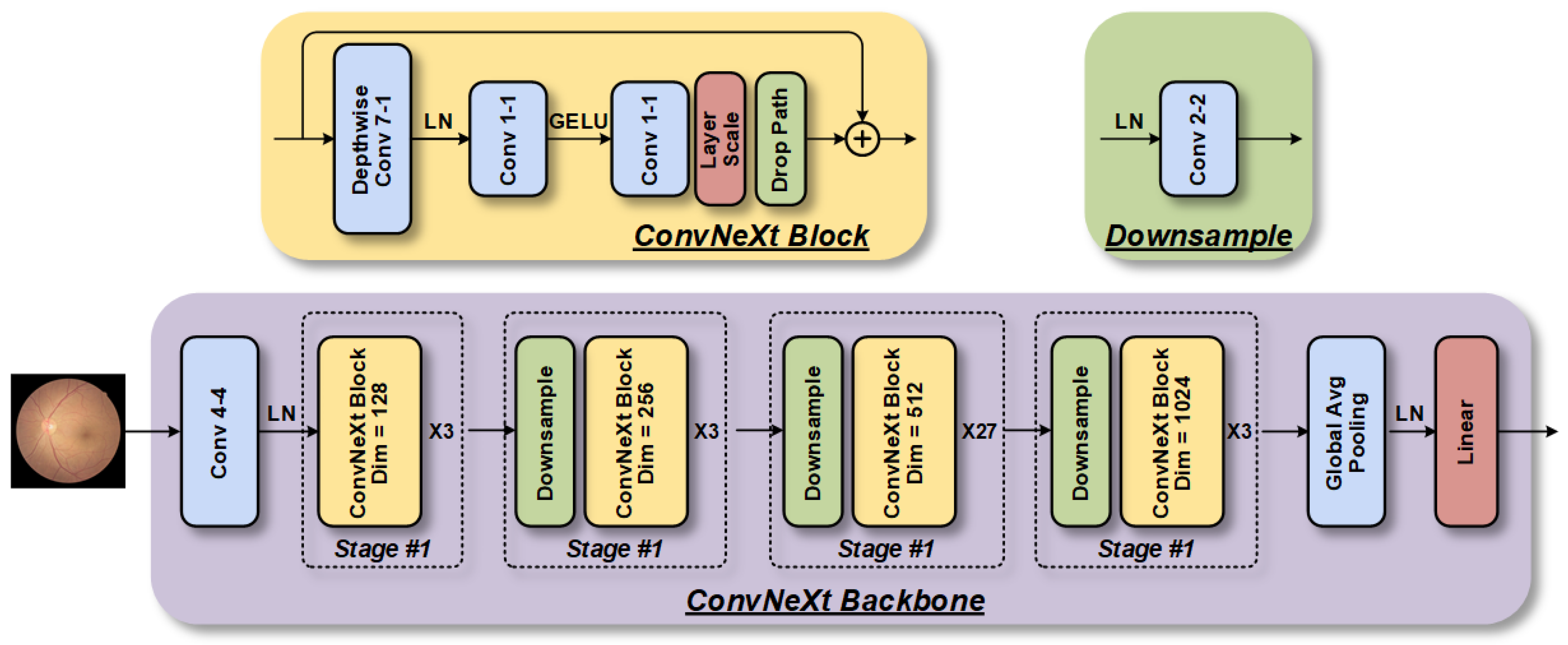
Thus, we first introduce CLRD, a collaborative learning-based online knowledge distillation framework. The objective of this framework is to enhance the utilization of fundus images and improve the accuracy of the model diagnosis while reducing the model’s running time, thereby optimizing the overall diagnostic performance. Collaborative learning strategies are employed to integrate student models of various scales and architectures, enabling the extraction of valuable pathological information from fundus images. Knowledge is transferred through the design of distortion information that is tailored to fundus images, enhancing the model’s invariance. In this study, Transformer-based BEiT [
12] and CNN-based ConvNeXt [
13] are selected as student models. The research results demonstrate that the CLRD framework can significantly reduce generalization errors while maintaining independent predictions of student models, offering new avenues for future research in retinopathy detection.
3. Experimental Setup
3.1. Data Description
This study was conducted in adherence to the Helsinki Declaration and approved protocol (NO. 2022101) by the ethics committee, which included a waiver of informed consent as it poses minimal risk to patients’ health and rights. The Macula-centered fundus images were captured from the ophthalmology department of Xuanwu Hospital between 1 August 2017 and 1 March 2022. The raw dataset was comprised of 1521 images obtained from 1137 patients who visited the department for examinations. Typically, patients undergoing these examinations required retinal color fundus photographs that were obtained through pharmacological pupil dilation, with multiple images taken per eye. However, since the goal of this project was to screen preoperative fundus images and diagnose potential lesions, all postoperative fundus images were excluded. Detailed statistical information regarding the dataset can be found in
Table 2.
3.2. Data Preprocessing
The intricacy of the retinal structure can often lead to confusion between retinopathy and other ocular diseases. Moreover, during our study, we encountered a multitude of imaging noises such as black spaces on both sides of the eye, low contrast, lens blurring, or insufficient lighting. As a result, the model failed to precisely identify minor fundus damage in the poorer quality photographs. Therefore, it was necessary to preprocess the images before conducting the study.
Initially, we designed an algorithm that effectively removed invalid black regions by cropping a fixed number of pixels from all four sides of each image, while avoiding any significant computational overhead caused by the black space. Subsequently, we normalized the resolutions of the original images, which varied from 2592 × 1728 to 3000 × 3000, to a uniform size, complying with the input requirements of the specific model. We also converted all images to grayscale to measure the light intensity of individual pixels in a single image. For images with an excessively bright or dark foreground and background, we employed histogram equalization to enhance visualization and discover hidden information. To improve the local contrast and enhance edge sharpness in the image regions, we used the adaptive histogram equalization method [
18]. Additionally, for enhancing the contrast effect in each region of the image in dark images, we provided a contrast stretching algorithm, which is defined as follows:
where
xi(
p,
q) is the gray value of a certain pixel in the original fundus image, and min
xi and max
xi are the actual minimum and maximum gray values in the original fundus image, respectively.
3.3. Training and Validation
The CLRD was trained using a five-fold cross-validation paradigm, ensuring a robust assessment. The dataset was partitioned into five subsets, with four subsets (n = 1216) used for training and one subset (n = 305) for validation, allowing for a representative estimation of model performance while mitigating data variability. By maximizing the utilization of available data, reliable estimates of the model’s performance on unseen data were obtained. To maintain independence in the predictions and ensure a reliable performance assessment, we carefully assigned both eyes from the same patient to either the training set or the outcome set during dataset splitting. A similar five-fold cross-validation approach was employed to evaluate the generalization capability of our proposed method on the external test set, EyePACS. All models underwent 200 epochs of training with an initial learning rate at 1 × 10−3 and decreased by 0.1 at the 100th and 150th epochs. The weight decay was set to 5 × 10−4, batch size to 32, and momentum to 0.9. The temperature value for T was 2.
3.4. Evaluation Criteria
We used various quantitative metrics to assess the performance of the model in retinopathy detection. The ACC metric represented the proportion of samples that were correctly classified as either retinopathy or normal, while PRE was the proportion of true-positive samples among those detected as retinopathy. For early screening systems, REC and SPE served as crucial indicators to determine referral and directly indicated the effectiveness of retinopathy detection. REC measured the proportion of all retinopathy samples that were correctly predicted, while SPE represented the proportion of all normal samples that were correctly identified. To further evaluate the balance of the model between REC and SPE, we utilized the receiver operating characteristic (ROC) curve and its AUC to visualize model performance. The F1 score, which is the averaged sum of PRE and REC, indicated good retinopathy detection ACC when its value was close to 1. Additionally, to demonstrate the interpretability of the models, we employed the gradient-weighted class-activation-mapping (Grad-CAM) [
19] method to visualize attention regions.
To evaluate model computational efficiency, we used the Params and FLOPs’ metrics. The Params metric represented the number of parameters in the model, which included the total number of weights and biases that need to be learned in the model. This metric is typically used to evaluate the size and storage requirements of the model. On the other hand, FLOPs referred to the floating-point operations per second, representing the computational complexity and speed of the model.
4. Results
4.1. Quantitative Analysis
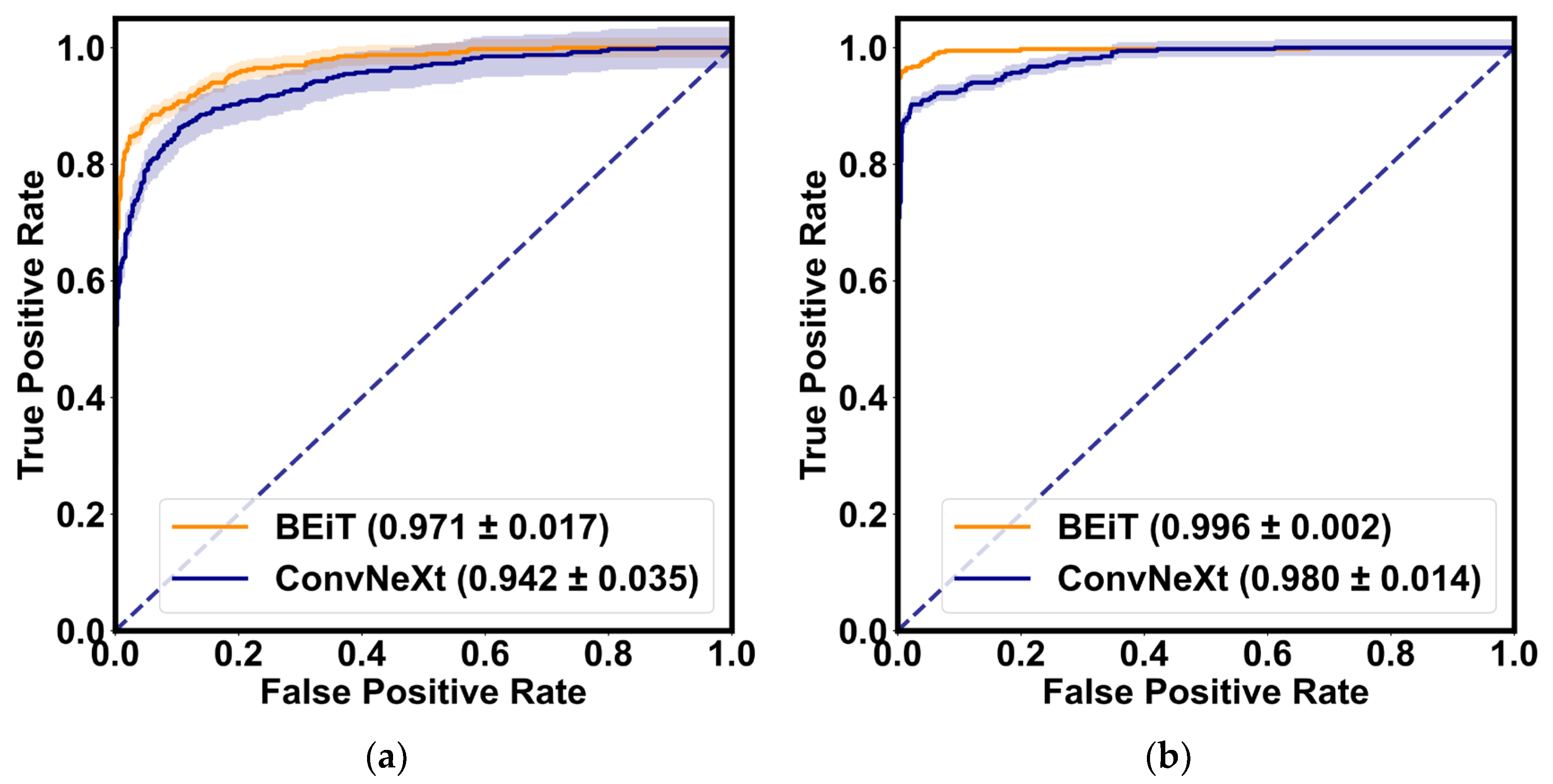
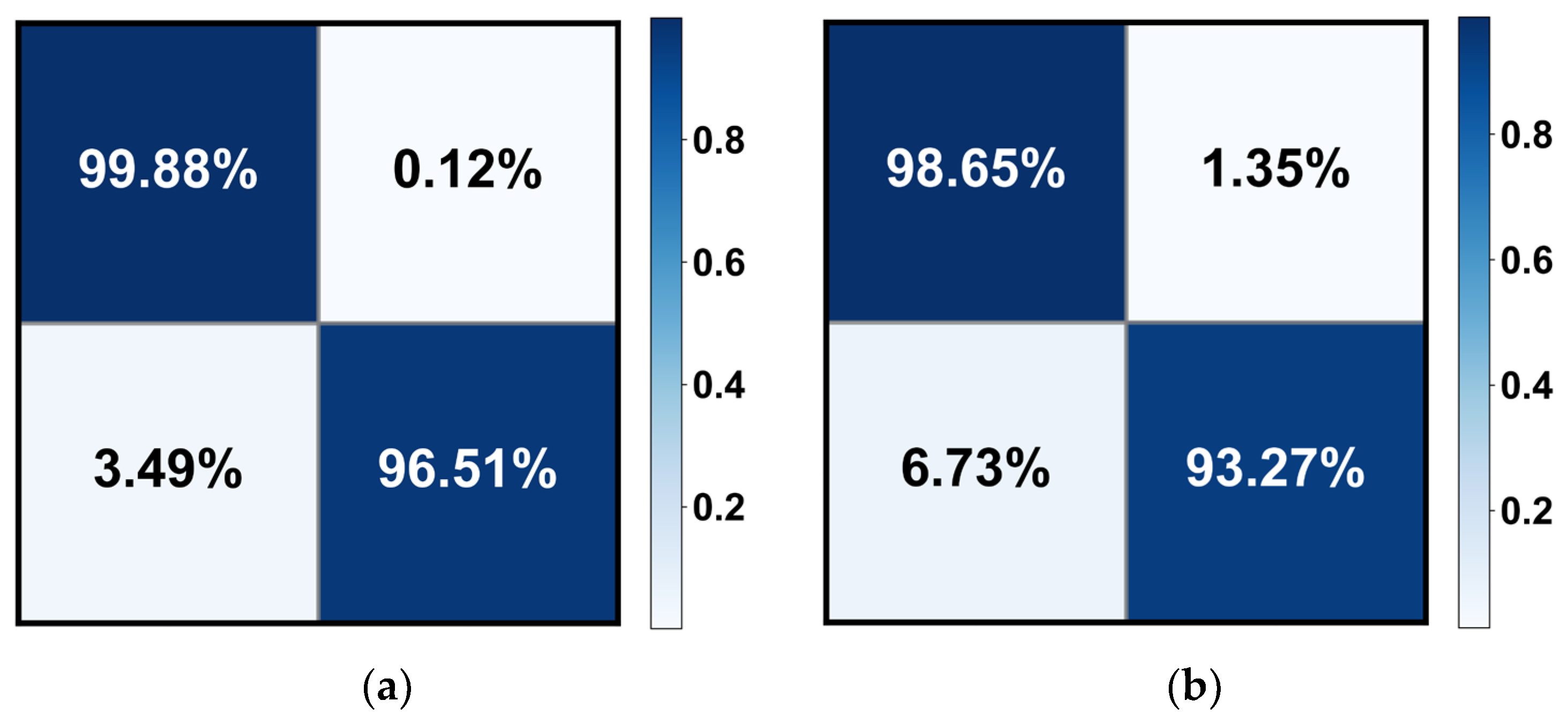
Table 3 demonstrates the quantitative evaluation results of the five-fold cross-validation of the CLRD student models, and
Figure 6 and
Figure 7 correspond to its ROC curve and confusion matrix. The experimental results show that the proposed CLRD has a high ACC in retinopathy detection. From the results, it can be seen that the average ACC, PRE, REC, SPE, and F1 scores of the student model based on the ConvNeXt architecture are 96.88%, 96.88%, 96.87%, 95.04%, and 96.86%, respectively. The model uses simple operations such as convolutional and pooling layers to extract features and is therefore more suitable for processing information with local relevance in fundus images. In contrast, BEiT introduces complex structures such as a self-attention mechanism and multiheaded attention mechanism, which can better handle data with global relationships. Therefore, the average ACC, PRE, REC, SPE, and F1 scores of the student model based on the BEiT architecture improved by 1.95%, 1.96%, 1.96%, 2.71%, and 1.96%, respectively. In addition, we found that the ROC curves of the BEiT model have lower standard deviations in the five-fold cross-validation, indicating that the self-supervised model based on the Transformer architecture has a more robust inference capability. Meanwhile, the confusion matrix confirms that the proposed CLRD framework can suppress the estimation bias caused by the imbalance of fundus images, thus improving the performance of the model.
4.2. Comparison with Different Architectures
We conducted a quantitative comparison of the feature extractor settings of different architectures in the student model of CLRD for retinopathy detection, with the aim of identifying the optimal architectural settings. In particular, we designed experiments using two types of CLRD for collaborative learning: CLRD-1, which replaces BEiT with Vanilla ViT; and CLRD-2, which replaces ConvNeXt with ResNetV2.
Table 4 presents the experimental results, which show that although the large pretrained ResNetV2 architecture has the lowest Params and FLOPs, it is not as effective in collaborative learning as the ConvNeXt architecture.
In detail, we observed that in CLRD-1, the average ACC, PRE, REC, SPE, and F1 scores of BEiT decrease by 1.34%, 1.26%, 2.67%, 2.87%, and 1.36%, respectively. Similarly, in CLRD-2, Vanilla ViT’s Params and FLOPs are 1.69% lower than the recommended CLRD-3 regarding the F1 score, despite being 26.19% and 32.91% higher than BEiT, respectively. Moreover, we found that the average ACC, PRE, REC, SPE, and F1 scores of ConvNeXt for collaborative learning decrease by 1.28%, 1.05%, 3.46%, 3.84%, and 1.34%, respectively. Based on these findings, we can conclude that feature extractors should be chosen carefully in the CLRD framework, and that a retinopathy detection performance can be improved by pairing student models with different architectures and complexities.
4.3. Interpretability Analysis
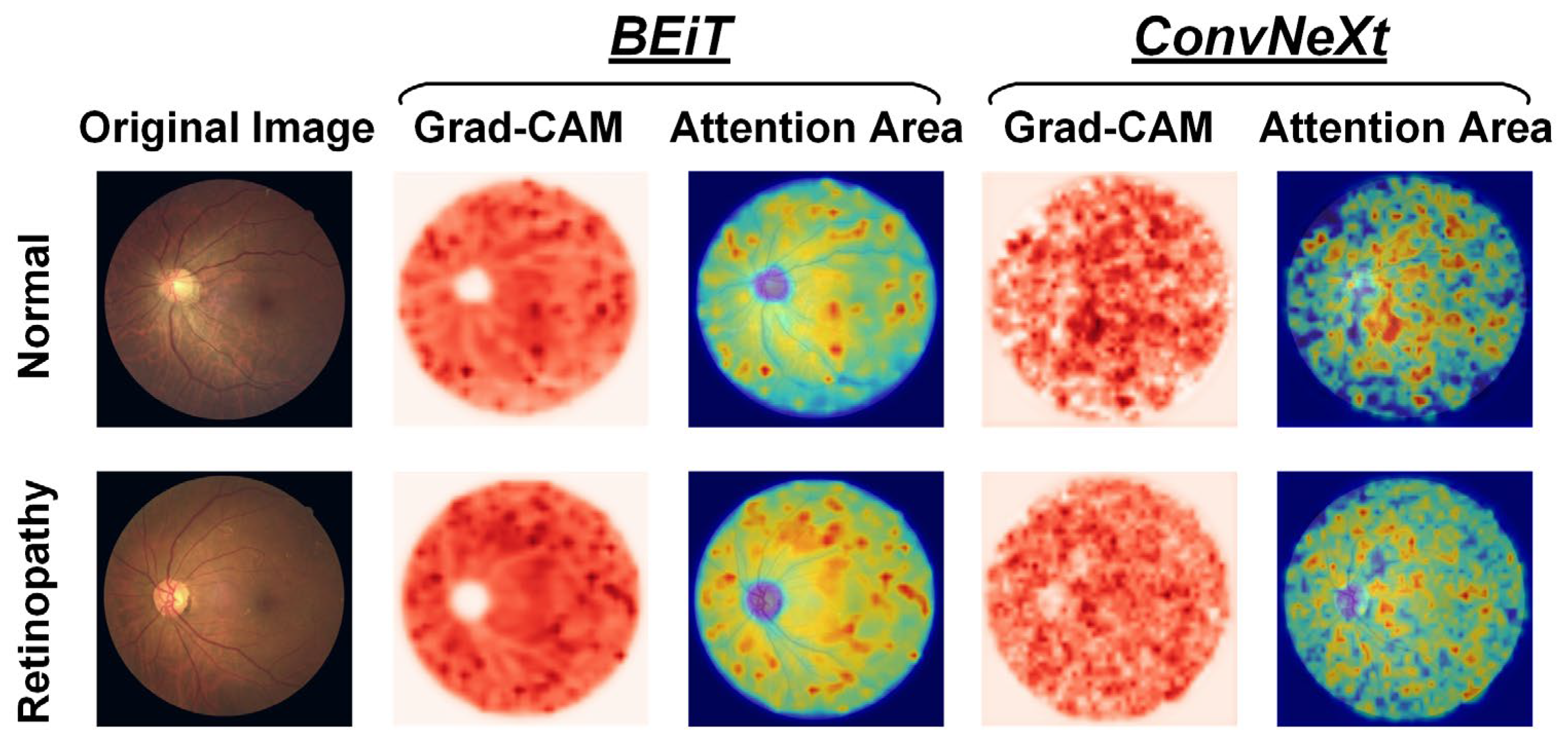
When visualizing the attention regions of a model through Grad-CAM technology, as depicted in
Figure 8, it becomes evident that there are differences in the model performance. Broadly speaking, CNN-based ConvNeXt has a propensity to focus on discrete regions that cover retinal vessels and unrelated backgrounds, whereas Transformer-based BEiT predominately attends to continuous areas that reflect global features. In particular, the ConvNeXt model emphasizes the fine-grained characteristics of fundus images, such as microvascular distortions and hemorrhages within lesion areas, which aid in detecting local information, including changes in vessel morphology like thickness, curvature, and branching, among others, as well as abnormal structures that are often present in retinopathy, such as exudates, tissue proliferation, and atrophy. Conversely, the BEiT model places greater focus on the tissues outside the optic disc in retinopathy samples, thereby facilitating its ability to more efficiently capture the coarse-grained global characteristics of fundus images, including factors such as eye size and shape, vessel distribution, and pigment changes, among others. The incorporation of global information is particularly advantageous in improving the surveillance of widespread illnesses, such as through the prediction of epidemic infection trends of uveitis. Based on prior research related to retinopathy detection through fundus images, our proposed CLRD methodology effectively combines models of varying scales and structures to supply highly pertinent, detailed local and global features that are beneficial in detecting retinal diseases with increased ACC. In turn, this is essential for enabling earlier diagnoses and treatments of retinopathy.
4.4. Ablation Studies
4.4.1. Sensitivity to Loss Hyperparameter
In all other experiments, we set the hyperparameter
α to 1 to emphasize the effectiveness of DCLR. However, in this ablation experiment, we varied the
α setting from 0.1 to 5 to conduct a sensitivity analysis of the loss hyperparameters. The experimental results are presented in
Table 5. These results indicate that performance was not greatly impacted by
α selections ranging from 0.2 to 1.5. Despite this, the careful adjustment of hyperparameters can lead to additional performance gains for retinopathy detection.
4.4.2. Sensitivity to Data Augmentation Policies
To compare the performance differences of various data augmentation methods during model training and testing, we conducted sensitivity analysis experiments. These involved applying different data augmentation techniques to the same set of fundus images and comparing their results to determine the optimal method. The experimental results depicted in
Table 6 indicate that our proposed data augmentation technique outperforms the others. Therefore, we posit that designing a specific data augmentation method for fundus images could lead to additional performance gains in retinopathy detection. However, when using only data augmentation methods derived from natural images (such as Cutout [
20]), the ACC in retinopathy detection may be impaired due to a lack of support for clinical physiological significance.
5. Discussion
5.1. Comparison with Competitive Models
To demonstrate the effectiveness of the CLRD framework in facilitating deep neural networks for retinopathy detection, we replicated several state-of-the-art (SOTA) models. These models consisted of DenseNet121 [
21], ResNetV2 [
15], Xception71 [
22], and EfficientNet [
23], which are based on the CNN architecture, as well as Vanilla ViT [
16], MobileViT [
24], Swin Transformer [
25], ConViT [
26], CaiT [
27], EfficientFormer [
28], and VOLO [
29], which are based on the Transformer architecture. We performed a quantitative comparison of these models using the same experimental setup, and the results are presented in
Table 7. Our findings indicate that the proposed CLRD model achieved the highest ACC for retinopathy detection, surpassing all other models. Specifically, when compared to the second-best performing model, MobileViT, CLRD-BEiT improved the average ACC, PRE, REC, SPE, and F1 scores by 5.69%, 5.37%, 5.74%, 11.24%, and 5.87%, respectively. Notably, most competing models achieved F1 scores below 80.00%, thereby underscoring the significant role of the collaborative learning training paradigm in enhancing the ACC of retinopathy detection.
Compared to other models used for automated output, collaborative learning offers several key benefits. Firstly, it promotes model invariance by incorporating the knowledge transfer through distortion information specific to fundus images. This enables the CLRD framework to effectively minimize the generalization error, ensuring reliable and accurate predictions. In the context of retinopathy detection, this is crucial for making informed decisions and facilitating early treatment.
Secondly, collaborative learning facilitates independent predictions made by each student model while still benefiting from their collective knowledge. This allows the CLRD framework to take advantage of the unique insights offered by each model, leading to improved accuracy, precision, recall, specificity, and F1 score compared to advanced visual models. The superior performance of the CLRD framework demonstrates its potential as a way forward in enhancing the detection of retinopathy.
Furthermore, collaborative learning offers new directions for further investigations into detecting retinopathy. By exploring the combination of different models and architectures, we can continue to improve the diagnostic accuracy and efficiency of retinopathy detection algorithms.
5.2. Generalizability and Clinical Implications
We utilized the EyePACS fundus image dataset as an external test set to validate the generalization ability of our proposed CLRD method for retinopathy detection. In order to ensure a fair comparison, we conducted five-fold cross-validation experiments on this test set using the same parameter settings and presented the average performance of the five estimates in
Table 8. Alongside this, we summarized the quantitative results from other SOTA work in
Table 8. The results demonstrate that our CLRD method exhibits the most accurate performance in retinopathy detection. Compared to other methods, CLRD improved the ACC, PRE, REC, and F1 scores by 1.07% to 22.59%, 13.47% to 54.91%, 0.43% to 28.84%, and 0.23% to 83.02%, respectively. The CLRD method produces more reliable results as it employs collaborative learning of online distillation methods. This facilitates the efficient handling of unbalanced datasets, prevents overfitting, and ensures independent predictions.
Specifically, the presence of unbalanced EyePACS datasets often leads to models being biased towards predicting normal categories while ignoring abnormal retinopathy samples. Relying solely on ACC or reporting too few quantitative metrics is considered unreliable. For instance, the authors of [
31] achieved an ACC of 87.37% and an F1 score of approximately 81.80% by calculating the entropy of each fundus image to highlight the lesion’s edge and creating regions of interest for the CNN model. However, this method disregards the imbalance of fundus images and employs only AUC as the core metric of performance. On the other hand, using an insufficient number of training samples carries the risk of overfitting. For instance, Xu et al. [
30] employed only 360 fundus images as the training set for an eight-layer CNN model. Although they achieved a 94.50% ACC, the model’s generalization ability remained limited due to the small amount of data. To address these challenges, some researchers have utilized the model ensemble, data augmentation, and multitask learning techniques to improve overall performance and generalization.
Model ensemble methods enhance the overall prediction accuracy by integrating the predictions of multiple independent models, thereby reducing the bias and variance of individual models. For example, Qummar et al. [
34] integrated five CNN models using stacking methods to extract salient features related to retinopathy. Additionally, certain studies have incorporated special preprocessing methods to enhance fundus images. For example, Nneji et al. [
35] employed two independent deep learning models, InceptionV3 and VGG16, to process separate channels of input fundus images. The outputs of these models were weighted and merged to obtain the final retinopathy detection results. Kaushik et al. [
33] proposed desaturation techniques in the preprocessing stage to address irregularities. They trained three CNN models concurrently and detected retinopathy by combining the optimal weights of these networks. These data augmentation-based preprocessing methods prevented the model from memorizing noise and training set details excessively, introducing stochasticity and diversity of transformations in the training data, and enabling the model to focus on key features and patterns of retinopathy in the fundus image.
On the other hand, Wang et al. [
32] presented a method that simultaneously performed various tasks, including image resolution enhancement, lesion segmentation, and severity grading, to achieve high-precision retinopathy classification. Image resolution enhancement aided the model in capturing fine lesion details, lesion segmentation enabled the model to learn about the location and shape information of the lesion, while severity grading assisted the model in understanding different disease levels. Training in combination with these tasks allowed the model to acquire richer and more diverse knowledge. For each task, they employed a CNN-based approach with a powerful feedback mechanism utilizing the task-aware loss function. However, this approach increased model complexity and required more labeled data, resulting in increased training and inference time and resource consumption. Additionally, conflicts or interferences may arise between different tasks, making effective learning challenging.
To address these challenges, we propose a new method called CLRD. It fuses soft knowledge extracted from the CNN and Transformer models through a collaborative learning training paradigm to achieve efficient online distillation. Notably, under the CLRD method, all models maintain independent high-precision retinopathy detection capabilities. In terms of clinical impact, CLRD offers multiple advantages. It employs a collaborative learning strategy to integrate student models of different scales and architectures, extracts valuable pathology information from fundus images, and enhances model invariance by designing fundus image-specific aberration information to transfer knowledge and minimize generalization errors through knowledge transfer. To the best of our knowledge, no assisted learning-based online distillation method for retinopathy detection exists. Our CLRD method outperforms all other SOTA work in retinopathy detection performance, and hence can assist physicians in accurately diagnosing and treating retinopathy, thereby reducing patients’ pain and financial burden.
5.3. Limitation and Future Work
While our CLRD framework has shown promising results in detecting retinopathy using fundus images, there are still some limitations and opportunities for improvement. Firstly, although the CLRD framework can be applied to vision models of different scales and architectures, we only tested it on a limited number of models and did not comprehensively evaluate all possible models. Therefore, further exploration is needed to enhance model performance and generalization capabilities through knowledge-sharing and transfer among different models.
Secondly, while our CLRD framework has demonstrated promising results, more research is required to assess its real-world applicability and generalizability. It is essential to train and validate the framework on larger and more diverse datasets to enhance its performance and evaluate its effectiveness across different populations. Additionally, we suggest exploring alternative collaborative learning strategies and knowledge distillation approaches to further enhance the model’s performance and generalization abilities.
We believe that with further refinements and advancements in deep learning techniques, it is feasible to incorporate additional quantitative outputs into the CLRD framework. These outputs may include measures such as lesion severity grading, disease progression assessment, and individualized risk prediction. Such enhancements would allow for a more comprehensive assessment of retinopathy and provide valuable insights for clinical decision-making.
In summary, collaborative learning, as exemplified by the CLRD framework, represents the way forward in automated output for retinopathy detection. Its abilities to harness the collective knowledge of multiple models, enhance model invariance, and improve diagnostic performance make it a promising approach in the biomedical field. We believe that our study sheds light on the potential of collaborative learning and opens up avenues for further advancements in retinopathy detection.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}