

RGSB-UNet: Hybrid Deep Learning Framework for Tumour Segmentation in Digital Pathology Images


Abstract
1. Introduction
- We propose a deep hybrid network that combines a transformer and CNN for automatic tumour region segmentation in pathology images of the colon.
- A newly-designed feature extraction block RGS is presented. The block can adaptively determine the optimal combination of normalizers for each layer, making our model robust to varying batch sizes.
- Our novel hybrid backbone encoder, which includes RGS and BoT blocks, can extract more refined features.
- Experimental results demonstrate that the proposed RGSB-UNet achieves higher evaluation scores and produces finer segmentation results than state-of-the-art segmentation methods under small batch sizes.
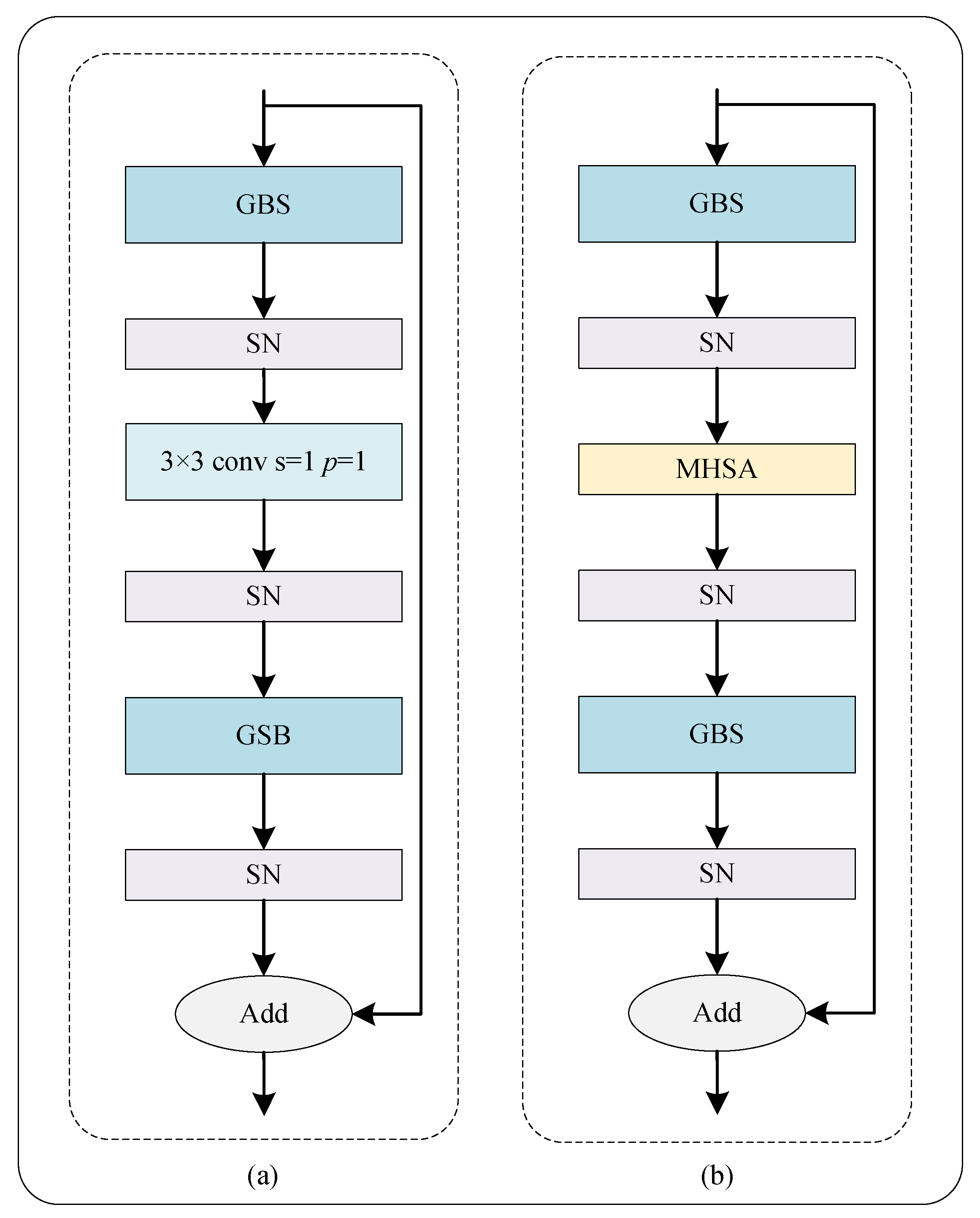
2. Proposed Method
2.1. Network Architecture
2.1.1. Encoder and Decoder
2.1.2. Ghost Block with Switchable Normalization
2.1.3. Residual Ghost Block with Switchable Normalization
2.1.4. Bottleneck Transformer
2.2. Loss Function
3. Evaluation and Datasets
3.1. Evaluation
3.2. Datasets and Implementation
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Goding Sauer, A.; Fedewa, S.A.; Butterly, L.F.; Anderson, J.C.; Cercek, A.; Smith, R.A.; Jemal, A. Colorectal cancer statistics, 2020. CA Cancer J. Clin. 2020, 70, 145–164. [Google Scholar] [CrossRef] [PubMed]
- Xia, C.; Dong, X.; Li, H.; Cao, M.; Sun, D.; He, S.; Yang, F.; Yan, X.; Zhang, S.; Li, N.; et al. Cancer statistics in China and United States, 2022: Profiles, trends, and determinants. Chin. Med. J. 2022, 135, 584–590. [Google Scholar] [CrossRef]
- Vega, P.; Valentín, F.; Cubiella, J. Colorectal cancer diagnosis: Pitfalls and opportunities. World J. Gastrointest. Oncol. 2015, 7, 422. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Fu, C.; Zheng, Y.; Cao, L.; Tie, M. A practical medical image cryptosystem with parallel acceleration. J. Ambient. Intell. Humaniz. Comput. 2022, 14, 9853–9867. [Google Scholar] [CrossRef]
- Wang, S.; Yang, D.M.; Rong, R.; Zhan, X.; Xiao, G. Pathology image analysis using segmentation deep learning algorithms. Am. J. Pathol. 2019, 189, 1686–1698. [Google Scholar] [CrossRef]
- Kumar, N.; Gupta, R.; Gupta, S. Whole slide imaging (WSI) in pathology: Current perspectives and future directions. J. Digit. Imaging 2020, 33, 1034–1040. [Google Scholar] [CrossRef]
- Wright, A.M.; Smith, D.; Dhurandhar, B.; Fairley, T.; Scheiber-Pacht, M.; Chakraborty, S.; Gorman, B.K.; Mody, D.; Coffey, D.M. Digital slide imaging in cervicovaginal cytology: A pilot study. Arch. Pathol. Lab. Med. 2013, 137, 618–624. [Google Scholar] [CrossRef]
- Zhang, W.; Fu, C.; Chang, X.; Zhao, T.; Li, X.; Sham, C.W. A more compact object detector head network with feature enhancement and relational reasoning. Neurocomputing 2022, 499, 23–34. [Google Scholar] [CrossRef]
- Xu, J.; Luo, X.; Wang, G.; Gilmore, H.; Madabhushi, A. A deep convolutional neural network for segmenting and classifying epithelial and stromal regions in histopathological images. Neurocomputing 2016, 191, 214–223. [Google Scholar] [CrossRef]
- Liu, Y.; Gadepalli, K.; Norouzi, M.; Dahl, G.E.; Kohlberger, T.; Boyko, A.; Venugopalan, S.; Timofeev, A.; Nelson, P.Q.; Corrado, G.S.; et al. Detecting Cancer Metastases on Gigapixel Pathology Images. arXiv 2017, arXiv:1703.02442. [Google Scholar]
- Wang, S.; Chen, A.; Yang, L.; Cai, L.; Xie, Y.; Fujimoto, J.; Gazdar, A.; Xiao, G. Comprehensive analysis of lung cancer pathology images to discover tumor shape and boundary features that predict survival outcome. Sci. Rep. 2018, 8, 10393. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.W. Adapting mask-rcnn for automatic nucleus segmentation. arXiv 2018, arXiv:1805.00500. [Google Scholar]
- Fan, K.; Wen, S.; Deng, Z. Deep learning for detecting breast cancer metastases on WSI. In Innovation in Medicine and Healthcare Systems, and Multimedia; Springer: Berlin/Heidelberg, Germany, 2019; pp. 137–145. [Google Scholar]
- Cho, S.; Jang, H.; Tan, J.W.; Jeong, W.K. DeepScribble: Interactive Pathology Image Segmentation Using Deep Neural Networks with Scribbles. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 761–765. [Google Scholar]
- Zhai, Z.; Wang, C.; Sun, Z.; Cheng, S.; Wang, K. Deep Neural Network Guided by Attention Mechanism for Segmentation of Liver Pathology Image. In Proceedings of the 2021 Chinese Intelligent Systems Conference, Fuzhou, China, 16–17 October 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 425–435. [Google Scholar]
- Deng, X.; Liu, E.; Li, S.; Duan, Y.; Xu, M. Interpretable Multi-Modal Image Registration Network Based on Disentangled Convolutional Sparse Coding. IEEE Trans. Image Process. 2023, 32, 1078–1091. [Google Scholar] [CrossRef] [PubMed]
- Jin, K.; Yan, Y.; Wang, S.; Yang, C.; Chen, M.; Liu, X.; Terasaki, H.; Yeo, T.H.; Singh, N.G.; Wang, Y.; et al. iERM: An Interpretable Deep Learning System to Classify Epiretinal Membrane for Different Optical Coherence Tomography Devices: A Multi-Center Analysis. J. Clin. Med. 2023, 12, 400. [Google Scholar] [CrossRef] [PubMed]
- Xiong, S.; Li, B.; Zhu, S. DCGNN: A single-stage 3D object detection network based on density clustering and graph neural network. Complex Intell. Syst. 2022, 9, 3399–3408. [Google Scholar] [CrossRef]
- Qaiser, T.; Tsang, Y.W.; Taniyama, D.; Sakamoto, N.; Nakane, K.; Epstein, D.; Rajpoot, N. Fast and accurate tumor segmentation of histology images using persistent homology and deep convolutional features. Med. Image Anal. 2019, 55, 1–14. [Google Scholar] [CrossRef]
- Zhu, C.; Mei, K.; Peng, T.; Luo, Y.; Liu, J.; Wang, Y.; Jin, M. Multi-level colonoscopy malignant tissue detection with adversarial CAC-UNet. Neurocomputing 2021, 438, 165–183. [Google Scholar] [CrossRef]
- Feng, R.; Liu, X.; Chen, J.; Chen, D.Z.; Gao, H.; Wu, J. A deep learning approach for colonoscopy pathology WSI analysis: Accurate segmentation and classification. IEEE J. Biomed. Health Inform. 2020, 25, 3700–3708. [Google Scholar] [CrossRef]
- Song, W.; Fu, C.; Zheng, Y.; Cao, L.; Tie, M.; Sham, C.W. Protection of image ROI using chaos-based encryption and DCNN-based object detection. Neural Comput. Appl. 2022, 34, 5743–5756. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Luo, P.; Ren, J.; Peng, Z.; Zhang, R.; Li, J. Differentiable Learning-to-Normalize via Switchable Normalization. In Proceedings of the 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16514–16524. [Google Scholar]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the Relationship between Self-Attention and Convolutional Layers. In Proceedings of the 8th International Conference on Learning Representations, ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. Stat 2018, 1050, 11. [Google Scholar] [CrossRef]
- Luo, P.; Zhang, R.; Ren, J.; Peng, Z.; Li, J. Switchable Normalization for Learning-to-Normalize Deep Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 712–728. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. PMLR 2015, 37, 448–456. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1510–1519. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Qadri, S.F.; Lin, H.; Shen, L.; Ahmad, M.; Qadri, S.; Khan, S.; Khan, M.; Zareen, S.S.; Akbar, M.A.; Bin Heyat, M.B.; et al. CT-Based Automatic Spine Segmentation Using Patch-Based Deep Learning. Int. J. Intell. Syst. 2023, 2023, 2345835. [Google Scholar] [CrossRef]
- Da, Q.; Huang, X.; Li, Z.; Zuo, Y.; Zhang, C.; Liu, J.; Chen, W.; Li, J.; Xu, D.; Hu, Z.; et al. DigestPath: A benchmark dataset with challenge review for the pathological detection and segmentation of digestive-system. Med. Image Anal. 2022, 80, 102485. [Google Scholar] [CrossRef]
- Sirinukunwattana, K.; Pluim, J.P.; Chen, H.; Qi, X.; Heng, P.A.; Guo, Y.B.; Wang, L.Y.; Matuszewski, B.J.; Bruni, E.; Sanchez, U.; et al. Gland segmentation in colon histology images: The glas challenge contest. Med. Image Anal. 2017, 35, 489–502. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Sri, S.V.; Kavya, S. Lung Segmentation Using Deep Learning. Asian J. Appl. Sci. Technol. AJAST 2021, 5, 10–19. [Google Scholar] [CrossRef]
- Pravitasari, A.A.; Iriawan, N.; Almuhayar, M.; Azmi, T.; Irhamah, I.; Fithriasari, K.; Purnami, S.W.; Ferriastuti, W. UNet-VGG16 with transfer learning for MRI-based brain tumor segmentation. TELKOMNIKA Telecommun. Comput. Electron. Control. 2020, 18, 1310–1318. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 20 September 2018; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Qi, X.; Yu, L.; Heng, P.A. DCAN: Deep contour-aware networks for accurate gland segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2487–2496. [Google Scholar]
- Wang, X.; Yao, L.; Wang, X.; Paik, H.Y.; Wang, S. Global Convolutional Neural Processes. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; pp. 699–708. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Crop Method | Dense Crop |
| Crop Stride | 512 |
| Crop Patch Size | |
| Batch Size | 2 |
| MHSA Head | 4 |
| Optimizer | SGD |
| Learning Rate | |
| Weight Deacy | |
| Momentum | 0.9 |
| Epoch Number | 500 |
| UNet | RSB | RGB | RGS | BoT | DSC |
|---|---|---|---|---|---|
| 0.8150 | |||||
| 0.8197 | |||||
| 0.8201 | |||||
| 0.8203 | |||||
| 0.8261 | |||||
| 0.8263 | |||||
| 0.8336 |
| Batch Size | 1 | 2 | ||||||
|---|---|---|---|---|---|---|---|---|
| MHSA Head | ☓ | 1 | 2 | 4 | ☓ | 1 | 2 | 4 |
| DSC | 0.8126 | 0.8241 | 0.8220 | 0.8331 | 0.8263 | 0.8294 | 0.8250 | 0.8336 |
| Methods | DSC | AUC | PA | JI | RVD | Precision |
|---|---|---|---|---|---|---|
| CAC-UNet [20] | 0.8292 | 1.0000 | 0.8935 | 0.7082 | 0.3219 | 0.9072 |
| UNet (Baseline) [37] | 0.8150 | 0.9060 | 0.8611 | 0.6914 | 0.2852 | 0.6511 |
| UNet (Backbone: Vgg11) [38] | 0.8258 | 0.9187 | 0.8796 | 0.7081 | 0.2964 | 0.6829 |
| UNet (Backbone: Vgg16) [39] | 0.8323 | 0.9562 | 0.9351 | 0.7177 | 0.2445 | 0.8000 |
| UNet (Backbone: Vgg19) [21] | 0.7417 | 0.5875 | 0.3889 | 0.5990 | 0.4803 | 0.2987 |
| UNet (Backbone: ResNet50) [40] | 0.8197 | 0.9312 | 0.8981 | 0.7019 | 0.3652 | 0.7179 |
| UNet (Backbone: DenseNet121) [41] | 0.2183 | 0.5758 | 0.5092 | 0.1441 | 0.4825 | 0.3076 |
| NestedUNet [42] | 0.7609 | 0.7625 | 0.6481 | 0.6254 | 0.5561 | 0.4242 |
| Unet3+ [43] | 0.7467 | 0.6250 | 0.4450 | 0.6127 | 0.3977 | 0.3181 |
| DeepLab (Backbone: Xception) [44] | 0.6999 | 0.9500 | 0.9259 | 0.5517 | 0.1925 | 0.7778 |
| DeepLab (Backbone: ResNet50) [44] | 0.7964 | 0.6375 | 0.4629 | 0.6684 | 0.3829 | 0.3255 |
| DeepLab (Backbone: Drn) [44] | 0.7917 | 0.7125 | 0.5740 | 0.6605 | 0.3214 | 0.3783 |
| DeepLab (Backbone: MobileNet) [44] | 0.7943 | 0.8250 | 0.7407 | 0.6658 | 0.4206 | 0.5000 |
| DCAN [45] | 0.8322 | 0.9562 | 0.9351 | 0.7169 | 0.2291 | 0.8000 |
| GCN [46] | 0.6372 | 0.6625 | 0.5000 | 0.4903 | 0.5051 | 0.3414 |
| SegNet [47] | 0.7564 | 0.7937 | 0.6944 | 0.6174 | 0.5845 | 0.4590 |
| Proposed | 0.8336 | 0.9813 | 0.9722 | 0.7190 | 0.2122 | 0.9032 |
| Methods | DSC | AUC | PA | JI | RVD | Precision |
|---|---|---|---|---|---|---|
| UNet (Baseline) [37] | 0.5132 | 0.4339 | 0.8125 | 0.3745 | 0.4959 | 0.9285 |
| UNet (Backbone: Vgg11) [38] | 0.7486 | 0.5068 | 0.9480 | 0.6195 | 0.6165 | 0.9313 |
| UNet (Backbone: Vgg16) [39] | 0.7324 | 0.6328 | 0.8265 | 0.6038 | 0.7378 | 0.8375 |
| UNet (Backbone: Vgg19) [21] | 0.7289 | 0.5979 | 0.8975 | 0.5999 | 0.7595 | 0.7928 |
| UNet (Backbone: ResNet50) [40] | 0.6511 | 0.5000 | 0.9375 | 0.5065 | 0.9228 | 0.9375 |
| UNet (Backbone: DenseNet121) [41] | 0.6491 | 0.5998 | 0.9263 | 0.5037 | 0.9046 | 0.9261 |
| NestedUNet [42] | 0.6003 | 0.4533 | 0.8500 | 0.4651 | 0.8031 | 0.9315 |
| Unet3+ [43] | 0.6650 | 0.6725 | 0.9450 | 0.5170 | 0.8459 | 0.9428 |
| DeepLab (Backbone: Xception) [44] | 0.6867 | 0.4735 | 0.8875 | 0.5564 | 0.4423 | 0.9342 |
| DeepLab (Backbone: ResNet50) [44] | 0.6887 | 0.4866 | 0.9125 | 0.5503 | 0.5648 | 0.9358 |
| DeepLab (Backbone: Drn) [44] | 0.7367 | 0.5306 | 0.9375 | 0.6039 | 0.6299 | 0.9375 |
| DeepLab (Backbone: MobileNet) [44] | 0.6839 | 0.4933 | 0.9250 | 0.5410 | 0.6062 | 0.9367 |
| DCAN [45] | 0.6415 | 0.6107 | 0.9177 | 0.4896 | 0.9459 | 0.9370 |
| GCN [46] | 0.5696 | 0.5079 | 0.6983 | 0.4220 | 0.9918 | 0.7863 |
| SegNet [47] | 0.5206 | 0.5533 | 0.8625 | 0.3799 | 0.3995 | 0.9445 |
| Proposed | 0.8865 | 0.8920 | 0.9823 | 0.7953 | 0.2128 | 0.9475 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, T.; Fu, C.; Tie, M.; Sham, C.-W.; Ma, H. RGSB-UNet: Hybrid Deep Learning Framework for Tumour Segmentation in Digital Pathology Images. Bioengineering 2023, 10, 957. https://doi.org/10.3390/bioengineering10080957
Zhao T, Fu C, Tie M, Sham C-W, Ma H. RGSB-UNet: Hybrid Deep Learning Framework for Tumour Segmentation in Digital Pathology Images. Bioengineering. 2023; 10(8):957. https://doi.org/10.3390/bioengineering10080957
Chicago/Turabian StyleZhao, Tengfei, Chong Fu, Ming Tie, Chiu-Wing Sham, and Hongfeng Ma. 2023. "RGSB-UNet: Hybrid Deep Learning Framework for Tumour Segmentation in Digital Pathology Images" Bioengineering 10, no. 8: 957. https://doi.org/10.3390/bioengineering10080957
APA StyleZhao, T., Fu, C., Tie, M., Sham, C.-W., & Ma, H. (2023). RGSB-UNet: Hybrid Deep Learning Framework for Tumour Segmentation in Digital Pathology Images. Bioengineering, 10(8), 957. https://doi.org/10.3390/bioengineering10080957