



Machine Learning Diffuse Optical Tomography Using Extreme Gradient Boosting and Genetic Programming




Abstract
1. Introduction
2. Materials and Methods
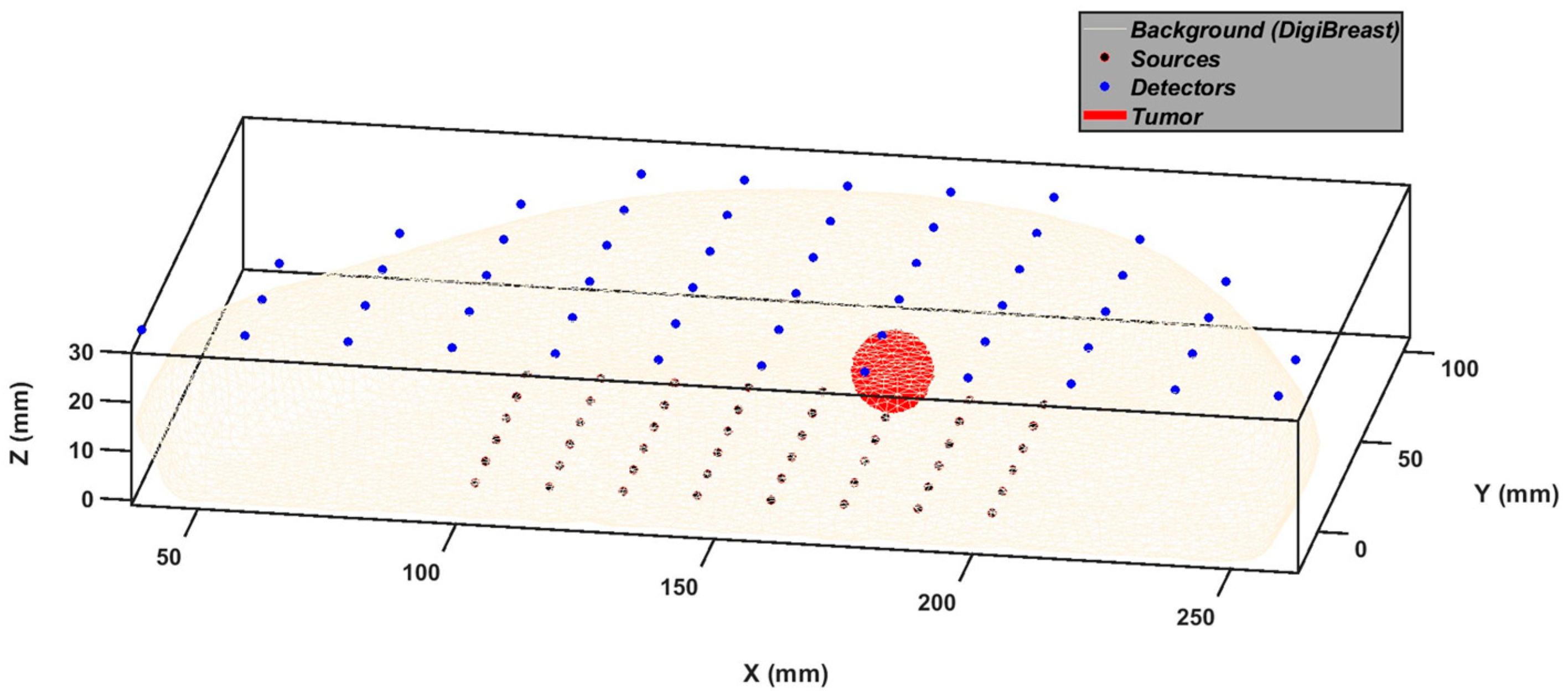
2.1. Simulating Photon Migration in Digital Breast Phantoms to Generate Dataset
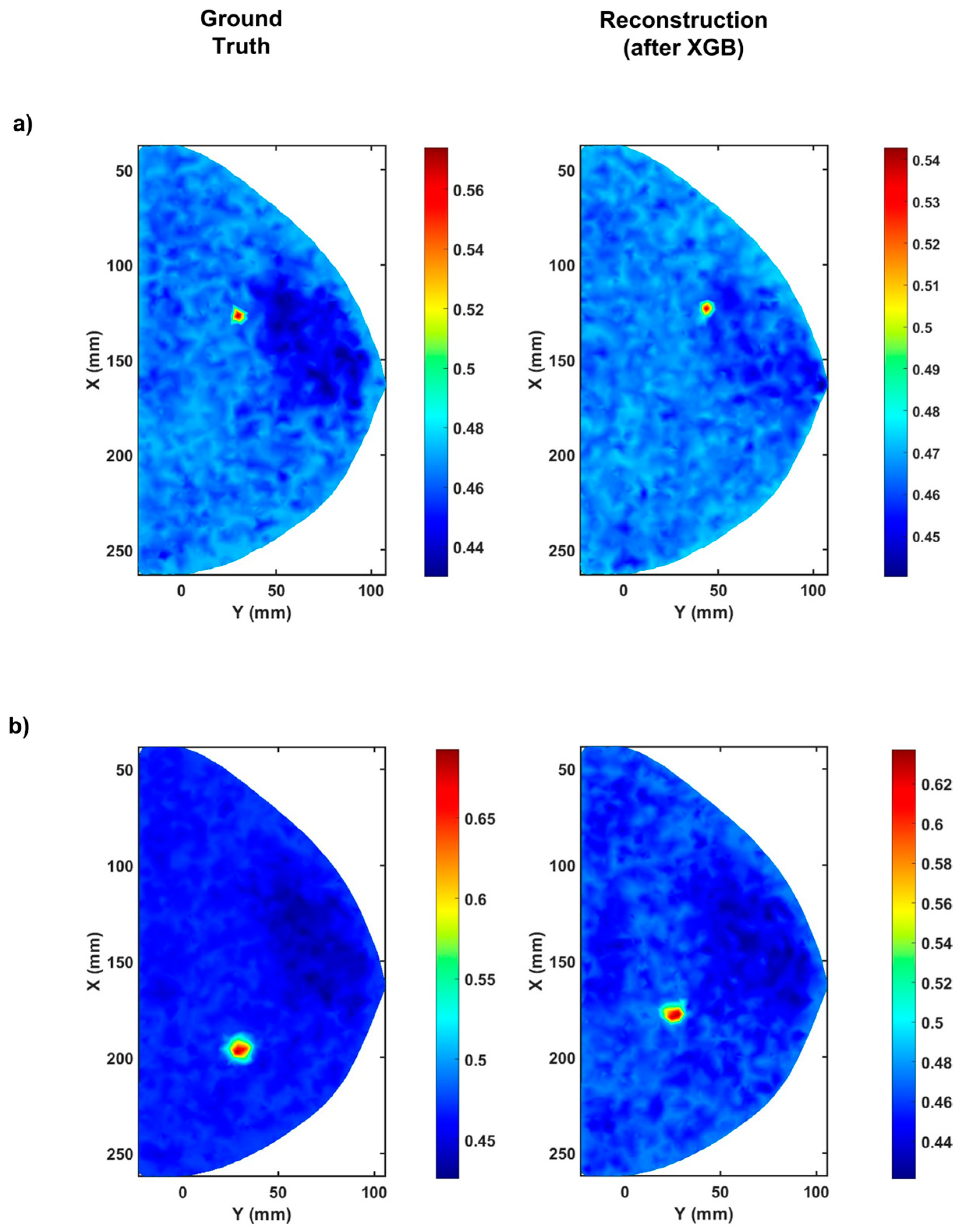
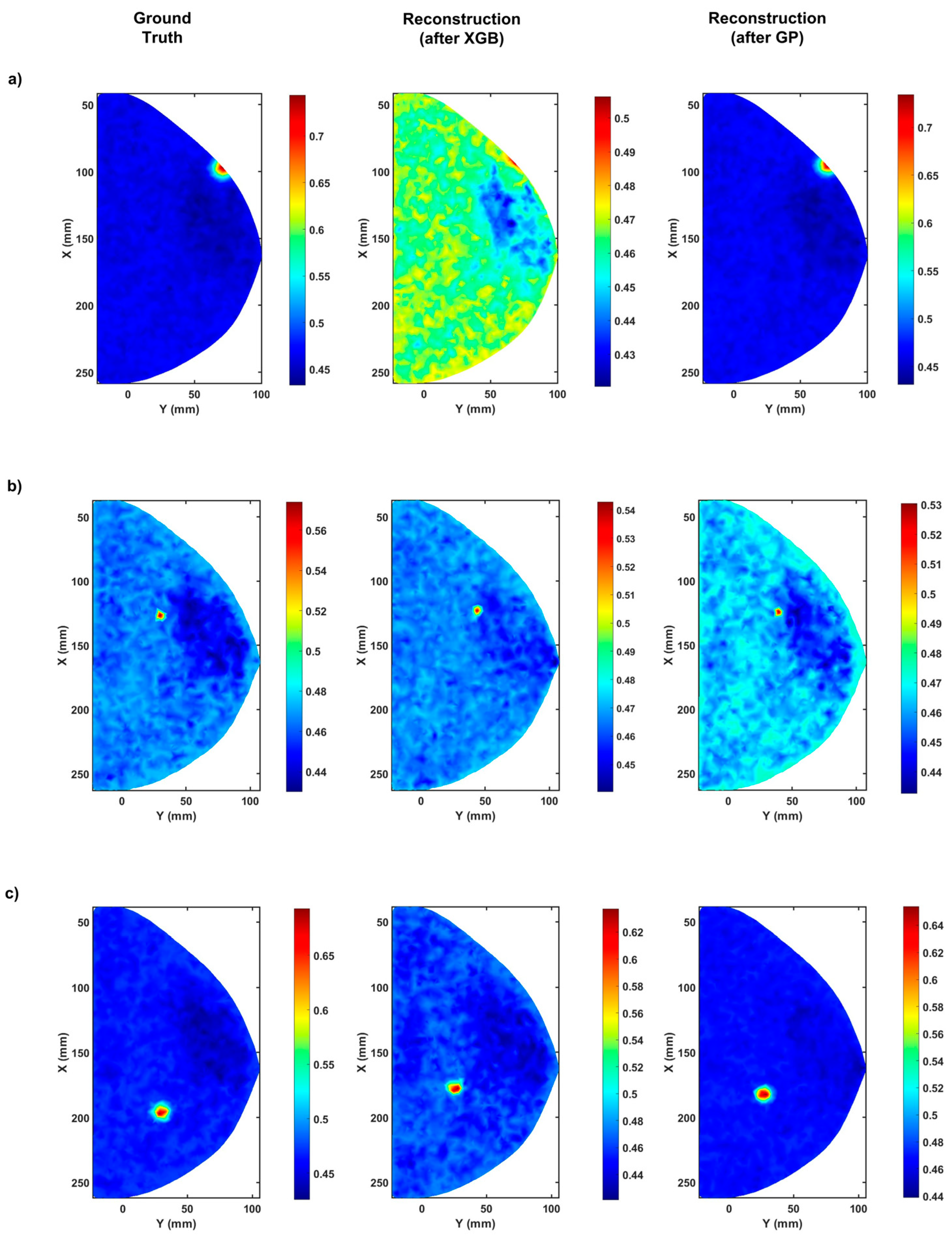
2.2. Detecting Tumors in the Compressed Breast Using Extreme Gradient Boosting
2.3. Enhancing Tumor Detection Capabilities Using Genetic Programming
- Randomly generate an initial population of solutions called individuals. Each individual is generated as a random tree of limited depth, consisting of nodes taken from the terminal set and the function set. The terminal set contains constants and variables, and the function set consists of various operators, for example, mathematical operations, logical operators, etc.
- While the termination criterion is not fulfilled, the following sub-steps are repeated:
- a.
- Evaluate the individuals in the current population according to the fitness function, which outputs a numerical value representing the quality of the individual as a solution.
- b.
- Select individuals from the population using a selection method, where the probability for selection is related to fitness values, for producing the next set of individuals.
- c.
- Apply the following genetic operators to produce new individuals with predetermined probabilities:
- I.
- Reproduction: clone an individual selected by the sub-step ”b” to the population.
- II.
- Crossover: randomly recombine two selected individuals to produce two new offspring.
- III.
- Mutation: randomly alter one selected individual to produce one new offspring.
- Output the best individual found during the run as the output.
3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shrestha, S.; Deshpande, A.; Farrahi, T.; Cambria, T.; Quang, T.; Majeski, J.; Na, Y.; Zervakis, M.; Livanos, G.; Giakos, G.C. Label-free discrimination of lung cancer cells through mueller matrix decomposition of diffuse reflectance imaging. Biomed. Signal Process. Control 2018, 40, 505–518. [Google Scholar] [CrossRef]
- Jeeva, J.B.; Singh, M. Reconstruction of optical scanned images of inhomogeneities in biological tissues by Monte Carlo simulation. Comput. Biol. Med. 2015, 60, 92–99. [Google Scholar] [CrossRef] [PubMed]
- Perkins, G.A.; Eggebrecht, A.T.; Dehghani, H. Multi-modulated frequency domain high density diffuse optical tomography. Biomed. Opt. Express 2022, 13, 5275–5294. [Google Scholar] [CrossRef] [PubMed]
- Marcos-Vidal, A.; Ripoll, J. Recent advances in optical tomography in low scattering media. Opt. Lasers Eng. 2020, 135, 10619. [Google Scholar] [CrossRef]
- Yoon, S.; Kim, M.; Jang, M.; Choi, Y.; Choi, W.; Kang, S.; Choi, W. Deep optical imaging within complex scattering media. Nat. Rev. Phys. 2020, 2, 141–158. [Google Scholar] [CrossRef]
- Bertolotti, J.; Katz, O. Imaging in complex media. Nat. Phys. 2022, 18, 1008–1017. [Google Scholar] [CrossRef]
- Ferrari, M.; Culver, J.P.; Hoshi, Y.; Wabnitz, H. Special Section Guest Editorial: Clinical near-infrared spectroscopy and imaging. J. Biomed. Opt. 2016, 21, 091301. [Google Scholar] [CrossRef]
- Zou, Y.; Zeng, Y.; Li, S.; Zhu, Q. Machine learning model with physical constraints for diffuse optical tomography. Biomed. Opt. Express 2021, 12, 5720–5735. [Google Scholar] [CrossRef]
- Dileep, B.P.V.; Dutta, P.K.; Prasad, P.M.K.; Santhosh, M. Sparse recovery based compressive sensing algorithms for diffuse optical tomography. Opt. Laser Technol. 2020, 128, 106234. [Google Scholar] [CrossRef]
- Zhang, M.; Li, S.; Zou, Y.; Zhu, Q. Deep learning-based method to accurately estimate breast tissue optical properties in the presence of the chest wall. J. Biomed. Opt. 2021, 26, 106004. [Google Scholar] [CrossRef]
- Paul, R.; Murali, K.; Varma, H.M. High-density diffuse correlation tomography with enhanced depth localization and minimal surface artefacts. Biomed. Opt. Express 2022, 13, 6081–6099. [Google Scholar] [CrossRef] [PubMed]
- Bowden, A.K.; Durr, N.J.; Erickson, D.; Ozcan, A.; Ramanujam, N.; Jacques, P.V. Optical Technologies for Improving Healthcare in Low-Resource Settings: Introduction to the feature issue. Biomed. Opt. Express 2020, 11, 3091–3094. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Cheung, M.R. The utility of a marched absorbing layer boundary condition in the finite element analysis of diffuse photon density wave propagation in tissues relevant to breast imaging. Comput. Biol. Med. 2009, 39, 934–939. [Google Scholar] [CrossRef] [PubMed]
- Balasubramaniam, G.M.; Wiesel, B.; Biton, N.; Kumar, R.; Kupferman, J.; Arnon, S. Tutorial on the Use of Deep Learning in Diffuse Optical Tomography. Electronics 2022, 11, 305. [Google Scholar] [CrossRef]
- Yoo, J.; Sabir, S.; Heo, D.; Kim, K.H.; Wahab, A.; Choi, Y.; Lee, S.I.; Chae, E.Y.; Kim, H.H.; Bae, Y.M.; et al. Deep Learning Diffuse Optical Tomography. IEEE Trans. Med. Imaging 2020, 39, 877–887. [Google Scholar] [CrossRef] [PubMed]
- Balasubramaniam, G.M.; Arnon, S. Deep-learning algorithm to detect anomalies in compressed breast: A numerical study. In Proceedings of the Bio-Opitcs: Design and Application, Washington, DC, USA, 12–16 April 2021. [Google Scholar]
- Balasubramaniam, G.M.; Arnon, S. Regression-based neural network for improving image reconstruction in diffuse optical tomography. Biomed. Opt. Express 2022, 13, 2006–2017. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, M.H.; Zhang, Y.; Wang, F.; De La Garza Evia Linan, J.; Markey, M.K.; Tunnell, J.W. Machine learning to extract physiological parameters from multispectral diffuse reflectance spectroscopy. J. Biomed. Opt. 2021, 26, 052912. [Google Scholar] [CrossRef]
- Fredriksson, I.; Larsson, M.; Strömberg, T. Machine learning for direct oxygen saturation and hemoglobin concentration assessment using diffuse reflectance spectroscopy. J. Biomed. Opt. 2020, 25, 112905. [Google Scholar] [CrossRef]
- Sabir, S.; Cho, S.; Kim, Y.; Pua, R.; Heo, D.; Kim, K.H.; Choi, Y.; Cho, S. Convolutional neural network-based approach to estimate bulk optical properties in diffuse optical tomography. Appl. Opt. 2020, 59, 1461–1470. [Google Scholar] [CrossRef]
- Hokr, B.H.; Bixler, J.N. Machine learning estimation of tissue optical properties. Sci. Rep. 2021, 11, 6561. [Google Scholar] [CrossRef]
- He, J.; Li, C.L.; Wilson, B.C.; Fisher, C.J.; Ghai, S.; Weersink, R.A. A Clinical Prototype Transrectal Diffuse Optical Tomography (TRDOT) System for in vivo Monitoring of Photothermal Therapy (PTT) of Focal Prostate Cancer. IEEE Trans. Biomed. Eng. 2020, 67, 2119–2129. [Google Scholar] [CrossRef] [PubMed]
- Arridge, S.R.; Hebden, J.C. Optical imaging in medicine: II. Modelling and reconstruction. Phys. Med. Biol. 1997, 42, 841–853. [Google Scholar] [CrossRef] [PubMed]
- Uddin, K.M.S.; Zhang, M.; Anastasio, M.; Zhu, Q. Optimal breast cancer diagnostic strategy using combined ultrasound and diffuse optical tomography. Biomed. Opt. Express 2020, 11, 2722–2737. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Deng, Y.; Bao, F.; Peterson, H.; Istfan, R.; Roblyer, D. Deep learning model for ultrafast multifrequency optical property extractions for spatial frequency domain imaging. Opt. Lett. 2018, 43, 5669–5672. [Google Scholar] [CrossRef]
- Kazanci, H.O.; Oral, O. Improving image quality in diffuse optical tomography. Opt. Quantum Electron. 2022, 54, 655. [Google Scholar] [CrossRef]
- Fogarty, M.; Tripathy, K.; Svoboda, A.M.; Schroeder, M.L.; Rafferty, S.; Mansfield, P.; Ulbrich, R.; Booth, M.; Richter, E.J.; Smyser, C.D.; et al. Machine Learning Feature Extraction in Naturalistic Stimuli for Human Brain Mapping Using High-Density Diffuse Optical Tomography. In Proceedings of the SPIE BiOS, San Francisco, CA, USA, 22–27 January 2022. [Google Scholar]
- Murad, N.; Pan, M.-C.; Hsu, Y.-F. Reconstruction and Localization of Tumors in Breast Optical Imaging via Convolution Neural Network Based on Batch Normalization Layers. IEEE Access 2022, 10, 57850–57864. [Google Scholar] [CrossRef]
- Mozumder, M.; Hauptmann, A.; Nissila, I.; Arridge, S.R.; Tarvainen, T. A Model-Based Iterative Learning Approach for Diffuse Optical Tomography. IEEE Trans. Med. Imaging 2022, 41, 1289–1299. [Google Scholar] [CrossRef]
- Ben Yedder, H.; Cardoen, B.; Hamarneh, G. Deep learning for biomedical image reconstruction: A survey. Artif. Intell. Rev. 2021, 54, 215–251. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, X.; Yan, C.; Gao, C.; Malin, B.A.; Chen, Y. Predicting Missing Values in Medical Data Via XGBoost Regression. J. Healthc. Inform. Res. 2020, 4, 383–394. [Google Scholar] [CrossRef]
- Liew, X.Y.; Hameed, N.; Clos, J. An investigation of XGBoost-based algorithm for breast cancer classification. Mach. Learn. Appl. 2021, 6, 100154. [Google Scholar] [CrossRef]
- Langdon, W.B.; Poli, R. Foundations of Genetic Programming; Springer International Publishing: Cham, Switzerland, 2002. [Google Scholar]
- Koza, J.R.; Bennett, F.H.; Andre, D.; Keane, M.A. Genetic programming III: Darwinian invention and problem solving [Book Review]. IEEE Trans. Evol. Comput. 2005, 3, 251–253. [Google Scholar] [CrossRef]
- Hauptman, A.; Elyasaf, A.; Sipper, M.; Karmon, A. GP-rush: Using genetic programming to evolve solvers for the rush hour puzzle. In Proceedings of the 11th Annual conference on Genetic and Evolutionary Computation (GECCO ‘09), Montreal, QC, Canada, 8–12 July 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 955–962. [Google Scholar]
- Bertero, M.; Boccacci, P. Introduction to Inverse Problems in Imaging, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Pogue, B.W.; McBride, T.O.; Osterberg, U.L.; Paulsen, K.D. Comparison of imaging geometries for diffuse optical tomography of tissue. Opt. Express 1999, 4, 270–286. [Google Scholar] [CrossRef] [PubMed]
- Schweiger, M.; Arridge, S. The Toast++ software suite for forward and inverse modeling in optical tomography. J. Biomed. Opt. 2014, 19, 040801. [Google Scholar] [CrossRef] [PubMed]
- Deng, B.; Brooks, D.H.; Boas, D.A.; Lundqvist, M.; Fang, Q. Characterization of structural-prior guided optical tomography using realistic breast models derived from dual-energy x-ray mammography. Biomed. Opt. Express 2015, 6, 2366–2379. [Google Scholar] [CrossRef]
- Jacques, S.L. Optical properties of biological tissues: A review. Phys. Med. Biol. 2013, 58, 37–61. [Google Scholar] [CrossRef]
- Luo, C.; Zhan, J.; Xue, X.; Wang, L.; Ren, R.; Yang, Q. Cosine normalization: Using cosine similarity instead of dot product in neural networks. In Proceedings of the Artificial Neural Networks and Machine Learning-ICANN 2018, Rhodes, Greece, 4–7 October 2018; pp. 382–391. [Google Scholar]
- Takamizu, Y.; Umemura, M.; Yajima, H.; Abe, M.; Hoshi, Y. Deep Learning of Diffuse Optical Tomography based on Time-Domain Radiative Transfer Equation. arXiv 2020, arXiv:2011.125020. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic programming as a means for programming computers by natural selection. Stat. Comput. 1994, 4, 87–112. [Google Scholar] [CrossRef]
- Ahvanooey, M.T.; Li, Q.; Wu, M.; Wang, S. A survey of genetic programming and its applications. KSII Trans. Internet Inf. Syst. 2019, 13, 1765–1794. [Google Scholar] [CrossRef]
- Al-Sahaf, H.; Bi, Y.; Chen, Q.; Lensen, A.; Mei, Y.; Sun, Y.; Tran, B.; Xue, B.; Zhang, M. A survey on evolutionary machine learning. J. R. Soc. N. Z. 2019, 49, 205–228. [Google Scholar] [CrossRef]
- Koza, J.R.; Poli, R. Genetic programming. In Search Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques; Springer International Publishing: Cham, Switzerland, 2005; pp. 127–164. [Google Scholar]
- Fortin, F.A.; De Rainville, F.M.; Gardner, M.A.; Parizeau, M.; Gagńe, C. DEAP: Evolutionary algorithms made easy. J. Mach. Learn. Res. 2012, 13, 2171–2175. [Google Scholar]
- Mudeng, V.; Ayana, G.; Zhang, S.-U.; Choe, S. Progress of Near-Infrared-Based Medical Imaging and Cancer Cell Suppressors. Chemosensors 2022, 10, 471. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Range of Values |
|---|---|
| Population size | Between 10,000 and 15,000 |
| Generation count | Between 100 and 250 |
| Reproduction probability | 0.35 |
| Crossover probability | 0.5 |
| Mutation probability | 0.15 (including ERC) |
| Tree depth | Between 2 and 6 |
| Tournament size | 4 |
| Values (Units) | RMSE (After XGBoost) | RMSE (After GP) |
|---|---|---|
| X coordinate (mm) | 0.1862 ± 0.0018 | 0.1808 ± 0.0014 |
| Y coordinate (mm) | 0.1678 ± 0.0042 | 0.1539 ± 0.0057 |
| Z coordinate (mm) | 0.1505 ± 0.0009 | 0.1340 ± 0.0032 |
| Radius (mm) | 0.2157 ± 0.0103 | 0.2017 ± 0.0126 |
| (mm−1) | 0.1131 ± 0.0091 | 0.0975 ± 0.0065 |
| S. No. | Article | Research Type | Background Type | RMSE |
|---|---|---|---|---|
| P. | Proposed algorithm (XGBoost + GP) | Simulation | Inhomogeneous background mesh (DigiBreast [40]) | 0.12 |
| 1. | Jaejun Yoo et al. [15] (Neural network for inverting Lippman–Schwinger equation) | Simulation and Experiment | Homogeneous background mesh (breast mesh and full body rat mesh) | 0.66 |
| 2. | Yun Zou et al. [8](ML-PC model) | Simulation and Experiment | Homogeneous background mesh | 0.30 |
| 3. | GM. Balasubramaniam et al. [17] (Cascaded feed-forward neural network) | Simulation | Homogeneous background mesh | 0.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hauptman, A.; Balasubramaniam, G.M.; Arnon, S. Machine Learning Diffuse Optical Tomography Using Extreme Gradient Boosting and Genetic Programming. Bioengineering 2023, 10, 382. https://doi.org/10.3390/bioengineering10030382
Hauptman A, Balasubramaniam GM, Arnon S. Machine Learning Diffuse Optical Tomography Using Extreme Gradient Boosting and Genetic Programming. Bioengineering. 2023; 10(3):382. https://doi.org/10.3390/bioengineering10030382
Chicago/Turabian StyleHauptman, Ami, Ganesh M. Balasubramaniam, and Shlomi Arnon. 2023. "Machine Learning Diffuse Optical Tomography Using Extreme Gradient Boosting and Genetic Programming" Bioengineering 10, no. 3: 382. https://doi.org/10.3390/bioengineering10030382
APA StyleHauptman, A., Balasubramaniam, G. M., & Arnon, S. (2023). Machine Learning Diffuse Optical Tomography Using Extreme Gradient Boosting and Genetic Programming. Bioengineering, 10(3), 382. https://doi.org/10.3390/bioengineering10030382