
DSE-NN: Deeply Supervised Efficient Neural Network for Real-Time Remote Photoplethysmography


Abstract
:1. Introduction
- We introduce spectral deep supervision to rPPG models, which learns quickly through spectral loss of intermediate layers that facilitates convergence and increases accuracy.
- Through investigation of visualization of intermediate layers we provide intuitions about the need for efficient networks as well as their guided supervision of the hidden neurons.
- Using the obtained basis for reducing model complexity, we optimized the spatiotemporal network for weight reduction accompanied by ablation studies, resulting in the number of trainable parameters being reduced by a factor of 11.
2. Related Works
2.1. rPPG Based on Deep Learning
2.2. Efficient Neural Networks for rPPG
2.3. Deep Supervision
3. Methods
3.1. Datasets for rPPG
3.2. Implementation Details
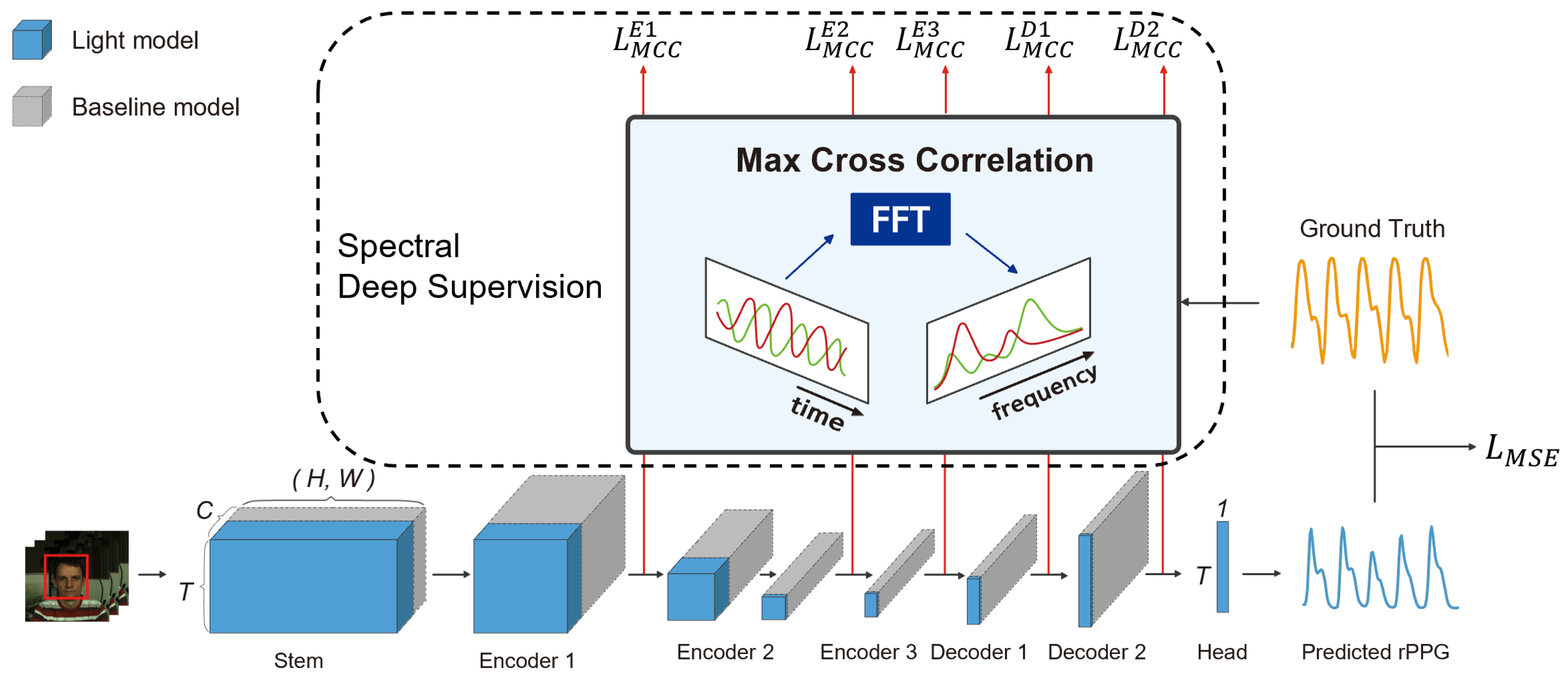
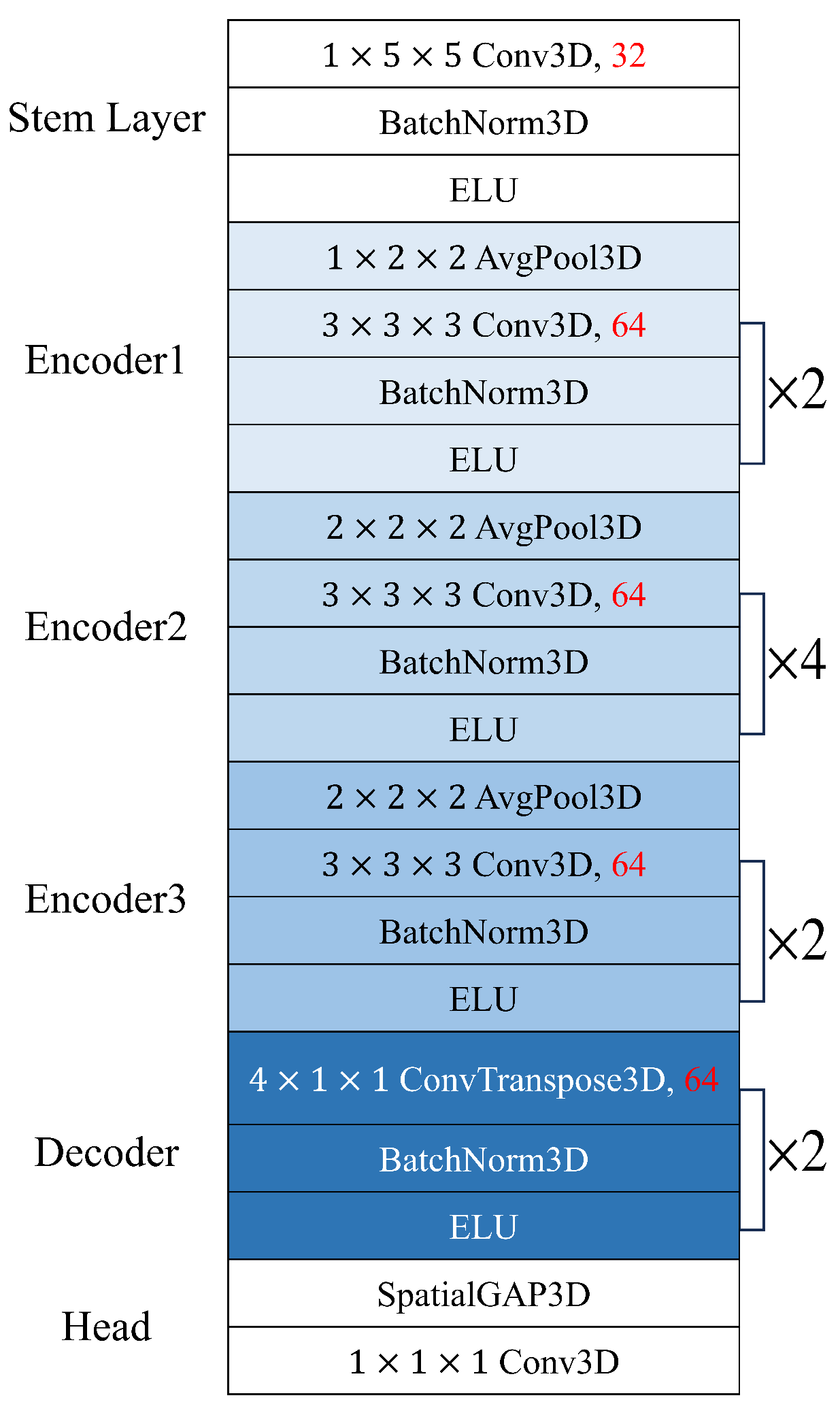
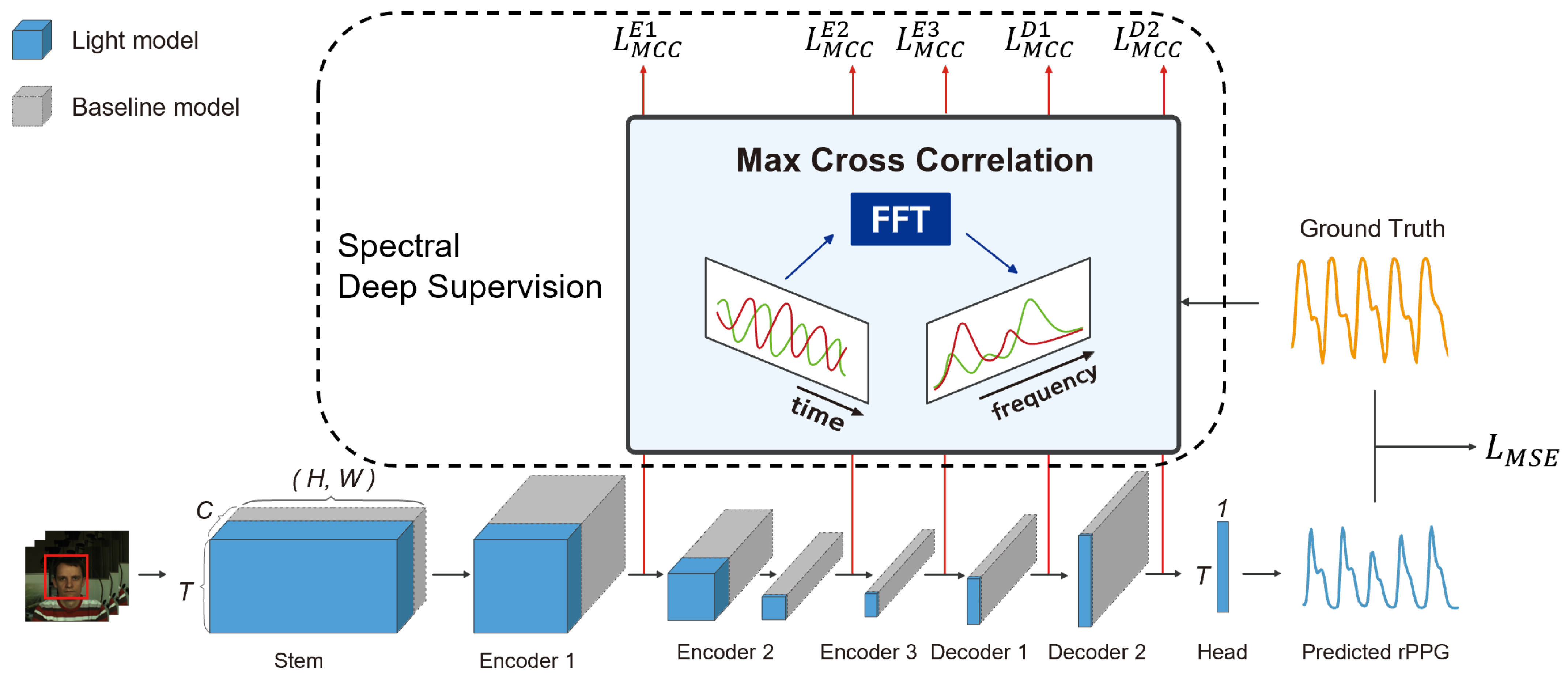
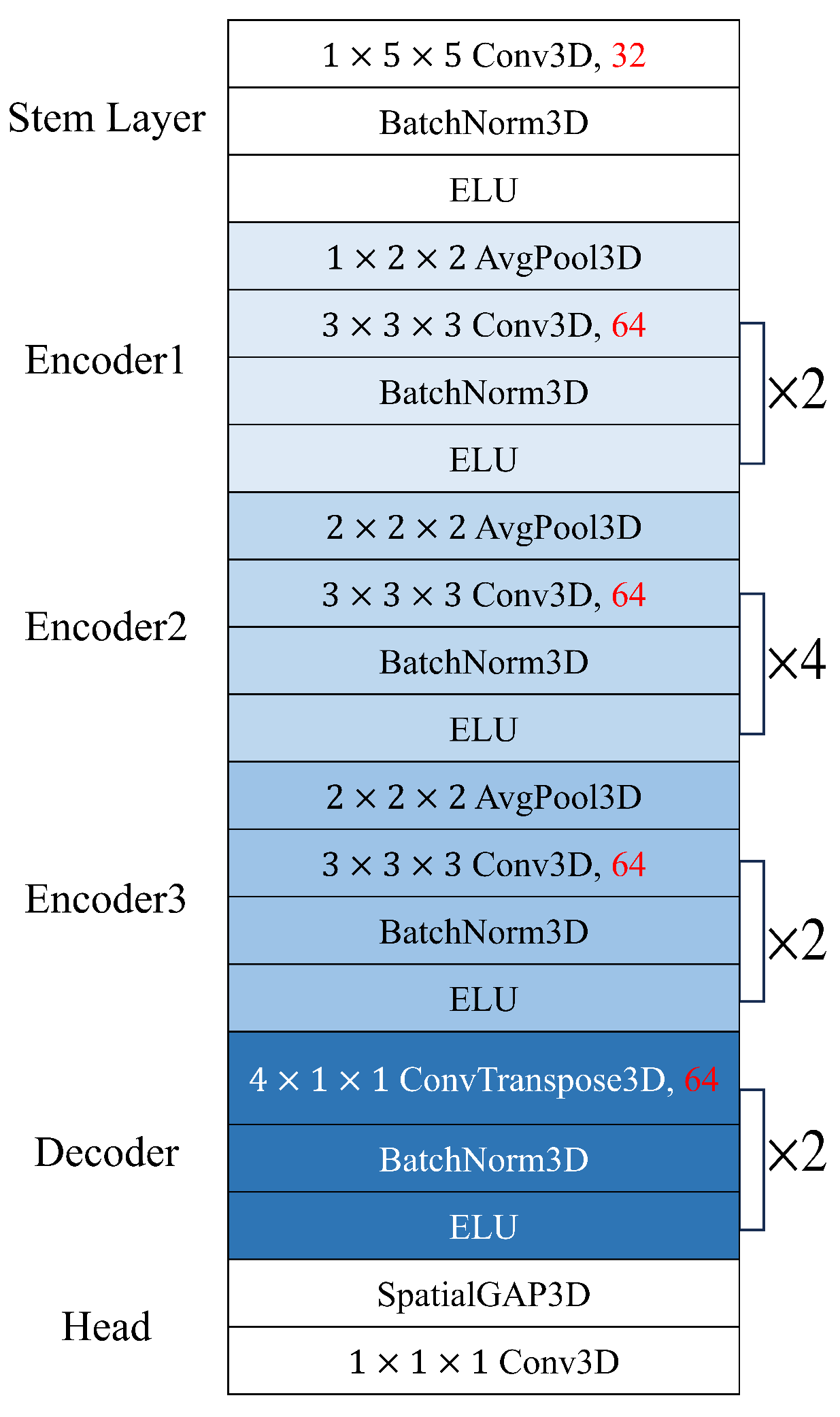
3.3. Spatiotemporal Encoder-Decoder Network
3.4. Deeply Supervised rPPG Network
3.5. Optimization of Network Architecture through Cost Function
3.6. Evaluation Metrics
3.7. Experimental Setup
4. Results
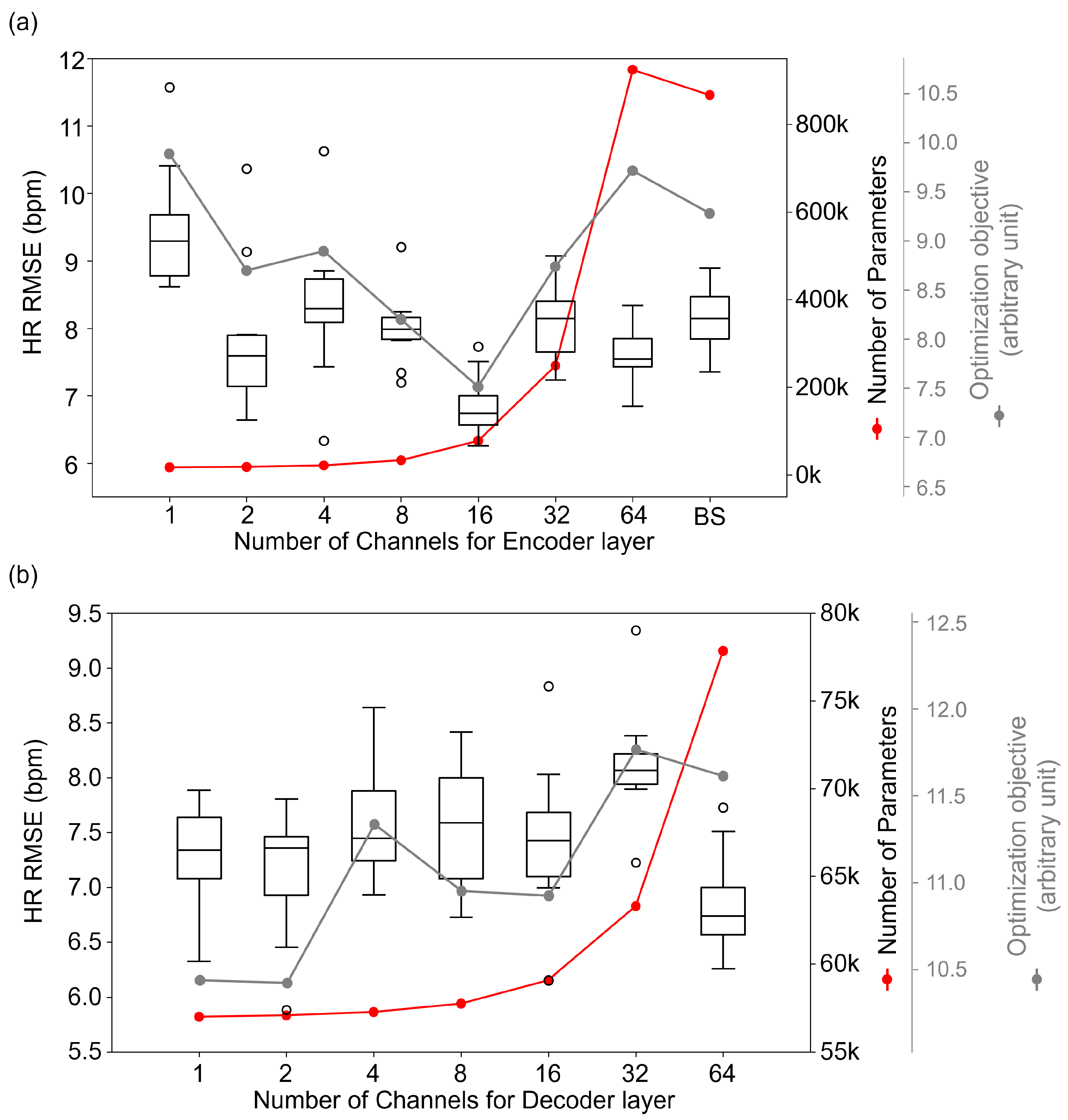
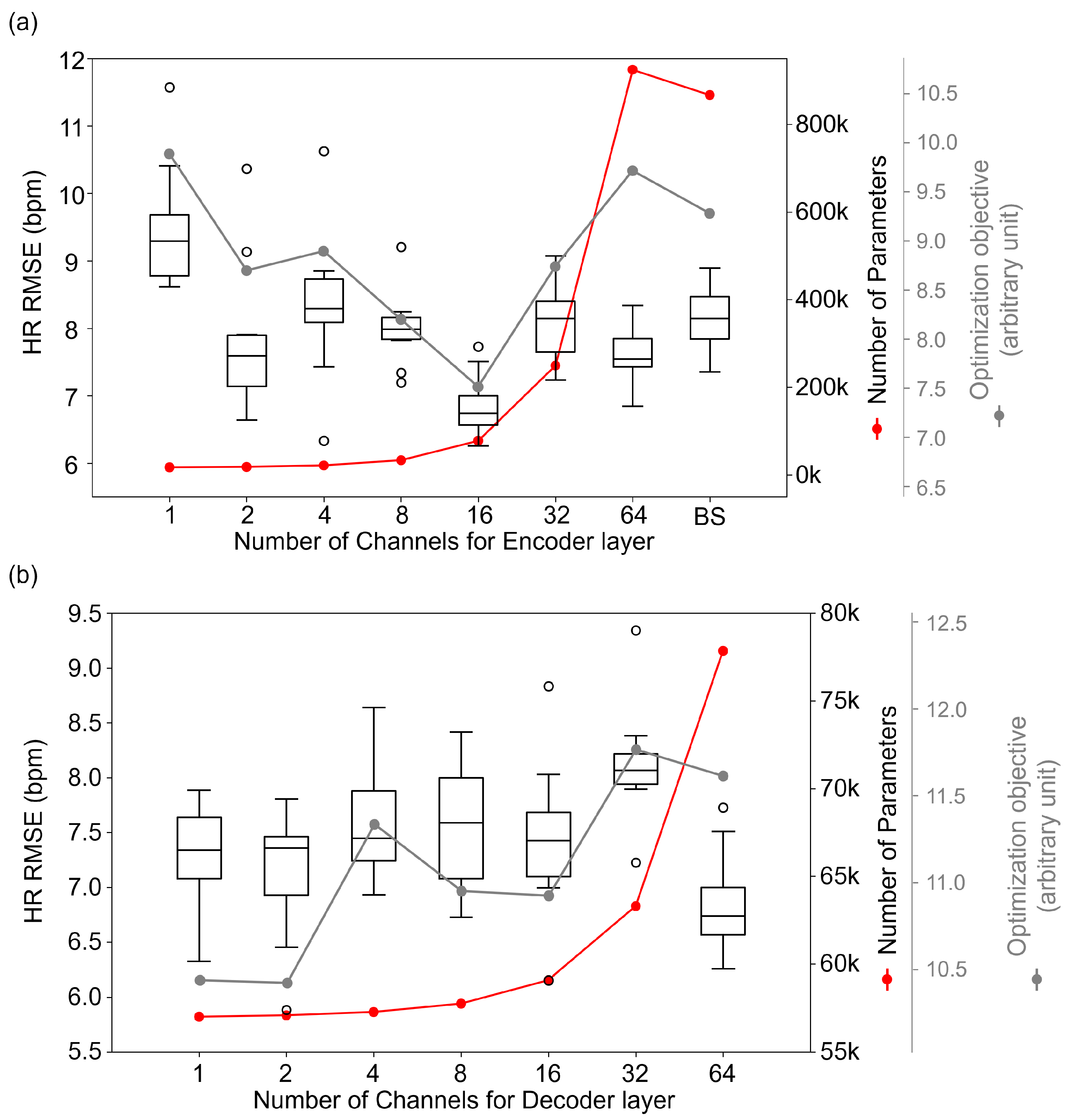
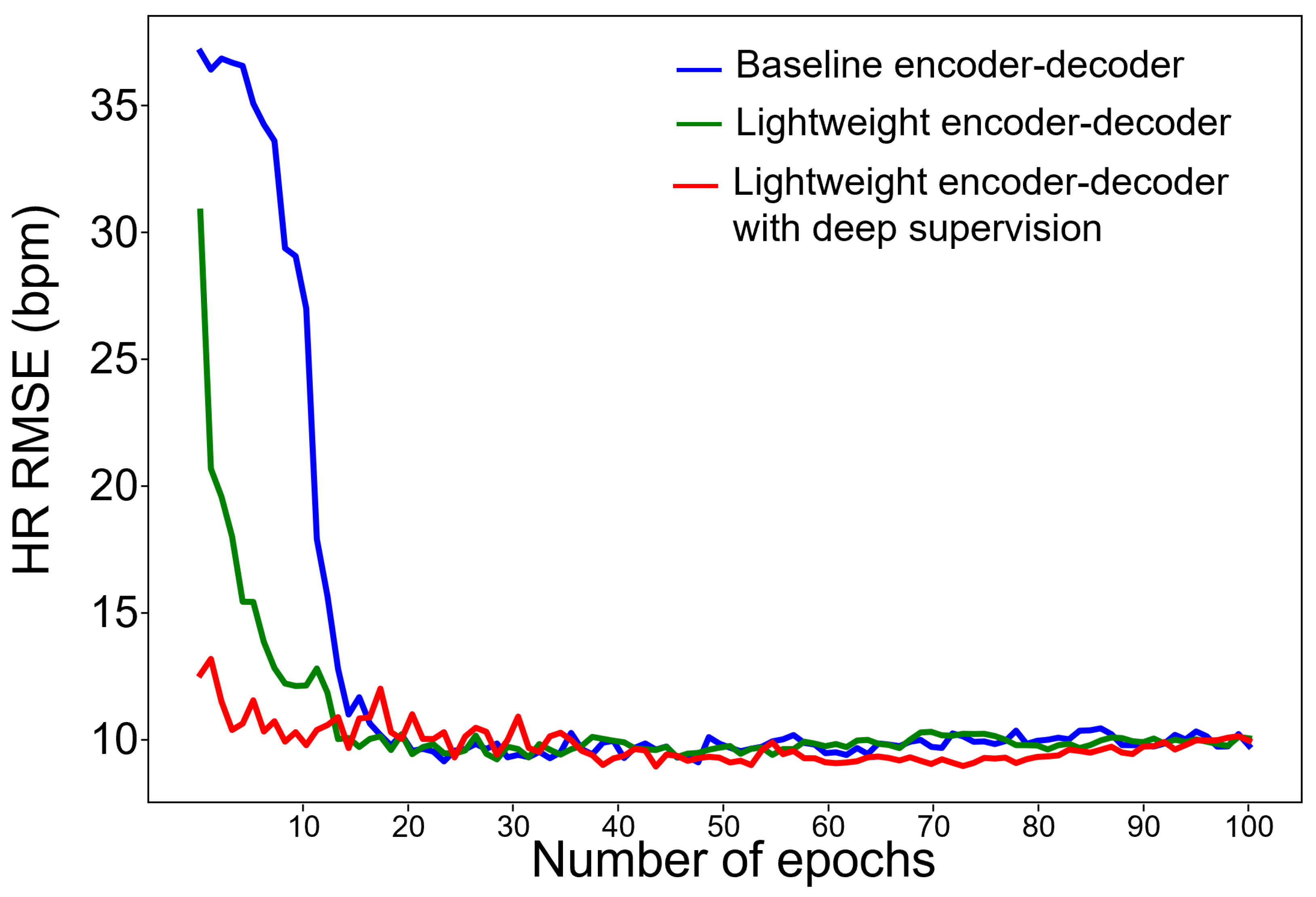
4.1. Optimization of Spatiotemporal Network
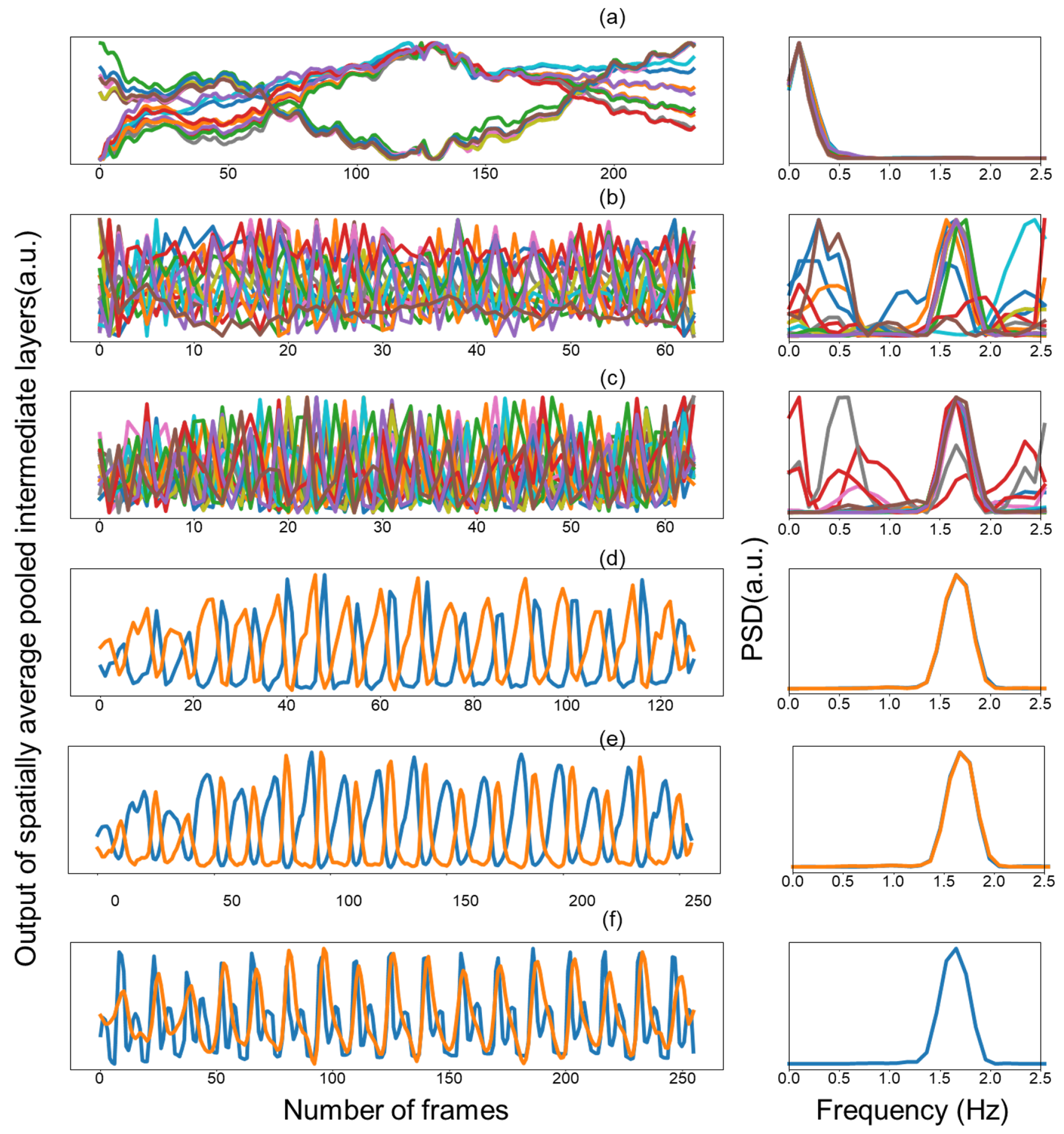
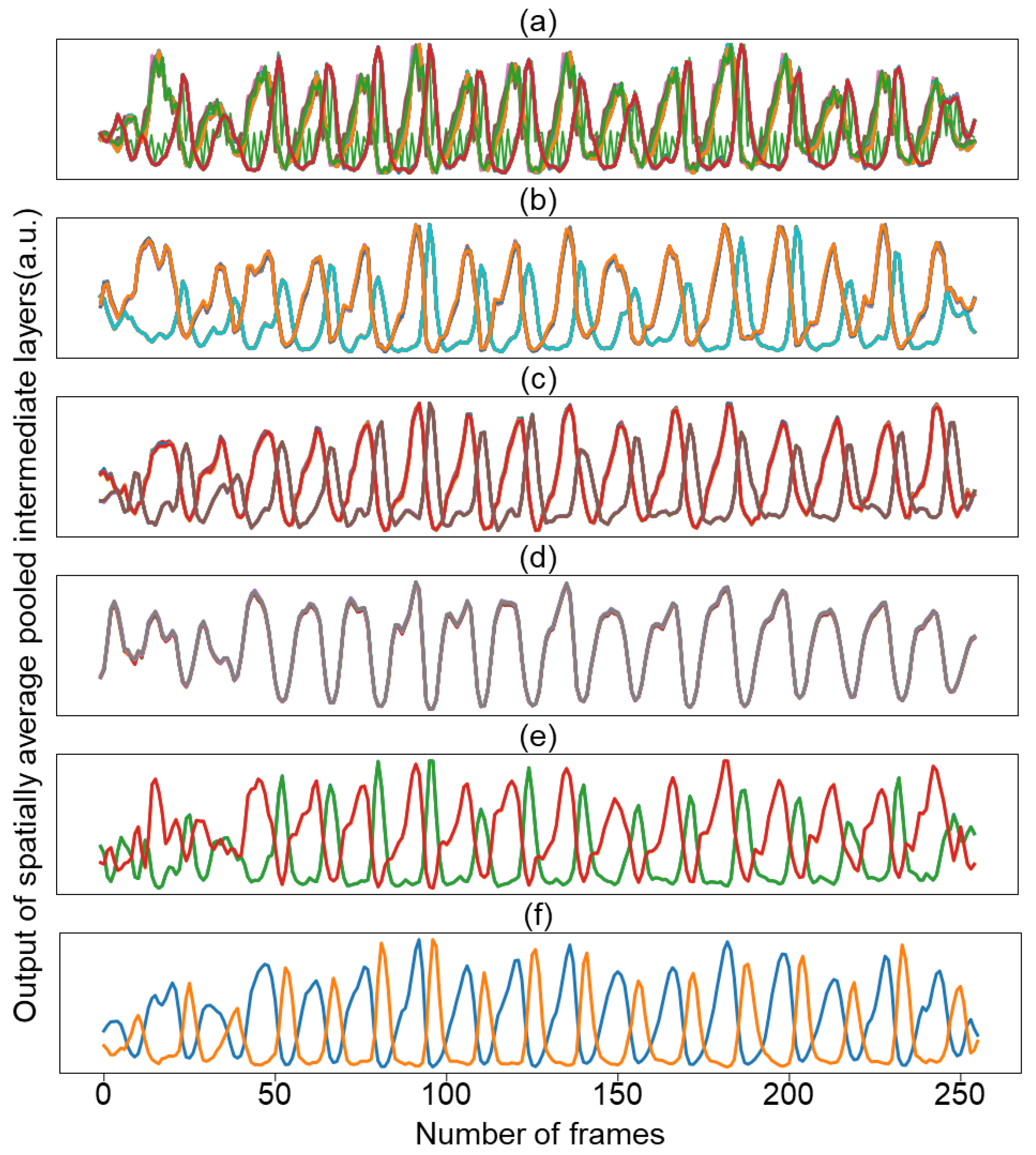
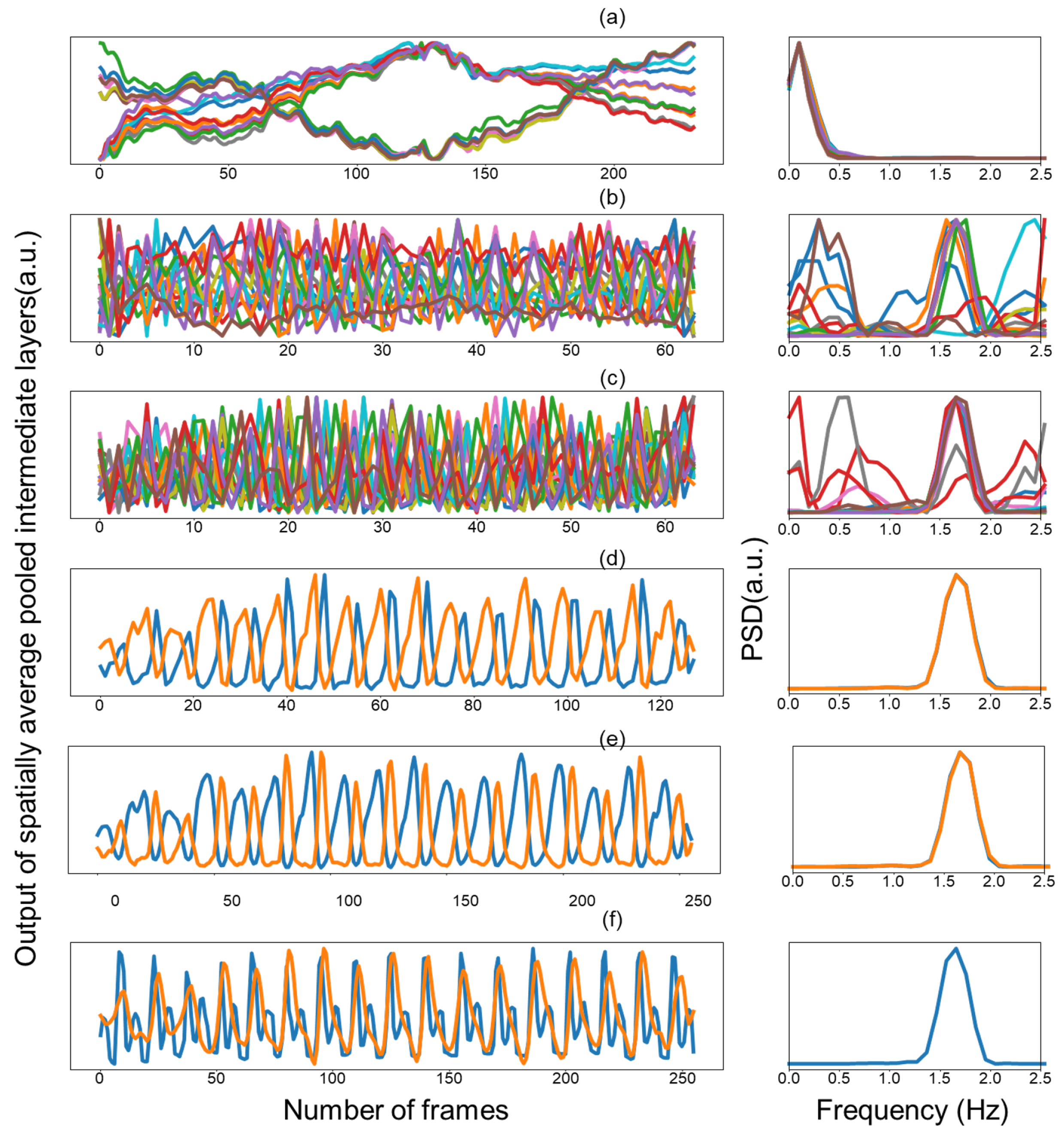
4.2. Visualization of Features and Learned Filters
4.3. Ablation Study
5. Discussion
5.1. Impacts of Deep Supervision
5.2. Performance on PURE, UBFC-rPPG, V4V
5.3. Comparison of Computational Complexity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| rPPG | Remote Photoplethysmography |
| PPG | Photoplethysmography |
| ROI | Region of Interest |
| CNN | Convolutional Neural Network |
| LSTM | Long Short Time Memory |
| DSE-NN | Deep Supervised Efficient Neural Network |
| HR | Heart Rate |
| V4V | Vision-for Vitals |
| MCC | Maximum Cross Correlation |
| RMSE | Root Mean Squared Error |
| MSE | Mean Squared Error |
| MAE | Mean Absolute Error |
| PCC | Pearson Correlation Coefficient |
| bpm | Beats per Minute |
| NegPCC | Negative Pearson Correlation Coefficient |
| a.u. | arbitrary unit |
References
- Zhao, P.; Lu, C.X.; Wang, B.; Chen, C.; Xie, L.; Wang, M.; Trigoni, N.; Markham, A. Heart Rate Sensing with a Robot Mounted mmWave Radar. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Online, 1 May–31 August 2020; pp. 2812–2818. [Google Scholar]
- Shen, Y.; Voisin, M.; Aliamiri, A.; Avati, A.; Hannun, A.; Ng, A. Ambulatory Atrial Fibrillation Monitoring Using Wearable Photoplethysmography with Deep Learning. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1909–1916. [Google Scholar]
- Pham, M.; Do, H.M.; Su, Z.; Bishop, A.; Sheng, W. Negative Emotion Management Using a Smart Shirt and a Robot Assistant. IEEE Robot. Autom. Lett. 2021, 6, 4040–4047. [Google Scholar] [CrossRef]
- Kawakami, K.; Ogawa, T.; Haseyama, M. Blood Circulation Based on PPG Signals for Thermal Comfort Evaluation. In Proceedings of the 2018 IEEE 7th Global Conference on Consumer Electronics (GCCE), Nara, Japan, 9–12 October 2018; pp. 194–195. [Google Scholar]
- Kontaxis, S.; Gil, E.; Marozas, V.; Lázaro, J.; García, E.; Posadas-de Miguel, M.; Siddi, S.; Bernal, M.L.; Aguiló, J.; Haro, J.M.; et al. Photoplethysmographic Waveform Analysis for Autonomic Reactivity Assessment in Depression. IEEE Trans. Biomed. Eng. 2021, 68, 1273–1281. [Google Scholar] [CrossRef] [PubMed]
- Jindal, V. Integrating Mobile and Cloud for PPG Signal Selection to Monitor Heart Rate during Intensive Physical Exercise. In Proceedings of the 2016 IEEE/ACM International Conference on Mobile Software Engineering and Systems (MOBILESoft), Austin, TX, USA, 16–17 May 2016; pp. 36–37. [Google Scholar]
- Stricker, R.; Müller, S.; Groß, H. Non-Contact Video-Based Pulse Rate Measurement on a Mobile Service Robot. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014. [Google Scholar]
- Gao, H.; Wu, X.; Shi, C.; Gao, Q.; Geng, J. A LSTM-Based Realtime Signal Quality Assessment for Photoplethysmogram and Remote Photoplethysmogram. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3831–3840. [Google Scholar]
- Shoushan, M.M.; Alexander Reyes, B.; Rodriguez, A.M.; Woon Chong, J. Contactless Heart Rate Variability (HRV) Estimation Using a Smartphone During Respiratory Maneuvers and Body Movement. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine Biology Society (EMBC), Guadalajara, Mexico, 1–5 November 2021; pp. 84–87. [Google Scholar]
- Wang, W.; Stuijk, S.; De Haan, G. Exploiting Spatial Redundancy of Image Sensor for Motion Robust rPPG. IEEE Trans. Biomed. Eng. 2014, 62, 415–425. [Google Scholar] [CrossRef] [PubMed]
- Boccignone, G.; Conte, D.; Cuculo, V.; D’Amelio, A.; Grossi, G.; Lanzarotti, R. An Open Framework for Remote-PPG Methods and Their Assessment. IEEE Access 2020, 8, 216083–216103. [Google Scholar] [CrossRef]
- Yin, R.-N.; Jia, R.-S.; Cui, Z.; Sun, H.-M. PulseNet: A Multitask Learning Network for Remote Heart Rate Estimation. Knowledge-Based Syst. 2022, 239, 108048. [Google Scholar] [CrossRef]
- Gudi, A.; Bittner, M.; Lochmans, R.; Van Gemert, J. Efficient Real-Time Camera Based Estimation of Heart Rate and Its Variability. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Tasli, H.E.; Gudi, A.; den Uyl, M. Remote PPG Based Vital Sign Measurement Using Adaptive Facial Regions. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1410–1414. [Google Scholar]
- Wang, W.; den Brinker, A.C.; Stuijk, S.; de Haan, G. Algorithmic Principles of Remote PPG. IEEE Trans. Biomed. Eng. 2017, 64, 1479–1491. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Fromm, J.; Patel, S.; McDuff, D. Multi-Task Temporal Shift Attention Networks for on-Device Contactless Vitals Measurement. Adv. Neural Inf. Process. Syst. 2020, 33, 19400–19411. [Google Scholar]
- Kuang, H.; Lv, F.; Ma, X.; Liu, X. Efficient Spatiotemporal Attention Network for Remote Heart Rate Variability Analysis. Sensors 2022, 22, 1010. [Google Scholar] [CrossRef] [PubMed]
- Comas, J.; Ruiz, A.; Sukno, F. Efficient Remote Photoplethysmography with Temporal Derivative Modules and Time-Shift Invariant Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2182–2191. [Google Scholar]
- Botina-Monsalve, D.; Benezeth, Y.; Miteran, J. RTrPPG: An Ultra Light 3DCNN for Real-Time Remote Photoplethysmography. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 2145–2153. [Google Scholar]
- Yu, Z.; Yu, Z.; Li, X.; Li, X.; Zhao, G.; Zhao, G. Remote Photoplethysmograph Signal Measurement from Facial Videos Using Spatio-Temporal Networks. In Proceedings of the British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019; p. 12. [Google Scholar]
- Chen, W.; McDuff, D. DeepPhys: Video-Based Physiological Measurement Using Convolutional Attention Networks. In Proceedings of the Computer Vision—ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Špetlík, R.; Franc, V.; Matas, J. Visual Heart Rate Estimation with Convolutional Neural Network. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; pp. 3–6. [Google Scholar]
- Qiu, Y.; Liu, Y.; Arteaga-Falconi, J.; Dong, H.; Saddik, A.E. EVM-CNN: Real-Time Contactless Heart Rate Estimation From Facial Video. IEEE Trans. Multimed. 2019, 21, 1778–1787. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-Supervised Nets. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics (PMLR 38), San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Revanur, A.; Dasari, A.; Tucker, C.S.; Jeni, L.A. Instantaneous Physiological Estimation Using Video Transformers. In Multimodal AI in Healthcare: A Paradigm Shift in Health Intelligence; Springer: Berlin/Heidelberg, Germany, 2022; pp. 307–319. [Google Scholar]
- Zhang, Z.; Girard, J.M.; Wu, Y.; Zhang, X.; Liu, P.; Ciftci, U.; Canavan, S.; Reale, M.; Horowitz, A.; Yang, H. Multimodal Spontaneous Emotion Corpus for Human Behavior Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3438–3446. [Google Scholar]
- Bobbia, S.; Macwan, R.; Benezeth, Y.; Mansouri, A.; Dubois, J. Unsupervised Skin Tissue Segmentation for Remote Photoplethysmography. Pattern Recognit. Lett. 2019, 124, 82–90. [Google Scholar] [CrossRef]
- Gideon, J.; Stent, S. The Way to My Heart Is through Contrastive Learning: Remote Photoplethysmography from Unlabelled Video. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3975–3984. [Google Scholar]
- Poh, M.-Z.; McDuff, D.J.; Picard, R.W. Advancements in Noncontact, Multiparameter Physiological Measurements Using a Webcam. IEEE Trans. Biomed. Eng. 2011, 58, 7–11. [Google Scholar] [CrossRef] [PubMed]
- Verkruysse, W.; Svaasand, L.O.; Nelson, J.S. Remote Plethysmographic Imaging Using Ambient Light. Opt. Express 2008, 16, 21434–21445. [Google Scholar] [CrossRef] [PubMed]
- De Haan, G.; Jeanne, V. Robust Pulse Rate From Chrominance-Based rPPG. IEEE Trans. Biomed. Eng. 2013, 60, 2878–2886. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.-K.; Kao, Y.; Hsu, C.-T. Vision-Based Heart Rate Estimation Via A Two-Stream CNN. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3327–3331. [Google Scholar]
- Song, R.; Chen, H.; Cheng, J.; Li, C.; Liu, Y.; Chen, X. PulseGAN: Learning to Generate Realistic Pulse Waveforms in Remote Photoplethysmography. IEEE J. Biomed. Health Inform. 2021, 25, 1373–1384. [Google Scholar] [CrossRef] [PubMed]
- Lee, E.; Chen, E.; Lee, C.-Y. Meta-rPPG: Remote Heart Rate Estimation Using a Transductive Meta-Learner. In Proceedings of the Computer Vision—ECCV, Virtual, 7–10 September 2020. [Google Scholar]
- Lokendra, B.; Puneet, G. AND-rPPG: A Novel Denoising-rPPG Network for Improving Remote Heart Rate Estimation. Comput. Biol. Med. 2022, 141, 105146. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Cao, P.; Xu, S.; Li, Z.; Feng, Y. Pruning rPPG networks: Toward small dense network with limited number of training samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2055–2064. [Google Scholar]
- Niu, X.; Shan, S.; Han, H.; Chen, X. Rhythmnet: End-to-end heart rate estimation from face via spatial-temporal representation. IEEE Trans. Image Process. 2019, 29, 2409–2423. [Google Scholar] [CrossRef] [PubMed]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PURE | UBFC-RPPG | V4V | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | RMSE | MAE | PCC | RMSE | MAE | PCC | RMSE | MAE | PCC |
| (bpm) | (bpm) | (a.u.) | (bpm) | (bpm) | (a.u.) | (bpm) | (bpm) | (a.u.) | |
| Encoder-decoder, MSE | 4.833 | 1.566 | 0.762 | 6.693 | 2.188 | 0.726 | 7.441 | 3.333 | 0.802 |
| Encoder-decoder, NegPCC | 3.750 | 1.131 | 0.810 | 5.558 | 2.078 | 0.887 | 6.671 | 2.830 | 0.855 |
| Light-weight, MSE | 2.227 | 1.155 | 0.537 | 6.324 | 1.988 | 0.811 | 6.765 | 2.946 | 0.848 |
| Light-weight, MCC | 5.042 | 1.634 | 0.141 | 7.039 | 2.469 | 0.817 | 7.035 | 2.968 | 0.858 |
| Light-weight, NegMCC | 4.379 | 1.401 | 0.779 | 7.566 | 2.453 | 0.841 | 7.935 | 3.745 | 0.844 |
| Light, DS (MCC), MSE | 1.062 | 0.652 | 0.979 | 4.339 | 1.618 | 0.764 | 6.650 | 2.821 | 0.873 |
| (a) PURE | |||
|---|---|---|---|
| Method | RMSE (bpm) | MAE (bpm) | PCC (a.u.) |
| Comas et al. [18], CHROM [39] | 2.50 | 2.07 | 0.99 |
| Comas et al. [18], POS [15] | 10.57 | 3.14 | 0.95 |
| Wang et al. [40] | 11.81 | 9.81 | 0.42 |
| Gideon et al. [36] | 2.9 | 2.3 | 0.99 |
| HR-CNN [22] | 2.37 | 1.84 | 0.98 |
| Proposed method | 1.06 | 0.65 | 0.98 |
| (b) UBFC-RPPG | |||
| Method | RMSE (bpm) | MAE (bpm) | PCC (a.u.) |
| PhysNet [20] | 5.10 | 4.12 | 0.83 |
| Meta-rPPG [42] | 7.42 | 5.97 | 0.53 |
| PulseGAN [41] | 2.10 | 1.19 | 0.98 |
| Gideon et al. [36] | 4.6 | 3.6 | 0.95 |
| AND-rPPG [43] | 4.75 | 3.15 | 0.92 |
| Proposed method | 4.34 | 1.62 | 0.76 |
| (c) V4V | |||
| Method | RMSE (bpm) | MAE (bpm) | PCC (a.u.) |
| GREEN [38] | 21.9 | 15.5 | - |
| ICA [37] | 20.6 | 15.1 | - |
| Comas et al. [18], POS [15] | 21.8 | 15.3 | - |
| DeepPhys [33] | 19.7 | 14.7 | - |
| Revanur et al. [33] | 18.8 | 13.0 | - |
| Proposed method | 6.65 | 2.81 | 0.87 |
| Name | Input Size | # of Layers | # of Parameters | FLOPs () |
|---|---|---|---|---|
| DeepPhys [21,44] | 3 × 150 × 36 × 36 (3 × 256 × 128 × 128) | 9 | 1.46 M | 9.62 (207.56) |
| HR-CNN [22,44] | 3 × 300 × 192 × 168 (3 × 256 × 128 × 128) | 13 | 1.87 M | 988.97 (428.66) |
| Liu et al. [16,44] | 3 × 150 × 36 × 36 (3 × 256 × 128 × 128) | 9 | 1.45 M | 9.61 (207.34) |
| RhythmNet [44,45] | 3 × 10 × 300 × 25 (3 × 256 × 128 × 128) | 21 | 11.42 M | 1.70 (95.07) |
| PhysNet Encoder-Decoder [20] | 3 × 256 × 128 × 128 | 12 | 866.69 k | 438.62 |
| Proposed method | 3 × 256 × 128 × 128 | 12 | 57.09 k | 44.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Lee, M.; Sim, J.Y. DSE-NN: Deeply Supervised Efficient Neural Network for Real-Time Remote Photoplethysmography. Bioengineering 2023, 10, 1428. https://doi.org/10.3390/bioengineering10121428
Lee S, Lee M, Sim JY. DSE-NN: Deeply Supervised Efficient Neural Network for Real-Time Remote Photoplethysmography. Bioengineering. 2023; 10(12):1428. https://doi.org/10.3390/bioengineering10121428
Chicago/Turabian StyleLee, Seongbeen, Minseon Lee, and Joo Yong Sim. 2023. "DSE-NN: Deeply Supervised Efficient Neural Network for Real-Time Remote Photoplethysmography" Bioengineering 10, no. 12: 1428. https://doi.org/10.3390/bioengineering10121428
APA StyleLee, S., Lee, M., & Sim, J. Y. (2023). DSE-NN: Deeply Supervised Efficient Neural Network for Real-Time Remote Photoplethysmography. Bioengineering, 10(12), 1428. https://doi.org/10.3390/bioengineering10121428