
BlobCUT: A Contrastive Learning Method to Support Small Blob Detection in Medical Imaging

 ,
,
Abstract
:1. Introduction
- A novel small blob detector: the proposed BlobCUT leverages Generative Adversarial Network (GAN) and Contrastive Learning to address the challenge of limited labeled data. By incorporating the assumption of geometric properties, BlobCUT offers a novel, effective and efficient solution for detecting small blobs.
- Novel constraints for improved performance: This work introduces a novel convexity consistency constraint, based on Hessian analysis, and a unique blob distribution consistency constraint, based on Kullback–Leibler divergence. These constraints are designed to preserve the geometry property and intensity distribution of blobs, resulting in enhanced segmentation performance.
- Comprehensive performance evaluation: Extensive comparisons were conducted with six state-of-the-art methods, spanning both simulated and real MRI datasets. The outcomes of these comparisons affirm the superior performance of BlobCUT, underlining its effectiveness in small blob detection compared to existing methodologies.
2. Literature Review
3. Materials and Methods
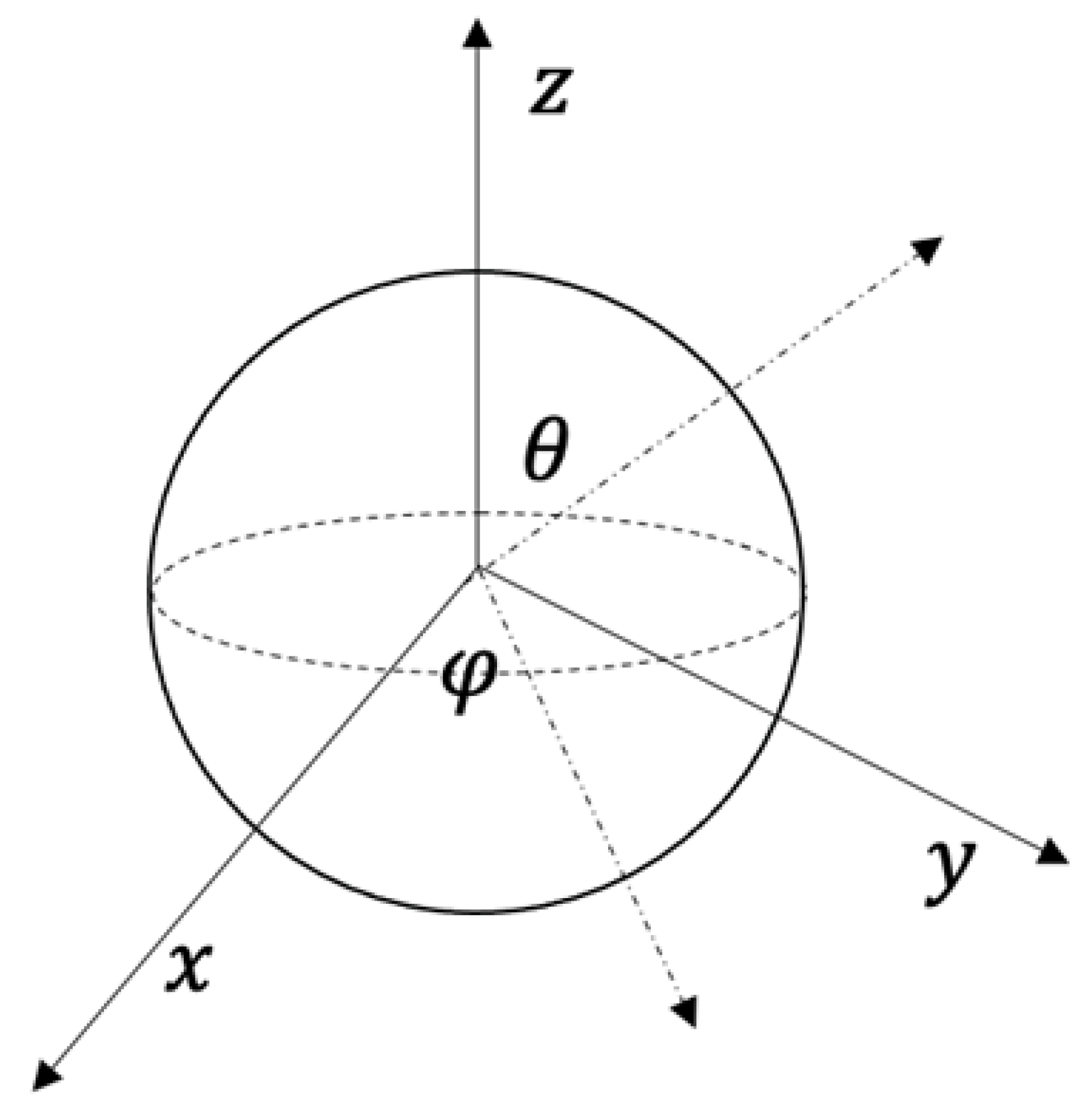
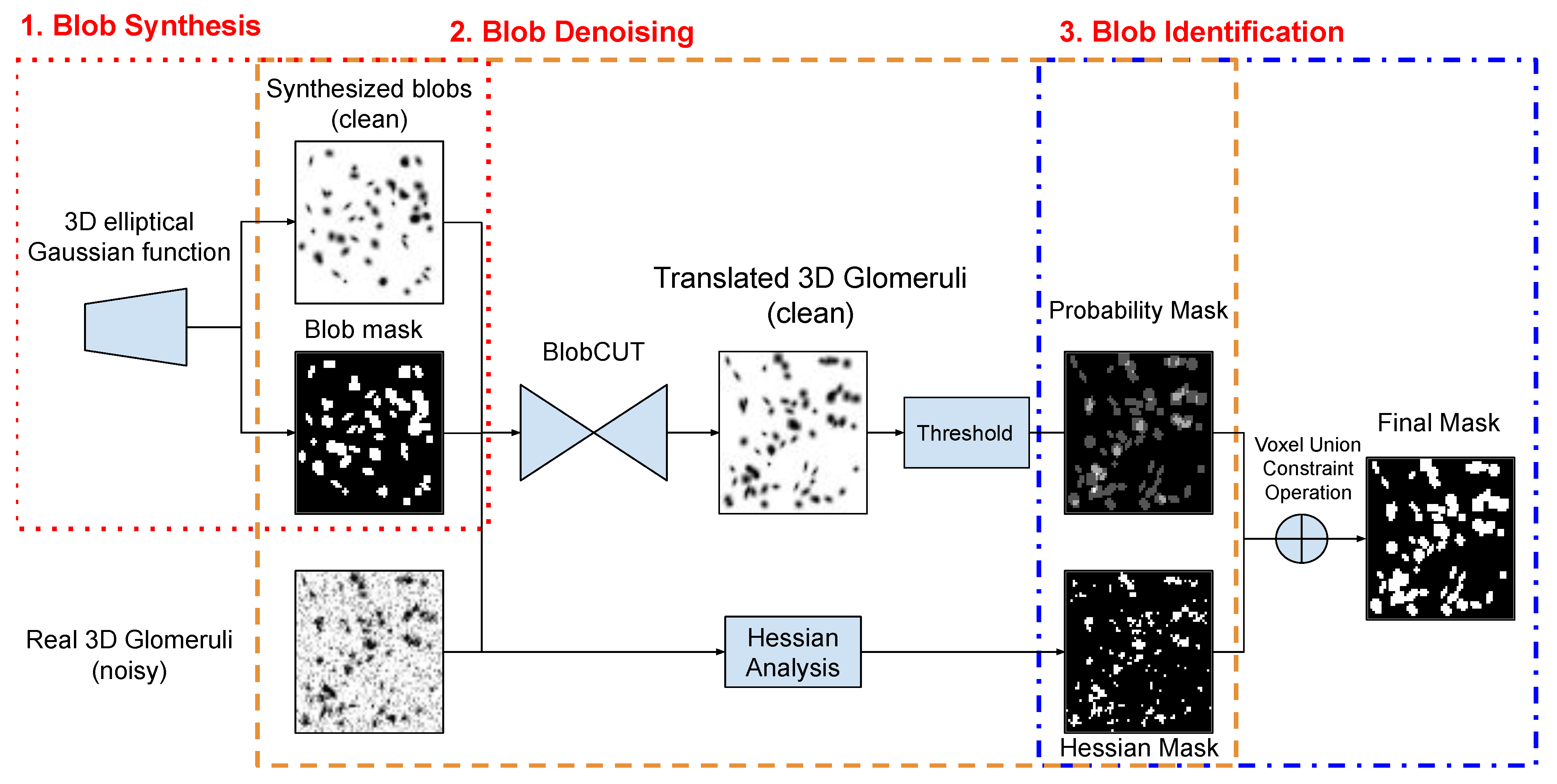
3.1. 3D Blob Synthesis through 3D Gaussian Function
3.2. 3D Blob Images Detecting through 3D GAN with Contrastive Learning
3.3. 3D Blob Identification through Voxel Union Constraint Operation
4. Experiments and Results
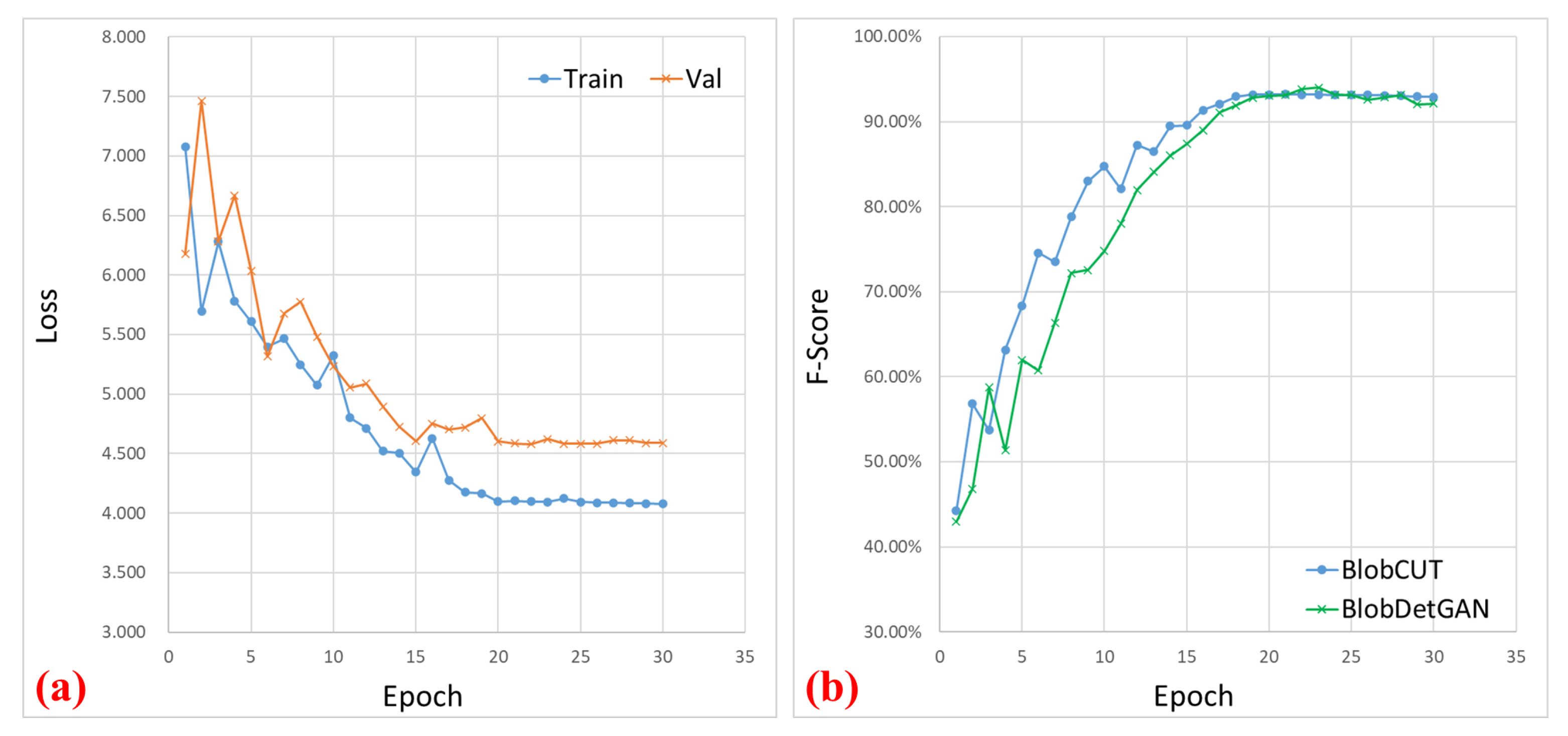
4.1. Networks and Hardware
4.2. Dataset Description
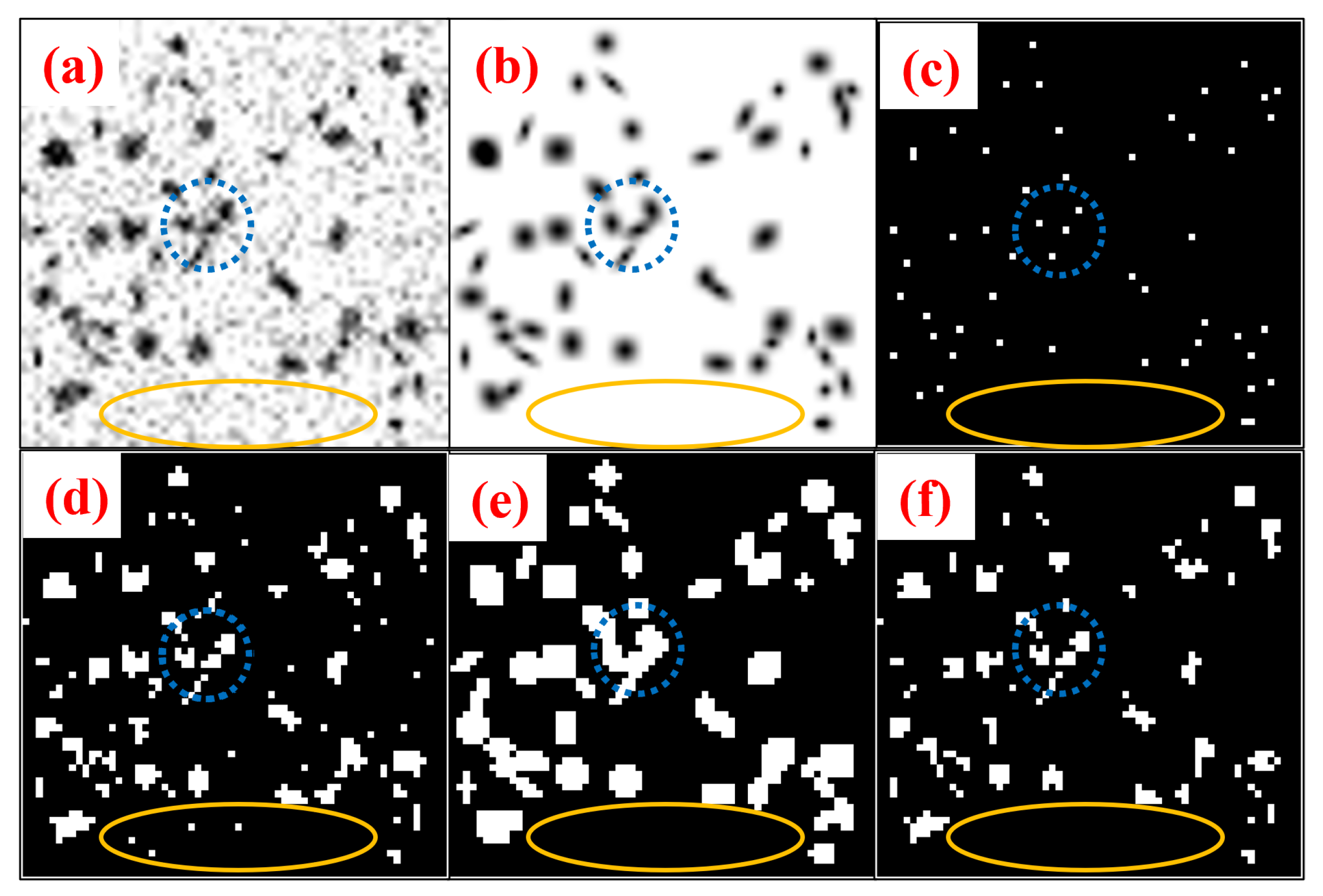
4.3. Experiment I: 3D Synthetic Image Data
4.4. Experiment II: 3D MR Images of Mouse Kidney
5. Discussion: Denoising and Applications
5.1. Denoising
5.2. Applications
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Dolz, J.; Gopinath, K.; Yuan, J.; Lombaert, H.; Desrosiers, C.; Ayed, I.B. HyperDense-Net: A hyper-densely connected CNN for multi-modal image segmentation. IEEE Trans. Med. Imaging 2018, 38, 1116–1126. [Google Scholar] [CrossRef]
- Chang, S.; Chen, X.; Duan, J.; Mou, X. A CNN-based hybrid ring artifact reduction algorithm for CT images. IEEE Trans. Radiat. Plasma Med. Sci. 2020, 5, 253–260. [Google Scholar] [CrossRef]
- Gupta, H.; Jin, K.H.; Nguyen, H.Q.; McCann, M.T.; Unser, M. CNN-based projected gradient descent for consistent CT image reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1440–1453. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Li, J.; Sarma, K.V.; Ho, K.C.; Shen, S.; Knudsen, B.S.; Gertych, A.; Arnold, C.W. Path R-CNN for prostate cancer diagnosis and gleason grading of histological images. IEEE Trans. Med. Imaging 2018, 38, 945–954. [Google Scholar] [CrossRef] [PubMed]
- Altarazi, S.; Allaf, R.; Alhindawi, F. Machine learning models for predicting and classifying the tensile strength of polymeric films fabricated via different production processes. Materials 2019, 12, 1475. [Google Scholar] [CrossRef] [PubMed]
- Alhindawi, F.; Altarazi, S. Predicting the tensile strength of extrusion-blown high density polyethylene film using machine learning algorithms. In Proceedings of the 2018 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Bangkok, Thailand, 16–19 December 2018; pp. 715–719. [Google Scholar]
- Al-Hindawi, F.; Soori, T.; Hu, H.; Siddiquee, M.M.R.; Yoon, H.; Wu, T.; Sun, Y. A framework for generalizing critical heat flux detection models using unsupervised image-to-image translation. Expert Syst. Appl. 2023, 227, 120265. [Google Scholar] [CrossRef]
- Al-Hindawi, F.; Siddiquee, M.M.R.; Wu, T.; Hu, H.; Sun, Y. Domain-knowledge Inspired Pseudo Supervision (DIPS) for unsupervised image-to-image translation models to support cross-domain classification. Eng. Appl. Artif. Intell. 2024, 127, 107255. [Google Scholar] [CrossRef]
- Rassoulinejad-Mousavi, S.M.; Al-Hindawi, F.; Soori, T.; Rokoni, A.; Yoon, H.; Hu, H.; Wu, T.; Sun, Y. Deep learning strategies for critical heat flux detection in pool boiling. Appl. Therm. Eng. 2021, 190, 116849. [Google Scholar] [CrossRef]
- Moridian, P.; Ghassemi, N.; Jafari, M.; Salloum-Asfar, S.; Sadeghi, D.; Khodatars, M.; Shoeibi, A.; Khosravi, A.; Ling, S.H.; Subasi, A.; et al. Automatic autism spectrum disorder detection using artificial intelligence methods with MRI neuroimaging: A review. Front. Mol. Neurosci. 2022, 15, 999605. [Google Scholar] [CrossRef]
- Shoeibi, A.; Ghassemi, N.; Khodatars, M.; Moridian, P.; Khosravi, A.; Zare, A.; Gorriz, J.M.; Chale-Chale, A.H.; Khadem, A.; Rajendra Acharya, U. Automatic diagnosis of schizophrenia and attention deficit hyperactivity disorder in rs-fMRI modality using convolutional autoencoder model and interval type-2 fuzzy regression. In Cognitive Neurodynamics; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–23. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Xu, Y.; Wu, T.; Gao, F.; Charlton, J.R.; Bennett, K.M. Improved small blob detection in 3D images using jointly constrained deep learning and Hessian analysis. Sci. Rep. 2020, 10, 326. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, T.; Charlton, J.R.; Gao, F.; Bennett, K.M. Small blob detector using bi-threshold constrained adaptive scales. IEEE Trans. Biomed. Eng. 2020, 68, 2654–2665. [Google Scholar] [CrossRef] [PubMed]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 319–345. [Google Scholar]
- Torbunov, D.; Huang, Y.; Yu, H.; Huang, J.; Yoo, S.; Lin, M.; Viren, B.; Ren, Y. Uvcgan: Unet vision transformer cycle-consistent gan for unpaired image-to-image translation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 702–712. [Google Scholar]
- Zhao, M.; Bao, F.; Li, C.; Zhu, J. Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Adv. Neural Inf. Process. Syst. 2022, 35, 3609–3623. [Google Scholar]
- Xu, Y.; Wu, T.; Gao, F. Deep Learning based Blob Detection Systems and Methods. US Patent 17/698,750, 6 October 2022. [Google Scholar]
- Beeman, S.C.; Zhang, M.; Gubhaju, L.; Wu, T.; Bertram, J.F.; Frakes, D.H.; Cherry, B.R.; Bennett, K.M. Measuring glomerular number and size in perfused kidneys using MRI. Am. J. Physiol.-Ren. Physiol. 2011, 300, F1454–F1457. [Google Scholar] [CrossRef] [PubMed]
- Kong, H.; Akakin, H.C.; Sarma, S.E. A generalized Laplacian of Gaussian filter for blob detection and its applications. IEEE Trans. Cybern. 2013, 43, 1719–1733. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, T.; Bennett, K.M. Small blob identification in medical images using regional features from optimum scale. IEEE Trans. Biomed. Eng. 2014, 62, 1051–1062. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Wu, T.; Beeman, S.C.; Cullen-McEwen, L.; Bertram, J.F.; Charlton, J.R.; Baldelomar, E.; Bennett, K.M. Efficient small blob detection based on local convexity, intensity and shape information. IEEE Trans. Med. Imaging 2015, 35, 1127–1137. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Gao, F.; Wu, T.; Bennett, K.M.; Charlton, J.R.; Sarkar, S. U-net with optimal thresholding for small blob detection in medical images. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 1761–1767. [Google Scholar]
- Tan, J.; Gao, Y.; Liang, Z.; Cao, W.; Pomeroy, M.J.; Huo, Y.; Li, L.; Barish, M.A.; Abbasi, A.F.; Pickhardt, P.J. 3D-GLCM CNN: A 3-dimensional gray-level Co-occurrence matrix-based CNN model for polyp classification via CT colonography. IEEE Trans. Med. Imaging 2019, 39, 2013–2024. [Google Scholar] [CrossRef]
- Zreik, M.; Van Hamersvelt, R.W.; Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Išgum, I. A recurrent CNN for automatic detection and classification of coronary artery plaque and stenosis in coronary CT angiography. IEEE Trans. Med. Imaging 2018, 38, 1588–1598. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Nazeri, K.; Ng, E.; Ebrahimi, M. Image colorization using generative adversarial networks. In Proceedings of the Articulated Motion and Deformable Objects: 10th International Conference, AMDO 2018, Palma de Mallorca, Spain, 12–13 July 2018; pp. 85–94. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Xu, Y. Novel Computational Algorithms for Imaging Biomarker Identification. Ph.D. Thesis, Arizona State University, Tempe, AZ, USA, 2022. [Google Scholar]
- Wang, G.; Lopez-Molina, C.; De Baets, B. Blob reconstruction using unilateral second order Gaussian kernels with application to high-ISO long-exposure image denoising. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4817–4825. [Google Scholar]
- Xu, Y.; Wu, T.; Charlton, J.R.; Bennett, K.M. GAN Training Acceleration Using Fréchet Descriptor-Based Coreset. Appl. Sci. 2022, 12, 7599. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning. PMLR—2020, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Henaff, O. Data-efficient image recognition with contrastive predictive coding. In Proceedings of the International conference on machine learning. PMLR—2020, Virtual, 13–19 July 2020; pp. 4182–4192. [Google Scholar]
- Misra, I.; Maaten, L.V.D. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6707–6717. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Gutmann, M.; Hyvärinen, A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics—JMLR Workshop and Conference Proceedings, Chia Laguna Resort, Italy, 13–15 May 2010; pp. 297–304. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Malisiewicz, T.; Gupta, A.; Efros, A.A. Ensemble of exemplar-svms for object detection and beyond. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 16–17 November 2011; pp. 89–96. [Google Scholar]
- Shrivastava, A.; Malisiewicz, T.; Gupta, A.; Efros, A.A. Data-driven visual similarity for cross-domain image matching. ACM Trans. Graph. 2011, 30, 154. [Google Scholar] [CrossRef]
- Alexey, D.; Fischer, P.; Tobias, J.; Springenberg, M.R.; Brox, T. Discriminative unsupervised feature learning with exemplar convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1734–1747. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Isola, P.; Zoran, D.; Krishnan, D.; Adelson, E.H. Learning visual groups from co-occurrences in space and time. arXiv 2015, arXiv:1511.06811. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 776–794. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Charlton, J.R.; Xu, Y.; Wu, T.; deRonde, K.A.; Hughes, J.L.; Dutta, S.; Oxley, G.T.; Cwiek, A.; Cathro, H.P.; Charlton, N.P.; et al. Magnetic resonance imaging accurately tracks kidney pathology and heterogeneity in the transition from acute kidney injury to chronic kidney disease. Kidney Int. 2021, 99, 173–185. [Google Scholar] [CrossRef]
- Hollandi, R.; Moshkov, N.; Paavolainen, L.; Tasnadi, E.; Piccinini, F.; Horvath, P. Nucleus segmentation: Towards automated solutions. Trends Cell Biol. 2022, 32, 295–310. [Google Scholar] [CrossRef]
- Basu, A.; Senapati, P.; Deb, M.; Rai, R.; Dhal, K.G. A survey on recent trends in deep learning for nucleus segmentation from histopathology images. In Evolving Systems; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–46. [Google Scholar]
- Gyawali, R.; Dhakal, A.; Wang, L.; Cheng, J. Accurate cryo-EM protein particle picking by integrating the foundational AI image segmentation model and specialized U-Net. bioRxiv 2023. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, T.; Chen, J.; Shen, Y.; Li, X. EPicker is an exemplar-based continual learning approach for knowledge accumulation in cryoEM particle picking. Nat. Commun. 2022, 13, 2468. [Google Scholar] [CrossRef] [PubMed]
- Pawłowski, J.; Majchrowska, S.; Golan, T. Generation of microbial colonies dataset with deep learning style transfer. Sci. Rep. 2022, 12, 5212. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Liu, B.; Wang, J.; Zhang, Z. Bibliometric analysis of artificial intelligence for biotechnology and applied microbiology: Exploring research hotspots and frontiers. Front. Bioeng. Biotechnol. 2022, 10, 998298. [Google Scholar] [CrossRef] [PubMed]
- Fan, Z.; Zhang, H.; Zhang, Z.; Lu, G.; Zhang, Y.; Wang, Y. A survey of crowd counting and density estimation based on convolutional neural network. Neurocomputing 2022, 472, 224–251. [Google Scholar] [CrossRef]
- Khan, M.A.; Menouar, H.; Hamila, R. Revisiting crowd counting: State-of-the-art, trends, and future perspectives. Image Vis. Comput. 2022, 129, 104597. [Google Scholar] [CrossRef]
- Tueller, P.; Kastner, R.; Diamant, R. Target detection using features for sonar images. IET Radar, Sonar Navig. 2020, 14, 1940–1949. [Google Scholar] [CrossRef]
- Pierleoni, P.; Belli, A.; Palma, L.; Palmucci, M.; Sabbatini, L. A machine vision system for manual assembly line monitoring. In Proceedings of the 2020 International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020; pp. 33–38. [Google Scholar]
- De Vitis, G.A.; Foglia, P.; Prete, C.A. Algorithms for the detection of blob defects in high speed glass tube production lines. In Proceedings of the 2019 IEEE 8th International Workshop on Advances in Sensors and Interfaces (IWASI), Otranto, Italy, 13–14 June 2019; pp. 97–102. [Google Scholar]
- De Vitis, G.A.; Di Tecco, A.; Foglia, P.; Prete, C.A. Fast Blob and Air Line Defects Detection for High Speed Glass Tube Production Lines. J. Imaging 2021, 7, 223. [Google Scholar] [CrossRef] [PubMed]
- DeCost, B.L.; Holm, E.A. A computer vision approach for automated analysis and classification of microstructural image data. Comput. Mater. Sci. 2015, 110, 126–133. [Google Scholar] [CrossRef]
- Agbozo, R.; Jin, W. Quantitative metallographic analysis of GCr15 microstructure using mask R-CNN. J. Korean Soc. Precis. Eng. 2020, 37, 361–369. [Google Scholar] [CrossRef]
- Ge, M.; Su, F.; Zhao, Z.; Su, D. Deep learning analysis on microscopic imaging in materials science. Mater. Today Nano 2020, 11, 100087. [Google Scholar] [CrossRef]
- Beeman, S.C.; Cullen-McEwen, L.A.; Puelles, V.G.; Zhang, M.; Wu, T.; Baldelomar, E.J.; Dowling, J.; Charlton, J.R.; Forbes, M.S.; Ng, A.; et al. MRI-based glomerular morphology and pathology in whole human kidneys. Am. J. Physiol.-Ren. Physiol. 2014, 306, F1381–F1390. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | BlobCUT | UHDoG | BTCAS | UVCGAN | EGSDE | BlobDetGAN | 3D CUT |
|---|---|---|---|---|---|---|---|
| DER | 0.085 ± 0.035 | ||||||
| (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | |||
| Precision | 0.972 ± 0.0013 | ||||||
| (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | ||
| Recall | 0.896 ± 0.031 | ||||||
| (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | |||
| F-score | 0.932 ± 0.018 | ||||||
| (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | |||
| Dice | 0.816 ± 0.061 | ||||||
| (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | ||
| IoU | 0.694 ± 0.074 | ||||||
| (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | ||
| Blobness | 0.542 ± 0.291 | ||||||
| (GT:0.519) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | (* < 0.001) | |
| Avg. Time | 1393 | \ | \ | \ | \ | 2176 | 1246 |
| (s/epoch) |
| Mouse Kidney | HDoG with VBGMM (Ground Truth) | BlobCUT (Diff. %) | BlobDet-GAN (Diff. %) | UH-DoG (Diff. %) | BTCAS (Diff. %) | UVCGAN (Diff. %) | EGSDE (Diff. %) | |
|---|---|---|---|---|---|---|---|---|
| CKD | ID 429 | 7656 | 7621 (0.46%) | 7633 (0.30%) | 7346 (4.05%) | 7719 (0.82%) | 7358 (3.89%) | 7295 (4.72%) |
| ID 466 | 8665 | 8843 (2.05%) | 8912 (2.85%) | 8138 (6.08%) | 8228 (5.04%) | 8365 (3.46%) | 8317 (4.01%) | |
| ID 467 | 8549 | 8812 (3.08%) | 8802 (2.96%) | 8663 (1.33%) | 8595 (0.54%) | 8368 (2.11%) | 8128 (4.92%) | |
| AVG | 8290 | 8425 (1.63%) | 8449 (1.92%) | 8049 (2.91%) | 8181 (2.13%) | 8030 (3.13%) | 7913 (4.54%) | |
| Control for CKD | ID 427 | 12,724 | 12,573 (1.18%) | 12,683 (0.32%) | 12,701 (0.18%) | 12,008 (5.63%) | 12,486 (1.87%) | 12,423 (2.37%) |
| ID 469 | 10,829 | 10,897 (0.63%) | 10,921 (0.85%) | 11,347 (4.78%) | 11,048 (2.02%) | 10,604 (2.08%) | 10,458 (3.43%) | |
| ID 470 | 10,704 | 10,579 (1.17%) | 10,774 (0.65%) | 11,309 (5.65%) | 10,969 (2.48%) | 10,281 (3.95%) | 10,299 (3.78%) | |
| ID 471 | 11,934 | 12,488 (4.56%) | 12,692 (6.27%) | 12,279 (2.81%) | 12,058 (0.96%) | 11,685 (2.08%) | 11,718 (1.81%) | |
| ID 472 | 12,569 | 12,590 (0.16%) | 12,786 (1.73%) | 12,526 (0.34%) | 13,418 (4.75%) | 11,952 (4.90%) | 12,152 (3.31%) | |
| ID 473 | 12,245 | 12,058 (1.53%) | 12,058 (1.53%) | 11,853 (3.20%) | 12,318 (0.60%) | 12,025 (1.79%) | 11,825 (3.43%) | |
| AVG | 11,836 | 11,864 (0.24%) | 11,986 (1.27%) | 12,003 (1.41%) | 11,970 (3.07%) | 11,505 (2.77%) | 11,479 (2.99%) | |
| AKI | ID 433 | 11,046 | 11256 (1.90%) | 11618 (5.18%) | 11,033 (0.12%) | 10,752 (2.66%) | 10,826 (1.99%) | 10,751 (2.67%) |
| ID 462 | 11,292 | 11,420 (1.13%) | 11,445 (1.35%) | 10,779 (4.54%) | 10,646 (5.75%) | 10,892 (3.54%) | 11,082 (1.86%) | |
| ID 463 | 11,542 | 11533 (0.07%) | 11,544 (0.02%) | 10,873 (5.80%) | 11,820 (2.41%) | 11,058 (4.19%) | 11,282 (2.25%) | |
| ID 464 | 11,906 | 11,704 (1.70%) | 11,562 (2.89%) | 11,340 (4.75%) | 11,422 (3.33%) | 11,526 (3.19%) | 11,290 (5.17%) | |
| AVG | 11,447 | 11,478 (0.27%) | 11,542 (0.83%) | 11,006 (3.85%) | 11,015 (3.78%) | 11,075 (3.24%) | 11,101 (3.01%) | |
| Control for AKI | ID 465 | 10,336 | 10,482 (1.41%) | 10,214 (1.18%) | 10,115 (2.14%) | 10,393 (0.55%) | 10,205 (1.26%) | 10,059 (2.68%) |
| ID 474 | 10,874 | 10,928 (0.50%) | 10,955 (0.74%) | 11,157 (2.60%) | 11,034 (1.47%) | 10,989 (1.05%) | 10,428 (4.10%) | |
| ID 475 | 10,292 | 10,196 (0.91%) | 10,222 (0.68%) | 10,132 (1.55%) | 9985 (2.98%) | 9982 (3.01%) | 9907 (3.74%) | |
| ID 476 | 10,954 | 10,764 (1.71%) | 11452 (4.55%) | 10,892 (0.57%) | 11,567 (5.60%) | 10,735 (2.00%) | 10,429 (4.79%) | |
| ID 477 | 10,885 | 11,047 (1.49%) | 10,929 (0.40%) | 11,335 (4.13%) | 11,143 (2.37%) | 10,789 (0.88%) | 10,216 (6.15%) | |
| AVG | 10,668 | 10,683 (0.14%) | 10,754 (0.81%) | 10,726 (0.54%) | 10,824 (2.59%) | 10,540 (1.20%) | 10,208 (4.32%) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Xu, Y.; Wu, T.; Charlton, J.R.; Bennett, K.M.; Al-Hindawi, F. BlobCUT: A Contrastive Learning Method to Support Small Blob Detection in Medical Imaging. Bioengineering 2023, 10, 1372. https://doi.org/10.3390/bioengineering10121372
Li T, Xu Y, Wu T, Charlton JR, Bennett KM, Al-Hindawi F. BlobCUT: A Contrastive Learning Method to Support Small Blob Detection in Medical Imaging. Bioengineering. 2023; 10(12):1372. https://doi.org/10.3390/bioengineering10121372
Chicago/Turabian StyleLi, Teng, Yanzhe Xu, Teresa Wu, Jennifer R. Charlton, Kevin M. Bennett, and Firas Al-Hindawi. 2023. "BlobCUT: A Contrastive Learning Method to Support Small Blob Detection in Medical Imaging" Bioengineering 10, no. 12: 1372. https://doi.org/10.3390/bioengineering10121372
APA StyleLi, T., Xu, Y., Wu, T., Charlton, J. R., Bennett, K. M., & Al-Hindawi, F. (2023). BlobCUT: A Contrastive Learning Method to Support Small Blob Detection in Medical Imaging. Bioengineering, 10(12), 1372. https://doi.org/10.3390/bioengineering10121372