
An Efficient Data Driven-Based Model for Prediction of the Total Sediment Load in Rivers

 ,
,  , , , and
, , , and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Dimensional Analysis
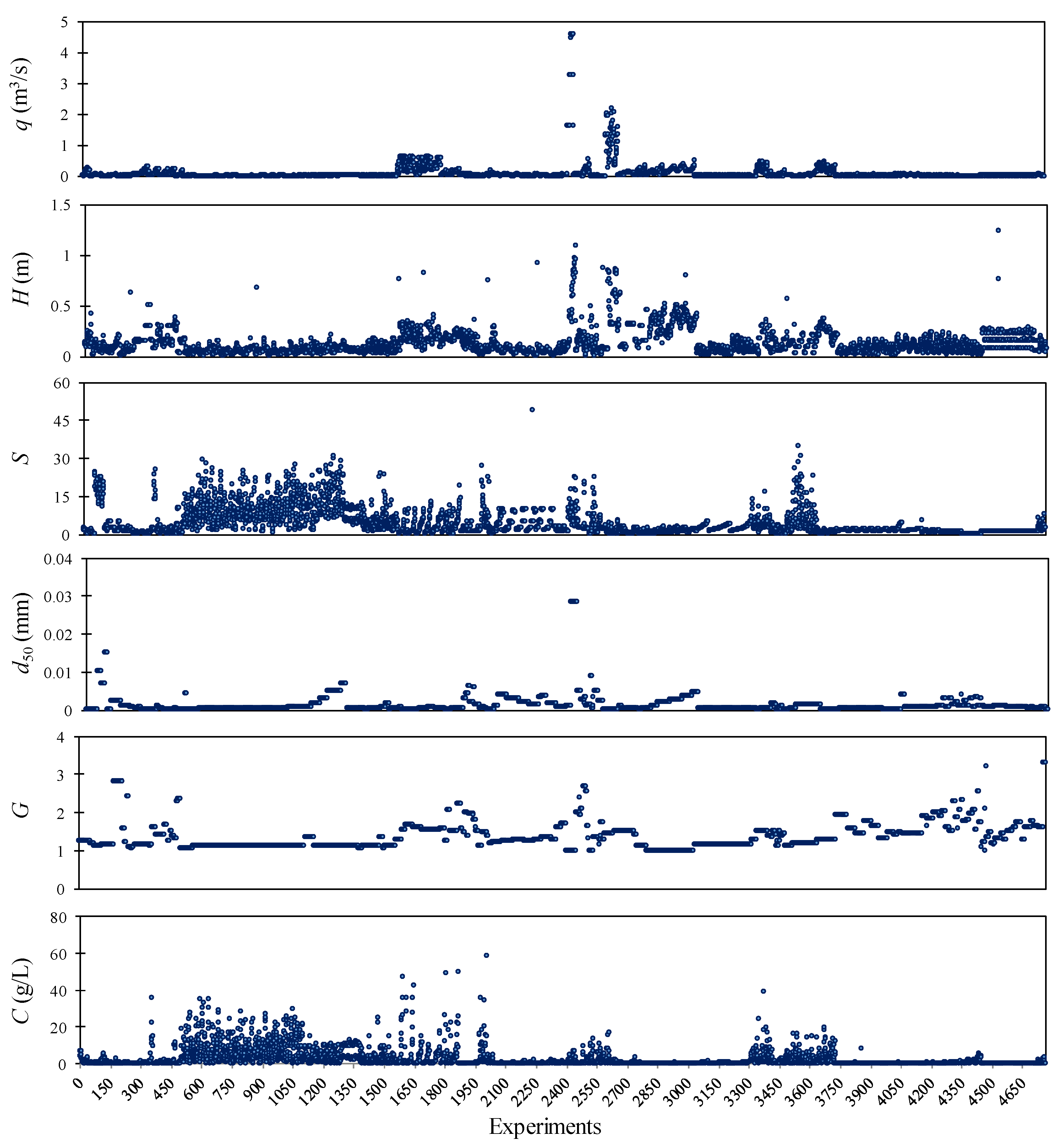
2.2. Database
2.3. Development of the TSL Regression-Based Models
2.3.1. Development of PCA-Based MLR Model for TSL Prediction
2.3.2. Development of PCA-Based SVR Model for TSL Prediction
2.4. Statistical Measures
3. Results and Discussion
3.1. Pre-Processing Data Using PCA
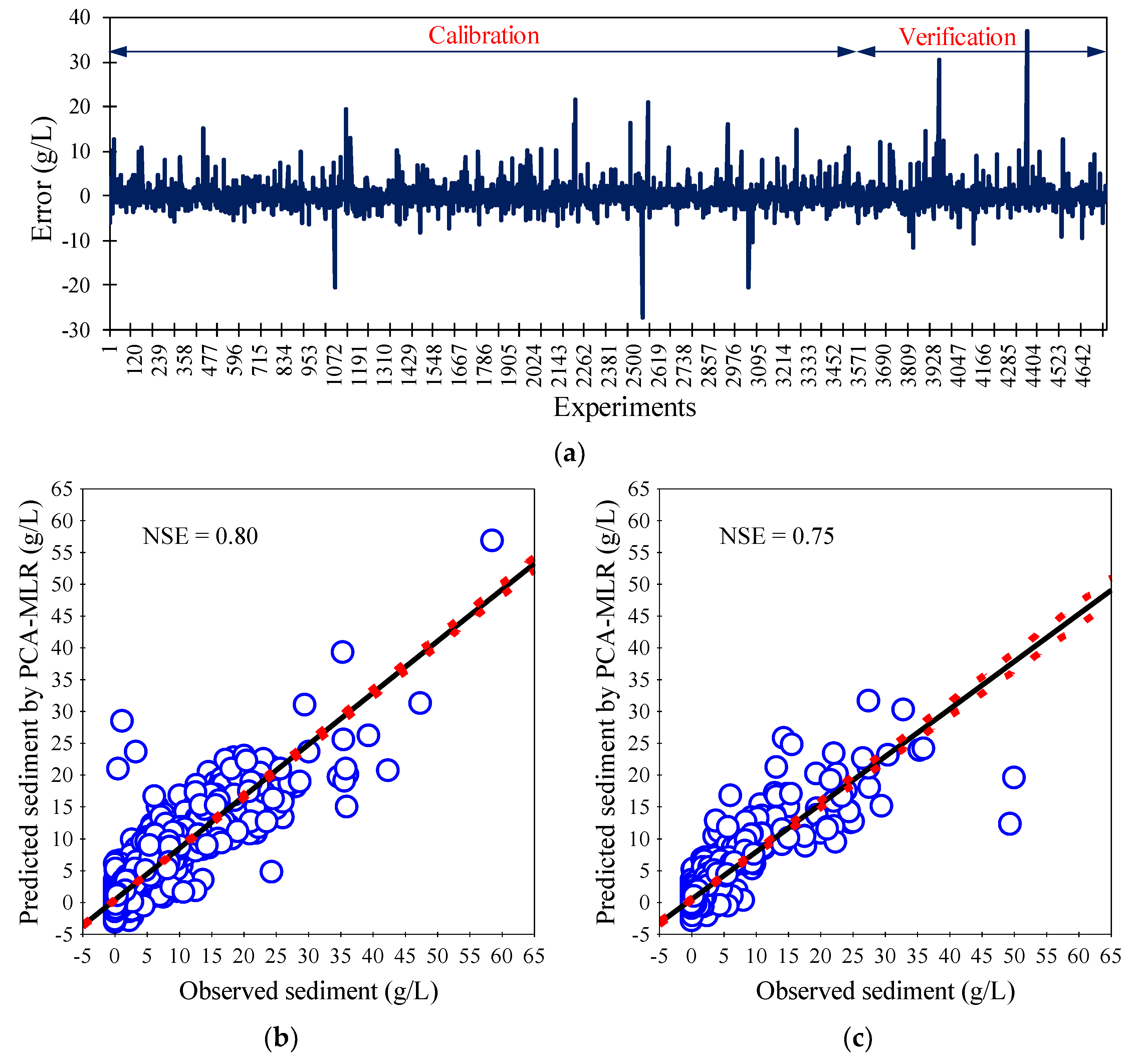
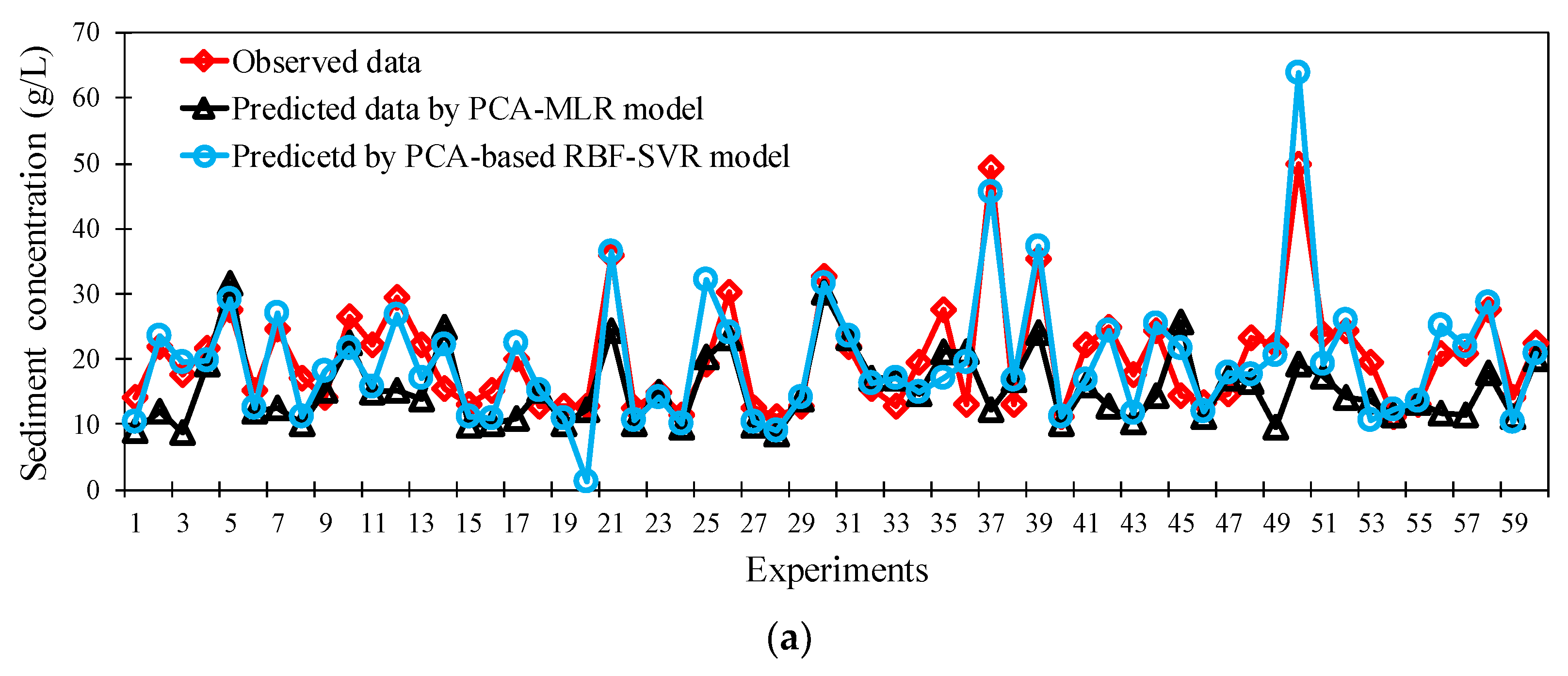
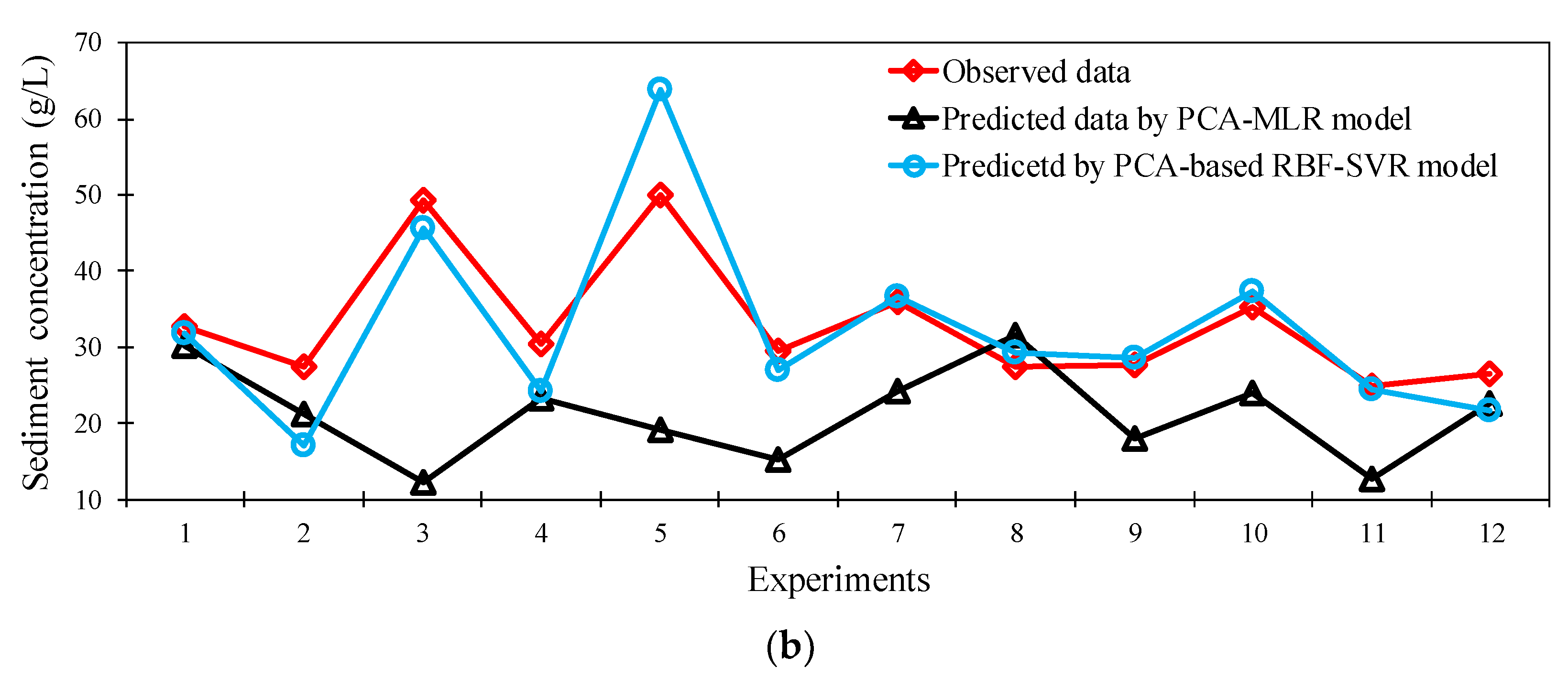
3.2. PCA-Based MLR Results
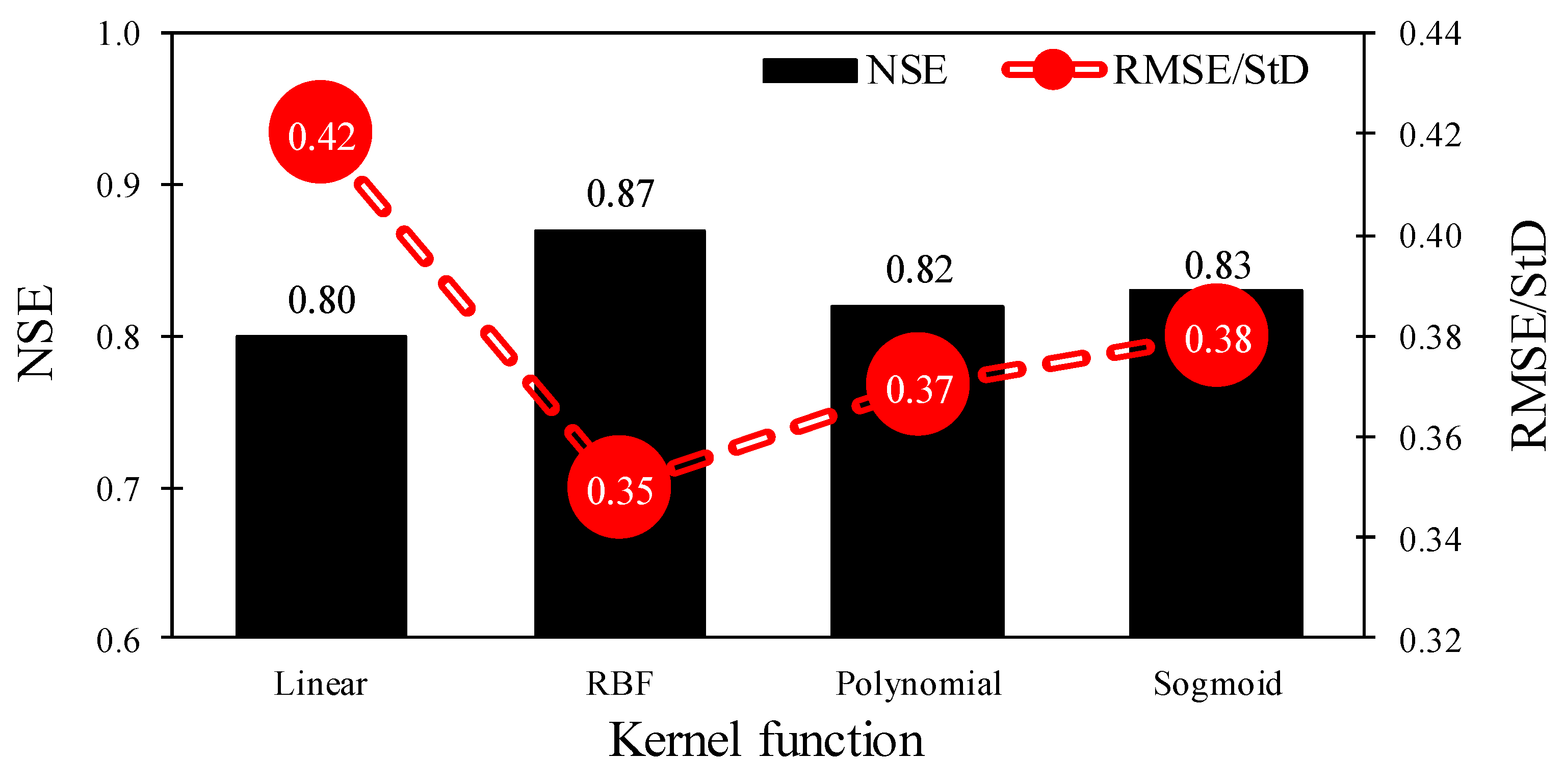
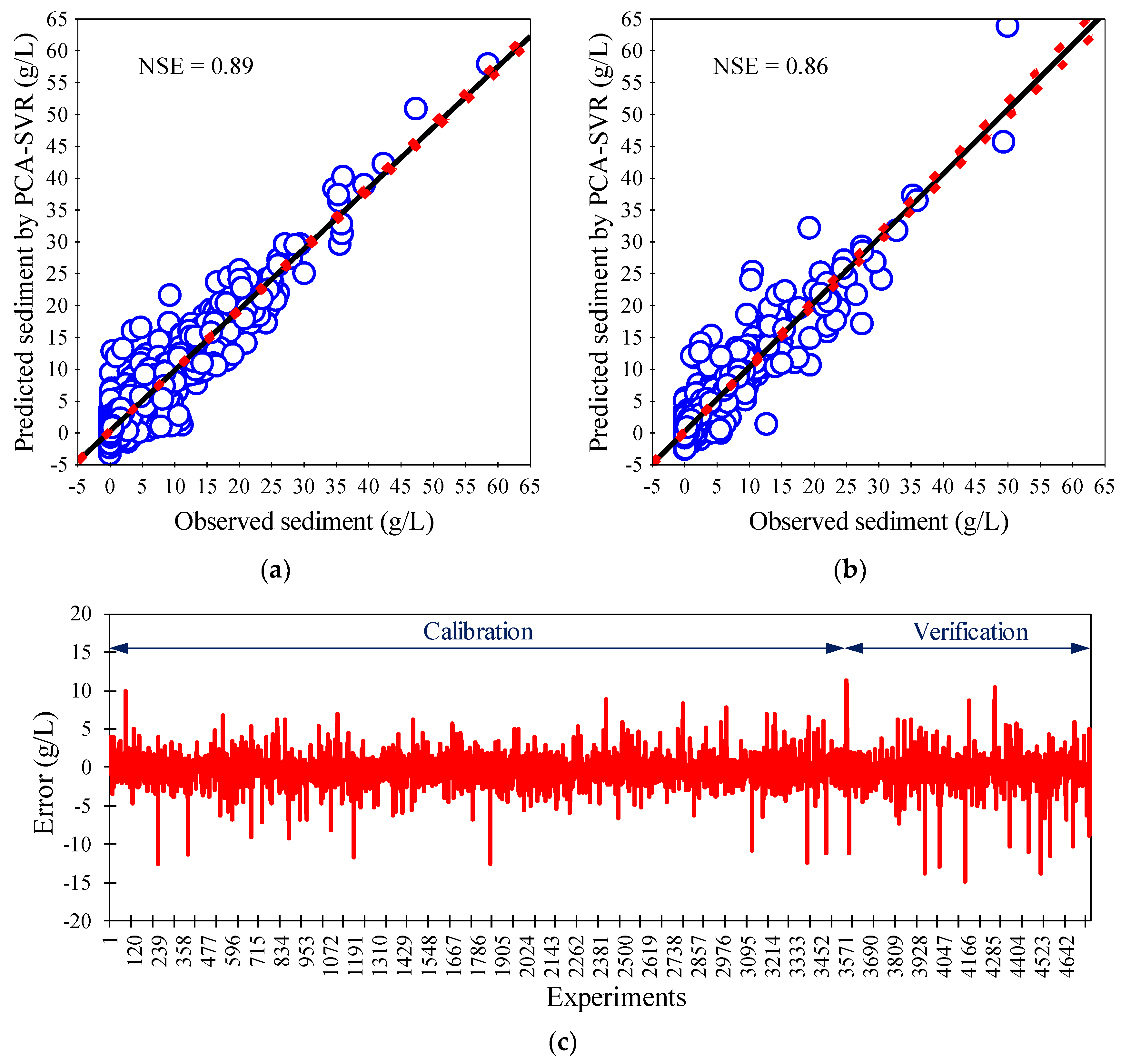
3.3. PCA-Based SVR Results
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Keeney, D.R. The nitrogen cycle in sediment-water systems. J. Environ. Qual. 1973, 2, 15–29. [Google Scholar] [CrossRef]
- Salomons, W. Sediments and water quality. Environ. Technol. 1985, 6, 315–326. [Google Scholar] [CrossRef]
- Wood, P.J.; Armitage, P.D. Biological effects of fine sediment in the lotic environment. Environ. Manag. 1997, 21, 203–217. [Google Scholar] [CrossRef]
- Chau, K.W. Persistent organic pollution characterization of sediments in Pearl River estuary. Chemosphere 2006, 64, 1545–1549. [Google Scholar] [CrossRef] [PubMed]
- Burton, G.A.; Johnston, E.L. Assessing contaminated sediments in the context of multiple stressors. Environ. Toxicol. Chem. 2010, 29, 2625–2643. [Google Scholar] [CrossRef] [PubMed]
- Marion, A.; Nikora, V.; Puijalon, S.; Bouma, T.; Koll, K.; Ballio, F.; Tait, S.; Zaramella, M.; Sukhodolov, A.; O’Hare, M.; et al. Aquatic interfaces: A hydrodynamic and ecological perspective. J. Hydraul. Res. 2014, 52, 744–758. [Google Scholar] [CrossRef]
- Frey, S.K.; Gottschall, N.; Wilkes, G.; Grégoire, D.; Topp, E.; Pintar, K.D.M.; Sunohara, M.; Marti, R.; Lapen, D.R. Rainfall-Induced Runoff from Exposed Streambed Sediments: An Important Source of Water Pollution. J. Environ. Qual. 2015, 44, 236–247. [Google Scholar] [CrossRef]
- Visescu, M.; Beilicci, E.; Beilicci, R. Sediment transport modelling with advanced hydroinformatic tool case study-modelling on Bega channel sector. Procedia Eng. 2016, 161, 1715–1721. [Google Scholar] [CrossRef]
- Cook, S.; Chan, H.L.; Abolfathi, S.; Bending, G.D.; Schäfer, H.; Pearson, J.M. Longitudinal dispersion of microplastics in aquatic flows using fluorometric techniques. Water Res. 2020, 170, 115337. [Google Scholar] [CrossRef]
- Cook, S.; Price, O.; King, A.; Finnegan, C.; van Egmond, R.; Schäfer, H.; Pearson, J.M.; Abolfathi, S.; Bending, G.D. Bedform characteristics and biofilm community development interact to modify hyporheic exchange. Sci. Total Environ. 2020, 749, 141397. [Google Scholar] [CrossRef]
- Khan, R.; Islam, S.; Tareq, A.R.M.; Naher, K.; Islam, A.R.M.T.; Habib, A.; Siddique, A.B.; Islam, M.A.; Das, S.; Rashid, B.; et al. Distribution, sources and ecological risk of trace elements and polycyclic aromatic hydrocarbons in sediments from a polluted urban river in central Bangladesh. Environ. Nanotechnol. Monit. Manag. 2020, 14, 100318. [Google Scholar] [CrossRef]
- Kumar, S.; Islam, A.R.M.T.; Hasanuzzaman Salam, R.; Khan, R.; Islam, S. Preliminary assessment of heavy metals in surface water and sediment in Nakuvadra-Rakiraki River, Fiji using indexical and chemometric approaches. J. Environ. Manag. 2021, 298, 113517. [Google Scholar] [CrossRef] [PubMed]
- Singh, J.; Knapp, H.V.; Arnold, J.G.; Demissie, M. Hydrological modeling of the Iroquois river watershed using HSPF and SWAT 1. JAWRA J. Am. Water Resour. Assoc. 2005, 41, 343–360. [Google Scholar] [CrossRef]
- Kiat, C.C.; Ab Ghani, A.; Abdullah, R.; Zakaria, N.A. Sediment transport modeling for Kulim River—A case study. J. Hydro-Environ. Res. 2008, 2, 47–59. [Google Scholar] [CrossRef]
- Kukuła, K.; Bylak, A. Synergistic impacts of sediment generation and hydrotechnical structures related to forestry on stream fish communities. Sci. Total Environ. 2020, 737, 139751. [Google Scholar] [CrossRef] [PubMed]
- Lama, G.F.C.; Errico, A.; Francalanci, S.; Solari, L.; Preti, F.; Chirico, G.B. Evaluation of Flow Resistance Models Based on Field Experiments in a Partly Vegetated Reclamation Channel. Geosciences 2020, 10, 47. [Google Scholar] [CrossRef]
- Lama, G.F.C.; Rillo Migliorini Giovannini, M.; Errico, A.; Mirzaei, S.; Padulano, R.; Chirico, G.B.; Preti, F. Hydraulic Efficiency of Green-Blue Flood Control Scenarios for Vegetated Rivers: 1D and 2D Unsteady Simulations. Water 2021, 13, 2620. [Google Scholar] [CrossRef]
- Box, W.; Järvelä, J.; Västilä, K. Flow resistance of floodplain vegetation mixtures for modelling river flows. J. Hydrol. 2021, 601, 126593. [Google Scholar] [CrossRef]
- Kastridis, A.; Theodosiou, G.; Fotiadis, G. Investigation of Flood Management and Mitigation Measures in Ungauged NATURA Protected Watersheds. Hydrology 2021, 8, 170. [Google Scholar] [CrossRef]
- Einstein, H.A. The Bed-Load Function for Sediment Transportation in Open Channel Flows (No. 1026); US Department of Agriculture: Washington, DC, USA, 1950.
- Van Rijn, L.C. Sediment transport, part I: Bed load transport. J. Hydraul. Eng. 1984, 110, 1431–1456. [Google Scholar] [CrossRef]
- Toffaleti, F.B. Definitive Computation of Sand Discharge in Rivers. J. Hydraul. Div. 1969, 95, 225–248. [Google Scholar] [CrossRef]
- Engelund, F.; Hansen, E. A Monograph on Sediment Transport in Alluvial Streams; Technical University of Denmark: Copenhagen, Denmark, 1967. [Google Scholar]
- Ackers, P.; White, W.R. Sediment transport: New approach and analysis. J. Hydraul. Div. 1973, 99, 2041–2060. [Google Scholar] [CrossRef]
- Brownlie, W.R. Prediction of Flow Depth and Sediment Discharge in Open Channels; W. M. Keck Laboratory of Hydraulics and Water Resources Report, 43A; California Institute of Technology: Pasadena, CA, USA, 1981. [Google Scholar] [CrossRef]
- Choi, S.U.; Lee, J. Prediction of Total Sediment Load in Sand-Bed Rivers in Korea Using Lateral Distribution Method. JAWRA J. Am. Water Resour. Assoc. 2015, 51, 214–225. [Google Scholar] [CrossRef]
- García, M.H.; Laursen, E.M.; Michel, C.; Buffington, J.M. The legend of AF Shields. J. Hydraul. Eng. 2000, 126, 718–723. [Google Scholar] [CrossRef]
- Chen, X.Y.; Chau, K.W. A hybrid double feedforward neural network for suspended sediment load estimation. Water Resour. Manag. 2016, 30, 2179–2194. [Google Scholar] [CrossRef]
- Chen, X.Y.; Chau, K.W. Uncertainty analysis on hybrid double feedforward neural network model for sediment load estimation with LUBE method. Water Resour. Manag. 2019, 33, 3563–3577. [Google Scholar] [CrossRef]
- Okcu, D.; Pektas, A.O.; Uyumaz, A. Creating a non-linear total sediment load formula using polynomial best subset re-gression model. J. Hydrol. 2016, 539, 662–673. [Google Scholar] [CrossRef]
- Alizadeh, M.J.; Nodoushan, E.J.; Kalarestaghi, N.; Chau, K.W. Toward multi-day-ahead forecasting of suspended sediment concentration using ensemble models. Environ. Sci. Pollut. Res. 2017, 24, 28017–28025. [Google Scholar] [CrossRef]
- Doriean, N.J.C.; Brooks, A.P.; Teasdale, P.; Welsh, D.T.; Bennett, W.W. Suspended sediment monitoring in alluvial gullies: A laboratory and field evaluation of available measurement techniques. Hydrol. Process. 2020, 34, 3426–3438. [Google Scholar] [CrossRef]
- Safari, M.J.S.; Mohammadi, B.; Kargar, K. Invasive weed optimization-based adaptive neuro-fuzzy inference system hybrid model for sediment transport with a bed deposit. J. Clean. Prod. 2020, 276, 124267. [Google Scholar] [CrossRef]
- Mohammadi, B.; Guan, Y.; Moazenzadeh, R.; Safari, M.J.S. Implementation of hybrid particle swarm optimiza-tion-differential evolution algorithms coupled with multi-layer perceptron for suspended sediment load estimation. Catena 2021, 198, 105024. [Google Scholar] [CrossRef]
- Riahi-Madvar, H.; Seifi, A. Uncertainty analysis in bed load transport prediction of gravel bed rivers by ANN and AN-FIS. Arab. J. Geosci. 2018, 11, 1–20. [Google Scholar] [CrossRef]
- AlDahoul, N.; Essam, Y.; Kumar, P.; Ahmed, A.N.; Sherif, M.; Sefelnasr, A.; Elshafie, A. Suspended sediment load pre-diction using long short-term memory neural network. Sci. Rep. 2021, 11, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Safari, M.J.S.; Mehr, A.D. Multigene genetic programming for sediment transport modeling in sewers for conditions of non-deposition with a bed deposit. Int. J. Sediment Res. 2018, 33, 262–270. [Google Scholar] [CrossRef]
- Khozani, Z.S.; Safari, M.J.S.; Mehr, A.D.; Mohtar, W.H.M.W. An ensemble genetic programming approach to develop incipient sediment motion models in rectangular channels. J. Hydrol. 2020, 584, 124753. [Google Scholar] [CrossRef]
- Noori, R.; Mirchi, A.; Hooshyaripor, F.; Bhattarai, R.; Haghighi, A.T.; Kløve, B. Reliability of functional forms for calcu-lation of longitudinal dispersion coefficient in rivers. Sci. Total Environ. 2021, 791, 148394. [Google Scholar] [CrossRef]
- Ghiasi, B.; Sheikhian, H.; Zeynolabedin, A.; Niksokhan, M.H. Granular computing–neural network model for predic-tion of longitudinal dispersion coefficients in rivers. Water Sci. Technol. 2019, 80, 1880–1892. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial Neural Networks in Hydrology. II: Hydrologic Applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar] [CrossRef]
- Yang, C.T. Unit stream power equations for total load. J. Hydrol. 1979, 40, 123–138. [Google Scholar] [CrossRef]
- Karim, F. Bed material discharge prediction for nonuniform bed sediments. J. Hydraul. Eng. 1998, 124, 597–604. [Google Scholar] [CrossRef]
- Molinas, A.; Wu, B. Transport of sediment in large sand-bed rivers. J. Hydraul. Res. 2001, 39, 135–146. [Google Scholar] [CrossRef]
- Streeter, V.L.; Bedford, K.W.; Wylie, E.B. Fluid Mechanics; McGraw-Hill: New York, NY, USA, 2010. [Google Scholar]
- Manly, B.F.; Alberto, J.A.N. Multivariate Statistical Methods: A Primer, 4th ed.; Chapman and Hall/CRC: London, UK, 2016. [Google Scholar]
- Saghafi, B.; Hassaniz, A.; Noori, R.; Bustos, M.G. Artificial Neural Networks and Regression Analysis for Predicting Faulting in Jointed Concrete Pavements Considering Base Condition. Int. J. Pavement Res. Technol. 2009, 2, 20–25. [Google Scholar]
- Friedman, L.; Wall, M. Graphical views of suppression and multicollinearity in multiple linear regression. Am. Stat. 2005, 59, 127–136. [Google Scholar] [CrossRef]
- Noori, R.; Farokhnia, A.; Morid, S.; Riahi Madvar, H. Effect of input variables preprocessing in artificial neural network on monthly flow prediction by PCA and wavelet transformation. J. Water Wastewater 2009, 69, 13–22. [Google Scholar]
- Noori, R.; Karbassi, A.R.; Ashrafi, K.; Ardestani, M. Mehrdadi, N. Development and application of reduced-order neural network model based on proper orthogonal decomposition for BOD 5 monitoring: Active and online prediction. Environ. Prog. Sustain. Energy 2013, 32, 120–127. [Google Scholar] [CrossRef]
- Noori, R.; Khakpour, A.; Omidvar, B.; Farokhnia, A. Comparison of ANN and principal component analysis-multivariate linear regression models for predicting the river flow based on developed discrepancy ratio statistic. Expert Syst. Appl. 2010, 37, 5856–5862. [Google Scholar] [CrossRef]
- Salmerón, R.; García, C.B.; García, J. Variance inflation factor and condition number in multiple linear regression. J. Stat. Comput. Simul. 2018, 88, 2365–2384. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar] [CrossRef]
- Noori, R.; Karbassi, A.R.; Moghaddamnia, A.; Han, D.; Zokaei-Ashtiani, M.H.; Farokhnia, A.; Gousheh, M.G. Assess-ment of input variables determination on the SVM model performance using PCA, Gamma test, and forward selection tech-niques for monthly stream flow prediction. J. Hydrol. 2011, 401, 177–189. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory, 2nd ed.; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Lin, J.Y.; Cheng, C.T.; Chau, K.W. Using support vector machines for long-term discharge prediction. Hydrol. Sci. J. 2006, 51, 599–612. [Google Scholar] [CrossRef]
- Moazenzadeh, R.; Mohammadi, B.; Shamshirband, S.; Chau, K.W. Coupling a firefly algorithm with support vector regression to predict evaporation in northern Iran. Eng. Appl. Comput. Fluid Mech. 2018, 12, 584–597. [Google Scholar] [CrossRef]
- Elbeltagi, A.; Kumari, N.; Dharpure, J.; Mokhtar, A.; Alsafadi, K.; Kumar, M.; Mehdinejadiani, B.; Etedali, H.R.; Brouziyne, Y.; Islam, A.T.; et al. Prediction of Combined Terrestrial Evapotranspiration Index (CTEI) over Large River Basin Based on Machine Learning Approaches. Water 2021, 13, 547. [Google Scholar] [CrossRef]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification 2003. Available online: http://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 3 September 2021).
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model Evaluation Guidelines for Systematic Quantification of Accuracy in Watershed Simulations. Trans. Am. Soc. Agric. Biol. Eng. 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Li, H.; Li, W.; Pan, X.; Huang, J.; Gao, T.; Hu, L.; Li, H.; Lu, Y. Correlation and redundancy on machine learning perfor-mance for chemical databases. J. Chemom. 2018, 32, e3023. [Google Scholar] [CrossRef]
- Noori, R.; Sabahi, M.; Karbassi, A.; Baghvand, A.; Zadeh, H.T. Multivariate statistical analysis of surface water quality based on correlations and variations in the data set. Desalination 2010, 260, 129–136. [Google Scholar] [CrossRef]
- Deng, Z.Q.; Bengtsson, L.; Singh, V.P.; Adrian, D.D. Longitudinal dispersion coefficient in single-channel streams. J. Hydraul. Eng. 2002, 128, 901–916. [Google Scholar] [CrossRef]
- Papadimitrakis, I.; Orphanos, I. Longitudinal dispersion characteristics of rivers and natural streams in Greece. Water Air Soil Pollut. Focus 2004, 4, 289–305. [Google Scholar] [CrossRef]
- Noori, R.; Karbassi, A.; Farokhnia, A.; Dehghani, M. Predicting the longitudinal dispersion coefficient using support vector machine and adaptive neuro-fuzzy inference system techniques. Environ. Eng. Sci. 2009, 26, 1503–1510. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Noori, R.; Afroozi, D.; Ghiasi, B.; Hosseini-Moghari, S.M.; Mirchi, A.; Haghighi, A.T.; Kløve, B. A com-prehensive uncertainty analysis of model-estimated longitudinal and lateral dispersion coefficients in open channels. J. Hydrol. 2021, 603, 126850. [Google Scholar] [CrossRef]
- Noori, R.; Ghiasi, B.; Sheikhian, H.; Adamowski, J.F. Estimation of the dispersion coefficient in natural rivers using a granular computing model. J. Hydraul. Eng. 2017, 143, 04017001. [Google Scholar] [CrossRef]
- Talebizadeh, M.; Morid, S.; Ayyoubzadeh, S.A.; Ghasemzadeh, M. Uncertainty analysis in sediment load modeling using ANN and SWAT model. Water Resour. Manag. 2010, 24, 1747–1761. [Google Scholar] [CrossRef]
- Van Rijn, L.C. Unified view of sediment transport by currents and waves. I: Initiation of motion, bed roughness, and bed-load transport. J. Hydraul. Eng. 2007, 133, 649–667. [Google Scholar] [CrossRef]
- Huisman, B.J.A.; Ruessink, B.G.; de Schipper, M.A.; Luijendijk, A.P.; Stive, M.J.F. Modelling of bed sediment com-position changes at the lower shoreface of the Sand Motor. Coast. Eng. 2018, 132, 33–49. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PCs | Eigenvalue | Conserved Variance of the Drivers | Cumulative Conserved Variance of the Drivers |
|---|---|---|---|
| PC1 | 2.90 | 28.98 | 28.98 |
| PC2 | 2.89 | 28.91 | 57.89 |
| PC3 | 1.34 | 13.37 | 71.26 |
| PC4 | 1.14 | 11.39 | 82.66 |
| PC5 | 1.07 | 10.68 | 93.34 |
| PC6 | 0.26 | 2.61 | 95.95 |
| PC7 | 0.17 | 1.73 | 97.67 |
| PC8 | 0.14 | 1.38 | 99.05 |
| PC9 | 0.06 | 0.62 | 99.67 |
| PC10 | 0.03 | 0.33 | 100.00 |
| Drivers | MLR Model | PCs | PCA-Based MLR Model | ||||
|---|---|---|---|---|---|---|---|
| t-Test | Sig. | VIF | t-Test | Sig. | VIF | ||
| uS/ω | 34.66 | 0.00 | 4.60 | PC1 | −6.77 | 0.00 | 1.00 |
| S | 46.49 | 0.00 | 2.93 | PC2 | 68.04 | 0.00 | 1.00 |
| u/ω | −23.11 | 0.00 | 6.43 | PC3 | −17.60 | 0.00 | 1.00 |
| u/(sqrt(G − 1)gd50 | 10.55 | 0.00 | 4.51 | PC4 | 33.21 | 0.00 | 1.00 |
| ω/u * | −8.93 | 0.00 | 15.08 | PC5 | 80.42 | 0.00 | 1.00 |
| ωd50/v | 13.15 | 0.00 | 25.30 | PC6 | 12.47 | 0.00 | 1.00 |
| u * d50/v | −8.75 | 0.00 | 21.74 | PC7 | −27.62 | 0.00 | 1.00 |
| u3/gHω | 8.24 | 0.00 | 6.61 | PC8 | 23.68 | 0.00 | 1.00 |
| H/d50 | 5.19 | 0.00 | 3.20 | PC9 | −7.42 | 0.00 | 1.00 |
| PC10 | −12.43 | 0.00 | 1.00 | ||||
| Model | NSE | RMSE/StD | ||||
|---|---|---|---|---|---|---|
| Overal1 | Top 0.05% | Top 0.01% | Overal1 | Top 0.05% | Top 0.01% | |
| PCA-based RBF-SVR | 0.87 | 0.68 | 0.50 | 0.35 | 0.56 | 0.68 |
| PCA-based MLR | 0.79 | –0.19 | –3.05 | 0.45 | 1.08 | 1.93 |
| Engelund and Hansen’s equation [23] | 0.41 | –1.17 | –4.31 | 0.74 | 1.46 | 2.21 |
| Yang’s equation [42] | 0.32 | –3.06 | –9.48 | 0.83 | 2.00 | 3.10 |
| Molinas and Wu’s equation [44] | –0.05 | –4.96 | –14.96 | 1.02 | 2.42 | 3.83 |
| Okcu’s et al. equation [30] | 0.65 | –1.74 | –5.17 | 0.62 | 1.64 | 3.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noori, R.; Ghiasi, B.; Salehi, S.; Esmaeili Bidhendi, M.; Raeisi, A.; Partani, S.; Meysami, R.; Mahdian, M.; Hosseinzadeh, M.; Abolfathi, S. An Efficient Data Driven-Based Model for Prediction of the Total Sediment Load in Rivers. Hydrology 2022, 9, 36. https://doi.org/10.3390/hydrology9020036
Noori R, Ghiasi B, Salehi S, Esmaeili Bidhendi M, Raeisi A, Partani S, Meysami R, Mahdian M, Hosseinzadeh M, Abolfathi S. An Efficient Data Driven-Based Model for Prediction of the Total Sediment Load in Rivers. Hydrology. 2022; 9(2):36. https://doi.org/10.3390/hydrology9020036
Chicago/Turabian StyleNoori, Roohollah, Behzad Ghiasi, Sohrab Salehi, Mehdi Esmaeili Bidhendi, Amin Raeisi, Sadegh Partani, Rojin Meysami, Mehran Mahdian, Majid Hosseinzadeh, and Soroush Abolfathi. 2022. "An Efficient Data Driven-Based Model for Prediction of the Total Sediment Load in Rivers" Hydrology 9, no. 2: 36. https://doi.org/10.3390/hydrology9020036
APA StyleNoori, R., Ghiasi, B., Salehi, S., Esmaeili Bidhendi, M., Raeisi, A., Partani, S., Meysami, R., Mahdian, M., Hosseinzadeh, M., & Abolfathi, S. (2022). An Efficient Data Driven-Based Model for Prediction of the Total Sediment Load in Rivers. Hydrology, 9(2), 36. https://doi.org/10.3390/hydrology9020036