Evaluation of Gridded Precipitation Data Products for Hydrological Applications in Complex Topography

Abstract
:1. Introduction
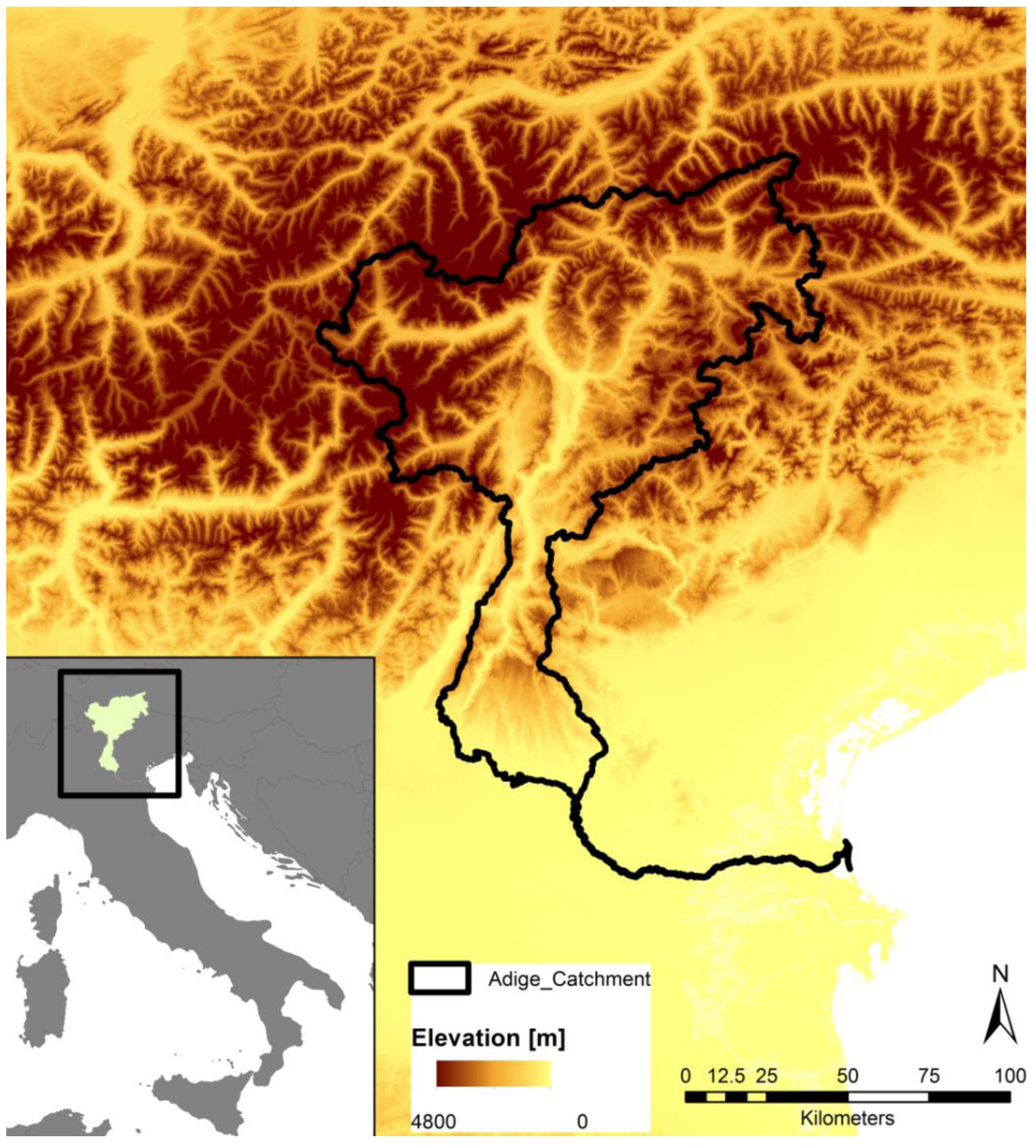
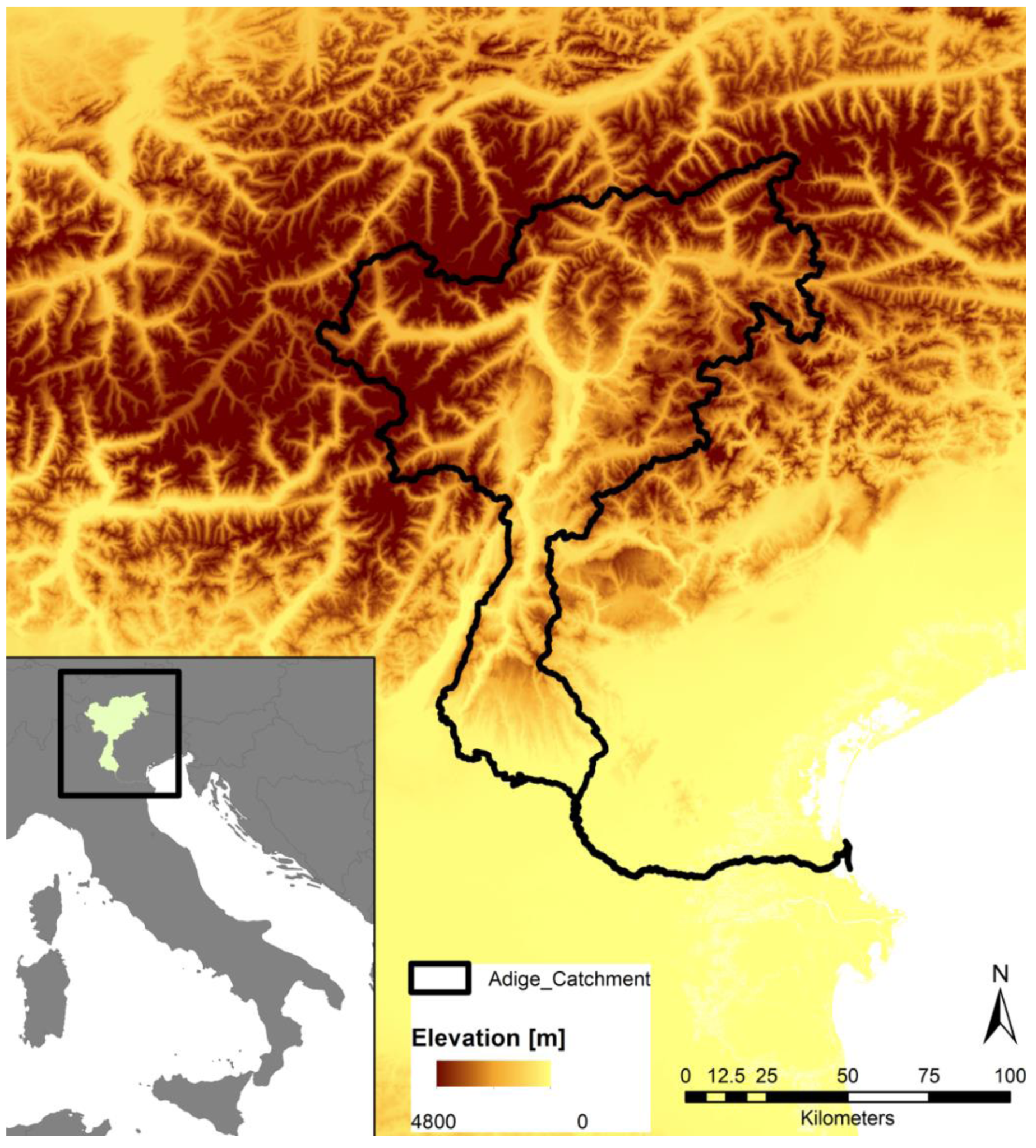
2. Study Area
3. Data Sets and Methods
3.1. Construction of the High-Resolution Reference Data Set
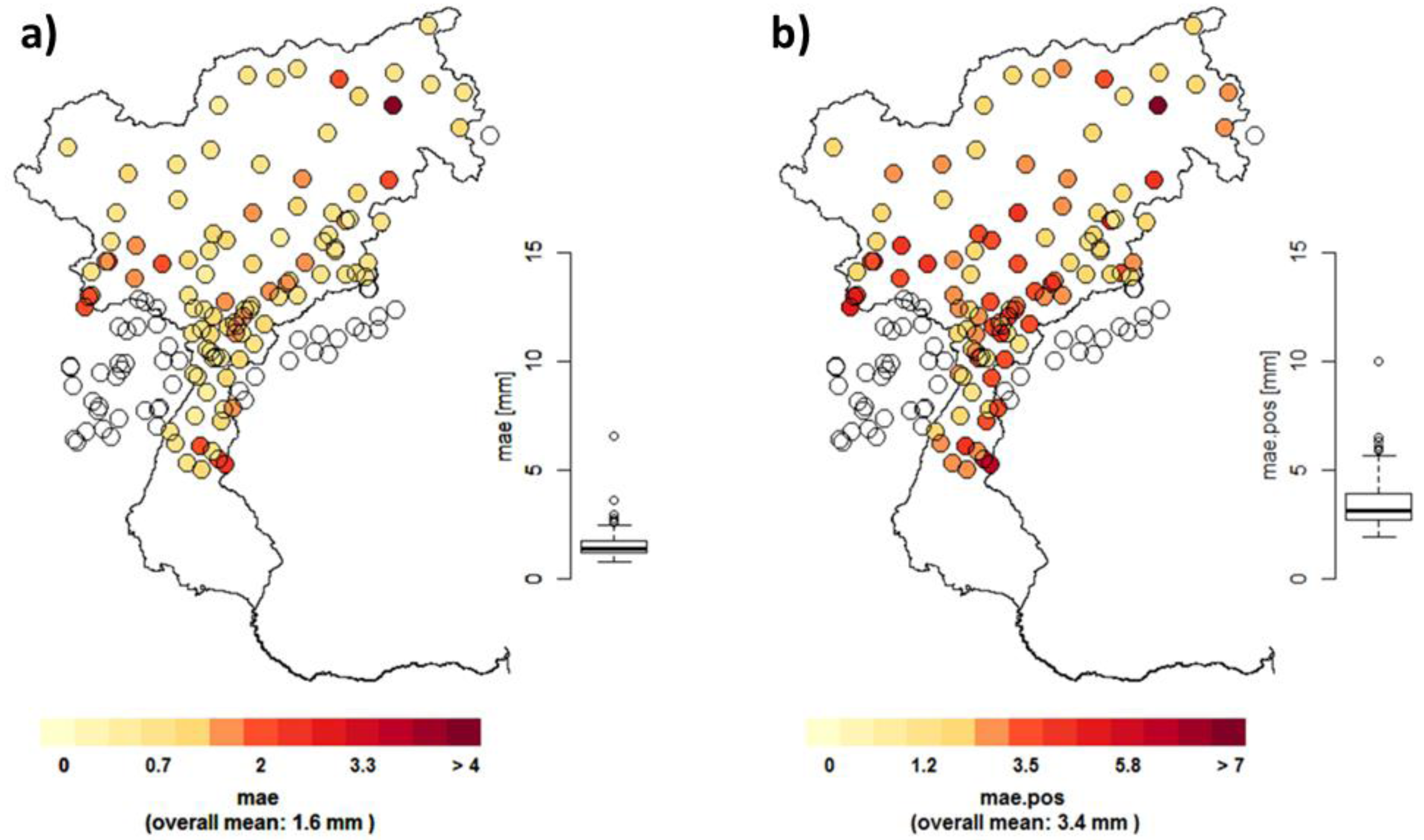
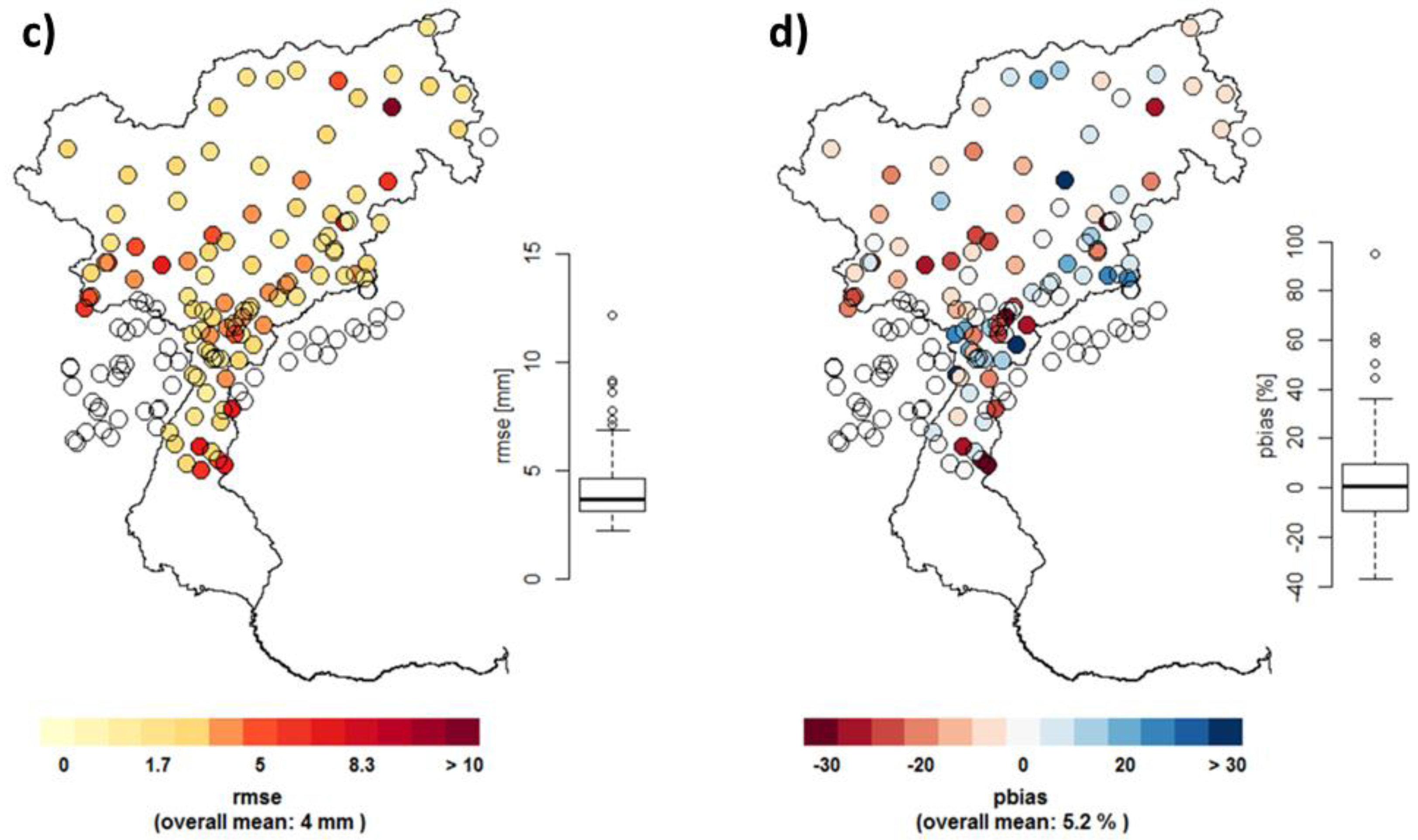
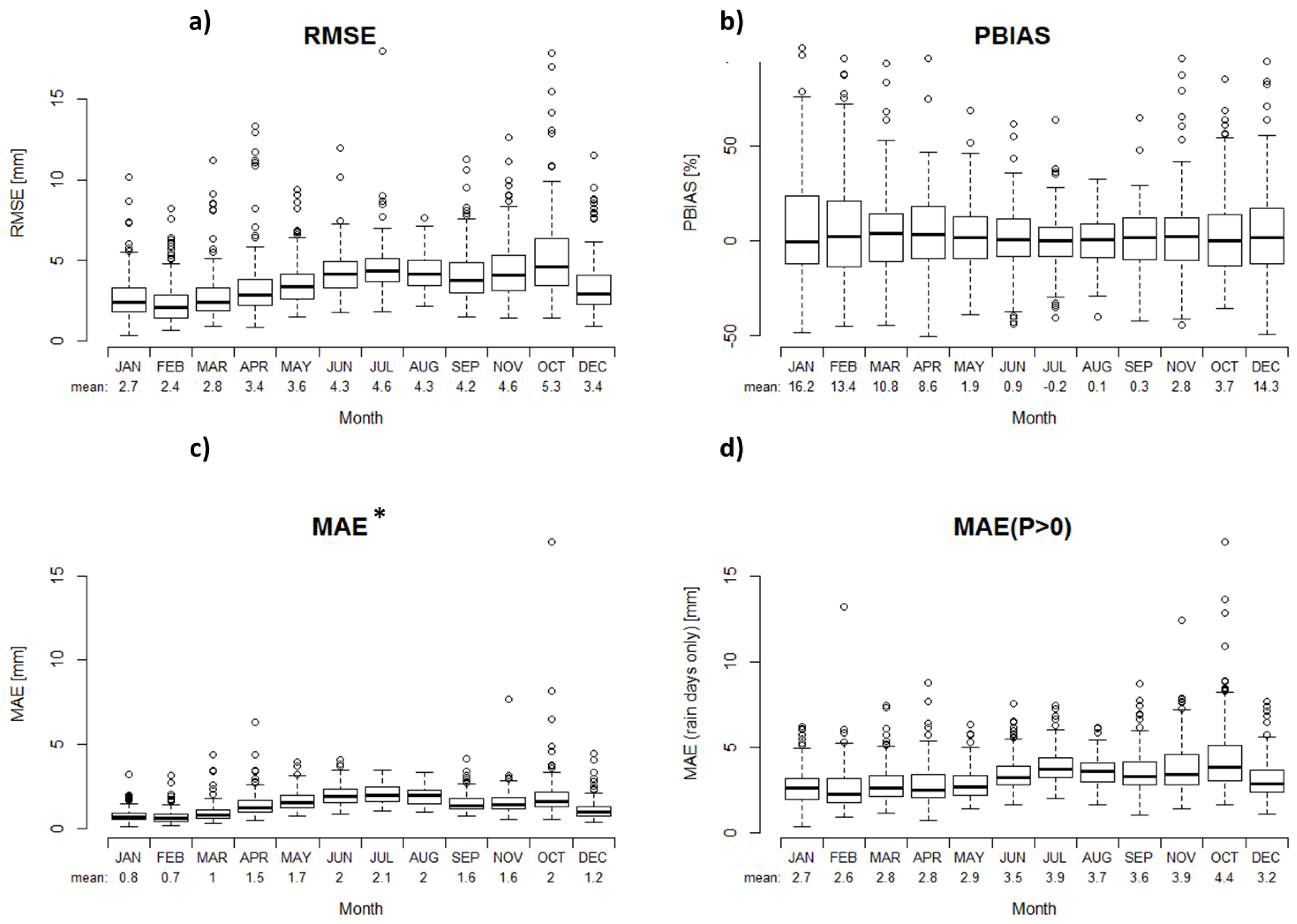
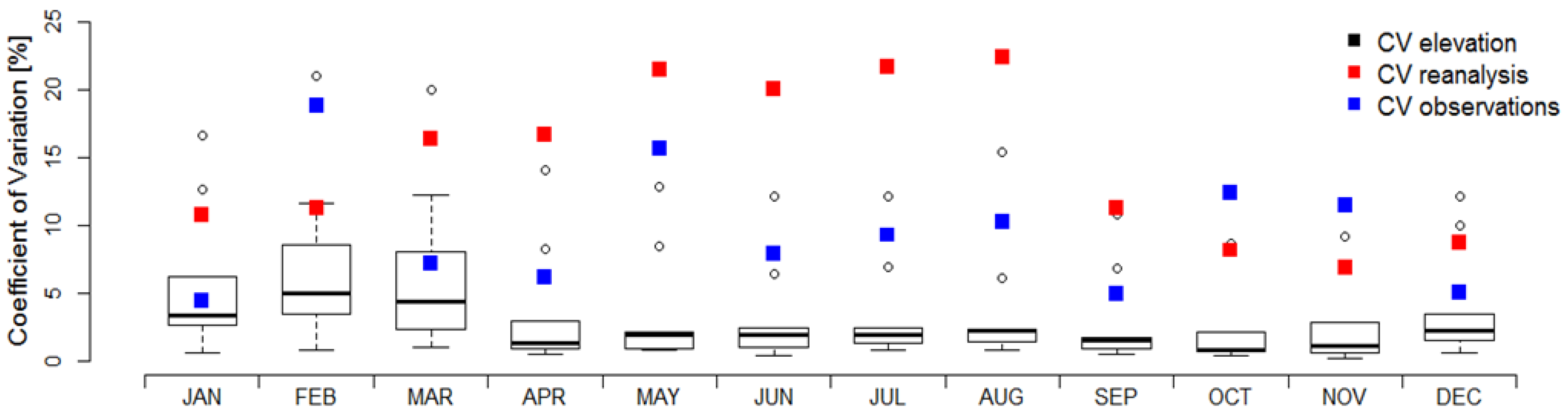
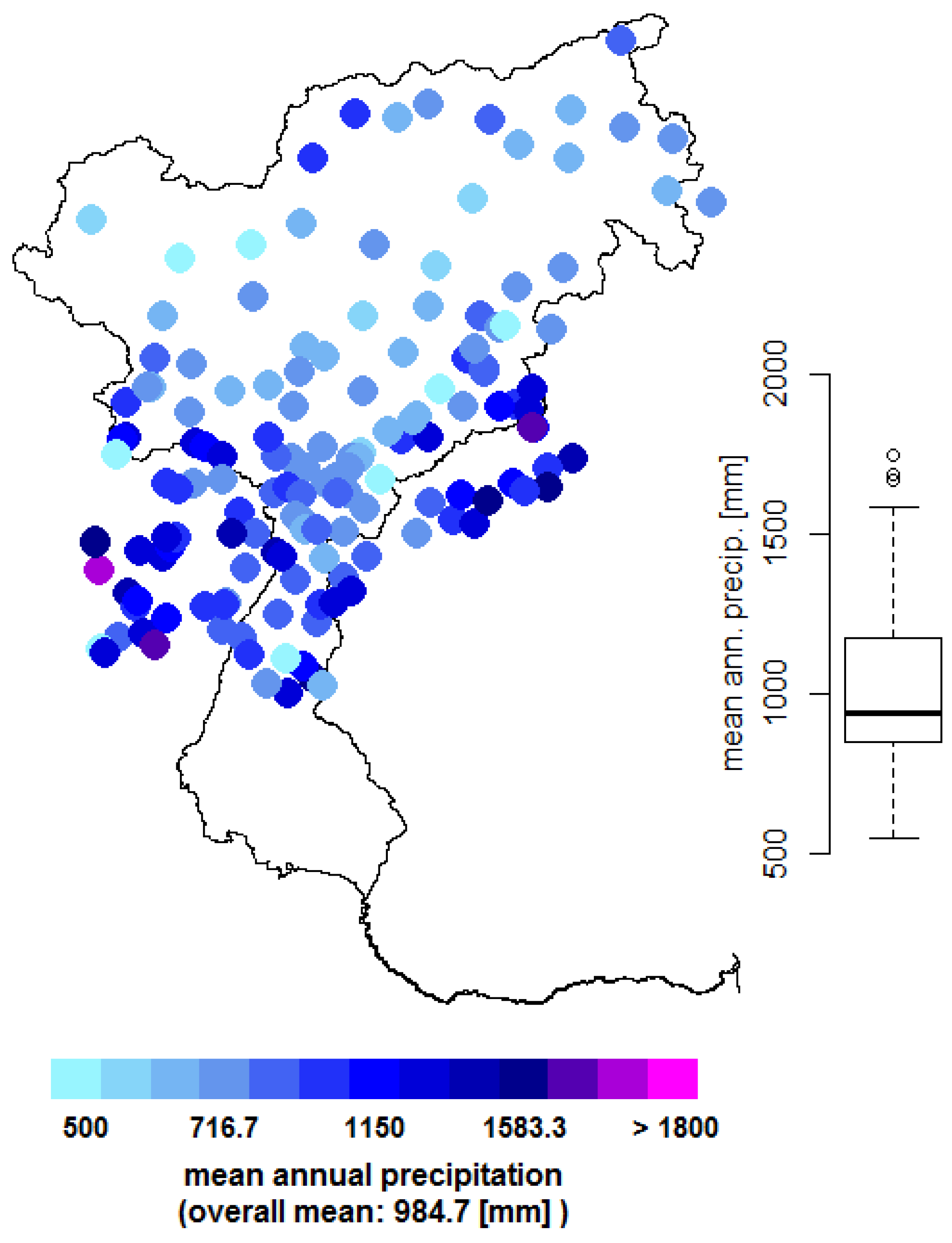
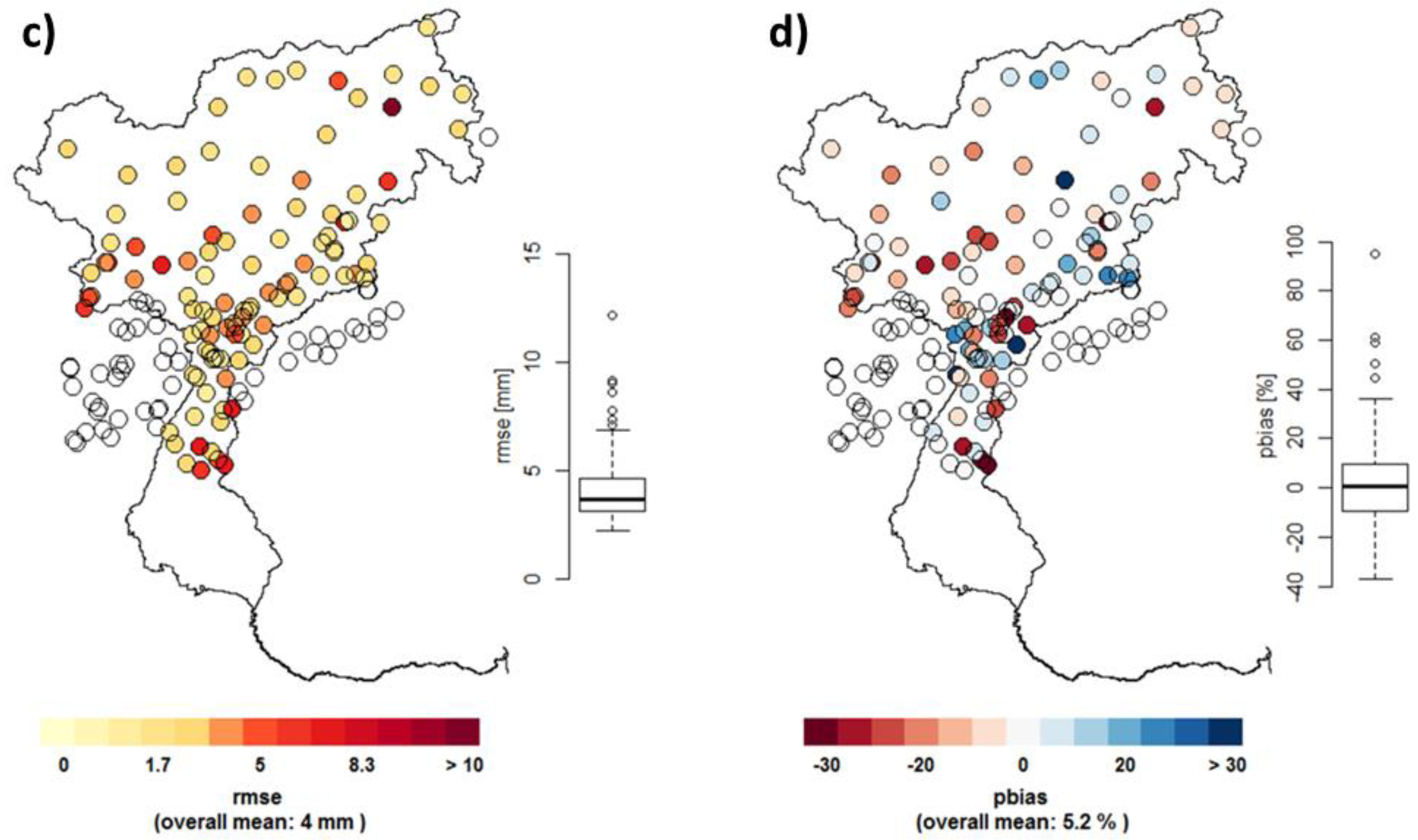
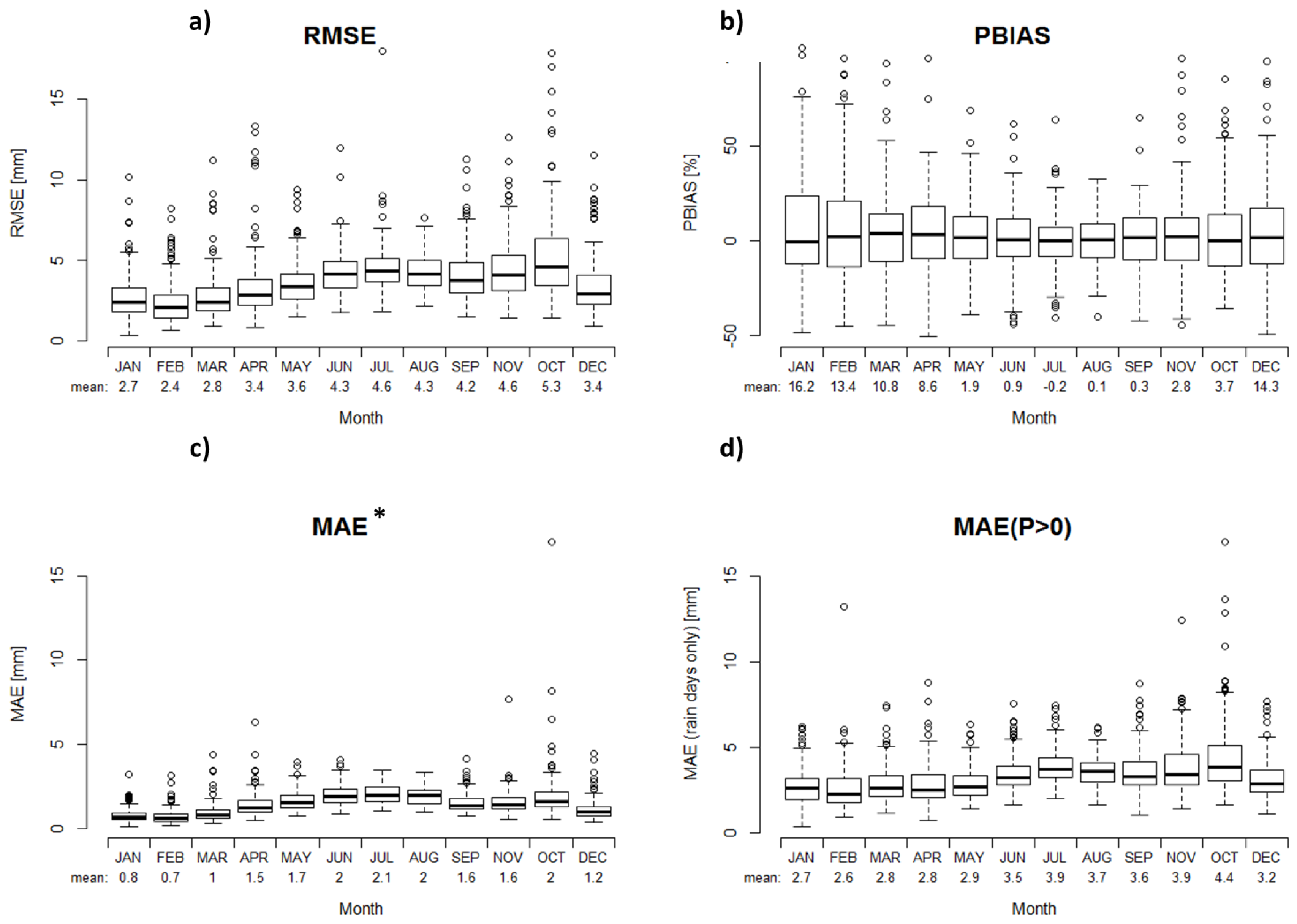
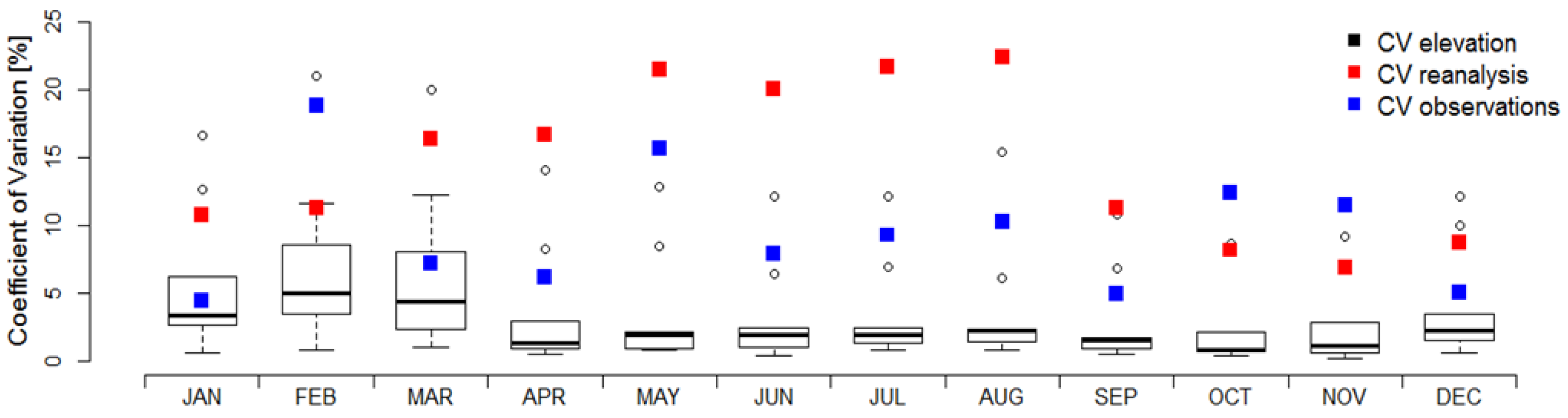
3.2. Performance Validation of the Constructed Reference Grid
3.3. Available Precipitation Data Sets
3.4. Remapping of the Reference Grid
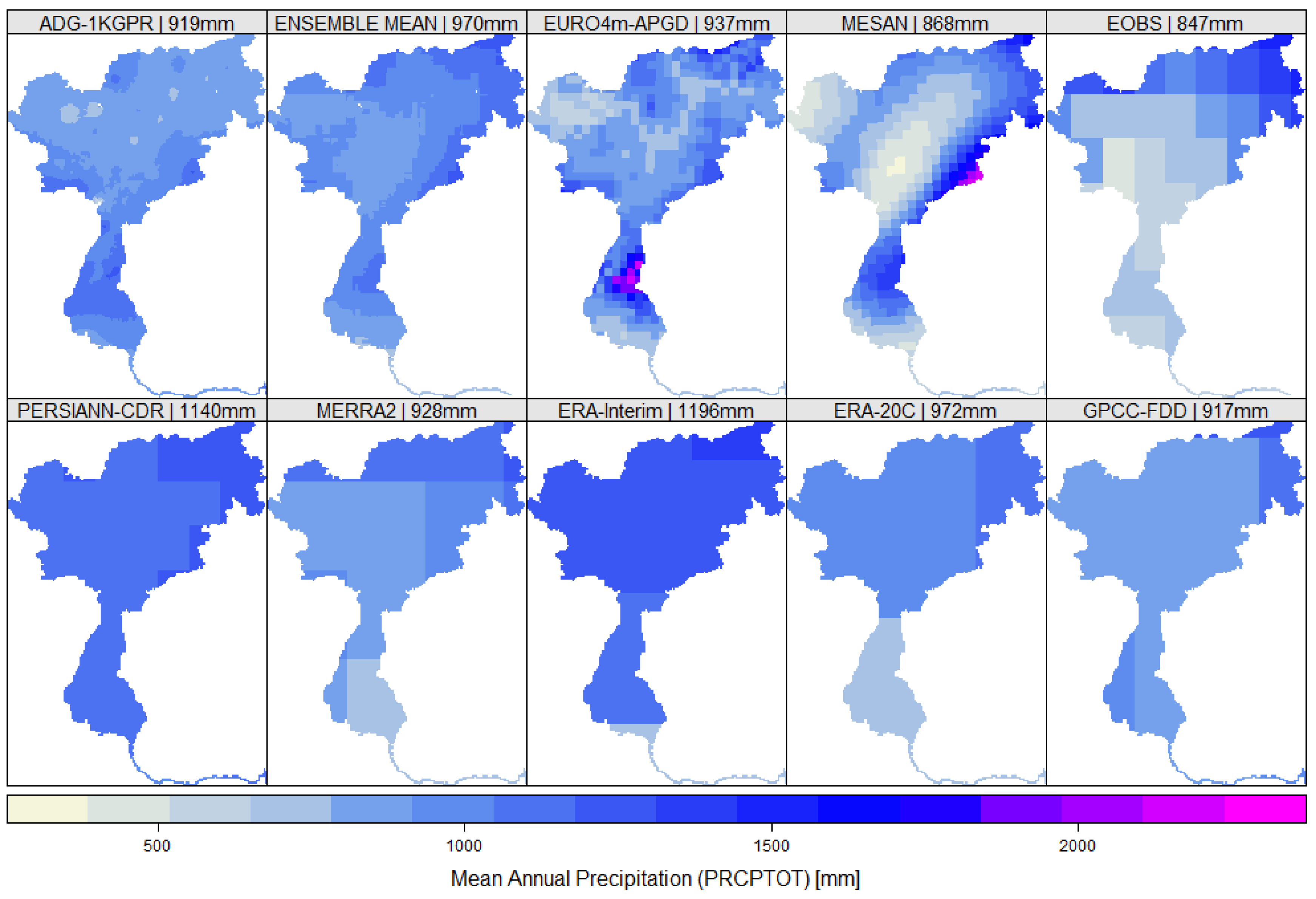
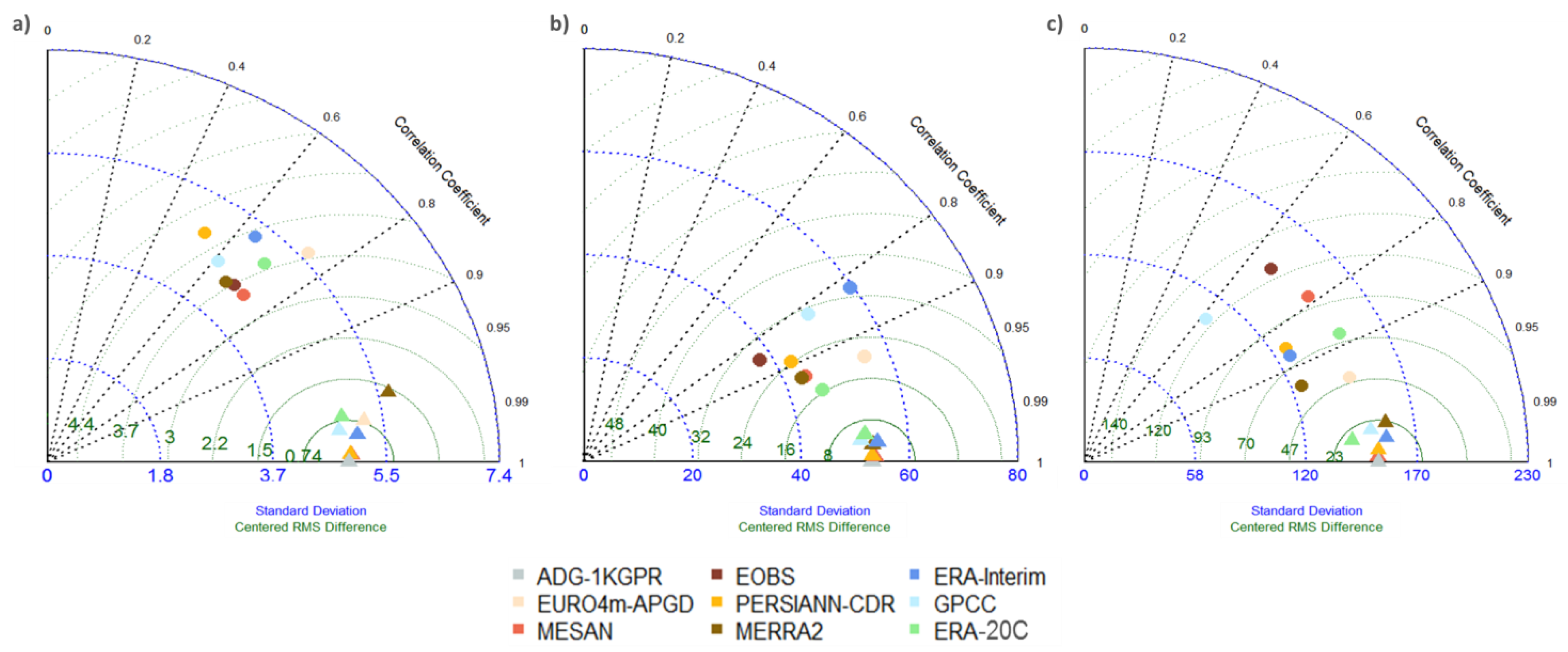
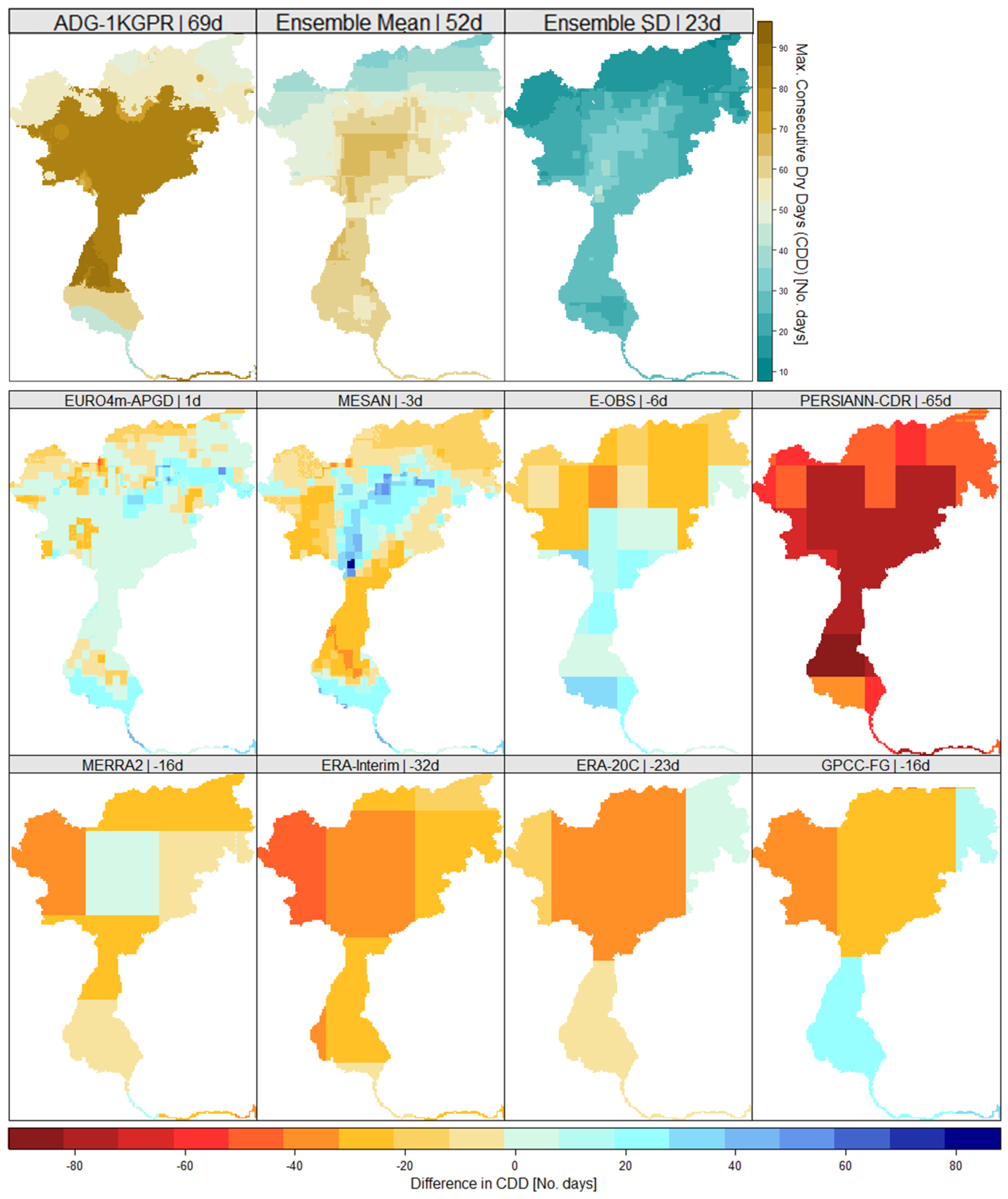
4. Results
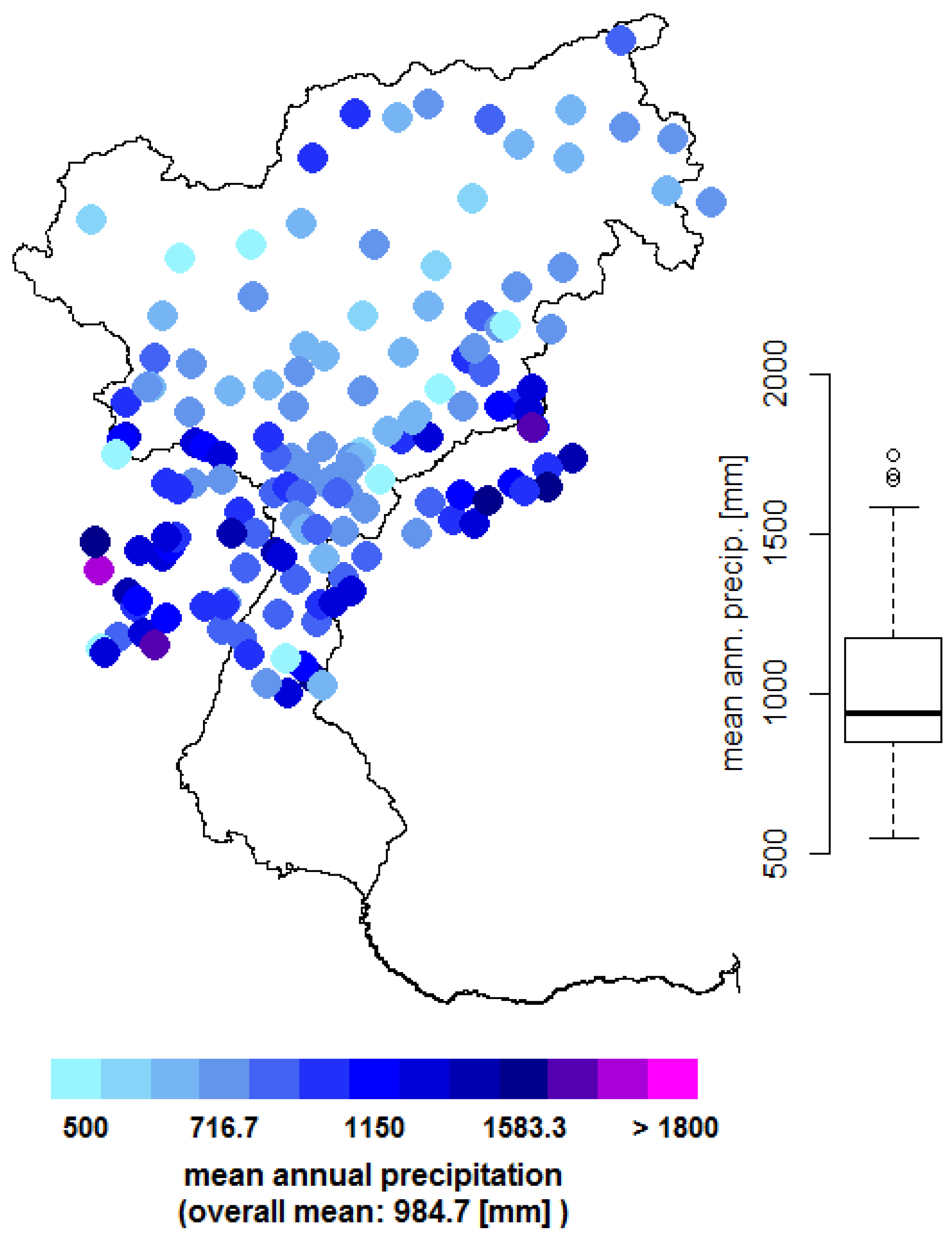
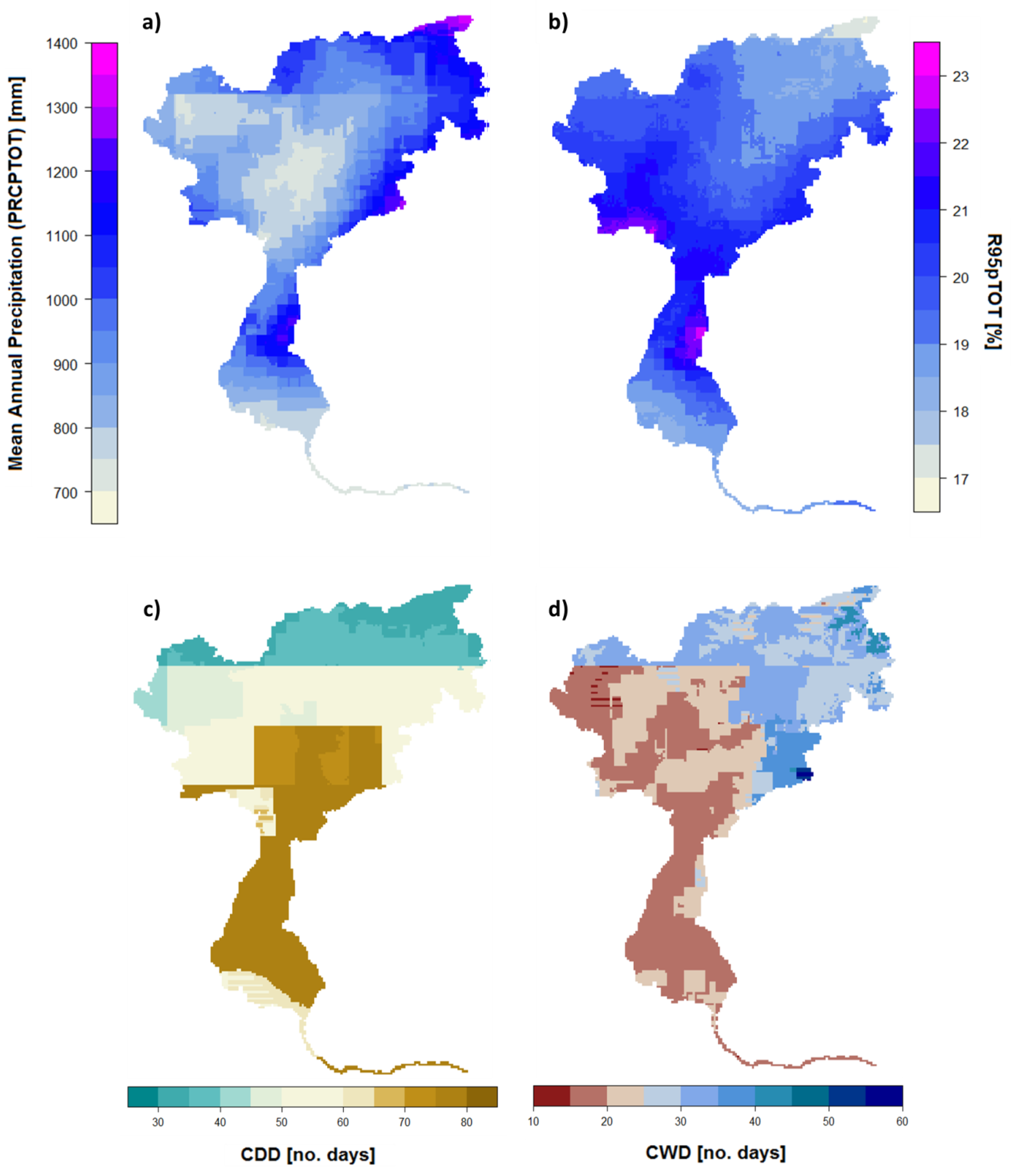
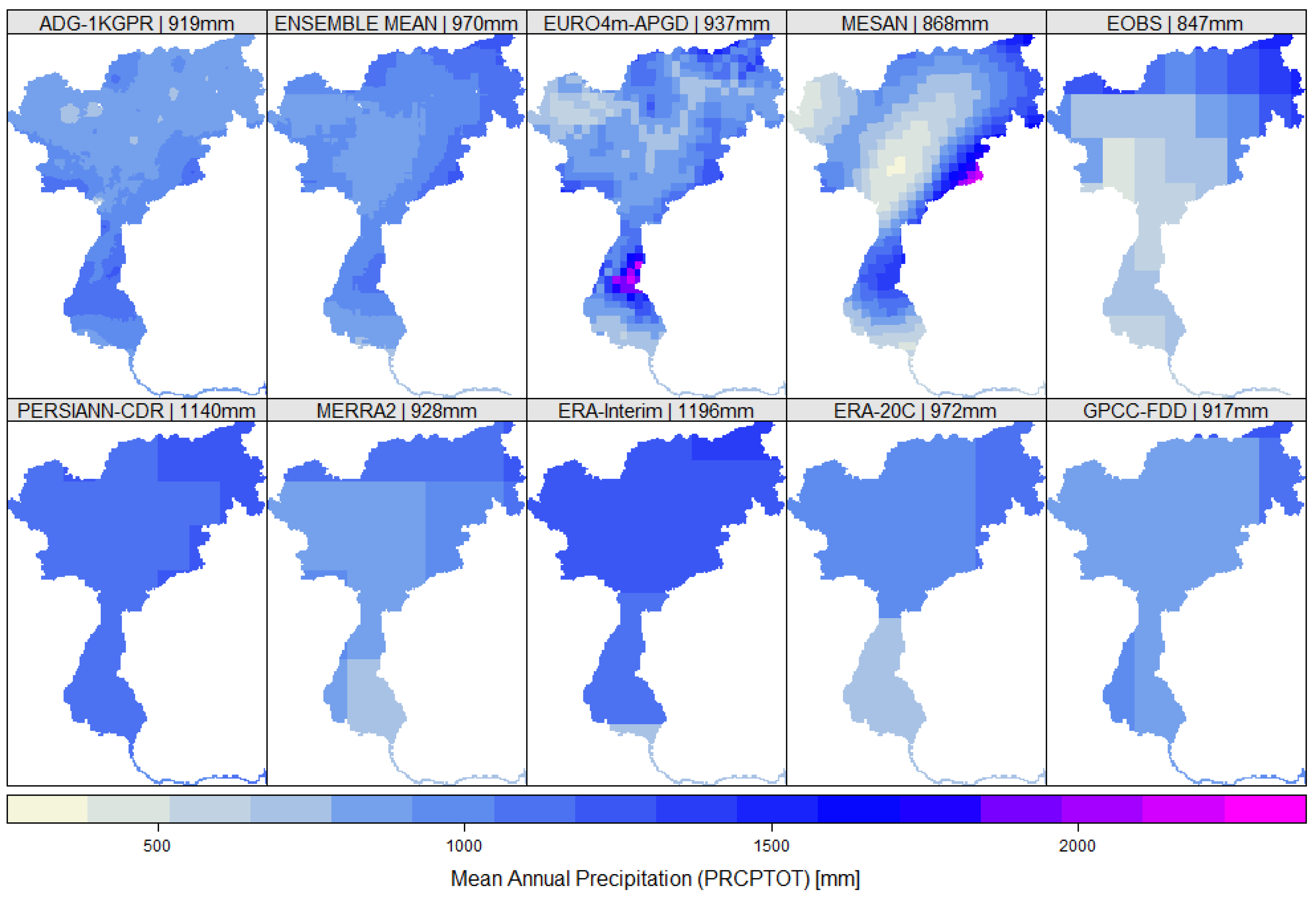
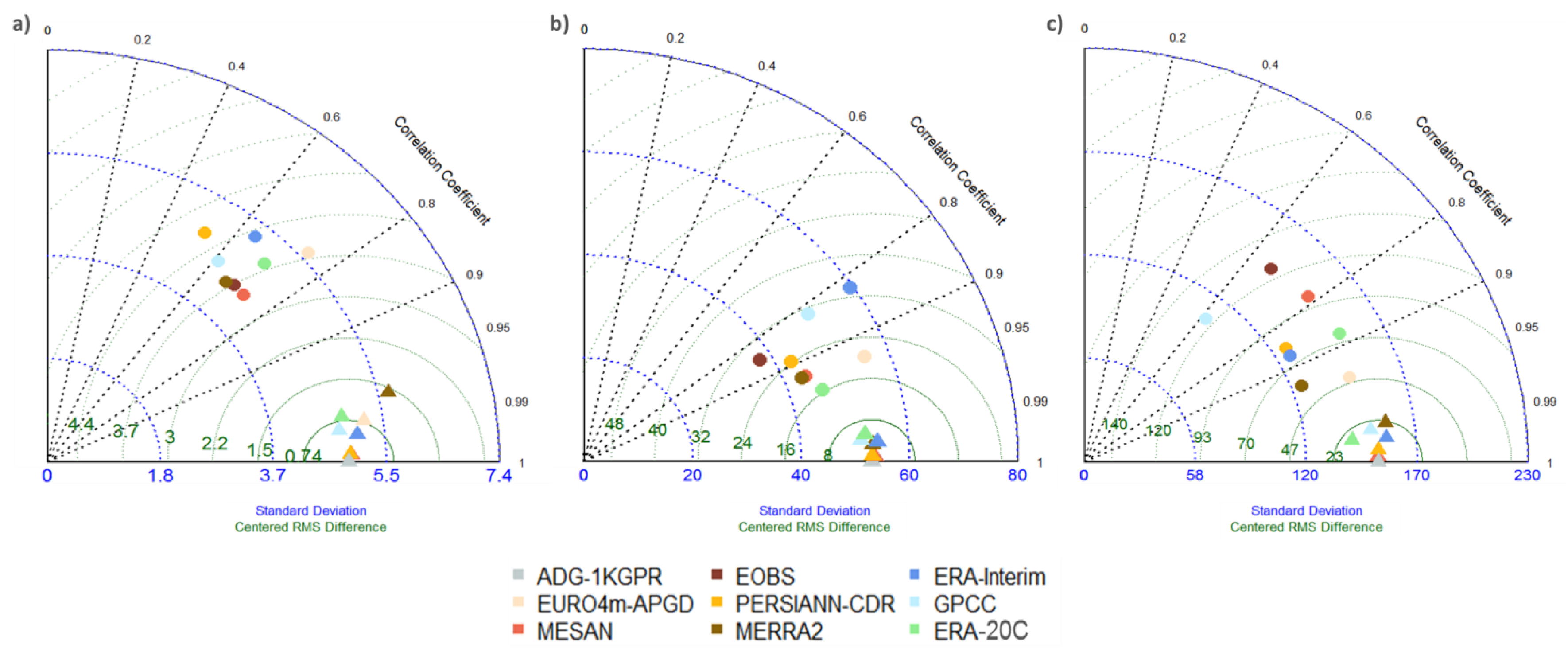
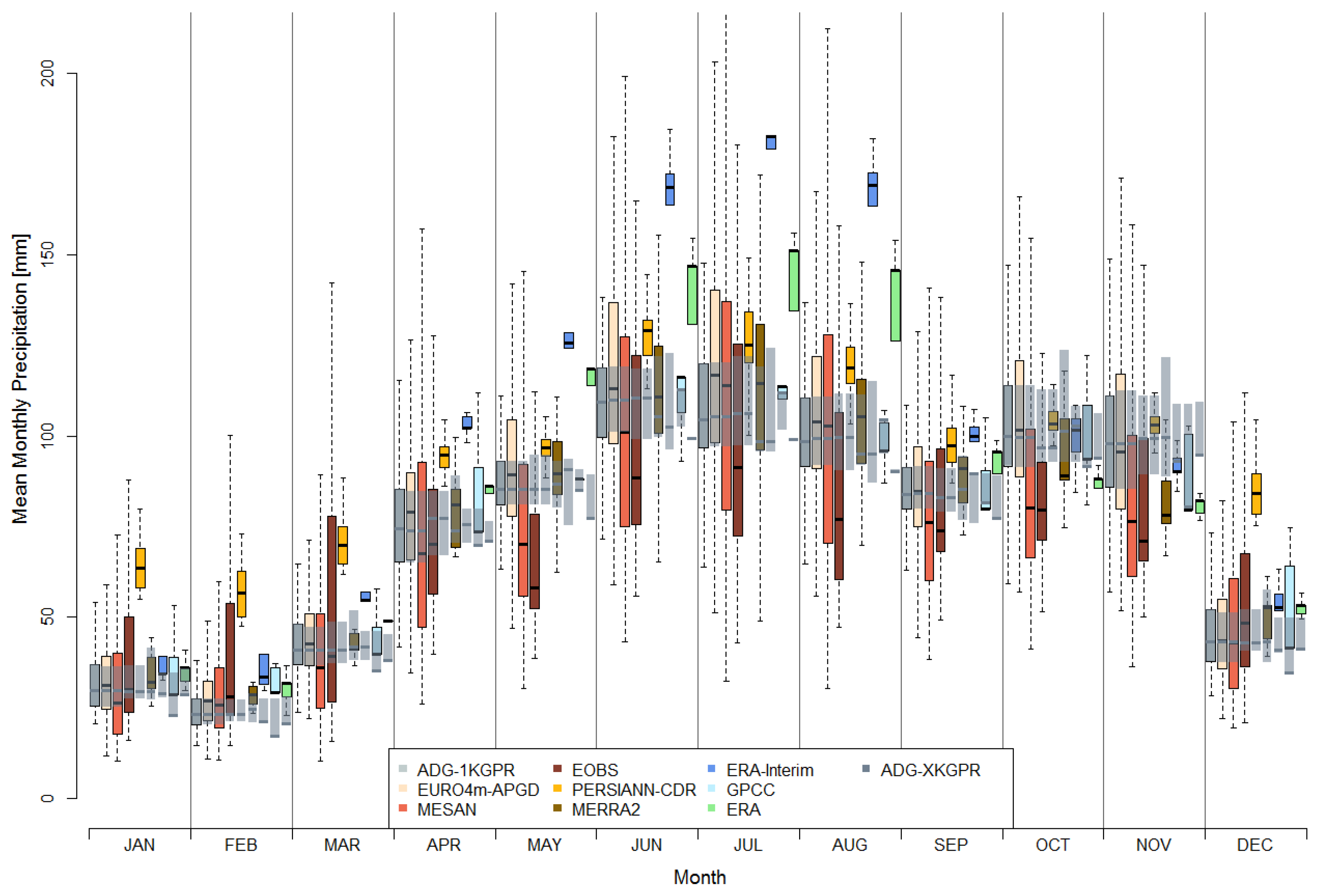
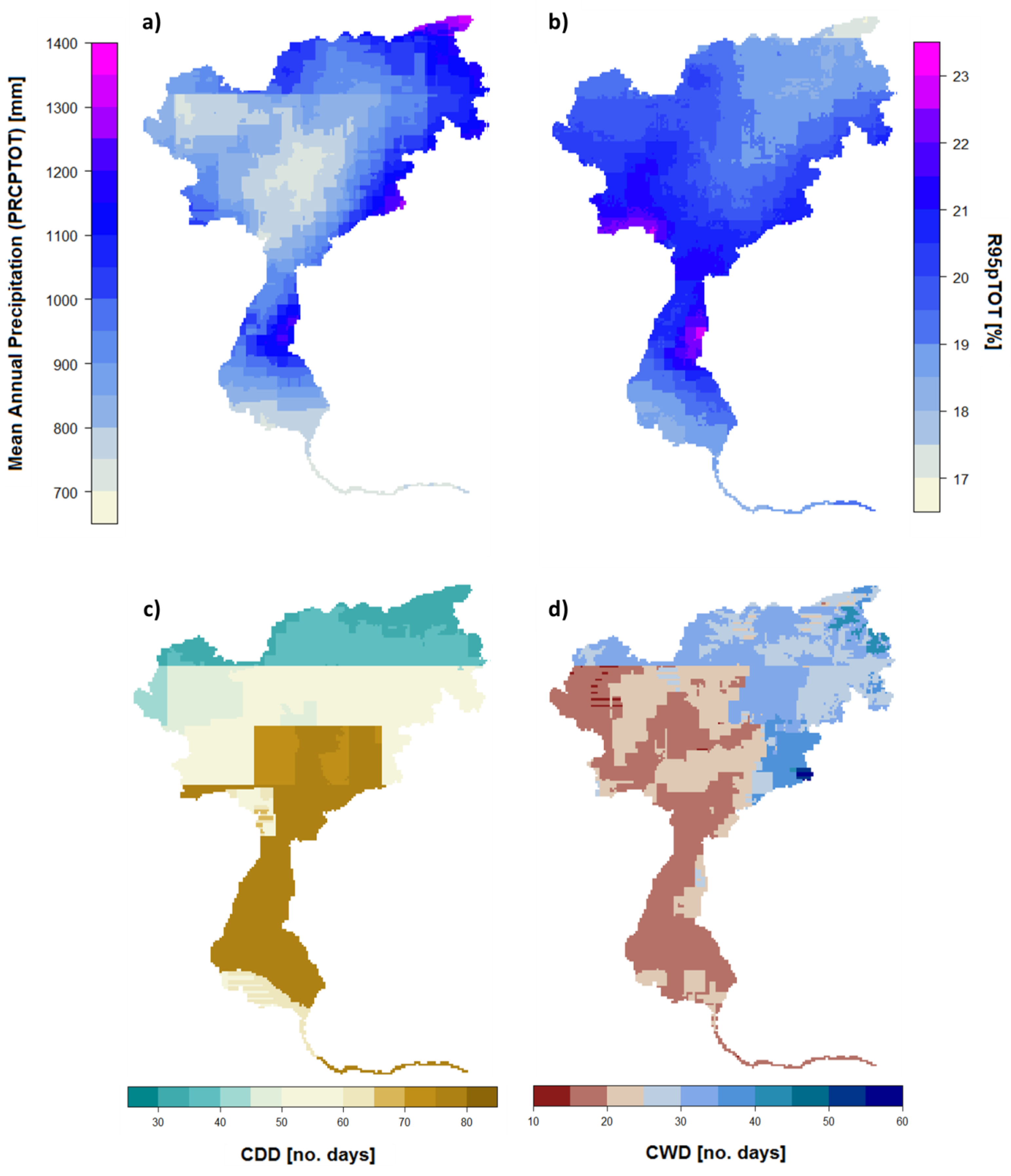
4.1. Mean Precipitation
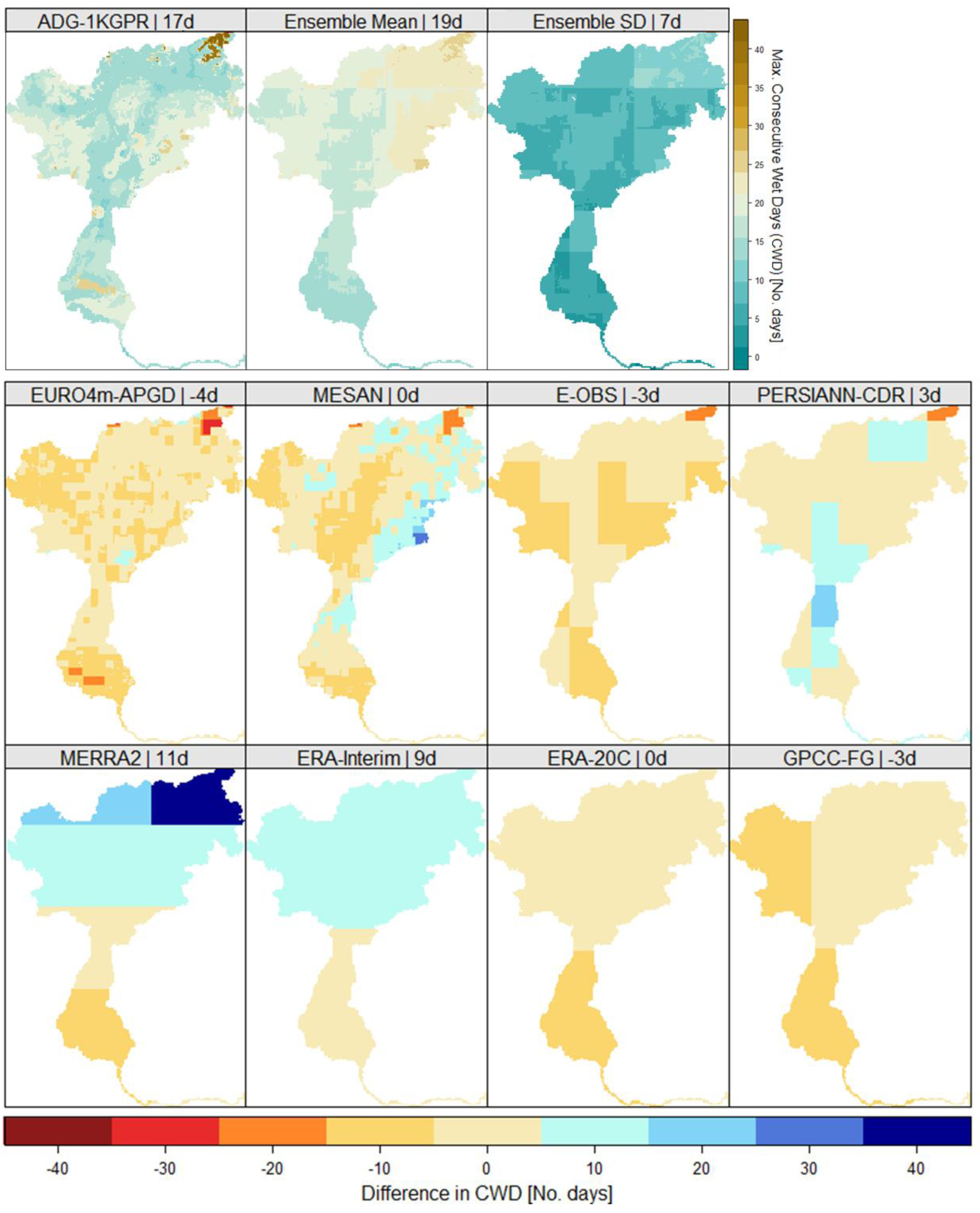
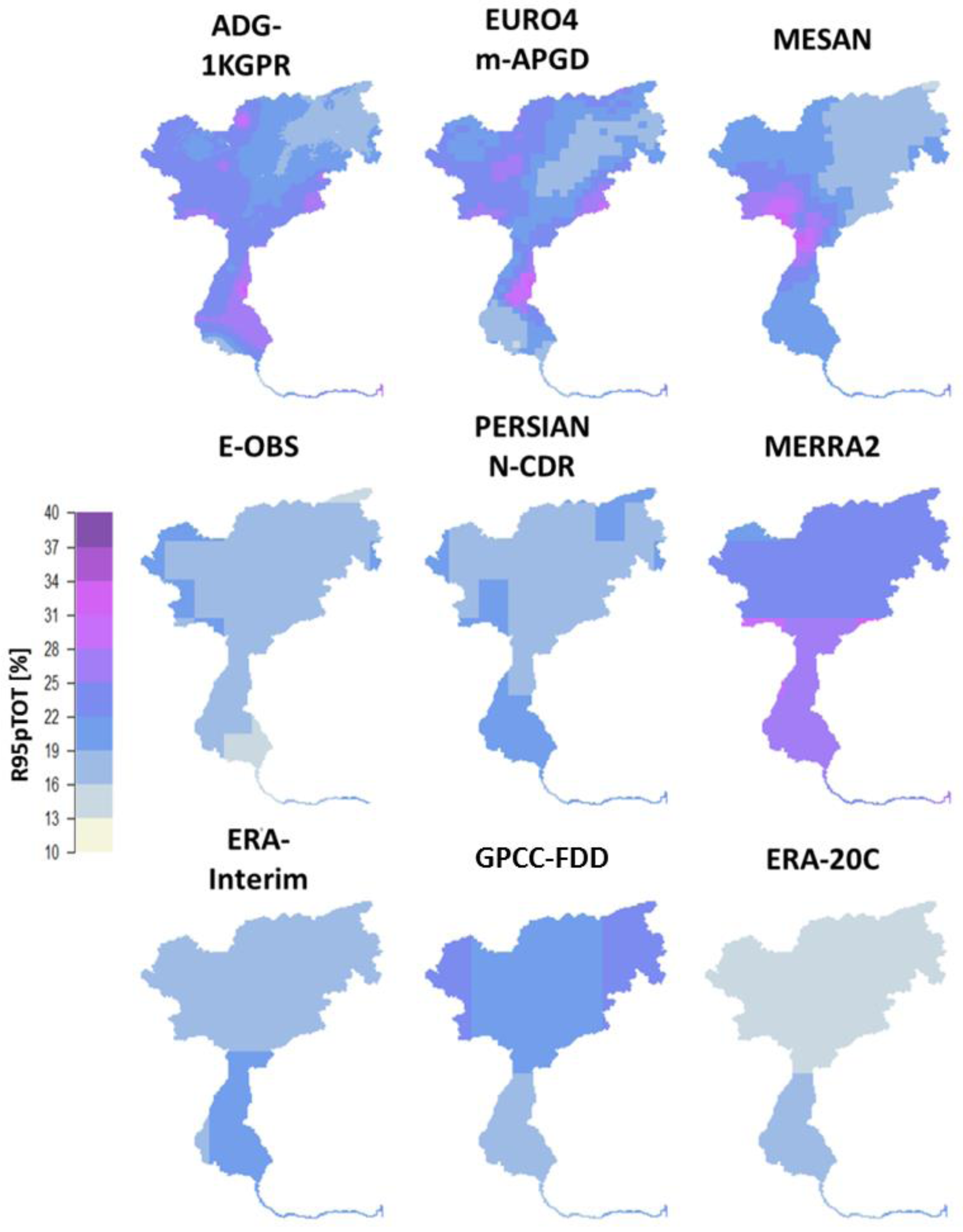
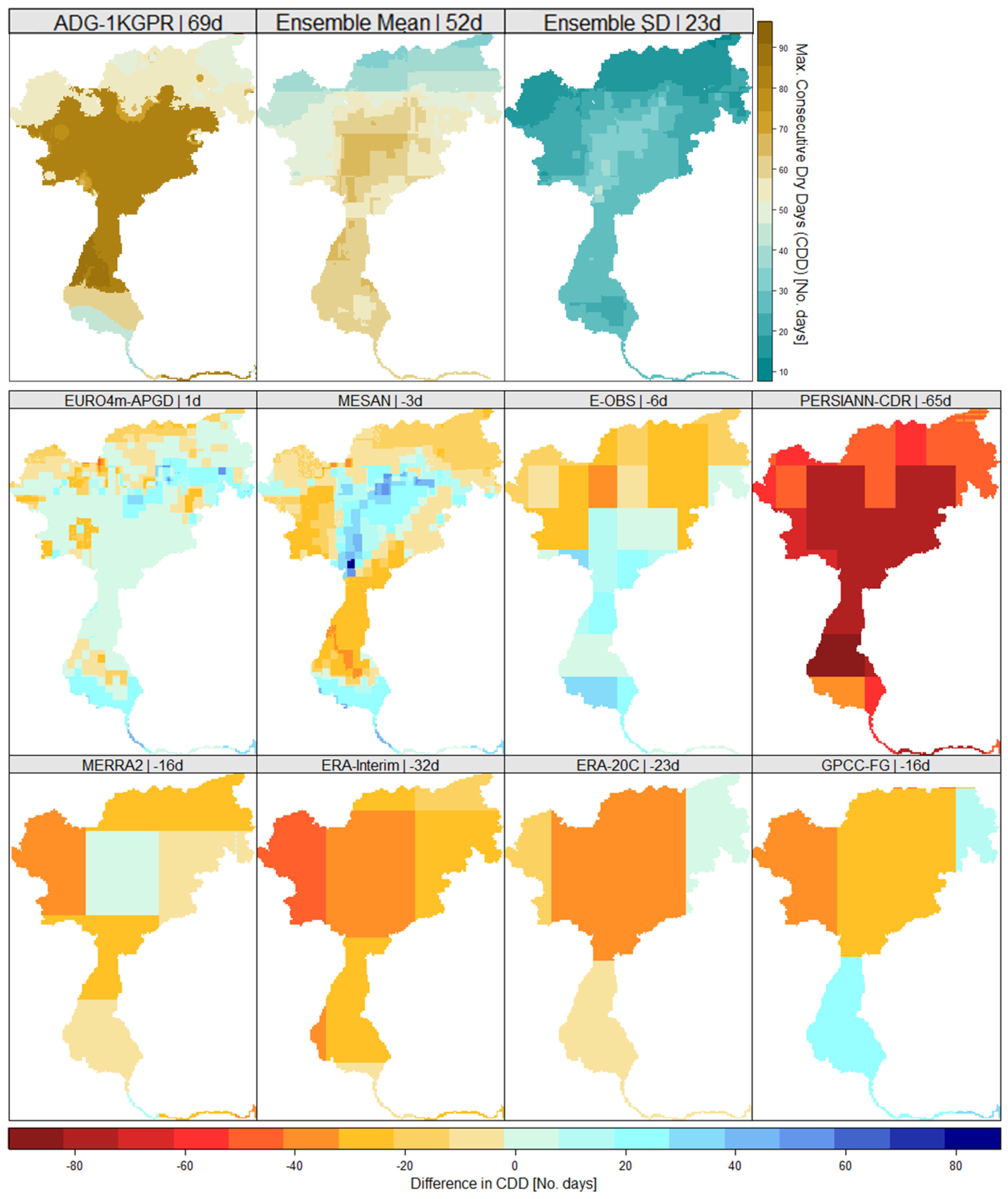
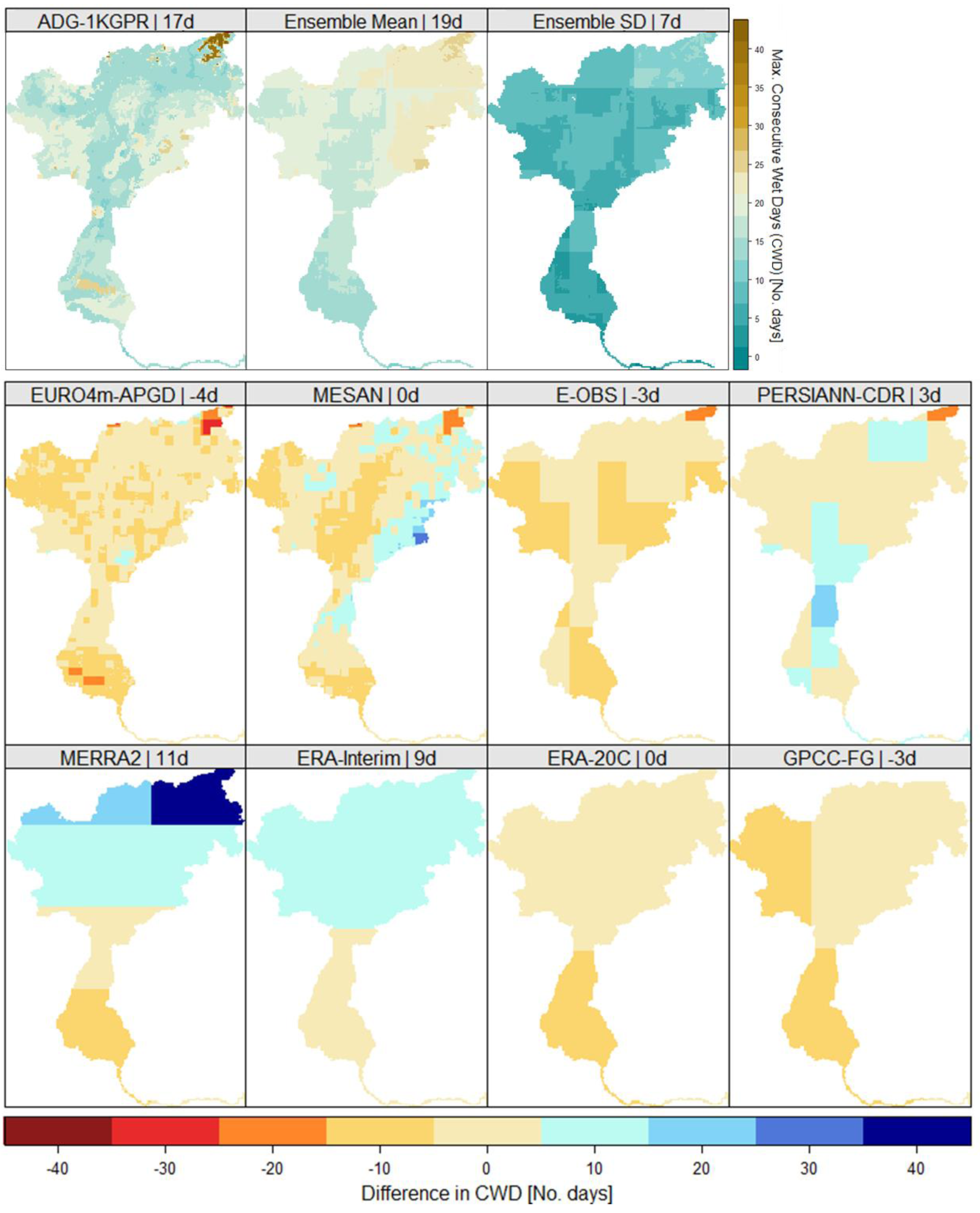
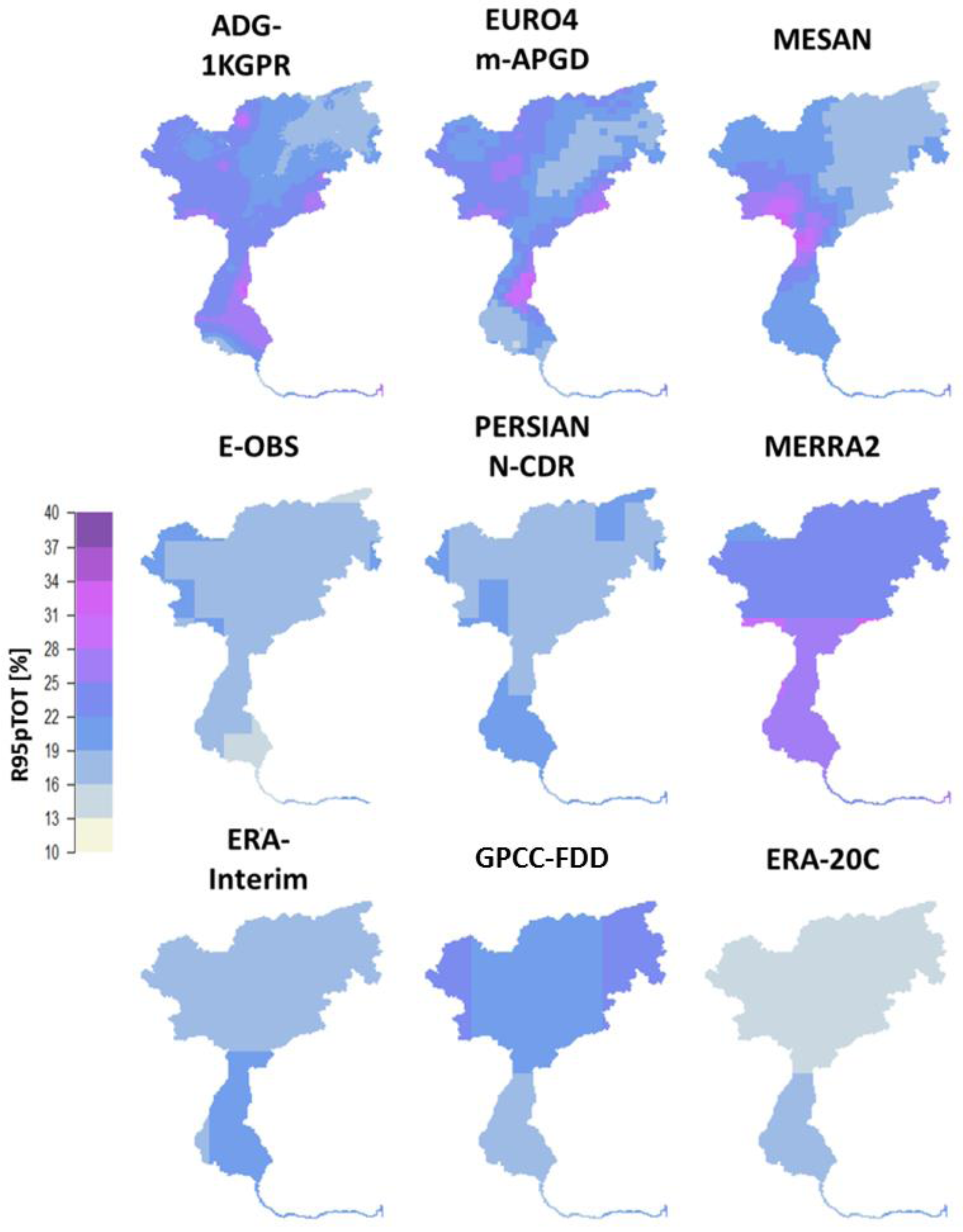
4.2. Comparison of Hydrologically Important Indicators
4.3. Uncertainties and Recommendation
5. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Schneider, U.; Ziese, M.; Meyer-Christoffer, A.; Finger, P.; Rustemeier, E.; Becker, A. The new portfolio of global precipitation data products of the Global Precipitation Climatology Centre suitable to assess and quantify the global water cycle and resources. Proc. Int. Assoc. Hydrol. Sci. 2016, 374, 29. [Google Scholar] [CrossRef]
- Daly, C.; Slater, M.E.; Roberti, J.A.; Laseter, S.H.; Swift, L.W. High-resolution precipitation mapping in a mountainous watershed: Ground truth for evaluating uncertainty in a national precipitation dataset. Int. J. Climatol. 2017, 37, 124–137. [Google Scholar] [CrossRef]
- Prein, A.F.; Gobiet, A.; Truhetz, H.; Keuler, K.; Goergen, K.; Teichmann, C.; Fox Maule, C.; van Mejgaard, E.; Déqué, M.; Nikulin, G.; et al. Precipitation in the EURO-CORDEX 0.11° and 0.44° simulations: High resolution, high benefits? Clim. Dyn. 2016, 46, 383–412. [Google Scholar] [CrossRef] [Green Version]
- Ivancic, T.J.; Shaw, S.B. Examining why trends in very heavy precipitation should not be mistaken for trends in very high river discharge. Clim. Chang. 2015, 133, 681–693. [Google Scholar] [CrossRef]
- Stephens, E.; Day, J.J.; Pappenberger, F.; Cloke, H. Precipitation and floodiness. Geophys. Res. Lett. 2015, 42, 316–323. [Google Scholar] [CrossRef]
- Madsen, H.; Lawrence, D.; Lang, M.; Martinkova, M.; Kjeldsen, T.R. Review of trend analysis and climate change projections of extreme precipitation and floods in Europe. J. Hydrol. 2015, 519, 3634–3650. [Google Scholar] [CrossRef] [Green Version]
- Bacchi, B.; Kottegoda, N.T. Identification and calibration of spatial correlation patterns of rainfall. J. Hydrol. 1995, 165, 311–348. [Google Scholar] [CrossRef]
- Paschalis, A.; Fatichi, S.; Molnar, P.; Rimkus, S.; Burlando, P. On the effects of small scale space–time variability of rainfall on basin flood response. J. Hydrol. 2014, 514, 313–327. [Google Scholar] [CrossRef]
- Hijmans, R.J.; Cameron, S.E.; Parra, J.L.; Jones, P.G.; Jarvis, A. Very high resolution interpolated climate surfaces for global land areas. Int. J. Climatol. 2005, 25, 1965–1978. [Google Scholar] [CrossRef]
- Compo, G.P.; Whitaker, J.S.; Sardeshmukh, P.D.; Matsui, N.; Allan, R.J.; Yin, X.; Gleason, E., Jr.; Vose, R.S.; Rutledge, G.; Bessemoulin, P.; et al. The twentieth century reanalysis project. Q. J. R. Meteorol. Soc. 2011, 137, 1–28. [Google Scholar] [CrossRef]
- Dee, D.; Uppala, S.M.; Simmons, A.J.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.A.; Balsamo, G.; Bauer, P.; et al. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Schamm, K.; Ziese, M.; Raykova, K.; Becker, A.; Finger, P.; Meyer-Christoffer, A.; Schneider, U. GPCC Full Data Daily Version 1.0: Daily Land-Surface Precipitation from Rain Gauges Built on GTS Based and Historic Data. Available online: https://rda.ucar.edu/datasets/ds497.0/ (accessed on 30 July 2017).
- Herrera, S.; Gutiérrez, J.M.; Ancell, R.; Pons, M.R.; Frías, M.D.; Fernández, J. Development and analysis of a 50-year high-resolution daily gridded precipitation dataset over Spain (Spain02). Int. J. Climatol. 2012, 32, 74–85. [Google Scholar] [CrossRef] [Green Version]
- Isotta, F.A.; Frei, C.; Weilguni, V.; Percec Tadic, M.; Lassègues, P.; Rudolf, B.; Pavan, V.; Cacciamani, C.; Antolini, G.; Ratto, S.M.; et al. The climate of daily precipitation in the Alps: Development and analysis of a high-resolution grid dataset from pan-Alpine rain-gauge data. Int. J. Climatol. 2014, 34, 1657–1675. [Google Scholar] [CrossRef]
- Häggmark, L.; Ivarsson, I.; Gollvik, S.; Olofsson, O. Mesan, an operational mesoscale analysis system. Tellus 2000, 52, 2–20. [Google Scholar] [CrossRef]
- Kalnay, E.; Kanamitsu, M.; Kistler, R.; Collins, W.; Deaven, D.; Gandin, L.; Iredell, M.; Saha, S.; White, G.; Woollen, J.; et al. The NCEP/NCAR 40-year reanalysis project. Bull. Am. Meteorol. Soc. 1996, 77, 437–471. [Google Scholar] [CrossRef]
- Rienecker, M.M.; Suarez, M.J.; Gelaro, R.; Todling, R.; Bacmeister, J.; Liu, E.; Bosilovich, M.G.; Schubert, S.D.; Takacs, L.; Kim, G.-K.; et al. MERRA: NASA’s modern-era retrospective analysis for research and applications. J. Clim. 2011, 24, 3624–3648. [Google Scholar] [CrossRef]
- Kummerow, C.; Barnes, W.; Kozu, T.; Shiue, J.; Simpson, J. The tropical rainfall measuring mission (TRMM) sensor package. J. Atmos. Ocean. Technol. 1998, 15, 809–817. [Google Scholar] [CrossRef]
- Ashouri, H.; Hsu, K.L.; Sorooshian, S.; Braithwaite, D.K.; Knapp, K.R.; Cecil, L.D.; Nelson, B.R.; Prat, O.P. PERSIANN-CDR: Daily precipitation climate data record from multisatellite observations for hydrological and climate studies. Bull. Am. Meteorol. Soc. 2015, 96, 69. [Google Scholar] [CrossRef]
- Haylock, M.R.; Hofstra, N.; Klein Tank, A.M.G.; Klok, E.J.; Jones, P.D.; New, M. A European daily high resolution gridded data set of surface temperature and precipitation for 1950–2006. J. Geophys. Res. 2008, 113, D20. [Google Scholar] [CrossRef]
- Isotta, F.A.; Vogel, R.; Frei, C. Evaluation of European regional reanalyses and downscalings for precipitation in the Alpine region. Meteorologische Zeitschrift 2015, 24, 15–37. [Google Scholar] [CrossRef]
- Beck, H.E.; van Dijk, A.I.J.M.; Levizzani, V.; Schellekens, J.; Miralles, D.G.; Martens, B.; de Roo, A. MSWEP: 3-h 0.25° global gridded precipitation (1979–2015) by merging gauge, satellite, and reanalysis data. Hydrol. Earth Syst. Sci. 2017, 21, 589–615. [Google Scholar] [CrossRef]
- Blenkinsop, S.; Lewsis, E.; Chan, S.C.; Fowler, H.J. Quality-control of an hourly rainfall dataset and climatology of extremes for the UK. Int. J. Climatol. 2016, 37, 722–740. [Google Scholar] [CrossRef] [PubMed]
- Goodison, B.E.; Louie, P.Y.T.; Yang, D. WMO Solid Precipitation Measurement Intercomparison; Final Report, WMO/TD-No. 872; World Meteorological Organization: Geneva, Switzerland, 1998. [Google Scholar]
- Rasmussen, R.; Baker, B.; Kochendorfer, J.; Meyers, T.; Landolt, S.; Fischer, A.P.; Black, J.; Thériault, J.M.; Kucera, P.; Gochis, D.; et al. How well are we measuring snow: The NOAA/FAA/NCAR winter precipitation test bed. Bull. Am. Meteorol. Soc. 2012, 93, 811–829. [Google Scholar] [CrossRef]
- Kotlarski, S.; Keuler, K.; Christensen, O.B.; Colette, A.; Déqué, M.; Gobiet, A.; Goergen, K.; Jacob, D.; Lüthi, D.; van Meijgaard, E.; et al. Regional climate modeling on European scales: A joint standard evaluation of the EURO-CORDEX RCM ensemble. Geosci. Model. Dev. 2014, 7, 1297–1333. [Google Scholar] [CrossRef]
- Bosilovich, M.G.; Chen, J.; Robertson, F.R.; Adler, R.F. Evaluation of global precipitation in reanalyses. J. Appl. Meteorol. Climatol. 2008, 47, 2279–2299. [Google Scholar] [CrossRef]
- Kidd, C.; Bauer, P.; Turk, J.; Huffman, G.J.; Joyce, R.; Hsu, K.L.; Braithwaite, D. Intercomparison of high-resolution precipitation products over Northwest Europe. J. Hydrometeorol. 2012, 13, 67–83. [Google Scholar] [CrossRef]
- Nkiaka, E.; Nawaz, N.R.; Lovett, J.C. Evaluating global reanalysis precipitation datasets with rain gauge measurements in the Sudano-Sahel region: Case study of the Logone catchment, Lake Chad Basin. Meteorol. Appl. 2017, 24, 9–18. [Google Scholar] [CrossRef]
- Palazzi, E.; Hardenberg, J.; Provenzale, A. Precipitation in the Hindu-Kush Karakoram Himalaya: Observations and future scenarios. J. Geophys. Res. Atmos. 2013, 118, 85–100. [Google Scholar] [CrossRef]
- Sikorska, A.E.; Seibert, J. Value of different precipitation data for flood prediction in an alpine catchment: A Bayesian approach. J. Hydrol. 2016. [Google Scholar] [CrossRef]
- Maggioni, V.; Nikolopoulos, E.I.; Anagnostou, E.N.; Borga, M. Modeling satellite precipitation errors over mountainous terrain: The influence of gauge density, seasonality, and temporal resolution. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4130–4140. [Google Scholar] [CrossRef]
- Mei, Y.; Anagnostou, E.N.; Nikolopoulos, E.I.; Borga, M. Error analysis of satellite precipitation products in mountainous basins. J. Hydrometeorol. 2014, 15, 1778–1793. [Google Scholar] [CrossRef]
- Nikolopoulos, E.I.; Anagnostou, E.N.; Borga, M. Using high-resolution satellite rainfall products to simulate a major flash flood event in northern Italy. J. Hydrometeorol. 2013, 14, 171–185. [Google Scholar] [CrossRef]
- Frei, C.; Schär, C. A precipitation climatology of the Alps from high-resolution rain-gauge observations. Int. J. Climatol. 1998, 18, 873–900. [Google Scholar] [CrossRef]
- Chiogna, G.; Majone, B.; Cano Paoli, K.; Diamantini, E.; Stella, E.; Mallucci, S.; Lencioni, V.; Zandonai, F.; Bellin, A. A review of hydrological and chemical stressors in the Adige catchment and its ecological status. Sci. Total Environ. 2016, 540, 429–443. [Google Scholar] [CrossRef] [PubMed]
- Navarro-Ortega, A.; Acuña, V.; Bellin, A.; Burek, P.; Cassiani, G.; Choukr-Allah, R.; Dolédec, S.; Elosegi, A.; Ferrari, F.; Ginebreda, A.; et al. Managing the effects of multiple stressors on aquatic ecosystems under water scarcity. The GLOBAQUA project. Sci. Total Environ. 2015, 503, 3–9. [Google Scholar] [CrossRef] [PubMed]
- Schulla, J.; Jasper, K. Model Description Wasim-Eth; Technical Report; Institute for Atmospheric and Climate Science, Swiss Federal Institute of Technology: Zürich, Switzerland, 2007. [Google Scholar]
- Camera, C.; Bruggeman, A.; Hadjinicolaou, P.; Pashiardis, S.; Lange, M.A. Evaluation of interpolation techniques for the creation of gridded daily precipitation (1 × 1 km2); Cyprus, 1980–2010. J. Geophys. Res. Atmos. 2014, 119, 693–712. [Google Scholar] [CrossRef]
- Di Luzio, M.; Johnson, G.; Daly, C.; Eischeid, J.K.; Arnold, J. Constructing retrospective gridded daily precipitation and temperature datasets for the conterminous united states. Am. Meteorol. Soc. 2008, 47, 475–497. [Google Scholar] [CrossRef]
- Lu, G.Y.; Wong, D.W. An adaptive inverse-distance weighting spatial interpolation technique. Comput. Geosci. 2008, 34, 1044–1055. [Google Scholar] [CrossRef]
- Hasenauer, H.; Merganicova, K.; Petritsch, R.; Pietsch, S.A.; Thornton, P.E. Validating daily climate interpolations over complex terrain in Austria. Agric. For. Meteorol. 2003, 119, 87–107. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model. Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Hutchinson, M.F.; McKenney, D.W.; Lawrence, K.; Pedlar, J.H.; Hopkinson, R.F.; Milewska, E.; Papadopol, P. Development and testing of Canada-wide interpolated spatial models of daily minimum–maximum temperature and precipitation for 1961–2003. Am. Meteorol. Soc. 2009, 48, 725–741. [Google Scholar] [CrossRef]
- Hunter, R.D.; Meentemeyer, R.K. Climatologically aided mapping of daily precipitation and temperature. J. Appl. Meteorol. 2005, 44, 1501–1510. [Google Scholar] [CrossRef]
- Xia, Y.; Fabian, P.; Winterhalter, M.; Zhao, M. Forest climatology: Estimation and use of daily climatological data for Bavaria, Germany. Agric. For. Meteorol. 2001, 106, 87–103. [Google Scholar] [CrossRef]
- Huffman, G.J.; Adler, R.F.; Bolvin, D.T.; Gu, G.; Nelkin, E.J.; Bowman, K.P.; Hong, Y.; Stocker, E.F.; Wolff, D.B. The TRMM Multisatellite Precipitation Analysis (TMPA): Quasi-global, multi-year, combined-sensor precipitation estimates at fine scales. J. Hydrometeorol. 2007, 8, 38–55. [Google Scholar] [CrossRef]
- Joyce, R.J.; Janowiak, J.E.; Arkin, P.A.; Xie, P. CMORPH: A method that produces global precipitation estimates from passive microwave and infrared data at high spatial and temporal resolution. J. Hydrometeorol. 2004, 5, 487–503. [Google Scholar] [CrossRef]
- Hou, A.Y.; Kakar, R.K.; Neeck, S.; Azarbarzin, A.A.; Kummerow, C.D.; Kojima, M.; Oki, R.; Nakamura, K.; Iguchi, T. The global precipitation measurement mission. Bull. Am. Meteorol. Soc. 2014, 95, 701–722. [Google Scholar] [CrossRef]
- Prein, A.; Gobiet, A. Impacts of uncertainties in European gridded precipitation observations on regional climate analysis. Int. J. Climatol. 2017, 37, 305–327. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Zhang, T.; Frauenfeld, O.W.; Ye, B.; Yang, D.; Qin, D. Evaluation of precipitation from the ERA-40, NCEP-1, and NCEP-2 Reanalyses and CMAP-1, CMAP-2, and GPCP-2 with ground-based measurements in China. J. Geophys. Res. 2009, 114, D9. [Google Scholar] [CrossRef]
- Reichle, R.H.; Liu, Q.; Koster, R.D.; Draper, C.S.; Mahanama, S.P.; Partyka, G.S. Land surface precipitation in MERRA-2. J. Clim. 2017, 30, 1642–1664. [Google Scholar] [CrossRef]
- Bosilovich, M.G.; Lucchesi, R.; Suarez, M. MERRA-2: File Specification; GMAO Office Note No. 9 (Version 1.1). 2015; 73p. Available online: https://gmao.gsfc.nasa.gov/pubs/ (accessed on 30 November 2017).
- Poli, P.; Hersbach, H.; Dee, D.P.; Berrisford, P.; Simmons, A.J.; Vitart, F.; Trémolet, Y. ERA-20C: An atmospheric reanalysis of the twentieth century. J. Clim. 2016, 29, 4083–4097. [Google Scholar] [CrossRef]
- Hersbach, H.; Poli, P.; Dee, D. The observation feedback archive for the ICOADS and ISPD data sets. ERA Rep. Ser. 2015, 18, 74–85. [Google Scholar]
- Adler, R.F.; Huffman, G.J.; Chang, A.; Ferraro, R.; Xie, P.P.; Janowiak, J.; Rudolf, B.; Schneider, U.; Curtis, S.; Bolvin, D.; et al. The version-2 global precipitation climatology project (GPCP) monthly precipitation analysis (1979–present). J. Hydrometeorol. 2003, 4, 1147–1167. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]
- Frich, P.; Alexander, L.V.; Della-Marta, P.; Gleason, B.; Haylock, M.; Klein, A.G.; Peterson, T. Observed coherent changes in climate extremes during the second half of the twentieth century. Clim. Res. 2002, 19, 193–212. [Google Scholar] [CrossRef]
- Kioutsioukis, I.; Melas, D.; Zerefos, C. Statistical assessment of changes in climate extremes over Greece (1955–2002). Int. J. Climatol. 2010, 30, 1723–1737. [Google Scholar] [CrossRef]
- Zolina, O.; Kapala, A.; Simmer, C.; Gulev, S.K. Analysis of extreme precipitation over Europe from different reanalyses: A comparative assessment. Glob. Planet. Chang. 2004, 44, 129–161. [Google Scholar] [CrossRef]
- Trenberth, K.E. The impact of climate change and variability on heavy precipitation, floods, and droughts. Encycl. Hydrol. Sci. 2008, 17. [Google Scholar] [CrossRef]
- Nicótina, L.; Alessi Celegon, E.; Rinaldo, A.; Marani, M. On the impact of rainfall patterns on the hydrologic response. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Diaz-Nieto, J.; Wilby, R.L. A comparison of statistical downscaling and climate change factor methods: Impacts on low flows in the River Thames, United Kingdom. Clim. Chang. 2005, 69, 245–268. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Resolution | Temporal Coverage | Type/Source | Reference |
|---|---|---|---|---|
| MESAN | 5 km | 1989–2010 | Downscaling/Reanalysis | [15] |
| EURO4m-APGD | 5 km | 1971–2008 | Observations | [14] |
| E-OBS v. 11 | 25 km | 1950–2015 | Observations | [20] |
| PERSIANN-CDR | 0.25° (~30 km) | 1983–present | Multisatellite (infrared), corrected | [19] |
| MERRA-2 | 0.5° latitude × 0.625° longitude (~50 km) | 1980–present | Reanalysis | [53] |
| ERA-Interim | 0.75° (~80 km) | 1979–present | Reanalysis | [11] |
| GPCC–FDD v1.0 | 1.0° (~100 km) | 1988–2013 | Observations | [12] |
| ERA-20C | 125 km | 1900–2010 | Reanalysis | [54] |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gampe, D.; Ludwig, R. Evaluation of Gridded Precipitation Data Products for Hydrological Applications in Complex Topography. Hydrology 2017, 4, 53. https://doi.org/10.3390/hydrology4040053
Gampe D, Ludwig R. Evaluation of Gridded Precipitation Data Products for Hydrological Applications in Complex Topography. Hydrology. 2017; 4(4):53. https://doi.org/10.3390/hydrology4040053
Chicago/Turabian StyleGampe, David, and Ralf Ludwig. 2017. "Evaluation of Gridded Precipitation Data Products for Hydrological Applications in Complex Topography" Hydrology 4, no. 4: 53. https://doi.org/10.3390/hydrology4040053
APA StyleGampe, D., & Ludwig, R. (2017). Evaluation of Gridded Precipitation Data Products for Hydrological Applications in Complex Topography. Hydrology, 4(4), 53. https://doi.org/10.3390/hydrology4040053