
A Comparative Analysis of Sediment Concentration Using Artificial Intelligence and Empirical Equations


Abstract
1. Introduction
2. Materials and Methods
2.1. Geographic Location and Description of Canal Characteristics
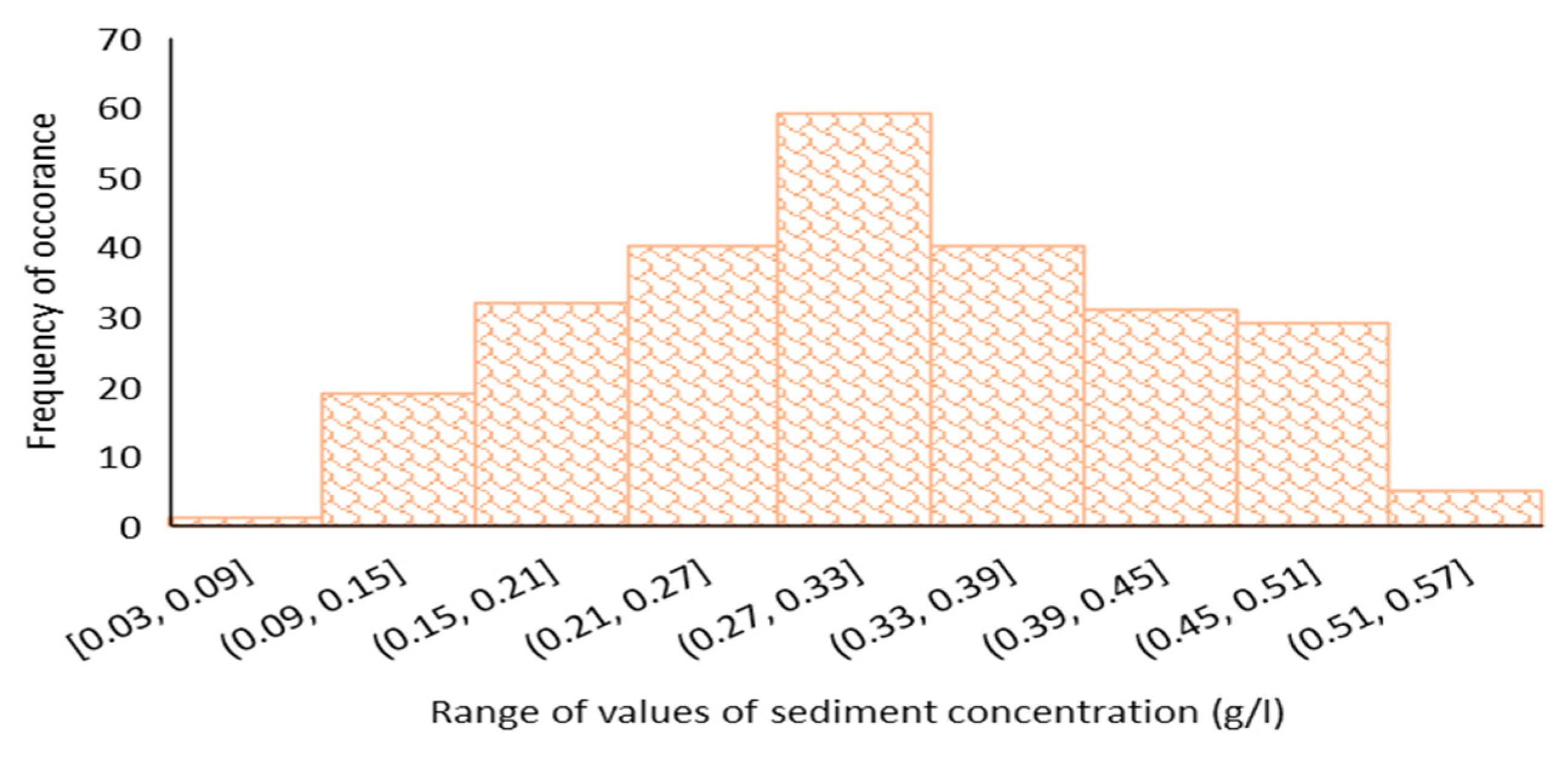
2.2. Data Sources and Measures
2.3. Data Analysis Methods
2.3.1. Artificial Intelligence (AI) Models
Adaptive Neuro-Fuzzy Inference Systems (ANFIS)
Particle Swarm Optimization (PSO) and Random Forest (RF) Models (AIM23 and 24)
Input Combinations (IC) for Artificial Intelligence (AI) models and Sensitivity Analysis of Parameters
2.4. Ackers and White Total Load Formula and Developed Equation
2.4.1. Ackers and White Total Load Formula
- Computation of a dimensionless particle size parameter:
- 2.
- Compute four parameters, P(m), P(n), P(A), and P(C), to be used later:
- 3.
- The mobility number is then computed (note simplification if n = 0):
- 4.
- The sediment concentration, c, is then given in weight-ppm
- 5.
- The concentration is multiplied with the Q (in m3/s) and divided by (10)3 to get the sediment load in kg/s.
2.4.2. Developed Empirical Equation
2.5. General Reduced Gradeint (GRG), an Optimization Tachniques
2.6. Performance Evaluation
2.7. Analysis of Variance (ANOVA), T-Test and Taylor’s Diagram
3. Results
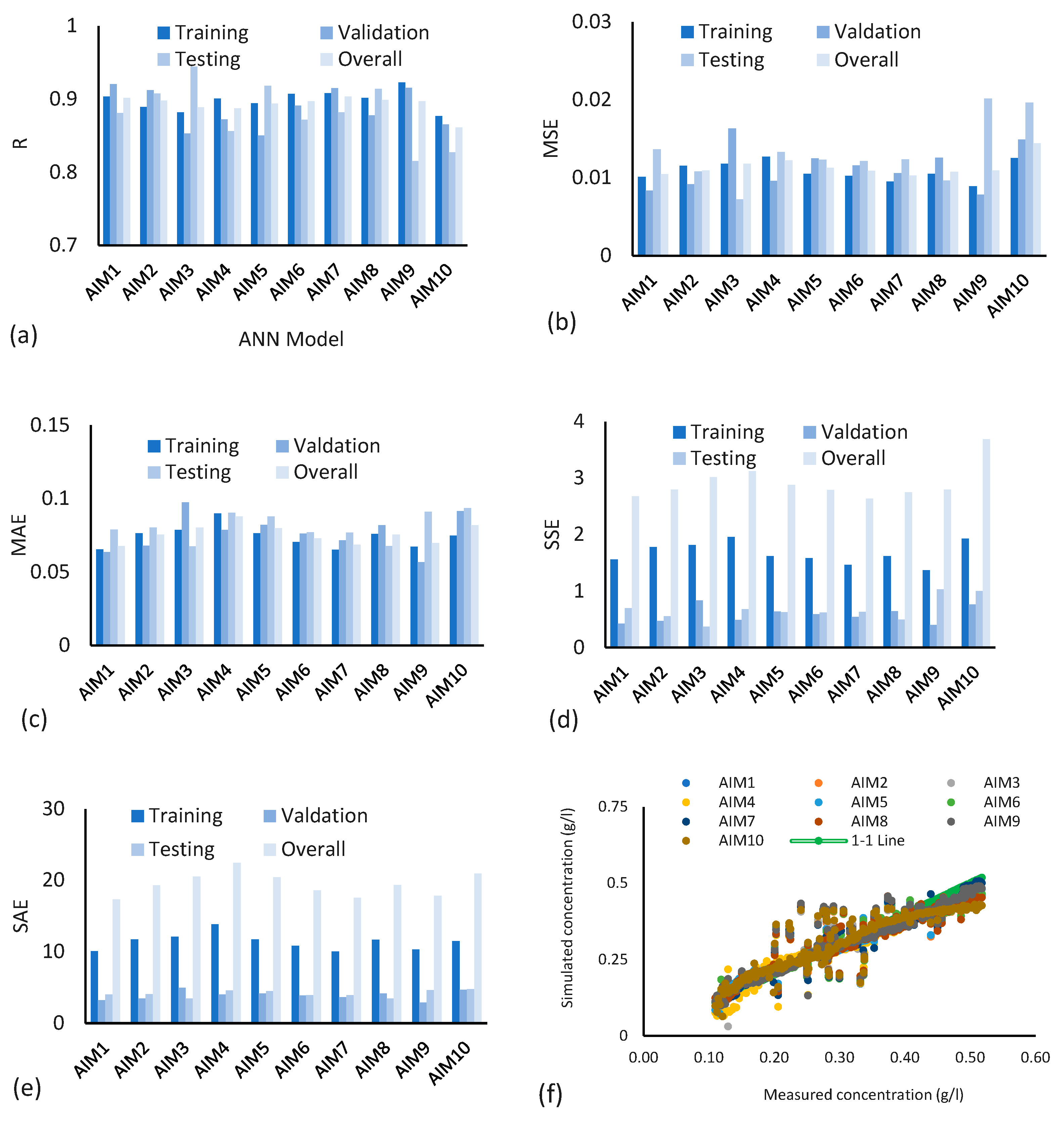
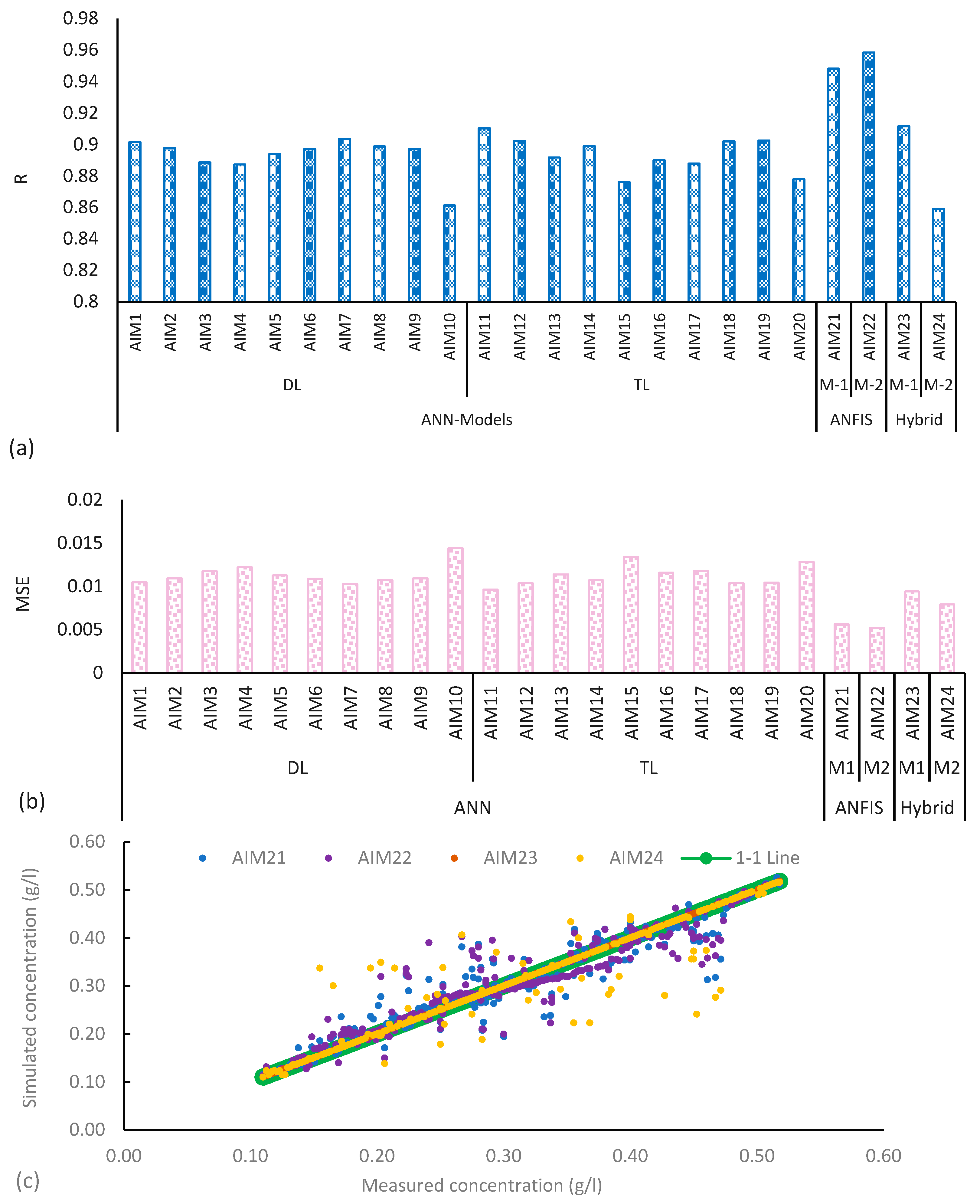
3.1. Evaluating Model Performance and Comparisons
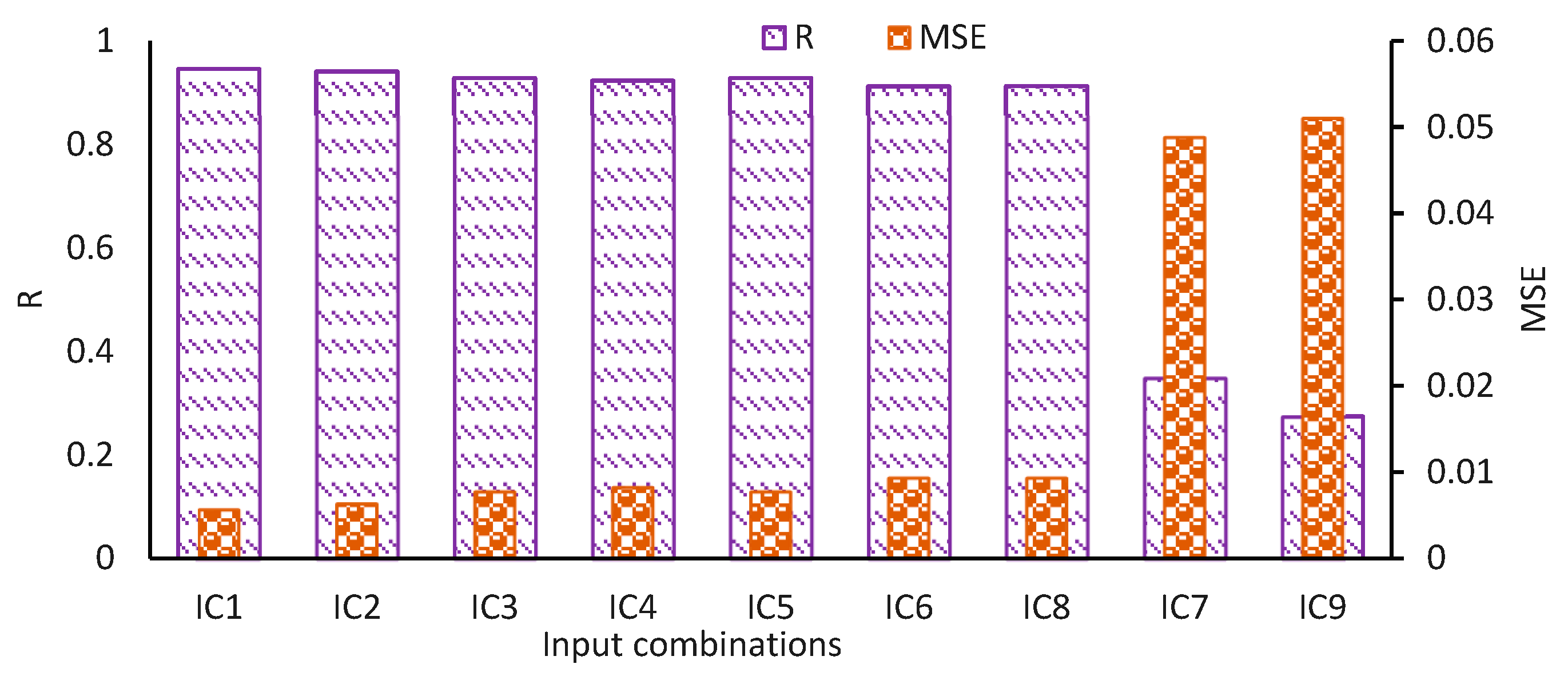
3.2. Input Combination (IC) Scenarios
3.3. Result of Analysis of Variance (ANOVA), T-Test, and Taylor’s Diagram
4. Discussions
5. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nigam, J.; Totakura, B.R.; Kumar, R. Assessment of Barriers to Canal Irrigation Efficiency for Sustainable Harnessing of Irrigation Potential. Water 2023, 15, 2558. [Google Scholar] [CrossRef]
- Einstein, H.A. The Bed-Load Function for Sediment Transportation in Open Channel Flows; Technical Bulletin, No. 1026; US Department of Agriculture: Washington, DC, USA, 1950.
- Toffaleti, F.B. Definitive Computation of Sand Discharge in Rivers. J. Hydraul. Div. 1969, 95, 225–248. [Google Scholar] [CrossRef]
- Van Rijn, L.C. Sediment Transport, Part I: Bed Load Transport. J. Hydraul. Eng. 1984, 110, 1431–1456. [Google Scholar] [CrossRef]
- Ackers, P.; White, W.R. Sediment Transport: New Approach and Analysis. J. Hydraul. Div. 1973, 99, 2041–2060. [Google Scholar] [CrossRef]
- Brownlie, W.R. Prediction of Flow Depth and Sediment Discharge in Open Channels; California Institute of Technology: Pasadena, CA, USA, 1982. [Google Scholar]
- Choi, S.; Lee, J. Prediction of Total Sediment Load in Sand-Bed Rivers in Korea Using Lateral Distribution Method. JAWRA J. Am. Water Resour. Assoc. 2015, 51, 214–225. [Google Scholar] [CrossRef]
- Engelund, F.; Hansen, E. A Monograph on Sediment Transport in Alluvial Streams; Rijkswaterstaat: Utrecht, The Netherlands, 1967. [Google Scholar]
- García, M.H.; Laursen, E.M.; Michel, C.; Buffington, J.M. The Legend of A. F. Shields. J. Hydraul. Eng. 2000, 126, 718–723. [Google Scholar] [CrossRef][Green Version]
- Bagnold, R.A. The flow of cohesionless grains in fluids. Philos. Trans. R. Soc. London. Ser. A Math. Phys. Sci. 1956, 249, 235–297. [Google Scholar] [CrossRef]
- Engelund, F.; Hansen, E. A Monograph on Sediment Transport in Alluvial Streams. TEKNISKFORLAG Skelbrekgade 4 Copenhagen V, Denmark, Hydraulic Engineering Reports, KWP-Collection. 1967. Available online: http://resolver.tudelft.nl/uuid:81101b08-04b5-4082-9121-861949c336c9 (accessed on 24 April 2024).
- Yang, C.T. Sediment Transport Theory and Practice; McGraw-Hill: New York, NY, USA, 1996; ISBN 9780079122650. [Google Scholar]
- Yang, S.-Q.; AL-Fadhly, I. Formulae of Sediment Transport in Steady Flows (Part 1). In Sediment Transport-Recent Advances; IntechOpen: London, UK, 2022. [Google Scholar] [CrossRef]
- Khosravi, K.; Chegini, A.H.N.; Mao, L.; Rodriguez, J.F.; Saco, P.M.; Binns, A.D. Experimental Analysis of Incipient Motion for Uniform and Graded Sediments. Water 2021, 13, 1874. [Google Scholar] [CrossRef]
- Braat, L.; Brückner, M.Z.M.; Sefton-Nash, E.; Lamb, M.P. Gravity-Driven Differences in Fluvial Sediment Transport on Mars and Earth. J. Geophys. Res. Planets 2024, 129, e2023JE007788. [Google Scholar] [CrossRef]
- Cheng, Y.; Xia, J.; Zhou, M.; Deng, S. Improved formula of sediment transport capacity and its application in the lower Yellow River. J. Hydrol. 2024, 631, 130812. [Google Scholar] [CrossRef]
- Sulaiman, S.O.; Al-Ansari, N.; Shahadha, A.; Ismaeel, R.; Mohammad, S. Evaluation of sediment transport empirical equations: Case study of the Euphrates River West Iraq. Arab. J. Geosci. 2021, 14, 825. [Google Scholar] [CrossRef]
- Van, L.N.; Le, X.-H.; Nguyen, G.V.; Yeon, M.; Jung, S.; Lee, G. Investigating Behavior of Six Methods for Sediment Transport Capacity Estimation of Spatial-Temporal Soil Erosion. Water 2021, 13, 3054. [Google Scholar] [CrossRef]
- Avgeris, L.; Kaffas, K.; Hrissanthou, V. Comparison between Calculation and Measurement of Total Sediment Load: Application to Streams of NE Greece. Geosciences 2022, 12, 91. [Google Scholar] [CrossRef]
- Haseeb, M.; Farid, H.U.; Khan, Z.M.; Anjum, M.N.; Ahmad, A.; Mubeen, M. Quantifying irrigation water demand and supply gap using remote sensing and GIS in Multan, Pakistan. Environ. Monit. Assess. 2023, 195, 990. [Google Scholar] [CrossRef]
- AbdulJaleel, Y.; Munawar, S.; Sarwar, M.K.; Haq, F.U.; Ahmad, K.B. Assessment of River Regime of Chenab River in Post-Chiniot Dam Project Scenario. Water 2023, 15, 3032. [Google Scholar] [CrossRef]
- Gupta, D.; Hazarika, B.B.; Berlin, M.; Sharma, U.M.; Mishra, K. Artificial intelligence for suspended sediment load prediction: A review. Environ. Earth Sci. 2021, 80, 346. [Google Scholar] [CrossRef]
- Shadkani, S.; Abbaspour, A.; Samadianfard, S.; Hashemi, S.; Mosavi, A.; Band, S.S. Comparative study of multilayer perceptron-stochastic gradient descent and gradient boosted trees for predicting daily suspended sediment load: The case study of the Mississippi River, U.S. Int. J. Sediment Res. 2021, 36, 512–523. [Google Scholar] [CrossRef]
- Hazarika, B.B.; Gupta, D. MODWT—Random vector functional link for river-suspended sediment load prediction. Arab. J. Geosci. 2022, 15, 966. [Google Scholar] [CrossRef]
- Allawi, M.F.; Sulaiman, S.O.; Sayl, K.N.; Sherif, M.; El-Shafie, A. Suspended sediment load prediction modelling based on artificial intelligence methods: The tropical region as a case study. Heliyon 2023, 9, e18506. [Google Scholar] [CrossRef]
- Schmidt, L.K.; Francke, T.; Grosse, P.M.; Bronstert, A. Projecting sediment export from two highly glacierized alpine catchments under climate change: Exploring non-parametric regression as an analysis tool. Hydrol. Earth Syst. Sci. 2024, 28, 139–161. [Google Scholar] [CrossRef]
- Asadi, M.; Fathzadeh, A.; Kerry, R.; Ebrahimi-Khusfi, Z.; Taghizadeh-Mehrjardi, R. Prediction of river suspended sediment load using machine learning models and geo-morphometric parameters. Arab. J. Geosci. 2021, 14, 1926. [Google Scholar] [CrossRef]
- Kim, H.D.; Aoki, S.-I. Artificial Intelligence Application on Sediment Transport. J. Mar. Sci. Eng. 2021, 9, 600. [Google Scholar] [CrossRef]
- Tao, H.; Al-Khafaji, Z.S.; Qi, C.; Zounemat-Kermani, M.; Kisi, O.; Tiyasha, T.; Chau, K.-W.; Nourani, V.; Melesse, A.M.; Elhakeem, M.; et al. Artificial intelligence models for suspended river sediment prediction: State-of-the art, modeling framework appraisal, and proposed future research directions. Eng. Appl. Comput. Fluid Mech. 2021, 15, 1585–1612. [Google Scholar] [CrossRef]
- Chachan, L.J.; Bahnam, B.S. Models for Predicting River Suspended Sediment Load Using Machine Learning: A Survey. Tech. Rom. J. Appl. Sci. Technol. 2022, 4, 239–249. [Google Scholar] [CrossRef]
- Podger, G.M.; Ahmad, M.-U.; Yu, Y.; Stewart, J.P.; Shah, S.M.M.A.; Khero, Z.I. Development of the Indus River System Model to Evaluate Reservoir Sedimentation Impacts on Water Security in Pakistan. Water 2021, 13, 895. [Google Scholar] [CrossRef]
- Mehmood, K.; Tischbein, B.; Mahmood, R.; Borgemeister, C.; Flörke, M.; Akhtar, F. Analysing and evaluating environmental flows through hydrological methods in the regulated Indus River Basin. Ecohydrology 2024, 17, e2624. [Google Scholar] [CrossRef]
- Stewart, J.P.; Ahmad, M.-U. Potential storage augmentation impacts on hydropower production, irrigation water supply and environmental flows in the Indus Basin in Pakistan. J. Hydrol. Reg. Stud. 2024, 51, 101618. [Google Scholar] [CrossRef]
- Peña-Arancibia, J.L.; Ahmad, M.-U. Early twenty-first century satellite-driven irrigation performance in the world’s largest system: Pakistan’s Indus Basin irrigated system. Environ. Res. Lett. 2020, 16, 014037. [Google Scholar] [CrossRef]
- Afan, H.A.; El-Shafie, A.; Mohtar, W.H.M.W.; Yaseen, Z.M. Past, present and prospect of an Artificial Intelligence (AI) based model for sediment transport prediction. J. Hydrol. 2016, 541, 902–913. [Google Scholar] [CrossRef]
- Shaukat, N.; Hashmi, A.; Abid, M.; Aslam, M.N.; Hassan, S.; Sarwar, M.K.; Masood, A.; Shahid, M.L.U.R.; Zainab, A.; Tariq, M.A.U.R. Sediment load forecasting of Gobindsagar reservoir using machine learning techniques. Front. Earth Sci. 2022, 10, 1047290. [Google Scholar] [CrossRef]
- Arifin, Z.; Fontana, A.; Wijayanto, S.H. The Determinant Factors of Technology Adoption for Improving Firm’s Performance: An Empirical Research of Indonesia’s Electricity Company. Gadjah Mada Int. J. Bus. 2016, 18, 237–261. [Google Scholar] [CrossRef]
- Sheela, K.G.; Deepa, S.N. Review on Methods to Fix Number of Hidden Neurons in Neural Networks. Math. Probl. Eng. 2013, 2013, 425740. [Google Scholar] [CrossRef]
- Safari, M.J.S.; Mohammadi, B.; Kargar, K. Invasive weed optimization-based adaptive neuro-fuzzy inference system hybrid model for sediment transport with a bed deposit. J. Clean. Prod. 2020, 276, 124267. [Google Scholar] [CrossRef]
- Javadi, F.; Qaderi, K.; Ahmadi, M.M.; Rahimpour, M.; Madadi, M.R.; Mahdavi-Meymand, A. Application of classical and novel integrated machine learning models to predict sediment discharge during free-flow flushing. Sci. Rep. 2022, 12, 19390. [Google Scholar] [CrossRef] [PubMed]
- Karami, H.; DadrasAjirlou, Y.; Jun, C.; Bateni, S.M.; Band, S.S.; Mosavi, A.; Moslehpour, M.; Chau, K.-W. A Novel Approach for Estimation of Sediment Load in Dam Reservoir With Hybrid Intelligent Algorithms. Front. Environ. Sci. 2022, 10, 821079. [Google Scholar] [CrossRef]
- Hasanipanah, M.; Noorian-Bidgoli, M.; Armaghani, D.J.; Khamesi, H. Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Eng. Comput. 2016, 32, 705–715. [Google Scholar] [CrossRef]
- Kisi, O.; Keshavarzi, A.; Shiri, J.; Zounemat-Kermani, M.; Omran, E.-S.E. Groundwater quality modeling using neuro-particle swarm optimization and neuro-differential evolution techniques. Hydrol. Res. 2017, 48, 1508–1519. [Google Scholar] [CrossRef]
- Han, T.; Jiang, D.; Zhao, Q.; Wang, L.; Yin, K. Comparison of random forest, artificial neural networks and support vector machine for intelligent diagnosis of rotating machinery. Trans. Inst. Meas. Control 2018, 40, 2681–2693. [Google Scholar] [CrossRef]
- Montes, C.; Kapelan, Z.; Saldarriaga, J. Predicting non-deposition sediment transport in sewer pipes using Random forest. Water Res. 2021, 189, 116639. [Google Scholar] [CrossRef]
- Al-Mukhtar, M. Random forest, support vector machine, and neural networks to modelling suspended sediment in Tigris River-Baghdad. Environ. Monit. Assess. 2019, 191, 673. [Google Scholar] [CrossRef]
- Lasdon, L.S.; Waren, A.D.; Jain, A.; Ratner, M. Design and Testing of a Generalized Reduced Gradient Code for Nonlinear Programming. ACM Trans. Math. Softw. 1978, 4, 34–50. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Strasak, A.M.; Zaman, Q.; Marinell, G.; Pfeiffer, K.P.; Ulmer, H. The Use of Statistics in Medical Research. Am. Stat. 2007, 61, 47–55. [Google Scholar] [CrossRef]
- Weissgerber, T.L.; Garcia-Valencia, O.; Garovic, V.D.; Milic, N.M.; Winham, S.J.; Weissgerber, T.L.; Garcia-Valencia, O.; Garovic, V.D.; Milic, N.M.; Winham, S.J. Why we need to report more than ‘Data were Analyzed by t-tests or ANOVA’. Elife 2018, 7, e36163. [Google Scholar] [CrossRef] [PubMed]
- Park, H.M. Comparing Group Means: T-Tests and One-Way ANOVA Using Stata, SAS, R, and SPSS. Ph.D. Thesis, Trustees of Indiana University, Indianapolis, IN, USA, 2009. [Google Scholar]
- Pradeep, T.; Samui, P. Prediction of Rock Strain Using Hybrid Approach of Ann and Optimization Algorithms. Geotech. Geol. Eng. 2022, 40, 4617–4643. [Google Scholar] [CrossRef]
- Ghumman, A.R.; Pasha, G.A.; Shafiquzzaman, M.; Ahmad, A.; Ahmed, A.; Khan, R.A.; Farooq, R. Simulation of Quantity and Quality of Saq Aquifer Using Artificial Intelligence and Hydraulic Models. Adv. Civ. Eng. 2022, 2022, 5910989. [Google Scholar] [CrossRef]
- Zhou, J.; Peng, T.; Zhang, C.; Sun, N. Data Pre-Analysis and Ensemble of Various Artificial Neural Networks for Monthly Streamflow Forecasting. Water 2018, 10, 628. [Google Scholar] [CrossRef]
- Alotaibi, K.; Ghumman, A.R.; Haider, H.; Ghazaw, Y.M.; Shafiquzzaman, M. Future Predictions of Rainfall and Temperature Using GCM and ANN for Arid Regions: A Case Study for the Qassim Region, Saudi Arabia. Water 2018, 10, 1260. [Google Scholar] [CrossRef]
- Boskidis, I.; Gikas, G.D.; Sylaios, G.K.; Tsihrintzis, V.A. Hydrologic and Water Quality Modeling of Lower Nestos River Basin. Water Resour. Manag. 2012, 26, 3023–3051. [Google Scholar] [CrossRef]
- Vafaei, S.; Soosani, J.; Adeli, K.; Fadaei, H.; Naghavi, H.; Pham, T.D.; Bui, D.T. Improving Accuracy Estimation of Forest Aboveground Biomass Based on Incorporation of ALOS-2 PALSAR-2 and Sentinel-2A Imagery and Machine Learning: A Case Study of the Hyrcanian Forest Area (Iran). Remote Sens. 2018, 10, 172. [Google Scholar] [CrossRef]
- Khosronejad, A.; Le, T.; DeWall, P.; Bartelt, N.; Woldeamlak, S.; Yang, X.; Sotiropoulos, F. High-fidelity numerical modeling of the Upper Mississippi River under extreme flood condition. Adv. Water Resour. 2016, 98, 97–113. [Google Scholar] [CrossRef]
- Khanam, N.; Biswal, S.K. Effect of hydrological variability on suspended sediment load at a river junction: A case study. Water Pract. Technol. 2024, 19, 960–976. [Google Scholar] [CrossRef]
- Hatono, M.; Yoshimura, K. Development of a global sediment dynamics model. Prog. Earth Planet. Sci. 2020, 7, 59. [Google Scholar] [CrossRef]
- Ouillon, S. Why and How Do We Study Sediment Transport? Focus on Coastal Zones and Ongoing Methods. Water 2018, 10, 390. [Google Scholar] [CrossRef]
- Andualem, T.G.; Hewa, G.A.; Myers, B.R.; Peters, S.; Boland, J. Erosion and Sediment Transport Modeling: A Systematic Review. Land 2023, 12, 1396. [Google Scholar] [CrossRef]
- Pearson, S.G.; van Prooijen, B.C.; Elias, E.P.L.; Vitousek, S.; Wang, Z.B. Sediment Connectivity: A Framework for Analyzing Coastal Sediment Transport Pathways. J. Geophys. Res. Earth Surf. 2020, 125, e2020JF005595. [Google Scholar] [CrossRef]
- Almubaidin, M.A.A.; Latif, S.D.; Balan, K.; Ahmed, A.N.; El-Shafie, A. Enhancing sediment transport predictions through machine learning-based multi-scenario regression models. Results Eng. 2023, 20, 101585. [Google Scholar] [CrossRef]
- Kang, W.; Lee, K.; Jang, E.-K. Evaluation and Validation of Estimated Sediment Yield and Transport Model Developed with Model Tree Technique. Appl. Sci. 2022, 12, 1119. [Google Scholar] [CrossRef]
- Nda, M.; Adnan, M.S.; Yusoff, M.A.B.M.; Nda, R.M. An Overview of Machine Learning Techniques for Sediment Prediction. In Proceedings of the 4th International Electronic Conference on Applied Sciences, Virtual, 27 October–10 November 2023; p. 204. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Training Function | Name | Description | |
|---|---|---|---|---|
| DL | TL | |||
| AIM1 | AIM11 | trainlm | Levenberg–Marquardt backpropagation | It is a sort of optimization for searching for best solution to minimize of a non-linear function. It is reasonably fast and stable to converge. |
| AIM2 | AIM12 | trainbr | Bayesian regularization | It is similar to the trainlm based on minimization of suitable weights with the objective function. |
| AIM3 | AIM13 | trainbfg | BFGS quasi-Newton backpropagation | It is an alternative function of the conjugate gradient methods for accelerated optimization |
| AIM4 | AIM14 | trainrp | Resilient backpropagation | In multilayer networks, sigmoid transfer functions are commonly employed in the hidden layers. These functions are frequently referred to as "squashing" functions, as they condense an infinite input range into a finite output range. |
| AIM5 | AIM15 | trainscg | Scaled conjugate gradient backpropagation | Trainscg is capable of training any network, provided that its weight, net input, and transfer functions have derivative functions. Backpropagation is employed to compute the derivatives of performance (perf) with respect to the weight and bias variables (X). |
| AIM6 | AIM16 | traincgb | Powell–Beale conjugate gradient backpropagation | A search is made along the direction of conjugate gradient to govern the step size for minimizing the performance function. The new direction of the steepest descent is combined with the previous search direction. |
| AIM7 | AIM17 | traincgf | Fletcher–Powell conjugate gradient backpropagation | It uses a similarity index for a non-supervised feature selection. |
| AIM8 | AIM18 | traincgp | Polak–Ribiere conjugate gradient backpropagation | Optimization with respect to the previous gradient at each iteration. |
| AIM9 | AIM19 | trainoss | One step secant backpropagation | An effort to minimize the gap between quasi-Newton and conjugate gradient. |
| AIM10 | AIM20 | traingdx | Gradient descent w/momentum and adaptive learning rate backpropagation | It is highly sensitive to the learning rate. The learning rate needs to be adjusted carefully, otherwise the algorithm will be unstable or too slow to converge |
| Model (Function) | Description of Training Function |
|---|---|
| AIM21 (gbellmf) | A bell-shaped function consisting of three categories of parameters for defining the curve. One parameter defines the width of the curve, the second parameter is for defining the center of the curve, and the third is simply a positive integer. |
| AIM22 (Trapmf) | A trapezoidal-shaped function includes four parameters for defining the curve. The first two parameters are meant for defining the feet, whereas the other two parameters are used for defining the curved shoulders, resulting in the shape of a truncated triangle. |
| Combination | Description | Combination | Description |
|---|---|---|---|
| IC1 | All variables together (Q, D, V, d50) | IC6 | Only one variable (Q) |
| IC2 | Three variables (Q, D, V) | IC7 | Only one variable (D) |
| IC3 | Two variables (Q, D) | IC8 | Only one variable (V) |
| IC4 | Two variables (D, V) | IC9 | Only one variable (d50) |
| IC5 | Two variables (Q, V) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khalid, M.A.; Ghumman, A.R.; Pasha, G.A. A Comparative Analysis of Sediment Concentration Using Artificial Intelligence and Empirical Equations. Hydrology 2024, 11, 63. https://doi.org/10.3390/hydrology11050063
Khalid MA, Ghumman AR, Pasha GA. A Comparative Analysis of Sediment Concentration Using Artificial Intelligence and Empirical Equations. Hydrology. 2024; 11(5):63. https://doi.org/10.3390/hydrology11050063
Chicago/Turabian StyleKhalid, Muhammad Ashraf, Abdul Razzaq Ghumman, and Ghufran Ahmed Pasha. 2024. "A Comparative Analysis of Sediment Concentration Using Artificial Intelligence and Empirical Equations" Hydrology 11, no. 5: 63. https://doi.org/10.3390/hydrology11050063
APA StyleKhalid, M. A., Ghumman, A. R., & Pasha, G. A. (2024). A Comparative Analysis of Sediment Concentration Using Artificial Intelligence and Empirical Equations. Hydrology, 11(5), 63. https://doi.org/10.3390/hydrology11050063