1. Introduction
Observing hydrological phenomena occurring in the natural environment is not an easy task, especially in hard-to-reach areas. Maintaining a monitoring network is expensive, which is why the number of traditional measurement stations decreases every year. However, there is a growing interest in using alternative sources of information, such as satellite images or images from surveillance cameras. This became possible mainly thanks to the rapid development in recent years of machine learning systems, which can automatically extract a lot of valuable information from such materials. This type of model is increasingly used in hydrology, e.g., to monitor the water level in rivers [
1,
2], flood monitoring [
3,
4] or determining flood zones [
5] Pally and Samadi [
6] used R-CNN, YOLOv3 and Fast R-CNN for flood image classification and semantic segmentation. Erfani et al. [
7] developed ATLANTIS, a benchmark for semantic segmentation of waterbody images.
The main directions of hydrological research are directly related to process and time series modeling, but machine learning is increasingly used in data pre-processing [
8].
One of the important elements influencing the water flow in the river is the riverbed roughness coefficient. It is related to the resistance due to friction acting along the perimeter of the wetted trough and the resistance created by objects directly washed by the water. Large objects such as stones, boulders, bushes, trees and logs significantly increase the bed roughness factor. When larger flows occur, they may cause water damming and pose a flood risk [
9,
10,
11]. This is why a good estimate of roughness has a significant impact on the results of hydrological models. However, in catchments with high flow dynamics, for example mountain ones, this parameter changes rapidly due to the material carried away by the floods and the vegetation developing intensively within the riverbeds. Tracking these changes using traditional methods would require frequent measurements and would be extremely expensive. One alternative to collecting and updating such data may be the use of various types of images. Computer vision was so far used by scientists mainly to estimate the height of the water table [
12]. However, modern computer vision systems make it possible to obtain semantic information from such data; for example, about the type of land cover. In addition to dedicated segmentation systems, such as state-of-the-art panoptic segmentation [
13], general-purpose segmentation systems are gaining popularity. One of the newest general models with zero-shot transfer capability is the Segment Anything Model (SAM) released by Meta in April 2023 [
14].
Thanks to its general-purpose structure and training data, the SAM can be used for many tasks. In medical imaging, the SAM can be used to segment different structures and tissues in images, such as tumors, blood vessels and organs [
15,
16]. This information can be used to assist doctors in diagnosis and treatment planning. So far, most publications exploiting the possibility of using the SAM for image segmentation have appeared in the field of medicine. In agriculture, the SAM can be used to monitor crop health and growth. By segmenting different areas of a field or crop, the SAM can identify areas that require attention, such as areas of pest infestation or nutrient deficiency [
17]. In earth sciences, the SAM has been used for superglacial lake mapping [
18], but for the task of flood inundation mapping we only managed to find information about the possible potential use of the SAM [
19]. This is therefore an area of applicability of the model to potentially explore.
The goal of the SAM is automatic promptable segmentation with minimal human intervention. It is a deep learning model, trained on the SA-1B dataset, the largest segmentation dataset to date—over one billion masks spread across 11 million carefully curated images [
14]. The model has been trained to achieve outstanding zero-shot performance, surpassing previous fully supervised results in numerous cases. Zero-shot transfer refers to the SAM’s ability to adapt to new tasks and object categories without requiring explicit training or prior exposure to specific examples [
20]. The model predicts object masks only and does not generate labels. The SAM was trained to return segmentation masks for any prompt understood as point, bounding box, text or any other information indicating what to segment on an image. An alternative method is the automatic segmentation of an image as a whole using a grid of points. In this case, the SAM tries to segment any object on the image. The SAM is available as source code in the public repository and as a web application (
https://segment-anything.com/demo#; acceseed on 20 January 2024), giving the opportunity to test its capabilities without the need for coding. Therefore, each user can choose a version of the model appropriate to his or her experience with machine learning models. One such potential user group may be hydrologists, and it is from their perspective that we tried to analyze the possibilities of using the SAM.
The aim of this study is to use the Segment Anything Model in hydrology to determine changes in the roughness of a mountain riverbed based on images in various vegetation periods over the years 2010–2023. The second goal is to estimate the extent of water in the streambed based on the same images. The results can be used to quickly determine flood zones in the event of floods.
2. Materials and Methods
This study focuses on a simple and automatic solution that allows obtaining data that can be used in hydrological modeling. From a modeling perspective, the type of coverage in the riverbed area is particularly important. In the case of mountain catchments covered with forest, obtaining this type of data is difficult when using only orthophotomaps and aerial photos. The best solution is field measurements or the use of local monitoring. Unfortunately, manual methods are time-consuming and expensive. Therefore, there is a need to use tools and methods that allow automatic or semi-automatic analysis using other data sources, e.g., photographic documentation or local video monitoring.
2.1. Study Area
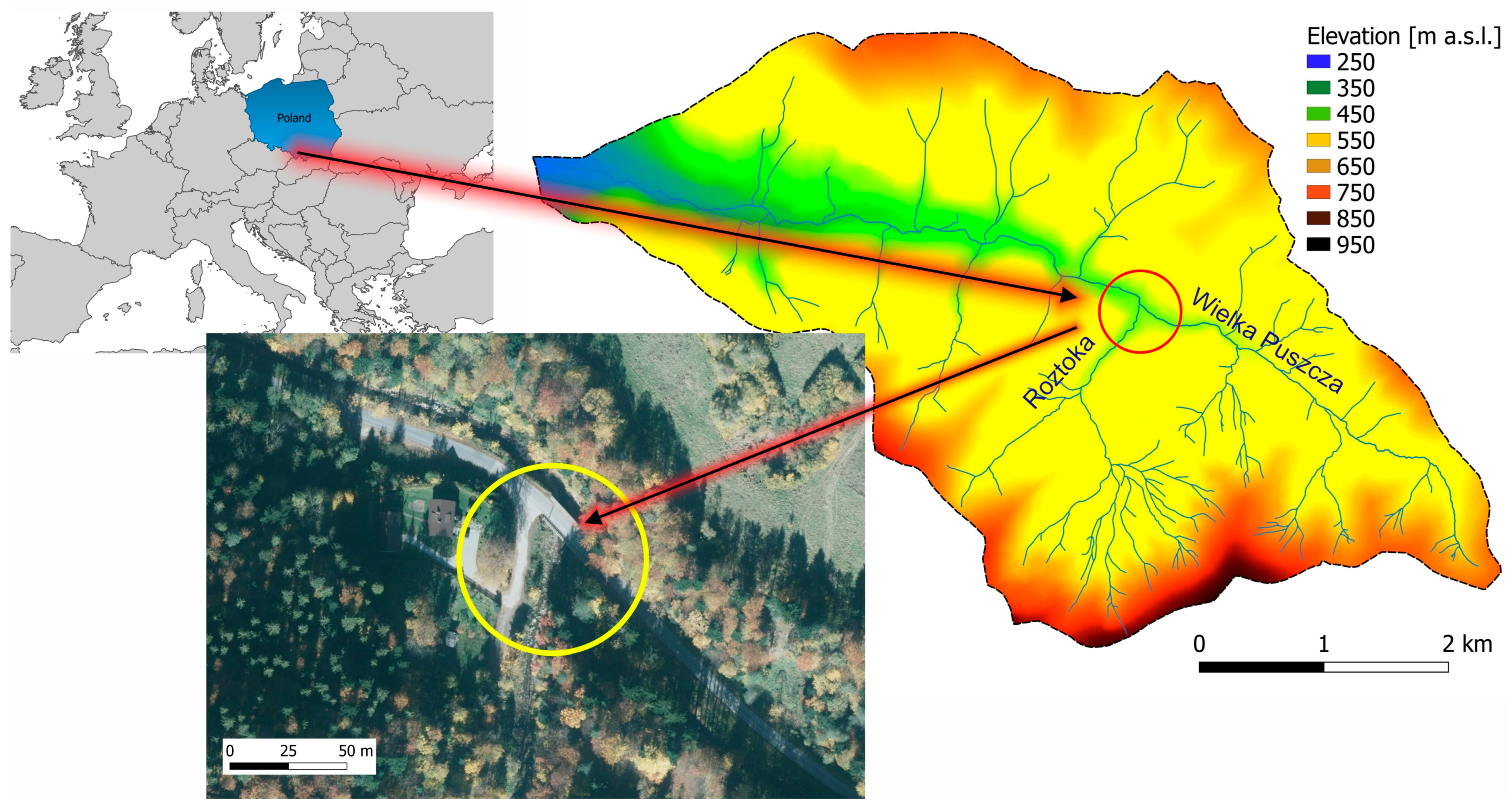
The study area is the Wielka Puszcza river catchment (Great Forest in Polish) located in the southern part of Poland, in the Beskid Mały Mountains. The stream is a right-bank tributary of the Soła River, which is a right-bank tributary of the Vistula, the largest river in the country. The mouth of the Wielka Puszcza stream is located in the backwater of the dam reservoir located in the town of Czaniec (
Figure 1). The Wielka Puszcza is a mountain catchment area characterized by steep slopes, impermeable soil and a dense river network. About 90% of the catchment area is forest, 7% is agricultural land and 3% is built-up area. The physiographic parameters of the catchment are presented in
Table 1.
The Wielka Puszcza stream has been a research catchment area of the Cracow University of Technology since the 1970s. In the 1990s, meteorological observations were carried out at seven measurement stations. Additionally, measurements of water levels and flows in one cross-section were also carried out. In 2005, as a result of catastrophic rainfall and flooding, the measuring station was destroyed, which resulted in its liquidation (
Figure 2).
In 2017, hydrological measurements resumed on a limited basis at a new location. Currently, observations of water levels using a radar sensor are being carried out, as well as visual monitoring of the water table level, in the form of images taken by an industrial camera operating in visible light and infrared (day and night). Two Hellmann’s trough rain gauges are also installed, providing an automatic system for measuring precipitation height every 10 min (
Figure 3). The data are collected in the recorder and sent to a server located at the Cracow University of Technology, which makes it possible to conduct online observations of the water table level in the stream and the precipitation.
2.2. Data
The analyzed area is a mountainous catchment with no continuous measurement system. The only publicly available data sources are orthophotos and satellite images. In the considered period 2010–2023, the orthophoto update took place only in year 2010 and 2023. Unfortunately, due to the nature of the terrain covered by dense forest, orthophotomaps, even in high resolution, are not suitable for assessing changes in the riverbed. For this reason, terrestrial photographs were used to determine the type of coverage in the streambed. Photographs do not allow results to be obtained as accurately as when using an orthophotomap, but by using characteristic points in the cross-section, it is possible to map the geometry of the riverbed even in photos taken from ground level. In the case of forested catchments, this is practically the only method. The data for the Segment Anything Model consist of photographic documentation by Marek Bodziony taken in the catchment area, at the junction of the Wielka Puszcza and Roztoka streams. Seven photos showing the riverbed in the selected cross-section were used for analysis. The photos are from three growing seasons: spring in the years 2010, 2011 and 2023, autumn in the years 2011, 2015 and 2023 and winter in 2012 (
Figure 4). Photographic documentation is available on the website
https://holmes.iigw.pl/~mbodzion/zaklad/wielka_puszcza/ (acceseed on 20 January 2024).
2.3. Methods
The presented workflow is divided into two parts using identical data and tools, but for different purposes. The basis for the analysis is photos showing the valley of a mountain stream at the junction of two watercourses.
The aim of the first part of the analysis was to estimate the roughness of the riverbed based on the segmentation results. The water category was omitted in this analysis. The aim of the second part was to assess to what extent the presented model can be used to estimate the extent of floods. Only the water category was used in this analysis.
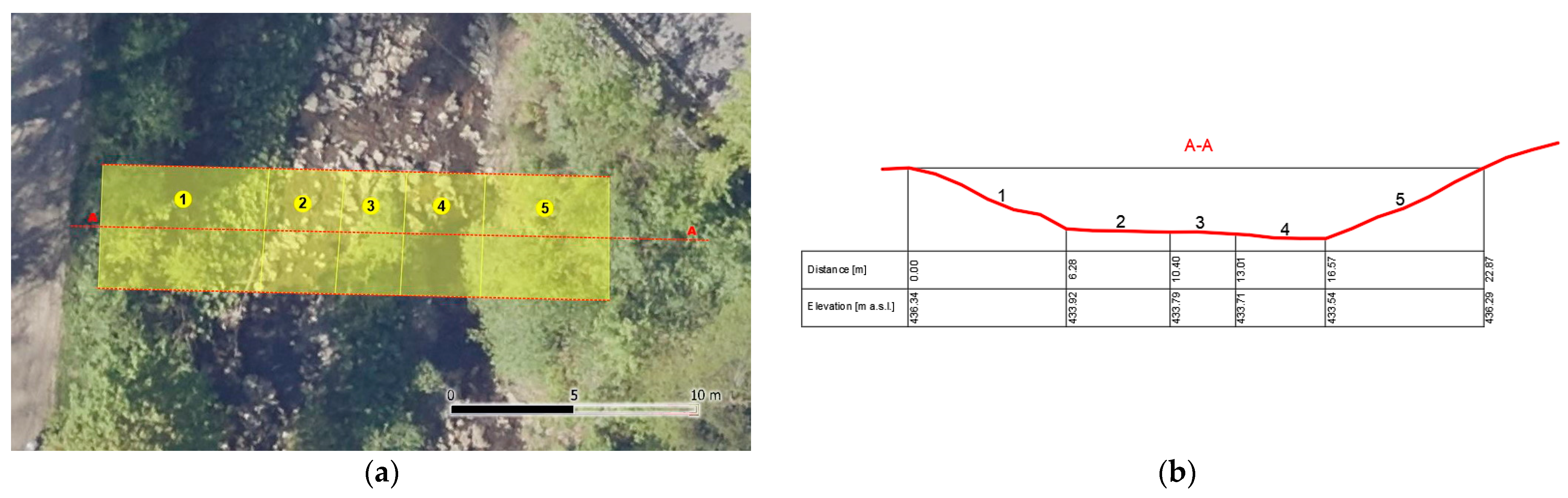
For ungauged catchments where the flow is not measured, the roughness coefficient cannot be optimized. An alternative solution is to adopt an average roughness coefficient for sections with a similar type of coverage. The proposed method involves determining a cross-section based on the Digital Elevation Model (DEM) divided into sections with a similar type of coverage (
Figure 5b). Because the photos were taken from known locations, it was possible to geometrically convert characteristic points from the photos into points from the orthophotomap. In this way, photo units (px) were converted to map units (m), enabling the calculation of the roughness coefficient in the entire examined cross-section. For each section (zone) shown in
Figure 5, the average roughness coefficient was calculated by analyzing the type of coverage 3 m upstream and downstream from the central A-A cross-section. Identification of the type of coverage based on photographs with the SAM model was used to estimate the weighted average roughness coefficient for the given cross-section. Based on the determined roughness coefficient, the flow in the stream can be estimated using Manning’s formula. Assuming steadyflow and one-dimensional schematization, the cross-sectional geometry and slope of the stream determined from the DEM can be used for calculations.
We estimate the initial Manning’s roughness coefficient n0 through the observation of the river channel coverage. This method is also documented by other authors [
21]. However, none of the methods we found used computer vision or machine learning to automate this process. There are only works that use satellite images to estimate coefficient n through LULC classification [
22,
23]. Usually, the last step in determining n is its optimization using available hydrological data which are, however, unavailable in the case of uncontrolled catchments.
Using the SAM automatic segmentation model, objects in photos are recognized, but without assigning labels to them. The labeling process was performed non-automatically by assigning designated segments to one of the categories specified in
Table 2. The segmentation analysis was limited in each case to the area defined as the streambed.
To determine the index related to the roughness of the riverbed (
), the relationship between Manning’s roughness coefficient (
n) and the area of coverage for each of the adopted coverage categories was assumed:
where:
—riverbed roughness index [m−1/3 s];
n—Manning’s roughness coefficient for category [m−1/3 s];
—coverage area for the category [px].
The SAM supports three main segmentation modes in the online version: fully automatic mode, bounding box mode and point mode. This study tested the first two modes. In addition, automatic segmentation was performed using the Google Colaboratory (Colab) environment using the Jupyter notebook provided by the SAM authors. Both versions are based on the same SAM, but only one of them (SAM Colab) offers the possibility of changing model parameters through scripts.
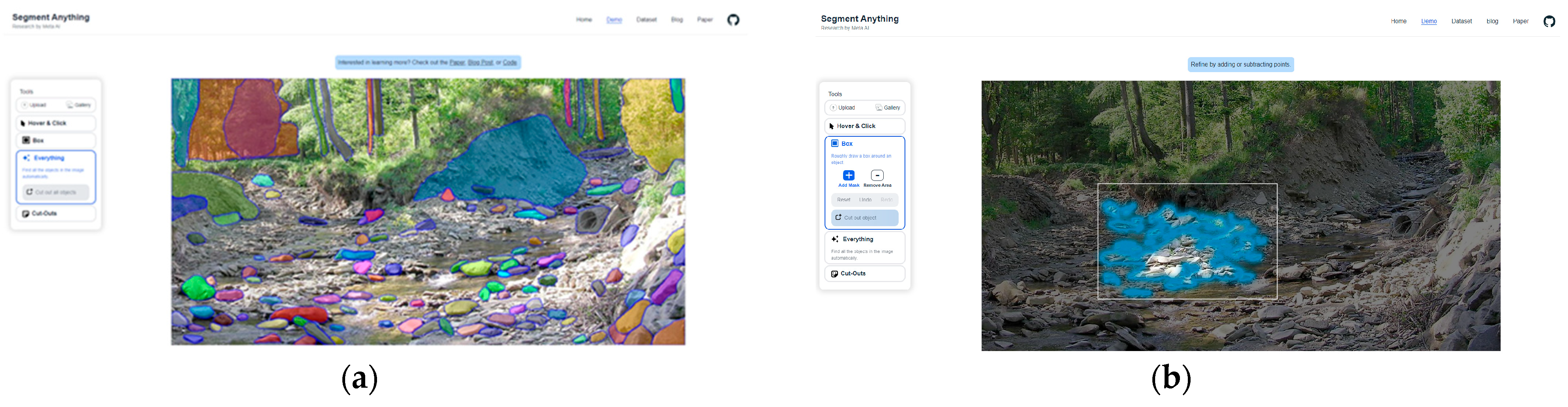
SAM
online: The fully automatic segmentation mode involves generating masks automatically based on a regular grid of points. An example of using this mode on a selected image is shown in
Figure 6a.
Bounding box online: To segment only a specific portion of an image, the bounding box mode can be used. An example of using this mode on a selected image is shown in
Figure 6b.
Image segmentation using the bounding box method requires manual selection of the objects. Its use is therefore not the best solution for automatically generating areas of land cover type in a watercourse area. Due to the necessity of pointing out objects each time, this method is time-consuming and unsuited to the needs of the presented analysis. Tests verifying the segmentation of water-covered areas showed its low efficiency, so already at the test stage this method was abandoned for analysis.
SAM C
olab: Google Colaboratory (Colab) is a public service for running Jupyter notebooks directly in the browser without configuration (
Figure 7). It provides free GPU access and facilitates code sharing. Using the sample Jupyter notebook provided in the project repository, image segmentation was performed. It should be mentioned that model parameters were not modified or tuned for this analysis. The results obtained in this way will therefore be suboptimal, but for the purposes of these tests it is assumed that the user of the tools is a hydrologist without in-depth knowledge of machine learning methods and optimization of these models. As a result of image segmentation, a segmentation mask is created, as well as a file containing the identifiers and geometry of the masks.
SAM online is a web-based version that can be used by inexperienced users. SAM Colab should be used by hydrologists with programming experience; however, in the presented study we used default model parameters. Unfortunately, based on the available literature, we were unable to determine what parameters were adopted for SAM online. Our analyses show that the SAM was trained for segmentation on physical objects with precisely defined area boundaries (objects). In the case of complex images with ambiguous object boundaries, such as forest areas, streams, etc., the segmentation results may require user intervention in the model parameters. In the case of SAM Colab, a large number of parameters to optimize requires additional research and is beyond the scope of this manuscript.
Four categories were adopted to identify the type of cover of the riverbed area, which have a decisive influence on the riverbed roughness parameter: earth channel, stones, grass and shrubs/trees. The earth channel category includes areas consisting of small stones and gravel constituting a uniform surface. Objects distinguished by their size and shape from the earth channel area were classified as stones. Grass is an area covered with low grassy vegetation. Areas of medium and tall vegetation were included in the shrubs/trees category. Image analysis in the SAM was carried out based on the segmentation of adopted categories, the areas of which were defined in image units (pixels), not in physical units. Areas for which the SAM did not assign a mask most often corresponded to the earth channel and water categories. When estimating the roughness of the riverbed, they were assigned the earth channel category. Ground truth segments were manually annotated by the authors directly on the photos and constituted reference material for analyses. The analysis of the photos was limited only to areas where water could potentially appear and where roughness estimation makes sense. They are marked in the photos as a white outline. These boundaries were determined manually by the authors after the photo segmentation process.
The image segmentation results were assessed using a confusion matrix, comparing actual (ground truth) segments to prediction settings [
25,
26]. Intersection over Union (
) was calculated from confusion matrix values to evaluate the SAM’s performance [
27] using True Positive (
TP), False Negative (
FN) and False Positive (
FP) values.
Since the SAM is not a classic sematic segmentation model, the effect of segmentation are masks, which are assigned to appropriate categories in our method. Therefore, since the assignment to categories is manual, and the shapes of the masks themselves reproduce the shapes of objects very well, a False Positive does not occur.
3. Results and Discussion
The effectiveness of the segmentation algorithm of the two SAM versions on images of a mountain streambed is the main effect of the presented analysis. The results in
Table 3 present two basic descriptive statistics of Intersection over Union (
). The average
value shows the averaged result, where the value of 0 can be interpreted as the worst possible result, and 1 as the best possible result to be obtained.
The standard deviation is a measure of model stability. It is clearly visible that, with the exception of the segmentation of the water and grass categories, the remaining results are similar for the two SAM launch modes used.
The best segmentation results of both models were obtained for the shrubs/trees category. However, this is also the category with the greatest variability of results. The most unstable results were obtained when estimating the extent of floods (water category), where the online SAM model achieved an average of 0.49, while SAM Colab practical did not recognize this category, with practically at the minimum level. Similar results were obtained for the stones category, but in this case both models were very stable, achieving an standard deviation in the range of 0.06–0.14. This is understandable because the SAM is better suited for segmenting specific objects, rather than larger areas in an image with a complex visual structure.
In the task of estimating riverbed roughness, SAM online performed well, considering the complexity of the images used. SAM Colab performed slightly worse, especially for the grass category. In the task of estimating the flood extent, SAM online performed well, obtaining an mean of 0.49, while SAM Colab practically did not segment this category. It should be noted that only some of the photos used had a clearly visible water table, so this was an extremely difficult task.
Some regularities can be noticed in the image segmentation results presented in
Table 3. The best results expressed by the Intersection over Union measure were obtained for categories that can be classified as physical objects. In this case, these are stones with an average
in both methods at the level of 0.61–0.68, but they are characterized by a very low standard deviation of 0.06–0.14. Even smaller variances with slightly worse results were obtained for the earth channel. In the case of segments covering a larger area (grass, shrubs/trees), significantly better identification is achieved using SAM online. This is especially visible in
Figure 8, in the photographs from 28 October 2023 and from 14 March 2012, in terms of identifying areas covered with grass and shrubs.
In general, grass constitutes the smallest share of the area and is segmented well by SAM online, but much worse by SAM Colab. This can be seen in the images from 22 October 2011 and 28 October 2023 (
Figure 8). Large stones pose the least problem to the segmentation model and are probably best identified in images. This can be explained by the fact that the SAM is designed to segment objects rather than uniform areas. Vegetation, if present in the image, is recognized well, probably due to a significantly different spectral signature than the background.
Detailed quantitative segmentation results for SAM online and SAM Colab are presented in
Table 4 and
Table 5, respectively. The
= 1 value means extreme cases of identification: either the model did not detect areas in a given category because they did not appear in the photo or 100% of them were identified. This situation applies primarily to shrubs and trees.
Both versions of the SAM model only perform segmentation occasionally (
= 0). For SAM online, this applies to the image from 22 October 2011 for shrubs/trees (
Table 4). For SAM Colab, such a situation occurred on 24 October 2015 for grass and on 14 March 2012 for shrubs/trees (
Table 5). It is for the vegetation-related categories that
takes on its most extreme values, which is most visible for SAM online at shrubs/trees (
Table 4). This may be related to the fact that there is relatively little vegetation in the area of the streambed, so the results obtained may be extremely different.
The worst segmentation results were obtained for grass with SAM Colab at a level not exceeding = 0.5. This is understandable because the complex texture of low vegetation can be difficult to identify as an object.
Based on the image segmentation results, mean Manning’s roughness coefficients were estimated by sections in cross-section A-A (
Table 6). The obtained values were used to determine the average roughness coefficient for the entire riverbed cross-section using the weighted average method. Manning’s roughness coefficient can be used in Manning’s formula along with cross-sectional geometry and channel slope to estimate the flow in a stream. Changes in the roughness coefficient value can be noticed, especially in Sections 1, 3 and 5 in
Table 6, where lush vegetation occurs especially in summer. The roughness coefficient is closely related to the growing season, as shown in
Figure 4 and
Table 6 and
Table 7. The obtained values of the roughness index
suggest a slightly different division into seasons than the division into seasons adopted in
Table 7.
The end of May (28 May 2023) should be interpreted as a period of intense vegetation (summer, autumn) and the vegetation shown in the photo 22 October 2011 is more consistent with the winter season. However, it is impossible to generalize by introducing a strict division into growing seasons, because each year the seasons may start or end at different times. Therefore, the analysis of the streambed based on SAM segmentation makes it possible to determine more actual parameters related to hydraulic resistance. It is also worth noting that the range of changes in the roughness coefficient for the analyzed section of the streambed is large (in the range of 0.027–0.059) and may significantly affect the flow conditions.
The second aim of the analysis was to assess the effectiveness of the SAM segmentation results for estimating flood extent. Detailed effects are presented in the segmentation results of the main stream (Wielka Puszcza on the left) and its tributary (Roztoka stream on the right) (
Figure 9). In this case, the focus was only on the water category.
A fragment of the streambed that has been subjected to vision analysis poses a great challenge to segmentation algorithms. In the image from 27 May 2011 (
Figure 9), it is difficult even for humans to recognize fragments with water because the photo was taken at an extremely low water level. The image from 24 October 2015 is equally difficult to segment. In this case, one of the streams was correctly identified, while the other one was not identified at all. In images where water is an important part (21 April 2010, 28 October 2023, 14 March 2012), SAM online had no problems with good segmentation of this category, although SAM Colab did not cope with this task. Analyzing the segmentation in terms of flood extent, it can be seen that only in one out of four cases for higher water levels did SAM online fail to detect the water table (
Table 8). In the remaining cases, the
results were no less than 0.94, which can be considered an excellent result.
The very large variance of the SAM online results is also significant, as only in one case (24 October 2015) was the not close to 0 or 1. The SAM Colab segmentation results were extremely poor. In many images, water appears only between the stones.
For the initial estimation of Manning’s roughness coefficient n in ungauged catchments, empirical formulas employing pebble count and field survey data can be applied [
28]. These tasks can be automated using the presented method for predefined gravel riverbed material (d50, d65, d75, d84 and d94). Changes in fluvial forms and cover within the riverbed can also be examined using aerial photos or photos from unmanned aerial vehicles [
29]. For some locations, these methods may prove to be the most economically effective. In our case, due to the dense tree crowns along the streams, such a solution could not be used. Seasonal changes in flows are visible in many places in the Carpathians [
30]. A detailed analysis of the impact of seasonal vegetation changes on the roughness coefficient estimation can be found in [
31]. Seasonal changes in flows are directly related to climate change in the area [
32] and have a direct impact on flood hazard mapping [
33]. According to hydrological and climatological research conducted in the Carpathian area, even greater variability in droughts and floods can be expected in the future [
34,
35,
36,
37]. As a result, there is a need for tools that can automatically track these changes.
The analyzed area is characterized by very fast and short-lasting floods. For this reason, very few photos are available from the flood period itself. The available photographic documentation from the studied stream cross-section did not contain a sufficient number of images from the flood; therefore, three additional photos were analyzed (
Figure 10).
An additional difficulty may be the lighting conditions, where the shadows of trees mix with stones and low vegetation. The SAM was created for object recognition, but such a complex structure as a mountain stream slightly filled with water seems too difficult a challenge. In the case of uniformly illuminated water surfaces (
Figure 10a,c), SAM online is easily able to segment the flood water table. The remaining image elements are segmented equally well. The third photo, taken during the flood at night (
Figure 10b), segments all objects very well, except for the turbulent and unevenly lit stream. However, it can be assumed that in this case the flood extent corresponds to the entire remaining area, so it is easy to identify and further process. The quality of segmentation depends not only on the texture of the object, but also on its lighting.
The SAM online provides automatic image segmentation without the ability to manage model parameters, which poses some limitations, but the quality of the results obtained is satisfactory. The average
ranges from 0.55 for grass to 0.82 for shrubs/trees. However, it is worth noting the high standard deviations of the results. The high variability of the SAM results, expressed here by high
standard deviations, was also observed by other authors [
15]. According to Mazurowski et al. [
16], the SAM’s performance based on single prompts highly varies depending on the dataset and the task, from
= 0.11 for a spine MRI (Magnetic Resonance Image) to
= 0.86 for a hip X-ray. In our study, most categories are either segmented well (very well) or not segmented at all. This is clearly visible in the online SAM results for the shrubs, trees and water categories, where
equal to 0 or close to 1 dominates. As reported by Huang et al. [
38], the SAM showed remarkable performance in some specific objects but was unstable, imperfect or even totally failed in other situations. As this study showed, with the appropriate selection of images, you can quickly obtain an estimate of the flood extent at the level of at least
= 0.94. For a similar task, Tedesco and Radzikowski [
5] reported
of 0.84–0.98 using deep convolutional neural networks (D-CNNs). In all analyzed cases, the quality of images and uniform lighting are of great importance. The SAM, which is a zero-shot model that does not require training, performs segmentation very well. Most importantly, it is available for free and does not require knowledge of machine learning for practical use.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}