

Predicting Optical Water Quality Indicators from Remote Sensing Using Machine Learning Algorithms in Tropical Highlands of Ethiopia


 ,
,  ,
,  and
and
Abstract
1. Introduction
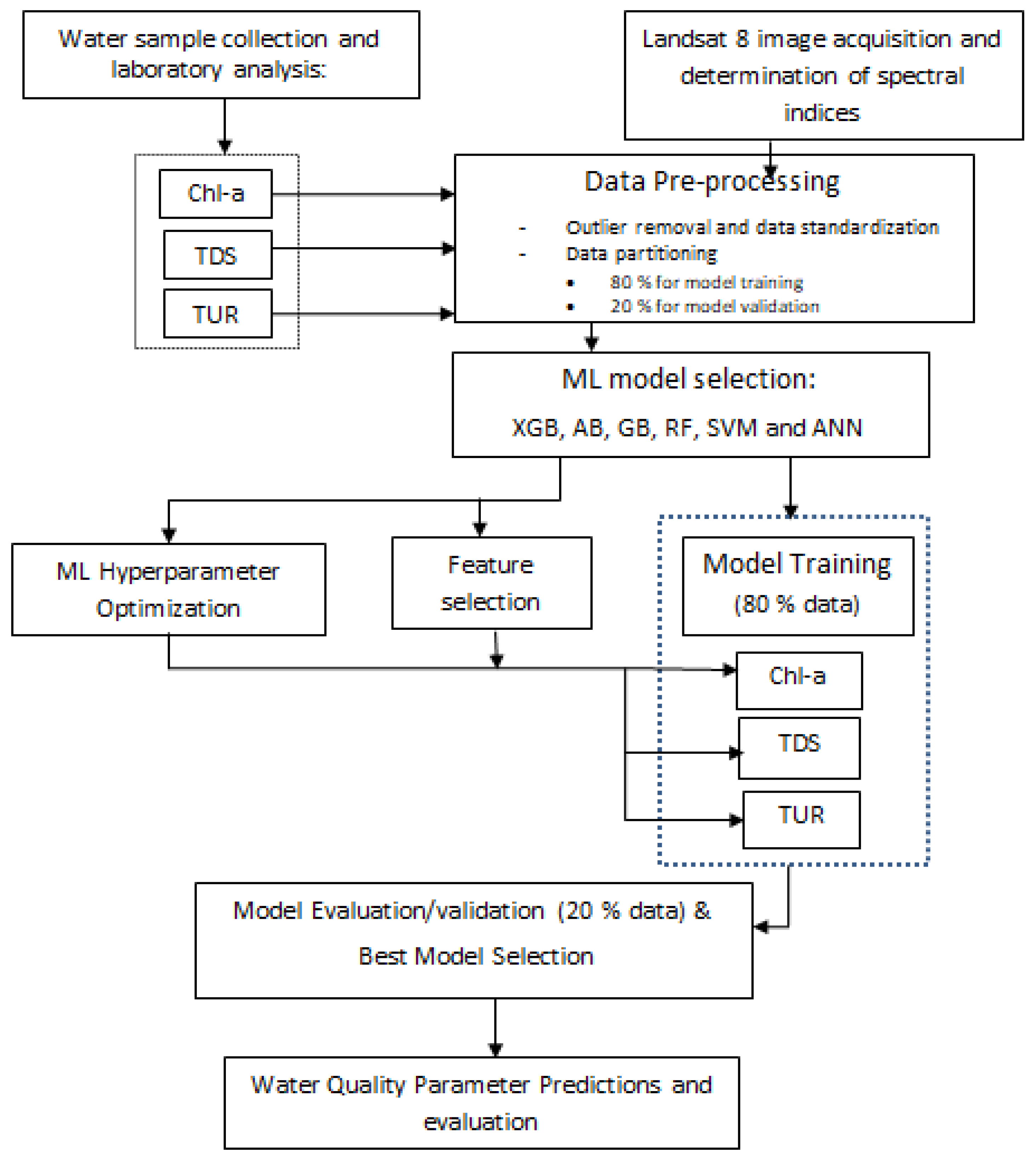
2. Materials and Methods
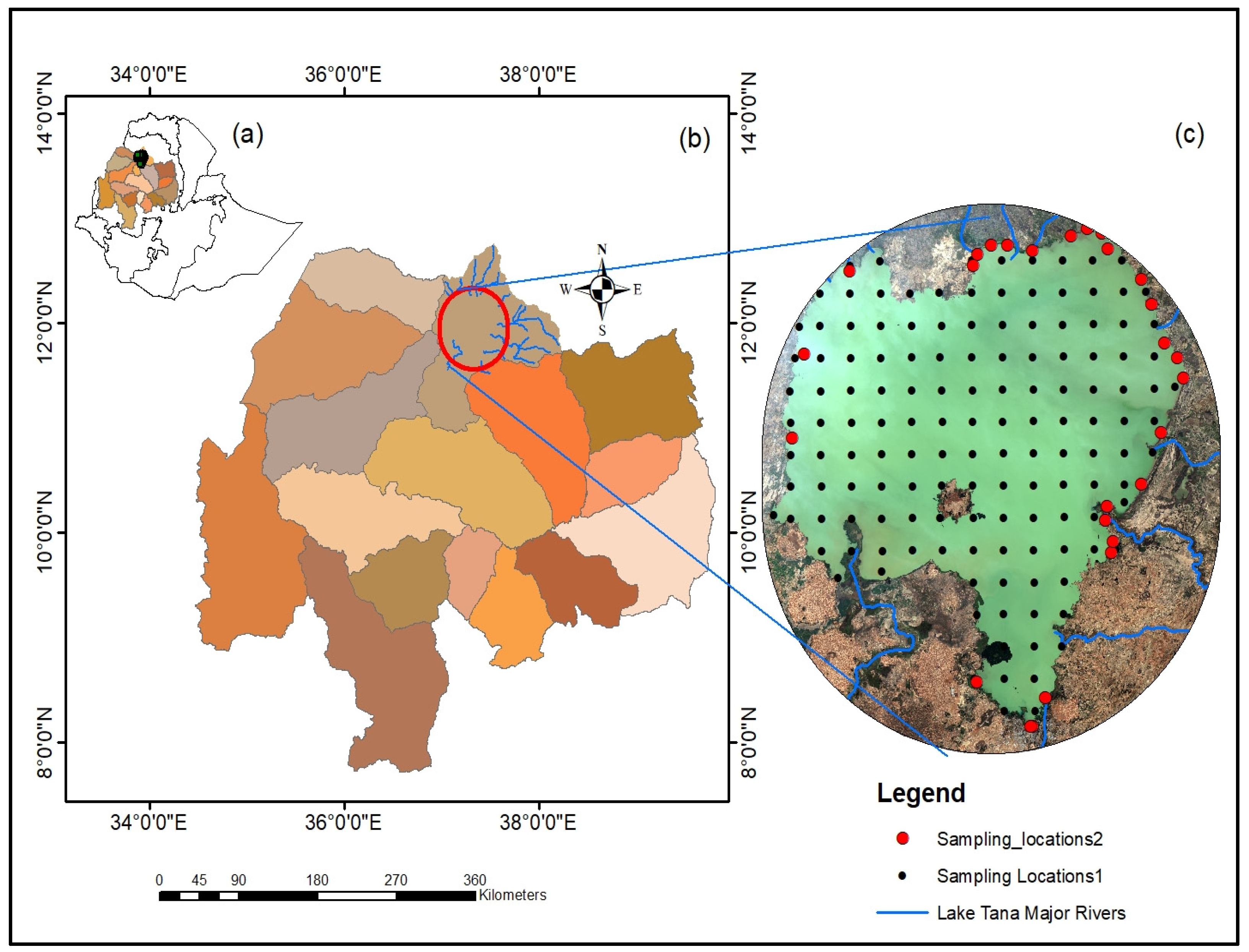
2.1. Study Area
2.2. Water Samples Collection and Laboratory Analysis
2.3. Landsat 8 OLI Image Acquisition and Pre-Processing
2.4. Model Description and Approach
2.4.1. Adaboost (AB)
2.4.2. Random Forest (RF)
2.4.3. Gradient Boost (GB)
2.4.4. Support Vector Machine (SVM)
2.4.5. Extreme Gradient Boost (XGB)
2.4.6. ANN
2.5. Model Performance
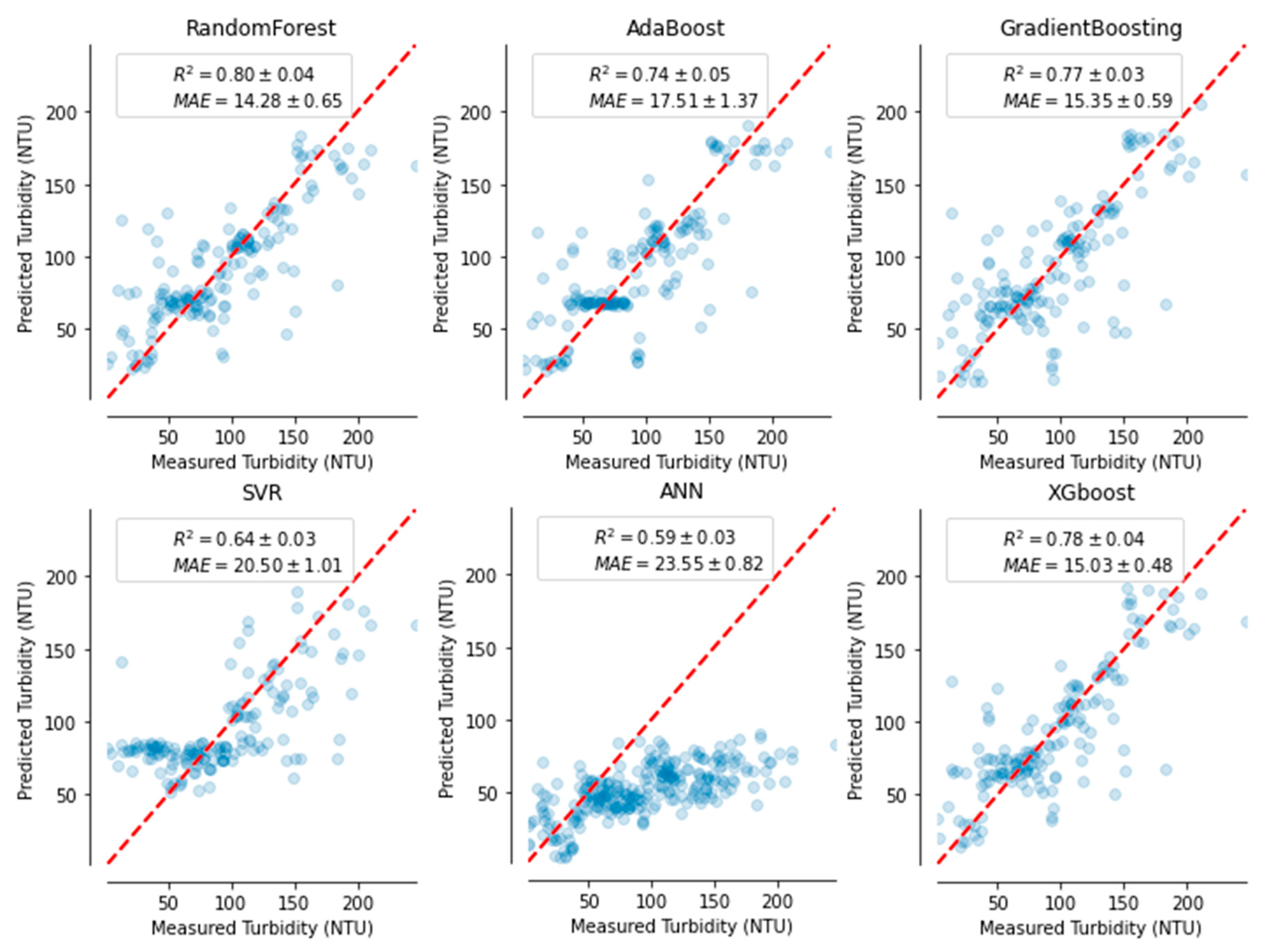
3. Results
3.1. Feature Selection for Data Input
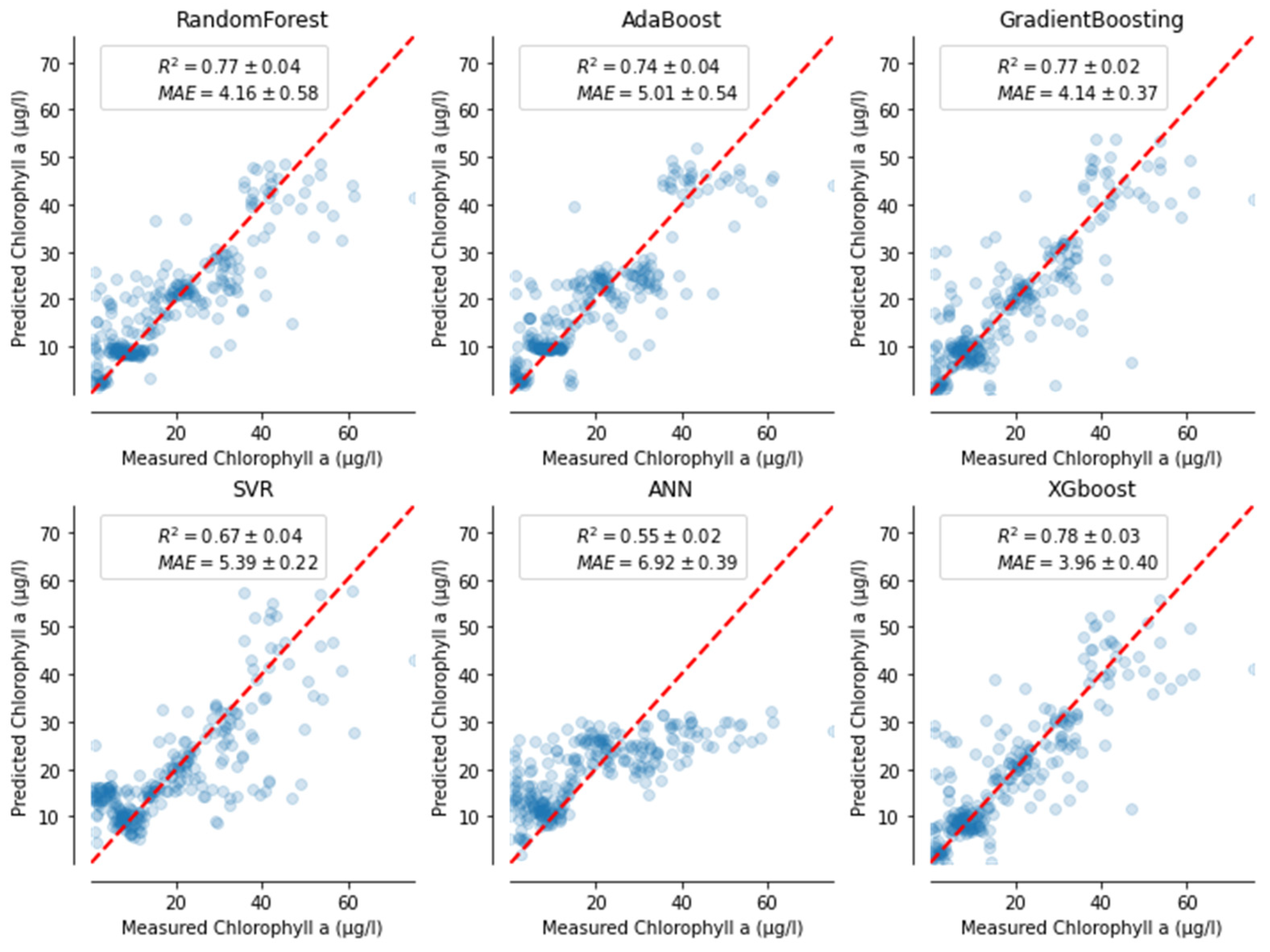
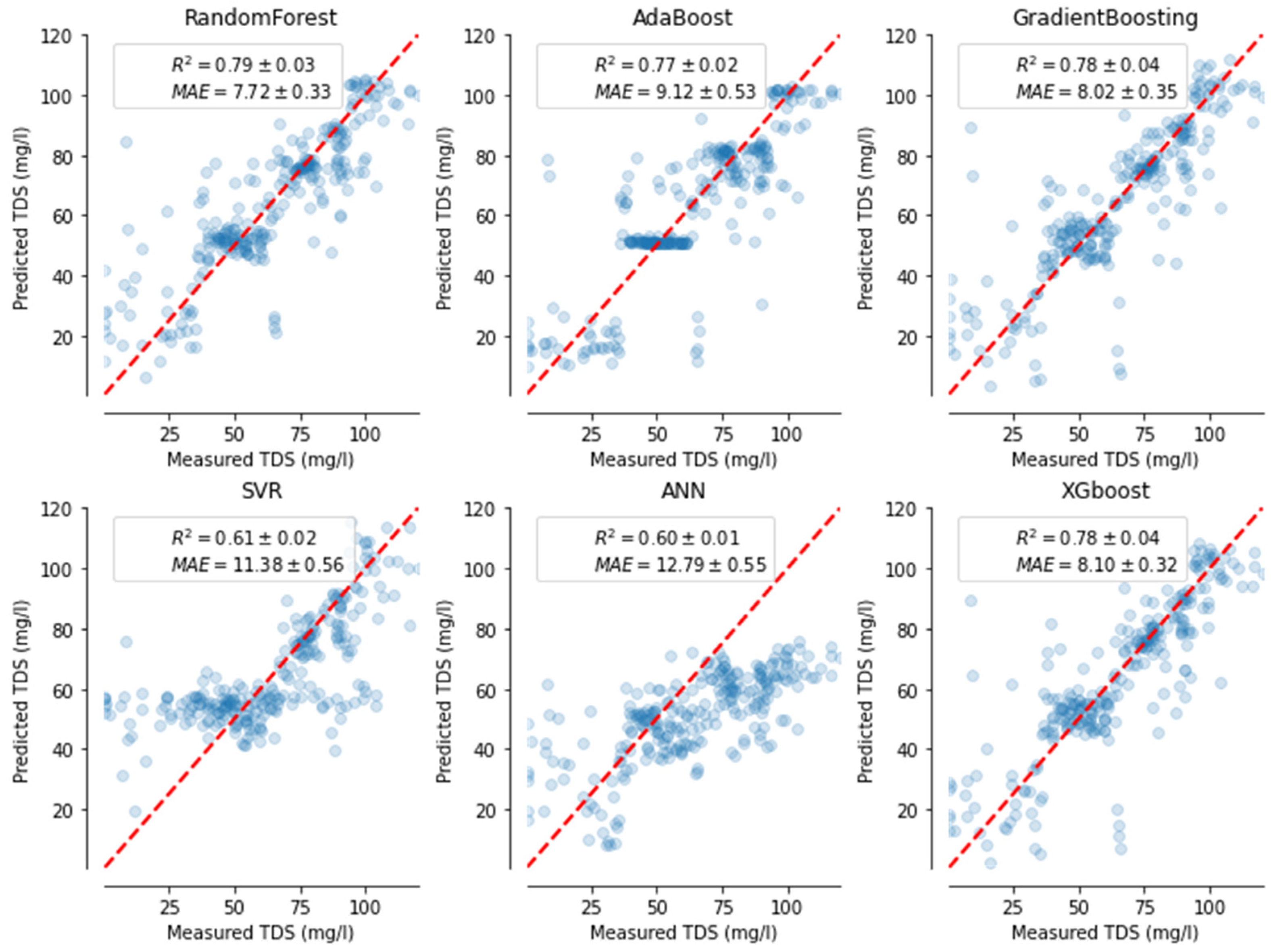
3.2. Comparision of ML Models’ Performances Metrics
4. Discussions
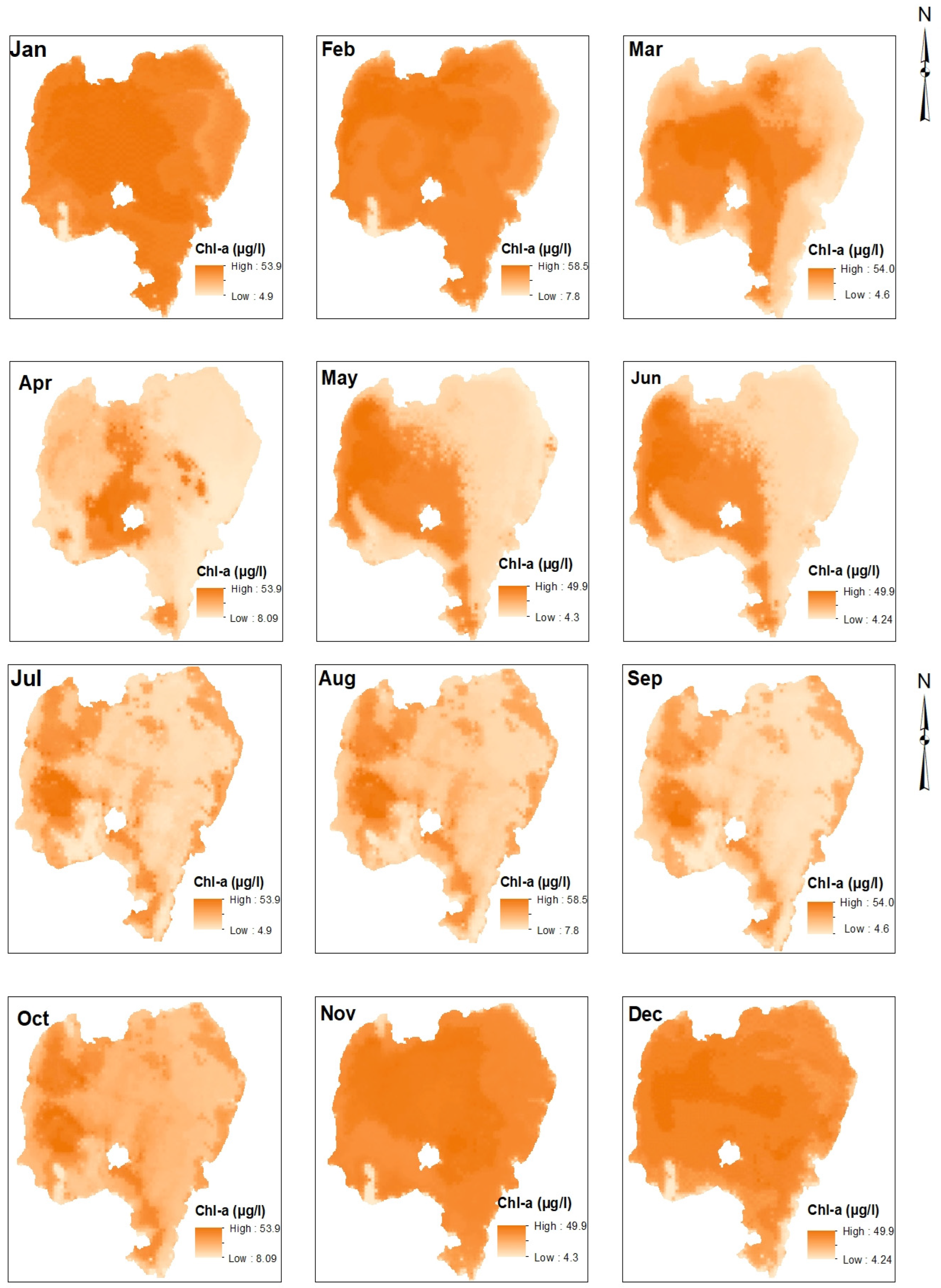
4.1. Chl-a Distribution of Lake Tana
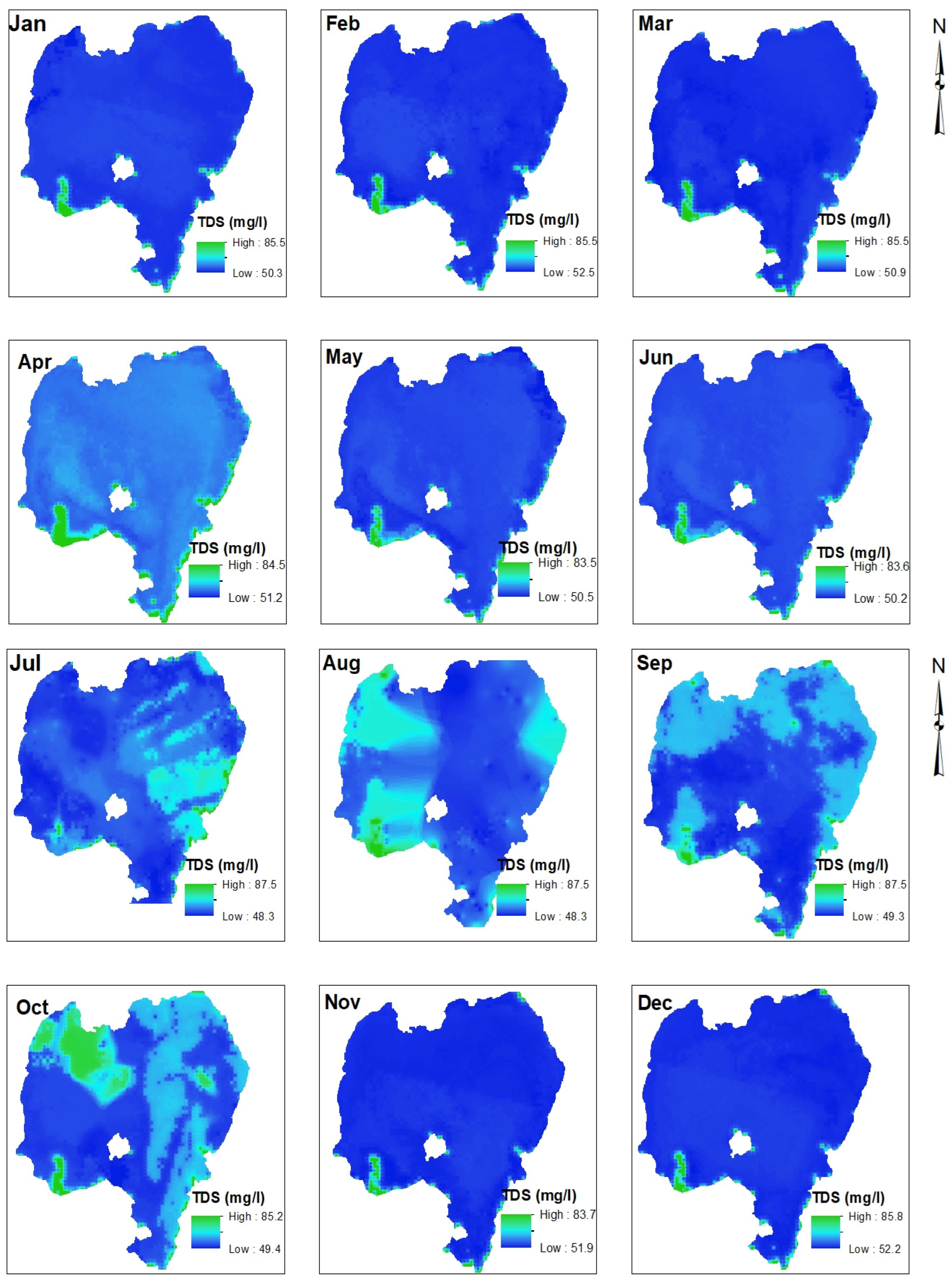
4.2. TDS Distribution of Lake Tana
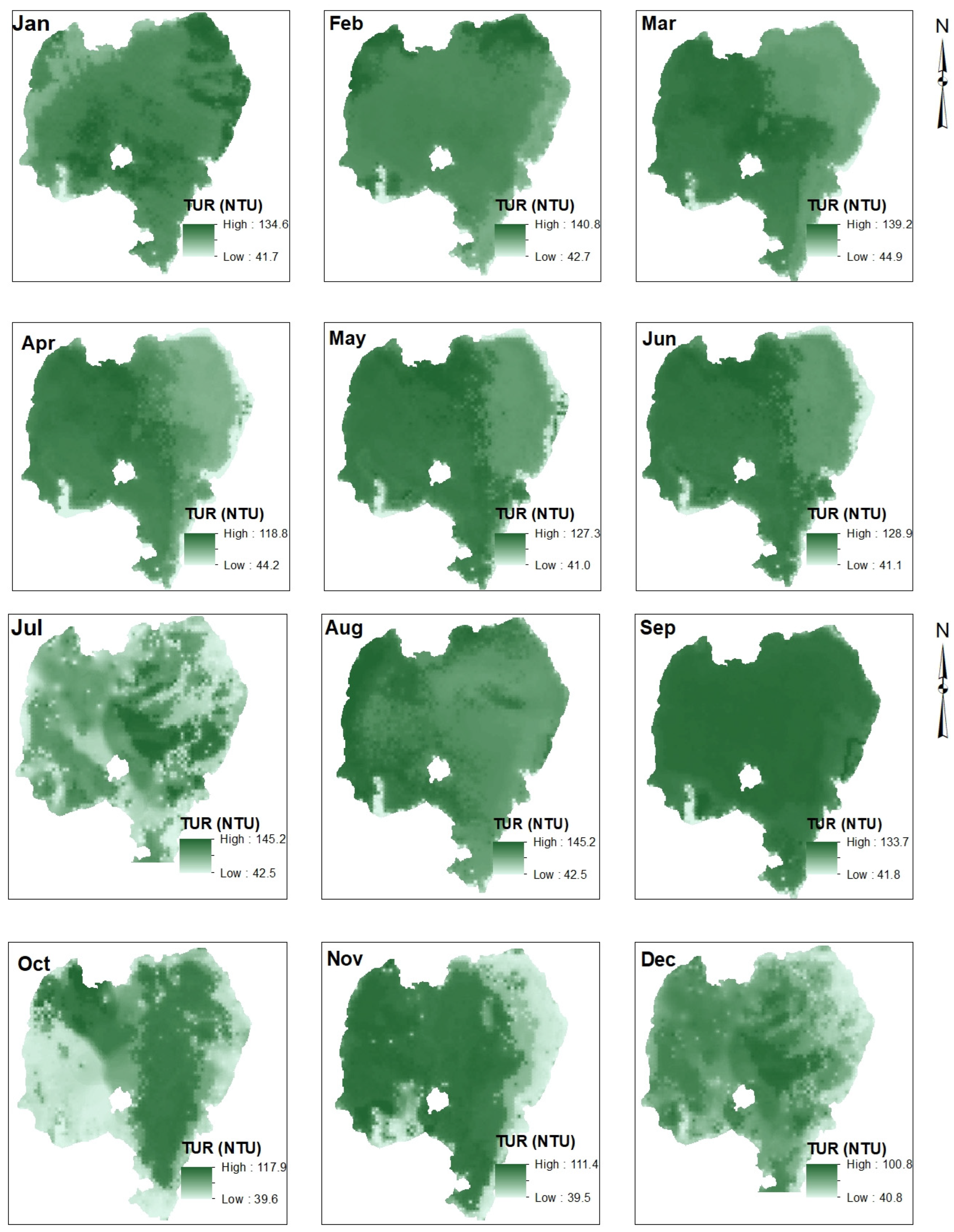
4.3. TUR Distribution of Lake Tana
4.4. Models Performances and Their Limitations
4.5. Significance of ML in Lake Water Quality Management
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Varela Pérez, P.; Greiner, B.E.; von Cossel, M. Socio-Economic and Environmental Implications of Bioenergy Crop Cultivation on Marginal African Drylands and Key Principles for a Sustainable Development. Earth 2022, 3, 652–682. [Google Scholar] [CrossRef]
- Wang, X.J.; Ma, T. Application of remote sensing techniques in monitoring and assessing the water quality of Taihu Lake. Bull. Environ. Contam. Toxicol. 2001, 67, 863–870. [Google Scholar] [CrossRef] [PubMed]
- Dersseh, M.G.; Kibret, A.A.; Tilahun, S.A.; Worqlul, A.W.; Moges, M.A.; Dagnew, D.C.; Abebe, W.B.; Melesse, A.M. Potential of water hyacinth infestation on Lake Tana, Ethiopia: A prediction using a GIS-based multi-criteria technique. Water 2019, 11, 1921. [Google Scholar] [CrossRef]
- Kallio, K. Remote sensing as a tool for monitoring lake water quality. Hydrol. Limnol. Asp. Lake Monit. 2000, 14, 237. [Google Scholar]
- Kibena, J.; Nhapi, I.; Gumindoga, W. Assessing the relationship between water quality parameters and changes in landuse patterns in the Upper Manyame River, Zimbabwe. Phys. Chem. Earth Parts ABC 2014, 67, 153–163. [Google Scholar] [CrossRef]
- Yin, J.; Medellin-Azuara, J.; Escriva-Bou, A.; Liu, Z. Bayesian machine learning ensemble approach to quantify model uncertainty in predicting groundwater storage change. Sci. Total Environ. 2021, 769, 144715. [Google Scholar] [CrossRef]
- Chen, K.; Chen, H.; Zhou, C.; Huang, Y.; Qi, X.; Shen, R. Comparative analysis of surface water quality prediction performance and identification of key water parameters using different machine learning models based on big data. Water Res. 2020, 171, 115454. [Google Scholar] [CrossRef]
- Kong, X.; Zhan, Q.; Boehrer, B.; Rinke, K. High frequency data provide new insights into evaluating and modeling nitrogen retention in reservoirs. Water Res. 2019, 166, 115017. [Google Scholar] [CrossRef]
- Bui, D.T.; Khosravi, K.; Tiefenbacher, J.; Nguyen, H.; Kazakis, N. Improving prediction of water quality indices using novel hybrid machine-learning algorithms. Sci. Total Environ. 2020, 721, 137612. [Google Scholar] [CrossRef]
- Zhang, W.; Xu, Q.; Wang, X.; Hu, X.; Wang, C.; Pang, Y.; Hu, Y.; Zhao, Y.; Zhao, X. Spatiotemporal Distribution of Eutrophication in Lake Tai as Affected by Wind. Water 2017, 9, 200. [Google Scholar] [CrossRef]
- Sudheer, K.P.; Chaubey, I.; Garg, V. Lake water quality assessment from landsat thematic mapper data using neural network: An approach to optimal band combination selection1. J. Am. Water Resour. Assoc. 2006, 42, 1683–1695. [Google Scholar] [CrossRef]
- Kim, Y.H.; Im, J.; Ha, H.K.; Choi, J.K.; Ha, S. Machine learning approaches to coastal water quality monitoring using GOCI satellite data. Gisci. Remote Sens. 2014, 51, 158–174. [Google Scholar] [CrossRef]
- Park, Y.; Cho, K.H.; Park, J.; Cha, S.M.; Kim, J.H. Development of early-warning protocol for predicting chlorophyll-a concentration using machine learning models in freshwater and estuarine reservoirs, Korea. Sci. Total Environ. 2015, 502, 31–41. [Google Scholar] [CrossRef] [PubMed]
- Moges, M.A.; Petra, S.; Tilahun, S.A.; Ayana, E.K.; Ketema, A.A.; Nigussie, T.E.; Steenhuis, T.S. Water Quality Assessment by Measuring and Using Landsat 7 ETM+ Images for the Current and Previous Trend Perspective: Lake Tana Ethiopia. J. Water Resour. Prot. 2017, 9, 1564–1585. [Google Scholar] [CrossRef]
- Dersseh, M.G.; Steenhuis, T.S.; Kiberet, A.A.; Enyew, B.M.; Kebedew, M.G.; Zimale, F.A.; Worklul, A.W.; Moges, M.A.; Abebe, W.B.; Mhiret, D.A.; et al. Water Quality Characteristics of a water Hyacinth Infected Tropical Highland Lake: Lake Tana, Ethiopia. Front. Water 2022, 4, 774710. [Google Scholar] [CrossRef]
- Goshu, G.; Strokal, M.; Kroeze, C.; Koelmans, A.A.; de Klein, J.J.M. Assessing seasonal nitrogen export to large tropical lakes. Sci. Total Environ. 2020, 731, 139199. [Google Scholar] [CrossRef]
- Alquraish, M.M.; Khadr, M. Remote-Sensing-Based Streamflow Forecasting Using Artificial Neural Network and Support Vector Machine Models. Remote Sens. 2021, 13, 4147. [Google Scholar] [CrossRef]
- Mulualem, G.M.; Liou, Y.A. Application of Artificial Neural Networks in Forecasting a Standardized Precipitation Evapotranspiration Index for the Upper Blue Nile Basin. Water 2020, 12, 643. [Google Scholar] [CrossRef]
- Ayehu, G.; Tadesse, T.; Gessesse, B.; Yigrem, Y. Soil Moisture Monitoring Using Remote Sensing Data and a Stepwise-Cluster Prediction Model: The Case of Upper Blue Nile Basin, Ethiopia. Remote Sens. 2019, 11, 125. [Google Scholar] [CrossRef]
- Gholizadeh, M.H.; Melesse, A.M.; Reddi, L. A comprehensive review on water quality parameters estimation using remote sensing techniques. Sensors 2016, 16, 1298. [Google Scholar] [CrossRef]
- Dejen, E.; Vijverberg, J.; Nagelkerke, L.A.; Sibbing, F.A. Temporal and spatial distribution of microcrustacean zooplankton in relation to turbidity and other environmental factors in a large tropical lake (L. Tana, Ethiopia). Hydrobiologia 2004, 513, 39–49. [Google Scholar] [CrossRef]
- Vijverberg, J.; Sibbing, F.A.; Dejen, E. Lake Tana: Source of the Blue Nile. In The Nile; Springer: Dordrecht, The Netherlands, 2009; pp. 163–192. [Google Scholar]
- Wondie, A.; Mengistou, S. Seasonal variability of secondary production of cladocerans and rotifers, and their trophic role in Lake Tana, Ethiopia, a large, turbid, tropical highland lake. Afr. J. Aquat. Sci. 2014, 39, 403–416. [Google Scholar] [CrossRef]
- Leggesse, E.; Beyene, B. Hydrology of Lake Tana Basin. In Social and Ecological System Dynamics, AESS Interdisciplinary Environmental Studies and Sciences Series.; Stave, K., Goshu, G., Aynalem, S., Eds.; Springer: Cham, Switzerland, 2017; pp. 117–126. [Google Scholar]
- Heide, Z. Feasibility Study for a Lake Tana Biosphere Reserve, Ethiopia; Federal Agency for Nature Conservation: Bonn, Germany, 2012.
- Taye, M.T.; Haile, A.T.; Fekadu, A.G.; Nakawuka, P. Effect of irrigation water withdrawal on the hydrology of the Lake Tana sub-basin. J. Hydrol. Reg. Stud. 2021, 38, 100961. [Google Scholar] [CrossRef]
- Abera, A.; Verhoest, N.E.; Tilahun, S.; Inyang, H.; Nyssen, J. Assessment of irrigation expansion and implications for water resources by using RS and GIS techniques in the Lake Tana Basin of Ethiopia. Environ. Monit. Assess. 2021, 193, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Liang, Q.; Zhang, Y.; Ma, R.; Loiselle, S.; Hu, M. A MODIS-Based Novel Method to Distinguish Surface Cyanobacterial Scums and Aquatic Macrophytes in Lake Taihu. Remote Sens. 2017, 9, 133. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Rogers, A.S.; Kearney, M.S. Reducing signature variability in unmixing coastal marsh thematic mapper scenes using spectral indices. Int. J. Remote Sens. 2004, 25, 2317–2335. [Google Scholar] [CrossRef]
- Xu, H.Q. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Hu, C. A novel ocean color index to detect floating algae in the global oceans. Remote Sens. Environ. 2009, 113, 2118–2129. [Google Scholar] [CrossRef]
- Lacaux, J.P.; Tourre, Y.M.; Vignolles, C.; Ndione, J.A.; Lafaye, M. Classification of ponds from high-spatial resolution remote sensing: Application to Rift Valley Fever epidemics in Senegal. Remote Sens. Environ. 2007, 106, 66–74. [Google Scholar] [CrossRef]
- Acharya, T.D.; Yang, I.T.; Lee, D.H. Surface Water Area Delineation in Landsat OLI Image using Reflectance and SRTM DEM derivatives. In Proceedings of the Conference on Geo-Spatial Information, Gunsan, Republic of Korea, 6–7 October 2016; The Korean Society for Geospatial Information Science: Gunsan, Republic of Korea, 2016; pp. 233–234. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Deo, R.K.; Russell, M.B.; Domke, G.M.; Woodall, C.W.; Falkowski, M.J.; Cohen, W.B. Using Landsat Time-Series and LiDAR to Inform Aboveground Forest Biomass Baselines in Northern Minnesota, USA. Can. J. Remote Sens. 2017, 43, 28–47. [Google Scholar] [CrossRef]
- Motoda, H.; Liu, H. Feature selection, extraction and construction. Towards the Foundation of Data Mining Workshop. In Proceedings of the Sixth Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD’02), Taipei, Taiwan, 6–8 May 2002; pp. 67–72. [Google Scholar]
- Oliveeria, M.; Torgo, L.; Santose Costa, V. Evaluation procedures for forecasting with Spatiotemporal Data. Mathematics 2021, 9, 691. [Google Scholar] [CrossRef]
- Worqlul, A.W.; Ayana, E.K.; Dile, Y.T.; Moges, M.A.; Dersseh, M.G.; Tegegne, G.; Kibret, S. Spatiotemporal Dynamics and Environmental Controlling Factors of the Lake Tana Water Hyacinth in Ethiopia. Remote Sens. 2020, 12, 2706. [Google Scholar] [CrossRef]
- Mucheye, T.; Haro, S.; Pa-paspyrou, S.; Caballero, I. Water Quality and Water Hyacinth Monitoring with the Sentinel-2A/B Satellites in Lake Tana (Ethiopia). Remote Sens. 2022, 14, 4921. [Google Scholar] [CrossRef]
- Wondie, A.; Mengistu, S.; Vijeverberg, J.; Dejen, E. Seasonal variation in primary production of a large high altitude tropical lake (Lake Tana, Ethiopia): Effects of nutrient availability and water transparency. Aquat. Ecol. 2007, 41, 195–207. [Google Scholar] [CrossRef]
- Freund, Y. Boosting a Weak Learning Algorithm by Majority; AT & T Laboratories: Murray Hill, NJ, USA, 1995. [Google Scholar]
- Freund, J.H. Greedy Function Approximation: A gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Milton Park, GA, USA, 2017. [Google Scholar]
- Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Chica-Rivas, M. Evaluation of different machine learning methods for land cover mapping of a Mediterranean area using multi-seasonal Landsat images and digital terrain models. Int. J. Digit. Earth 2012, 7, 492–509. [Google Scholar] [CrossRef]
- Ghatkar, J.G.; Singh, R.K.; Shanmugam, P. Classification of algal bloom species from remote sensing data using an extreme gradient boosted decision tree model. Int. J. Remote Sens. 2019, 40, 9412–9438. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.C.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Nolan, B.T.; Fienen, M.N.; Lorenz, D.L. A statistical learning framework for groundwater nitrate models of the Central Valley, California, USA. J. Hydrol. 2015, 531, 902–911. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support Vector Machines in Remote Sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the KDD’16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Niazkar, M.; Goodarzi, M.R.; Fatehifar, A.; Abedi, M.J. Machine learning-based downscaling: Application of multi-gene genetic programming for downscaling daily temperature at Dogonbaden, Iran, Under CMIP6 scenarios. Theor. Appl. Climatol. 2023, 151, 153–168. [Google Scholar] [CrossRef]
- Fox, E.W.; Ver Hoef, J.M.; Olsen, A.R. Comparing spatial regression to random forests for large environmental data sets. PLoS ONE 2020, 15, e0229509. [Google Scholar] [CrossRef]
- Zelalem, R.W.; Zimale, F.A.; Kebedew, M.G.; Asers, B.W.; DeLuca, N.M.; Guzman, C.D.; Tilahun, S.A.; Zaitchik, B.F. Estimation of Suspended Sediment Concentration from Remote Sensing and In Situ Measurement over Lake Tana, Ethiopia. Adv. Civ. Eng. 2021, 17, 9948780. [Google Scholar]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high class imbalance in big data. J. Big Data 2018, 5, 1–30. [Google Scholar] [CrossRef]
- Thomas, M.K.; Fontana, S.; Reyes, M.; Kehoe, M.; Pomati, F. The predictability of a lake phytoplankton community, over time-scales of hours to years. Ecol. Lett. 2018, 21, 619–628. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Weiss, G.M.; Provost, F. Learning when training data are costly: The effect of class distribution on tree induction. J. Artif. Intell. Res. 2003, 19, 315–354. [Google Scholar] [CrossRef]
- Loosvelt, L.; Petersb, J.; Skriverc, H.; Lievensa, H.; Van Coillied, F.M.B.; De Baetsb, B.; Verhoesta, N.E.C. Random forests as a tool for estimating uncertainty at pixel-level in SAR image classification. Int. J. Appl. Earth Obs. Geoinf. 2012, 19, 173–184. [Google Scholar] [CrossRef]
- Chen, Y.; Song, L.; Liu, Y.; Yang, L.; Li, D. A Review of the Artificial Neural Network Models for Water Quality Prediction. Appl. Sci. 2020, 10, 5776. [Google Scholar] [CrossRef]
- Getachew, B. and Manjunatha, B.R. Impacts of Land-Use Change on the Hydrology of Lake Tana Basin, Upper Blue Nile River Basin, Ethiopia. Glob. Chall. 2022, 6, 2200041. [Google Scholar] [CrossRef] [PubMed]
- Kebedew, M.G.; Tilahun, S.A.; Belete, M.A.; Zimale, F.A.; Steenhuis, T.S. Sediment deposition (1940–2017) in a historically pristine lake in a rapidly developing tropical highland region in Ethiopia. Earth Surf. Process. Landf. 2021, 46, 1521–1535. [Google Scholar] [CrossRef]
- Setegn, S.G.; Srinivasan, R.; Melesse, A.M.; Dargahi, B. SWAT model application and prediction uncertainty analysis in the Lake Tana Basin, Ethiopia. Hydrol. Process. Int. J. 2010, 24, 357–367. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Water Quality Parameter | Metrics | Aug. 2016 | Dec. 2016 | Mar. 2017 | Dec. 2019 | Jun. 2019 | Jul. 2019 | Aug. 2019 | Mar. 2020 | Oct. 2021 | Apr. 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| N. Sample | 170 | 170 | 170 | 27 | 27 | 27 | 27 | 27 | 143 | 143 | |
| Chl-a (µg/L) | SD | 0.1 | 0.1 | 0.10 | 1.1 | 4.0 | 3.3 | 2.0 | 1.8 | 0.76 | 16.8 |
| Max | 19.4 | 191.6 | 191.6 | 7.2 | 19.5 | 14.2 | 11.4 | 12.0 | 185.8 | 125.0 | |
| Min | 0.05 | 0.05 | 0.05 | 3.7 | 0.8 | 1.1 | 1.5 | 6.2 | 0.01 | 0.01 | |
| Mean | 2.2 | 17.1 | 20.6 | 5.4 | 4.4 | 5.7 | 6.3 | 8.8 | 6.7 | 8.6 | |
| TUR (NTU) | SD | - | - | - | - | - | - | - | - | 19.0 | 19.7 |
| Max | - | - | - | - | - | - | - | - | 344 | 104.0 | |
| Min | - | - | - | - | - | - | - | - | 0.27 | 5.0 | |
| Mean | - | - | - | - | - | - | - | - | 41.7 | 23.7 | |
| TDS (mg L−1) | SD | 2.8 | 26.4 | 25.7 | - | - | - | - | - | 34.0 | 5.7 |
| Max | 113.3 | 107.3 | 107.3 | - | - | - | - | - | 99.0 | 78.0 | |
| Min | 50.7 | 34.7 | 34.7 | - | - | - | - | - | 30.0 | 7.30 | |
| Mean | 90.1 | 87.0 | 99.4 | - | - | - | - | - | 58.6 | 68.2 | |
| Water Quality Parameter | Models | Number of Features Selected | Selected Features |
|---|---|---|---|
| Chl-a | AB | 12 | B6, B7, B11, CI, GNDVI_4, TWI_2, Norm R, NDSI, SRSWIR1/NIR, ABI, B4/B3, (B3 + B4 + B5)/3 |
| RF | 20 | B1, B3, B4, B10, CI, GDVI, EVI, TWI_2, GARI, NormR, NDSI, SRSWIR1/NIR, SRSWIR2/NIR, ABI, FAI, (B4 + B2)/2, (B4 + B5)/2, (B2 + B3 + B5)/3, (B3 + B4 + B5)/3, (B5 − B4)/(B2 + B3) | |
| GB | 10 | B2, B3, B6, B11, GNDVI_4, TWI_1, GARI, ABI, (B4 + B5)/2, (B2 − B4)/B3 | |
| SVM | 15 | B2, B3, B4, B6, B7, B11, CI, GNDVI_1, GNDVI_4, PPR, MSRNir/Red, RGR, (B4 + B5)/2, (B3 + B4 + B5)/3, (B2 − B4)/B3 | |
| XGB | 12 | B1, B2, B10, CI, GNDVI_3, GNDVI_5, TWI_1, TWI_2, Laterite, H, IF, SRSWIR1/NIR, SRSWIR2/NIR, FAI | |
| ANN | 87 | See Table S1 | |
| TDS | AB | 15 | B3, B4, B7, B10, B11, TWI_1, BNDVI, GARI, Laterite, mCRIG, NDSI, B4/B3, (B3 + B5)/2, (B2 + B5)/2, (B4 + B5)/2 |
| RF | 18 | B1, B3, B4, B6, B10, B11, GNDVI_3, GNDVI_4, MNDWI_2, TWI_2, Gossan, I, MVI, AWEInsh, (B4 + B3)/2, (B4 + B2)/2, (B3 + B2)/2, (B2 + B3 + B4)/3 | |
| GB | 10 | B2, B3, CI, TWI_1, GARI, PPR, Laterite, ABI, (B4 + B3)/2, (B2 + B3 + B5)/3 | |
| SVM | 13 | B10, B11, TWI_1, BNDVI, GARI, Laterite, mCRIG, ABI, FAI, (B4 + B2)/2, (B2 + B3 + B5)/3, (B3 + B4 + B5)/3, (B2 − B4)/B3 | |
| XGB | 10 | B2, B3, B7, B10, B11, CI, GNDVI_4, GNDVI_6, TWI_2, Gossan | |
| ANN | 87 | See Table S1 | |
| Turbidity | AB | 15 | B3, B4, B7, B10, B11, TWI_1, BNDVI, GARI, Laterite, mCRIG, NDSI, B4/B3, (B3 + B5)/2, (B2 + B5)/2, (B4 + B5)/2 |
| RF | 15 | B3, B4, B10, CI, GNDVI_3, TWI_1, TWI_2, Gossan, GARI, PVR, I, MVI, IF, SR550/670, SRSWIR1/NIR, SRSWIR2/NIR, RGR, FAI, (B4 + B3)/2, (B2 + B3 + B4)/3 | |
| GB | 10 | B2, B3, CI, TWI_1, GARI, PPR, Laterite, ABI, (B4 + B3)/2, (B2 + B3 + B5)/3 | |
| SVM | 13 | B10, B11, TWI_1, BNDVI, GARI, Laterite, mCRIG, ABI, FAI, (B4 + B2)/2, (B2 + B3 + B5)/3, (B3 + B4 + B5)/3, (B2 − B4)/B3 | |
| XGB | 10 | B2, B3, B7, B10, B11, CI, GNDVI_4, GNDVI_6, TWI_2, Gossan | |
| ANN | 87 | See Table S1 |
| Water Quality Parameter | Algorithm | R2 (TRST) | R2 (STBPT) | MARE (TRST) | MARE (STBPT) | RMSE (TRST) | RMSE (STBPT) | NSE (TRST) | NSE (STBPT) |
|---|---|---|---|---|---|---|---|---|---|
| ANN | 0.55 | 0.124 | 7.14 | 0.56 | |||||
| XGB | 0.78 | 0.082 | 9.79 | 0.78 | |||||
| Chl-a | SVM | 0.67 | 0.120 | 8.27 | 0.65 | ||||
| (µg/L) | GB | 0.77 | 0.091 | 5.85 | 0.78 | ||||
| AB | 0.74 | 0.095 | 7.32 | 0.71 | |||||
| RF | 0.77 | 0.093 | 6.81 | 0.77 | |||||
| ANN | 0.60 | 0.133 | 17.04 | 0.58 | |||||
| XGB | 0.78 | 0.085 | 12.51 | 0.78 | |||||
| TDS | SVM | 0.61 | 0.112 | 16.86 | 0.62 | ||||
| (mg/L) | GB | 0.79 | 0.096 | 12.40 | 0.78 | ||||
| AB | 0.77 | 0.095 | 12.99 | 0.77 | |||||
| RF | 0.79 | 0.082 | 12.30 | 0.80 | |||||
| ANN | 0.22 | 0.60 | 0.33 | 0.132 | 30.1 | 10.97 | 0.34 | 0.61 | |
| XGB | 0.53 | 0.79 | 0.20 | 0.076 | 24.5 | 8.05 | 0.55 | 0.80 | |
| TUR | SVM | 0.23 | 0.64 | 0.24 | 0.122 | 15.6 | 10.17 | 0.35 | 0.64 |
| (NTU) | GB | 0.45 | 0.77 | 0.22 | 0.085 | 21.5 | 8.26 | 0.46 | 0.77 |
| AB | 0.44 | 0.74 | 0.21 | 0.092 | 13.5 | 8.60 | 0.45 | 0.75 | |
| RF | 0.48 | 0.80 | 0.26 | 0.072 | 18.4 | 7.82 | 0.48 | 0.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leggesse, E.S.; Zimale, F.A.; Sultan, D.; Enku, T.; Srinivasan, R.; Tilahun, S.A. Predicting Optical Water Quality Indicators from Remote Sensing Using Machine Learning Algorithms in Tropical Highlands of Ethiopia. Hydrology 2023, 10, 110. https://doi.org/10.3390/hydrology10050110
Leggesse ES, Zimale FA, Sultan D, Enku T, Srinivasan R, Tilahun SA. Predicting Optical Water Quality Indicators from Remote Sensing Using Machine Learning Algorithms in Tropical Highlands of Ethiopia. Hydrology. 2023; 10(5):110. https://doi.org/10.3390/hydrology10050110
Chicago/Turabian StyleLeggesse, Elias S., Fasikaw A. Zimale, Dagnenet Sultan, Temesgen Enku, Raghavan Srinivasan, and Seifu A. Tilahun. 2023. "Predicting Optical Water Quality Indicators from Remote Sensing Using Machine Learning Algorithms in Tropical Highlands of Ethiopia" Hydrology 10, no. 5: 110. https://doi.org/10.3390/hydrology10050110
APA StyleLeggesse, E. S., Zimale, F. A., Sultan, D., Enku, T., Srinivasan, R., & Tilahun, S. A. (2023). Predicting Optical Water Quality Indicators from Remote Sensing Using Machine Learning Algorithms in Tropical Highlands of Ethiopia. Hydrology, 10(5), 110. https://doi.org/10.3390/hydrology10050110