
Machine-Learning-Based Precipitation Reconstructions: A Study on Slovenia’s Sava River Basin



Abstract
1. Introduction
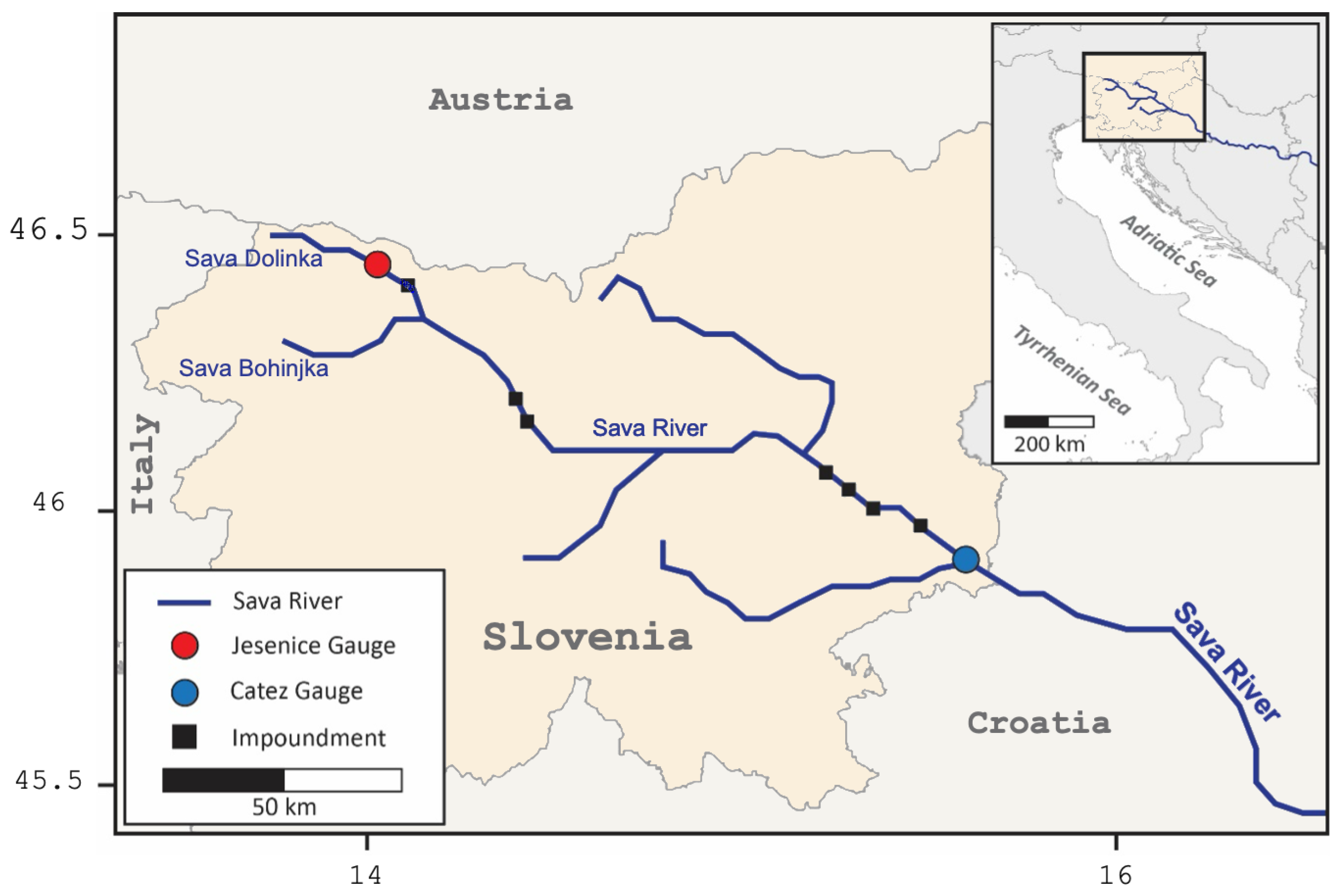
2. Materials and Methods
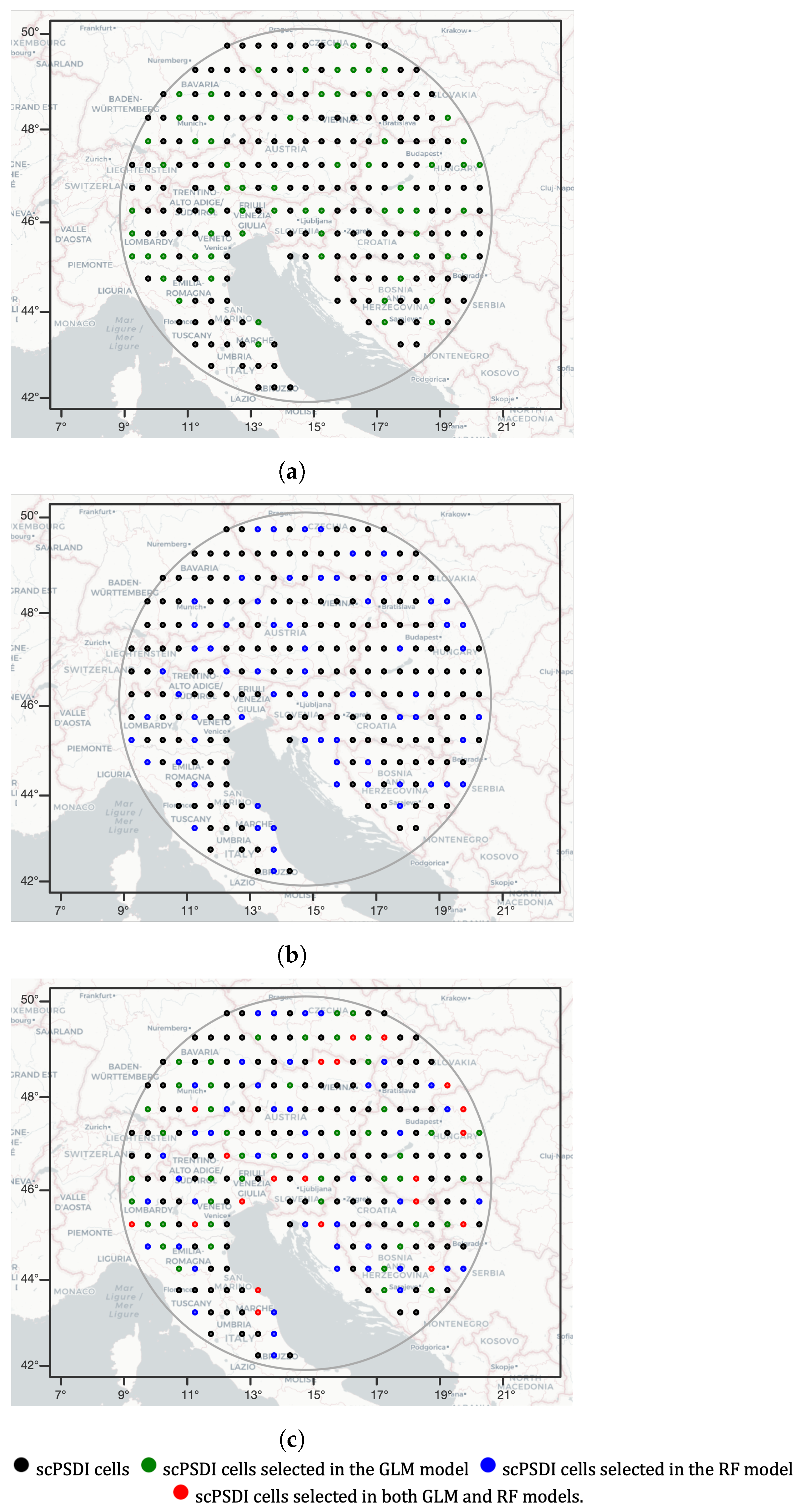
- A set of 249 self-calibrated Palmer Drought Severity Index (scPDSI) cells located within a 450 km radius of the SRB and a portion of the Old Water Drought Atlas (OWDA) developed from summer-related tree-ring proxies over a period from year 0 to 2012 were used [19]. This index has been shown to have significant and positive correlations with SR water flux, making it a valuable proxy for streamflow reconstructions in SRB [13].
- The reconstructed alpine monthly precipitation dataset, also known as the Long-term Alpine Precipitation Reconstruction (LAPrec), is derived from in situ observations. This dataset provides gridded fields of monthly precipitation for the Alpine region, covering eight countries. It has been meticulously constructed to meet high climatological standards, ensuring temporal consistency and the realistic reproduction of spatial patterns over complex terrains. The dataset spans from 1871 to 2020 and boasts a horizontal resolution of 5 km [20]. LAPrec combines two primary data sources:
- –
- Historical Instrumental Climatological Surface Time Series of the Greater Alpine Region (HISTALP) offers homogenized station series of monthly precipitation that date back to the 19th century. This version of the dataset, which starts in 1871, uses 85 almost-continuous series that are uniformly distributed across the Alpine region [20].
- –
- Alpine Precipitation Grid Dataset (APGD) provides daily precipitation gridded data for the period 1971–2008 constructed from more than 8500 rain gauges. This dataset incorporates daily precipitation measurements from over 5500 rain gauges on average per day, covering the entire Alpine region and ensuring a dense in situ observation network over high-alpine topography [20].
- The LAPrec dataset was developed using the Reduced Space Optimal Interpolation (RSOI) method, which establishes a linear model between station and grid data. This method involves Principal Component Analysis (PCA) of the high-resolution grid data followed by Optimal Interpolation (OI) using the long-term station data. The dataset was developed as a collaboration between the national meteorological services of Switzerland (MeteoSwiss, Federal Office of Meteorology and Climatology) and Austria (ZAMG, Zentralanstalt für Meteorologie und Geodynamik).
- It is important to note that climate conditions have been changing through the decades, and the selection of the dataset can impact the results. However, the dataset chosen for this study was constructed using state-of-the-art climatological approaches, ensuring a homogeneous dataset that adheres to the standards set by European meteorological offices.
- For this study, the SRB catchment average monthly precipitation was extracted based on the gridded precipitation data, with a focus on the seasonal April–May–June–July–August–September (AMJJAS) period.
2.1. Metrics
2.2. General Machine Learning Models
2.3. Specialized Machine Learning Models
2.4. Bias Correction
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AMJJAS | April–May–June–July–August–September |
| APGD | Alpine Precipitation Grid Dataset |
| CDF | Cumulative Distribution Functions |
| DL | Deep Learning |
| DR | Danube River |
| DT | Decision Tree |
| GBT | Gradient Boosted Tree |
| GLM | Generalized Linear Model |
| GP | Gaussian Process |
| HISTALP | Historical Instrumental Climatological Surface Time Series of the Greater Alpine Region |
| KGE | Kling–Gupta Efficiency |
| kNN | k-Nearest Neighbors |
| LAPrec | Long-term Alpine Precipitation Reconstruction |
| LR | Linear Regression |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| NSE | Nash–Sutcliffe Efficiency |
| OWDA | Old Water Drought Atlas |
| ReLU | Rectifier Linear Unit |
| RF | Random Forest |
| RMSE | Root Mean Squared Error |
| scPDSI | self-calibrated Palmer Drought Severity Index |
| SLR | Stepwise Linear Regression |
| SR | Sava River |
| SRB | Sava River Basin |
| SVM | Support Vector Machine |
References
- Leščešen, I.; Šraj, M.; Basarin, B.; Pavić, D.; Mesaroš, M.; Mudelsee, M. Regional Flood Frequency Analysis of the Sava River in South-Eastern Europe. Sustainability 2022, 14, 9282. [Google Scholar]
- Brilly, M. (Ed.) Hydrological Processes of the Danube River Basin: Perspectives from the Danubian Countries; Springer: Dordrecht, The Netherlands, 2010. [Google Scholar] [CrossRef]
- Bezak, N.; Horvat, A.; Šraj, M. Analysis of flood events in Slovenian streams. J. Hydrol. Hydromech. 2015, 63, 134–144. [Google Scholar] [CrossRef][Green Version]
- Frantar, P.; Hrvatin, M. Pretočni režimi v Sloveniji med letoma 1971 in 2000. Geogr. Vestn. 2005, 77, 115–127. [Google Scholar]
- Tootle, G.; Oubeidillah, A.; Elliott, E.; Formetta, G.; Bezak, N. Streamflow Reconstructions Using Tree-Ring-Based Paleo Proxies for the Sava River Basin (Slovenia). Hydrology 2023, 10, 138. [Google Scholar] [CrossRef]
- Vrzel, J.; Solomon, D.K.; Blažeka, Ž.; Ogrinc, N. The study of the interactions between groundwater and Sava River water in the Ljubljansko polje aquifer system (Slovenia). J. Hydrol. 2018, 556, 384–396. [Google Scholar] [CrossRef]
- Copernicus Emergency Management Service. Flood in Slovenia: EMSR680-Situational reporting. EGUsphere 2023, 2023, 1–13. [Google Scholar]
- Agencija Republike Slovenije za Okolje—ARSO. Nalivi in obilne padavine od 3. do 6. avgusta 2023. Ministrstvo za Okolje, Podnebje in Energijo. 2023. Available online: https://meteo.arso.gov.si/uploads/probase/www/climate/text/sl/weather_events/padavine_3-6avg2023.pdf (accessed on 10 September 2023).
- Steinhausen, M.; Paprotny, D.; Dottori, F.; Sairam, N.; Mentaschi, L.; Alfieri, L.; Lüdtke, S.; Kreibich, H.; Schröter, K. Drivers of future fluvial flood risk change for residential buildings in Europe. Glob. Environ. Chang. 2022, 76, 102559. [Google Scholar] [CrossRef]
- Zalokar, L.; Kobold, M.; Šraj, M. Investigation of Spatial and Temporal Variability of Hydrological Drought in Slovenia Using the Standardised Streamflow Index (SSI). Water 2021, 13, 3197. [Google Scholar] [CrossRef]
- Predin, A.; Fike, M.; Pezdevšek, M.; Hren, G. Lost Energy of Water Spilled over Hydropower Dams. Sustainability 2021, 13, 9119. [Google Scholar] [CrossRef]
- Trček, B.; Mesarec, B. Impact of the Hydroelectric Dam on Aquifer Recharge Processes in the Krško Field and the Vrbina Area: Evidence from Hydrogen and Oxygen Isotopes. Water 2023, 15, 412. [Google Scholar] [CrossRef]
- Trlin, D.; Mikac, S.; Žmegač, A.; Orešković, M. Dendrohydrological Reconstructions Based on Tree-Ring Width (TRW) Chronologies of Narrow-Leaved Ash in the Sava River Basin (Croatia). Sustainability 2021, 13, 2408. [Google Scholar] [CrossRef]
- Ho, M.; Lall, U.; Cook, E.R. Can a paleodrought record be used to reconstruct streamflow?: A case study for the Missouri River Basin. Water Resour. Res. 2016, 52, 5195–5212. [Google Scholar] [CrossRef]
- Ho, M.; Lall, U.; Sun, X.; Cook, E.R. Multiscale temporal variability and regional patterns in 555 years of conterminous US streamflow. Water Resour. Res. 2017, 53, 3047–3066. [Google Scholar] [CrossRef]
- Formetta, G.; Tootle, G.; Bertoldi, G. Streamflow Reconstructions Using Tree-Ring Based Paleo Proxies for the Upper Adige River Basin (Italy). Hydrology 2022, 9, 8. [Google Scholar] [CrossRef]
- Formetta, G.; Tootle, G.; Therrell, M. Regional Reconstruction of Po River Basin (Italy) Streamflow. Hydrology 2022, 9, 163. [Google Scholar] [CrossRef]
- Isaev, E.; Ermanova, M.; Sidle, R.C.; Zaginaev, V.; Kulikov, M.; Chontoev, D. Reconstruction of Hydrometeorological Data Using Dendrochronology and Machine Learning Approaches to Bias-Correct Climate Models in Northern Tien Shan, Kyrgyzstan. Water 2022, 14, 2297. [Google Scholar] [CrossRef]
- Cook, E.R.; Seager, R.; Kushnir, Y.; Briffa, K.R.; Büntgen, U.; Frank, D.; Krusic, P.J.; Tegel, W.; van der Schrier, G.; Andreu-Hayles, L.; et al. Old World megadroughts and pluvials during the Common Era. Sci. Adv. 2015, 1, e1500561. [Google Scholar] [CrossRef] [PubMed]
- Climate Change Service. Alpine Gridded Monthly Precipitation Data Since 1871 Derived from In-Situ Observations. 2021. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/10.24381/cds.6a6d1bc3?tab=overview (accessed on 28 August 2023).
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Nash, J.; Sutcliffe, J. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Knoben, W.J.M.; Freer, J.E.; Woods, R.A. Technical note: Inherent benchmark or not? Comparing Nash–Sutcliffe and Kling–Gupta efficiency scores. Hydrol. Earth Syst. Sci. 2019, 23, 4323–4331. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Skiena, S.S. The Data Science Design Manual, 1st ed.; Texts in Computer Science; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Faisal, A.A.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- Bonaccorso, G. Machine Learning Algorithms, 2nd ed.; Packt: Birmingham, UK, 2018; p. 522. [Google Scholar]
- RapidMiner Inc. RapidMiner Documentation-Operators. 2023. Available online: https://docs.rapidminer.com/latest/studio/operators/ (accessed on 29 June 2023).
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980v9. [Google Scholar]
- Gudmundsson, L.; Bremnes, J.B.; Haugen, J.E.; Engen-Skaugen, T. Technical Note: Downscaling RCM precipitation to the station scale using statistical transformations—A comparison of methods. Hydrol. Earth Syst. Sci. 2012, 16, 3383–3390. [Google Scholar] [CrossRef]
- RC Team. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 11 September 2023).
- Robeson, S.M.; Maxwell, J.T.; Ficklin, D.L. Bias Correction of Paleoclimatic Reconstructions: A New Look at 1200+ Years of Upper Colorado River Flow. Geophys. Res. Lett. 2020, 47, e2019GL086689. [Google Scholar] [CrossRef]
- Wang, K.; Wang, P.; Xu, C. Toward Efficient Automated Feature Engineering. In Proceedings of the 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023; pp. 1625–1637. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
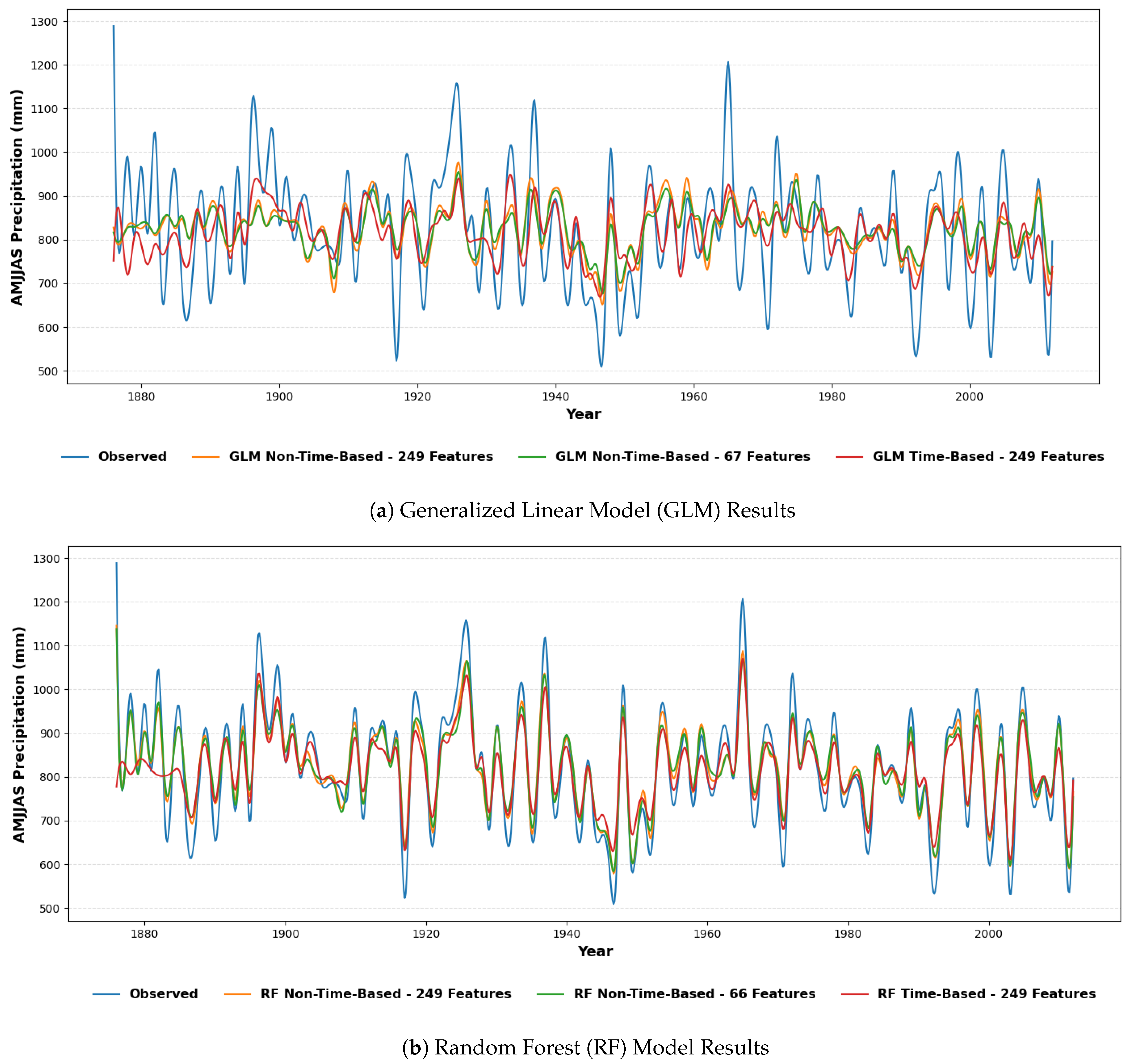
| Model | RMSE | NSE | KGE |
|---|---|---|---|
| Linear Regression (LR) | 230.890 | 0.233 | 0.339 |
| Support Vector Machine (SVM) | 128.060 | 0.252 | 0.425 |
| Deep Learning (DL) | 138.517 | 0.161 | 0.281 |
| Generalized Linear Model (GLM) | 116.070 | 0.281 | 0.408 |
| k-Nearest Neighbors (kNN) | 122.142 | 0.217 | 0.358 |
| Gradient Boosted Trees (GBT) | 125.479 | 0.187 | 0.353 |
| Decision Tree (DT) | 141.717 | 0.201 | 0.385 |
| Random Forest (RF) | 119.210 | 0.265 | 0.405 |
| Gaussian Process (GP) | 835.935 | 0.064 | −4.137 |
| Model | Entire Data Set (249 Features) | Reduced-Feature Datasets (67 Features for GLM and 66 for RF) | ||||
|---|---|---|---|---|---|---|
| RMSE | NSE | KGE | RMSE | NSE | KGE | |
| Generalized Linear Model (GLM) | 116.070 | 0.281 | 0.408 | 115.631 | 0.327 | 0.447 |
| Random Forest (RF) | 119.210 | 0.265 | 0.405 | 120.226 | 0.251 | 0.378 |
| Model | Non-Time-Based Analysis | Time-Based Analysis | ||
|---|---|---|---|---|
| RMSE (Whole Feature Set) | RMSE (Post-Feature Engineering) | RMSE (Whole Feature Set) | RMSE (Post-Feature Engineering) | |
| Generalized Linear Model (GLM) | 116.070 | 115.631 | 133.328 | 133.694 |
| Random Forest (RF) | 119.210 | 120.226 | 133.211 | 132.975 |
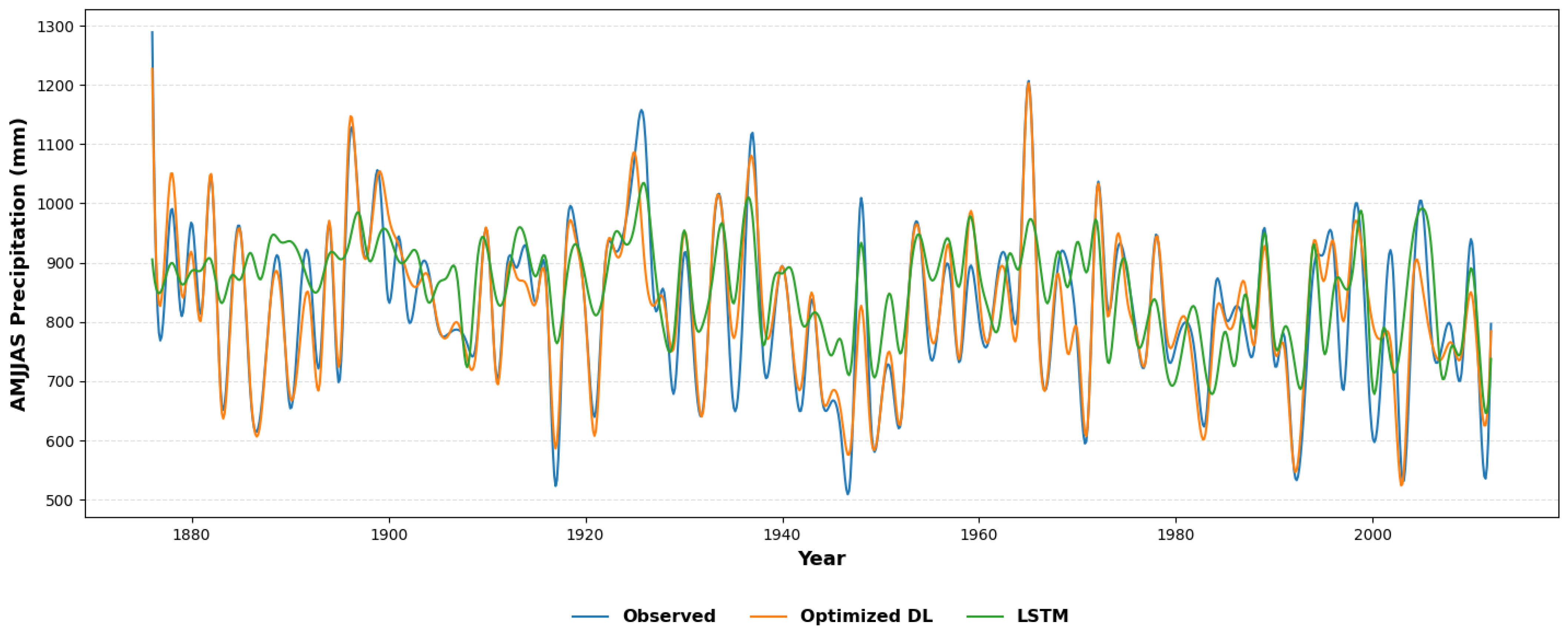
| Model | RMSE | NSE | KGE |
|---|---|---|---|
| Optimized Deep Learning (Optimized DL) | 89.225 | 0.367 | 0.468 |
| Long Short-Term Memory (LSTM) | 109.005 | 0.150 | 0.580 |
| Model | Original Model Predictions | Bias-Corrected Predictions | ||||
|---|---|---|---|---|---|---|
| RMSE | NSE | KGE | RMSE | NSE | KGE | |
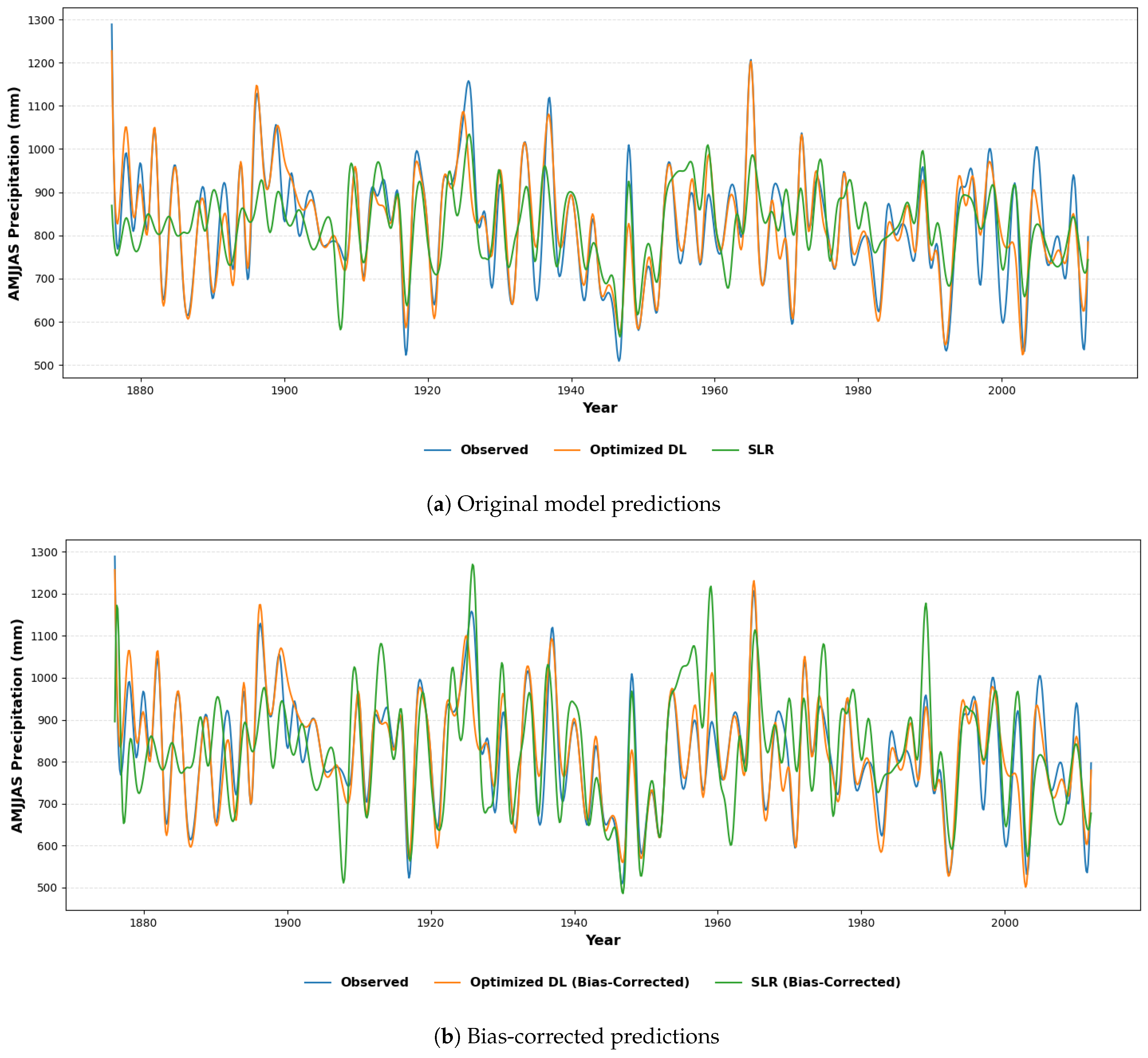
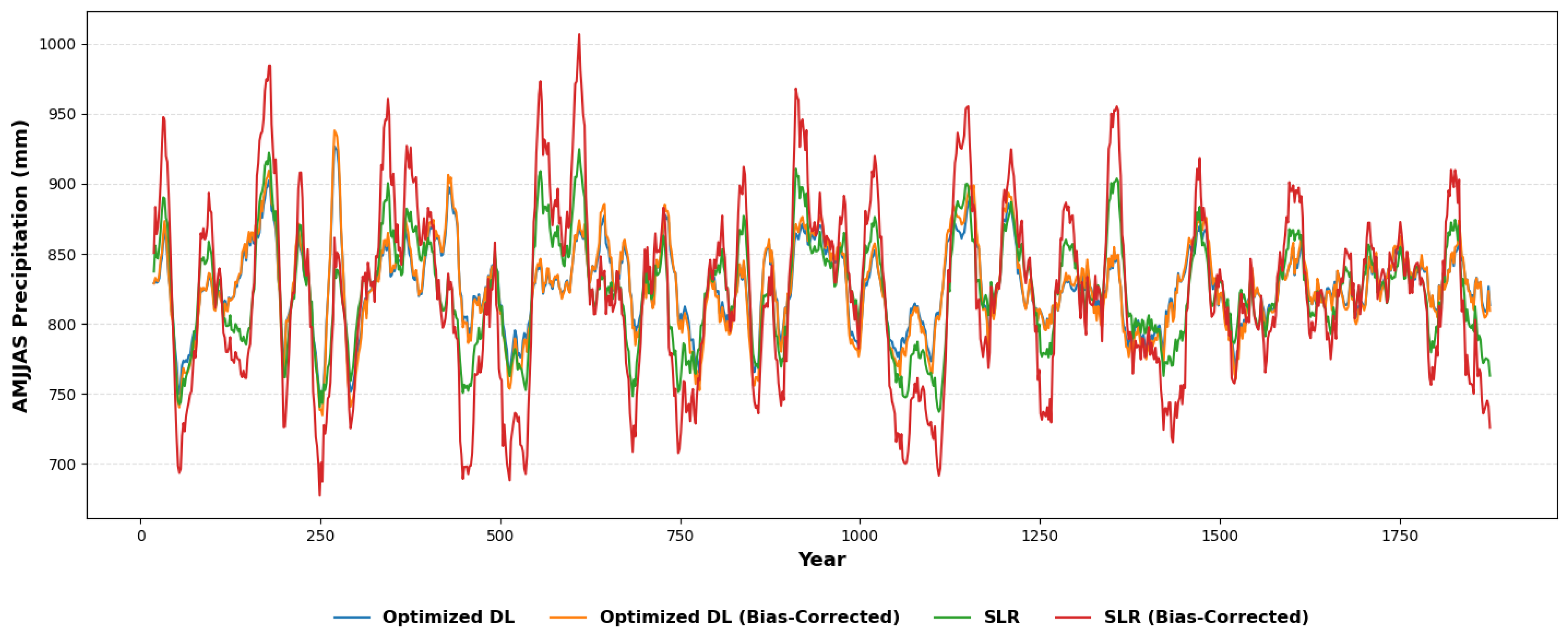
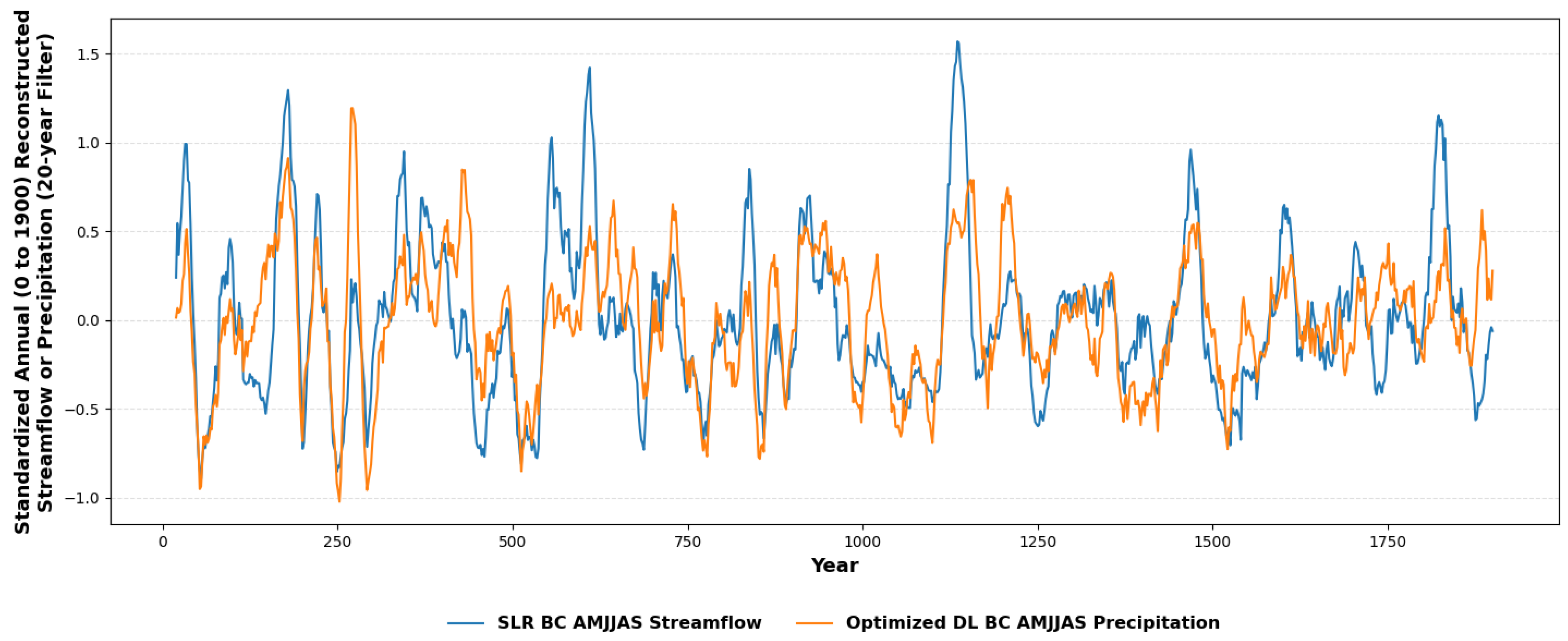
| Optimized Deep Learning (Optimized DL) | 52.207 | 0.852 | 0.891 | 53.632 | 0.844 | 0.922 |
| Stepwise Linear Regression (SLR) | 107.257 | 0.377 | 0.454 | 119.833 | 0.223 | 0.611 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramírez Molina, A.A.; Bezak, N.; Tootle, G.; Wang, C.; Gong, J. Machine-Learning-Based Precipitation Reconstructions: A Study on Slovenia’s Sava River Basin. Hydrology 2023, 10, 207. https://doi.org/10.3390/hydrology10110207
Ramírez Molina AA, Bezak N, Tootle G, Wang C, Gong J. Machine-Learning-Based Precipitation Reconstructions: A Study on Slovenia’s Sava River Basin. Hydrology. 2023; 10(11):207. https://doi.org/10.3390/hydrology10110207
Chicago/Turabian StyleRamírez Molina, Abel Andrés, Nejc Bezak, Glenn Tootle, Chen Wang, and Jiaqi Gong. 2023. "Machine-Learning-Based Precipitation Reconstructions: A Study on Slovenia’s Sava River Basin" Hydrology 10, no. 11: 207. https://doi.org/10.3390/hydrology10110207
APA StyleRamírez Molina, A. A., Bezak, N., Tootle, G., Wang, C., & Gong, J. (2023). Machine-Learning-Based Precipitation Reconstructions: A Study on Slovenia’s Sava River Basin. Hydrology, 10(11), 207. https://doi.org/10.3390/hydrology10110207