
Robust Enhanced Auto-Tuning of PID Controllers for Optimal Quality Control of Cement Raw Mix via Neural Networks

Abstract
1. Introduction
2. Process Description and Control
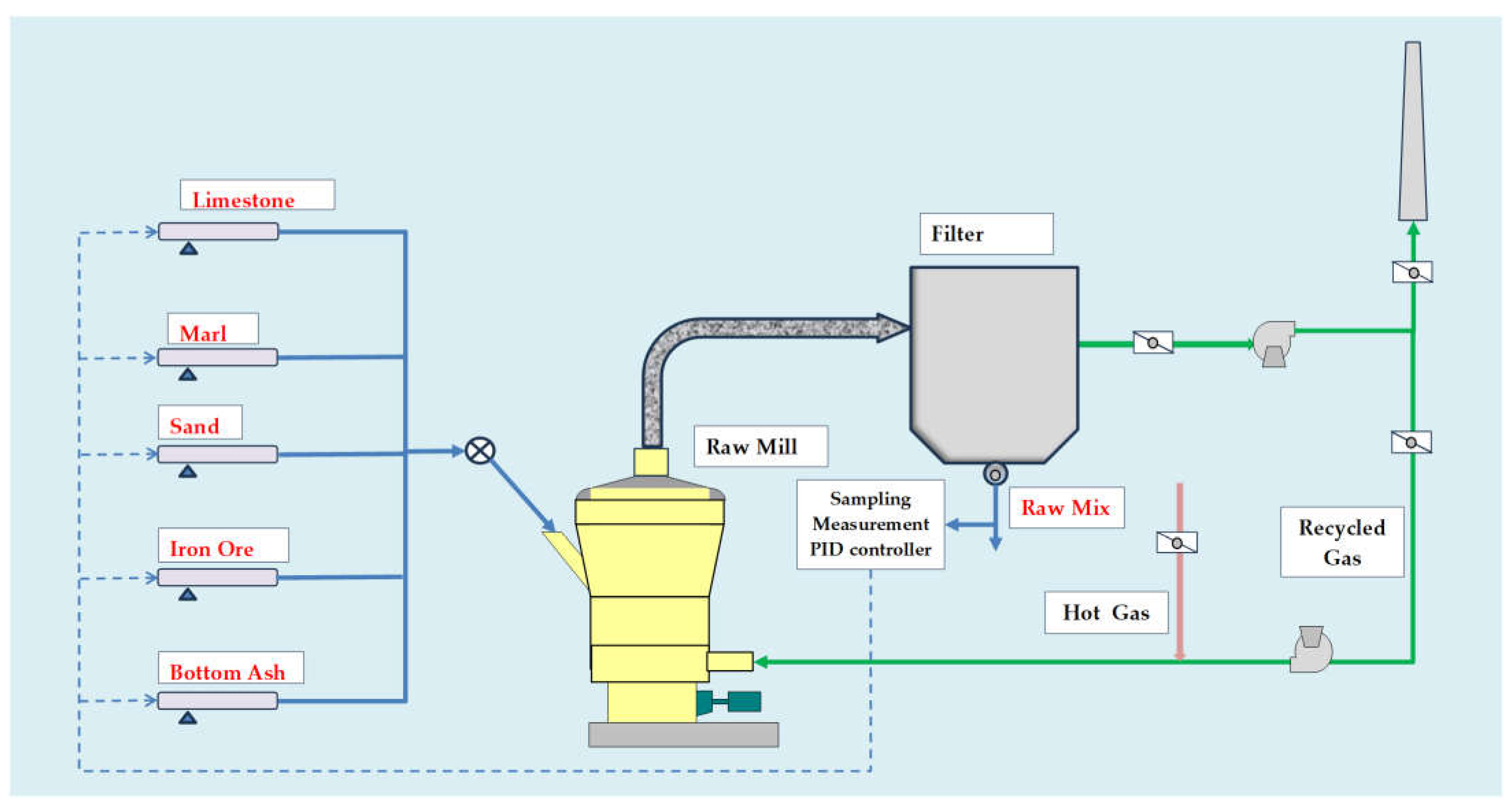
2.1. Process Description
2.2. Process Control and PID Design
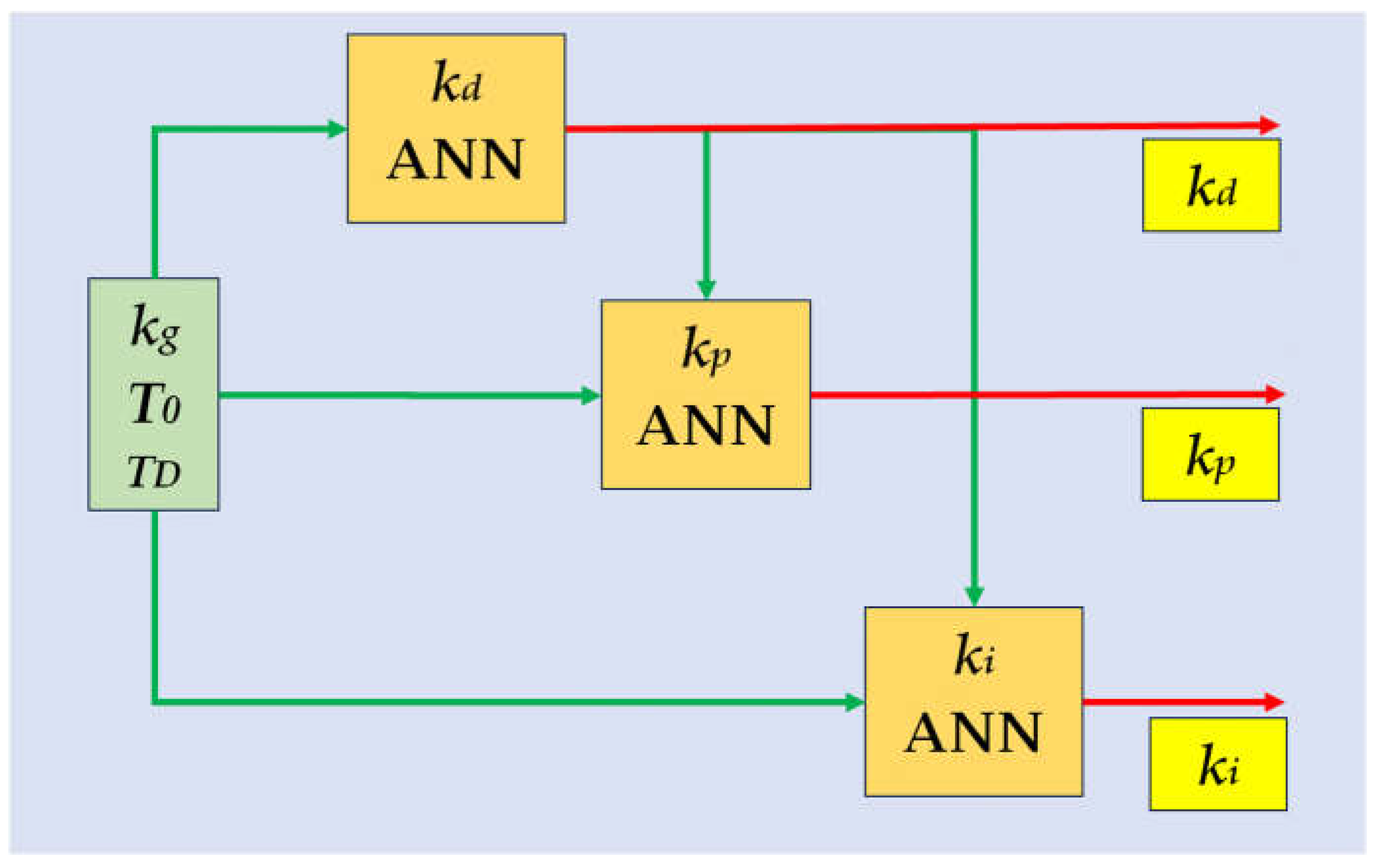
3. PID Auto-Tuner Design Using ANNs
3.1. ANN Design and Structure
- (1)
- A training set and the corresponding test set are selected.
- (2)
- For a specified λ and number of nodes NN, the weights of the ANN are optimized by minimizing the objective function, and both the training and test errors are computed.
- (3)
- Steps (1) and (2) are repeated, averaging each new training and test error with the previous results.
- (4)
- The algorithm iterates through steps (1) to (3) for a total of 1000 training and test sets to ensure that the test error converges to a constant value.
- (5)
- Steps (1) to (4) are performed across a range of λ and NN values to identify the optimal λ and NN that yield the minimum average test error.
3.2. Final Design of the Auto-Tuner
- -
- Firstly, our software retrieves the most recent RM quality data—specifically, the raw meal composition and LSF—for which the RM dynamic parameters have not yet been calculated.
- -
- The dynamic parameters are computed using the algorithm described in Section 3.2 of [8], with significant results being those for which the square root of the adjusted R2 is greater than 0.7.
- -
- The sets of significant dynamic results are divided into consecutive groups of 200 sets, and the size Ns of the remaining most recent group is checked. If Ns < 200, the auto-tuner does not proceed with further action and instead waits for Ns to reach the value 200.
- -
- When Ns becomes equal to 200, the algorithm computes the average values of kg, T0, and TD for the latest group and compares these averages with the respective mean values of the preceding group, which also has Ns = 200, by calculating the absolute difference between them.
- -
- If at least one of the three absolute differences exceeds a tolerance of 0.001, the most recent dynamic parameters are considered significantly different from the previous ones, prompting the algorithm to calculate new PID gains. Otherwise, the differences are deemed insignificant, and the auto-tuner retains the previous PID gains.
- -
- In the event of a significant difference between the latest and the preceding dynamic parameters, the auto-tuner calculates two new sets of PID gains [kp, ki, kd]T for sampling periods Ts = 1 h and Ts = 2 h, using the ANNs described in Section 3.1. The computation employs the optimal number of nodes, NN, and weight decay term, λ, as determined by the algorithm of 3.1. The new gains are transferred to the software regulating raw meal quality, either automatically or manually. All new data are saved in the plant’s quality database.
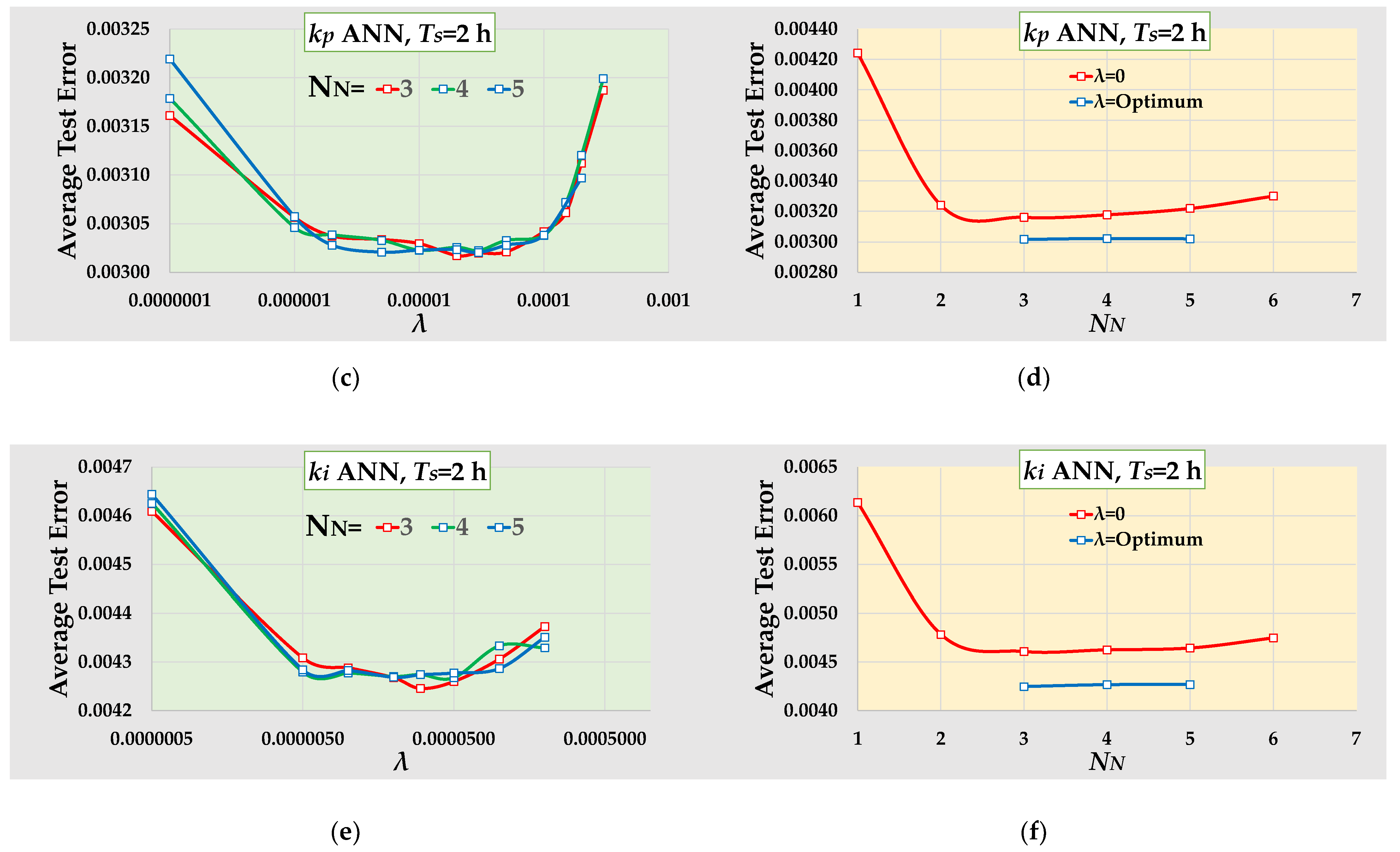
4. Optimization of the ANNs
5. Simulation Studies
5.1. General Description
5.2. Initial Simulations
5.3. Full Simulation
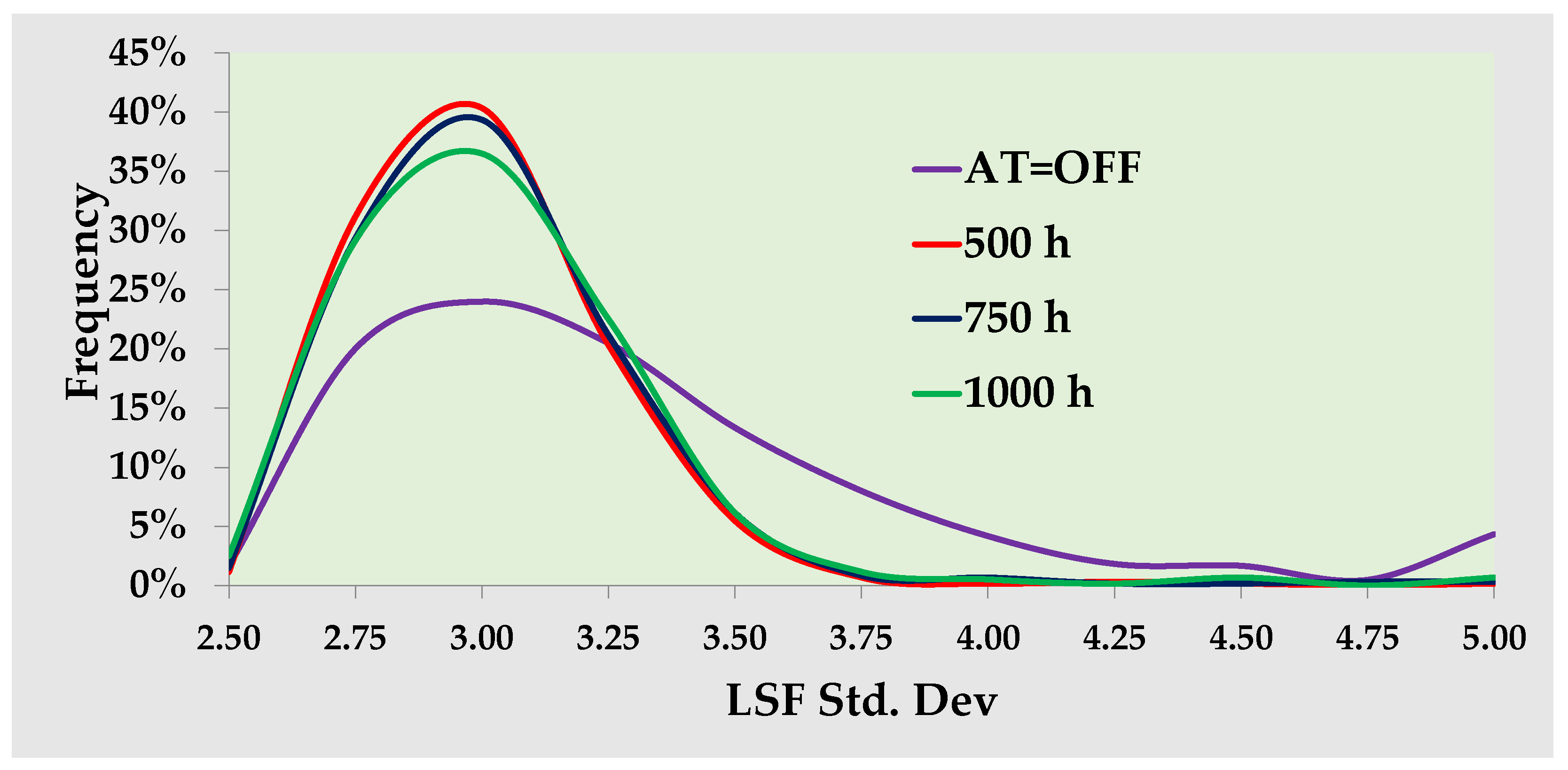
- A total of 20 consecutive datasets (NOp = 20) are used, with TOp = 2000 h and TF = 500 h, 750 h, and 1000 h with the auto-tuner activated, and the same datasets with the auto-tuner deactivated.
- For each consecutive dataset the T0 and TD values are determined using the random generator, such that T0 ∈ [0.3 h, 0.5 h] and TD ∈ [0.3 h, 0.5 h].
- The simulator executes all the steps outlined in Section 5.1 and Section 5.2 for the 20 datasets.
- Afterward, a new group of NOp datasets is selected, and the steps (1) to (4) are repeated.
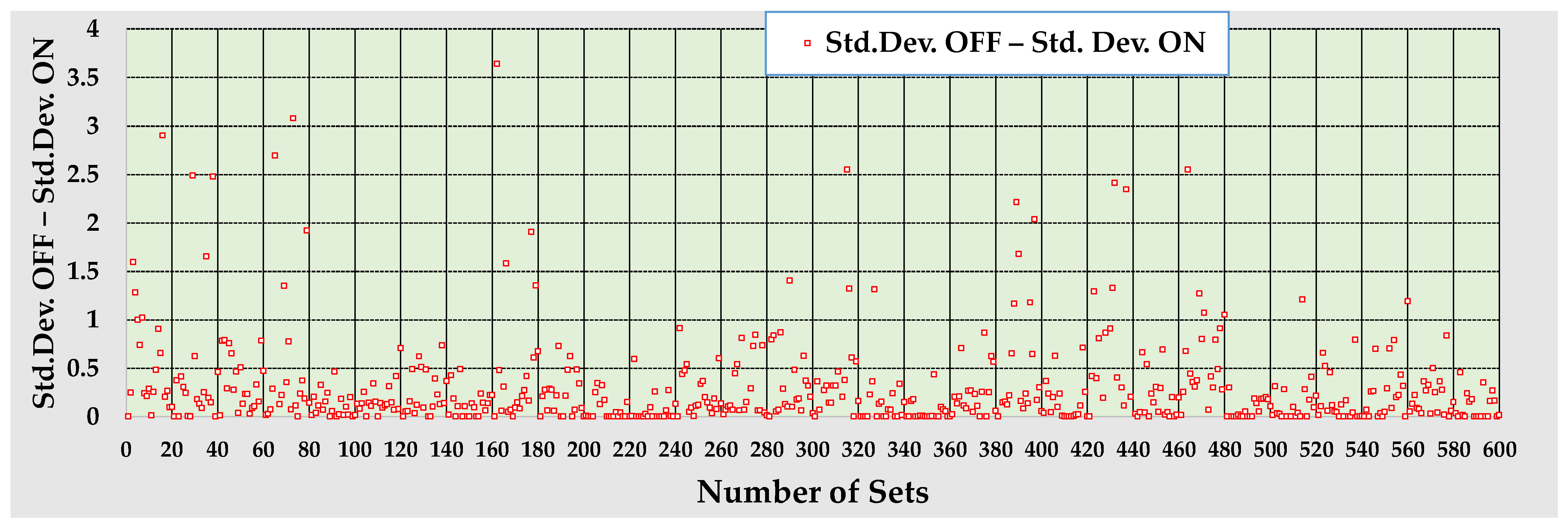
- The procedure continues until a total of 30 groups of NOp datasets are completed. Therefore, the results are based on 600 datasets.
- The nonnegative difference varies from 0 to approximately 3.0. There are groups of 20 datasets where DiffStd remains consistently below 0.5, as well as groups where DiffStd is higher than 0.5 for a non-negligible number of datasets.
- DiffStd is equal to zero for the first dataset of each group and stays around zero for approximately 20% of the datasets, including the initial 30 zeros. The reason that sometimes the constant PID seems to work well is the random generation of the dynamic parameters kg, T0, TD. If randomly occurs that the range of each parameter over the 20 datasets is short and the initial parameters are in the middle of these ranges, then the initial PID can indeed function effectively for all 20 datasets. In such cases, the auto-tuner will also make only slight adjustments to the PID gains. Examples of this behavior can be observed in datasets 341–360 and 481–500. Our auto-tuner design algorithm, as described in Section 3.2, predicts this scenario.
6. Long-Term Operation of the Control System Using the Auto-Tuner
7. Conclusions
- The three developed ANNs correlate each triad of dynamic parameters kg, T0, and TD to their optimum PID gains kp, ki, and kd. Each ANN contains a single hidden layer. The ANN predicting kd has three inputs, and its output serves as an additional input to the ANNs predicting kp and ki. The number of nodes in each ANN requires optimization for both sampling periods, using the minimization of the test error as the criterion. Consequently, the total number of the ANNs to be optimized for the two sampling periods is six. The optimal parameters that minimize the objective function are determined using the Levenberg–Marquardt technique.
- The L2 regularization methodology has proven to be highly effective in preventing overfitting. The value of the weight decay term λ, which requires optimization, significantly impacts the test error. Our algorithm optimizes both the number of nodes and the weight decay term. The average values of adjusted R2 of the training error and R2 of the test error are quite similar, suggesting that the use of L2 regularization is successful in preventing overfitting across all the developed ANNs.
- Our full simulation of the long-term operation of the raw mill, where the LSF is regulated by a PID controller and the auto-tuner is either activated or deactivated, indicates that the standard deviation when the auto-tuner is off is greater than when it is on. The difference between the two standard deviations exceeds 1 in about 8.6% of the datasets. If the PID is poorly tuned due to changes in process dynamics without adjustments to the PID gains, combined with low raw mix volumes in the stock silo, the high standard deviation of the LSF in the kiln feed can lead to instabilities in kiln operation and lower clinker quality. This situation can cause a decreased utilization of alternative fuels and raw materials as a means to address the decline in quality.
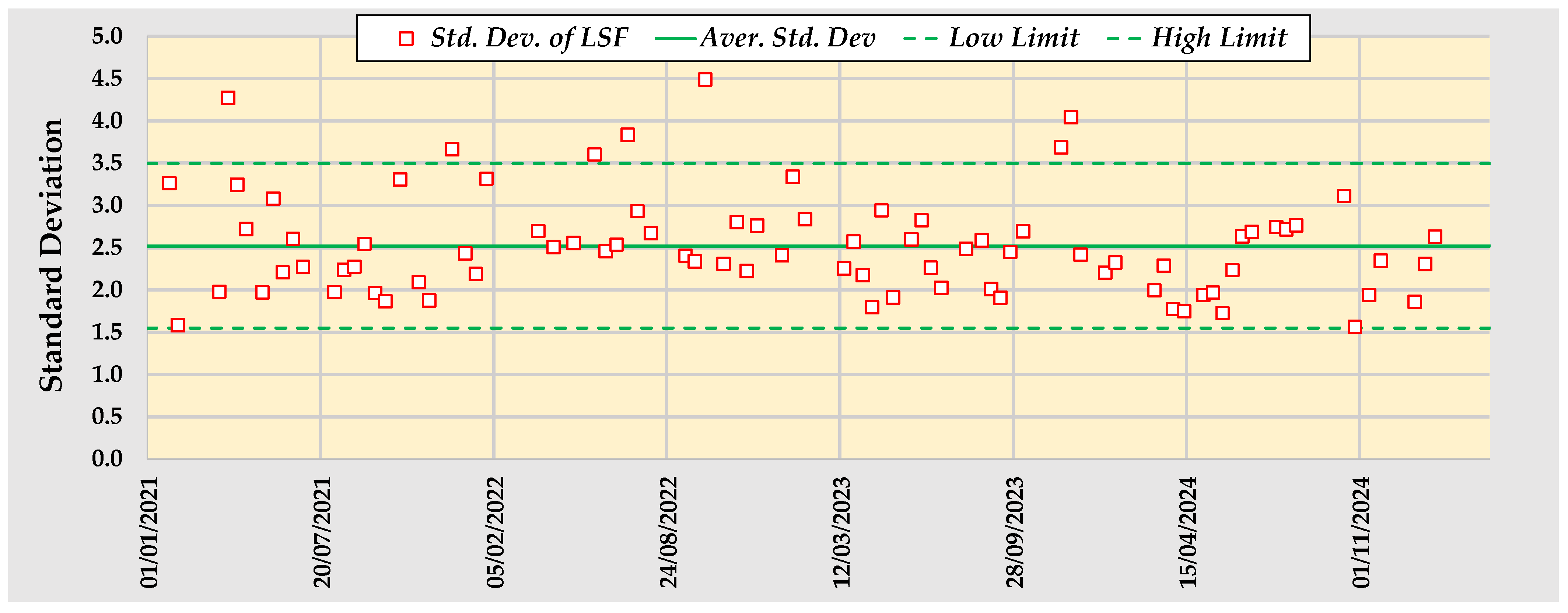
- The long-term industrial operation of our control system using the auto-tuner demonstrates that an average standard deviation of the LSF equal to 2.5 has been achieved, with less than 10% of the result datasets exhibiting a standard deviation higher than 3.5. This indicates a high level of long-term performance for the integrated control technique. Since more than 90% of the standard deviations are less than 3.5, and for a low mixing ratio of the silo equal to 2, the LSF standard deviation in the kiln feed is equal to or less than 1.75, which is very close to the reproducibility of the analysis. The actual results of LSF standard deviation in the kiln feed support this conclusion. Ten out of the thirteen LSF standard deviations from samples collected quarterly are less than or equal to 1.8. This indicates that any disturbance in the raw meal feed practically disappears.
- The utilization of a robust tuning method, such as loop-shaping, in conjunction with a robust auto-tuner for PID gains based on artificial neural networks (ANNs), ensures the successful long-term implementation of an adaptive PID controller for quality control of the raw mix, effectively managing process uncertainties, disturbances, and changes.
- In conclusion, integrating traditional, well-established tools with newer advanced techniques can yield innovative solutions.
Supplementary Materials
Funding
Data Availability Statement
Conflicts of Interest
References
- Kawai, S.; Koike, Y. Real Time Computer Control of Cement Industry. In Real Time Microcomputer Control of Industrial Processes. Microprocessor-Based Systems Engineering; Tzafestas, S.G., Pal, J.K., Eds.; Springer: Dordrecht, The Netherlands, 1990; Volume 5, pp. 435–480. [Google Scholar] [CrossRef]
- Walther, T. Digital transformation of the global cement industry. In Proceedings of the 2018 IEEE-IAS/PCA Cement Industry Conference (IAS/PCA), Nashville, TN, USA, 6–10 May 2018. [Google Scholar] [CrossRef]
- 10 Ways AI Is Being Used by the Cement Industry. 2024. Available online: https://digitaldefynd.com/IQ/ai-in-cement-industry/ (accessed on 11 January 2025).
- Swain, A.K.; Subuthi, B. Computer Control of Cement Raw Mill with an Improved Material Mix Control Scheme. Available online: http://dspace.nitrkl.ac.in/dspace/bitstream/2080/487/1/Computer-1996.pdf (accessed on 14 January 2025).
- Araromi, D.O.; Odewal, S.A.; Hamed, J.O. Neuro-fuzzy modelling of blending process in cement plant. Adv. Sci. Technol. Res. J. 2015, 9, 27–33. [Google Scholar] [CrossRef] [PubMed]
- Tiryaki, A.E.; Kozan, R.; Adar, N.G. Mathematical modeling of a cement raw-material blending process using a neural network. Mater. Technol. 2016, 50, 485–490. Available online: http://mit.imt.si/izvodi/mit164/tiryaki.pdf (accessed on 14 January 2025).
- Zhang, Z.; Nielsen, M.K.; Muralidharan, G.; Hørsholt, S.; Jørrgensen, J.B. Model Predictive Control for Blending Processes in Cement Plants. IFAC-PapersOnLine 2022, 55, 483–488. Available online: https://www.sciencedirect.com/science/article/pii/S2405896322008965 (accessed on 14 January 2025). [CrossRef]
- Tsamatsoulis, D. Robust Adaptive Control System of Variable Sampling Period for Cement Raw Mix Quality Control. ChemEngineering 2024, 8, 113. [Google Scholar] [CrossRef]
- Tsamatsoulis, D.; Zlatev, G. PID parameterization of Cement Kiln Pre-Calciner Based on Simplified Modeling. Available online: https://www.naun.org/main/NAUN/neural/2016/a142016-083.pdf (accessed on 14 January 2025).
- Zhang, J.; Meng, Q.; Yu, H. The Application of Dynamic Matrix Control in the Grate Cooler. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference, Chongqing, China, 25–26 March 2017; pp. 2630–2633. Available online: https://ieeexplore.ieee.org/document/8054501 (accessed on 14 January 2024).
- Seraj, M.; Shooredeli, M.A. Data-Driven Predictor and Soft-Sensor Models of a Cement Grate Cooler Based on Neural Network and Effective Dynamics. In Proceedings of the 2017 Iranian Conference on Electrical Engineering, Tehran, Iran, 2–4 May 2017; pp. 726–731. Available online: https://ieeexplore.ieee.org/document/7985134 (accessed on 14 January 2025).
- Meng, Q.; Wang, Y.; Xu, F.; Shi, X. Control strategy of cement mill based on Bang-Bang and fuzzy PID self-tuning. In Proceedings of the 2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Shenyang, China, 8–12 June 2015; pp. 1977–1981. Available online: https://ieeexplore.ieee.org/document/7288250 (accessed on 14 January 2025).
- Ma, T.; Li, Z.; Liu, J.; Alkhateeb, A.F.; Jahanshahi, H. A novel self-learning fuzzy predictive control method for the cement mill: Simulation and experimental validation. Eng. Appl. Artif. Intell. 2023, 120, 105868. [Google Scholar] [CrossRef]
- Pawuś, D.; Paszkiel, S. Research Towards an Optimal Method of Modeling and Regulating a Cement Mill Using AI Algorithms. In Automation 2024: Advances in Automation, Robotics and Measurement Techniques. Lecture Notes in Networks and Systems; Szewczyk, R., Zieliński, C., Kaliczyńska, M., Bučinskas, V., Eds.; Springer: Cham, Switzerland, 2025; Volume 1219, pp. 3–16. [Google Scholar] [CrossRef]
- Tsamatsoulis, D. Prediction of Cement Compressive Strength by Combining Dynamic Models of Neural Networks. Chem. Biochem. Eng. Q. 2021, 35, 295–318. [Google Scholar] [CrossRef]
- Åström, K.J. Model Uncertainty and Robust Control, Lecture Notes on Iterative Identification and Control Design, Lund University. 2000. Available online: https://www.researchgate.net/publication/228602986_Model_Uncertainty_and_Robust_Control/ (accessed on 14 January 2025).
- Rivas-Echeverría, F.; Ríos-Bolívar, A.; Casales-Echeverría, J. Neural Network-based AutoTuning for PID Controllers. Neural Netw. World 2001, 11, 277–284. Available online: https://www.researchgate.net/publication/242777564_Neural_Network-based_AutoTuning_for_PID_Controllers (accessed on 14 January 2025).
- Åström, K.J.; Hägglund, T. Advanced PID Control; Instrumentation, Systems and Automatic Society: Research Triangle Park, NC, USA, 2006; pp. 112–114, 206–221, 296–297, 414–421. [Google Scholar]
- Vesely, V.; Ilka, A. Gain-scheduled PID controller design. J. Process Control 2013, 23, 1141–1148. [Google Scholar] [CrossRef]
- Pavković, D.; Polak, S.; Zorc, D. PID controller auto-tuning based on process step response and damping optimum criterion. ISA Trans. 2014, 53, 85–96. [Google Scholar] [CrossRef]
- Kim, K.H.; Bae, J.E.; Chu, S.C.; Sung, S.W. Improved Continuous-Cycling Method for PID Autotuning. Processes 2021, 9, 509. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, S.; De Keyser, R.; Ionescu, C.-M. The Application of a New PID Autotuning Method for the Steam/Water Loop in Large Scale Ships. Processes 2020, 8, 196. [Google Scholar] [CrossRef]
- Hoshu, A.A.; Wang, L.; Sattar, A.; Fisher, A. Auto-Tuning of Attitude Control System for Heterogeneous Multirotor UAS. Remote Sens. 2022, 14, 1540. [Google Scholar] [CrossRef]
- Muresan, C.I.; Birs, I.; Ionescu, C.; Dulf, E.H.; De Keyser, R. A Review of Recent Developments in Autotuning Methods for Fractional-Order Controllers. Fractal Fract. 2022, 6, 37. [Google Scholar] [CrossRef]
- Feliu-Batlle, V.; Sotomayor-Moriano, J.; Rivas-Perez, R. Adaptive Smith Predictor Controller Design for Industrial Processes with Time Varying Time Delay. IFAC-PapersOnLine 2024, 58, 37–42. [Google Scholar] [CrossRef]
- Qu, S.; He, T.; Zhu, G. Model-Assisted Online Optimization of Gain-Scheduled PID Control Using NSGA-II Iterative Genetic Algorithm. Appl. Sci. 2023, 13, 6444. [Google Scholar] [CrossRef]
- Berner, J.; Åström, K.J.; Hägglund, T. Towards a New Generation of Relay Autotuners. In Proceedings of the 19th World Congress of the International Federation of Automatic Control, Cape Town, South Africa, 24–29 August 2014; Volume 47, pp. 11288–11293. [Google Scholar] [CrossRef]
- Åström, K.J.; Hägglund, T. Automatic tuning of simple regulators for phase and amplitude margins specifications. In Proceedings of the IFAC Workshop on Adaptive Systems in Control and Signal Processing, San Francisco, CA, USA, 20–22 June 1983; Volume 16, pp. 271–276. [Google Scholar] [CrossRef]
- Pirabakaran, K.; Becerra, V.M. PID autotuning using neural networks and model reference adaptive control. In Proceedings of the 15th IFAC World Congress, Barcelona, Spain, 21–26 July 2002; Volume 35, pp. 451–456. [Google Scholar] [CrossRef]
- D’Emilia, G.; Marra, A.; Natale, E. Use of neural networks for quick and accurate auto-tuning of PID controller. Robot. Comput.-Integr. Manuf. 2007, 23, 170–179. [Google Scholar] [CrossRef]
- Rodríguez-Abreo, O.; Fuentes-Silva, C.; Rodriguez, J. Self-Tuning Neural Network PID with Dynamic Response Control. IEEE Access 2021, 9, 65206–65215. [Google Scholar] [CrossRef]
- Park, D.; Le, T.-L.; Quynh, N.V.; Long, N.K.; Hong, S.K. Online Tuning of PID Controller Using a Multilayer Fuzzy Neural Network Design for Quadcopter Attitude Tracking Control. Available online: https://www.researchgate.net/publication/348567011_Online_Tuning_of_PID_Controller_Using_a_Multilayer_Fuzzy_Neural_Network_Design_for_Quadcopter_Attitude_Tracking_Control (accessed on 17 January 2025).
- Mohamed-Seghir, M.; Krama, A.; Refaat, S.S.; Trabelsi, M.; Abu-Rub, H. Artificial Intelligence-Based Weighting Factor Autotuning for Model Predictive Control of Grid-Tied Packed U-Cell Inverter. Energies 2020, 13, 3107. [Google Scholar] [CrossRef]
- Lakhani, A.I.; Chowdhury, M.A.; Lu, Q. Stability-preserving automatic tuning of PID control with reinforcement learning. Complex Eng. Syst. 2021, 2, 3. [Google Scholar] [CrossRef]
- Lee, F.M. The Chemistry of Cement and Concrete, 3rd ed.; Chemical Publishing Company Inc.: New York, NY, USA, 1971; pp. 164–165. [Google Scholar]
- Chen, Y.; Bhaskaran, T.; Xue, D. Practical Tuning Rule Development for Fractional Order Proportional and Integral Controllers. J. Comput. Nonlinear Dynam. 2008, 3, 021403. [Google Scholar] [CrossRef]
- Romero Perez, J.A.; Balaguer Herrero, P. Extending the AMIGO PID tuning method to MIMO systems. In Proceedings of the 2nd IFAC Conference on Advances in PID Control, Brescia, Italy, 28–30 March 2012; pp. 211–216. [Google Scholar] [CrossRef]
- Bhowate, A.; Deogade, S. Comparison of PID tuning techniques for closed loop controller of dc-dc boost converter. IJAET 2015, 8, 2064–2073. [Google Scholar]
- Soltesz, K.; Cervin, A. When is PID a good choice? IFAC-PapersOnLine 2018, 51, 250–255. [Google Scholar] [CrossRef]
- Yumuk, E.; Copot, C.; Muresan, C.I.; Ionescu, C.M. A Novel Approach to Robust PID Auto-tuner for Overdamped Systems: Case Study on Liquid Level System. Processes 2024, 12, 2825. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks. A Comprehensive Foundation, 2nd ed.; Pearson Prentice Hall: Delhi, India, 2005; p. 24. Available online: https://cdn.preterhuman.net/texts/science_and_technology/artificial_intelligence/Neural%20Networks%20-%20A%20Comprehensive%20Foundation%20-%20Simon%20Haykin.pdf (accessed on 1 February 2025).
- Tsamatsoulis, D.C.; Korologos, C.A.; Tsiftsoglou, D.V. Optimizing the Sulfates Content of Cement Using Neural Networks and Uncertainty Analysis. ChemEngineering 2023, 7, 58. [Google Scholar] [CrossRef]
- Smith, L.N. A Disciplined Approach to Neural Network Hyper-Parameters: Part 1—Learning Rate, Batch Size, Momentum, and Weight Decay. Available online: https://arxiv.org/abs/1803.09820 (accessed on 1 February 2025).
- Nakamura, K.; Hong, B.W. Adaptive weight decay for deep neural networks. IEEE Access 2019, 7, 118857. Available online: https://ieeexplore.ieee.org/document/8811458 (accessed on 14 January 2025). [CrossRef]
- Yadav, A.; Chithaluru, P.; Singh, A.; Joshi, D.; Elkamchouchi, D.H.; Pérez-Oleaga, C.M.; Anand, D. An Enhanced Feed-Forward Back Propagation Levenberg–Marquardt Algorithm for Suspended Sediment Yield Modeling. Water 2022, 14, 3714. [Google Scholar] [CrossRef]
- Hussain, M.T.; Sarwar, A.; Tariq, M.; Urooj, S.; BaQais, A.; Hossain, M.A. An Evaluation of ANN Algorithm Performance for MPPT Energy Harvesting in Solar PV Systems. Sustainability 2023, 15, 11144. [Google Scholar] [CrossRef]
- Balkan, D. Delamination Prediction in Layered Composites Using Optimized ANN Algorithms: A Comparative Analysis. Symmetry 2025, 17, 91. [Google Scholar] [CrossRef]
- ISO/TC 69; Control Chart—Part 2: Shewhart Control Charts, 1st ed. ISO: Geneva, Switzerland, 2013; pp. 8–9.
- Schoonhoven, Μ.; Does, R.J.M.M. A Robust Standard Deviation Control Chart. Technometrics 2012, 54, 73. [Google Scholar] [CrossRef]
- EN 196-2:2013; Methods of Testing Cement—Part 2: Chemical Analysis of Cement; CEN/TC 51. CEN Management Centre: Brussels, Belgium, 2013.
- Joint Committee for Guides in Metrology/Working Group 1. (JCGM/WG 1) Evaluation of Measurement Data—Guide to the Expression of Uncertainty in Measurement. pp. 18–23. Available online: https://www.bipm.org/documents/20126/2071204/JCGM_100_2008_E.pdf/cb0ef43f-baa5-11cf-3f85-4dcd86f77bd6 (accessed on 1 March 2025).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ANN | Ts, h | NN | λ | Average of Adjusted R2 | Std. Dev. of Adjusted R2 | Average of R2 | Std. Dev. of R2 |
|---|---|---|---|---|---|---|---|
| kd | 1 | 6 | 2·10−6 | 0.9520 | 2.14·10−3 | 0.9482 | 9.34·10−3 |
| kd | 2 | 4 | 1·10−6 | 0.9597 | 1.98·10−3 | 0.9593 | 7.56·10−3 |
| kp | 1 | 6 | 3·10−6 | 0.9695 | 1.48·10−3 | 0.9657 | 7.28·10−3 |
| kp | 2 | 3 | 2·10−5 | 0.9359 | 2.94·10−3 | 0.9351 | 1.18·10−3 |
| ki | 1 | 6 | 1·10−5 | 0.9617 | 1.77·10−3 | 0.9563 | 8.84·10−3 |
| ki | 2 | 3 | 3·10−5 | 0.8036 | 8.19·10−3 | 0.8014 | 3.34·10−3 |
| Combination | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| %CaO Limestone | 54.0 | 54.5 | 55.0 | 55.0 | 55.0 | 55.0 | 55.0 | 55.0 | 55.0 | 55.0 |
| %CaO Marl | 19.3 | 18.0 | 17.4 | 16.2 | 15.0 | 14.2 | 13.3 | 12.3 | 11.2 | 9.0 |
| kg | 3.95 | 4.10 | 4.17 | 4.30 | 4.42 | 4.51 | 4.60 | 4.71 | 4.82 | 5.05 |
| Series 1 (S1) | Series 2 (S2) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| iAT | %CaO Lim. | %CaO Marl | kg | T0 | TD | %CaO Lim. | %CaO Marl | kg | T0 | TD |
| 1 | 54.0 | 19.3 | 3.95 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.30 |
| 2 | 54.5 | 18 | 4.1 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.31 |
| 3 | 55 | 17.4 | 4.17 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.32 |
| 4 | 55 | 16.2 | 4.3 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.33 |
| 5 | 55 | 15 | 4.42 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.34 |
| 6 | 55 | 14.2 | 4.51 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.35 |
| 7 | 55 | 13.3 | 4.6 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.36 |
| 8 | 55 | 12.3 | 4.71 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.37 |
| 9 | 55 | 11.2 | 4.82 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.38 |
| 10 | 55 | 9 | 5.05 | 0.30 | 0.30 | 55 | 14.2 | 4.51 | 0.30 | 0.39 |
| DiffStd ≥ | 0.2 | 0.35 | 0.5 | 0.75 | 1.0 | 1.25 | 1.5 |
|---|---|---|---|---|---|---|---|
| % of datasets | 43.8 | 27.2 | 19.2 | 12.6 | 8.6 | 7.6 | 5.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsamatsoulis, D. Robust Enhanced Auto-Tuning of PID Controllers for Optimal Quality Control of Cement Raw Mix via Neural Networks. ChemEngineering 2025, 9, 52. https://doi.org/10.3390/chemengineering9030052
Tsamatsoulis D. Robust Enhanced Auto-Tuning of PID Controllers for Optimal Quality Control of Cement Raw Mix via Neural Networks. ChemEngineering. 2025; 9(3):52. https://doi.org/10.3390/chemengineering9030052
Chicago/Turabian StyleTsamatsoulis, Dimitris. 2025. "Robust Enhanced Auto-Tuning of PID Controllers for Optimal Quality Control of Cement Raw Mix via Neural Networks" ChemEngineering 9, no. 3: 52. https://doi.org/10.3390/chemengineering9030052
APA StyleTsamatsoulis, D. (2025). Robust Enhanced Auto-Tuning of PID Controllers for Optimal Quality Control of Cement Raw Mix via Neural Networks. ChemEngineering, 9(3), 52. https://doi.org/10.3390/chemengineering9030052