1. Introduction
The process of object identification through images can be performed using both video and static images, which, when applied correctly, becomes highly relevant in certain processes. Currently, object identification algorithms are being studied in various fields [
1]. Examples include visual inspection systems designed to identify defective objects in manufacturing processes [
2], image classification tasks that extract specific patterns from images and categorize them [
3], security systems featuring facial recognition, movement detection, and the identification of individuals through surveillance cameras [
4], and robotics applications, such as mobile robots identifying routes and objects or autonomous vehicles detecting signs, pedestrians, and other obstacles [
5].
Many visual inspection tasks are repetitive, particularly when analyzing large volumes of data. For example, manually identifying objects across numerous photographs without algorithmic assistance can be both exhausting and imprecise. The development and application of object detection algorithms aim to optimize time and refine these processes, thus producing more accurate and satisfactory results [
6]. Detecting patterns in images through advanced technology has become essential for precisely identifying flaws in various scenarios. This technology improves execution, reduces the demand for human labor, and improves overall accuracy.
This study focuses on tree detection, with the goal of simplifying the identification of vegetation that could obstruct access to structures, such as dams, in mining companies. In environments with abundant vegetation, it is common for trees to block pathways, obscure signs, or interfere with sensors and cameras, complicating technical inspections. Traditionally, employees must manually identify these obstructions, photograph them, and report anomalies, a process that can be time-consuming and prone to errors. By automating tree detection using algorithms, this study aims to reduce human effort, accelerate the process, and improve accuracy in identifying obstructions.
Detection algorithms can be broadly categorized into traditional methods and deep learning-based approaches. Traditional algorithms include SIFT, a descriptor for local features, HOG, an effective extractor of unique features, and DPM, as highlighted in [
7]. In contrast, machine learning-based methods, such as R-CNN, SPPNet, Faster R-CNN, SSD, and YOLO (including versions YOLOv1 through YOLOv5 and YOLO-NAS), have gained prominence for their superior accuracy and speed in object detection tasks [
7].
This study builds on the work of [
8], which serves as the primary methodological reference. However, the current research introduces a custom image dataset specific to tree detection. While [
8] primarily focused on hyperparameter tuning to optimize detection, this study extends the methodology by incorporating different optimizers, such as SGD, Adam, and AdamW, enhancing the models’ adaptability and precision. Additionally, a comparative analysis using YOLOv5, YOLOv8, and YOLOv11 was conducted to further improve system performance under varying conditions. These advancements resulted in a more effective and robust system, offering significant progress compared to the referenced study.
The datasets for this study were created using Roboflow [
9], a web-based tool that allows users to select desired images and generate corresponding object annotation files directly in the browser. These annotations were then used for model training, enabling the development of accurate tree detection systems.
To contextualize the contributions of this study, recent works utilizing YOLO-based techniques for tree detection or segmentation were analyzed, highlighting similarities and differences in relation to the proposed approach. In [
10], YOLOv4 was improved for the detection of bayberry trees in drone images, achieving an accuracy of 97.78% and a recall of 98.16% by integrating techniques such as the Leaky ReLU activation function and the DIoU NMS method, demonstrating the effectiveness of this approach for the rapid counting of trees in orchards. Similarly, ref. [
11] used YOLOv5 to identify date palm trees in plantations in the Middle East, reporting a mean average precision (mAP) of 92. 34% and highlighting the robustness of the model in handling overlapping environments and sparse distributions. Finally, ref. [
12] explored the classification of tree species in transmission line corridors using YOLOv7, incorporating specific adjustments such as a weighted loss function and attention mechanisms to enhance segmentation performance in complex environments.
Furthermore, additional studies have employed YOLO-based techniques in challenging environments, emphasizing their applicability to forestry and ecological monitoring. For example, ref. [
13] used YOLOv5 to detect arboreal individuals in the Amazon rainforest using UAV imagery, achieving satisfactory classification results. However, they identified the need for more diverse training data to improve precision, highlighting challenges specific to dense and biodiverse forest ecosystems. Similarly, ref. [
14] used YOLOv7 for tree semantic segmentation, integrating weighted loss functions and attention mechanisms to improve segmentation accuracy in complex environments. Their results demonstrated the superiority of YOLOv7 in detection speed and segmentation performance compared to traditional methods, providing an effective solution to tree segmentation tasks in various settings.
In comparison, the present study differentiates itself by systematically optimizing hyperparameters, such as learning rate and momentum, and employing multiple optimizers, including SGD, Adam, and AdamW, with YOLOv5, YOLOv8, and YOLOv11. As a result, precision metrics of 97.3% for SGD, 100% for Adam, and 96.8% for AdamW were achieved on YOLOv8, while YOLOv11 attained 100% for SGD, 97.6% for Adam, and 96.8% for AdamW. For the recall metric, Adam achieved 88. 2% in YOLOv5, 91. 5% in AdamW and YOLOv8, and SGD reached 89. 4% in YOLOv11. Furthermore, mAP metrics stood out, with YOLOv11 on SGD achieving 95.2% and AdamW on YOLOv8 reaching 95.6%. These results demonstrate the effectiveness of the proposed approach in achieving precise and adaptable detection on a custom tree dataset, offering distinct advancements to the field and complementing the methodologies described in the analyzed studies.
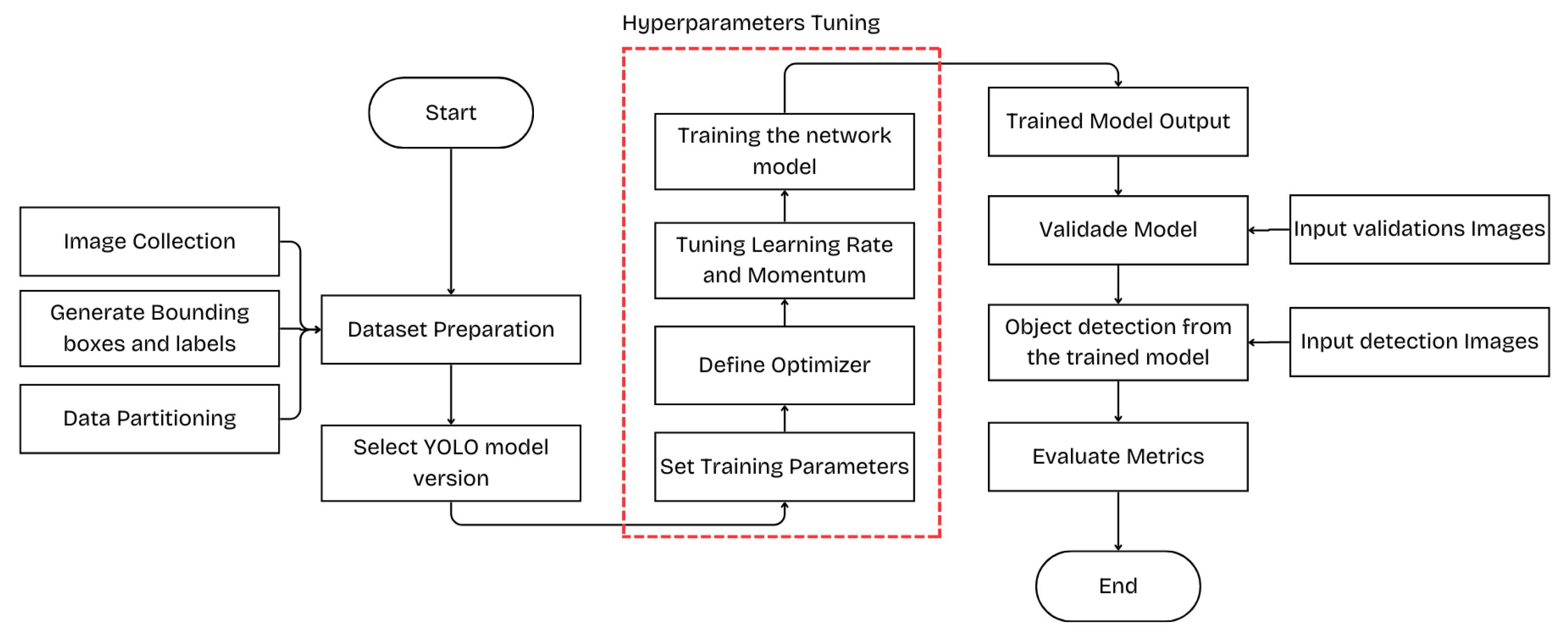
The first section of this article describes the concepts of architecture and the operation of the models used in the study. It also highlights the commonalities between YOLOv5, YOLOv8, and YOLOv11, detailing the evolution across these versions. Additionally, the section provides an overview of the hyperparameters and optimizers, emphasizing their role in optimizing the models used in this research. In the methodology section, the step-by-step process for extracting results is outlined, including key elements such as dataset creation, model training, model validation, and object detection using the trained models. Finally, the results section presents a comparison of the different simulation scenarios, allowing for an accurate assessment of the optimizations and adjustments applied during the study.
4. Results and Discussion
After the training carried out, important metrics were obtained to evaluate the results of the model obtained.
Among the metrics extracted, precision is observed, which is equivalent to the measurement of the proportion of positive examples correctly identified in relation to the sum of true positives and false positives. In other words, an accuracy of 1 indicates that all examples identified as positive by the model are really positive; therefore, there are no false positives. A precision of 0 represents that all examples identified as positive by the model are negative; that is, they are all false positives.
The recall graph evaluates the proportion of positive examples that were correctly identified by the model in relation to the total number of positive examples in the data set. Thus, a recall of 1 means that the model correctly identified all positive examples, with no false negatives. On the other hand, a recall of 0 represents that the model was unable to identify any positive examples, with only false negatives.
Thus, with the precision and recall values, it becomes possible to calculate the average precision, the mAP (mean average precision). As presented in [
24], the mAP, precision (P) and recall (R) are initially calculated:
where:
TP (true positive) represents the number of samples whose labels are positive, meaning the true predictions are positive;
FP (false positive) indicates the number of samples whose labels are negative, meaning the real predictions are positive;
FN (false negative) represents the number of samples whose labels are positive, meaning the real predictions are negative (not detected).
Therefore, the mAP represents the average of different APs, where AP represents the area under the PR curve. The mAP is calculated as follows:
where K represents the number of categories, R is recall, and P is precision.
The F1 score is a widely used metric in the evaluation of object detection models, particularly for adjusting the balance between precision and recall. Precision is related to the model’s ability to correctly identify objects present in an image, while recall is associated with the model’s ability to detect all objects, including those that may be more difficult to identify. However, there is a trade-off between these two metrics, where an increase in precision typically results in a decrease in recall, and vice versa. The F1 score, which represents the harmonic mean between precision and recall, is an effective metric for evaluating the performance of object detection models, as it takes into account both precision and recall in a balanced way [
8,
25,
26].
This mAP value is represented over a specific range of confidence values. That is, the detection is considered correct if the model confidence is equal to or greater than the mAP value. In this case, YOLOv5, YOLOv8, and YOLOv11 provide two types of data and graphs: one with a confidence interval greater than 0.5, and another with values ranging between 0.5 and 0.95
Next, the values obtained after validating the trained model will be demonstrated, consisting of precision values, recall, mAP50, mAP50-95. This is carried out, initially for YOLOv5 and later for YOLOv8 and YOLOv11, using an image bank composed of 211 images, created specifically by the author in this study.
The different training scenarios can be seen in
Table 3 and
Table 4. Thus, for each table, the highest values for each extracted metric have been highlighted. It is worth mentioning that the first case in each table relates to the standard values brought by the YOLOv5 algorithm, with values of 0.01 and 0.937, for the learning rate and momentum, respectively.
As shown in
Table 3, for example, it is noted that when using the SGD optimizer with YOLOv5, the configuration that achieved the highest precison and recall values for the model was obtained by adjusting the hyperparameters with a learning rate of 0.001 and a momentum of 0.999, producing values of 0.864 and 0.872, respectively. This indicated an improvement in performance in terms of correctly identifying positive examples, thereby reducing the false positive rate in the results.
Meanwhile, the F1 score values calculated for the different configurations show that although variations in the learning rate and momentum significantly impact the model’s performance, the F1 score provides a comprehensive view of overall effectiveness, considering both precision and recall. In the case of a configuration with a learning rate of 0.001 and momentum of 0.999, the F1 score of 0.868 reflects a good balance between precision and recall, indicating that the model was able to maintain a solid equilibrium between true positives and the identification of all relevant instances.
Table 4 presents the scenario with the Adam optimizer, where an improvement in the recall (0.882) and mAP50-95 (0.646) metrics was observed when using hyperparameters with values of 0.001 and 0.9. The best precision scenario, 0.97, was achieved by adjusting the learning rate and momentum parameters to 0.0001 and 0.999, respectively. Therefore, it can be concluded that hyperparameter adjustments, in these scenarios, lead to improvements in both precision and confidence intervals in image detection, as evidenced by the increase in mAP, which reached 0.646 for mAP50-95 and 0.920 for mAP50.
The hyperparameter adjustment, lr = 0.0001 and m = 0.999, also resulted in an F1 score of 0.826. This configuration stood out for its balance between precision (0.970) and recall (0.725), reflecting robust and optimized performance, indicating a significant improvement in results, and showing that a lower learning rate contributed to higher precision in training.
Finally, when using the AdamW optimizer, improvements were observed by adjusting the parameters to 0.001 and 0.9. In this scenario, the model demonstrated better precision (0.916) and a higher mAP rate (0.916 and 0.657), as presented in
Table 5. In this way, the best result presented by the YOLOv5 model in terms of mAP50-95 stands out, representing the scenario with the highest confidence interval in detection, where its value reached 0.657.
In this table, the best F1 score values are also observed with the combination of learning rate = 0.001 and momentum = 0.9, with an F1 score of 0.888. This value stands out not only for its superior precision and recall but also for providing a significant gain compared to other configurations, reflecting a good balance between the learning rate and momentum. The variation in momentum, especially for higher values like 0.99 and 0.999, did not bring considerable improvements, suggesting that a more balanced choice of 0.9 is more effective.
As shown in
Table 6, the use of YOLOv8 with the SGD optimizer and the variation of the hyperparameter with the selected values is evident. In this context, the value that brought the highest precision (0.973) to the model was achieved by adjusting the hyperparameters to have a learning rate of 0.001 and a momentum of 0.9.
Another important aspect to highlight in this scenario is that a learning rate of 0.0001 and a momentum of 0.999 were associated with the highest average mAP (0.936), indicating a greater number of cases where object detection had a confidence rate above 50%. Furthermore, using hyperparameter values of 0.001 and 0.999, the best result was obtained for the confidence interval between 50% and 95% in mean mAP (0.693).
In the case of the SGD optimizer and YOLOv8, the best F1 score value was achieved with a learning rate = 0.0001 and momentum = 0.99, with an F1 score of 0.908. This value is remarkable because it reflects an excellent balance between precision and recall, with an impressive recovery for higher momentum values. Although the model with learning rate = 0.001 and momentum = 0.9 achieved higher precision (0.973), its performance in recall and F1 score of 0.878 was not surpassed. The improvement in F1 score across the different learning rate combinations also emphasizes the importance of optimally adjusted hyperparameters.
The training results using the Adam optimizer and YOLOv8 can be seen in
Table 7, and they demonstrate that, out of all the configurations, this one achieved the best result in terms of precision. With a precision value of 1.00 for a learning rate of 0.001 and momentum of 0.99, it indicates that all examples identified as positive by the model are indeed positive. Therefore, there are no false positives in this case.
Additionally, another notable scenario used values of learning rate = 0.0001 and momentum = 0.9, which led to an improvement in results related to recall (0.893) and an average mAP of 0.931 and 0.697.
In the table with Adam and YOLOv8, the best performance was also achieved for the F1 score with a learning rate = 0.0001 and momentum = 0.9, reaching a value of the F1 score of 0.924. This value stood out due to the optimized balance between precision (0.902) and recall (0.882), providing an excellent combination of object detection capability and minimization of false negatives. The significant improvement in F1 score with this configuration reflects a considerable gain compared to other hyperparameter combinations. The choice of a lower learning rate with momentum = 0.9 appears to be one of the main contributors to this strong performance. The high precision value, compared to other momentum combinations, further highlights the model’s ability to correctly classify objects.
The results in
Table 8 demonstrated an improvement when using the parameters 0.001 and 0.9 for the learning rate and momentum. In this case, the best scenario for recall (0.915) is highlighted, where the model correctly identified a larger number of positive examples, resulting in fewer false negatives. The scenario with the best mAP index (0.956) was also achieved using the AdamW optimizer, but with learning rate values of 0.0001 and momentum values of 0.9. For precision (0.968), the improvement was notable when using learning rate = 0.001 and momentum = 0.999.
The highest F1 score was recorded with learning rate = 0.0001 and momentum = 0.9, with an F1 score of 0.892. The improvement in F1 score is significant compared to the other hyperparameters, especially considering that the model with learning rate = 0.0001 and momentum = 0.999 achieved only a slightly lower performance (0.889). The increase in F1 score when using momentum = 0.9 instead of higher values, such as 0.99 and 0.999, suggests that more subtle adjustments to this parameter can lead to substantial improvements. The improvement in F1 score reflects not only an increase in precision but also a significant recovery in terms of recall, resulting in a very efficient overall combination.
Table 9 presents an analysis of the impact of hyperparameter adjustments during the training of the YOLOv11 model using the SGD optimizer. Among the configurations evaluated, the combination of a learning rate of 0.001 and a momentum of 0.9 achieved the highest performance in terms of precision (1.000) and F1 score (0.926). However, in terms of the average mAP50 and mAP50-95 metrics, the configuration with a learning rate of 0.0001 and a momentum of 0.999 proved to be more effective (0.952 and 0.689). These results highlight that different objectives can be achieved through specific hyperparameter adjustments, emphasizing the importance of careful calibration to optimize the model’s overall performance according to the training priorities.
Table 10 presents the hyperparameter adjustments using the Adam optimizer, highlighting significant improvements in accuracy across all simulated scenarios. Notably, the case where the learning rate was adjusted to 0.001 achieved an accuracy of 0.976 and a balance between precision and recall, as demonstrated by the F1 score of 0.880. Additionally, by adjusting the hyperparameters to a learning rate of 0.0001 and momentum of 0.999, the trained model showed remarkable evolution in terms of recall (0.863), mAP50 (0.926), and mAP50-90 (0.684).
In the case of the AdamW optimizer applied to the YOLOv11 model, as indicated in
Table 11, significant advancements in the evaluated metrics were observed. The most prominent scenario occurred when the learning rate was set to 0.001 and momentum to 0.9, where the model achieved an accuracy of 0.968, recall of 0.843, mAP50 of 0.930, and F1 score of 0.901. It is worth noting that in the other analyzed scenarios, improvements were also observed in all metrics, with consistently higher values than the standard benchmarks. In particular, the accuracies and mAP50 indices exceeded 0.9 in most cases of hyperparameter adjustment.
Next, we observe the evolution of the mAP indices throughout the model iterations, for each hyperparameter adjustment performed with each optimizer and for YOLOv5, YOLOv8, and YOLOv11 models.
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16 show the evolution of this metric, where each line in the graph represents a combination of hyperparameters composed of a learning rate (lr) and momentum (m). Furthermore, it is worth highlighting that each figure corresponds to an optimizer used, i.e., SGD, Adam, or AdamW for a given model, be it YOLOv5, YOLOv8, or YOLOv11.
In
Figure 8, it is shown that the best case for an mAP:50 effectively occurred when using the default value of lr = 0.01 and m = 0.937. It is also observed that some cases maintained behavior very close to the standard, without significant gains, while others had a decline in performance, bringing values below the standard.
When using the Adam optimizer in conjunction with YOLOv5, positive gains were obtained when adjusting the hyperparameters to lr = 0.001 and m = 0.9. As shown in
Figure 9, the curve that represents the model’s behavior, with these values converging to its value far more rapidly. It is also observed that around the time 60, the curve already becomes more constant, meaning that there are no longer significant improvements in the validation metric for a specified number of consecutive epochs. With the standard values, the curve takes longer to converge, occurring only from the 90s onwards, proving a gain in performance and speed when reaching these values.
Similarly, an improvement is observed when reaching the mAP metrics in
Figure 10, through faster convergence to its final value. In this scenario, the best mAP value also stands out for lr = 0.001 and m = 0.9. Another positive result is for cases in which lr = 0.001 and momentum vary with values of 0.99 and 0.999, as in these cases, the values were also reached more quickly compared to the standard.
These same scenarios were also replicated in YOLOv8, as represented in
Figure 11,
Figure 12 and
Figure 13, in which we have the result of the behavior when generating the mAP50 metrics.
For the SGD, the hyperparameters that best generated an average mAP50 were the values of lr = 0.0001 and momentum = 0.999. In addition to being the best value scenario, it is a quick approximation of the final value. From the 60th epoch onwards, a value closer to the end was already obtained, unlike the standard case, which presented a lower performance characterized by large variations in its mAP value until approximately the 80th epoch. All other scenarios with different hyperparameter values had a good result, with similar behavior between them and a close average value, with the exception of the case where lr = 0.0001 and momentum = 0.9, which performed poorly.
Figure 11 exemplifies these results.
When using Adam as an optimizer for YOLOv8, the case that stood out the most was using hyperparameters lr = 0.0001 and momentum = 0.9, in which it presented the highest value of mAP50. At this stage, good behavior stands out for all curves referring to lr = 0.0001. Even with momentum 0.9, 0.99 or 0.99, the model converged to a good mAP value of close to 0.900. An advantage observed when using momentum = 0.999 was a case of early stopping, in which around the 80th epoch, the model had already stabilized without presenting significant changes in the metric values, thus ending the simulation early. This reinforces a performance gain in this case (
Figure 12).
For the AdamW optimizer applied to YOLOv8, the worst performance case was obtained with the default values, proving the gain when adjusting the hyperparameters. For the best case, we have lr = 0.0001 and m = 0.9. A peculiarity of YOLOv8 is the early stopping, which can be seen in the following graph, as from the 80th iteration executed (epoch) onwards, there were no significant gains in improving metrics. Therefore, the model automatically terminates the process. In this way, you obtain a much faster result, as you have identified that it would no longer be necessary to carry out further iterations, as you have reached your best value. Also noteworthy is the behavior of other values, which, in turn, converge quickly, being faster than the standard case (
Figure 13).
Regarding the evolution of the mAP50 metric using SGD and YOLOv11, as illustrated in
Figure 14, a consistent improvement in model performance was observed when applying the combination of a learning rate of 0.0001 and a momentum of 0.999. This configuration resulted in higher mAP50 values and exhibited a faster convergence to the maximum value, highlighting the effectiveness of hyperparameter adjustments. In contrast, the default configuration, with a learning rate of 0.01 and a momentum of 0.973, showed frequent oscillations, a longer convergence time, and lower values compared to the other configurations.
Regarding the evolution of mAP50 when using the Adam optimizer and the YOLOv11 model, as illustrated in
Figure 15, it is observed that hyperparameter adjustments resulted in significant improvements. All curves reach higher values and converge more quickly compared to the standard settings (lr = 0.001 and m = 0.937). The best scenarios are highlighted, where the mAP50 metric exceeded 0.9 when using combinations of lr and momentum such as 0.001 and 0.99, 0.0001 and 0.99, and 0.0001 and 0.999. These results demonstrate that lower learning rate values and higher momentum values yield better performances for this model.
Finally,
Figure 16 shows the evolution of mAP50 for the AdamW optimizer applied to the YOLOv1 model. This case also highlights the model’s improvement with hyperparameter adjustments, as once again, the curves corresponding to the adjusted learning rate and momentum values outperform the standard curve.
5. Conclusions
This study implemented improvements in the performance of YOLO models in tree detection through the optimization of hyperparameters combined with the SGD, Adam, and AdamW optimizers. When comparing the different scenarios, the adjustments to these parameters actually brought improvements in relation to precision, recall, F1 score, and average mAP.
Regarding YOlOv5, when using AdamW together with learning rate = 0.001 and momentum, it resulted in the highest mAP index, with values of 0.916 for mAP50 and 0.657 for mAP50-95, in the general context. We also noted gains in precision and recall for all simulated cases, in addition to the improvement in the speed with which the mAP graphs converge to the metric value, as presented in the discussion.
In the YOLOv8 model, improvements were observed across all metrics, with emphasis on the case where the Adam optimizer was used with a learning rate of 0.0001 and momentum of 0.9, achieving precision of 95.8%, recall of 89.3%, mAP50 of 93.31%, mAP50:95 of 69.7%, and an F1 score of 92.4%. Additionally, AdamW demonstrated effectiveness with configurations of learning rate = 0.0001 and momentum = 0.9, as well as learning rate = 0.0001 and momentum = 0.999, where early stopping occurred due to metric values stabilizing without significant changes. These AdamW configurations yielded higher mAP50 values (0.956 and 0.918), further validating the performance gains achieved through the implemented changes.
Regarding the latest YOLOv11 version, the improvements obtained through hyperparameter adjustments were observed in the majority of simulated scenarios. The model demonstrated higher accuracy metrics compared to standard configurations when using SGD. Specifically, it achieved a precision of 1.000 with a learning rate (lr) of 0.001 and momentum (m) of 0.9, and 0.977 for lr = 0.001 and m = 0.999. The most notable case occurred with lr = 0.0001 and m = 0.999, achieving a recall of 0.894, mAP50 of 0.952, mAP50:95 of 0.689, and an F1 score of 0.906.
When using the ADAM optimizer, the best results for recall (0.863), mAP50 (0.932), mAP50:95 (0.706), and F1 score (0.888) were achieved with a learning rate of 0.0001 and momentum values ranging from 0.9 to 0.999. The highest precision value (0.976) was obtained with a learning rate of 0.001 and momentum (m) of 0.9. These findings demonstrate that combining a reduced learning rate with appropriate momentum values can maximize the model’s performance across the evaluated metrics.
For the configuration using the AdamW optimizer with YOLOv11, the highest precision values (0.968), recall (0.843), mAP50 (0.930), mAP50:95 (0.677), and F1 score (0.901) were obtained with a learning rate of 0.001 and a momentum of 0.9. This configuration highlights that a moderate learning rate combined with well-tuned momentum can offer superior performance by ensuring effective model training. Furthermore, AdamW’s weight regularization improvements significantly contributed to the improvement in performance metrics.
In fact, more effective values were observed in relation to YOLOv11 when compared to YOLOv5 and YOLOv8, but it was also concluded that when adjusting the hyperparameters combined with different optimizers, they became effective for all and gave better results and metrics. The performances of YOLOv5, YOLOv8, and YOLOv11 were satisfactory when identifying trees in a non-standard image bank, and the present study presented the behavior of each model so that, in future applications, they can assist in decision-making when implementing the algorithm in an application.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}