1. Introduction
There are many opportunities and difficulties that arise in the international economy’s rapid development. The domestic perspective does not include huge firms’ activities. In globalization, it is important to pay attention to the entire world. Multinational corporations engage in outsourcing and offshore production, which are important strategic decisions to maintain reduced risk [
1]. In financially and economically underdeveloped areas, cost-depression-oriented supply chains and distribution channels are formed. The structural stability and financial cost of the entire supply chain are impacted by Small and Medium-sized Enterprises (SMEs), which have limited financial resources [
2]. The marginal impact of continual investment has declined based on the information flow and logistics developed in supply chain management [
3]. But, most scholars and professionals are focused on capital restraints in the supply chain [
4]. Supply chain financing is particularly significant because it becomes necessary to move the target of supply chain exploration and research to the supply chain. While efficient productivity, fast services, reduced costs, and safe product delivery are the goals of supply chain management, the complexity is only increased by having several vendors, channels, producers, and distributors [
5]. It is more difficult to analyze and gather data because of the huge number of resources involved. Big data analytics ultimately offers processes with simple and appropriate solutions. Big data intends to be more cumulative. The information gathered and used in one application is easily transferable to another [
6]. Additionally, it results in more accurate forecasts, and the outcomes are better with more available data sources.
Downstream and upstream businesses have supplied new finance, and enterprises and funding channels have enlarged the development area to improve the determination of the crucial domain, which is the core value of the supply chain members. A golden age of development has been achieved by specific plans in mobile environments, the cloud, big data, and blockchain, as well as the depth of application of related financial and artificial intelligence technologies, the growth of online financial supply chains using the Internet as a singular financial mode, and ongoing high-speed upgrades. Enterprises are subjected to objective and global supply chain risks [
7]. The fragility of the supply chain system becomes increasingly apparent as a result of the complexity of the supply chain and the unpredictability of its external environment, both of which raise the likelihood of supply chain risks [
8]. A crucial problem is handling supply chain risks rationally and successfully [
9]. Risk evaluation, risk management, risk identification, risk monitoring, and risk decision-making are all parts of managing supply chain risks. However, it is important to ensure the security of the supply chain by assessing the risks faced and clarifying their levels before taking effective risk management and monitoring measures to reduce the supply chain’s vulnerability, reduce costs, and control and mitigate risks and losses. Risk evaluation is the foundation of risk management and decision-making and is a crucial component of supply chain risk management. Consequently, it is crucial to research supply chain risk assessment.
One typical approach to assessing the credit risks of SCF is the credit risk evaluation model based on professional experience [
10]. The simple processing of qualitative information and high flexibility are advantages of the SCF system. It depends on expert judgment [
11]. The credit risk assessment system relates to conventional financial indicators, and its benefit is that it can thoroughly take into account numerous financial indicators, even though it only focuses on assessing financial data [
12]. The most popular techniques include regression analysis, fuzzy comprehensive evaluation, the analytical hierarchy process, and the gray system method [
13]. However, the current approaches also have some drawbacks. Sometimes, only one or a few evaluation factors are chosen [
5]. When establishing the index’s weight, artificial effects and subjective effects are very significant. Furthermore, the characteristics of each index frequently exhibit complicated nonlinear relationships, although the linear regression analysis approach deals with the link between the components and original values according to a linear relationship, which is very different from reality [
14].
The numerous contributions made to the established financial risk prediction process in the supply chain management system are discussed here. In this paper, we have implemented effective deep learning-based financial risk prediction in the supply chain management model to predict financial risk and help avoid financial losses. An effective hybrid algorithm is proposed for optimizing the parameters, and the developed SGSO algorithm is used to maximize the accuracy and thus improve the performance of the financial risk prediction model in the supply chain management system. We developed an effective ASCALSMLP approach that increases the financial risk prediction model’s performance and enhances the analysis of the prediction data by optimizing the epochs and hidden neuron count in LSTM, the hidden neuron count and epochs in the autoencoder, and the learning rate and hidden neuron count in the MLP model. Lastly, the efficiency of several commonly used financial risk prediction methods and heuristic algorithms is compared with that of the newly developed model for financial risk prediction in the supply chain.
The proposed model is briefly explained in the subsequent parts.
Section 2 discusses the numerous financial risk prediction algorithms and approaches recently used.
Section 3 presents the recommended model for the newly developed financial risk prediction process and an explanation of the dataset.
Section 4 describes the data transformation stages, deep learning techniques, and newly developed algorithms.
Section 5 explains the methodology used to construct the financial risk prediction model in the supply chain.
Section 6 illustrates the outcomes of financial risk prediction in the supply chain model and evaluation measures. The conclusion regarding the developed financial risk prediction model is finally provided in
Section 7.
2. Literature Survey
In 2020, Cai et al. [
15] suggested a new risk evaluation system using a deep learning approach for analyzing the factors of the supply chain. The findings demonstrated that BPNN has distinct advantages for tackling extremely nonlinear situations in supply chain risk assessment. The implemented approach was recognized to identify supply chain risks. Therefore, the developed system leads to better business profits.
In 2022, Bassiouni et al. [
16] proposed a new COVID-19 risk prediction model using deep learning. Denoising, feature extraction, pre-processing, classification, and data collection were the four primary phases of the implemented deep learning technique. Two primary deep learning model variations were required for the feature extraction phase. Six distinct classifiers were used in the overall proposed procedure. An online dataset was utilized with the developed model. The outcomes of the demonstrated model showed accurate prediction in estimating the risk of shipping to a specific location while subject to COVID-19 constraints.
In 2021, Feng et al. [
17] designed a deep learning-based risk prediction system for corporate finance. First, forecast indexes were chosen based on the index selection concept, and an index system for early warning was built. After that, factor analysis was used to optimize the index system. The developed financial risk prediction system showed high accuracy and precision. The developed deep learning-based financial crisis forecasting model produced better outcomes.
In 2021, Zhang et al. [
18] implemented a credit risk prediction model of finance using deep learning with an optimization strategy. Thirteen and fifteen third-level indicators were ultimately identified. The dataset was chosen from the Electronic and Computer Manufacturing Industry. The inputs were chosen through application analysis. The supply chain financial evaluation used the firefly algorithm in the developed model.
In 2022, Yao et al. [
19] suggested a unique ensemble feature selection approach using deep learning. The best and most stable feature subset could be produced using the FS-MRI method, which could also implement an automatic threshold function while considering model performance. Compared to other ensemble models and single classifiers, the developed model performed better in terms of KS and AUC. With maximum AUC and KS values, the two algorithms worked together to produce the best prediction performance.
In 2022, Dang et al. [
20] implemented a deep learning-based risk prediction model with a blockchain framework. The financial risks were first examined using the pertinent monetary inward theory. In order to discuss the potential credit risk associated with supply chain finance, the financing model of this industry was also examined. At last, the testing process and simulation process were performed on the developed model. An analysis of the results revealed that the developed model was capable of accurately predicting the prospective credit risk of the industry. The developed model had higher accuracy than other existing approaches.
In 2021, Zhang et al. [
21] developed a new risk prediction model using deep learning. To build the accompanying system and index model for online financial risk prediction in supply chain management based on enhanced random forest, an improved stochastic algorithm was applied to online supply chain risk prediction. Data analysis demonstrated the precision and viability of the enhanced random forest for online financial risk prediction in supply chain management.
In 2021, Wu et al. [
22] proposed a deep learning-based credit risk management model using optimization. Indicator selection was implemented in this model. The behaviors of these indicators were chosen using principal component analysis because several elements affect credit risks, which causes difficulties in choosing characteristics. An ideal credit risk assessment approach was established, and the case analysis method was used to validate the suggested risk assessment method. Through validation, it was discovered that the optimization method performed better in predicting agricultural credit risk, and both the accuracy and speed of its prediction were increased. As a result, the proposed model employed in agricultural risk prediction in supply chain management had good results when assessing the financial risk to lower agricultural risks.
In 2022, Ghazikhani et al. [
23] argued that recent advancements in meteorological prediction models, such as the Climate Forecast System Version 2 (CFSV2), have not fully resolved issues related to accuracy, prompting the need for effective post-processing methods. Post-processing techniques, particularly those employing machine learning algorithms, have become essential in refining these models’ predictions. The random forest (RF) algorithm, in particular, demonstrated notable success, achieving a correlation coefficient above 0.87, making it more accurate than other methods. This study not only proposed a post-processing method for CFSV2 but also developed a Decision Support System (DSS) that leverages this method to address precipitation-related challenges, such as floods and droughts, thereby contributing to sustainable development goals (SDGs). The research also highlighted the innovative transition from academic concepts to industrial applications, facilitated by a user-friendly graphical interface, marking a significant step in improving meteorological prediction accuracy and utility.
In 2023, Mamoudan et al.’s study [
24] contributed to this growing body of knowledge by proposing innovative hybrid neural network-based metaheuristic algorithms for more accurate signal analysis in the precious metals market. The previous literature had explored various deep learning and machine learning models for financial prediction, but this study’s novelty lay in combining a convolutional neural network (CNN) and a bidirectional gated recurrent unit (BiGRU), with hyperparameters optimized using the firefly algorithm. Additionally, the study employed the moth–flame optimization algorithm to select the most influential variables, enhancing the model’s predictive performance. Comparative analyses with other state-of-the-art methods demonstrate that the proposed hybrid approach significantly improves the reliability of technical analysis indicators, offering a valuable decision support tool for investors navigating the volatile financial and precious metals markets.
In 2024, Zhan et al. [
25] explored various methods for assessing and improving sustainable transportation, with recent studies highlighting the effectiveness of hybrid approaches combining quantitative and qualitative analysis techniques. This study contributed to the existing body of knowledge by introducing a novel hybrid method that integrates the Criteria Importance Through Intercriteria Correlation (CRITIC) and Decision-Making Trial and Evaluation Laboratory (DEMATEL) with deep learning features. This approach not only enhances the accuracy of low-carbon transportation assessments but also objectively identifies key influencing factors and their interconnections. The application of this method in a Chinese case study, validated through sensitivity analysis, demonstrated its potential for informing policy- and decision-making, thereby advancing sustainable transportation initiatives in China.
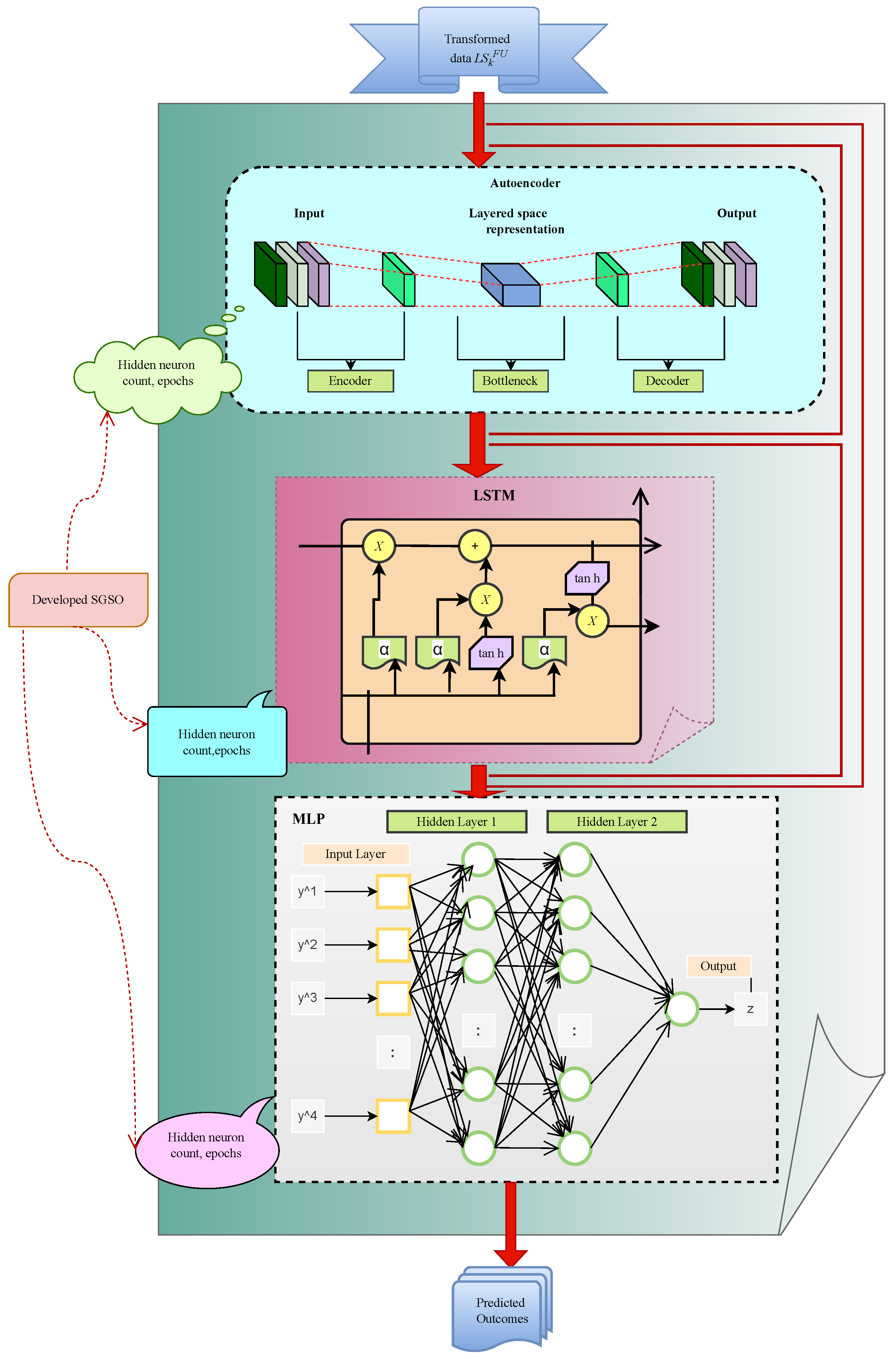
In the reviewed literature, most studies rely on either one or two prediction-based models, each having its own strengths and weaknesses. In this paper, we propose a hybrid supply chain management framework called SGSOASCALSMLP by amalgamating three deep learning architectures, namely, an autoencoder, LSTM, and MLP, which achieves better efficiency and accuracy than conventional risk prediction approaches by leveraging their various advantages and mitigating their disadvantages.
5. Data Transformation with the Use of Deep Learning Models for Financial Risk Prediction in Supply Chain Management
5.1. Data Transformation
The gathered data applied to the data transformation method are denoted by . Data transformation involves translating data from one format to another, often from the source system’s format to the desired destination system’s format, without altering the dataset content. Usually, it is employed to increase the data quality. Most data integration and management operations include data wrangling, data warehousing, and different types of data transformation.
Step 1: Normalization: The input applied to the normalization method is . Here, data are transformed into similar-scale data through data normalization. Depending on the size of the data, data normalization models recenter and rescale the data so that they lie between 0 and 1 or −1 and 1. This enhances the model’s training stability and functionality. The output of the normalized data is indicated by .
Step 2: Replacement of NAN and NULL values: The normalized data are given to the NAN and NULL replacing section. Eliminating rows or columns containing null values is one method for addressing missing values. The entire column is removed if any columns contain one or more null values. Similar to how columns can be dropped if one or more of their values are null, rows can be dropped. The output is denoted by .
Step 3: Removal of duplicate values: The input given to the duplicate removal stage is denoted by . Duplicates are not always present in the same column but can be present anywhere in the data. This may result in skewed performance predictions, which would decrease the model’s performance when it comes to its actual use. This step eliminates duplicate rows based on all columns by default. The output of the transformed data is indicated by .
5.2. Autoencoder-Based Feature Extraction
The transformed data are given to the autoencoder and are denoted by
. There are three levels in the autoencoder: an output layer, an input layer, and a concealed layer. Decoding is handled by the output layer. Encoding is handled by the hidden layer. In order to produce the intended output, the network is configured to copy or recreate its input. In an autoencoder, the dimensions of the output and input layers must coincide. The encoder’s hidden layer is provided in Equation (
1):
The input decoder’s hidden representation is given in Equation (
2):
The error loss of the squared function is computed from Equation (
3):
Finally, the term h is an activation function. The term denotes the reconstructed input, and the weight Y is indicated with c bias. The autoencoder contains three parts: the encoder, decoder, and code. An incomplete autoencoder can capture all of the essential details of the inputs. The autoencoder may display both linear and nonlinear changes. An under-complete autoencoder is often used for data denoising and dimension reduction. Therefore, the autoencoder extracts the relevant features, and it is indicated by .
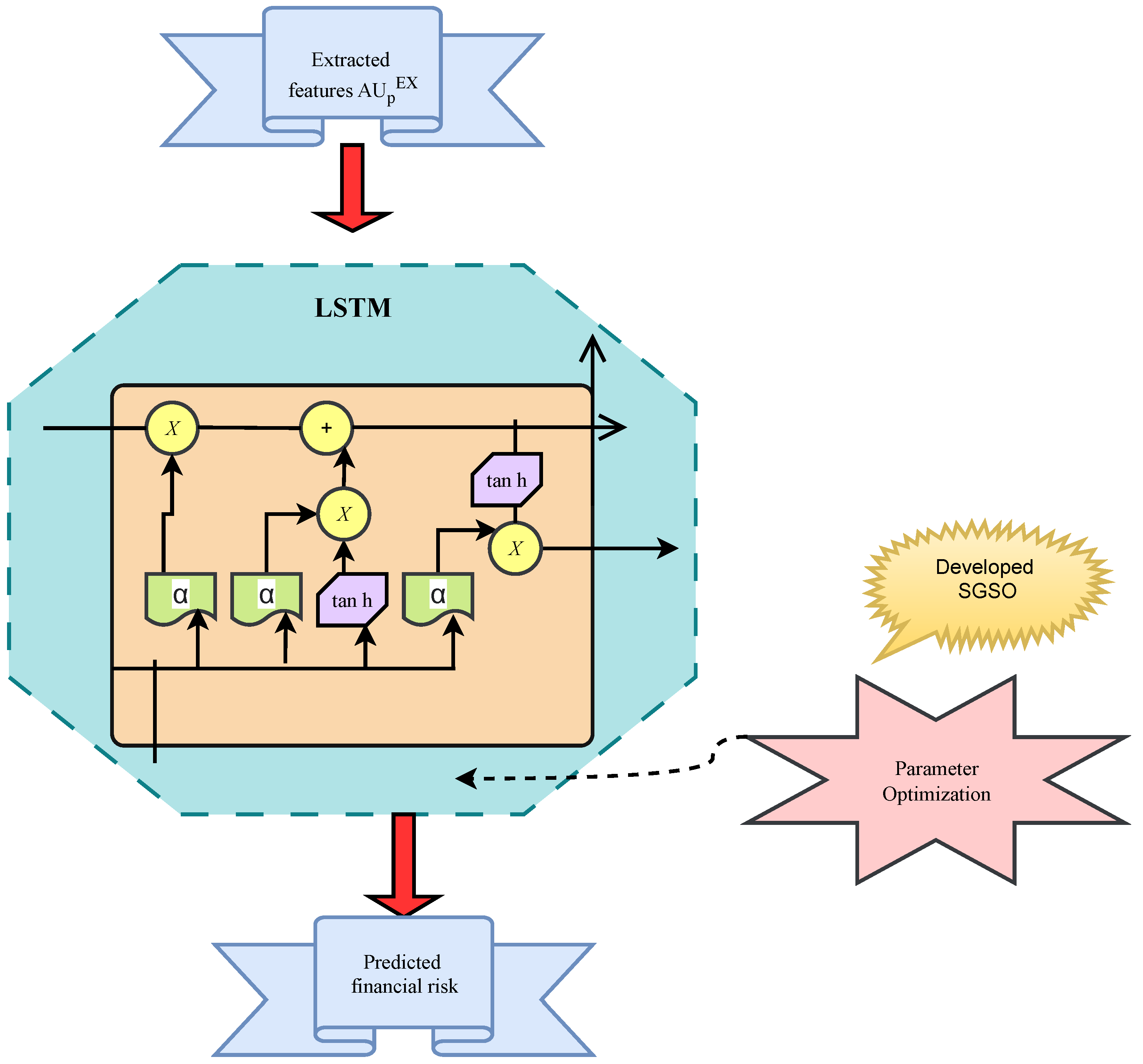
5.3. LSTM-Based Prediction
The deep features given to LSTM [
26] are represented by
. Variants are developed by the internal activities of the LSTM cell. Data operations can be forgotten by the LSTM. The core of the LSTM network is composed of a cell state and several gates. The cell state serves as a conduit for the transmission of important data during data processing. It is also said to be the memory of the network. The information that can be applied to a cell state is controlled by several neural networks that act as gates. Throughout training, the gates discover what knowledge they should remember and what they should forget. Three distinct gates of the LSTM cell control the information flow. The terms v and v − 1 represent the input and output times, respectively. The output and input times are calculated by Equation (
4):
Here, the weight of the LSTM is indicated by W, and the bias is denoted by d:
The term tanh is an activation function, and the cell state is denoted by c. The output is represented by
, and the vector of inputs z is estimated from Equation (
8):
Therefore, the forget function is represented by
. The basic LSTM model in supply chain management is shown in
Figure 3.
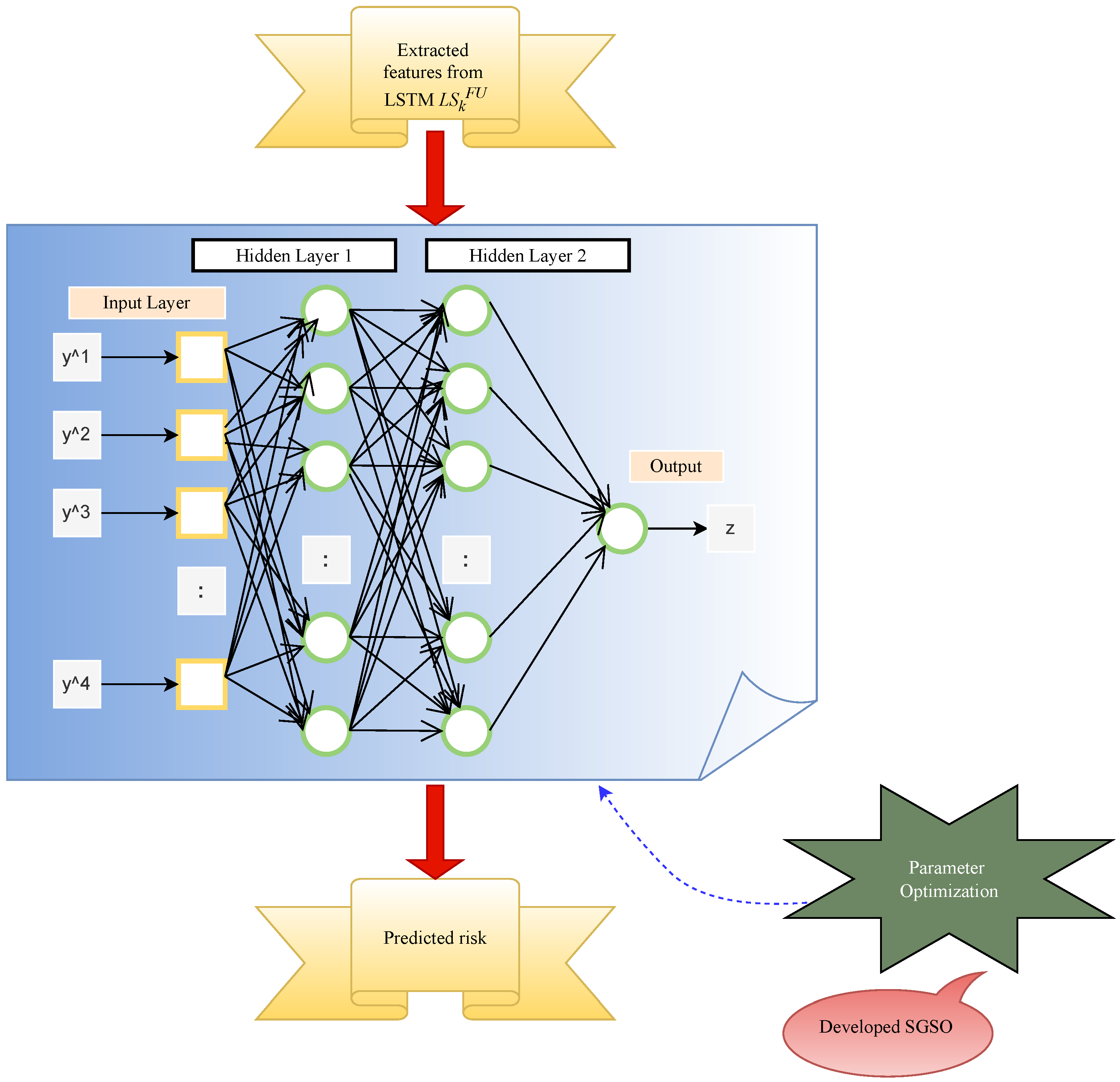
5.4. MLP-Based Prediction
Currently, most deep learning methods use MLP [
27] for financial risk prediction in supply chain management. Simple neurons, known as perceptrons, are the building blocks of the MLP network. The perceptron creates a linear combination based on the input weights. Also, they express the output through a nonlinear transfer function to create a single output from many real-valued inputs. This mathematical expression can be calculated using Equation (
9):
Here, the input vector is indicated by
, and the bias is denoted by c. The transfer function is indicated by g. The logistic sigmoid function and transfer function are calculated using Equation (
10):
The tangent sigmoid function transfers the functions using a variable t, and it is given in Equation (
11):
Here, the output is denoted by b, and the term
is a weight vector. A basic diagram of the MLP is shown in
Figure 4.
8. Conclusions and Future Work
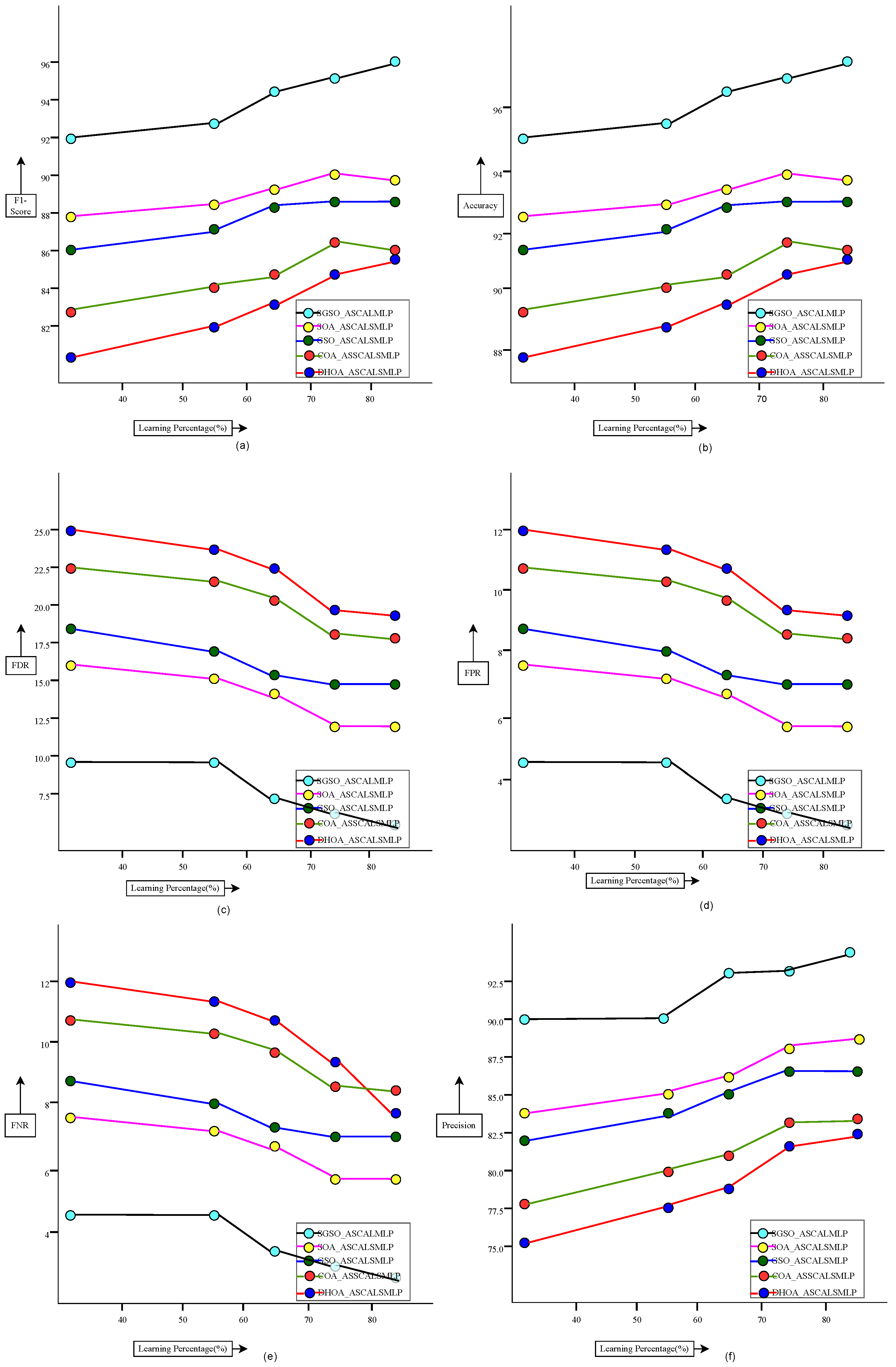
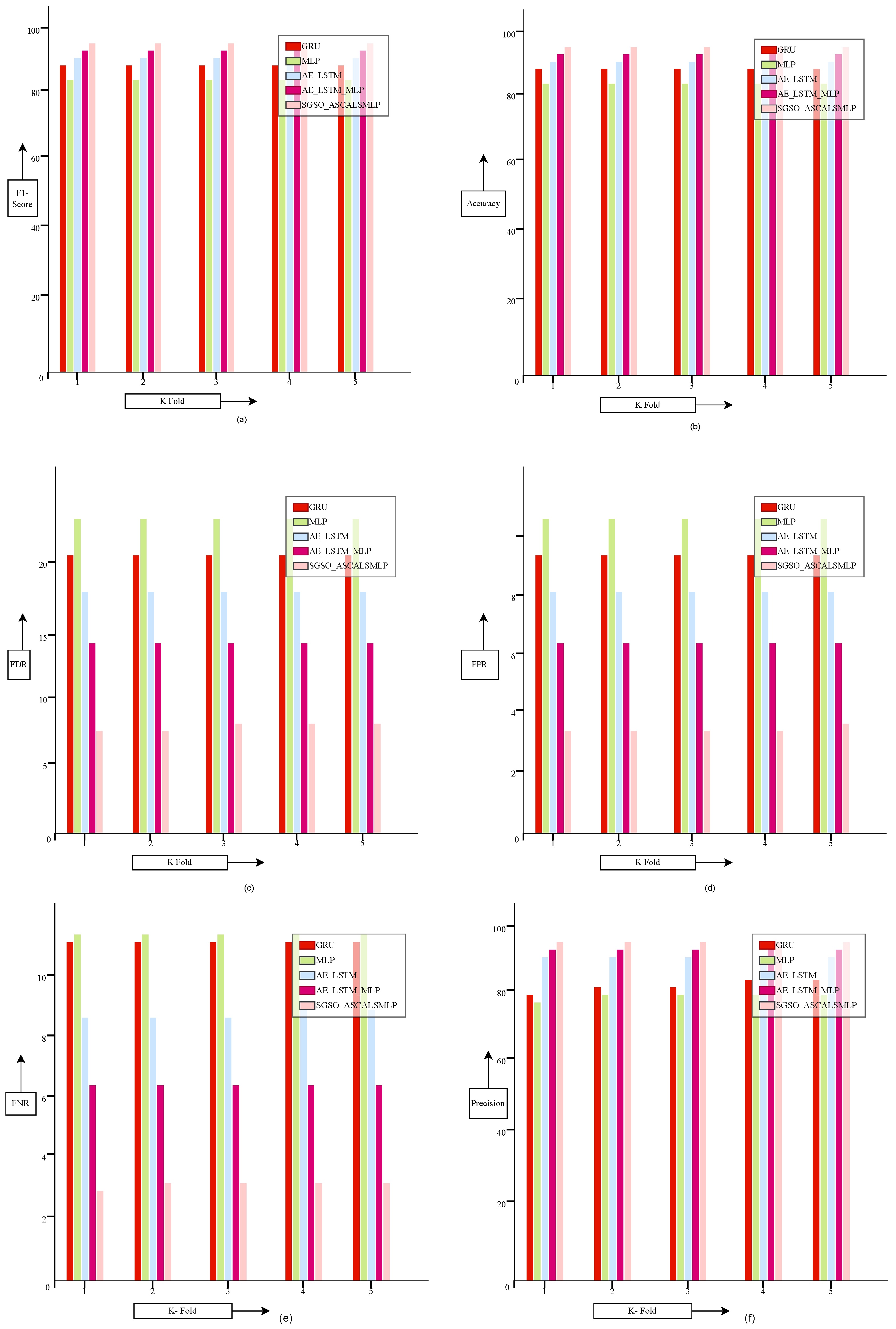
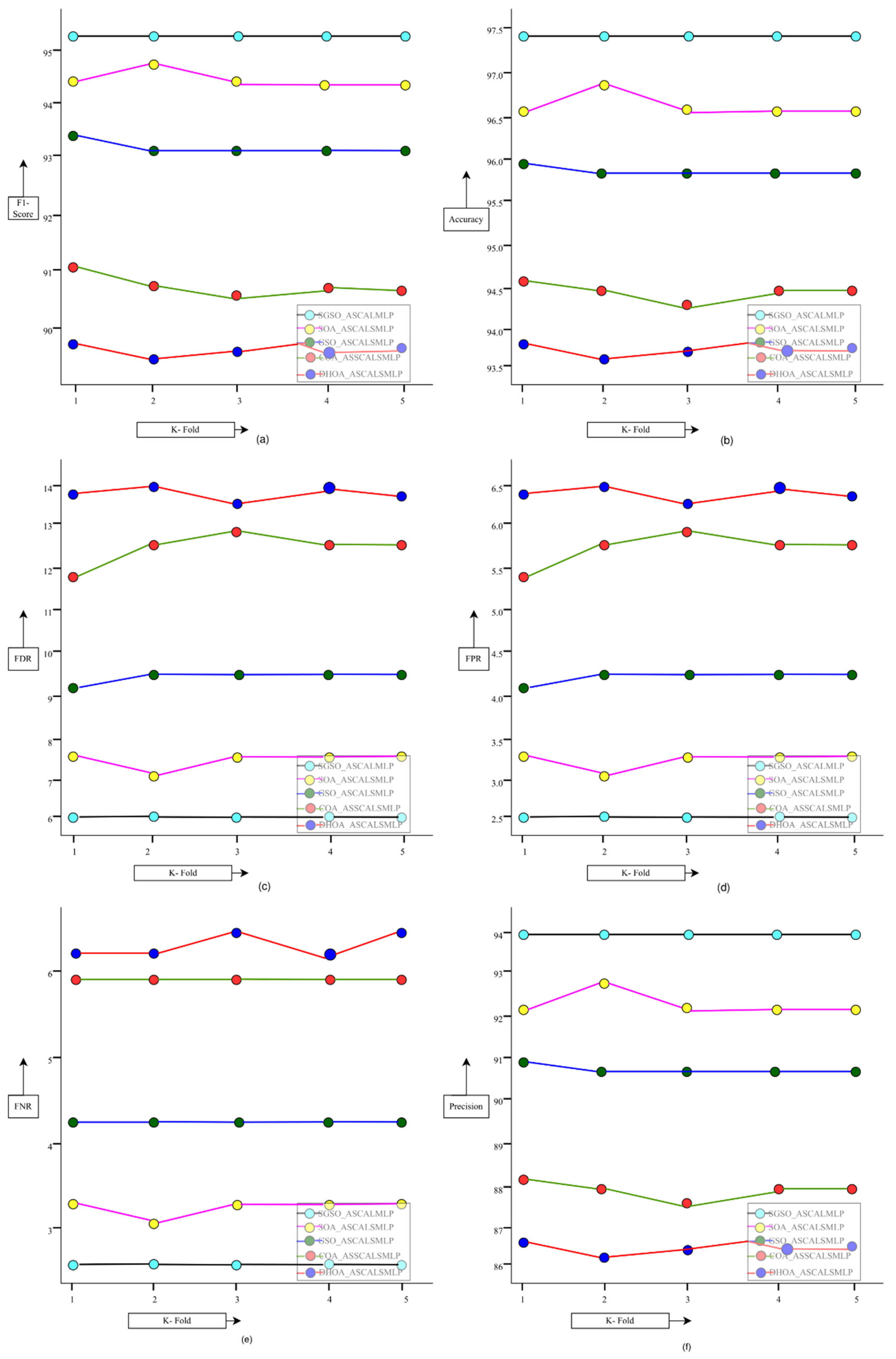
The newly investigated deep learning-based financial risk prediction model in the supply chain management framework was specifically adopted to predict financial risks with greater precision. To achieve this, the required financial data were gathered from online resources and subjected to a pre-processing stage. This pre-processing involved the transformation of the raw data through normalization, the removal of duplicates, and the replacement of missing values (NAN and NULL), ensuring that the dataset was clean and suitable for further analysis. Once transformed, the data were passed on to the financial risk prediction module, where the ASCALSMLP (Stacked Cascaded Autoencoder with LSTM and MLP) system was employed. This system integrates multiple deep learning techniques—LSTM (Long Short-Term Memory), autoencoder, and MLP (Multi-Layer Perceptron)—which were serially cascaded to enhance their predictive capabilities. In the prediction stage, the transformed data were initially processed using the autoencoder method, enabling the extraction of deep features. These features were then passed to the LSTM network, which is adept at handling sequential data, making it particularly suitable for time-series financial risk analysis. The final prediction of financial risk was achieved using both LSTM and MLP techniques, working in tandem to ensure effective prediction. To further improve accuracy, the proposed SGSO (Sparrow Search and Genetic Swarm Optimization) algorithm was incorporated. This hybrid optimization algorithm helped maximize the accuracy of the ASCALSMLP system by optimizing hyperparameters and model performance. As a result, the SGSO-ASCALSMLP-based financial risk prediction model for the supply chain management system achieved significantly higher performance compared to conventional risk prediction approaches. Specifically, it outperformed other models by achieving a greater F1-score, showing a 3.03% improvement over the GRU-ASCALSMLP model, a 7.22% improvement over the MLP-ASCALSMLP model, a 10.7% improvement over the AE-LSTM-ASCALSMLP model, and a 10.9% improvement over the AE-LSTM-MLP-ASCALSMLP model. This demonstrates the superior performance of the proposed model. In addition to improving prediction accuracy, the developed system also enhances the security of financial data in the supply chain. By employing robust deep learning techniques, the model reduces vulnerability to data breaches and ensures secure data handling throughout the prediction process. This added layer of security makes the system more reliable for real-world applications, where financial risk management is crucial.
There are a few potential limitations of our proposed framework: (1) Complexity of Model Integration: The integration of multiple advanced techniques, such as the Adaptive Serial Cascaded Autoencoder (ASCA), Long Short-Term Memory (LSTM), and Sandpiper Galactic Swarm Optimization (SGSO), may introduce complexity into the model, making it challenging to implement and maintain. (2) Data Dependency: The effectiveness of the SGSO-ASCALSMLP model relies heavily on the quality and quantity of big data available. Any inconsistencies, biases, or missing data during the data transformation process could affect the accuracy and reliability of the financial risk predictions. (3) Computational Resources: Given the sophisticated nature of the deep learning techniques involved, the model likely requires significant computational resources, which may not be feasible for all organizations, particularly smaller ones. (4) Generalization to Different Contexts: While the model has shown superior performance in the tested scenarios, its generalization to different industries, supply chain structures, or financial conditions may be limited. The model may need to be fine-tuned or adapted to different contexts. (5) Interpretability and Transparency: The use of advanced deep learning models can make it difficult to interpret the decision-making process, potentially reducing transparency. This might be a concern for stakeholders who require clear justification for financial risk predictions. (6) Lack of Benchmarking Against a Wider Range of Methods: Although the model outperforms several conventional techniques, it should be compared to a wider range of machine learning or statistical methods, which could offer insights into its relative strengths and weaknesses.
While the proposed SGSO-ASCALSMLP-based financial risk prediction model has demonstrated superior accuracy and performance compared to existing approaches, several areas for future research and enhancement remain. (1) Real-time Prediction: One area for future work is integrating real-time data streams into the risk prediction model. Incorporating dynamic, real-time data could further enhance the system’s predictive accuracy and responsiveness to sudden changes in the supply chain environment, such as unexpected disruptions or market fluctuations. (2) Scalability: Another direction for future work is scaling the system to handle larger and more complex datasets. As global supply chains generate vast amounts of financial data, ensuring that the system can efficiently process and analyze this information is critical. Employing distributed computing or cloud-based infrastructure could help improve the system’s scalability. (3) Cross-domain Adaptation: The model could be adapted and tested in different financial sectors or industries beyond supply chain management. This would involve cross-domain learning, where the model’s robustness is tested against different types of financial risk scenarios in industries such as banking, insurance, and healthcare. (4) Explainability and Interpretability: Deep learning models, while powerful, are often viewed as “black boxes”. Future work could focus on making the risk prediction process more interpretable by incorporating explainable AI (XAI) techniques. This would provide decision-makers with insights into why certain predictions are made, leading to more informed risk management strategies. (5) Incorporation of External Factors: The current model focuses primarily on internal financial data. Future iterations could consider the integration of external factors, such as geopolitical risks, environmental changes, or regulatory shifts, to further enhance the predictive power of the system. This would make the model more holistic and adaptive to real-world complexities. (6) Multi-objective Optimization: While the SGSO algorithm improves the model’s accuracy, there is room for further exploration of other multi-objective optimization techniques. These could optimize the trade-offs between prediction accuracy, computational efficiency, and model robustness, leading to a more balanced system. (7) Combination with Blockchain: Lastly, exploring the integration of blockchain technology could be an interesting avenue. Blockchain can enhance data transparency and security within the supply chain, potentially complementing the existing financial risk prediction model by ensuring the integrity and immutability of financial data.
In summary, while the proposed SGSO-ASCALSMLP model has demonstrated significant advancements in predicting financial risk within supply chain management, future research could further enhance its capabilities by focusing on real-time processing, scalability, cross-domain applications, model interpretability, and the incorporation of emerging technologies such as blockchain. These improvements would not only increase the system’s effectiveness but also broaden its applicability across various industries and risk scenarios.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}