Archetypes of Supply Chain Analytics Initiatives—An Exploratory Study


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Theoretical Background
2.1. Analytics
2.2. Supply Chain Analytics
2.3. Dismantling Supply Chain Analytics Initiatives
3. Methodology
3.1. Data Collection
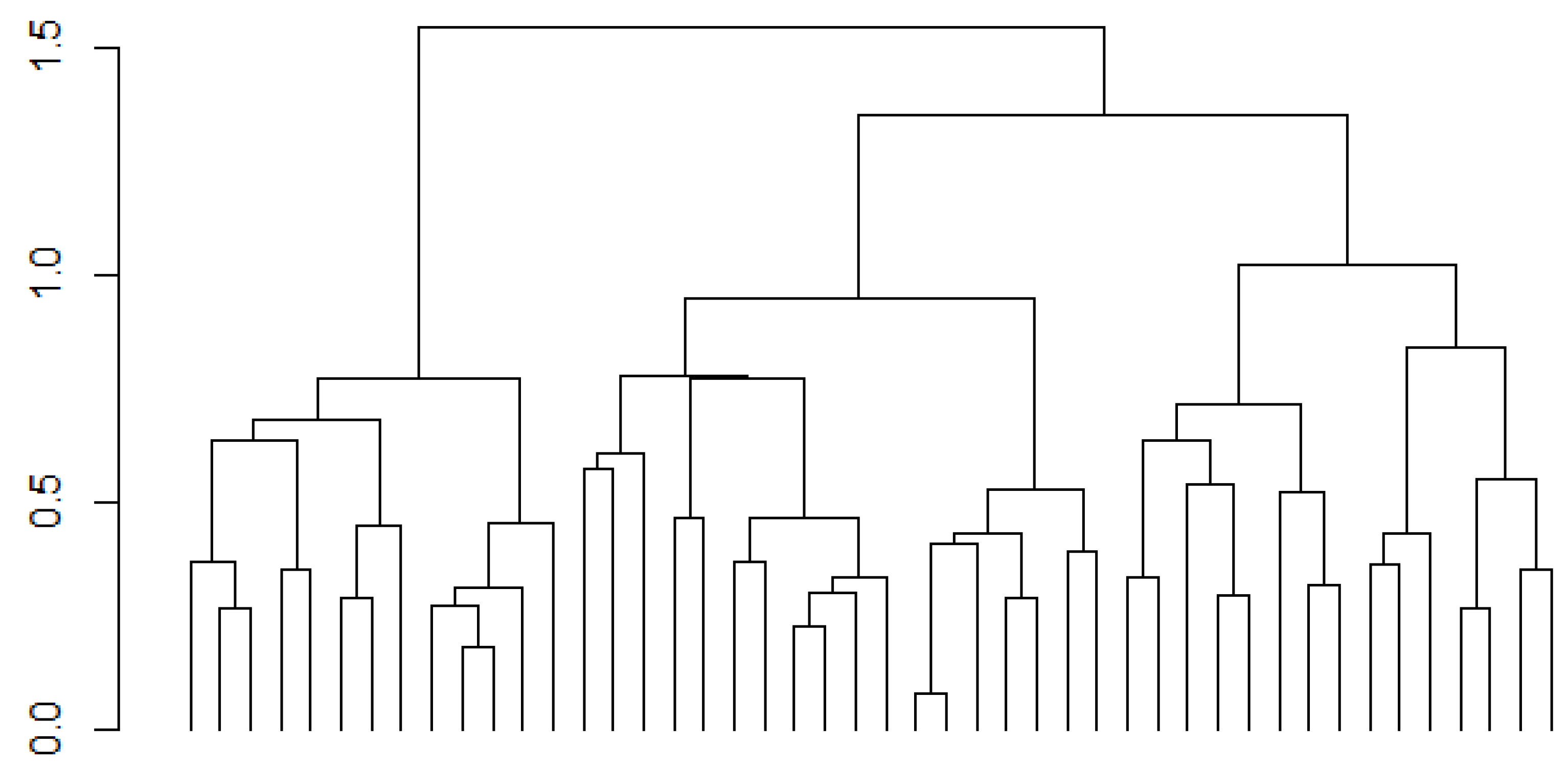
3.2. Data Analysis
4. Results and Discussion
4.1. Cluster 1—Educating
4.2. Cluster 2—Observing
4.3. Cluster 3—Alerting
4.4. Cluster 4—Advancing
4.5. Cluster 5—Refining
4.6. Cluster 6—Investigating
4.7. Discussion on Archetypes
4.8. Discussion on Overcoming Barriers with Archetypes
5. Conclusions
- Supply chain objective that shall be addressed which represents the problem or deficiency in the LSCM process;
- Analytics objective, which is addressing how data and Analytics are supposed to support, effect, or change the LSCM process;
- Human expertise in areas relevant to the initiative as Analytics, IT and the LSCM process (and how it is sourced);
- Applied software and hardware for analytical tasks and deployment of developed solutions and tools;
- Data sources and characteristics;
- Applicated types of Analytics (and subsequently analytical methods).
- Educating: The LSCM process remains as existing but will be enhanced with new data (sources) information as process input to improve decisions to be made during the process resulting in enhanced LSCM process output quality and customer orientation. This typically emerges as an improved tool used in the process such as a new forecasting model in a product allocation process or new forecast model for a risk evaluation process.
- Observing: The LSCM process is extensively investigated for conditions that indicate process deficiencies or issues in the short-term or medium-term future with a resulting tool to monitor the process based on the newly gained insight. The knowledge about the conditions improves process quality and costs due to earlier reaction. Examples include detection of engine vibration patterns enabling maintenance planning of vehicles such that a repair shop is the final stop of a route on a suitable point in time instead of random breakdown far away from access to maintenance, or detection of weather patterns resulting in traffic and road conditions demanding changing of routes. However, identified conditions are indications and leave room for human decision making.
- Alerting: LSCM process owners are provided with alerts on critical conditions and events that immediately demand reactions. The conditions are usually known by process owners without the need of analytical identification and certain in their negative impact on the process demanding actions. Alerting initiatives’ central task is making the necessary data available to automate the alert as opposed to repeated human check-up actions. Examples include alerts on closed roads for vehicle routing or automated recommendations of price changes and acceptance of shipments for cargo airlines in close to departure time-windows. Here again, the LSCM process is typically supported but not altered.
- Advancing: The LSCM processes and business models will be advanced by enabling changes due to insight made available with intense data collection and analysis. Large scale data collection is central to the initiative, using sensors and mobile devices to create data-availability-based transparency and evaluation of LSCM process steps. The insight is used to improve process quality by changing process steps under incorporation of the insight and creating analytics driven innovations replacing process steps as well as making insight available to interested third parties as business model innovation. Examples are machine profiles allowing determination of accurate predictive maintenance processes which can be sold by the machine manufacturer to the machine user, or driver profiles to create new monitoring steps to reduce idle time. These initiatives differ from observing and alerting by extensiveness of data collection and analysis typically demanding big data technologies, and range of the resulting tool, which changes the process to become tool and thus data focused as opposed to a minor process support.
- Refining: The LSCM processes are changed to incorporating faster, broader, and more frequent guidance on actions and decision support. Instead of optimized plans that are executed, the objective of these initiatives is to optimize plans during execution dynamically based on data about current events and conditions. Examples are dynamic changes of routes of vehicles already on the road, or dynamic changes of picker routes in distribution centers already picking. The LSCM process is changed due to extensive focus on guidance tools guidance during process execution.
- Investigating: The LSCM process (and asset) deficiencies and issues are investigated for their causes to enable the solution search for design changes to the process. These changes are supposed to create new processes with improved costs and quality over the process under investigation. As opposed to issues described in advancing or refining, process changes such as automation or data-driven tools for guidance will not create control over the process issues addressed in these initiatives. Thus, creativity and engineering design is required. Examples include the investigation of occurrence of empty shelf space in retail stores to redesign replenishment processes of products or the investigation of process environment factors in production lines leading to quality issues that must be avoided.
5.1. Theoretical Contribution
5.2. Managerial Contribution
6. Final Remarks
6.1. Limitations
6.2. Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Keen, A. Battle Lines Drawn as Data Becomes Oil of Digital Age. CNN. 2012. Available online: http://edition.cnn.com/2012/01/25/opinion/keen-technology-data/ (accessed on 6 May 2018).
- Davenport, T.H.; Harris, J.G. Competing on Analytics: The New Science of Winning; Harvard Business School Press: Boston, MA, USA, 2007. [Google Scholar]
- Cao, G.; Duan, Y.; Li, G. Linking Business Analytics to Decision Making Effectiveness: A Path Model Analysis. IEEE Trans. Eng. Manag. 2015, 62, 384–395. [Google Scholar] [CrossRef] [Green Version]
- Davenport, T.H. Realizing the Potential of Retail Analytics Plenty of Food for Those with the Appetite; Babson Park: Wellesley, MA, USA, 2009. [Google Scholar]
- Simchi-Levi, D.; Simchi-Levi, E.; Kaminsky, P. Designing and Managing the Supply Chain: Concepts, Strategies, and Cases; McGraw-Hill: New York, NY, USA, 2003. [Google Scholar]
- Jeske, M.; Grüner, M.; WeiB, F. Big Data in Logistics; DHL Customer Solutions & Innovation: Troisdorf, Germany, 2013. [Google Scholar]
- Christopher, M. Logistics & Supply Chain Management; Financial Times Prentice Hall: Harlow, UK, 2011. [Google Scholar]
- Bose, R. Advanced analytics: Opportunities and challenges. Ind. Manag. Data Syst. 2009, 109, 155–172. [Google Scholar] [CrossRef]
- Holsapple, C.; Lee-Post, A.; Pakath, R. A unified foundation for business analytics. Decis. Support Syst. 2014, 64, 130–141. [Google Scholar] [CrossRef]
- Souza, G.C. Supply chain analytics. Bus. Horiz. 2014, 57, 595–605. [Google Scholar] [CrossRef]
- Trkman, P.; McCormack, K.; de Oliveira, M.P.V.; Ladeira, M.B. The impact of business analytics on supply chain performance. Decis. Support Syst. 2010, 49, 318–327. [Google Scholar] [CrossRef]
- De Oliveira, M.P.V.; McCormack, K.; Trkman, P. Business analytics in supply chains—The contingent effect of business process maturity. Expert Syst. Appl. 2012, 39, 5488–5498. [Google Scholar] [CrossRef]
- Chae, B.; Olson, D.; Sheu, C. The impact of supply chain analytics on operational performance: A resource-based view. Int. J. Prod. Res. 2014, 52, 4695–4710. [Google Scholar] [CrossRef]
- Schoenherr, T.; Speier-Pero, C. Data Science, Predictive Analytics, and Big Data in Supply Chain Management: Current State and Future Potential. J. Bus. Logist. 2015, 36, 120–132. [Google Scholar] [CrossRef]
- Waller, M.A.; Fawcett, S.E. Data Science, Predictive Analytics, and Big Data: A Revolution That Will Transform Supply Chain Design and Management. J. Bus. Logist. 2013, 34, 77–84. [Google Scholar] [CrossRef]
- Wang, G.; Gunasekaran, A.; Ngai, E.W.T.; Papadopoulos, T. Big data analytics in logistics and supply chain management: Certain investigations for research and applications. Int. J. Prod. Econ. 2016, 176, 98–110. [Google Scholar] [CrossRef]
- Pearson, M.; Gjendem, F.H.; Kaltenbach, P.; Schatteman, O.; Hanifan, G. Big Data Analytics in Supply Chain: Hype or Here to Stay? Accenture: Munich, Germany, 2014. [Google Scholar]
- Opher, A.; Onda, A.; Chou, A.; Sounderrajan, K. The Rise of the Data Economy: Driving Value through Internet of Things Data Monetization; IBM Corporation: Somers, NY, USA, 2016. [Google Scholar]
- Schmidt, B.; Rutkowsky, S.; Petersen, I.; Kloetzke, F.; Wallenburg, M.; Einmahl, L. Digital Supply Chains: Increasingly Critical for Competitive Edge; ATKearney: Düsseldorf, Germany, 2015. [Google Scholar]
- Marchese, K.; Dollar, B. Supply Chain Talent of the Future. 2015. Available online: https://www2.deloitte.com/us/en/pages/operations/articles/supply-chain-talent-of-the-future-survey.html (accessed on 3 May 2018).
- Thieullent, A.-L.; Colas, M.; Buvat, J.; Kvj, S.; Bisht, A. Going Big: Why Companies Need to Focus on Operational Analytics. Paris, 2016. Available online: https://www.capgemini.com/wp-content/uploads/2017/07/going_big-_why_companies_need_to_focus_on_operational_analytics.pdf (accessed on 3 May 2018).
- Ransbotham, S.; Kiron, D.; Prentice, P.K. Beyond the hype: The hard work behind analytics success. MIT Sloan Manag. Rev. 2016, 57, 1–6. [Google Scholar]
- Hahn, G.J.; Packowski, J. A perspective on applications of in-memory analytics in supply chain management. Decis. Support Syst. 2015, 76, 45–52. [Google Scholar] [CrossRef]
- MacInnis, D.J. A Framework for Conceptual Contributions in Marketing. J. Mark. 2011, 75, 136–154. [Google Scholar] [CrossRef]
- Viaene, S.; Van den Bunder, A. The secrets to managing business analytics projects. MIT Sloan Manag. Rev. 2011, 53, 65–69. [Google Scholar]
- Chen, H.; Chiang, R.H.; Storey, V.C. Business intelligence and analytics: from big data to big impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar] [CrossRef]
- Barton, D.; Court, D. Making advanced analytics work for you. Harv. Bus. Rev. 2012, 90, 78–83. [Google Scholar] [CrossRef] [PubMed]
- Sanders, N.R. Big Data Driven Supply Chain Management: A Framework for Implementing Analytics and Turning Information into Intelligence; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2014. [Google Scholar]
- Das, S. Computational Business Analytics; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Spiess, J.; Joens, Y.T.; Dragnea, R.; Spencer, P. Using Big Data to Improve Customer Experience and Business Performance. Bell Labs Tech. J. 2014, 18, 3–17. [Google Scholar] [CrossRef]
- Provost, F.; Fawcett, T. Data Science for Business; O’Reilly Media: Sebastopol, CA, USA, 2013. [Google Scholar]
- Akter, S.; Wamba, S.F.; Gunasekaran, A.; Dubey, R.; Childe, S.J. How to improve firm performance using big data analytics capability and business strategy alignment? Int. J. Prod. Econ. 2016, 182, 113–131. [Google Scholar] [CrossRef]
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity, and Variety, 2001. Available online: https://www.bibsonomy.org/bibtex/263868097d6e1998de3d88fcbb7670ca6/sb3000 (accessed on 8 May 2018).
- Sivarajah, U.; Kamal, M.M.; Irani, Z.; Weerakkody, V. Critical analysis of Big Data challenges and analytical methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef]
- Fosso Wamba, S.; Akter, S.; Edwards, A.; Chopin, G.; Gnanzou, D. How “big data” can make big impact: Findings from a systematic review and a longitudinal case study. Int. J. Prod. Econ. 2015, 165, 234–246. [Google Scholar] [CrossRef]
- Dutta, D.; Bose, I. Managing a big data project: The case of Ramco cements limited. Int. J. Prod. Econ. 2015, 165, 293–306. [Google Scholar] [CrossRef]
- Bowersox, D.J.; Closs, D.J.; Cooper, M.B. Supply Chain Logistics Management; McGraw-Hill/Irwin: New York, NY, USA, 2007. [Google Scholar]
- Chan, F.T.S. Performance Measurement in a Supply Chain. Int. J. Adv. Manuf. Technol. 2003, 21, 534–548. [Google Scholar] [CrossRef]
- Gunasekaran, A.; Patel, C.; McGaughey, R.E. A framework for supply chain performance measurement. Int. J. Prod. Econ. 2004, 87, 333–347. [Google Scholar] [CrossRef]
- Ambe, I.M. Key Indicators For Optimising Supply Chain Performance: The Case Of Light Vehicle Manufacturers In South Africa. J. Appl. Bus. Res. 2013, 30, 277–290. [Google Scholar] [CrossRef]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, A.H. Big Data: The next Frontier for Innovation, Competition, and Productivity. McKinsey Glob. Inst. 2011. Available online: https://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/big-data-the-next-frontier-for-innovation (accessed on 8 May 2018).
- Dietrich, D.; Heller, B.; Yang, B. Data Science & Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data; John Wiley & Sons: Indianapolis, IN, USA, 2015. [Google Scholar]
- Fang, H. Managing data lakes in big data era: What’s a data lake and why has it became popular in data management ecosystem. In Proceedings of the 2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Senyang, China, 8–12 June 2015. [Google Scholar]
- Kambatla, K.; Kollias, G.; Kumar, V.; Grama, A. Trends in big data analytics. J. Parallel Distrib. Comput. 2014, 74, 2561–2573. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Buttermann, G.; Germain, R.; Iyer, K.N.S. Contingency theory “fit” as gestalt: An application to supply chain management. Transp. Res. Part E Logist. Transp. Rev. 2008, 44, 955–969. [Google Scholar] [CrossRef]
- Flynn, B.B.; Huo, B.; Zhao, X. The impact of supply chain integration on performance: A contingency and configuration approach. J. Oper. Manag. 2010, 28, 58–71. [Google Scholar] [CrossRef]
- Rossetti, C.L.; Dooley, K.J. Job types in the supply chain management profession. J. Supply Chain Manag. 2010, 46, 40–56. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Gower, J.C. A General Coefficient of Similarity and Some of Its Properties. Biometrics 1971, 27, 857–871. [Google Scholar] [CrossRef]
- Faith, D.P. Asymmetric binary similarity measures. Oecologia 1983, 57, 287–290. [Google Scholar] [CrossRef] [PubMed]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Dunn, J.C. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters. J. Cybern. 1973, 3, 32–57. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Wu, L.; Yue, X.; Jin, A.; Yen, D.C. Smart supply chain management: a review and implications for future research. Int. J. Logist. Manag. 2016, 27, 395–417. [Google Scholar] [CrossRef]
- Kiron, D.; Shockley, R.; Kruschwitz, N.; Finch, G.; Haydock, M. Analytics: The Widening Divide. MIT Sloan Manag. Rev. 2012, 53, 1–22. [Google Scholar]
- McAfee, A.; Brynjolfsson, E. Big data: the management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar] [PubMed]
- Lavalle, S.; Lesser, E.; Shockley, R.; Hopkins, M.S.; Kruschwitz, N. Big Data, Analytics and the Path From Insights to Value. MIT Sloan Manag. Rev. 2011, 52, 21–32. [Google Scholar]
- Suddaby, R. Challenges for Institutional Theory. J. Manag. Inq. 2010, 19, 14–20. [Google Scholar] [CrossRef]
- Banks, G.C.; Pollack, J.M.; Bochantin, J.E.; Kirkman, B.L.; Whelpley, C.E.; O’Boyle, E.H. Management’s science-practice gap: A grand challenge for all stakeholders. Acad. Manag. J. 2016, 59, 2205–2231. [Google Scholar] [CrossRef]



© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herden, T.T.; Bunzel, S. Archetypes of Supply Chain Analytics Initiatives—An Exploratory Study. Logistics 2018, 2, 10. https://doi.org/10.3390/logistics2020010
Herden TT, Bunzel S. Archetypes of Supply Chain Analytics Initiatives—An Exploratory Study. Logistics. 2018; 2(2):10. https://doi.org/10.3390/logistics2020010
Chicago/Turabian StyleHerden, Tino T., and Steffen Bunzel. 2018. "Archetypes of Supply Chain Analytics Initiatives—An Exploratory Study" Logistics 2, no. 2: 10. https://doi.org/10.3390/logistics2020010
APA StyleHerden, T. T., & Bunzel, S. (2018). Archetypes of Supply Chain Analytics Initiatives—An Exploratory Study. Logistics, 2(2), 10. https://doi.org/10.3390/logistics2020010