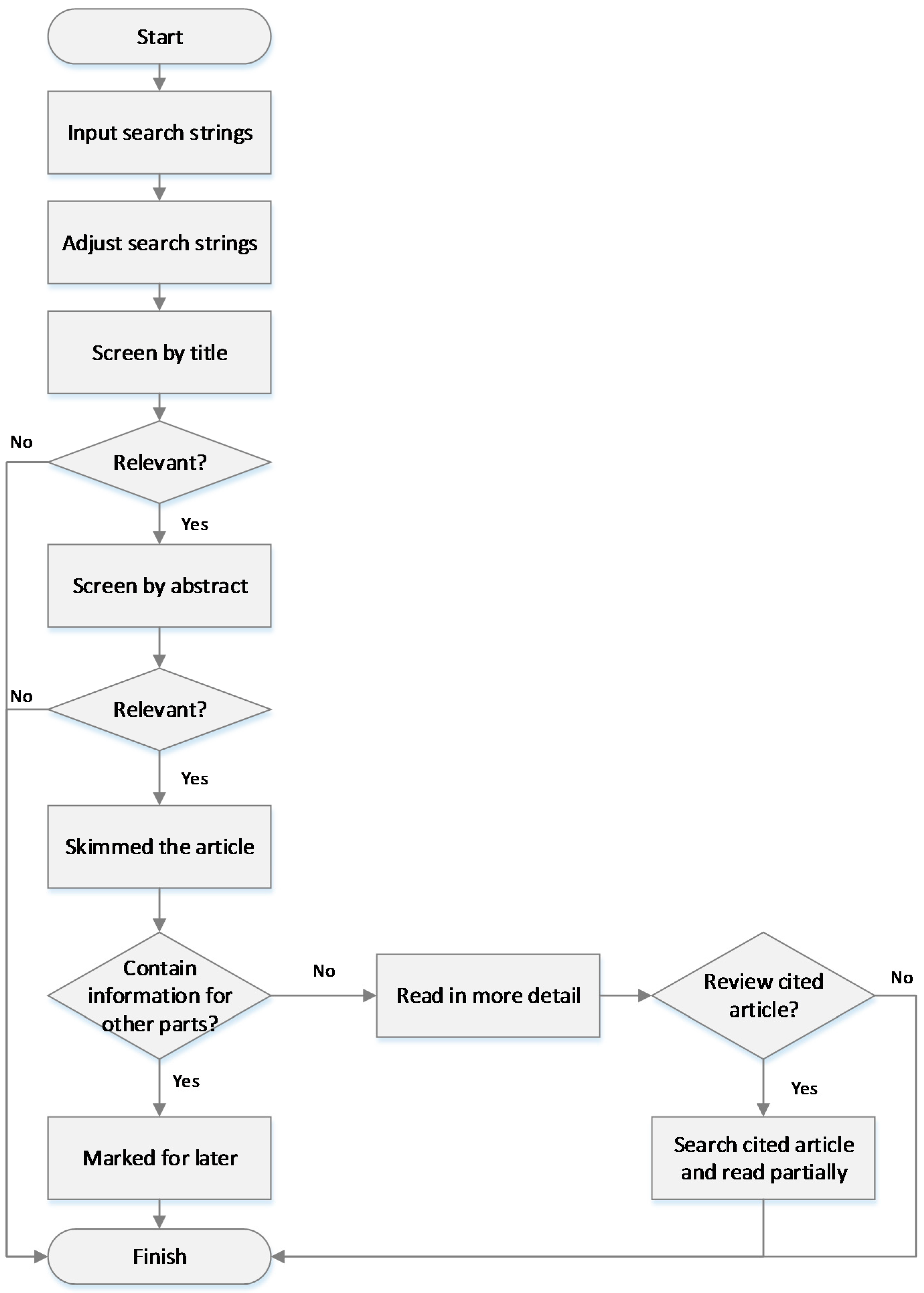
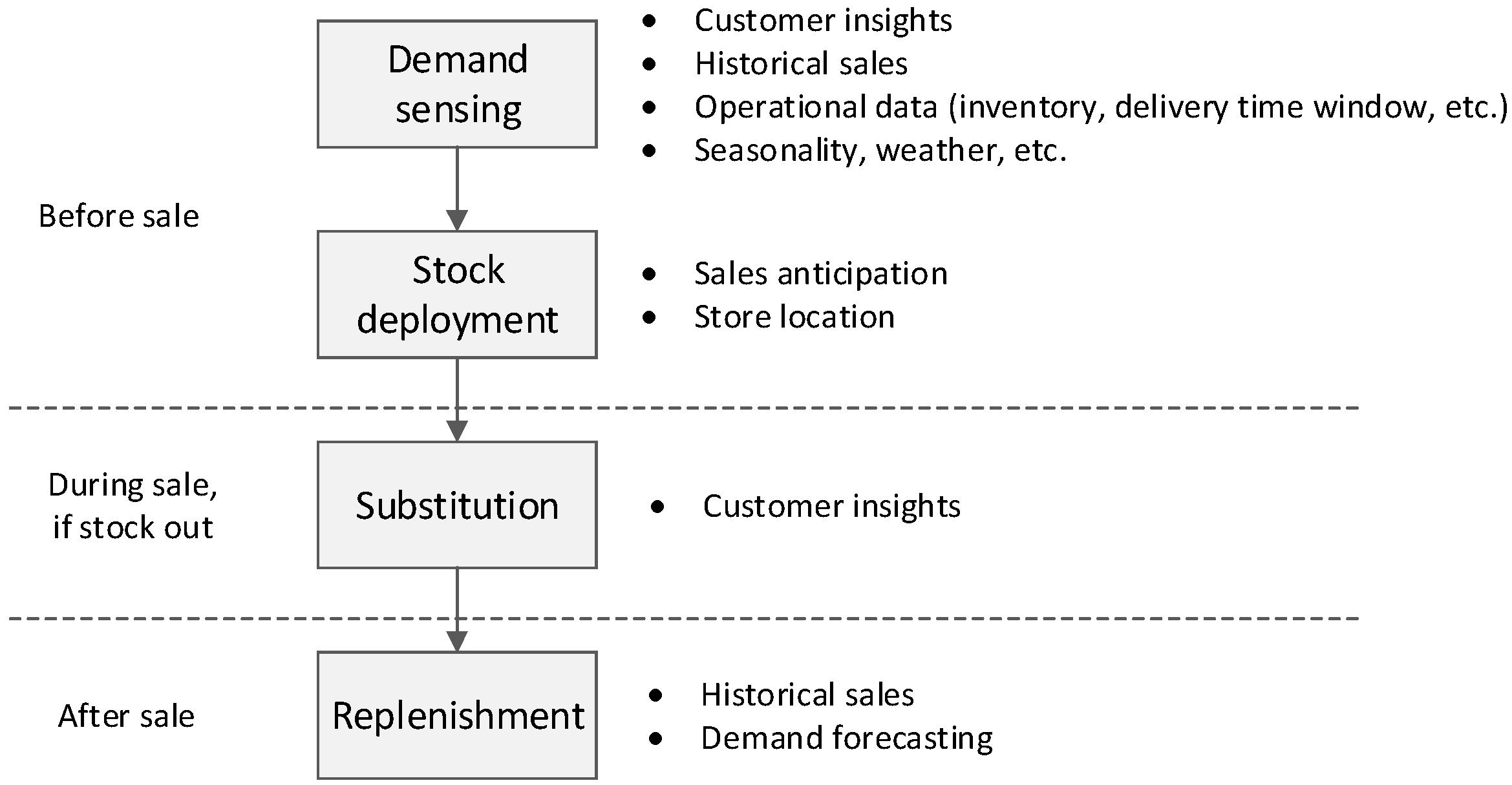
4.1. Availability
As availability can involve multiple processes and activities before and after sales, findings are further grouped into demand sensing (primarily in terms of volume, to avoid overlaps with ranging), stock deployment, replenishment and inventory management, and substitution management.
In terms of demand sensing, using historical sales data to forecast the future demand is a common practice among retailers, as is mentioned by many respondents (R3, R4, R5, R9, R10, R11, R13). However, the granularity and richness of insights obtained from these data can be different from one retailer to another. To start with, historical sales data can be used to identify trends and therefore make forecasts about future demand (I2E3, I4E21, I9E1). Based on this, some models would also have elements such as seasonality (I4E23, I9E12, I12E33), weather (I9E13), consumer behavior (I2E4, I2E14, I3E86, I10E6), lifestyle (I3E4, I3E5, I3E90), demographic (I12E4), delivery time window (I3E47, I9E11), inventory (I3E80, I4E24, I5E25), and store location (I8E33) to enrich the analysis. Seasonality and weather are quite straightforward to incorporate in models built to exploit big data; holidays such as Christmas or Easter coupled with weather temperature would influence sales on certain products (I2E18, I9E13, I9E14). Some would use this forecast to determine the purchase order quantity quarterly (I4E24, I4E39), but in extreme cases, this sort of forecast can be used to inform replenishments within a day (I3E49). Besides the purpose of analysis, the capability and the degree of sophistication in analysis are also the reasons for differences across retailers (I9E14).
Consumer behavior is another area for retailers to benefit from big data applications. With loyalty schemes, they can monitor customers’ purchase history, and gain some insights into customer preferences and demand patterns for each individual shopper, hence potentially better anticipating what a customer is going to buy in a shopping trip (I3E86, I3E90, I3E91, I3E92, I12E47, I12E51). However, this is not yet mature (I12E51). With more advanced location based technologies such as iBeacon, retailers would be able to update their forecasts if they detect a certain loyal customer stepping into a store (I3E88). If a retailer operates in more than one channel or even more than one business, they can collect more information about their customers’ lifestyles and build a clearer picture of the individual (I3E5, I12E4). This, coupled with demographic information can benefit retailers in demand sensing in a way similar to the loyalty scheme, but the demographic information is used at a more aggregated level.
Operational data can also be used to enrich the analysis of historical sales. Delivery time windows and inventory levels can help determine purchasing and replenishment quantities at a more granular level. Store locations enable sales to be analyzed per store or per region to inform stock deployment decisions. In addition, with more advanced technologies, demand information can be more visible further up the pipeline, and especially for general merchandise, items may be labeled to specific customers rather than to stores (I8E4, I10E28, I10E29).
Suppliers would also have their own analysis and sometimes share that with retailers, especially in the case of new product launches (I9E10, I9E33, I10E39, I10E40, I10E42, I10E44, I10E46, I11E11, I11E19). This is because historically, suppliers, especially big-brand manufacturers have the knowledge and the capability to analyze sales of their products. In addition, forecasting sales for new products would have more elements of an art than forecasting of existing products as there is no statistical data to inform the new product forecasts (I3E70). Sometimes it is possible for retailers to consider product characteristics from historical sales and compare it with the new product features (I4E8, I4E9, I9E10).
Although big data can help retailers to have better anticipation of future demand, the forecasts it supports may contain errors and should be treated with caution (I8E29, I8E31). Retailers can now personalize promotions, but to predict the demand it generates is still difficult in general, but possible in theory (I6E21, I7E6, I12E51). In addition, this information may not be capitalized on if actions it suggested are beyond the physical capability of the supply chain (I8E26, I12E29). Therefore, how the supply chain operates in terms of stock deployment and replenishment are indispensable components in delivering availability.
By analyzing the historical demand of stores or regions, retailers can deploy their stock more effectively by segmenting stores and understanding differences in demand patterns among them (I8E33, I8E35, I8E38, I8E41). This decision can be regarded as assortment in terms of volume and may include not only stores but also warehouses. Detailed transaction data enable retailers to analyze how each individual SKU performs in different stores, even at different times within a day (I8E38, I10E35). Therefore, retailers can make stock deployment decisions based on this. However, some retailers would also consider performance in clusters, as sales between stores with geographic proximity can be interrelated (I5E34, I12E27). In terms of sophistication in analysis, some retailers do this using an algorithm or a mathematical model (I8E39) and some rely on guesswork (I9E29, I9E31). More data with better quality can help improve sales and stock investment (I9E14, I9E17). Retailers are segmenting stores and this would also be reflected in the stock deployment decisions (I8E38, I12E22). For example, some stores may function more like a showroom or collection point (I5E6); therefore, do not necessarily have to maintain a high stock level. This is particularly the case for general merchandise.
In terms of the replenishment and inventory management, measuring availability is a crucial activity, as it triggers and drives replenishment decisions. Although measuring availability is not a new concept, with the advancement of technology and customers who are more demanding, what it means can be different. In a store environment, normally the customer would only interact with what is available on the shelf; therefore, on-shelf availability is what the retailers are interested in. However, what stock data retailers have on hand may only indicate the stock level in the stores, but not necessarily on the shelf, therefore, a discrepancy may exist between the physical stock and the stock records in the business systems (I3E29, I3E30, I8E1, I8E3, I9E16). One direct way to solve this problem is to conduct a stock check to make sure the data are up-to-date (I5E12, I9E19). These stock checks would also record gaps on the shelf and whether the customer chooses a substitute, especially in the environment of general merchandise, as staff can interact with customers and suggest substitutions (I2E10).
Indirectly, but maybe more cost effectively, some retailers also measure availability using sales data. They match historical demand patterns with actual demand at the SKU level, and if the actual demand is significantly lower than what is indicated in the pre-identified demand pattern, there might be gaps on the shelf (I3E45, I3E46, I3E52, I3E53, I3E56, I9E18). Similar to the case of demand sensing, differences in velocity are also identified. Some retailers would monitor this based on minutes (I3E53, I3E55), whereas some would do that in days (I9E18). To make sure the variances can reflect on-shelf availability, the retailer who monitors the variance in minutes would also monitor their rate of check out, making sure the differences come from stock outs, not from long queues at the till (I3E54).
Availability has evolved to reflect customer satisfaction level (I3E6, I10E55, I10E56). In the past, the indicator may refer to stock level at one point in time on a specific day; nowadays, it can refer to the stock level at any one time (I10E55). Replenishment process efficiency can be monitored at the store or shelf level. Replenishing the stores in the past would be done by generating a mass replenishment order at a certain time in a day, and that would capture all demand within a day (I3E48). A more advanced practice would be setting a reorder level, and when the stock is consumed to that level, placing an order (I9E3). To sum, these practices are similar in nature, which is to replenish what is sold and it is difficult to detect the lost sales.
Some retailers allow the store managers to place orders based on their anticipations (I9E5), in this way they can be more proactive in fulfilling future demand. However, since this would rely on the store manager’s own judgment, it might be used less frequently in the future (I9E7, I9E8). With advanced technologies, it is possible to integrate sales forecast, minimum presentation level of stock depending on space planning, delivery time windows, and sales in real time to manage the process more systematically. To be more specific, from sales forecast and delivery time windows, the retailer can work out what the demand would be between the next two deliveries; therefore, would be able to decide to which level the stock should be replenished to meet the demand (I3E48, I9E11). Taking the minimum presentation stock level into consideration could help adjust the quantity and make the order more economic (I3E80). Real time sales information could feed into the forecast and update it, but more importantly, it is used to calculate stock levels within the store (I3E92).
The abovementioned solution considers detailed demand forecasts; however, as forecasts contain error, retailers have developed another application to only respond to actual demand, the continuous replenishment method. In this case, demand would be accumulated as items go through the tills. Once what is sold (retailer’s order to its supplier) reaches the point where it can fill a vehicle, the order is released. In this way, replenishment transport is optimized (I3E50).
Although the focus of methods is different, both require the supply chain to be able to handle more items in smaller quantities and on a more frequent basis. It places new pressures on the supply chain in terms of responsiveness and reliability, and raises the standard for information technology (I10E23, I10E27, I10E58). Traditionally, supply chain activities end at the point when stocks are replenished to the stores (I10E24). However, to realize the benefit from the above-mentioned applications, replenishing activities within stores should also be part of the solution, as it can influence the overall responsiveness as well as discrepancy between stock data and actual stock level on the shelf. This notion starts when some retailers start fulfilling online orders by picking inside the stores and finding their actual on-shelf availability is below what they expect (I3E28, I3E31). The discrepancy, as a shocking fact for retailers, drives them to make the process of moving stock from the back of the receiving area to the shelf more smoothly and efficiently (I3E32), considering also package size and shelf design (I3E79). Ideally, all goods within one case could be filled into the shelf in one ‘touch’ (I3E80), which necessitates shelf and space planning.
Although retailers have been trying to improve availability, stock-outs and substitutions are inevitable. Managing the stock-out situations effectively can affect customer experience, especially for grocery home delivery, as customers do not have the opportunity to choose substitutions themselves, whereas in a store environment, especially for general merchandise, staff can suggest substitutions (I2E10) or consumers themselves can find similar products to the items that have stocked-out. In the past, retailers tended to substitute items with lower value, however they found customers are not quite satisfied with this (I3E35). Today the retailers provide substitute products that are more valuable than the customer’s original order, increasing the value of the basket size (I3E38). Overtime, retailers will accumulate a pool of information on acceptance rates for substitutions and hence will be able to make better decisions on substitute products. In addition, with loyalty scheme data, the acceptance rate can be based on individual customers and therefore can suggest substitutions that are more likely to be accepted for a specific item in an order placed by a specific consumer (I3E39).
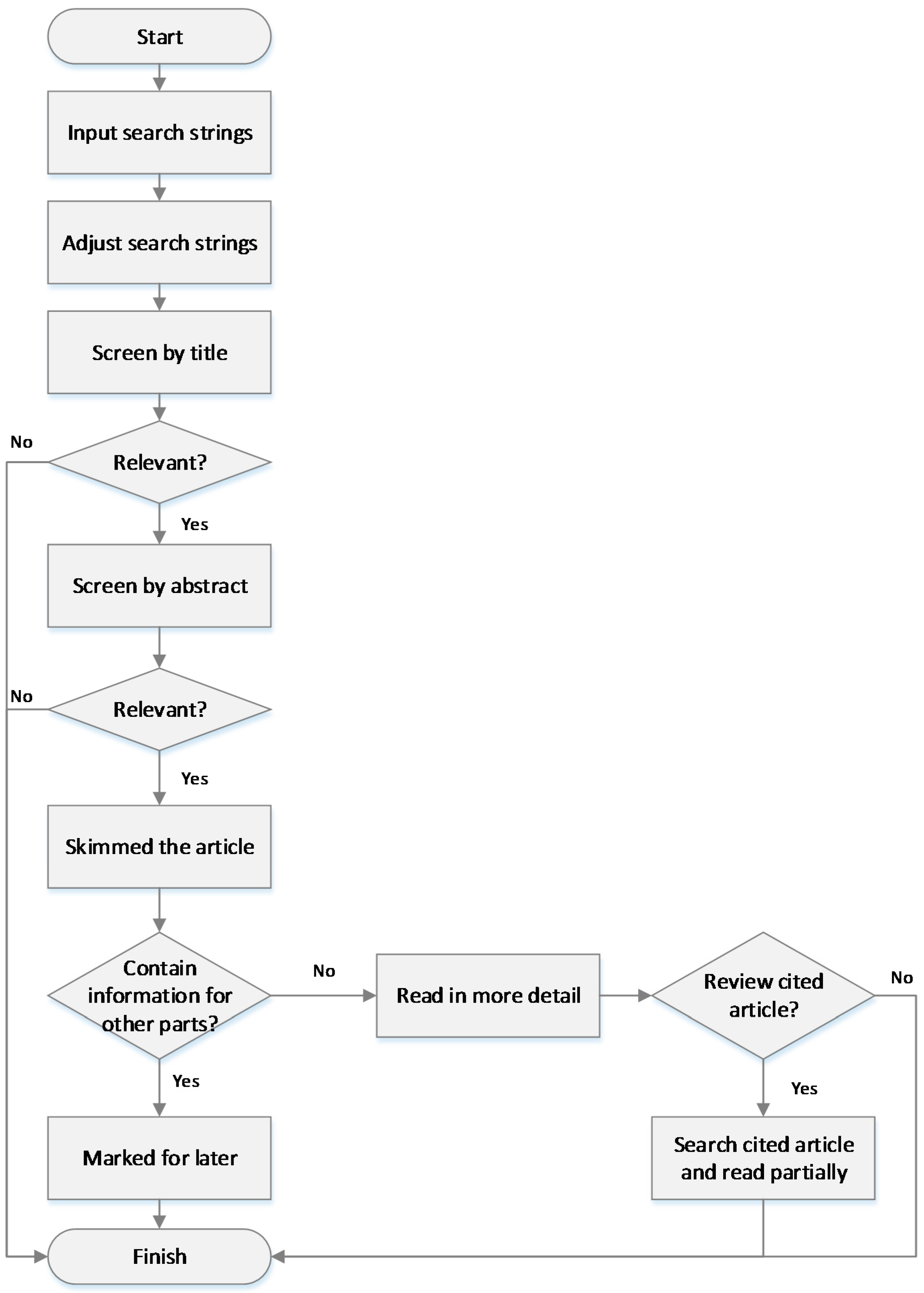
The availability issues encompass several activities before and after the sale. Big data have potential to be used in all these aspects, as shown in
Figure 2.
Before sales, demand sensing and forecasting is the starting point for the rest of the activities. Sophisticated methods and algorithms that involve several different factors, such as customer insights, historical data, weather forecasting, etc., are used. Then, stock is deployed to individual stores based on anticipated demand. In case of stock-outs, effective substitution management prevents poor customer experience. Customer insights can be used to propose alternatives that are more likely to be accepted. Once stock level goes down, the replenishment process should be sufficiently effective to support further sales. Velocity in transmitting sales data can help detect gaps on the shelf and forecasted demand to be more proactive.
4.2. Assortment Planning
Historical sales data is the major source for making assortment decisions in most retailers. Typically, retailers examine what sells well in a specific fashion or category (I3E67, I4E1, I4E6, I9E10, I9E31), and then use this information to reach an assortment decision. In addition to the sales, retailers also consider the margin performance, although it acts more like an incentive and target (I4E12, I6E14). Some retailers consider forecasted sales of specific products in certain stores together with the margin to decide if it is economic to range the item (I3E64, I8E39), whereas others carry out assortment trials and review the results (I3E63, I3E65). Companies that do not analyze assortment decisions in detail mainly lack the capabilities to approach assortment planning scientifically (I9E34).
Whether to conduct trials or not would also depend on the nature of the business. Some businesses are rigorous in controlling the range of their products to get true cost advantages (I3E60, I3E66). In these cases, the number of SKUs they carry is stable, so items need to demonstrate the ability to have better performance in terms of the range offered in stores (I3E64). In contrast, other businesses choose to grow in variety and give items the opportunity to be tested in the store environment as part of the assortment decision (I3E65). Due to the space constraints of physical stores, it might not be possible to range all products in the store (I9E35), which is tightly linked to space planning. The retailers generally decide on the SKUs to present in the store, but some retailers also consider store performance in clusters as part of planning the stock deployment (I5E34).
Consumer insight data have the potential to enrich sales data and help localize ranging decisions for stores; however, this idea has not matured sufficiently yet to be of any real use in operations (I10E5, I12E32). Consumer insights are more often used to identify trends in the long term, and the marketing team is using this to segment shoppers for marketing purposes (I2E3, I6E5). Historical sales data merged with loyalty schemes can help the retailer understand not only what has been bought but also who bought it (I6E15, I12E10, I12E11). If this information can be linked to customer lifestyles, assortment decisions can be made more effectively (I10E11, I12E12). Tuning product range to a different time within a day for each individual store is possible, so the same store could carry different products in the same day to meet customer demand more effectively (I10E8, I10E34). For example, the data may be able to tell that most customers of a specific store are people who work nearby; therefore, during lunchtime, sandwiches and hot meals sell better, whereas in the afternoon, evening ready meals are more popular. Some retailers are learning to adapt their assortment accordingly, but this idea is yet to mature (I10E9, I10E10, I10E35).
A rather mature application is to examine repeat purchases as a reliable source to judge the success of a product (I5E20). If a consumer declines to buy a product twice it is likely that the demand will decline when there is a lack of first time purchasers. Although historically retailers would segment stores according to demographic factors (I12E25, I12E26), consumer insights data give them new evidence on this aspect (I10E12, I12E27). This type of segmentation enables retailers to make judgements on what is more likely to be sold in which store. The analysis technology enables product ranges to be changed more frequently to meet the demand, but it is unknown if the supply chain has the physical capability to carry that out (I6E36, I8E32, I10E13, I12E29), and consumers may not get used to frequent changes on ranging; therefore, it may even have an opposite effect (I10E13).
Collaboration with suppliers can benefit the assortment planning, although suppliers may have their own anticipation and that may not necessarily be the same as those shared by retailers (I3E72, I9E9, I9E33, I10E39, I10E43, I10E45, I11E10). This is because suppliers tend to be more focused when analyzing how a specific item performs and what element drives the sales up for that item, whereas retailers are more interested in performances across retail estates (I10E39, I10E40). Therefore, especially in the case of launching a new product, the supplier would have a better idea of how new products share similarities with existing products and have a better anticipation of demand consequently (I9E9). It is possible to exploit big data by integrating supplier and retailer data when launching new products collaboratively (I9E9, I11E10).
On the other hand, if the retailer could share certain sales information of products with suppliers, suppliers could make better forecasts as the input data quality is improved (I10E41). Using repeat purchases to determine if products are successful is an example of this (R7E16). However, not all suppliers have the capability to analyze such data and therefore, not all suppliers are interested in such information (I3E19, I3E20, I6E26). What retailers would do consequently is to tier suppliers, and have a different degree of information exchange and monetize that exchange at different degrees (I3E21, I4E40). While some retailers would have a portal for suppliers to access such data (I3E18), some retailers would exchange information by communication documents (I9E9).
Besides anticipating sales collaboratively, another reason for retailers to work with suppliers in coordinating retail logistics is that suppliers, especially big-brand manufactures, would put certain marketing budgets behind their product, and some of these budgets would go to retailers as a listing fee (I3E69). There would still be room for better collaboration between the two parties to improve the decision-making (I10E41, I11E11, I11E12) where the trust between the two sides may pose an issue (I3E71).
4.3. Pricing
Pricing is an essential element in the retail business, and differences in pricing strategies are identified across companies from the interviews. Some companies would have a pre-defined price band for their product range (I4E10, I9-This retailer has only pre-set price for their products) where dynamic pricing would not be applicable in the selling season, but relevant for regular price reviews across the year. Alternatively, these companies focus on working out the purchase cost and push that back to customers (I4E18). Some retailers have an overall pricing strategy, i.e., ‘so much higher than the competitors’ for everyday prices, but are flexible at the SKU level (I2E41, I5E28, I10E17). In these cases, retailers would include competition and margins to work out prices (I2E43, I5E30). Some retailers would also monitor sell-through rate, which is the number of products that can be sold before they are discounted, as an indicator to judge the success of pricing decisions. If the rate is not as expected, they would revise the price (I2E42). In some cases, the retailer would build these elements into a pricing algorithm so that they are able to respond to competition more swiftly and update the price more regularly, even daily (I5E28). However, stock information must be built into such an algorithm that takes availability into consideration (I5E29).
Although the analysis can be run daily, retailers may not necessarily change the prices that frequently, especially those operate in more than one channel. Changing the prices on the website is relatively easy compared to the off-line channel. The retailers mention that they have put effort into price consistency, but it is difficult to keep it stable and their customers are now aware of the differences between channels (I5E31). If the dynamic pricing strategy is extended to the off-line channel, technologies such as digital price tags for display prices will be indispensable (I10E58).
Promotions are a special case in pricing and a traditional marketing activity; customer insights data is used more heavily in this area (I10E52). With loyalty scheme data, retailers can build a more complete picture of how people react to price changes and their preferences; therefore, they can personalize offers for individual customers according to purchase history (I3E7, I12E16, I12E17). Over time, as retailers accumulate more data about how customers shop, the models they use in discounting products become more refined. For example, retailers can trace customer browsing history in the online channel and identify when and after how much time a customer drops out (I3E23). In the past, retailers may have sent a customer a discount offer about the item, which the customer would have viewed, straight away. Today the retailer realizes the shopping journey: customers compare the product with similar items or in different retailers, ask people’s view on it, visit the store to try the product off-line, etc.; consequently, retailers would not send out the offer so soon (I3E11).
Big data and the insights from it can be used to improve space utilization and to maximize the range within a limited space as well as to improve the attractiveness of the store and maximize the sales on a limited range. Big data has recently been incorporated to the processes that inform stock location decisions (I10E52). Retailers would segment stores according to demand patterns and demography, besides stock deployment and ranging, this segmentation would also influence layout and space planning. Retailers would have a standard design based on store types, although they can still use different sizes (I3E74). When considering utilization, the challenge is to fit more ranges into a limited space. Some retailers can only get 40% of their range into one store (I9E35).
Retailers would use computer modelling to optimize space based on the forecasted sales (I3E78, I6E9). With advanced technologies, it is possible to develop 3D models for the store layout design (I3E84). To do this, product information such as volume, weight, and dimensions as well as shelf specifications such as height, width, and depth would need to be included in the model (I3E78). Combined with the forecasted sales rate, the model can work out how many facings are needed for a specific product (I3E81, I12E15).
As the planning is on product or packaging size, it is not surprising that this has always been a collaborative activity with suppliers (I10E48). To make the replenishment process more efficient, the packaging size should allow fitting a complete incoming case into the shelf so that the retailer does not need to replenish piece by piece (I3E80). This would also influence the minimum presentation stock level. Because the retailer would prefer to replenish a complete case at a time, it is acceptable to have fewer items on the shelf which can be easily replenished, keeping the display looking good (I3E80). This practice is already adopted by some retailers and there are also other retailers who have a plan to implement this soon (I9E37). Although the packaging sizes are decreasing to use the shelf space more efficiently, this is not a sustainable way for the future as this may introduce more variances in packaging size and stresses the supply chain (I10E53). Therefore, the feasible way may be dynamic ranging and dynamic shelf space to use the shelves more effectively (I10E51, I10E54).
Whereas the utilization aims to increase sales by increasing the range, attractiveness deals with how to increase sales of limited range. This can be achieved by making the shopping journey more pleasant for customers (I2E36, I12E28). One application is a heat-mapping planogram based on historical sales data (I2E34, I3E87). Fast moving items would be presented as ‘hot spots’ and slow moving items as ‘cold spots’. If hot spots are moved around cold spots, slow moving items could be exposed to more customers (I2E35, I3E93). Consequently, sales may be increased. In addition, this ‘hot’ and ‘cold’ difference can go down to different levels on a shelf (I3E81).
Analyzing correlations among the items purchased in one basket can inform which products should be placed near each other (I3E94, I10E50). However, this is still a conceptual application although there are ‘stories’ (I3E94, I10E52), such as placing nappies next to beer for fathers doing the grocery shopping. Similarly, another way for the layout planning to prompt more purchases is to understand the ‘mission’ customers have when they are shopping, and use that information to plan layouts that are convenient to them (I12E28).
Effort that has been put into reflecting the trends on store design to appeal customers and therefore the layout may change significantly if the range of products to be displayed or trend is changed (I2E36, I3E63). Big data can help in terms of identifying those trends. Unlike utilization, attractiveness is more difficult to measure, at least in the design phase. Therefore, retailers could set up pilot stores to see if the new design is working before it is rolled out (I2E39, I3E83). There are also retailers who do not have fixed layouts and are very flexible in placing stocks (I5E35). In any case, some techniques in warehouse design, such as placing certain items near checkouts are applied to enable customers flow through the store more quickly (I5E36).
4.4. Challenges
There is great potential to use big data and analysis methods to improve retail operations; however, some challenges are also identified in interviews. These challenges are grouped into managerial issues, people and capabilities, technical issues, and customer concerns around privacy.
4.4.1. Managerial Issues
Managerial issues refer to the culture within an organization and the process integration that is required for successful big data applications and implementation of learnings. Main issues are being open to changes even if there is a possibility of failure, and information sharing. Implementing big data applications can mean the traditional processes need to be changed and people within the organization can be resistant to these changes (I6E24). The organization should be curious and open to innovative ways of running the business, although the new process cannot guarantee success (I8E42). In more advance retailing, there is a culture that can be called ‘fast fail’ (I3E100) and it has two parts to its meaning: The first part is to be a little more adventurous and open to new opportunities when success is not guaranteed (I3E102), which does not tend to sit well in traditional retailing (I3E101). The second part is that once the change has proven to be faulty, they should be able to get out of it quickly before further resources are invested (I3E100). This is validated as respondents mentioned trials and prototypes having been carried out and tested for improving big data applications (I2E40, I5E29, I5E38, I9E36).
Another managerial issue is the willingness to integrate processes and share information between functions. Currently more organizations are starting to exploit the value of data; however, historically these data are handled in isolation (I10E38). In some cases, people in different positions would make their own analysis and manipulate data for their own interests (I5E17); therefore, effort would be spent in reaching an agreement rather than solving problems. If data cannot be integrated for further analysis or solutions carried out without impact are fully assessed, it would have the opposite result once implemented (I8E24). A typical example may be promotions. If the customer-facing team wants to implement promotions within a time frame that is not aligned with the supply chain capability, it is possible that the availability cannot be assured and the customer would be let down (I8E24). Even within the same function, if information is not shared, there is a risk to obtain different results from different data sets (I12E7). In short, faster and more robust analyses are only possible when people work in alignment (I3E103).
4.4.2. People and Capabilities
Before implementing big data analysis to enhance current retail operations the following issues should be addressed: people, timeliness, and support from suppliers. One of the barriers for implementing more advanced data analysis is the lack of human resources with the right skills set, which may be different for each organization. Sometimes there are not enough people to use the system effectively; especially when they try to consolidate functions and integrate processes, some experts are lost along the way (I4E30). Training the people to use the system is relatively easy (I1E22), and it is not too difficult to find people who can produce and analyze complex data (I5E15). However, there are no right people to interpret the analysis results and develop insights, especially when it comes to integrating data across organizations (I5E15). A third party would be used to help retailers in this (I5E39, I10E42), but a third party can only be useful for specific analyses, if the organization has a clear idea of what is going to be analyzed and in what way (I8). When it comes to interpreting data, it is important and more reliable to have in-house or fully controlled data analysis capability (I12—The company did not provide services to competitors of its main client).
Besides interpreting the data, organizations should also be able to have foresight and understand how things can be improved with knock-on effects (I3E96). To do this, organizations need people who are motivated by data and who would be able to find solutions to the problems that might arise from the data, understand patterns, implications, and then develop and test hypotheses (I3E96, I3E98). These people are difficult to find and are expensive to keep (I3E97, I3E98).
Timeliness is a challenge for either implementing solutions or further enhancing current retail operations practices. Main issues include data processing and reporting, physical capability as well as managerial issues. Firstly, data need to be processed in a more timely manner, and this could mean that improvements in both hardware and software are needed. The IT infrastructure within the organization might be old and need to be updated to enable a faster and more sophisticated analysis (I6E36, I6E37). In addition, in terms of software, most retailers have a degree of batch processing built in, which hinders the system from handling information in real time (I10E59). Besides, in many cases data are available, but not reported in a format that can be worked on (I1E20, I2E22, I8E23); therefore, the overall process of analyzing and interpreting data is not prompt enough.
Other issues, such as not having the right skills set and managerial issues also have an influence on the overall responsiveness. Lastly, some companies do not have the physical capability with sufficient agility to leverage the data (I8E32, I12E29). For example, if retailers want to implement dynamic assortment in their stores, the supply chain would need to be able to handle more items in smaller quantities and on a more frequent basis (I10E19, I10E20), which may not be easily achieved.
When leveraging the big data for retail operations, it is important that suppliers provide the necessary support (I2E15, I5E41, I5E48). This is straightforward for a collaborative process such as space planning. In addition, supplier performance can also influence other activities. For example, if the supplier cannot deliver products as required by the retailer, no matter how advanced the replenishment process, availability cannot be ensured (I5E44). Retailers who performed better in availability mentioned that they have had good relationships with suppliers, and the supply chain is geared up to enable them to be responsive (I2E15). A retailer who realizes the problem has initiatives to interact with suppliers more frequently (I5E48).
4.4.3. Technical and Data Issues
IT integration impacts data quality and data availability. Companies have many different systems managed by different functions historically, and linking these together is a challenge (I1E1, I11E25). While some companies have overcome this challenge (I1E9, I2E23, I12E8), some are just starting to tackle it (I4E5, I8E23, I11E26). The integration process, the lack of clarification in data generating processes, and different format of data lead to poor data quality (I4E29, I8E22). Manually created data are likely to have many errors, especially when there are several different systems in use (I5E54, I11E16, I11E17, I11E18).
The data available still have value to be discovered (I3E95, I6E23, I8E28, I10E36). Transactional data are available at a detailed level and storing the data is no longer an issue (I1E25, I8E28). The barrier now is how these data are reported and accessed (I10E38). This is partly a historical issue because systems have originally been set up for different purposes (I8E44, I8E46, I10E38). These data are handled in isolation by different functions resulting in different kinds of reporting schemes. Retailers try to maintain the integrity of these reports (I8E23) and develop reporting tools for further analysis (I1E26, I11E29). However, reporting requirements from other functions can change frequently (I1E18) and be challenging depending on the requirements (I1E19).
4.4.4. Customer Concerns over Privacy
Lastly, customer concerns over privacy may hinder the retailer from implementing big data applications because it can prevent retailers from using customer data for specific operational decisions. When the customers realize the value of sharing their data to get for example personalized offers, they might not have an objection for their data to be used (I3E105). In the past, consumers were quite nervous about retailers having insight into their life (I3E8). More recently, they would expect personalized offers from retailers (I3E9). Customers’ attitude towards big data solutions around their data have changed, because of the benefit they get from sharing their data. Although some people do not prefer sharing their data, the customer pool is sufficiently large to allow retailers to make inferences about shoppers who are not included in their loyalty schemes (I3E107).
Customer insights, as a most-recognized big data benefit, play a role in all these activities. In some cases, data do not necessarily need to be analyzed to yield insights. The sheer granularity and volume can help businesses improve the process, for example, in the case of optimizing replenishment deliveries according to customer demand. In addition, insights yielded from proposed applications, for example, customer demand, is not new in concept, but with better granularity and velocity, and if used more integrally it can lead to significant improvements. “The principle of supply chain has not really changed, what has changed is the degree of granularity and the acuteness of the need for all activities to be working optimally” (I10E30), and advanced technologies and big data applications enable this.




{kind=link}
{kind=link}
{kind=link}