How Much Credence Does It Take? Evidence on the Trade-Off between Country-Of-Origin Information and Credence Attributes for Beef from a Choice Experiment in Sweden


Abstract
1. Introduction
2. Theoretical Background
2.1. Cue-Based Decision Making
2.2. Information Processing and Use of Labels
3. Material and Methods
3.1. Recruitment and Data Collection
3.2. Stimuli: The Discrete Choice Experiment
3.3. Statistical Analysis
- The model was set to explain the choice of the dependent variable ‘EU/non-EU origin’ as a function of price level and the number of additional attributes provided as explanatory variables X.
- Alternative specifications of Z were estimated as random effects; the selection of the best random effects specification was based on Likelihood Ratio tests for model selection.
- The model was tested under alternative specifications of the explanatory variables, treating ‘Price level’ and ‘Number of information items provided’ as either discrete or continuous variables or as a combination thereof.
- In a second set of regressions, the variable containing the number of information attributes was replaced by dummy variables for the actual information categories that were provided.
4. Results
4.1. Consumer Use of Labelling Information
4.2. Attribute Information Search
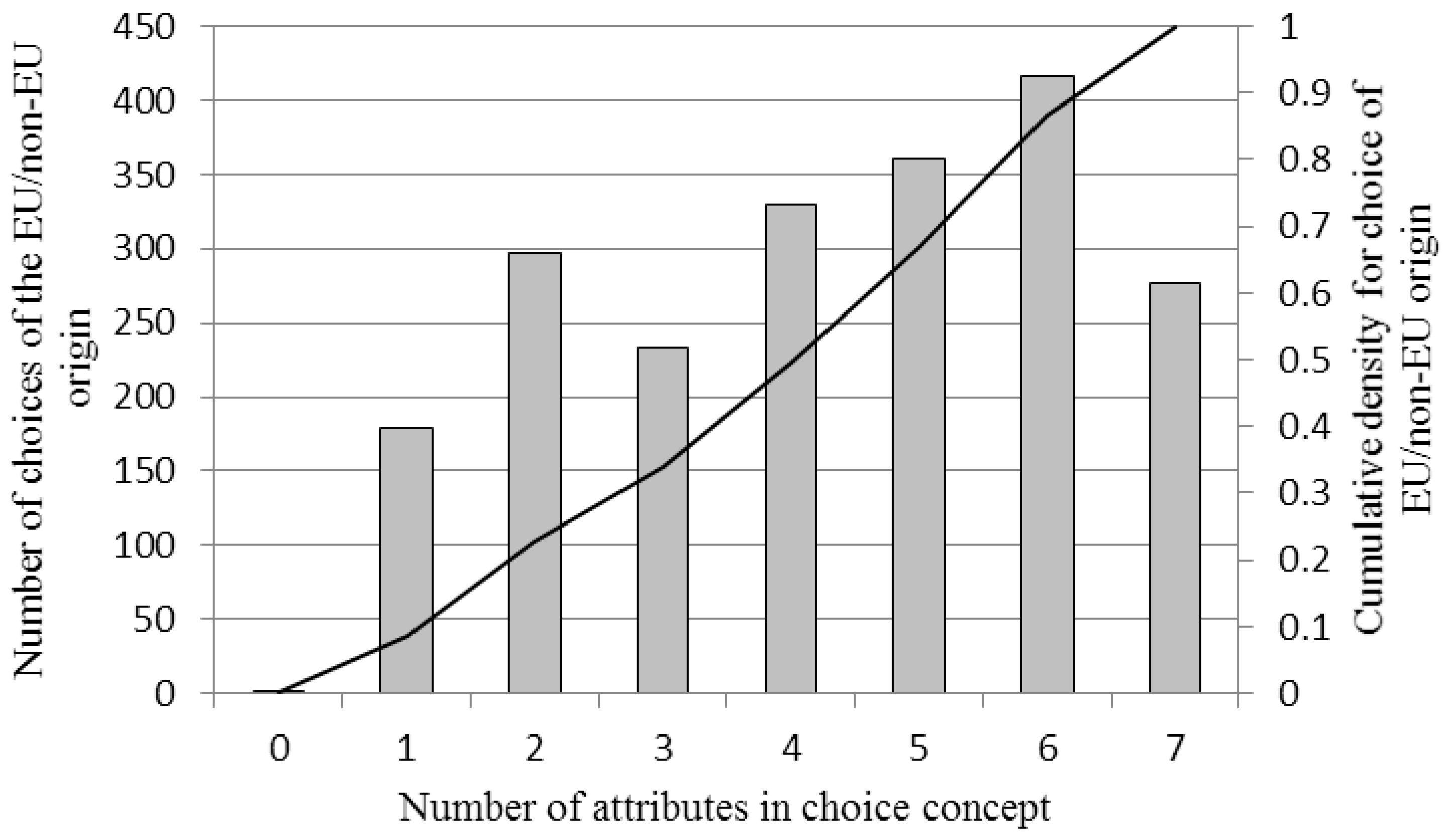
4.3. Amount of Information Sought
4.4. Content and Compensatory Effects Related to Origin
5. Discussion
5.1. Amount of Information Sought
5.2. Content and Compensatory Effects Related to Origin
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Grunert, K.G. Current issues in the analysis of consumer food choice. In Proceedings of the Food Consumer in the Early 21st Century, Zaragoza, Spain, 19–20 April 2001; Agricultural Economic Unit: Zaragoza, Aragon, Spain, 2001. [Google Scholar]
- Bernués, A.; Olaizola, A.; Corcoran, K. Labelling information demanded by European consumers and relationships with purchasing motives, quality and safety of meat. Meat Sci. 2003, 65, 1095–1106. [Google Scholar] [CrossRef]
- Kehlbacher, A.; Bennet, R.; Balcombe, K. Measuring the consumer benefits of improving farm animal welfare to inform welfare labelling. Food Policy 2012, 37, 627–633. [Google Scholar] [CrossRef]
- Cowan, C. Irish and European consumer view on food safety. J. Food Saf. 1998, 18, 275–295. [Google Scholar] [CrossRef]
- Verbeke, W.; Pérez-Cueto, F.J.A.; de Barcellos, M.D.; Krystallis, A.; Grunert, K.G. European citizen and consumer attitudes and preferences regarding beef and pork. Meat Sci. 2010, 84, 284–292. [Google Scholar] [CrossRef] [PubMed]
- Dickinson, D.L.; Bailey, D. Meat traceability: Are US consumers willing to pay for it? J. Agr. Resour. Econ. 2002, 27, 348–364. [Google Scholar]
- Study on ‘Mandatory Origin Labelling for Pig, Poultry and Sheep and Goat Meat’. 2013. Available online: https://ec.europa.eu/agriculture/external-studies/origin-labelling-2013_sv (accessed on 30 May 2017).
- Jacoby, J.; Speller, D.E.; Kohn-Berning, C.A. Brand choice behavior as a function of information load: Replication and extension. J. Consum. Res. 1974, 1, 33–42. [Google Scholar] [CrossRef]
- Hamlin, R.P. Cue-based decision making. A new framework for understanding the uninvolved food consumer. Appetite 2010, 55, 89–98. [Google Scholar] [CrossRef] [PubMed]
- Hirsch, F. Social Limits to Growth; Routledge & Kegan: London, UK, 1977. [Google Scholar]
- Zand, D.E. Information, Organization and Power: Effective Management in the Knowledge Society; McGraw-Hill: New York, NY, USA, 1981. [Google Scholar]
- Bettman, J.R. An Information Processing Theory of Consumer Choice; Addison-Wesley: Reading, MA, USA, 1979. [Google Scholar]
- Bettman, J.R.; Jacoby, J. Patterns of Processing in Consumer Information Acquisition; Anderson, B.B., Ed.; Association for Consumer Research: Provo, UT, USA, 1976; Volume 3, pp. 315–320. [Google Scholar]
- Alba, J.J.; Hutchinson, J.W.; Lynch, J.G., Jr. Memory and Decision Making; Robertson, T.S., Kassarjian, H.H., Eds.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1991; pp. 1–49. [Google Scholar]
- Van Ittersum, K.; Pennings, J.M.P.; Wansink, B.; Trijp, H.C.M. The validity of attribute-importance measurement: A review. J. Bus. Res. 2007, 60, 1177–1190. [Google Scholar] [CrossRef]
- Olson, J.C.; Jacoby, J. Cue Utilization in the Quality Perception Process. In Proceedings of the Third Annual Conference of the Association for Consumer Research, Chicago, IL, USA, 3–5 November 1972; Venkatesan, M., Ed.; Association for Consumer Research: Chicago, IL, USA, 1972; pp. 167–179. [Google Scholar]
- Park, C.W.; Lessig, V.P. Familiarity and its impact on consumer decision biases and heuristics. J. Consum. Res. 1981, 8, 223–230. [Google Scholar] [CrossRef]
- Han, C.M.; Terpstra, V. Country-of-origin effects for uni-national and bi-national products. J. Int. Bus. Stud. 1988, 19, 235–255. [Google Scholar] [CrossRef]
- Verlegh, P.W.J.; Steenkamp, J-B.E.M. A review and meta-analysis of country-of-origin research. J. Econ. Psychol. 1999, 20, 521–546. [Google Scholar] [CrossRef]
- Shimp, T.A.; Sharma, S. Consumer ethnocentrism: Construction and validation of the CETSCALE. J. Mark. Res. 1987, 24, 280–289. [Google Scholar] [CrossRef]
- Chisik, R. Export industry policy and reputational comparative advantage. J. Int. Econ. 2003, 59, 423–451. [Google Scholar] [CrossRef]
- Grunert, K.G.; Juhl, H.J.; Esbjerg, L.; Jensen, B.B.; Bech-Larsen, T.; Brunsø, K.; Madsen, C.O. Comparing methods for measuring consumer willingness to pay for basic and improved ready-made soup product. Food Qual. Preference 2009, 20, 607–619. [Google Scholar] [CrossRef]
- Lockshin, L.; Jarvis, W.; d´Hauteville, F.; Perrouty, J-P. Using simulations from discrete choice experiments to measure consumer sensitivity to brand, region, price and awards in wine choice. Food Qual. Preference 2006, 17, 166–178. [Google Scholar] [CrossRef]
- Verbeke, W.; Ward, R.W. Consumer interest in information cues denoting quality, traceability and origin. An application of ordered probit models to beef labels. Food Qual. Preference 2006, 17, 453–467. [Google Scholar] [CrossRef]
- Gao, Z.; Schroeder, T.C. Effects of label information on consumer willingness-to-pay for food attributes. Am. J. Agric. Econ. 2009, 91, 795–809. [Google Scholar] [CrossRef]
- Gracia, A.; Loureiro, M.L.; Nayga, R.M., Jr. Consumers valuation of nutritional information: A choice experiment study. Food Qual. Preference 2009, 20, 463–471. [Google Scholar] [CrossRef]
- Balcome, K.; Fraser, I. A general treatment of ‘don’t know’ responses from choice experiments. Eur. Rev. Agric. Econ. 2011, 38, 171–191. [Google Scholar] [CrossRef]
- Caputo, V.; Scarpa, R.; Nayga, R.M., Jr. Cue versus independent food attributes: the effect of adding attributes in choice experiments. Eur. Rev. Agric. Econ. 2017, 44, 211–230. [Google Scholar] [CrossRef]
- Hensher, D. How do respondents process stated choice experiments? Attribute consideration under varying information load. J. Appl. Econom. 2006, 21, 861–878. [Google Scholar] [CrossRef]
- Green, P.E. On the design of choice experiments involving multi-factor alternatives. J. Consum. Res. 1974, 1, 61–68. [Google Scholar] [CrossRef]
- Green, P.E.; Srinivasan, V. Conjoint analysis in marketing: new developments with implications for research and practice. J. Mark. 1990, 54, 3–19. [Google Scholar] [CrossRef]
- Bradley, M.; Daly, A. Use of the logit scaling approach to test for rank-order and fatigue effects in stated preference data. Transportation 1994, 21, 167–184. [Google Scholar] [CrossRef]
- Hess, S.; Hensher, D.; Daly, A.J. Not bored yet—revisiting respondent fatigue in stated choice experiments. Transport. Res. A-Policy Pract. 2012, 46, 626–644. [Google Scholar] [CrossRef]
- Louviere, J.J.; Islam, T.; Wasi, N.; Street, D.; Burgess, L. Designing discrete choice experiments: Do optimal design come at a price? J. Consum. Res. 2008, 35, 360–375. [Google Scholar] [CrossRef]
- Johnson, R.; Orme, B. How Many Questions should You Ask in Choice-Based Conjoint Studies? American Marketing Association Advanced Research Forum: Beaver Creek, CO, USA, 1996. [Google Scholar]
- Bateman, I.; Carson, R.; Dupont, D.; Day, B.; Louviere, J.J.; Morimoto, S.; Scarpa, R.; Wang, P. Choice set awareness and ordering effects in choice experiments. In Proceedings of the 16th Annual Conference of the European Association of Environmental and Resource Economics (EAERE), Gothenburg, Sweden, 25–28 June 2008; p. 44. [Google Scholar]
- Carlsson, F.; Mørkbak, M.R.; Olsen, S.B. The first time is the hardest: A test of ordering effects in choice experiments. J. Choice Model. 2012, 5, 19–37. [Google Scholar] [CrossRef]
- Sándor, Z.; Wedel, M. Heterogeneous conjoint choice designs. J. Mark. Res. 2005, 42, 210–218. [Google Scholar] [CrossRef]
- Louviere, J.J.; Flynn, T.N.; Carson, T.T. Discrete choice experiments are not conjoint analysis. J. Choice Model. 2010, 3, 57–72. [Google Scholar] [CrossRef]
- Pinheiro, J.; Bates, D. Mixed-Effects Models in S and S-PLUS; Springer: New York, NY, USA, 2000. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- R Development Core Team. R, A Language and Environment for Statistical Computing. Available online: http://www.R-project.org.(accessed on 15 June 2017).
- Fernihough, A. Simple Logit and Probit Marginal Effects in R; University College Dublin: Dublin, Ireland, 2011. [Google Scholar]
- Luomala, H.T. Exploring the role of food origin as a source of meanings for consumers and as a determinant of consumers’ actual food choices. J. Bus. Res. 2007, 60, 122–129. [Google Scholar] [CrossRef]
- Van der Lans, I.A.; Van Ittersum, K.; De Cicco, A.; Loseby, M. The role of the region of origin and EU certificates of origin in consumer evaluation of food products. Eur. Rev. Agric. Econ. 2001, 28, 451–477. [Google Scholar] [CrossRef]
- Alfnes, F. Stated preferences for imported and hormone-treated beef: Application of a mixed logit model. Eur. Rev. Agric. Econ. 2004, 31, 19–37. [Google Scholar] [CrossRef]
- Lagerkvist, C.J.; Berthelsen, T.; Sundström, K.; Johansson, H. Country of origin or EU/non-EU labelling of beef? Comparing structural reliability and validity of discrete choice experiments for measurement of consumer preferences for origin and extrinsic quality cues. Food Qual. Preference 2014, 34, 50–61. [Google Scholar] [CrossRef]
- Tonsor, G.T.; Schroeder, T.C.; Lusk, J.L. Consumer valuation of alternative meat origin labels. J. Agr. Econ. 2012, 64, 676–692. [Google Scholar] [CrossRef]
- Verbeke, W.; Roosen, J. Market differentiation potential of origin, quality and traceability labelling. Estey Centre J. Intern. Law Trade Policy 2009, 10, 20–35. [Google Scholar]
- Mesías, F.J.; Escibano, M.; de Ledesma, A.R.; Pulindo, F. Consumers’ preferences for beef in the Spanish region of Extremedura: A study using conjoint analysis. J. Sci. Food Agric. 2005, 85, 2487–2494. [Google Scholar] [CrossRef]
- Kearney, J. Food consumption trends and drivers. Philos. Trans. R. Soc. B 2010, 365, 2793–2807. [Google Scholar] [CrossRef] [PubMed]
- Hansson, H.; Lagerkvist, C.J. Decision making for animal health and welfare: integrating risk-benefit analysis with prospect theory. Risk Anal. 2014, 34, 1149–1159. [Google Scholar] [CrossRef] [PubMed]
- Lagerkvist, C.J.; Carlsson, F.; Viske, D. Swedish Consumer Preferences for Animal Welfare and Biotech: A Choice Experiment. AgBioForum 2006, 9, 51–58. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Category | Proportion |
|---|---|---|
| Age a | 18–34 | 29.9 |
| 35–49 | 35.1 | |
| 50–75 | 45.0 | |
| Gender b | Male | 54.0 |
| Female | 46.0 | |
| Household income (gross monthly) | ≤SEK 20,000 | 11.3 |
| SEK 20–40,000 | 30.2 | |
| SEK 40,001–60,000 | 31.5 | |
| ≥SEK 60,000 | 14.1 | |
| No information | 12.9 | |
| Household size | 1 person | 24.8 |
| 2 persons | 42.4 | |
| 3–4 persons | 25.4 | |
| ≥4 persons | 7.4 | |
| Location of dwelling | Large city area (≥150,000) | 34.4 |
| Medium size city area (50–150,000) | 30.5 | |
| Rural or small city area (≤50,000) | 34.7 | |
| No information | 0.3 | |
| Level of highest education | Primary school | 5.8 |
| Secondary school | 36.3 | |
| College or equiv. (≤3 years) | 18.0 | |
| University or equiv. (>3 years) | 28.6 | |
| Other higher education | 10.9 | |
| Other | 0.3 |
| Statement 1 | Alternative | Proportion |
|---|---|---|
| To what extent would you say that you look at the labelling information (on the package) when you buy beef today? | I look at all | 17.4 |
| I look at most | 36.0 | |
| I look at some, but not all | 32.5 | |
| I look at just a few | 11.6 | |
| I do not look at it | 2.6 |
| Attribute 1 | Level |
|---|---|
| Origin | Label for specific country of origin available; or label for geographical zone of origin (beef labelled with origin as either inside or outside the EU) available |
| Reference code | Label present on package/not present |
| Traceability to specific slaughterhouse | Label present on package/not present |
| Traceability to group or specific animal | Label present on package/not present |
| Traceability to specific breeder | Label present on package/not present |
| Extent of good animal welfare for livestock production a | Label present on package/not present |
| Health impact from consumption of beef a | Label present on package/not present |
| Extent of social responsibility for livestock production a | Label present on package/not present |
| The animal was medicated for preventative purposes | Label present on package/not present |
| Type of animal feed given during raising the animal | Label present on package/not present |
| Price b (SEK) per kilogram | 200, 225, 250, 275, 300, 325 |
| Statement | Alternative | Proportion |
|---|---|---|
| It was easy to understand how I should provide my choices | Disagree | 6.1 |
| Partly disagree | 18.6 | |
| Neutral (neither disagree nor agree) | 21.9 | |
| Partly agree | 24.4 | |
| Agree | 28.9 | |
| I understood the meaning of the labelling alternatives | Disagree | 2.6 |
| Partly disagree | 10.9 | |
| Neutral (neither disagree nor agree) | 21.9 | |
| Partly agree | 37.6 | |
| Agree | 27.0 | |
| I was able to express what was important for me concerning beef labelling | Disagree | 2.9 |
| Partly disagree | 10.6 | |
| Neutral (neither disagree nor agree) | 20.3 | |
| Partly agree | 41.2 | |
| Agree | 25.1 | |
| How did you find expressing which type of beef labelling information was important to you? | Very easy | 10.3 |
| Fairly easy | 39.5 | |
| Neither easy nor difficult | 24.4 | |
| Fairly difficult | 23.8 | |
| Very difficult | 1.9 |
| Parameter Estimates | Estimate | Standard Error | Standard Score (z) | Probability (>|z|) | Marginal Effects | Standard Error |
|---|---|---|---|---|---|---|
| (Intercept) | −5.834 | 0.724 | −8.062 | <0.001 | ||
| Price level 1 = 2 | −0.151 | 0.072 | −2.097 | 0.036 | −0.012 | 0.012 |
| Price level = 3 | −0.374 | 0.075 | −4.993 | <0.001 | −0.029 | 0.024 |
| Price level = 4 | −0.682 | 0.079 | −8.601 | <0.001 | −0.053 | 0.042 |
| Price level = 5 | −1.026 | 0.086 | −11.938 | <0.001 | −0.080 | 0.063 |
| Price level = 6 | −1.296 | 0.093 | −13.885 | <0.001 | −0.101 | 0.079 |
| Info = 1 | 3.743 | 0.722 | 5.181 | <0.001 | 0.292 | 0.229 |
| Info = 2 | 3.309 | 0.720 | 4.593 | <0.001 | 0.258 | 0.212 |
| Info = 3 | 3.124 | 0.721 | 4.332 | <0.001 | 0.244 | 0.200 |
| Info = 4 | 3.716 | 0.720 | 5.157 | <0.001 | 0.289 | 0.234 |
| Info = 5 | 3.968 | 0.720 | 5.509 | <0.001 | 0.309 | 0.246 |
| Info = 6 | 4.182 | 0.720 | 5.809 | <0.001 | 0.326 | 0.261 |
| Info = 7 | 4.077 | 0.721 | 5.654 | <0.001 | 0.318 | 0.254 |
| Random effects | Groups | Name | Variance | Standard Deviation. | ||
| Respondents | (Intercept) | 1.2809 | 1.1318 | |||
| Alternative | (Intercept) | 0.0073 | 0.0855 | |||
| Akaike Information Criterion | Bayesian Information Criterion | Log Likelihood | Deviance | |||
| 12,530 | 12,650 | −6250 | 12,500 | |||
| Number of observations | 22,176 |
| Parameter Estimates | Estimate | Standard Error | Standard Score (z) | Probability (>|z|) | Marginal Effects | Standard Error |
|---|---|---|---|---|---|---|
| (Intercept) | −2.249 | 0.140 | −16.006 | <0.001 | ||
| Price level1 = 2 | −0.440 | 0.170 | −2.591 | 0.010 | −0.035 | 0.030 |
| Price level = 3 | −0.716 | 0.174 | −4.112 | <0.001 | −0.057 | 0.044 |
| Price level = 4 | −1.202 | 0.191 | −6.306 | <0.001 | −0.095 | 0.070 |
| Price level = 5 | −1.611 | 0.212 | −7.611 | <0.001 | −0.128 | 0.094 |
| Price level = 6 | −1.780 | 0.227 | −7.929 | <0.001 | −0.143 | 0.104 |
| Info | 0.023 | 0.026 | 0.902 | 0.367 | 0.002 | 0.003 |
| Price level = 2 × Info | 0.071 | 0.037 | 1.907 | 0.057 | 0.006 | 0.0053 |
| Price level = 3 × Info | 0.083 | 0.038 | 2.188 | 0.029 | 0.007 | 0.006 |
| Price level = 4 × Info | 0.122 | 0.041 | 3.008 | 0.003 | 0.010 | 0.008 |
| Price level = 5 × Info | 0.139 | 0.044 | 3.180 | 0.002 | 0.011 | 0.009 |
| Price level = 6 × Info | 0.123 | 0.048 | 2.585 | 0.010 | 0.010 | 0.008 |
| Random effects | Groups | Name | Variance | Std.Dev. | ||
| Respondents | (Intercept) | 1.247 | 1.117 | |||
| Alternative | (Intercept) | 0.008 | 0.090 | |||
| Akaike Information Criterion | Bayesian Information Criterion | Log Likelihood | Deviance | |||
| 12,812 | 12,924 | −6392 | 12,784 | |||
| Number of observations | 22,176 |
| Parameter Estimates | Estimate | Standard Error | Standard Score (z) | Probability (>|z|) | Marginal Effects | Standard Error |
|---|---|---|---|---|---|---|
| (Intercept) | −3.237 | 0.113 | −28.631 | <0.001 | ||
| Price level1 = 2 | −0.145 | 0.072 | −2.000 | 0.046 | −0.011 | 0.011 |
| Price level = 3 | −0.385 | 0.076 | −5.099 | <0.001 | −0.030 | 0.025 |
| Price level = 4 | −0.713 | 0.080 | −8.921 | <0.001 | −0.055 | 0.044 |
| Price level = 5 | −1.0636 | 0.087 | −12.279 | <0.001 | −0.082 | 0.066 |
| Price level = 6 | −1.308 | 0.094 | −13.924 | <0.001 | −0.101 | 0.081 |
| Reference code | 0.303 | 0.051 | 5.971 | <0.001 | 0.023 | 0.019 |
| Trace. to spec. slaughterhouse | 0.211 | 0.051 | 4.155 | <0.001 | 0.016 | 0.013 |
| Trace. to group/spec. animal | 0.290 | 0.051 | 5.710 | <0.001 | 0.022 | 0.018 |
| Trace. to spec. breeder | 0.216 | 0.051 | 4.255 | <0.001 | 0.017 | 0.014 |
| Animal welfare | 0.419 | 0.050 | 8.351 | <0.001 | 0.032 | 0.026 |
| Medicated prevent. purposes | 0.366 | 0.050 | 7.249 | <0.001 | 0.028 | 0.023 |
| Organic production | 0.294 | 0.050 | 5.846 | <0.001 | 0.023 | 0.018 |
| Environmental impact | 0.244 | 0.050 | 4.817 | <0.001 | 0.019 | 0.016 |
| Health impact | 0.248 | 0.051 | 4.861 | <0.001 | 0.019 | 0.016 |
| Extent social responsibility | 0.284 | 0.051 | 5.604 | <0.001 | 0.022 | 0.018 |
| Type of animal feed | 0.209 | 0.051 | 4.115 | <0.001 | 0.016 | 0.014 |
| Random effects | Groups | Name | Variance | Std.Dev. | ||
| Respondents | (Intercept) | 1.321 | 1.149 | |||
| Alternative | (Intercept) | 0.009 | 0.097 | |||
| Akaike Information Criterion | Bayesian Information Criterion | Log Likelihood | Deviance | |||
| 12,415 | 12,567 | −6188 | 12,377 | |||
| Number of observations | 22,176 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lagerkvist, C.J.; Hess, S.; Johansson, H. How Much Credence Does It Take? Evidence on the Trade-Off between Country-Of-Origin Information and Credence Attributes for Beef from a Choice Experiment in Sweden. Foods 2017, 6, 84. https://doi.org/10.3390/foods6100084
Lagerkvist CJ, Hess S, Johansson H. How Much Credence Does It Take? Evidence on the Trade-Off between Country-Of-Origin Information and Credence Attributes for Beef from a Choice Experiment in Sweden. Foods. 2017; 6(10):84. https://doi.org/10.3390/foods6100084
Chicago/Turabian StyleLagerkvist, Carl Johan, Sebastian Hess, and Helena Johansson. 2017. "How Much Credence Does It Take? Evidence on the Trade-Off between Country-Of-Origin Information and Credence Attributes for Beef from a Choice Experiment in Sweden" Foods 6, no. 10: 84. https://doi.org/10.3390/foods6100084
APA StyleLagerkvist, C. J., Hess, S., & Johansson, H. (2017). How Much Credence Does It Take? Evidence on the Trade-Off between Country-Of-Origin Information and Credence Attributes for Beef from a Choice Experiment in Sweden. Foods, 6(10), 84. https://doi.org/10.3390/foods6100084