
Authentication of Edible Oil by Real-Time One Class Classification Modeling


 ,
, 

Abstract

1. Introduction
2. Materials and Methods
2.1. Avocado Oil Samples
2.2. Chemicals and Reagents
2.3. Chemical Composition
2.4. Statistical Analysis
2.5. OCPLS
3. Results and Discussion
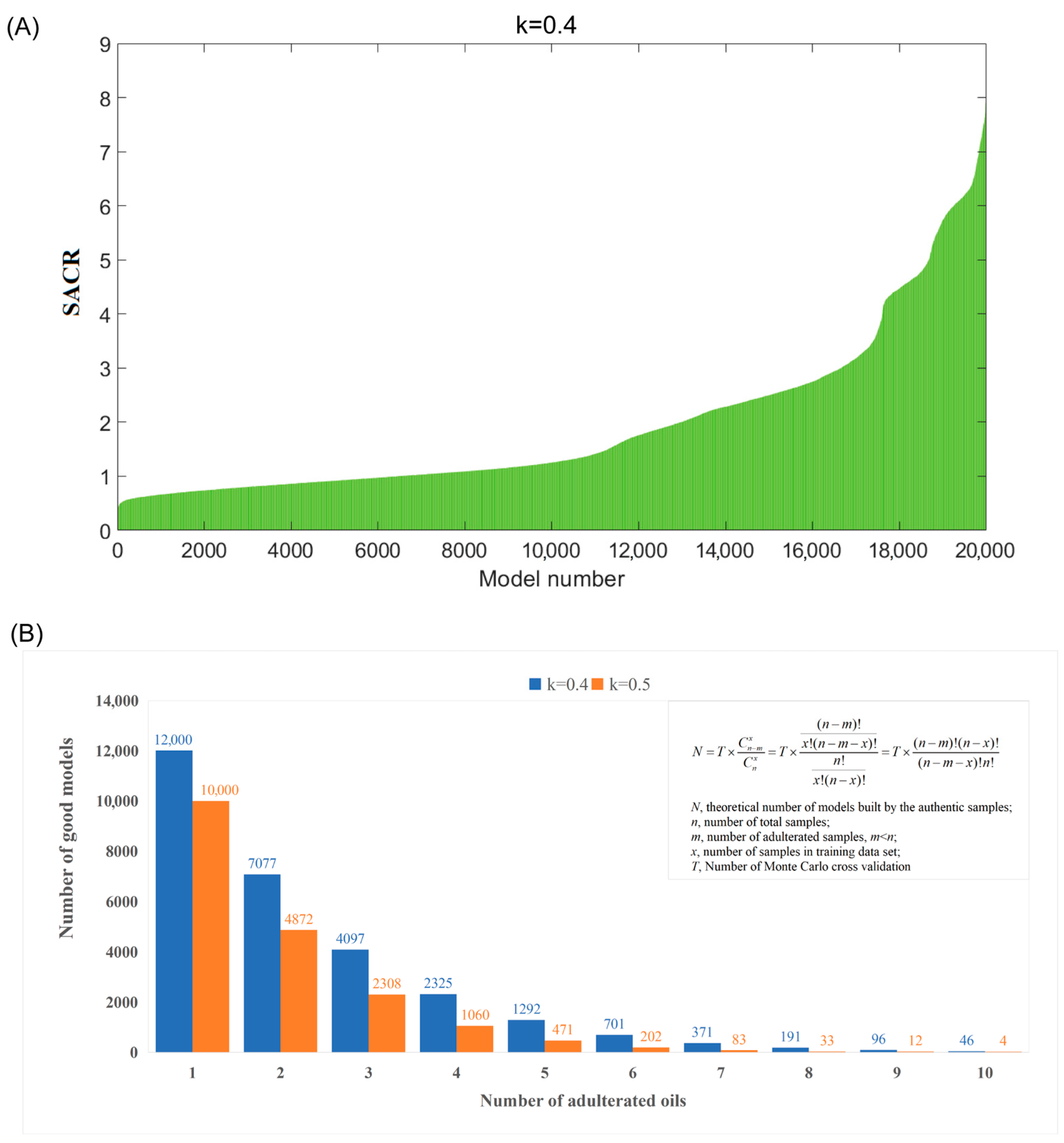
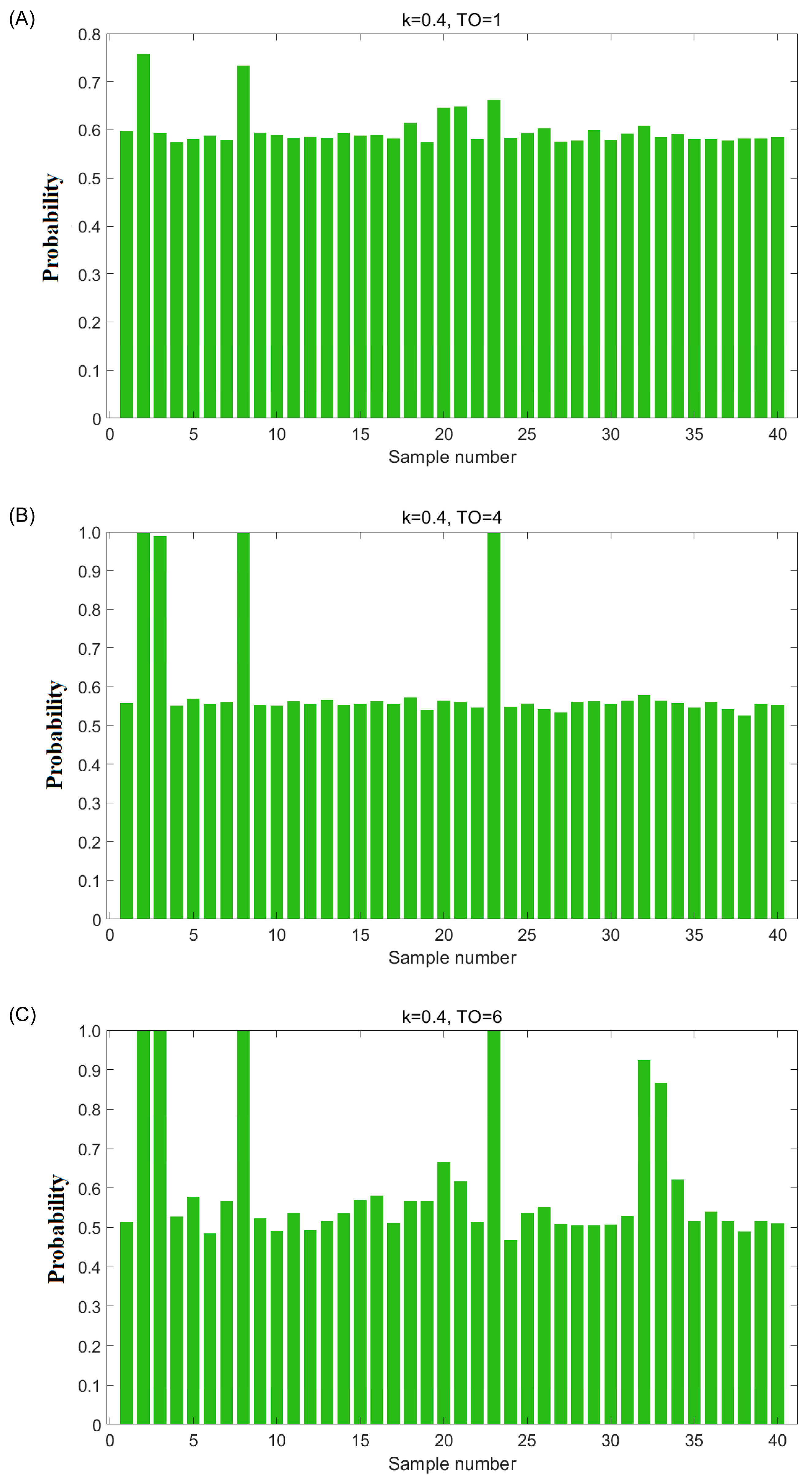
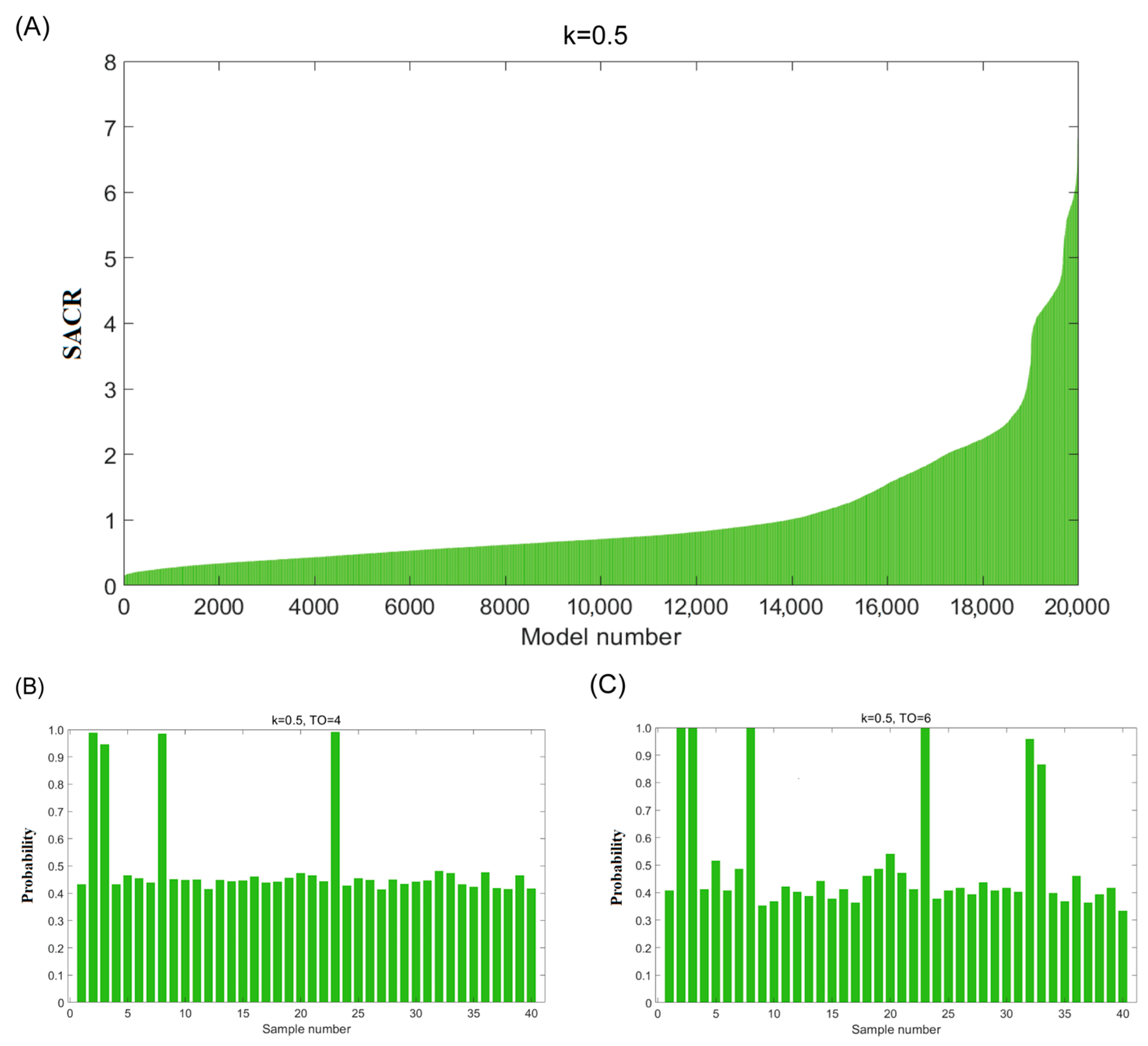
3.1. Adulteration Detection Theory
3.2. Adulteration Detection in Inspected Avocado Oil Samples
3.3. Validation by Chemical Markers
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Robson, K.; Dean, M.; Haughey, S.; Elliott, C. A comprehensive review of food fraud terminologies and food fraud mitigation guides. Food Control 2021, 120, 107516. [Google Scholar]
- Spink, J.W. The GFSI food fraud prevention compliance development & requirements: A ten-year review. Trends Food Sci. Technol. 2023, 138, 766–773. [Google Scholar]
- Talib, T.H.; Chatterjee, N.S.; Banerjee, K.; Petchkongkaew, A.; Elliott, C.T.; Wu, D. A two-tier approach for the detection of contaminants and adulterants in sunflower oil to protect consumer safety. Trends Food Sci. Technol. 2024, 150, 104559. [Google Scholar]
- Everstine, K.D.; Chin, H.B.; Lopes, F.A.; Moore, J.C. Database of Food Fraud Records: Summary of Data from 1980 to 2022. J. Food Prot. 2024, 87, 100227. [Google Scholar]
- Green, H.S.; Wang, S.C. First report on quality and purity evaluations of avocado oil sold in the US. Food Control 2020, 116, 107328. [Google Scholar]
- Shi, T.; Wu, G.; Jin, Q.; Wang, X. Camellia oil authentication: A comparative analysis and recent analytical techniques developed for its assessment. A review. Trends Food Sci. Technol. 2020, 97, 88–99. [Google Scholar]
- Ye, Q.; Meng, X. Highly efficient authentication of edible oils by FTIR spectroscopy coupled with chemometrics. Food Chem. 2022, 385, 132661. [Google Scholar]
- Shen, F.; Feng, X.; Li, Y.; Lin, X.; Cai, F. Compact three-dimensional fluorescence spectroscopy and its application in food safety. LWT 2024, 202, 116324. [Google Scholar]
- Meng, X.; Yin, C.; Yuan, L.; Zhang, Y.; Ju, Y.; Xin, K.; Chen, W.; Lv, K.; Hu, L. Rapid detection of adulteration of olive oil with soybean oil combined with chemometrics by Fourier transform infrared, visible-near-infrared and excitation-emission matrix fluorescence spectroscopy: A comparative study. Food Chem. 2023, 405, 134828. [Google Scholar]
- Bavali, A.; Rahmatpanahi, A.; Chegini, R.M. Quantitative detection of adulteration in avocado oil using laser-induced fluorescence and machine learning models. Microchem. J. 2025, 211, 113080. [Google Scholar]
- Malavi, D.; Nikkhah, A.; Raes, K.; Van Haute, S. Hyperspectral Imaging and Chemometrics for Authentication of Extra Virgin Olive Oil: A Comparative Approach with FTIR, UV-VIS, Raman, and GC-MS. Foods 2023, 12, 429. [Google Scholar] [CrossRef] [PubMed]
- Alonso-Salces, R.M.; Viacava, G.E.; Tres, A.; Vichi, S.; Valli, E.; Bendini, A.; Gallina Toschi, T.; Gallo, B.; Berrueta, L.Á.; Héberger, K. Stepwise strategy based on untargeted metabolomic 1H NMR fingerprinting and pattern recognition for the geographical authentication of virgin olive oils. Food Control 2025, 173, 111216. [Google Scholar]
- Shi, T.; Wu, G.; Jin, Q.; Wang, X. Detection of camellia oil adulteration using chemometrics based on fatty acids GC fingerprints and phytosterols GC–MS fingerprints. Food Chem. 2021, 352, 129422. [Google Scholar] [PubMed]
- Dou, X.; N’Diaye, K.; Harkaoui, S.E.; Willenberg, I.; Ma, F.; Zhang, L.; Li, P.; Matthäus, B. Authentication of Virgin Olive Oil Based on Untargeted Metabolomics and Chemical Markers. Eur. J. Lipid Sci. Technol. 2025, 127, e202400126. [Google Scholar]
- Dou, X.; Zhang, L.; Yang, R.; Wang, X.; Yu, L.; Yue, X.; Ma, F.; Mao, J.; Wang, X.; Li, P. Adulteration detection of essence in sesame oil based on headspace gas chromatography-ion mobility spectrometry. Food Chem. 2022, 370, 131373. [Google Scholar]
- Mahanti, N.K.; Shivashankar, S.; Chhetri, K.B.; Kumar, A.; Rao, B.B.; Aravind, J.; Swami, D.V. Enhancing food authentication through E-nose and E-tongue technologies: Current trends and future directions. Trends Food Sci. Technol. 2024, 150, 104574. [Google Scholar]
- Shen, Q.; Wang, S.; Wang, H.; Liang, J.; Zhao, Q.; Cheng, K.; Imran, M.; Xue, J.; Mao, Z. Revolutionizing food science with mass spectrometry imaging: A comprehensive review of applications and challenges. Compr. Rev. Food Sci. Food Saf. 2024, 23, e13398. [Google Scholar]
- Islam, M.; Kaczmarek, A.; Montowska, M.; Tomaszewska-Gras, J. Comparing Different Chemometric Approaches to Detect Adulteration of Cold-Pressed Flaxseed Oil with Refined Rapeseed Oil Using Differential Scanning Calorimetry. Foods 2023, 12, 3352. [Google Scholar] [CrossRef]
- Wu, X.; Shin, S.; Gondhalekar, C.; Patsekin, V.; Bae, E.; Robinson, J.P.; Rajwa, B. Rapid Food Authentication Using a Portable Laser-Induced Breakdown Spectroscopy System. Foods 2023, 12, 402. [Google Scholar] [CrossRef]
- Nanou, E.; Pliatsika, N.; Couris, S. Rapid Authentication and Detection of Olive Oil Adulteration Using Laser-Induced Breakdown Spectroscopy. Molecules 2023, 28, 7960. [Google Scholar] [CrossRef]
- Sun, X.M.; Zhang, L.X.; Li, P.W.; Xu, B.C.; Ma, F.; Zhang, Q.; Zhang, W. Fatty acid profiles based adulteration detection for flaxseed oil by gas chromatography mass spectrometry. LWT 2015, 63, 430–436. [Google Scholar]
- Dou, X.J.; Zhang, L.X.; Chen, Z.; Wang, X.F.; Ma, F.; Yu, L.; Mao, J.; Li, P.W. Establishment and evaluation of multiple adulteration detection of camellia oil by mixture design. Food Chem. 2023, 406, 135050. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.X.; Huang, X.R.; Li, P.W.; Na, W.; Jiang, J.; Mao, J.; Ding, X.X.; Zhang, Q. Multivariate adulteration detection for sesame oil. Chemom. Intellig. Lab. Syst. 2017, 161, 147–150. [Google Scholar] [CrossRef]
- Rodionova, O.Y.; Titova, A.V.; Pomerantsev, A.L. Discriminant analysis is an inappropriate method of authentication. TrAC Trends Anal. Chem. 2016, 78, 17–22. [Google Scholar] [CrossRef]
- Zhang, L.X.; Li, P.W.; Sun, X.M.; Mao, J.; Ma, F.; Ding, X.X.; Zhang, Q. One-class classification based authentication of peanut oils by fatty acid profiles. RSC Adv. 2015, 5, 85046–85051. [Google Scholar] [CrossRef]
- Dou, X.J.; Tu, F.Q.; Yu, L.; Yang, Y.; Ma, F.; Wang, X.F.; Wang, D.; Zhang, L.X.; Jiang, X.M.; Li, P.W. Adulteration detection of edible oil by one-class classification and outlier detection. Food Front. 2024, 5, 1806–1818. [Google Scholar] [CrossRef]
- Zhang, L.X.; Yuan, Z.; Li, P.W.; Wang, X.F.; Mao, J.; Zhang, Q.; Hu, C.D. Targeted multivariate adulteration detection based on fatty acid profiles and Monte Carlo one-class partial least squares. Chemom. Intellig. Lab. Syst. 2017, 169, 94–99. [Google Scholar] [CrossRef]
- Dou, X.J.; Wang, X.F.; Ma, F.; Yu, L.; Mao, J.; Jiang, J.; Zhang, L.X.; Li, P.W. Geographical origin identification of camellia oil based on fatty acid profiles combined with one-class classification. Food Chem. 2024, 433, 137306. [Google Scholar] [CrossRef]
- Flores, M.; Saravia, C.; Vergara, C.; Avila, F.; Valdés, H.; Ortiz-Viedma, J. Avocado Oil: Characteristics, Properties, and Applications. Molecules 2019, 24, 2172. [Google Scholar] [CrossRef]
- Wang, J.-S.; Wang, A.-B.; Zang, X.-P.; Tan, L.; Xu, B.-Y.; Chen, H.-H.; Jin, Z.-Q.; Ma, W.-H. Physicochemical, functional and emulsion properties of edible protein from avocado (Persea americana Mill.) oil processing by-products. Food Chem. 2019, 288, 146–153. [Google Scholar] [CrossRef]
- Tan, C.X.; Chong, G.H.; Hamzah, H.; Ghazali, H.M. Characterization of Virgin Avocado Oil Obtained via Advanced Green Techniques. Eur. J. Lipid Sci. Technol. 2018, 120, 1800170. [Google Scholar]
- Salehi, B.; Rescigno, A.; Dettori, T.; Calina, D.; Docea, A.O.; Singh, L.; Cebeci, F.; Özçelik, B.; Bhia, M.; Dowlati Beirami, A.; et al. Avocado–Soybean Unsaponifiables: A Panoply of Potentialities to Be Exploited. Biomolecules 2020, 10, 130. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-K.; Zhong, L.; Santiago, J.L. Anti-Inflammatory and Skin Barrier Repair Effects of Topical Application of Some Plant Oils. Int. J. Mol. Sci. 2018, 19, 70. [Google Scholar]
- Younis, I.Y.; Khattab, A.R.; Selim, N.M.; Sobeh, M.; Elhawary, S.S.; Bishbishy, M.H.E. Metabolomics-based profiling of 4 avocado varieties using HPLC–MS/MS and GC/MS and evaluation of their antidiabetic activity. Sci. Rep. 2022, 12, 4966. [Google Scholar]
- Aktar, T.; Adal, E. Determining the Arrhenius Kinetics of Avocado Oil: Oxidative Stability under Rancimat Test Conditions. Foods 2019, 8, 236. [Google Scholar] [CrossRef]
- Fernandes, G.D.; Gómez-Coca, R.B.; Pérez-Camino, M.C.; Moreda, W.; Barrera-Arellano, D. Chemical characterization of commercial and single-variety avocado oils. Grasas Aceites 2018, 69, e256. [Google Scholar]
- Gliszczyńska-Świgło, A.; Sikorska, E. Simple reversed-phase liquid chromatography method for determination of tocopherols in edible plant oils. J. Chromatogr. A 2004, 1048, 195–198. [Google Scholar] [CrossRef]
- Fernandes, L.; Pereira, J.A.; Lopéz-Cortés, I.; Salazar, D.M.; Ramalhosa, E.; Casal, S. Fatty acid, vitamin E and sterols composition of seed oils from nine different pomegranate (Punica granatum L.) cultivars grown in Spain. J. Food Compos. Anal. 2015, 39, 13–22. [Google Scholar]
- Zhao, X.; Ma, F.; Li, P.; Li, G.; Zhang, L.; Zhang, Q.; Zhang, W.; Wang, X. Simultaneous determination of isoflavones and resveratrols for adulteration detection of soybean and peanut oils by mixed-mode SPE LC-MS/MS. Food Chem. 2015, 176, 465–471. [Google Scholar]
- Zhao, Z.; Huang, J.; Jin, Q.; Wang, X. Influence of oryzanol and tocopherols on thermal oxidation of rice bran oil during the heating process at Chinese cooking temperatures. LWT 2021, 142, 111022. [Google Scholar]
- Xu, L.; Goodarzi, M.; Shi, W.; Cai, C.; Jiang, J. A MATLAB toolbox for class modeling using one-class partial least squares (OCPLS) classifiers. Chemom. Intellig. Lab. Syst. 2014, 139, 58–63. [Google Scholar]
- Xie, D.; Zhou, H.; Jiang, X. Effect of chemical refining on the levels of bioactive components and hazardous substances in soybean oil. J. Food Meas. Charact. 2019, 13, 1423–1430. [Google Scholar]
- Nasri, C.; Halabi, Y.; Harhar, H.; Mohammed, F.; Bellaouchou, A.; Guenbour, A.; Tabyaoui, M. Chemical characterization of oil from four Avocado varieties cultivated in Morocco. OCL 2021, 28, 19. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fatty Acid a (%) | Production Area b | Mean (n = 34) | ||||||
|---|---|---|---|---|---|---|---|---|
| Mexico (n = 10) | New Zealand (n = 8) | France (n = 7) | Australia (m = 3) | USA (n = 2) | Spain (n = 2) | Kenya (n = 2) | ||
| C16:0 | 10.15 | 13.89 | 13.46 | 15.36 | 16.71 | 12.90 | 11.44 | 12.80 |
| C16:1 | 3.16 | 3.96 | 3.56 | 5.89 | 5.95 | 2.35 | 4.13 | 3.85 |
| C17:0 | 0.03 | 0.05 | 0.05 | 0.04 | 0.05 | 0.07 | 0.04 | 0.05 |
| C17:1 | 0.06 | 0.10 | 0.09 | 0.09 | 0.10 | 0.12 | 0.06 | 0.08 |
| C18:0 | 2.10 | 1.38 | 1.76 | 0.50 | 1.15 | 2.43 | 1.98 | 1.67 |
| C18:1 | 73.24 | 68.75 | 68.27 | 67.61 | 63.57 | 69.85 | 65.50 | 69.44 |
| C18:2 | 10.36 | 10.78 | 11.75 | 9.71 | 11.46 | 11.08 | 15.75 | 11.11 |
| C18:3 | 0.48 | 0.65 | 0.58 | 0.52 | 0.69 | 0.59 | 0.72 | 0.58 |
| C20:0 | 0.21 | 0.22 | 0.26 | 0.10 | 0.16 | 0.36 | 0.20 | 0.22 |
| C20:1 | 0.21 | 0.21 | 0.21 | 0.17 | 0.17 | 0.26 | 0.18 | 0.20 |
| SFA | 12.49 | 15.55 | 15.54 | 16.00 | 18.07 | 15.76 | 13.66 | 14.74 |
| MUFA | 76.67 | 73.02 | 72.13 | 73.77 | 69.79 | 72.57 | 69.87 | 73.57 |
| PUFA | 10.85 | 11.44 | 12.33 | 10.23 | 12.14 | 11.67 | 16.47 | 11.69 |
| PUFA/SFA | 0.91 | 0.74 | 0.81 | 0.65 | 0.69 | 0.74 | 1.31 | 0.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Wang, X.; Yang, Y.; Tu, F.; Yu, L.; Ma, F.; Wang, X.; Jiang, X.; Dou, X.; Li, P.; et al. Authentication of Edible Oil by Real-Time One Class Classification Modeling. Foods 2025, 14, 1235. https://doi.org/10.3390/foods14071235
Liu M, Wang X, Yang Y, Tu F, Yu L, Ma F, Wang X, Jiang X, Dou X, Li P, et al. Authentication of Edible Oil by Real-Time One Class Classification Modeling. Foods. 2025; 14(7):1235. https://doi.org/10.3390/foods14071235
Chicago/Turabian StyleLiu, Min, Xueyan Wang, Yong Yang, Fengqin Tu, Li Yu, Fei Ma, Xuefang Wang, Xiaoming Jiang, Xinjing Dou, Peiwu Li, and et al. 2025. "Authentication of Edible Oil by Real-Time One Class Classification Modeling" Foods 14, no. 7: 1235. https://doi.org/10.3390/foods14071235
APA StyleLiu, M., Wang, X., Yang, Y., Tu, F., Yu, L., Ma, F., Wang, X., Jiang, X., Dou, X., Li, P., & Zhang, L. (2025). Authentication of Edible Oil by Real-Time One Class Classification Modeling. Foods, 14(7), 1235. https://doi.org/10.3390/foods14071235