
Proteomic Analysis of the Major Alkali-Soluble Inca Peanut (Plukenetia volubilis) Proteins

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Sacha Inchi Protein Concentrate (SPC) Production
2.2. Sodium Dodecyl Sulfate–Polyacrylamide Gel Electrophoresis (SDS-PAGE)
2.3. Proteomic Analysis and Functional Annotations
2.3.1. Protein Identification
2.3.2. Gene Ontology (GO) Classification
3. Results and Discussion
3.1. Electrophoretic Profile
3.2. Proteomic Analysis, Gene Ontology (GO) Annotations, and Functional Analysis
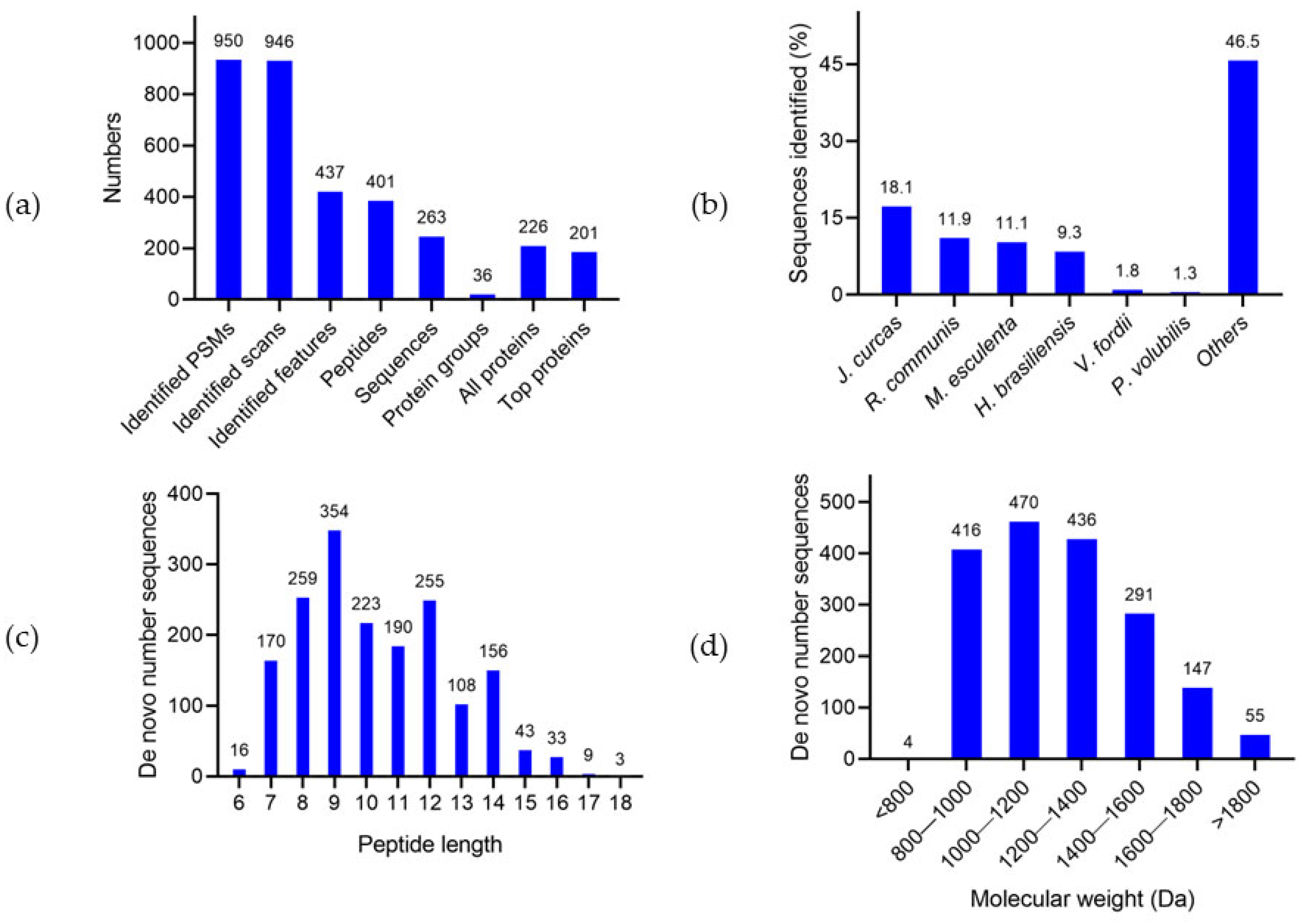
3.2.1. Proteomic Analysis
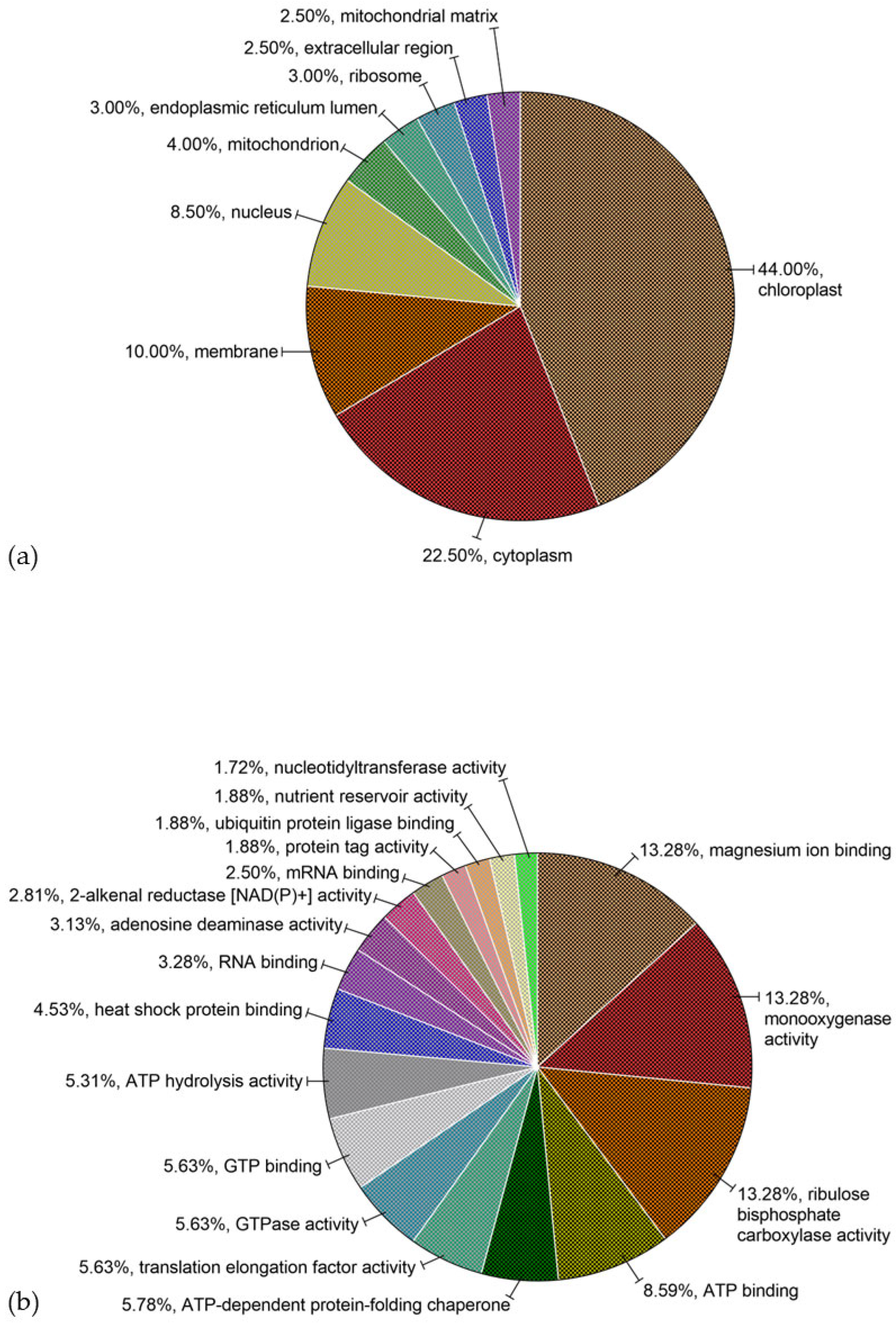
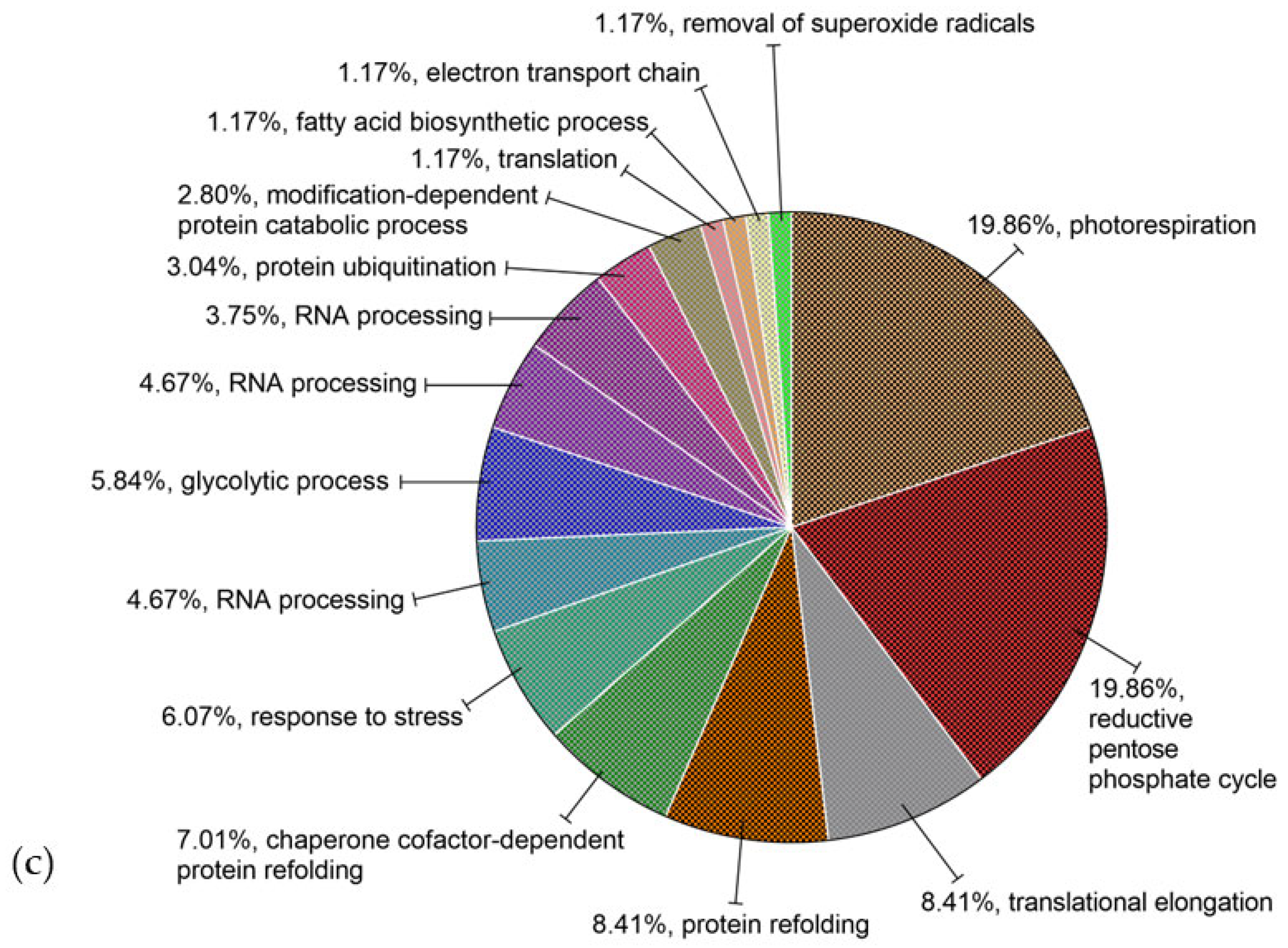
3.2.2. Gene Ontology (GO) Annotations in Proteins
3.2.3. Protein Functional Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pojić, M.; Mišan, A.; Tiwari, B. Eco-Innovative Technologies for Extraction of Proteins for Human Consumption from Renewable Protein Sources of Plant Origin. Trends Food Sci. Technol. 2018, 75, 93–104. [Google Scholar] [CrossRef]
- Hernández-Ledesma, B.; Ramos, M.; Gómez-Ruiz, J.Á. Bioactive Components of Ovine and Caprine Cheese Whey. Small Rumin. Res. 2011, 101, 196–204. [Google Scholar] [CrossRef]
- Joshi, S.; Shah, S.; Kalantar-Zadeh, K. Adequacy of Plant-Based Proteins in Chronic Kidney Disease. J. Ren. Nutr. 2019, 29, 112–117. [Google Scholar] [CrossRef]
- Hsieh, C.-C.; Hernández-Ledesma, B.; de Lumen, B.O. Cancer Chemopreventive Potential of Seed Proteins and Peptides. In Nuts and Seeds in Health and Disease Prevention Nuts and Seeds in Health and Disease Prevention, 2nd ed.; Preedy, V.R., Watson, R.R., Eds.; Academic Press: Cambridge, MA, USA, 2020; Chapter 28; pp. 403–420. ISBN 978-0-12-818553-7. [Google Scholar]
- Gravel, A.; Doyen, A. The Use of Edible Insect Proteins in Food: Challenges and Issues Related to Their Functional Properties. Innov. Food Sci. Emerg. Technol. 2020, 59, 102272. [Google Scholar] [CrossRef]
- Gençdağ, E.; Görgüç, A.; Yılmaz, F.M. Recovery of Bioactive Peptides from Food Wastes and Their Bioavailability Properties. Turkish J. Agric. Food Sci. Technol. 2020, 8, 855–863. [Google Scholar] [CrossRef]
- Rawdkuen, S.; Ketnawa, S. Extraction, Characterization, and Application of Agricultural and Food Processing By-Products. In Food Preservation and Waste Exploitation; Socaci, S.A., Farcas, A.C., Aussenac, T., Laguerre, J.-C., Eds.; IntechOpen: London, UK, 2019; pp. 1–32. [Google Scholar]
- Gutiérrez, L.-F.; Rosada, L.-M.; Jiménez, Á. Chemical Composition of Sacha Inchi (Plukenetia volubilis L.) Seeds and Characteristics of Their Lipid Fraction. Grasas Aceites 2011, 62, 76–83. [Google Scholar] [CrossRef]
- Sanchez-Reinoso, Z.; Mora-Adames, W.I.; Fuenmayor, C.A.; Darghan-Contreras, A.E.; Gardana, C.; Gutiérrez, L.F. Microwave-Assisted Extraction of Phenolic Compounds from Sacha Inchi Shell: Optimization, Physicochemical Properties and Evaluation of Their Antioxidant Activity. Chem. Eng. Process.Process Intensif. 2020, 153, 107922. [Google Scholar] [CrossRef]
- Torres Sánchez, E.G.; Hernández-Ledesma, B.; Gutiérrez, L.-F. Sacha Inchi Oil Press-Cake: Physicochemical Characteristics, Food-Related Applications and Biological Activity. Food Rev. Int. 2023, 39, 148–159. [Google Scholar] [CrossRef]
- Rodríguez, G.; Avellaneda, S.; Pardo, R.; Villanueva, E.; Aguirre, E. Bread Leaf Enriched with Extruded Cake from Sacha Inchi (Plukenetia volubilis L.): Chemistry, Rheology, Texture and Acceptability. Sci. Agropecu. 2018, 9, 199–208. [Google Scholar] [CrossRef]
- Mendoza Ordoñez, G.; Sánchez Pereyra, G.; León Gallardo, Z.; Loyaga Cortéz, B. Effect of Dietary Sacha Inchi Pressed Cake as a Protein Source on Guinea Pig Carcass Yield and Meat Quality. Pak. J. Nutr. 2019, 18, 1021–1027. [Google Scholar] [CrossRef]
- Lima, B.T.M.; Takahashi, N.S.; Tabata, Y.A.; Hattori, R.S.; da Silva Ribeiro, C.; Moreira, R.G. Balanced Omega-3 and -6 Vegetable Oil of Amazonian Sacha Inchi Act as LC-PUFA Precursors in Rainbow Trout Juveniles: Effects on Growth and Fatty Acid Biosynthesis. Aquaculture 2019, 509, 236–245. [Google Scholar] [CrossRef]
- Chirinos, R.; Aquino, M.; Pedreschi, R.; Campos, D. Optimized Methodology for Alkaline and Enzyme- Assisted Extraction of Protein from Sacha Inchi (Plukenetia volubilis) Kernel Cake. J. Food Process Eng. 2016, 3, e12412. [Google Scholar] [CrossRef]
- Rawdkuen, S.; Rodzi, N.; Pinijsuwan, S. Characterization of Sacha Inchi Protein Hydrolysates Produced by Crude Papain and Calotropis Proteases. LWT Food Sci. Technol. 2018, 98, 18–24. [Google Scholar] [CrossRef]
- Sathe, S.K.; Kshirsagar, H.H.; Sharma, G.M. Solubilization, Fractionation, and Electrophoretic Characterization of Inca Peanut (Plukenetia volubilis L.) Proteins. Plant Foods Hum. Nutr. 2012, 67, 247–255. [Google Scholar] [CrossRef]
- Torres-Sánchez, E.; Hernández-Ledesma, B.; Gutiérrez, L.-F. Isolation and Characterization of Protein Fractions for Valorization of Sacha Inchi Oil Press-Cake. Foods 2023, 12, 2401. [Google Scholar] [CrossRef]
- Paterson, S.; Fernández-Tomé, S.; Galvez, A.; Hernández-Ledesma, B. Evaluation of the Multifunctionality of Soybean Proteins and Peptides in Immune Cell Models. Nutrients 2023, 15, 1220. [Google Scholar] [CrossRef]
- Shevchenko, A.; Tomas, H.; Havli, J.; Olsen, J.V.; Mann, M. In-Gel Digestion for Mass Spectrometric Characterization of Proteins and Proteomes. Nat. Protoc. 2006, 1, 2856–2860. [Google Scholar] [CrossRef]
- Shevchenko, A.; Wilm, M.; Vorm, O.; Mann, M. Mass Spectrometric Sequencing of Proteins from Silver-Stained Polyacrylamide Gels. Anal. Chem. 1996, 68, 850–858. [Google Scholar] [CrossRef]
- Alonso, R.; Pisa, D.; Marina, A.I.; Morato, E.; Rábano, A.; Rodal, I.; Carrasco, L. Evidence for Fungal Infection in Cerebrospinal Fluid and Brain Tissue from Patients with Amyotrophic Lateral Sclerosis. Int. J. Biol. Sci. 2015, 11, 546–558. [Google Scholar] [CrossRef]
- Tran, N.H.; Zhang, X.; Xin, L.; Shan, B.; Li, M. De Novo Peptide Sequencing by Deep Learning. Proc. Natl. Acad. Sci. USA 2017, 114, 8247–8252. [Google Scholar] [CrossRef]
- Tran, N.H.; Qiao, R.; Xin, L.; Chen, X.; Liu, C.; Zhang, X.; Shan, B.; Ghodsi, A.; Li, M. Deep Learning Enables de Novo Peptide Sequencing from Data-Independent-Acquisition Mass Spectrometry. Nat. Methods 2019, 16, 63–66. [Google Scholar] [CrossRef]
- Perez-Riverol, Y.; Bai, J.; Bandla, C.; García-Seisdedos, D.; Hewapathirana, S.; Kamatchinathan, S.; Kundu, D.J.; Prakash, A.; Frericks-Zipper, A.; Eisenacher, M.; et al. The PRIDE Database Resources in 2022: A Hub for Mass Spectrometry-Based Proteomics Evidences. Nucleic Acids Res. 2022, 50, D543–D552. [Google Scholar] [CrossRef]
- Götz, S.; García-Gómez, J.M.; Terol, J.; Williams, T.D.; Nagaraj, S.H.; Nueda, M.J.; Robles, M.; Talón, M.; Dopazo, J.; Conesa, A. High-Throughput Functional Annotation and Data Mining with the Blast2GO Suite. Nucleic Acids Res. 2008, 36, 3420–3435. [Google Scholar] [CrossRef]
- Rahman, M.; Liu, L.; Barkla, B.J. A Single Seed Protein Extraction Protocol for Characterizing Brassica Seed Storage Proteins. Agronomy 2021, 11, 107. [Google Scholar] [CrossRef]
- Yang, J.S.; Dias, F.F.G.; Pham, T.T.K.; Barile, D.; de Moura Bell, J.M.L.N. A Sequential Fractionation Approach to Understanding the Physicochemical and Functional Properties of Aqueous and Enzyme-Assisted Aqueous Extracted Black Bean Proteins. Food Hydrocoll. 2024, 146, 109250. [Google Scholar] [CrossRef]
- Čepková, P.H.; Jágr, M.; Viehmannová, I.; Dvořáček, V.; Huansi, D.C.; Mikšík, I. Diversity in Seed Storage Protein Profile of Oilseed Crop Plukenetia volubilis from Diversity in Seed Storage Protein Profile of Oilseed Crop Plukenetia volubilis from Peruvian Amazon. Int. J. Agric. Biol. 2019, 21, 679–688. [Google Scholar]
- Shevkani, K.; Singh, N.; Chen, Y.; Kaur, A.; Yu, L. Pulse Proteins: Secondary Structure, Functionality and Applications. J. Food Sci. Technol. 2019, 56, 2787–2798. [Google Scholar] [CrossRef]
- Han, Y.; Zhang, K. SPIDER: Software for Protein Identification from Sequence Tags with de Novo Sequencing Error. J. Bioinform. Comput. Biol. 2005, 3, 697–716. [Google Scholar] [CrossRef]
- Amorim, F.G.; Redureau, D.; Crasset, T.; Freuville, L.; Baiwir, D.; Mazzucchelli, G.; Menzies, S.K.; Casewell, N.R.; Quinton, L. Next-Generation Sequencing for Venomics: Application of Multi-Enzymatic Limited Digestion for Inventorying the Snake Venom Arsenal. Toxins 2023, 15, 357. [Google Scholar] [CrossRef]
- Rashid, M.H.U.; Yi, E.K.J.; Amin, N.D.M.; Ismail, M.N. An Empirical Analysis of Sacha Inchi (Plantae: Plukenetia volubilis L.) Seed Proteins and Their Applications in the Food and Biopharmaceutical Industries. Appl. Biochem. Biotechnol. 2023, 196, 4823–4836. [Google Scholar] [CrossRef]
- Ma, B.; Zhang, K.; Hendrie, C.; Liang, C.; Li, M.; Doherty-Kirby, A.; Lajoie, G. PEAKS: Powerful Software for Peptide de Novo Sequencing by Tandem Mass Spectrometry. Rapid Commun. Mass Spectrom. 2003, 17, 2337–2342. [Google Scholar] [CrossRef]
- He, Z.; Lin, J.; Peng, D.; Zeng, J.; Pan, X.; Zheng, R.; Li, P.; Du, B. Peptide Fractions from Sacha Inchi Induced Apoptosis in HepG2 Cells via P53 Activation and a Mitochondria-Mediated Pathway. J. Sci. Food Agric. 2023, 103, 7621–7630. [Google Scholar] [CrossRef]
- Wang, K.; Liu, X.; Zhang, X. Isolation and Identification of Lipid-Lowering Peptides from Sacha Inchi Meal. Int. J. Mol. Sci. 2023, 24, 1529. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.; Liu, X.; Zhang, X. Isolation and Identification of Dipeptidyl Peptidase-IV Inhibitory Peptides from Sacha Inchi Meal. J. Sci. Food Agric. 2023, 103, 2926–2938. [Google Scholar] [CrossRef]
- Rahman, M.; Guo, Q.; Baten, A.; Mauleon, R.; Khatun, A.; Liu, L.; Barkla, B.J. Shotgun Proteomics of Brassica Rapa Seed Proteins Identifies Vicilin as a Major Seed Storage Protein in the Mature Seed. PLoS ONE 2021, 16, e0253384. [Google Scholar] [CrossRef]
- Ramzan, A.; Shah, M.; Ullah, N.; Sheheryar; Nascimento, J.R.S.; Campos, F.A.P.; Domont, G.B.; Nogueira, F.C.S.; Abdellattif, M.H. Proteomic Analysis of Embryo Isolated from Mature Jatropha curcas L. Seeds. Front. Plant Sci. 2022, 13, 843764. [Google Scholar] [CrossRef]
- Sathe, S.K.; Hamaker, B.R.; Sze-Tao, K.W.C.; Venkatachalam, M. Isolation, Purification, and Biochemical Characterization of a Novel Water Soluble Protein from Inca Peanut (Plukenetia volubilis L.). J. Agric. Food Chem. 2002, 50, 4906–4908. [Google Scholar] [CrossRef]
- Quinteros, M.; Vilcacundo, R.; Carpio, C.; Carrillo, W. Isolation of Proteins from Sacha Inchi (Plukenetia volubilis L.) in Presence of Water and Salt. Asian J. Pharm. Clin. Res. 2016, 9, 193–196. [Google Scholar]
- He, Y.; Wang, S.; Ding, Y. Identification of Novel Glutelin Subunits and a Comparison of Glutelin Composition between Japonica and Indica Rice (Oryza sativa L.). J. Cereal Sci. 2013, 57, 362–371. [Google Scholar] [CrossRef]
- Dunwell, J.M.; Purvis, A.; Khuri, S. Cupins: The Most Functionally Diverse Protein Superfamily? Phytochemistry 2004, 65, 7–17. [Google Scholar] [CrossRef]
- Hamaker, B.R.; Valles, C.; Gilman, R.; Hardmeier, R.M.; Clark, D.; Garcia, H.H.; Gonzales, A.E.; Kohlstad, I.; Castro, M.; Valdivia, R.; et al. Amino Acid and Fatty Acid Profiles of the Inca Peanut (Plukenetia volubilis). Cereal Chem. 1992, 69, 461–463. [Google Scholar]
- Wang, W.; Vinocur, B.; Shoseyov, O.; Altman, A. Role of Plant Heat-Shock Proteins and Molecular Chaperones in the Abiotic Stress Response. Trends Plant Sci. 2004, 9, 244–252. [Google Scholar] [CrossRef]
- Rozza, A.L.; de Mello Moraes, T.; Kushima, H.; Nunes, D.S.; Hiruma-Lima, C.A.; Pellizzon, C.H. Involvement of Glutathione, Sulfhydryl Compounds, Nitric Oxide, Vasoactive Intestinal Peptide, and Heat-Shock Protein-70 in the Gastroprotective Mechanism of Croton Cajucara Benth. (Euphorbiaceae) Essential Oil. J. Med. Food 2011, 14, 1011–1017. [Google Scholar] [CrossRef]
- Schobert, C.; Großmann, P.; Gottschalk, M.; Komor, E.; Pecsvaradi, A.; Mieden, U. zur Sieve-Tube Exudate from Ricinus Communis L. Seedlings Contains Ubiquitin and Chaperones. Planta 1995, 196, 205–210. [Google Scholar] [CrossRef]
- Parra, P.P.; Aime, M.C. New Species of Bannoa Described from the Tropics and the First Report of the Genus in South America. Mycologia 2019, 111, 953–964. [Google Scholar] [CrossRef]
- Mangena, P. Phytocystatins and Their Potential Application in the Development of Drought Tolerance Plants in Soybeans (Glycine max L.). Protein Pept. Lett. 2020, 27, 135–144. [Google Scholar] [CrossRef]
- Ishimoto, M.; Kuroda, M.; Yoza, K.; Nishizawa, K.; Teraishi, M.; Mizutani, N.; Ito, K.; Moriya, S. Heterologous Expression of Corn Cystatin in Soybean and Effect on Growth of the Stink Bug. Biosci. Biotechnol. Biochem. 2012, 76, 2142–2145. [Google Scholar] [CrossRef]
- Faisal, M.; Sarnaik, A.P.; Kannoju, N.; Hajinajaf, N.; Asad, M.J.; Davis, R.W.; Varman, A.M. RuBisCO Activity Assays: A Simplified Biochemical Redox Approach for in Vitro Quantification and an RNA Sensor Approach for in Vivo Monitoring. Microb. Cell Fact. 2024, 23, 83. [Google Scholar] [CrossRef]
- Leprince, O.; van Aelst, A.C.; Pritchard, H.W.; Murphy, D.J. Oleosins Prevent Oil-Body Coalescence during Seed Imbibition as Suggested by a Low-Temperature Scanning Electron Microscope Study of Desiccation-Tolerant and -Sensitive Oilseeds. Planta 1998, 204, 109–119. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accession a | Specie b | Unique c | Average Mass d | Description e |
|---|---|---|---|---|
| A0A6A6LG23 | Hevea brasiliensis | 2 | 182,269.31 | Beta-galactosidase |
| A0A2C9W8Z9 | Manihot esculenta | 2 | 100,566.17 | Beta-galactosidase |
| B9S377 | Ricinus communis | 2 | 85,277.63 | Neutral ceramidase |
| A0A2C9WL90 | Manihot esculenta | 2 | 85,249.52 | Neutral ceramidase |
| A0A2C9WFX1 | Manihot esculenta | 2 | 85,241.37 | Neutral ceramidase |
| A0A6A6MFZ7 | Hevea brasiliensis | 2 | 84,464.71 | Neutral ceramidase |
| A0A6A6LBT4 | Hevea brasiliensis | 2 | 74,518.06 | Uncharacterized protein |
| A0A6A6MIV4 | Hevea brasiliensis | 2 | 73,365.3 | Neutral ceramidase |
| A0A2C9W9U3 | Manihot esculenta | 2 | 73,318.14 | Uncharacterized protein |
| Accession a | −10LgP b | Coverage (%) c | Peptides d | Unique e | Average Mass f | Description g |
|---|---|---|---|---|---|---|
| Q9M4Q8 | 306.11 | 35.08 | 20 | 1 | 53,668 | Legumin B, putative |
| B9SF36 | 304.76 | 25.59 | 21 | 1 | 57,338 | Legumin A, putative |
| B9SDX6 | 302.79 | 33.82 | 19 | 1 | 53,652 | Legumin B, putative |
| A0A067K2P3 | 254.89 | 26.88 | 17 | 10 | 54,585 | Cupin type-1 domain-containing protein |
| B9SF35 | 250.92 | 15.16 | 13 | 6 | 53,490 | Legumin A, putative |
| B9T5E7 | 248.94 | 20.32 | 12 | 5 | 55,970 | Glutelin type-A 3, putative |
| A0A2C9UPV6 | 244.61 | 15.55 | 12 | 6 | 53,821 | Cupin type-1 domain-containing protein |
| A0A2C9UTB0 | 219.39 | 12.68 | 9 | 4 | 53,609 | Cupin type-1 domain-containing protein |
| A0A6A6KGZ5 | 205.96 | 14.55 | 8 | 1 | 49,303 | Cupin type-1 domain-containing protein |
| A0A6A6KD91 | 205.42 | 14.16 | 8 | 1 | 49,020 | Cupin type-1 domain-containing protein |
| B9T1B8 | 202.98 | 15.62 | 7 | 2 | 51,163 | Legumin A, putative |
| R4I518 | 192.83 | 18.31 | 7 | 4 | 46,572 | Legumin B (Fragment) |
| A0A067K3Z1 | 172.17 | 8.61 | 5 | 1 | 52,443 | Cupin type-1 domain-containing protein |
| R4I3K1 | 171.53 | 8.03 | 5 | 2 | 55,864 | Glutelin type-A 3 (Fragment) |
| A0A2C9UDP9 | 166.13 | 6.76 | 4 | 1 | 56,598 | Cupin type-1 domain-containing protein |
| A0A067KW23 | 162.61 | 7.09 | 5 | 2 | 57,166 | Cupin type-1 domain-containing protein |
| A0A2C9W805 | 144.81 | 6.82 | 3 | 1 | 57,672 | Cupin type-1 domain-containing protein |
| B9S9Q7 | 140.58 | 11.40 | 4 | 2 | 43,597 | 11S globulin subunit beta, putative |
| B9SKF4 | 131.46 | 6.94 | 4 | 1 | 40,099 | Nutrient reservoir, putative |
| A0A2C9UDV1 | 102.04 | 4.58 | 2 | 1 | 29,405 | Cupin type-1 domain-containing protein |
| A0A6A6KD87 | 65.72 | 6.82 | 1 | 1 | 25,130 | Cupin type-1 domain-containing protein |
| A0A067KVT0 | 65.29 | 1.75 | 1 | 1 | 66,360 | Cupin type-1 domain-containing protein |
| A0A6A6NJ14 | 63.36 | 1.52 | 1 | 1 | 82,874 | Cupin type-1 domain-containing protein |
| A0A6A6NIY9 | 63.36 | 2.24 | 1 | 1 | 55,956 | Cupin type-1 domain-containing protein |
| Accession a | −10LgP b | Coverage (%) c | Peptides d | Unique e | Average Mass f | Description g |
|---|---|---|---|---|---|---|
| A0A6A6LLV6 | 173.49 | 12.67 | 6 | 4 | 71,856 | Uncharacterized protein |
| B9RGN2 | 173.49 | 12.69 | 6 | 4 | 71,610 | Heat shock protein, putative |
| A0A2C9V090 | 173.49 | 12.67 | 6 | 4 | 71,884 | Uncharacterized protein |
| B2MW33 | 173.49 | 12.67 | 6 | 4 | 71,738 | Heat shock protein 70 |
| A0A6A6LJD5 | 173.49 | 14.54 | 6 | 4 | 63,321 | Uncharacterized protein |
| B9RGN3 | 173.49 | 12.67 | 6 | 4 | 71,867 | Heat shock protein, putative |
| A0A2C9W9U3 | 159.70 | 6.63 | 4 | 2 | 73,318 | Uncharacterized protein |
| A0A6A6LBT4 | 159.70 | 6.56 | 4 | 2 | 74,518 | Uncharacterized protein |
| A0A067JQG5 | 97.24 | 11.69 | 2 | 2 | 17,247 | Ubiquitin-like domain-containing protein |
| A0A6A6L0J0 | 97.24 | 6.06 | 2 | 2 | 33,548 | Ubiquitin-like domain-containing protein |
| A0A2C9UND2 | 97.24 | 11.54 | 2 | 2 | 17,702 | Ubiquitin-like domain-containing protein |
| A0A6A6KXT8 | 97.24 | 6.47 | 2 | 2 | 31,580 | Ubiquitin-like domain-containing protein |
| A0A067KV44 | 97.24 | 5.84 | 2 | 2 | 34,484 | Ubiquitin-like domain-containing protein |
| A0A6A6L0Z6 | 97.24 | 5.10 | 2 | 2 | 39,593 | Ubiquitin-like domain-containing protein |
| A0A6A6N2G6 | 97.24 | 6.79 | 2 | 2 | 30,429 | Ubiquitin-like domain-containing protein |
| D6BR61 | 97.24 | 14.06 | 2 | 2 | 14,673 | Ubiquitin C variant |
| A0A6A6KMK8 | 97.24 | 14.06 | 2 | 2 | 14,673 | Ubiquitin-like domain-containing protein |
| J3SA20 | 97.24 | 10.23 | 2 | 2 | 19,771 | Ubiquitin (Fragment) |
| A0A6A6NCA8 | 97.24 | 3.76 | 2 | 2 | 53,550 | Ubiquitin-like domain-containing protein |
| A0A6A6NCR1 | 97.24 | 3.47 | 2 | 2 | 58,001 | Ubiquitin-like domain-containing protein |
| A0A6A6LEU2 | 96.25 | 4.44 | 2 | 2 | 47,446 | Elongation factor 1-alpha |
| B9TK78 | 96.25 | 7.17 | 2 | 2 | 28,942 | Elongation factor 1-alpha, putative (Fragment) |
| A0A6A6LG04 | 96.25 | 4.28 | 2 | 2 | 49,009 | Elongation factor 1-alpha |
| A0A0H3YHL9 | 96.25 | 4.23 | 2 | 2 | 49,522 | Elongation factor 1-alpha |
| Q5VBE3 | 96.25 | 11.52 | 2 | 2 | 17,642 | Elongation factor 1-alpha |
| A0A067JPF4 | 62.90 | 13.51 | 1 | 1 | 12,240 | Cystatin domain-containing protein |
| A0A067JQS0 | 62.90 | 13.51 | 1 | 1 | 12,155 | Cystatin domain-containing protein |
| Accession a | −10LgP b | Coverage (%) c | Peptides d | Unique e | Average Mass f | Description g |
|---|---|---|---|---|---|---|
| Q9FSJ2 | 156.38 | 27.80 | 5 | 2 | 22,915 | Superoxide dismutase (fragment) |
| Q9STB5 | 156.38 | 27.80 | 5 | 2 | 22,915 | Superoxide dismutase (fragment) |
| A0A2C9VLE6 | 156.38 | 24.46 | 5 | 2 | 25,865 | Superoxide dismutase |
| A0A067K4A7 | 133.61 | 14.54 | 4 | 1 | 36,668 | Glyceraldehyde-3-phosphate dehydrogenase |
| J9S4Z6 | 115.99 | 20.41 | 3 | 3 | 15,767 | Oleosin2 |
| A0A8A4JBY4 | 95.49 | 4.77 | 2 | 2 | 53,346 | Ribulose bisphosphate carboxylase large chain |
| A7BGA7 | 95.49 | 5.19 | 2 | 2 | 48,923 | Ribulose bisphosphate carboxylase large chain |
| A0A2I6R6R7 | 95.49 | 5.23 | 2 | 2 | 48,712 | Ribulose bisphosphate carboxylase large chain |
| Q3T5B9 | 95.49 | 4.95 | 2 | 2 | 51,525 | Ribulose bisphosphate carboxylase large chain |
| E0D956 | 95.49 | 5.45 | 2 | 2 | 46,624 | Ribulose bisphosphate carboxylase large chain |
| J9RZJ1 | 64.51 | 7.91 | 1 | 1 | 14,862 | Oleosin3 |
| J9S7S3 | 63.76 | 6.29 | 1 | 1 | 15,279 | Oleosin1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torres-Sánchez, E.; Morato, E.; Hernández-Ledesma, B.; Gutiérrez, L.-F. Proteomic Analysis of the Major Alkali-Soluble Inca Peanut (Plukenetia volubilis) Proteins. Foods 2024, 13, 3275. https://doi.org/10.3390/foods13203275
Torres-Sánchez E, Morato E, Hernández-Ledesma B, Gutiérrez L-F. Proteomic Analysis of the Major Alkali-Soluble Inca Peanut (Plukenetia volubilis) Proteins. Foods. 2024; 13(20):3275. https://doi.org/10.3390/foods13203275
Chicago/Turabian StyleTorres-Sánchez, Erwin, Esperanza Morato, Blanca Hernández-Ledesma, and Luis-Felipe Gutiérrez. 2024. "Proteomic Analysis of the Major Alkali-Soluble Inca Peanut (Plukenetia volubilis) Proteins" Foods 13, no. 20: 3275. https://doi.org/10.3390/foods13203275
APA StyleTorres-Sánchez, E., Morato, E., Hernández-Ledesma, B., & Gutiérrez, L.-F. (2024). Proteomic Analysis of the Major Alkali-Soluble Inca Peanut (Plukenetia volubilis) Proteins. Foods, 13(20), 3275. https://doi.org/10.3390/foods13203275