
Security Risk Level Prediction of Carbofuran Pesticide Residues in Chinese Vegetables Based on Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.1.1. Data Sources
2.1.2. Data Preprocessing
2.2. Security Risk Assessment Model
2.2.1. Nemerow Integrated Pollution Index
2.2.2. Acute Exposure Assessment
2.2.3. Chronic Dietary Exposure Assessment
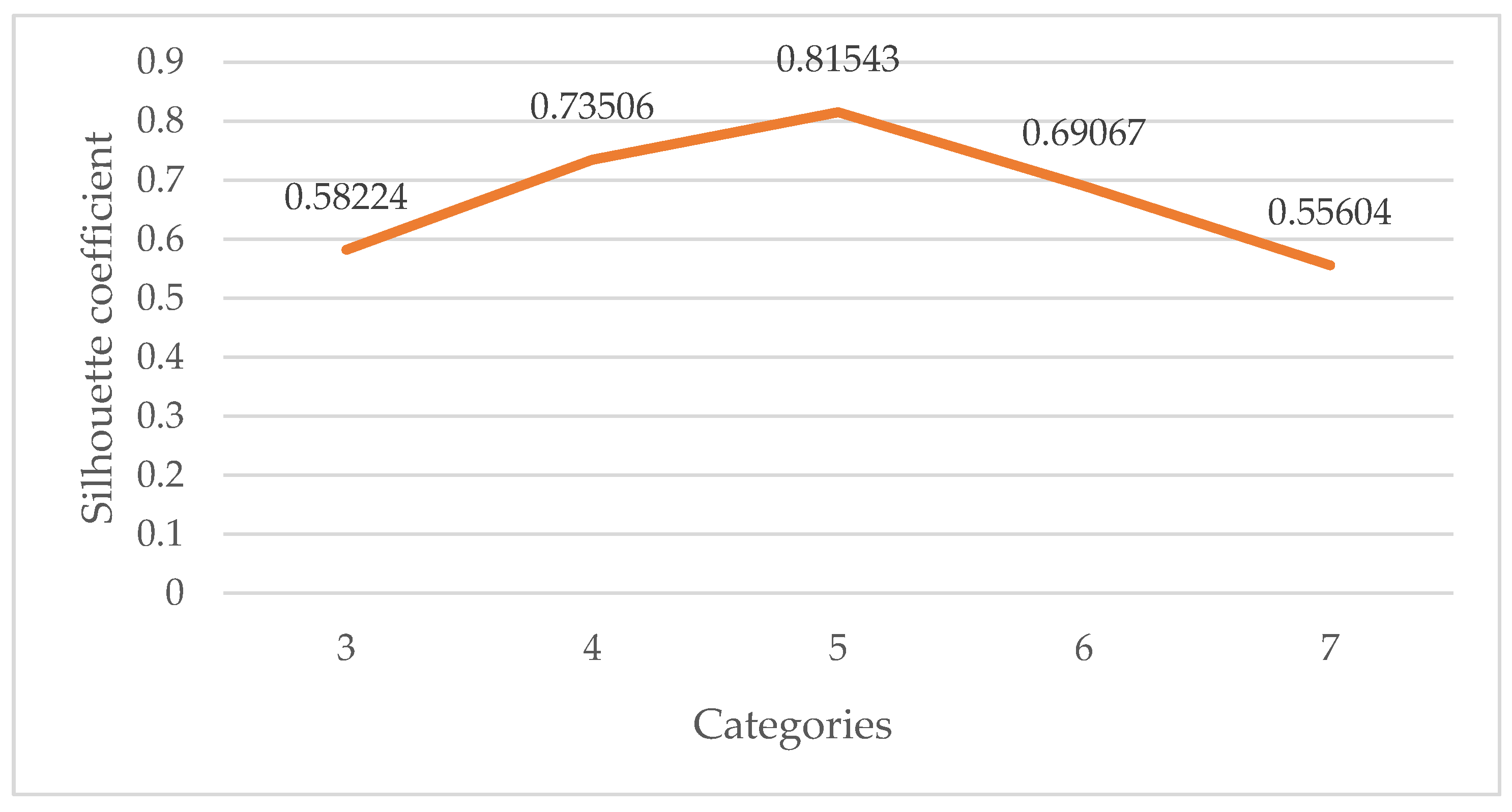
2.3. Security Risk Classification Based on K-Means++
- (1)
- Select a point randomly from the set of input data points as the first clustering center.
- (2)
- For each point x in the data set, calculate the distance D(x) between it and the nearest cluster center (referring to the existing cluster center).
- (3)
- A new data point is selected as the new clustering center, and the selection principle is as follows: the point with larger D(x) has a higher probability of being selected as the clustering center.
- (4)
- Repeat (2) and (3) until k cluster centers are selected.
- (5)
- The k initial clustering centers are used to run the standard k-means algorithm.
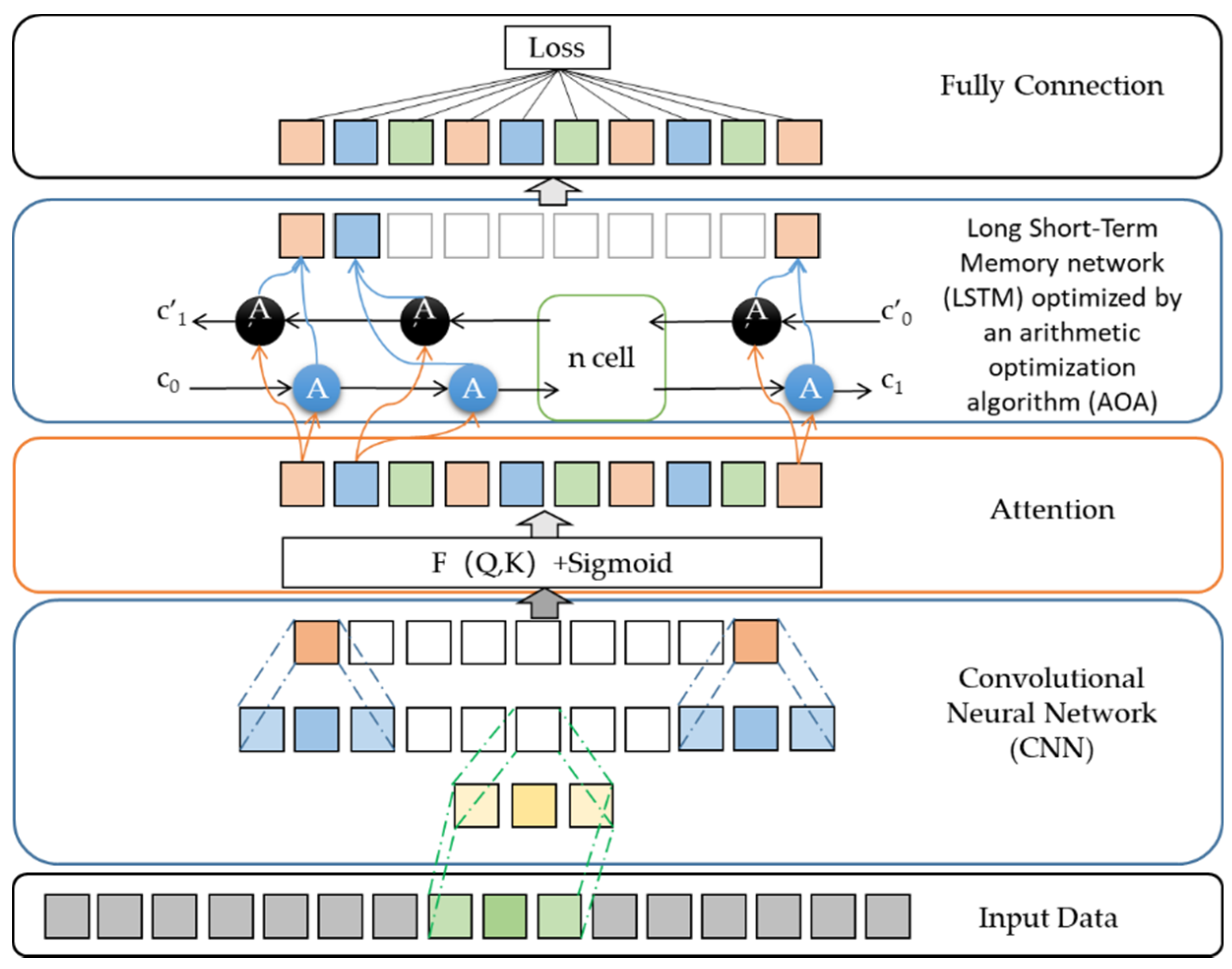
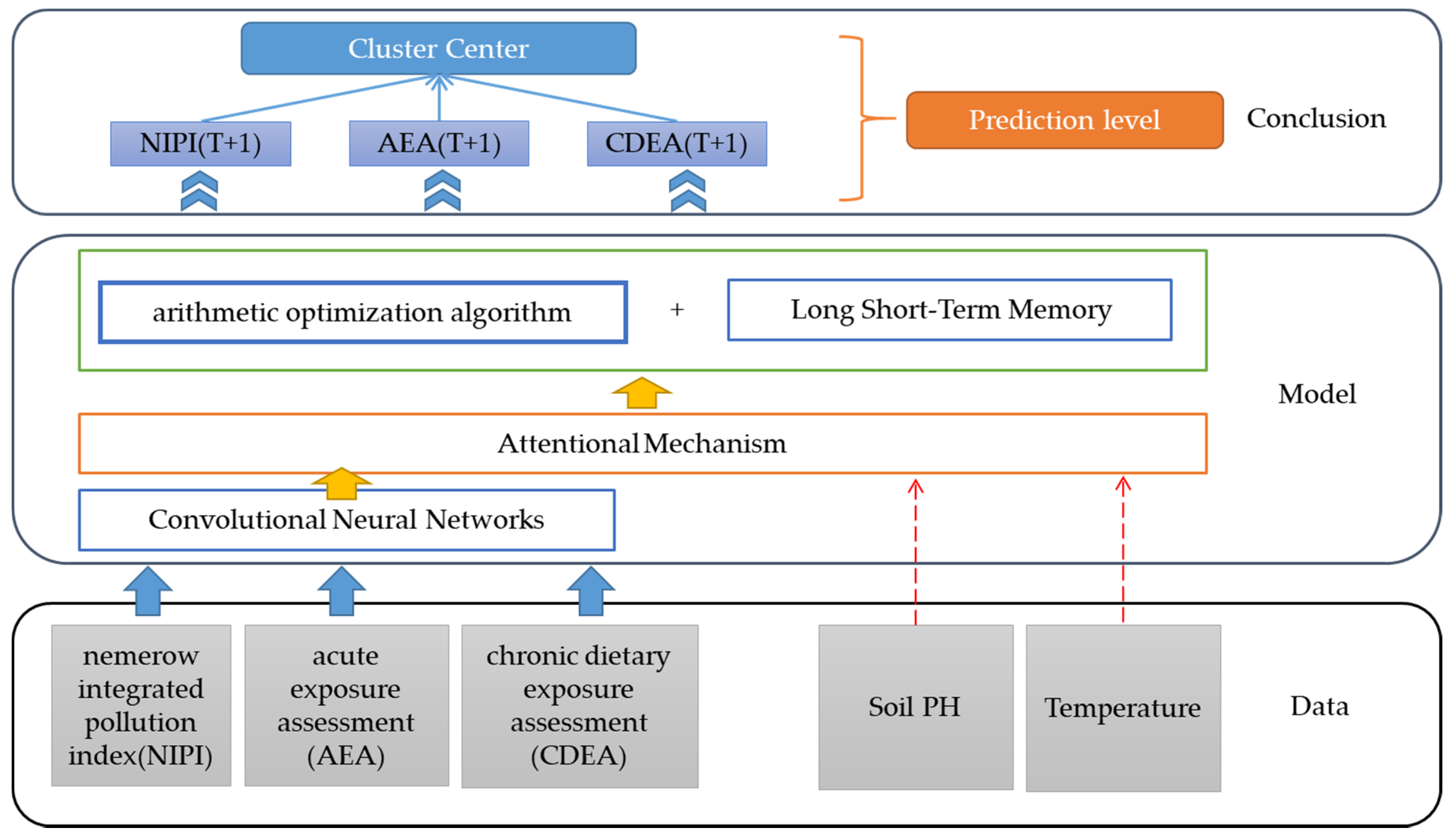
2.4. CNN-AOA-LSTM Security Risk Level Prediction Model Based on Attention Mechanism
2.4.1. Framework of CNN-AOA-LSTM Model
2.4.2. Attention Mechanism Based on PH of Soil and Temperature
3. Results
3.1. Data Set and Experimental Parameters
3.1.1. Data Set
3.1.2. Experimental Environment
3.1.3. Experimental Parameters
3.2. Model Evaluation Indexes
3.2.1. Prediction Performance Evaluation Indexes
3.2.2. Prediction Accuracy Evaluation Index
3.3. Security Risk Assessment and Classification
3.3.1. Security Risk Assessment Indexes
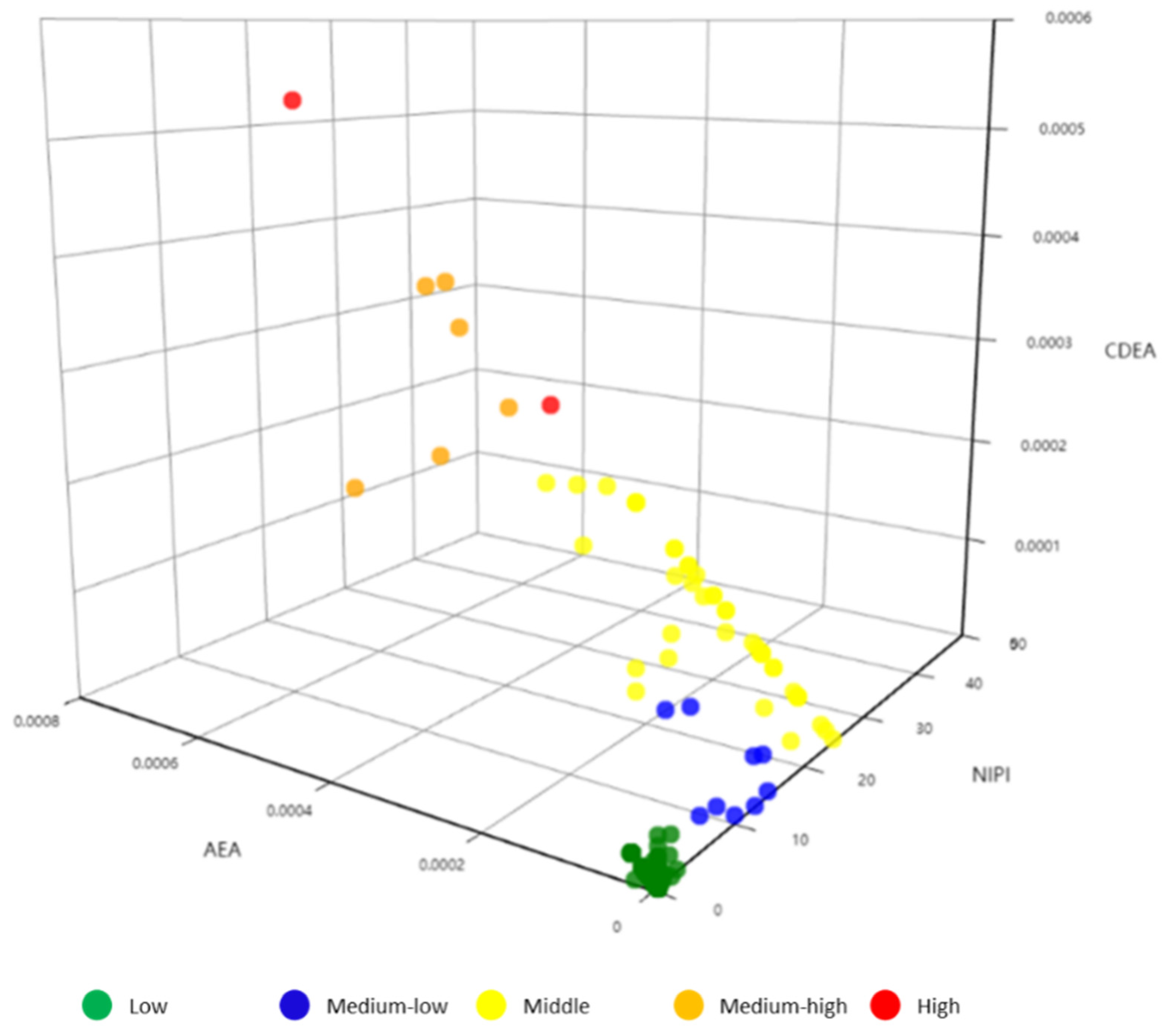
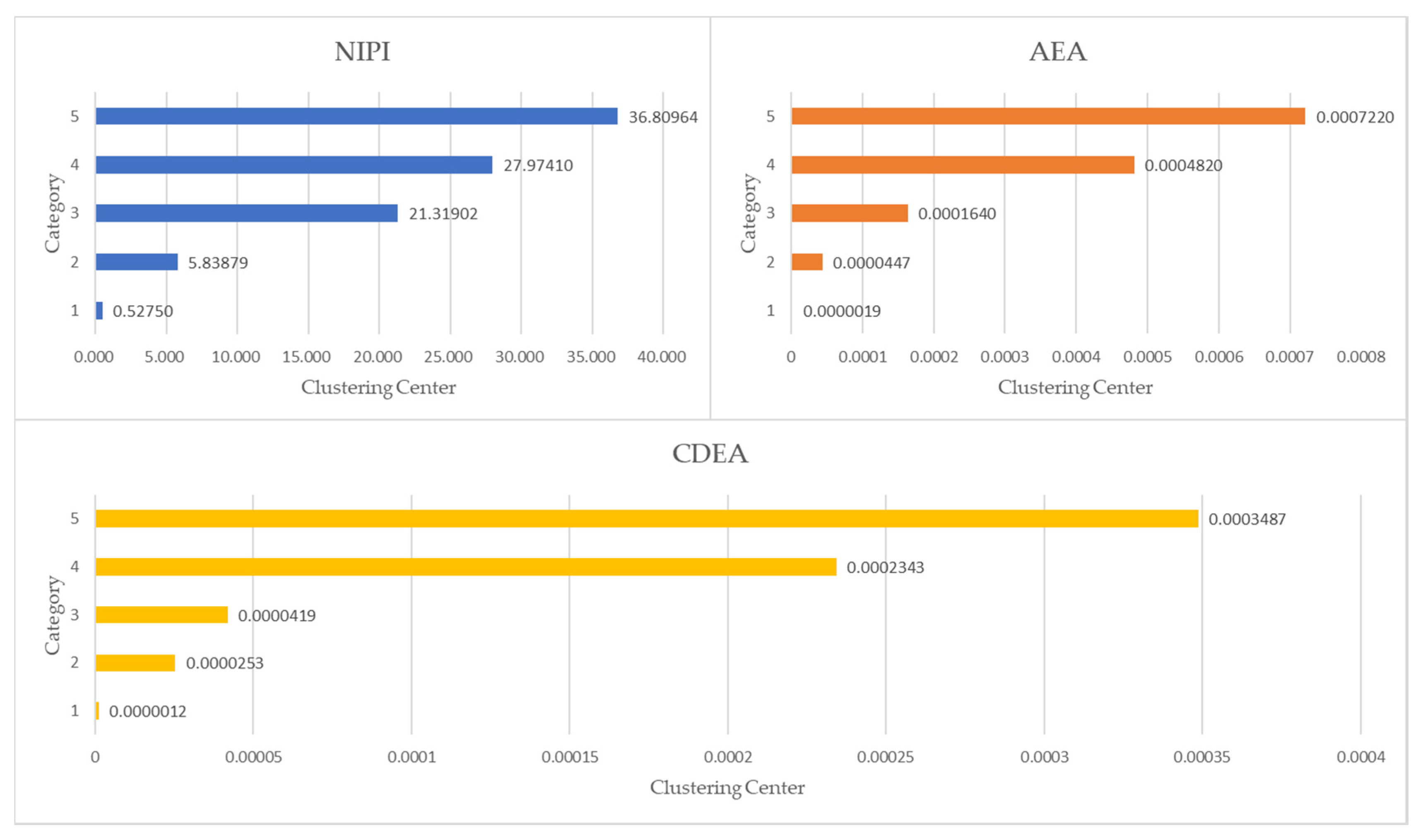
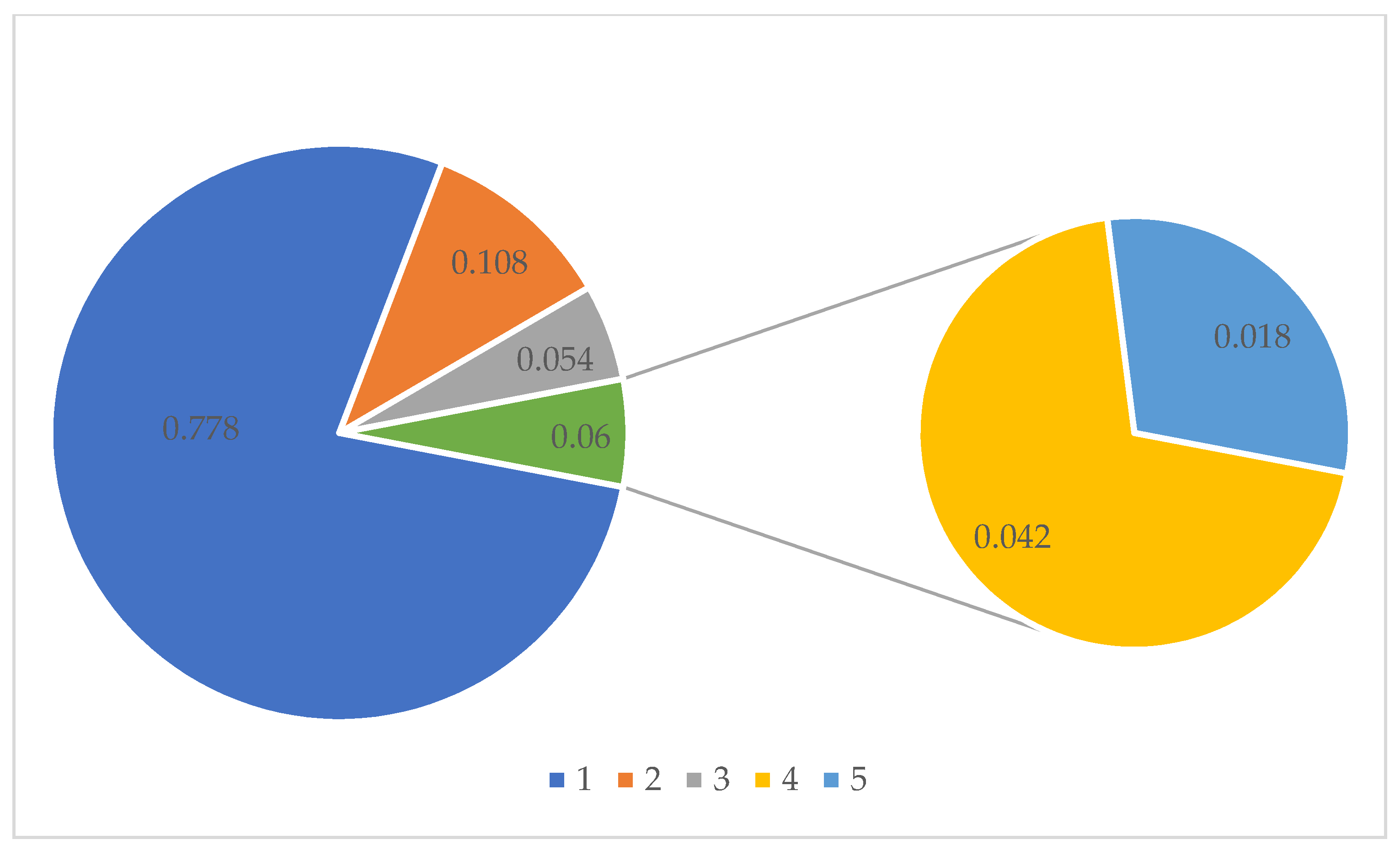
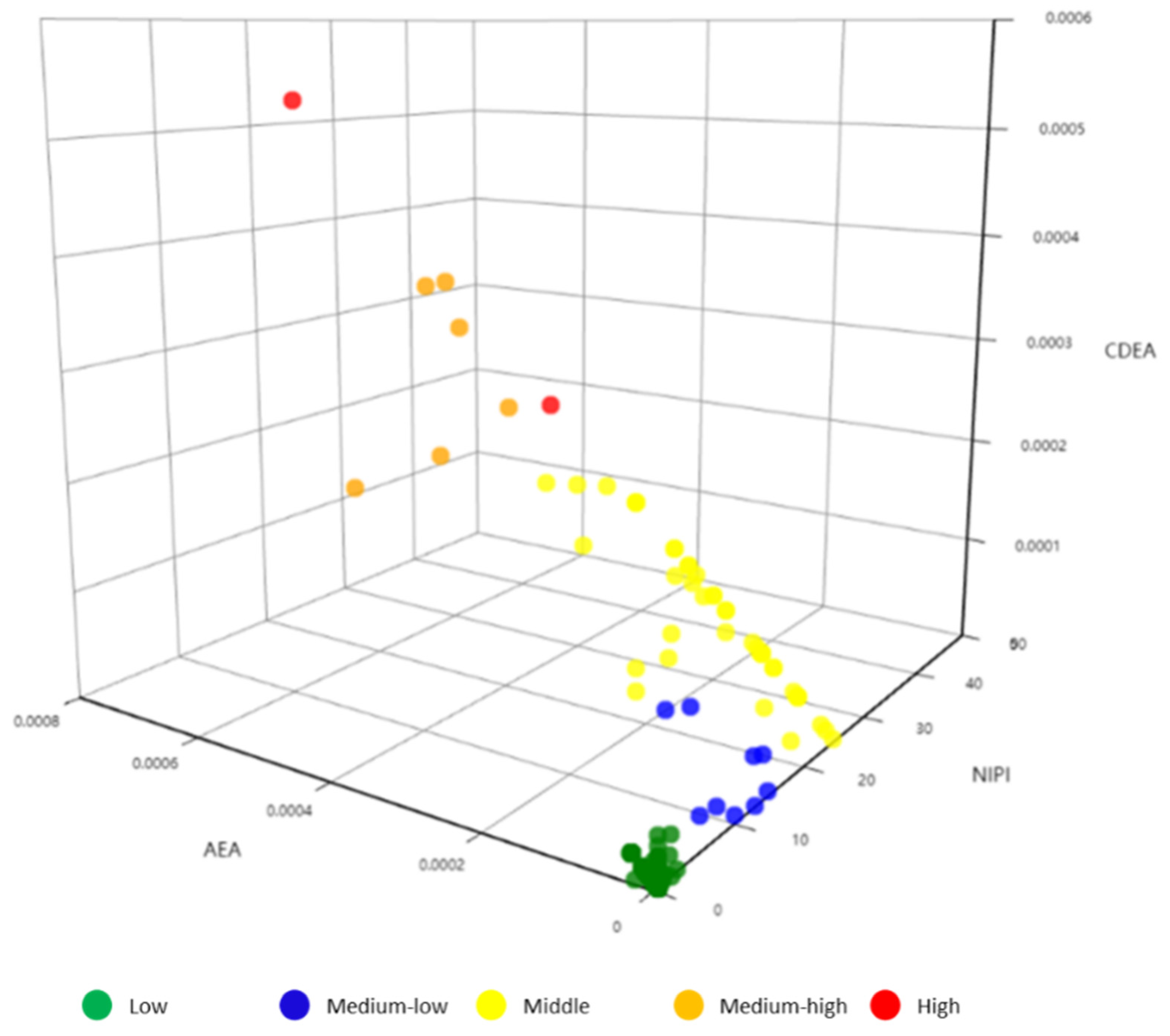
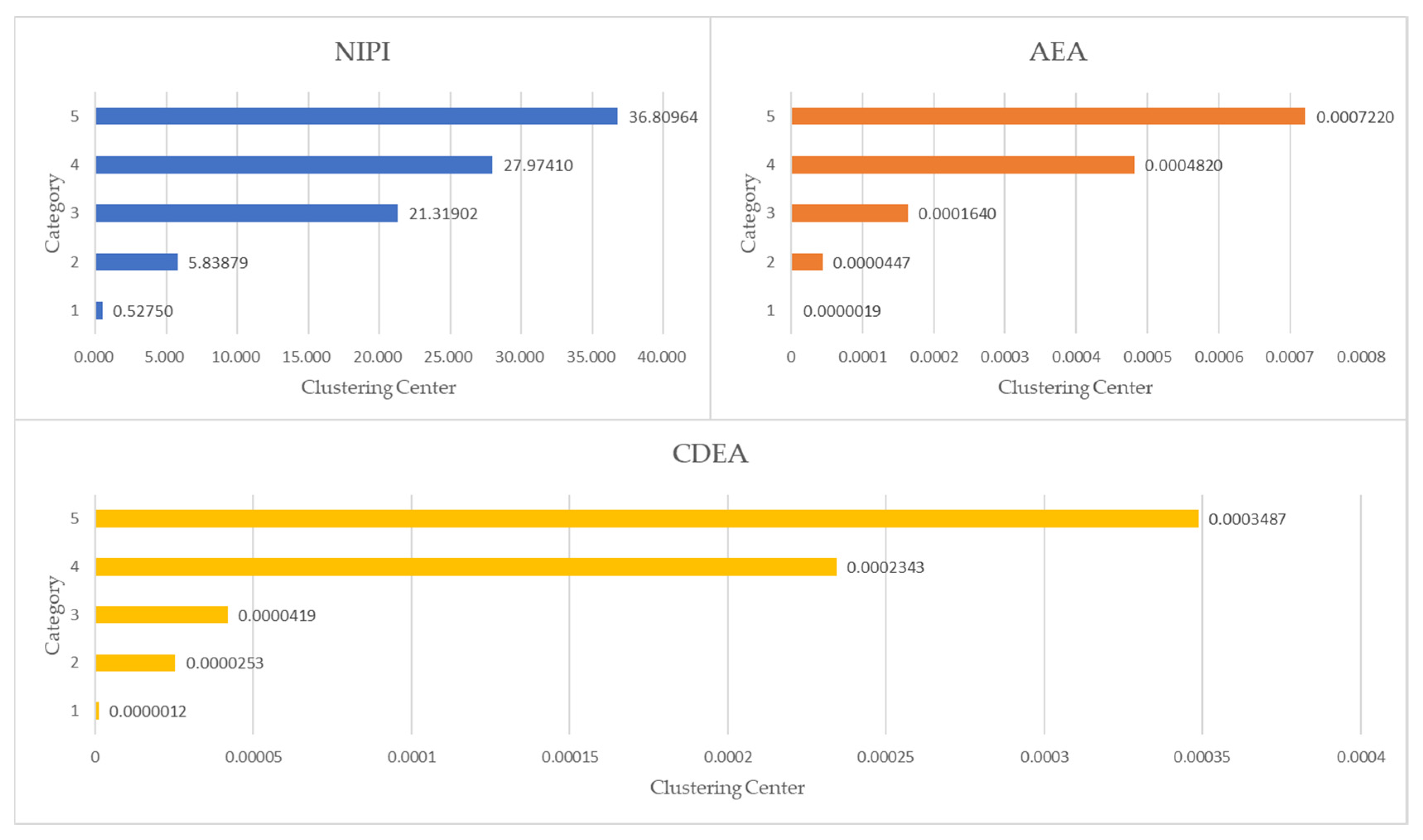
3.3.2. Security Risk Classification
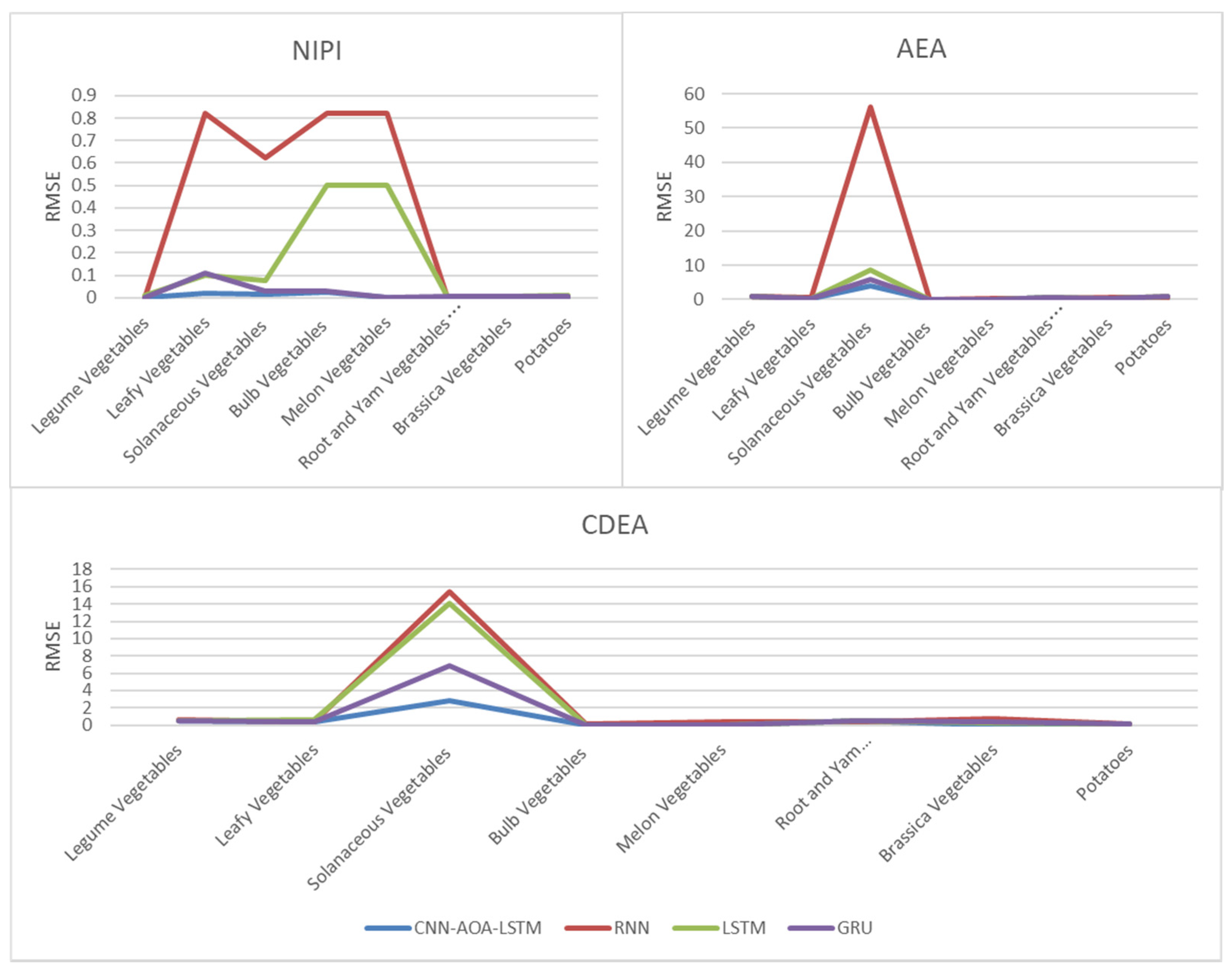
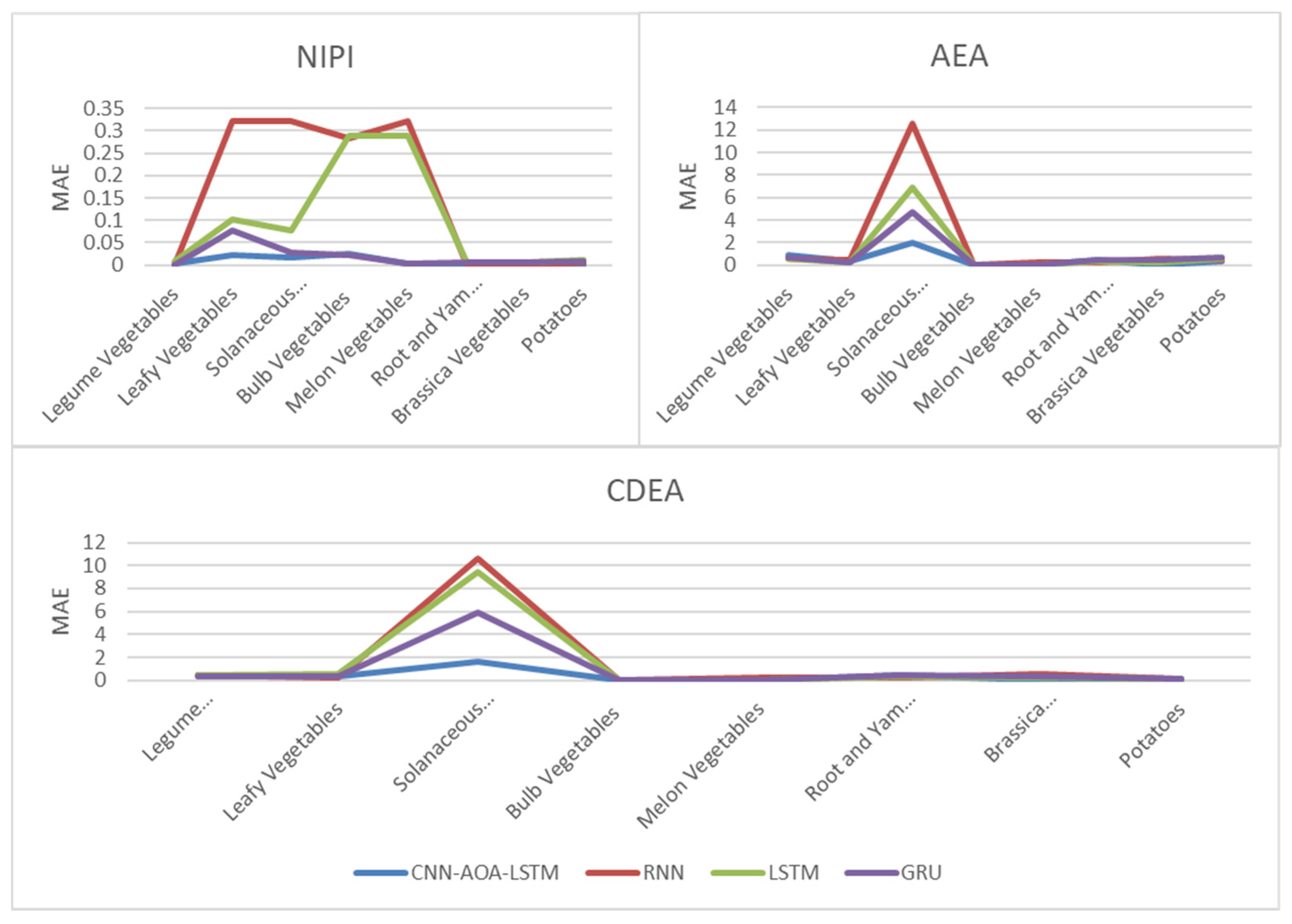
3.3.3. Analysis of Security Risk Classification Results
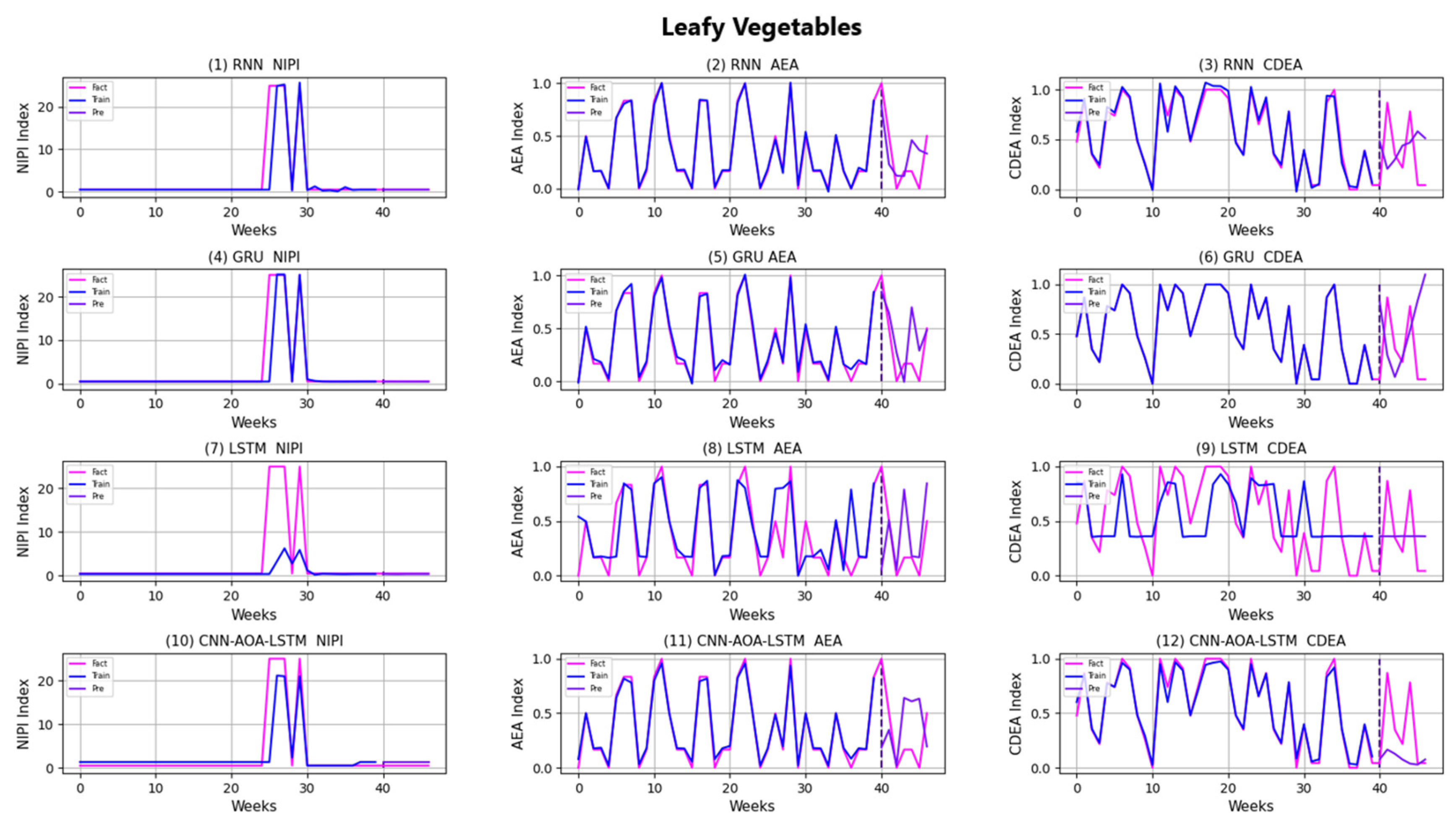
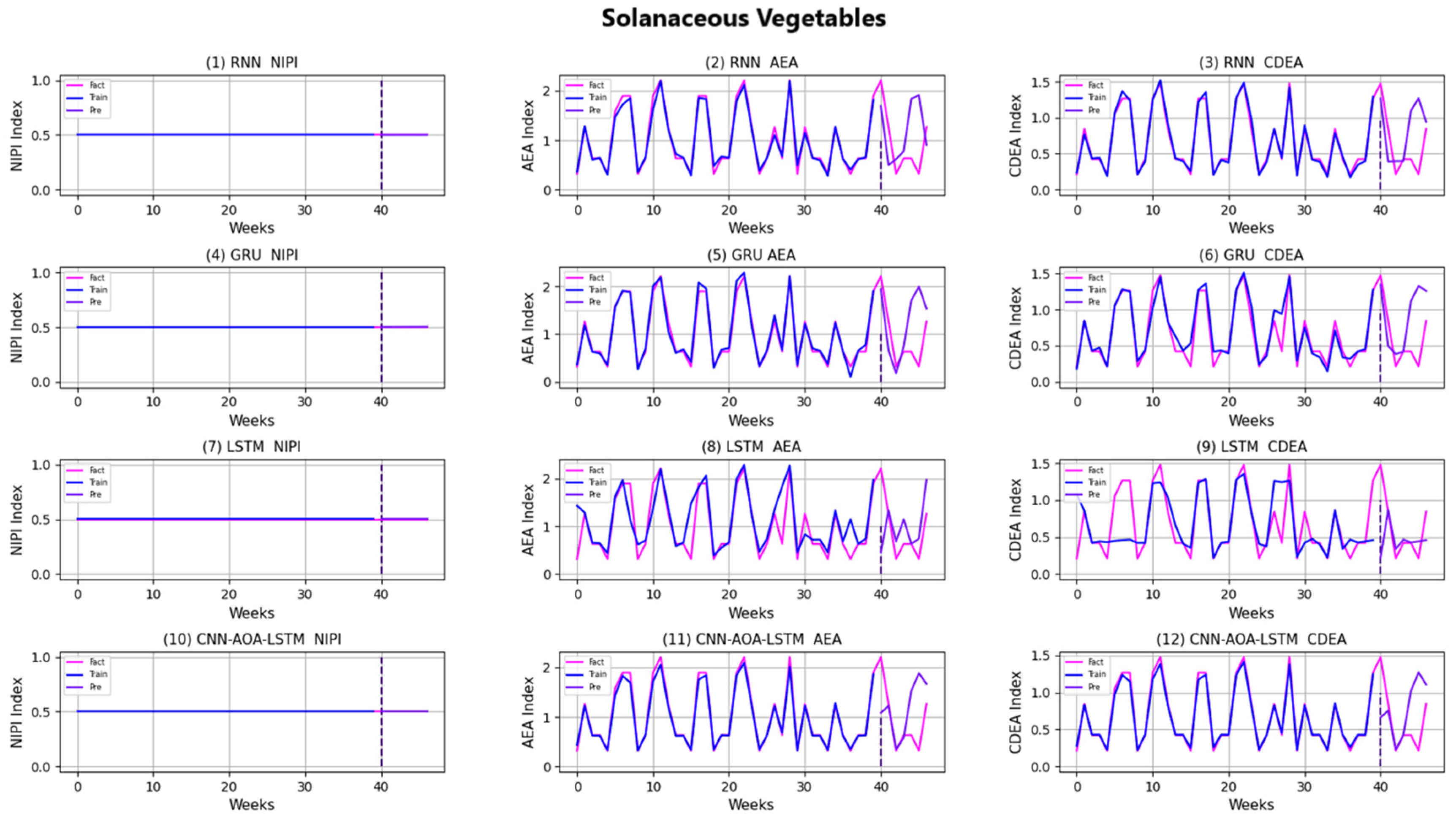
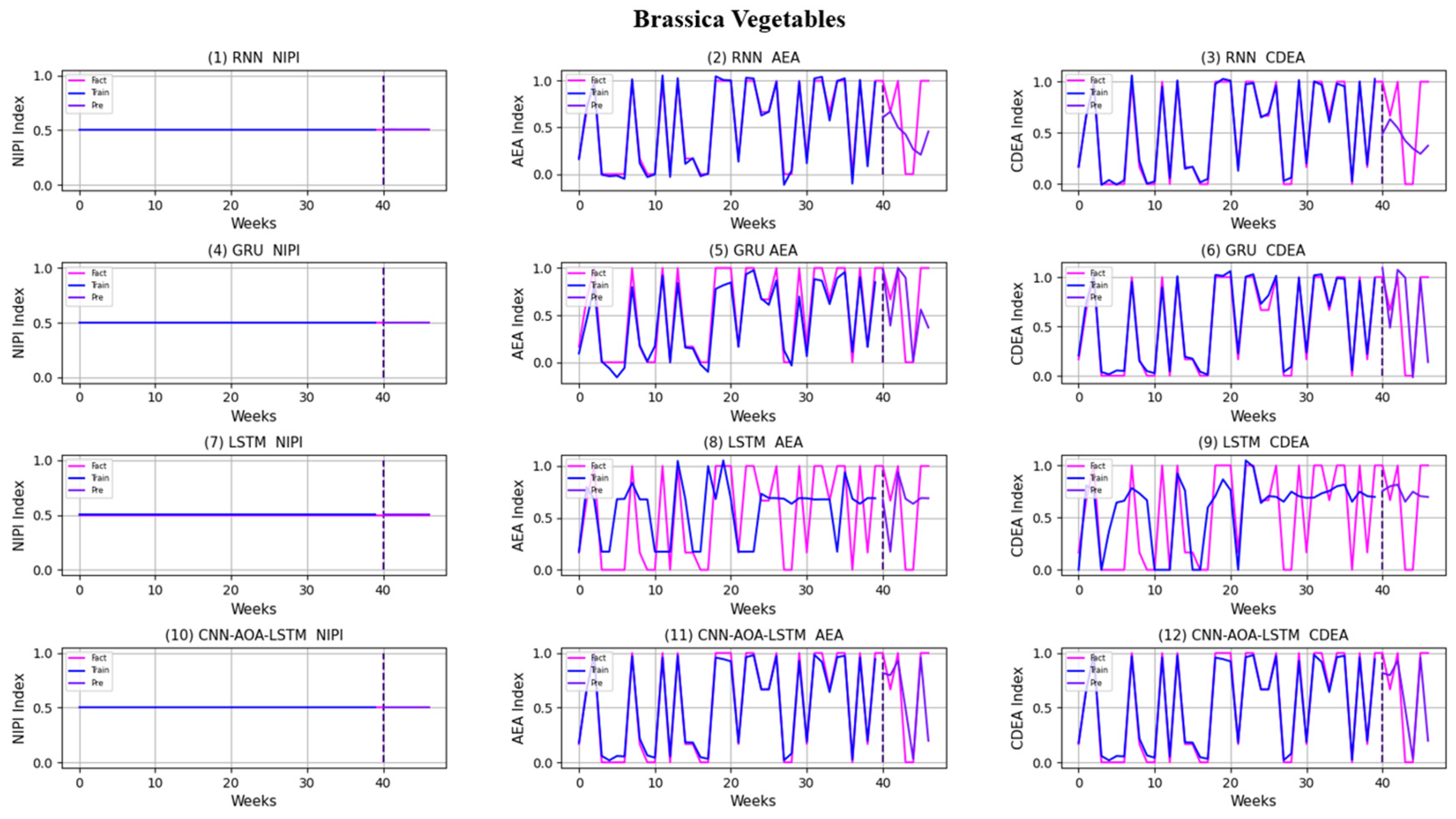
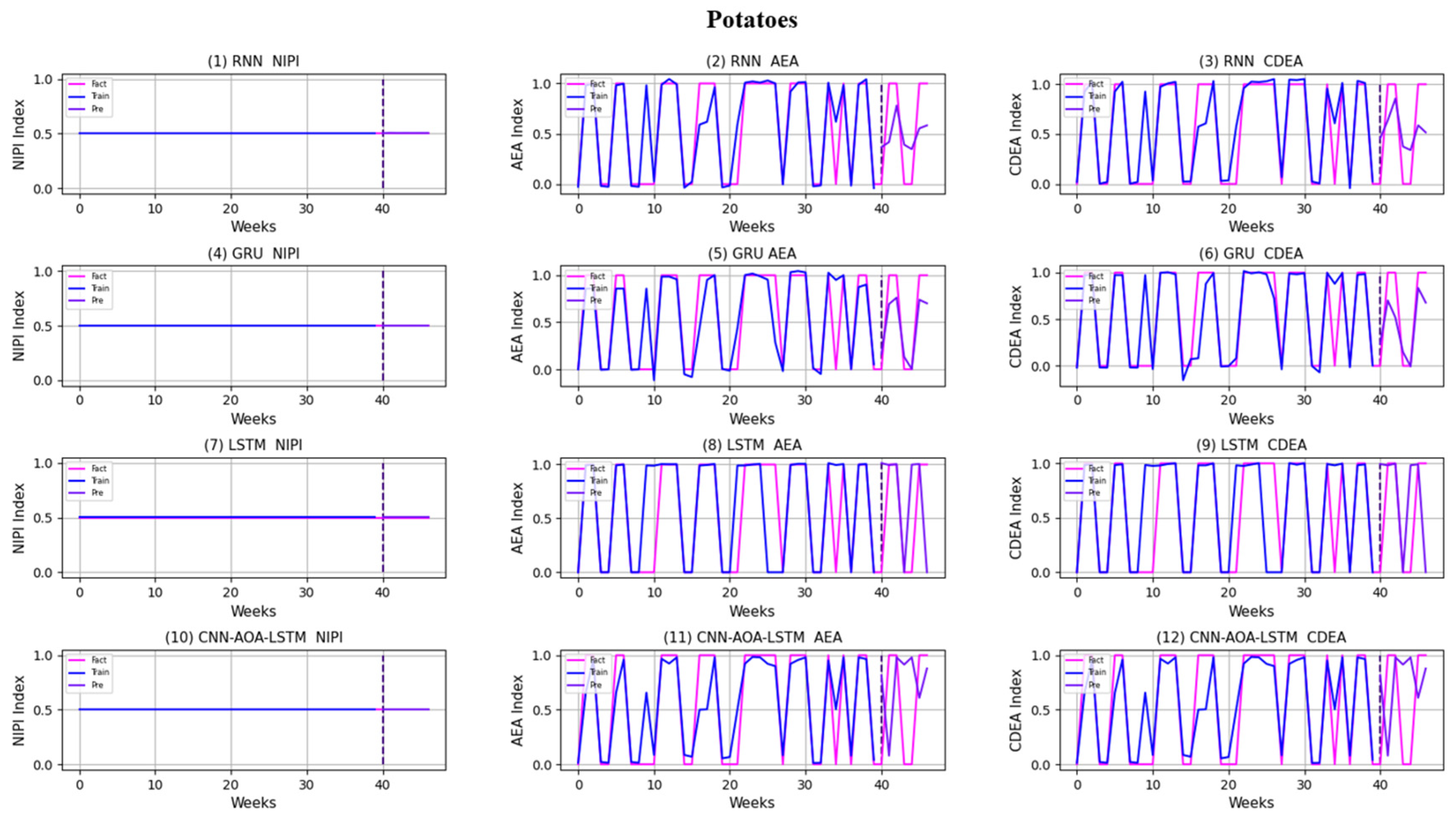
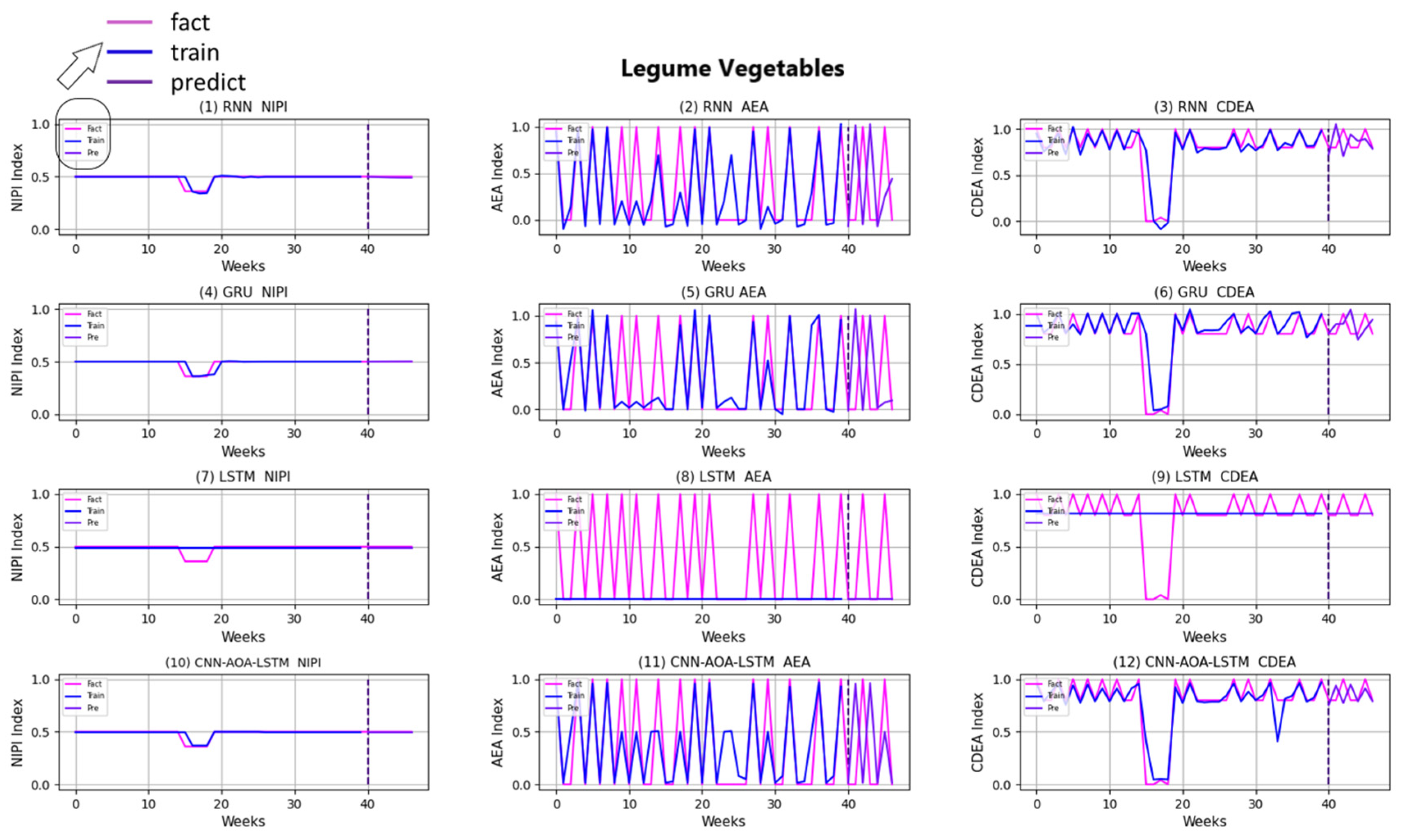
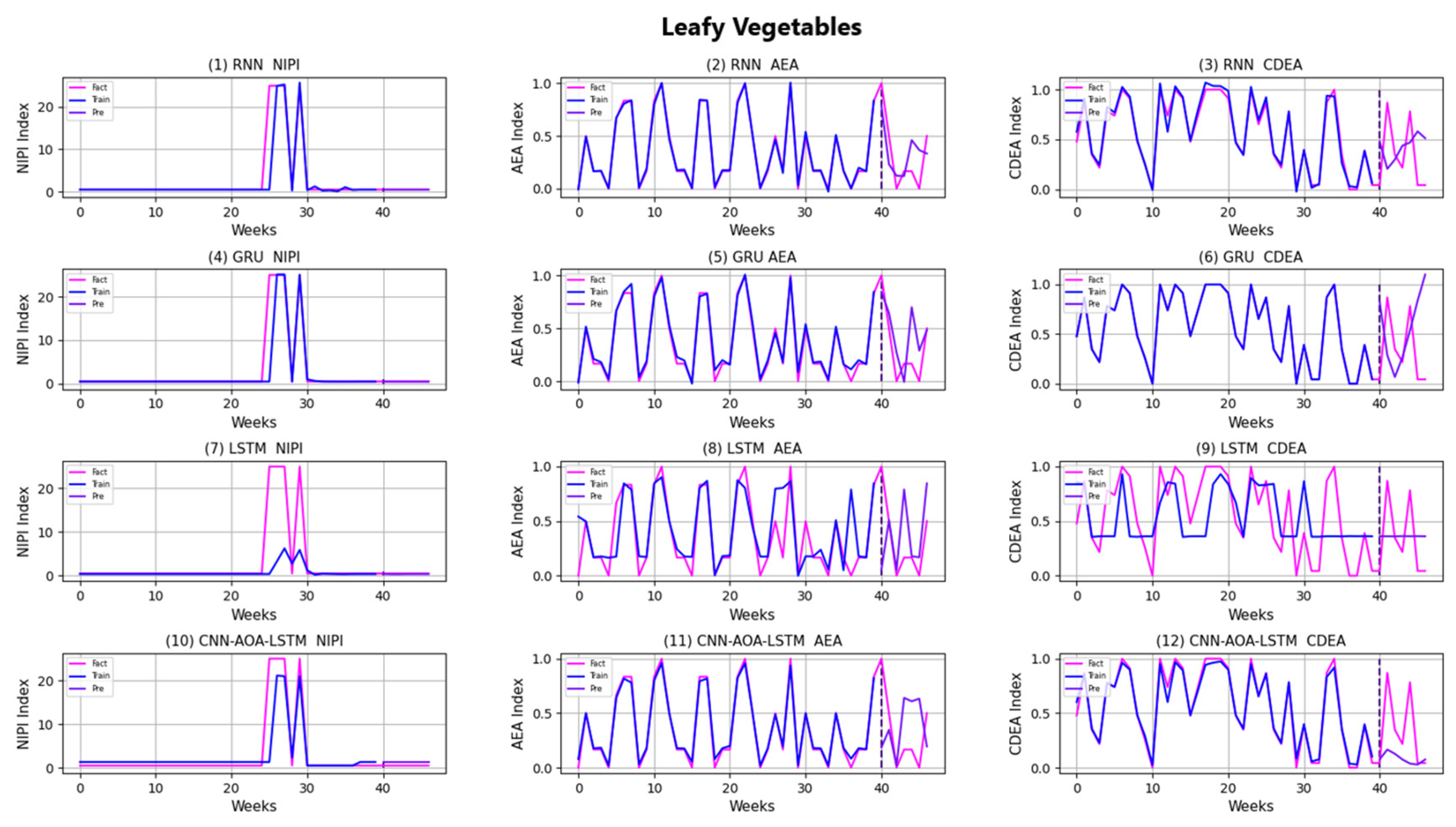
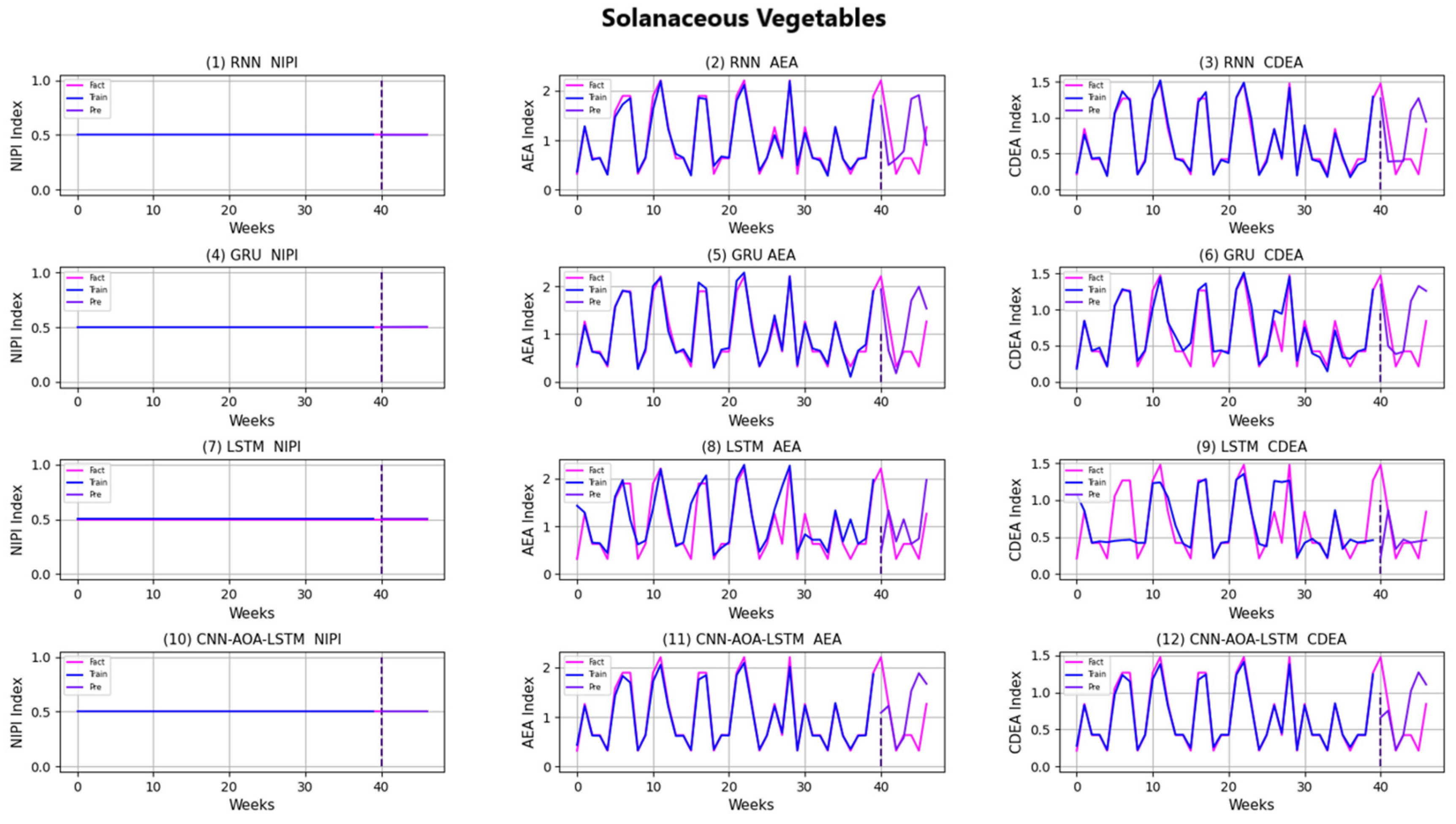
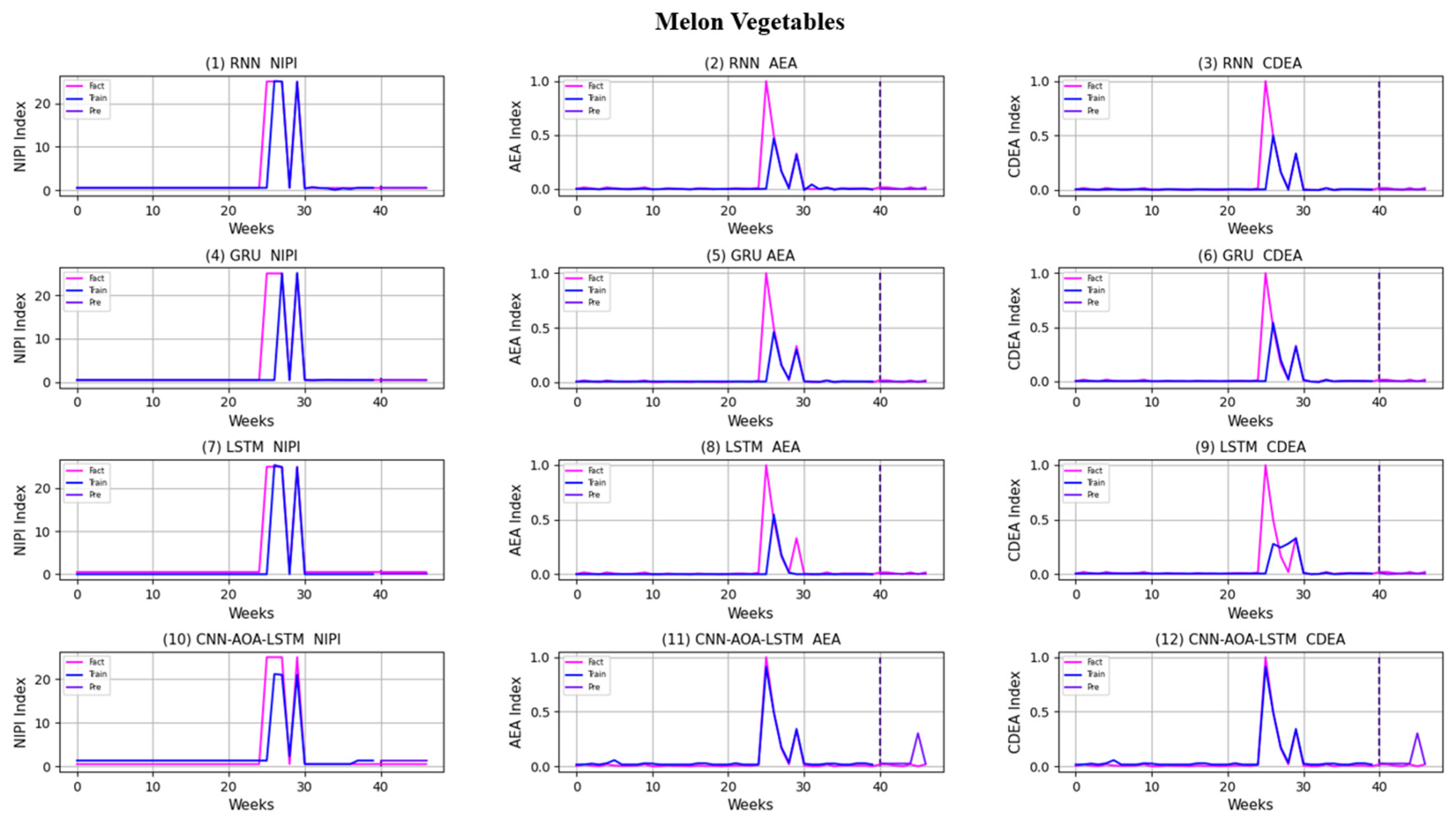
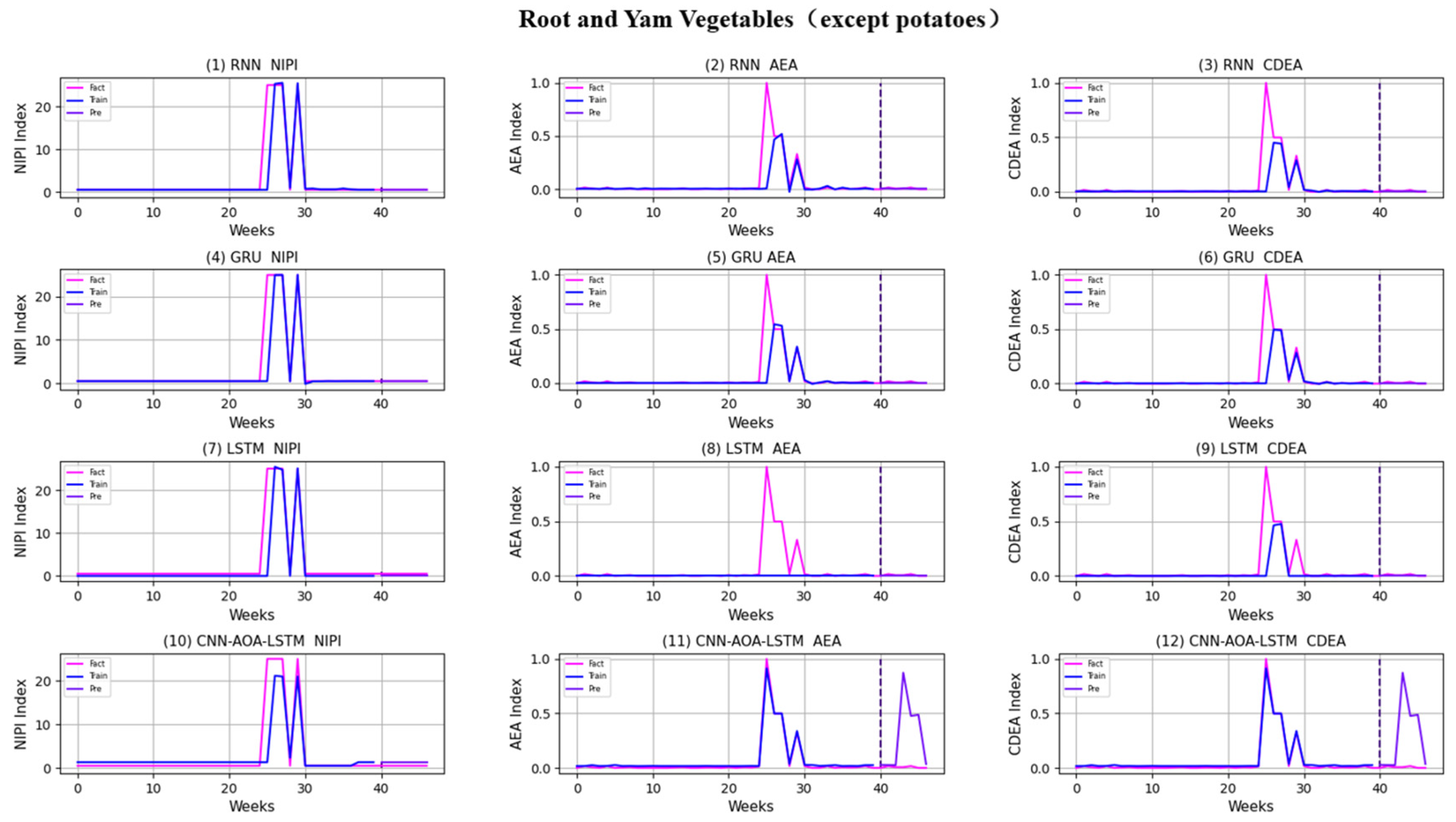
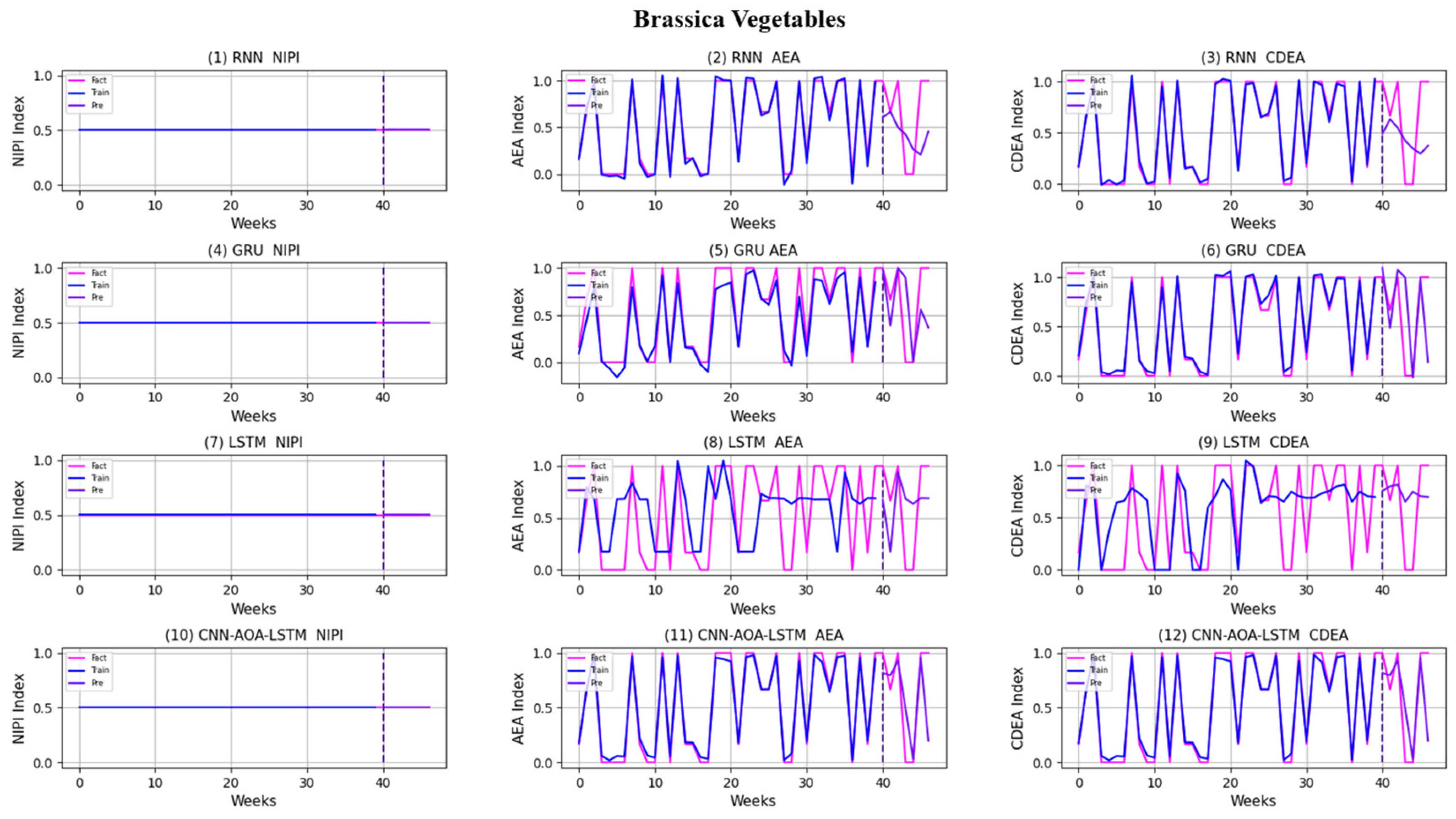
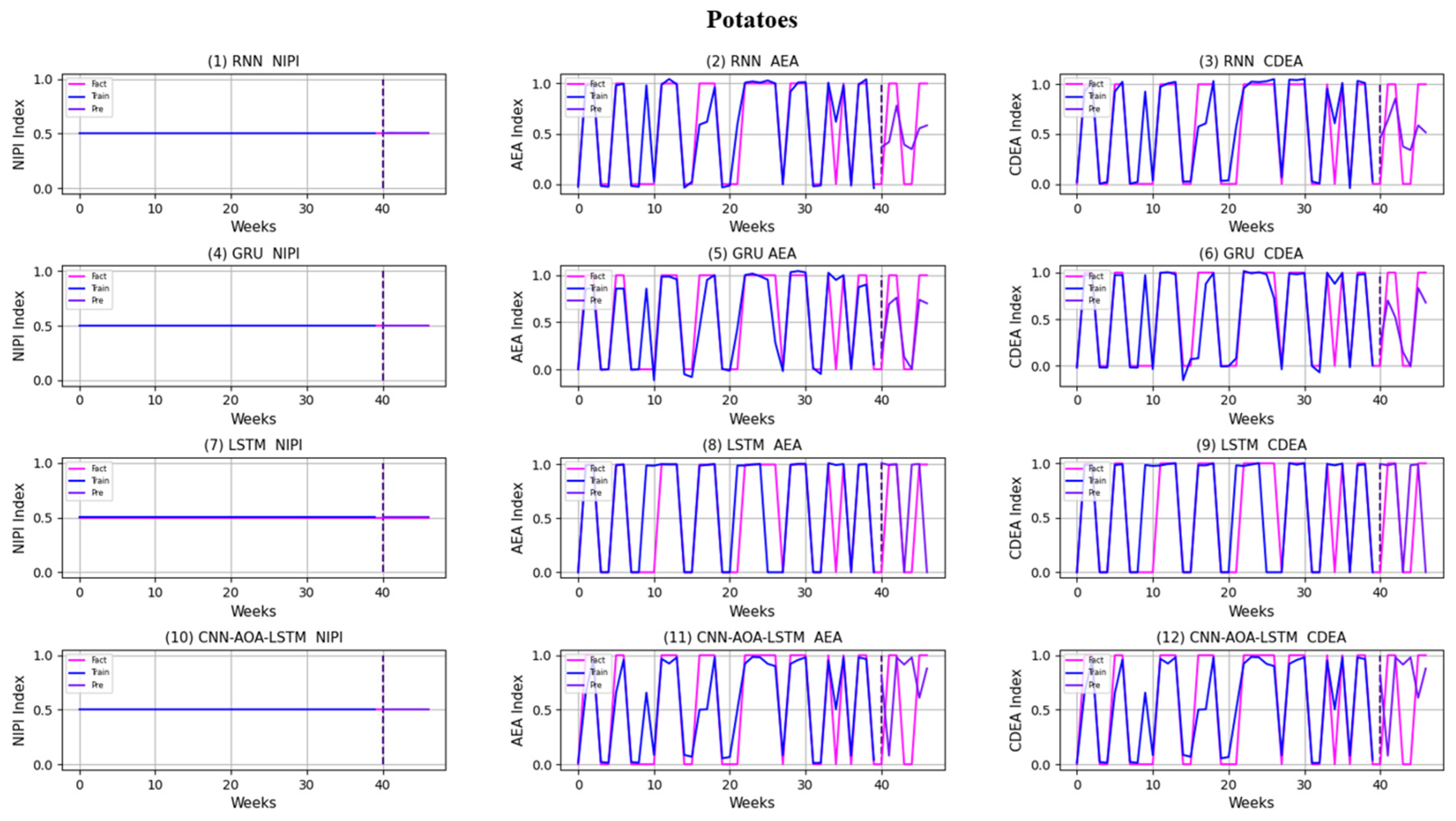
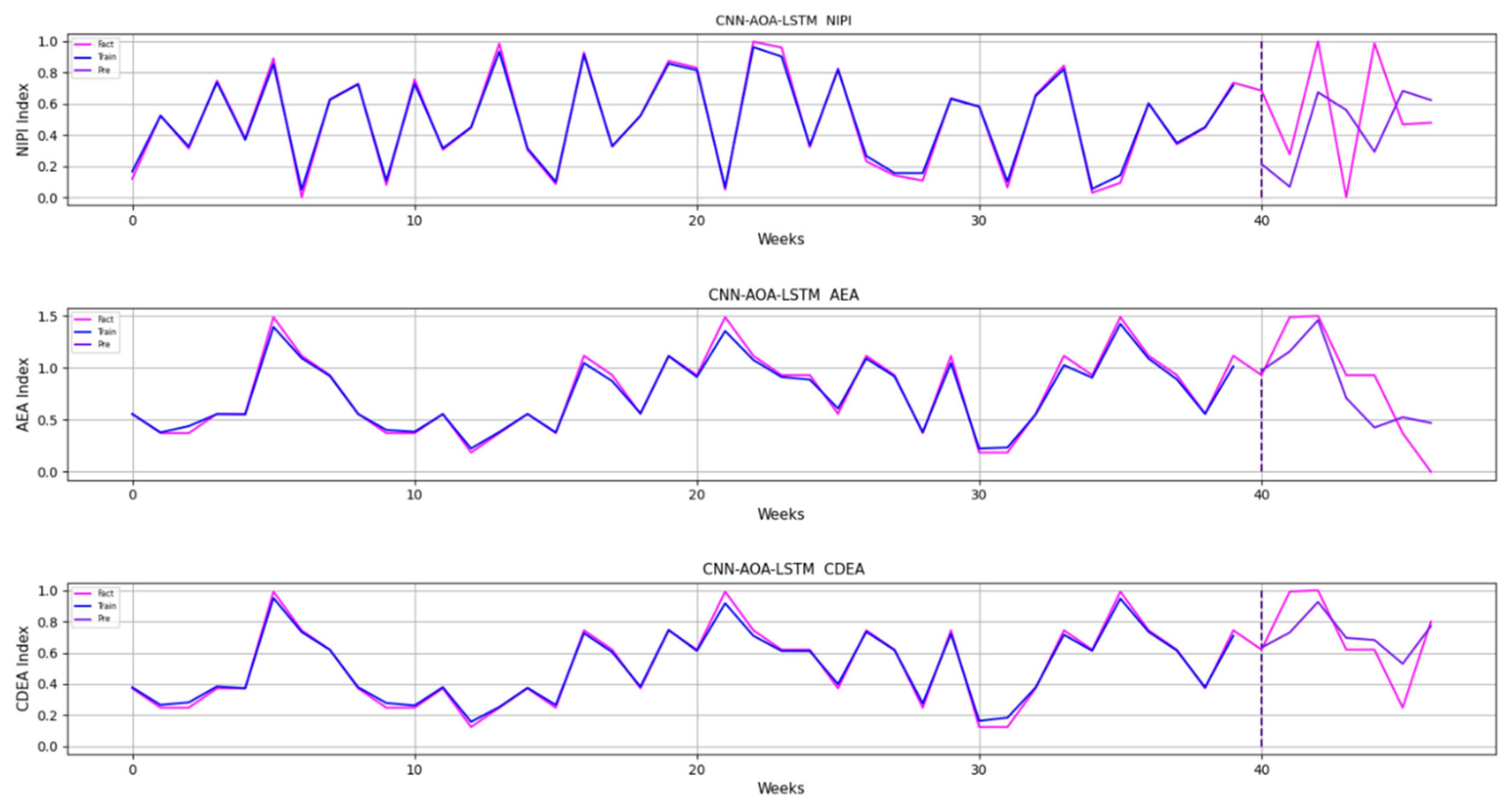
3.4. Security Risk Level Prediction Model of CNN-AOA-LSTM Based on Attention Mechanism
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- FAO. Pesticide residues in food. Pestic. Residues Food 1997, 17, 27–28. [Google Scholar]
- Song, H.Y.; Wang, J. Environmental endocrine disruptors and pesticides. Pestic. Sci. Adm. 2001, 22, 23–25. [Google Scholar] [CrossRef]
- Zhang, L.J.; Min, S.G.; Li, G.X.; Xiong, Y.M.; Sun, Y. Spectroscopic study on the interaction between carbofuran and DNA. Spectrosc. Spectr. Anal. 2005, 25, 739–742. [Google Scholar] [CrossRef]
- Xu, G.Z.; He, M. Investigation and risk assessment of pesticide residues in vegetables sold in Yancheng. Sci. Technol. Innov. Guide 2017, 14, 114–116. [Google Scholar] [CrossRef]
- Xu, J.; Dai, F.F.; Nie, D.D. Situation of pesticide residues in vegetables and fruits of Weifang City in 2015. Trop. Med. China 2016, 16, 141–144, 148. [Google Scholar] [CrossRef]
- Zheng, Q.W. Inner Mongolia: The over standard of carbofuran in jianjiao is caused by the fake pesticide. Pestic. Market. Inf. 2018, 612, 17. [Google Scholar]
- Nie, W.J.; Li, T.P. Research review of food security risk assessment model. J. Food Secur. Qual. 2014, 5, 1551–1556. [Google Scholar] [CrossRef]
- He, W.Z.; Tao, Y.X.; Yan, Q.L.; Liu, S.H.; An, R.; Wang, C. Risk Assessment and Hazard Rank of Pesticide Residues in Jujube from Xinjiang. Sci. Technol. Food Ind. 2018, 39, 202–206. [Google Scholar] [CrossRef]
- Zhao, F.; Liu, J. Effects of the cooking modes on commonly used pesticides residue in vegetables and their chronic dietary exposure risk in South China. Food Addit. Contam. 2020, 37, 121–130. [Google Scholar] [CrossRef]
- Fang, L.; Zhang, S.; Chen, Z.; Du, H.; Zhu, Q.; Dong, Z.; Li, H. Risk assessment of pesticide residues in dietary intake of celery in China. Regul. Toxicol. Pharmacol. 2015, 73, 578–586. [Google Scholar] [CrossRef]
- Kumari, D.; John, S. Health risk assessment of pesticide residues in fruits and vegetables from farms and markets of Western Indian Himalayan region. Chemosphere 2019, 224, 162–167. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Haghighat, F.; Fung, B. A review of the-state-of-the-art in data-driven approaches for building energy prediction. Energy Build. 2020, 221, 110022. [Google Scholar] [CrossRef]
- Sun, J.; Kim, J. Joint prediction of next location and travel time from urban vehicle trajectories using long short-term memory neural networks. Transp. Res. Part C Emerg. Technol. 2021, 128, 103114. [Google Scholar] [CrossRef]
- Wang, R.; Peng, C.; Gao, J.; Gao, Z.; Jiang, H. A dilated convolution network-based LSTM model for multi-step prediction of chaotic time series. Comput. Appl. Math. 2020, 39, 30. [Google Scholar] [CrossRef]
- Alexander, J.; Edwards, R.A.; Brodsky, M.; Manca, L.; Grugni, R.; Savoldelli, A.; Bonfanti, G.; Emir, B.; Whalen, E.; Watt, S.; et al. Using time series analysis approaches for improved prediction of pain outcomes in subgroups of patients with painful diabetic peripheral neuropathy. PLoS ONE 2018, 13, e0212959. [Google Scholar] [CrossRef]
- Yu, W.P.; Han, X.Y.; Wang, Y.Y.; Yang, J. Prediction of pesticide residues in agricultural products based on time series model in Chengdu, China. IOP Conf. Ser. Earth Environ. Sci. 2020, 594, 012022. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Chen, Q.; Wu, X.; Hang, Y. A deep learning based regression method on hyperspectral data for rapid prediction of cadmium residue in lettuce leaves. Chemom. Intell. Lab. Syst. 2020, 200, 103996. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2007, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Wu, Y.; Zhao, Y.; Li, J. Chapter Two: Food consumption data. In The Fifth China Total Diet Study; Luo, J., Yue, M., Eds.; Science Press: Beijing, China, 2018; pp. 66–69. [Google Scholar]
- Wang, X.Q.; Wu, Y.N.; Cheng, J.S. Low level data processing in food contamination monitoring. Chin. J. Prev. Med. 2002, 4, 63–64. [Google Scholar]
- Bekhet, H.A.; Yasmin, T. Exploring EKC, trends of growth patterns and air pollutants concentration level in Malaysia: A Nemerow Index Approach. In Proceedings of the International Conference on Energyand Environment, Putrajaya, Malaysia, 5–6 March 2013. [Google Scholar] [CrossRef] [Green Version]
- Mazurek, R.; Kowalska, J.; Gąsiorek, M.; Zadrożny, P.; Józefowska, A.; Zaleski, T.; Kępka, W.; Tymczuk, M.; Orłowska, K. Assessment of heavy metals contamination in surface layers of Roztocze National Park forest soils (SE Poland) by indices of pollution. Chemosphere 2017, 168, 839–850. [Google Scholar] [CrossRef]
- Han, W.; Gao, G.; Geng, J.; Li, Y.; Wang, Y. Ecological and health risks assessment and spatial distribution of residual heavy metals in the soil of an e-waste circular economy park in Tianjin, China. Chemosphere 2018, 197, 325–335. [Google Scholar] [CrossRef]
- Wei, J.X.; Geng, Y.B.; Ceng, K. The Heavy Metal Content Monitoring and Dietary Risk Assessment of Commercial Rice in Beijing. Mod. Food Sci. Technol. 2018, 34, 267–273. [Google Scholar] [CrossRef]
- Li, R.-Z.; Pan, C.-R.; Xu, J.-J.; Chen, J.; Jiang, Y.-M. Contamination and Health Risk for Heavy Metals via Consumption of Vegetables Grown in Fragmentary Vegetable Plots from a Typical Nonferrous Metals Mine City. Environ. Sci. 2013, 34, 1076–1085. [Google Scholar]
- Zhang, S.B.; Hu, B.X. Heavy Metal Element Pollution of Cultivated Vegetables in Leather Industrial Zone by ICP-AES with Nimerlo Composite Index. Food Sci. 2015, 36, 221–225. [Google Scholar] [CrossRef]
- Sawut, R.; Kasim, N.; Maihemuti, B.; Hu, L.; Abliz, A.; Abdujappar, A.; Kurban, M. Pollution characteristics and health risk assessment of heavy metals in the vegetable bases of northwest China. Sci. Total Environ. 2018, 642, 864–878. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.M.; Dong, H.Y.; Ying, L. Risk assessment of Carbofuran intake of parts of foods in Yunnan province. J. Food Saf. Food Qual. 2019, 10, 6. [Google Scholar]
- Yang, Y.; Zhang, H.; Zhou, G.; Zhang, S.; Chen, J.; Deng, X.; Qu, X.; Chen, Q.; Niu, B. Risk assessment of veterinary drug residues in pork on the market in China. J. Food Prot. 2022. [Google Scholar] [CrossRef] [PubMed]
- Niu, B.; Zhang, H.; Zhou, G.; Zhang, S.; Chen, Q. Security risk assessment and early warning of chemical contamination in vegetable oil. Food Control 2021, 125, 107970. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Deutsch, C.A.; Tewksbury, J.J.; Tigchelaar, M.; Battisti, D.S.; Merrill, S.C.; Huey, R.B.; Naylor, R.L. Increase in crop losses to insect pests in a warming climate. Science 2018, 361, 916–919. [Google Scholar] [CrossRef] [Green Version]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Elaziz, M.A.; Gandomi, A.H. The Arithmetic Optimization Algorithm. Comput. Methods Appl. Mech. Eng. 2021, 376, 113609. [Google Scholar] [CrossRef]
- Dai, W.; Huang, Y.; Wu, L.; Yu, J. Relationships between soil organic matter content (SOM) and pH in topsoil of zonal soils in China. Turang Xuebao 2009, 46, 851–860. [Google Scholar] [CrossRef]
- Xie, E.P.; Lin, Q.T.; Yang, R.B. The research development of residue and degredation for carbofuran, benfuracarb and carbosulfan. Pestic. Sci. Adm. 2002, 3, 18–20, 28. [Google Scholar] [CrossRef]
- Schnitzer, J.K.; Rice, D.J.; Cruickshank, R.F.; Zajkowski, A.J. Data Normalization. U.S. Patent 20030110250, 12 June 2003. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Kong, J.; Wang, H.; Wang, X.; Jin, X.; Fang, X.; Lin, S. Multi-stream hybrid architecture based on cross-level fusion strategy for fine-grained crop species recognition in precision agriculture. Comput. Electron. Agric. 2021, 185, 106134. [Google Scholar] [CrossRef]
- Zheng, Y.-Y.; Kong, J.-L.; Jin, X.-B.; Wang, X.-Y.; Su, T.-L.; Zuo, M. Crop Deep: The crop vision dataset for deep-learning-based classification and detection in precision agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [Green Version]
- Kong, J.L.; Yang, C.C.; Wang, J.L.; Wang, X.; Zuo, M.; Jin, X.; Lin, S. Deep-stacking network approach by multisource data mining for hazardous risk identification in IoT-based intelligent food management systems. Comput. Intell. Neurosci. 2021, 2021, 1194565. [Google Scholar] [CrossRef]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. A Spatial Feature-Enhanced Attention Neural Network with High-Order Pooling Representation for Application in Pest and Disease Recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Jin, X.B.; Gong, W.T.; Kong, J.L.; Bai, Y.T.; Su, T.L. PFVAE: A planar flow-based variational auto-encoder prediction model for time series data. Mathematics 2022, 10, 610. [Google Scholar] [CrossRef]
- Jin, X.B.; Gong, W.T.; Kong, J.L.; Bai, Y.T.; Su, T.L. A variational Bayesian deep network with data self-screening layer for massive time-series data forecasting. Entropy 2022, 24, 335. [Google Scholar] [CrossRef]
- Jin, X.B.; Zhang, J.S.; Kong, J.L.; Su, T.L.; Bai, Y.T. A reversible automatic selection normalization (RASN) deep network for predicting in the smart agriculture system. Agronomy 2022, 12, 591. [Google Scholar] [CrossRef]
- Jin, X.-B.; Zheng, W.-Z.; Kong, J.-L.; Wang, X.-Y.; Bai, Y.-T.; Su, T.-L.; Lin, S. Deep-Learning Forecasting Method for Electric Power Load via Attention-Based Encoder-Decoder with Bayesian Optimization. Energies 2021, 14, 1596. [Google Scholar] [CrossRef]
- Jin, X.-B.; Zheng, W.-Z.; Kong, J.-L.; Wang, X.-Y.; Zuo, M.; Zhang, Q.-C.; Lin, S. Deep-Learning Temporal Predictor via Bidirectional Self-Attentive Encoder–Decoder Framework for IOT-Based Environmental Sensing in Intelligent Greenhouse. Agriculture 2021, 11, 802. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | NIPI | AEA | CDEA | Risk Level |
|---|---|---|---|---|
| 1 | 0.52750 | 0.0000019 | 0.0000012 | Low |
| 2 | 5.83879 | 0.0000447 | 0.0000253 | Medium-low |
| 3 | 21.31902 | 0.0001640 | 0.0000419 | Middle |
| 4 | 27.97410 | 0.0004820 | 0.0002343 | Medium-high |
| 5 | 36.80964 | 0.0007220 | 0.0003487 | High |
| Model | Index-Data | ||
|---|---|---|---|
| P% | R% | F1% | |
| RNN | 74.38 | 73.69 | 74.03 |
| LSTM | 79.37 | 78.73 | 79.05 |
| GRU | 87.25 | 86.51 | 86.88 |
| CNN-AOA-LSTM | 93.37 | 93.12 | 93.24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, T.; Liu, T.; Dong, W.; Liu, Y.; Zhang, Q. Security Risk Level Prediction of Carbofuran Pesticide Residues in Chinese Vegetables Based on Deep Learning. Foods 2022, 11, 1061. https://doi.org/10.3390/foods11071061
Jiang T, Liu T, Dong W, Liu Y, Zhang Q. Security Risk Level Prediction of Carbofuran Pesticide Residues in Chinese Vegetables Based on Deep Learning. Foods. 2022; 11(7):1061. https://doi.org/10.3390/foods11071061
Chicago/Turabian StyleJiang, Tongqiang, Tianqi Liu, Wei Dong, Yingjie Liu, and Qingchuan Zhang. 2022. "Security Risk Level Prediction of Carbofuran Pesticide Residues in Chinese Vegetables Based on Deep Learning" Foods 11, no. 7: 1061. https://doi.org/10.3390/foods11071061
APA StyleJiang, T., Liu, T., Dong, W., Liu, Y., & Zhang, Q. (2022). Security Risk Level Prediction of Carbofuran Pesticide Residues in Chinese Vegetables Based on Deep Learning. Foods, 11(7), 1061. https://doi.org/10.3390/foods11071061