1. Introduction
This research focuses on the problem of identifying without human supervision whether the use of a term in its context inside a long portion of text is considered non-inclusive in the modern Spanish language. A term itself does not have the characteristic of being inclusive or not: It is how it is utilized in context that determines whether the use of the term is inclusive or not. For instance, the word “
profesor” (teacher) may be used in a context where it is not considered non-inclusive: “
… los profesores Ricardo Marín y Enrique Mandado, creadores de los grupos de …” (professors Ricardo and Enrique, creators of the groups …); on the other hand, it may be used in a different context where it is considered non-inclusive: “…
en el aula, los profesores debería tener autoridad para que haya respeto …” (in the classroom, teachers should have authority for respect to be …), having one (or many) more inclusive alternatives: “…
en el aula, el profesorado debería …” or “
en el aula, el cuerpo docente debería …” (no difference in English). A key factor throughout this research is how gender is used in the Spanish language. In this sense, Wasserman observes that languages where gender is grammaticalized, as is the case with Spanish, seem to imply the representation of two social classes, men and women, considering three assumptions: (a) “Reading languages with grammatical gender may prime people to express more sexist attitudes than when reading a language that does not have grammatical gender”, (b) “Reading in a language with grammatical gender may make salient the historical oppression women have faced as a group”, and (c) “As a result, girls may rationalize the discrimination women have faced by expressing more sexist views” [
1]. García Meseguer suggests two sources of linguistic sexism: Lexical, related to words, and syntactic, relating to constructs [
2]. In this work, we focus on morphemes on gender.
The goal is to build an automated algorithm and to train it using an annotated dataset to learn when the use of a particular term might be considered as non-inclusive. After the algorithm is trained, it is used in the same context for validation, within a relevant amount of text, showing interesting results. To achieve this goal, a dictionary of terms that potentially might be used in a non-inclusive manner was generated, and relevant inclusive alternatives were defined for each term. A summary of the steps taken in this project is as follows:
A large dataset of documents is collected to be used for training and validation purposes. Selected documents are all electronic accessible doctoral theses created in Spain. Doctoral theses are usually very carefully written, deeply reviewed, and authors often have a reasonable culture background; that provides a better training dataset for our algorithm in terms of how difficult to find a non-inclusive usage is.
A dictionary of potential non-inclusive terms is generated:
- a.
Terms already present in several non-sexist writing guides (to the best of our knowledge, there is no dictionary of non-inclusive terms in the Spanish language).
- b.
Terms found in the document data set that are susceptible to being transformed to the feminine form; for instance, from “profesores” to “profesoras” (teacher). These were reviewed to rule out false positives.
The terms in the dictionary were located in the documents, and a representative context was extracted and stored (WIC, word in context, refer to section “Word in context identification” section.
All WICs were tagged using POS and transformed into an array of quaternions by mapping grammatical categories to integer numbers that algorithms can work with.
A non-linear SVM was trained with a split of the data set under supervision and tested against labelled data.
The paper is organized as follow:
Section 2 provides the background found in literature and the gaps this research tries to fill;
Section 3 describes the materials used in this project, especially the dataset, including its collection;
Section 4 depicts the algorithm used, including alternatives evaluated;
Section 5 shows how the annotation process was developed, in a four-step procedure until validation was performed; results are displayed in
Section 6, evaluating the performance of the different alternatives tested, while
Section 7 discusses results, and shows future lines of work.
2. State of the Art
The study of language in terms of gender inequality has attracted the attention of linguists over the past few decades. Major progress has recently been made in this area mainly for reasons related to equity, feminism, and even ideology. Several intergovernmental organizations and agencies (EIGE—European Institute for Gender Equality 2018—and United Nations 2020, among others) have newly developed toolkits and easy-to-use guides on how to use more gender-inclusive language [
3]. However, some official institutions do not agree with the use of inclusive alternatives. In fact, Royal Spanish Academy (“Real Academia Española”, or RAE), the official institution and highest authority for the regulation of the Spanish language, established that the grammatical masculine in animate beings nouns is to be used to name all individuals of the species, without making distinctions between sexes [
4]. Nevertheless, it is a controversial topic; in fact, several prestigious editorials, such as Elsevier, recommend the use of inclusive language for their publications [
5].
The driving force in addressing the issue of language and gender research is the article
Language and Woman’s Place [
6] Since then, many scientists have continued to work in depth on this line of inquiry, demonstrating that discourse is a socially conditioned and institutionalized practice that reveals “meaning force and effect within a social context” [
7]. Therefore, we may conceptualize this relationship in our case as follows: “if we take it that no expression has a meaning independent of its linguistic and non-linguistic context, we can plausibly explain the sexism of language by saying that all speech events in patriarchal cultures have as part of their context the power relations that hold between women and men …” [
8]. Accordingly, language does not represent reality in a neutral manner but is rather a tool to strategically build the gender dimension in the public sphere [
9,
10,
11].
There is ongoing work, therefore, that shows the link between women’s social status and gender asymmetries in languages [
1], [
12] and stresses the need to analyze beliefs and discourse about men and women and how they are reflected in or compromised by language [
7]. Having said this, we must not ignore that relationships between language and sexism are complex, as Cameron also acknowledges [
8]. Many studies have been carried out on these aspects. For example, Newman et al. [
13] focus on different uses of language by men and women; Foertsch and Gemsbacher [
14] show how more and more frequently speakers and listeners, to combat prescriptivism, use the plural pronoun “they” to refer to singular antecedents to make language more inclusive. The requirements for the specification of referents’ gender vary across languages and have further been explored in studies on several languages, including English [
15,
16], German [
17,
18], Swedish [
19], Chinese [
20,
21,
22], Polish [
23], Italian [
24,
25], and French [
26]. Other research has focused on the use of pronouns and their relation with gender marking [
27,
28,
29,
30,
31,
32].
In this vein, there have also been several research studies conducted with respect to the Spanish language [
2], [
33,
34,
35]. A great deal of current research focuses on whether Spanish is sexist or not. Cabello summarizes the arguments put forward by different authors [
36]. On the one hand, those who argue that Spanish is not a sexist language put special focus on systemic and structural aspects [
2,
35,
37], marginalizing the social dimension, while on the other hand, we have those who, placing emphasis on language as the creator of social reality, hold that Spanish is a clearly sexist language [
38,
39]. Almost all works and publications focus on the search for equity; that is, they try to find strategies to prevent discriminatory linguistic practices in terms of gender, race, etc. This search is associated with two strategies: Neutralization and feminization. In those languages in which the gender difference is not grammatically marked, the first strategy is used more often. The second is common when the objective is to provide more visibility to the feminine form. In the Spanish case, as reflected in practically all easy-to-use guides on how to use more gender-inclusive language, both strategies have already been used: Neutralization, for example, in those cases where generic nouns are used (“
persona” instead of “
hombre/mujer”, or in English, person instead of man/woman); and feminization, where in the case of gender doublets, a generic feminine is proposed or the feminine forms of nouns that traditionally only presented masculine form (“
jueza”, “
médica”, etc.) are generalized (judge, medic).
Text mining refers to the process of extracting useful information from a document by identifying hidden patterns in unstructured text and has been a research subject for many different areas in recent years [
40,
41,
42,
43]. The analysis of the use of inclusive language in a text might be considered parallel to automatic sentiment classification, where opinion mining tries to extract subjective opinions from expressions. Most lines of investigation for text classification have been based on using a training set of samples to extract algorithms, including support vector machine (SVM) [
44,
45,
46], k-nearest neighbor (kNN) [
47,
48], naïve Bayes (NB) [
49,
50,
51], and decision tree [
52,
53], inside the classification paradigm [
54,
55,
56].
Automated detection of specific language use has already been covered in previous studies, specifically on the problems of detection of hate speech [
57], terrorism [
58], racism [
59], sexism [
60], or any offensive language [
61]. For the general problem of classification in text mining, [
62] delves into classification techniques, and [
63] combines several approaches to obtaining proper categorization. Support vector machines have historically been successfully used as a solution for binary classification in text environments [
64] under different approaches [
65]. A common issue found through literature review is the problem of the bias that word embeddings suffer from, according to the text corpora the different solutions are built with. The subject has been studied and some research suggest that gender bias has not been solved yet [
66]. Several attempts to remove that bias in the gender context stand out, including those that tackle the problem with a similar point of view as our research [
67]; in [
68], unintended bias is tackled from the misogyny detection perspective with reasonable results; in [
69], authors claim to remove gender stereotypes while keeping reasonable and natural embeddings; in [
70], bias in the hate speech detection context is quantified, and a novel knowledge-based generalization is proposed to remove that bias. Although most of the literature is focused on the English language, interesting approaches are also extending research to other languages such as French and Spanish [
71,
72]: They both show that word embeddings suffer from bias in hate speech and gender analysis, and different methods are proposed to overcome this issue. Despite the extensive research and to the best of our knowledge, no research has been carried out on the automatic detection of non-inclusive language in Spanish, whether it is in the academic production or any other context; the issue is different from hate speech or misogyny in that the exact same sentence can be considered as non-inclusive or not, according to a broader context. Finally, to the best of our investigations, no algorithm has been published to perform automatic detection of non-inclusive language in Spanish for these purposes.
In conclusion, the novelty of this work lies in the ability to detect, within a text, whether the words are used in a non-inclusive manner, based on the learning done in the training phase. Once trained, the algorithm can be fed with a document, and the non-inclusive expressions are found, based on their context. The research uses a wide dataset so that training effectively provides context to identify terms and compile them in a non-inclusive dictionary.
3. Materials
3.1. Technological Stack
The development was designed under Debian Linux using Pycharm (for Python text mining scripts, NLTK and Freeling), MS Windows 10 using versus Code (for C# validation software), and Debian virtual machines deployed in Azure for algorithm processing; hardware characteristics were based on a E16v3 Azure instance (16vCPU, 128GB RAM, 400 GB storage) for processing, and a DS2v2 modified Azure instance (2vCPU, 7GB RAM, 1,500 GB storage), for storing the documents and database.
3.2. Dataset
As for the scope, the initial goal is to use the automated decision maker inside the context of Spanish university academic and scientific production, where the texts to be analyzed are doctoral theses. In the 17 Spanish autonomous regions, there are, at the time of writing this paper, 73 universities, that have generated 257,564 doctoral theses; 102,914 of those theses were public domain and accessible, and after downloading and processing them, 100,450 theses were usable (the rest were not in Spanish language or in a legible format file). It is this area where the algorithm is to be designed, tested, and validated, with the thesis writers’ age ranges and gender distribution presented in
Figure 1.
The distribution per autonomous region is shown in the following table, where Madrid and Cataluña are the most thriving regions of the country, and Andalucía the most populated, as displayed in
Table 1.
As for the subjects of the documents, they are organized under six categories (basics sciences, geosciences, biology and health sciences, engineering, social sciences, and humanities), that group the 24 epigraphs shown in
Table 2.
An additional requirement comes from the quantity of text.
Table 3 summarizes the key data indicators compiled after initial investigations with regards to the context.
The doctoral theses created from April 1974 to February 2020 at 73 universities of Spain are the documents used in the dataset. They were treated in the same PDF format in which they are registered and range from 172 to 496 pages, with an average word count per document of 124,012. In this document corpus, we have found 12,457,005,400 words (9326 unique words), so care was taken at the design of the computing requirements and techniques to allow the handling of that amount of data (more than 12 billion elements). Moreover, since the aim of the project was to identify the non-inclusive use of term in modern Spanish texts regardless of the size of the text, special attention was paid to the methodologies used so that they would fit other use cases.
3.3. Document Collection and Storage
Doctoral theses from Spanish universities are stored in official repositories belonging to those public institutions. The first step consisted of not only downloading the documents and their metadata but also providing an automated system to obtain new documents as doctoral theses are uploaded without human intervention. University of La Rioja [
73] maintains a repository that holds doctoral theses from Spanish universities (and others) and was used as source in this project. An ad hoc Python system service running inside a virtual machine was obtained for the official repository URL, showing the list of documents present, and compared with the documents already obtained (in the first run, none). The differential (new) items were then downloaded, and their metadata were stored in a relational database present on a second virtual machine.
Along with the documents themselves, the scraper also obtained metadata that described the document and relevant information for later steps: Publication date, language, author, thesis title, contributors, and the UNESCO code that refers to the area of knowledge of the doctoral thesis; this information was saved in JSON format as show in
Figure 2 and stored in a Mongo database.
Plain text was obtained from the documents using several libraries in the Python language related to text extraction and treatment and a natural language processor. The words extracted were again stored in a database, properly configured to be able to store a large amount of information. Once stored, extracted words were transformed according to a set of rules that converted them into a numerical representation, that allowed the generation of the classification algorithm. A lexical analysis was completed to tokenize and separate the lexical components of the text (isolating lexical separators such as white spaces and punctuation signs). The text was also curated by eliminating words that, given their location in the document, would not receive the non-inclusive use check: Tables of contents, text inside tables, text inside pictures and diagrams, formulae, numbers, units, words in languages other than Spanish (checked on a Spanish word dictionary), references, and page numbers. Although section titles might display a non-inclusive use, their presence in the table of contents was skipped to avoid text repetition. A morphological tag was also assigned to every lexical component in a process known as part-of-speech (POS) tagging, in which every lexical component receives a characterization consisting of a type (article, substantive, verb, adjective, adverb, etc.), gender (masculine or feminine), number (singular or plural), etc. Finally, the text was again stored in the database related to the doctoral thesis it came from. Duplicate words were not filtered out, since many repetitive ones like definite-indefinite articles take a key part in the WIC as well as in the non-inclusive detection.
4. Algorithm Design
Classification is a well-known problem: A sample is obtained; the unstructured data (text) are organized in a structured format; every example is measured in the same way, and the answer is expressed in terms of true or false, a binary decision. In mathematical terms, a solution is a function that maps examples to labels, f: w → L, where w is a vector of attributes and L is a label (for supervised learning) [
74]. In this case, the attributes are words’ grammatical characteristics, and the label is the inclusive or non-inclusive use of the term in the context. Given there are two alternatives (inclusive and non-inclusive) for the classification, we are at the boundaries of binary classification;
Figure 3 displays the process, where dictionary terms susceptible to being used in a non-inclusive way were populated using the reviewed part of the document dataset; the dataset was transformed into numerical vectors to feed into the algorithm and be used as classifiers.
In supervised classification, the model is tuned to the training samples, which are a portion of the dataset to be observed. The algorithm is based on the vectors that are already labelled and generate a predictor for future (unlabeled) cases; although such algorithms may suffer from issues (e.g., overtraining and dependency on the similarity of the labelled samples and the dataset), they have been successfully used in many different scenarios [
75].
Figure 4 depicts classification process.
In the case of text mining, the words in the document are the characteristic features; therefore, the text must be transformed into numerical values the algorithms can work on. Moreover, there are terms that are susceptible to being used in a non-inclusive manner and others that will not be used in any context. Finally, even terms that are considered non-inclusive in one context may not be considered so in a different context.
With our requirements in mind, the goal was to find a machine learning classification algorithm that would identify (classify) whether the use in its context of every term in the dictionary we compiled is inclusive. After reinforcement learning and unsupervised learning were considered, supervised learning was the chosen option. First, the algorithm was given insights on a small training set of documents (for learning when a term is inclusive or not in context) and then it was fed with the test set of documents (for tagging terms in different contexts and validating the model). After a group of linguistic experts labelled the text words of a subset of the documents as inclusive or not based on the relative contexts, a 10-fold cross-validation method was implemented to avoid under-fitting or over-fitting. To prevent the results of the learning phase analysis from being independent of the subset chosen, document collection was divided into two parts: A training set for the machine learner to build the model and a test set to be validated. Every word that might plausibly be used in an inclusive or non-inclusive way (whether found in the learning step, or susceptible to being used in both genders) was then analyzed by the algorithm to predict a discrete binary property (non-inclusive or inclusive).
Figure 5 shows an overview of the training process.
For building the classification model, the classification method used was a support vector machine. Previous authors’ projects in the area of predicting intentions have shown SVM (with a reasonable false-positive and true-negative ratios) was a successful mechanism to build classification algorithms; moreover, those experiences provided certain methods and library functions that made SMV something authors were confident and comfortable with. SVM, considered an extension of the perceptron algorithm, has the optimization goal of setting a decision line that marks a frontier between the classes of data and maximizing the margin between that frontier and the sample points closer to this hyperplane; those points are, in fact, the support vectors. Each data entry (belonging to the set of samples for learning) is represented as an n-dimensional vector, where every component is a number.
The mission of SVM is to find the hyperplane that yields the largest minimum distance to the points of the training set (the margin), using a small subset of vectors from the training set. Whether in a linear or non-linear problem, SVM separates the data into two classes (in our case, non-inclusive or inclusive) by mapping the information into spaces with more than two dimensions. Once the model was created, the test data were incorporated, and the classification supervised, as shown in
Figure 6:
Supervised classification is widely used within either pure statistics (logistic regression, discriminant analysis) or artificial intelligence paradigms (neural networks, decision trees, Bayesian networks) [
76,
77]. At this stage, a set T of n training feature vectors X
i ∈ R
D was separated, where I = 1,…, n, and the corresponding class labels y
i ∈ {+1, −1} (for the binary non-inclusive/inclusive classification). Sample vectors labelled as inclusive have the class label +1 (are class C+, positive values), and the rest are non-inclusive (belong to the negative class C-).
The linearity of the problem (existence of a hyperplane function defined by x · w + b = 0 that keeps the maximum distance between the inclusive or non-inclusive classes) was discarded after initial convergence tests. The characteristics of the WICs in our cases do not allow us to find the w vector that would maximize the distance from the binary classes in the form of
with the
parameters solved by the function
where the
variables are the Lagrange multipliers and C is a parameter that penalizes WICs that do not have a correct classification; after iterating through different values of C (beginning in C = 1), C = 145 was selected for showing the lowest cross-validation error:
When dividing the two groups with an n-dimensional hyperplane is not possible, since the data points are separated by a nonlinear region, classification cannot be obtained by simply calculating the direct inner product between the points. The non-linearity can be solved by using a kernel function to map the information to a different space and then perform separation (kernel functions construct non-linear decision surfaces for sample classification). According to the Hilbert–Schmidt theorem, a symmetric operation that meets Mercer’s condition can be represented as if it were an inner product when
when
and
.
In this way, the problem is rewritten to maximize
where
an
, resulting in an optimal classification function as:
Two non-linear kernels were tested in the preliminary phases with 109 WICs to test suitability (RBF and polynomial). The sigmoid was discarded because of convergence and computation issues. Thus, the functions used were as follows:
An RBF (radial basis function) kernel, which has the property that each basis function depends only on the radial distance from a center, written as:
where
.
A poly(nomial) kernel, which is directional (the output depends on the two vectors in the low-dimensional space because of the dot product), following:
where
.
5. Annotation Process
In this section, the steps performed on the dataset until the whole system was validated are described, as shown in
Figure 7.
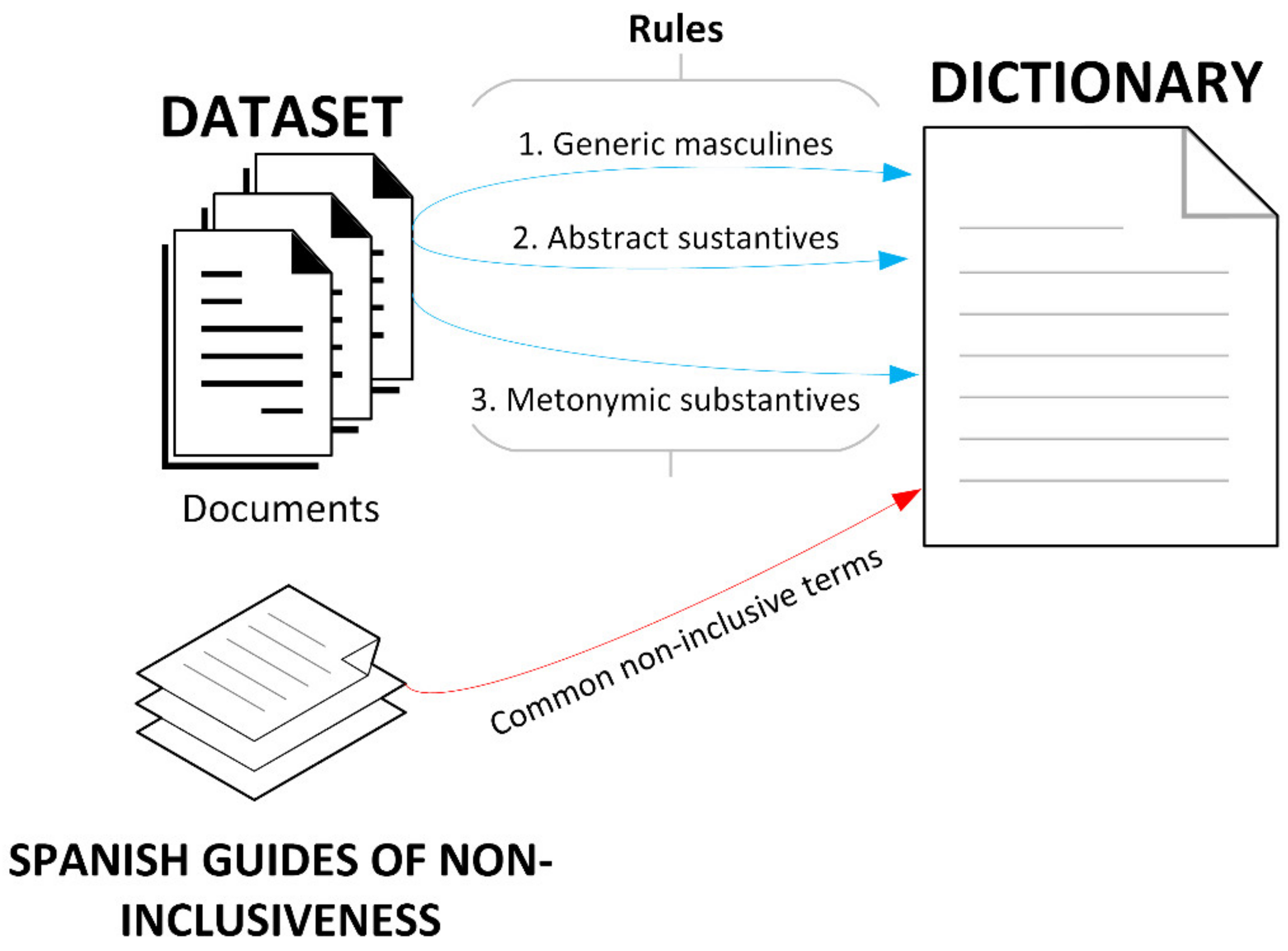
5.1. Generation of the Dictionary of Potential Non-Inclusive Terms
In this section, the process for the generation of the dictionary of terms with potential non-inclusive use is depicted. Two sources for that dictionary were used: First, a list of terms that, found in the dataset, matched a rule to be a candidate; second, a list of terms compiled from different non-inclusiveness guides. The process is shown in
Figure 8.
Considering the quantity of words involved (more than 12 billion), the size of the training subset exceeded the human resources available for tagging the data. For this reason, a dictionary of terms that potentially might be used in a non-inclusive manner was created to guide and speed up the process. The words for the dictionary came from two different sources: First, a compilation of different guides on inclusive use of language [
78,
79,
80] and second, terms that were found in the dataset used in their masculine form and that were located in their feminine form as well. This second group of terms represented those words that match one of the generic rules for inclusive language: First, the case of “generic masculine” terms, such as “
usuarios” (users), which should come with their feminine form (“
usuarios y usuarias”, no difference in English) or be replaced with a truly generic alternative “
personas”, (persons); second, the case of abstract substantive terms, such as “
alumnado” (student body) instead of “
alumnos” (student); third, the case of metonymic substantive terms, which refer to the position/profession/activity of a person: “
… la edad para el ciclista puede …” (the age of the cyclist) versus “…
la edad para practicar el ciclismo …” (the age to practise cycling); and fourth, the case of the adjectives in the past participle, where a gender neutral noun is inserted: “
los ciegos” versus “
las personas ciegas” (blind people in English for both cases) or the wording changed: “…
todos los que quieran …” versus “…
quien quiera …”, (who wants in English for both cases).
To find the second group of terms to be added to the proposed dictionary, the following process was performed. First, every noun: “
niño” (boy), “
profesor” (teacher), and adjective: “
correcto” (right), “incorrecto” (wrong) in masculine form was obtained from the documents, and then alternatives were selected to generate a list of unique terms. Then, stemming and lemmatization was performed to normalize words to a single form; this is to choose the word that has a match in the Spanish dictionary; for instance, from plural “
profesores” (teachers) to singular “
profesor” (teacher). Once normalized, a feminine form was looked for: Considering the rules of feminine construction in Spanish, the Freeling library with the Spanish tag set was checked to determine whether any combinations would create a valid term as shown in
Table 4.
Once the dictionary was created and the unique terms isolated, it was reviewed by a panel of experts in Spanish linguistics, who ruled out 13.8% as false positives: Words that matched at least of the feminine generation patterns but are not susceptible to non-inclusive use. It is important to mention that new forms of inclusive language including “wildcard” characters to abstract the word from being masculine or feminine (as “todes”, “tod@s”, “tod*s” or “todxs”) were explicitly looked for, but not found in any document as part of the dissertation.
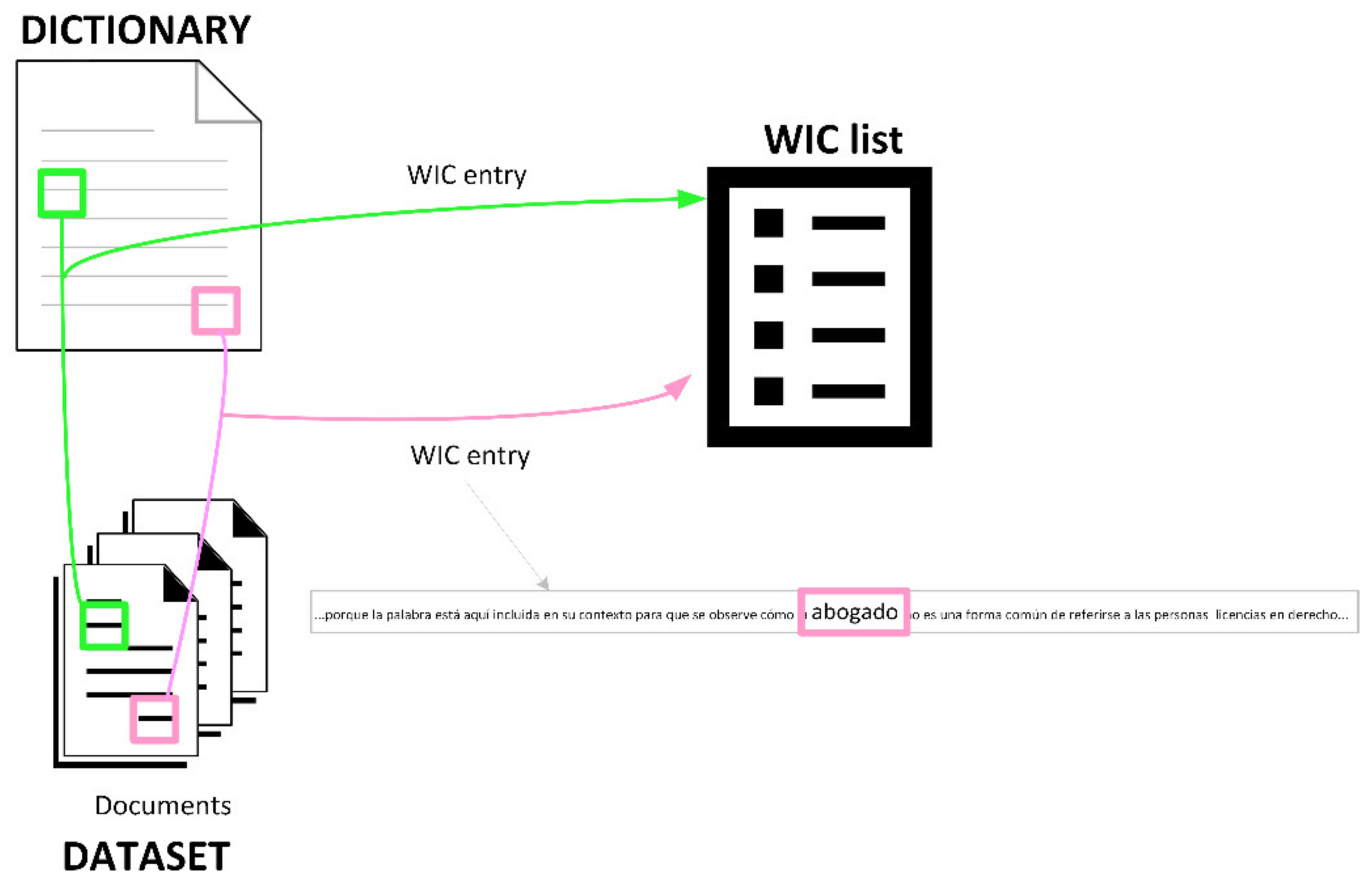
5.2. Word in Context Identification
In this section, the transformation of the dataset into a list of potentially non-inclusive terms with their broad context is addressed. As displayed in
Figure 9, every word in the dictionary was looked for in the documents in the dataset, and if found, it was extracted with a relevant context that will allow later identify the inclusiveness or not of its use.
Since the characteristic of being non-inclusive applies not to the existence of a term but to its use in a specific context, for every word included in the dictionary, every document in the dataset was scanned for that word. When found, a data structure was generated using the following rules:
The 17 words preceding and 17 words following the located dictionary term were initially taken to generate the word in context (WIC), having thus enough context to keep its meaning. “… a bolsa de 2002. El equipo de Alemania pasa de estar constituido como asociación propiedad de sus socios a ser una sociedad mercantil cotizada en bolsa con la propiedad totalmente diluida. Este ejemplo no fue …” (‘socios’ is the term in the dictionary, and the rest of the words are the 17+17 context); in English, (…to 2002 stock exchange. The team in Germany went from being incorporated as an association owned by its partners to being a publicly traded trading company with fully diluted ownership. This example was not…).
The WIC was adjusted to a sentence, so that when a period was found, the trailing words were discarded. “El equipo de Alemania pasa de estar constituido como asociación propiedad de sus socios a ser una sociedad mercantil cotizada en bolsa con la propiedad totalmente diluida.”
The WIC was characterized into lexical categories by classifying and labelling the words in it with the NLTK Stanford POS combined taggers for the Spanish language:
- ◦
Unigram and bigram taggers were trained.
- ◦
The bigram tagger tried to tag every token in the WIC. If unsuccessful, unigram or default taggers were tried sequentially.
- ◦
The results were evaluated to check for tagging success, and in that case, the WIC was stored as the sequence of ordered tagged elements (using the EAGLE tag-set): [(‘El’, ‘da0ms0’), (‘equipo’, ‘ncms000’), (‘de’, ‘sps00’), (‘Alemania’, ‘np0000l’), (‘pasa’, ‘vmip3s0’), (‘de’, ‘sps00’), (‘estar’, ‘vmn0000’), (‘constituido’, ‘vmp00sm’), (‘como’, ‘cs’), (‘propiedad’, ‘ncfs000’), (‘de’, ‘sps00’), (‘sus’, ‘dp3cp0’), (‘socios’, ‘ncmp000’), (‘a’, ‘sps00’), (‘ser’, ‘vsn0000’), (‘una’, ‘di0fs0’), (‘sociedad’, ‘ncfs000’), (‘mercantil’, None), (‘cotizada’, None), (‘en’, ‘sps00’), (‘bolsa’, ‘ncfs000’), (‘con’, ‘sps00’), (‘la’, ‘da0fs0’), (‘propiedad’, ‘ncfs000’), (‘totalmente’, ‘rg’), (‘diluida’, vpm00sf)]
The WIC was translated to a vector of false quaternions and stored, to generate, in the next step, the sample vector the algorithm uses to predict the non-inclusive/inclusive classification of the WIC. Every word is given four properties: Category, type, gender, and number. Each property is assigned an integer value according to
Table 5,
Table 6 and
Table 7, depicting the mapping.
Thus, for instance, the word “equipo” (team) would map to the vector [4,11,2,1], being a common noun that is masculine and singular. This rule was applied to every word in the stored WICs.
After the validation of 617 WICs with an average sentence length of 26 words, it was determined that the necessary context was given by extending the WIC 17 words both left and right, centered on the non-inclusive term. The algorithm was also tested in different contexts having less average length (general audience magazines, newspapers, blogs) and others with greater average length (legal documents).
The summary of the more relevant information stored as a result of this step is as follows. The following list illustrates data structure for storing information:
Non-inclusive term: The word that is used in a potentially non-inclusive way in the found context.
Where used: The group of contexts where the non-inclusive term has been found in the dataset:
- ◦
Document ID: The document where it was found.
- ◦
WIC: The different contexts in the present document.
Starting point: The word number inside the document where the WIC begins.
Length: The number of words of the WIC.
Text: The text of the WIC.
POS: The EAGLE tagging for the WIC.
Inclusive: Whether the term is considered to be used in an inclusive manner or not; this is informed with human intervention in the training (next) step or marked by the algorithm.
WIC correction: In case the use of the term is marked as non-inclusive, an alternative writing using an inclusive replacement is given, including (potentially) a modification of the WIC (substituting some terms with alternatives).
Inclusive alternatives: A list of alternative inclusive terms with example WICs, obtained in the training step.
Sample vector: The vector of properties for the WIC, containing the information used for labelling (training) and prediction.
5.3. Labeling
In this section, the process of labelling the elements in the WIC list is described, as well as how that labelling helps building the classification algorithm. On the WIC list, two actions are performed on it. First, it is transformed into a mathematical representation according a series of mapping rules. Second, it is labelled by a panel of three teams that annotate WIC elements divided into three groups; part of the elements are distributed to two different teams, and whenever a disagreement in the evaluation was found, it was also evaluated by the remaining team, to decide final evaluation. The mathematical representation of the WIC and the labels, all together, lead to the labelled matrix of features and the binary characteristic, foundation for the SVM to build the classification algorithm. The whole process is shown in
Figure 10.
Once the WICs for each entry in the non-inclusive terms dictionary had been identified and tagged, 6132 WICs out of the documents in the dataset were labelled for algorithm training and validation purposes. The WICs corresponded to 20 WICs per term in the non-inclusive dictionary. For the ultimate goal of projecting the results of the learning step to the unlabeled samples, 20% of the labelled samples were retained for validation and error measurement.
The WICs were presented for labelling in an ad hoc application as shown in
Figure 11 that allowed several linguistics to simultaneously classify each of them into one of the binary categories: Inclusive use or non-inclusive use. For that purpose, our data structure was modified with the “inclusive” Boolean value and the sample vector (Xi, yi), where Xi is the p-dimensional feature and yi represents the binary inclusive characteristic that is evaluated. Whenever a term in the non-inclusive dictionary was found in a document, its relevant context was extracted and shown, providing a means for linguists to validate its inclusivity or to supply a re-written alternative and select an inclusive term.
Out of the labelled WICs, 4906 were separated for training purposes (corresponding to the 80% not reserved for validation). Each of them was categorized into one of the two classes (inclusive or non-inclusive). The process was performed by three teams of linguists, with their assistants; the WICs were distributed randomly among the teams: 1535, 1535, and 1536 unique WICs (labelled by one group) plus 300 shared WICs, that were split in two groups to be analyzed by two teams at a time.
Table 8 summarizes process information.
Labelling was carried out in three steps: In the first step, the members of all groups agreed on the non-inclusive language rules to be used, which resulted in the considerations in
Section 5.1; in the second step, shared WICs were labelled using a shared spreadsheet containing WIC number, WIC’s text, and the classification given by two different groups (“I” for inclusive, “NI” for non-inclusive); in the third step, every WIC that had been classified differently in step two was labelled by the group that had not yet given label for that WIC. The final classification for the WIC was given, consequently, by two votes (when there was initial agreement), or three votes (should there had been a different classification). Of the 300 shared WICs, nine discrepancies were found: Seven needed the third vote to achieve final classification, and two were classification mistakes by human error (that turned out to be agreed after revision); of the 4906 classified WICs, 3129 were finally labelled as non-inclusive, which represents 64%.
Figure 12 displays selected records to illustrate the different cases. Columns show WIC number, and classification given by groups one, two, and three (“I” for inclusive, “NI” for non-inclusive). The fourth column shows final classification, that is “I”/”NI”. That final classification was straightforward for cases where the two votes were aligned (record 121) or needed an extra vote (record 162).
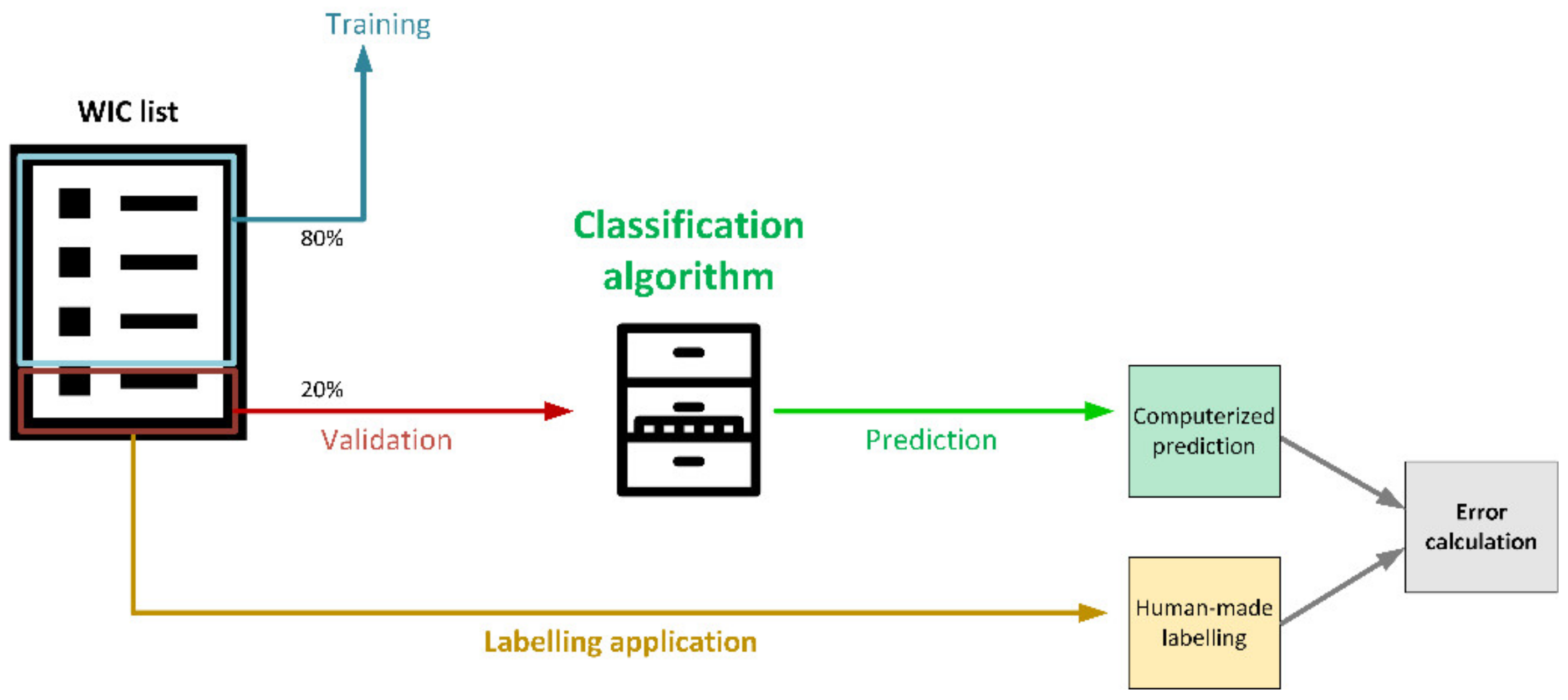
5.4. Validation
In this section, validation of the whole process is addressed. The WIC list is split into two groups: 80% for training the algorithm and 20% for validation. That 20% group of labelled samples is applied the prediction algorithm to classify the use of the term as inclusive, or not; that computerized predicted value is then compared with the label provided by annotators in the previous step (human-made labelling), so that error, accuracy, and other key indicators can be obtained to evaluate the prediction.
Figure 13 depicts this process.
As in many classification problems, one of the most important performance measures is the classification accuracy (ratio of terms classified the right way versus detected cases). Nevertheless, extra indicators were added since there is a certain asymmetry in cases of classification failure: Detection of non-inclusive use of language where this issue is not happening has a greater impact than does the failure to detect non-inclusive terms because in the event of the former, we may lose users’ confidence from the misclassification. For this reason, the type of classification error was also added as an additional key indicator to evaluate performance. To obtain both parameters, the subsequent notation was used, as shown in
Table 9.
It is assumed that a false positive is obtained when a WIC is classified as inclusive but it is actually non-inclusive; a false negative occurs when a WIC is categorized as non-inclusive but is actually inclusive; and true positives and true negatives are inclusive and non-inclusive detections that are not misjudged.
Table 10 defines the notation used.
According to this notation, selected key indicators can be written as follows:
Based on these parameters, two other key indicators were defined: FPR and FNR. The false positive rate (FPR) is the ratio between the WICs categorized as inclusive when there is a non-inclusive usage (number of false positives, or FP) and the ground truth negatives (where ground truth negatives are the sum of true negatives, TN, plus false positives, FP); the false negative rate (FNR) is the ratio between the WICs categorized as non-inclusive where there is in fact a normal inclusive usage (number of false negatives or FN) and the ground truth positives (where ground truth positives are the sum of true positives, TP, plus false negatives, FN).
Finally, three other indicators were included to evaluate classification: Precision (P, confirmed positive class predictions), recall (R, to show missed positive predictions), and F-measure (balance between precision and recall in one indicator); according to expected class imbalance, micro-average was selected to compute the indicators:
6. Results
After the validation step, where the dataset of unused labelled sample points reserved for verification were utilized for testing performance, the values displayed in
Table 11 for the key indicators were calculated following the formulae shown in the previous section.
RBF seemed to perform better than polynomial, especially on false negatives (the most concerning point). Using RBF, consequently, the accuracy indicator of the algorithm reached nearly 90%, fulfilling initial expectations (considering that a certain quantity of classification errors was inevitable). Despite the fact that null classification was not achieved, it is the false negatives (terms used properly in an inclusive way that were wrongly detected as non-inclusive usage, making up 6.1696% of the manually labelled samples reserved for validation) that will require greater attention for this algorithm to work in a production environment. False positives are more easily addressed, as a 0% error rate is not to be expected, and undetected non-inclusive usages do not cause loss of confidence: False detections actually occur only when users experience such losses.
The third column displays a comparison of the SVM classifier against a baseline that was also performed. Having certain imbalanced distributions between our binary classes, majority class was selected to label every test instance to the majority class in the test set. As expected, the algorithm performed better than the baseline.
In terms of the most common non-inclusive terms found in the whole dataset,
Table 12 summarizes the top 80% of the phrases found in the WICs categorized as non-inclusive, once a potentially non-inclusive term was detected:
Statistics on the doctoral theses by year of publication showed an unexpected evolution in the last two years of our sample period. In
Figure 14, the number of documents by year is shown (blue line), and the orange line shows the number of non-inclusive terms found in those documents per year at an adjusted scale. For the rest of the period under study, the percentage of non-inclusive terms generally followed the overall trend in the number of documents (that is, more documents imply more cases of non-inclusive usage of terms).
That general rule applies until the last two years under study (2018 and 2019), where the ratio of non-inclusive usages found per document declined by 36.3% versus the average of previous years. Perhaps the explanation can be found in the current gender equality politics and regulations put in place by the Spanish universities to raise awareness of gender-sensitive language.
After reviewing the corpus of doctoral theses, we verify that the sexist traits in the analyzed language area are less frequent. Therefore, despite aspects such as the use of the generic masculine or the low social acceptance of the feminine grammatical gender of some nouns, the results show that awareness is increasing, something fundamental considering the influence that can be exerted by academia on society.
7. Discussion and Future Work
This research represents the first step taken to provide automated tools dedicated to the use of inclusive language for the Spanish language: the goal is to identify, within a text, if the words are used in a non-inclusive manner (on the basis that the words are all inclusive, but it is the way of using them that might be non-inclusive). The approach involves the use of a dictionary of potential non-inclusive words, the categorization of the “suspicious” words found in their context, and an SVM classifier to categorize whether the use of that word in that context cab be considered as non-inclusive. The dataset used to train, validate, and test the system was the digital accessible Spanish doctoral thesis (more than 100,000 documents, averaging 300 pages each file), considered wide enough for this purpose.
The results of this research are in two directions: First, the algorithm itself, that can be applied on other type of Spanish documents to detect non-inclusiveness with a small false-negative ratio; second, the analysis of the most common words used in a non-inclusive way, to be fed to many governmental inclusive awareness actions. Two further projects are expected to be executed as continuation: First, the creation of a Python library with the trained algorithm to perform this type of classification on any Spanish text; second, the publication of the dictionary of more frequent terms used in a non-inclusive manner, with its inclusive alternative recommendations, based on the preliminary one built within this project.
To evaluate the dictionary, a final test was performed. Ten doctoral theses (2836 pages, for a total of 1,187,712 words) were selected randomly, but using the following criteria: First, written in the last eight years; second, half of them written by men, the other half by women; third, their topics distributed according to the percentage of subjects in the entire dataset (
Table 2). The documents were labelled by the algorithm, and then manually tagged to discover non-inclusive usages of terms that were not in the dictionary (and consequently, that had not been found by the algorithm). In that experiment, three different terms were found (as shown in
Table 13).
The WICs in which those terms were found are 422, of which 29 were considered as non-inclusive, and the rest were labelled as inclusive. The case of those words showed that dictionary has a solid basis (three in more than 1 million), since they are quite exceptional (they use the same form for masculine and feminine and are exceptions to the standard rules described in
Table 4).
Results showed that algorithm would also detect non-inclusive uses of the language that are not related to masculine forms of nouns and adjectives. For instance, the case of “… el estudiante de una lengua extranjera …” (the student of a foreign language); the word “estudiante” (student) can be used for the masculine and feminine form. In this case, the algorithm detected this use as non-inclusive because of the determinant in the noun phrase, not the kernel of the noun phrase. The main limitation of this approach comes from the fact that it needs to be given a suitable context for a word to be detected as used in a non-inclusive manner. In order for it to be used to validate inclusiveness in very short sentences given with no further context, it will not find enough background to detect non-inclusive used: For sentences like “los profesores van a venir” (“the teachers are going to come”), with no further context, no classification is obtained. Apart from that, there are still many relevant fields to be further investigated and improved:
Other well-known solutions for the kernel non-linear approach to the problem may help to reduce the error rate and specially eliminate the false negatives issue. Different alternatives shall be tested and compared to find a solution that optimizes convergence, computing time, and a minimum false negative rate.
In this research, every doctoral thesis was considered to be an independent sample point regardless of its origin. It is expected that according to certain characteristics related to the origin of the document (gender and age of the author, knowledge area of the document, and/or the internal department to which the author is attached, date of publication, etc.), an asymmetry in the results would arise. Another study will try to find correlations between a document’s external properties and the ratio of non-inclusive terms per total number of words in a doctoral thesis.
The document set used in this project was made of doctoral theses. Another study should be put in place to compare results in a non-academic environment, and check if the most common non-inclusive terms match the ones got int this research.
Although for creating and training the algorithm performance was not an issue, we consider that computation time should be reduced so that actual rate analysis (16 days to analyze the whole dataset) could be improved and adapt its performance to an online “on-the-fly” analyzer embedded on a web service. Apart from horizontal scaling considerations, threading could be considered to set several workers analyzing numerous documents at the same time.
It is expected that these next steps can be taken to extend the coverage of the research already performed.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}