Curation and Publication of Simulation Data in DesignSafe, a Natural Hazards Engineering Open Platform and Repository


Abstract
:1. Introduction
2. Related Work
3. Research Methods and Development for Simulation Data Design
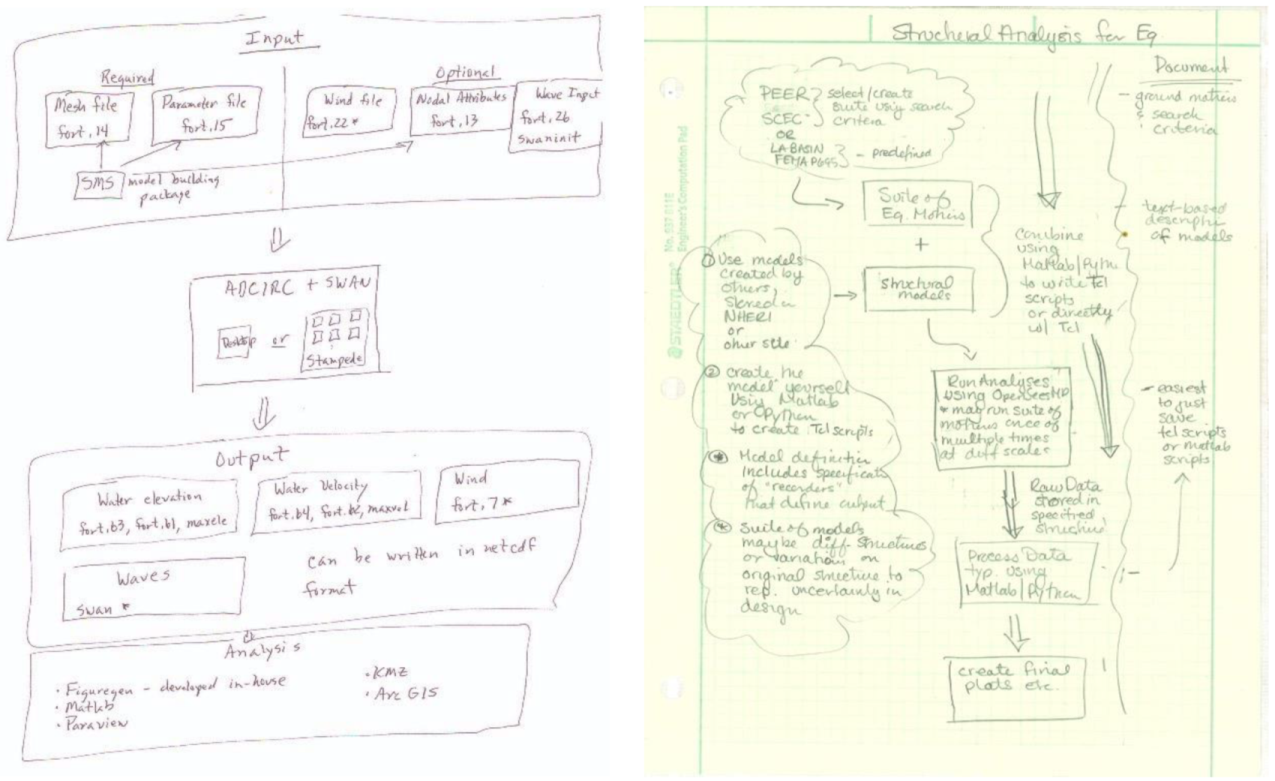
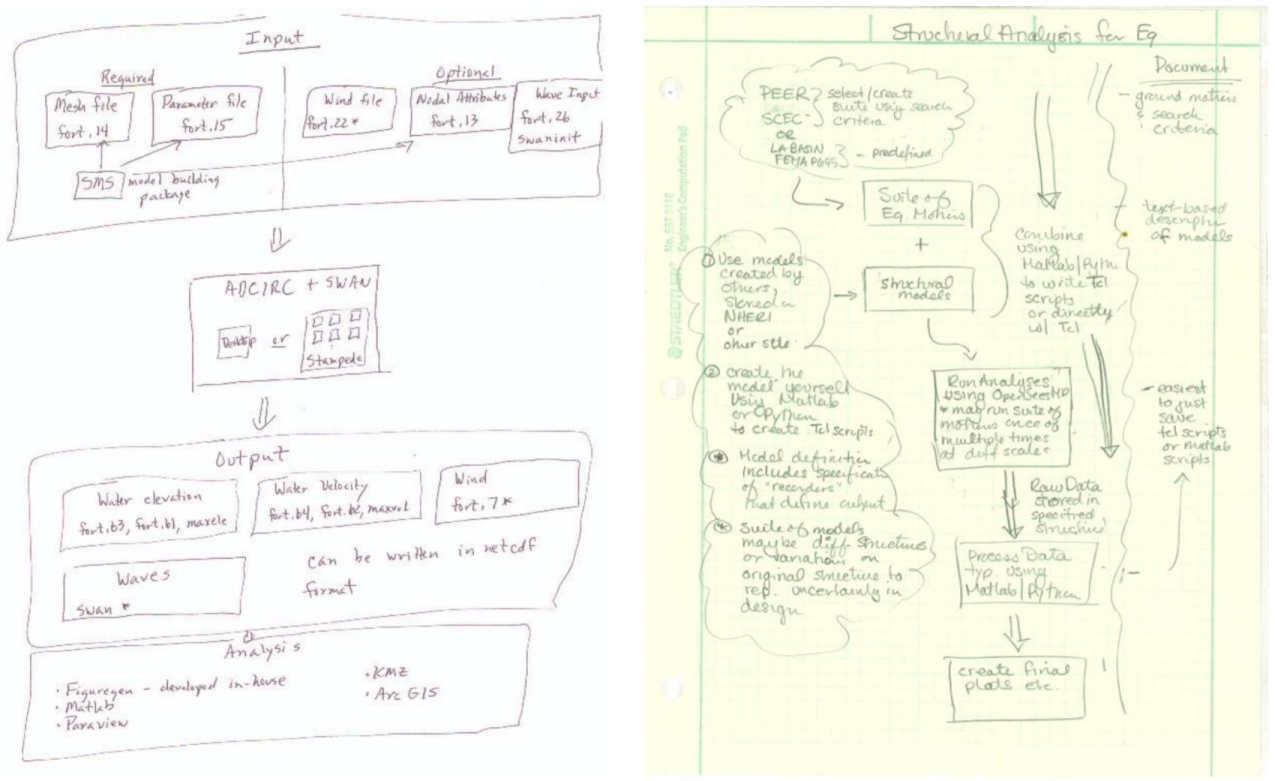
3.1. Simulation Research Narratives
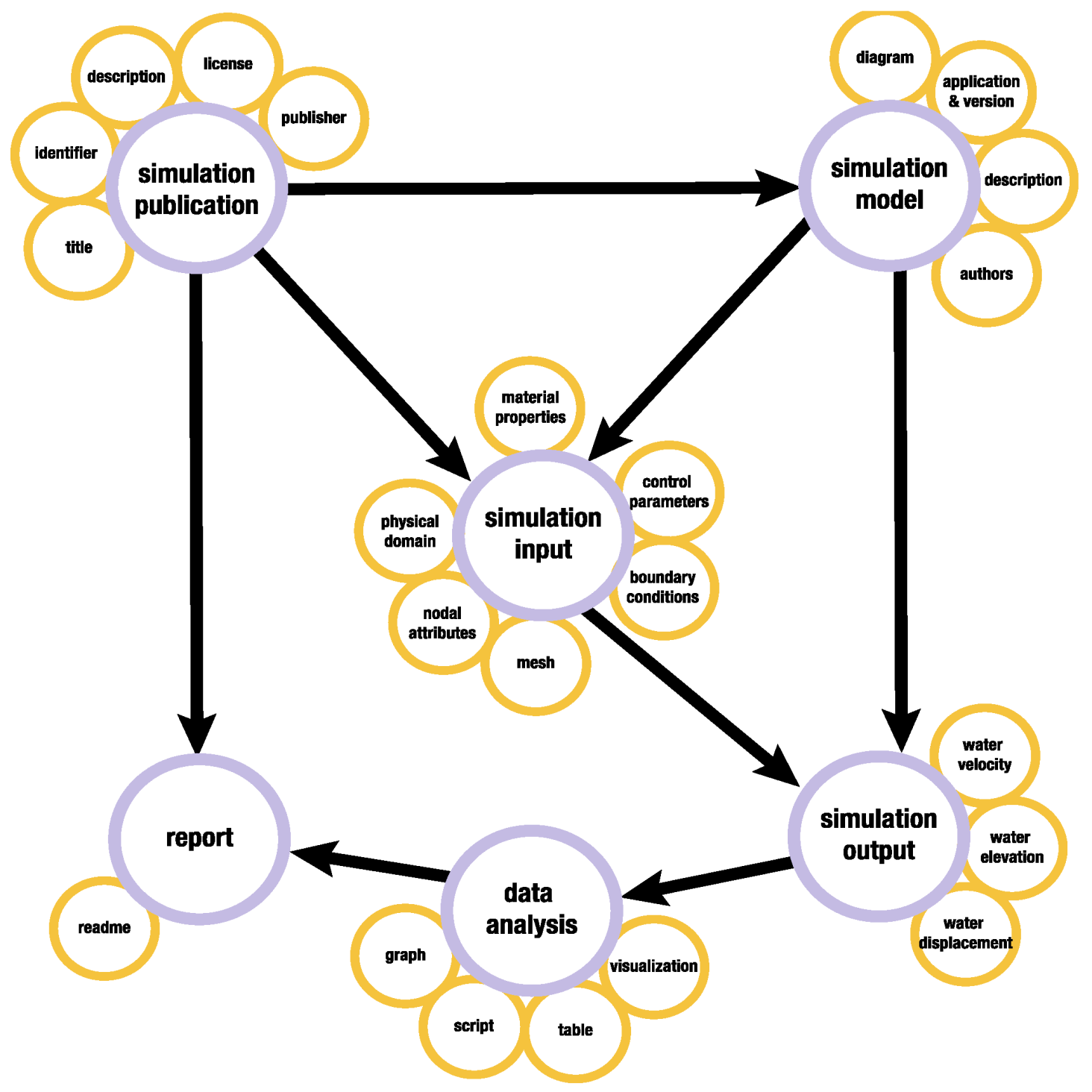
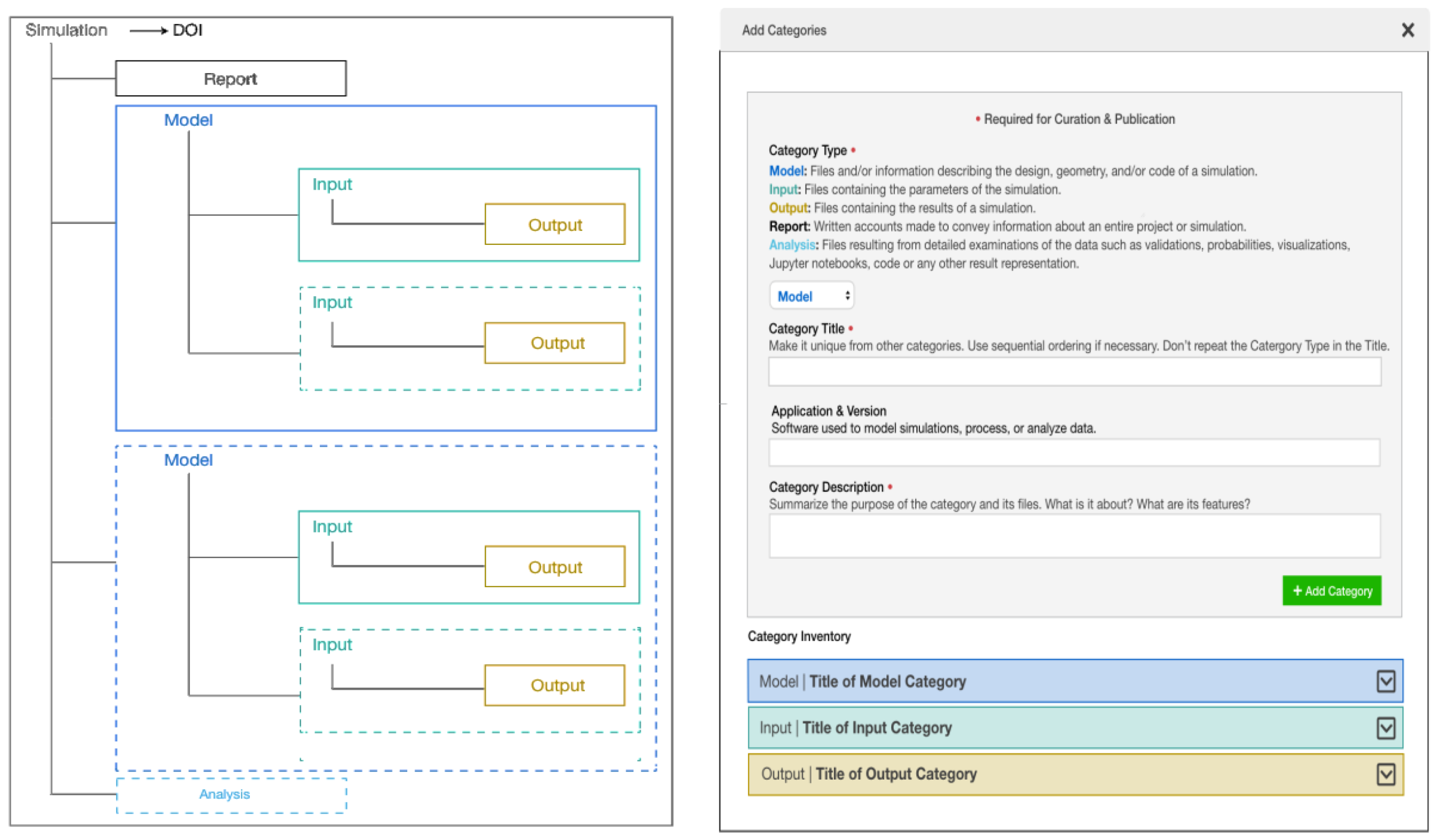
3.2. Modeling Simulation Workflows to Data Organization and Metadata
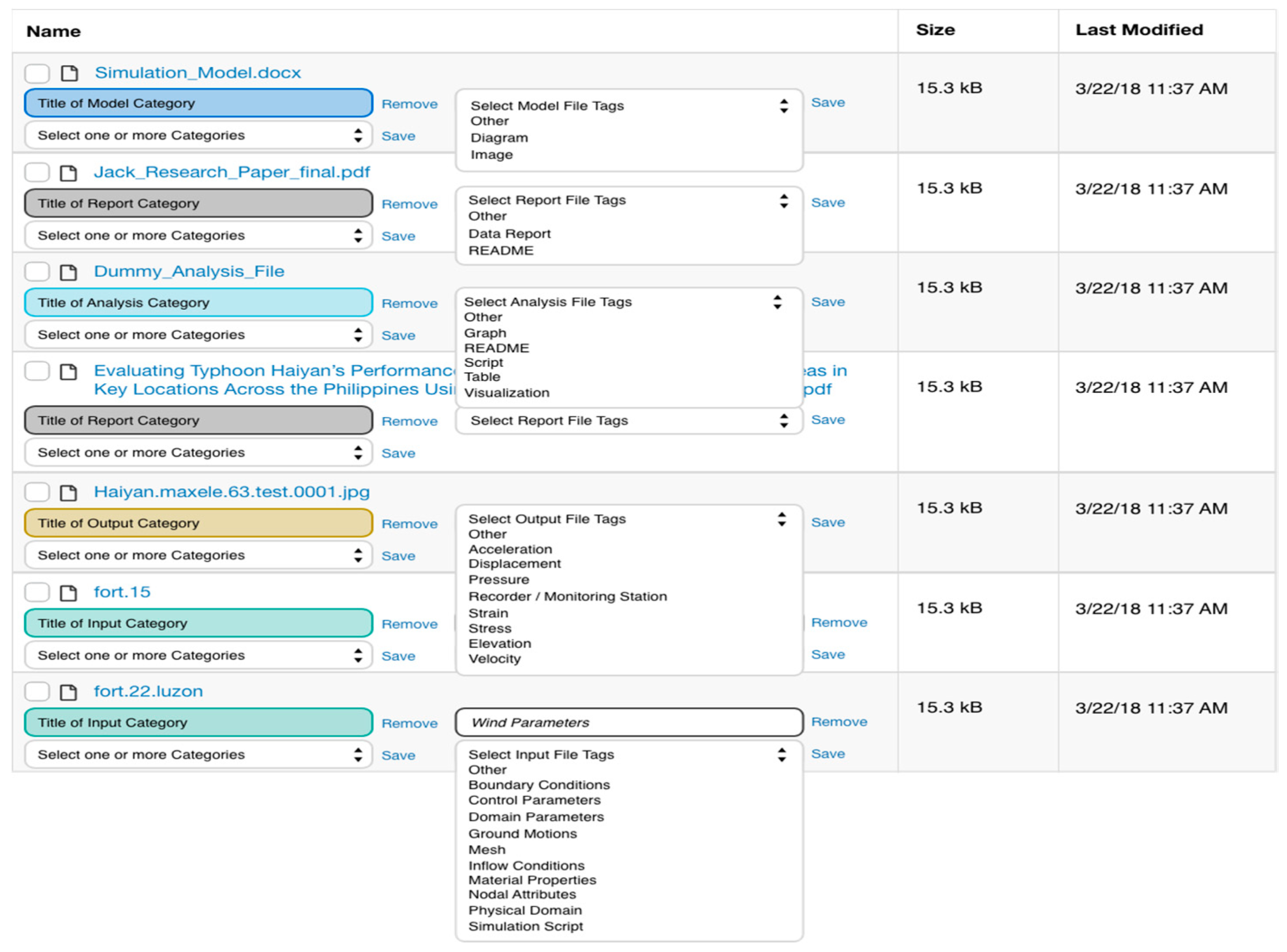
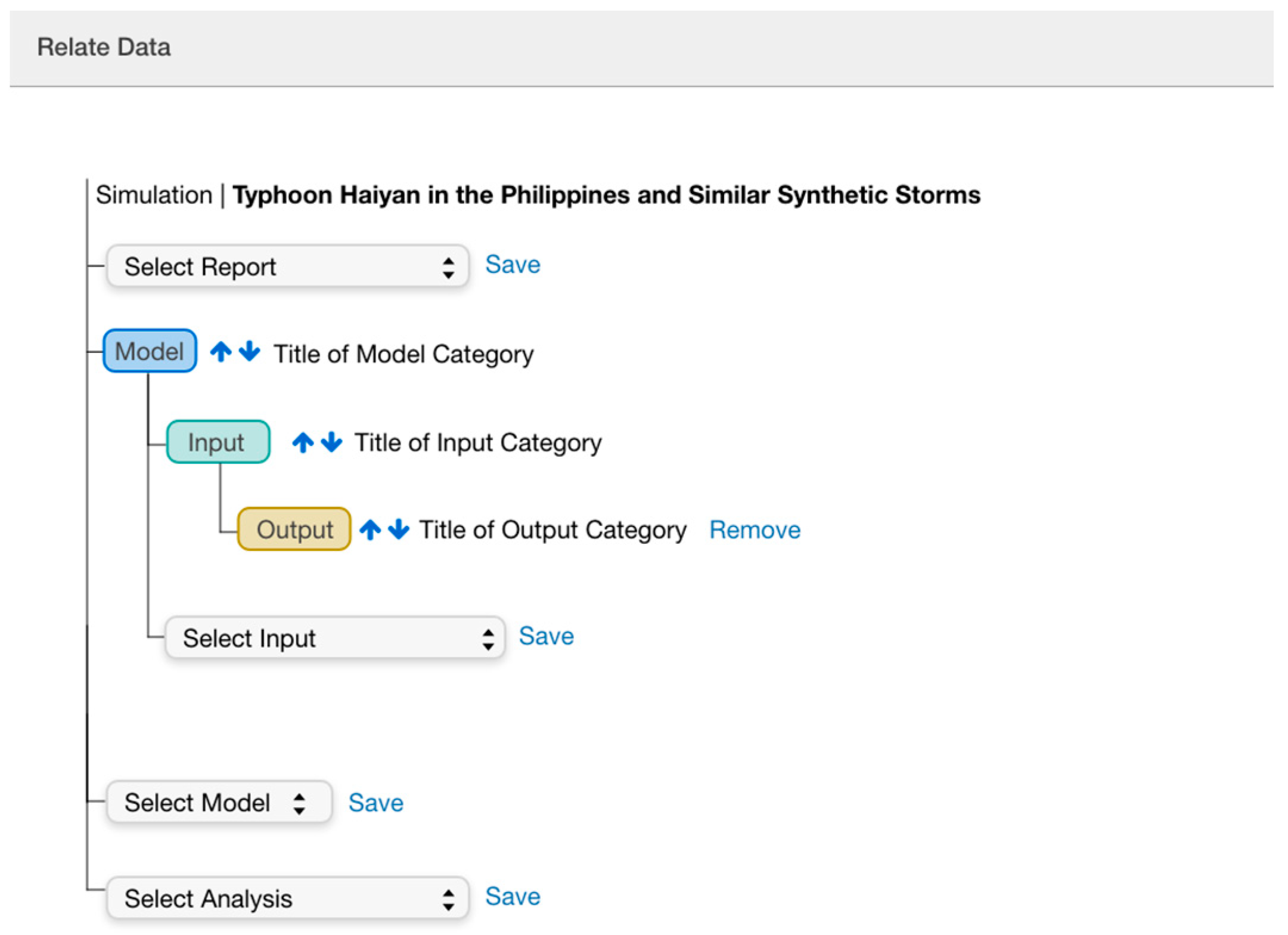
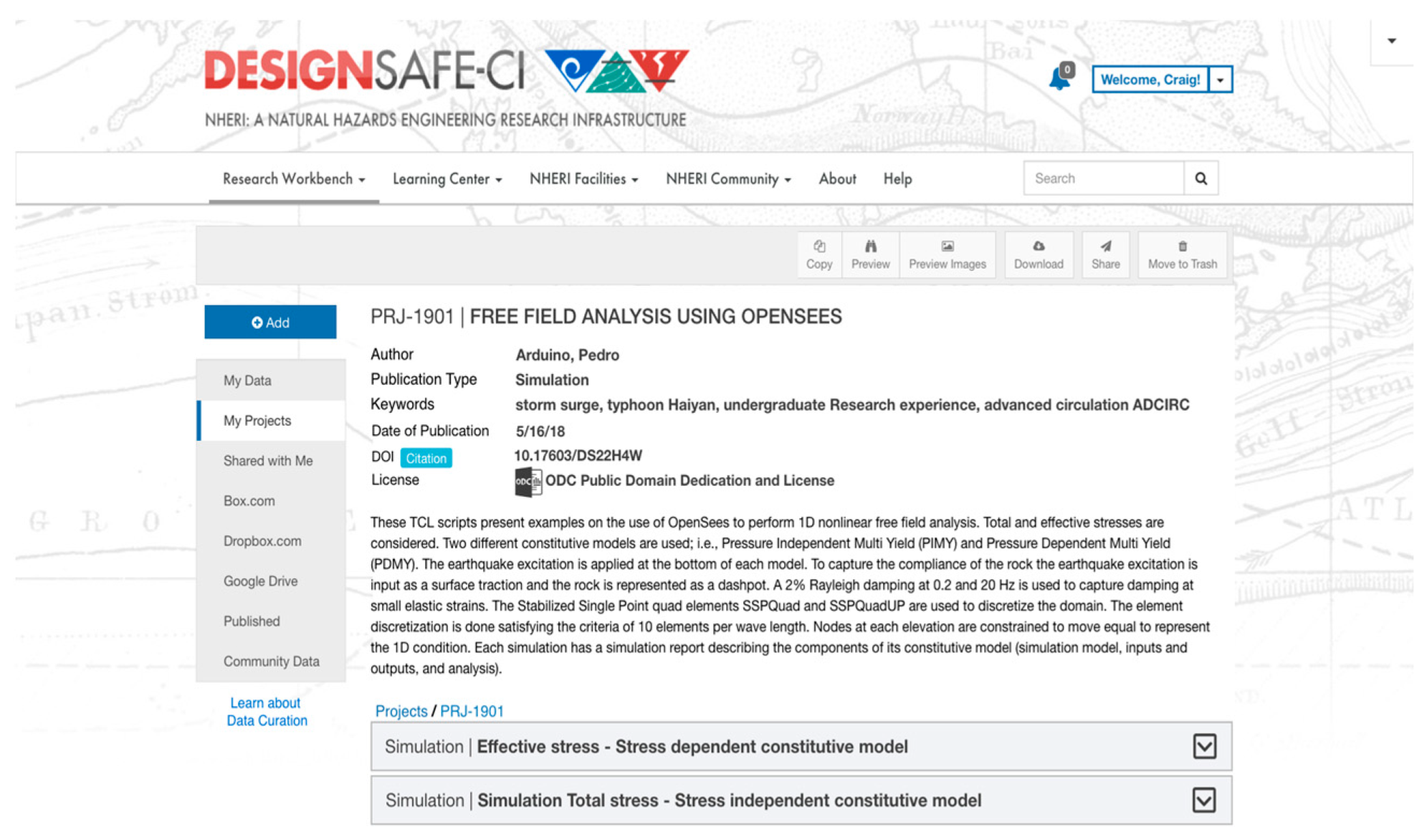
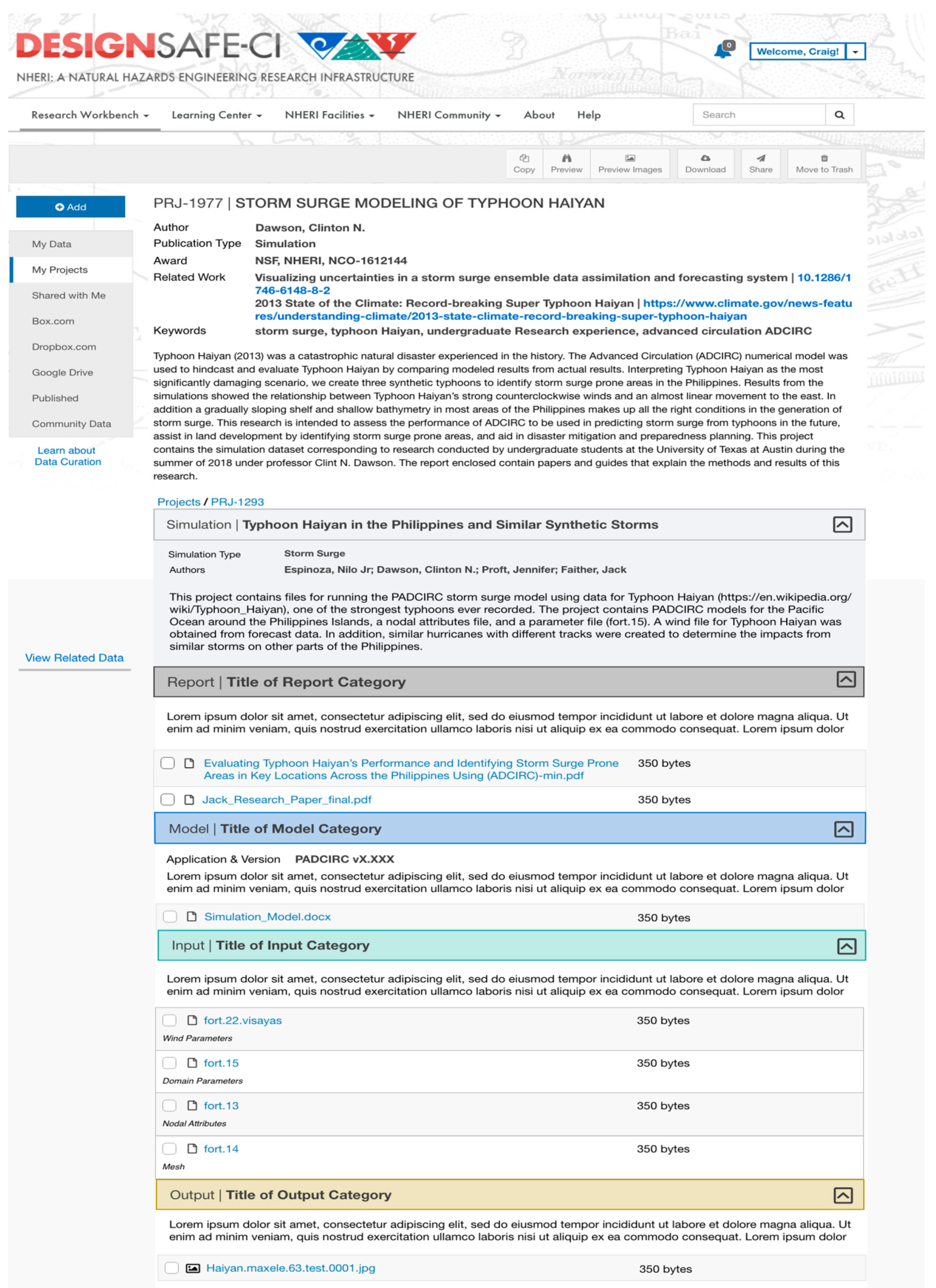
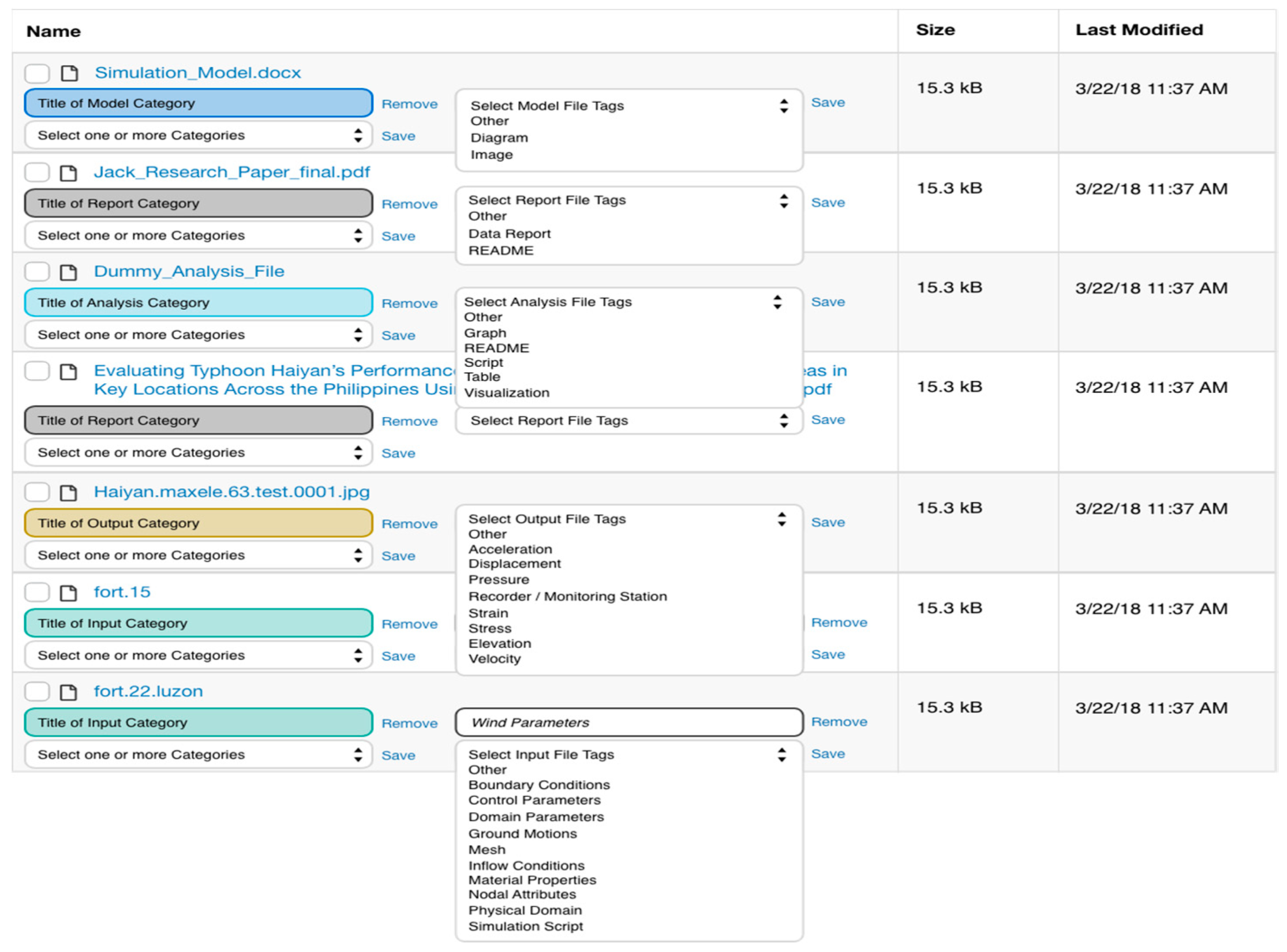
3.3. Mapping the Model to Interactive Interfaces
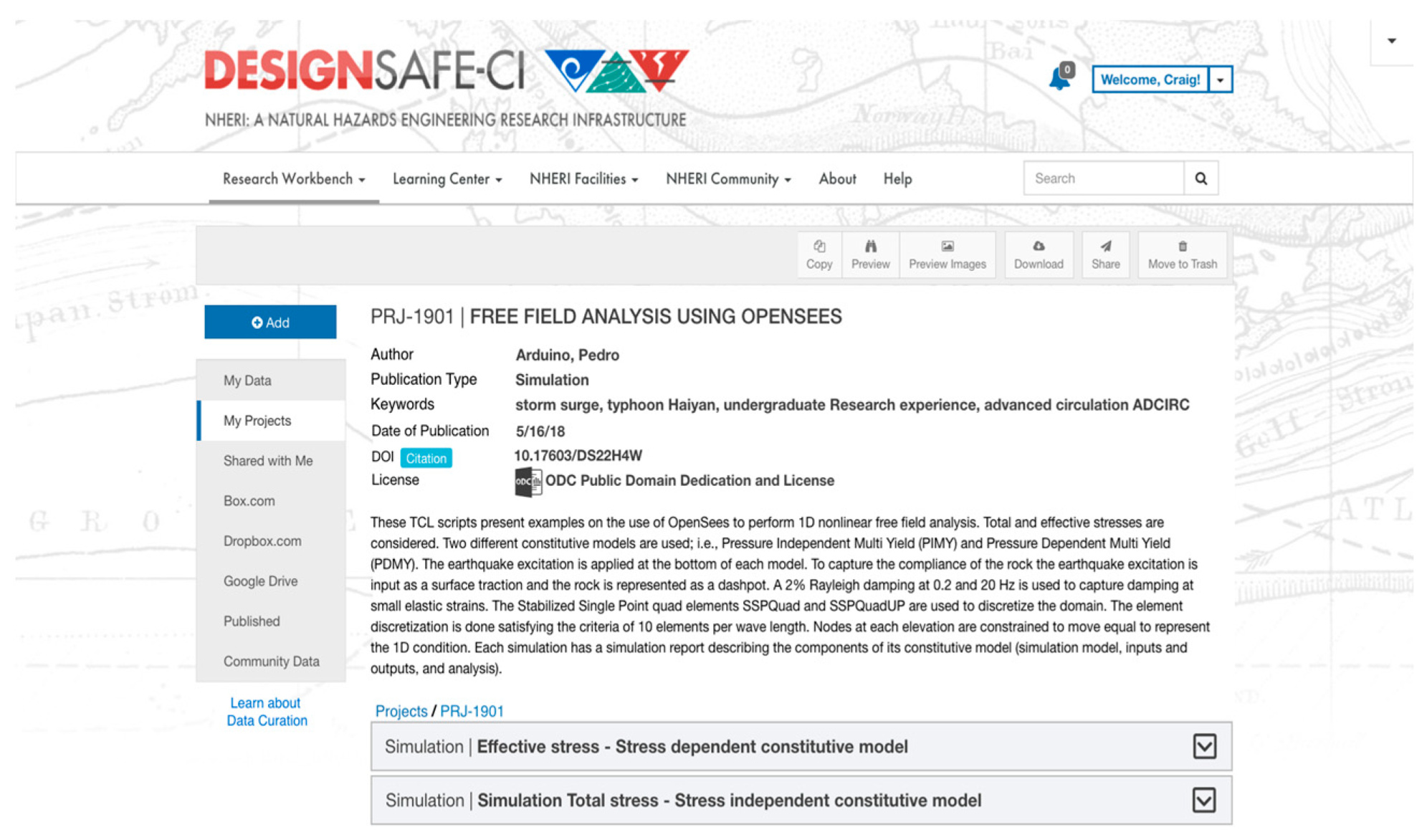
3.3.1. Interfaces for Interactive Lifecycle Curation
3.3.2. Representation of Large Datasets
3.4. Lifecycle Curation within an HPC Infrastructure
4. Discussion: Evaluation of the Interactive Curation and Representation Interfaces
5. Conclusions and Discussions of Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Rathje, E.M.; Dawson, C.; Padgett, J.E.; Pinelli, J.P.; Stanzione, D.; Adair, A.; Arduino, P.; Brandenberg, S.J.; Cockerill, T.; Dey, C.; et al. DesignSafe: A New Cyberinfrastructure for Natural Hazards Engineering. Nat. Hazards Rev. 2017. [Google Scholar] [CrossRef]
- Pejša, S.; Dyke, S.J.; Hacker, T.J. Building Infrastructure for Preservation and Publication of Earthquake Engineering Research Data. Int. J. Digit. Curation 2014, 9, 83–97. [Google Scholar] [CrossRef]
- Beagrie, N. Digital Curation for Science, Digital Libraries, and Individuals. Int. J. Digit. Curation 2008, 1, 3–16. [Google Scholar] [CrossRef]
- Esteva, M.; Brandenburg, S.; Eslami, M.; Adari, A.; Kulasekaran, S. Modelling Natural Hazards Engineering Data to Cyberinfrastructure. In Proceedings of the SciDataCon, Denver, CO, USA, 11–13 September 2016. [Google Scholar] [CrossRef]
- The Dataverse Project—Dataverse. Org. Available online: https://dataverse.org/home (accessed on 22 May 2019).
- GRIIDC|Home. Available online: https://data.gulfresearchinitiative.org/ (accessed on 22 May 2019).
- The Organization—Dryad. Available online: https://datadryad.org/pages/organization (accessed on 18 March 2019).
- Merchant, N.; Lyons, E.; Goff, S.; Vaughn, M.; Ware, D.; Micklos, D.; Antin, P. The iPlant Collaborative: Cyberinfrastructure for Enabling Data to Discovery for the Life Sciences. PLoS Biol. 2016, 14, 1002342. [Google Scholar] [CrossRef] [PubMed]
- DataONE. Available online: https://www.dataone.org/ (accessed on 22 May 2019).
- Matthews, B.; Sufi, S.; Flannery, D.; Lerusse, L.; Griffin, T.; Cleaves, M.; Kleese, K. Using a Core Scientific Metadata Model in Large-Scale Facilities. IJDC 2010, 5, 106–118. [Google Scholar] [CrossRef]
- Prodanovic, M.; Esteva, M.; Hanlon, M.; Nanda, G.; Agarwal, P. Digital Rocks Portal: A Repository for Porous Media Images. 2015. Available online: http://dx.doi.org/10.17612/P7CC7K (accessed on 20 March 2019).
- Datacenterhub—Datacenterhub. Available online: https://datacenterhub.org/aboutus (accessed on 22 May 2019).
- Maria, E.; Craig, J.; Josue, B.-C. Designing and Building Interactive Curation Pipelines for Natural Hazards in Engineering Data. Int. J. Digit. Curation 2018. [Google Scholar] [CrossRef]
- Esteva, M.; Walls, R.L.; Magill, A.B.; Xu, W.; Huang, R.; Carson, J.; Song, J. Identifier Services: Modeling and Implementing Distributed Data Management in Cyberinfrastructure. Data Inf. Manag. 2019, 1. [Google Scholar] [CrossRef]
- Dallmeier-Tiessen, S.; Khodiyar, V.; Murphy, F.; Nurnberger, A.; Raymond, L.; Whyte, A. Connecting Data Publication to the Research Workflow: A Preliminary Analysis. Int. J. Digit. Curation 2017, 12, 88–105. [Google Scholar] [CrossRef]
- Goble, C.; Stevens, R.; Hull, D.; Wolstencroft, K.; Lopez, R. Data Curation + Process Curation=data Integration + Science. Brief. Bioinform. 2008, 9, 506–517. [Google Scholar] [CrossRef] [PubMed]
- Gray, J.; Liu, D.T.; Nieto-Santisteban, M.; Szalay, A.; DeWitt, D.D.; Heber, G. Scientific Data Management in the Coming Decade. ACM Sigmod Rec. 2005, 34, 34–41. [Google Scholar] [CrossRef]
- Frey, J. Curation of Laboratory Experimental Data as Part of the Overall Data Lifecycle. Int. J. Digit. Curation 2008, 3. [Google Scholar] [CrossRef]
- Gray, J.; Szalay, A.S.; Thakar, A.R.; Stoughton, C.; Berg, J.V. Online Scientific Data Curation, Publication, and Archiving. In Proceedings SPIE 4846, Virtual Observatories; SPIE Digital Library: Bellingham, WA, USA, 16 December 2002. [Google Scholar]
- Wynholds, L.A.; Wallis, J.C.; Borgman, C.L.; Sands, A.; Traweek, S. Data, Data Use, and Scientific Inquiry: Two Case Studies of Data Practices. In Proceedings of the 12th ACM/IEEE-CS joint conference on Digital Libraries (JCDL ‘12), Washington, DC, USA, 10–14 June 2012; pp. 19–22. [Google Scholar] [CrossRef]
- Beckles, Z.; Debra Hiom, S.G.; Kirsty, M.; Kellie, S.; Damian, S. Disciplinary Data Publication Guides. Int. J. Digit. Curation 2018, 13. [Google Scholar] [CrossRef]
- NSF Arctic Data Center Data Submission Guidelines. Guidelines for Large Models. Available online: https://arcticdata.io/submit/ (accessed on 28 May 2019).
- Sandusky, R.J. Computational Provenance: DataONE and Implications for Cultural Heritage Institutions. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3266–3271. [Google Scholar] [CrossRef]
- Cisco, S. Big Buckets for Simplifying Records Retention Schedules. Inf. Manag. J. 2008, 42, S3. [Google Scholar]
- Data Life Cycle. DataONE. Available online: https://www.dataone.org/data-life-cycle (accessed on 24 May 2019).
- DCC Curation Lifecycle Model. Digital Curation Centre. Available online: http://www.dcc.ac.uk/resources/curation-lifecycle-model (accessed on 28 May 2019).
- Arduino, P.; Chen, L.; Ghofrani, A. Effective stress—Stress Dependent Constitutive Model. DesignSafe-CI 2018. [Google Scholar] [CrossRef]
- Four Kitchens. We Make Content Go! Available online: https://www.fourkitchens.com/ (accessed on 26 February 2019).
- Dooley, R.; Brandt, S.; Fonner, J. The Agave platform: An open, science-as-a service platform for digital science. In Proceedings of the Practice and Experience on Advanced Research Computing (PEARC ‘18), Pittsburgh, PA, USA, 22–26 July 2018. [Google Scholar] [CrossRef]
- Stampede2—Texas Advanced Computing Center. Available online: https://www.tacc.utexas.edu/systems/stampede2 (accessed on 28 May 2019).
- Lonestar 5—Texas Advanced Computing Center. Available online: https://www.tacc.utexas.edu/systems/lonestar (accessed on 28 May 2019).
- Corral—Texas Advanced Computing Center. Available online: https://www.tacc.utexas.edu/systems/corral (accessed on 3 September 2018).
- Welcome to DataCite. Available online: https://datacite.org/ (accessed on 28 May 2019).
- Fedora Repository. DuraSpaceWiki. Available online: https://wiki.duraspace.org/display/FF/Fedora+Repository+Home (accessed on 27 February 2019).
- Esteva, M.; Adair, A.; Jansen, C.; Coronel, J.B.; Kulasekaran, S. A Data Model for Lifecycle Management of Natural Hazards Engineering Data. In Proceedings of the International Conference on Dublin Core and Metadata Applications, Washington, DC, USA, 26–29 October 2017; pp. 73–74. [Google Scholar]
- Liu, Y. Sea Level Rise Projection at Sewells Point (6838610) in Norfolk. DesignSafe-CI 2018. [Google Scholar] [CrossRef]
- Dawson, C.N.; Fleming, J. Hurricane Maria ADCIRC Surge Guidance System Storm Surge Forecasts. DesignSafe-CI 2018. [Google Scholar] [CrossRef]
- Hsu, T.-J.; Kim, Y.; Puleo, J. Large Eddy Simulation of Dam-Break-Driven Swash on a Rough-Planar Beach. DesignSafe-CI 2018. [Google Scholar] [CrossRef]
- Fang, N. Identification of Urban Flood Impacts Caused by Land Subsidence and Sea Level Rise for the Houston-Galveston Region. DesignSafe-CI 2018. [Google Scholar] [CrossRef]
- FEMA Flood Map Service Center. Available online: https://msc.fema.gov/portal/advanceSearch (accessed on 11 March 2019).
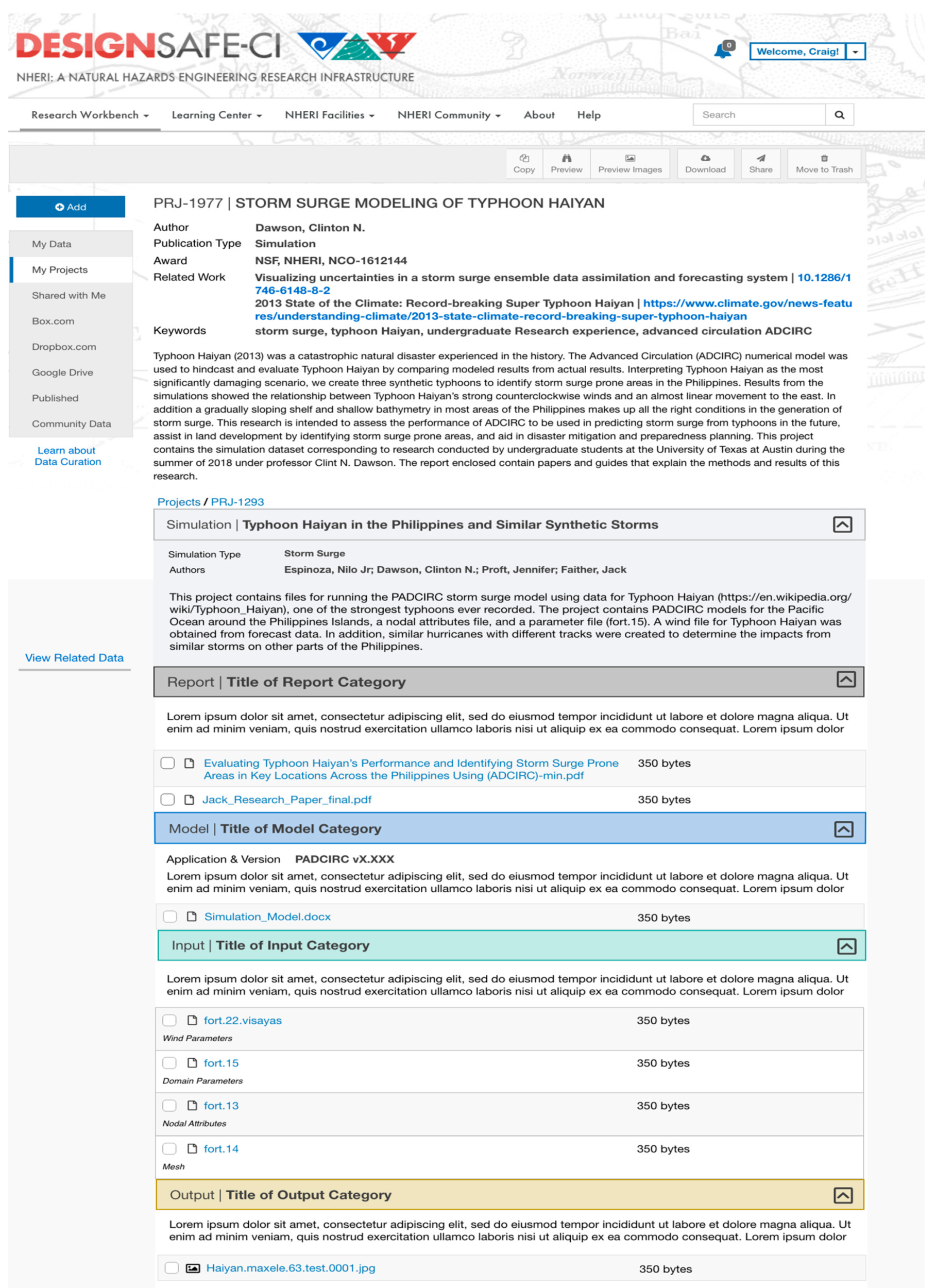
- Dawson, C.N. Storm Surge Modeling of Typhoon Haiyan. DesignSafe-CI 2018. [Google Scholar] [CrossRef]
- US Department of Commerce, NOAA. Active Alerts. Available online: https://www.weather.gov/alerts (accessed on 11 March 2019).
- Kameshwar, S.; Vishnu, N.; Padgett, J. Earthquake Analyses for Portfolios of Seven Highway Bridge Classes in Response and Fragility Modeling of Aging Bridges Subjected to Earthquakes and Truck Loads. DesignSafe-CI 2019. [Google Scholar] [CrossRef]
- Ingram, C. Research Data: To Keep or Not to Keep? Research Data Management. 7 March 2019. Available online: https://researchdata.jiscinvolve.org/wp/2019/03/07/research-data-to-keep-or-not-to-keep/ (accessed on 22 March 2019).
| 1 | For clarity, through this paper, we call the members of the simulation requirements team experts, and the researchers and public who use the platform users. |
| 2 | User studies were part of development activities and were not formalized as human subject studies with IRB authorization. We are procuring IRB evaluation for the next testing cycle to discuss and publish the study results. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
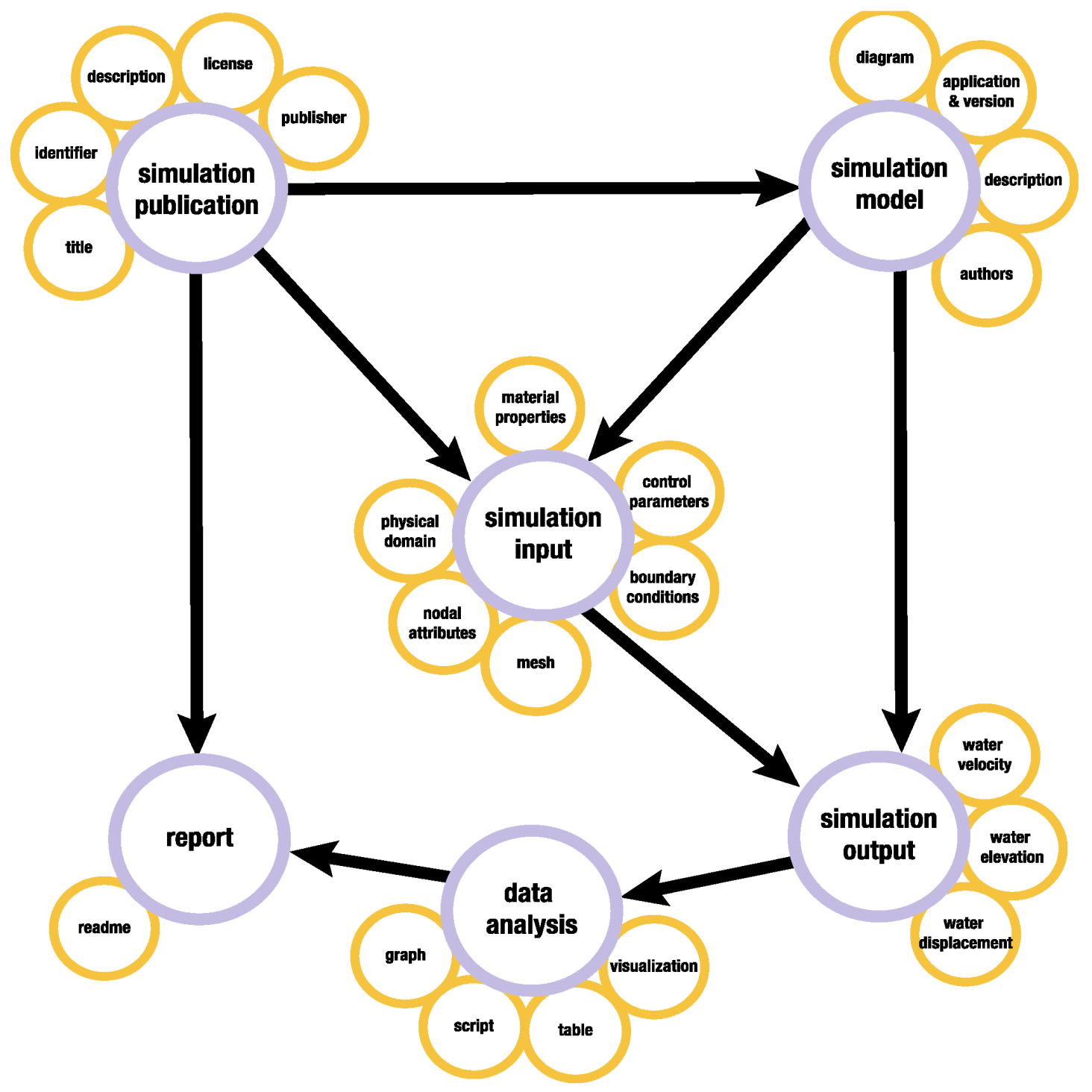
| Category | Corresponding Research Lifecycle | Definition |
|---|---|---|
| Simulation publication | Data sharing and discovery, representation information, access, reuse. | General metadata including creators, identifier, license, and description of the simulation research project. |
| Simulation model | Plan, project set up, research questions, conceptualize. | Information and or files corresponding to the design, geometry and code of a simulation. A model may be embedded in software in which case we record its version and documentation. |
| Simulation input | Running the simulation, data creation/collection/gathering. | Files used to run a simulation model. Include configuration, parameters, and loads. |
| Simulation output | Data processing, results. | Data resulting from a simulation run. |
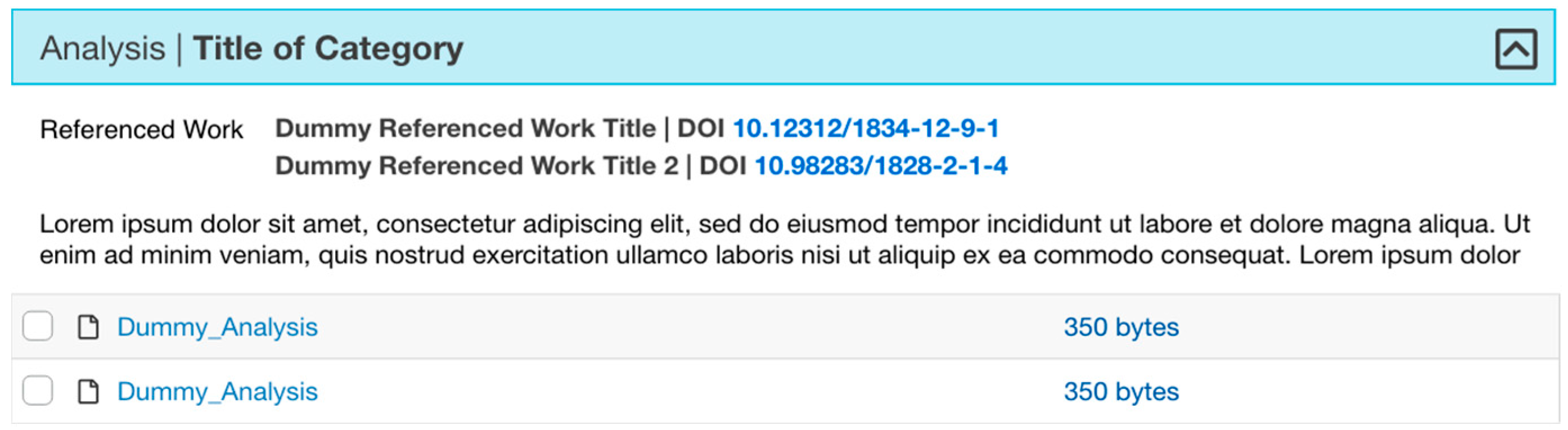
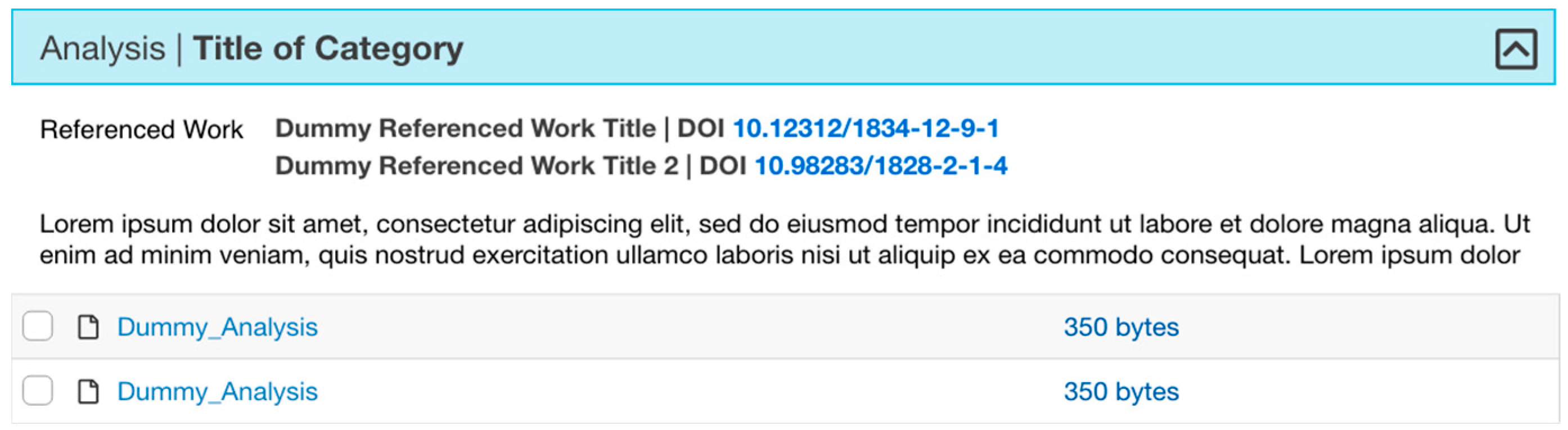
| Analysis | Interpretation, transform. | Files resulting from examinations of the results. May include validations, probabilities, visualizations, code or other representations. |
| Report | Description, dissemination, reuse. | Written account made to convey information and instructions about the simulation |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Esteva, M.; Jansen, C.; Arduino, P.; Sharifi-Mood, M.; Dawson, C.N.; Balandrano-Coronel, J. Curation and Publication of Simulation Data in DesignSafe, a Natural Hazards Engineering Open Platform and Repository. Publications 2019, 7, 51. https://doi.org/10.3390/publications7030051
Esteva M, Jansen C, Arduino P, Sharifi-Mood M, Dawson CN, Balandrano-Coronel J. Curation and Publication of Simulation Data in DesignSafe, a Natural Hazards Engineering Open Platform and Repository. Publications. 2019; 7(3):51. https://doi.org/10.3390/publications7030051
Chicago/Turabian StyleEsteva, Maria, Craig Jansen, Pedro Arduino, Mahyar Sharifi-Mood, Clint N. Dawson, and Josue Balandrano-Coronel. 2019. "Curation and Publication of Simulation Data in DesignSafe, a Natural Hazards Engineering Open Platform and Repository" Publications 7, no. 3: 51. https://doi.org/10.3390/publications7030051
APA StyleEsteva, M., Jansen, C., Arduino, P., Sharifi-Mood, M., Dawson, C. N., & Balandrano-Coronel, J. (2019). Curation and Publication of Simulation Data in DesignSafe, a Natural Hazards Engineering Open Platform and Repository. Publications, 7(3), 51. https://doi.org/10.3390/publications7030051