Abstract
This study evaluates the efficiency and accuracy of Generative AI (GAI) tools, specifically ChatGPT and Gemini, in comparison with traditional academic databases for industrial engineering research. It was conducted in two phases. First, a survey was administered to 101 students to assess their familiarity with GAIs and the most commonly used tools in their academic field. Second, an assessment of the quality of the information provided by GAIs was carried out, in which 11 industrial engineering professors participated as evaluators. The study focuses on the query process, response times, and information accuracy, using a structured methodology that includes predefined prompts, expert validation, and statistical analysis. A comparative assessment was conducted through standardized search workflows developed using the Bizagi tool, ensuring consistency in the evaluation of both approaches. Results demonstrate that GAIs significantly reduce query response times compared to conventional databases, although the accuracy and completeness of responses require careful validation. A Chi-Square analysis was performed to statistically assess accuracy differences, revealing no significant disparities between the two AI tools. While GAIs offer efficiency advantages, conventional databases remain essential for in-depth literature searches requiring high levels of precision. These findings highlight the potential and limitations of GAIs in academic research, providing insights into their optimal application in industrial engineering education.
1. Introduction
Today, search systems and academic research platforms are undergoing a radical transformation driven by artificial intelligence and process automation advances. Incorporating advanced exploration techniques and data-driven methodologies has made information searches faster, more accurate, and contextually relevant (Singh et al., 2024). Among these developments, Generative Artificial Intelligence (GAI) stands out as a disruptive breakthrough, providing more seamless, personalized interactions tailored to users’ specific needs (Mutia et al., 2024; Tiwari et al., 2024).
As these technologies continue to evolve, their impact increasingly extends to sectors such as higher education, where their ability to personalize learning experiences and optimize the search for academic information makes them key players (Sikand et al., 2024). GAI-based chatbots are expected to play a key role in improving research efficiency, assisting in decision-making, and optimizing workflows in academic and professional environments (Rani et al., 2023).
ChatGPT, Gemini, Apple’s Siri, Claude AI, and Bard AI are among the most widely used GAI tools (Guillén-Yparrea & Hernández-Rodríguez, 2024; Oliński et al., 2024). These technologies provide multiple benefits, including accessing vast information databases, decision support, automated content generation, and rapid resolution of specific questions and issues. Their real-time responsiveness and ability to customize interactions according to the context position them as efficient solutions in various fields, especially in academic and professional environments (Chung, 2024; Ding & Raman, 2024).
However, despite their great potential, these tools have limitations. One of the main challenges lies in the accurate interpretation of queries, as they may sometimes have difficulties understanding the semantics or context of the questions asked, which may result in the need to reformulate queries (Śliwiak & Shah, 2024; Tanaka et al., 2024). This limitation can lead to inaccurate or outdated answers, affecting the results’ quality, especially in more complex investigations that require precision and rigor. In addition, generative models, not being infallible, may incorporate biases in the information provided, adding uncertainty in decision-making based on their answers (Aravinth et al., 2023; Milutinovic et al., 2024).
For these reasons, it is crucial that users carefully verify the information provided by these generative AI tools and that obtained from other research platforms. This verification process should focus not only on the data themselves but also on the sources from which the information comes to ensure the validity, accuracy, and completeness of the results (Agliata et al., 2024). A rigorous review minimizes the risk of incorporating errors or biases that could compromise the quality of the analysis or research (Khan et al., 2025; Ogunfunmi, 2024).
It is equally important to remember that although these technologies are advanced, their use should be complementary and not a complete substitute for traditional sources of information (Subramani et al., 2024; Xiao & Yu, 2025). Cross-checking the results obtained with reliable and additional sources is essential to ensure the accuracy and relevance of the data. In addition, avoiding the false belief that the technology is entirely neutral is critical. While AI tools are powerful, they are still the product of biases inherent in those who develop them and the data with which they have been trained. Therefore, their prudent use and critical thinking are indispensable to obtaining quality results in academic and professional research (Olson, 2024; Sun et al., 2025).
GAI tools offer a more dynamic and interactive approach unlike conventional databases, such as Google Scholar, Scopus, or Web of Science, which rely primarily on keyword-based algorithms and indexing systems. Traditional databases provide static, ordered results according to predefined criteria, such as relevance or number of citations, which may be effective for systematic searches but lack the flexibility to adapt to more complex or specific queries (Gatla et al., 2024; Turgel & Chernova, 2024). GAI tools, on the other hand, can understand the semantic context of queries and generate more precise and personalized answers tailored to the user’s immediate needs. This represents a significant advantage in situations where a deeper interpretation of the content is required rather than a simple keyword search (Du et al., 2024; Sim et al., 2025).
This study aims to systematically compare the efficiency and accuracy of generative AI tools, specifically ChatGPT and Gemini, against traditional academic databases in the context of industrial engineering research. To achieve this, custom-designed and validated questionnaires were developed for industrial engineering students and teachers, allowing us to assess the effectiveness of GAIs in information retrieval and compare their usability with traditional databases. Additionally, expert evaluations were incorporated to provide insights into the accuracy and relevance of AI-generated responses.
Furthermore, to enhance the understanding of search workflows, flowcharts were developed using the Bizagi tool, specifically for this study, to illustrate and compare the step-by-step processes involved in both generative AI and traditional search engine queries. These diagrams offer a structured visualization of the retrieval methodologies, serving as a solid foundation for direct performance comparisons. By integrating time efficiency analysis, expert-driven accuracy assessments, and structured workflow comparisons, this research provides a comprehensive evaluation of the potential advantages and limitations of GAIs in academic and professional research environments. Given this, two research questions can be formulated as follows:
- How does the response time of Generative AI tools compare to traditional academic databases when retrieving information for industrial engineering research?
- What is the accuracy and reliability of responses provided by Generative AI tools compared to traditional academic databases in industrial engineering subjects?
2. Study Case
GAI has experienced significant growth and has been widely adopted in the business, industry, education, and labor sectors. Its use has spread remarkably among the population, reflecting its growing integration in various daily activities. Aware of this phenomenon, a research study was carried out to analyze GAI’s impact in higher education (Modgil et al., 2025; Yang et al., 2025).
The study was carried out at a university located in the central region of Ecuador, with the participation of the Industrial Engineering program. The goals of the experiment were twofold. First, a survey was conducted among students to get to know their familiarity with GAIs and those most used in their academic field. The total population comprised 136 students. Using a standard sample size estimation formula (see Equation (1)), it was calculated that a representative sample would consist of 101 participants. These people were surveyed to assess the frequency of use of GAI tools and the level of knowledge they had about these technologies.
where
- : Total number of students surveyed;
- : Z-score, 95% confidence level;
- : Assumed proportion for maximum variability;
- ;
- : Margin of error.
The survey instrument underwent a validation process carried out by three experts with over five years of experience in education and the implementation of emerging technologies (Beghetto et al., 2025; Pathak et al., 2025). These reviewers, including professionals in industrial and electronic engineering, assessed the instrument for clarity, relevance, and alignment with the study’s objectives, following the methodology outlined in the Chilean Adventist University’s guide for validating research instruments (Universidad Adventista de Chile, 2020). Each expert provided individual evaluations regarding the structure and coherence of the questionnaire to ensure its adequacy. The questions are shown in Appendix A.
Following the analysis of the data obtained from the surveys, the key Industrial Engineering subjects in which GAI tools had the highest usage were identified. It should be noted that students may use GAIs in more than one subject, which explains the overlap in the percentages reported. The results show that Industrial Innovation is the subject in which GAIs were most frequently used, with 66.3% of students using these tools in this subject. This subject, considered fundamental in the career curriculum, was followed by Plant Location and Design with 46.5%, and Technological Project with 37.6% of GAI use in the development of academic activities.
As for the most used GAI tools, the results confirm that ChatGPT, in its free version, was the most popular, with 90.1% of respondents stating that they used it regularly in their academic work. Gemini, meanwhile, was in second place, with 34.7% usage. These data show that many students used more than one GAI tool to support their assignments, reflecting the accessibility of and preference for ChatGPT, especially for its ease of use in searching for information and assistance in Industrial Engineering-related tasks. Regarding the demographics of the participants, 83.2% were in their eighth semester, while 16.8% were in their seventh semester. In addition, 99% of respondents said they were familiar with GAI tools, while only 1% said they were unfamiliar, minimizing potential biases due to differences in expertise. Regarding frequency of use, 85.1% of the students indicated that they used GAI tools or applications occasionally in their research work, while 14.9% used them constantly. These percentages may overlap regarding occasional and constant use of different tools in different subjects. Regarding the perception of the usefulness of GAIs, 72.3% of the respondents considered that the answers provided by these tools are useful in the context of Industrial Engineering. In comparison, 25.7% doubted their effectiveness and only 2.0% stated that they did not find them useful. Finally, 77.2% of the respondents considered that GAI systems are relevant to Industrial Engineering careers, reinforcing their role in developing technological competencies within the academic field.
After collecting the above information, three key questions were used as standardized prompts for evaluating the response accuracy and relevance of Generative AI tools. Participants were instructed to use these predefined prompts when retrieving information from GAIs, ensuring consistency in the comparative analysis with traditional databases. This approach eliminates variability in user-generated queries and allows for a structured assessment of response quality across different platforms (Netland et al., 2025; Ngo & Hastie, 2025). These queries are designed in natural language and require contextual interpretation rather than exact keyword matches, making them complex queries. Unlike traditional databases that retrieve structured results, GAIs process such queries holistically to generate direct, synthesized answers.
Industrial Innovation
- What are the main challenges that companies face due to insufficient knowledge of 4.0 technologies, and how can these challenges be effectively addressed to promote successful adoption?
- What are the key steps an organization should follow to carry out an effective digital transformation of its internal processes, and how can the priority areas for optimization be identified through the implementation of digital technologies?
- What are the fundamental concepts that a person needs to understand when entering the world of Big Data, including key definitions, associated technologies, and common challenges, and how can these insights be applied in practical projects?
Plant Location and Design
- How are process flow diagrams and plant flow diagrams used in the design and evaluation of plant layout?
- What are the current trends in optimizing industrial location to improve productivity and global competitiveness?
- How do digital technologies and automation influence the efficient layout of industrial processes?
3. Key Stages of Interaction
To compare the time and efficiency of GAI tools and conventional databases, the specific processes of each were illustrated through flow diagrams (Espinosa et al., 2021; Sánchez-Rosero et al., 2023). The flow corresponding to using GAIs such as ChatGPT and Gemini is presented below.
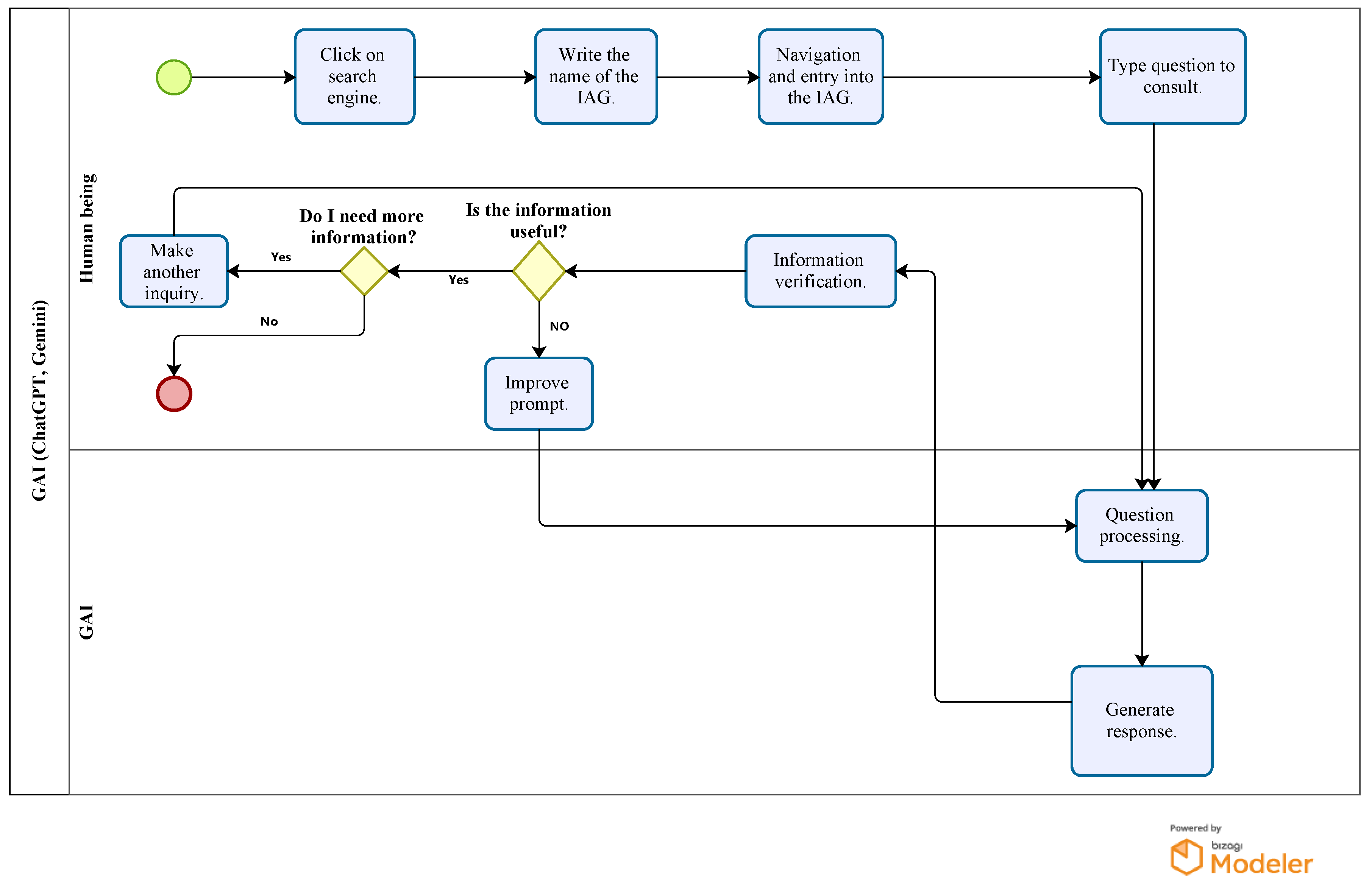
Figure 1 details the interaction process between a user and a GAI system, highlighting the key stages from formulating the query to obtaining a processed response. This flowchart visualizes the decisions the user must make based on the usefulness and accuracy of the information provided by the GAI system.
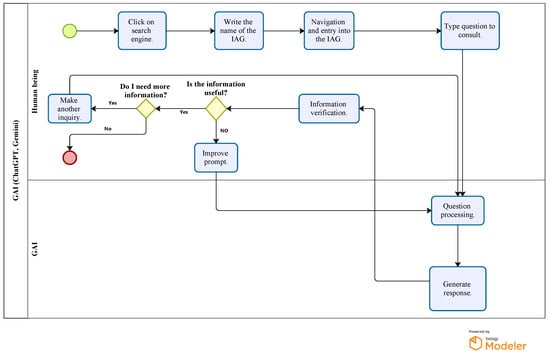
Figure 1.
ChatGPT–Gemini flowchart.
The figure presented illustrates the interaction process between a user and an GAI, such as ChatGPT or Gemini, by means of a flowchart detailing each step from the query initiation to obtaining and verifying the generated response. The process begins when the user accesses a search engine, as the starting point, by clicking on the platform containing the GAI. Once inside, the user proceeds to type in the name of the GAI tool he/she wishes to use, such as ChatGPT or Gemini, which allows him/her to navigate and enter the corresponding GAI interface.
After accessing the platform, the user enters a specific question or query. This step is crucial, as the query’s precise wording directly influences the response’s quality. The GAI system then processes the question and, after a short time, generates an answer for the user to review. At this point, the information verification process is essential. The user evaluates whether the response provided by the GAI is useful and adequate to meet his or her needs. If the information is satisfactory, the user can choose to terminate the process or make a new query, starting the cycle again.
If the information is inadequate, the user can improve the prompt or adjust the query formulation, allowing him to optimize the results obtained in the next interaction. The diagram also shows an additional step where the user decides whether he/she needs more information on the queried topic. If so, the cycle is repeated until it is considered that it is not necessary to continue searching for more data.
Finally, the process ends if the user determines that the information received is sufficient. Otherwise, another query can be made and the cycle continues. This flow of interaction ensures that the user can refine their query to obtain answers more closely aligned with their specific needs, taking full advantage of the capabilities of the GAI tools.
Once the users’ workflow when using a GAI was established, we measured the time required to complete each task in the key stages of the process, with special emphasis on processing the question and generating the answer. These two activities were consolidated into a single measurement to obtain a more representative and meaningful time for the overall process. This decision was made based on previous studies on the usability of generative systems, where it has been shown that the user perceives processing and answer generation as a single operational phase, since the user does not interact with the system until receiving the requested information. Therefore, breaking down these activities could generate artificially separate estimates that would not reflect the user’s actual behavior in an everyday environment.
Table 1 shows the times recorded (in seconds) for each of the activities of the ChatGPT process. The times correspond to the average of 30 samples (Industrial Engineering students with the back-to-zero technique) taken for each activity in six evaluated questions, three corresponding to the Industrial Innovation course and three to Plant Location and Design (Luo et al., 2018). The decision to use 30 samples was not arbitrary, but is based on sound statistical grounds. According to research in fields such as software usability and operational efficiency analysis, 30 samples represent a sufficient size to ensure a robust estimation of average times, minimizing the margin of error and providing a realistic view of the time distribution (Tighiouart et al., 2018). This is consistent with the use of descriptive statistics in similar studies, where sample sizes of 30 or more are considered adequate to describe general patterns without the need to apply additional corrections as in smaller samples (Riley et al., 2022).

Table 1.
Calculated times for ChatGPT GAI (seconds). The table shows the average time required to complete the tasks.
At first glance, it can be observed that some times, such as those corresponding to clicking and starting the search engine and browsing and entering the GAI, are homogeneous in all samples and queries. These times, which range from 1.99 to 3.64 s, remain practically constant because the actions involved in these stages do not depend on the complexity of the query, but on factors such as system loading speed and server response. These types of times, known as “base interaction times”, are considered stable in human–computer interaction (HCI) studies, where it has been shown that variations in repetitive activities are minimal (Lin et al., 2024). These times reflect the initial operational phases where the interaction is purely technical and does not affect the user’s cognitive experience.
In contrast, the highest level of variability is found in the question entry stage, where the times recorded fluctuate between 23.02 and 53.22 s. This variability directly reflects the complexity of the queries formulated by users, particularly in the questions corresponding to the Industrial Innovation subject. As observed in the table, the questions in this subject require a higher cognitive load on the user’s part to formulate specific and technical queries involving multiple concepts related to Industry 4.0 and digital transformation. In comparison, Plant Location and Design questions tend to be more concrete and less conceptual, resulting in shorter question formulation times.
It is important to note that, although “query entry” times vary markedly, the following stages, such as processing and answer generation, also show variations. However, these are less pronounced, with average times ranging from 19.27 to 25.61 s. These differences reflect the capabilities of the GAI processing engine to correctly interpret queries, since the more complex the query, the longer it takes to generate an accurate and relevant answer. However, the difference is not as marked as at the question entry stage, indicating that the GAI system is optimized to handle variations in question complexity without significantly affecting processing time.
Another relevant consideration is the constancy in the base times, which is observed in the initial activities of the workflow. As mentioned, search engine click and start times and GAI navigation and login times are repeated in all samples because they depend not on the user’s cognitive interaction, but on external factors such as Internet speed and system performance. In usability studies, these types of times are classified as “constant” times and, although they are useful for determining the operational efficiency of the system, they do not provide information about the complexity of the task itself (Shoaib et al., 2024).
Table 2 shows the times recorded by Gemini, using the same methodological approach applied in the previous table. To calculate these times, the activities described in the flowchart were considered, consolidating the processing and response generation phases into a single measurement to more accurately represent the user experience.
Table 2.
Calculated times for Gemini GAI (seconds). The table shows the average time required to complete the tasks.
As in the previous analysis, 30 measurements were taken for each question (Industrial Engineering students), and statistical methods were applied to calculate the average times for each of the activities evaluated. This approach minimizes variability and ensures that the results reflect a generalized and consistent behavior in using the GAI.
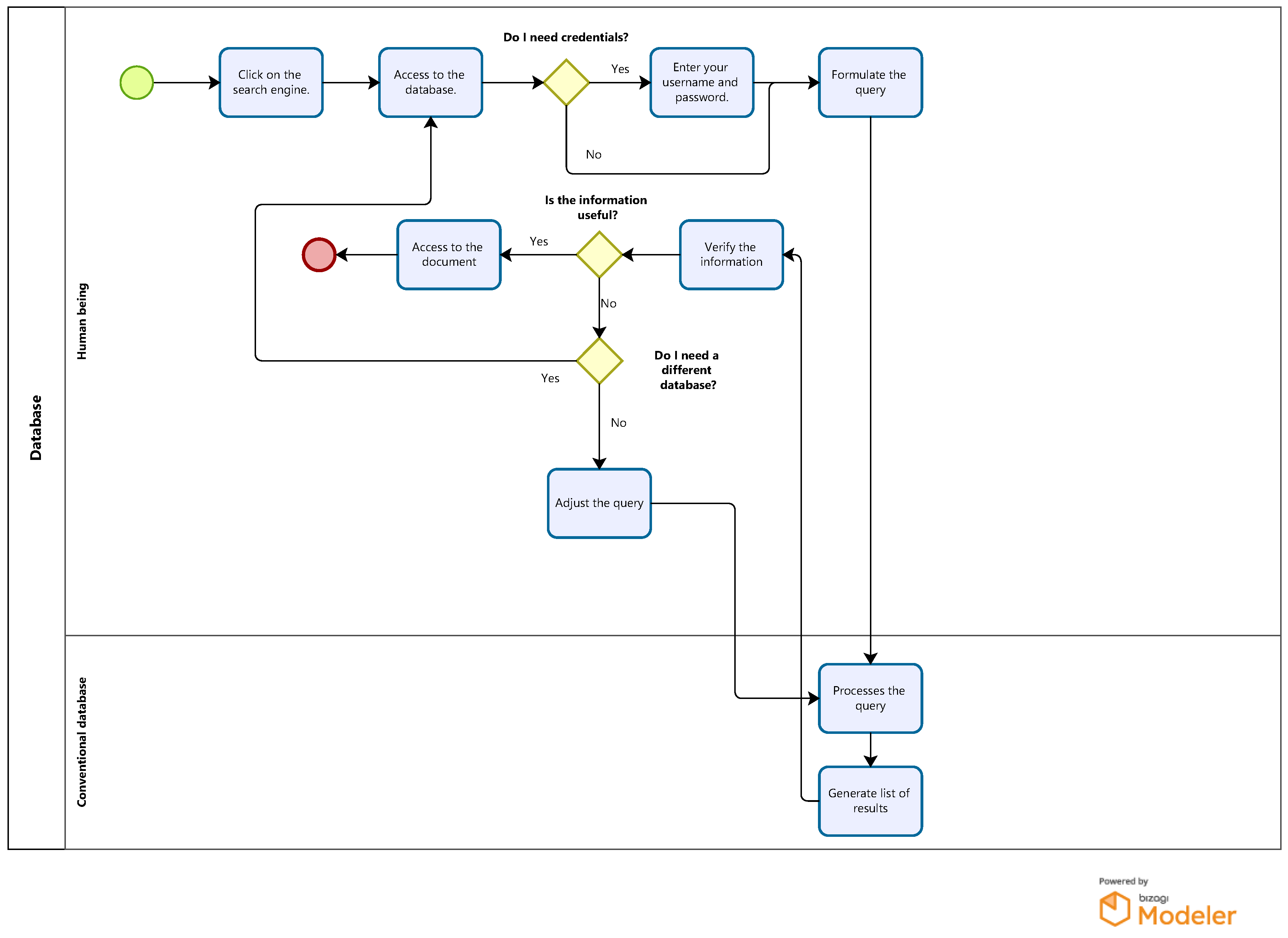
In Figure 2, the complete interaction process between the user and a conventional database (such as Google Scholar or Scopus) is detailed in a technical manner, focusing on decision-making and search adaptation throughout the query flow. This diagram highlights the importance of the steps involved, from initial access to obtaining and validating relevant information, through various critical decisions that guide the workflow.
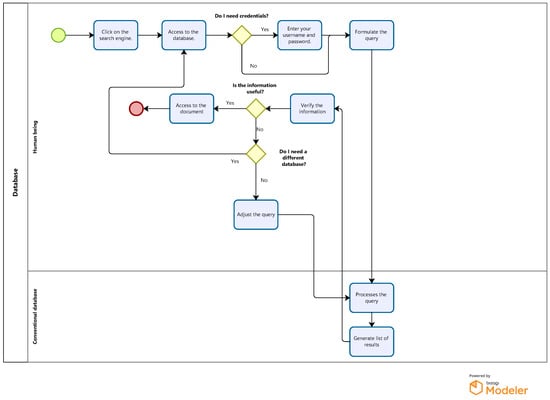
Figure 2.
Conventional database flowchart.
The process starts when the user accesses the search engine, which may vary depending on the access platform. This action is fundamental since it defines the starting point of the interaction with the database. Depending on the database selected, the system determines whether it is necessary to authenticate through credentials, as in the case of Scopus, which requires access through an institutional or personal account. If necessary, the user must enter his or her credentials, which adds a layer of security and ensures that the resources accessed are restricted according to the database policies. This step is omitted on open access platforms, such as Google Scholar, and the flow continues uninterrupted, facilitating more agile access.
The user then moves on to the query formulation stage. This phase is of particular importance, since the search’s quality and accuracy depends largely on the terms used. The conventional database search system operates on the logic of keyword matching and Boolean operators, which means that a well-formulated query can filter through millions of documents and reduce them to a manageable list of relevant results. Here, the user’s knowledge of the use of technical terms and Boolean operators is crucial to optimize the efficiency of the search process.
The database then processes the query and generates a results list based on the terms provided. This process can vary in time depending on the database, the complexity of the query, and the volume of documents available. In more advanced platforms such as Scopus, the results include the option to apply additional filters (by year, author, journal, document type, etc.), allowing the user to further refine the results obtained. This stage of results generation is key to ensuring that the user does not have to manually review an extensive list of documents, but can focus their analysis on those most relevant to their query.
The next step in the process is verifying the information obtained. Here, the user must evaluate the relevance and usefulness of the documents found. In conventional databases, this step may involve reviewing abstracts, keywords, and bibliographic references before deciding whether to access the full text. The ability to quickly identify whether a document is relevant is a critical skill in using these platforms.
If the information is useful, the user can access the full document and download or consult it online. This access may be conditioned by licenses or permissions depending on the database, especially in the case of Scopus or other platforms that require institutional subscriptions to access certain documents. In the case of Google Scholar, many documents are available via open access, simplifying this part of the process.
If the information is not useful, the diagram provides two paths. First, the user can choose to adjust the query. This adjustment may involve modifying keywords, using synonyms, or applying additional filters to improve the accuracy of the results. This step is critical to maximize the efficiency of the search system and reduce the number of irrelevant results. Second, if the results are unsatisfactory after query tuning, the user may choose to switch databases. At this point, the system allows the flexibility to switch to another platform offering different coverage of the scientific literature.
Finally, the process concludes when the user finds the appropriate information or decides that no more options are available in the consulted databases. This iterative approach ensures that the user’s interaction with the system is adaptive, efficient, and aligned with the search objectives, providing a logical and optimized flow that systematically obtains relevant information.
This process not only represents a basic search but also reflects best practices in academic research, where a rigorous and structured approach is required to ensure that the information collected is valid, up-to-date, and relevant to the study’s context. The different research platforms, by offering different functionalities and databases, complement this workflow, providing the user with the flexibility to adjust to the specific needs of each query.
Table 3 shows the calculated times for querying a conventional database. It provides a detailed breakdown of the activities required to obtain academic information, covering each step from the start of the search to the final verification of the results. This table is based on an average of 30 samples (taken from Industrial Engineering students who demonstrated proficiency in searching for information in conventional databases, ensuring that the measured times reflect an efficient use of these resources. However, this study does not explicitly differentiate between varying levels of expertise in database navigation, which could influence the comparative evaluation of Generative AI tools. Future research should consider incorporating expertise-level assessments to better understand this impact). This detail ensures that the data obtained reflect an efficient use of the database, minimizing delays that could arise from unfamiliarity with the system.
Table 3.
Calculated times for conventional database search (seconds). The table shows the average time required to complete each task, including information verification.
The first step, “Click and start search engine”, represents the average time it takes to start the search engine or access the main database interface (such as Google Scholar or Scopus). Since this activity is a direct user action and requires minimal interaction, the times are low, ranging from 1.80 to 1.90 s. This consistency in times reflects the speed with which participants can initiate the process, an almost mechanical task that does not depend on the complexity of the query. Next, once inside the search engine, the user accesses the specific database. In this step, the selected platform loads and presents the interface to perform the search. The times for this activity vary between 2.29 and 2.42 s, reflecting slight differences in loading speed and platform performance. This step is crucial because it establishes the connection with the system that hosts the documents, facilitating access to the available academic resources.
In the case of databases that require authentication, such as Scopus, the user must enter his or her credentials to access the complete content. This activity takes an average of 5.60 to 5.72 s, attributable to entering login information and the platform’s authentication process. Compared to direct access, this step adds time but ensures that the user has access to valuable and complete resources. The user can proceed directly without authentication for open access databases, such as Google Scholar. This direct access takes between 1.46 and 1.52 s, streamlining the process and allowing for a seamless workflow. The difference between direct access and login times highlights the efficiency of open access platforms compared to those that require authentication, although databases that require authentication tend to have complete and specific content.
The “Formulate query” step is one of the most complex, as it involves the formulation of a precise and well-structured query. Here, the user employs keywords and Boolean operators to optimize the results.
Here, users must construct well-structured Boolean queries using specific operators such as AND, OR, and NOT to refine search results. Unlike natural language queries, Boolean queries require precise keyword matching to retrieve relevant documents. Based on the queries used in this study, the Boolean queries were structured as follows:
Industrial Innovation Queries: “4.0 technologies” AND “challenges” AND “successful adoption” “digital transformation” AND “internal processes” AND “priority areas” “Big Data” AND (“key definitions” OR “associated technologies”) AND “practical applications”
Plant Location and Design Queries: “process flow diagrams” AND “plant layout evaluation” “industrial location optimization” AND (“productivity” OR “global competitiveness”) “digital technologies” AND “automation” AND “industrial processes”
The times for this activity range from 26.93 to 50.87 s, reflecting the variability in query complexity. Queries related to technical topics, such as Industrial Innovation, tend to have higher times due to the precision required in the keywords to obtain specific results. The quality of the results is highly dependent on the formulation of the query, making this step critical in the search process.
Once the query is submitted, the database processes the request and displays a list of results, including theses, articles, books, and other academic documents. This processing takes between 12.87 and 14.02 s, depending on the speed of the system and the number of documents related to the search terms. Unlike GAI systems such as ChatGPT and Gemini, where the user receives a specific answer directly, the system returns a list of documents that the user must evaluate manually. This list of documents allows the user to explore multiple sources, albeit at the cost of additional time.
The additional “Verification of information” column represents the time required for the user to verify and evaluate the relevance of the documents obtained. In this step, the user reviews each document’s title, abstract, and keywords to determine its relevance. This verification process is manual and variable, depending on the number of results and the clarity of the abstracts. On average, this activity takes between 30 and 60 s per document. Verification of information is a key difference between GAI systems and conventional databases. Although the user can verify the information provided in GAI systems, the response is direct and designed to answer the query without requiring selection from multiple documents. This streamlines the search process compared to conventional databases. It also limits the scope of information available, as GAIs rely on pre-existing data in their training and do not allow for exhaustive exploration of individual documents.
Information verification in conventional databases is important because it allows the user to critically evaluate each document before accessing its full content. This verification process is especially valuable in an academic or research context, where the accuracy and relevance of information are essential. In conventional databases, the user can choose from various documents, allowing for a more comprehensive and detailed search. In contrast, GAI systems such as ChatGPT and Gemini provide a specific answer, reducing search time, but limiting the user’s ability to explore multiple perspectives.
4. Results
4.1. Time Comparison
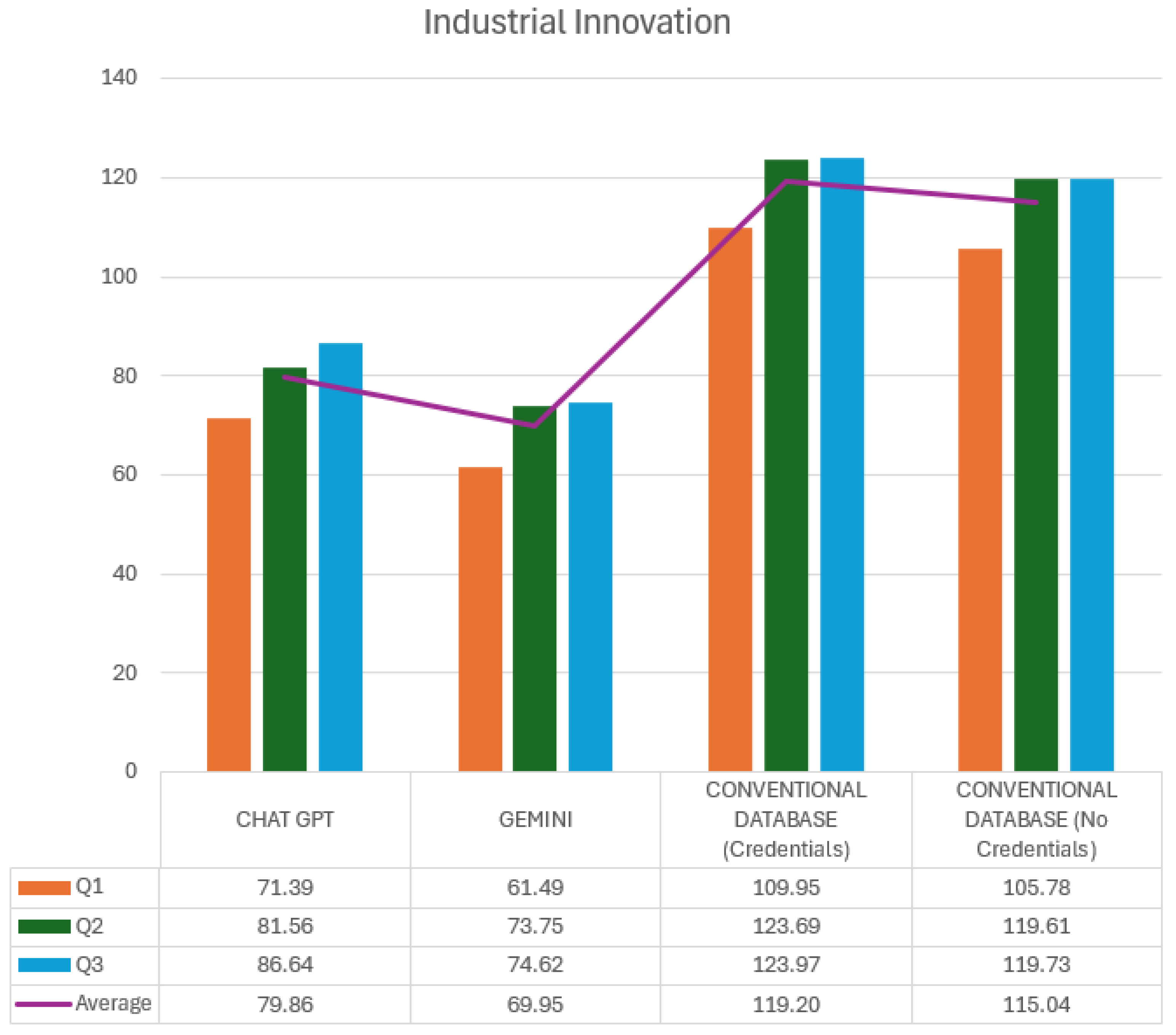
The following is a comparative analysis of the times recorded using the two GAI tools, ChatGPT and Gemini, vs. a conventional database, with and without authentication, in the selected subjects of Industrial Innovation and Plant Location and Design. This study aims to determine the efficiency of each platform in terms of response speed, evaluating the total time taken to answer each query. Figure 3 shows the specific response times for the Industrial Innovation subject, broken down into three queries (Q1, Q2, and Q3) with the calculation of an average for each tool used.
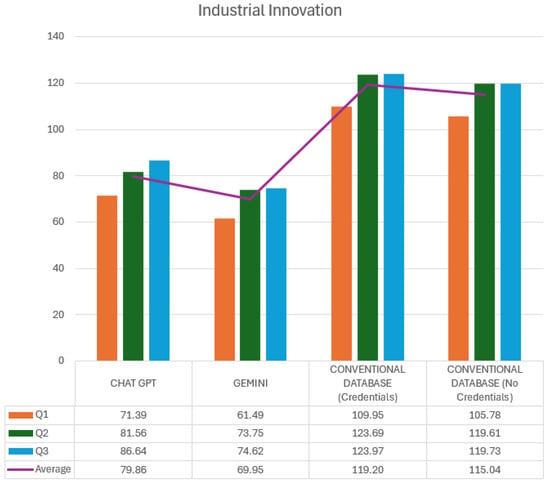
Figure 3.
Industrial Innovation times (seconds).
Each query (Q1, Q2, and Q3) is represented in the graph by different colored bars for each platform. The purple line represents the average times for the three queries within each platform. The ChatGPT section shows that the response times are relatively consistent, with an average of 79.86 s, with Q3 being the query with the highest time (86.64 s) and Q1 the lowest (71.39 s). This behavior suggests that ChatGPT presents a stable, though slightly variable, response depending on the complexity of the specific query.
In the case of Gemini, response times also show consistency, but with a lower overall average of 69.95 s. This indicates a speed advantage over ChatGPT. Here, query Q2 shows the highest time (73.75 s), while Q1 and Q3 are slightly lower, staying in a range close to 70 s. This lower variability in Gemini could be attributed to optimizing its ability to process and deliver information.
On the other hand, when examining the conventional database use, there is a significant difference between access with and without credentials. With credentials, the average time is 119.20 s, considerably higher than for the GAIs. In this configuration, Q3 represents the highest time (123.97 s), while Q1 is the lowest (109.95 s). This time increase can be explained by the additional authentication and database access processes, which increase the total query duration.
Finally, in conventional database access without credentials, the average time decreases slightly to 115.04 s, which is still higher than the times recorded for GAIs. Here, the times for Q2 and Q3 are similar, with Q2 at 119.61 s and Q3 at 119.73 s, while Q1 is lower (105.78 s). A direct comparison between conventional databases and GAIs indicates that, although access without credentials reduces time, using a GAI is still significantly faster for queries in Industrial Innovation.
This analysis shows that ChatGPT and Gemini offer speed advantages over conventional databases, which is beneficial in environments where the speed of information retrieval is critical. However, the additional time on conventional databases must be considered in applications that require authentication and access control.
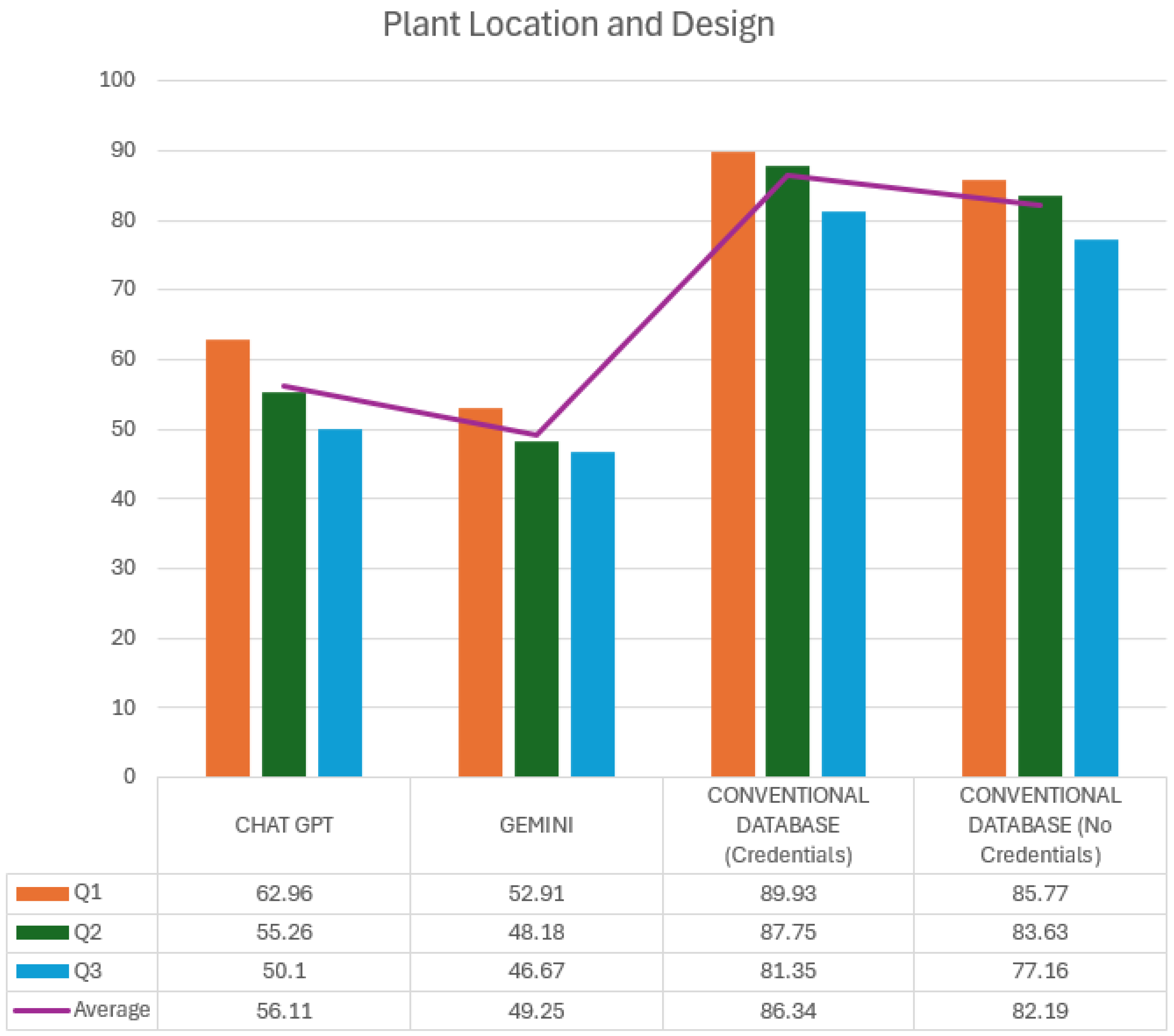
On the other hand, a detailed analysis of response times for the Plant Location and Design subject using the two GAI tools, ChatGPT and Gemini, compared to a conventional database with and without the need for authentication is shown in Figure 4. This analysis focuses on measuring the efficiency of each platform for answering specific queries (Q1, Q2, and Q3) and the average of these times for each.
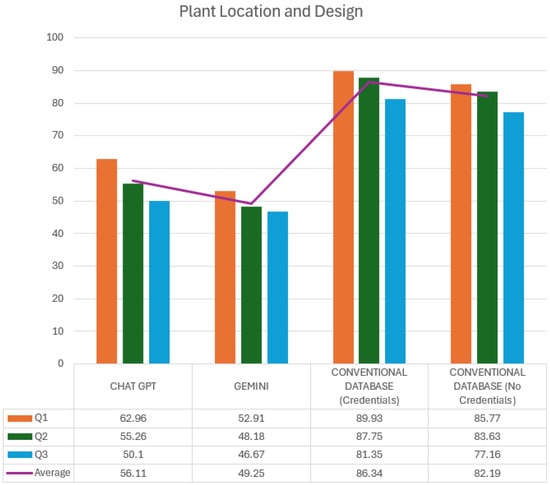
Figure 4.
Plant Location and Design times (seconds).
The graph’s colored bars represent the times for each query on the different platforms. In addition, the purple line shows the overall average time for each platform on the subject. ChatGPT’s response times for Q1, Q2, and Q3 are 62.96, 55.26, and 50.1 s, respectively, with an overall average of 56.11 s. This behavior suggests that ChatGPT maintains a consistent and efficient response in this subject, with a slight decrease in time as questions progress. This could be due to familiarity with the context of the queries or optimization in information processing as each query is performed.
Gemini has even lower response times than ChatGPT, averaging 49.25 s, highlighting its speed advantage. The times for each query were 52.91 s for Q1, 48.18 s for Q2, and 46.67 s for Q3, reflecting a progressive improvement in each query. This time decrease suggests that Gemini may have greater adaptability or efficiency in handling sequential queries within the same subject, which could be attributed to optimized response algorithms or a contextual predictive capability in related queries.
On the other hand, the analysis of the conventional database reveals significant differences in times depending on whether authentication is required or not. When authentication is required, the average time is 86.34 s, with Q1 being the slowest query (89.93 s) and Q3 the fastest (81.35 s). This additional time, mainly due to the login process, represents an essential factor in the efficiency of conventional databases since this step can considerably delay access to relevant information.
In contrast, when using the conventional database without credentials, the average time decreases slightly to 82.19 s, although it remains above the times recorded for GAIs. The times for each query are 85.77 s for Q1, 83.63 s for Q2, and 77.16 s for Q3, suggesting that, although access without credentials reduces the total duration, the process of searching and filtering results in the database is still an aspect that increases the total time compared to the GAI tools.
It is essential to highlight the fundamental difference in the workflow between GAIs and conventional databases. In GAIs, users directly obtain the requested information, whereas in conventional databases, especially with authentication, the user has to search and verify each result’s relevance manually. This additional step is a crucial difference that makes conventional databases, although accurate, require significantly longer response times to complete the query process than ChatGPT and Gemini.
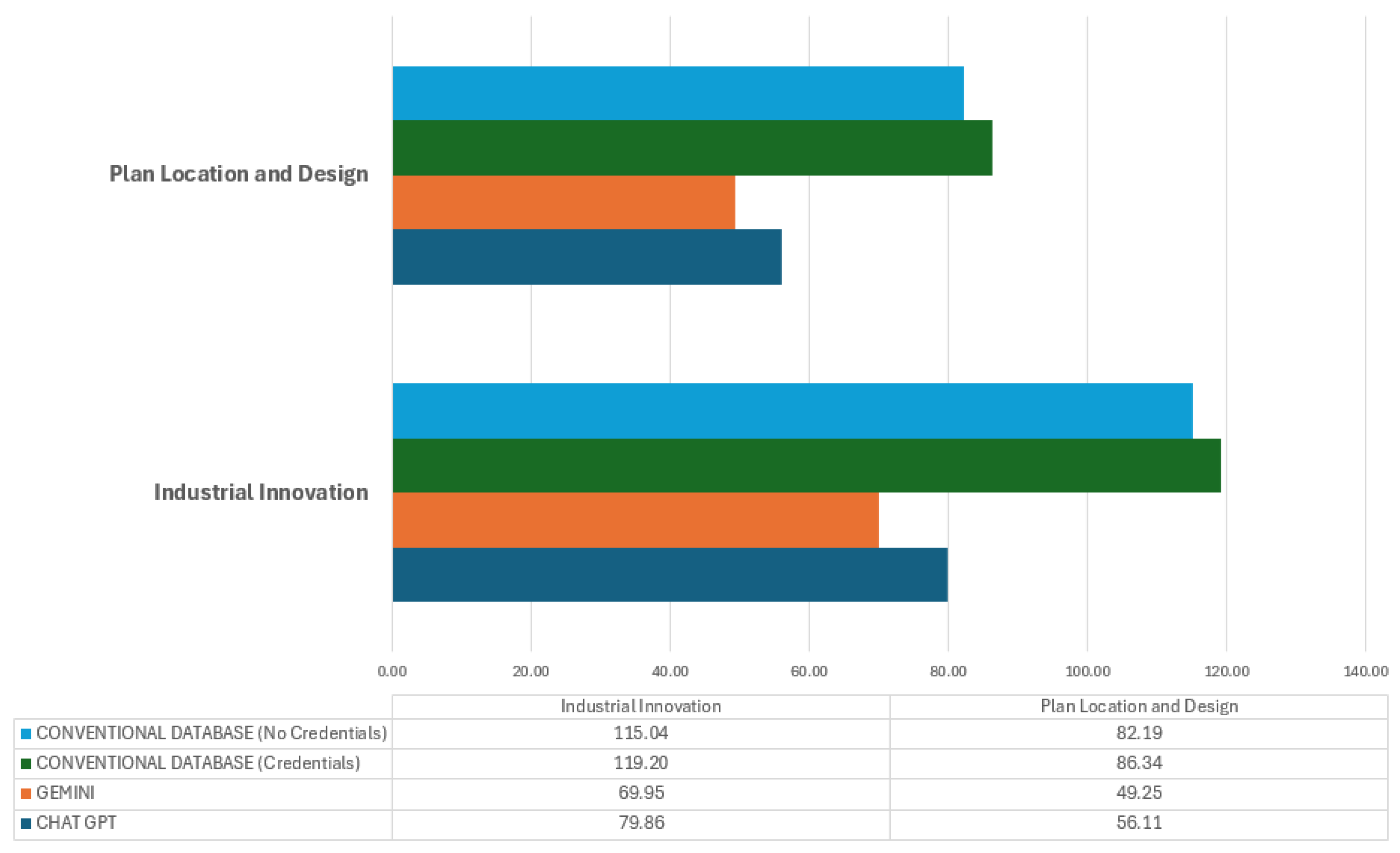
Finally, Figure 5 highlights the efficiency of GAI tools versus conventional databases regarding response speed. The performance of Gemini, which presents the lowest time in the Plant Location and Design subject, reflects an optimization for queries of a technical nature that require speed and precision in generating specific answers. The agility of this tool could be due to its ability to process sequential queries efficiently, thus reducing the user’s cognitive load and avoiding intermediate processes.
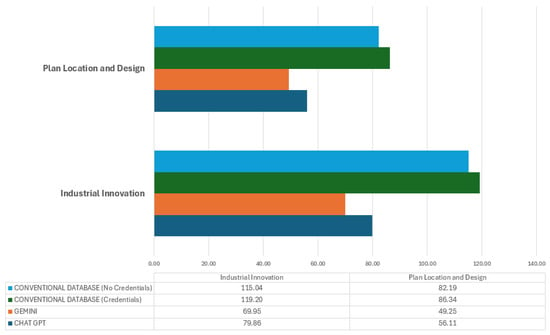
Figure 5.
Average Times comparison (seconds).
In contrast, the use of a conventional database leads to significantly longer response times, especially when authentication is required, as seen in Industrial Innovation. This increase in time is related to the multiple stages that the user must complete: authenticate, formulate the query, and then analyze a list of documents to verify which one is relevant. This introduces additional complexity since the user does not receive an immediate answer but a list of results to evaluate. The need to select and verify information individually contributes to the increase in time, regardless of whether access is with or without credentials.
This contrast highlights the suitability of AGI for scenarios where the speed of information retrieval is crucial, allowing users to access relevant data without additional procedures quickly. Conventional databases, on the other hand, offer greater security in terms of authentication and allow the user to make an exhaustive selection of sources, which is valuable in contexts where information validation is critical. This difference is essential to understand how to choose the right tool depending on the specific objectives: if the priority is speed, GAIs are superior; if it is accuracy and control source selection, conventional databases are preferable, albeit at higher response times.
Statistical Analysis
A thorough statistical analysis was conducted to determine whether the observed differences in response times across the evaluated platforms ChatGPT, Gemini, and traditional databases with and without credentials were statistically significant. The objective of this analysis was to establish a robust foundation supporting the results presented, ensuring that the variations in response times are not due to random fluctuations but rather reflect systematic differences in platform efficiency (Sadraoui et al., 2025; Srivastava & Sahoo, 2025).
Before performing any statistical tests, the normality of the response time distributions for each platform was assessed using the Shapiro–Wilk test. This test evaluates whether a dataset follows a normal distribution, which is a prerequisite for parametric statistical tests such as ANOVA. The results indicated that the dataset was normally distributed (), justifying the use of a one-way Analysis of Variance (ANOVA) to compare the mean response times across the four platforms (Alharithi et al., 2025).
The ANOVA test produced a highly significant result (), indicating that at least one platform had a response time that significantly differed from the others. However, ANOVA does not specify which groups differ; thus, a post hoc analysis was conducted using Tukey’s Honestly Significant Difference (HSD) test to determine pairwise differences.
The Tukey HSD test was employed to compare the mean response times for all possible platform pairs (Bassi & Singh, 2025). Table 4 presents the results of this analysis, indicating the mean differences, confidence intervals, and statistical significance for each comparison.
Table 4.
Tukey HSD test results for pairwise comparisons of response times across evaluated platforms.
The results presented provide substantial evidence that Generative AI tools outperform traditional databases in terms of response time. Specifically, the following key observations were made:
- ChatGPT and Gemini significantly outperform both traditional databases. The mean response times for these AI-driven tools are significantly lower, with **ChatGPT showing a mean difference of 30.63 s and 34.78 s compared to DB_No_Credentials and DB_With_Credentials, respectively**. The confidence intervals confirm these differences are robust.
- Gemini is the fastest platform overall. The statistical tests confirm that Gemini is significantly faster than all other methods, including ChatGPT, which exhibits a mean response time 8.39 s longer than Gemini ().
- Traditional databases, regardless of credential access, do not significantly differ. The comparison between **DB_No_Credentials and DB_With_Credentials** yielded a mean difference of only 4.16 s, with a p-value of 0.2068, indicating that this difference is not statistically significant.
- The largest performance gap is between Gemini and DB_With_Credentials. This difference amounts to **43.18 s**, confirming that conventional academic search engines remain significantly slower than AI-based solutions.
This statistical analysis substantiates the findings by demonstrating that the efficiency of AI tools is not merely anecdotal but is supported by rigorous hypothesis testing. The highly significant p-values obtained through ANOVA and Tukey HSD validate the claim that Generative AI tools—particularly Gemini—are substantially more time-efficient compared to conventional databases. These results highlight the potential of AI-driven tools in enhancing information retrieval workflows within industrial engineering applications, minimizing search time, and improving accessibility to relevant academic materials. This answers research question 1.
4.2. Assessment of the Quality of the Information Provided by the GAIs
In the second phase of this study, a questionnaire composed of six key questions was designed and applied to evaluate the accuracy and relevance of the information provided by the GAIs studied. This evaluation instrument was subjected to a rigorous validation process by three external experts who specialized in the use of emerging technologies and with extensive experience in teaching industrial engineering and artificial intelligence. The experts reviewed the questionnaire in detail, evaluating the structure of each question and its clarity and relevance in the research context.
Based on their recommendations, the final version of the questionnaire was defined, thus ensuring that the questions were adequate to accurately measure the effectiveness of the GAIs in providing answers that meet the user’s informational needs. The questions presented in Appendix B were part of the final questionnaire used (for each of the GAIs mentioned earlier in this study) to analyze the users’ perception of the usefulness and accuracy of the answers generated by the GAIs in Industrial Engineering.
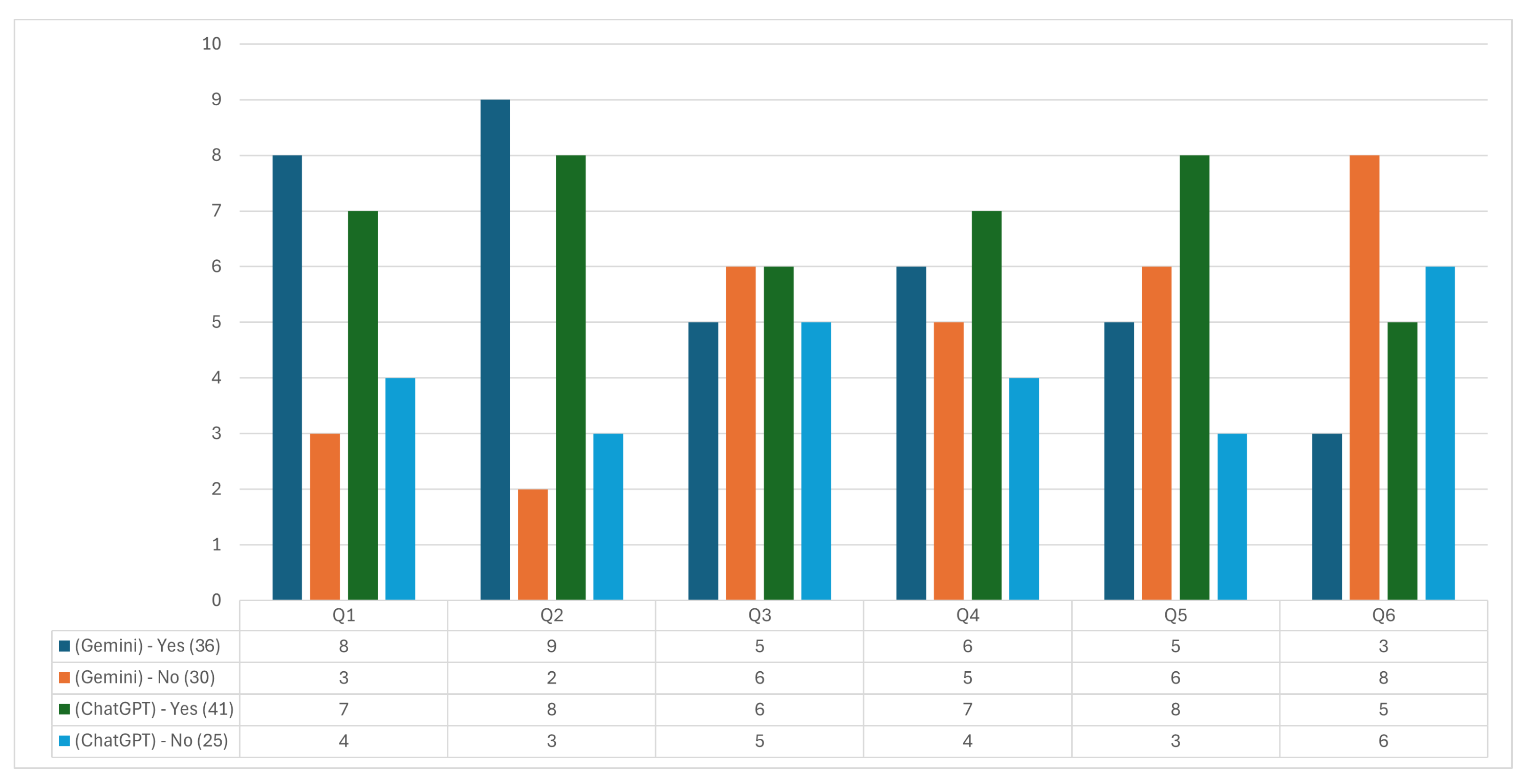
After issuing the questionnaire to a sample of 11 Industrial Engineering professors, the results shown in Figure 6 were obtained. This analysis evaluates ChatGPT and Gemini regarding accuracy, relevance, ease of comprehension, agreement with reliable sources, updating, and completeness of the information provided.
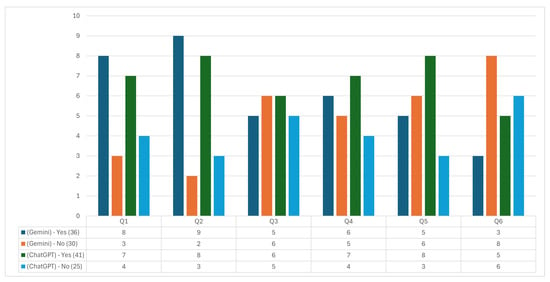
Figure 6.
Industrial Innovation questionnaire answers.
The results indicate a favorable trend towards ChatGPT in several key categories. In Question 1, which assesses the accuracy of the information provided, ChatGPT scored seven “yes” and four “no” responses, while Gemini scored eight “yes” and three “no” responses. This distribution suggests that both systems are well rated in accuracy, although Gemini scored slightly ahead. This distribution suggests that both systems are well rated in accuracy, although Gemini gained a slight advantage.
Question 2 assesses whether the response addresses the queried topic in a relevant way. ChatGPT obtained eight affirmative and three negative responses, compared to nine affirmative and two negative responses for Gemini. This result implies that both systems meet the thematic relevance in most cases, with Gemini slightly superior.
For Question 3, which examines the ease of understanding the information, ChatGPT showed a slight advantage with six affirmative responses vs. five negative, while Gemini scored seven affirmative and four negative. This suggests that, although both systems are considered relatively understandable, ChatGPT’s perception of clarity is marginally better.
Question 4 evaluates the information’s coincidence with reliable external sources. ChatGPT received five affirmatives and six negatives in this category, while Gemini received six affirmatives and five negatives. These results indicate a slight advantage for Gemini regarding perceived reliability and alignment with external sources, although both systems show room for improvement.
Question 5 explores whether the response appears to be up to date. ChatGPT scored six affirmative and five negative, while Gemini scored seven affirmative and four negative, suggesting a slightly higher perception of up-to-dateness in Gemini. This aspect is crucial in industrial innovation, where the timeliness of information can significantly impact decision-making.
Finally, in Question 6, which analyzes whether any relevant information was omitted, ChatGPT registered five negative and six affirmative answers, while Gemini obtained seven negative and four affirmative answers. This result suggests that, in terms of completeness, users perceive Gemini as a tool that omits less crucial information than ChatGPT.
Both GAI systems show strengths and weaknesses in terms of the dimensions evaluated. Gemini showed better accuracy, relevance, and timeliness results, while ChatGPT scored slightly better in clarity and comprehensiveness. However, both systems require improvements in matching with external sources and completeness of responses. This detailed evaluation allows inferring that the selection of the GAI tool should depend on the user’s specific needs in the field of Industrial Innovation and suggests critical areas for improvement to optimize the effectiveness of these technologies in academic and professional applications.
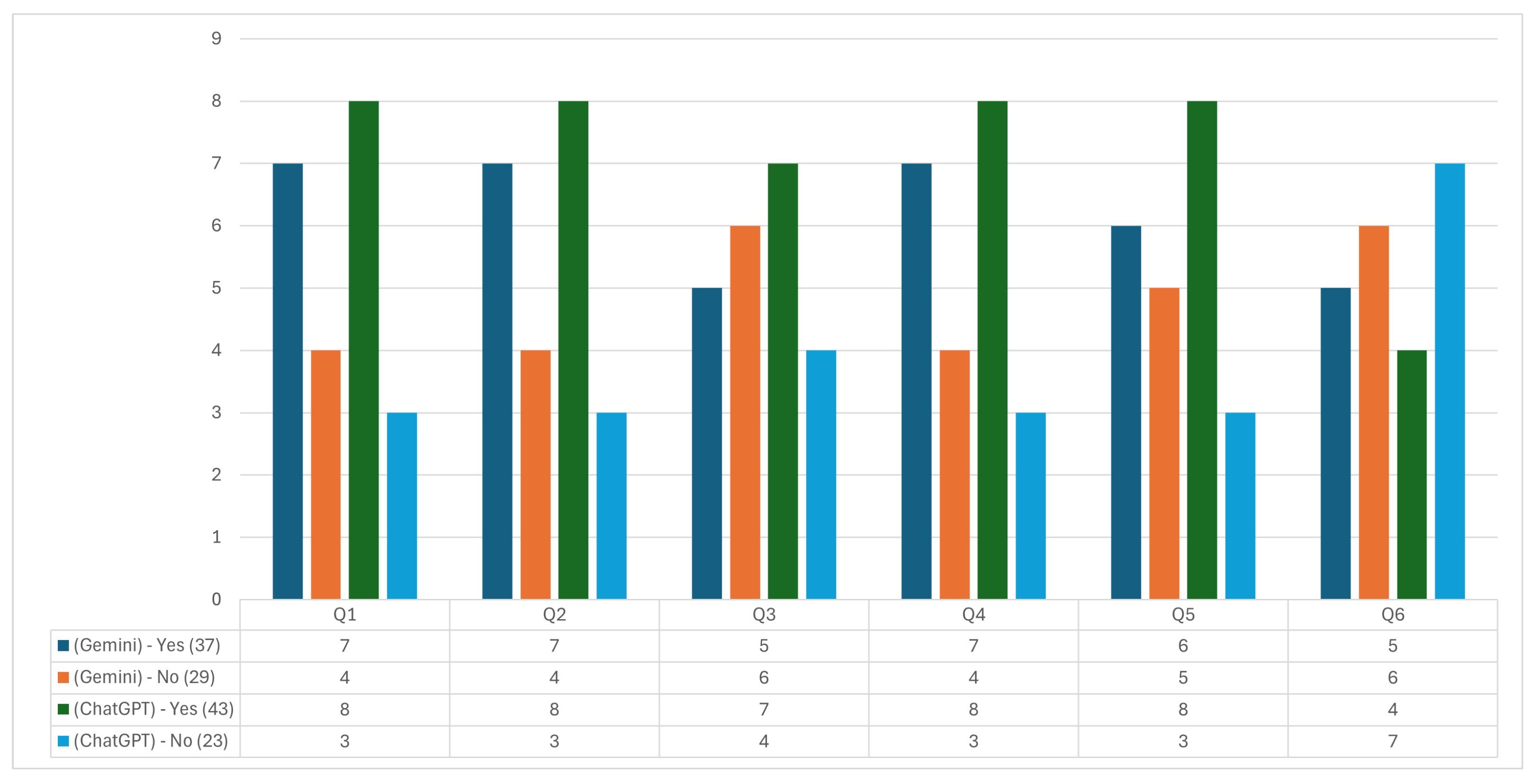
In the evaluation of the Plant Location and Design subject, Figure 7 provides a detailed breakdown of the responses, allowing us to observe how both tools were evaluated in terms of accuracy, relevance, ease of understanding, matching with reliable external sources, updating, and completeness of information.
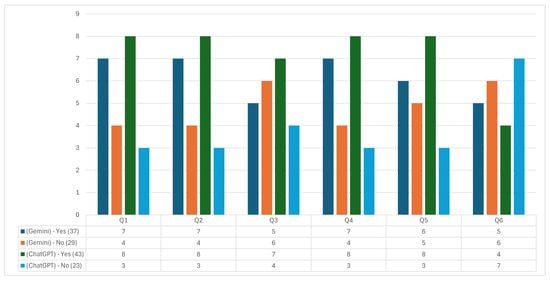
Figure 7.
Plant Location and Design questionnaire answers.
In Question 1, related to the accuracy of the information provided, ChatGPT received a positive rating with eight affirmative and three negative responses. In comparison, Gemini received seven affirmative and four negative responses. This trend suggests a favorable perception towards both tools, although ChatGPT presents a slight perceived accuracy predominance.
Question 2 analyzes whether the response addresses the topic consulted in a relevant way. ChatGPT received eight affirmative and three negative responses, while Gemini received seven affirmative and four negative, again highlighting ChatGPT as slightly superior in relevance. Evaluation in this area is critical for a technical subject such as Plant Location and Design, where answers are required to address specific and applied aspects.
In Question 3, which measures ease of understanding, ChatGPT achieved seven affirmative and four negative responses, while Gemini achieved five affirmative and six negative responses. This result highlights ChatGPT’s considerable advantage in terms of clarity of information, a relevant aspect for understanding complex topics.
Question 4 examines the information’s coincidence with reliable external sources. Here, ChatGPT received seven affirmatives and four negatives, while Gemini received six and five negatives. Although both tools show adequate alignment with academic sources, ChatGPT slightly excels in this aspect, which could indicate more excellent reliability regarding the accuracy and validation of the information presented.
For Question 5, on updating information, ChatGPT received eight affirmative and three negative responses, while Gemini received six affirmative and five negative responses. This difference suggests that the evaluators perceive that ChatGPT handles more updated information, an essential characteristic in fields where technical knowledge advances rapidly.
Finally, in Question 6, related to completeness of information, ChatGPT had four affirmative and seven negative responses, while Gemini achieved five affirmative and six negative responses. Neither tool showed a clear advantage in this case, indicating that both have room for improvement in providing complete and detailed information.
The results of this evaluation suggest that, for the Plant Location and Design subject, ChatGPT is slightly preferred over Gemini in terms of accuracy, relevance, ease of understanding, matching with external sources, and up-to-dateness. However, both tools show weaknesses in information completeness. This assessment enables academic users to make informed decisions about using GAI tools and highlights key areas for improvement to optimize their applicability in academic and technical contexts.
4.3. Statistical Analysis of GAI Response Accuracy
To provide statistical validation for the accuracy of responses generated by Generative Artificial Intelligence (GAI) tools, a Chi-Square independence test was conducted (Schmitz, 2024; Takefuji, 2025). This statistical method determines whether significant differences exist between the accuracy results obtained from ChatGPT and Gemini, based on the expert evaluations of responses to specific questions. The following hypotheses were formulated for the analysis:
Null Hypothesis (H0):
There is no significant difference between the accuracy of responses provided by ChatGPT and Gemini.
Alternative Hypothesis (Ha):
There is a significant difference in the accuracy of responses between ChatGPT and Gemini.
The accuracy evaluation data were structured into a contingency table, categorizing the number of correct (Yes) and incorrect (No) responses for each tool.
Applying the Chi-Square test to the contingency table, the following statistical values were obtained:
- Chi-Square Statistic: .
- Degrees of Freedom: .
- p-value: .
The p-value () is significantly higher than the typical significance level (), indicating that the null hypothesis cannot be rejected. This means there is no statistically significant evidence to assert that the accuracy of responses differs between ChatGPT and Gemini.
In practical terms, this suggests that both tools provide a similar level of accuracy in answering questions related to Industrial Innovation and Plant Location and Design. While minor differences exist in the number of correct responses, they are not pronounced enough to be considered statistically significant. This answers research question 2.
Conclusions
The analysis confirms that there is no statistically significant difference in the accuracy of responses provided by ChatGPT and Gemini. Therefore, the choice between these tools may depend more on other factors, such as response speed or ease of understanding the generated content, rather than on accuracy itself.
4.4. Limitations and Shortcomings
Although revealing in several aspects, the present study presents certain limitations that should be considered when interpreting the results and their applicability in broader contexts. First, it should be noted that we worked with the accessible version of ChatGPT, which implies restrictions in access to some advanced functions and in the volume of data with which this model can work. The free version may have limitations in terms of updating its knowledge base and in the depth of the responses it can provide, which could impact the accuracy and relevance of the information generated compared to paid versions or GAI models that offer additional functionalities and optimization in response processing.
The surveys were conducted using a relatively simple design, primarily due to the rapid evolution of large language models (LLMs). The landscape of generative AI tools is continuously changing, with new models emerging frequently, such as DeepSeek, Mistral, and Command R+. The availability and capabilities of these tools are likely to expand, introducing new functionalities and improvements that may significantly impact user adoption and effectiveness.
Additionally, the adoption of generative AI tools is still in an early stage, and the trends observed in this study are likely to evolve as technology advances and user familiarity increases. The rapid development of AI models and improvements in their capabilities suggest that future studies should monitor changes in adoption rates, accuracy, and integration into academic workflows. This study serves as a baseline, but a follow-up investigation in the near future could provide valuable insights into the long-term role of GAI in industrial engineering education.
Another limitation of this study is the use of closed-ended, yes/no questions in the questionnaire. While this design facilitates quantifiable comparisons and ensures consistency in responses, it limits the depth of qualitative insights that could provide a more nuanced understanding of participants’ experiences and perceptions.
The study was also limited to two specific subjects within the field of Industrial Engineering: Industrial Innovation and Plant Location and Design. This decision was made based on the results of a preliminary survey, which revealed that these two subjects mostly used GAI tools in the academic context evaluated. However, this selection may reduce the results’ applicability since a wider variety of subjects that could offer additional insights into the use and effectiveness of GAI in different engineering settings are omitted. Therefore, the findings presented here may not be generalizable to all areas of Industrial Engineering or other disciplines, as each subject may present different needs and challenges regarding the use of generative AI technologies.
Additionally, the sample used in this study consisted of 11 Industrial Engineering professors who participated in evaluating the ChatGPT and Gemini systems based on several criteria, such as accuracy, relevance, ease of understanding, coincidence with external sources, and updating of the information. Although these professors have extensive knowledge in their areas and represent a valuable source of qualitative data, the small sample size limits the generalizability of the results obtained.
Another aspect to consider is the nature of the questions and the scope of the evaluations performed. By working with questionnaires of six questions (Appendix B) oriented to measure specific parameters, there is a possibility that not all the relevant dimensions for a complete evaluation of GAI systems are covered. However, a theoretical basis and a solid questionnaire are left for future studies on the same subject. In particular, factors such as the adaptability of responses in dynamic contexts or the ability of the tools to suggest additional information were not considered, which could be relevant in a more comprehensive study. In addition, the questionnaire and evaluation parameters were defined in consultation with experts. However, they may require further validation to ensure that they truly capture all critical aspects of GAI evaluation in academic and industrial settings.
Finally, the complexity of queries used in the study should be considered. Different levels of complexity may influence the relative performance of generative AI tools and conventional databases. For traditional databases, queries were entered using Boolean logic (e.g., “digital transformation” AND “internal processes” AND “priority areas”), requiring precise keyword matching and structured search operators to retrieve documents effectively. In contrast, queries submitted to GAIs were written in natural language (e.g., “What are the key steps an organization should follow to carry out an effective digital transformation?”), allowing AI tools like ChatGPT and Gemini to interpret intent and generate synthesized responses rather than retrieving specific documents.
This difference highlights how traditional databases favor structured retrieval for well-defined topics, whereas AI tools offer flexibility in processing complex, contextualized queries. However, GAIs may introduce variability in results due to their probabilistic nature, whereas Boolean searches produce consistent and replicable outcomes.
5. Conclusions and Ongoing Work
In this study, the capabilities and limitations of GAI systems, specifically ChatGPT and Gemini, were evaluated in comparison to conventional databases in the context of the Industrial Engineering subjects of Industrial Innovation and Plant Location and Design. The results show that while Gemini offers faster response times for both subjects, ChatGPT provides higher-quality information regarding accuracy, relevance, and alignment with external sources. However, these generative tools do not entirely replace querying conventional databases, especially in contexts that require detailed and verified technical information.
Gemini excels in time efficiency, significantly reducing query time compared to ChatGPT and mainly conventional databases. This speed makes it ideal for preliminary queries or when time is crucial. However, the speed benefits also imply limitations, especially regarding information relevance and accuracy. ChatGPT, although slower, provides answers that better align with external sources and present more straightforward and relevant context for advanced users. This translates into greater user understanding, which is beneficial in academic settings where a complete understanding of the subject matter is essential.
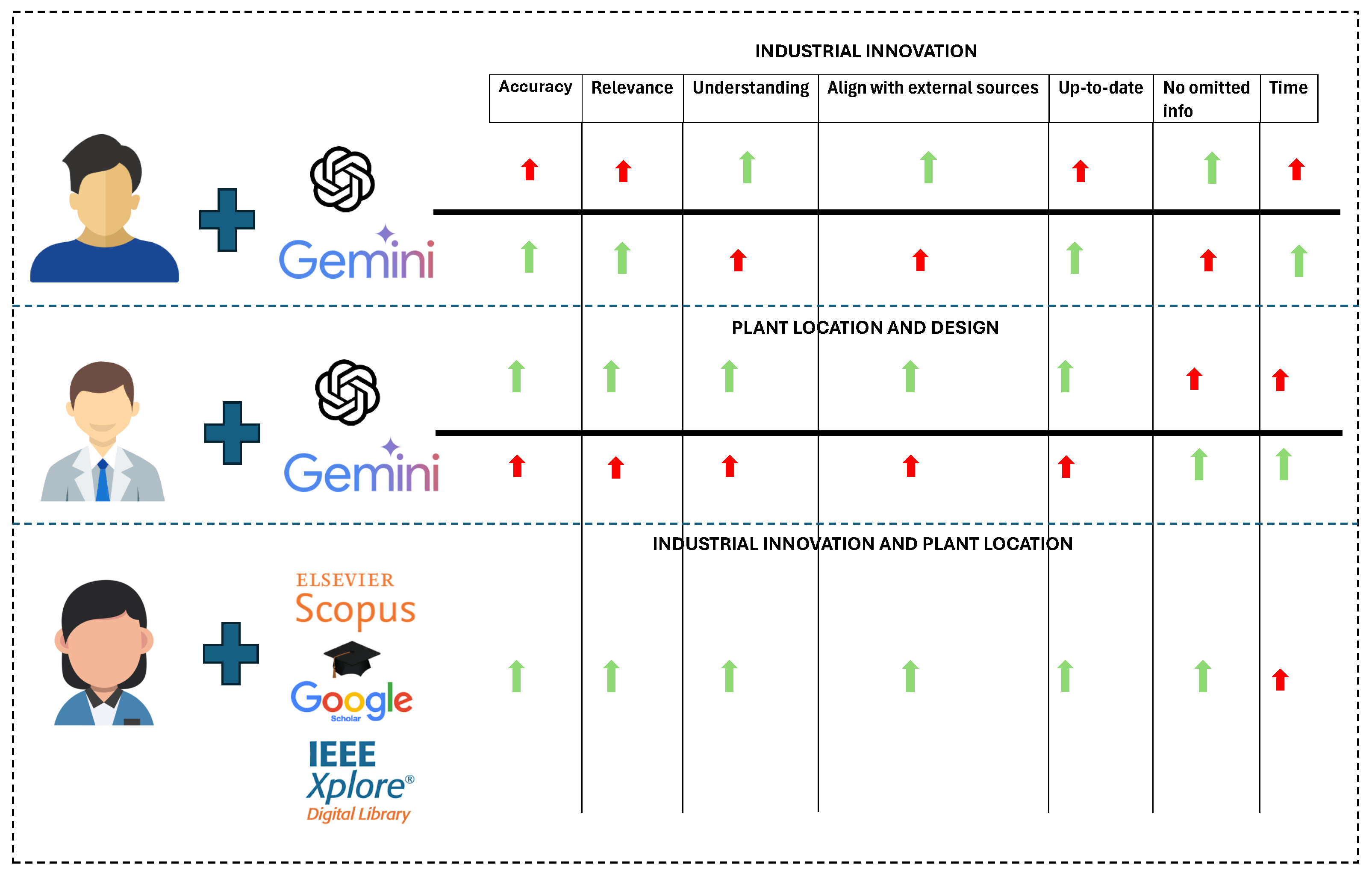
Conventional databases, although the slowest in response time, continue to be an irreplaceable source of highly accurate and reliable technical information. The limitations of GAIs in verifying and updating information are significant since, in industrial and academic contexts, the accuracy and timeliness of data are critical. In this regard, conventional databases offer a unique advantage by allowing the user to directly access full documents, such as scientific articles, patents, and theses, whose credibility and depth of content are crucial for advanced research. See Figure 8. While this study highlights the efficiency of generative AI tools in terms of response time, it is important to acknowledge that time alone is not the sole determinant of effectiveness. The quality and completeness of responses play a crucial role in selecting the appropriate tool for different types of searches. For straightforward queries, generative AI’s speed and contextual summarization may be advantageous, whereas systematic reviews, technical research, and highly specialized searches might still benefit from the depth and rigor of traditional databases. Future research should explore a quantitative framework for evaluating response summarization and accuracy in relation to time efficiency, providing a more holistic assessment of retrieval performance across different query complexities and domains.
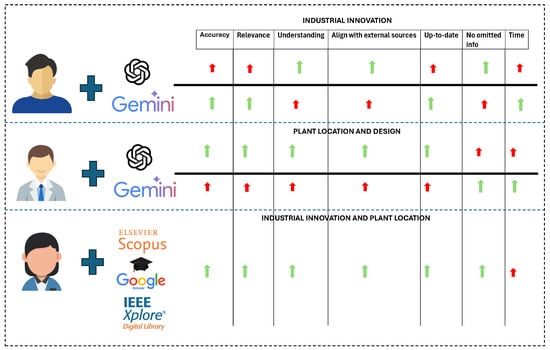
Figure 8.
GAIs vs. conventional database. The red arrows represent the limitations in each parameter studied, while the green arrows indicate the advantages.
In future studies, it would be desirable to expand the sample size, including more teachers, industry professionals, and even students, to obtain a broader perspective on the usefulness and effectiveness of these tools at different levels of training and experience. Future research should also consider expanding the scope of the survey by including a more extensive dataset, incorporating professionals from various industries, and evaluating a broader set of AI tools to capture a more comprehensive picture of how these technologies impact academic and industrial applications. Additionally, we could complement this approach with open-ended questions or structured interviews to capture more detailed qualitative data on how users interact with Generative AI tools in academic and industrial settings.
Author Contributions
Conceptualization, J.E.N. and M.M.L.; methodology, J.E.N.; software, C.X.E.; validation, W.D.V. and M.M.L.; formal analysis, J.E.N.; investigation, M.M.L. and W.D.V.; resources, J.E.N.; data curation, C.X.E.; writing original draft preparation, J.E.N.; writing review and editing, M.M.L. and W.D.V.; visualization, C.X.E.; supervision, J.E.N.; project administration, J.E.N. and M.M.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors would like to express their gratitude to the research network INTELIA, supported by REDU, for their valuable assistance throughout the course of this research. Additionally, we would like to thank the Universidad Técnica de Cotopaxi for its support in the research processes.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Study Case Survey
- What semester are you currently in?
- 7th semester
- 8th semester
- Are you familiar with Generative Artificial Intelligence (ChatGPT, Bard IA, Gemini, etc.)?
- Yes
- No
- What level of knowledge do you think you have regarding generative AI systems?
- Advanced
- Intermediate
- Moderate
- Basic
- In which Industrial Engineering subjects do you use generative AI?
- Integrated Systems
- Production Management
- Industrial Innovation
- Maintenance Engineering
- Marketing and Sales
- Methods Engineering
- Technological Project
- Plant Location and Design
- Which generative AI tools do you know?
- Bard IA
- Gemini
- ChatGPT
- Copy IA
- Which generative AI tools do you use most frequently?
- Gemini
- ChatGPT
- Bard IA
- Copy IA
- How often do you use a generative AI tool in your academic work?
- Always
- Sometimes
- Never
- Have you found the responses provided by generative AI systems useful in the context of Industrial Engineering?
- Yes
- No
- Maybe
- Do you believe generative AI systems are relevant to the field of Industrial Engineering?
- Strongly agree
- Agree
- Neutral
- Disagree
- Strongly disagree
Appendix B. Assessment of the Quality of the Information Survey
- Is the information provided by the GAI accurate?
- Yes
- No
- Does the response from the GAI address the consulted topic in a relevant manner?
- Yes
- No
- Is the information provided by the GAI easy to understand?
- Yes
- No
- Does the information align with what can be found in reliable external sources, such as books and academic articles?
- Yes
- No
- Does the response from the GAI appear to be up-to-date concerning the consulted topic?
- Yes
- No
- Was any important information omitted in the response from the GAI?
- Yes
- No
References
- Agliata, A., Pilato, A., Mariacarmen, S., Bottiglieri, S., Nardo, E. D., & Ciaramella, A. (2024, June 26–29). Generative AI and emotional health: Innovations with Haystack. 2024 IEEE Symposium on Computers and Communications (ISCC) (pp. 1–4), Paris, France. [Google Scholar] [CrossRef]
- Alharithi, M., Almetwally, E. M., Alotaibi, O., Eid, M. M., El-kenawy, E. S. M., & Elnazer, A. A. (2025). A comparative study of statistical and intelligent classification models for predicting airlines passenger management satisfaction. Alexandria Engineering Journal, 119, 99–110. [Google Scholar] [CrossRef]
- Aravinth, S. S., Srithar, S., Joseph, K. P., Gopala Anil Varma, U., Kiran, G. M., & Jonna, V. (2023, March 21–22). Comparative analysis of generative AI techniques for addressing the tabular data generation problem in medical records. 2023 International Conference on Recent Advances in Science and Engineering Technology (ICRASET) (pp. 1–5), Bangkok, Thailand. [Google Scholar] [CrossRef]
- Bassi, D., & Singh, H. (2025). The empirical analysis of multi-objective hyperparameter optimization in software vulnerability prediction. International Journal of Computers and Applications, 47, 197–215. [Google Scholar] [CrossRef]
- Beghetto, R. A., Ross, W., Karwowski, M., & Glăveanu, V. P. (2025). Partnering with AI for instrument development: Possibilities and pitfalls. New Ideas in Psychology, 76, 101121. [Google Scholar] [CrossRef]
- Chung, S. J. (2024). Revolutionizing persona design with generative AI: Insights from experts. International Journal of Design Management and Professional Practice, 18, 109–124. [Google Scholar] [CrossRef]
- Ding, S., & Raman, V. (2024, June 3–6). Harness the power of generative AI in healthcare with Amazon AI/ML services. 2024 IEEE 12th International Conference on Healthcare Informatics (ICHI) (pp. 490–492), Orlando, FL, USA. [Google Scholar] [CrossRef]
- Du, H., Niyato, D., Kang, J., Xiong, Z., Zhang, P., Cui, S., Shen, X., Mao, S., Han, Z., Jamalipour, A., Poor, H. V., & Kim, D. I. (2024). The age of generative AI and AI-generated everything. IEEE Network, 38, 501–512. [Google Scholar] [CrossRef]
- Espinosa, R. V., Soto, M., Garcia, M. V., & Naranjo, J. E. (2021, October 28–31). Challenges of implementing cleaner production strategies in the food and beverage industry: Literature review. Advances and Applications in Computer Science, Electronics and Industrial Engineering: Proceedings of CSEI 2020 (pp. 121–133), Ambato, Ecuador. [Google Scholar] [CrossRef]
- Gatla, R. K., Gatla, A., Sridhar, P., Kumar, D. G., & Rao, D. S. N. M. (2024, May 2–3). Advancements in generative AI: Exploring fundamentals and evolution. 2024 International Conference on Electronics, Computing, Communication and Control Technology (ICECCC) (pp. 1–5), Bengaluru, India. [Google Scholar] [CrossRef]
- Guillén-Yparrea, N., & Hernández-Rodríguez, F. (2024, May 8–11). Unveiling generative AI in higher education: Insights from engineering students and professors. 2024 IEEE Global Engineering Education Conference (EDUCON) (pp. 1–5), Kos, Greece. [Google Scholar] [CrossRef]
- Khan, N. D., Khan, J. A., Li, J., Ullah, T., & Zhao, Q. (2025). Leveraging Large Language Model ChatGPT for enhanced understanding of end-user emotions in social media feedbacks. Expert Systems with Applications, 261, 125524. [Google Scholar] [CrossRef]
- Lin, P., Li, C., Chen, S., Huangfu, J., & Yuan, W. (2024). Intelligent gesture recognition based on screen reflectance multi-band spectral features. Sensors, 24(17), 5519. [Google Scholar] [CrossRef]
- Luo, D., Wan, X., Liu, J., & Tong, T. (2018). Optimally estimating the sample mean from the sample size, median, mid-range, and/or mid-quartile range. Statistical Methods in Medical Research, 27, 1785–1805. [Google Scholar] [CrossRef] [PubMed]
- Milutinovic, S., Petrovic, M., Begosh-Mayne, D., Lopez-Mattei, J., Chazal, R. A., Wood, M. J., & Escarcega, R. O. (2024). Evaluating performance of ChatGPT on MKSAP cardiology board review questions. International Journal of Cardiology, 417, 132576. [Google Scholar] [CrossRef] [PubMed]
- Modgil, S., Gupta, S., Kar, A. K., & Tuunanen, T. (2025). How could generative AI support and add value to non-technology companies—A qualitative study. Technovation, 139, 103124. [Google Scholar] [CrossRef]
- Mutia, F., Masrek, M. N., Baharuddin, M. F., Shuhidan, S. M., Soesantari, T., Yuwinanto, H. P., & Atmi, R. T. (2024). An exploratory comparative analysis of librarians’ views on AI support for learning experiences, lifelong learning, and digital literacy in malaysia and Indonesia. Publications, 12, 21. [Google Scholar] [CrossRef]
- Netland, T., von Dzengelevski, O., Tesch, K., & Kwasnitschka, D. (2025). Comparing human-made and AI-generated teaching videos: An experimental study on learning effects. Computers and Education, 224, 105164. [Google Scholar] [CrossRef]
- Ngo, T. N., & Hastie, D. (2025). Artificial Intelligence for Academic Purposes (AIAP): Integrating AI literacy into an EAP module. English for Specific Purposes, 77, 20–38. [Google Scholar] [CrossRef]
- Ogunfunmi, T. (2024, May 19–22). Exploration of generative AI tools for an electric circuits course. 2024 IEEE International Symposium on Circuits and Systems (ISCAS) (pp. 1–5), Singapore. [Google Scholar] [CrossRef]
- Oliński, M., Krukowski, K., & Sieciński, K. (2024). Bibliometric overview of ChatGPT: New perspectives in social sciences. Publications, 12, 9. [Google Scholar] [CrossRef]
- Olson, L. (2024, April 14–15). Custom developer GPT for ethical AI solutions. 2024 IEEE/ACM 3rd International Conference on AI Engineering—Software Engineering for AI (CAIN) (pp. 282–283), Lisbon, Portugal. [Google Scholar]
- Pathak, K., Prakash, G., Samadhiya, A., Kumar, A., & Luthra, S. (2025). Impact of Gen-AI chatbots on consumer services experiences and behaviors: Focusing on the sensation of awe and usage intentions through a cybernetic lens. Journal of Retailing and Consumer Services, 82, 104120. [Google Scholar] [CrossRef]
- Rani, G., Singh, J., & Khanna, A. (2023, November 23–24). Comparative analysis of generative AI models. 2023 International Conference on Advances in Computation, Communication and Information Technology (ICAICCIT) (pp. 760–765), Faridabad, India. [Google Scholar] [CrossRef]
- Riley, R. D., Collins, G. S., Ensor, J., Archer, L., Booth, S., Mozumder, S. I., Rutherford, M. J., van Smeden, M., Lambert, P. C., & Snell, K. I. E. (2022). Minimum sample size calculations for external validation of a clinical prediction model with a time-to-event outcome. Statistics in Medicine, 41, 1280–1295. [Google Scholar] [CrossRef] [PubMed]
- Sadraoui, Y., Er-Ratby, M., Kadiri, M. S., & Kobi, A. (2025). Improving measurement system fidelity through the optimization of preventive maintenance and operating conditions: A comparative study of measurement system analysis approaches. Engineering Research Express, 7, 015415. [Google Scholar] [CrossRef]
- Sánchez-Rosero, C., Lalaleo, J. P., Rosero-Mantilla, C., & Naranjo, J. E. (2023, November 13–17). Early stage proposal of a multi-tool lean manufacturing methodology to improve the productivity of a textile company. International Conference on Computer Science, Electronics and Industrial Engineering (CSEI) (pp. 662–677), Ambato, Ecuador. [Google Scholar] [CrossRef]
- Schmitz, G. (2024). An unsupervised machine learning analysis of environmental sustainability indicators using the K-Means clustering algorithm among 2485 global corporations. The International Journal of Sustainability Policy and Practice, 21, 77–100. [Google Scholar] [CrossRef]
- Shoaib, M., Sayed, N., Singh, J., Shafi, J., Khan, S., & Ali, F. (2024). AI student success predictor: Enhancing personalized learning in campus management systems. Computers in Human Behavior, 158, 108301. [Google Scholar] [CrossRef]
- Sikand, S., Mehra, R., Sharma, V. S., Kaulgud, V., Podder, S., & Burden, A. P. (2024, April 16). Do generative AI tools ensure green code? An investigative study. 2024 IEEE/ACM International Workshop on Responsible AI Engineering (RAIE) (pp. 52–55), Lisbon, Portugal. [Google Scholar]
- Sim, Y. S., Lee, C. K., Hwang, J. S., Kwon, G. Y., & Chang, S. J. (2025). AI-based remaining useful life prediction for transmission systems: Integrating operating conditions with TimeGAN and CNN-LSTM networks. Electric Power Systems Research, 238, 111151. [Google Scholar] [CrossRef]
- Singh, G., Srivastava, V., Kumar, S., Bhatnagar, V., & Dhondiyal, S. A. (2024, August 7–9). Exploring the creative capacities of generative AI: A comparative study. 2024 5th International Conference on Electronics and Sustainable Communication Systems (ICESC) (pp. 1809–1813), Coimbatore, India. [Google Scholar] [CrossRef]
- Srivastava, K., & Sahoo, R. R. (2025). Taguchi and ANN model optimization for uni-array vortex generator incorporated rectangular channel for high thermo-hydraulic performance. International Journal of Thermal Sciences, 210, 109634. [Google Scholar] [CrossRef]
- Subramani, S., Sarensanth, C., Soundappan, M., Mohanapriya, T., & Murali, M. (2024, April 26–27). Learn buddy—Transforming education with generative AI. 2024 International Conference on Computing and Data Science (ICCDS) (pp. 1–5), Chennai, India. [Google Scholar] [CrossRef]
- Sun, H., Kim, M., Kim, S., & Choi, L. (2025). A methodological exploration of generative artificial intelligence (AI) for efficient qualitative analysis on hotel guests’ delightful experiences. International Journal of Hospitality Management, 124, 103974. [Google Scholar] [CrossRef]
- Śliwiak, P., & Shah, S. A. A. (2024). Text-to-text generative approach for enhanced complex word identification. Neurocomputing, 610, 128501. [Google Scholar] [CrossRef]
- Takefuji, Y. (2025). Visualizing disparity trends on felony sentence-imposed months by gender and race with generative AI. Cities, 159, 105767. [Google Scholar] [CrossRef]
- Tanaka, H., Ide, M., Yajima, J., Onodera, S., Munakata, K., & Yoshioka, N. (2024, April 14–15). Taxonomy of generative AI applications for risk assessment. 2024 IEEE/ACM 3rd International Conference on AI Engineering—Software Engineering for AI (CAIN) (pp. 288–289), Lisbon, Portugal. [Google Scholar]
- Tighiouart, M., Cook-Wiens, G., & Rogatko, A. (2018). A Bayesian adaptive design for cancer phase I trials using a flexible range of doses. Journal of Biopharmaceutical Statistics, 28, 562–574. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, H., Raj, A., Singh, U. K., & Fatima, H. (2024, February 28–March 1). Generative AI for NFTs using GANs. 2024 11th International Conference on Computing for Sustainable Global Development (INDIACom) (pp. 488–492), New Delhi, India. [Google Scholar] [CrossRef]
- Turgel, I. D., & Chernova, O. A. (2024). Open science alternatives to scopus and the web of science: A case study in regional resilience. Publications, 12, 43. [Google Scholar] [CrossRef]
- Universidad Adventista de Chile. (2020). Formato de validación por expertos. Universidad Adventista de Chile. [Google Scholar]
- Xiao, Y., & Yu, S. (2025). Can ChatGPT replace humans in crisis communication? The effects of AI-mediated crisis communication on stakeholder satisfaction and responsibility attribution. International Journal of Information Management, 80, 102835. [Google Scholar] [CrossRef]
- Yang, X., Song, B., Chen, L., Ho, S. S., & Sun, J. (2025). Technological optimism surpasses fear of missing out: A multigroup analysis of presumed media influence on generative AI technology adoption across varying levels of technological optimism. Computers in Human Behavior, 162, 108466. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).